
C#のプログラミングにおいて、文字列の比較は避けては通れない非常に重要な処理の一つです。
特に「大文字と小文字を区別せずに比較したい」という場面は、ユーザー入力の検証や検索機能の実装などで頻繁に登場します。
しかし、単純にToLower()やToUpper()を使用して変換してから比較する方法は、パフォーマンス面や言語文化(カルチャ)の観点から推奨されません。
モダンなC#開発では、StringComparison列挙型を適切に使い分けることがベストプラクティスとされています。
本記事では、大文字小文字を無視した比較の正しい実装方法から、なぜその手法が選ばれるのかという理由、そしてパフォーマンスに及ぼす影響までを詳しく解説します。
C#における文字列比較の基本
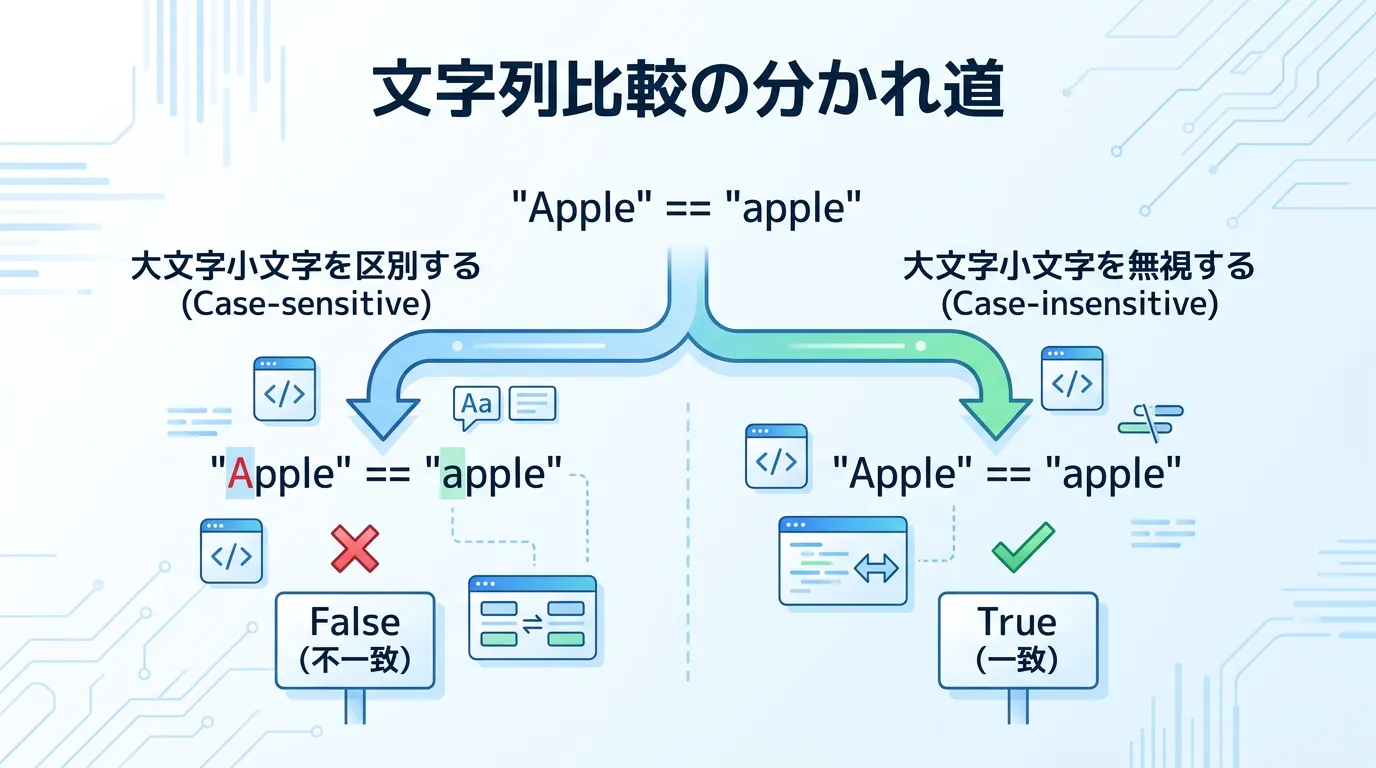
C#で文字列を比較する際、最も単純な方法は==演算子を使用することです。
しかし、この演算子はデフォルトで大文字と小文字を厳密に区別します。
コンピュータにとって、大文字の「A」と小文字の「a」は全く異なる文字コード(ASCII/Unicode値)として割り当てられているためです。
デフォルトの比較動作を確認する
まずは、標準的な比較がどのようになされるかを確認してみましょう。
using System;
class Program
{
static void Main()
{
string str1 = "CSharp";
string str2 = "csharp";
// == 演算子による比較
bool result = (str1 == str2);
// 結果を出力
Console.WriteLine($"str1: {str1}");
Console.WriteLine($"str2: {str2}");
Console.WriteLine($"比較結果 (==): {result}");
}
}str1: CSharp
str2: csharp
比較結果 (==): Falseこのように、人間にとっては同じ意味の単語であっても、プログラム上は一致しないと判定されます。
これを解決するために、.NETでは比較方法を柔軟に指定できる仕組みが用意されています。
StringComparison列挙型の種類と特徴
大文字小文字を無視した比較を行うための鍵となるのが、StringComparison列挙型です。
この列挙型をメソッドの引数に渡すことで、どのように文字列を評価するかを明示的に指定できます。
StringComparisonの主な値
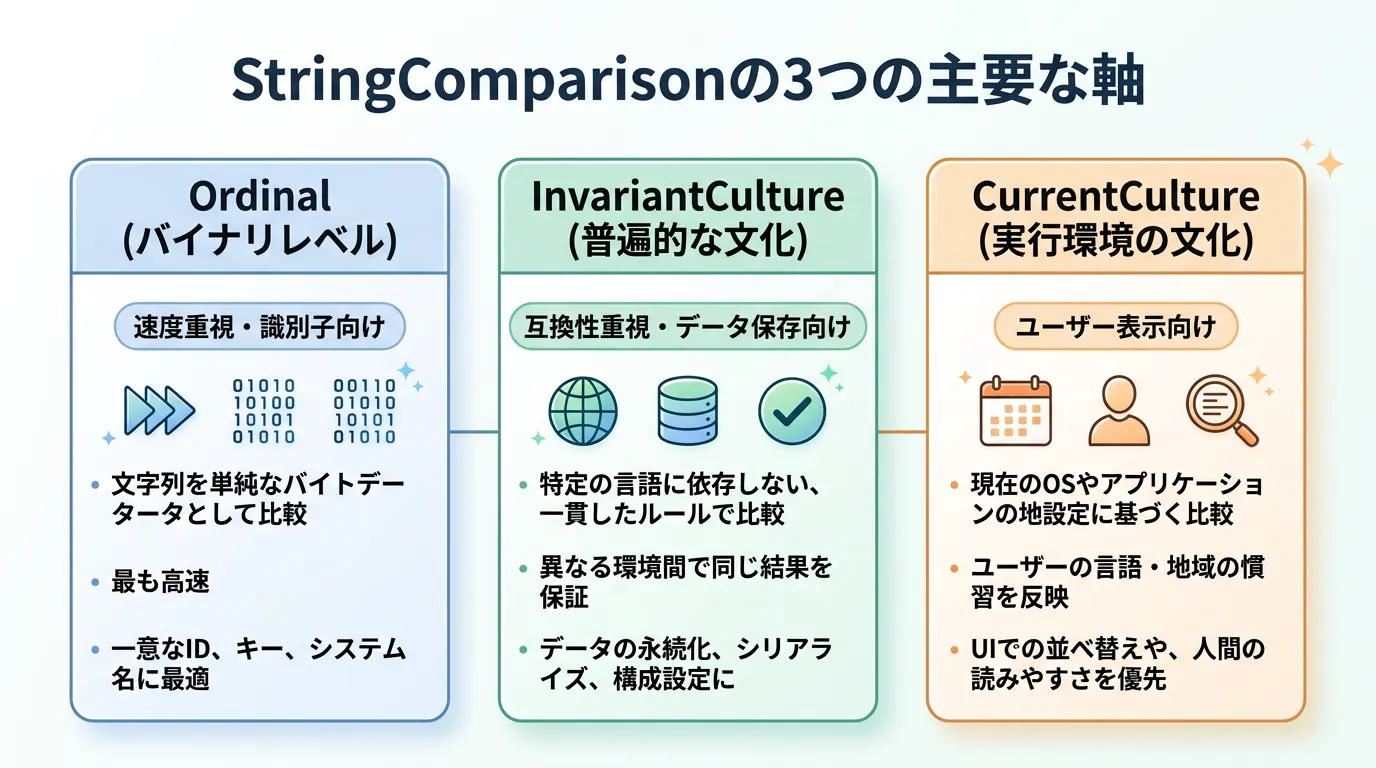
主に使用される設定は以下の通りです。
| 設定値 | 説明 | 推奨用途 |
|---|---|---|
Ordinal | 各文字のバイナリ値を直接比較する。大文字小文字を区別する。 | 内部的なIDやファイルパスの比較 |
OrdinalIgnoreCase | バイナリ値を基にしつつ、大文字小文字を無視して比較する。 | 最も一般的。プログラムの制御ロジックなど |
InvariantCultureIgnoreCase | 特定の国に依存しない「不変のカルチャ」を用いて大文字小文字を無視する。 | 永続化されたデータの検索など |
CurrentCultureIgnoreCase | 実行されているOSの地域設定(日本語など)に基づき、大文字小文字を無視する。 | 最終的にユーザーに表示するリストのソートや検索 |
多くの場合、開発者が求める「単純な大文字小文字の無視」は、StringComparison.OrdinalIgnoreCaseを使用することで実現できます。
これは、特定の言語ルールに縛られず、高速かつ安全に動作するためです。
各メソッドでの具体的な実装例
それでは、実際にStringComparisonを使用して、大文字小文字を無視する実装方法を見ていきましょう。
Equalsメソッドでの比較
文字列が完全に一致するかどうかを確認する場合、Equalsメソッドを使用します。
using System;
class Program
{
static void Main()
{
string input = "HELLO WORLD";
string target = "hello world";
// StringComparison.OrdinalIgnoreCase を指定して比較
if (input.Equals(target, StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine("大文字小文字を無視して一致しました。");
}
else
{
Console.WriteLine("一致しませんでした。");
}
}
}大文字小文字を無視して一致しました。Contains / StartsWith / EndsWith メソッド
特定の文字列が含まれているか、あるいは特定の文字で始まっているかを判定する場合も同様です。
※ContainsでStringComparisonが使えるようになったのは.NET Core 2.1以降(.NET Standard 2.1以降)です。
using System;
class Program
{
static void Main()
{
string sentence = "C# is a powerful programming language.";
// 指定した文字列が含まれているか(大文字小文字無視)
bool contains = sentence.Contains("POWERFUL", StringComparison.OrdinalIgnoreCase);
// 指定した文字列で始まっているか(大文字小文字無視)
bool starts = sentence.StartsWith("c#", StringComparison.OrdinalIgnoreCase);
Console.WriteLine($"Contains: {contains}");
Console.WriteLine($"StartsWith: {starts}");
}
}Contains: True
StartsWith: TrueCompareメソッドによる大小比較
文字列のソート順などを判定するためのCompareメソッドでも、第3引数または引数の構成によって大文字小文字の無視を指定できます。
using System;
class Program
{
static void Main()
{
string a = "apple";
string b = "APPLE";
// 返り値が 0 なら一致
int result = string.Compare(a, b, StringComparison.OrdinalIgnoreCase);
Console.WriteLine($"比較結果(0なら一致): {result}");
}
}なぜ ToLower() や ToUpper() を使ってはいけないのか
初心者のコードでよく見かけるのが、if (str1.ToLower() == str2.ToLower())という書き方です。
動かないわけではありませんが、実務では避けるべき理由が2つあります。
1. メモリ効率の悪化
ToLower()を呼び出すと、元の文字列を変換した新しい文字列のインスタンスがメモリ上に作成されます。
大量の文字列比較を行うループ内でこれを行うと、ガベージコレクション(GC)の負荷が高まり、アプリケーションのパフォーマンスが低下します。
一方、StringComparisonを使用する方法は、新しい文字列を生成せずに内部で比較を行うため、非常に効率的です。
2. トルコ語の「I」問題(国際化の壁)
これは「トルコ問題(Turkish I Problem)」として有名な現象です。
例えば、トルコ語のカルチャ設定では、小文字の「i」を大文字にすると、点がついた「İ」になります。
通常の英語の「I」とは異なります。
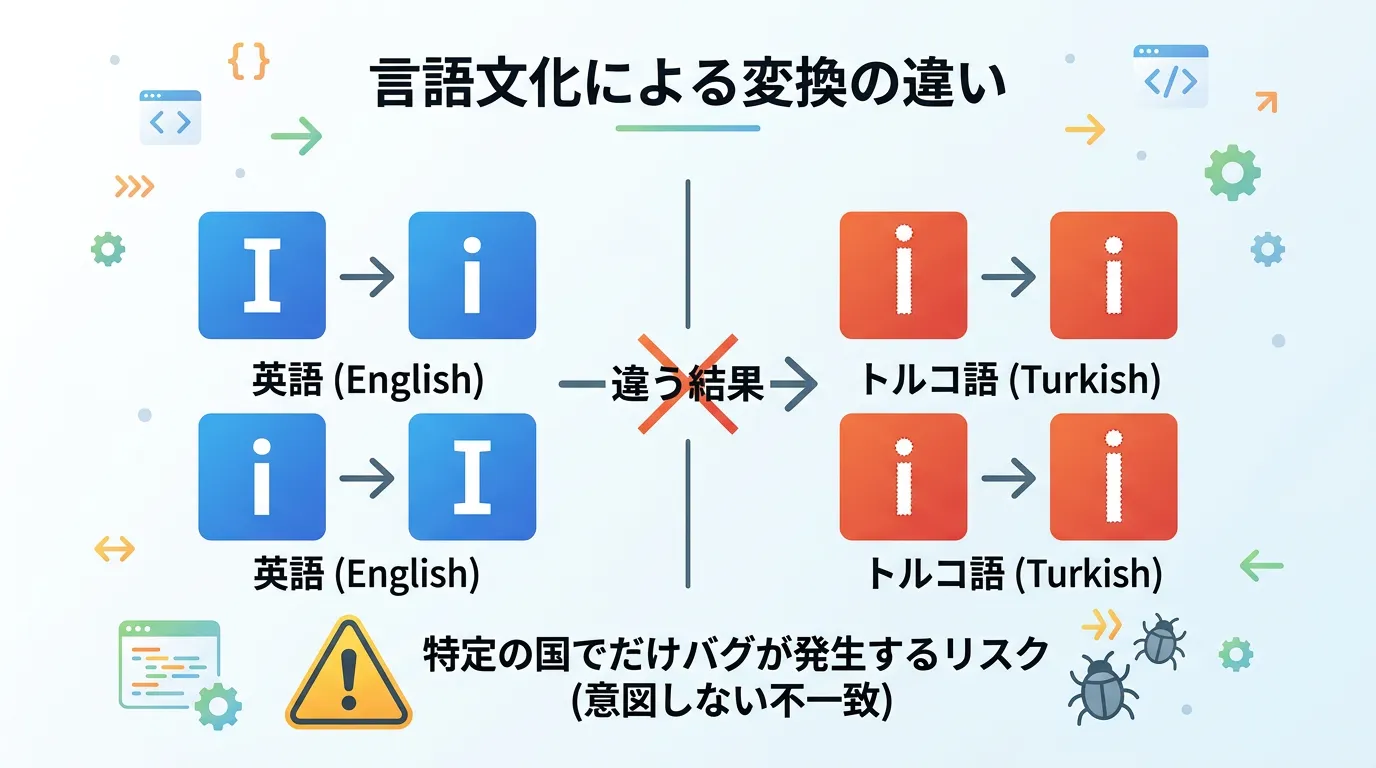
もし、CurrentCulture設定下でToUpper()を使用してしまうと、実行環境がトルコだった場合に、期待した比較結果が得られないという深刻なバグの原因となります。
システム内部のIDなどを比較する際は、常にカルチャに依存しないOrdinalIgnoreCaseを使用するのが安全です。
パフォーマンスと最適な選択肢
実際にどの程度の速度差が出るのか、一般的な傾向を理解しておきましょう。
文字列比較の速度は、以下の順序で高速です。
- Ordinal
最速:単なるバイナリ比較
- OrdinalIgnoreCase
高速:大文字小文字をビット演算等で効率的に無視
- InvariantCultureIgnoreCase
普通:言語中立な辞書順
- CurrentCultureIgnoreCase
低速:現在のOS言語設定を考慮
通常、ユーザーの目に触れないプログラム内部の処理(辞書のキー、設定値、列挙型のパースなど)では、常に OrdinalIgnoreCase を選択するのがプロフェッショナルの鉄則です。

よくある質問:どれを使えばいいか迷ったら?
多くの選択肢があるため、迷うこともあるでしょう。
基本的には以下のガイドラインに従ってください。
- StringComparison.OrdinalIgnoreCase
プログラム内の識別子、プロトコル、ファイルパスを比較する場合
- StringComparison.InvariantCultureIgnoreCase
設定ファイルやデータベースから取得した、言語に依存させたくない値を比較する場合
- StringComparison.CurrentCultureIgnoreCase
ユーザーが入力した氏名や住所など、言語のルールに従ってソートや検索をする場合
まとめ
C#で大文字小文字を無視して文字列を比較する方法について解説しました。
単にToLower()で共通のケースに揃えるのではなく、StringComparison列挙型を引数に取るメソッドを活用することが、高品質なコードを書くための第一歩です。
特にStringComparison.OrdinalIgnoreCaseは、不必要なメモリ割り当てを防ぎ、かつ多言語環境での予期せぬ動作を回避できるため、日常的な開発における「デフォルトの選択肢」として定着しています。
パフォーマンスと堅牢性の両立を目指し、適切な比較方法をマスターしていきましょう。
