
Pythonで読みやすく保守しやすいコードを書くためには、PEP8というコーディング規約を押さえておくことがとても大切です。
本記事では、PEP8の概要から命名規則、インデントや空白のルール、コメントや文字列の扱い、さらには自動チェックツールの使い方まで、実務で最初に知っておくべきポイントを体系的に解説します。
PEP8とは何か?Pythonのコーディング規約の基本
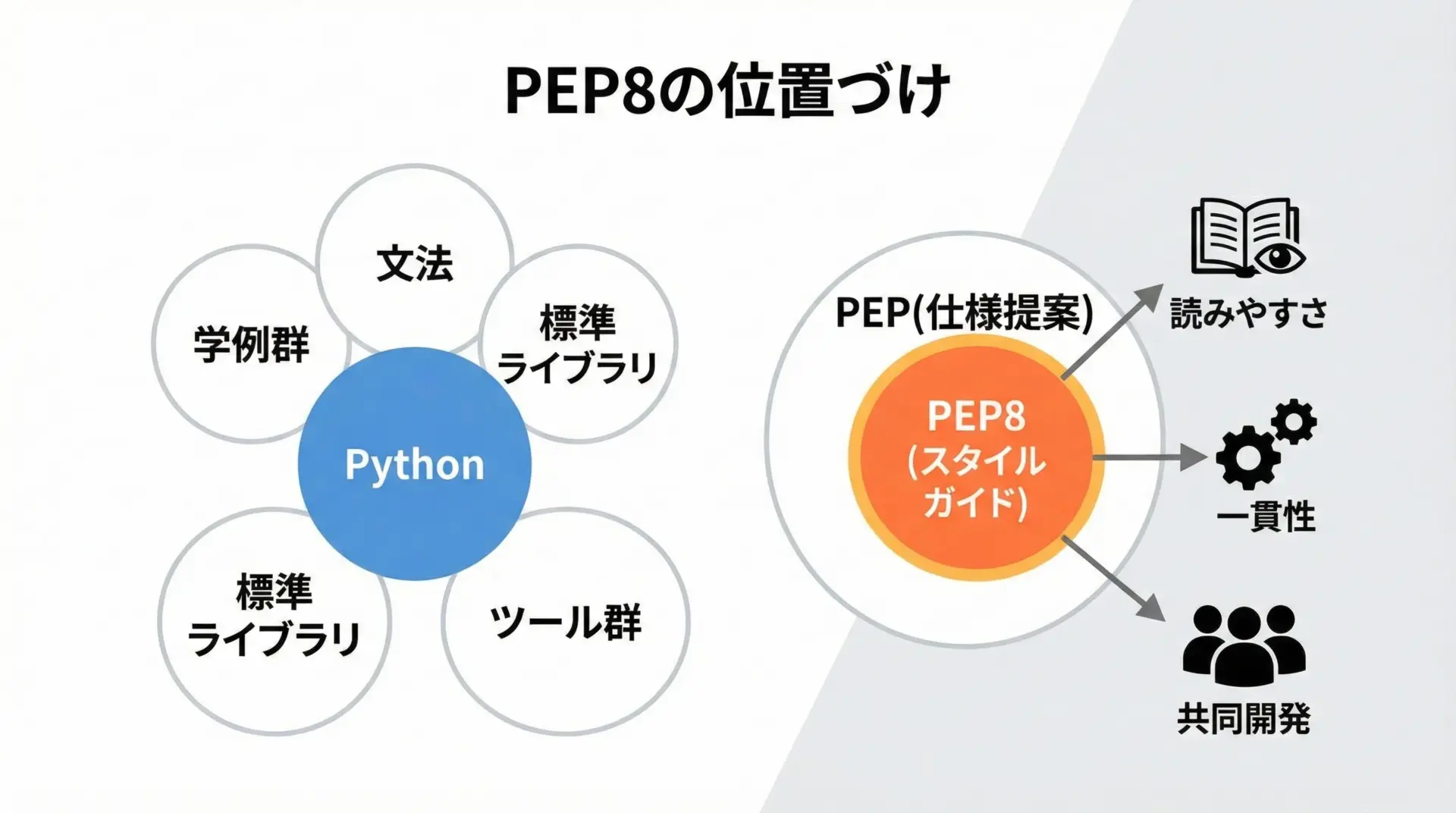
PEP8は、Pythonでコードを書くときのスタイル(書き方)を定めた公式ガイドラインです。
文法そのものではなく、「どう書くと読みやすく統一されたコードになるか」を示しています。
Pythonコミュニティが合意したルールであり、多くのライブラリやフレームワークがこのスタイルを採用しています。
なぜPEP8がPythonの事実上の標準スタイルなのか
PEP8が事実上の標準スタイルとみなされている理由はいくつかあります。
まず、Pythonのコア開発者によって公式に提案・承認されたPEP(Enhancement Proposal)であることが大きなポイントです。
そのため、標準ライブラリをはじめ、多数の公式ドキュメントがPEP8に準拠しています。
また、以下のような理由から、現場でも広く採用されています。
- コードレビュー時に「好み」ではなく共通の基準として使える
- チームメンバーが入れ替わってもスタイルの連続性を保ちやすい
- 外部ライブラリやサンプルコードとのスタイルの差異を減らせる
このように、PEP8は単なる推奨ではなく、Pythonを書く上での共通言語として扱われています。
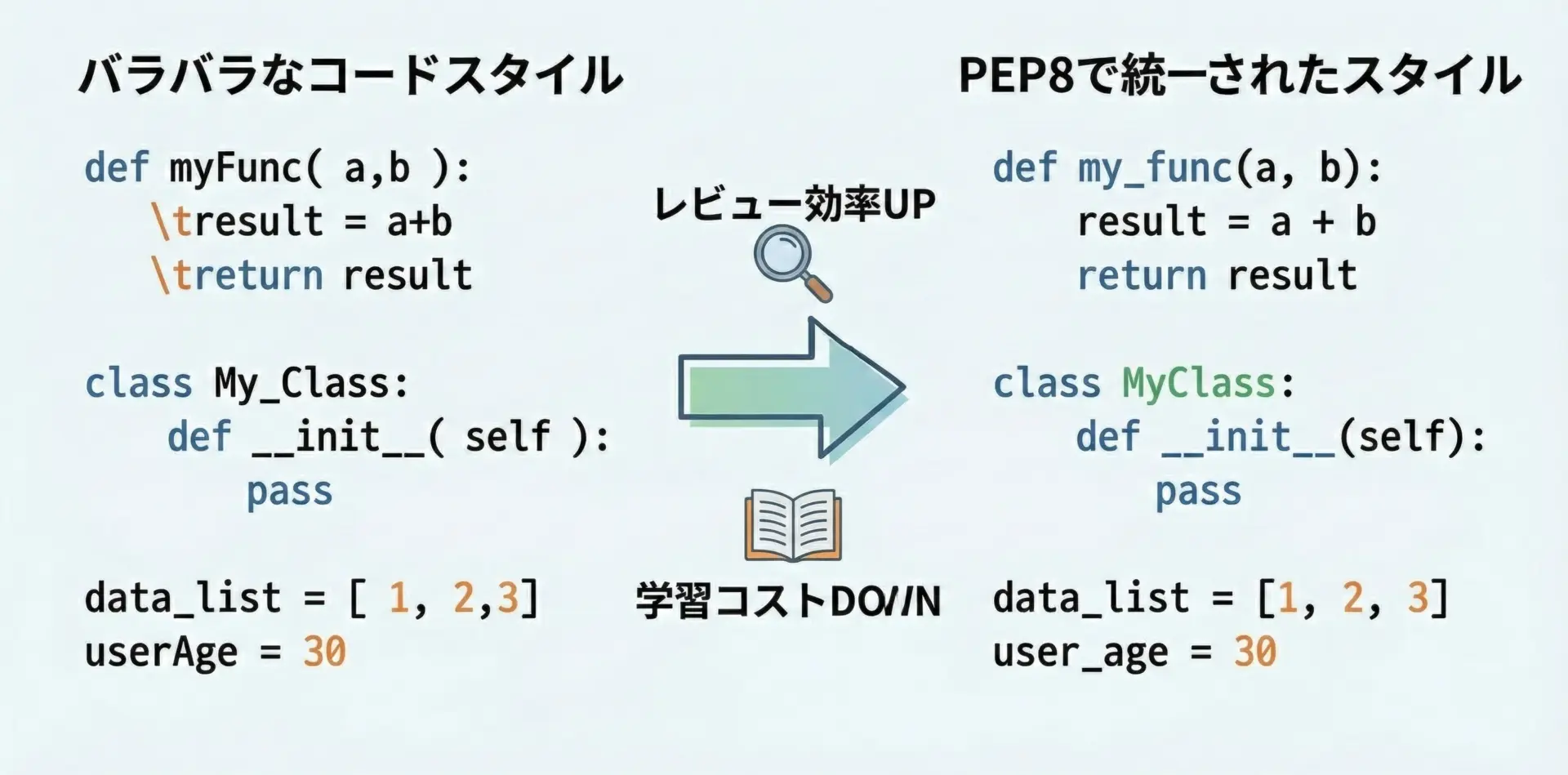
PEP8を守るメリット
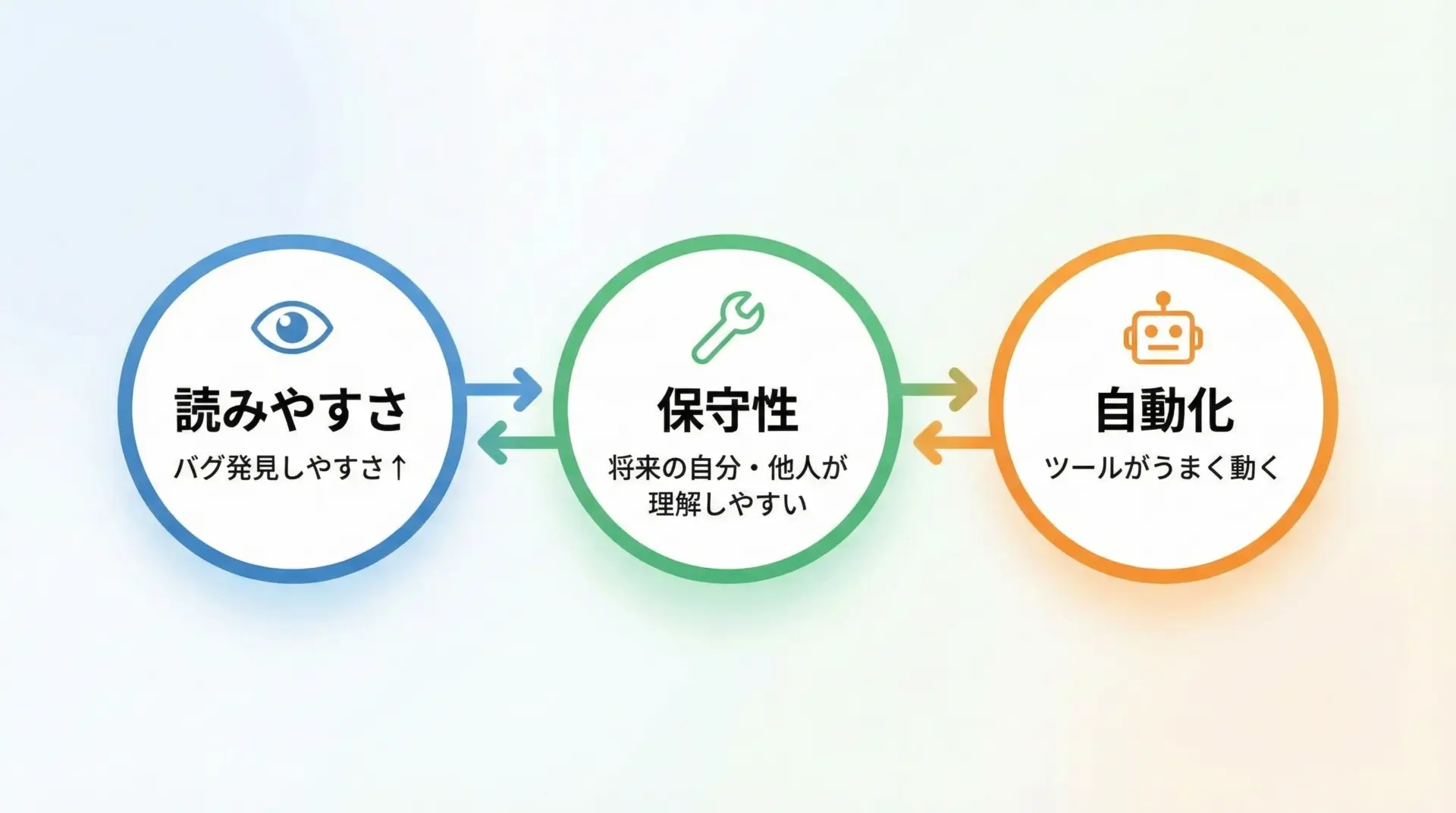
PEP8を守ると、実務的に次のようなメリットがあります。
まず、コードの読みやすさが大きく向上します。
インデントや空白、命名が整っているだけで、処理の意図が格段に追いやすくなります。
読みやすいコードは、バグの早期発見やレビュー時間の短縮にもつながります。
次に、保守性が高くなります。
半年後、一年後の自分や、あなたのあとにプロジェクトを引き継ぐ人がコードを読むとき、ルールに沿って書かれたコードであれば、理解コストが大きく下がります。
さらに、静的解析・自動整形ツールが最大限に活用できるようになります。
多くのツールがPEP8を前提に設計されているため、最小限の設定で自動チェックや整形が機能します。
Pythonの命名規則
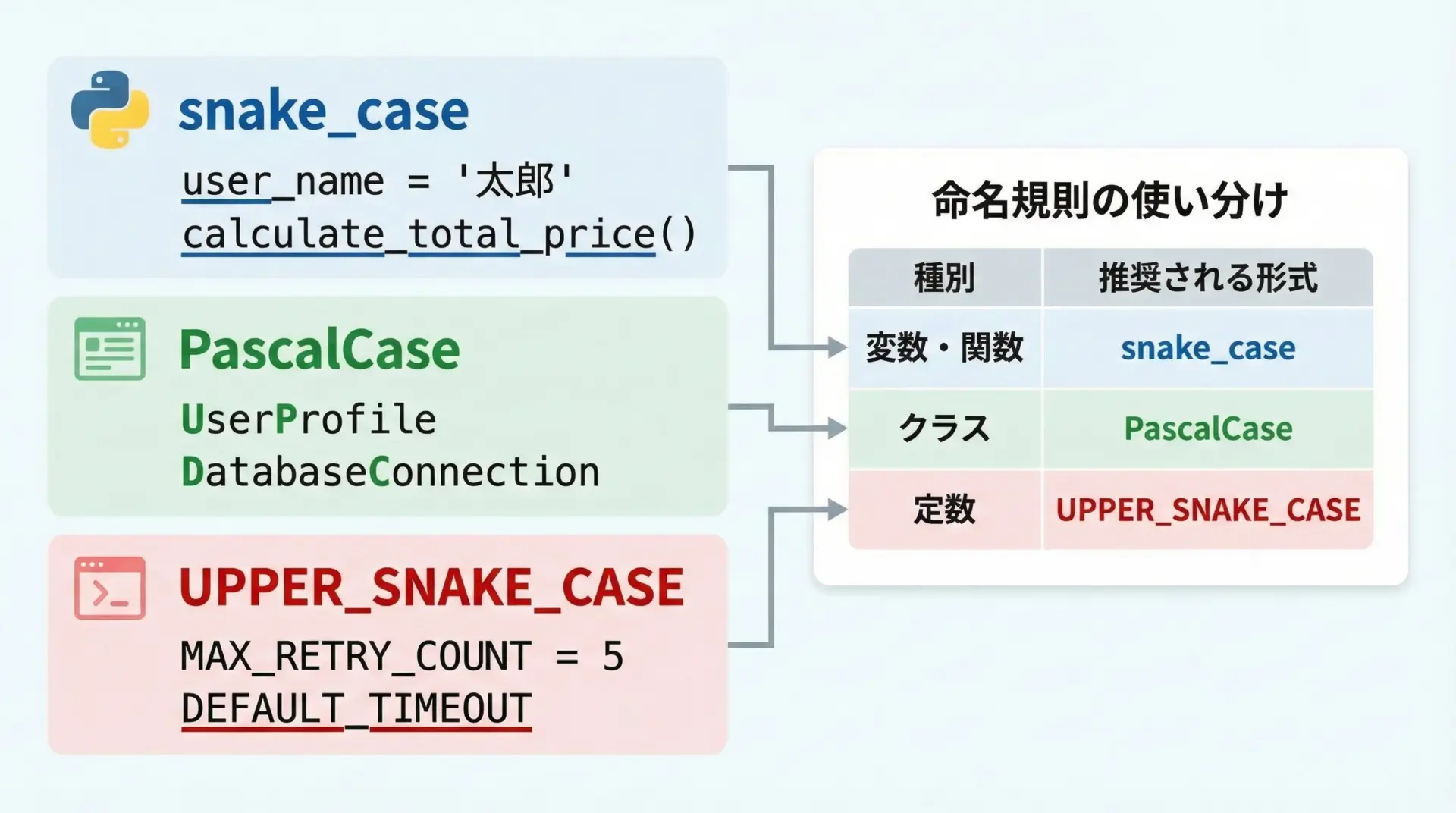
PEP8では、識別子(変数名・関数名・クラス名など)の付け方についても、細かくルールを定めています。
命名規則はコードの「見た目の情報」を増やし、役割を一目で把握できるようにするために重要です。
変数名・関数名の命名規則
変数名と関数名は、基本的に小文字とアンダースコアを用いたsnake_caseで記述します。
# 良い例: snake_case を使用
user_name = "Taro"
item_count = 3
def calculate_total_price(price, tax_rate):
"""合計金額を計算する関数"""
return price * (1 + tax_rate)
# 悪い例: Java風の camelCase は Python では一般的でない
userName = "Taro"
itemCount = 3
def calculateTotalPrice(price, taxRate):
return price * (1 + taxRate)1文字の変数名は原則避けるべきですが、iやjなど、ループカウンタとして慣例的に使われている場合のみ、例外的に使用されます。
また、意味のない略語より、少し長くても意味が明確な名前を付けるほうが良いとされています。
クラス名の命名規則
クラス名は、先頭大文字+単語の先頭を大文字にするPascalCase(CapWords)を用います。
class UserProfile:
"""ユーザーのプロフィールを表すクラス"""
def __init__(self, name, age):
self.name = name
self.age = age
# 悪い例: クラス名を snake_case で書く
class user_profile:
pass抽象クラスやインタフェースのような役割を持つクラスも、同様にPascalCaseで命名します。
クラス名から役割や概念が分かる名前を付けることが重要です。
定数・モジュール・パッケージ名の付け方
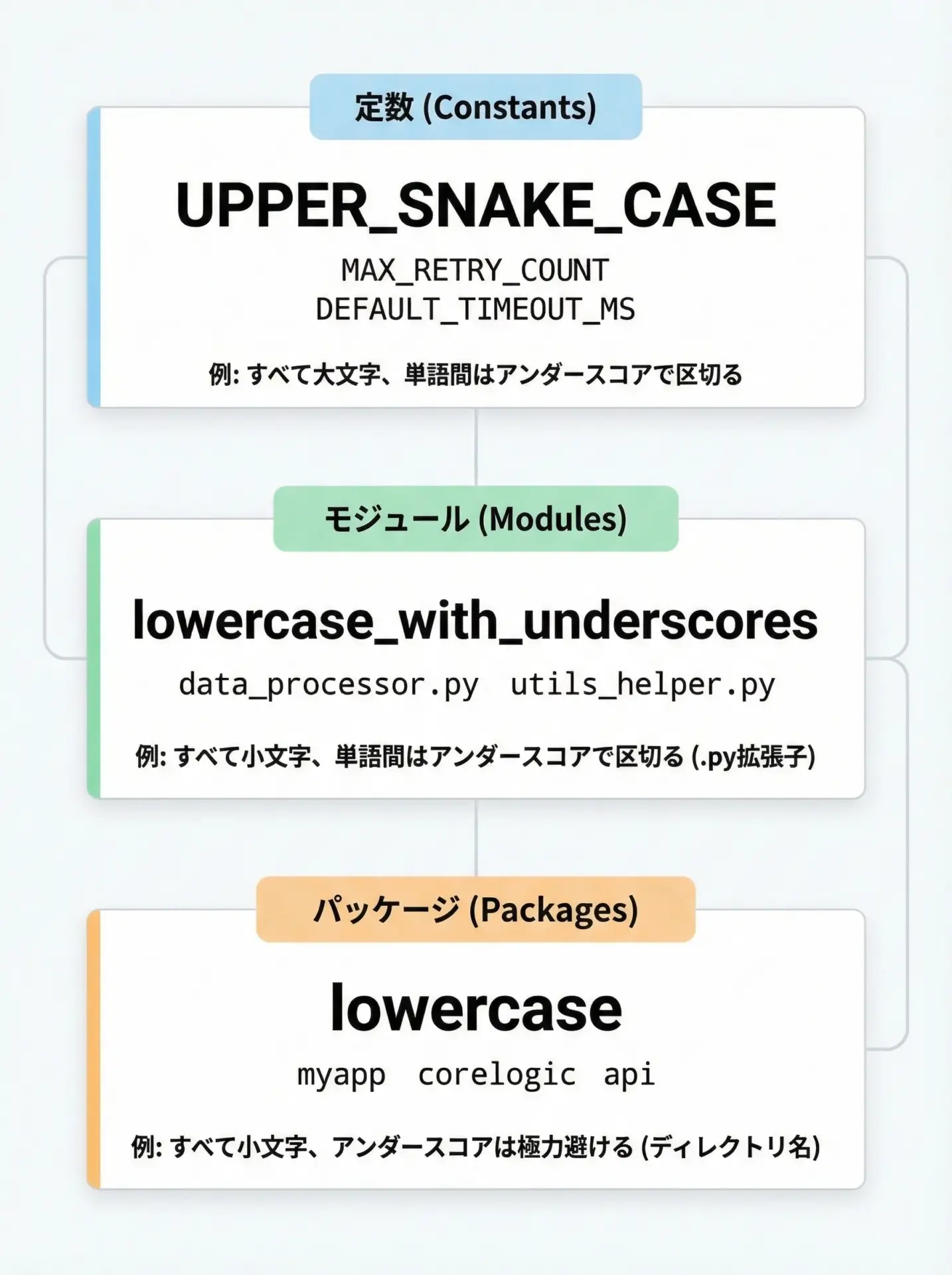
PEP8では、定数・モジュール・パッケージ名には次のような規則があります。
定数の命名
定数はすべて大文字+アンダースコアのUPPER_SNAKE_CASEで書きます。
Pythonには「本当の定数」はありませんが、変更しないことを慣例的に示すためにこの形式を使います。
MAX_RETRY_COUNT = 3
DEFAULT_TIMEOUT_SECONDS = 10
PI = 3.14159モジュール・パッケージの命名
- モジュール名(ファイル名)は小文字+必要に応じてアンダースコア
- パッケージ名(ディレクトリ名)は小文字のみで、できればアンダースコアなし
my_project/
config.py # 良い例: 小文字
data_loader.py # 良い例: snake_case
utils.py大文字を含むモジュール名や、過度に長い名前は避けることが推奨されています。
Pythonで避けるべき名前の付け方
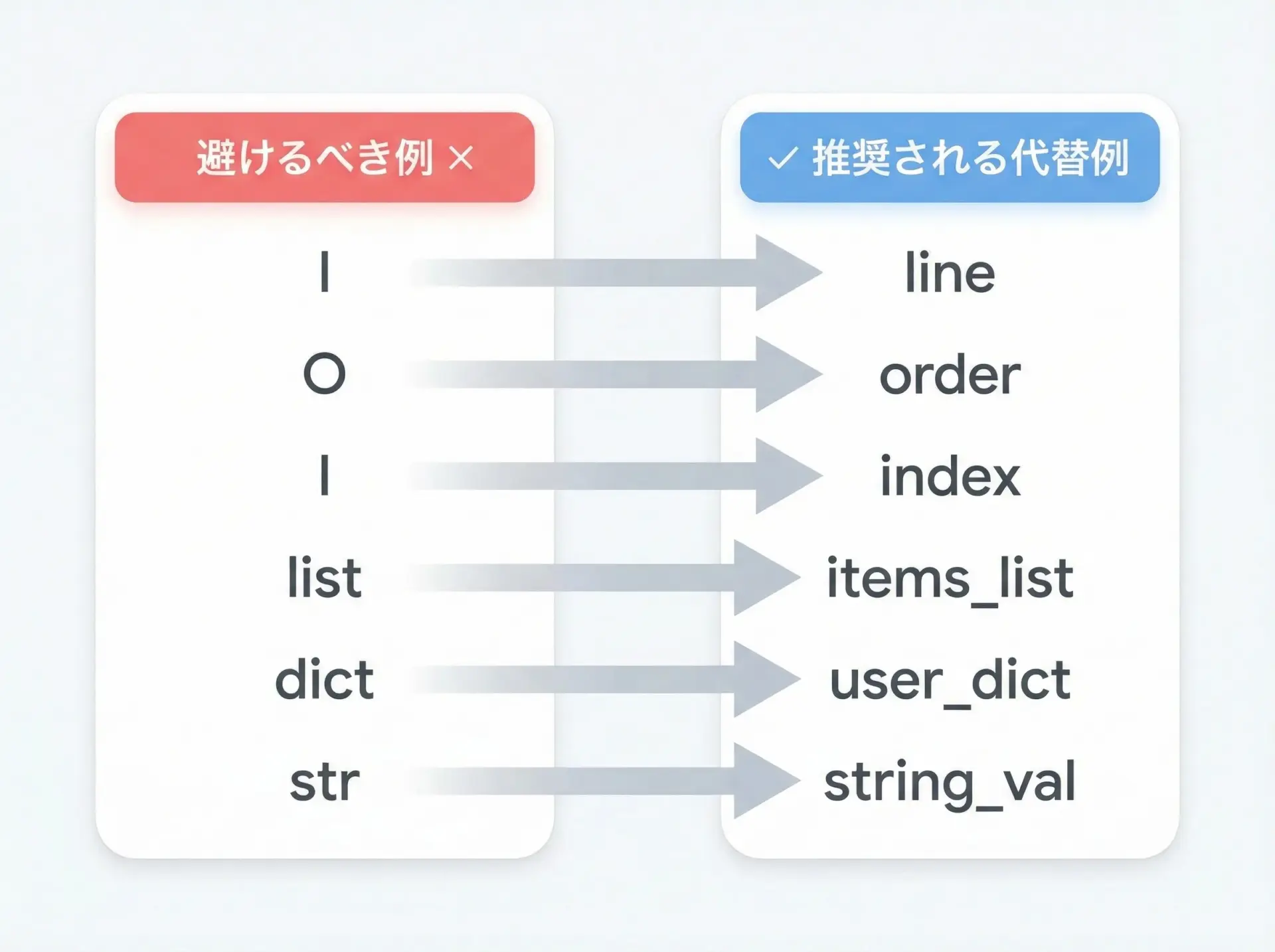
PEP8では、特に次のような名前を避けるよう強く推奨しています。
l、O、Iの1文字変数
これらはフォントによって1や0と見分けが付きにくいためです。
# 悪い例
l = 1
O = 0
I = 2
# 良い例
line_count = 1
order_index = 0
item_id = 2また、組み込み関数と同じ名前を変数に使うことも避けるべきです。
例えば、listやdict、strなどを再定義してしまうと、元の組み込み関数を使えなくなるためです。
# 悪い例: 組み込み関数 list を上書きしてしまっている
list = [1, 2, 3]
# 良い例
numbers = [1, 2, 3]コードレイアウトの基本

コードレイアウトとは、インデントや行の長さ、空行の挿入、インポートの並べ方など、コード全体の見た目を整えるためのルールです。
PEP8では、これらについても細かく定義しています。
インデントは半角スペース4つに統一する
Pythonではインデントが文法の一部です。
PEP8では、インデントには半角スペース4つを使用し、タブは使用しないことが推奨されています。
def process_items(items):
# 良い例: スペース4つのインデント
for item in items:
print(item)
def process_items_bad(items):
# 悪い例: インデント幅がバラバラ
for item in items:
print(item)タブとスペースが混在すると、エディタや環境によって見え方が変わり、意図しないインデントエラーを招きます。
そのため、エディタの設定でタブ入力をスペース4つに変換するようにしておくと安全です。
行の長さ(行数制限)と折り返しのルール
PEP8では、1行の長さは原則79文字以内に収めることが推奨されています。
これは、狭い画面でも横スクロールせずに読めるようにするためです。
# 悪い例: 1行が長すぎる
result = some_function_with_very_long_name(arg1, arg2, arg3, arg4, arg5, arg6, arg7)
# 良い例: 括弧の中で改行して揃える
result = some_function_with_very_long_name(
arg1,
arg2,
arg3,
arg4,
arg5,
arg6,
arg7,
)関数引数やリスト・辞書などを改行するときは、カンマの後で改行し、インデントを揃えて読みやすくします。
また、論理行の連結には\より括弧()や[]、{}による暗黙的な連結を使うことが推奨されています。
空行の使い方

空行は、コードの論理的なかたまりを視覚的に区切るために使います。
PEP8では、主に次のようなルールがあります。
- トップレベルの関数・クラス定義の間には2行の空行
- クラス内のメソッド定義の間には1行の空行
- 関数内では、概念的なブロックを分けるときに適宜空行を入れる
def load_config():
...
def initialize_app():
...
class UserService:
def __init__(self):
...
def create_user(self, name):
...
def delete_user(self, user_id):
...空行を入れすぎると逆に読みにくくなるため、区切りたいところだけに意図して入れることがポイントです。
インポート文の書き方と順序
PEP8では、インポート文の順序についても規定があります。
基本的な順序は次の通りです。
- 標準ライブラリのインポート
- サードパーティのインポート
- 自分のアプリケーション/ライブラリのインポート
それぞれのグループの間には1行の空行を入れます。
# 標準ライブラリ
import os
import sys
# サードパーティ
import requests
from sqlalchemy import create_engine
# 自分のモジュール
from my_project.config import settings
from my_project.services.user import UserServiceまた、from module import *のようなワイルドカードインポートは、名前空間が汚染され何がどこから来たか分からなくなるため、原則禁止とされています。
空白・コメント・文字列のPEP8ルール

PEP8では、空白(スペース)の使い方についても詳細なルールがあり、「詰め込みすぎない」「意味のある空白だけを入れる」ことが重視されています。
また、コメントやdocstring、文字列リテラルの書き方にもガイドラインがあります。
演算子まわりの空白の入れ方
代入演算子や比較演算子、算術演算子の前後には、1つのスペースを入れるのが基本です。
# 良い例
x = 1
y = x + 2
is_valid = (x == 1)
# 悪い例: スペースなし
x=1
y=x+2
is_valid=(x==1)ただし、優先順位の違いを強調したい場合などには、あえてスペースを調整することもあります。
# 例: 優先度を見せたい場合
value = x*2 + y*3関数呼び出しの()の前にはスペースを入れないことも、よくあるルールです。
# 良い例
result = func(x, y)
# 悪い例
result = func (x, y) # func と ( の間にスペースを入れないカンマ・コロン・括弧の前後のスペース

カンマやコロン、セミコロンの前後には、次のようなルールがあります。
# 良い例
items = [1, 2, 3, 4]
user = {"name": "Taro", "age": 20}
if x == 1:
print("x is 1")
# 悪い例
items = [1 ,2 ,3 ,4 ]
user = { "name" : "Taro" , "age" :20 }
if x == 1 :
print("x is 1")- カンマ
,やコロン:の前にスペースは入れない - カンマ
,の後には1つだけスペース - コロン
:の後は、状況に応じてスペース(辞書やスライスなど)
また、括弧の内側に不要なスペースを入れないというルールもあります。
# 良い例
items = [1, 2, 3]
result = (x + y) * z
# 悪い例
items = [ 1, 2, 3 ]
result = ( x + y ) * zコメントの書き方とdocstringの基本
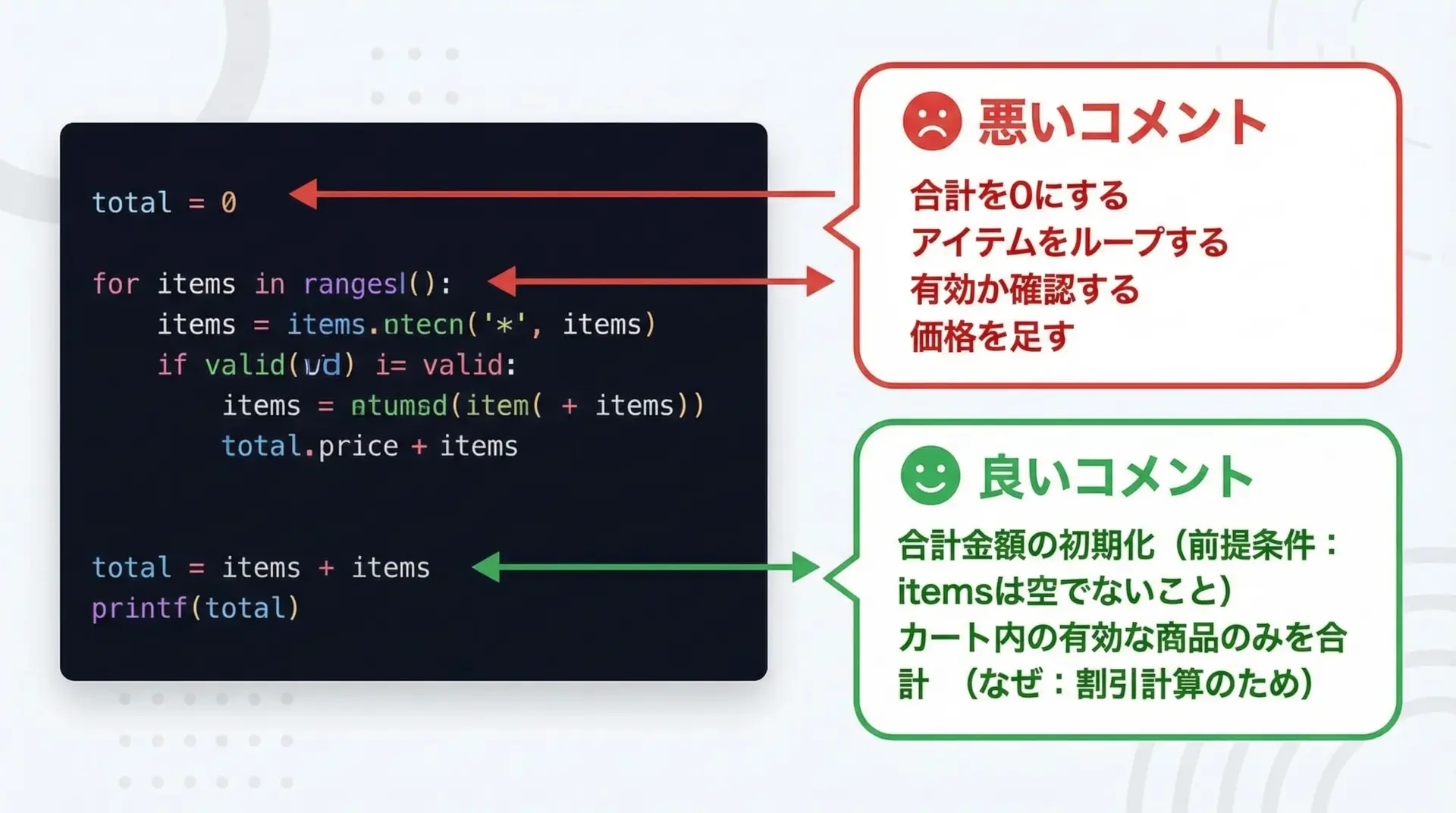
PEP8は、コメントは「なにをしているか」より「なぜそうしているか」を書くことを推奨しています。
行コメント(Line comment)
行コメントは#の後に1つスペースを入れて書きます。
count = 0 # 処理したアイテム数をカウントする
# 悪い例: # の後にスペースがない
count = 0 #良くないコメントブロックコメント(Block comment)
複数行の説明が必要な場合は、上の行にコメントをまとめて書くようにします。
# ユーザー情報をデータベースから読み込み、
# キャッシュに保存してから返却する。
def load_user(user_id):
...docstringの基本
関数やクラス、モジュールには、docstring(ドキュメンテーション文字列)を付けることが推奨されています。
docstringは"""で囲った文字列で、オブジェクトの.__doc__として参照されます。
def add(x, y):
"""2つの数値を受け取り、その合計を返します。"""
return x + y
class User:
"""アプリケーション内のユーザーを表すクラス。"""
def __init__(self, name):
"""ユーザー名を受け取り、User を初期化します。"""
self.name = name1行docstringのときは、開始と終了の"""を同じ行に書き、最後はピリオドで終えるのが推奨されます。
複数行docstringでは、2行目から説明を続け、最後の"""は新しい行に置きます。
文字列リテラルとクォートの使い分け

PEP8では、シングルクォート'とダブルクォート"のどちらを使うかはプロジェクト内で統一すればよいとされています。
Python自体はどちらも同等に扱います。
ただし、文字列中に含まれるクォートの種類に応じて使い分けると、エスケープが減って読みやすくなります。
# 良い例
message = "It's a pen."
title = 'He said "Hello".'
# 悪い例: 不要なエスケープが増える
message = 'It\'s a pen.'
title = "He said \"Hello\"."また、複数行の文字列やdocstringではトリプルクォート"""を使用するのが一般的です。
PEP8チェックツールの使い方と実践

PEP8を完全に覚えて手作業で守るのは現実的ではありません。
静的解析ツールや自動整形ツールを活用して、機械的にチェック・修正するのが現代的なスタイルです。
PEP8を自動チェックするツール
代表的なPEP8準拠チェックツールとして、以下のものがあります。
- pycodestyle (旧pep8)
- flake8
- ruff (高速でモダンなリンター)
flake8の簡単な例
# flake8 のインストール
pip install flake8
# カレントディレクトリ以下の .py ファイルをチェック
flake8 .エラーがある場合、次のように出力されます。
example.py:3:5: E303 too many blank lines (3)
example.py:10:1: E302 expected 2 blank lines, found 1上記のように、ファイル名:行番号:列番号:エラーコード+説明の形式で、どこがPEP8違反かを教えてくれます。
自動整形ツール(black, autopep8)でPEP8対応を効率化

PEP8違反を1つ1つ手で直すのは大変です。
そのため、自動整形ツールを利用して、スタイルを一括で整える方法が広く使われています。
代表的なツールとして、blackとautopep8があります。
blackの基本的な使い方
# black のインストール
pip install black
# カレントディレクトリ配下を一括整形
black .blackは非常に強い意見を持ったフォーマッタ(opinionated formatter)で、細かな調整の余地をほとんど残さず、「blackスタイル」に自動的に揃えます。
PEP8を基本としつつ、より厳格なスタイルになるため、チームでスタイル議論を減らしたい場合に特に有効です。
autopep8の基本的な使い方
# autopep8 のインストール
pip install autopep8
# ファイルを上書きで整形
autopep8 --in-place --aggressive example.pyautopep8はpycodestyle(pycodestyle/pep8)が指摘するPEP8違反を自動で修正するツールです。
blackよりも柔軟で、既存プロジェクトに段階的に導入したい場合に使いやすいです。
既存コードをPEP8スタイルにリファクタリングするコツ
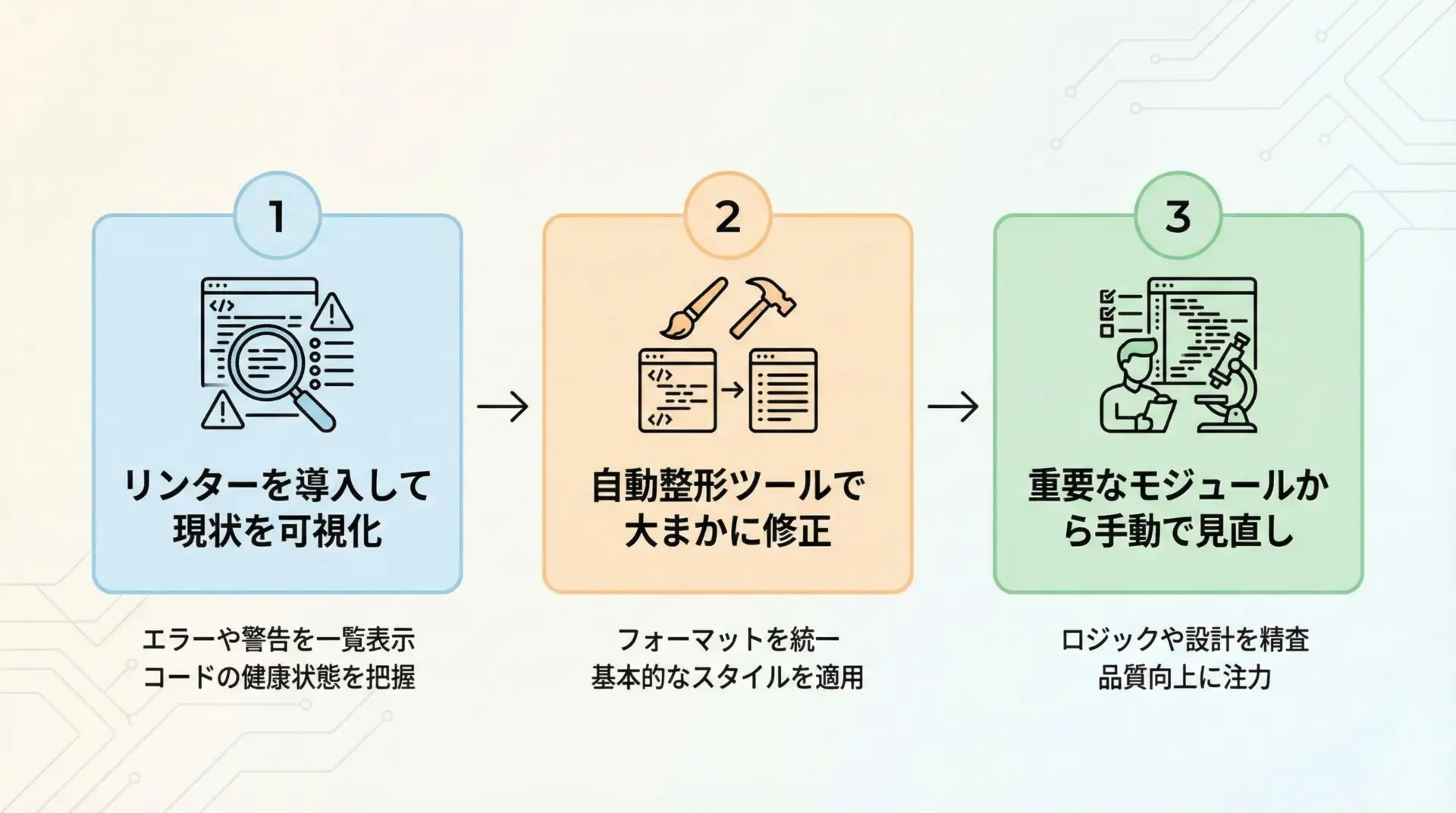
既存コードベースを一気にPEP8準拠にしようとすると、差分が膨大になりレビューが困難になることがあります。
そのため、次のような段階的アプローチがおすすめです。
- まずはリンターを導入し、現状の問題点を把握する
flake8やruffを導入し、どの程度のPEP8違反があるかを可視化します。 - 自動整形ツールで「明らかに安全」な部分から修正する
例えば、空白やインデント、行長、インポート順などは自動修正しやすい部分です。 - ビジネスロジックの重要なファイルは、個別にレビューしながら整形
自動整形の影響がロジックに及ばないかを確認しつつ、命名やコメントも改善していきます。
また、CI(継続的インテグレーション)にリンターとフォーマッタを組み込むことで、新しいコードが常にPEP8準拠になるように仕組み化できます。
まとめ
PEP8は、Pythonコミュニティが共有する「読みやすく一貫したコード」のためのスタイルガイドです。
命名規則やインデント、空白やコメントなどを統一することで、バグの発見が容易になり、長期的な保守性も高まります。
すべてを暗記する必要はなく、flake8やruffによる自動チェック、blackやautopep8による自動整形を活用しながら、少しずつPEP8スタイルに慣れていくことが現実的なアプローチです。
プロジェクトやチームでルールを共有し、ツールと組み合わせて運用することで、Pythonコードの品質と開発効率を大きく向上させることができます。
