
Pythonで文字数や出現回数をカウントできると、ログ解析やテキストマイニング、レポート作成など、さまざまな場面で役立ちます。
本記事では、len関数やcountメソッドといった基本から、collections.Counterや正規表現を用いた応用的な頻度カウント、さらにファイル内テキストの集計まで、実践でそのまま使える形で詳しく解説していきます。
Pythonで文字数をカウントする基本方法
文字列の長さをlen関数でカウントする
まずは、もっとも基本的な「文字列の長さ」をカウントする方法です。
Pythonではlen関数を使うだけで、簡単に文字列の長さを取得できます。
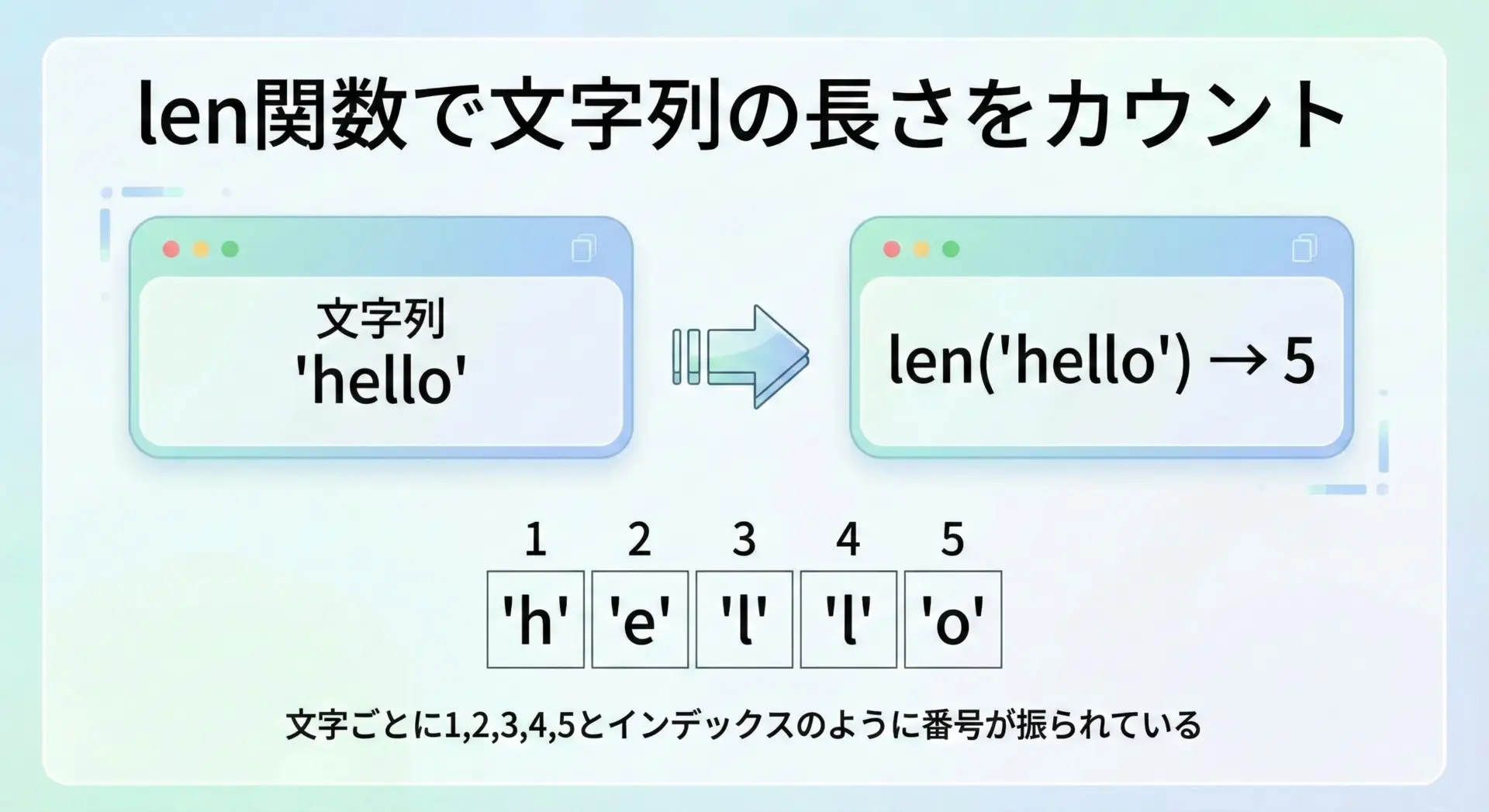
文字列の長さを数える最もシンプルな例を示します。
# 文字列の長さをlen関数で取得する基本例
text = "Hello, Python!"
# len関数は、文字列に含まれる「文字の個数」を返します
length = len(text)
print("文字列:", text)
print("文字数:", length)文字列: Hello, Python!
文字数: 14ここでのポイントは、len関数は文字列の「見た目」ではなく、文字一つ一つをカウントするという点です。
半角のアルファベットや記号はもちろん、スペースや改行も文字として数えられます。
改行やスペースを含めた文字数・含めない文字数の違い
実務では、「スペースや改行も含めた文字数」と「それらを除いた正味の文字数」を分けて数えたいことがよくあります。
たとえば、文章のボリュームを測りたい場合にはスペースを除外したい一方で、ファイルサイズの目安を知りたい場合にはスペースや改行も含めて数えたい、というような場面です。
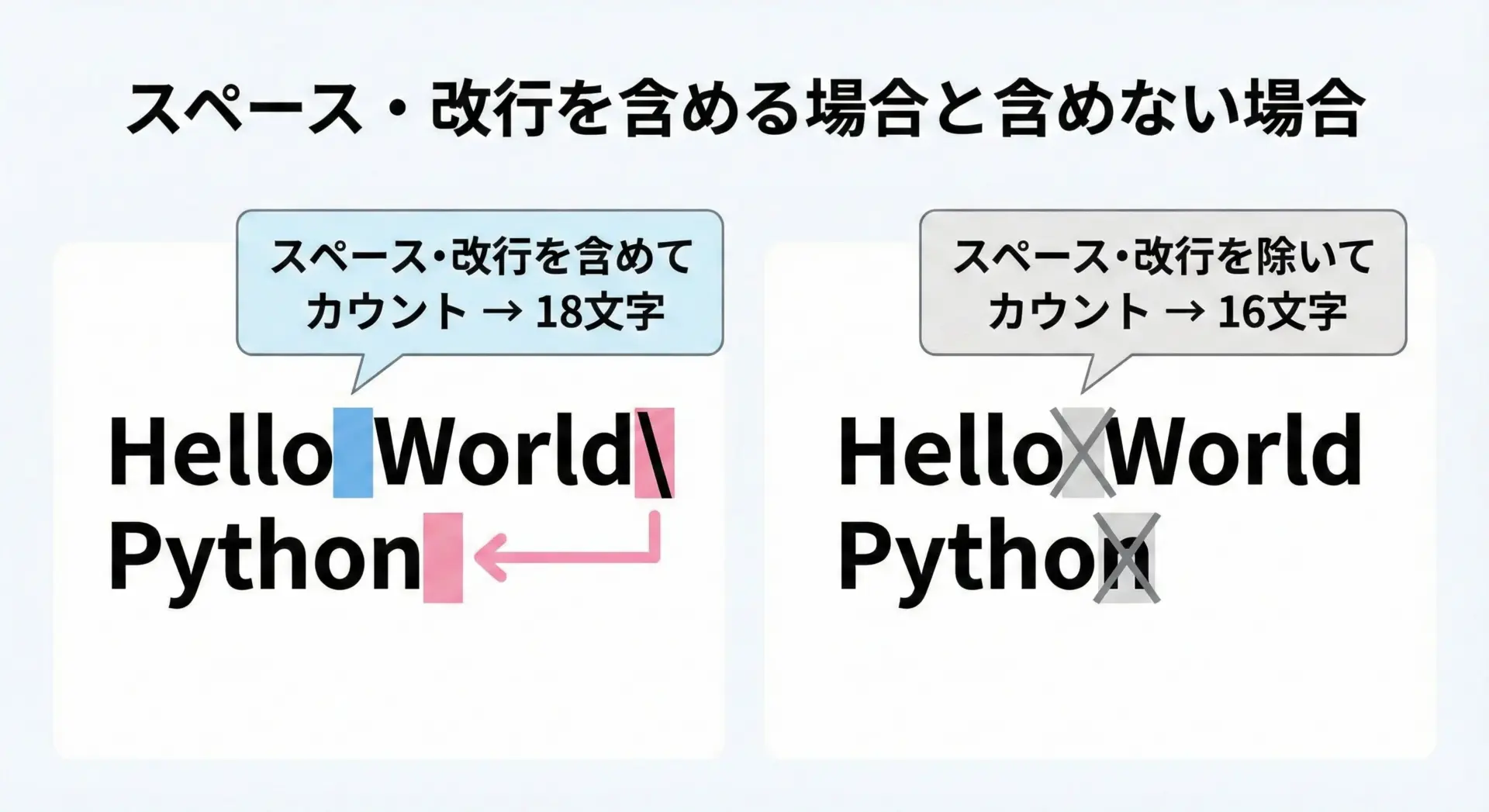
次のサンプルでは、同じ文字列に対して、スペースや改行を含めた場合と除外した場合の文字数を比較します。
# 改行やスペースを含めた文字数と、含めない文字数を比較する例
text = "Hello World\nPython"
# そのままの文字数(スペース・改行を含む)
length_with_space = len(text)
# スペースと改行を取り除いた文字列を作る
# replaceで空白文字を削除し、lenで文字数を数える
text_without_space = text.replace(" ", "").replace("\n", "")
length_without_space = len(text_without_space)
print("元の文字列:", repr(text)) # reprで改行などを可視化
print("スペース・改行を含む文字数:", length_with_space)
print("スペース・改行を含まない文字数:", length_without_space)元の文字列: 'Hello World\nPython'
スペース・改行を含む文字数: 18
スペース・改行を含まない文字数: 16スペースや改行を除外するときには、どの文字を「除外対象」にするかを明確に決めることが大切です。
スペースだけを消すのか、タブ\tや改行\n、全角スペースも含めるのかで結果が変わってしまうためです。
マルチバイト(日本語)文字の文字数カウントの注意点
日本語や中国語などの文字は、内部的に複数バイトで表現されるため「マルチバイト文字」と呼ばれます。
文字コードやバイト数を扱う場面では注意が必要ですが、Pythonの文字列はUnicodeで管理されているため、len関数は「文字数」として正しく数えてくれます。
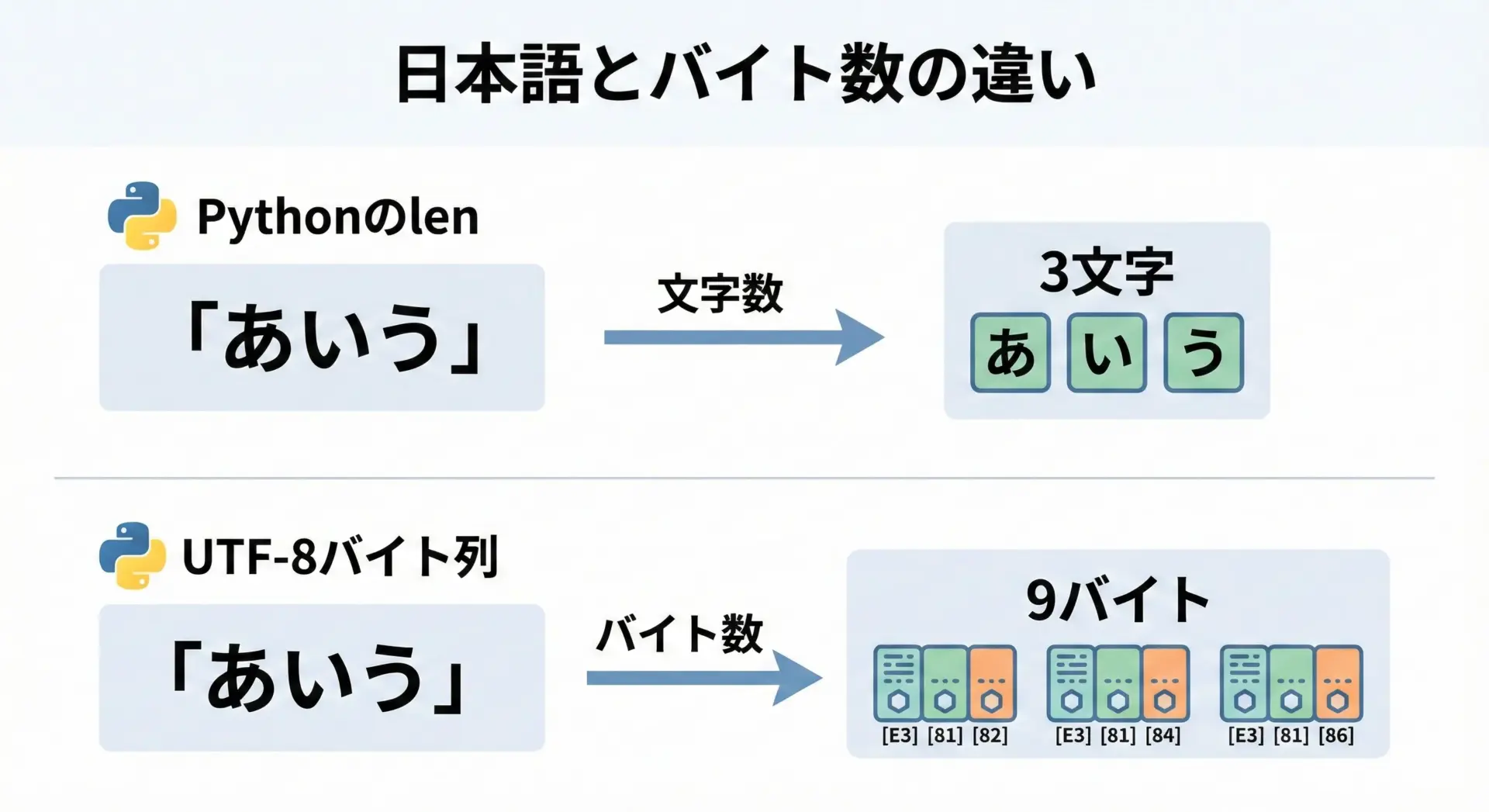
次の例では、日本語文字列とそのエンコード(バイト列)でlenを比較してみます。
# 日本語(マルチバイト文字)とバイト列のlenの違いを確認する例
text = "あいう"
# 文字列としての長さ(文字数)
char_length = len(text)
# UTF-8にエンコードした場合のバイト数
byte_data = text.encode("utf-8")
byte_length = len(byte_data)
print("文字列:", text)
print("文字数(len):", char_length)
print("UTF-8のバイト数(len):", byte_length)文字列: あいう
文字数(len): 3
UTF-8のバイト数(len): 9このように、文字数を知りたいときは文字列のままlenを使い、バイト数を知りたいときはエンコードしてからlenを使う、という使い分けが重要です。
データベースのカラム制限やファイルサイズなどバイト数の制約が関わる場面では、文字数と混同しないように注意してください。
文字や単語の出現回数をカウントする方法
countメソッドで特定文字・部分文字列の出現回数をカウントする
特定の文字や部分文字列が、ある文字列の中に何回出てくるかを知りたい場合は、文字列のcountメソッドを使います。
完全一致の部分文字列の回数を数えるのに向いています。
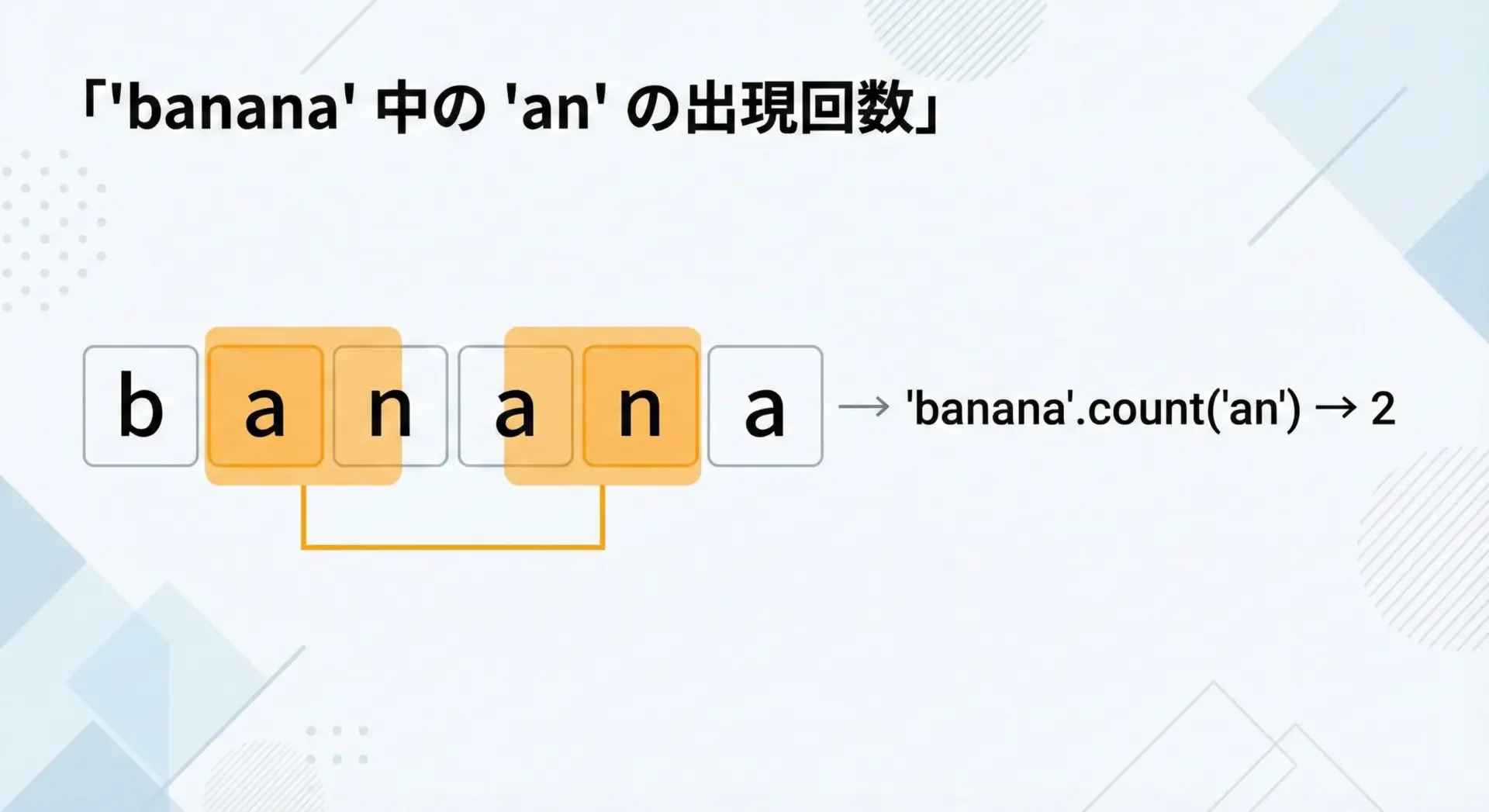
次のサンプルで、単一文字と部分文字列の両方の例を示します。
# 文字列のcountメソッドで出現回数を数える例
text = "banana banana BANANA"
# 小文字の"a"の出現回数
count_a = text.count("a")
# 部分文字列"ana"の出現回数
count_ana = text.count("ana")
# 大文字・小文字を区別する点に注意
count_BANANA = text.count("BANANA")
print("文字列:", text)
print("'a' の出現回数:", count_a)
print("'ana' の出現回数:", count_ana)
print("'BANANA' の出現回数:", count_BANANA)文字列: banana banana BANANA
'a' の出現回数: 6
'ana' の出現回数: 4
'BANANA' の出現回数: 1ここで注意したいのは、countメソッドは大文字・小文字を区別するということです。
大文字・小文字を区別したくない場合は、あらかじめlower()やupper()で揃えてからカウントするとよいです。
splitとcountで単語の出現回数をカウントする
単語の出現回数を数えたいときは、文字列をsplitで分割してから、リストのcountメソッドを使うと簡単です。
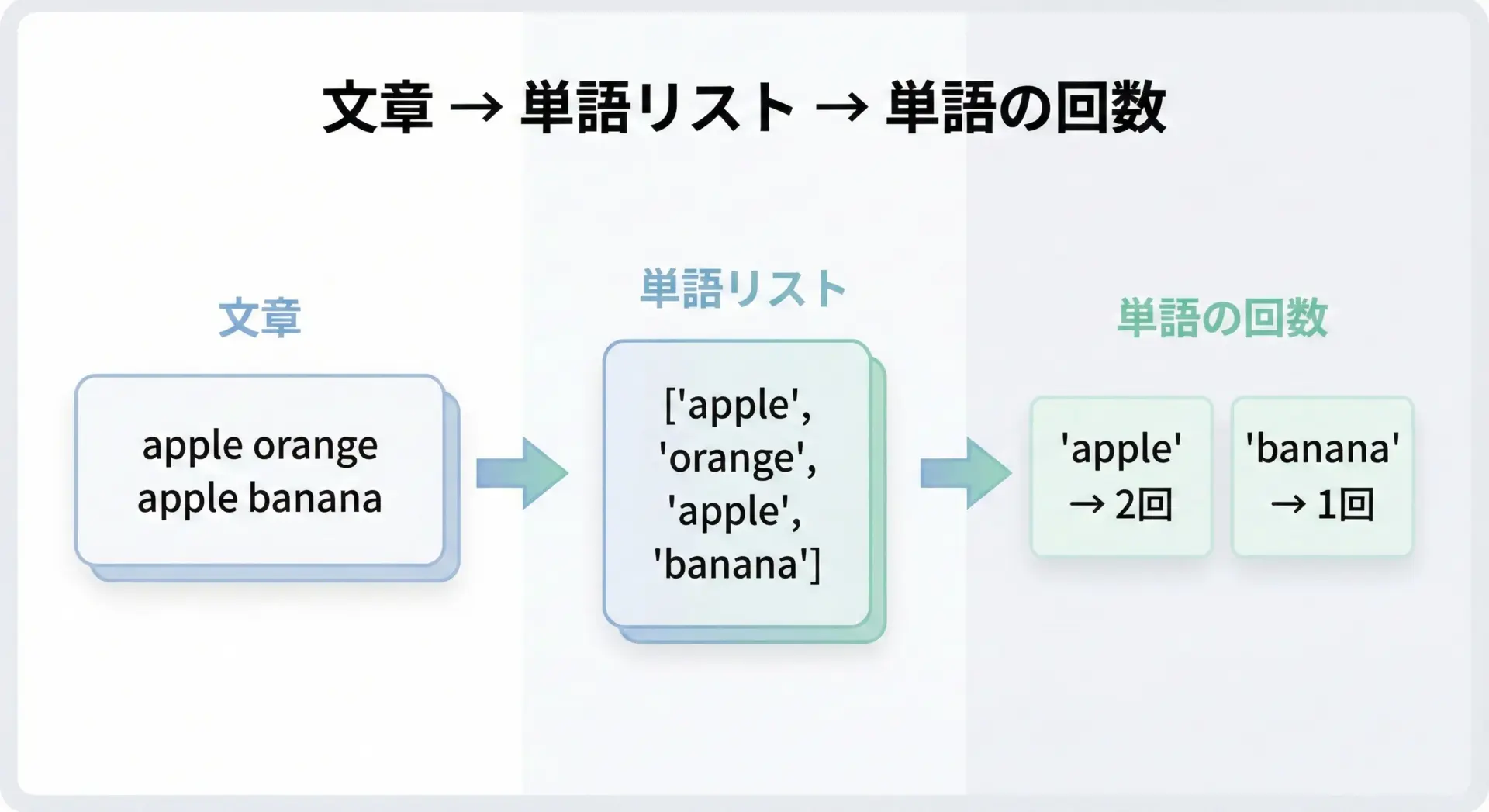
まずはシンプルに、空白で区切られた英単語をカウントする例です。
# splitとcountを使った単語の出現回数カウント
text = "apple orange apple banana orange apple"
# デフォルトのsplit()は空白文字で分割します
words = text.split()
# リストに対してcountメソッドを使う
apple_count = words.count("apple")
orange_count = words.count("orange")
print("単語リスト:", words)
print("'apple' の出現回数:", apple_count)
print("'orange' の出現回数:", orange_count)単語リスト: ['apple', 'orange', 'apple', 'banana', 'orange', 'apple']
'apple' の出現回数: 3
'orange' の出現回数: 2日本語の場合は、単語の区切りがスペースではないため、この方法はそのままでは使えません。
日本語の「単語頻度」を求めるには、MeCabなどの形態素解析ツールで単語に分割してからカウントする、という別ステップが必要になります。
本記事では主にPython標準の機能に焦点を当てるため、形態素解析の詳細は割愛しますが、日本語テキストを扱う際にはこの点を意識しておくとよいです。
正規表現(re)で柔軟に出現回数をカウントする
countメソッドは便利ですが、「単語の境界をまたいではいけない」「大文字小文字を無視したい」といった、もう少し柔軟な条件が必要な場合があります。
そのようなときは、標準ライブラリのre(正規表現)を使うと便利です。
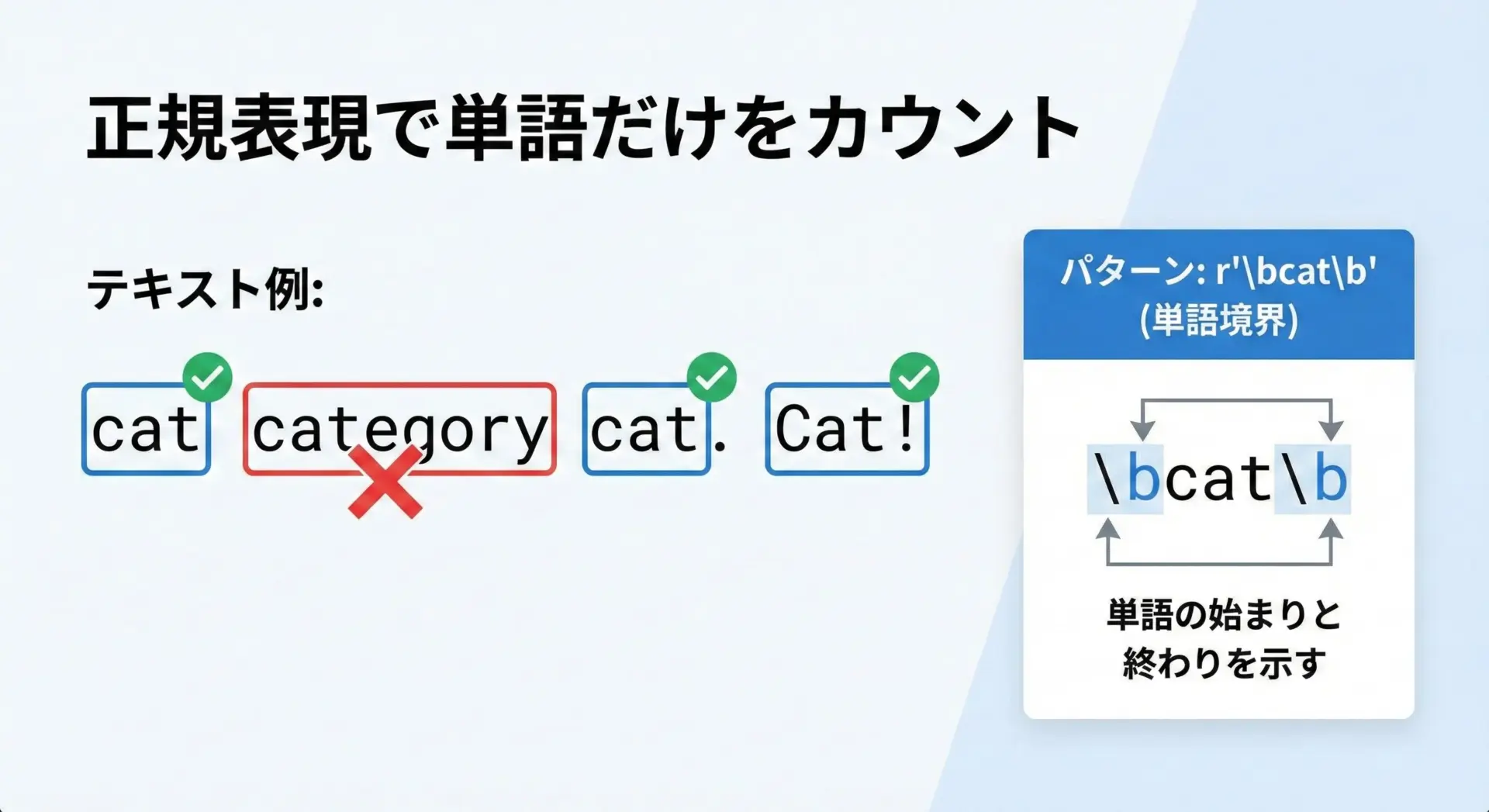
以下の例では、単語としての"cat"だけを、大文字小文字を区別せずに数えます。
# 正規表現を使った出現回数カウントの例
import re
text = "cat category Cat catalog cat."
# \b は「単語の境界」を意味し、単語としての「cat」のみを対象にします
pattern = r"\bcat\b"
# flags=re.IGNORECASE で大文字・小文字を区別しない
matches = re.findall(pattern, text, flags=re.IGNORECASE)
print("対象文字列:", text)
print("マッチした要素:", matches)
print("単語 'cat' の出現回数:", len(matches))対象文字列: cat category Cat catalog cat.
マッチした要素: ['cat', 'Cat', 'cat']
単語 'cat' の出現回数: 3このようにre.findallでマッチしたリストを取得し、その長さをlenで数えることで、条件に合う出現回数をカウントできます。
正規表現を使えば、例えば「数字だけを数える」「メールアドレス形式の文字列の個数を数える」といった柔軟なカウントも可能になります。
collections.Counterによる頻度カウント
Counterで文字の出現回数を一括カウントする
標準ライブラリcollectionsのCounterクラスは、「要素の頻度」を数える専用の便利ツールです。
文字列を渡すだけで、各文字が何回出現したかを一括で集計してくれます。
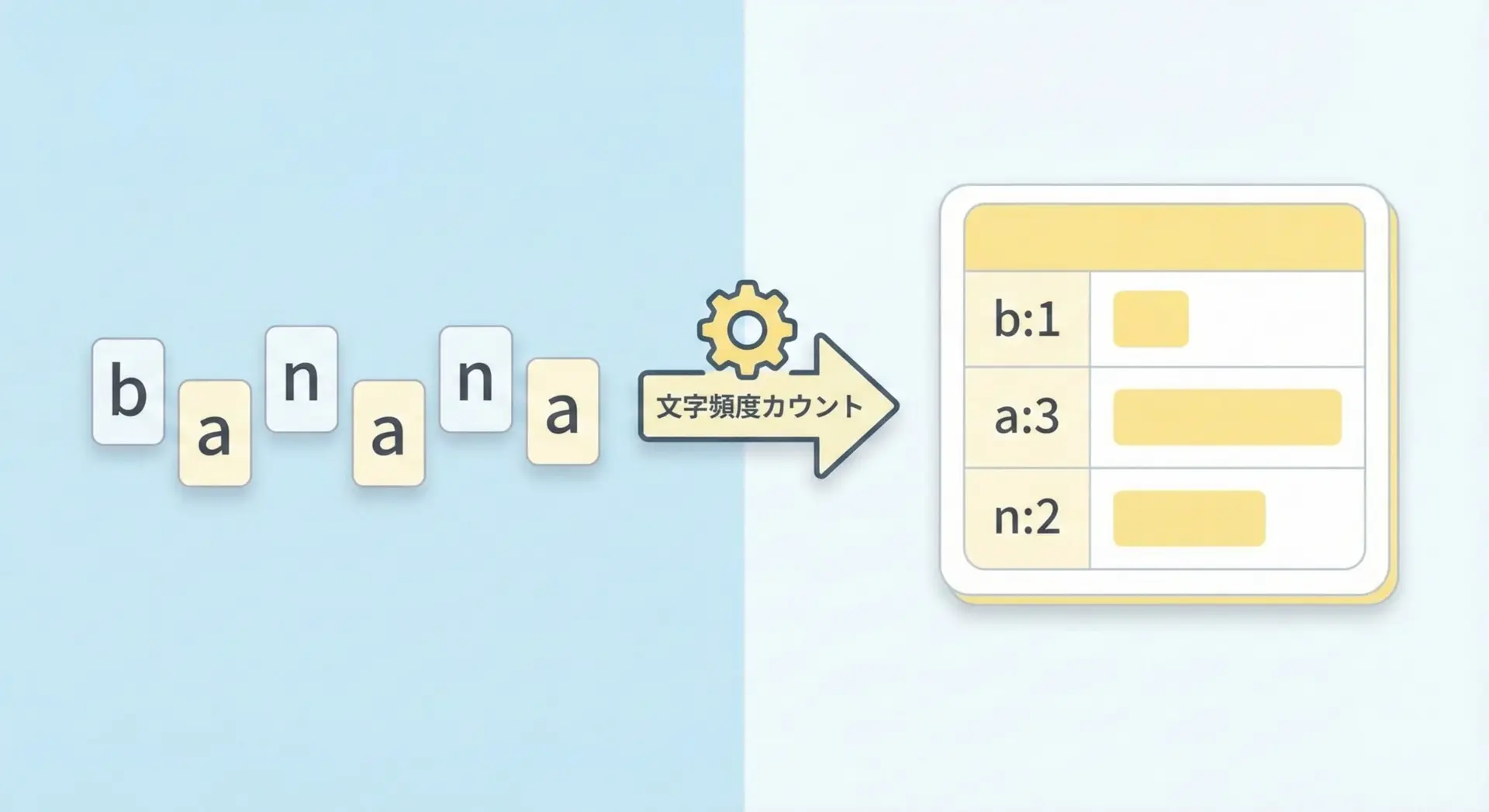
次のサンプルは、文字単位での頻度カウントです。
# Counterで文字ごとの出現回数をカウントする例
from collections import Counter
text = "banana banana"
# 文字列をそのままCounterに渡すと、1文字ごとの頻度が数えられます
char_counter = Counter(text)
print("対象文字列:", text)
print("文字ごとの出現回数:")
# items()で(文字, 回数)のペアを取得
for char, count in char_counter.items():
print(repr(char), ":", count)対象文字列: banana banana
文字ごとの出現回数:
'b' : 2
'a' : 6
'n' : 4
' ' : 1スペースも1文字としてカウントされている点に注目してください。
「スペースは無視したい」「記号だけを対象にしたい」といった場合には、Counterに渡す前に文字列をフィルタリングしておくとよいです。
Counterで単語頻度(単語数)をカウントする
Counterの真価は、単語の頻度カウントで特に発揮されます。
単語リストを作ってからCounterに渡すだけで、各単語の出現回数を手軽に集計できます。
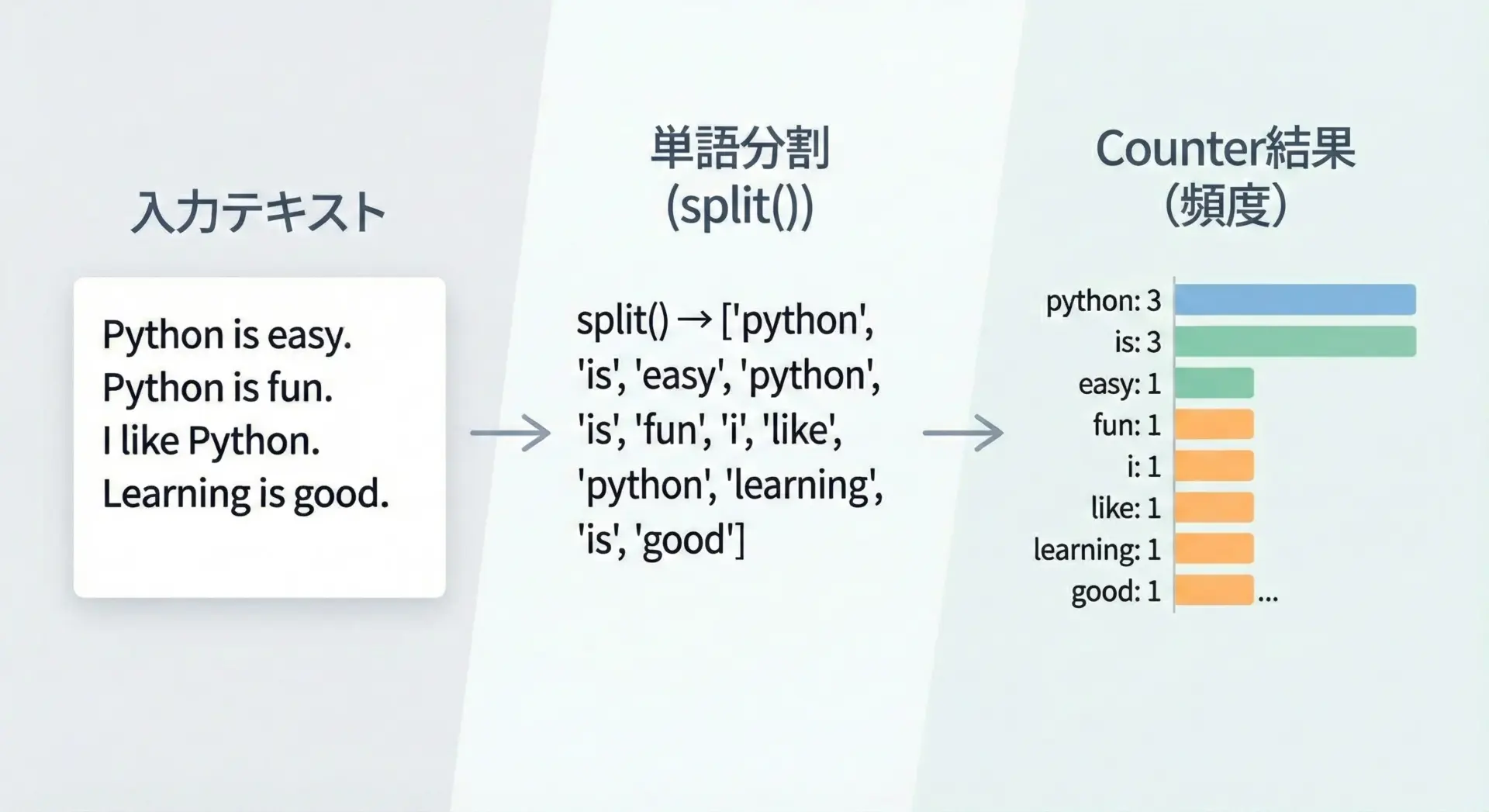
次の例では、文章の中の単語頻度をカウントします。
# Counterで単語頻度を集計する例
from collections import Counter
text = "Python is easy to learn. Python is powerful. I like Python."
# 句読点を簡易的に取り除き、小文字に統一する
clean_text = text.replace(".", "").replace(",", "").lower()
# 空白で分割して単語リストを作る
words = clean_text.split()
# 単語リストをCounterに渡す
word_counter = Counter(words)
print("単語ごとの出現回数:")
for word, count in word_counter.items():
print(word, ":", count)単語ごとの出現回数:
python : 3
is : 2
easy : 1
to : 1
learn : 1
powerful : 1
i : 1
like : 1ここでは簡易的にreplaceで記号を削除していますが、実際には正規表現で「単語」として抽出したり、自然言語処理ライブラリを用いると、より精度の高い単語頻度カウントが行えます。
most_commonでよく出る文字・単語を取得する
Counterが便利なのは、most_commonメソッドで頻出要素をランキング形式で取得できる点です。
テキストマイニングやログ分析などで「よく出てくる単語トップ10を見たい」といった場合に非常に役立ちます。
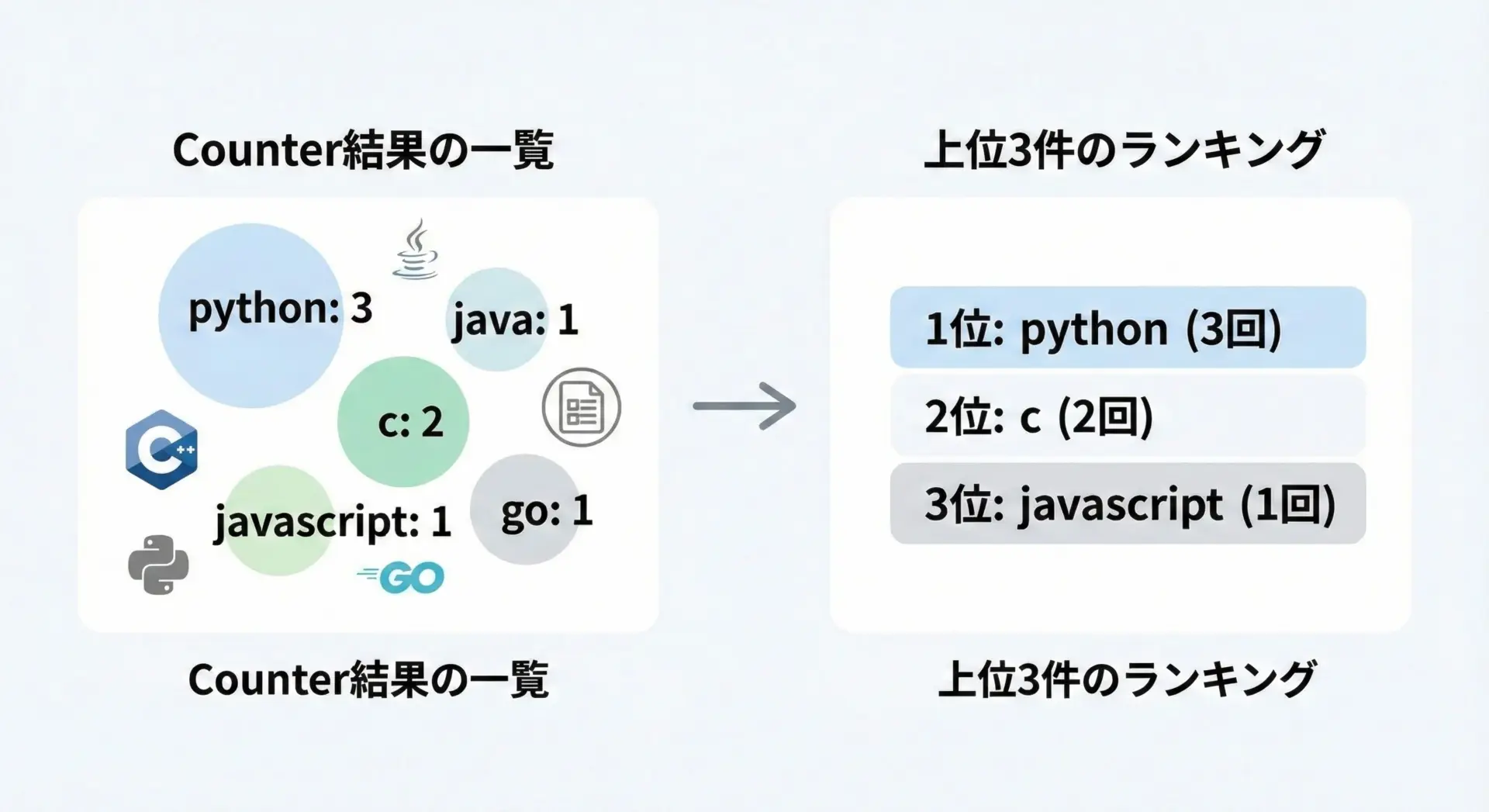
以下は、単語頻度から上位3つを取り出す例です。
# Counter.most_commonで頻出単語ランキングを取得する例
from collections import Counter
text = "apple orange apple banana orange apple grape banana"
words = text.split()
counter = Counter(words)
# 上位3件を取得
top3 = counter.most_common(3)
print("単語頻度ランキング(上位3件):")
for rank, (word, count) in enumerate(top3, start=1):
print(f"{rank}位: {word} ({count}回)")単語頻度ランキング(上位3件):
1位: apple (3回)
2位: orange (2回)
3位: banana (2回)most_common()に引数を渡さない場合は、すべての要素を頻度順に返すため、ランキング全体を見たいときにも利用できます。
ファイル内テキストの文字数・出現回数をカウントする
テキストファイルの文字数をカウントする基本手順
実務では、文字列リテラルではなく、テキストファイルの中身を対象に文字数や出現回数をカウントすることが多くなります。
Pythonでは、ファイルを開いて中身を読み込み、その文字列に対してこれまで紹介してきた方法を適用するだけです。
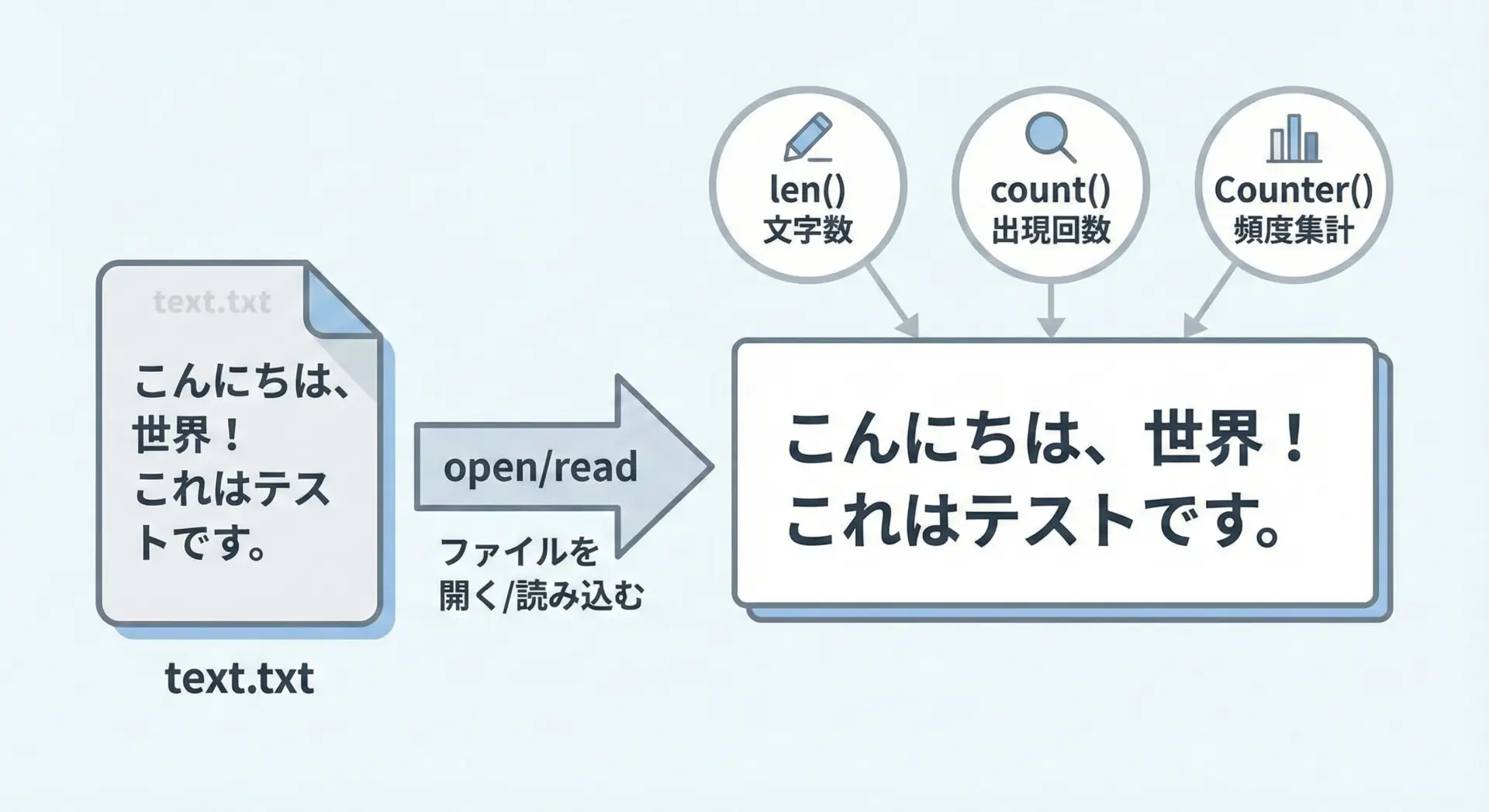
以下の例では、ファイル全体の文字数を数えます。
ファイル名は仮にsample.txtとします。
# ファイル内テキストの文字数をカウントする基本例
file_path = "sample.txt"
# 文字コードはUTF-8を想定しています
with open(file_path, "r", encoding="utf-8") as f:
text = f.read()
total_chars = len(text)
print("ファイル名:", file_path)
print("ファイル内の文字数:", total_chars)ファイル名: sample.txt
ファイル内の文字数: 1234encoding引数を明示しておくと、文字化けや読み込みエラーを避けやすくなります。
日本語を含むテキストであれば、UTF-8か、環境に応じてcp932(Shift_JIS)などを指定するとよいです。
ファイル内の特定文字・単語の出現回数をカウントする
ファイルの文字数だけでなく、特定の文字や単語が何回出現するかを知りたい場面もあります。
やり方は、読み込んだ文字列に対してcountやCounterを適用するだけです。
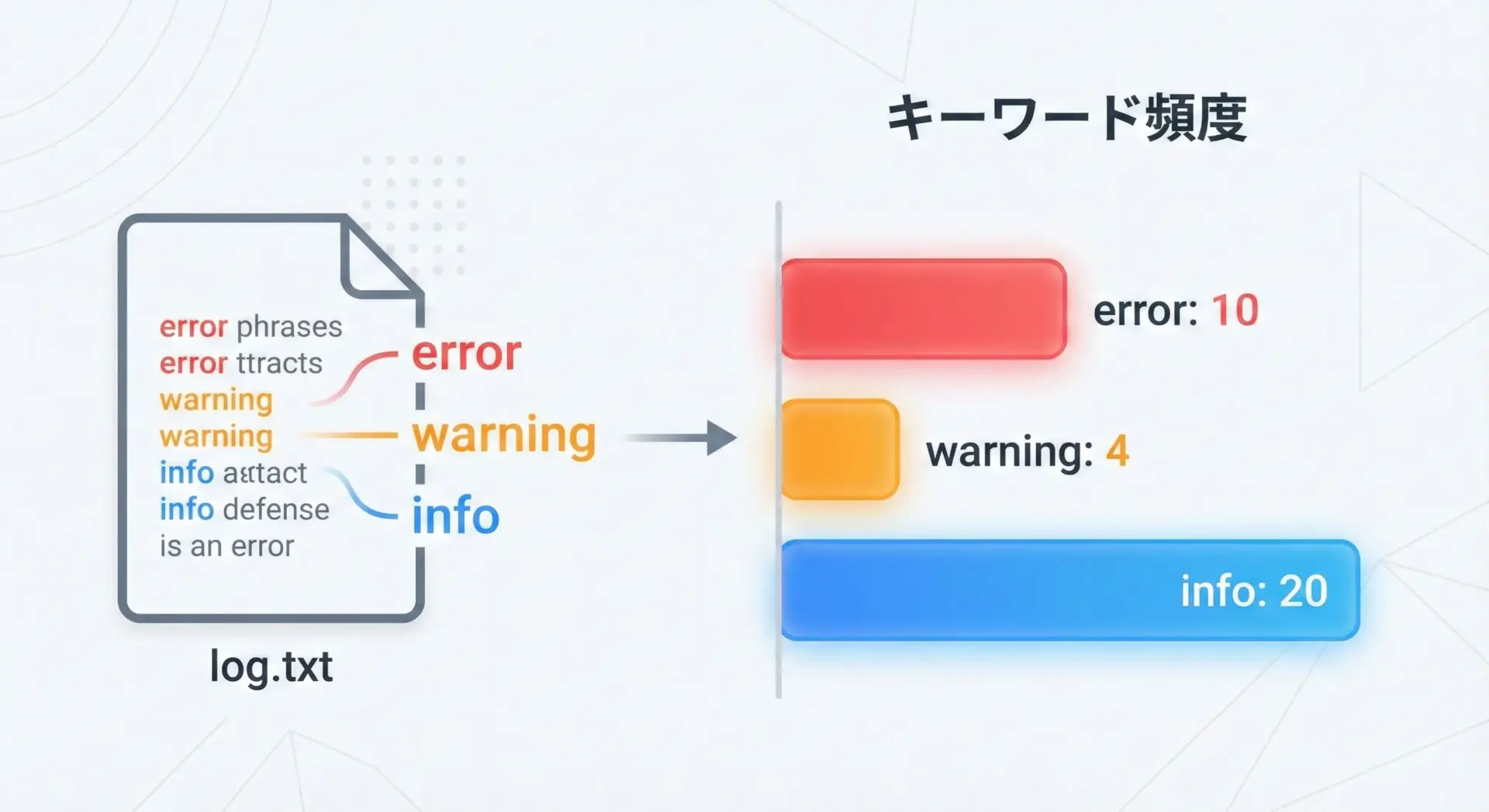
次のサンプルでは、ログファイル内の"ERROR"の出現回数を数えます。
# ファイル内の特定文字列の出現回数をカウントする例
file_path = "app.log"
target = "ERROR"
with open(file_path, "r", encoding="utf-8") as f:
text = f.read()
error_count = text.count(target)
print("ファイル名:", file_path)
print(f"'{target}' の出現回数:", error_count)ファイル名: app.log
'ERROR' の出現回数: 42単語頻度を知りたい場合は、先ほどのCounterと組み合わせます。
# ファイル内テキストの単語頻度をCounterで集計する例
from collections import Counter
file_path = "article.txt"
with open(file_path, "r", encoding="utf-8") as f:
text = f.read()
# 小文字に統一し、簡易的に句読点を取り除く
clean_text = text.lower()
for ch in [".", ",", "!", "?", ":", ";", "(", ")", "\"", "'"]:
clean_text = clean_text.replace(ch, " ")
words = clean_text.split()
counter = Counter(words)
# 上位5単語を表示
for word, count in counter.most_common(5):
print(word, ":", count)python : 15
data : 12
analysis : 9
code : 8
learning : 7このように、ファイルを一度文字列として読み込んでしまえば、あとは文字列操作の知識をそのまま応用できる、というのがポイントです。
大文字小文字や全角半角を正規化してカウント精度を上げる
テキストを集計するときに問題になりがちなのが、「表記揺れ」です。
たとえば、次のようなケースがあります。
- 大文字と小文字の違い(例:
Pythonとpython) - 全角と半角の違い(例:
ABCとABC) - カタカナの全角・半角(例:
カタカナとカタカナ)
これらをそのままカウントすると、実質同じ意味のものが別々の単語として扱われてしまいます。
カウントの精度を上げるには、事前に「正規化」を行って表記をそろえることが重要です。
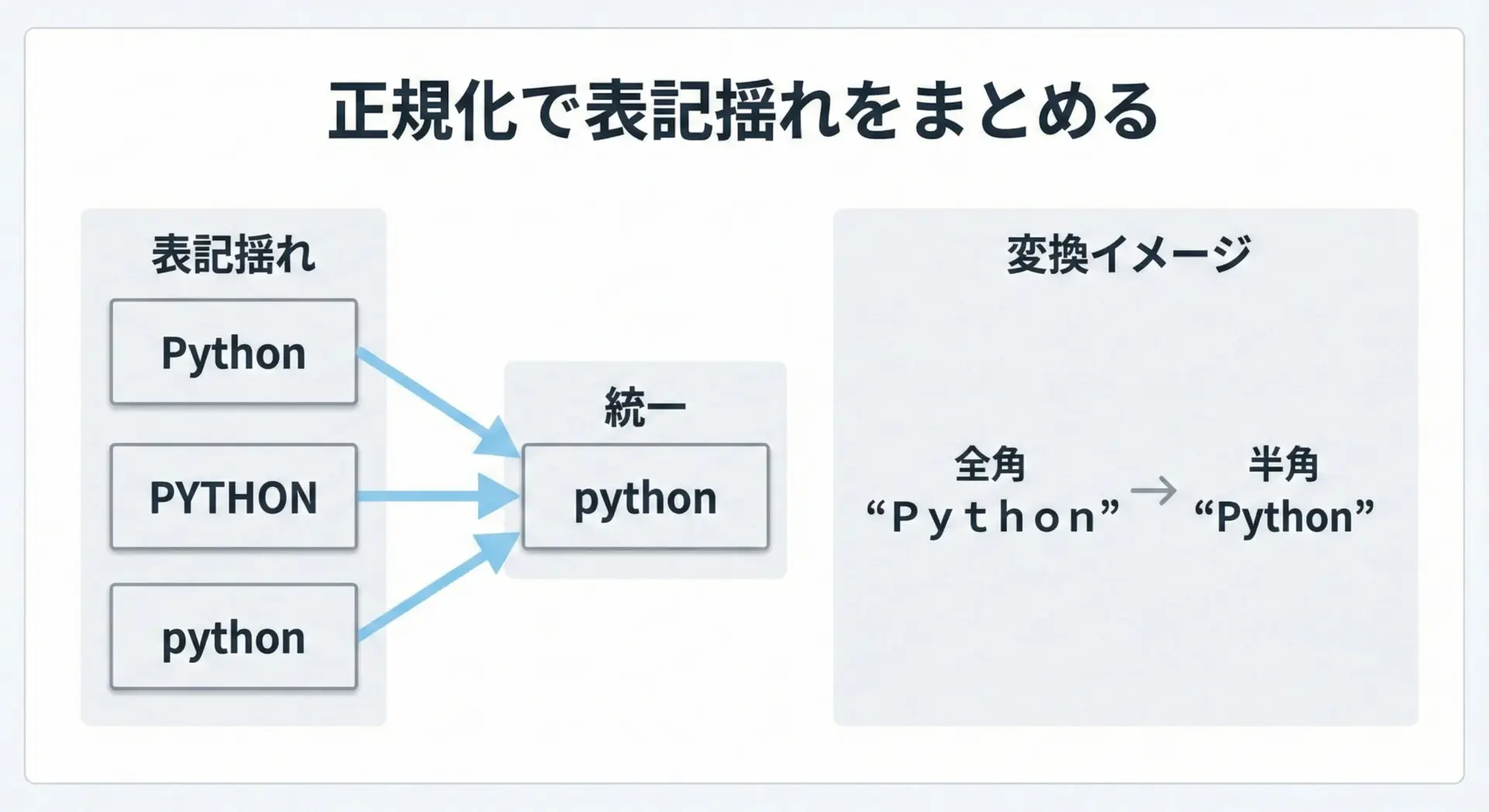
Pythonでは、標準ライブラリunicodedataを使うことで、全角半角をそろえるnormalize処理が行えます。
また、大文字小文字はlower()やcasefold()で揃えます。
# 大文字小文字と全角半角を正規化してからカウントする例
import unicodedata
from collections import Counter
text = "Python PYTHON python パイソン パイソン"
def normalize_text(s: str) -> str:
# NFKC正規化で全角・半角の差を吸収
s = unicodedata.normalize("NFKC", s)
# 大文字小文字を無視するために小文字へ
s = s.lower()
return s
normalized = normalize_text(text)
print("元の文字列:", text)
print("正規化後文字列:", normalized)
# 空白区切りで単語カウント
words = normalized.split()
counter = Counter(words)
print("単語ごとの出現回数:")
for word, count in counter.items():
print(word, ":", count)元の文字列: Python PYTHON python パイソン パイソン
正規化後文字列: python python python パイソン パイソン
単語ごとの出現回数:
python : 3
パイソン : 2このように、正規化を行うことで、表記ゆれのあるテキストでも、意味のある頻度カウントがしやすくなります。
日本語環境では特に全角・半角の混在が起こりやすいため、意識しておくとよいポイントです。
まとめ
Pythonでは、len関数を使った基本的な文字数カウントから、文字列のcountメソッドや正規表現による柔軟な出現回数カウント、さらにcollections.Counterによる頻度集計まで、テキストを分析するための機能が標準で豊富に備わっています。
ファイル内テキストにも同じ考え方を適用でき、正規化によって表記ゆれを抑えることで、より精度の高い集計が可能になります。
実務や学習の中で、必要に応じてこれらの手法を組み合わせて活用してみてください。
