
C#を利用してアプリケーションを開発する際、画像データや暗号化されたバイナリデータをテキスト形式で扱いたい場面が多々あります。
そのような時に欠かせない技術がBase64エンコード・デコードです。
Base64は、バイナリデータを64種類の英数字のみを用いて表現する手法であり、通信プロトコル上の制約を回避したり、JSONやXMLの中にデータを埋め込んだりする際に非常に重宝されます。
本記事では、C#の標準ライブラリを用いた基本的な実装方法から、モダンなC#でのパフォーマンスを意識した手法、実戦で役立つURLセーフな変換方法までを詳しく解説します。
Base64の基本概念とC#での役割
Base64とは、すべてのデータを「A-Z」、「a-z」、「0-9」、「+」、「/」の64種類の文字と、パディング(埋め合わせ)用の「=」のみを使って表現するエンコード方式です。
コンピュータが扱うデータは本来バイナリ(0と1の羅列)ですが、メール送信やWeb APIなどのテキストベースの通信では、特定のバイナリ値が制御文字として誤認されるリスクがあります。
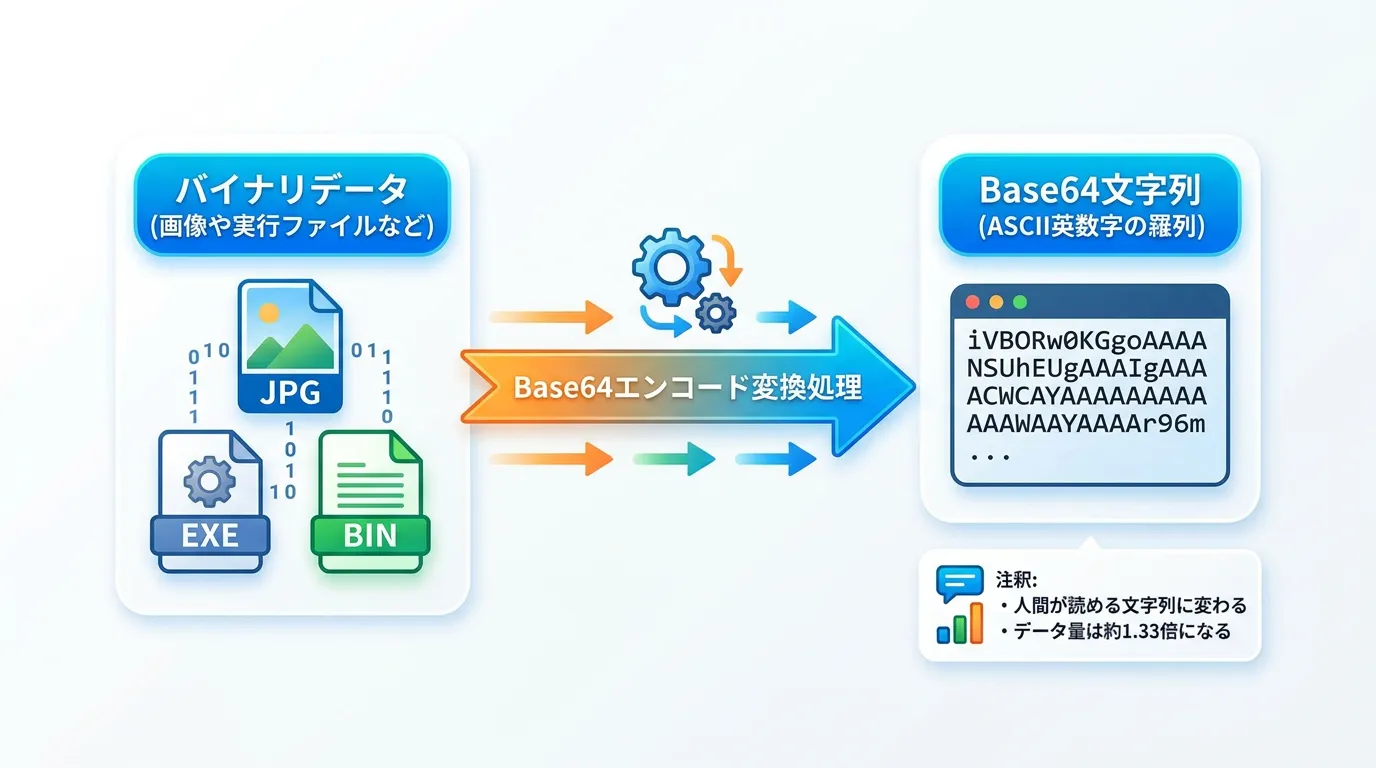
Base64を利用することで、どのようなデータも「純粋なテキストデータ」として安全にやり取りできるようになります。
C#においては、System.Convertクラスを使用するのが最も一般的で簡単な方法です。
C#でBase64エンコードを行う基本手順
C#でデータをBase64に変換する場合、対象が「文字列」であっても「ファイル」であっても、最終的には一度byte[](バイト配列)にする必要があります。
Convert.ToBase64Stringメソッドの使い方
最も標準的な方法は、System.Convert.ToBase64Stringメソッドを使用することです。
このメソッドは、引数として渡されたバイト配列を即座にBase64文字列へ変換します。
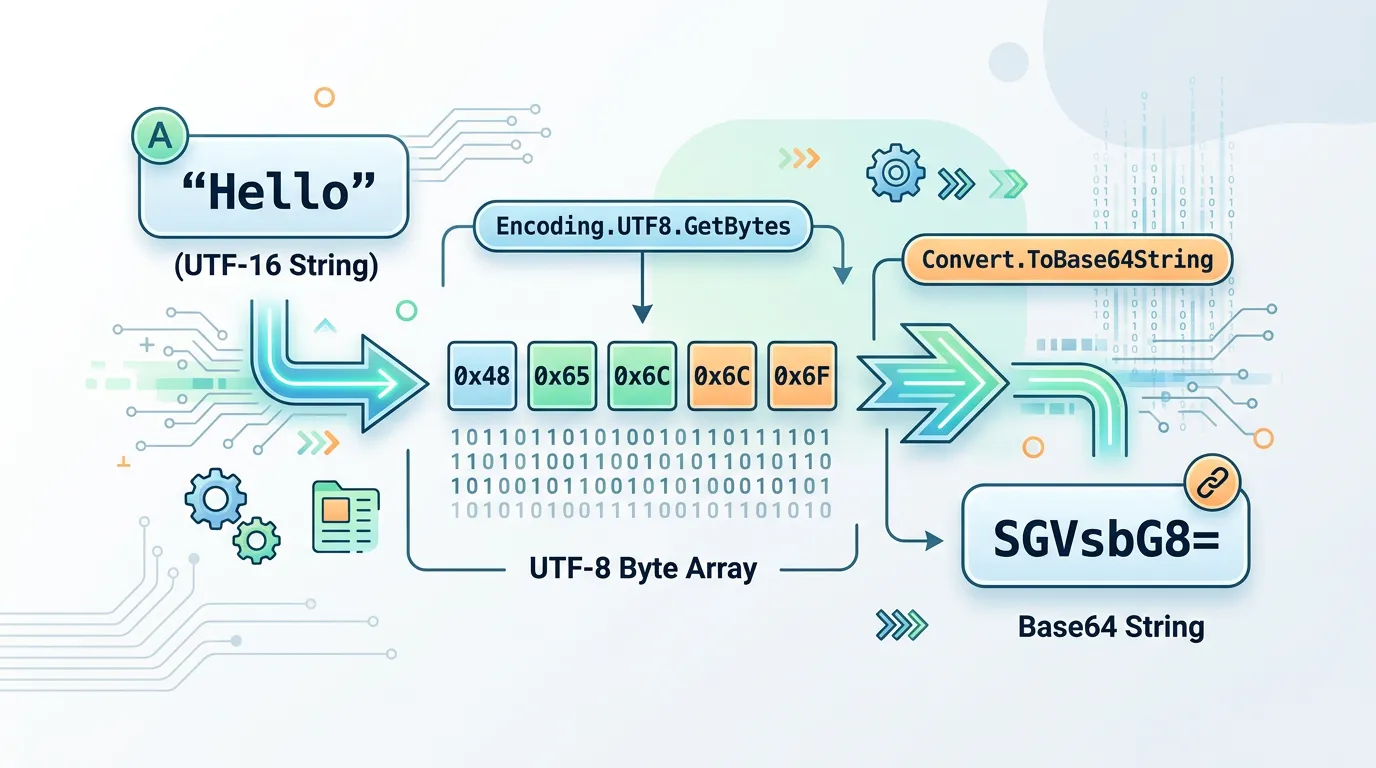
以下に、文字列をBase64にエンコードする具体的なサンプルコードを示します。
using System;
using System.Text;
class Program
{
static void Main()
{
// エンコード対象の文字列
string originalText = "C#でBase64を学ぼう!";
// 1. 文字列をバイト配列に変換 (UTF-8エンコーディングを使用)
byte[] byteData = Encoding.UTF8.GetBytes(originalText);
// 2. バイト配列をBase64文字列に変換
string base64String = Convert.ToBase64String(byteData);
Console.WriteLine("元の文字列: " + originalText);
Console.WriteLine("Base64文字列: " + base64String);
}
}元の文字列: C#でBase64を学ぼう!
Base64文字列: QyPjga9CYXNlNjTjgpLlrablvproG78=C#の文字列は内部的にUnicode(UTF-16)で保持されているため、バイト配列に変換する際は適切なエンコーディング(通常はUTF-8)を指定することが非常に重要です。
C#でBase64デコードを行う基本手順
デコード(復元)はエンコードの逆の手順を踏みます。
Base64文字列をバイト配列に戻し、そのバイト配列を元のデータ形式(文字列やファイル)に変換します。
Convert.FromBase64Stringメソッドの使い方
デコードには、System.Convert.FromBase64Stringメソッドを使用します。
このメソッドは、無効な文字が含まれている場合やパディングが正しくない場合にFormatExceptionをスローするため、例外処理を考慮するのが一般的です。
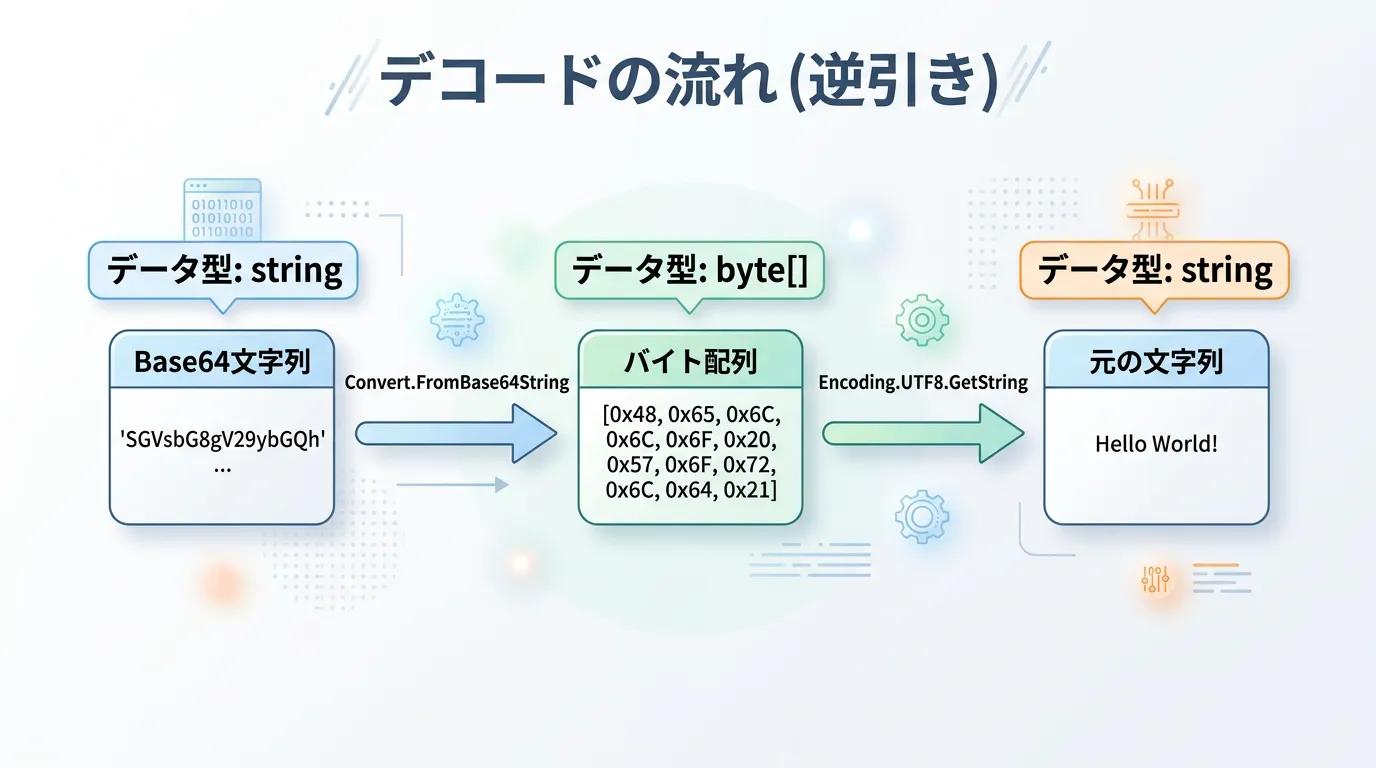
using System;
using System.Text;
class Program
{
static void Main()
{
// デコード対象のBase64文字列
string base64Input = "QyPjgadCYXNlNjTjgpLlrabjgbzjgYbvvIE=";
try
{
// 1. Base64文字列をバイト配列に復元
byte[] decodedBytes = Convert.FromBase64String(base64Input);
// 2. バイト配列を元の文字列に変換 (UTF-8を使用)
string decodedText = Encoding.UTF8.GetString(decodedBytes);
Console.WriteLine("デコード後の文字列: " + decodedText);
}
catch (FormatException)
{
Console.WriteLine("無効なBase64文字列です。");
}
}
}デコード後の文字列: C#でBase64を学ぼう!もし、デコード対象の文字列に空白や改行が含まれている可能性がある場合は、事前にReplace("\n", "").Trim()などでクリーニングを行うとエラーを防ぎやすくなります。
ファイルをBase64に変換する方法
画像などのバイナリファイルをBase64にするケースも多いでしょう。
例えば、HTMLの<img>タグに画像を直接埋め込む(Data URI Scheme)場合などに利用します。
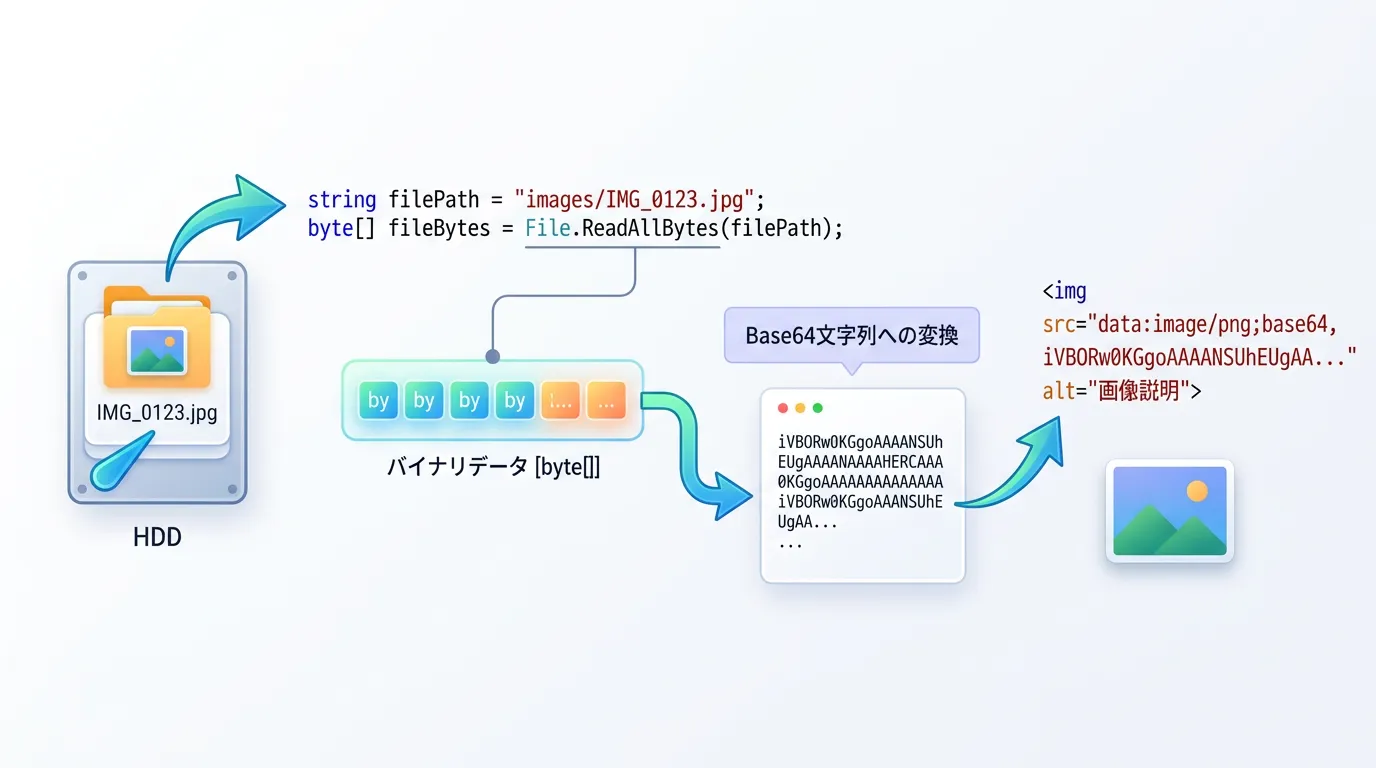
using System;
using System.IO;
class FileToBase64
{
public static void EncodeFile(string filePath)
{
if (File.Exists(filePath))
{
// ファイルをすべてバイト配列として読み込む
byte[] fileBytes = File.ReadAllBytes(filePath);
// Base64に変換
string base64String = Convert.ToBase64String(fileBytes);
// 先頭の一部だけ表示
Console.WriteLine("Base64(先頭50文字): " + base64String.Substring(0, 50) + "...");
}
}
}ファイルを扱う場合は、メモリ消費量に注意が必要です。
File.ReadAllBytesはファイル全体を一度にメモリへ読み込むため、巨大な動画ファイルなどを変換しようとすると、メモリ不足(OutOfMemoryException)が発生する恐れがあります。
大容量ファイルを扱う場合は、ストリームを用いて分割処理を行うことを検討してください。
URLセーフなBase64エンコードの作成
標準的なBase64には、「+」や「/」といった文字が含まれます。
これらはURLのクエリパラメータとして使用すると特別な意味を持ってしまう(あるいはエンコードが必要になる)ため、Web開発では不都合が生じることがあります。
そこで一般的に行われるのが、URLセーフ(URL Safe)なBase64への変換です。
| 標準Base64の文字 | 置換後の文字 | 理由 |
|---|---|---|
| + | – (ハイフン) | URLエンコードを避けるため |
| / | _ (アンダースコア) | パス区切り文字との混同を避けるため |
| = | (除去) | 末尾のパディングは省略可能 |
以下に、URLセーフなBase64を相互変換するユーティリティコードを紹介します。
using System;
public static class Base64UrlConverter
{
// エンコード:標準Base64をURLセーフに変換
public static string ToBase64Url(byte[] data)
{
string base64 = Convert.ToBase64String(data);
return base64.Replace("+", "-").Replace("/", "_").TrimEnd('=');
}
// デコード:URLセーフBase64を標準に戻してデコード
public static byte[] FromBase64Url(string base64Url)
{
string base64 = base64Url.Replace("-", "+").Replace("_", "/");
// パディングの復元 (4の倍数になるように'='を補完)
switch (base64.Length % 4)
{
case 2: base64 += "=="; break;
case 3: base64 += "="; break;
}
return Convert.FromBase64String(base64);
}
}この手法は、JWT(JSON Web Token)などのモダンなWeb技術でも標準的に採用されている仕様です。
パフォーマンスを追求する:Span<T>とBase64
高頻度で変換処理を行うサーバーサイドアプリケーションなどでは、Convert.ToBase64Stringによる新しい文字列生成のオーバーヘッドが無視できない場合があります。
最新のC#(.NET Core 2.1以降)では、Span<T>を活用して、メモリ割り当て(アロケーション)を最小限に抑えることが可能です。
System.Buffers.Text.Base64クラスを利用すると、バイト配列からバイト配列へ、文字列を介さずに直接変換できます。
using System;
using System.Buffers.Text;
using System.Text;
class HighPerformanceBase64
{
public void Execute()
{
byte[] sourceBytes = Encoding.UTF8.GetBytes("高速変換のテスト");
// 必要なバッファサイズを計算
int expectedSize = Base64.GetMaxEncodedToUtf8Length(sourceBytes.Length);
Span<byte> destination = stackalloc byte[expectedSize];
// UTF-8バイトとしてエンコード(文字列を生成しない)
if (Base64.EncodeToUtf8(sourceBytes, destination, out int bytesConsumed, out int bytesWritten) == OperationStatus.Done)
{
Console.WriteLine($"エンコード成功: {bytesWritten}バイト書き込み");
}
}
}stackallocを用いることで、ヒープメモリを汚さずにスタック上で高速に処理を完結させることができます。
これは、超高並列なWebサーバーなどでスループットを向上させるための重要なテクニックです。
Base64利用時の注意点とベストプラクティス
Base64は非常に便利ですが、銀の弾丸ではありません。
利用にあたっては以下の点に留意してください。
1. データサイズの増大
Base64エンコードを行うと、元のバイナリデータよりもサイズが約33%増加します。
モバイル通信など帯域が限られている環境で大量のデータをBase64で送る際は、この増分を考慮する必要があります。
2. 暗号化ではない
Base64は単なる「データ形式の変換」であり、暗号化ではありません。
誰でも簡単にデコードできるため、機密情報をパスワードなしでBase64化して保持するのは絶対に避けましょう。
機密データを扱う場合は、必ずAESなどの暗号化アルゴリズムと併用してください。
3. 文字コードの不一致
デコード時に「文字化け」が発生する最大の原因は、エンコード時とデコード時で異なるEncoding(UTF-8、Shift-JISなど)を使用していることです。
現代の開発では、特別な理由がない限りEncoding.UTF8に統一することを強く推奨します。

まとめ
C#におけるBase64エンコード・デコードは、System.Convertクラスを利用することで非常にシンプルに実装できます。
文字列を扱う際はEncoding.UTF8によるバイト配列化を忘れずに行い、Web用途ではURLセーフな変換を適用するのが定石です。
また、近年の.NETではSpan<T>を活用した低アロケーションな手法も提供されており、用途に応じて最適な方法を選択することが可能です。
Base64は単なるデータ変換であり、セキュリティ機能は持たないという特性を正しく理解した上で、効率的なデータ受け渡しに活用していきましょう。
今回の解説が、皆様のC#開発におけるデータ処理の一助となれば幸いです。
