C#において、文字データを扱う際に必ず登場するのがchar型とstring型です。
一見するとどちらも「文字」を扱うための型に見えますが、その性質やコンピュータ内部での処理方法は根本的に異なります。
プログラミング初心者の方が最初につまずきやすいポイントであり、中級者以上にとってもパフォーマンス最適化やメモリ効率を考える上で避けては通れない知識です。
本記事では、これら2つの型の違いを基礎から応用、そして相互変換の方法まで詳しく解説していきます。
charとstringの基本的な概念
C#でテキスト情報を扱う際、私たちは「1文字」を指すのか「複数の文字(文字列)」を指すのかによって型を使い分ける必要があります。
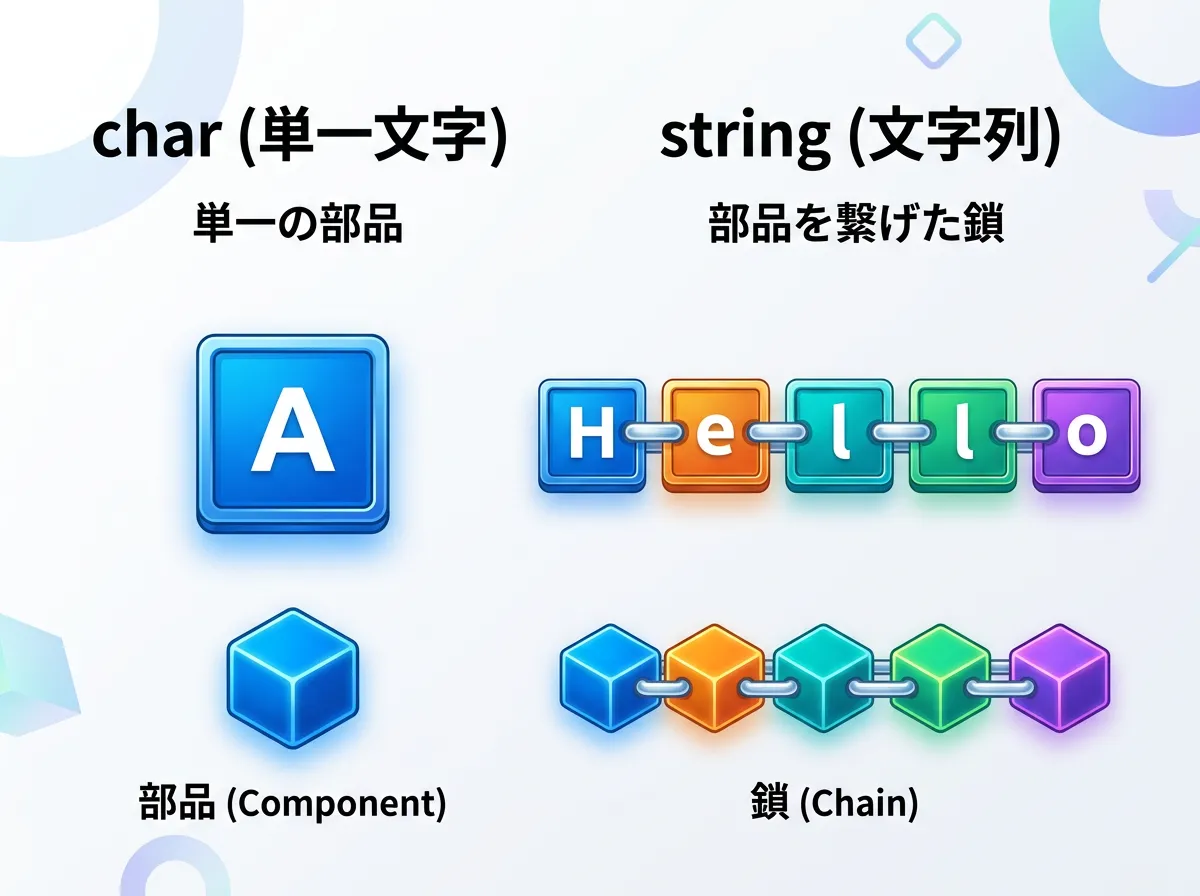
char型とは何か
char型は、単一のUnicode文字を表すための型です。
コンピュータ内部では16ビット(2バイト)の数値として保持されており、一文字だけを格納することに特化しています。
C#においてcharのリテラルを記述する際は、必ずシングルクォーテーション(‘ ‘)で囲む必要があります。
例えば、'A'や'あ'のように記述します。
string型とは何か
string型は、char型のオブジェクトを連続して並べたものです。
0文字以上の文字の集合を表し、文章や単語、識別子などを保持するために使用されます。
stringのリテラルを記述する際は、ダブルクォーテーション(” “)で囲みます。
例えば、"Hello"や空の文字列""などがこれに該当します。
charとstringの決定的な違い
これら2つの型には、構文上の違いだけでなく、システム的な性質の違いがいくつか存在します。
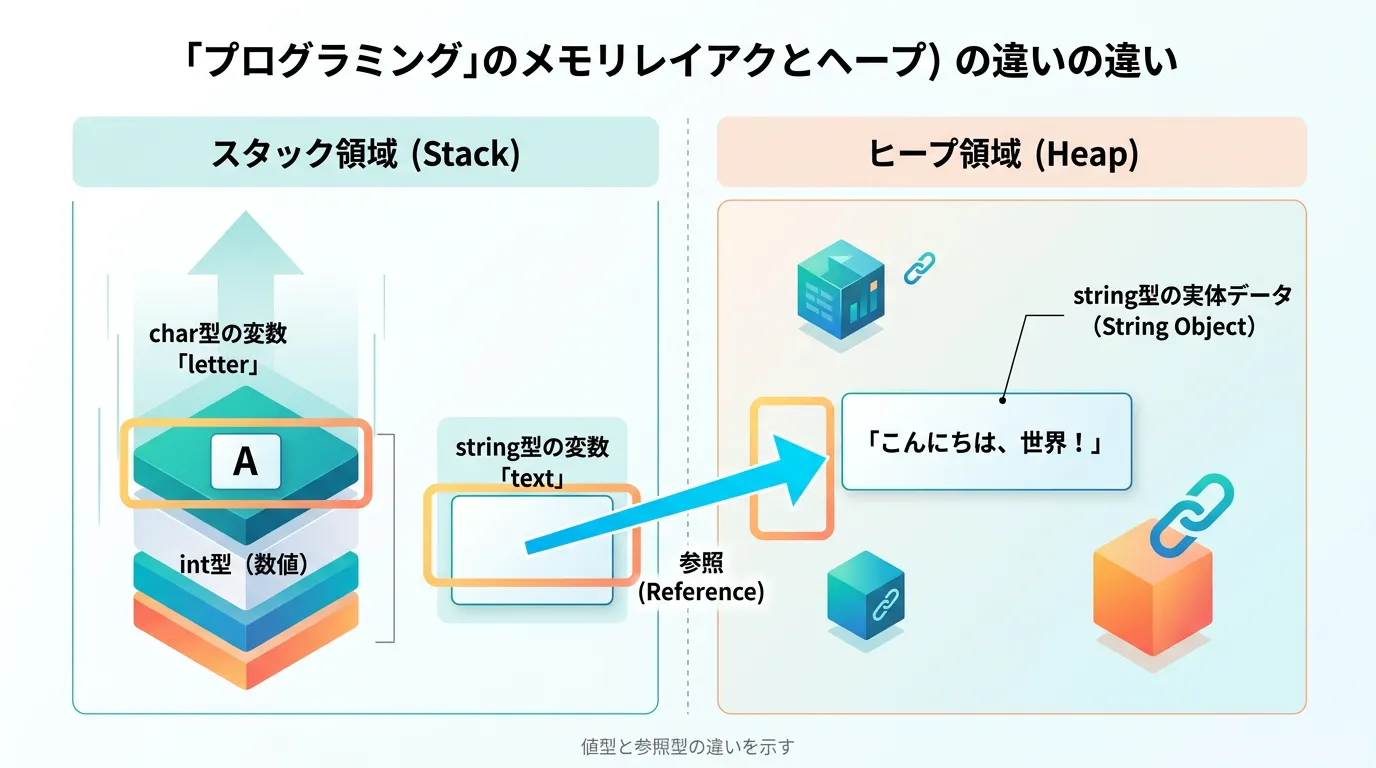
値型と参照型の違い
C#において、charは値型(Value Type)であり、stringは参照型(Reference Type)です。
値型であるcharは、変数そのものが文字データを直接保持します。
一方、参照型であるstringは、メモリ上のどこかにデータの実体が置かれ、変数はその場所(アドレス)を指し示しています。
この違いは、データのコピー時やメモリ管理の挙動に影響を与えます。
nullの許容性
charは値型であるため、基本的にはnullを代入することができません。
空の状態を表現したい場合は、'\0'(ヌル文字)を使用するか、char?(Nullable型)を使用する必要があります。
対して、stringは参照型であるため、nullを持つことが可能です。
何も入っていない「空文字("")」と、参照先がない「null」は明確に区別されるため、注意が必要です。
比較表によるまとめ
| 特徴 | char | string |
|---|---|---|
| 分類 | 値型 | 参照型 |
| 囲み文字 | シングルクォーテーション(‘) | ダブルクォーテーション(“) |
| 長さ | 常に1文字 | 0文字以上(可変) |
| null | 不可(Nullable型を除き) | 可能 |
| 内部表現 | System.Char | System.String |
実際のコードで見る違いと使い分け
それでは、具体的なプログラムコードを通じて、それぞれの宣言方法や使い分けを見ていきましょう。
using System;
class Program
{
static void Main()
{
// char型の宣言
char singleLetter = 'A';
char japaneseLetter = 'あ';
// string型の宣言
string word = "Apple";
string sentence = "こんにちは、C#の世界へ!";
// 出力
Console.WriteLine($"charの値: {singleLetter}");
Console.WriteLine($"stringの値: {word}");
// stringはcharの集合なので、添字でアクセス可能
char firstCharOfWord = word[0]; // 'A'が取得できる
Console.WriteLine($"wordの1文字目: {firstCharOfWord}");
}
}charの値: A
stringの値: Apple
wordの1文字目: A上記のコードにある通り、string型は配列のように添字(インデックス)を指定することで、特定の文字をchar型として取り出すことができます。
しかし、その逆はできません。
つまり、char型に対して添字アクセスをすることは不可能です。
string型の「イミュータブル(不変)」という性質
string型を扱う上で非常に重要な特性が、イミュータブル(Immutable)であるという点です。
これは、一度作成された文字列オブジェクトの内容は後から変更できないことを意味します。
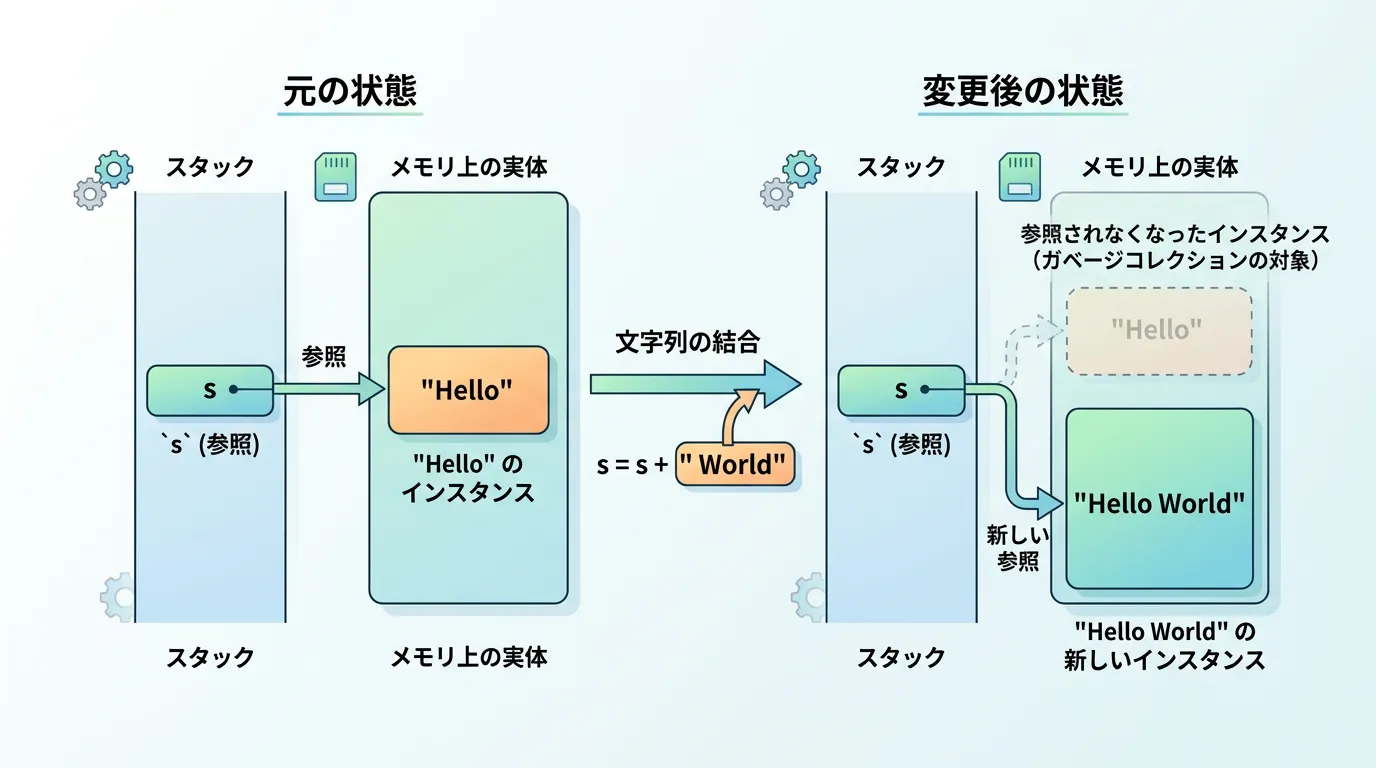
一見すると、text += "!" のように文字列を編集できているように見えますが、実際には内部で新しい文字列オブジェクトが再生成されています。
大量の文字列結合を繰り返すと、新しいオブジェクトが次々と作られてメモリを圧迫するため、そのような場合はStringBuilderクラスを使用するのが一般的です。
一方で、charは単なる数値データとして扱えるため、配列(char[])であれば中身を自由に書き換えることができます。
charとstringの相互変換
開発中には、charをstringに変換したり、あるいはその逆が必要になる場面が多くあります。
charからstringへの変換
もっとも簡単な方法は、ToString()メソッドを使用することです。
char c = 'G';
string s = c.ToString(); // "G" に変換されるまた、新しい文字列を作成するコンストラクタを使用することも可能です。
char c = 'X';
string s = new string(c, 5); // "XXXXX" のように繰り返すこともできるstringからcharへの変換
文字列から特定の1文字を取得する場合は、前述のインデックス参照を使用します。
string text = "C#";
char first = text[0]; // 'C'文字列全体を文字の配列に変換したい場合は、ToCharArray()メソッドを使用します。
これは、文字列を1文字ずつループで処理したい場合に非常に便利です。
string target = "Hello";
char[] charArray = target.ToCharArray();
foreach (char ch in charArray)
{
Console.WriteLine(ch);
}H
e
l
l
oパフォーマンスを意識した使い分け
どちらの型を使うべきか迷った際、基本的には「1つの文字だけを厳密に扱う」のであればcharを選択し、それ以外はstringを選択します。
パフォーマンスの観点は、charの方が圧倒的に軽量です。
参照型であるstringは、ヒープメモリの確保やガベージコレクション(GC)の対象となるコストが発生しますが、charはスタック上で効率的に処理されます。
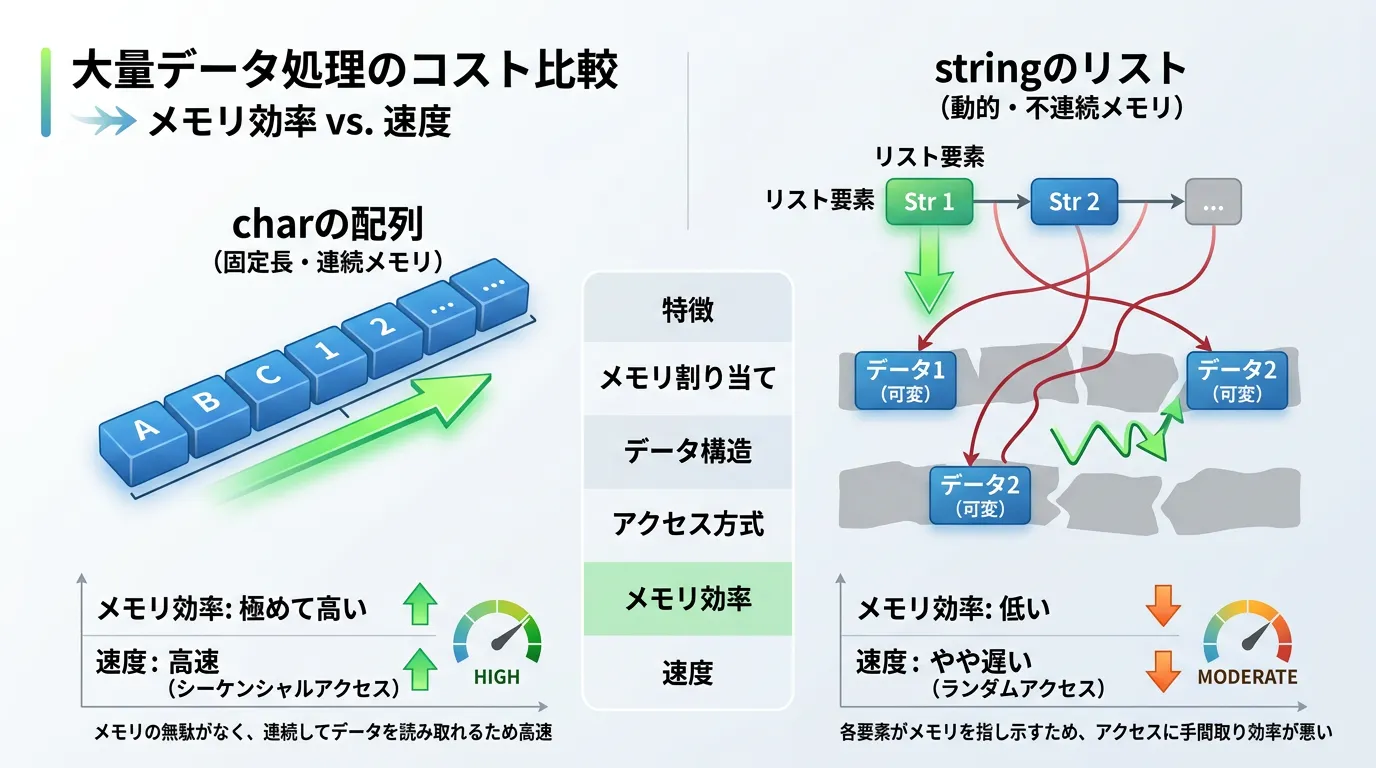
例えば、特定の文字が含まれているかを判定する際、文字列として比較するよりもcharとして比較する方が高速です。
string data = "Example";
// 文字列での比較(オーバーヘッドが少し大きい)
if (data.Substring(0, 1) == "E") { /* 処理 */ }
// charでの比較(高速で効率的)
if (data[0] == 'E') { /* 処理 */ }このように、可能な限り小さい単位(char)で扱うことが、C#プログラムの実行速度向上に繋がります。
エスケープシーケンスの扱い
charもstringも、通常の文字だけでなく「改行」や「タブ」といった特殊な文字を扱うことができます。
これらはエスケープシーケンスと呼ばれます。
'\n'または"\n":改行'\t'または"\t":水平タブ''':シングルクォーテーション(char型で必須)""":ダブルクォーテーション(string型で必須)
これらはchar型においては「2文字」と書いてあるように見えますが、内部的には「バックスラッシュ+特定の文字」で1つの特殊な文字コードを表しているため、char型に格納することが可能です。
まとめ
C#におけるcharとstringは、文字データを扱うという共通点がありながら、その実態は「値型」と「参照型」という対照的な性質を持っています。
charはシングルクォーテーションで囲まれた単一の16ビットUnicode文字であり、メモリ効率が良く高速に動作します。
一方のstringはダブルクォーテーションで囲まれた文字の集合であり、不変(イミュータブル)という特性を持つ参照型です。
これら2つの違いを正しく理解することは、バグの少ないコードを書くだけでなく、アプリケーションのパフォーマンスを最適化する上でも欠かせません。
1文字だけが必要な場面ではcharを、言葉や文章を扱う場面ではstringを適切に選択しましょう。
また、相互変換のメソッドを使いこなすことで、より柔軟なテキスト処理が可能になります。
今回の内容を参考に、日々のコーディングでこの2つの型を意識的に使い分けてみてください。
