Pythonのreplaceメソッドは、文字列の一部を書き換えるとても便利な機能です。
しかし、使い方を誤るとパフォーマンスの悪化や誤置換などの問題を引き起こしてしまいます。
本記事では、Pythonのstr.replaceの基本から、やってはいけないNG例、そして実務で使えるベストプラクティスまで、図解を交えながら丁寧に解説します。
Pythonのreplaceとは
str.replaceの基本構文と特徴
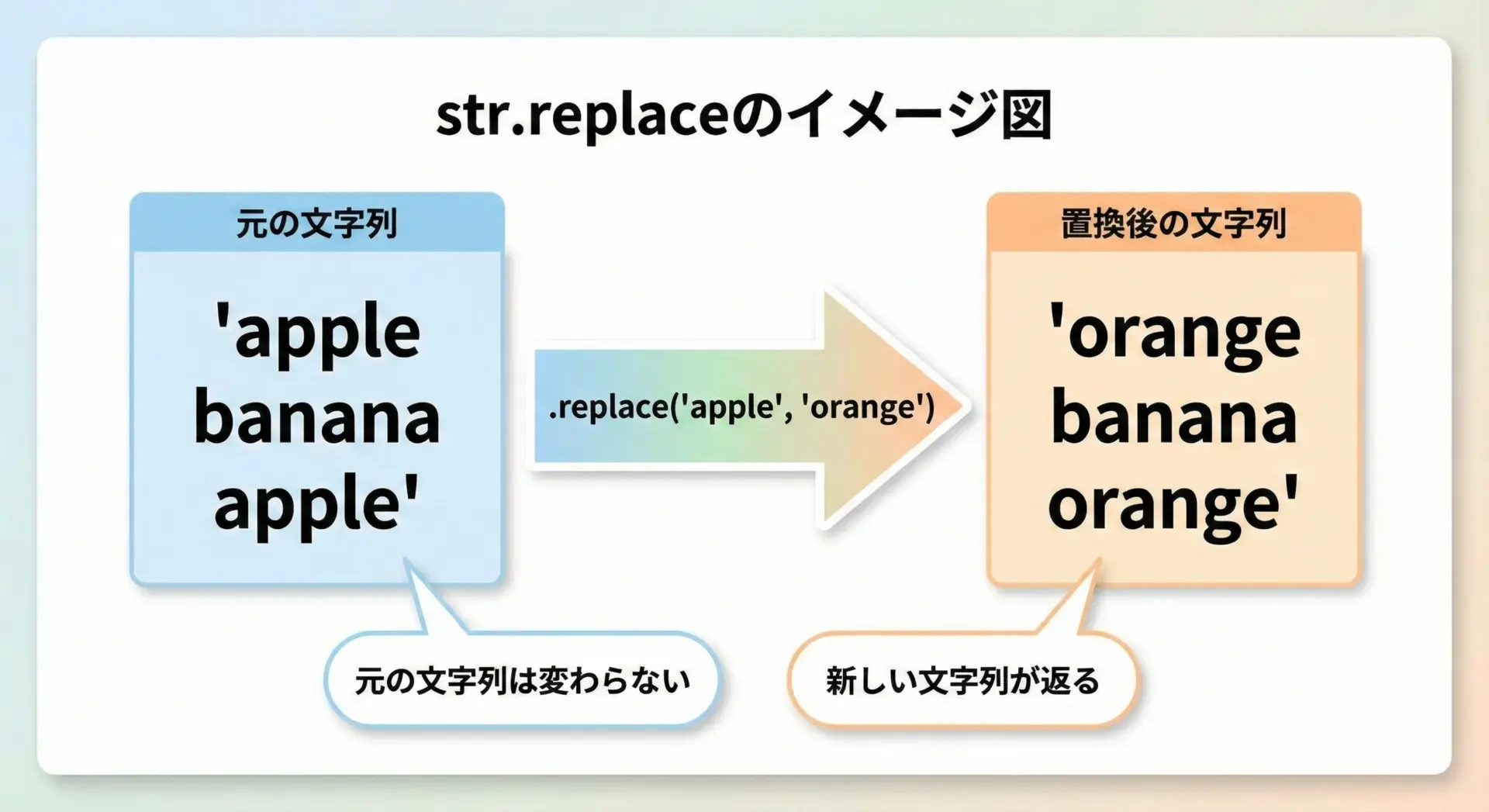
Pythonのreplaceは、文字列型strが持つメソッドで、指定した文字列を、別の文字列に置き換えた新しい文字列を返すものです。
元の文字列そのものを書き換えるのではなく、新しい文字列オブジェクトを作成して返す点が重要です。
基本構文
str.replaceの基本構文は次の通りです。
文字列.replace(置換前, 置換後, 置換回数)各引数の意味は次のようになります。
置換前: 探して置き換える対象の文字列置換後: 置き換え後の文字列置換回数: 何回まで置換するかを指定する整数(省略可能、省略時はすべて置換)
次の例で具体的な動きを確認してみます。
text = "apple banana apple"
# "apple" を "orange" にすべて置換
replaced = text.replace("apple", "orange")
print("元の文字列:", text)
print("置換後文字列:", replaced)元の文字列: apple banana apple
置換後文字列: orange banana orangeこのように、元のtextは変わらず、新しいreplacedに置換結果が入っていることが分かります。
文字列はイミュータブル
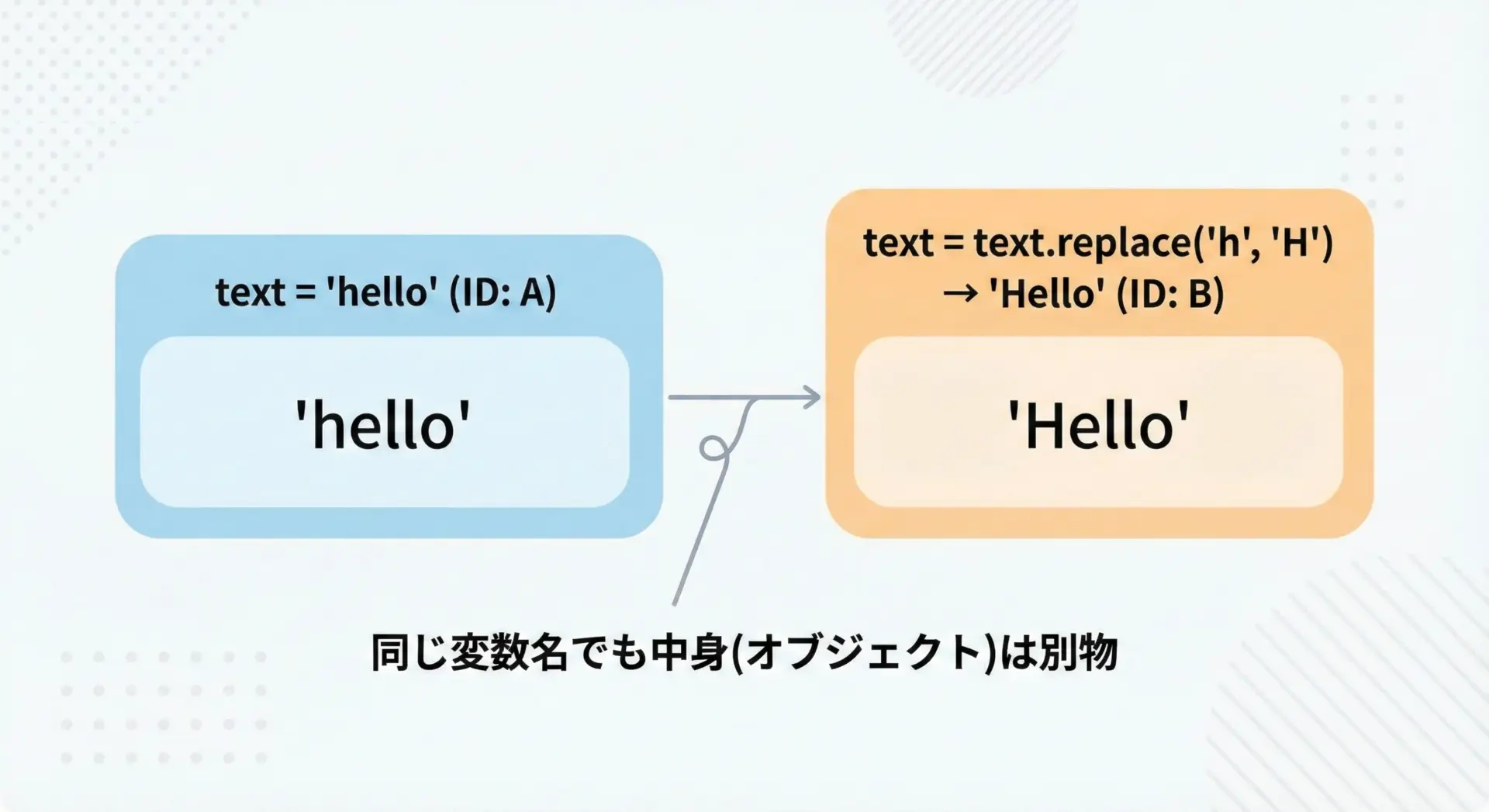
Pythonの文字列(str)はイミュータブル(immutable: 不変)なオブジェクトです。
これは、一度作られた文字列は内部の文字を変更できない、という性質を意味します。
そのためreplaceを呼び出すと、次のような流れになります。
- 元の文字列を読み取る
- 指定したルールにしたがって新しい文字列を作る
- その新しい文字列を戻り値として返す
元の文字列は決して書き換えられません。
次のコードで確認してみます。
text = "hello"
# replaceの結果を受け取らずに呼び出す
text.replace("h", "H")
print("replace後(代入なし):", text)
# replaceの結果を代入して反映させる
text = text.replace("h", "H")
print("replace後(代入あり):", text)replace後(代入なし): hello
replace後(代入あり): Helloreplaceの結果を使いたい場合は、必ず変数に代入するか、その場でチェーンして使用する必要があることを覚えておきましょう。
replaceの基本的な使い方
単純な文字列置換
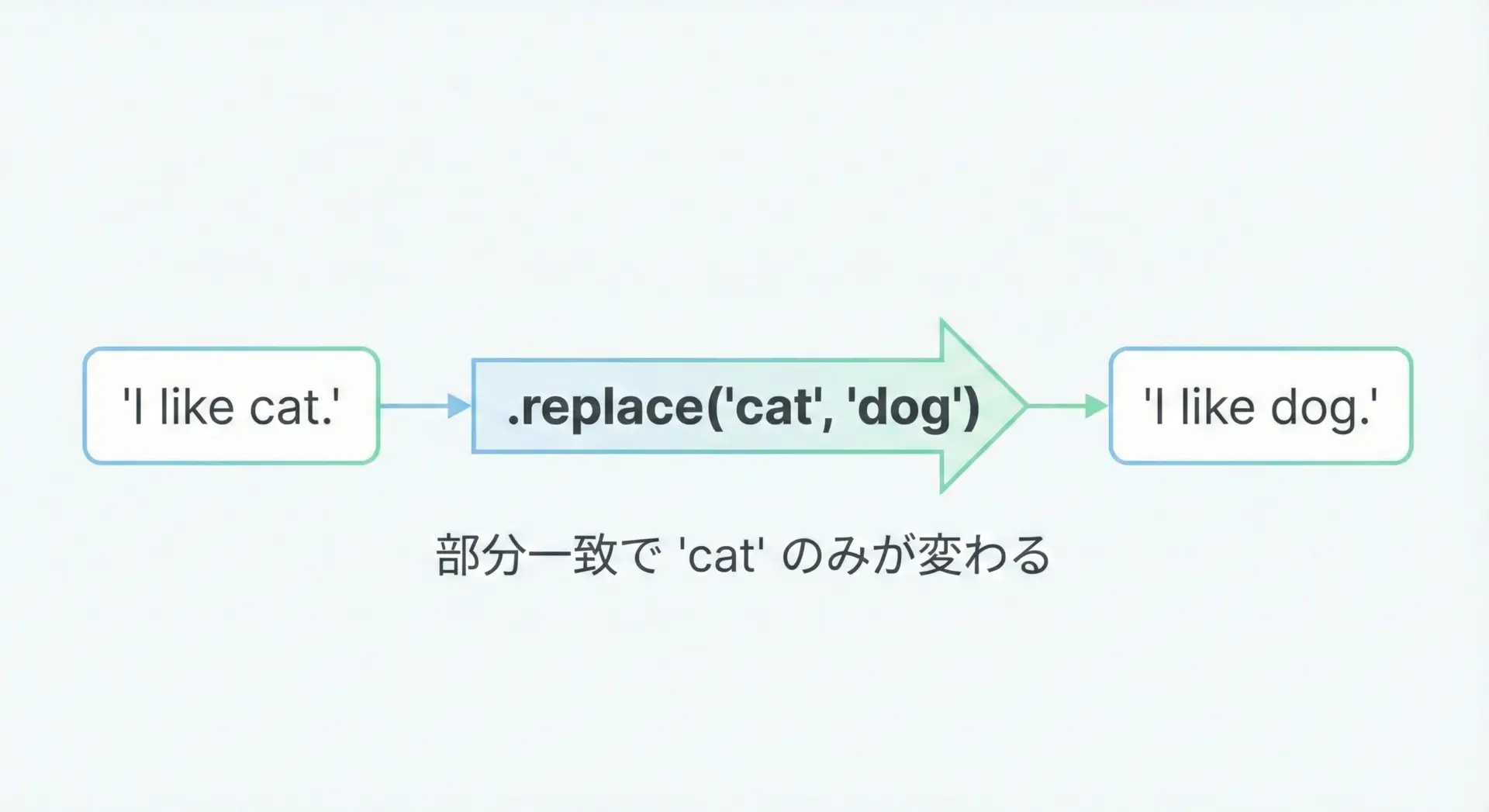
最も基本的な使い方は、単純に1種類の文字列を別の文字列に置換する方法です。
text = "I like cat. Cats are cute."
# "cat" を "dog" に置換
replaced_once = text.replace("cat", "dog")
print("元の文字列:", text)
print("置換後文字列:", replaced_once)元の文字列: I like cat. Cats are cute.
置換後文字列: I like dog. Dogs are cute.この例では"cat"だけでなく"Cats"の"Cat"部分も置換されるため"Dogs"になっています。
replaceは大文字小文字を区別し、そのままの形で置き換えるので、このような副作用も生じます。
この点はNG例の章で詳しく触れます。
第3引数countで置換回数を制限する方法
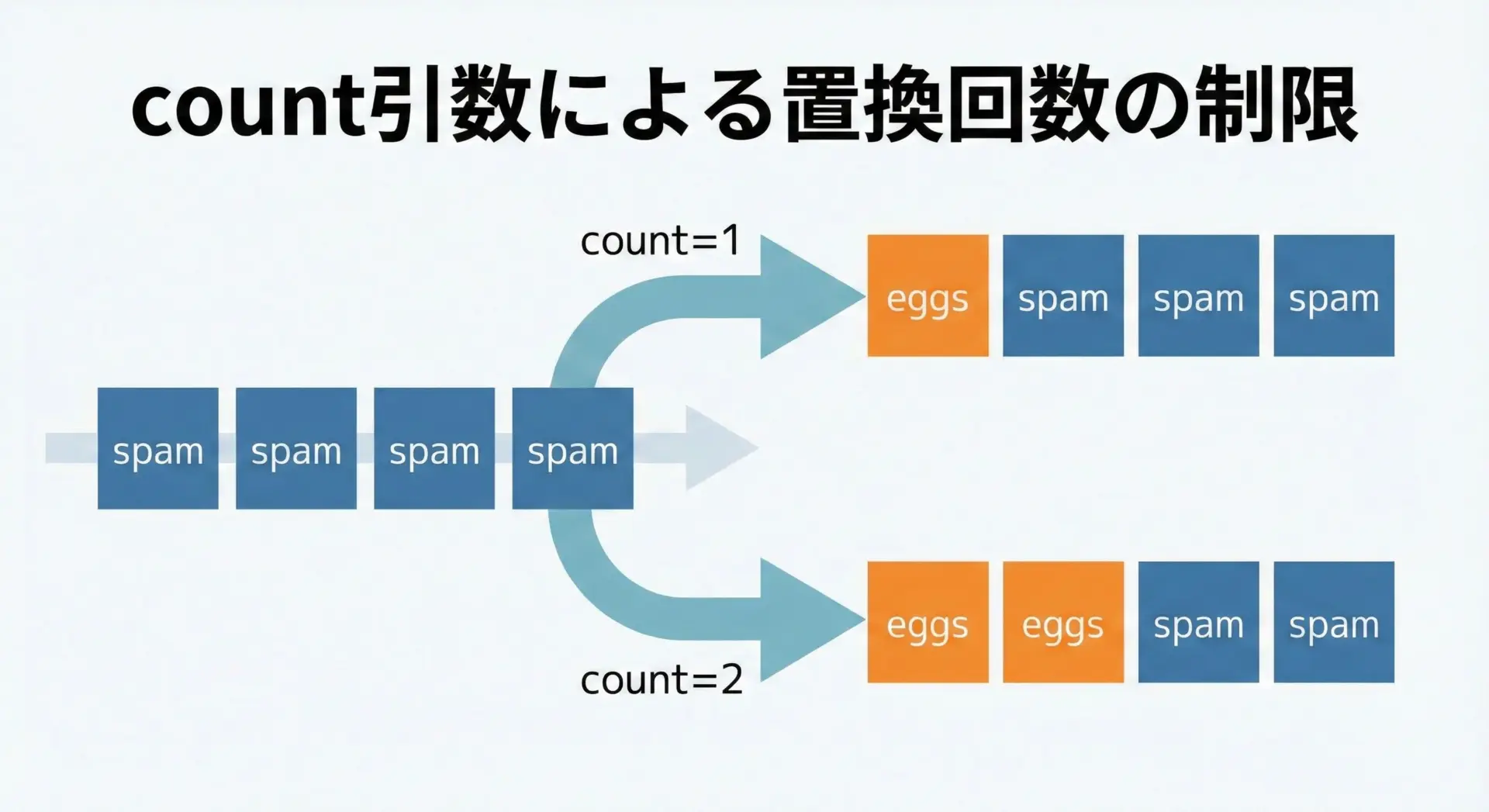
str.replaceには、第3引数としてcountを指定できます。
これは置換する回数の上限を指定するためのものです。
text = "spam spam spam spam"
# 先頭から1回だけ置換
once = text.replace("spam", "eggs", 1)
# 先頭から2回まで置換
twice = text.replace("spam", "eggs", 2)
# 全て置換(第3引数を省略)
all_ = text.replace("spam", "eggs")
print("元の文字列 :", text)
print("1回だけ置換:", once)
print("2回だけ置換:", twice)
print("すべて置換 :", all_)元の文字列 : spam spam spam spam
1回だけ置換: eggs spam spam spam
2回だけ置換: eggs eggs spam spam
すべて置換 : eggs eggs eggs eggs置換は常に左(先頭)から順に行われ、指定した回数に達した時点で止まる点を押さえておくと、制御しやすくなります。
複数パターンをまとめて置換するシンプルな書き方
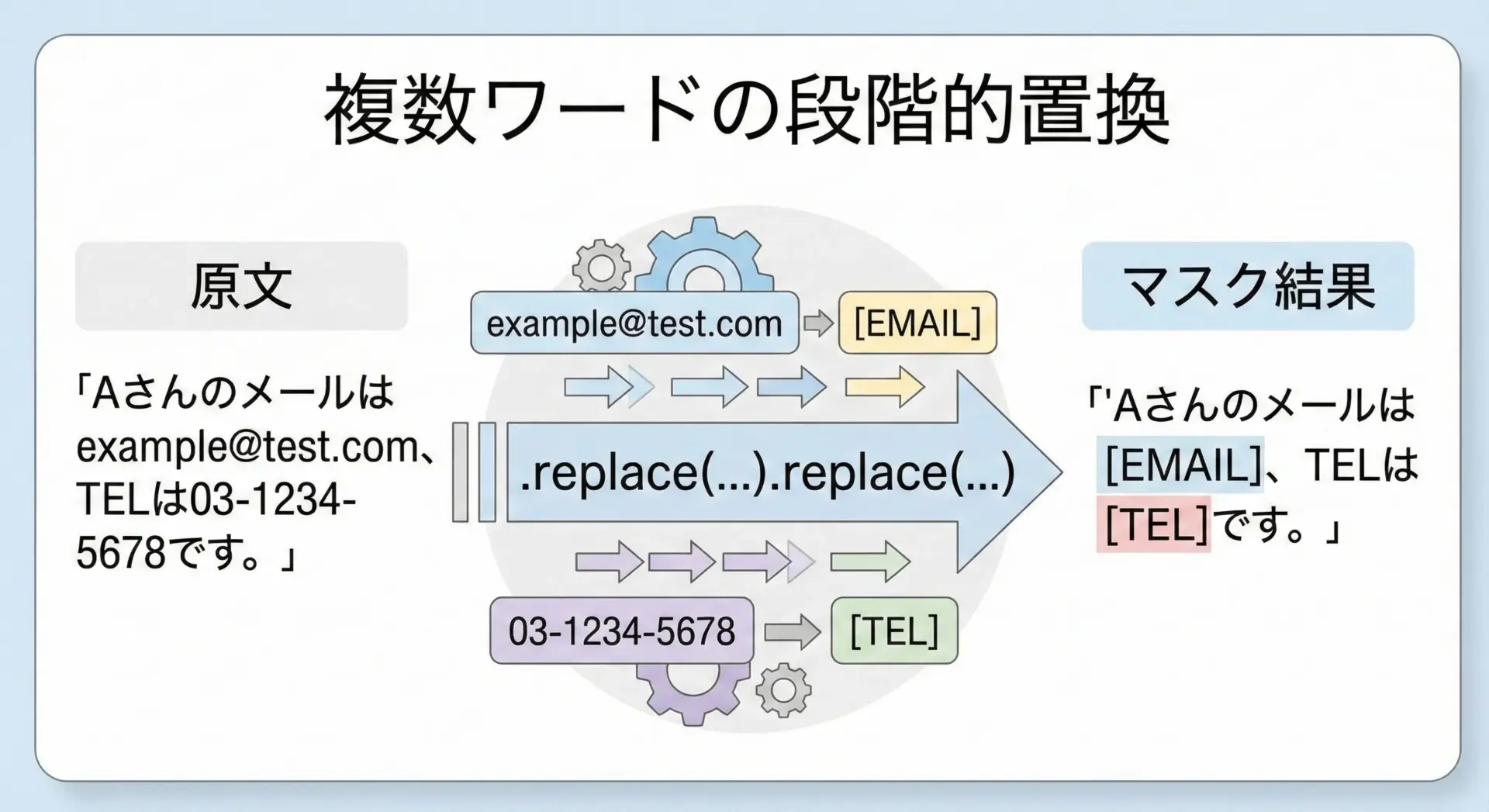
複数の文字列を順番に置換したい場合、replaceをチェーンさせる簡単な方法があります。
まずはシンプルなパターンから見てみましょう。
text = "Aさんのメールはexample@test.com、TELは03-1234-5678です。"
masked = (
text
.replace("example@test.com", "[EMAIL]")
.replace("03-1234-5678", "[TEL]")
)
print(masked)Aさんのメールは[EMAIL]、TELは[TEL]です。このように、1つの文字列に対して複数回replaceを呼び出すことで、段階的に複数のパターンを置換できます。
ただし、データ量が大きい場合やパターン数が多い場合には、パフォーマンス面で問題になりやすいため、後述のベストプラクティスでよりよい方法を紹介します。
replaceのNG例
大量データに対する無駄な連続replace
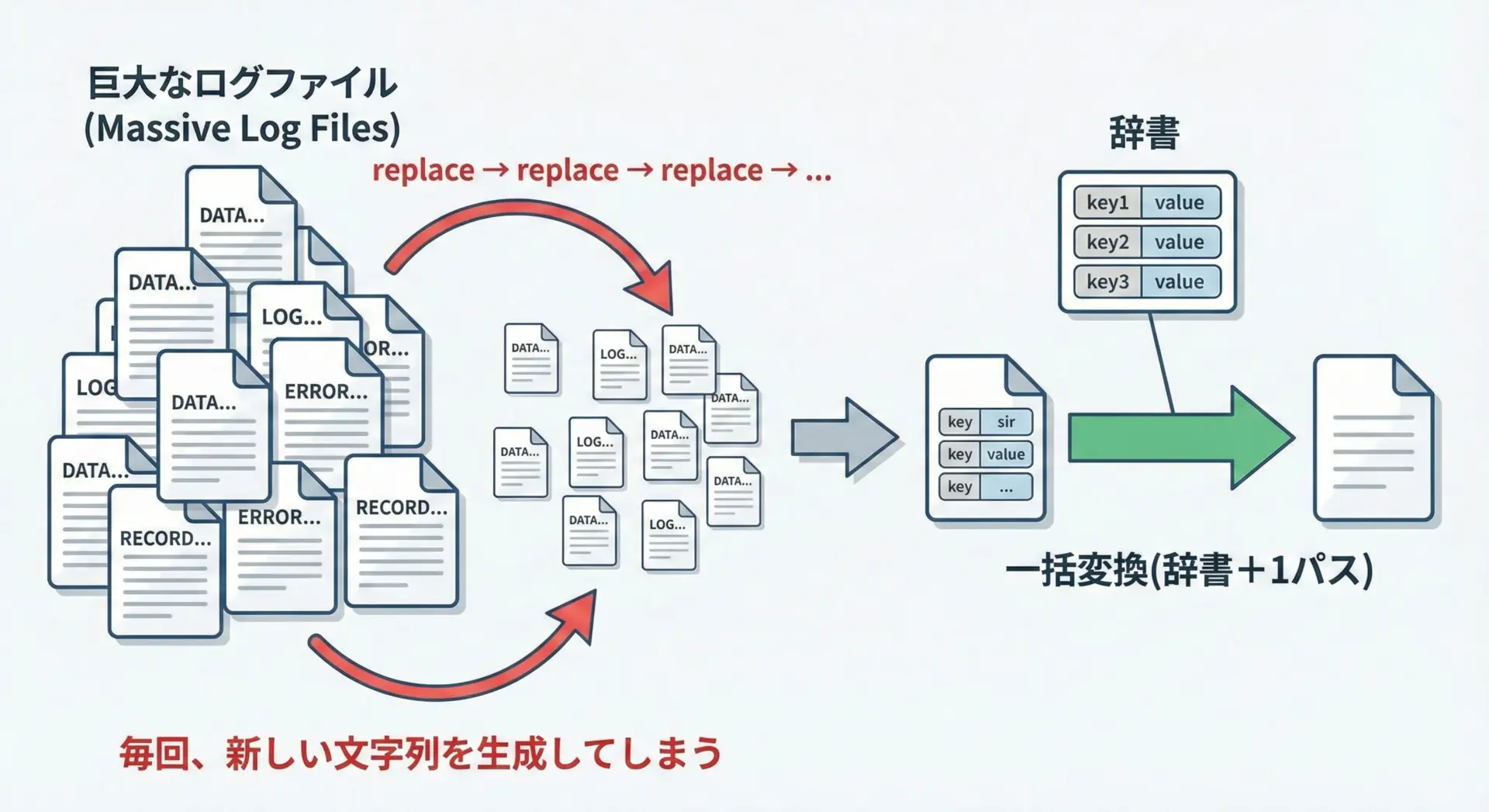
最もありがちなNG例が、大量の文字列データに対してreplaceを何十回、何百回と連続でかけてしまうケースです。
次のようなコードは、小さな文字列なら問題ありませんが、大量データではパフォーマンスを大きく損ないます。
log = load_huge_log() # 巨大なログ文字列を読み込む想定
# 悪い例: 毎回全体を走査し直している
log = log.replace("ERROR", "E")
log = log.replace("WARNING", "W")
log = log.replace("INFO", "I")
log = log.replace("DEBUG", "D")
log = log.replace("TRACE", "T")
# ... さらに多数の置換が続くこれは、置換のたびに全文字列を走査し、新しい文字列オブジェクトを作っているためです。
パターンが増えると、O(n × パターン数)のコストがかかり、データ量が大きい場合に極めて非効率になります。
大量データや多数の置換パターンがある場合は、辞書を使った一括置換や正規表現の活用など、1パスで処理する手段を検討する必要があります。
この点についてはベストプラクティスの章で詳しく解説します。
予期せぬ部分一致で誤置換してしまうケース
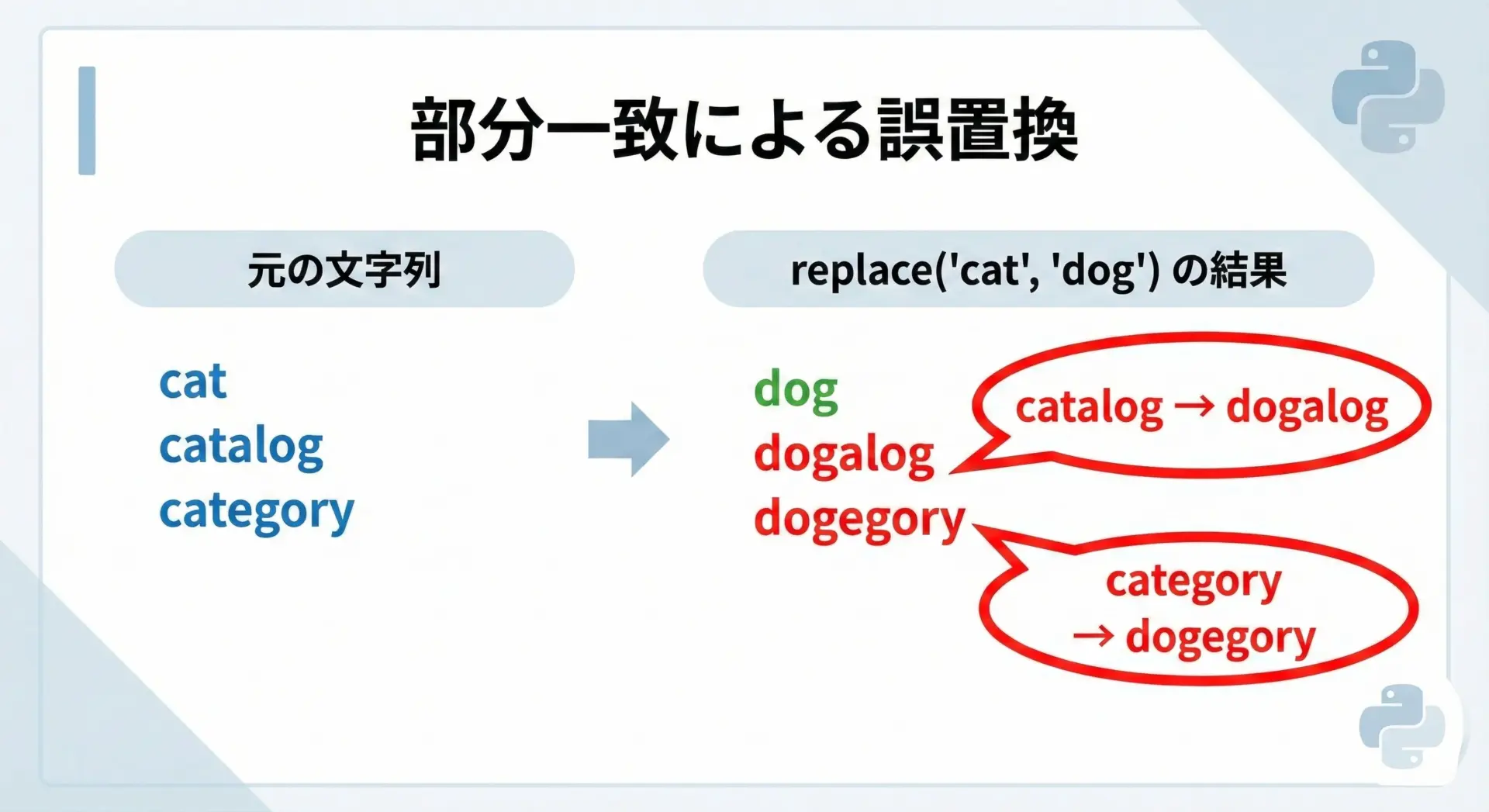
replaceは、指定した文字列が現れる全ての位置を単純に置換するだけです。
そのため、単語の区切りや意味を考慮せずに動作します。
これにより意図しない部分まで書き換えてしまうことがあります。
text = "cat catalog category"
replaced = text.replace("cat", "dog")
print(replaced)dog dogalog dogegory多くの場合、意図していたのは"cat"という単語だけを置き換えることであり、“catalog”や“category”を壊したいわけではないはずです。
このようなケースでは、次のような対策が必要になります。
- スペースや記号などの単語境界を含めて置換文字列を指定する
- 正規表現(
re.sub)を用いて、単語単位でマッチさせる - プレースホルダやテンプレート構文を用いて、置換対象の範囲を限定する
「部分一致があっても全部置き換わる」という挙動を常に意識することが重要です。
正規表現が必要なのにreplaceで無理に対応する例
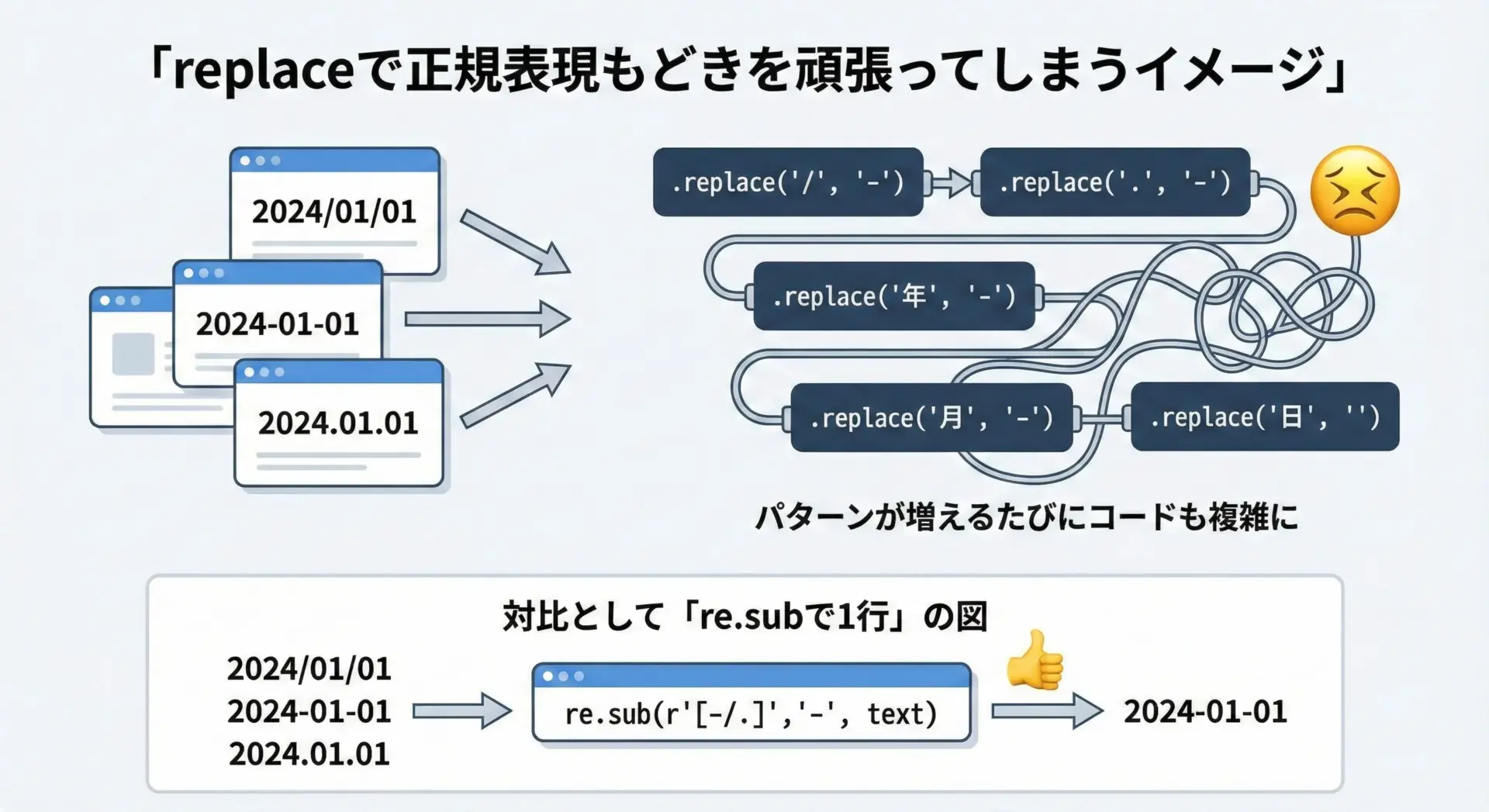
日付や電話番号のように、「形」(パターン)でマッチさせたい場合に、replaceだけで対応しようとすると、非常に複雑で壊れやすいコードになりがちです。
例えば、さまざまなフォーマットの日付の区切り記号を-に統一したい場合を考えます。
text = "2024/01/01 と 2024-02-03 と 2024.03.04"
# 無理にreplaceだけで対応しようとする例
normalized = (
text
.replace("/", "-")
.replace(".", "-")
)
print(normalized)2024-01-01 と 2024-02-03 と 2024-03-04この程度ならまだ動きますが、より複雑なパターン(空白の有無、2桁・1桁混在、時刻付きなど)に対応しようとすると、replaceだけでは破綻してしまいます。
このようなケースでは、最初から正規表現(re.sub)を使うべきです。
正規表現であれば、日付のパターンを1つの式で定義し、柔軟かつ安全に置換できます。
この点は後ほど「re.subとの使い分け」で具体例を示します。
文字コードや全角・半角の違いを無視した置換
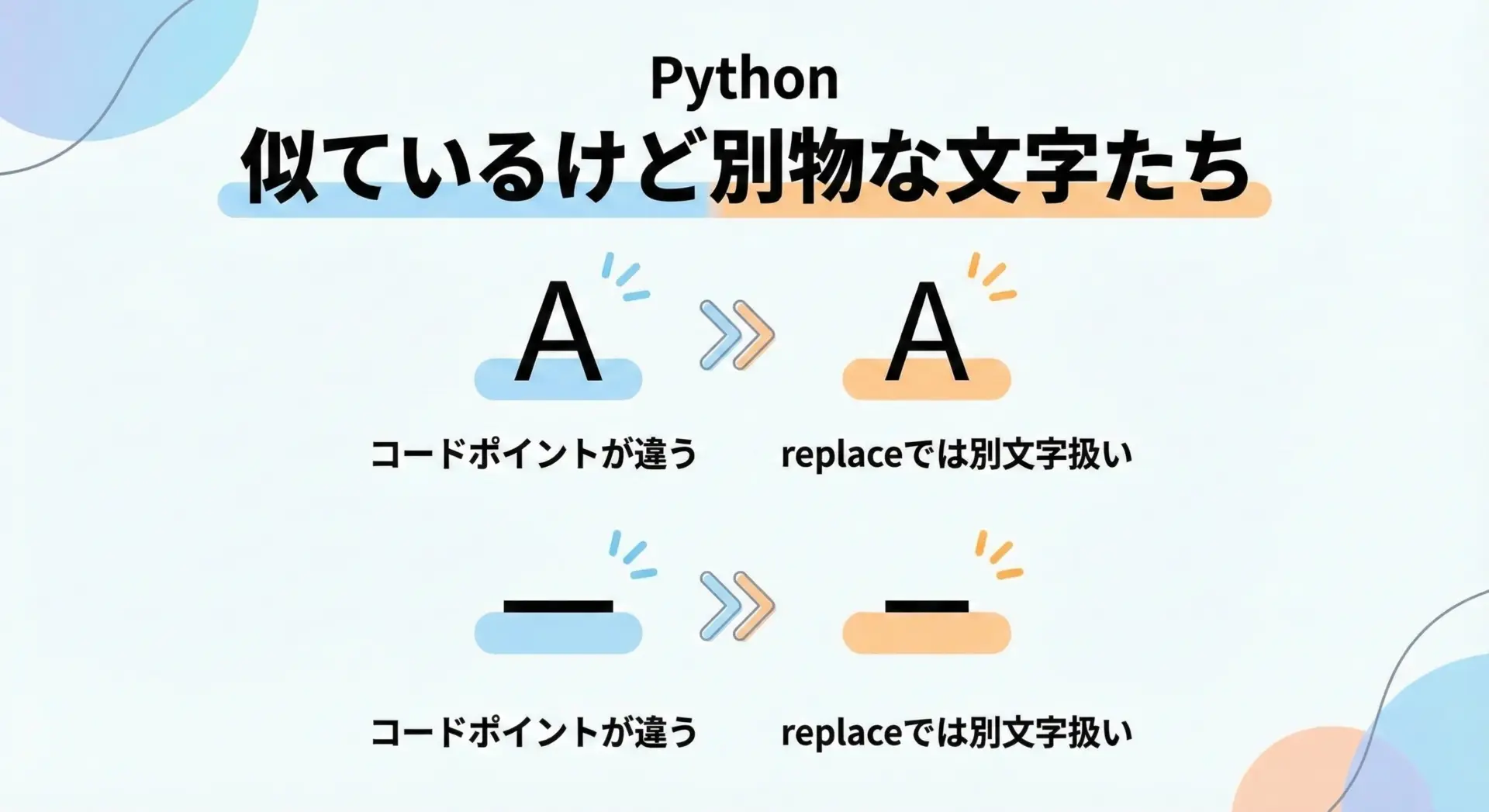
日本語を扱う際に注意が必要なのが、全角・半角や似た記号の違いを無視してしまうケースです。
replaceは、文字コードレベルで一致した場合にしか置換を行いません。
text = "ABC-123" # 全角英数字+半角ハイフン
print(text.replace("ABC", "XYZ")) # 半角ABC
print(text.replace("ABC", "XYZ")) # 全角ABCABC-123
XYZ-123前者は何も置換されません。
見た目が似ていても、全角と半角、ハイフンとダッシュなどは別の文字コードだからです。
このような場合、次のようなアプローチを検討すべきです。
- 事前に全角・半角変換を行い、表記を正規化してから置換する
- Unicode正規化(
unicodedata.normalize)を用いる - 日本語処理用のライブラリ(例えば
jaconvなど)を活用する
「目で見て同じなら置換されるだろう」という感覚を持たず、常に文字コードレベルでの一致を意識することが重要です。
replaceのベストプラクティス
辞書(dict)を使って複数文字列を一括置換する
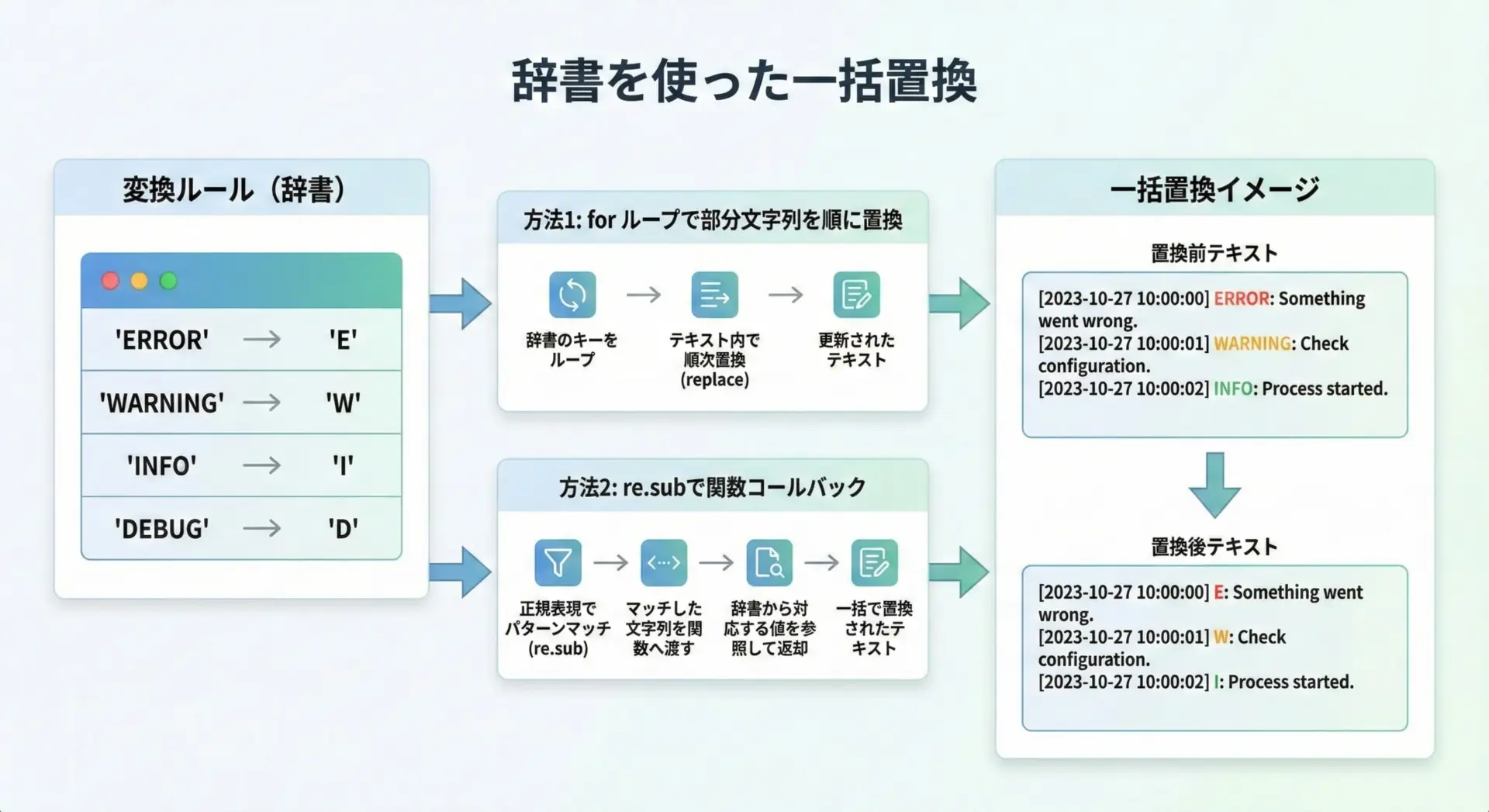
複数のパターンを効率よく置換したい場合、辞書(dict)で「置換前→置換後」の対応表を作り、一括処理する方法が有効です。
簡単な例として、ログのレベル名を短縮表記に変換するケースを考えます。
text = "ERROR and WARNING and INFO and DEBUG"
replacements = {
"ERROR": "E",
"WARNING": "W",
"INFO": "I",
"DEBUG": "D",
}
# 辞書を使って順番に置換するシンプルな実装
result = text
for old, new in replacements.items():
result = result.replace(old, new)
print(result)E and W and I and Dこの方法はとても分かりやすいですが、パターンが増えるとやはり文字列全体を何度も走査することになるため、大量データでのパフォーマンスには注意が必要です。
よりパフォーマンスを意識する場合は、正規表現と辞書を組み合わせて「1パスで複数パターンを置換」する方法が有効です。
これはre.subとの使い分けのセクションでコード例を示します。
re.subとの使い分け
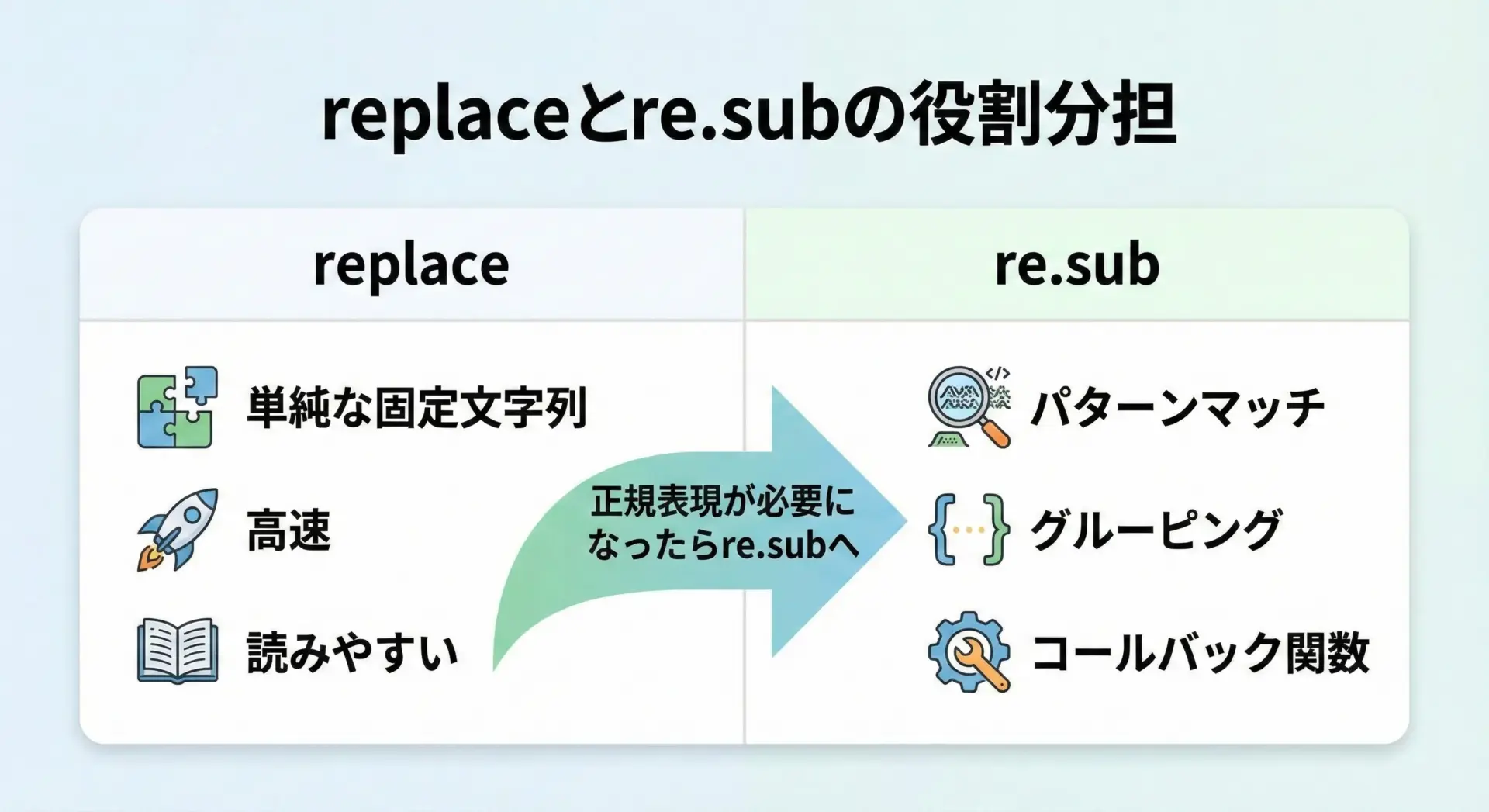
固定の文字列をただ別の文字列に置き換えたいだけならreplaceが第一候補です。
一方で、「パターンにマッチする部分」や「単語境界」などを扱いたいときはre.subを使うのが適切です。
以下の表のように、両者には向き・不向きがあります。
| 項目 | str.replace | re.sub |
|---|---|---|
| マッチ方法 | 完全一致のみ | 正規表現パターン |
| 使いやすさ | とても簡単 | 正規表現の知識が必要 |
| 柔軟性 | 単純置換向き | 単語単位、条件付き置換など |
| パフォーマンス | 固定文字列に強い | パターン依存、やや重くなりがち |
| 複数パターン | チェーンやループで対応 | 1パスで同時置換も可能 |
例として、"cat"という単語だけを置き換えたい場合のre.subを見てみます。
import re
text = "cat catalog category cat"
# 単語としての "cat" だけを "dog" にする
pattern = r"\bcat\b" # \b は単語境界
replaced = re.sub(pattern, "dog", text)
print(replaced)dog catalog category dog単純な置換 → replace、パターンや条件付き → re.subという形で役割分担すると、コードが分かりやすく保守しやすくなります。
パフォーマンスを意識したreplaceの書き方
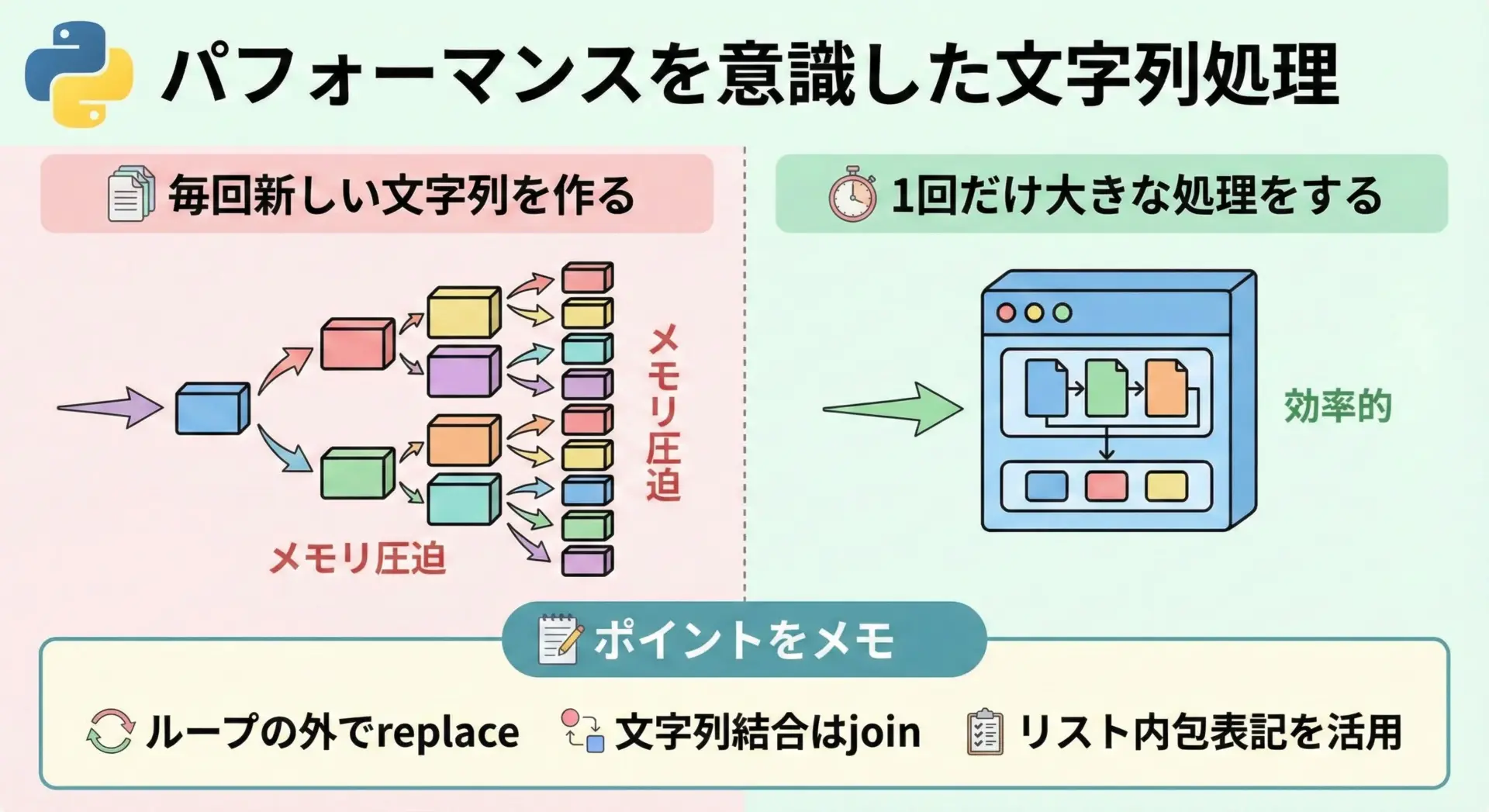
大量のテキストを扱う場合、何度もreplaceを呼ばない、不要な文字列生成を避けるといった工夫が効いてきます。
いくつかの具体的なポイントを挙げます。
1. 繰り返し処理の中で同じreplaceをしない
# 悪い例: ループのたびに同じreplaceを実行
lines = load_lines()
for i, line in enumerate(lines):
# ここで毎回全行を走査していることになる
clean = full_text.replace("\t", " ")
# ...このような場合は、ループの外で一度だけreplaceを行うようにします。
lines = load_lines()
# ループの前に一括置換
clean_lines = [line.replace("\t", " ") for line in lines]
for i, line in enumerate(clean_lines):
# 置換済みの行を利用
...2. 大きな文字列を何度も連結しない
大量の行を処理して1つの文字列にまとめたい場合、文字列の足し算(+)で都度連結するのではなく、str.joinを使う方が効率的です。
置換と連結を組み合わせる場合にも、この原則は有効です。
lines = load_lines()
# 各行で置換を行い、その後で一度だけ結合する
processed_lines = [line.replace("ERROR", "E") for line in lines]
result = "".join(processed_lines)これにより、中間的な巨大文字列を何度も作らずに済むため、メモリ効率と速度の両方を改善できます。
安全に置換するためのテストとデバッグのコツ
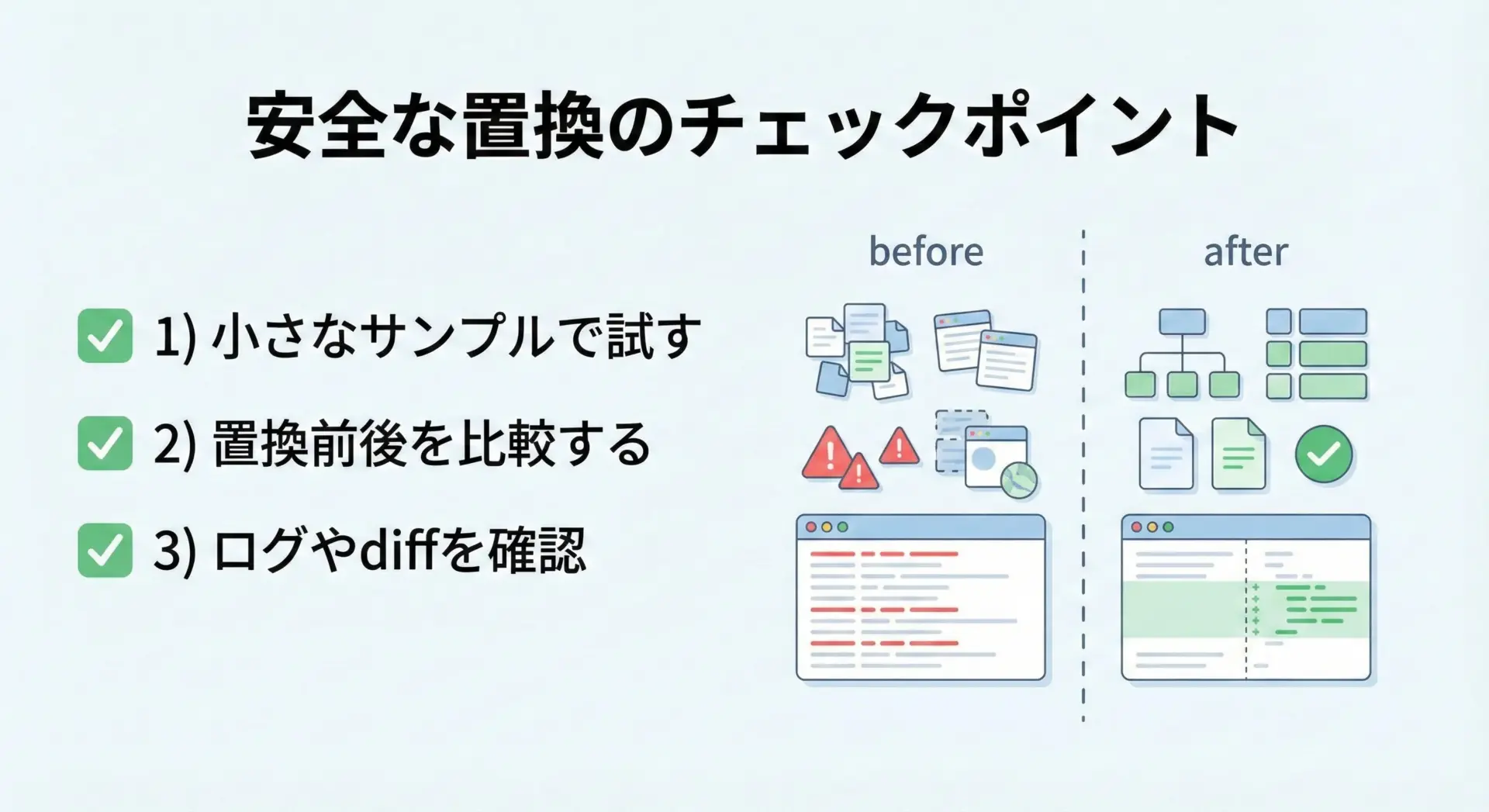
最後に、本番データに対して安全に置換処理を行うためのテストとデバッグのコツをまとめます。
特に、大量データや重要なテキストを扱うときには慎重さが求められます。
1. 小さなサンプルデータで挙動を確認する
いきなり全データに対して置換をかけるのではなく、まずは数行だけ、あるいは代表的なパターンを含むサンプルデータで挙動を確かめます。
sample = "ERROR: something.\nWARNING: something else.\nINFO: ok.\n"
print("=== 置換前 ===")
print(sample)
replaced = sample.replace("ERROR", "E").replace("WARNING", "W")
print("=== 置換後 ===")
print(replaced)=== 置換前 ===
ERROR: something.
WARNING: something else.
INFO: ok.
=== 置換後 ===
E: something.
W: something else.
INFO: ok.「どこがどう変わったか」を目視で確認することで、意図しない置換に気付きやすくなります。
2. 置換前後の差分を取って確認する
より厳密に確認したい場合は、difflibを使ってテキストの差分を表示すると便利です。
import difflib
before = "cat catalog category cat"
after = before.replace("cat", "dog")
diff = difflib.ndiff(before.split(), after.split())
print("\n".join(diff))- cat
+ dog
- catalog
+ dogalog
- category
+ dogegory
- cat
+ dogこのように、どの単語がどのように変わったかが明確に表示されるため、誤置換の検出に役立ちます。
3. 危険な置換はバックアップやロールバック手段を用意する
ファイルやデータベースを直接書き換えるような置換処理では、必ずバックアップを取るか、元に戻せるロールバック手段を用意しておくべきです。
具体的には次のような工夫があります。
- 処理前にファイルをコピーしておく
- 処理結果を別ファイルに書き出し、検証後に置き換える
- トランザクション対応のデータベースなら、テスト後にコミットする
置換処理は見た目以上に破壊力が大きいため、「一度壊したら戻せない」状況を作らないようにすることが重要です。
まとめ
Pythonのstr.replaceは、固定文字列の単純な置換を行ううえで最も手軽で強力なメソッドです。
ただし、文字列がイミュータブルであることを理解しない連続置換や、大量データに対する多重のreplaceは、パフォーマンスや安全性の面で問題を生みがちです。
部分一致の誤置換や、正規表現が必要な場面での無理な利用も、典型的なNGパターンといえるでしょう。
実務では、辞書やre.subを組み合わせて1パスで複数置換を行う、テストデータで挙動を確認してから本番に適用するなどの工夫により、読みやすく、安全で、高速な文字列置換を実現できます。
用途に応じてreplaceとre.subを使い分け、安心してテキスト処理ができるコード設計を心掛けてください。
