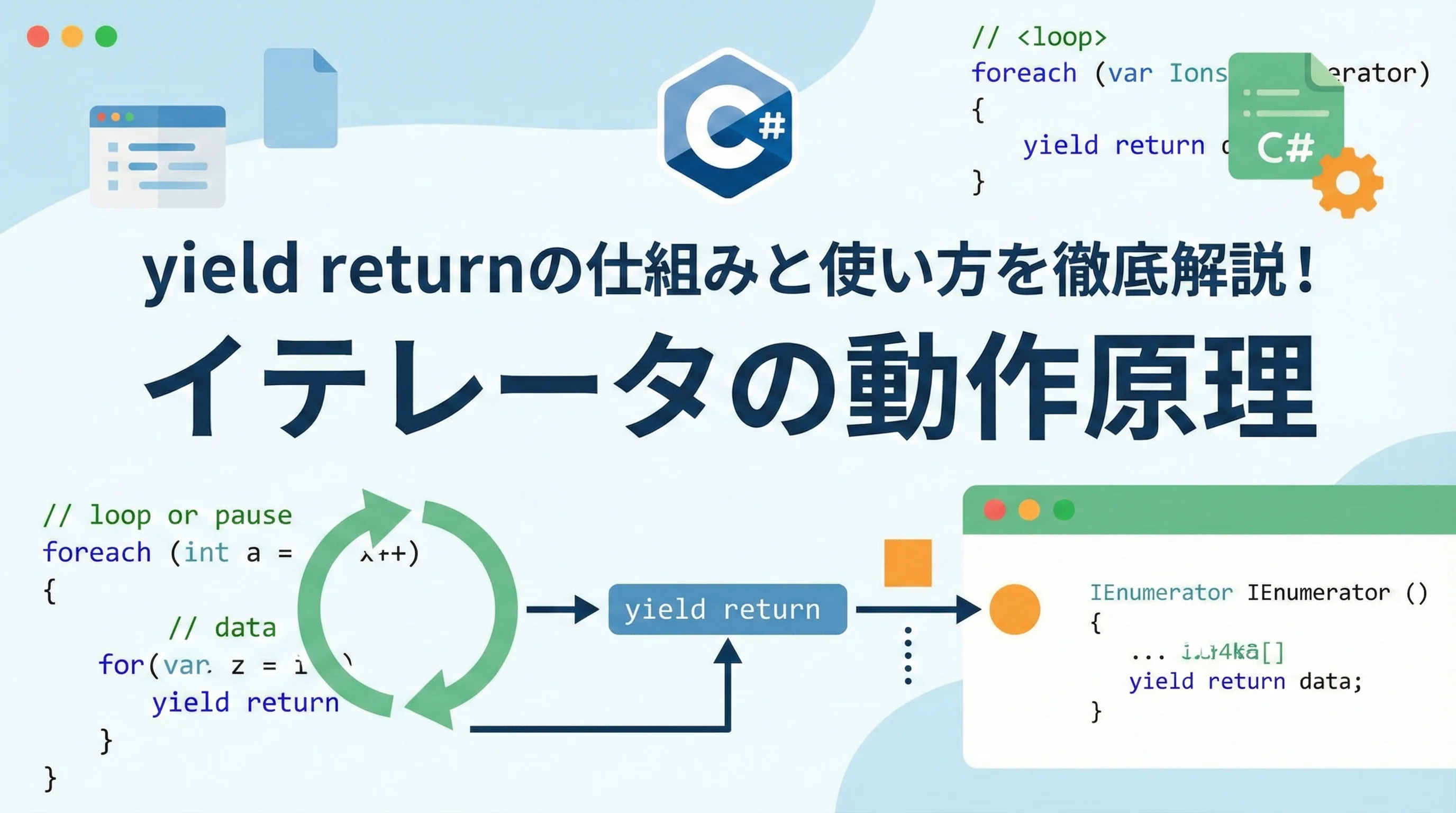
C#を利用して開発を行う際、コレクションの要素を順番に取得するために便利なのがイテレータという仕組みです。
その中心的な役割を果たすのがyield returnキーワードですが、実際にどのような挙動でメモリやCPUを効率化しているのかを深く理解している方は少ないかもしれません。
この記事では、yield returnの基本的な使い方から、コンパイラが裏側で生成するステートマシン(状態管理クラス)の仕組みまで、初心者から中級者向けに徹底解説します。
yield returnの基本とイテレータの役割
C#においてyield returnは、メソッドが列挙可能(Enumerable)であることを示すために使用されます。
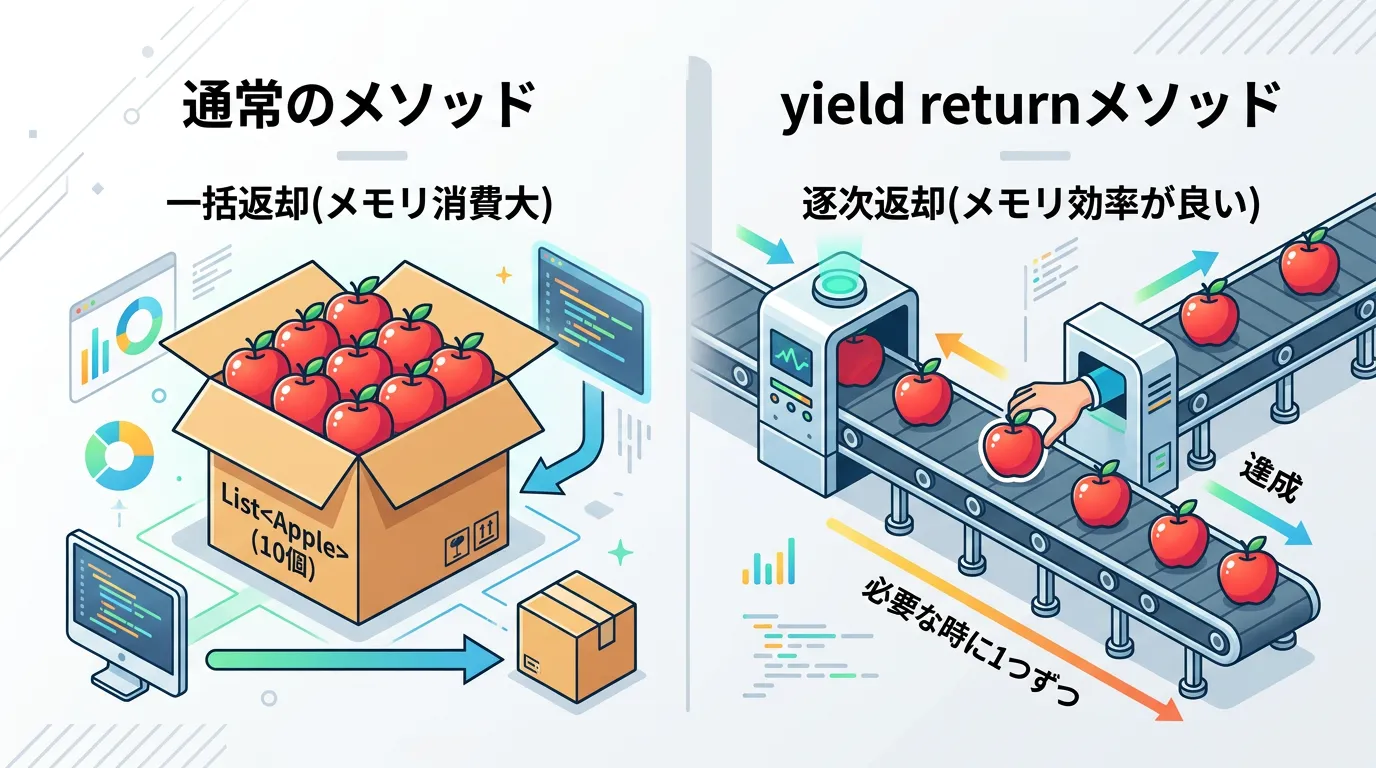
通常、リストや配列を返すメソッドは、すべてのデータをメモリ上に確保してから呼び出し元に返しますが、yield returnを使うと「必要なときに必要な分だけ」要素を生成して返すことができます。
イテレータの基本的な構文
イテレータを作成するには、戻り値をIEnumerable、IEnumerable<T>、IEnumerator、またはIEnumerator<T>にする必要があります。
その中でyield returnを記述すると、そのメソッドは自動的にイテレータとして機能します。
using System;
using System.Collections.Generic;
public class Program
{
public static void Main()
{
// GetNumbersメソッドを呼び出す(この時点では実行されない)
IEnumerable<int> numbers = GetNumbers();
Console.WriteLine("foreachループを開始します。");
// 要素が必要になったタイミングでGetNumbersの処理が走る
foreach (int n in numbers)
{
Console.WriteLine($"取得した値: {n}");
}
}
// yield returnを使用したイテレータメソッド
public static IEnumerable<int> GetNumbers()
{
Console.WriteLine("1つ目の値を生成します");
yield return 10;
Console.WriteLine("2つ目の値を生成します");
yield return 20;
Console.WriteLine("3つ目の値を生成します");
yield return 30;
}
}foreachループを開始します。
1つ目の値を生成します
取得した値: 10
2つ目の値を生成します
取得した値: 20
3つ目の値を生成します
取得した値: 30逐次実行(遅延評価)の特性
上記のコードの実行結果を見るとわかる通り、MainメソッドでGetNumbers()を呼び出した直後には、メソッド内の「1つ目の値を生成します」というメッセージは表示されません。
実際にforeachで要素を要求したタイミングで初めてメソッド内の処理が実行されます。
これを遅延評価(Lazy Evaluation)と呼びます。
この特性により、巨大なデータを扱う際でも、すべてのデータを一度にメモリに載せる必要がなく、メモリ消費を劇的に抑えることが可能になります。
yield returnの動作原理:ステートマシンの仕組み
なぜyield returnを使うと、メソッドの中断と再開ができるのでしょうか。
通常のメソッドはreturnするとスタックから情報が消えてしまいますが、yield returnはコンパイラによって魔法のような処理が行われています。
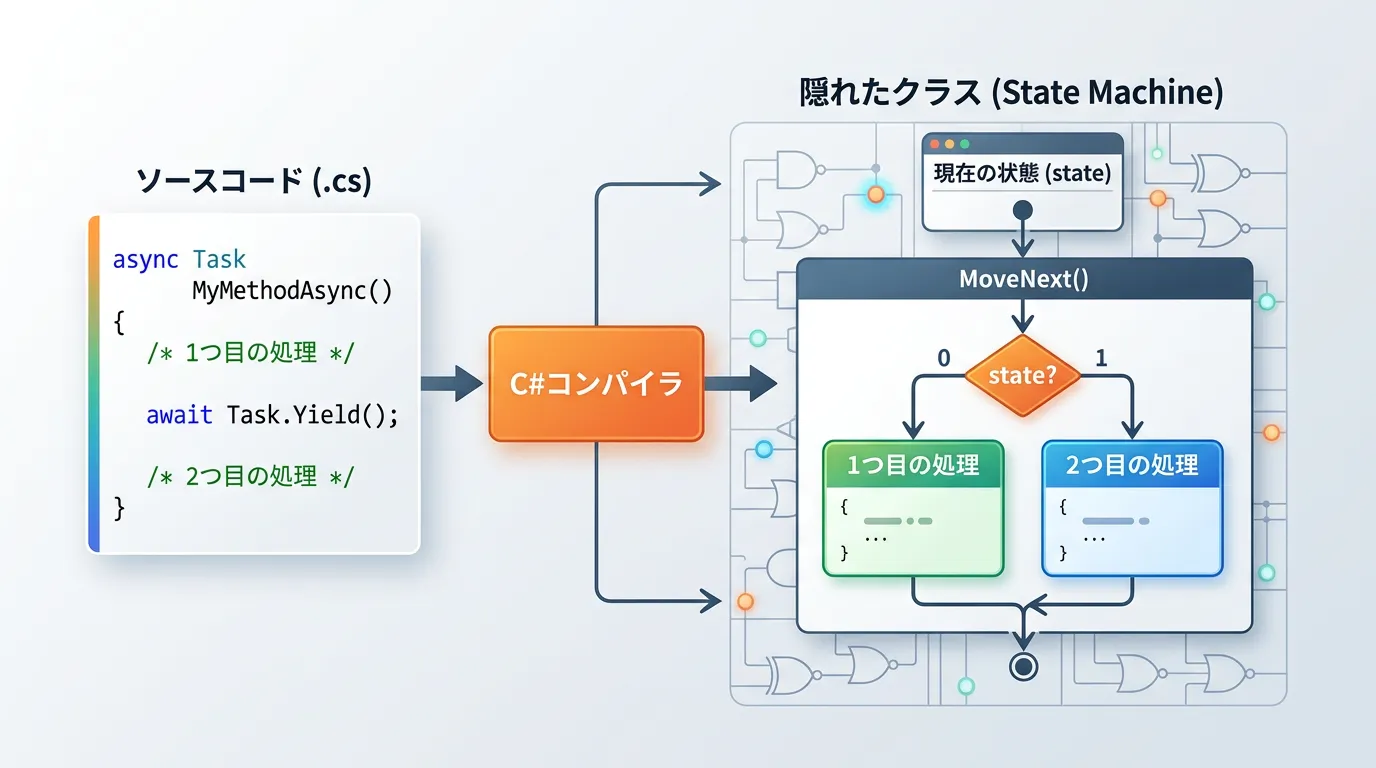
コンパイラが生成する「隠しクラス」
C#コンパイラはyield returnを含むメソッドを見つけると、そのメソッドをそのまま実行するのではなく、内部的に新しいクラスを生成します。
このクラスはIEnumeratorインターフェースを実装しており、以下のような情報を保持します。
- 現在の状態 (State)
メソッドのどこまで実行したかを記録する整数値。
- 現在の値 (Current)
現在返すべき値。
- ローカル変数のコピー
メソッド内で使っていた変数の値を保持するフィールド。
MoveNext()メソッドの役割
イテレータの実体は、実はwhileループやswitch文を組み合わせた巨大なMoveNext()メソッドです。
呼び出し元のforeachが次の要素を欲しがると、生成されたクラスのMoveNext()が呼ばれます。
このメソッド内では「状態(State)」を確認し、前回のyield returnの直後から処理を再開します。
そして次のyield returnに到達すると、現在の値を保持し、状態を更新してtrueを返します。
これによって、「メソッドの途中で一時停止し、後でそこから再開する」という動作が実現されています。
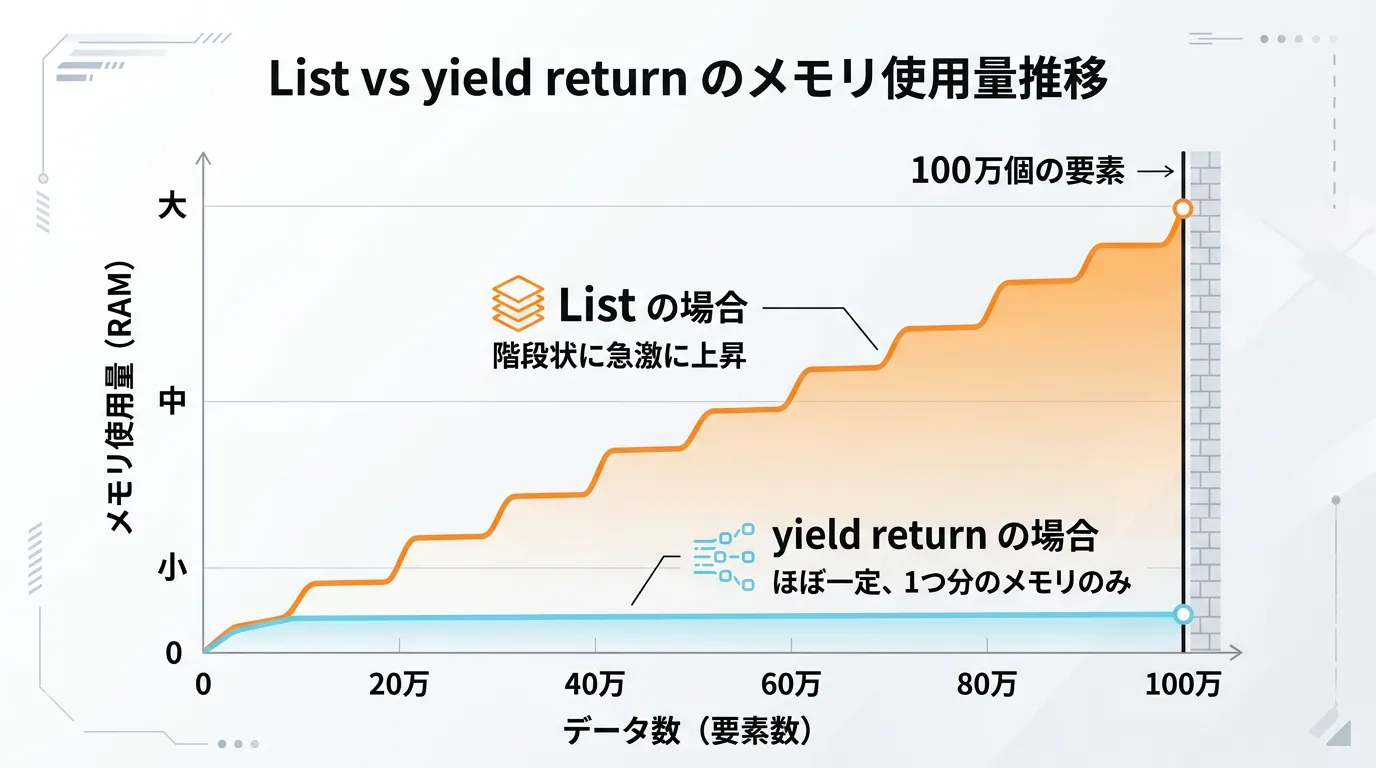
メモリ効率とパフォーマンスの比較
通常のリスト返却とyield returnを使ったイテレータでは、パフォーマンス特性が大きく異なります。
特に大量のデータをフィルタリングしたり加工したりする場合、その差は顕著です。
List返却とyield returnの比較表
以下の表は、両者の主な違いをまとめたものです。
| 項目 | List<T> を返す方法 | yield return を使う方法 |
|---|---|---|
| 評価のタイミング | 呼び出し時にすべて完了(即時評価) | 必要になった時に実行(遅延評価) |
| メモリ消費量 | 全要素分を確保するため大きい | 1要素分(+状態保持)のため非常に小さい |
| 初回アクセス速度 | 全件処理が終わるまで待機が必要 | 即座に1件目の処理が開始される |
| 再利用性 | 何度でもループ可能(メモリに残っている) | 再度取得するにはメソッドを再実行する必要がある |
実践:大量データの処理
例えば、100万個の整数から偶数だけを抽出する処理を考えてみましょう。
Listを使うと100万個の領域を一度に確保しますが、yield returnなら必要なのは現在の1つだけです。
// メモリを大量に消費する書き方
public IEnumerable<int> GetEvensList(int max)
{
var result = new List<int>();
for (int i = 0; i < max; i++)
{
if (i % 2 == 0) result.Add(i);
}
return result; // 全件入ったリストを返す
}
// メモリを節約する書き方
public IEnumerable<int> GetEvensYield(int max)
{
for (int i = 0; i < max; i++)
{
if (i % 2 == 0) yield return i; // 見つかるたびに1つずつ返す
}
}GetEvensYieldの場合、maxが1億であっても、メソッド自体が巨大な配列を生成することはありません。
これにより、OutMemoryException(メモリ不足例外)を防ぐことができ、大規模システムの安定性が向上します。
yield breakによる途中の終了
イテレータの途中で「これ以上データがない」と判断して処理を終了させたい場合があります。
その際に使用するのがyield breakです。
yield breakの使い方
yield breakが呼び出されると、そのイテレータの列挙は終了し、呼び出し元のループも終了します。
これは通常のメソッドにおけるreturnに相当しますが、戻り値を指定することはできません。
public IEnumerable<string> GetNames(bool stopEarly)
{
yield return "Alice";
yield return "Bob";
if (stopEarly)
{
// ここで列挙を終了する
yield break;
}
yield return "Charlie";
}このコードでstopEarlyがtrueの場合、”Charlie”は決して返されません。
コンパイラが生成するステートマシン内では、状態を「終了(通常は-1)」に設定する処理に変換されます。
yield returnを使用する際の注意点と制限
非常に便利なyield returnですが、いくつかの制約や注意点が存在します。
1. try-catchブロック内での使用制限
yield returnは、try-catchブロックの中に記述することができません。
これは、例外が発生した際にステートマシンの状態を安全に復元することが難しいためです。
- NG:
try { yield return 1; } catch { ... }はコンパイルエラー。 - OK:
try { yield return 1; } finally { ... }は許可されています。
例外処理を行いたい場合は、イテレータを呼び出す側のforeachでラップするか、イテレータの外部でロジックを分離する必要があります。
2. 引数のバリデーション
遅延評価の性質上、メソッドが呼び出された瞬間に引数のチェックが行われないという罠があります。
public IEnumerable<int> GetData(int[] source)
{
if (source == null) throw new ArgumentNullException(nameof(source)); // ここでチェックしたい
foreach (var item in source)
{
yield return item * 2;
}
}上記のコードを呼び出した際、戻り値を受け取った時点では例外は発生しません。
実際にforeachで回し始めた時に初めて例外が飛びます。
これを防ぐには、「通常のメソッド(バリデーション用)」と「イテレータメソッド(本体)」を分けるのが一般的なテクニックです。
public IEnumerable<int> GetData(int[] source)
{
if (source == null) throw new ArgumentNullException(nameof(source));
return GetDataInternal(source);
}
private IEnumerable<int> GetDataInternal(int[] source)
{
foreach (var item in source) yield return item * 2;
}3. 副作用のある処理に注意
yield returnを含むメソッド内で外部の変数を書き換えたり、ファイルに書き込んだりするような副作用を持たせるのは危険です。
列挙が途中で止まったり、何度も繰り返されたりする可能性があるため、意図しない挙動を引き起こす原因になります。
非同期ストリーム:IAsyncEnumerable
最新のC#では、yield returnの仕組みを非同期に応用したIAsyncEnumerable<T>が導入されています。
これは「データの準備に時間がかかる(API通信やDB取得など)」場合に、スレッドをブロックせずに逐次データを返す仕組みです。
public async IAsyncEnumerable<int> GetNumbersAsync()
{
for (int i = 0; i < 3; i++)
{
await Task.Delay(1000); // 非同期で待機
yield return i;
}
}呼び出し側ではawait foreachを使用します。
これにより、ネットワーク越しに巨大なデータをストリーミング再生するように1件ずつ処理することが可能になりました。
まとめ
C#のyield returnは、単なる記述の簡略化ツールではなく、コンパイラが裏側で複雑なステートマシンを構築することで実現されている高度な機能です。
その最大のメリットは遅延評価によるメモリ効率の向上にあり、特にビッグデータやストリーム処理においてその真価を発揮します。
しかし、ステートマシン特有の「実行タイミングのずれ」や「例外処理の制限」といった注意点を正しく把握しておく必要があります。
今回の内容を整理すると以下の通りです。
yield returnは必要なときに1件ずつ値を返す。- 内部的にはコンパイラが状態を管理するクラス(ステートマシン)を生成している。
- メモリ消費を抑え、巨大なデータでも安全に扱える。
- 引数チェックや例外処理には工夫が必要。
- 現代のC#では非同期ストリームへと進化している。
イテレータの仕組みを正しく理解し、効率的で読みやすいコードを目指しましょう。
