C#を利用してアプリケーションを開発していると、データの送受信やファイルの保存などでBase64形式のデータを扱う機会が非常に多くあります。
Base64はバイナリデータをテキスト形式で表現するための便利な手法ですが、いざデコードして「文字列」として取得しようとすると、文字化けや例外エラーに悩まされることも少なくありません。
この記事では、C#でBase64をデコードして文字列に変換する基本から応用、そして文字化けを完全に防ぐためのエンコーディングの知識までを徹底的に解説します。
初心者の方でもスムーズに実装できるよう、具体的なサンプルコードとともに、内部でどのような処理が行われているのかを図解を交えて詳しく紐解いていきましょう。
Base64デコードの基本概念を理解する
Base64デコードを正しく実装するためには、まず「Base64とは何か」と「C#における変換の流れ」を正確に把握しておく必要があります。
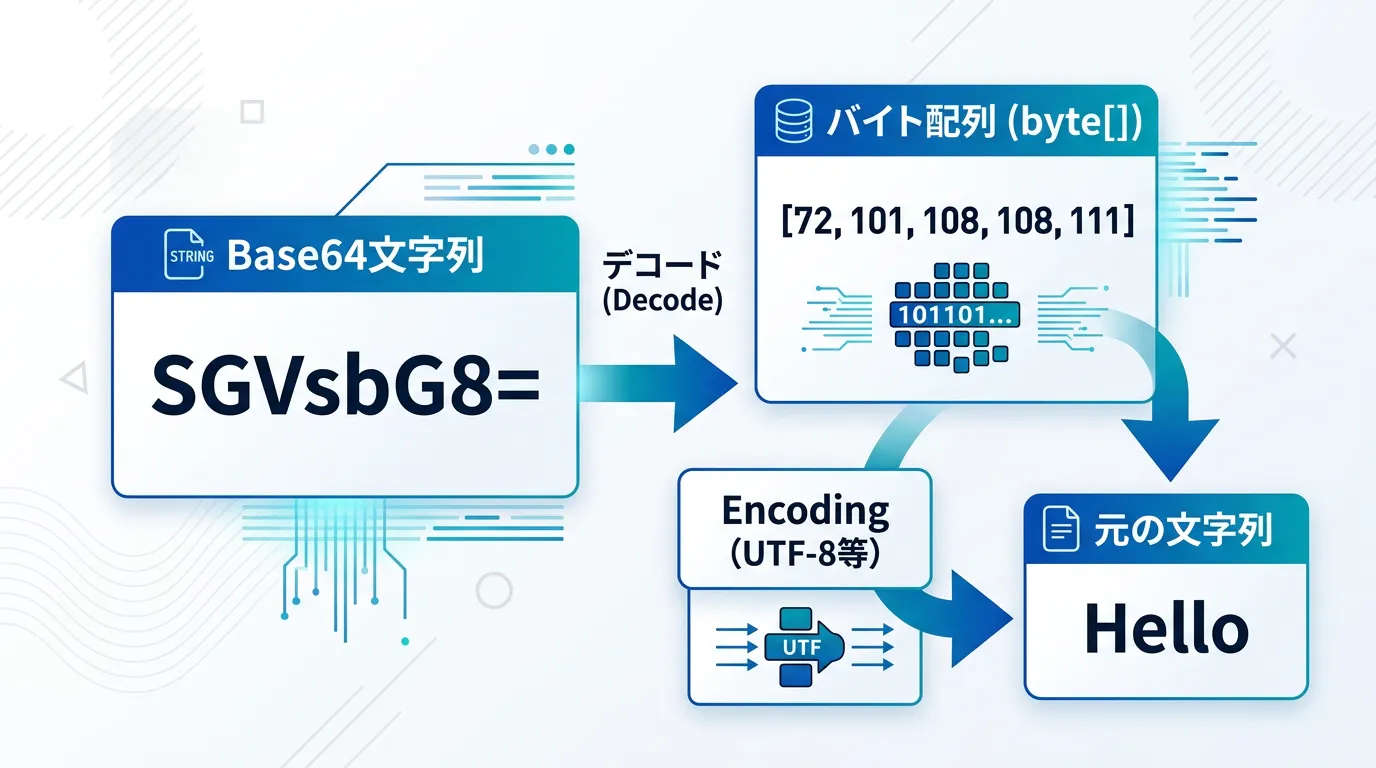
C#でBase64デコードを行うプロセスは、大きく分けて2つのステップで構成されています。
- Base64文字列をバイト配列 (byte[]) に変換する
- バイト配列を特定のエンコーディング (UTF-8など) で文字列に変換する
多くの初心者が陥る罠は、Base64を直接「文字列」に変換できると思い込んでしまうことです。
しかし、Base64はあくまで「バイナリデータ」を可視文字に置き換えたものに過ぎません。
そのため、一度byte[]という生のバイナリ形式に戻してから、そのバイナリが何の文字コードで書かれているかを指定して解釈し直す必要があるのです。
Base64の役割と必要性
Base64は、A-Z、a-z、0-9の62文字に、プラス(+)とスラッシュ(/)を加えた合計64文字、そしてパディング用のイコール(=)を使用してデータを表現します。
なぜこのような変換が必要なのでしょうか。
それは、通信プロトコルやデータフォーマットの中には、制御文字やバイナリデータを直接扱えないものがあるからです。
例えば、電子メールの添付ファイルや、JSONの中に画像を埋め込む場合、バイナリデータがそのまま含まれているとシステムが誤作動を起こす可能性があります。
Base64でテキスト化することで、安全にデータを転送できるようになるのです。
C#でBase64をデコードする標準的な方法
C#で最も一般的に使われるのは、System.ConvertクラスのFromBase64Stringメソッドです。
Convert.FromBase64Stringを使用した基本コード
まずは、最もシンプルなデコードの例を見てみましょう。
ここでは標準的なUTF-8エンコーディングを使用します。
using System;
using System.Text;
public class Base64Example
{
public static void Main()
{
// デコードしたいBase64文字列
string base64String = "44GT44KT44Gr44Gh44Gv44CBQyPjga9CYXNlNjTjg4fjgrPjg7zjg4njgYznsKHljZjjgafjgZnjgII=";
try
{
// ステップ1: Base64文字列をバイト配列に変換
byte[] buffer = Convert.FromBase64String(base64String);
// ステップ2: バイト配列を文字列に変換 (UTF-8を指定)
string decodedString = Encoding.UTF8.GetString(buffer);
// 結果の出力
Console.WriteLine("デコード結果:");
Console.WriteLine(decodedString);
}
catch (FormatException ex)
{
// Base64の形式が正しくない場合のエラーハンドリング
Console.WriteLine("エラー: 入力文字列は有効なBase64形式ではありません。");
Console.WriteLine(ex.Message);
}
}
}デコード結果:
こんにちは、C#はBase64デコードが簡単です。コードの解説
上記のプログラムでは、まずConvert.FromBase64Stringを呼び出しています。
このメソッドは、引数に渡されたBase64文字列を解析し、元のbyte[]を生成します。
次に、Encoding.UTF8.GetString(buffer)を使用して、バイトデータを人間が読める文字列に変換しています。
ここが非常に重要なポイントです。
Base64そのものには「どの文字コードでエンコードされたか」という情報は含まれていません。
デコードする側が正しいエンコーディング(この場合はUTF-8)を指定しないと、次のセクションで解説する「文字化け」の原因となります。
文字化けを防ぐ!正しいエンコーディングの選択
Base64デコードにおいて、最も多いトラブルが文字化けです。
デコード自体は成功しているように見えても、表示される文字が支離滅裂な場合、それはエンコーディングの不一致が原因です。
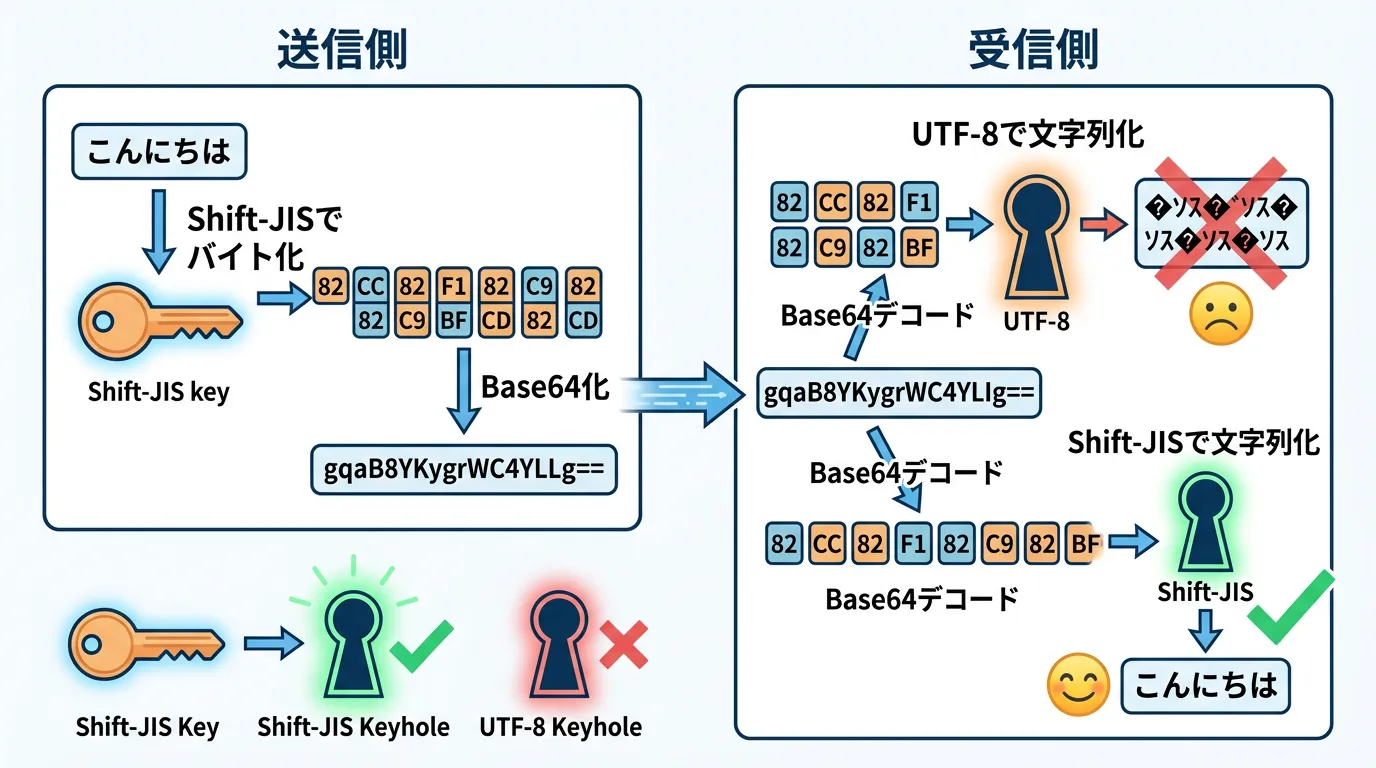
なぜ文字化けが起こるのか
コンピューターにとって、文字は数値の羅列です。
例えば「あ」という文字を数値にする際、UTF-8なら「E3 81 82」という3バイトになりますが、Shift-JISなら「82 A0」という2バイトになります。
Base64は、この「数値の羅列」をそのままテキスト化しただけのものです。
デコードして「E3 81 82」を取り出したとしても、それをEncoding.GetEncoding("Shift-JIS").GetString()で処理しようとすれば、当然正しい文字には戻りません。
日本語環境でよく使われるエンコーディングの指定方法
現代のWeb開発ではUTF-8が標準ですが、古いシステムやWindowsのデスクトップアプリとの連携ではShift-JISやEUC-JPが使われていることがあります。
C#でこれらを扱う場合は、System.Text.Encodingを使い分けます。
| エンコーディング | C#での記述方法 | 特徴 |
|---|---|---|
| UTF-8 | Encoding.UTF8 | 現代の標準。多言語対応に強い。 |
| Shift-JIS | Encoding.GetEncoding("shift_jis") | 日本語Windows環境で広く使われてきた。 |
| UTF-16 | Encoding.Unicode | C#内部の文字列表現に近い。 |
| ASCII | Encoding.ASCII | 英数字のみ。日本語は扱えない。 |
※Shift-JISを使用する場合、.NET Coreや.NET 5以降ではEncoding.RegisterProvider(CodePagesEncodingProvider.Instance);を事前に実行しておく必要があることに注意してください。
Shift-JISでエンコードされたBase64をデコードする例
using System;
using System.Text;
public class ShiftJisExample
{
public static void Main()
{
// .NET 5+ でShift-JISを扱うために必要
Encoding.RegisterProvider(CodePagesEncodingProvider.Instance);
// "こんにちは" をShift-JISでBase64化したもの
string base64String = "grGC8YLJgr+CzQ==";
byte[] buffer = Convert.FromBase64String(base64String);
// Shift-JISを指定してデコード
Encoding sjis = Encoding.GetEncoding("shift_jis");
string decodedString = sjis.GetString(buffer);
Console.WriteLine($"Shift-JISデコード結果: {decodedString}");
}
}Shift-JISデコード結果: こんにちはこのように、データの生成元がどの方式を使っているかを事前に把握しておくことが、文字化けを未然に防ぐ唯一の方法です。
URLセーフなBase64への対応
Webの世界では、Base64の標準文字であるプラス(+)やスラッシュ(/)がURLの中で特別な意味を持ってしまうため、これらをマイナス(-)やアンダースコア(_)に置き換えたURLセーフBase64が使われることがよくあります。
標準のConvert.FromBase64Stringは、これらのURLセーフ文字をそのままではデコードできません。
そのため、デコード前に文字を置換する必要があります。
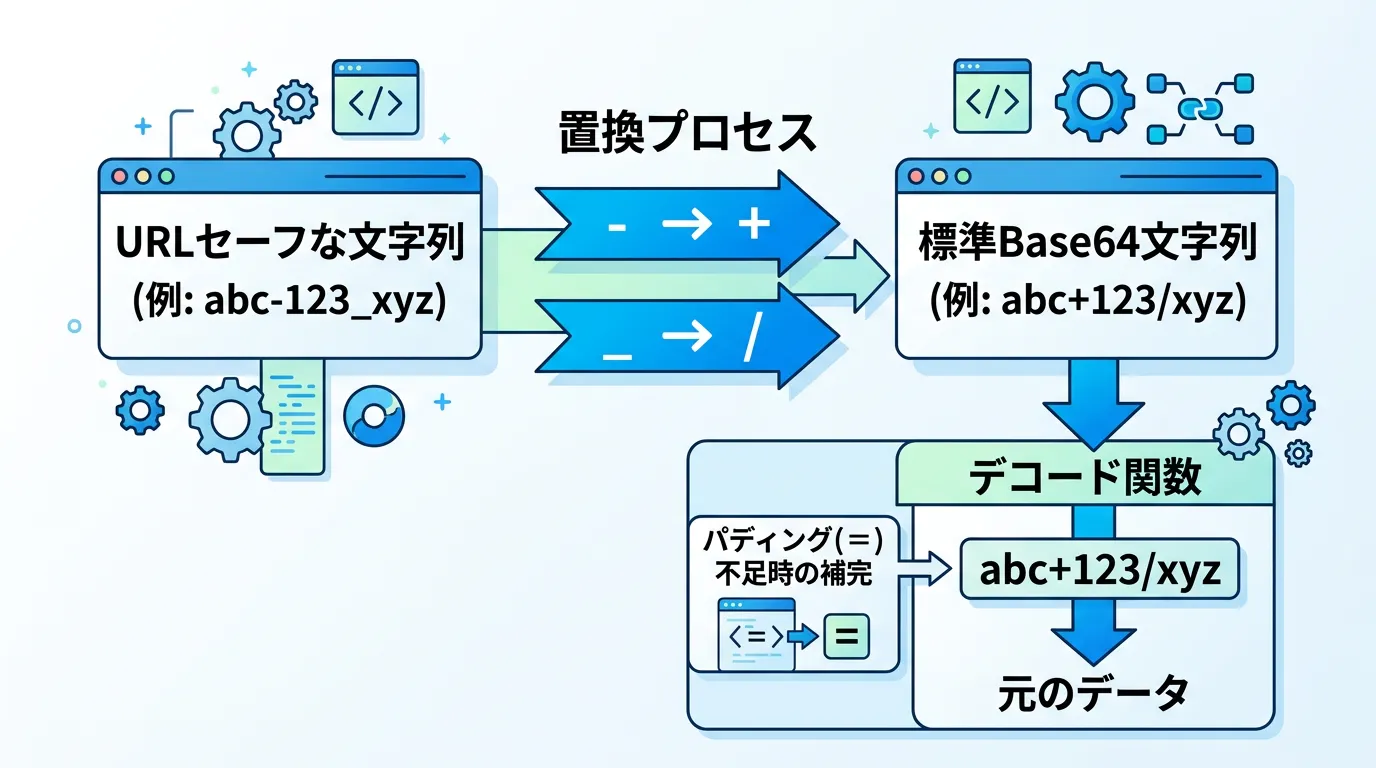
URLセーフBase64をデコードする実装パターン
以下のコードは、URLセーフなBase64文字列を標準形式に戻してからデコードする汎用的なメソッドの例です。
public static string DecodeUrlSafeBase64(string urlSafeBase64)
{
// 文字の置換: '-' を '+' に、'_' を '/' に戻す
string base64 = urlSafeBase64.Replace('-', '+').Replace('_', '/');
// パディングの補完: 長さが4の倍数になるように '=' を追加
switch (base64.Length % 4)
{
case 2: base64 += "=="; break;
case 3: base64 += "="; break;
}
byte[] data = Convert.FromBase64String(base64);
return Encoding.UTF8.GetString(data);
}Web APIから渡されるトークン(JWTなど)を自前で解析する場合、この処理は必須となります。
パディングの補完を忘れるとデコード時に例外が発生するため、注意が必要です。
パフォーマンスを意識したデコード手法
大量のデータや、高頻度で実行される処理において、文字列の生成やアロケーション(メモリ確保)はパフォーマンスのボトルネックになります。
最新のC#(.NET 6/7/8以降)では、Span<T>やReadOnlySpan<T>を活用することで、より効率的なデコードが可能です。
Span<T> を利用したメモリ効率の良いデコード
System.Buffers.Text.Base64クラスを使用すると、バイト配列からバイト配列へ、中間的な文字列を生成することなく直接デコードできます。
using System;
using System.Buffers.Text;
using System.Text;
public class PerformanceExample
{
public static void EfficientDecode(string base64Input)
{
// 入力文字列を読み取り専用スパンとして扱う
ReadOnlySpan<char> base64Span = base64Input.AsSpan();
// デコード後の最大サイズを見積もる
int maxByteLength = (base64Input.Length * 3 + 3) / 4;
Span<byte> buffer = stackalloc byte[maxByteLength]; // 小さなデータならスタック割り当て
// Base64デコードを実行
if (Convert.TryFromBase64String(base64Input, buffer, out int bytesWritten))
{
// デコード成功
string result = Encoding.UTF8.GetString(buffer.Slice(0, bytesWritten));
Console.WriteLine($"デコード成功: {result}");
}
}
}stackallocを利用することで、ヒープメモリへの負担を減らし、ガベージコレクション(GC)の発生を抑制できます。
これは、リアルタイム性が求められるサーバーサイドの処理などで非常に有効なテクニックです。
よくあるエラーとトラブルシューティング
Base64デコードを実装している際に出会う代表的なエラーとその対処法をまとめました。
1. FormatException: 「入力は有効な Base-64 文字列ではありません」
このエラーは、Base64の仕様に反する文字が含まれている場合や、パディングが不足している場合に発生します。
- 原因1:空白や改行が含まれている
メールソフトなどからコピーしたデータには改行が含まれることがあります。
base64.Trim()や、改行コードの除去を試してください。- 原因2:URLセーフ文字の混入
前述の通り、
-や_が含まれていないか確認してください。- 原因3:データが欠けている
末尾の
=が削られているとこのエラーになります。
2. 文字化け(「?」や「」の表示)
これはデコード処理そのものの失敗ではなく、デコード後の解釈ミスです。
データの作成元がUTF-8 なのか Shift-JIS なのか、あるいは UTF-16 なのかを再確認してください。
もしバイナリデータ(画像やPDF)を無理やり文字列としてデコードしようとしているなら、それは根本的に不可能な操作です。
3. メモリ不足(OutOfMemoryException)
非常に巨大なファイルをBase64文字列として一度にメモリに読み込むと発生します。
巨大なデータを扱う場合は、CryptoStreamやFromBase64Transformを使用して、ストリーム形式で逐次デコードすることを検討してください。
まとめ
C#でBase64をデコードして文字列に変換する作業は、一見単純ですが、実は「バイト配列への変換」と「適切なエンコーディングの適用」という2つの重要な工程で成り立っています。
基本的にはConvert.FromBase64StringとEncoding.UTF8.GetStringを組み合わせるだけで十分ですが、URLセーフな文字列への対応や、パフォーマンスを重視したSpan<T>の活用など、状況に応じた最適な手法を選択できることがプロフェッショナルな実装への近道です。
文字化けに遭遇したときは、まず「元データは何の文字コードでバイト化されたのか」という原点に立ち返ってみてください。
この記事で紹介した手法をマスターすれば、もうC#のBase64処理で迷うことはないでしょう。
確実なデコード処理を実装し、堅牢なアプリケーションを構築してください。
