
ChatGPTの登場以来、私たちの生活やビジネスシーンにおいて「LLM (大規模言語モデル)」という言葉を耳にしない日はありません。
AIが人間のように自然な文章を書き、複雑な質問に答え、さらにはプログラミングコードまで生成する姿は、まさに技術革新の象徴といえます。
しかし、その驚異的な能力がどのような仕組みで実現されているのかを正確に理解している方は、まだ少ないのではないでしょうか。
LLMは単なる「高性能な検索エンジン」ではありません。
膨大なデータから言語のパターンを学習し、次に来る言葉を予測するという数学的なプロセスを経て、知的な出力を生み出しています。
本記事では、プロの視点からLLMの基礎知識から内部構造、学習のプロセス、さらには最新の活用事例までを徹底的に解説します。
技術的な背景を知ることで、LLMをより効果的に活用するためのヒントが見つかるはずです。
LLM(大規模言語モデル)とは何か
LLM(Large Language Model)は、日本語で「大規模言語モデル」と訳されます。
これは、膨大な量のテキストデータを学習し、人間が使う自然言語を理解・生成できるように設計されたAIモデルのことです。
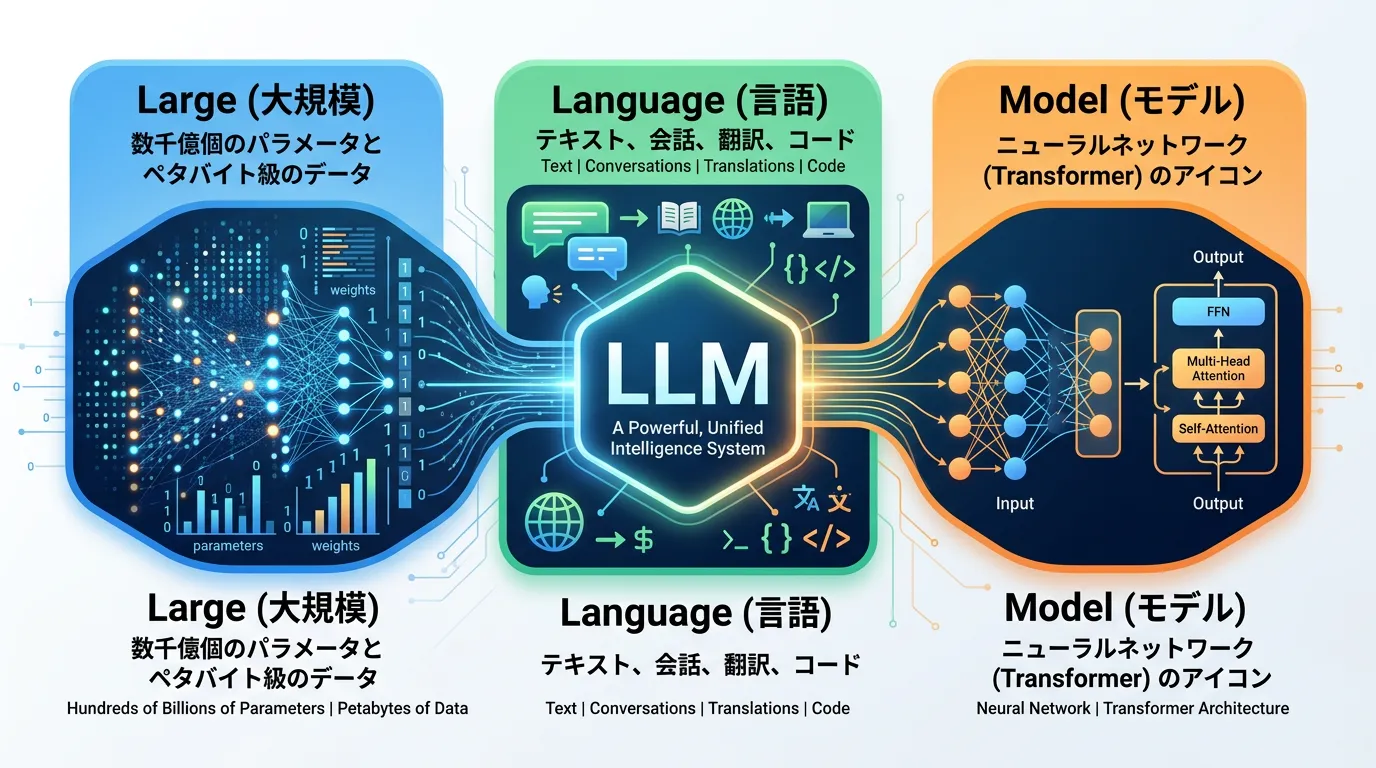
LLMという言葉を分解すると、その本質がより明確になります。
モデルを構成する「パラメータ (学習によって調整される数値)」の数が数千億から数兆規模に達していることを意味します。
また、学習に使用されるデータの量も、インターネット上のテキスト、書籍、論文など、人類が蓄積した膨大なアーカイブに及びます。
人間の話す言葉(自然言語)を対象としています。
単なる文字の羅列としてではなく、文脈やニュアンス、専門知識までを包含した「言語のルール」を扱います。
特定の入力を受け取り、計算処理を行って出力を出す「数学的な仕組み」を指します。
具体的には、人間の脳の仕組みを模した「ニューラルネットワーク」というアルゴリズムがベースになっています。
従来の自然言語処理との違い
LLMが登場する以前からも、翻訳ソフトやチャットボットなどの自然言語処理(NLP)技術は存在していました。
しかし、従来の技術は「特定のタスク」に特化したものが主流でした。
例えば、翻訳専用のAIは要約が得意ではなく、要約専用のAIは詩を書くことができませんでした。
これに対し、LLMは「汎用性」が極めて高いのが特徴です。
一つのモデルで、翻訳、要約、創作、論理的推論、感情分析など、あらゆる言語タスクをこなすことができます。
これは、モデルが特定のルールを覚えるのではなく、言語そのものの構造や概念を抽象的に捉えているためです。
LLMを支える基盤技術「Transformer」
LLMの飛躍的な進化の背景には、2017年にGoogleの研究者らによって発表された「Transformer (トランスフォーマー)」というニューラルネットワークのアーキテクチャがあります。
この技術の登場が、現代のAI革命の決定的な転換点となりました。
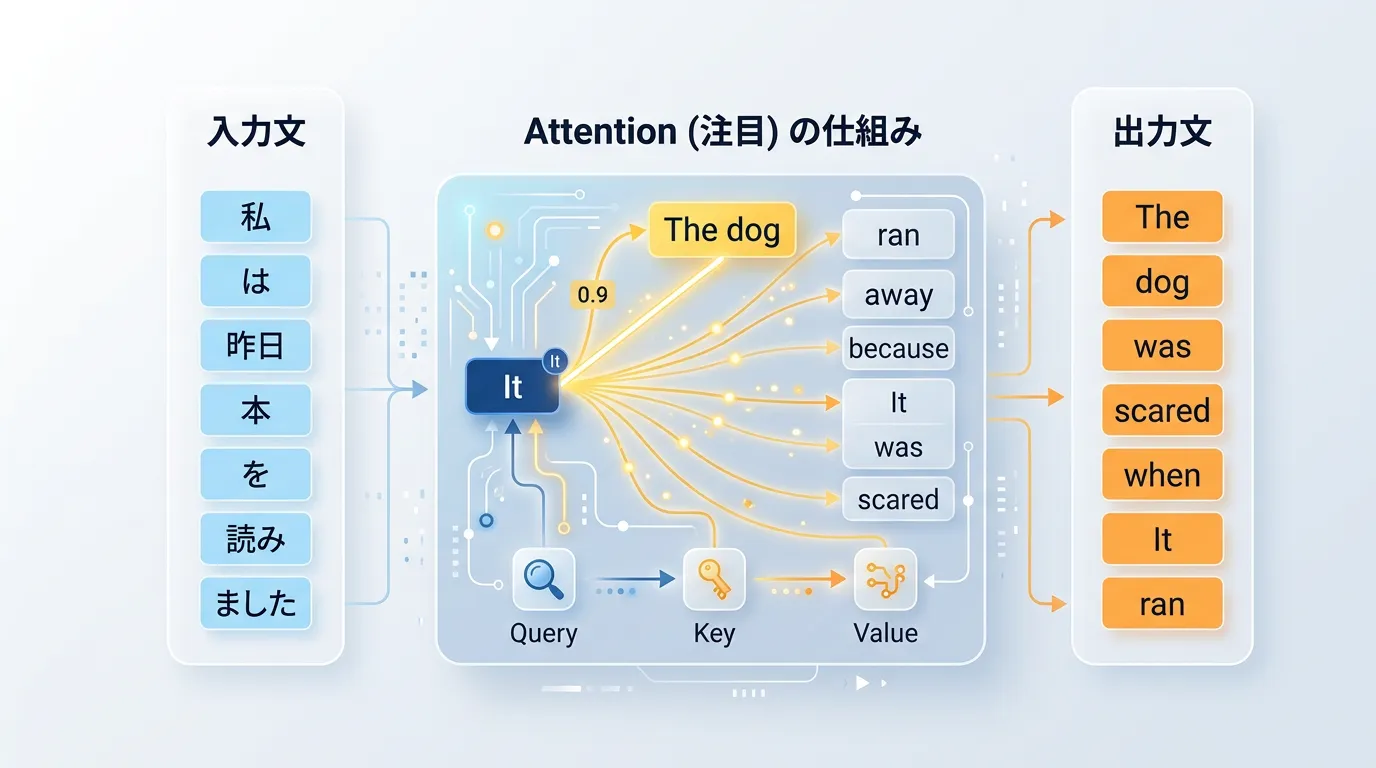
Attention(アテンション)メカニズムの革命
Transformerの核心は、「Self-Attention (セルフ・アテンション)」という仕組みにあります。
これは、文章の中の「どの単語が、他のどの単語と関連が深いか」を動的に計算する技術です。
例えば、「その犬は公園で走り回った。彼はとても元気だった。」という一文を考えてみましょう。
私たち人間は、「彼」が「その犬」を指していることを自然に理解します。
従来のAIは文章を前から順番に一語ずつ処理していたため、長い文章になると文頭の情報を忘れてしまう欠点がありました。
しかし、Attentionメカニズムを搭載したTransformerは、文章全体を一度に読み込み、各単語の関連性を並列的に計算します。
これにより、「彼」と「犬」の強い結びつきを数値として認識し、正確な文脈を把握することが可能になったのです。
並列処理による学習効率の向上
Transformerのもう一つの大きな利点は、並列処理に適していることです。
従来のRNN(再帰型ニューラルネットワーク)というモデルは、データを順番に処理する必要があったため、学習に膨大な時間がかかっていました。
Transformerは大量のデータを同時に計算できるため、GPU(画像処理装置)などのハードウェア性能を最大限に引き出すことができます。
この「高速な学習が可能になったこと」こそが、膨大なデータを用いた「大規模」なモデルの開発を実現させたのです。
LLMが回答を生成する仕組み
LLMがユーザーの質問に対して回答を生成するプロセスは、実は非常にシンプルな原理に基づいています。
それは、「次に来る最も確率の高い単語(トークン)を予測する」というものです。
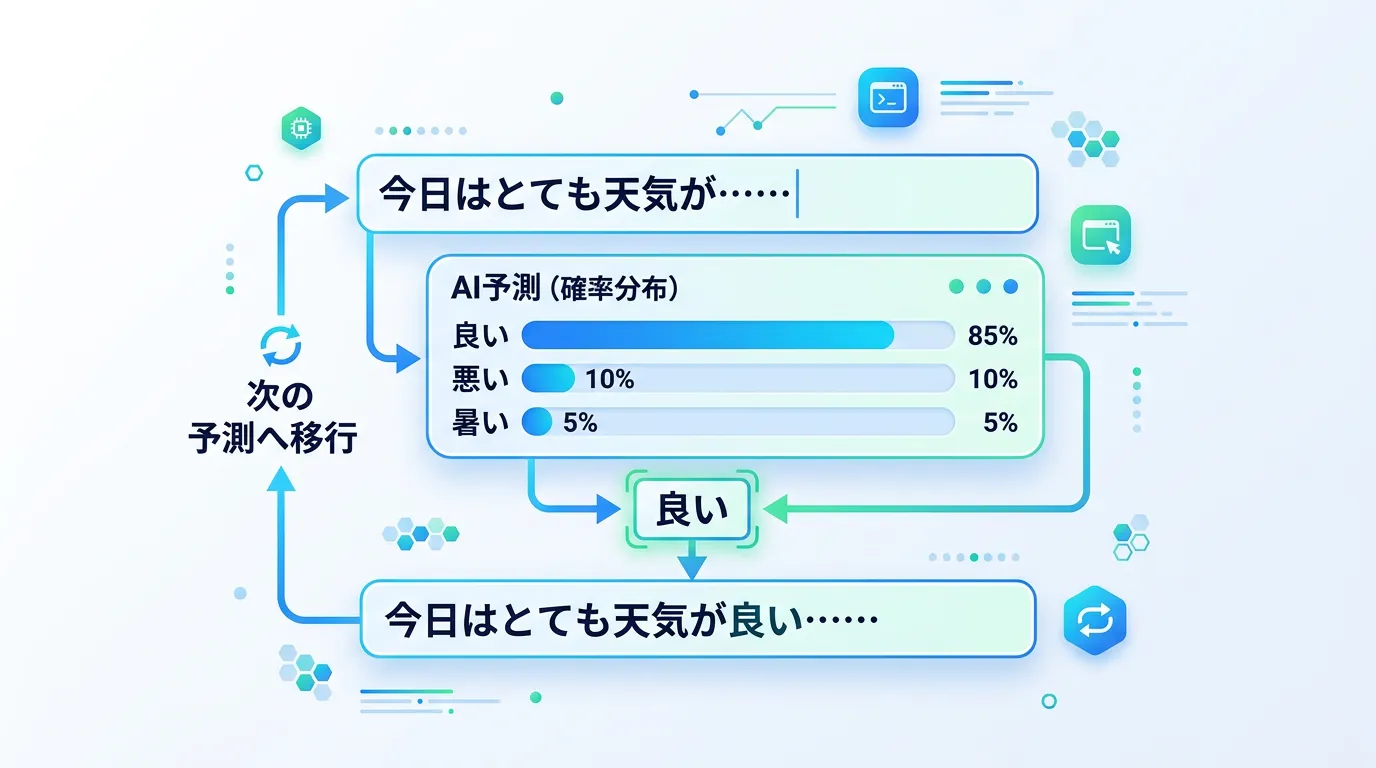
1. トークン化(Tokenization)
AIはテキストをそのまま理解するのではなく、まずトークンと呼ばれる小さな単位に分割します。
トークンは単語単位であったり、文字単位、あるいは単語の一部分であったりします。
分割されたトークンは、AIが計算しやすいように「数値(ベクトル)」に変換されます。
2. 次トークン予測(Next Token Prediction)
LLMは学習の過程で、「この文脈の次には、どのような言葉が来ることが多いか」というパターンを徹底的に叩き込まれています。
例えば、「昔々、あるところに……」という入力があれば、AIは統計的に「おじいさんと」や「お姫様が」といった言葉が続く確率が高いと判断します。
LLMは一文字ずつ、あるいは一単語ずつ、「最もそれらしい続き」を選び続け、それを繋ぎ合わせることで一つの文章を完成させているのです。
3. 文脈の保持(Context Window)
LLMには、一度に処理できる情報の限界量があり、これを「コンテキストウィンドウ」と呼びます。
最近のモデル(例:Claude 3.5 SonnetやGemini 1.5 Pro)では、この窓が非常に大きく設計されており、本一冊分に相当する情報を一度に読み込んでも、文脈を失わずに一貫した回答を生成できるようになっています。
LLMの学習プロセス:3つのステップ
LLMが賢くなるまでには、大きく分けて3つの学習段階を経るのが一般的です。
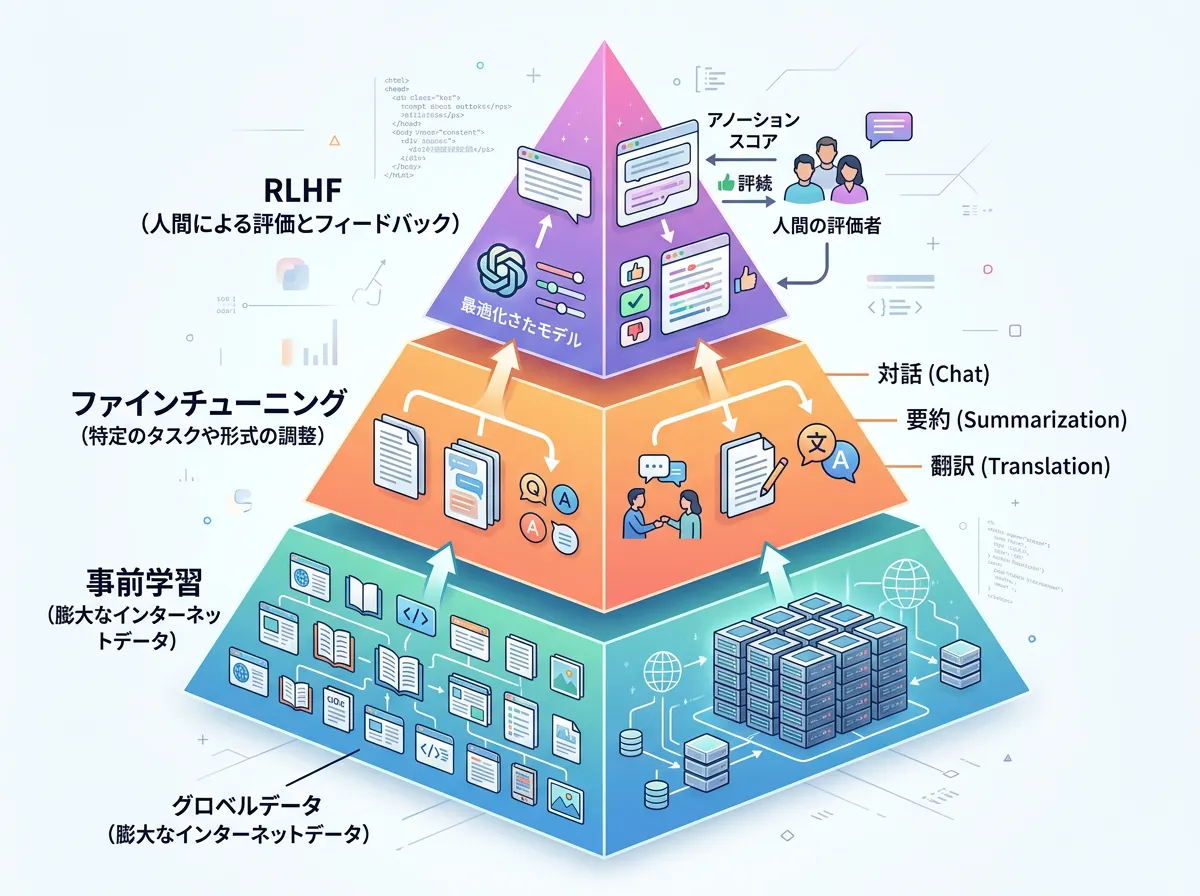
ステップ1:事前学習(Pre-training)
まずは、インターネット上の膨大なテキストデータを「教師なし」の状態で学習させます。
この段階の目的は、「言語そのものの仕組み」や「世界に関する一般的な知識」を習得することです。
この時点のAIは、優れた「続き予測マシン」ですが、まだ人間の指示に従うことや、会話をすることは得意ではありません。
例えば「富士山の高さは?」と聞くと、質問に答えるのではなく、「富士山の高さは? 日本一高い山の魅力」といったタイトルの続きを生成してしまうことがあります。
ステップ2:ファインチューニング(Fine-tuning)
事前学習を終えたモデルに対し、特定のタスク(質問への回答、翻訳、要約など)に特化した高品質なデータセットを追加で学習させます。
これを「指示チューニング(Instruction Tuning)」とも呼びます。
これにより、AIは「ユーザーの指示(プロンプト)を理解し、適切な形式で回答する」という振る舞いを身につけます。
ステップ3:RLHF(人間からのフィードバックによる強化学習)
最後に、RLHF (Reinforcement Learning from Human Feedback)というプロセスを行います。
これは、AIが生成した複数の回答案を人間が評価し、「どちらがより親切で正確か」「不適切な内容が含まれていないか」を教え込む工程です。
このステップによって、AIは人間の倫理観や好みに沿った、安全で使いやすい回答を生成できるようになります。
現在のChatGPTなどが非常に「人間らしい」のは、このRLHFの工程が極めて緻密に行われているからです。
主要なLLMの種類と特徴
現在、世界中のテック企業が独自のLLMを開発し、しのぎを削っています。
それぞれのモデルには得意分野や特徴があります。
| 開発元 | モデル名 | 特徴・強み |
|---|---|---|
| OpenAI | GPT-5.2 | 業界標準。論理的思考、マルチモーダル処理、汎用性が極めて高い。 |
| Gemini | Googleのエコシステムと連携。巨大なコンテキストウィンドウが強み。 | |
| Anthropic | Claude 3.5 | 自然な日本語表現、高い安全性、アーティファクト機能による作業効率。 |
| Meta | Llama 3 | オープンソースモデルの代表格。カスタマイズ性が高く、自社サーバーで運用可能。 |
| CyberAgent / LINE等 | 日本語特化LLM | 日本独自の文化や文脈に強く、国内企業での活用が進んでいる。 |
プロプライエタリ(商用)モデルとオープンソースモデル
LLMには、OpenAIのGPTシリーズのように中身が非公開の「プロプライエタリ・モデル」と、MetaのLlamaのようにモデルの重み(構造)が公開されている「オープンソース・モデル」があります。
企業の機密情報を扱う場合や、独自のカスタマイズを安価に行いたい場合は、Llamaなどのオープンソースモデルを自社環境に構築するケースが増えています。
LLMの具体的な活用事例
LLMの仕組みを理解したところで、それらが実際にどのようなシーンで活用されているのかを見ていきましょう。
1. カスタマーサポート(AIチャットボット)
従来のチャットボットは、あらかじめ設定された「シナリオ」に沿った回答しかできませんでした。
LLMを活用したボットは、ユーザーの曖昧な質問の意図を汲み取り、社内のマニュアルを読み込んだ上で、最適な回答を自然な言葉で提示できます。
これにより、有人対応のコストを大幅に削減することが可能です。
2. コンテンツ制作・ライティング支援
ブログ記事の構成案作成、メールの代筆、キャッチコピーの生成など、クリエイティブな分野での活用が進んでいます。
単に文章を書くだけでなく、「プロの編集者の視点で校正してほしい」といった役割(ロール)を与えることで、質の高いアウトプットが得られます。
3. プログラミングとコード生成
LLMは自然言語だけでなく、PythonやJavaScriptといったプログラミング言語も「言語」として学習しています。
GitHub Copilotなどのツールを使えば、コメントを書くだけで関数を丸ごと生成したり、バグの原因を特定して修正案を提示したりすることが可能です。
4. 膨大なドキュメントの要約と分析
数百ページの報告書や、何時間にも及ぶ会議の議事録を瞬時に要約できます。
また、複数の資料から特定の情報を抽出・比較する作業も、LLMが得意とする領域です。
LLMを利用する上での注意点と課題
非常に強力なLLMですが、万能ではありません。
利用する際には、以下のリスクを十分に理解しておく必要があります。
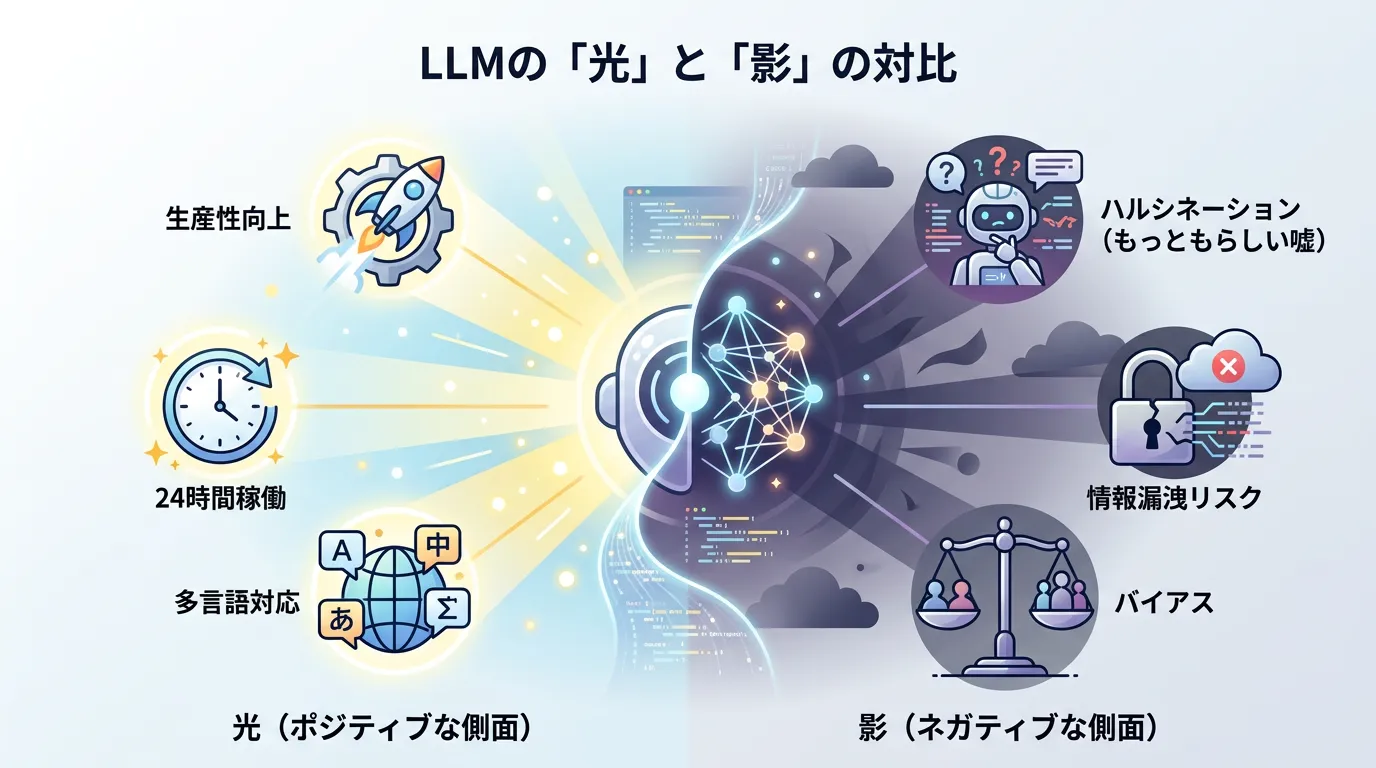
ハルシネーション(幻覚)
LLMが「事実ではないことを、さも真実であるかのように堂々と回答してしまう現象」をハルシネーション(Hallucination)と呼びます。
これは、LLMが「真実」を理解しているのではなく、あくまで「確率的に高い言葉」を繋いでいるために起こります。
重要な情報の確認には、必ず人間によるファクトチェックや、RAG(検索拡張生成)と呼ばれる「外部知識を参照させる仕組み」を組み合わせることが不可欠です。
セキュリティとプライバシー
パブリックなLLMサービスに入力した情報は、モデルの再学習に利用される可能性があります。
企業の機密情報や個人情報を入力する際は、「学習に利用しない設定(オプトアウト)」を選択するか、API経由での利用、あるいはセキュアな法人向けプラン(ChatGPT Team/Enterpriseなど)を活用する必要があります。
著作権とバイアスの問題
LLMの学習データには、著作権で保護されたコンテンツが含まれている場合があります。
また、インターネット上の偏った情報を学習することで、差別的な表現やバイアスを含んだ回答をしてしまうリスクもゼロではありません。
LLMの未来:マルチモーダルとエージェント化
LLMは今、さらなる進化を遂げています。
一つは「マルチモーダル化」です。
テキストだけでなく、画像、音声、動画を同時に処理できるようになっています。
例えば、「スマートフォンの写真を見せて、故障箇所を指摘してもらう」といった使い方が現実のものとなっています。
もう一つは「AIエージェント」としての進化です。
AIが単に答えるだけでなく、「航空券を予約する」「資料を作成してメールで送信する」といった「行動」を伴うタスクを自律的に遂行する方向へと開発が進んでいます。
まとめ
LLM(大規模言語モデル)は、Transformerという革新的なアーキテクチャと、Attentionメカニズムによる高度な文脈理解、そして膨大な計算リソースによって実現された「知能の新しい形」です。
その仕組みは「次に来る言葉を予測する」という統計的なプロセスに基づいたものですが、その規模が拡大することで、かつてのAIでは不可能だった論理的推論や創造的な活動が可能になりました。
LLMをビジネスや日常生活に導入する際は、その仕組みを正しく理解し、ハルシネーション等のリスクを適切に管理しながら活用することが成功の鍵となります。
今後、LLMは私たちの「思考のパートナー」として、ますます欠かせない存在になっていくでしょう。
最新のモデルや技術動向を常にキャッチアップし、この強力なテクノロジーを味方につけていきましょう。
