
C++において、特定のフォルダ内にあるファイルやサブディレクトリを順番に処理するディレクトリ走査は、ファイル管理システムやデータ解析ツールを開発する上で欠かせない機能です。
かつてのC++では、OS固有のAPI(WindowsのFindFirstFileやPOSIXのopendirなど)を直接叩く必要があり、プラットフォーム間の移植性に課題がありました。
しかし、C++17から導入されたstd::filesystemライブラリにより、標準機能だけで簡潔かつ強力なファイル操作が可能になりました。
その中でも中心的な役割を担うのがdirectory_iteratorです。
本記事では、このイテレータを用いた基本的な走査方法から、再帰的な探索、効率的なエラーハンドリングまで、現場で役立つ知識を詳しく解説します。
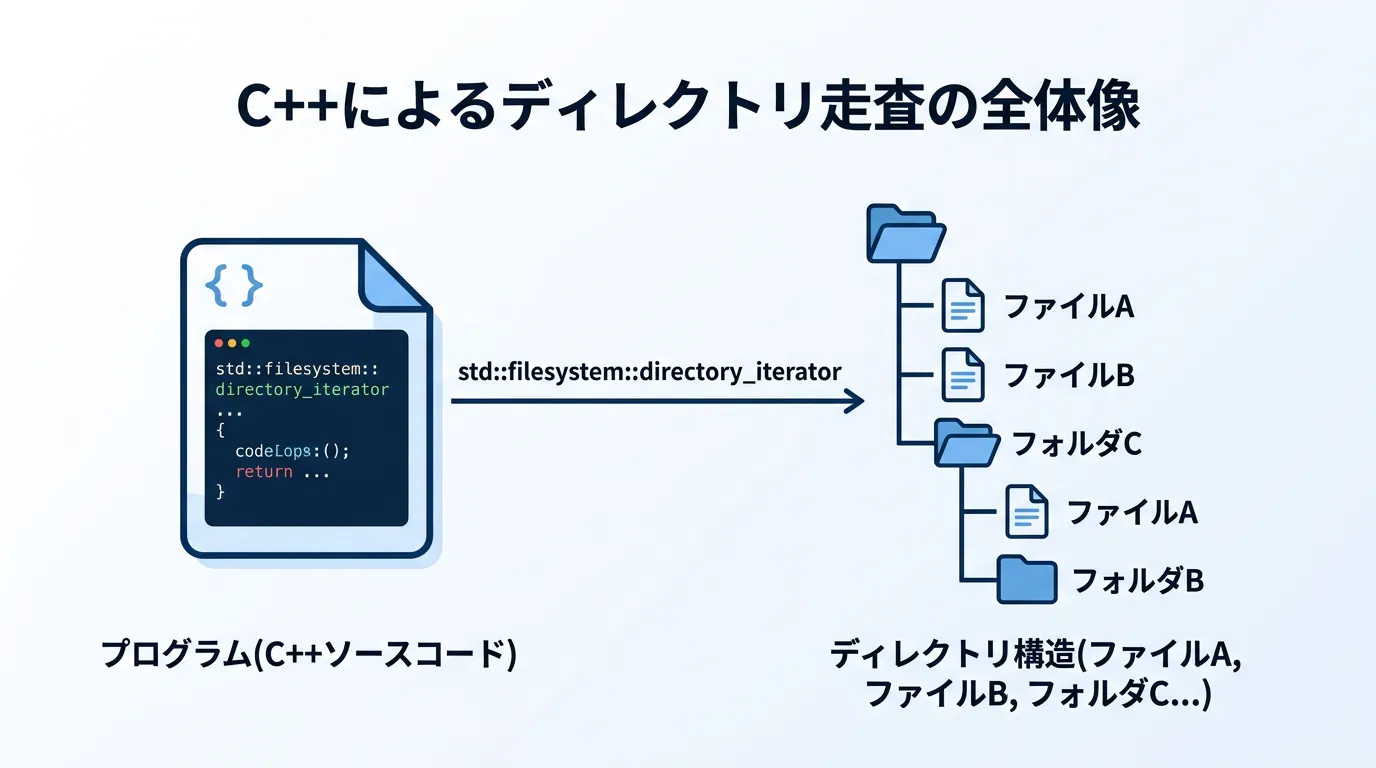
C++におけるディレクトリ操作の進化
従来のC++では、標準ライブラリだけでディレクトリ内の一覧を取得する手段が存在しませんでした。
そのため、開発者はプロジェクトごとにプラットフォーム依存のコードを記述するか、Boost.Filesystemのような外部ライブラリを導入する必要がありました。
C++17以降、これらの機能は<filesystem>ヘッダーとして標準化されました。
これにより、Windows、Linux、macOSなどの異なる環境でも、全く同じコードでファイルシステムを操作できるようになったのです。
std::filesystemの導入準備
この機能を利用するためには、まず<filesystem>をインクルードする必要があります。
また、名前空間がstd::filesystemと長いため、多くの開発現場ではnamespace fs = std::filesystem;というエイリアスが用いられます。
#include <iostream>
#include <filesystem> // ファイルシステムライブラリのインクルード
// 名前空間のエイリアス作成
namespace fs = std::filesystem;
int main() {
// ここに処理を記述
return 0;
}std::filesystem::directory_iteratorの基本
directory_iteratorは、指定したパスのディレクトリ内にある要素(ファイルやディレクトリ)を指す入力イテレータです。
このイテレータを使用することで、範囲ベースのforループを利用した直感的な記述が可能になります。
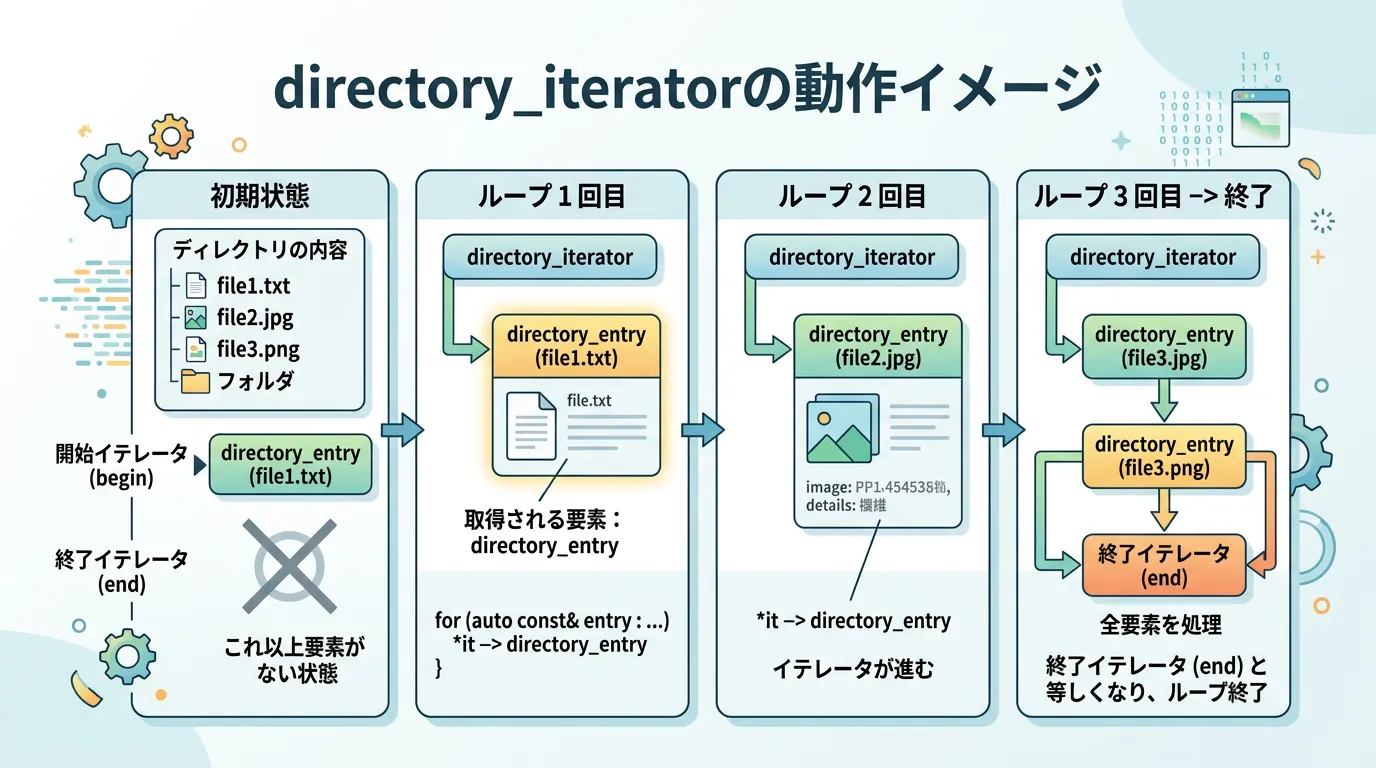
基本的な走査コード
まずは、特定のディレクトリ内にある全てのファイル名を表示するシンプルなプログラムを見てみましょう。
#include <iostream>
#include <filesystem>
namespace fs = std::filesystem;
int main() {
// 走査対象のパスを指定(カレントディレクトリ ".")
fs::path target_path = ".";
try {
// directory_iteratorを使用してディレクトリ内を走査
for (const fs::directory_entry& entry : fs::directory_iterator(target_path)) {
// entry.path() でフルパスを取得し、filename() でファイル名のみを抽出
std::cout << entry.path().filename() << std::endl;
}
} catch (const fs::filesystem_error& e) {
// ディレクトリが存在しない場合などのエラー処理
std::cerr << "エラーが発生しました: " << e.what() << std::endl;
}
return 0;
}main.cpp
data.txt
images
output.logこのコードでは、target_pathで指定された場所にある要素を一つずつentryという変数に取り出しています。
ここで重要なのは、取得されるものが単なる文字列(パス)ではなく、directory_entry型のオブジェクトであるという点です。
directory_entryの役割
directory_entryは、ファイルパスだけでなく、そのファイルの「ステータス(属性)」を保持しています。
このオブジェクトを利用することで、ファイルサイズや更新日時といった情報を、OSへの追加の問い合わせを最小限に抑えつつ高速に取得できます。
ファイル情報の取得とフィルタリング
ディレクトリを走査する際、単にファイル名を知るだけでなく、「ファイルのみを対象にしたい」「特定の拡張子だけを探したい」といったケースが多々あります。
directory_entryのメンバ関数を活用することで、これらの条件分岐を簡単に実装できます。
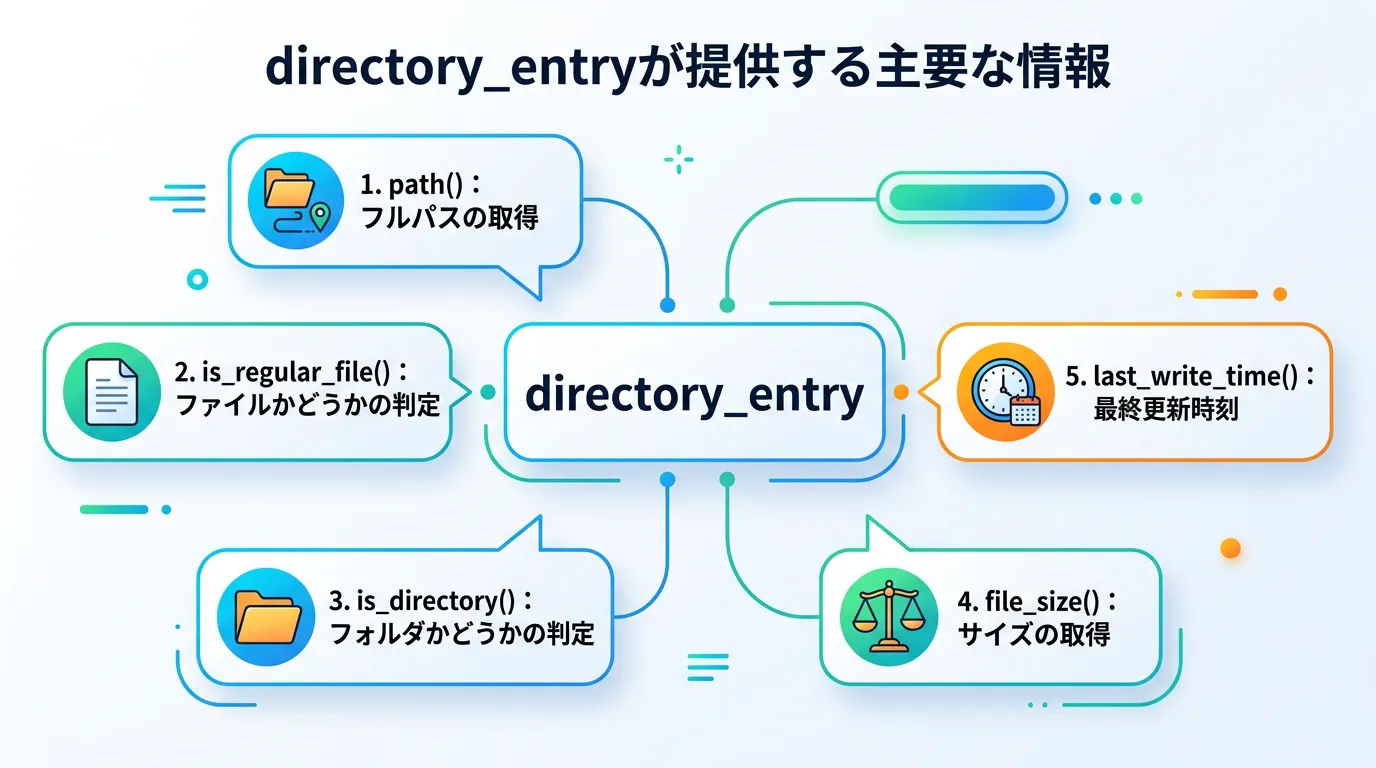
ファイルとディレクトリを区別する
以下のコードは、走査中にファイルとディレクトリを判別し、異なる情報を表示する例です。
#include <iostream>
#include <filesystem>
#include <iomanip> // std::setwのため
namespace fs = std::filesystem;
int main() {
fs::path p = "./test_dir";
if (!fs::exists(p)) {
std::cout << "ディレクトリが存在しません。" << std::endl;
return 1;
}
std::cout << std::left << std::setw(20) << "名前" << " | " << "タイプ" << std::endl;
std::cout << "------------------------------------------" << std::endl;
for (const auto& entry : fs::directory_iterator(p)) {
// ファイル名の取得
std::string name = entry.path().filename().string();
// 属性の判定
std::string type;
if (entry.is_directory()) {
type = "[Directory]";
} else if (entry.is_regular_file()) {
type = "[File] " + std::to_string(entry.file_size()) + " bytes";
} else {
type = "[Other]";
}
std::cout << std::left << std::setw(20) << name << " | " << type << std::endl;
}
return 0;
}名前 | タイプ
------------------------------------------
documents | [Directory]
config.ini | [File] 1024 bytes
readme.md | [File] 542 bytes
script.sh | [File] 210 bytes特定の拡張子でフィルタリングする
pathオブジェクトのextension()メソッドを使用すると、拡張子の比較が容易になります。
for (const auto& entry : fs::directory_iterator(p)) {
// .cpp または .h ファイルのみを抽出
if (entry.path().extension() == ".cpp" || entry.path().extension() == ".h") {
std::cout << "ソースファイル発見: " << entry.path().filename() << std::endl;
}
}再帰的なディレクトリ走査:recursive_directory_iterator
directory_iteratorは指定された直下の階層しか見ませんが、サブディレクトリの中まで深く潜って全てのファイルを探索したい場合には、recursive_directory_iteratorを使用します。
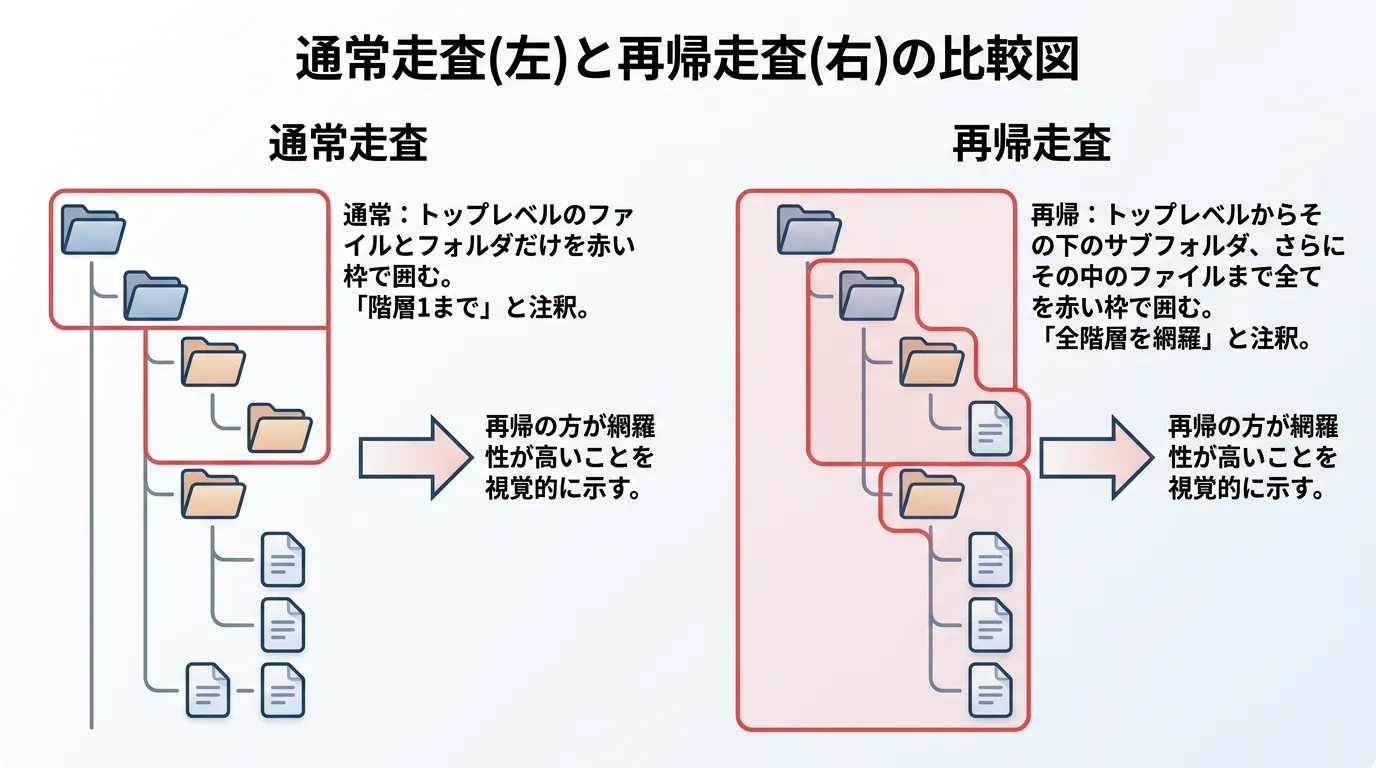
recursive_directory_iteratorの実装例
使い方はdirectory_iteratorとほぼ同じですが、自動的に下の階層へ降りていく点が異なります。
#include <iostream>
#include <filesystem>
namespace fs = std::filesystem;
int main() {
fs::path p = "./project";
std::cout << "プロジェクト内の全ファイルをリストアップします:" << std::endl;
// 再帰的なイテレータを使用
for (const auto& entry : fs::recursive_directory_iterator(p)) {
// 現在の階層(深さ)を取得
auto depth = fs::recursive_directory_iterator(p).depth(); // 注意:これは別の方法で取得が必要
// entry自体から深さを知るには、イテレータを明示的に定義する
}
// 正しい深さの取得方法を含むループ
fs::recursive_directory_iterator iter(p);
fs::recursive_directory_iterator end;
while (iter != end) {
// インデントで階層を表現
for (int i = 0; i < iter.depth(); ++i) std::cout << " ";
std::cout << "-> " << iter->path().filename() << std::endl;
// 次の要素へ
++iter;
}
return 0;
}階層を制御するオプション
recursive_directory_iteratorには、走査の挙動を制御するオプションがあります。
例えば、シンボリックリンクを辿るかどうか、権限エラーが発生した際にスキップするかどうかなどを設定できます。
| オプション | 内容 |
|---|---|
directory_options::none | デフォルト設定(シンボリックリンクを辿らない) |
directory_options::follow_directory_symlink | ディレクトリへのシンボリックリンクを辿る |
directory_options::skip_permission_denied | アクセス権限のないディレクトリをスキップする |
// 権限エラーを無視して再帰走査する例
fs::recursive_directory_iterator(p, fs::directory_options::skip_permission_denied);エラーハンドリングの重要性
ディレクトリ走査中に「権限のないフォルダに遭遇した」「走査中にディレクトリが削除された」といった予期せぬ事態が発生することは珍しくありません。
C++のfilesystemライブラリでは、例外とエラーコードの2種類のハンドリング手法が用意されています。
1. 例外処理(try-catch)による方法
最も一般的な方法です。
エラーが発生するとfs::filesystem_errorがスローされます。
try {
for (const auto& entry : fs::directory_iterator("/root/private")) {
// 処理
}
} catch (const fs::filesystem_error& e) {
std::cerr << "アクセスできません: " << e.what() << std::endl;
}2. std::error_codeによる方法
高頻度でエラーが予想される場合や、例外によるオーバーヘッドを避けたい場合は、引数にstd::error_codeを渡します。
この場合、例外はスローされず、エラー情報が変数に格納されます。
std::error_code ec;
fs::directory_iterator iter("/invalid/path", ec);
if (ec) {
std::cerr << "エラー通知: " << ec.message() << std::endl;
} else {
// 正常な処理
}パフォーマンス向上のためのポイント
大量のファイルを扱う場合、ディレクトリ走査のパフォーマンスがボトルネックになることがあります。
効率を最大化するためのテクニックをいくつか紹介します。
directory_entryの再利用
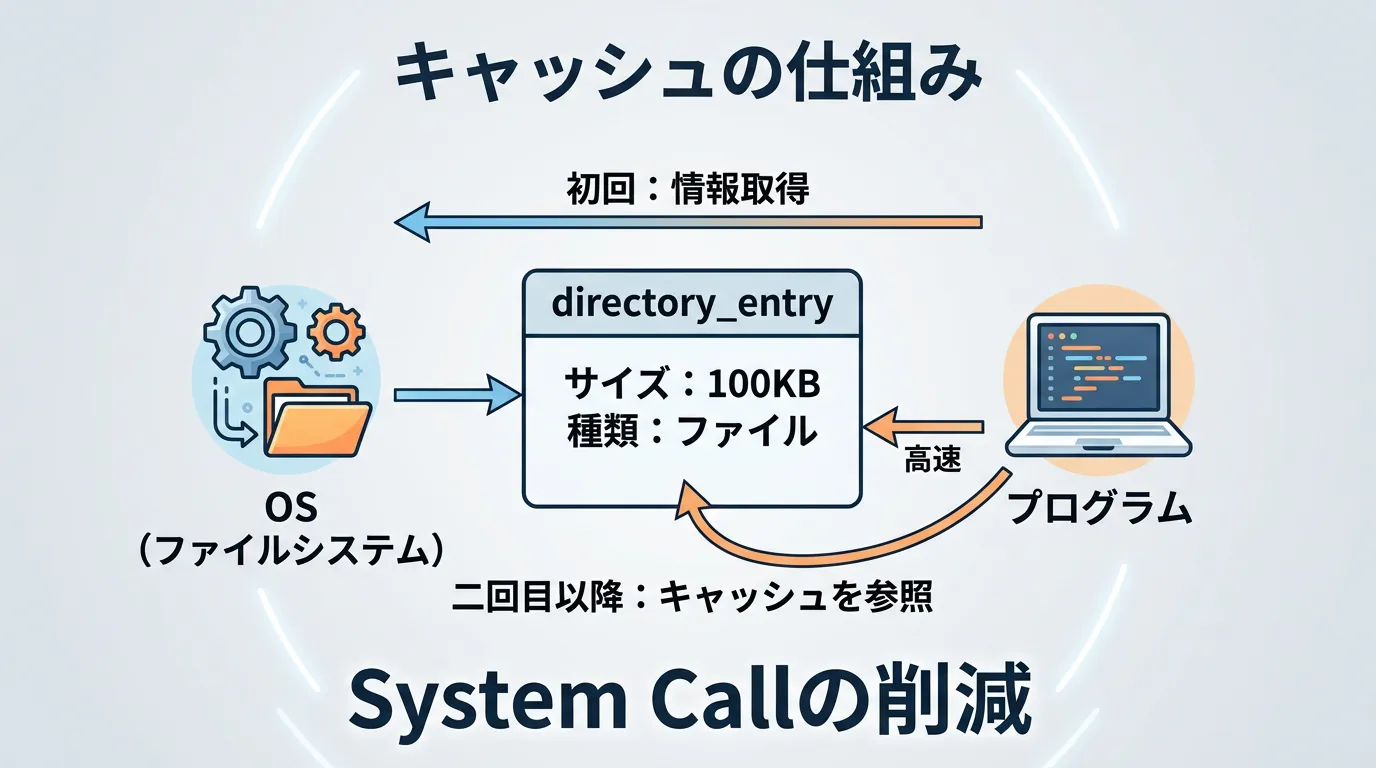
イテレータが返すdirectory_entryオブジェクトは、ファイルの状態(サイズ、属性など)を内部でキャッシュしています。
そのため、以下のコードのうちパターンAの方が高速です。
// パターンA: キャッシュを利用(推奨)
for (const auto& entry : fs::directory_iterator(p)) {
if (entry.is_regular_file()) { // キャッシュされた状態を確認
auto size = entry.file_size(); // キャッシュされたサイズを取得
}
}
// パターンB: 再度問い合わせ(非推奨)
for (const auto& entry : fs::directory_iterator(p)) {
if (fs::is_regular_file(entry.path())) { // 改めてOSに問い合わせる
auto size = fs::file_size(entry.path()); // 改めてOSに問い合わせる
}
}パターンBでは、ループのたびにOSのシステムコールが発生し、ディスクI/Oの負荷が増大します。
必ずentryオブジェクト自身のメンバ関数を使うようにしましょう。
まとめ
std::filesystem::directory_iteratorの登場により、C++でのディレクトリ走査は劇的に簡単かつ安全になりました。
最後に、本記事の重要ポイントを振り返ります。
- directory_iteratorは単一階層、recursive_directory_iteratorは全階層の走査に使い分ける。
- 取得できる
directory_entryにはファイル情報がキャッシュされており、これを利用することで高速な処理が可能になる。 is_regular_file()やextension()などを組み合わせて、必要なファイルだけをフィルタリングする。- アクセス権限エラーなどに備え、
try-catchやstd::error_codeによる適切なエラーハンドリングを行う。
これらの機能を使いこなすことで、堅牢でクロスプラットフォームなファイル操作プログラムを効率的に作成できるようになります。
ぜひ、ご自身のプロジェクトでも活用してみてください。
