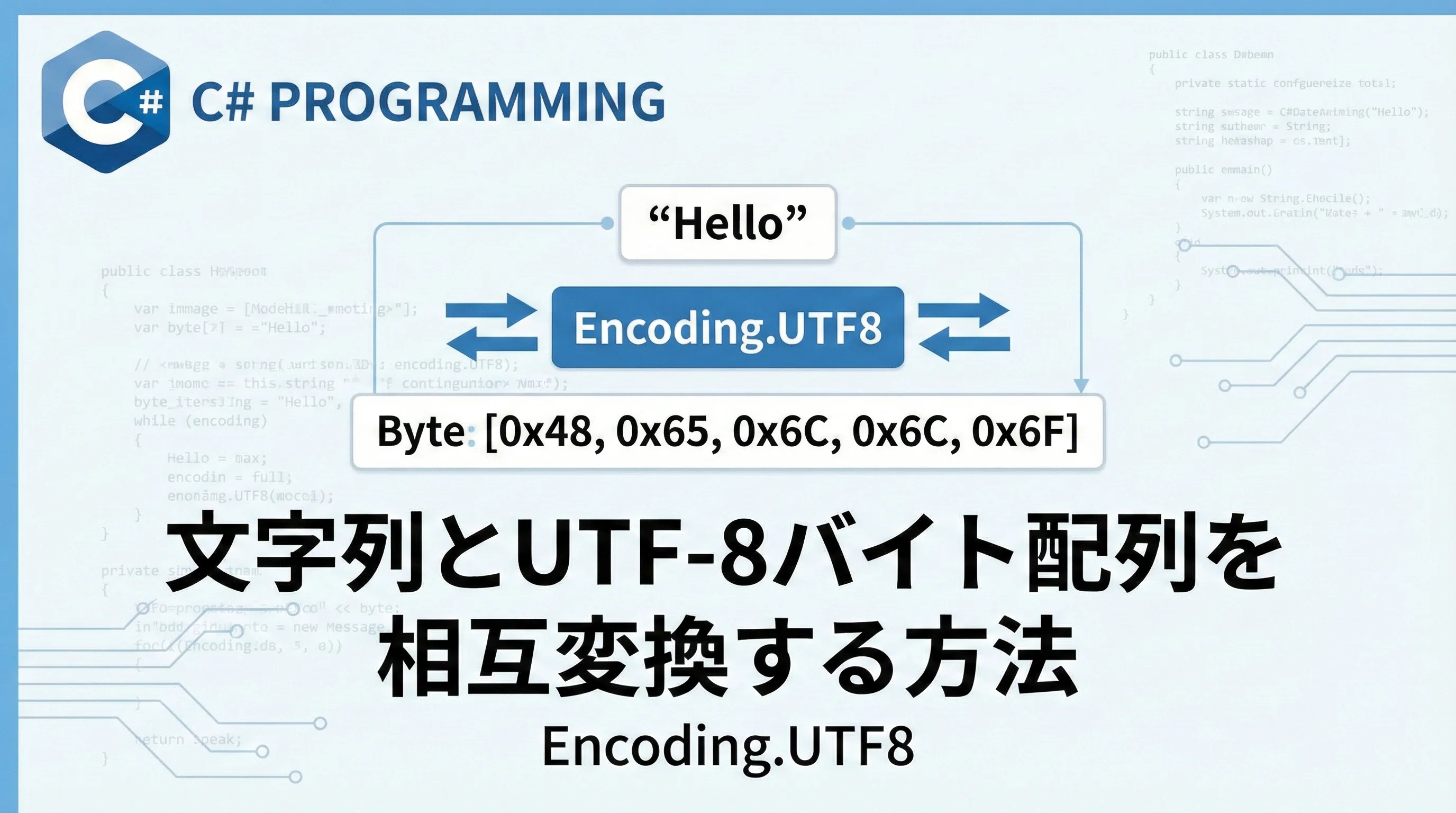
C#において、文字列は内部的にUTF-16形式で保持されています。
しかし、Web APIとの通信、データベースへの保存、あるいはテキストファイルの書き出しといった場面では、世界標準であるUTF-8形式のバイト配列に変換して扱うのが一般的です。
本記事では、C#で文字列とUTF-8バイト配列を相互変換する基本的な方法から、パフォーマンスを意識した最新の書き方までを詳しく解説します。
文字列とバイト配列の変換が必要な理由
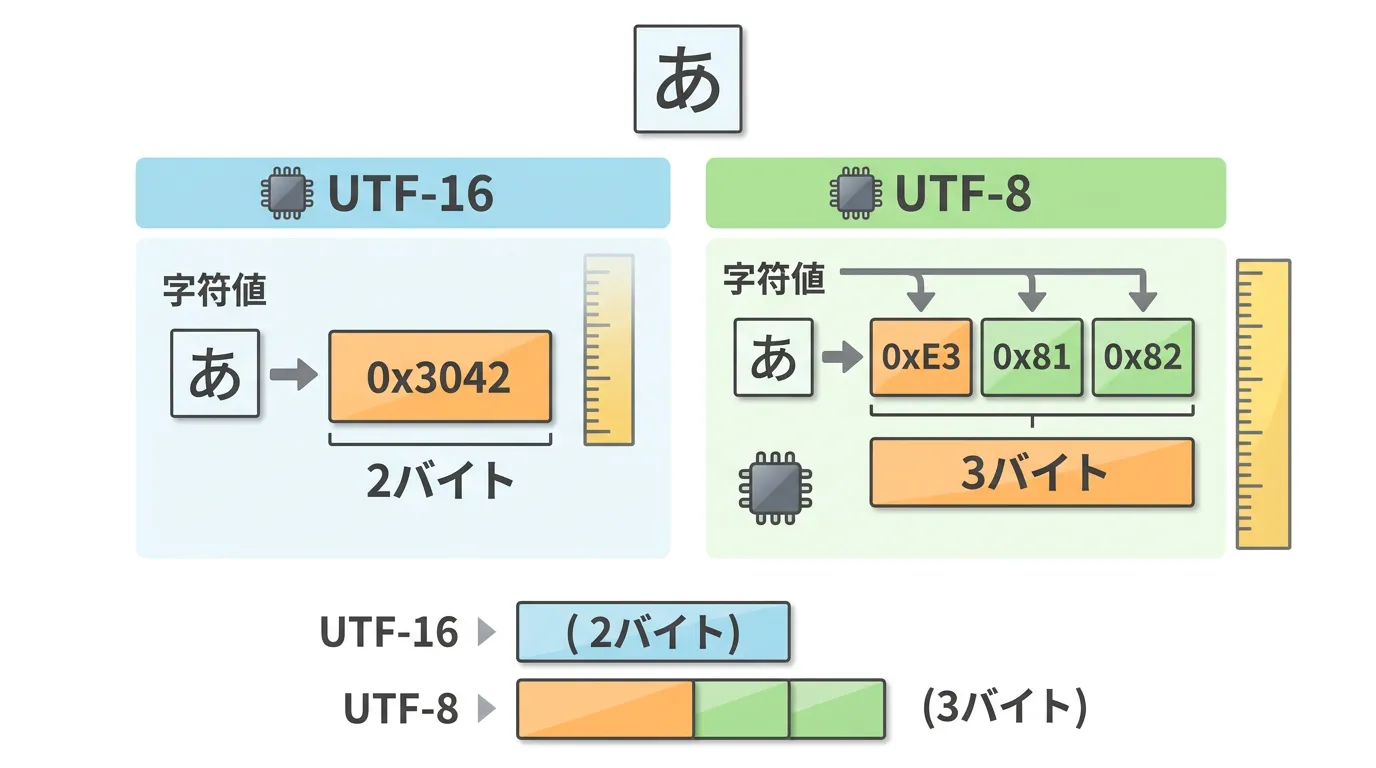
C#のstring型は、Unicodeの文字を16ビット(2バイト)単位で扱うUTF-16を採用しています。
一方で、インターネット上のデータの多くは、1文字を1~4バイトの可変長で表現するUTF-8でやり取りされます。
この「内部的な形式」と「外部とのやり取りの形式」の橋渡しをするのが、エンコーディング(符号化)というプロセスです。
文字列からUTF-8バイト配列への変換
文字列をバイト配列に変換することを「エンコード」と呼びます。
C#でこれを行う最も一般的かつ標準的な方法は、System.Text.Encoding.UTF8.GetBytesメソッドを使用することです。
Encoding.UTF8.GetBytesの基本
このメソッドは、引数に指定した文字列を解析し、UTF-8形式のbyte[]として返却します。
using System;
using System.Text;
class Program
{
static void Main()
{
// 変換対象の文字列
string sourceString = "こんにちは、C#!";
// 文字列をUTF-8バイト配列に変換
// Encoding.UTF8プロパティを使用するのが一般的です
byte[] utf8Bytes = Encoding.UTF8.GetBytes(sourceString);
// 結果の出力
Console.WriteLine("元の文字列: " + sourceString);
Console.WriteLine("バイト配列の長さ: " + utf8Bytes.Length);
Console.WriteLine("16進数表記: " + BitConverter.ToString(utf8Bytes));
}
}元の文字列: こんにちは、C#!
バイト配列の長さ: 22
16進数表記: E3-81-93-E3-82-93-E3-81-AB-E3-81-A1-E3-81-AF-E3-80-81-43-23-EF-BC-81上記の結果からわかるように、日本語(全角文字)はUTF-8では1文字あたり3バイトとして扱われ、半角英数字の「C」や「#」は1バイトとして変換されています。
パフォーマンスを考慮した変換
大量のデータを扱う場合や、高頻度で変換を行うループ内では、新しい配列を毎回作成するGetBytesはメモリ割り当て(アロケーション)の負荷が無視できません。
その場合、Span<byte>を使用して、あらかじめ確保したバッファに書き込む方法が有効です。
using System;
using System.Text;
class Program
{
static void Main()
{
string text = "高速な変換";
// 必要なバイト数を計算
int byteCount = Encoding.UTF8.GetByteCount(text);
// stackallocを使ってスタック領域にバッファを確保(短尺文字列の場合)
Span<byte> buffer = stackalloc byte[byteCount];
// バッファに直接書き込み
int written = Encoding.UTF8.GetBytes(text, buffer);
Console.WriteLine($"書き込まれたバイト数: {written}");
}
}UTF-8バイト配列から文字列への変換
バイト配列を文字列に戻すことを「デコード」と呼びます。
これは、ファイルから読み込んだデータや、ネットワークから受信したバイナリデータをプログラムで扱えるテキスト形式に直す際に使用します。
Encoding.UTF8.GetStringの基本
逆の変換には、Encoding.UTF8.GetStringメソッドを使用します。
using System;
using System.Text;
class Program
{
static void Main()
{
// UTF-8形式のバイト配列(「C#」という文字列)
byte[] utf8Bytes = { 0x43, 0x23 };
// バイト配列を文字列にデコード
string result = Encoding.UTF8.GetString(utf8Bytes);
Console.WriteLine("復元された文字列: " + result);
}
}復元された文字列: C#部分的な変換
大きなバイト配列の一部だけを文字列に変換したい場合は、オフセット(開始位置)と長さを指定するオーバーロードを使用します。
// バイト配列の2番目の要素から3バイト分だけを変換する例
string partialText = Encoding.UTF8.GetString(utf8Bytes, 2, 3);高度な変換手法:System.Text.Unicode.Utf8
最新のC#(.NET 8以降など)では、System.Text.Unicode.Utf8静的クラスを利用することで、より低レベルかつ高速な変換が可能です。
これは特にSpanやReadOnlySpanを多用するシステムプログラミングにおいて威力を発揮します。
using System;
using System.Text.Unicode;
class Program
{
static void Main()
{
string source = "Advanced C#";
ReadOnlySpan<char> sourceSpan = source.AsSpan();
// 変換先のバッファを準備
Span<byte> destination = new byte[32];
// Utf8.FromUtf16を使用して変換
var status = Utf8.FromUtf16(sourceSpan, destination, out int charsRead, out int bytesWritten);
if (status == System.Buffers.OperationStatus.Done)
{
Console.WriteLine($"変換成功: {bytesWritten}バイト書き込み");
}
}
}この方法は、例外をスローせずにステータスコードを返すため、パフォーマンスが極めて重要なパスに適しています。
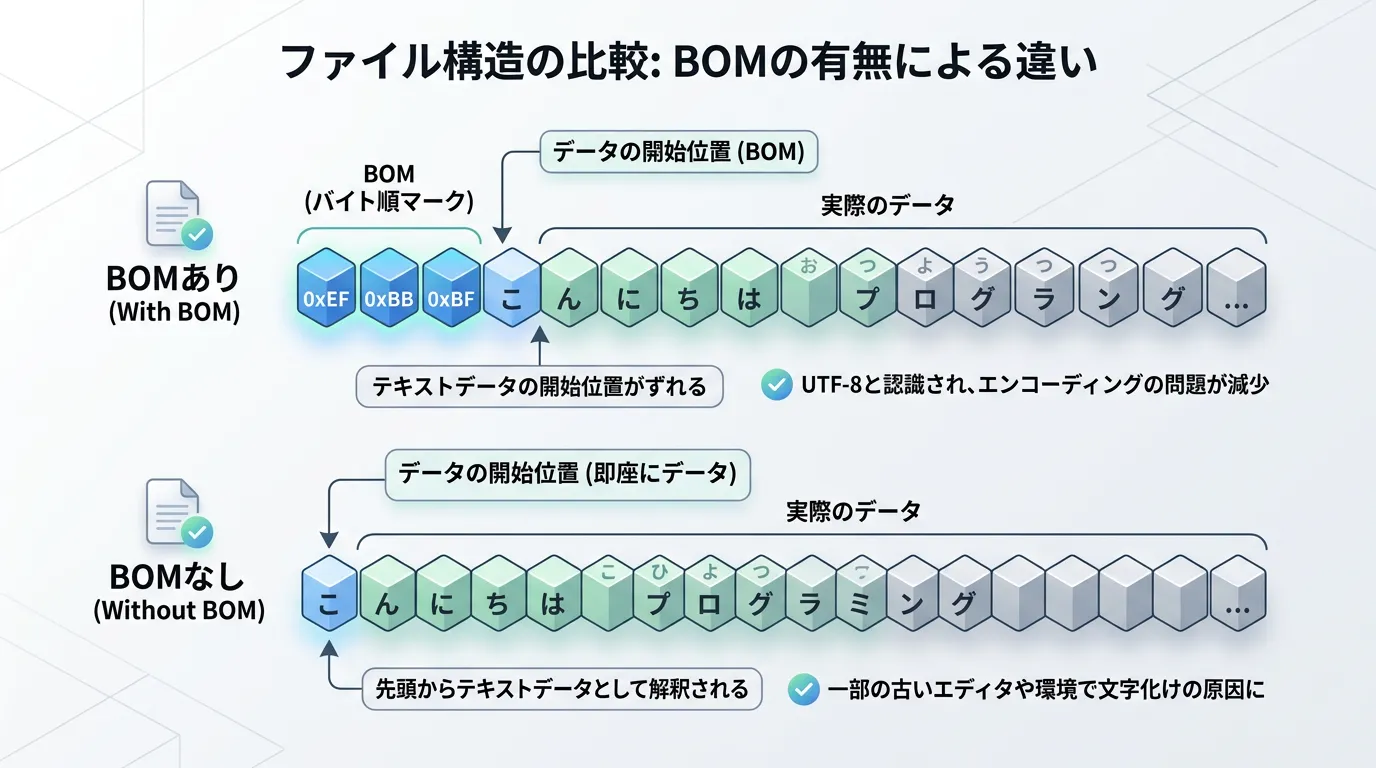
BOM(Byte Order Mark)の取り扱い
UTF-8には、ファイルの先頭に「これはUTF-8ファイルです」という印を付けるBOM(バイトオーダーマーク)という仕組みがあります。
| プロパティ名 | BOMの有無 | 主な用途 |
|---|---|---|
Encoding.UTF8 | 無し(デフォルト) | Web API、一般的な通信、モダンなエディタ |
new UTF8Encoding(true) | 有り | Windowsの古いソフトウェアとの互換性 |
注意点として、Encoding.UTF8.GetBytesはBOMを付与しません。
BOM付きのデータを作成したい場合は、Encoding.GetPreamble()メソッドでBOMのバイト配列を取得し、手動でデータの先頭に結合する必要があります。
不正な文字の扱い
変換対象の文字列に壊れたサロゲートペアが含まれている場合や、バイト配列に不正なシーケンスが含まれている場合、デフォルトでは「」(置換文字)に置き換えられます。
厳格なチェックが必要な場合は、EncoderFallbackを設定して例外を発生させることも可能です。
// 不正な文字があった場合に例外を投げるエンコーディングの設定
var strictEncoding = new UTF8Encoding(false, true);
try
{
// 不正なバイト列の例
byte[] invalidBytes = { 0xFF, 0xFE };
string result = strictEncoding.GetString(invalidBytes);
}
catch (DecoderFallbackException ex)
{
Console.WriteLine("不正な文字を検知しました: " + ex.Message);
}C#で文字列とUTF-8バイト配列を変換する際は、以下のポイントを押さえておきましょう。
文字列のエンコード・デコードには、Encoding.UTF8.GetBytesおよびEncoding.UTF8.GetStringを基本として使用します。
メモリ効率が重要なパフォーマンスが求められる場面では、Span<T>を活用したバッファへの直接的な書き込みを検討してください。
Web環境では「BOMなし」が標準ですが、特定のWindowsレガシーアプリケーションなどでは「BOMあり」のエンコーディングが必要となるケースがあるため注意してください。
日本語などのマルチバイト文字を扱う際、UTF-8では1文字あたり3バイト(絵文字等の場合は4バイト)を消費することを設計時に念頭に置いてください。
これらの知識を使い分けることで、堅牢かつ高速なデータ処理を実装することができます。
データの入出力が発生するプログラムにおいて、文字エンコーディングの正しい理解は欠かせないスキルです。
まとめ
C#における文字列とUTF-8バイト配列の変換は、現代のアプリケーション開発において避けては通れない基本操作です。
標準的なEncoding.UTF8クラスの利用から、最新のSpan<T>を用いた高効率な手法まで、用途に合わせて最適な手段を選択することが重要です。
特にネットワークを介した通信や大規模なファイル処理では、アロケーションを抑える設計がパフォーマンスに直結します。
本記事で紹介した手法を参考に、正確で効率の良い文字列操作をマスターしてください。
BOMの有無やサロゲートペアの扱いなど、細かな仕様に気を配ることで、文字化けトラブルのない堅牢なシステムを構築できるはずです。
