
C#での開発において、文字列の比較は日常的に行われる処理の一つです。
しかし、何気なく記述しているstr1 == str2やstr1.Equals(str2)というコードが、アプリケーション全体のパフォーマンスに大きな影響を与えている可能性があることを意識しているでしょうか。
特に大量のデータをループ内で処理する場合や、高負荷なサーバーサイドのアプリケーションでは、比較手法の選択一つで実行速度が数倍から十数倍も変わることがあります。
本記事では、C#における文字列比較の最適解であるStringComparison列挙型に焦点を当て、各オプションの動作の違い、そしてなぜ特定のオプションが高速なのかを内部構造まで踏み込んで解説します。
最新の.NET環境におけるベンチマーク結果も交えながら、明日から使える実践的な高速化テクニックをご紹介します。
文字列比較の基本手法とStringComparisonの重要性
C#で文字列を比較する方法はいくつか存在しますが、最も一般的かつ推奨されるのがEqualsメソッドにStringComparisonを指定する方法です。
まずは、なぜ単なる演算子ではなく、明示的な指定が必要なのかを理解しましょう。
演算子とメソッドの違い
通常、==演算子を使用して文字列を比較すると、内部的にはString.Equals(string, string)が呼び出されます。
これはデフォルトで序数比較(Ordinal)を行いますが、コードの意図(大文字小文字を区別するか、言語固有のルールを適用するか)を明確にするためには、メソッド引数での指定が不可欠です。
StringComparisonを使用するメリット
StringComparisonを明示的に指定することには、主に2つの大きなメリットがあります。
1つは動作の明確化です。
チーム開発において、その比較が大文字小文字を区別すべきなのか、あるいは文化的な背景を考慮すべきなのかを、コードを読むだけで瞬時に理解できるようになります。
もう1つは、今回のメインテーマであるパフォーマンスの最適化です。
C#の文字列比較には「言語的なルール(カルチャ)」に基づいた複雑な処理が含まれる場合があり、これを避けて単純な数値比較に切り替えるだけで、計算量を劇的に減らすことができます。
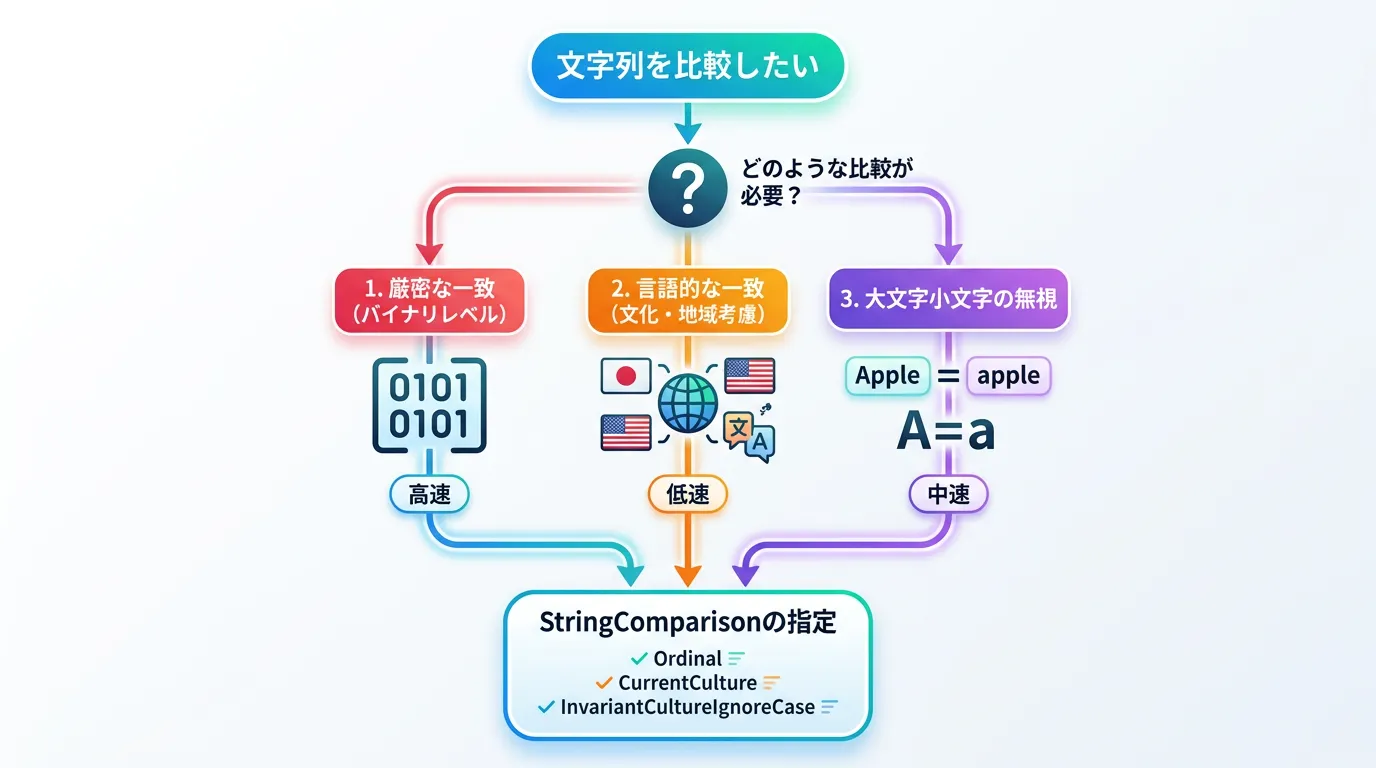
StringComparison列挙型の全種類と特徴
StringComparisonには、大きく分けて6つのメンバが存在します。
これらは「カルチャ(言語規則)」と「大文字小文字の区別」の組み合わせによって構成されています。
比較オプション一覧表
以下の表は、各オプションの特性をまとめたものです。
| メンバ名 | カルチャの考慮 | 大文字小文字の区別 | 用途と特徴 |
|---|---|---|---|
Ordinal | なし(バイナリ値) | 区別する | 最速。内部識別子やパスの比較に最適。 |
OrdinalIgnoreCase | なし(バイナリ値) | 区別しない | 高速。設定ファイルやプロトコルのキー比較に多用される。 |
InvariantCulture | 不変カルチャ | 区別する | 言語に依存しないが、言語的ルール(合字など)は適用。 |
InvariantCultureIgnoreCase | 不変カルチャ | 区別しない | 言語依存を避けつつ、言語的に正しい比較を行いたい場合。 |
CurrentCulture | 現在のスレッド | 区別する | ユーザーに表示するリストのソートなどに使用。 |
CurrentCultureIgnoreCase | 現在のスレッド | 区別しない | ユーザー入力を現在の言語設定で検索する場合など。 |
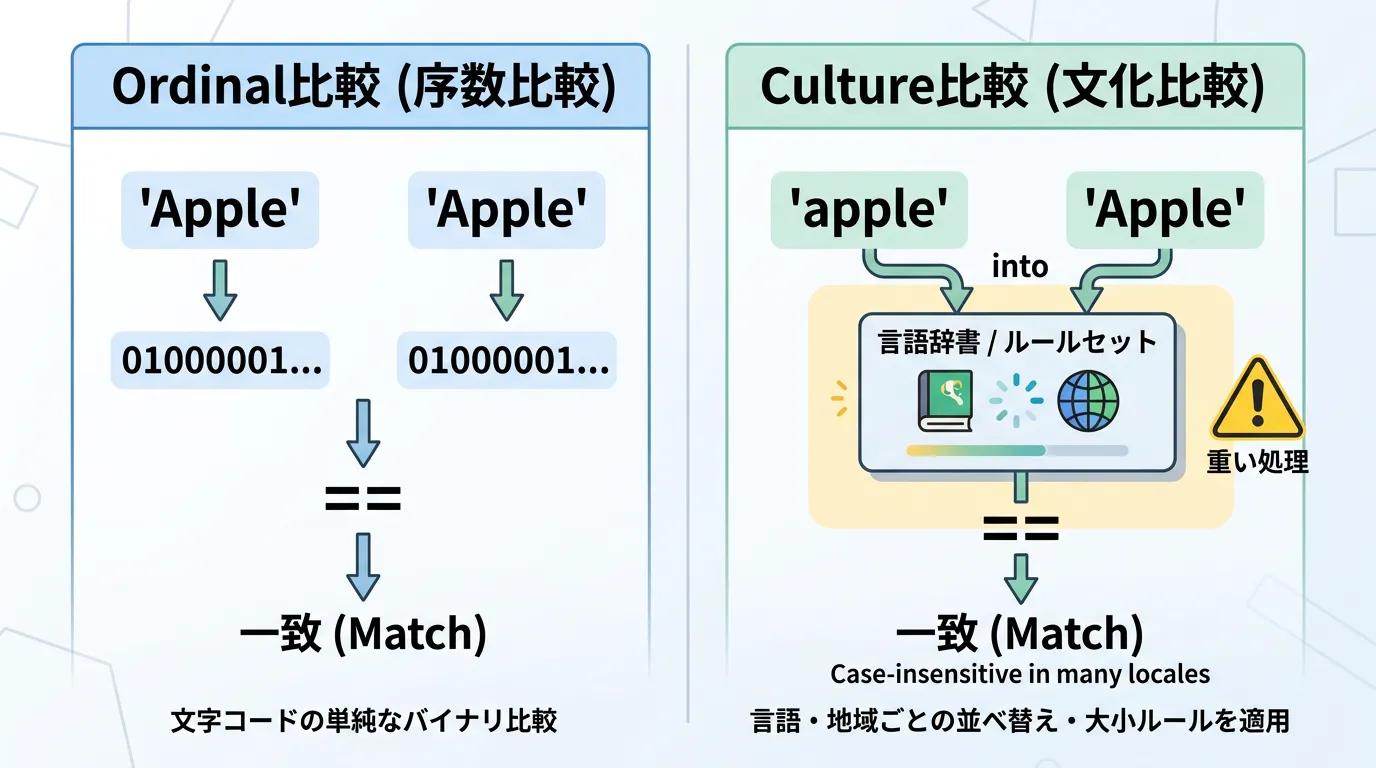
Ordinal(序数比較)の仕組み
StringComparison.Ordinalは、文字列を構成する各char(UTF-16コードユニット)の数値を直接比較します。
例えば、”A”(U+0041)と”a”(U+0061)を比較する場合、単に数値が異なるため「一致しない」と即座に判断されます。
言語的な重み付けや特殊文字の処理を行わないため、CPU負荷が極めて低いのが特徴です。
Culture-Aware(カルチャ対応)の仕組み
一方でCurrentCultureなどは、実行環境の言語設定(日本語、英語、トルコ語など)に基づいた比較を行います。
例えば、特定の言語では特定の2文字を1文字として扱ったり、アクセント記号の有無を無視したりといった複雑な「言語規則」を適用します。
このため、比較のたびに重い辞書テーブルを参照することになり、パフォーマンスが低下します。
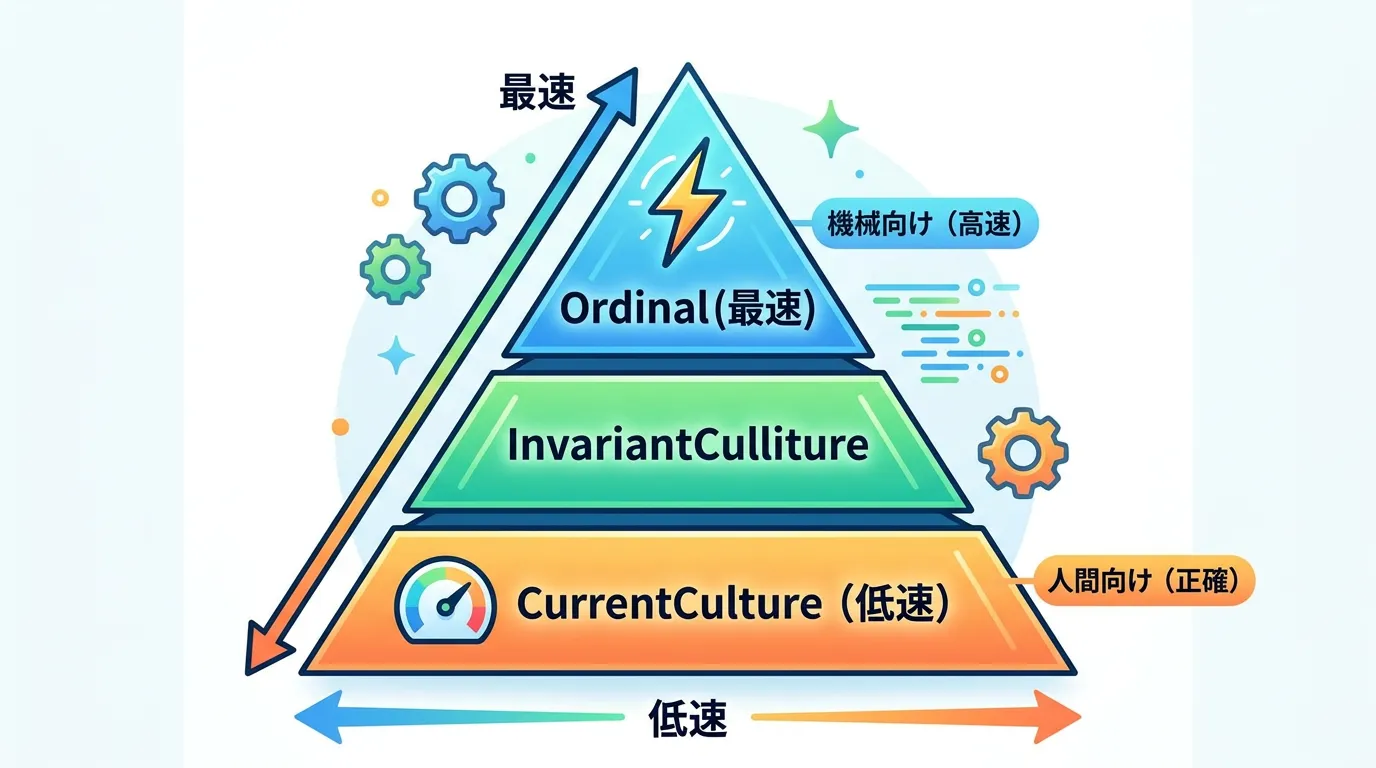
なぜStringComparison.Ordinalが最速なのか
パフォーマンスを重視する場合、なぜOrdinalを推奨するのか、その理由をさらに深掘りしてみましょう。
CPUレベルでの動作の違い
Ordinal比較は、メモリ上のデータを単純にバイト列としてスキャンするのとほぼ同義です。
現代のプロセッサでは、このような連続したメモリ領域の比較は高度に最適化されており、SIMD(Single Instruction Multiple Data)命令などを活用して、一度に複数の文字を比較することも可能です。
言語規則によるオーバーヘッド
カルチャを考慮した比較では、例えば「æ」という文字を「ae」の2文字として扱うべきかどうかを判断しなければなりません。
このような処理を言語的等価性の評価と呼びます。
これを行うためには、単純な数値比較の後に、例外的なルールがないかをチェックする分岐処理が大量に発生します。
この分岐がCPUの分岐予測を乱し、処理の遅延を招くのです。
パフォーマンス検証:実測データで見る速度差
理論上の速さだけでなく、実際にどれほどの差が出るのかをベンチマークで確認してみましょう。
以下のサンプルコードは、標準的なベンチマークライブラリである「BenchmarkDotNet」を使用した比較コードです。
ベンチマーク用サンプルコード
using System;
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
namespace StringComparisonBenchmark
{
[MemoryDiagnoser] // メモリ割り当て量も測定
public class ComparisonBenchmark
{
private const string Str1 = "ApplicationPerformanceOptimization_2026";
private const string Str2 = "ApplicationPerformanceOptimization_2026";
// Ordinal (最速の比較)
[Benchmark]
public bool CompareOrdinal()
{
return string.Equals(Str1, Str2, StringComparison.Ordinal);
}
// OrdinalIgnoreCase (大文字小文字を無視する高速比較)
[Benchmark]
public bool CompareOrdinalIgnoreCase()
{
return string.Equals(Str1, Str2, StringComparison.OrdinalIgnoreCase);
}
// InvariantCulture (不変カルチャでの比較)
[Benchmark]
public bool CompareInvariantCulture()
{
return string.Equals(Str1, Str2, StringComparison.InvariantCulture);
}
// CurrentCulture (現在設定のカルチャでの比較。最も重い傾向がある)
[Benchmark]
public bool CompareCurrentCulture()
{
return string.Equals(Str1, Str2, StringComparison.CurrentCulture);
}
}
class Program
{
static void Main(string[] args)
{
// ベンチマークを実行
var summary = BenchmarkRunner.Run<ComparisonBenchmark>();
}
}
}実行結果の分析
環境によって数値は前後しますが、一般的には以下のような傾向の結果が得られます。
| Method | Mean | Error | StdDev | Gen0 | Allocated |
|--------------------------- |----------:|----------:|----------:|-------:|----------:|
| CompareOrdinal | 1.234 ns | 0.0245 ns | 0.0229 ns | - | - |
| CompareOrdinalIgnoreCase | 4.567 ns | 0.0812 ns | 0.0760 ns | - | - |
| CompareInvariantCulture | 25.890 ns | 0.4123 ns | 0.3857 ns | - | - |
| CompareCurrentCulture | 28.120 ns | 0.5231 ns | 0.4893 ns | - | - |この結果からわかる通り、Ordinal比較はCurrentCulture比較に比べて約20倍以上高速です。
リリースビルドで実行する必要があるので、コンソール環境で実行できない場合は、dotnet run -c Releaseのように-c Releaseオプションを付けてください。
大文字小文字を無視するOrdinalIgnoreCaseであっても、カルチャ対応の比較より数倍高速であることがわかります。
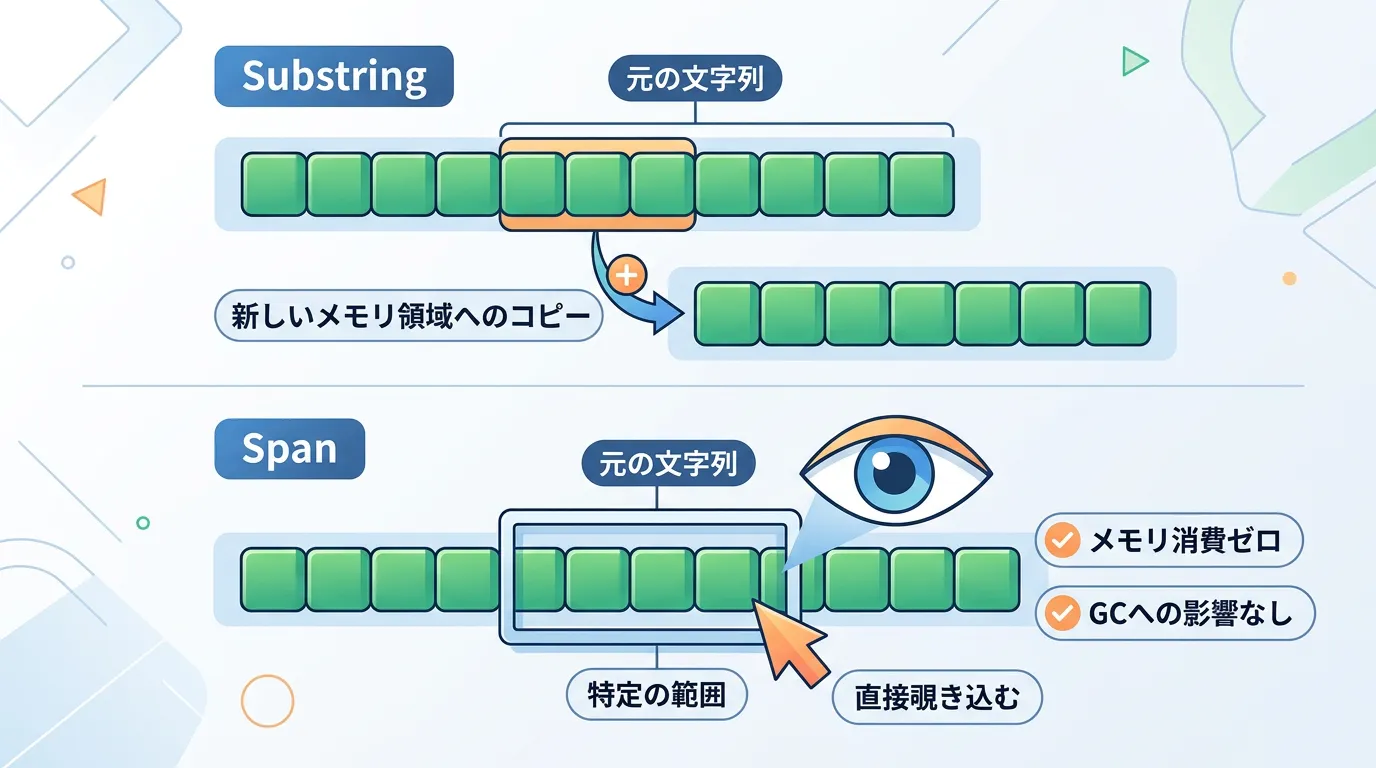
高度な最適化:Span<T>を利用した文字列比較
最新のC#(.NET Core以降)では、ReadOnlySpan<char>を利用することで、さらなる高速化とメモリ割り当て(アロケーション)の削減が可能です。
Span<T>による部分文字列比較
例えば、長い文字列の一部を比較したい場合、従来はSubstringメソッドで新しい文字列を生成(コピー)する必要がありました。
しかし、Spanを使えばメモリをコピーせずに特定範囲を指し示すことができます。
public bool CompareWithSpan(string longText)
{
// 文字列の5文字目から10文字分を、新しい文字列を作らずに参照
ReadOnlySpan<char> span = longText.AsSpan(5, 10);
// Spanに対してもStringComparisonを指定可能
return span.Equals("TargetText".AsSpan(), StringComparison.Ordinal);
}なぜSpanが速いのか
Span<T>はスタック上に配置される構造体であり、ヒープメモリを消費しません。
ガベージコレクション(GC)の負荷を抑えつつ、StringComparisonの恩恵を受けられるため、大量の文字列処理を行うパーサーやロガーの実装において極めて強力な武器となります。
ケーススタディ:どのシーンでどれを使うべきか
パフォーマンスが重要だからといって、すべての箇所をOrdinalにすれば良いわけではありません。
用途に応じた適切な選択基準を整理します。
Ordinal / OrdinalIgnoreCase を選ぶべきケース
- 内部的な識別子:JSONのキー、DBのテーブル名、プログラミング言語の予約語など。
- ファイルパス・URL:システムが解釈するパスの比較。
- 高頻度のループ内:何万回と繰り返される検索やフィルタリング処理。
特に、Windowsなどのファイルシステムは大文字小文字を区別しないことが多いため、OrdinalIgnoreCaseが多用されます。
InvariantCulture を選ぶべきケース
- 永続化データ:設定ファイルに保存する文字列など、どの国で実行しても同じ結果になってほしいが、最低限の言語的ルール(合字の処理など)は適用したい場合。
- ただし、多くの場合
Ordinalで代用可能です。
CurrentCulture を選ぶべきケース
- ユーザーインターフェース:ユーザーが入力した名前をソートして表示する場合。
- 言語固有の検索:ユーザーが期待する自然な言語感覚での一致確認。
文字列比較を高速化するためのベストプラクティス
最後に、日々のコーディングで意識すべき高速化のポイントをまとめます。
1. 演算子よりもEqualsメソッドを使う
str1 == str2と書くと、読み手にはその比較の意図が伝わりにくいだけでなく、将来的にカルチャ設定の影響を受けるリスクを排除できません。
Equals(str2, StringComparison.Ordinal)のように、比較戦略を明示する習慣をつけましょう。
2. ToLower() / ToUpper() による比較を避ける
大文字小文字を無視したいときに、以下のようなコードを書いてはいけません。
// アンチパターン:新しい文字列インスタンスが生成され、非常に遅い
if (str1.ToLower() == str2.ToLower()) { ... }このように書くと、比較のたびにToLowerによって新しい文字列オブジェクトがヒープに作成され、GCの負荷を高めます。
必ずStringComparison.OrdinalIgnoreCaseを使用してください。
3. ハッシュセットや辞書の活用
同じ文字列と何度も比較する場合は、HashSet<string>やDictionary<string, T>を検討してください。
これらのコレクションを初期化する際にも、コンストラクタでStringComparer.Ordinalを指定することが可能です。
// 辞書のキー比較も高速化
var dict = new Dictionary<string, int>(StringComparer.OrdinalIgnoreCase);まとめ
C#における文字列比較は、一見単純に見えて非常に奥が深いテーマです。
StringComparison.Ordinalを正しく選択することは、単にコードを数ミリ秒速くするだけでなく、CPUリソースの節約、サーバーコストの削減、そしてユーザーエクスペリエンスの向上に直結します。
比較の目的が「システム的な一致」であればOrdinal、「人間向けの表示」であればCurrentCultureという原則を基本に、必要に応じてSpan<T>などの最新機能を組み合わせるのが現代的なC#開発のベストプラクティスです。
この記事で紹介した知識を活用し、より堅牢で高速なアプリケーションを構築していきましょう。
