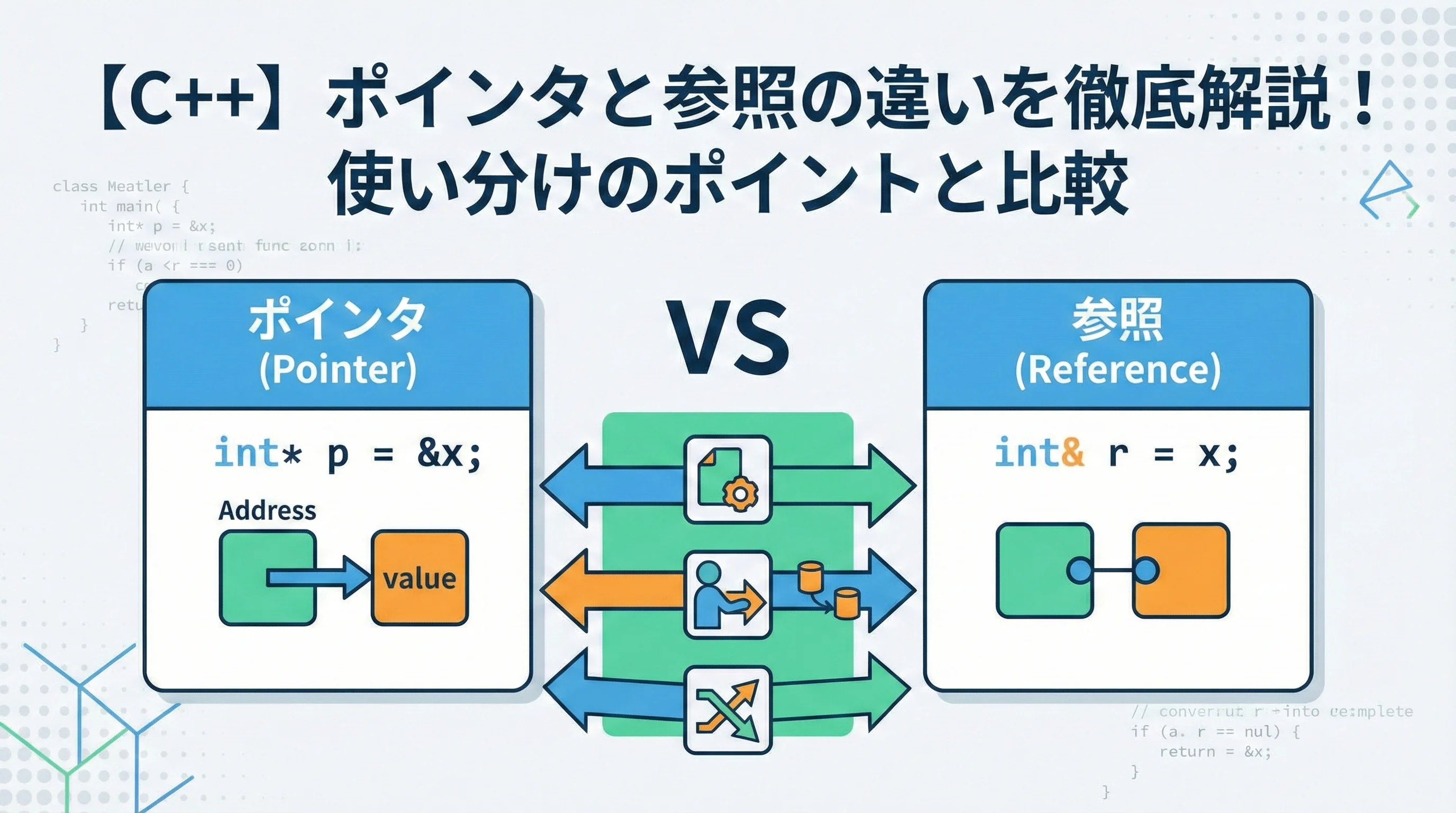
C++を学習する上で、多くのプログラミング初心者が最初に突き当たる壁の一つがポインタと参照の違いです。
どちらも「他の変数を指し示す」という役割を持っており、一見すると同じように思えるかもしれません。
しかし、これら二つは内部構造や安全性、使用できるシーンが明確に異なります。
この記事では、ポインタと参照の基本的な仕組みから、現場で役立つ具体的な使い分けの判断基準まで、エンジニアが知っておくべき知識を網羅的に分かりやすく解説します。
ポインタの基本概念と仕組み
ポインタは、C++の基礎でありながら最も強力なツールの一つです。
まずはポインタがメモリ上でどのような状態になっているのかを理解しましょう。
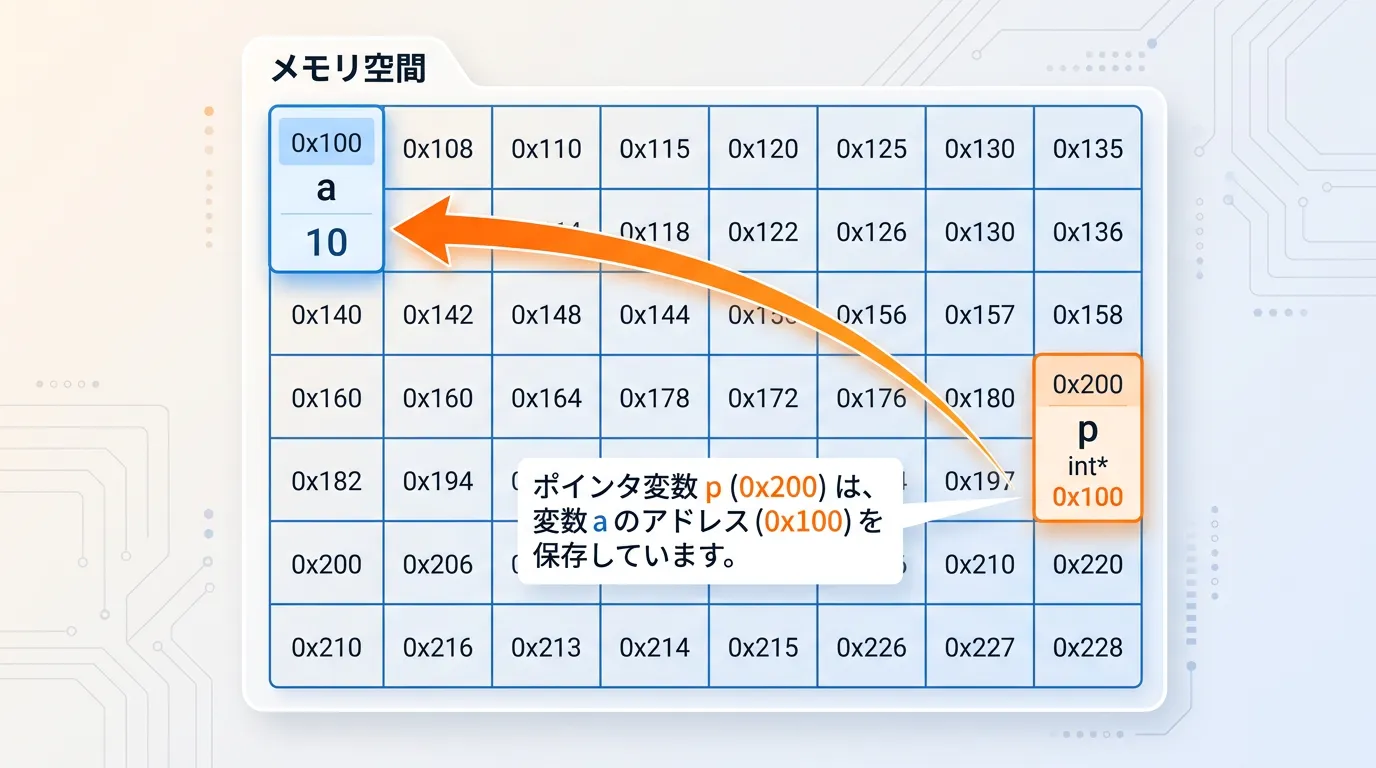
ポインタとはアドレスを格納する変数
ポインタの本質は、メモリ上のアドレスを値として持つ変数です。
通常の変数が数値や文字そのものを保持するのに対し、ポインタは「データがどこにあるか」という場所情報を保持します。
以下のコードは、ポインタの基本的な宣言と利用方法を示しています。
#include <iostream>
int main() {
int value = 100;
// int型の変数valueのアドレスを、ポインタ変数ptrに代入
int* ptr = &value;
std::cout << "valueの値: " << value << std::endl;
std::cout << "valueのアドレス(&value): " << &value << std::endl;
std::cout << "ptrが保持しているアドレス: " << ptr << std::endl;
// 間接参照演算子(*)を使って、ポインタが指す先の値を取得
std::cout << "ptrが指す先の値(*ptr): " << *ptr << std::endl;
return 0;
}valueの値: 100
valueのアドレス(&value): 0x7ffee1b5a9ac
ptrが保持しているアドレス: 0x7ffee1b5a9ac
ptrが指す先の値(*ptr): 100ポインタの特徴と柔軟性
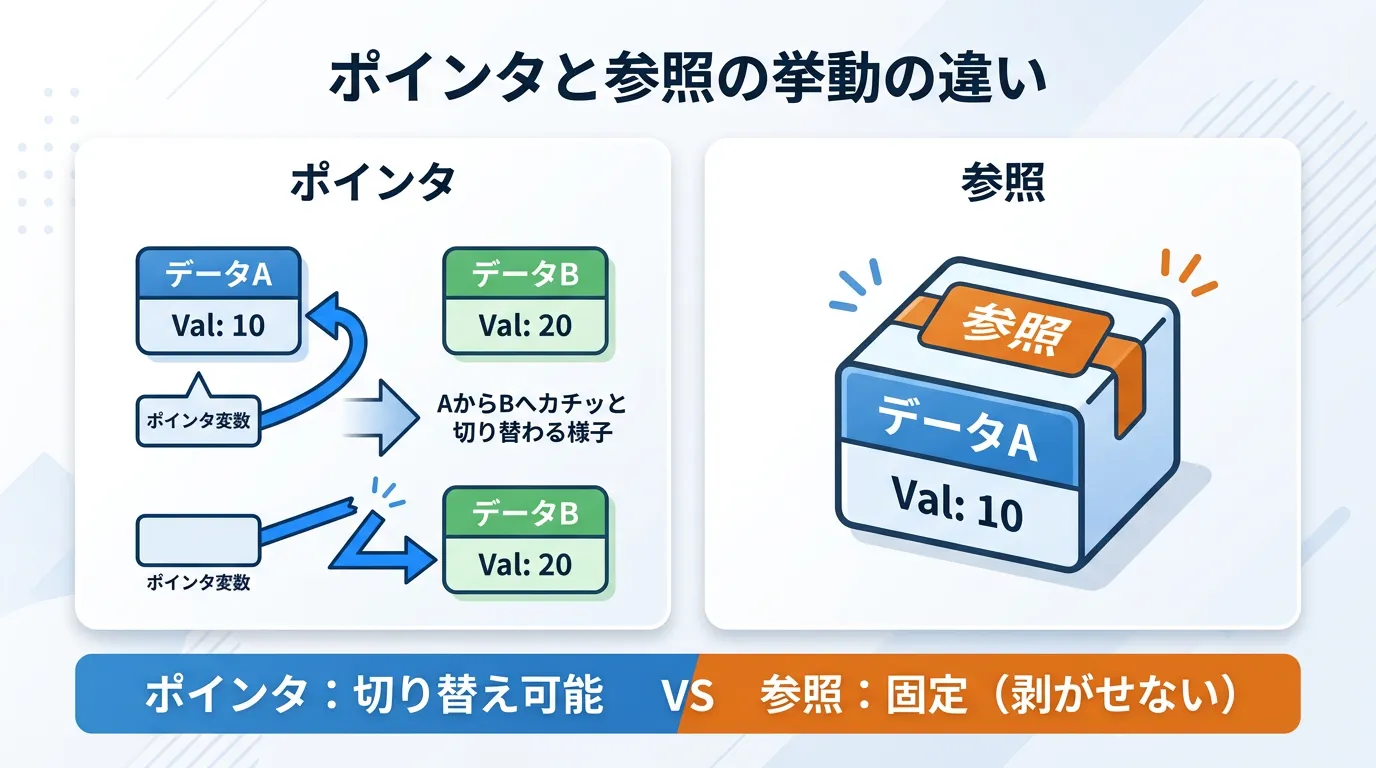
ポインタの最大の特徴は、指し示す対象を後から自由に変更できる点にあります。
また、何も指していない状態を示すnullptrを代入できるため、「対象が存在しない可能性がある」場合に非常に有効です。
ただし、不正なアドレスを指してしまった場合にプログラムがクラッシュする危険性も孕んでいます。
参照の基本概念と仕組み
参照は、ポインタよりも後に導入された概念で、特定の変数の「別名(エイリアス)」として機能します。

参照とは変数の別名
参照は、宣言時に必ず初期化する必要があり、一度初期化すると別の変数を指し直すことはできません。
構文上は通常の変数と同じように扱えるため、ポインタのように*演算子を使って中身を取り出す手間がなく、コードが直感的で読みやすくなります。
#include <iostream>
int main() {
int value = 50;
// valueの参照(別名)としてrefを定義
int& ref = value;
std::cout << "valueの値: " << value << std::endl;
std::cout << "refの値: " << ref << std::endl;
// refを書き換えると、実体であるvalueも書き換わる
ref = 200;
std::cout << "ref更新後のvalueの値: " << value << std::endl;
return 0;
}valueの値: 50
refの値: 50
ref更新後のvalueの値: 200参照の安全性
参照はヌル(nullptr)を許容しません。
必ず有効なオブジェクトを指していることが保証されるため、ポインタに比べてバグが発生しにくいというメリットがあります。
また、ポインタ演算(アドレスの加算など)もできないため、意図しないメモリ領域へのアクセスを防ぐことができます。
ポインタと参照の決定的な違い
これら二つの違いを整理するために、主要な項目を比較表にまとめました。
| 比較項目 | ポインタ (int*) | 参照 (int&) |
|---|---|---|
| 初期化 | 必須ではない(推奨はされる) | 必須 |
| ヌル許容 | 可能 (nullptr) | 不可 |
| 再代入(対象の変更) | 可能 | 不可 |
| アドレスの有無 | 自身のメモリアドレスを持つ | 実体と同じアドレスを共有する |
| 文法上の扱い | * や -> が必要 | 通常の変数と同じ |
1. 再代入の可否
ポインタは変数の寿命の途中で「今はAを指しているが、次はBを指す」といった変更が可能です。
一方で、参照は一度決めたらその一生をその変数の別名として全うします。
2. メモリの存在
ポインタはそれ自体がアドレスを保持するための「メモリ領域」を消費します。
参照はコンパイラの最適化によって、多くの場合メモリを消費せず、単に名前の置き換えとして処理されます。
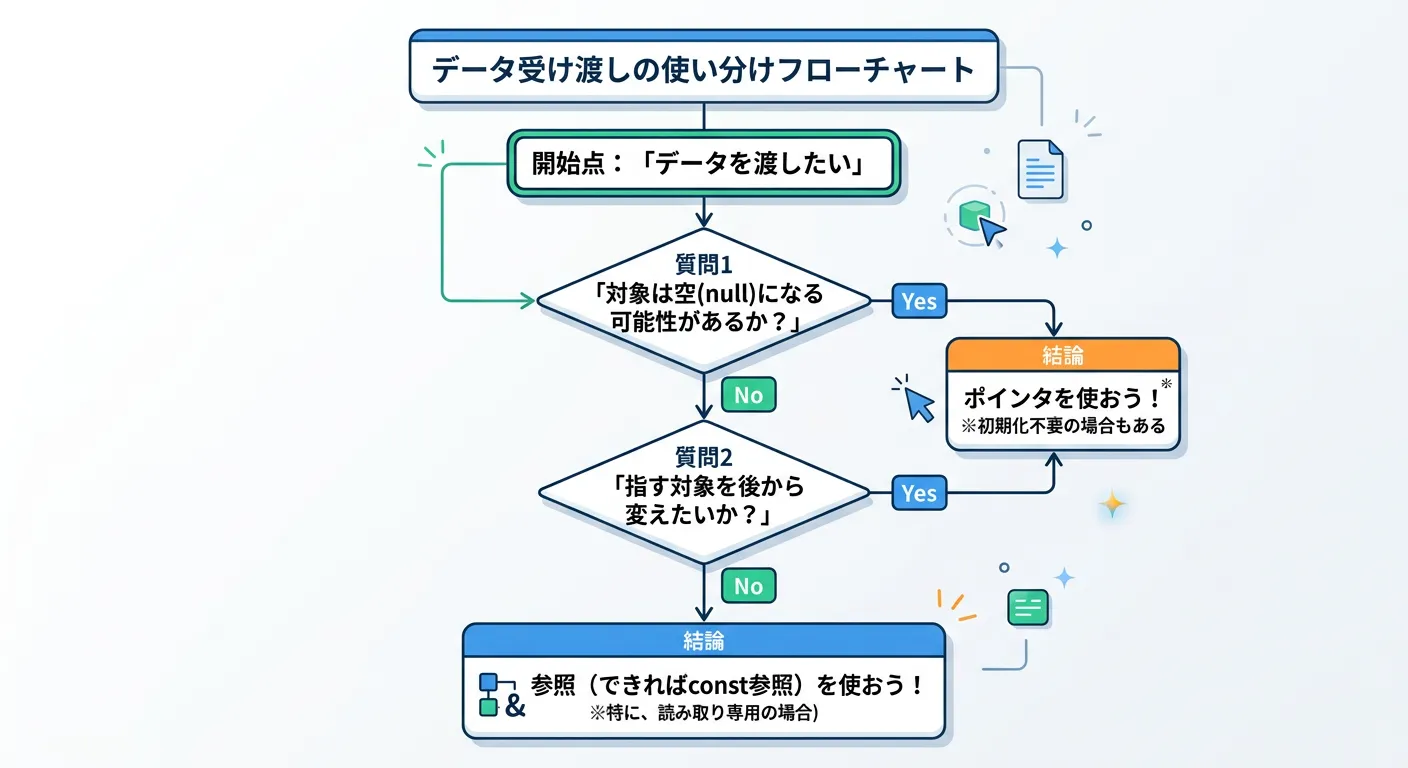
実践的な使い分けのポイント
「どちらを使えばいいのか」という問いに対する答えは、「原則として参照を使い、必要な時だけポインタを使う」という考え方が現代のC++では一般的です。
参照を使うべきケース
関数の引数としてオブジェクトを渡す場合、参照(特に const 参照)を使うのが最も標準的です。
- 大きな構造体やクラスの受け渡し: コピーを避けてパフォーマンスを向上させるため。
- 関数内で引数を書き換えたい場合: 呼び出し元の変数に直接アクセスするため。
- 演算子オーバーロード: 代入演算子など、直感的な記述が求められる場所。
ポインタを使うべきケース
参照では実現できない特定の機能が必要な場合にのみ、ポインタを選択します。
- 対象が存在しない場合がある(Nullの許容): 検索関数などで「見つからなかったらnullptrを返す」といった設計にする場合。
- 指し示す対象を途中で切り替えたい: 反復子(イテレータ)のような実装。
- C言語のライブラリとの連携: 古いAPIはポインタを要求することが多いため。
- 動的メモリ確保:
newで確保した領域を管理する場合(ただし現代ではスマートポインタが推奨されます)。
引数渡しの比較:値渡し・ポインタ渡し・参照渡し
関数の設計において、この三つの違いを理解しておくことは非常に重要です。
以下のサンプルコードで動作の違いを確認してみましょう。
#include <iostream>
// 値渡し: 中身をコピーするため、元の変数は変わらない
void callByValue(int x) {
x = 10;
}
// ポインタ渡し: アドレスを受け取る。nullptrチェックが可能
void callByPointer(int* x) {
if (x != nullptr) {
*x = 20;
}
}
// 参照渡し: 別名を受け取る。構文がスッキリする
void callByReference(int& x) {
x = 30;
}
int main() {
int n = 0;
callByValue(n);
std::cout << "値渡し後: " << n << std::endl;
callByPointer(&n);
std::cout << "ポインタ渡し後: " << n << std::endl;
callByReference(n);
std::cout << "参照渡し後: " << n << std::endl;
return 0;
}値渡し後: 0
ポインタ渡し後: 20
参照渡し後: 30値渡しはデータのコピーが発生するため、大きなデータを扱うと速度が低下します。
対して、ポインタ渡しと参照渡しはアドレス情報をやり取りするだけなので、データ量に関わらず高速です。
まとめ
C++におけるポインタと参照は、どちらもメモリ効率の良いプログラムを書くために欠かせない概念です。
ポインタは「どこを指すかを自由に変更でき、空の状態も許容する柔軟なツール」であり、参照は「一度決めた対象を安全かつ簡潔に扱うための強力な別名」といえます。
基本的には、安全性が高く記述がシンプルな参照を優先的に使用し、「nullを扱いたい」「指し先を変えたい」という明確な理由がある場合にのみポインタを選択するようにしましょう。
この使い分けをマスターすることで、バグが少なく、かつメンテナンス性の高い洗練されたC++コードを記述できるようになります。
複雑に見えるメモリ操作も、この基本原則を忘れなければ、自信を持って設計に組み込めるはずです。
