
C#において、文字列の長さを取得する際に最もよく使われるのはstring.Lengthプロパティです。
しかし、このプロパティが返す値が必ずしも「人間の目に見える文字の数」や「保存時のバイト数」と一致しないことをご存知でしょうか。
現代のアプリケーション開発では、多言語対応や絵文字の利用が当たり前となっており、これらの違いを正確に理解していないと思わぬバグやデータ欠損の原因となります。
本記事では、C#における「文字数(Length)」と「バイト数」の決定的な違い、そしてサロゲートペアやエンコーディングによる挙動の変化について、初心者の方でも直感的に理解できるよう詳しく解説していきます。
C#における文字列の基本構造
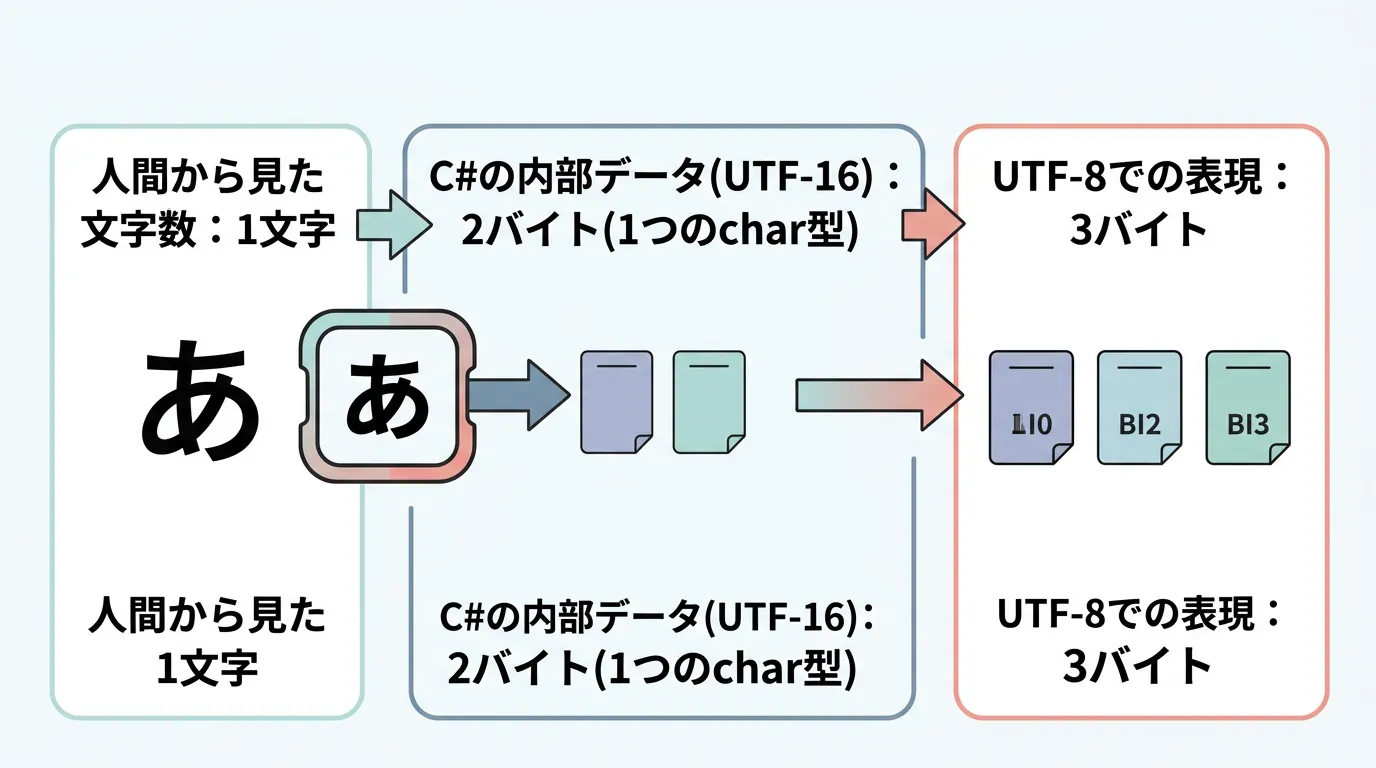
C#で扱うstring型は、内部的にはUTF-16という形式で文字を保持しています。
この基本的な性質を理解することが、文字数とバイト数の違いを紐解く第一歩となります。
UTF-16とchar型の関係
C#の文字列は、System.Char(char)のシーケンス、つまり配列のような構造になっています。
このchar型は、1つあたり2バイト(16ビット)の固定長で設計されています。
かつては「1文字=2バイト(UTF-16)」というシンプルなルールですべての文字を表現できると考えられていましたが、コンピュータで扱う文字が増えるにつれ、2バイト(65,536通り)では足りなくなってしまいました。
そこで登場したのが「サロゲートペア」という仕組みですが、これがstring.Lengthの挙動を複雑にする要因となっています。
string.Lengthが返す値の真実
多くの開発者が誤解しがちなポイントですが、string.Lengthプロパティが返しているのは「文字の数」ではなく、「保持しているcharオブジェクトの数」です。
通常の英数字や一般的なひらがな・漢字は1つのcharで表現されるため、Lengthの結果は直感と一致します。
しかし、サロゲートペアで表現される特殊な漢字や絵文字の場合、1文字を表現するのに2つのcharを使用するため、Lengthの結果は「2」となります。

バイト数の計測とエンコーディング
プログラムで「バイト数」を意識しなければならない場面の多くは、外部との通信やファイルの保存、データベースへの格納時です。
C#の内部(メモリ上)ではUTF-16で保持されていても、外部へ出力する際には必ずエンコーディング(符号化)という処理が行われます。
Encodingクラスの役割
C#でバイト数を取得するには、System.Text.Encodingクラスを使用します。
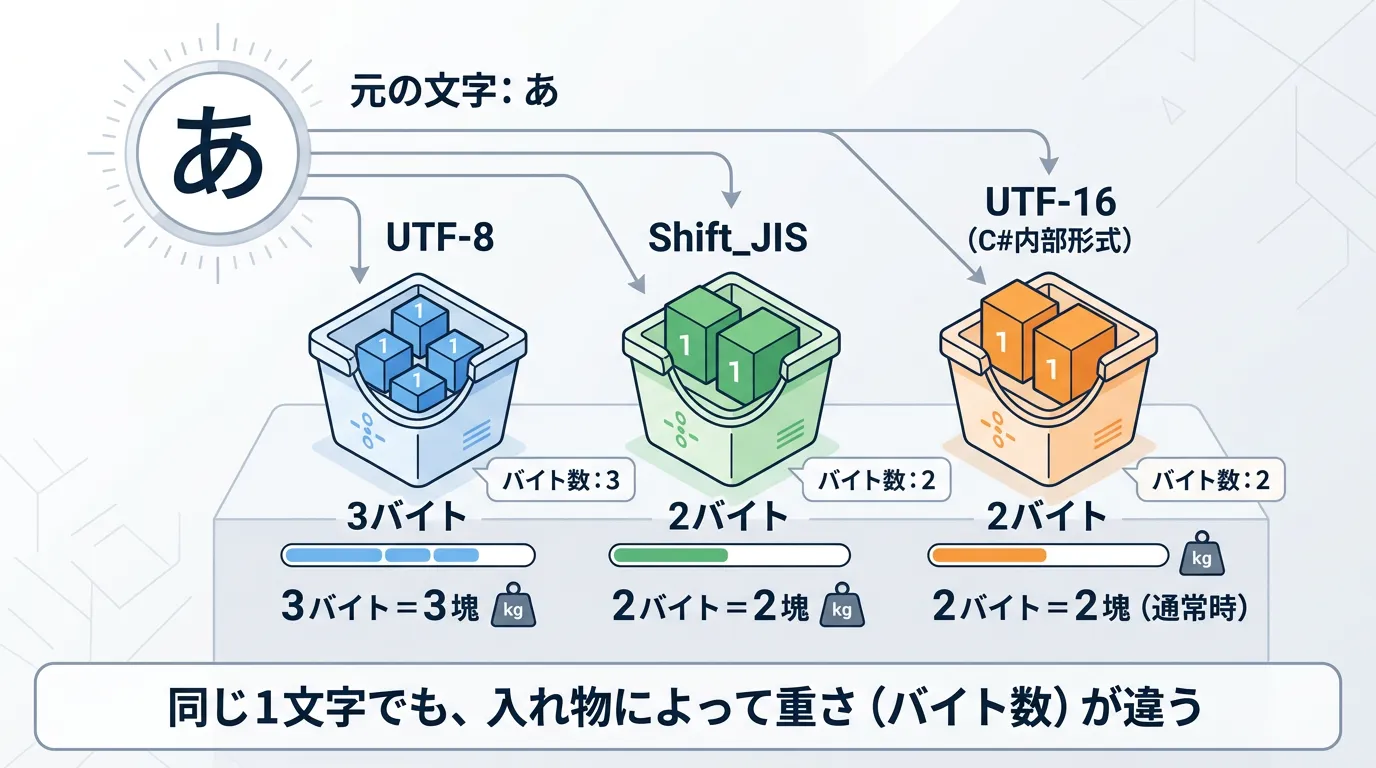
同じ文字列であっても、どのエンコーディング方式を選択するかによって、結果のバイト数は大きく異なります。
主なエンコーディング方式と特徴は以下の通りです。
| エンコーディング名 | 特徴 |
|---|---|
UTF-8 | 世界的に標準的な形式。英数字は1バイト、日本語は主に3バイト。 |
UTF-16 | C#内部形式に近い。多くの文字を2バイトまたは4バイトで表現。 |
Shift_JIS | 日本の古いWindows環境で主流。英数字は1バイト、日本語は2バイト。 |
ASCII | 7ビット。日本語は扱えず、すべて「?」などに化ける。 |
なぜバイト数が必要なのか
データベースの設計において、カラムの型がVARCHAR(10)となっている場合、多くのシステムでは「10バイトまで」という意味になります。
ここに日本語を入力する場合、UTF-8なら3〜4文字、Shift_JISなら5文字までしか入りません。
このように、「保存先の制限」を確認する際には、Lengthではなくバイト数を計算する必要があるのです。
実践コードによる比較検証
それでは、実際にC#のコードを動かして、文字数(Length)と各エンコーディングにおけるバイト数の違いを確認してみましょう。
基本的な文字列の検証
まずは、英数字と日本語が混在した文字列での挙動を確認します。
using System;
using System.Text;
class Program
{
static void Main()
{
// 5文字の文字列(英数字とひらがな)
string text = "ABCあいう";
// C#のLength(charの数)
Console.WriteLine($"文字列: {text}");
Console.WriteLine($"string.Length: {text.Length}");
// 各エンコーディングでのバイト数取得
// UTF-8
int utf8Bytes = Encoding.UTF8.GetByteCount(text);
Console.WriteLine($"UTF-8 バイト数: {utf8Bytes}");
// Shift_JIS (Encoding.RegisterProviderが必要な場合がある)
Encoding.RegisterProvider(CodePagesEncodingProvider.Instance);
Encoding sjis = Encoding.GetEncoding("shift_jis");
int sjisBytes = sjis.GetByteCount(text);
Console.WriteLine($"Shift_JIS バイト数: {sjisBytes}");
// UTF-16 (Unicode)
int utf16Bytes = Encoding.Unicode.GetByteCount(text);
Console.WriteLine($"UTF-16 バイト数: {utf16Bytes}");
}
}文字列: ABCあいう
string.Length: 6
UTF-8 バイト数: 12
Shift_JIS バイト数: 9
UTF-16 バイト数: 12この結果からわかるように、string.Lengthは「6」を返します。
これは「A, B, C, あ, い, う」の6文字がそれぞれ1つのchar(UTF-16の1ユニット)で構成されているからです。
一方で、バイト数はエンコーディングによってバラバラです。
UTF-8では日本語1文字を3バイトで数えるため、3 + (3 * 3) = 12バイトとなります。
サロゲートペアと絵文字の罠
次に、見た目の文字数とstring.Lengthが乖離する例を見てみましょう。
ここでは、サロゲートペアとして知られる「𠮷(つちよし)」と、絵文字を使用します。
using System;
using System.Text;
class Program
{
static void Main()
{
// 見た目は2文字だが...
string specialText = "𠮷😊";
Console.WriteLine($"対象文字列: {specialText}");
// Lengthは「2」ではない
Console.WriteLine($"string.Length: {specialText.Length}");
// バイト数の確認
Console.WriteLine($"UTF-8 バイト数: {Encoding.UTF8.GetByteCount(specialText)}");
Console.WriteLine($"UTF-16 バイト数: {Encoding.Unicode.GetByteCount(specialText)}");
}
}対象文字列: 𠮷😊
string.Length: 4
UTF-8 バイト数: 8
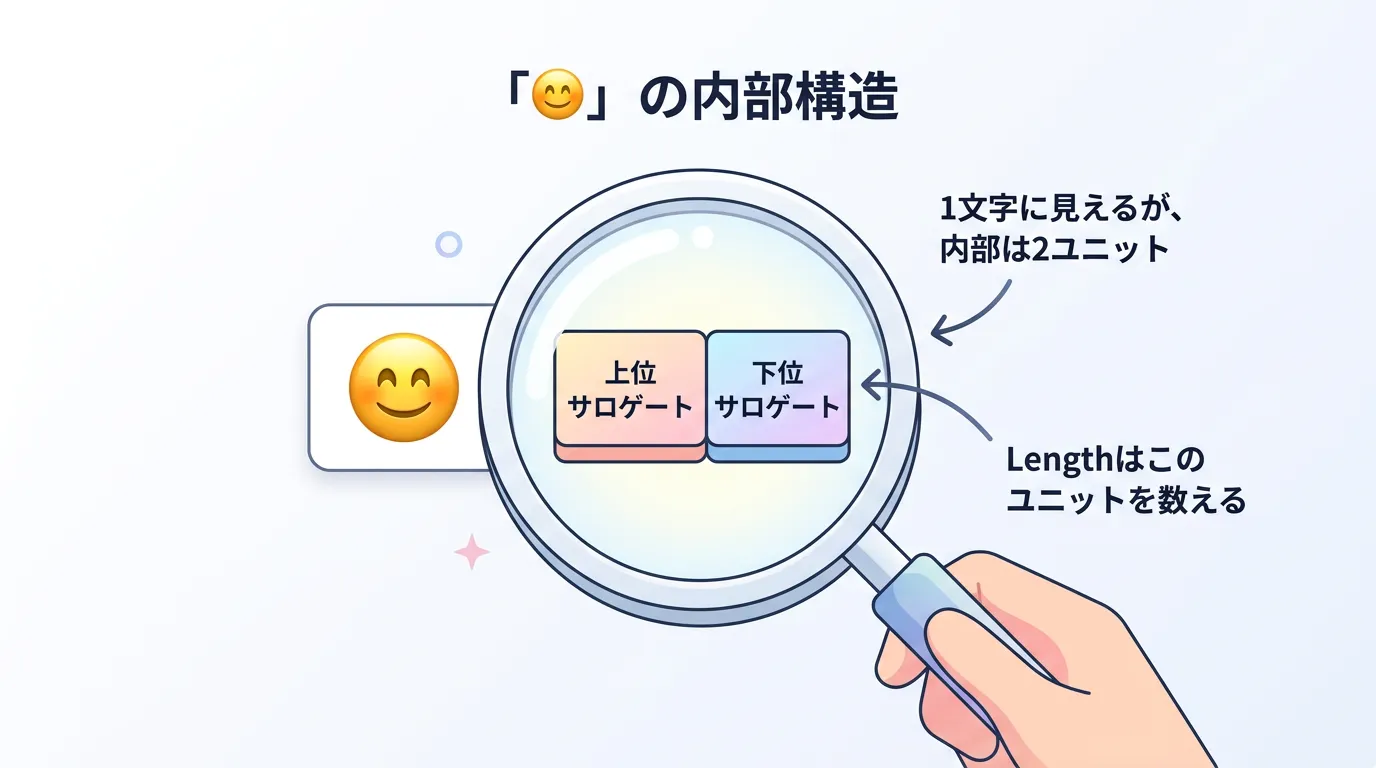
UTF-16 バイト数: 8驚くべきことに、見た目は2文字なのにLengthは「4」となります。
これは「𠮷」が2つのchar(4バイト)、「😊」も2つのchar(4バイト)で構成されているためです。
もし、Twitterのような「140文字制限」をstring.Lengthだけで実装してしまうと、絵文字を多用するユーザーは本来よりも少ない文字数で制限に達してしまうことになります。
人間の見た目通りの文字数を数える方法
では、サロゲートペアや絵文字を含めて、人間が「1文字」と認識する単位で正しくカウントするにはどうすればよいのでしょうか。
C#には、このための専用クラスStringInfoが用意されています。
StringInfoクラスの活用
System.Globalization.StringInfoクラスを使用すると、「テキスト要素(Text Element)」という単位で文字列を解析できます。
これにより、サロゲートペアを正しく1文字として扱うことが可能です。
using System;
using System.Globalization;
class Program
{
static void Main()
{
string specialText = "𠮷😊";
// 従来のLength
Console.WriteLine($"string.Length: {specialText.Length}");
// 正しい文字数のカウント
StringInfo si = new StringInfo(specialText);
Console.WriteLine($"StringInfoの文字数: {si.LengthInTextElements}");
}
}string.Length: 4
StringInfoの文字数: 2このLengthInTextElementsプロパティを使用することで、ようやく「人間から見た文字数」と一致する値を得ることができました。
最新のアプリケーション開発では、バリデーション(入力チェック)においてこの手法が必要不可欠となっています。
開発現場での使い分けガイドライン
これまでの内容を踏まえ、どのように使い分けるべきかを整理します。
1. string.Length を使うべき場面
- ループの制御:文字列を
char配列として処理する場合のインデックス管理。 - メモリ効率の算出:.NET内部でのメモリ消費量を概算する場合。
- 単純な空文字チェック:
str.Length == 0は最も高速に動作します。
2. Encoding.GetByteCount を使うべき場面
- ファイル入出力:指定したエンコーディングで保存した際のファイルサイズを知りたい時。
- ネットワーク通信:HTTPヘッダーの
Content-Lengthなどを計算する時。 - DBのバイト数制限:
VARCHARなどのバイト単位の制約を確認する時。
3. StringInfo を使うべき場面
- ユーザーへの表示:「あと〇文字入力できます」といったUI上のフィードバック。
- 論理的な文字数制限:SNSの投稿制限や、名前フィールドの文字数制限など。
まとめ
C#における文字列の扱いは、一見シンプルに見えて非常に奥が深いテーマです。
かつての「1文字=1バイト」や「1文字=2バイト」という固定観念を捨て、「メモリ上のサイズ(Length)」「保存時のサイズ(バイト数)」「視覚的な数(テキスト要素数)」の3つを明確に区別することが、プロフェッショナルなエンジニアへの第一歩となります。
特にサロゲートペアや絵文字が一般的になった現代では、string.Lengthだけで全ての仕様を満たすことは困難です。
今回紹介したEncodingクラスやStringInfoクラスを適切に使い分け、データの欠損や意図しないエラーのない堅牢なコードを目指しましょう。
これらの知識は、C#以外の言語に触れる際にも必ず役立つ共通の概念となるはずです。
