C++を学び始めると、データをまとめるためのstruct(構造体)と、オブジェクト指向の核となるclass(クラス)という2つのキーワードに出会います。
これらは非常によく似ており、どちらを使えば良いのか迷う方も多いのではないでしょうか。
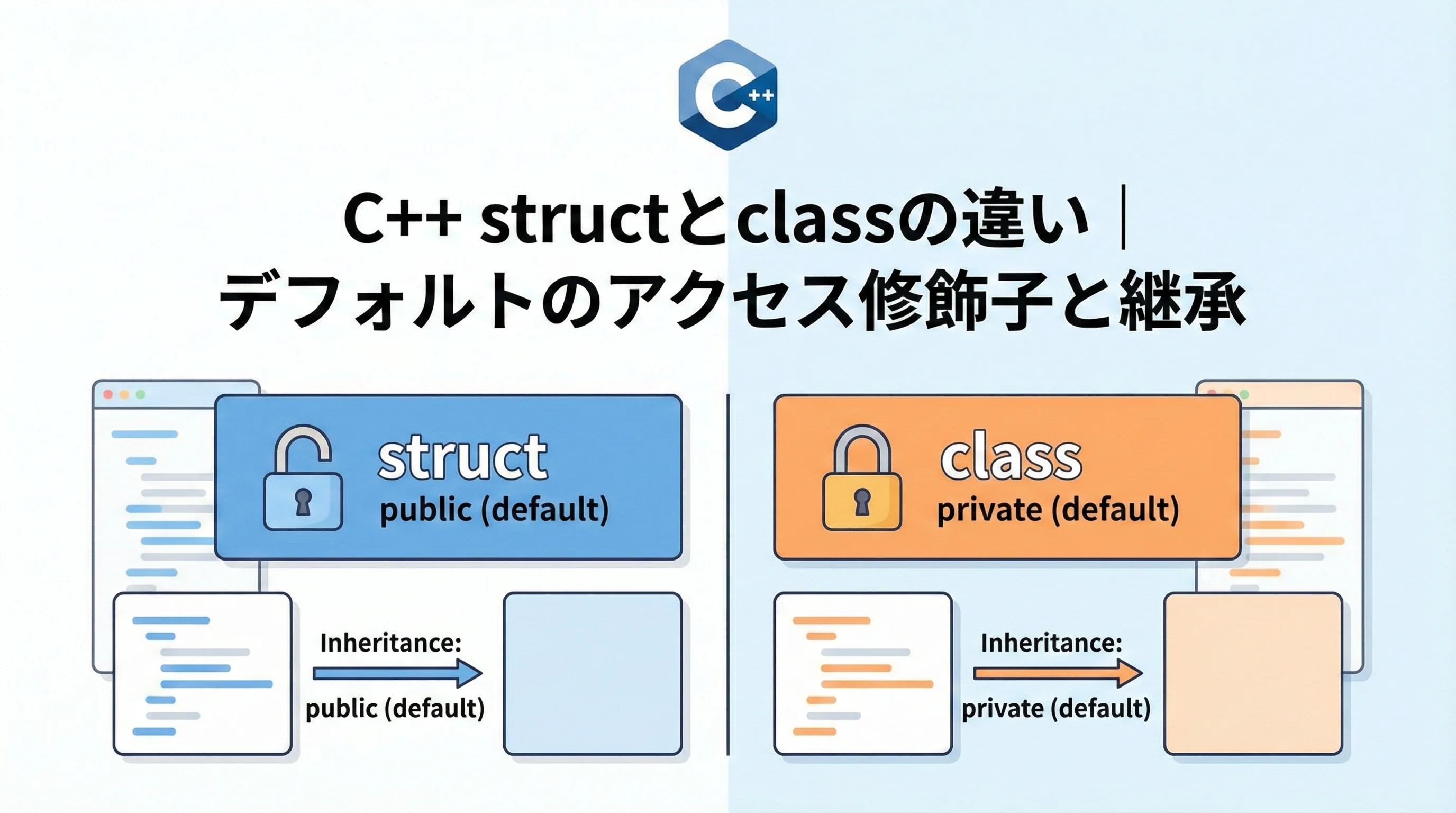
実は、C++におけるこれらの違いは非常にわずかですが、「デフォルトの状態」に決定的な差があります。
本記事では、アクセス修飾子や継承における挙動の違いを詳しく解説し、現場でどのように使い分けるべきかを解き明かします。
structとclassの根本的な違い
C++において、structとclassの機能的な違いは、デフォルトのアクセス制御に集約されます。
C言語の構造体はデータのみを保持するものでしたが、C++の構造体はクラスと同様にメンバ関数(メソッド)やコンストラクタを持つことが可能です。
デフォルトのアクセス修飾子
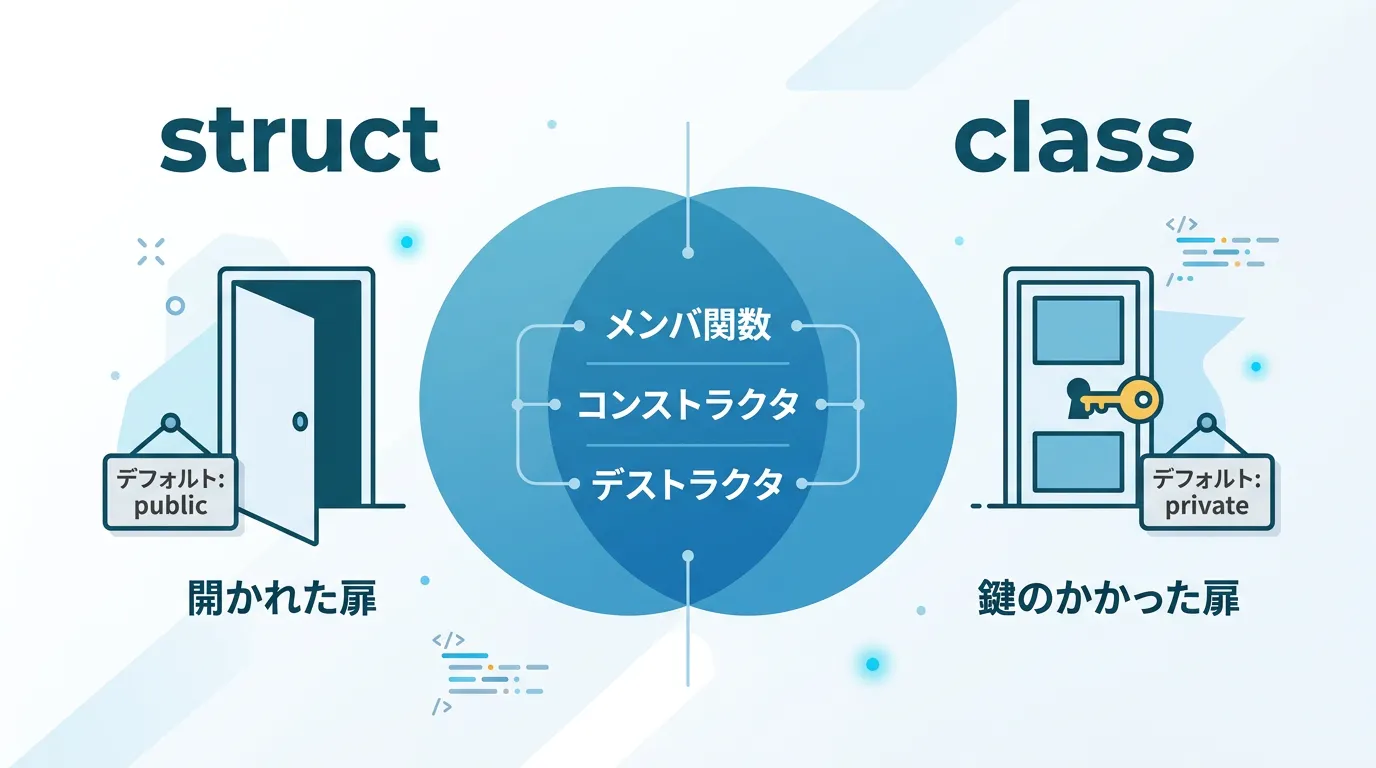
最も大きな違いは、メンバに対してアクセス修飾子(public, private, protected)を指定しなかった場合の挙動です。
構造体のデフォルトはpublic
structで定義されたメンバは、明示的に指定しない限りすべてpublicとして扱われます。
これは、外部から自由に変数を読み書きできることを意味します。
クラスのデフォルトはprivate
一方で、classで定義されたメンバは、デフォルトでprivateとして扱われます。
これにより、外部から直接メンバ変数にアクセスすることはできず、カプセル化が自然に促される仕組みになっています。
次のコードで、その挙動を確認してみましょう。
#include <iostream>
#include <string>
// structの定義
struct PersonStruct {
std::string name; // デフォルトでpublic
};
// classの定義
class PersonClass {
std::string name; // デフォルトでprivate
};
int main() {
PersonStruct s;
s.name = "田中太郎"; // アクセス可能
std::cout << "Struct name: " << s.name << std::endl;
PersonClass c;
// c.name = "佐藤花子"; // コンパイルエラー!外部からアクセスできません。
return 0;
}Struct name: 田中太郎上記のサンプルコードでは、PersonStructの変数は直接操作できますが、PersonClassの変数は外部から見えないため、代入しようとするとコンパイルエラーが発生します。
これが情報の隠蔽(カプセル化)の第一歩となります。
継承における挙動の違い
もう一つの重要な違いは、クラスを継承する際のデフォルトの継承形式です。
C++では、継承時にもアクセス修飾子を指定できますが、省略した場合の振る舞いが異なります。
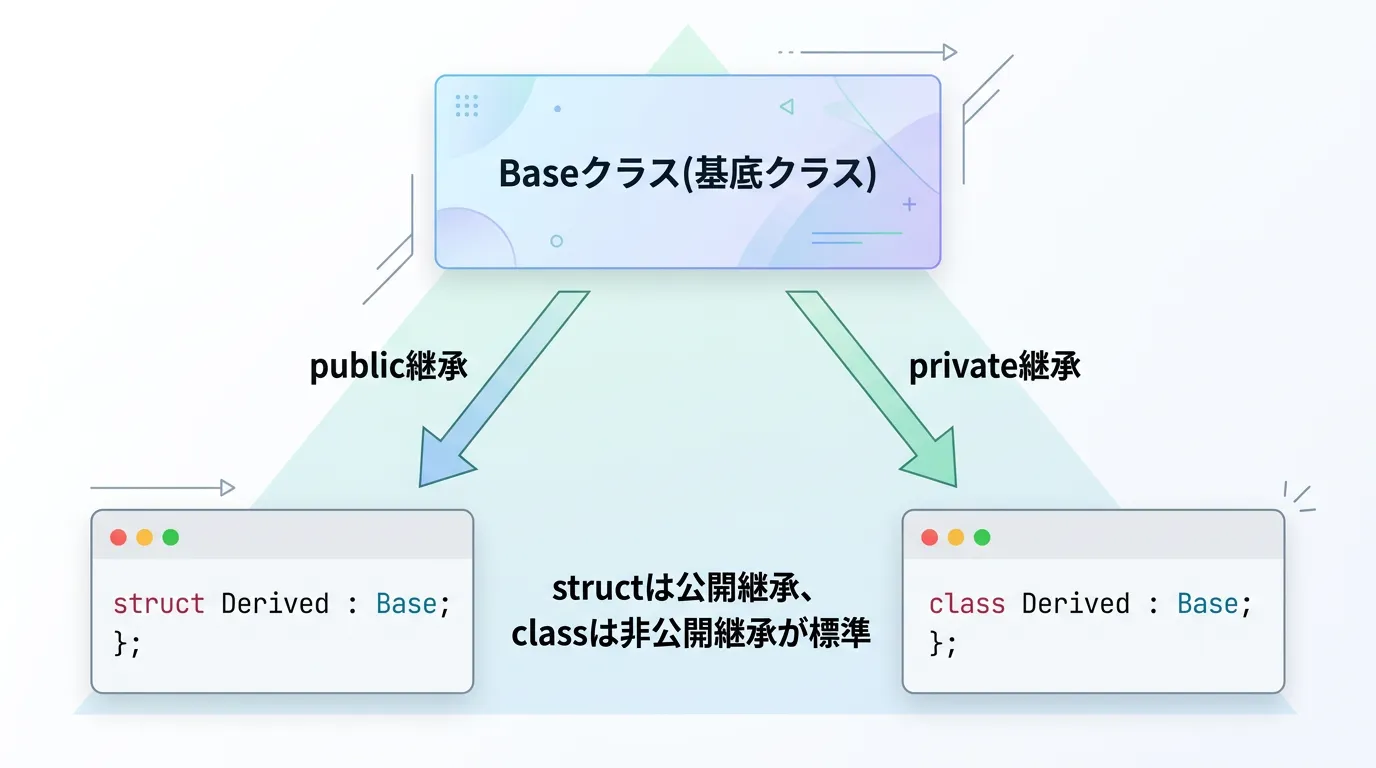
structによる継承
構造体が他のクラスや構造体を継承する場合、デフォルトでpublic継承となります。
これは「基底クラスの公開メンバを、派生クラスでも公開メンバとして引き継ぐ」という動作です。
classによる継承
クラスが他のクラスを継承する場合、デフォルトでprivate継承となります。
基底クラスでpublicだったメンバであっても、派生クラス内ではprivateなものとして扱われ、派生クラスの外部からはアクセスできなくなります。
具体的な挙動をコードで見てみましょう。
#include <iostream>
class Base {
public:
void sayHello() {
std::cout << "Hello from Base!" << std::endl;
}
};
// structでの継承 (デフォルトは public Base)
struct DerivedStruct : Base {};
// classでの継承 (デフォルトは private Base)
class DerivedClass : Base {};
int main() {
DerivedStruct ds;
ds.sayHello(); // 実行可能 (public継承のため)
DerivedClass dc;
// dc.sayHello(); // コンパイルエラー! (private継承のため外部から呼べない)
return 0;
}Hello from Base!このように、classキーワードを使って継承を行う際は、意図的にpublicキーワードを付け忘れると、予期せぬアクセス制限がかかってしまうことがあります。
一般的にはclass Derived : public Baseと明示的に記述するのが通例です。
実践的な使い分けのガイドライン
機能的にはほぼ同一であるstructとclassですが、C++プログラマの間では慣習的な使い分けが存在します。
これに従うことで、コードの意図が読み手に伝わりやすくなります。
structを使うべき場面
structは、主に「データの集まり(Data Transfer Object)」として利用されます。
| 特徴 | 推奨される用途 |
|---|---|
| 透明性 | メンバ変数を直接操作しても問題ない単純なデータ保持。 |
| C言語互換 | C言語のライブラリとやり取りするためのデータ定義。 |
| POD | シンプルなメンバ変数のみを持つPOD(Plain Old Data)型。 |
例えば、座標を示すPoint型や、設定値をまとめるConfig型などは、いちいちゲッターやセッターを用意するよりも、structで公開してしまった方がコードが簡潔になります。
classを使うべき場面
一方で、classは「振る舞いを持つオブジェクト」の定義に適しています。
| 特徴 | 推奨される用途 |
|---|---|
| 不変性の維持 | 内部状態を勝手に書き換えられないよう保護する必要がある場合。 |
| 複雑なロジック | コンストラクタやデストラクタでリソース管理(RAII)を行う場合。 |
| 抽象化 | インターフェースや大規模な継承階層を構築する場合。 |
メモリレイアウトとパフォーマンス
多くの初心者が抱く疑問として「classの方が機能が多いから重いのではないか?」というものがありますが、結論から言うと、両者のメモリレイアウトや実行速度に違いはありません。
C++のコンパイラにとって、structもclassも同じようにメモリ上に配置されます。
仮想関数(virtual)を使用すれば、どちらであっても「仮想関数テーブル」へのポインタが付与され、メモリ消費が増えます。
逆に、メンバ関数を持たない純粋な構造体であれば、どちらのキーワードを使ってもC言語の構造体と同じように効率的なバイナリが生成されます。
C言語との互換性(POD型)
C++には、POD(Plain Old Data)という概念があります。
これは、C言語の構造体と互換性を持つ、単純なメモリ配置の型を指します。
structを使って定義し、プライベートメンバや仮想関数を持たないようにすれば、C言語で書かれたプログラムからそのデータを直接読み取ることが可能です。
#include <iostream>
#include <type_traits>
struct SimpleData {
int id;
double value;
};
class ComplexData {
public:
virtual void func() {} // 仮想関数を持つ
private:
int id;
};
int main() {
std::cout << "SimpleData is POD: " << std::is_standard_layout<SimpleData>::value << std::endl;
std::cout << "ComplexData is POD: " << std::is_standard_layout<ComplexData>::value << std::endl;
return 0;
}SimpleData is POD: 1
ComplexData is POD: 0※ is_podは古い規格のため、現代ではis_standard_layoutなどが使われます。
このように、外部ライブラリとの連携やネットワーク通信用のパケット定義には、structを用いるのが一般的です。
まとめ
C++におけるstructとclassの違いは、本質的にはデフォルトのアクセス権と継承形式の差だけに過ぎません。
しかし、この小さな違いがコードの設計思想に大きな影響を与えます。
単純なデータの入れ物として利用し、外部からの自由なアクセスを許容する場合はstructを、内部状態を保護し、厳格なオブジェクト指向設計を行う場合はclassを選択するのがベストプラクティスです。
どちらを使うべきか迷ったときは、「その型は、単なるデータの集まりか、それとも意志を持つオブジェクトか」を自問してみてください。
適切なキーワードを選択することで、メンテナンス性が高く、他の開発者にとっても意図が明確な美しいコードを書くことができるようになるでしょう。
