
Pythonでテキストデータを扱うとき、特定の文字列が「どこに現れるか」を知ることはとても重要です。
この記事では、Pythonのfindとindexを中心に、文字列の検索方法とその違い、エラー対策や応用テクニックまで、初心者の方にもわかりやすく丁寧に解説していきます。
Pythonでの文字列検索の基本
Pythonで文字列を検索する代表的な方法
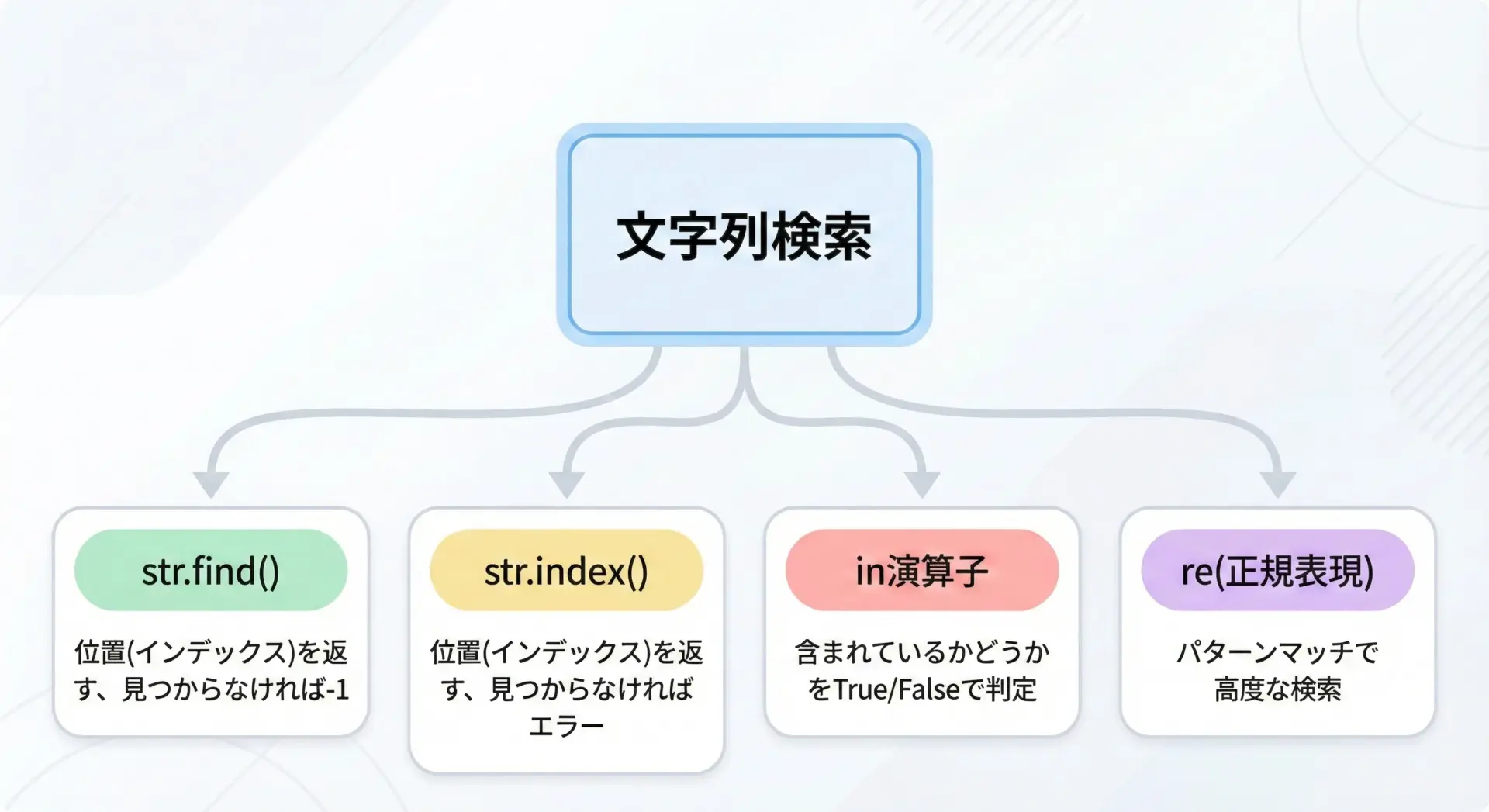
Pythonで文字列を検索する場合、主に次のような方法があります。
いずれも「どの程度の情報がほしいか」によって使い分けることが大切です。
- 位置(インデックス)がほしい場合
代表的なのがstr.find()とstr.index()です。どちらも、見つかった位置を0から始まるインデックスとして返します。 - 含まれているかどうかだけ知りたい場合
in演算子を使うことで、対象の文字列に部分文字列が含まれるかどうかをTrue/Falseで判定できます。 - もっと複雑なパターンを検索したい場合
正規表現モジュールreを使うことで、条件に合うパターンを柔軟に検索できます。
この記事では、このうち位置を取得するfindとindexに焦点を当てて詳しく解説し、その周辺のテクニックにも触れていきます。
findとindexの違い

findもindexも、どちらも「文字列の中で部分文字列が最初に現れる位置」を返しますが、決定的な違いがあります。
- find
部分文字列が見つからない場合は-1を返します。そのため、エラーが発生せず、安全に呼び出せるのが特徴です。 - index
部分文字列が見つからない場合はValueErrorという例外を送出します。したがって、エラーを前提にtry-exceptで囲んだり、事前にinで存在確認を行う必要があります。
この違いから、「必ずあるはずの文字列」を前提にしたい場合はindex、「あるかどうかわからない文字列」を探すときにはfindと使い分けるのが基本方針になります。
文字列検索で知っておきたい注意点
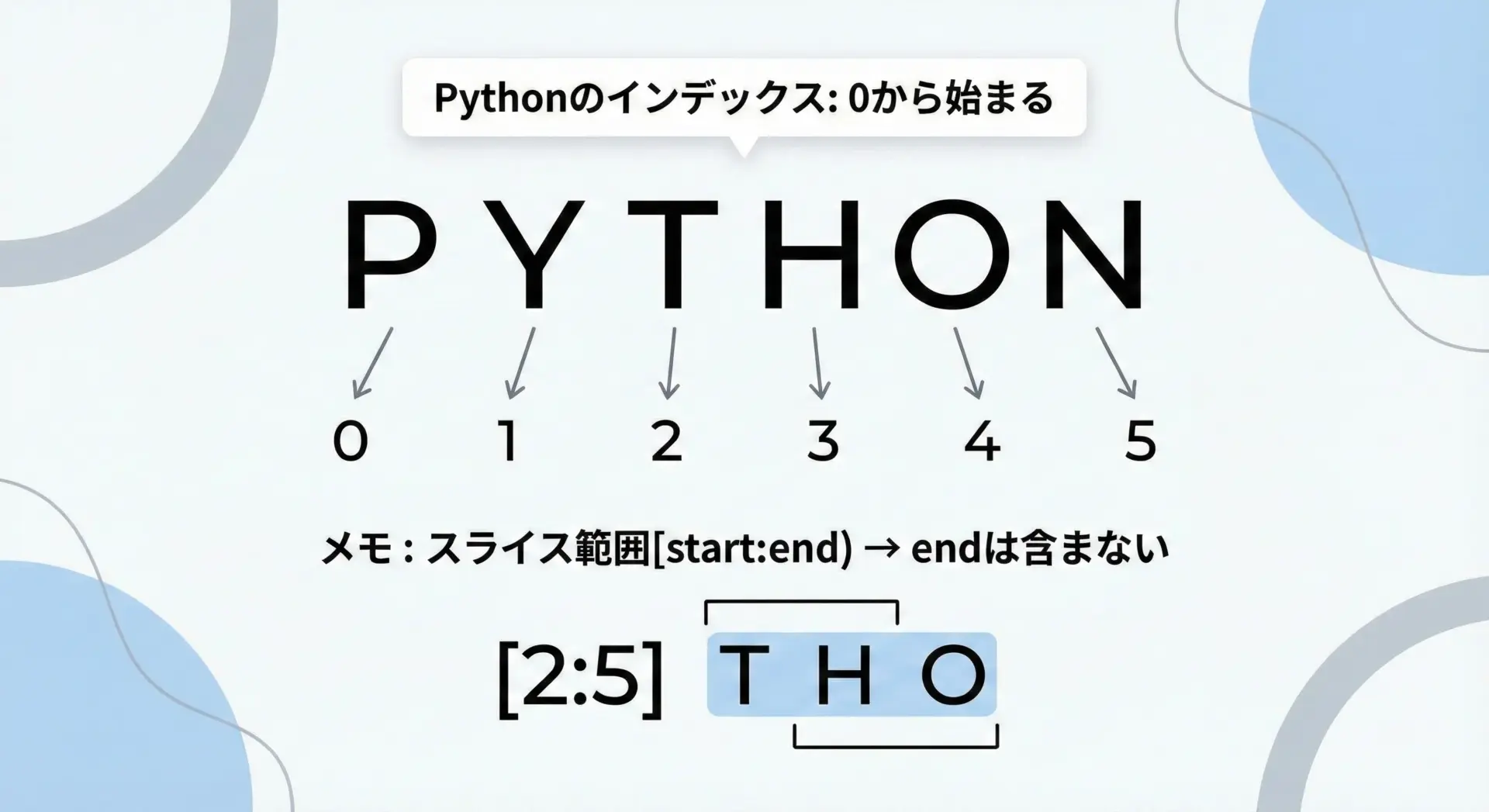
文字列検索では、次のような基本的なルールと注意点を理解しておくと混乱が少なくなります。
まず、Pythonのインデックスは0から始まるという点です。
例えば文字列"Python"であれば、'P'の位置は0、'y'は1というように続きます。
また、findやindexでは、検索範囲を(start, end)のように指定できますが、このときのendは「含まれない」という点も重要です。
これは、リストのスライスなどPython全体で共通しているルールです。
さらに、日本語や絵文字など、マルチバイト文字を含む文字列でも、findやindexは「文字数」ベースでインデックスを返すため、通常は特別な意識をせずに利用できます。
ただし、バイト列bytesを扱う場合は別物になるので、文字列strかバイト列かを区別して考えるようにしてください。
str.findで文字列を検索する方法
findの基本的な使い方

str.find()は、文字列の中から部分文字列を検索し、見つかった最初の位置(インデックス)を返します。
基本的な構文は次のとおりです。
text.find(sub[, start[, end]])sub: 探したい部分文字列start: 検索を開始する位置(省略可能)end: 検索を終了する位置(省略可能、endは含まない)
最もシンプルな使い方はtext.find('探したい文字列')のように、部分文字列だけを指定する方法です。
# 基本的なfindの例
text = "Hello, world!"
pos_hello = text.find("Hello") # "Hello" の開始位置を検索
pos_world = text.find("world") # "world" の開始位置を検索
print(pos_hello)
print(pos_world)0
7この例では、「Hello」は先頭から始まるので位置は0、「world」は7文字目から始まるので7が返っています。
findで部分文字列の位置を取得する例

findは単に位置を返すだけでなく、その位置を利用して部分文字列の抽出などにも応用できます。
# findの結果を使って部分文字列を取り出す例
text = "Pythonはとても人気のあるプログラミング言語です。"
# 「人気」という言葉の位置を検索
pos = text.find("人気")
print("位置:", pos)
if pos != -1:
# 見つかった位置から2文字分を取り出す
keyword = text[pos:pos + 2]
print("見つかった単語:", keyword)位置: 7
見つかった単語: 人気このように、findで位置を求めてからスライスで取り出すことで、特定のキーワードを抽出したり、その前後の文脈を取得することができます。
見つからない場合は-1を返す動作と注意点

findの最も重要な性質は、「見つからなければ-1を返す」という点です。
これは、プログラムの中で条件分岐を行う際に非常に役立ちます。
# 見つからない場合のfindの動作
text = "ABCDEFG"
pos = text.find("Z") # 存在しない文字を探す
print(pos)
# 結果を条件分岐に使う
if pos == -1:
print("見つかりませんでした。")
else:
print("見つかりました。位置:", pos)-1
見つかりませんでした。注意したいのは、インデックス0は有効な位置であり、-1と混同しないことです。
例えば次のようなチェックは誤りです。
# よくある間違いの例
text = "apple"
pos = text.find("a")
# これは誤り。位置0と-1が同じ扱いになってしまう
if not pos:
print("見つからない")posが0の場合、PythonではFalseと評価されてしまうため、「見つからない」と誤判定されます。
必ず== -1で比較するようにしてください。
# 正しい判定方法
if pos == -1:
print("見つからない")
else:
print("見つかった。位置:", pos)開始位置・終了位置を指定してfindする方法
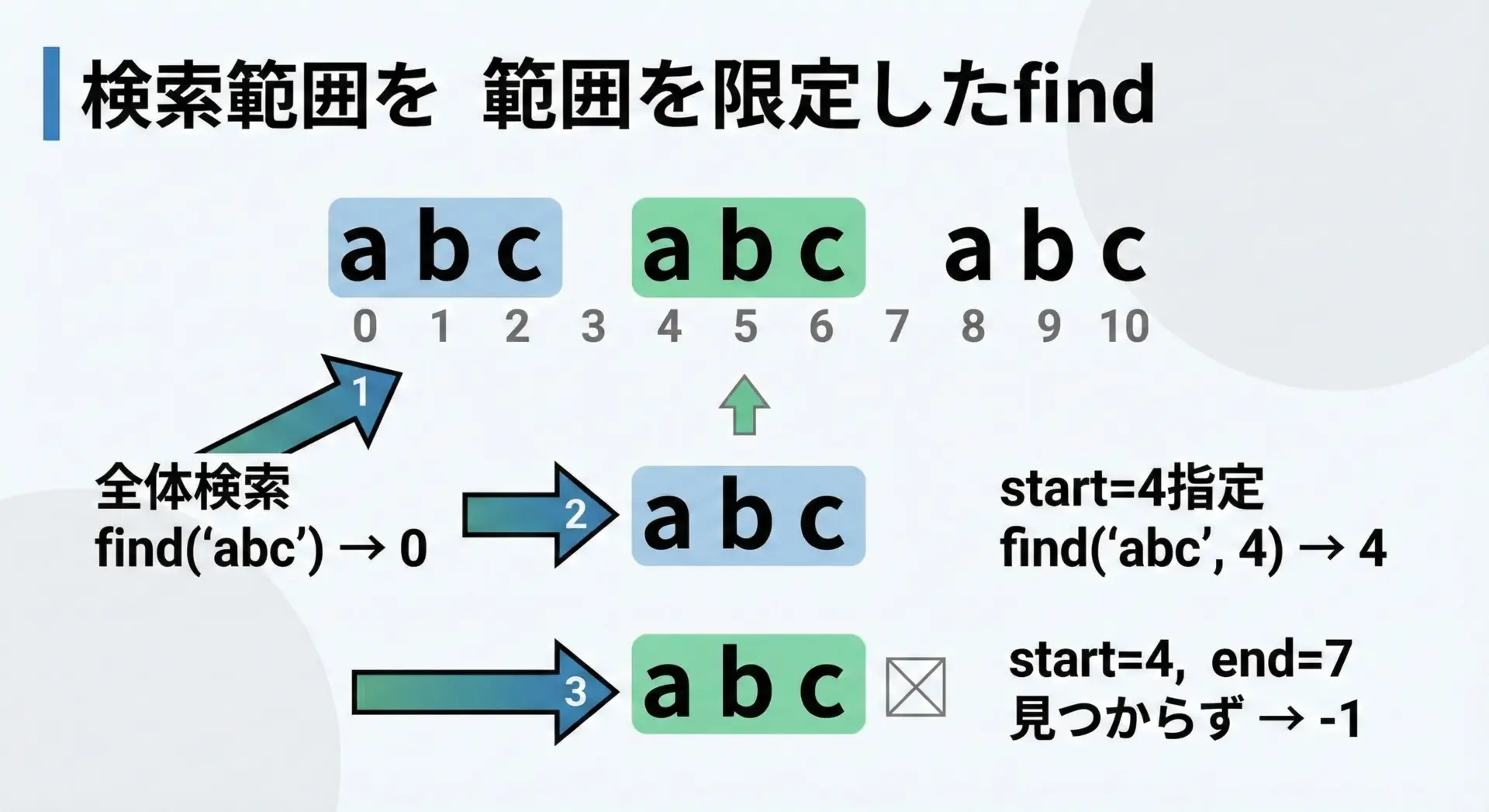
findは、オプション引数としてstartとendを指定できます。
これにより、文字列の一部分だけを検索対象にすることができます。
# 開始位置・終了位置を指定したfindの例
text = "abc abc abc"
pos1 = text.find("abc") # 全体から検索
pos2 = text.find("abc", 4) # インデックス4以降から検索
pos3 = text.find("abc", 4, 7) # インデックス4以上7未満の範囲で検索
print("pos1:", pos1)
print("pos2:", pos2)
print("pos3:", pos3)pos1: 0
pos2: 4
pos3: -1ここで重要なのは、endの位置は「含まれない」という点です。
インデックス4から7未満、つまり4、5、6だけが検索対象になります。
その範囲内には完全な"abc"が存在しないため、結果は-1になります。
この機能は、findで見つけた位置より後をさらに検索するようなケースや、文字列の一部だけを調べたい場合に非常に役立ちます。
str.indexで文字列を検索する方法
indexの基本的な使い方

str.index()は、基本的な使い方や引数はfindとほぼ同じですが、見つからなかったときの挙動が異なります。
text.index(sub[, start[, end]])実際の使用例は次のとおりです。
# indexの基本的な使い方
text = "Hello, world!"
pos_hello = text.index("Hello")
pos_world = text.index("world")
print(pos_hello)
print(pos_world)0
7このように、findと同様に見つかった位置のインデックスが返ります。
indexで部分文字列の位置を取得する例

indexも、部分文字列の位置を求めてからスライスする使い方がよく行われます。
# indexで区切り文字の位置を見つけて値を取り出す例
record = "ユーザーID: 12345; 名前: Taro"
# 「ユーザーID: 」の後にある数値部分を取り出したい
label = "ユーザーID: "
start = record.index(label) + len(label) # ラベルの直後の位置
end = record.index(";") # セミコロンの位置
user_id = record[start:end]
print("ユーザーID:", user_id)ユーザーID: 12345ここではindexを2回使い、開始位置と終了位置をそれぞれ求めています。
必ず存在する前提の区切り文字を扱うときには、このようにindexを使うとコードがシンプルになります。
見つからない場合のエラー(ValueError)の仕組み
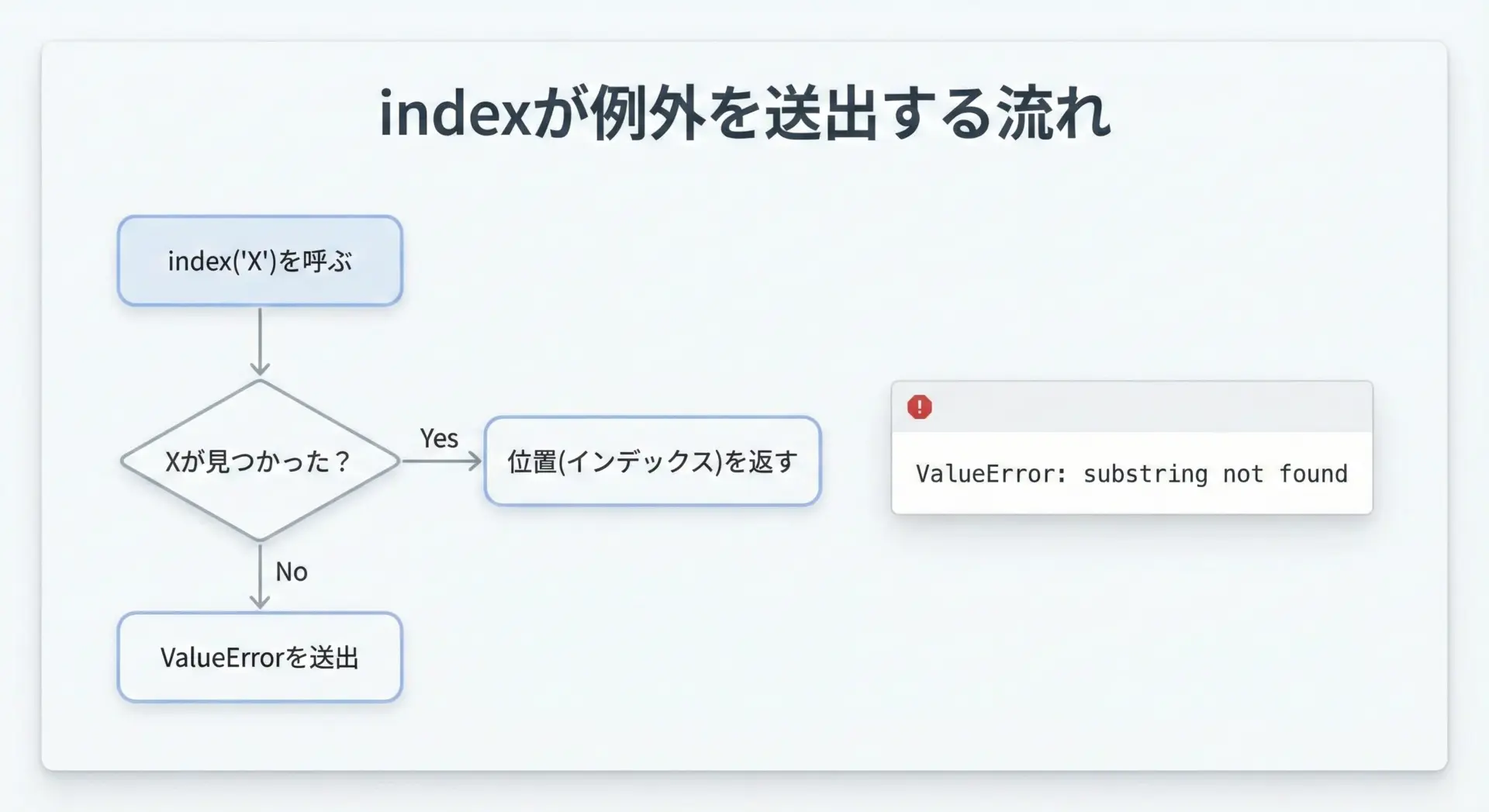
indexが検索対象が見つからない場合、PythonはValueErrorという例外を送出します。
実際の様子を確認してみましょう。
# indexで見つからない場合の挙動
text = "ABCDEFG"
# 存在しない部分文字列を検索
pos = text.index("Z")
print(pos)このコードを実行すると、次のようなエラーが発生します。
Traceback (most recent call last):
File "example.py", line 5, in <module>
pos = text.index("Z")
ValueError: substring not foundプログラムがこの時点で止まってしまうため、indexを使う際には、この例外をどう扱うかをあらかじめ考えておく必要があります。
index使用時のエラー対策とtry-exceptの書き方
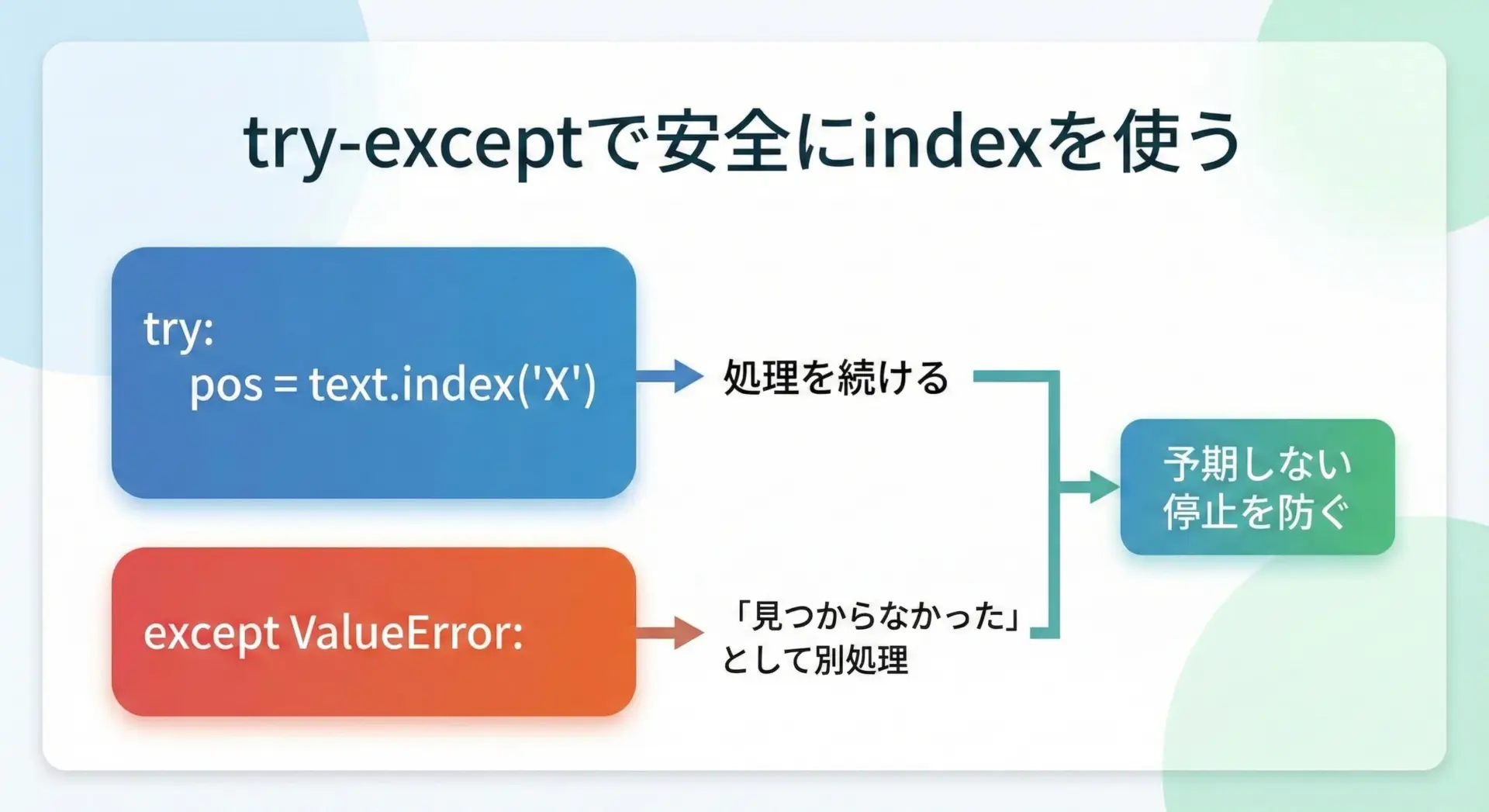
indexを安全に利用するには、主に2つの方法があります。
1つ目は、try-exceptでValueErrorを捕まえる方法です。
# try-exceptでindexのエラーを処理する例
text = "ABCDEFG"
try:
pos = text.index("Z")
print("見つかりました。位置:", pos)
except ValueError:
print("見つかりませんでした。")見つかりませんでした。2つ目は、事前にin演算子で存在確認をする方法です。
# in演算子で存在確認をしてからindexを呼ぶ例
text = "ABCDEFG"
if "C" in text:
pos = text.index("C")
print("位置:", pos)
else:
print("見つかりませんでした。")位置: 2どちらの方法も有効ですが、「絶対にあるはずだが、万一のために安全装置をつけたい」といったケースではtry-exceptを、「あるかどうかわからない前提で処理フローを分岐させたい」場合にはinを使うのが自然です。
findとindexの使い分けのポイント
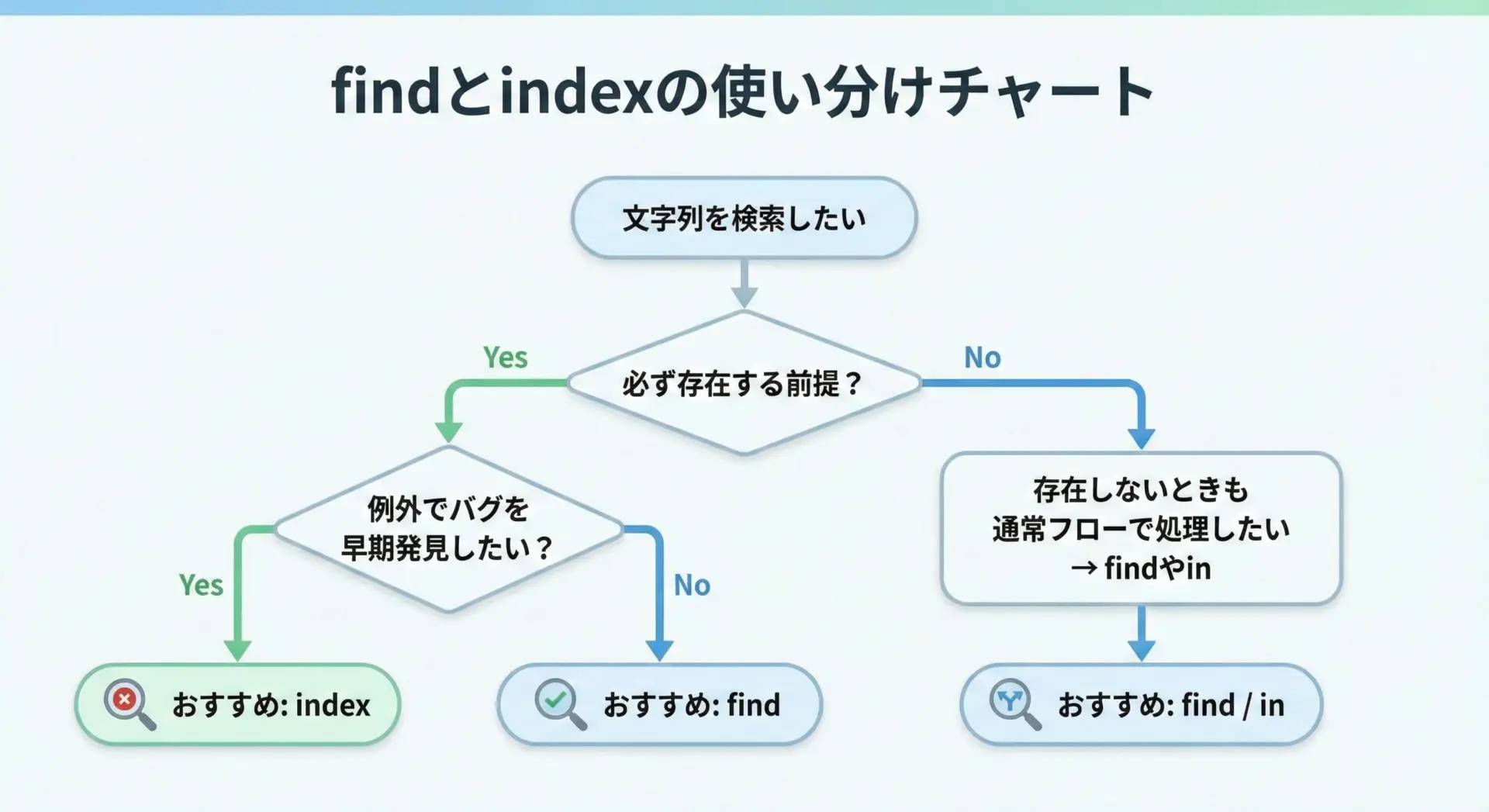
ここまでの内容を踏まえて、findとindexの使い分けを整理しておきます。
- findを使うとよい場面
文字列が存在するかどうかわからないが、エラーで止まってほしくない場合です。戻り値が-1かどうかで分岐すればよいため、ログ解析や検索機能など、多くの実務コードではfindが多用されます。 - indexを使うとよい場面
ビジネスロジック上必ず存在しているべき文字列であり、もし存在しないならそれはバグやデータ不整合とみなしたい場合です。このときindexを使っておくと、想定外の状況で早めにエラーとして気づけるというメリットがあります。
状況に応じて、エラーで「落ちてほしい」のか、「落ちてほしくない」のかを判断材料にするとよいでしょう。
応用的な文字列検索テクニック
複数回出現する文字列の位置をループで検索する方法
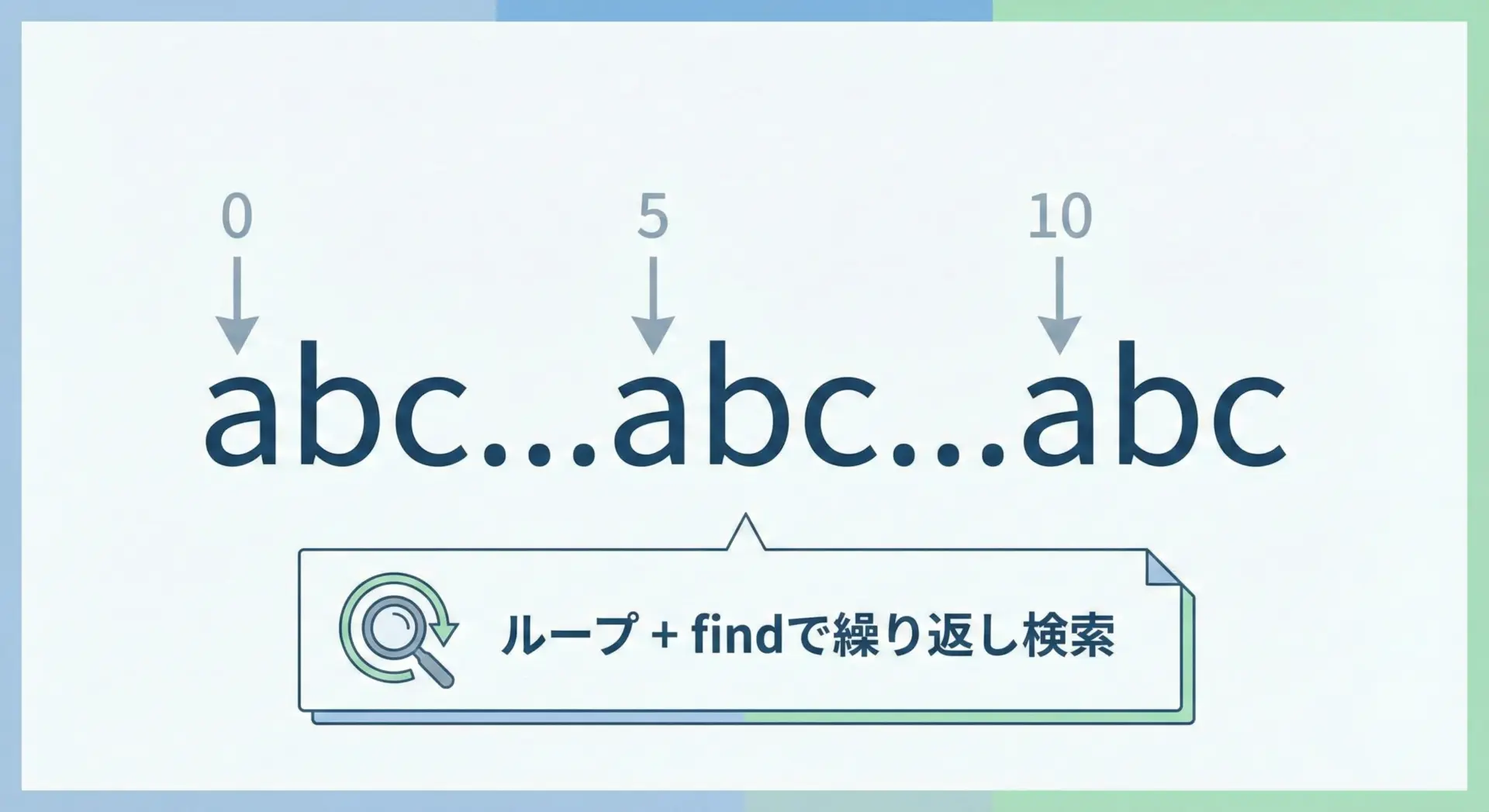
findやindexは、基本的には最初に見つかった位置しか返しません。
文字列が複数回現れるとき、すべての位置を知りたい場合には、ループで繰り返し検索するのが典型的なパターンです。
# 文字列が複数回出現する位置をすべて取得する例
text = "abc XYZ abc 123 abc"
target = "abc"
positions = []
start = 0 # 検索開始位置
while True:
pos = text.find(target, start) # start以降から検索
if pos == -1:
break # これ以上見つからなければループ終了
positions.append(pos)
start = pos + len(target) # 見つかった位置のすぐ後ろから再検索
print("見つかった位置一覧:", positions)見つかった位置一覧: [0, 8, 16]ここでは見つかった位置の直後から次の検索を始めることで、同じ場所を何度も調べないようにしています。
区切り文字やタグの出現位置をすべて列挙したいときなどに、このパターンはよく使われます。
大文字・小文字を無視して文字列検索する方法
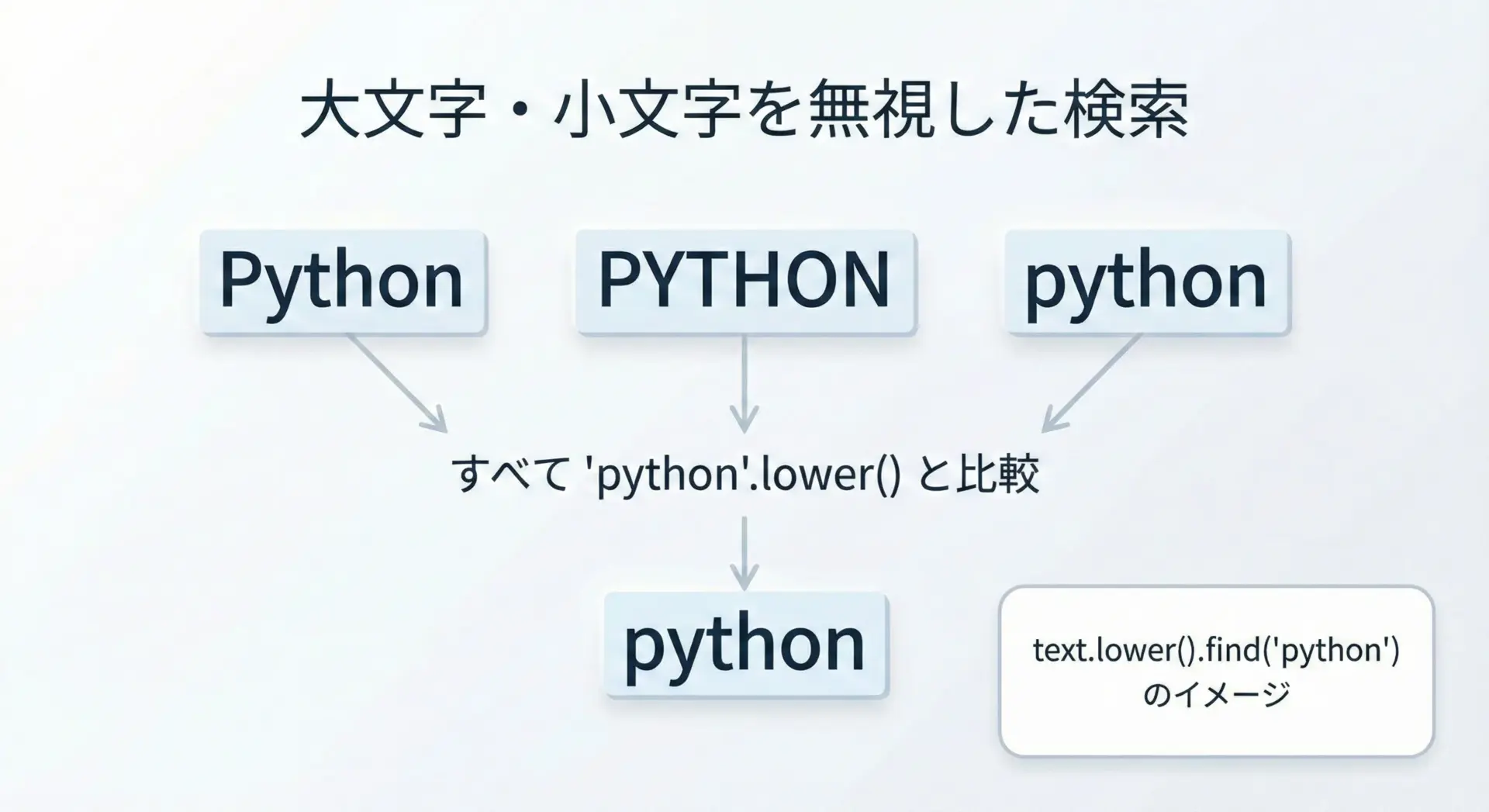
Pythonのfindやindexは大文字・小文字を区別して検索します。
そのため、「Python」「PYTHON」「python」をすべて同じものとして扱いたい場合は、事前に小文字(または大文字)にそろえるのが一般的です。
# 大文字・小文字を無視して検索する例
text = "I like PYTHON programming."
keyword = "python"
# どちらも小文字に変換してから検索
lower_text = text.lower()
lower_keyword = keyword.lower()
pos = lower_text.find(lower_keyword)
print("位置:", pos)
if pos != -1:
# 元の文字列で、対応する位置を確認できる
print("元の文字列の該当部分:", text[pos:pos + len(keyword)])位置: 7
元の文字列の該当部分: PYTHONこのようにすることで、入力の揺れ(大文字・小文字の違い)を吸収できます。
検索フォームやログ解析など、ユーザー入力を扱う場面でよく使われるテクニックです。
in演算子との違いと使い分け

in演算子は、次のように「含まれているかどうか」だけを知りたいときに便利です。
# in演算子の基本
text = "Hello, world!"
print("Hello" in text)
print("Python" in text)True
False一方find/indexは位置(インデックス)が必要なときに使います。
使い分けの基本は次のとおりです。
- 「含まれているかどうかだけ」でよい →
in
例: 「NGワードが含まれているか」など、位置が不要なチェック - 「どこにあるか(位置)も知りたい」 →
find/index
例: 「見つかった単語の前後を切り出したい」など、後続処理に位置情報が必要なケース
また、indexを使う際に、inで事前チェックするパターンもよくあります。
# inとindexを組み合わせる例
text = "Order ID: #12345"
if "#" in text:
pos = text.index("#")
order_id = text[pos + 1:] # #の後ろをすべて取得
print("注文ID:", order_id)
else:
print("#が含まれていません。")注文ID: 12345このように、inは軽量な存在チェックとして、find/indexと組み合わせて使うと便利です。
文字列検索に正規表現(re)を使う場合との比較
Pythonのreモジュールを使うと、「数字が続く場所」や「メールアドレスのようなパターン」といった複雑な条件で検索ができます。
一方で、find/indexは固定の文字列をそのまま探すだけです。
単純な文字列検索ならfind/indexで十分ですが、次のようなケースではreを検討するとよいでしょう。
- 数字だけの連続部分を探したい
- 日付形式(例: 2025-12-31)の部分を探したい
- メールアドレスらしき文字列を抽出したい
例として、数字が連続する部分を探すreのコードを見てみます。
import re
text = "会員番号: 12345, 注文番号: 67890"
# \d+ は「1文字以上の数字」
matches = re.findall(r"\d+", text)
print("見つかった数字列:", matches)見つかった数字列: ['12345', '67890']単純な「固定文字列検索」ならfind/index、複雑な「パターン検索」ならreと覚えておくとよいでしょう。
必要以上に正規表現を使うとコードが読みにくくなるため、まずはfind/indexで書けないかを検討するのがおすすめです。
まとめ
Pythonで文字列を検索する際には、findとindexの違い(見つからないときに-1を返すか、例外を送出するか)を理解しておくことが重要です。
存在するか曖昧な文字列にはfindを、必ずある前提でバグ検知にも利用したい場合にはindexを使うとよいでしょう。
また、複数回出現の検索、大小文字の無視、inやreとの使い分けを身につけることで、実務レベルの文字列処理がぐっと書きやすくなります。
