C#において、配列やコレクションの特定の部分を抽出する操作は、データ処理の基本と言えます。
かつてはSubstringメソッドや、ループ処理による手動のコピー、あるいはLINQのSkipやTakeを組み合わせて実現していましたが、C# 8.0以降、Index(インデックス)とRange(範囲)という新しい型と演算子が導入されました。
これにより、直感的かつ簡潔に配列の切り出し(スライシング)が可能になっています。
本記事では、末尾からのインデックス指定を行う^演算子や、範囲を定義する..演算子の詳細な使い方から、内部的な挙動、パフォーマンス上のメリットまで徹底的に解説します。
Index(末尾からのインデックス)の基本
C#で配列の要素にアクセスする場合、通常は「0番目」から始まる整数を使用します。
しかし、「最後からn番目」という指定をしたい場合、これまではarray.Length - nという計算が必要でした。
これを解決するのが、Index構造体と^演算子です。
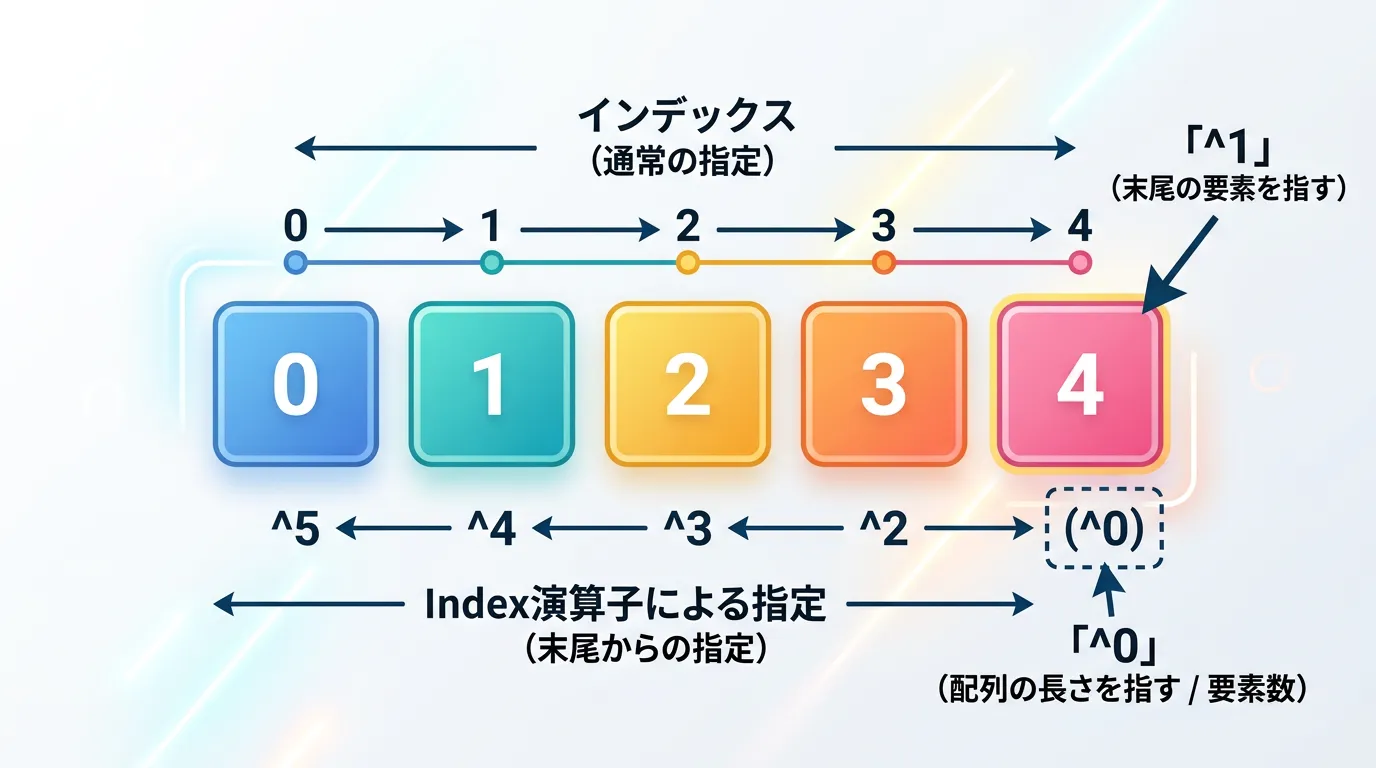
^演算子による末尾指定の仕組み
^演算子は、末尾からの相対的な位置を表します。
最も重要な点は、末尾の要素は「^1」で表現されるということです。
^1:最後の要素(length - 1)^2:最後から2番目の要素(length - 2)^0:配列の長さそのもの(length)
^0は、配列の有効なインデックス範囲外(長さと同じ値)を指すため、array[^0]のように直接要素にアクセスしようとするとIndexOutOfRangeExceptionが発生します。
しかし、後述する「範囲」の指定においては、「末尾まで」を表現するために非常に重要な役割を果たします。
System.Index型の実体
この^演算子によって生成される値は、System.Indexという構造体のインスタンスです。
内部的には整数値を持ち、「先頭からか、末尾からか」を判別するフラグを保持しています。
using System;
class Program
{
static void Main()
{
// 文字列配列の作成
string[] fruits = { "Apple", "Banana", "Cherry", "Dragonfruit", "Elderberry" };
// 従来のアクセス方法(最後から1番目)
string lastOld = fruits[fruits.Length - 1];
// Index型(^1)を使用したアクセス
string lastNew = fruits[^1];
// 最後から3番目の要素
string thirdFromEnd = fruits[^3];
Console.WriteLine($"従来の最後: {lastOld}");
Console.WriteLine($"新しい最後: {lastNew}");
Console.WriteLine($"最後から3番目: {thirdFromEnd}");
// Index型の変数として保持することも可能
Index idx = ^2;
Console.WriteLine($"最後から2番目: {fruits[idx]}");
}
}従来の最後: Elderberry
新しい最後: Elderberry
最後から3番目: Cherry
最後から2番目: Dragonfruitこのように、コードが非常に短くなり、「意図した場所がどこか」がひと目で理解できるようになります。
Range(範囲演算子)による配列の切り出し
次に、複数の要素をまとめて抽出するRange(範囲)について解説します。
範囲を指定するには、..演算子を使用します。
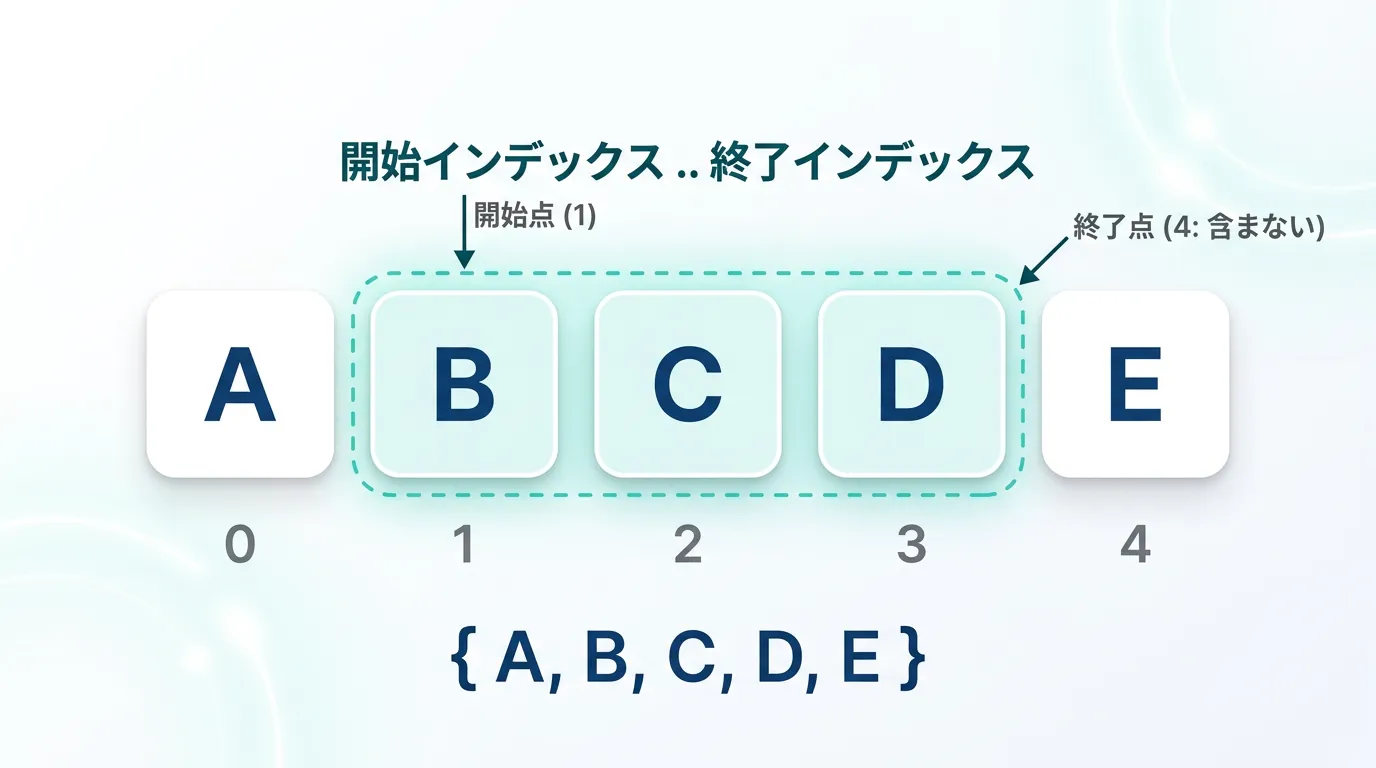
..演算子の基本ルール
Range演算子start..endには、非常に重要なルールがあります。
それは、開始インデックスは「含む(inclusive)」、終了インデックスは「含まない(exclusive)」という点です。数学の半開区間 [start, end) と同じ考え方です。
| 記述例 | 意味 |
|---|---|
1..4 | インデックス1から、4の直前(3)までを抽出 |
0..2 | インデックス0から、2の直前(1)までを抽出 |
^3..^1 | 最後から3番目から、最後から1番目の直前までを抽出 |
この「終了を含まない」という仕様は、一見不便に見えるかもしれませんが、プログラムにおいては「終了 - 開始 = 要素数」になるため、計算が非常に楽になるというメリットがあります。
例えば1..4なら、要素数は 4 - 1 = 3 個であることが保証されます。
範囲の省略記法
Range演算子は、開始または終了、あるいはその両方を省略することができます。
start..:指定したインデックスから末尾まで。..end:先頭から、指定したインデックスの直前まで。..:全範囲(コピーを作成する際に便利)。
using System;
class Program
{
static void Main()
{
int[] numbers = { 0, 10, 20, 30, 40, 50, 60 };
// インデックス1から4の直前まで(10, 20, 30)
int[] sub1 = numbers[1..4];
// インデックス3から末尾まで(30, 40, 50, 60)
int[] sub2 = numbers[3..];
// 先頭から最後から2番目の直前まで(0, 10, 20, 30, 40)
int[] sub3 = numbers[..^2];
// 全範囲(配列全体のコピー)
int[] sub4 = numbers[..];
Console.WriteLine($"sub1: {string.Join(", ", sub1)}");
Console.WriteLine($"sub2: {string.Join(", ", sub2)}");
Console.WriteLine($"sub3: {string.Join(", ", sub3)}");
Console.WriteLine($"要素数 (sub1): {sub1.Length}");
}
}sub1: 10, 20, 30
sub2: 30, 40, 50, 60
sub3: 0, 10, 20, 30, 40
要素数 (sub1): 3System.Range型の変数利用
Range演算子の結果は、System.Range型の値として変数に代入できます。
特定の範囲を「フィルタ」のように定義して、複数の配列に対して使い回すことが可能です。
Range middleRange = 1..^1; // 先頭と末尾を除外する範囲
int[] data1 = { 1, 2, 3, 4, 5 };
int[] data2 = { 100, 200, 300, 400 };
int[] result1 = data1[middleRange]; // { 2, 3, 4 }
int[] result2 = data2[middleRange]; // { 200, 300 }このように、ロジックとデータを分離できるため、コードの再利用性が高まります。
文字列(string)への応用
Range演算子は、配列だけでなく文字列に対しても非常に強力に機能します。
従来のSubstringメソッドよりも直感的に記述でき、読みやすさが劇的に向上します。
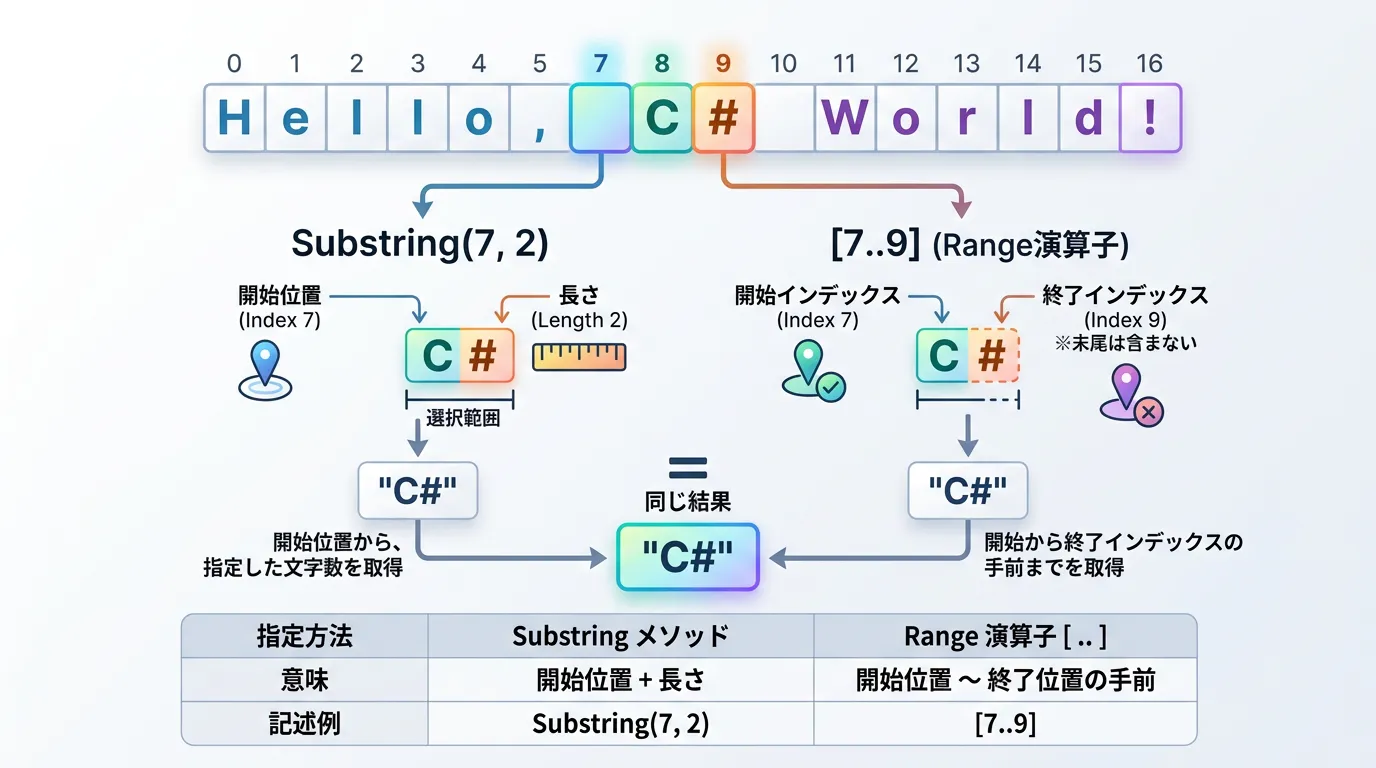
Substringとの違い
従来のstring.Substring(int startIndex, int length)は、第2引数が「長さ」でした。
これに対し、Range演算子は「終了位置」を指定します。
string text = "C# Programming is fun!";
// 従来のSubstring (15文字目から3文字分)
string subOld = text.Substring(15, 3);
// Range演算子 (15文字目から18文字目の直前まで)
string subNew = text[15..18];
// 末尾から4文字を切り出し
string lastFour = text[^4..];
Console.WriteLine($"Old: {subOld}"); // "fun"
Console.WriteLine($"New: {subNew}"); // "fun"
Console.WriteLine($"Last: {lastFour}"); // "fun!"text[^4..]のような記述は、末尾の文字数が動的に変わる可能性がある処理(例えばファイルの拡張子チェックなど)において、計算ミスによるバグを劇的に減らす効果があります。
文字列操作におけるパフォーマンス
文字列に対してRange演算子を使用すると、内部的にはSubstringが呼び出されます。
そのため、新しい文字列オブジェクトがヒープに割り当てられる(アロケーションが発生する)という点に注意が必要です。
大量の文字列を切り出すループ処理などでは、後述するReadOnlySpan<char>との組み合わせが推奨されます。
Span<T> との組み合わせによる最適化
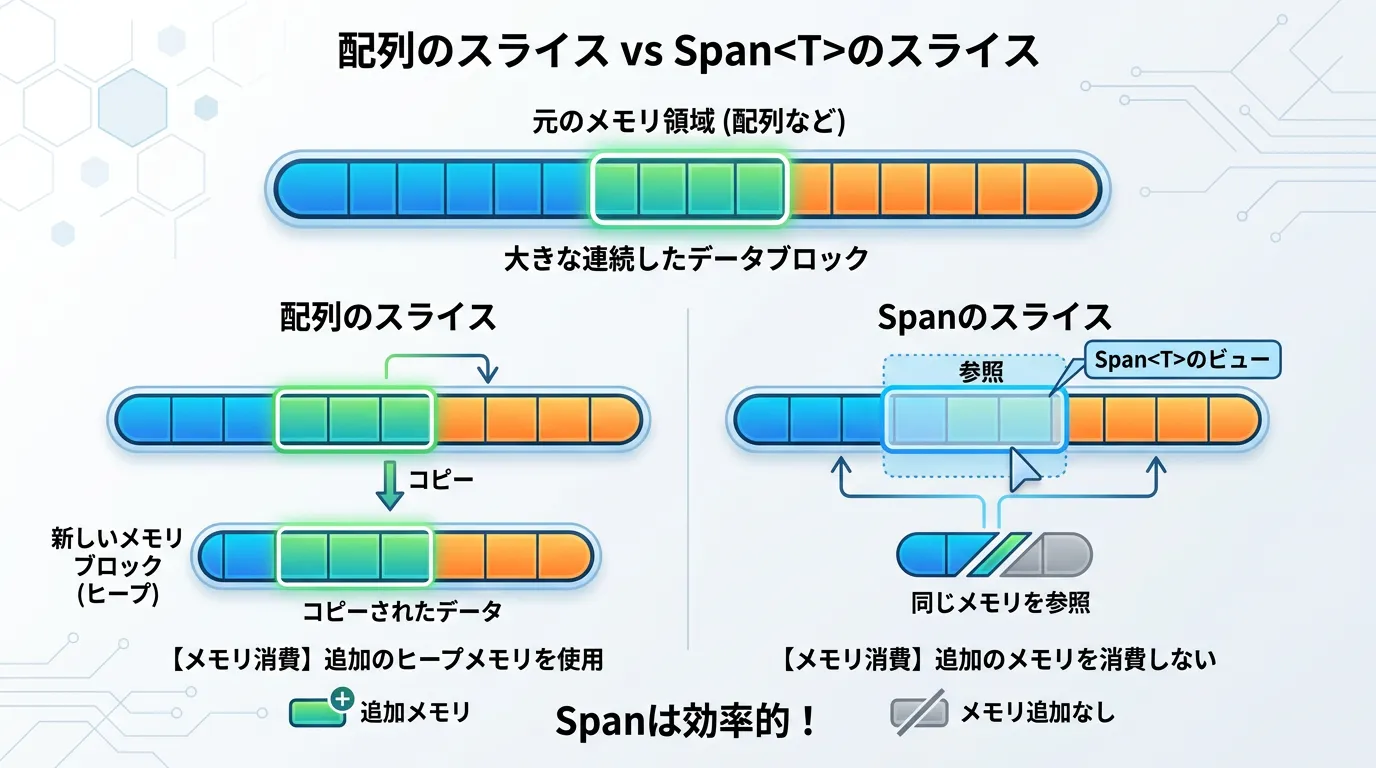
Range演算子の真価を発揮するのが、Span<T>やReadOnlySpan<char>といった「ビュー」を提供する型との併用です。
メモリコピーを発生させないスライシング
通常、配列に対してarray[1..4]と記述すると、その範囲の要素が新しい配列としてコピーされます。
これは安全ですが、巨大な配列や高頻度の処理ではメモリの消費が問題になります。
これに対し、Span<T>を介してRangeを使用すると、コピーを作成せずに元のメモリ領域を指し示す「窓」のようなものが作成されます。
using System;
class Program
{
static void Main()
{
int[] heavyData = new int[10000];
// 配列のスライス(新しい配列が生成され、メモリを消費する)
int[] copy = heavyData[1000..2000];
// Spanのスライス(メモリコピーが発生せず、高速)
Span<int> view = heavyData.AsSpan()[1000..2000];
// viewの値を書き換えると、元のheavyDataも書き換わる
view[0] = 999;
Console.WriteLine($"元の配列の値: {heavyData[1000]}"); // 999
}
}このように、Span<T>に対してRangeを使うことで、パフォーマンスと記述の簡潔さを両立させることができます。
文字列解析の高速化
文字列の解析(パーサ)を作成する場合も、ReadOnlySpan<char>を活用することで、アロケーションフリーな処理が可能になります。
string log = "2026-01-16:ERROR:Database connection failed";
ReadOnlySpan<char> logSpan = log.AsSpan();
// コピーを発生させずに部分文字列を取得
ReadOnlySpan<char> datePart = logSpan[..10];
ReadOnlySpan<char> levelPart = logSpan[11..16];
Console.WriteLine(datePart.ToString());
Console.WriteLine(levelPart.ToString());ToString()を呼び出すまでは、新しい文字列は生成されません。
これにより、大規模なログファイルの解析などにおいて、ガベージコレクション(GC)の負荷を大幅に軽減できます。
実践的な活用シーン
RangeとIndexは、単なるシンタックスシュガー(書き方の工夫)に留まらず、実際の開発において多くのメリットをもたらします。
1. CSVや固定長データの解析
固定のフォーマットを持つデータを扱う際、IndexとRangeを使うとコードが宣言的になります。
string csvRow = "ID12345,TaroYamada,25,Tokyo";
// カンマの位置を探す手間を省き、固定位置なら以下のように書ける
// (実際にはSplitやSpanでの検索を併用しますが、固定幅なら非常に強力)2. 配列の「最後以外」を処理する
例えば、リストを表示する際に「最後の要素だけカンマを付けない」といった処理を行う場合、items[..^1]で最後以外の全要素を回すことができます。
string[] tags = { "C#", "DotNet", "Programming" };
// 最後以外の要素に対してループ
foreach (var tag in tags[..^1])
{
Console.Write(tag + ", ");
}
// 最後の要素だけ個別に処理
Console.WriteLine(tags[^1]);3. アルゴリズムの実装(二分探索など)
探索範囲を狭めていくアルゴリズムでは、Range型を変数として管理することで、今どの範囲を探索しているのかを明確にコードで表現できます。
RangeとIndexの注意点と限界
非常に便利な機能ですが、使用する際に気を付けるべきポイントがいくつかあります。
多次元配列には直接使えない
残念ながら、int[,] array = new int[5, 5];のような多次元配列に対して、array[1..3, 1..3]のように範囲指定することはできません。
ジャグ配列(配列の配列 int[][])であれば、各次元に対して適用可能です。
負の数は指定できない
Indexの^演算子は「末尾から」を意味する正の整数を受け取ります。
^-1のような記述はコンパイルエラーとなります。
実行時の例外
指定した範囲が配列のサイズを超えている場合、実行時にArgumentOutOfRangeExceptionが発生します。
動的に範囲を指定する場合は、事前にIndexやRangeの値が有効な範囲に収まっているかチェックする必要があります。
| 状況 | 結果 |
|---|---|
| 開始位置 > 終了位置 | 例外発生 |
| インデックスが負 | コンパイルエラー |
| 範囲が配列長を超える | 例外発生 |
カスタムクラスでのRange対応
もし自分で作成したクラスで..や^を使えるようにしたい場合、特別なインターフェースを実装する必要はありません。
特定のパターンに従ったメソッドを定義するだけで、コンパイラが自動的に認識してくれます。
LengthまたはCountプロパティ(int型)を持っていること。int型を引数に取るインデクサを持っていること。Slice(int start, int length)メソッドを持っていること。
これらの条件を満たすと、そのクラスに対してRange演算子による切り出しができるようになります。
これは「パターンベース」の機能と呼ばれます。
public class MyDataList
{
private int[] _data = { 1, 2, 3, 4, 5 };
public int Length => _data.Length;
public int this[int index] => _data[index];
// Range演算子を使ったときに呼ばれるメソッド
public int[] Slice(int start, int length)
{
int[] result = new int[length];
Array.Copy(_data, start, result, 0, length);
return result;
}
}
// 利用例
var myDoc = new MyDataList();
var sub = myDoc[1..3]; // Slice(1, 2) が呼ばれるこのように、自作のコレクションクラスでもC#の標準的な構文を利用可能にすることで、ライブラリの利用者に一貫したコーディング体験を提供できます。
まとめ
C#のRange(範囲演算子)とIndex(末尾からのインデックス)は、モダンなC#プログラミングにおいて欠かせない要素です。
これらを利用することで、配列や文字列の切り出しが非常に簡潔になり、array.Length - 1のような冗長でミスを誘発しやすい記述を排除できます。
特に^1による末尾アクセスや、start..endによる半開区間での切り出しは、コードの意図を明確にする効果があります。
さらに、Span<T>と組み合わせることで、パフォーマンスを犠牲にすることなく高度なメモリ操作も実現可能です。
最初は「終了インデックスを含まない」という仕様に戸惑うかもしれませんが、慣れてしまえばこれほど合理的な記法はありません。
ぜひ日々の開発に取り入れ、より安全で読みやすいクリーンなコードを目指してください。
