ChatGPTなどの生成AI(LLM:大規模言語モデル)の普及により、ビジネスにおけるAI活用は急速に加速しました。
しかし、最新の情報に基づいた回答ができない、あるいは事実に基づかないもっともらしい嘘をつく「ハルシネーション(幻覚)」という課題に直面している企業も少なくありません。
これらの課題を解決し、生成AIを実務で真に役立つツールへと進化させる技術がRAG(Retrieval-Augmented Generation:検索拡張生成)です。
本記事では、RAGの基礎知識から仕組み、導入メリット、具体的な活用事例まで、専門的な視点から徹底的に解説します。
RAG(検索拡張生成)とは何か
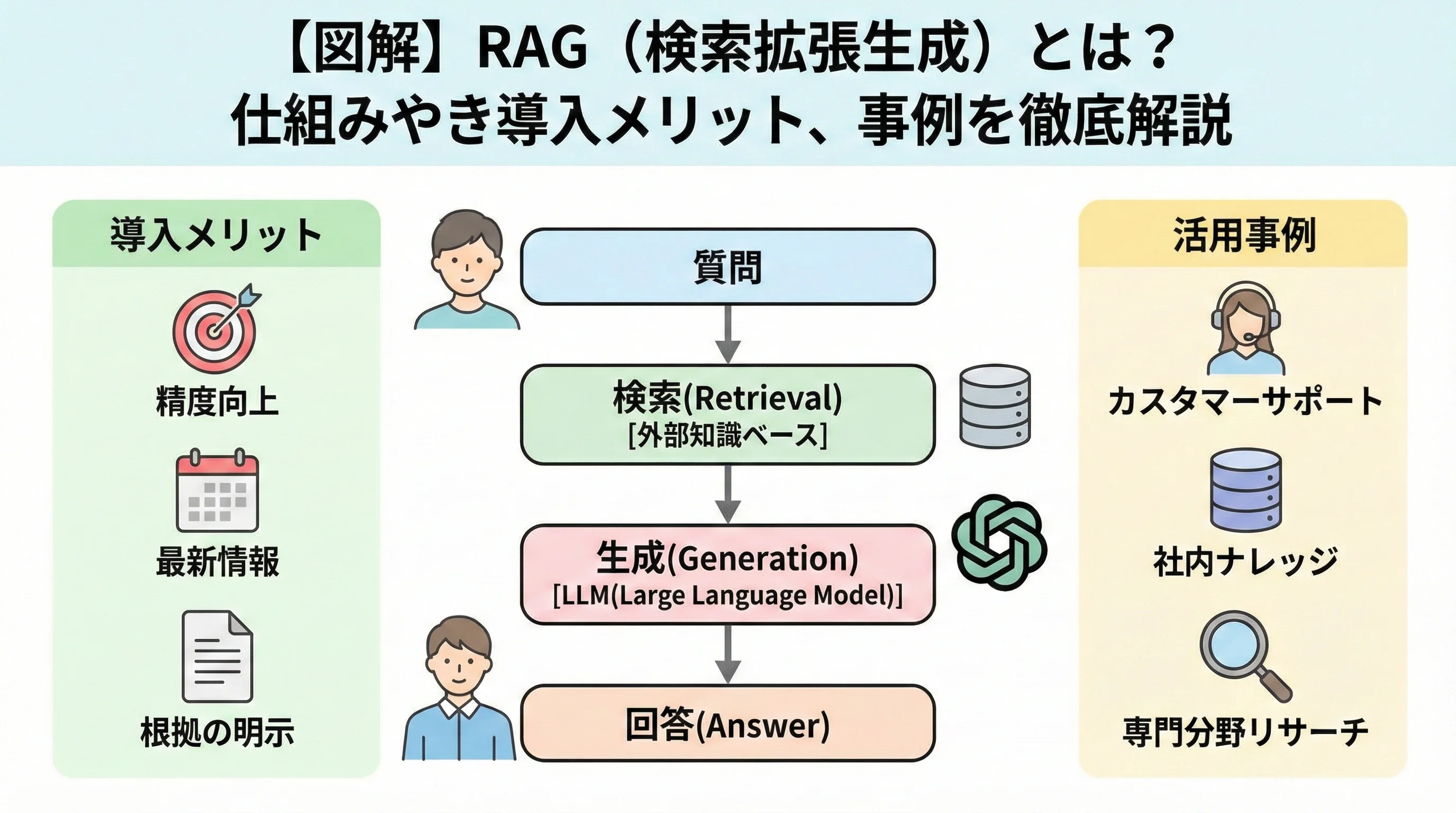
RAG(Retrieval-Augmented Generation)とは、日本語で「検索拡張生成」と訳される技術です。
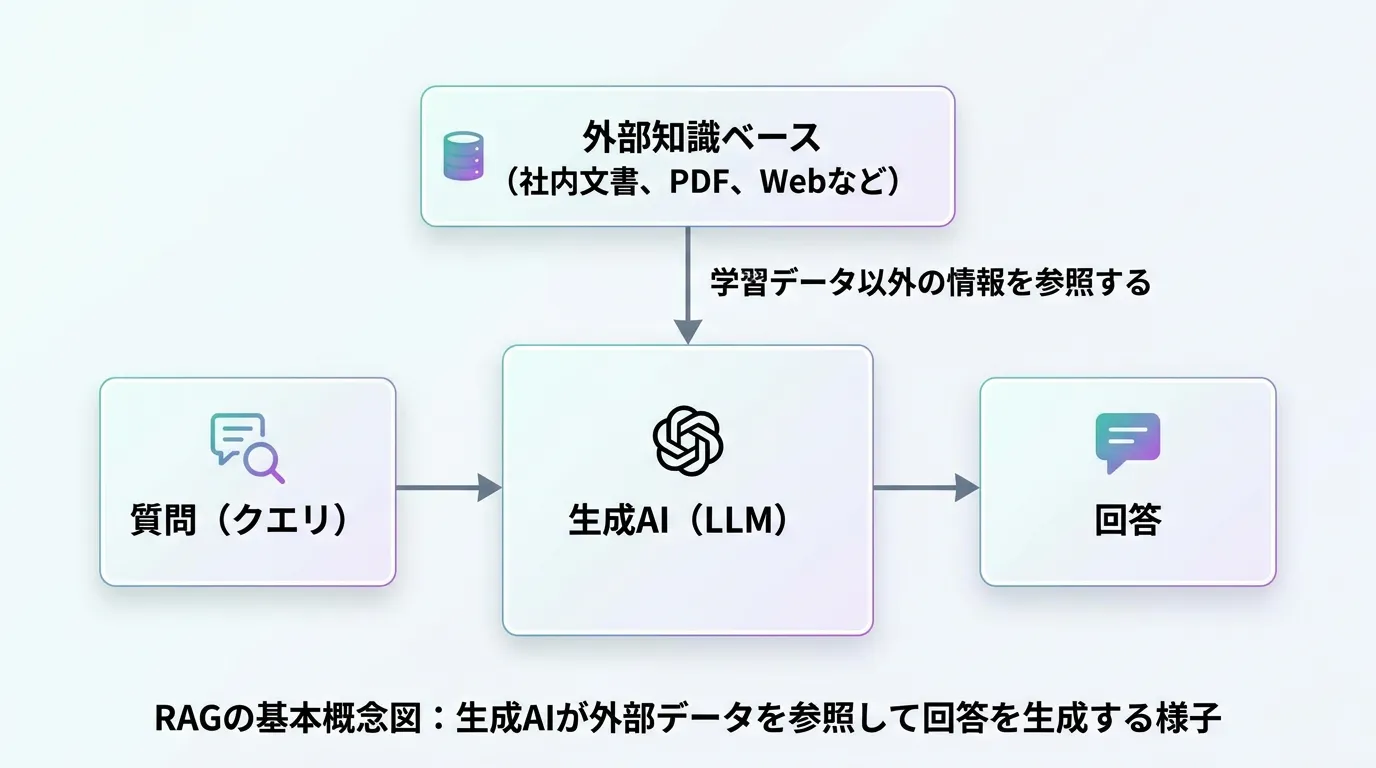
一言で言えば、生成AI(LLM)が回答を生成する前に、信頼できる外部知識ベースから関連情報を検索し、その情報を付加して回答を生成させる手法のことを指します。
ChatGPTなどのLLMは、膨大な学習データに基づいてトレーニングされていますが、学習が完了した時点までの情報しか持っていません(ナレッジカットオフ)。
そのため、昨日のニュースや自社独自の内部文書、マニュアルの内容については答えることができません。
RAGを導入することで、LLMに「最新の辞書」や「社内マニュアル」を読ませながら答えさせるような仕組みを構築でき、回答の精度と信頼性を飛躍的に高めることが可能になります。
なぜ今RAGが注目されているのか
現在、多くの企業がRAGの導入を急いでいる理由は、生成AIの標準的な機能だけではビジネス要件を満たせないケースが増えているからです。
従来のLLMには、以下の3つの大きな課題がありました。
- 情報の鮮度不足:学習データに含まれない最新情報に対応できない。
- ハルシネーション(幻覚):知らないことでも、それらしい嘘をついてしまう。
- 秘匿情報の欠如:社内規定や独自の技術仕様など、一般に公開されていない情報を扱えない。
RAGは、これらの課題を「LLM自体を再学習させる」という膨大なコストと時間がかかる手法ではなく、「外部から情報を与える」という低コストかつ柔軟なアプローチで解決します。
これが、多くの企業にとって現実的かつ強力なソリューションとして支持されている理由です。
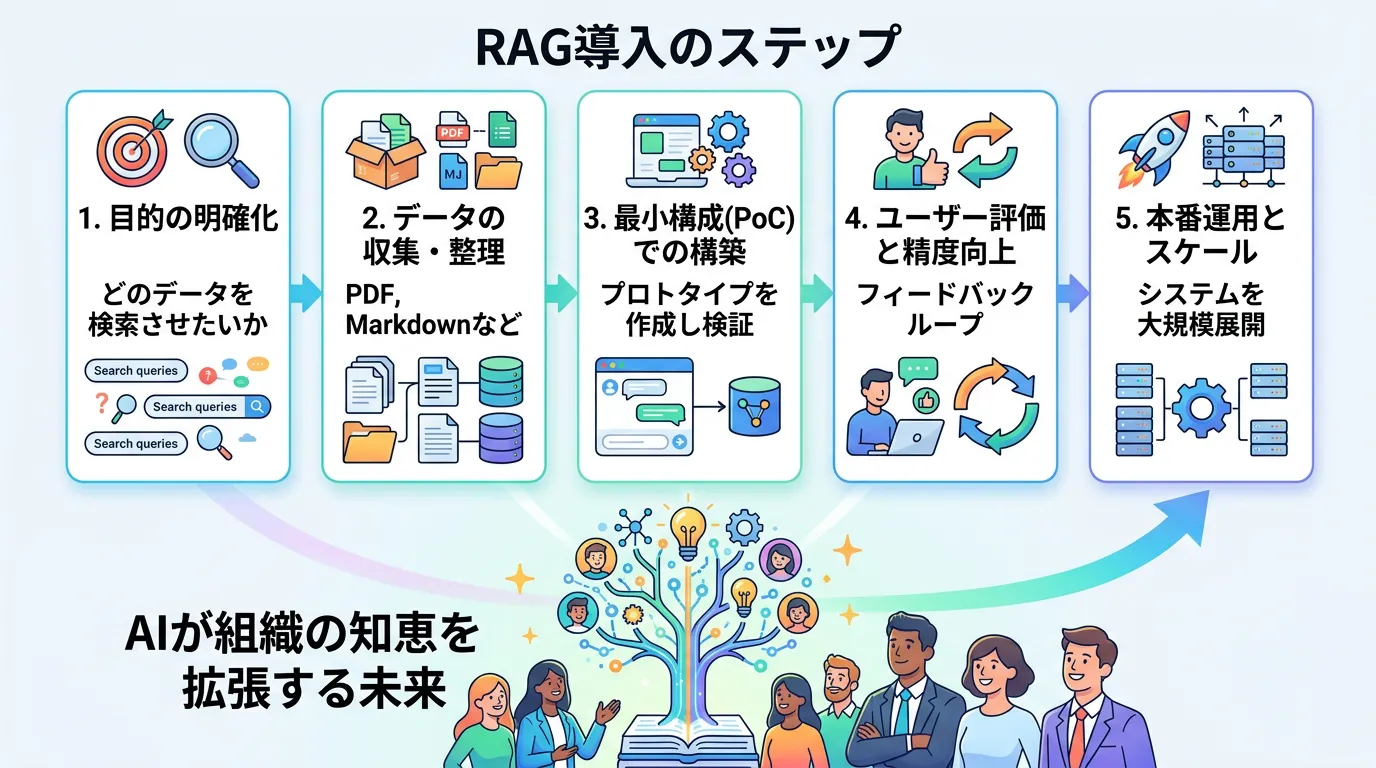
RAGの仕組み:4つのステップ
RAGがどのようにして情報を取得し、回答を生成しているのか、その技術的なフローを詳しく見ていきましょう。
RAGのプロセスは、大きく分けて「インデクシング(事前準備)」と「検索・生成(実行時)」のプロセスに分かれます。
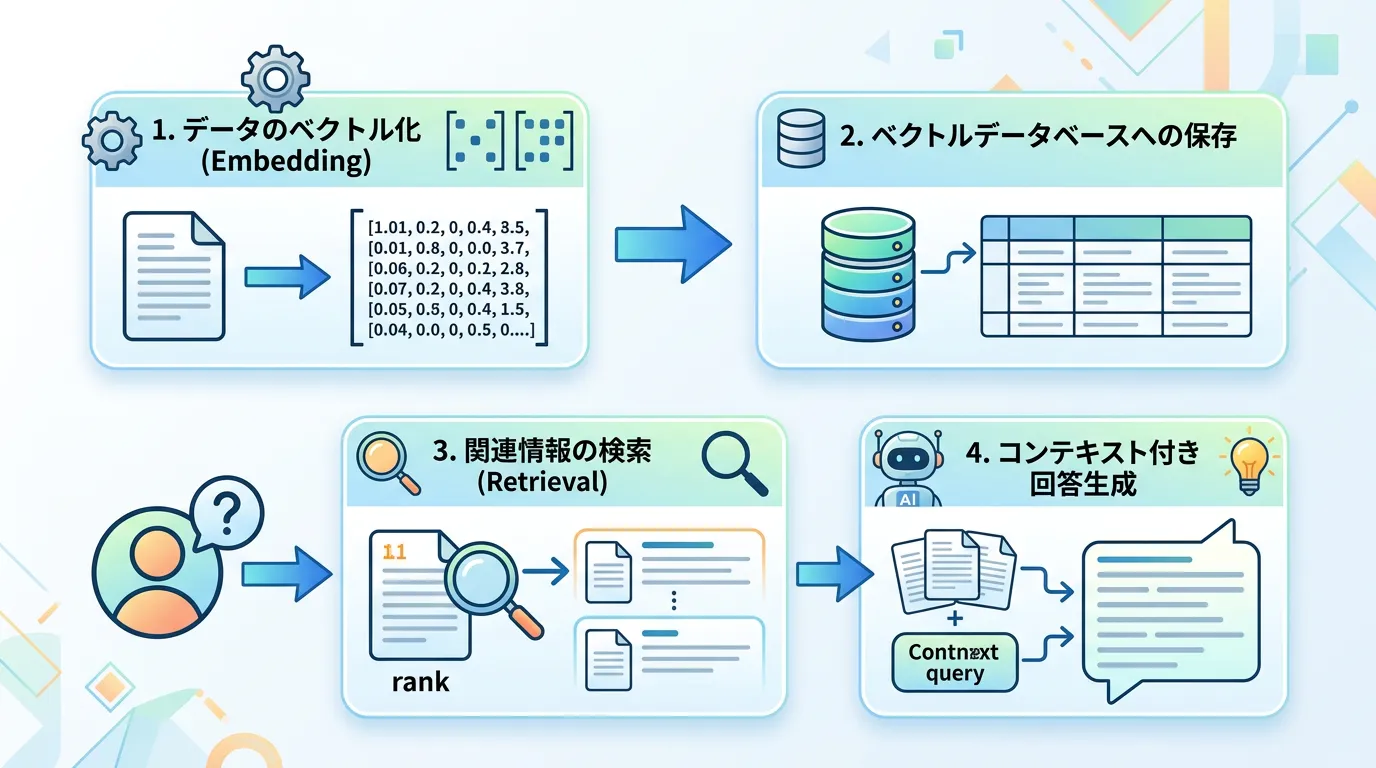
1. データのベクトル化(Embedding)
まず、参照させたい外部知識(PDF、Word、Excel、Webサイト、DBのテキストなど)を、AIが理解できる数値の羅列である「ベクトル(Vector)」に変換します。
この変換作業をEmbedding(埋め込み)と呼びます。
テキストをベクトル化することで、「意味の近さ」を計算できるようになります。
例えば、「リンゴ」と「アップル」は、文字としては全く異なりますが、ベクトル空間上では非常に近い位置に配置されます。
2. ベクトルデータベースへの保存
ベクトル化されたデータは、「ベクトルデータベース(Vector Database)」に保存されます。
代表的なものには、Pinecone、Milvus、Chroma、あるいはAzureやAWSが提供するマネージドサービスなどがあります。
このデータベースは、膨大なデータの中から、ユーザーの質問に「意味が最も近い」情報を高速に探し出すために特化しています。
3. 関連情報の検索(Retrieval)
ユーザーがAIに対して質問を投げると、その質問自体も同様にベクトル化されます。
そして、ベクトルデータベース内を検索し、質問の意味に最も合致するドキュメントの断片(チャンク)を数件ピックアップします。
ここで重要なのは、単なるキーワードマッチングではなく、文脈や意味に基づいた検索(セマンティック検索)が行われるという点です。
4. 回答の生成(Generation)
最後に、LLMに対して以下のようなプロンプト(命令文)を送信します。
「あなたは優秀なアシスタントです。以下の【参考資料】に基づいて、ユーザーの質問に正確に答えてください。【参考資料】に答えがない場合は『わかりません』と回答してください。 【参考資料】:(検索で見つかったドキュメントの内容) 【質問】:(ユーザーの入力内容)」
このように、「検索した事実」を制約条件として与えることで、LLMは自身の記憶に頼るのではなく、与えられた資料に基づいて回答を構成します。
これが、検索拡張生成(RAG)の核心です。
RAGとファインチューニングの違い
生成AIをカスタマイズする手法として、よく比較されるのが「ファインチューニング(Fine-tuning)」です。
どちらを採用すべきか判断するために、その違いを整理しておきましょう。
| 比較項目 | RAG(検索拡張生成) | ファインチューニング |
|---|---|---|
| アプローチ | 外部データを検索して参照する | モデル自体の重みを更新して学習する |
| 情報の更新 | データベースの更新だけで即時反映 | 再学習が必要(コストと時間がかかる) |
| 回答の根拠 | 明確(出典を表示できる) | 不透明(モデルの記憶に基づく) |
| ハルシネーション | 抑制しやすい | 完全には抑制できない |
| コスト | 比較的低コスト | 高い(計算リソースと専門知識が必要) |
| 適した用途 | 知識の提供、社内検索、FAQ | 口調の変更、特定の専門領域の言語習得 |

結論として、「特定の知識を正確に答えさせたい」場合はRAGが圧倒的に有利です。
一方で、「モデルの話し方を変えたい」あるいは「極めてニッチな業界用語の構造自体を理解させたい」といった場合にはファインチューニングが検討されます。
多くのビジネスシーンでは、まずRAGを導入し、必要に応じてファインチューニングを組み合わせる「ハイブリッド戦略」が推奨されています。
RAGを導入する5つの大きなメリット
企業がRAGを採用することで得られる具体的なメリットは、単なる利便性の向上に留まりません。
1. ハルシネーション(嘘の回答)の劇的な抑制
LLMの最大の弱点は、もっともらしい嘘をつくことです。
RAGでは、「検索したドキュメントの中に答えがない場合は、回答を控える」という制約をかけることができるため、不正確な情報を発信するリスクを最小限に抑えることができます。
これは、信頼性が重視されるビジネス用途において不可欠な要素です。
2. 回答の根拠(ソース)の提示が可能
RAGは外部のドキュメントを参照するため、「どのドキュメントの、どのページを参考にしたか」というソース(出典)を回答に付与できます。
ユーザーはAIの回答が正しいかどうかを自分自身で確認できるため、情報の透明性と信頼性が向上します。
3. 最新情報のリアルタイム反映
ファインチューニングのようにモデルを再学習させる必要がないため、データベースに新しい資料を追加した瞬間から、AIはその情報を回答に反映できるようになります。
日次で更新される在庫情報や、頻繁に変更される社内規定などの運用に最適です。
4. 高いコストパフォーマンス
大規模なモデルを再学習させるには、高価なGPUリソースと高度なエンジニアリングスキルが必要であり、数百万〜数千万円単位のコストがかかることも珍しくありません。
対してRAGは、既存のLLM(OpenAI APIなど)とベクトルデータベースを組み合わせるだけで構築できるため、開発コストと運用コストを大幅に抑えることが可能です。
5. セキュリティと権限管理の両立
LLM自体に社外秘情報を学習させてしまうと、その情報がモデルの中に固定され、適切な権限管理が難しくなります。
RAGであれば、検索の段階で「ユーザーAには閲覧権限のあるドキュメントのみを検索対象にする」といったフィルタリングをかけることができ、エンタープライズレベルのセキュリティ要件を満たすことができます。
RAGの実装における主要な技術スタック
RAGを実際に構築する際によく利用されるツールやフレームワークを紹介します。
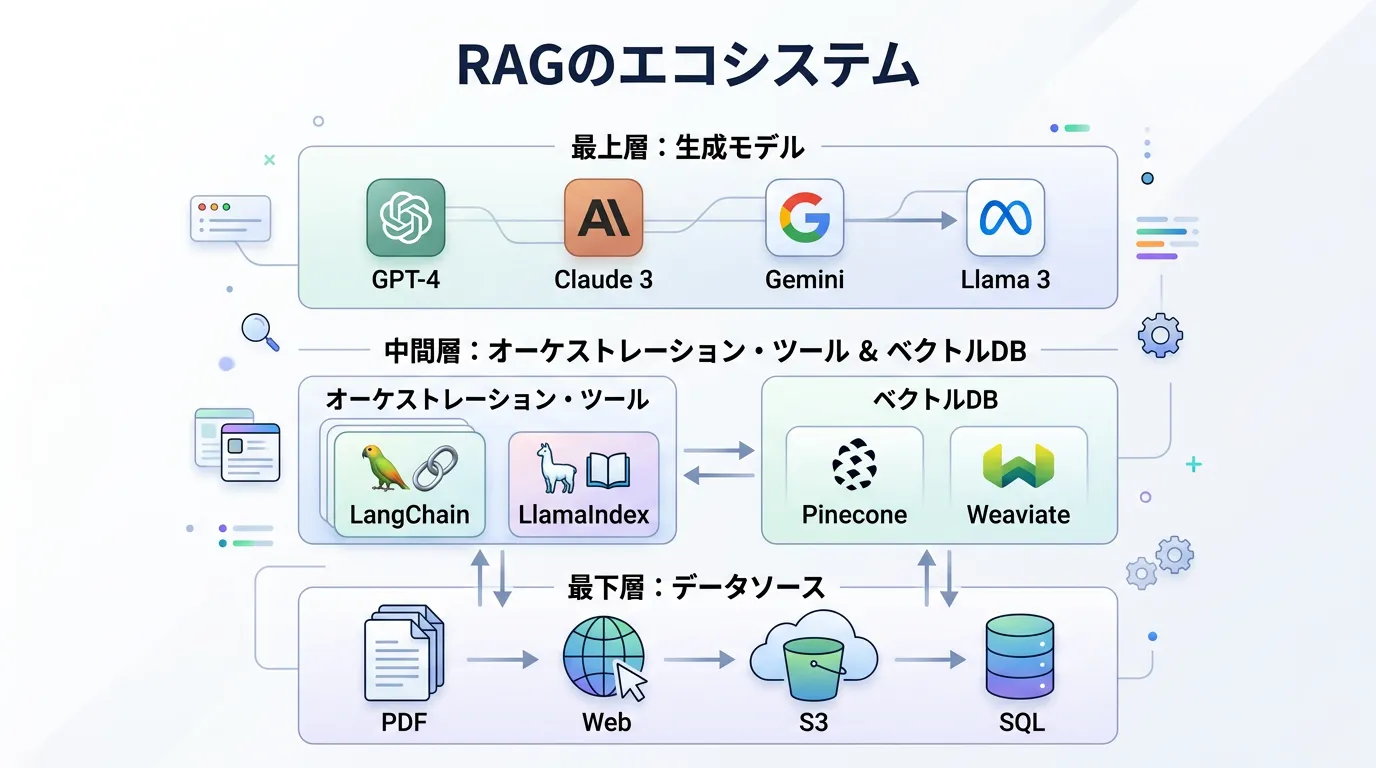
オーケストレーション・フレームワーク
RAGの複雑なパイプライン(ドキュメントの読み込み、分割、ベクトル化、検索、LLMへの橋渡し)を管理するためのフレームワークです。
- LangChain:生成AIアプリケーション開発のデファクトスタンダード。
- LlamaIndex:データ接続と検索に特化した、RAGに最適なフレームワーク。
ベクトルデータベース
- Pinecone:マネージドサービスで、スケーラビリティに優れる。
- Chroma:オープンソースで、ローカル環境でも軽量に動作。
- Azure AI Search:Microsoft Azureの統合サービス。日本語検索に強いハイブリッド検索機能が特徴。
エンベディングモデル
テキストをベクトル化するためのモデルです。
text-embedding-3-small(OpenAI):高性能かつ低コスト。Cohere Embed:多言語対応に優れる。
RAGの精度を高めるための「高度なテクニック」
RAGを単に構築しただけでは、期待した精度が出ないことがあります。
実用性を高めるためには、以下のような高度な最適化が求められます。
チャンキング(Chunking)の最適化
長いドキュメントをそのままベクトル化すると、情報が薄まってしまい、適切な検索ができなくなります。
そのため、ドキュメントを適切な長さ(チャンク)に分割する必要があります。
- 固定長分割:500文字ずつ区切る。
- 再帰的分割:段落や章の区切りを考慮して分割する。
- オーバーラップ:チャンク同士に一部重複を持たせることで、文脈の断絶を防ぐ。
ハイブリッド検索(Hybrid Search)
ベクトル検索(意味検索)は、キーワードの完全一致に弱いという側面があります。
例えば「製品番号 A-100」という特定の固有名詞を探す場合、キーワード検索の方が確実です。
ベクトル検索と従来のキーワード検索(BM25など)を組み合わせた「ハイブリッド検索」を採用することで、検索精度は劇的に向上します。
リランキング(Re-ranking)
検索ステップで取得した上位のドキュメントを、別の高精度なモデル(Cohere Rerankなど)で再度並び替える手法です。
LLMに渡す前に、本当に最も関連性の高い情報をトップに持ってくることで、回答の質を高めます。
クエリ変換(Query Transformation)
ユーザーの質問が曖昧な場合、そのまま検索しても良い結果が得られません。
LLMを使って「検索に適したクエリ」に書き換えたり、質問を複数のサブクエリに分解して検索を行ったりする手法も有効です。
RAGの具体的な活用事例
RAGはすでに多くの業界で実用化されています。
1. 社内ナレッジ・マニュアル検索
最も一般的な事例です。
数千ページに及ぶ社内規定、就業規則、技術マニュアル、過去の議事録などをRAGで検索可能にします。
- 効果:バックオフィス部門や情報システム部への問い合わせを50%以上削減。社員が情報を探す時間を大幅に短縮。
2. カスタマーサポートの高度化
コールセンターのオペレーター向けに、顧客からの問い合わせ内容に対する回答案を、製品仕様書やFAQから自動生成します。
- 効果:新人オペレーターの習熟期間の短縮と、回答品質の均一化。
3. 法務・コンプライアンスチェック
膨大な過去の契約書や法律の条文の中から、特定の条項やリスクに該当する箇所を瞬時に探し出します。
- 効果:法務確認のスピードアップと、見落としによるリスクの低減。
4. 自社製品のレコメンド・ECサイト
商品の詳細スペックやレビュー情報をRAGに読み込ませることで、ユーザーの抽象的な要望(例:「キャンプ初心者で、雨でも安心して使えるテントを教えて」)に対して、根拠に基づいた製品提案を行います。
RAG導入における注意点と課題
非常に強力なRAGですが、導入時に留意すべき課題も存在します。
1. 回答スピード(レイテンシ)
「検索」と「生成」の2つのステップを踏むため、単純なLLMの利用よりも回答までに時間がかかる傾向があります。
ストリーミング表示を採用したり、検索エンジンを高速化したりする工夫が必要です。
2. データの品質管理
RAGの精度は、元となるデータの質に100%依存します。
いわゆる「Garbage In, Garbage Out(ゴミを入れたらゴミが出てくる)」の原則です。
重複したデータ、古い情報、フォーマットが崩れたPDFなどが混ざっていると、回答の質が低下します。
3. トークンコスト
プロンプトに検索したドキュメントを大量に詰め込むと、LLMのトークン使用量が増え、コストが増加します。
必要な情報だけを効率的に抽出する技術が重要になります。
まとめ
RAG(検索拡張生成)は、生成AIのポテンシャルを最大限に引き出し、ビジネスの現場で「使えるAI」へと昇華させるための鍵となる技術です。
ハルシネーションの抑制、最新情報の参照、根拠の提示といったメリットは、これまでのAI活用における最大の障壁を打破するものです。
一方で、高い精度を実現するためには、適切なチャンキング戦略やハイブリッド検索、データのクレンジングといった技術的なノウハウも求められます。
今後、LLMはさらに進化を続けますが、「自社特有の情報」をAIに扱わせるための手法としてのRAGの重要性は変わることはないでしょう。
まずは小規模な社内ナレッジの検索から、RAGの導入を検討してみてはいかがでしょうか。