
C++を学ぶと、ほぼ必ずと言ってよいほどusing namespace std;という記述を目にします。
便利に見えるこの1行ですが、実は大規模開発や保守性の観点からは多くの問題を抱えています。
本記事では、なぜC++でusing namespace stdを避けるべきなのかを、図解やサンプルコードを交えながら、4000文字以内でわかりやすく解説します。
C++でusing namespace stdとは何か
using宣言とusingディレクティブの違い
using宣言とは
using宣言は、特定の名前だけを現在のスコープに導入する書き方です。
using std::cout; // std名前空間からcoutだけを導入
using std::string; // stringだけを導入この方法では、必要な名前だけを明示的に持ち込むため、名前の衝突が起きにくくなります。
usingディレクティブとは
usingディレクティブは、名前空間内の名前を一括で現在のスコープに導入する書き方です。
その代表例がusing namespace std;です。
using namespace std; // std名前空間にある名前をすべて導入便利な反面、どの名前がどこから来ているのかが分かりづらくなり、名前の衝突や可読性の低下を招きます。
using namespace stdのイメージ図解
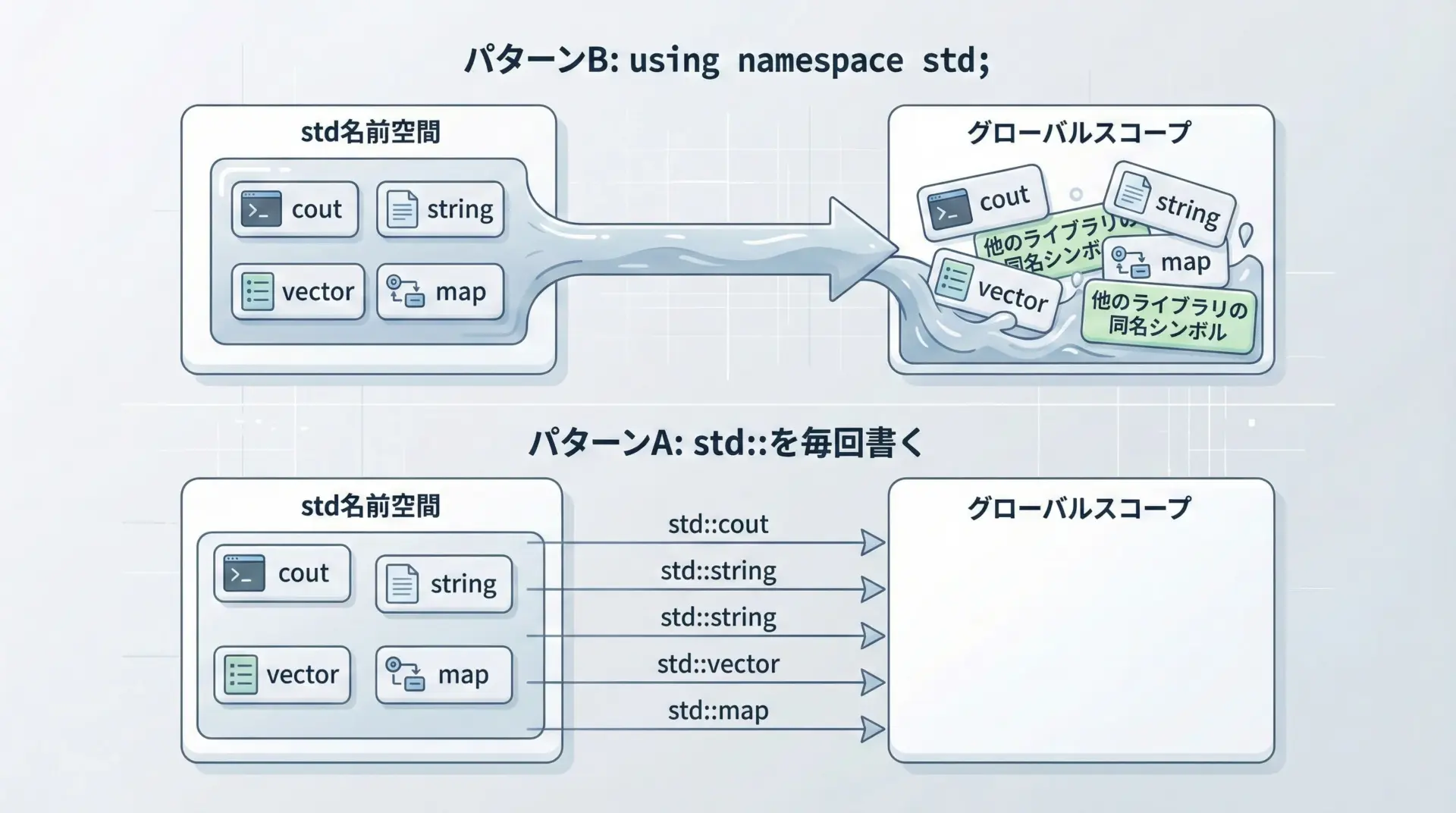
この図から分かるように、using namespace stdは「stdの中身を全部グローバルにばらまく」動作をします。
これが後述するさまざまな弊害を生む原因です。
代表的な弊害1: 名前の衝突と予期しない動作
ライブラリ同士の名前衝突
他のライブラリもcountやdistanceのような一般的な名前を提供していることがあります。
その場合、using namespace std;によって、どの関数が呼び出されているのか分かりにくくなります。
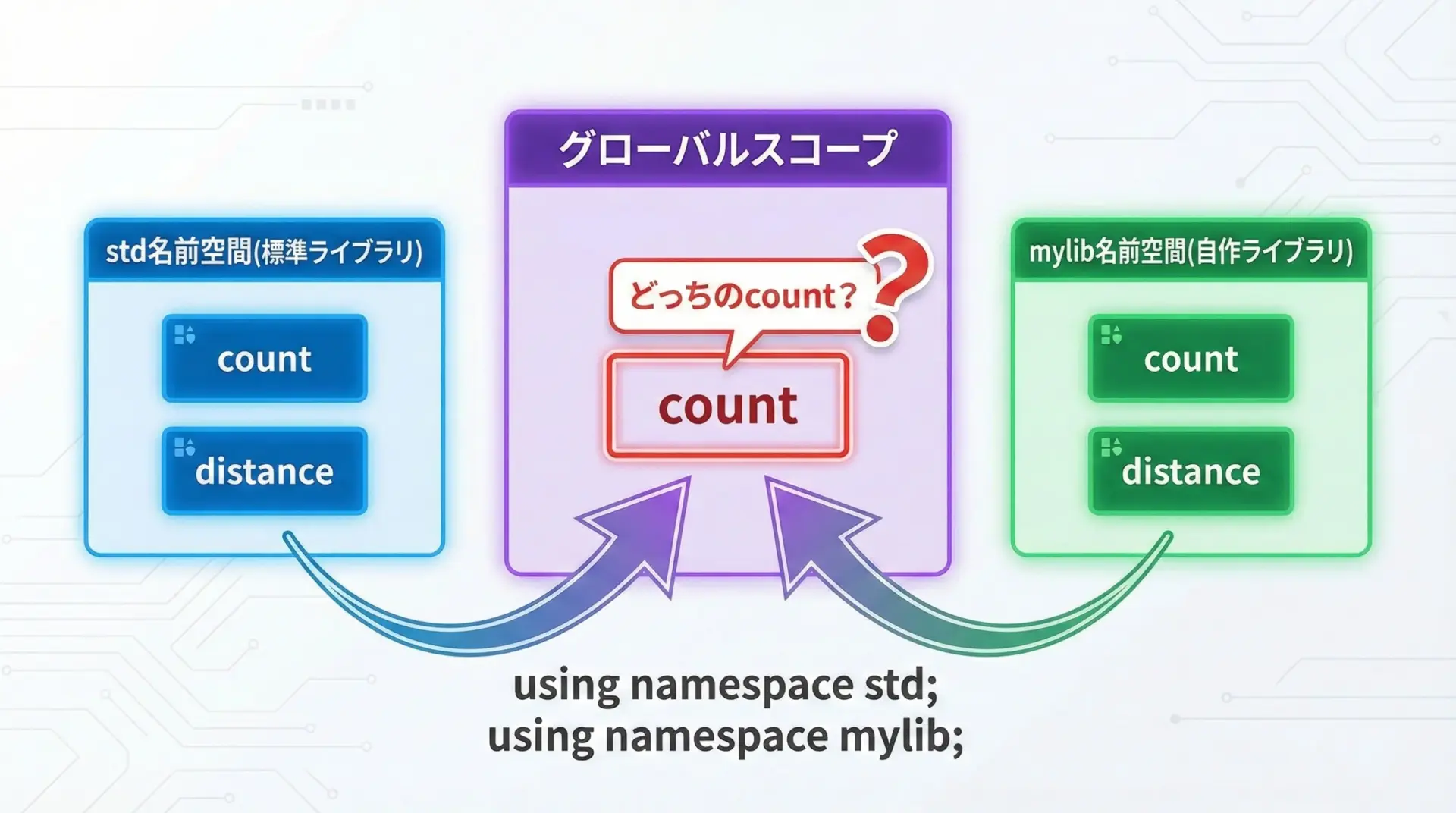
衝突の例
#include <algorithm>
#include <vector>
namespace mylib {
// 自作のcount関数
int count(int a, int b) {
return a + b;
}
}
using namespace std;
using namespace mylib;
int main() {
vector<int> v{1, 2, 3, 4};
// どのcountが呼ばれるのかパッと見て分かりません
auto c = count(v.begin(), v.end(), 2);
return 0;
}このコードは、標準ライブラリのstd::countと自作のmylib::countが混在し、名前解決が複雑になります。
コンパイルエラーになることもあれば、意図しない関数が呼ばれてしまうこともあります。
代表的な弊害2: 可読性と保守性の低下
コードを読む負担が増える
コードを読む人が「この名前はどこから来ているのか」を常に推測しなければならない状態は、レビューや保守の負担を増やします。

比較例
// 良くない例
#include <iostream>
#include <vector>
using namespace std;
int main() {
string name;
vector<int> nums{1, 2, 3};
cout << "Name: ";
cin >> name;
for (auto n : nums) {
cout << n << endl;
}
}// より良い例
#include <iostream>
#include <vector>
int main() {
std::string name;
std::vector<int> nums{1, 2, 3};
std::cout << "Name: ";
std::cin >> name;
for (auto n : nums) {
std::cout << n << std::endl;
}
}後者は「どのクラス・関数が標準ライブラリなのか」が一目で分かるため、レビュー時の理解コストが下がります。
代表的な弊害3: ヘッダファイルに書いた場合の大問題
ヘッダ内のusing namespace stdは汚染を拡散させる
最も避けるべき場所は、ヘッダファイルでのusing namespace stdです。
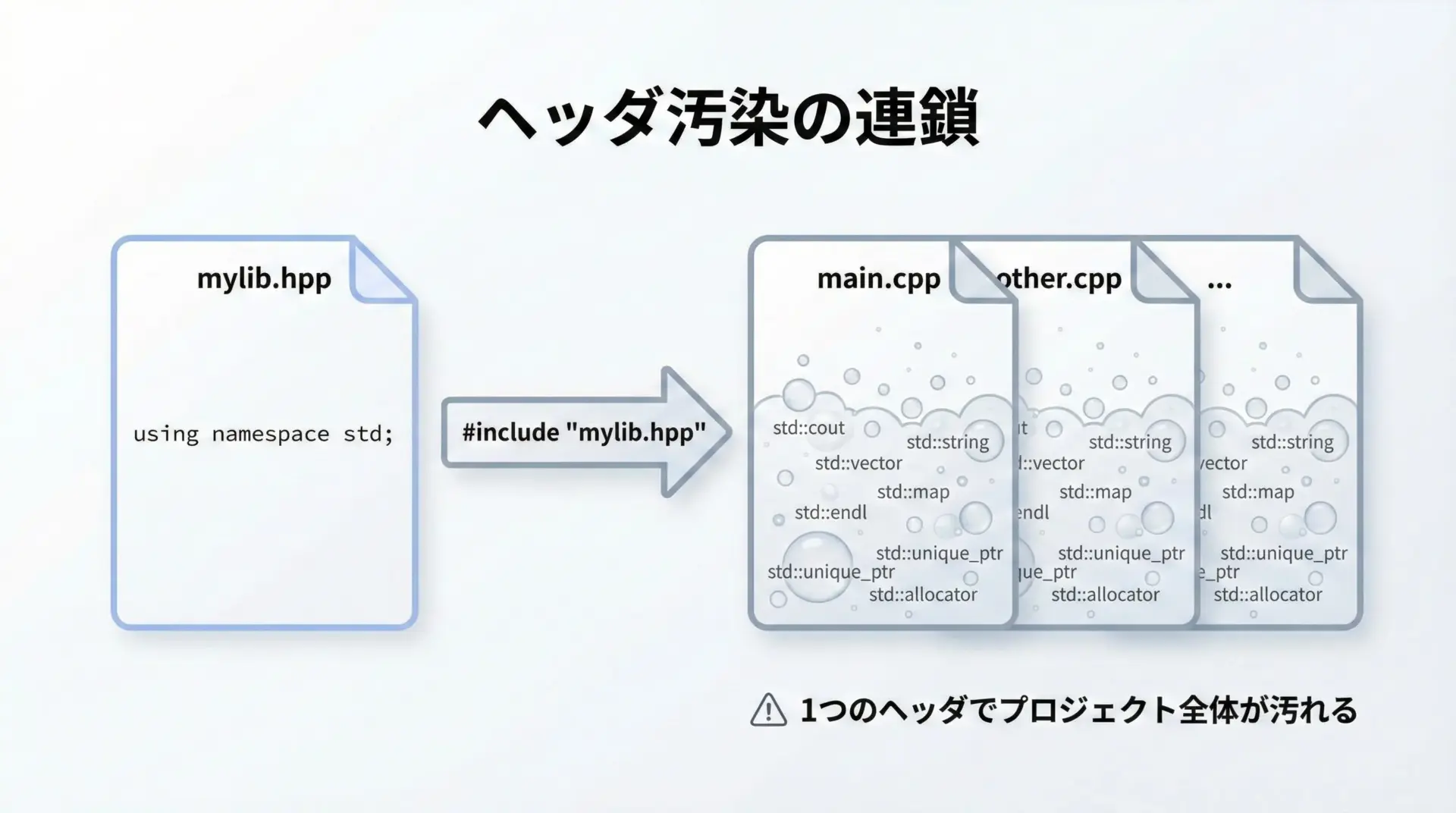
ヘッダファイルにusing namespace std;を書くと、そのヘッダを#includeしたすべてのソースファイルのグローバルスコープが汚染されます。
結果としてプロジェクト全体の名前解決が不安定になり、バグやコンパイルエラーの原因になります。
悪い例
// mylib.hpp
#pragma once
#include <string>
#include <vector>
using namespace std; // ヘッダでこれは非常に危険
class User {
public:
string name; // std::stringのつもり
vector<int> scores; // std::vector<int>のつもり
};// main.cpp
#include "mylib.hpp"
int main() {
User u;
u.name = "Taro";
u.scores.push_back(100);
}この時点では動いていても、他ライブラリを導入した途端に同名シンボルと衝突する可能性があります。
ヘッダは多くの翻訳単位に影響するため、局所的なミスでは済まなくなる点が問題です。
代表的な弊害4: 教材・学習面での悪影響
初学者が名前空間の概念を誤解しやすい
多くの入門書やサンプルコードがusing namespace std;をトップに置いてしまうことで、名前空間そのものの重要性を学ぶ機会が失われてしまいます。
学習初期からstd::を明示的に書く習慣をつけておけば、次のような点が自然と身につきます。
- 標準ライブラリと自作コードの区別
- 複数の名前空間を使う際の衝突や曖昧さへの感覚
- 大規模プロジェクトでの設計感覚
それでも使われる理由と許容されるケース
使いたくなる主な理由
記述量が減って楽に見えることが最大の理由です。
競技プログラミングなど、短いソースコードを高速に書きたい場面では、簡潔さを優先してusing namespace std;を使うことがあります。
例外的に許容されやすい場面
一般的に、次のようなケースでは比較的容認されることがあります。
- 1ファイル完結の、ごく小さなスクリプトや検証コード
- 競技プログラミングやオンラインジャッジ向けの短い提出コード
- 教材の「最初の10分」など、概念導入前のごく短いサンプル
ただし、商用開発・チーム開発・長期保守を前提とするコードでは避けるのが現在の事実上のスタンダードです。
実践的な回避方法と具体例
基本方針: std::を明示的に書く
最も単純で安全な方法は、標準ライブラリを使うときには常にstd::を付けることです。
#include <iostream>
#include <string>
int main() {
std::string name = "Taro";
std::cout << "Hello, " << name << std::endl;
return 0;
}using宣言を局所的に使う
書く量を少し減らしたい場合は、必要な名前だけを限定的なスコープで導入する方法が有効です。
#include <iostream>
#include <string>
int main() {
using std::cout; // この関数の中だけで有効
using std::endl;
using std::string;
string name = "Taro";
cout << "Hello, " << name << endl;
}この場合、影響範囲がmain関数の中に限定されるため、ヘッダや他ファイルへの影響を避けることができます。
サンプルプログラム: using namespace stdの有無による違い
例: 名前衝突を避けた書き方
#include <iostream>
#include <string>
namespace mylib {
// 自作のprint関数
void print(const std::string& msg) {
std::cout << "[mylib] " << msg << std::endl;
}
}
int main() {
std::string msg = "Hello";
// std::と名前空間を明示することで衝突の余地をなくす
std::cout << "[main] " << msg << std::endl;
mylib::print(msg);
return 0;
}[main] Hello
[mylib] Helloこのようにどの名前空間のどの関数が呼ばれているかを明示的に書くことで、コードの意図が明確になります。
まとめ
using namespace stdは、短期的には便利に見えるものの、長期的な保守性やチーム開発、ライブラリとの共存を考えると多くの弊害を生みます。
特にヘッダファイルでの使用は厳禁といってよく、名前空間汚染による予期しないバグやコンパイルエラーの原因になります。
標準ライブラリはstd::を付けて利用し、必要に応じてusing std::cout;のような局所的なusing宣言を活用することが、安全で読みやすいC++コードへの近道です。
実務や大規模開発を見据えるなら、「using namespace stdを書かない」ことを最初の習慣として身につけておくことをおすすめします。
