
C++でプログラミングを行う際、プログラム内で変更しない「定数」を定義する方法はいくつか存在します。
古くから使われている#defineプリプロセッサ指令と、C++の型システムに統合されたconst修飾子はその代表例です。
しかし、これらには動作原理や安全性、スコープ管理において決定的な違いがあります。
現代的なC++開発においては、どちらを選択すべきかという基準が明確になっており、不適切な選択はデバッグの困難さや予期せぬバグを招く原因となります。
本記事では、これら二つの定義手法の違いを徹底解説し、2026年現在の開発現場で推奨される使い分けについて詳しく説明します。
#defineとconstの根本的な違い
C++において定数を定義する際、#defineとconstは全く異なるレイヤーで処理されます。
まずは、それぞれの処理フローの違いを視覚的に理解しましょう。
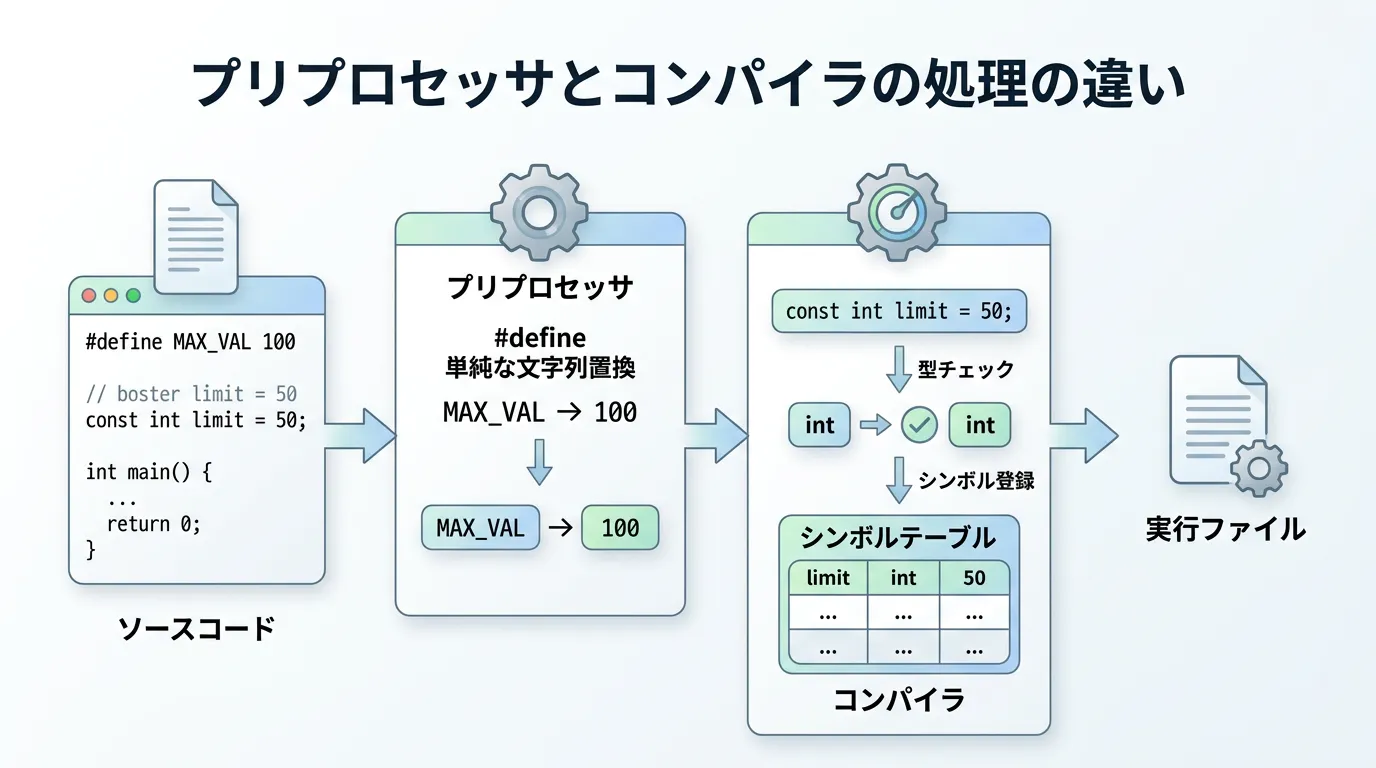
#define:プリプロセッサによる文字列置換
#defineは、コンパイルが始まる前の段階である「プリプロセッサ」によって処理されます。
これは単なるテキストの置き換えであり、C++の文法や型システムとは無関係に動作します。
例えば、#define LIMIT 100と記述した場合、コンパイラがソースコードを読む前に、コード内のすべてのLIMITという文字列が100に書き換えられます。
そのため、コンパイラ自体は「LIMIT」という名前の定数が存在したことすら認識しません。
const:コンパイラによる定数定義
一方でconstは、C++の型システムの一部としてコンパイラが処理します。
これは「読み取り専用の変数」を定義するものであり、メモリ上の領域確保や型情報の保持が行われます。
コンパイラはconst変数の型をチェックし、不正な代入や型不一致があればエラーを出力します。
また、シンボルテーブルに名前が登録されるため、デバッグ時に変数名を確認することが可能です。
機能と特性の比較表
#defineとconstの主な違いを以下の表にまとめました。
| 特徴 | #define (マクロ) | const (定数) |
|---|---|---|
| 処理タイミング | プリプロセッサ (コンパイル前) | コンパイラ (コンパイル時) |
| 型の有無 | なし | あり |
| スコープ管理 | なし (定義以降すべて) | あり (関数内、クラス内など) |
| デバッグ | 困難 (名前が消える) | 容易 (名前が残る) |
| メモリ確保 | 置換箇所ごとに発生する場合がある | 通常、最適化により効率化される |
| 重複定義 | 警告なしに上書きされるリスク | コンパイルエラーで防止 |
なぜconstが推奨されるのか:3つの決定的な理由
現代のC++開発において、特別な理由がない限りconst(あるいはconstexpr)の使用が推奨されます。
その理由は、開発の安全性と効率性に直結するためです。
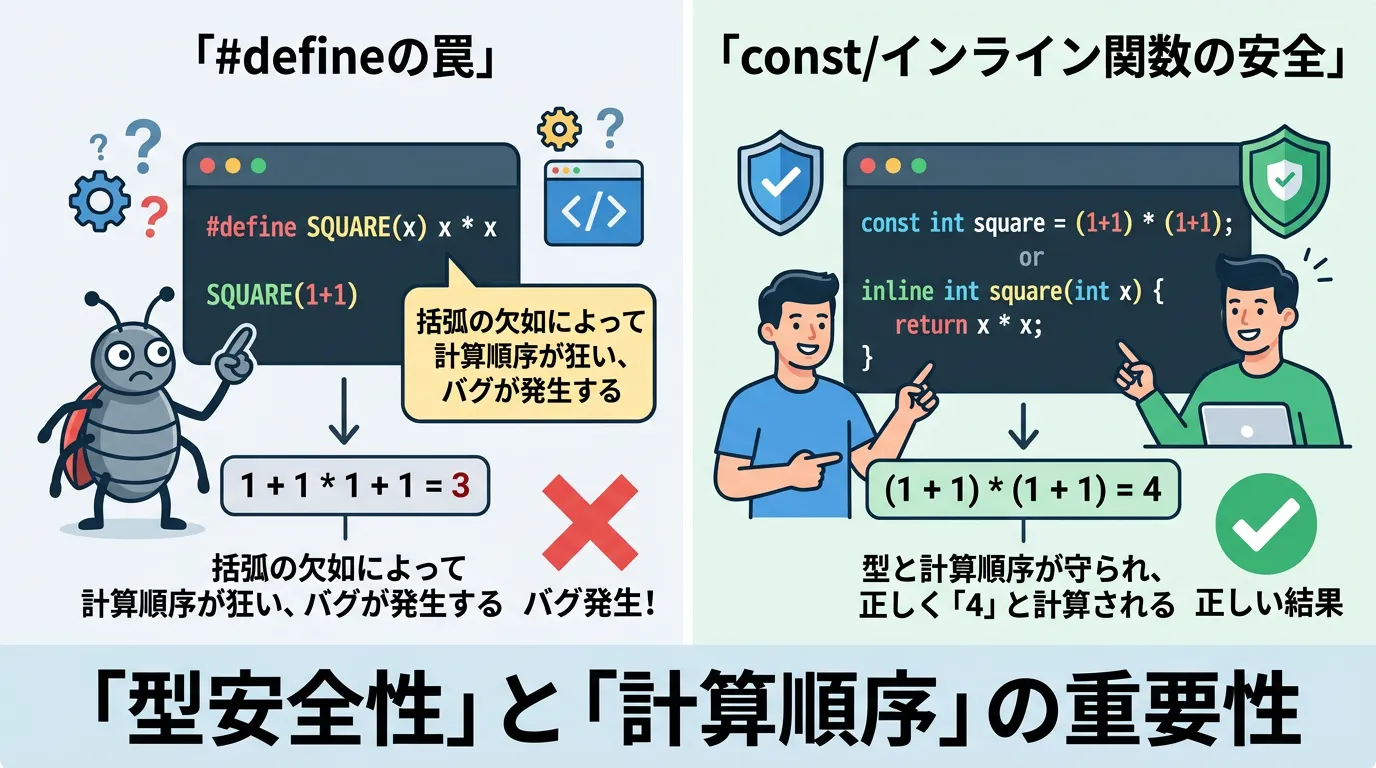
1. 型安全性の確保
#defineには型という概念がありません。
そのため、意図しない型として扱われたり、代入時にエラーを検知できなかったりすることがあります。
constを使用すれば、intやdoubleといった型を明示できるため、型不整合によるバグをコンパイル時に防ぐことができます。
2. スコープの制御
マクロ(#define)は、定義された場所以降のファイル内すべてに影響を与えます。
これを「名前空間の汚染」と呼びます。
例えば、あるライブラリで定義されたマクロ名が、自分のコード内の変数名と衝突して予期せぬ置換が行われるトラブルは非常に一般的です。
constであれば、特定の関数内やクラス内、あるいは特定の名前空間内に限定して定義できるため、名前の衝突を回避し、コードの影響範囲を最小限に抑えることが可能です。
3. デバッグの容易さ
デバッガを使用してコードを追跡する際、#defineで定義した名前はすでに数値に置き換わっているため、ソースコード上の名前を確認することができません。
しかし、constであればデバッガがその名前を保持しているため、「この数値は何を意味する定数なのか」をデバッグ中に即座に判別できます。
具体的なコード例で見る動作の違い
実際のプログラムでどのように挙動が異なるかを確認してみましょう。
#defineを使用した場合の例
以下のコードでは、マクロの単純置換による副作用を示しています。
#include <iostream>
// マクロによる定数定義
#define BUFFER_SIZE 100 + 100
int main() {
// 期待される結果は 200 * 2 = 400 だが...
// 実際には 100 + 100 * 2 = 300 と展開される
int result = BUFFER_SIZE * 2;
std::cout << "Result of #define: " << result << std::endl;
return 0;
}Result of #define: 300#defineは単なる文字列の置き換えであるため、演算の優先順位が考慮されず、バグの原因となります。
これを防ぐには#define BUFFER_SIZE (100 + 100)のように括弧を多用する必要があります。
constを使用した場合の例
同じ処理をconstで行うと、安全に処理されます。
#include <iostream>
int main() {
// constによる定数定義(型安全)
const int BufferSize = 100 + 100;
// 型として計算が完了してから代入されるため、200 * 2 = 400 となる
int result = BufferSize * 2;
std::cout << "Result of const: " << result << std::endl;
return 0;
}Result of const: 400const変数は、初期化時に右辺の計算が完了し、その値が固定されるため、数学的に直感的な挙動を示します。
2026年現在の使い分けガイドライン
現在では、定数の定義にはconst、さらにはconstexprを使用するのが標準です。
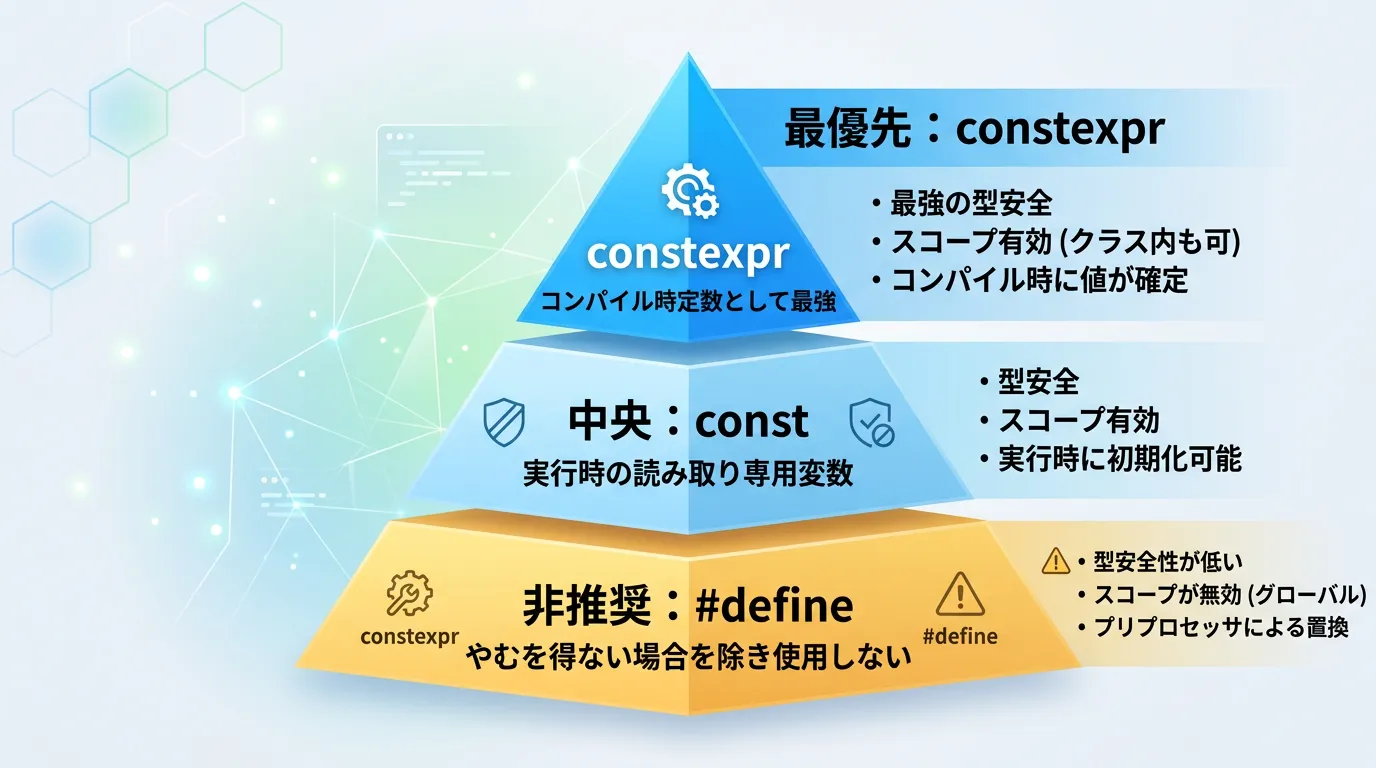
constexprの登場とconstとの違い
C++11以降、さらに強力な定数定義としてconstexprが導入されました。
constが「実行時の読み取り専用」を意味するのに対し、constexprは「コンパイル時に値が確定していること」を保証します。
// 現代的なC++での定数定義
constexpr int MaxUserCount = 50;コンパイル時定数として利用したい(配列のサイズ指定など)場合は、constexprを使用するのが最もハイクオリティなコードと言えます。
それでも#defineを使うべきケース
現在でも#defineが必要とされるのは、主に以下のケースに限られます。
- インクルードガード:ヘッダーファイルの二重読み込みを防止する場合。
- 条件付きコンパイル:OSやデバッグ/リリースモードによってコードを切り替える場合(
#ifdef DEBUGなど)。 - 文字列の連結や特殊なマクロ操作:
__FILE__や__LINE__といった特殊なマクロを利用してログを出力する場合。
これら以外の「単なる数値や文字列の定数」を定義する用途で#defineを使うことは、現代のプラクティスでは推奨されません。
まとめ
C++における#defineとconstの最大の違いは、それが「プリプロセッサによる単純な置き換え」なのか、「コンパイラによる型安全な変数」なのかという点にあります。
マクロは型のチェックが行われず、スコープも無視されるため、大規模な開発や複雑な計算を伴う場合にはリスクが伴います。
一方でconstや、より強力なconstexprは、C++の強力な型システムを最大限に活かし、安全でメンテナンス性の高いコードを実現します。
2026年の開発においては、定数定義には原則として constexpr または const を選択し、マクロは条件付きコンパイルなどのメタ的な制御に限定することが、バグのない堅牢なプログラムへの近道です。
