C#で文字列を処理する際、見た目は全く同じなのに、比較演算子で比較すると「一致しない」と判定される不可解な現象に遭遇したことはないでしょうか。
特に日本語の「濁点」を含む文字(「が」や「ぱ」など)を扱う場合、この問題は顕著に現れます。
これは、Unicodeにおける「正規化形式」の差異が原因です。
macOSから転送されたファイル名や、特定の入力フォームから送信されたデータには、濁点が分離した状態の文字が含まれていることがあります。
本記事では、C#のString.Normalizeメソッドを駆使して、これらの濁点分離問題をスマートに解決し、堅牢な文字列操作を実現する方法を詳しく解説します。
Unicode正規化と濁点分離のメカニズム
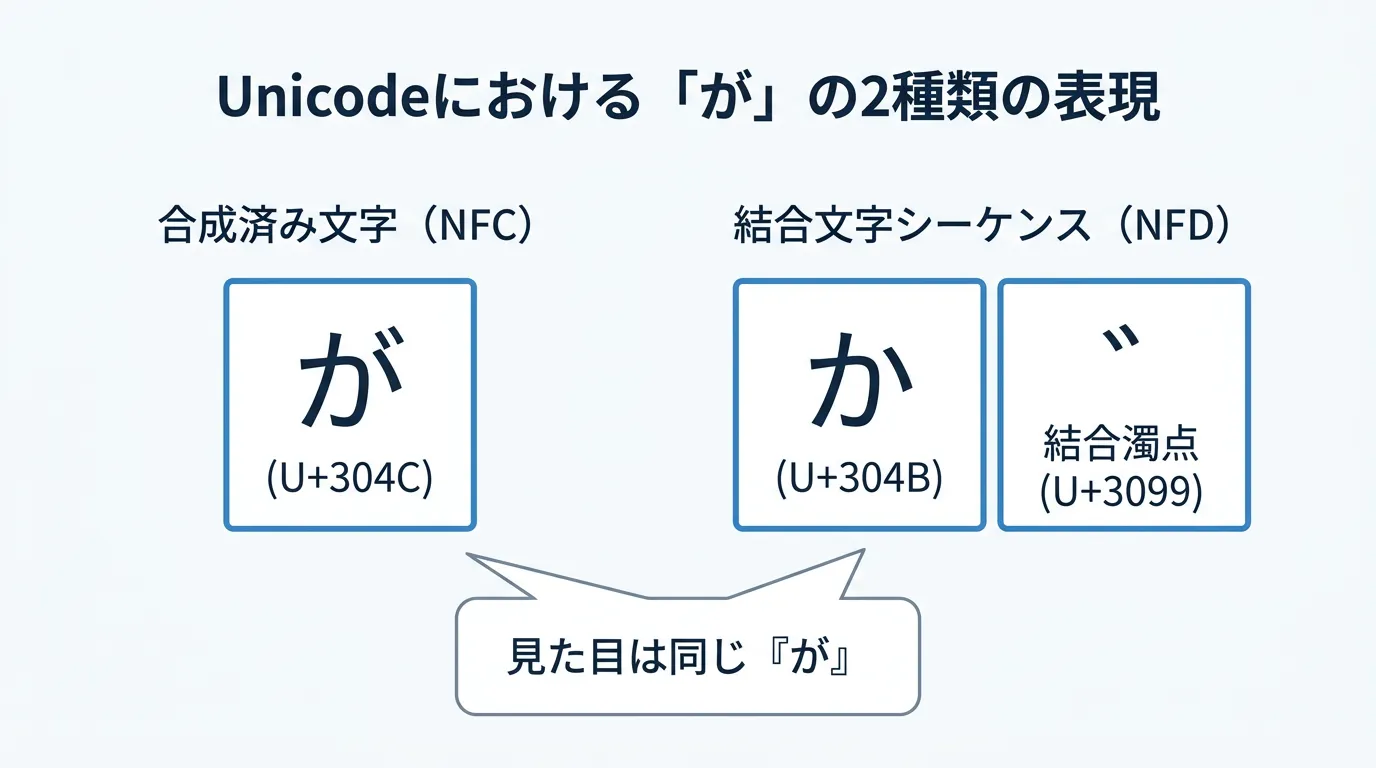
日本語の文字を扱う上で避けて通れないのが、Unicodeにおける「結合文字」の存在です。
私たちが普段目にする「が」という文字は、内部的なデータ構造として1つの文字として保持される場合と、基底文字「か」と結合用濁点「゛」の2つに分かれて保持される場合があります。
なぜ濁点が分離するのか
この現象が起こる主な理由は、システムの設計思想の違いにあります。
特に有名なのが、macOS(旧HFS+ファイルシステム)の仕様です。
macOSではファイル名を保存する際、文字を極力分解して保存する「NFD (Normalization Form D)」に近い形式を採用してきました。
一方で、Windowsや一般的なWebサイトの入力フォームでは、1文字にまとめられた「NFC (Normalization Form C)」が主流です。
このため、Macで作成された「がぎぐげご.txt」というファイルをWindowsで読み込むと、見た目は同じでもバイナリデータとしては「か+゛」「き+゛」…となっており、単純な文字列比較が失敗する原因となります。
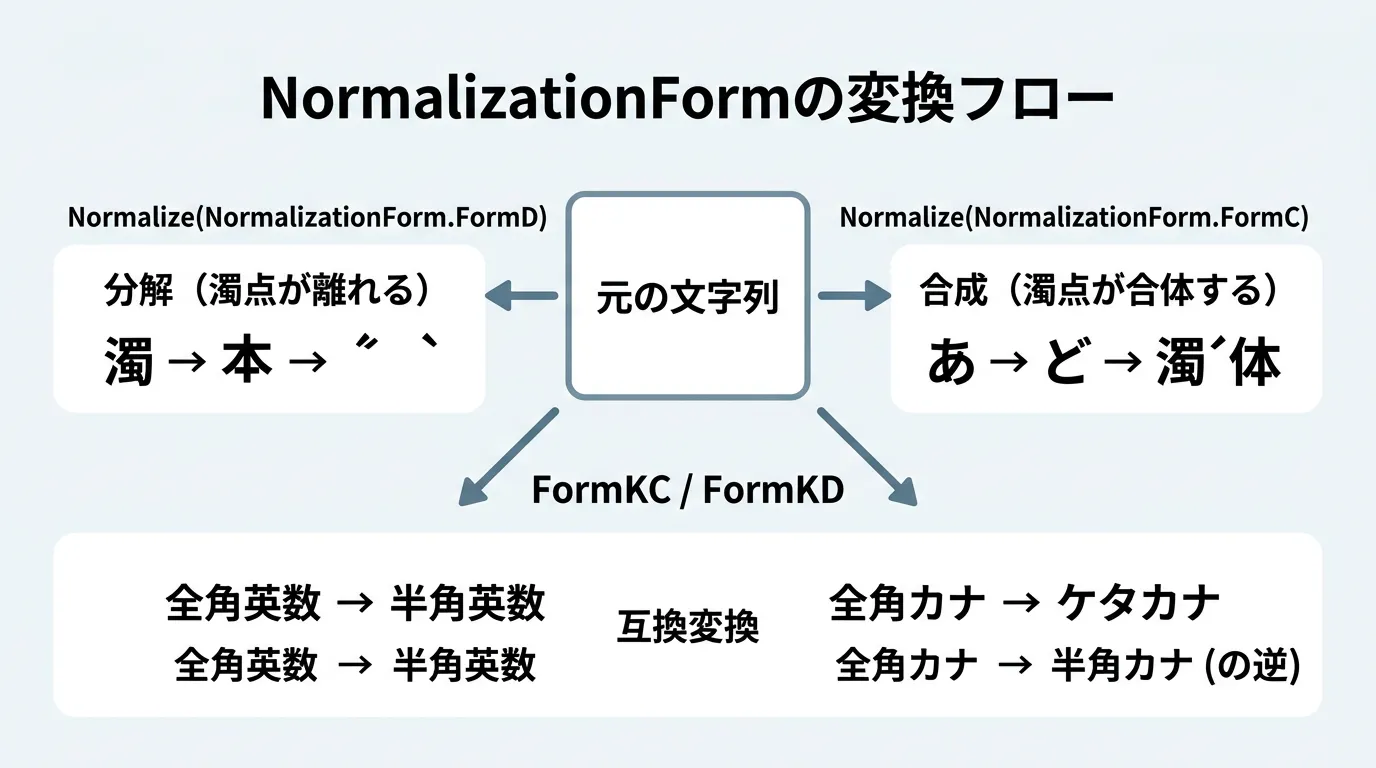
四種類の正規化形式
C#のNormalizeメソッドでは、NormalizationForm列挙型を使用して、以下の4つの形式を指定できます。
| 形式 | 名称 | 説明 |
|---|---|---|
| FormC | 正準等価性による合成 | 結合文字を可能な限り1つの文字に合成します(一般的)。 |
| FormD | 正準等価性による分解 | 文字を基底文字と結合文字に分解します。 |
| FormKC | 互換等価性による合成 | 全角・半角の差異などを統合した上で、FormCを適用します。 |
| FormKD | 互換等価性による分解 | 全角・半角の差異などを統合した上で、FormDを適用します。 |
C#におけるString.Normalizeの実装方法
C#で文字列を正規化するには、stringクラスのインスタンスメソッドであるNormalize()を呼び出します。
引数を省略した場合は、デフォルトでFormC(合成)が適用されます。
基本的な正規化コードの例
以下のサンプルプログラムでは、意図的に作成した「分離した濁点」を持つ文字列を、正規化によって1つの文字に統合する過程を示します。
using System;
using System.Text;
class Program
{
static void Main()
{
// 1. 合成済み文字の「が」 (U+304C)
string nfcString = "が";
// 2. 分解された状態の「か」+「゛」 (U+304B + U+3099)
// \u3099 は結合用濁点です
string nfdString = "か\u3099";
// 見た目の出力(どちらも「が」に見える)
Console.WriteLine($"NFC文字列: {nfcString}");
Console.WriteLine($"NFD文字列: {nfdString}");
// 長さを比較(NFCは1文字、NFDは2文字になる)
Console.WriteLine($"NFCの長さ: {nfcString.Length}");
Console.WriteLine($"NFDの長さ: {nfdString.Length}");
// 単純比較は false になる
Console.WriteLine($"比較 (そのまま): {nfcString == nfdString}");
// NormalizeメソッドでNFCに統一
string normalizedString = nfdString.Normalize();
// 正規化した後の比較は true になる
Console.WriteLine($"正規化後の長さ: {normalizedString.Length}");
Console.WriteLine($"比較 (正規化後): {nfcString == normalizedString}");
}
}NFC文字列: が
NFD文字列: が
NFCの長さ: 1
NFDの長さ: 2
比較 (そのまま): False
正規化後の長さ: 1
比較 (正規化後): TrueNormalizationForm列挙型の活用
特定の正規化形式を明示的に指定する場合は、System.Text.NormalizationFormを引数に渡します。
FormD(分解)を使用する場合
あえて濁点を切り離したい場合はFormDを使用します。
これは、文字列から濁点だけを除去したい場合などの前処理として利用されることがあります。
string text = "デジカメ";
// 分解を実行
string decomposed = text.Normalize(NormalizationForm.FormD);
// 分解された状態だと、濁点部分だけを取り出すなどの操作が可能
foreach (char c in decomposed)
{
Console.WriteLine($"文字: {c} (U+{(int)c:X4})");
}文字: テ (U+30C6)
文字: ゙ (U+3099)
文字: シ (U+30B7)
文字: ゙ (U+3099)
文字: カ (U+30AB)
文字: メ (U+30E1)実践的な活用シーン:ユーザー入力のクレンジング
システムの外部から入力される文字列は、必ずしも期待した形式であるとは限りません。
特に「検索機能」や「ID照合」を実装する場合、正規化を行わないと「登録されているのに検索にヒットしない」といった致命的なバグを招きます。
検索エンジンにおける正規化の重要性
ユーザーがMacからアップロードしたファイル名が「レポート.pdf」だったとします。
これをサーバー側(LinuxやWindows)で保存し、後にユーザーがWindows端末から「レポート」というキーワードで検索した場合、もしサーバー側で正規化を行わずに保存していると、検索に失敗してしまいます。
これを防ぐためには、「データ受け入れ時」または「検索クエリ発行時」のいずれかで必ず正規化を行う必要があります。
public bool IsMatch(string input, string target)
{
// 両方をNFCに正規化してから比較する
return input.Normalize() == target.Normalize();
}FormKCによる表記揺れの吸収
濁点の問題以外にも、日本語には「全角の1」と「半角の1」といった表記揺れが存在します。
NormalizationForm.FormKC(Compatibility Decomposition, followed by Canonical Composition)を使用すると、これらの互換文字も統合することができます。
string input = "C# プログラミング123"; // 全角英数と全角スペース
string normalized = input.Normalize(NormalizationForm.FormKC);
Console.WriteLine($"変換前: {input}");
Console.WriteLine($"変換後: {normalized}");変換前: C# プログラミング123
変換後: C# プログラミング123このように、FormKCを利用することで、全角英数や記号を標準的な半角(ASCII範囲)に変換し、データの一貫性を高めることが可能です。
ただし、カタカナの全角・半角変換については、プロジェクトの要件に応じて慎重に検討してください。
一般的にFormKCは「半角カタカナを全角カタカナ」に変換します。
注意点とパフォーマンス
String.Normalizeは非常に強力ですが、いくつかの注意点があります。
パフォーマンスへの影響
文字列の正規化は、文字列内の各文字を走査し、必要に応じて置換や結合を行うため、ループ内での大量実行には注意が必要です。
大量のデータを処理する場合は、あらかじめ正規化が必要かどうかをIsNormalized()メソッドでチェックすることで、不要な処理をスキップできます。
string text = "対象の文字列";
// すでにNFCであれば、Normalize()を呼ばない
if (!text.IsNormalized(NormalizationForm.FormC))
{
text = text.Normalize(NormalizationForm.FormC);
}一方向に変換できない文字
Unicode正規化は、多くの場合で可逆的ではありません。
特にFormKCやFormKDを使用した場合、一度変換すると元の「全角英数」の状態には戻せないため、元の入力を保持しておく必要があるシステムでは、検索用インデックスのみを正規化するなどの工夫が必要です。
結合文字の最大数
Unicodeの仕様上、1つの基底文字に対して複数の結合文字が付くこともあります(例:濁点とアクセント記号の両方が付く場合など)。
C#のNormalizeはこれらの複雑な仕様にも準拠していますが、あまりにも特殊な結合文字を扱う場合は、フォント側が対応していないと正しく表示されないという「見た目」の問題が発生する可能性があることも考慮しておきましょう。
まとめ
C#のString.Normalizeメソッドは、日本語特有の濁点分離問題を解決するための最も確実な手段です。
macOSとのデータのやり取りや、Webフォームからの入力値のクレンジングにおいて、正規化は必須の工程と言えます。
基本的には、文字列を比較したりデータベースに保存したりする直前にデフォルトのNormalize()(FormC)を呼び出す習慣をつけるだけで、多くのトラブルを未然に防ぐことができます。
また、表記揺れをより強力に排除したい場合はFormKCの活用も検討してください。
Unicodeの正規化を正しく理解し、ユーザーにとってストレスのない、一貫性のある文字列処理を実現しましょう。
