
C++で配列を使うとき、サイズが決め打ちでよければ通常の配列宣言で十分ですが、実行時にサイズが決まる場合は動的確保が必要になります。
その代表的な手段がnew[]による動的配列の確保と、delete[]による解放です。
本記事では、固定配列との違いから、new[]/delete[]の正しい書き方、陥りやすいミス、そして現代C++でのより安全な代替手段まで、図解とコード例を交えながら詳しく解説します。
【C++】配列の動的確保new[]と解放delete[]の基礎
new[]とdelete[]とは何か
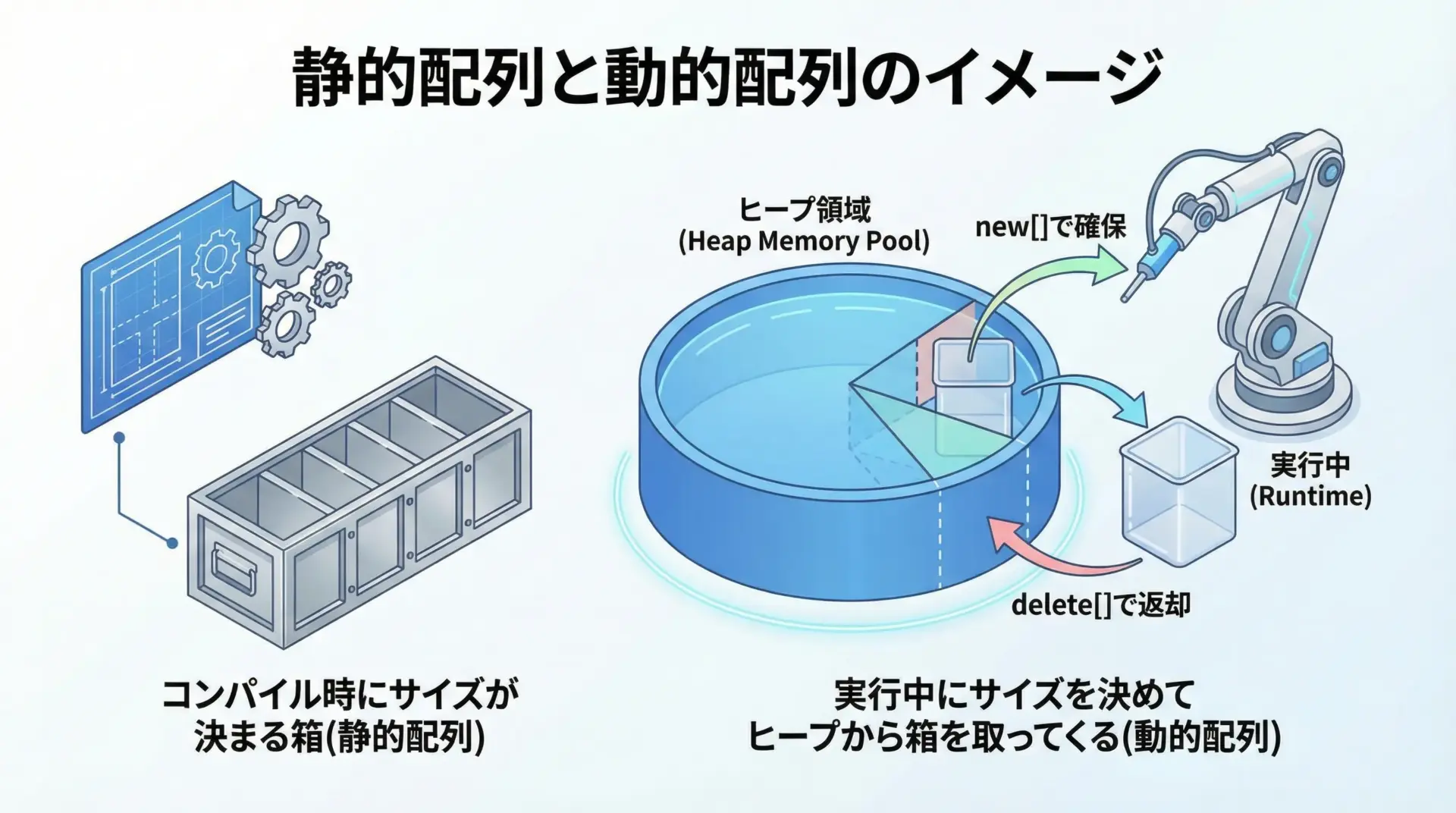
C++では、配列は大きく分けて2種類あります。
ひとつはコンパイル時に要素数が決まっている静的配列、もうひとつは実行時に要素数を決める動的配列です。
静的配列は、次のように宣言します。
int a[10]; // 要素数10の静的配列一方、実行してみないと必要な要素数がわからない場合、C++ではnew[]演算子を使ってヒープ領域に配列を動的に確保します。
そのメモリを使い終わったら、delete[]で解放します。
#include <iostream>
int main() {
int n = 0;
std::cout << "要素数を入力してください: ";
std::cin >> n;
// new[] で int 型の配列を動的に確保
int* arr = new int[n];
// 何らかの処理(例としてインデックスを代入)
for (int i = 0; i < n; ++i) {
arr[i] = i;
}
// 使用後は必ず delete[] で解放
delete[] arr;
return 0;
}なぜdelete[]が必要なのか
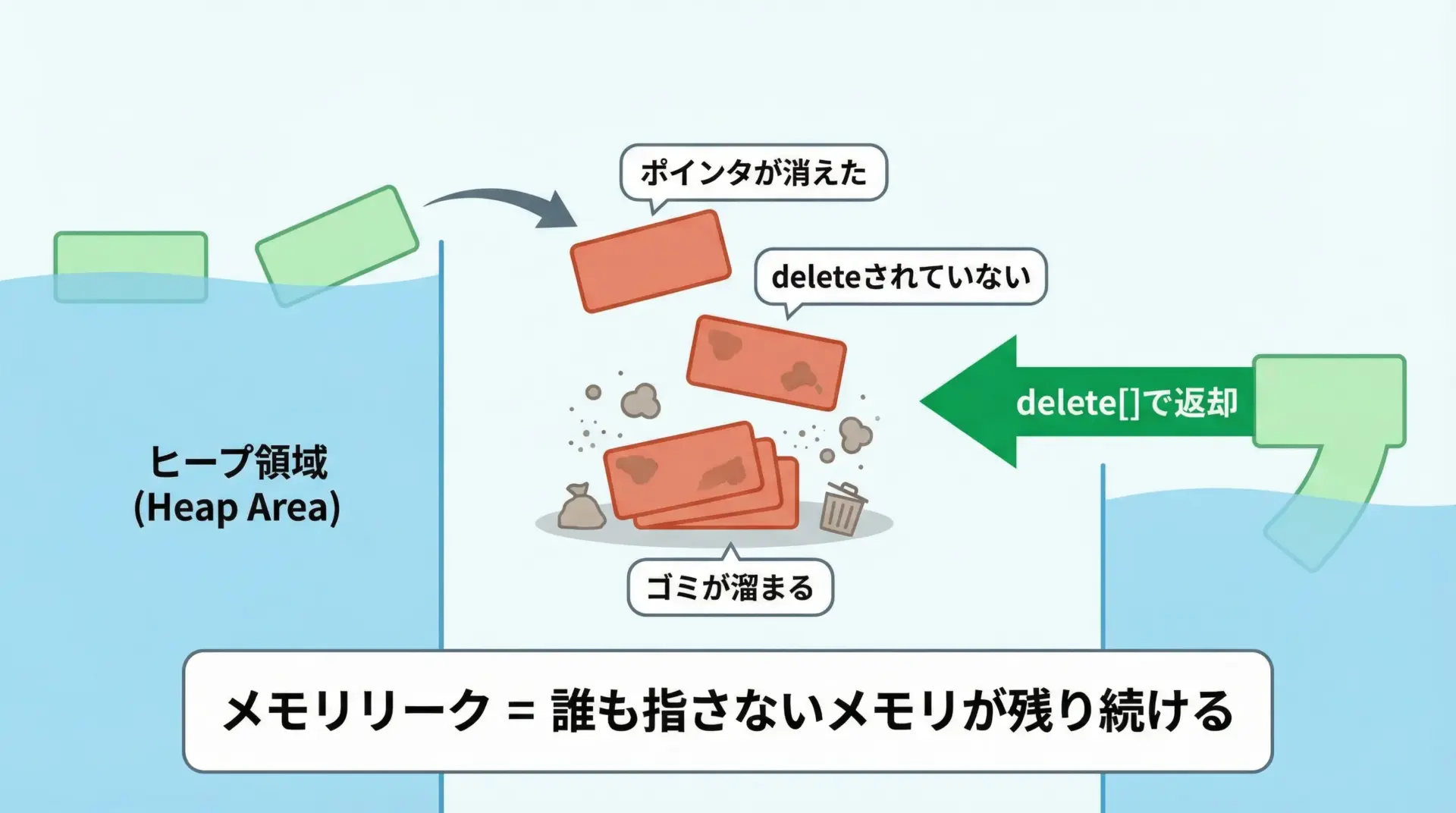
new[]で確保したメモリは、プログラムが終了するまで自動では解放されません。
もしdelete[]を書き忘れると、解放されないメモリが積み重なり、メモリリークという不具合を引き起こします。
そのため、new[]で確保したら、対応するdelete[]を必ず書くことが基本ルールになります。
静的配列とnew[]による動的配列の違い
宣言タイミングと寿命の違い
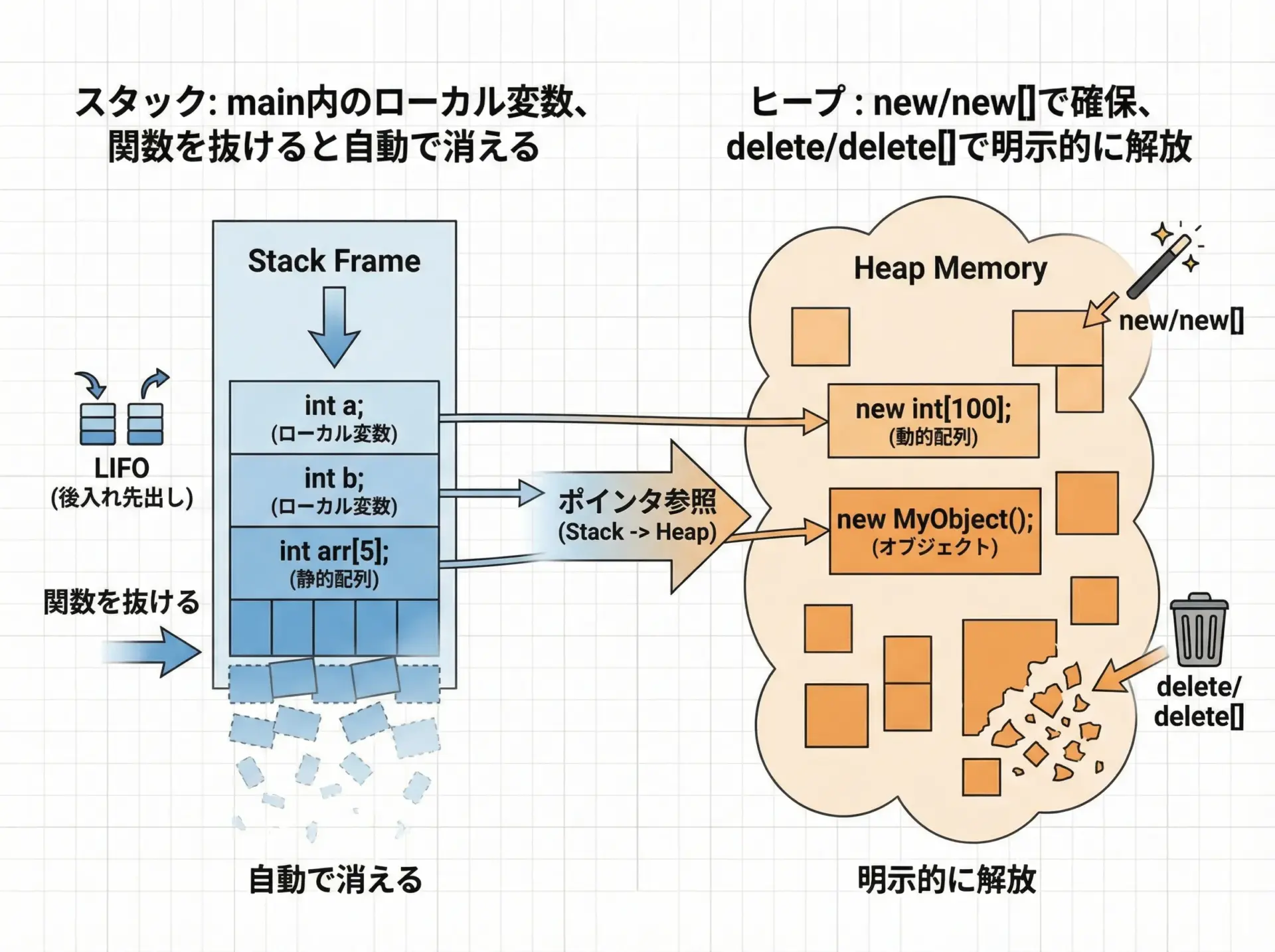
静的配列int a[10];は、通常スタック領域に確保されます。
関数のローカル変数として宣言された場合、その関数を抜けると自動的に破棄されます。
一方、new[]で確保された配列はヒープ領域に存在し、delete[]を呼ぶまで生き続けます。
この違いによって、次のような特徴が生まれます。
- 静的配列
関数を抜けると自動的に解放され、メモリ管理が簡単です。ただし要素数はコンパイル時に決める必要があります。 - new[]配列
実行時に要素数を決めることができますが、解放を自分で管理しなければならないという負担があります。
配列の宣言方法の比較
次の表で、静的配列とnew[]配列の宣言イメージを整理します。
| 種類 | 宣言例 | 要素数の決定タイミング | 解放方法 |
|---|---|---|---|
| 静的配列 | int a[10]; | コンパイル時 | 自動(スコープを抜ける) |
| new[]動的配列 | int* p = new int[n]; | 実行時 | 手動(delete[] p;) |
実行時にサイズを決めたい場合だけnew[]を使うという方針で考えると、使いどころがはっきりしてきます。
new[]の正しい使い方とサンプルコード
基本的なnew[]の書き方
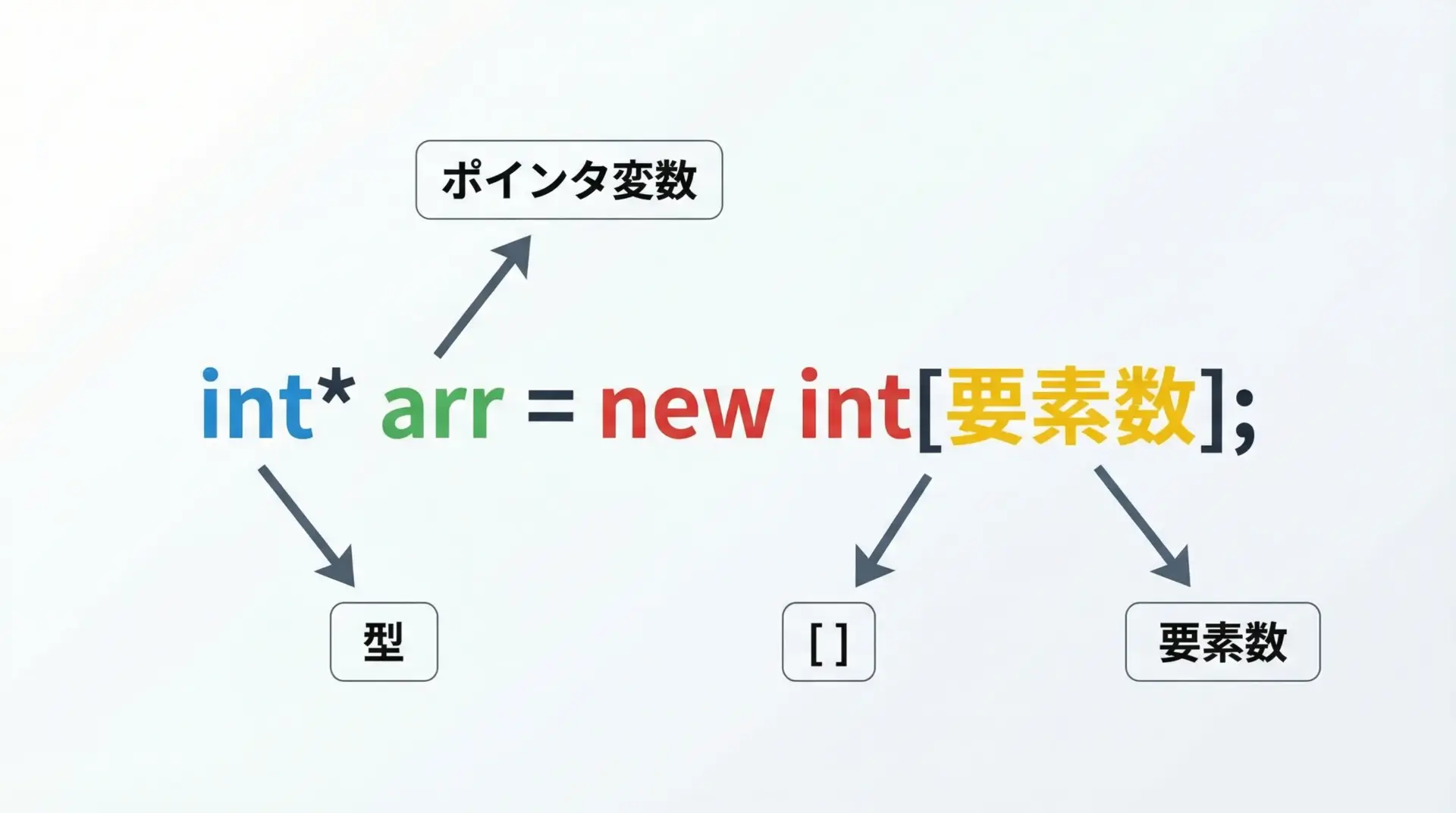
new[]による配列確保の基本形は次のとおりです。
型名* 変数名 = new 型名[要素数];実際の例を示します。
#include <iostream>
int main() {
int n = 0;
std::cout << "要素数を入力してください: ";
std::cin >> n;
// int 型の配列を n 要素ぶん確保
int* data = new int[n];
// 配列を初期化(ここではすべて0にする)
for (int i = 0; i < n; ++i) {
data[i] = 0; // 添字演算子で通常の配列と同じようにアクセス可能
}
// 処理例: インデックスと値を表示
for (int i = 0; i < n; ++i) {
std::cout << "data[" << i << "] = " << data[i] << '\n';
}
// 必ず delete[] で解放する
delete[] data;
return 0;
}0初期化したい場合の書き方
new[]にも値を0で初期化する書き方があります。
// 全要素を 0 で初期化する new[] の例
int* arr = new int[n](); // () を付けると値の初期化(ゼロ初期化)が行われるnew intn; と new int[n] の違いを意識しておくと、未初期化の値によるバグを減らせます。
delete[]の正しい使い方と注意点
delete[]の基本形
new[]で確保した配列を解放するには、対応するdelete[]を使います。
int* arr = new int[10];
// ... 何らかの処理 ...
delete[] arr; // new[] で確保したら delete[] で解放するここでdelete arr; のように [] を付け忘れると、挙動は未定義になります。
クラス型の場合、デストラクタが正しく呼ばれないなど、深刻な不具合につながります。
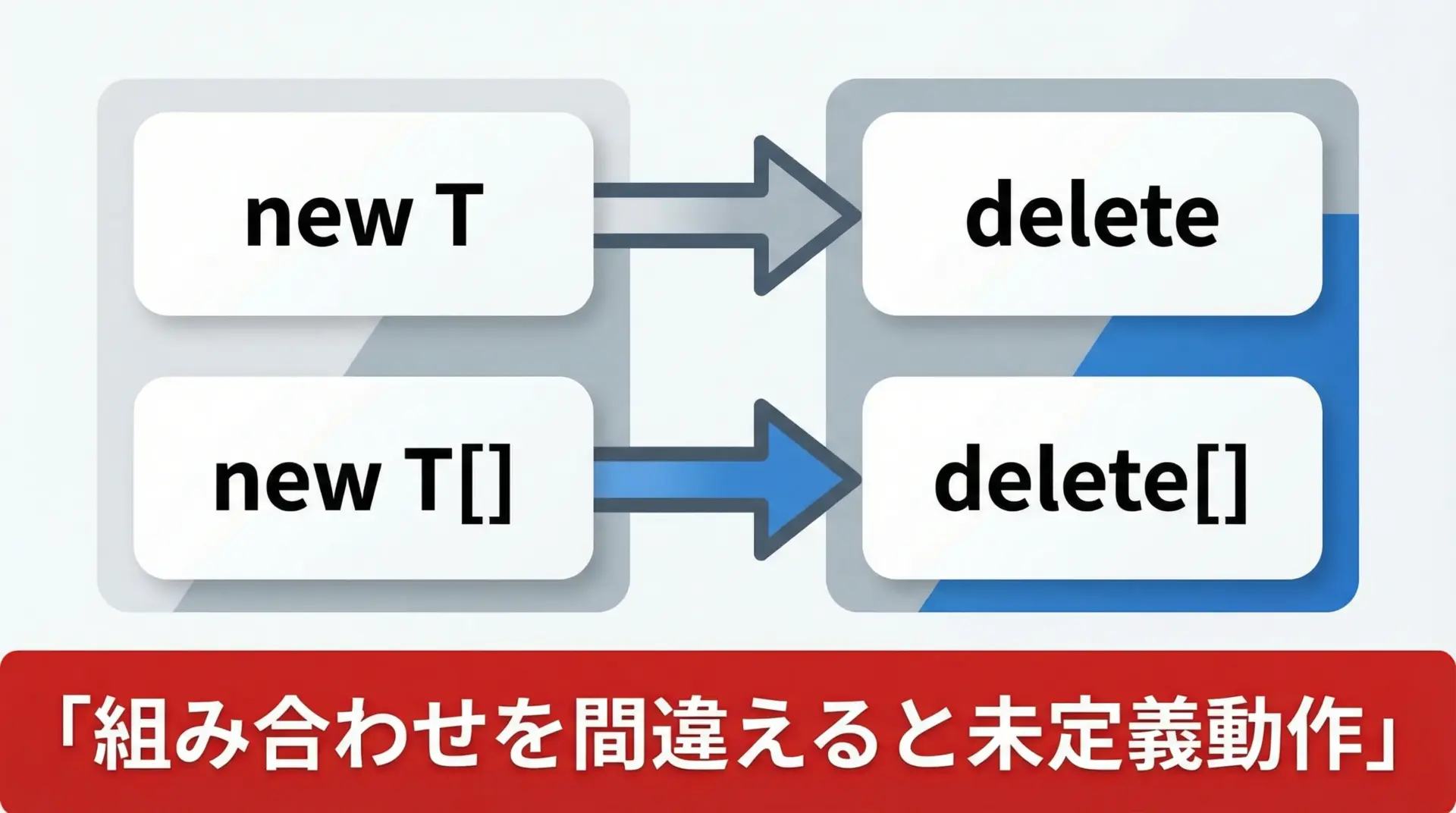
newとnew[]、deleteとdelete[]の組み合わせ
newとdelete、new[]とdelete[]は必ずセットで対応させる必要があります。
| 確保側 | 解放側 | 結果 |
|---|---|---|
new T | delete p; | 正しい組み合わせ |
new T[] | delete[] p; | 正しい組み合わせ |
new T | delete[] p; | 未定義動作(誤り) |
new T[] | delete p; | 未定義動作(誤り) |
どのnewで確保したものかを必ず意識し、対応するdeleteを使うことが重要です。
クラス型配列とコンストラクタ・デストラクタ
クラス型をnew[]したときの動作
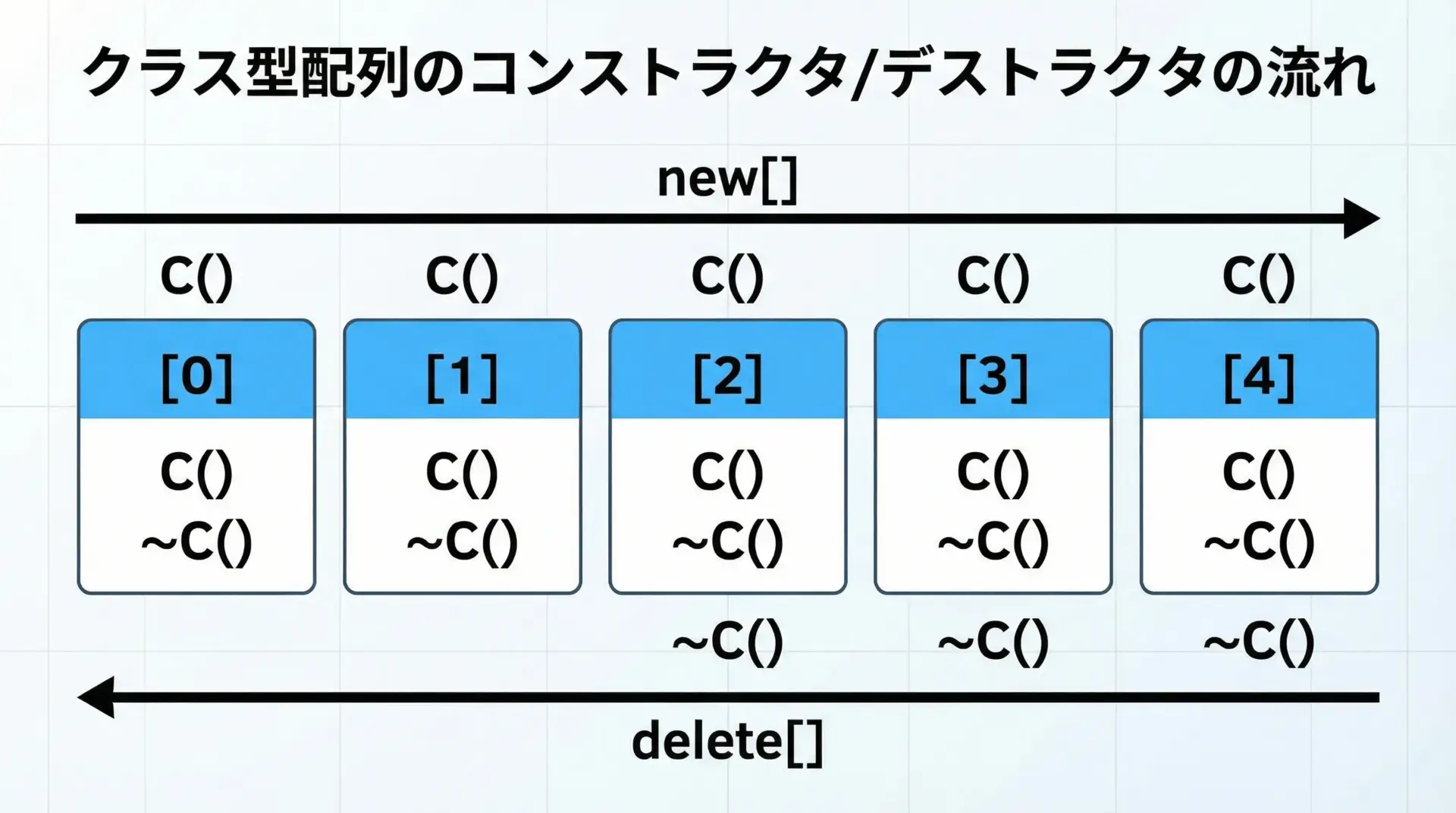
クラス型(ユーザ定義型)の配列をnew[]で確保した場合、配列の全要素に対してコンストラクタが呼ばれます。
同様に、delete[]を呼ぶと、全要素のデストラクタが呼ばれます。
#include <iostream>
#include <string>
class Person {
public:
Person() {
std::cout << "Person コンストラクタ\n";
}
~Person() {
std::cout << "Person デストラクタ\n";
}
};
int main() {
std::cout << "配列を new[] します\n";
Person* people = new Person[3]; // 3人分のPersonを確保
std::cout << "配列を delete[] します\n";
delete[] people;
return 0;
}配列を new[] します
Person コンストラクタ
Person コンストラクタ
Person コンストラクタ
配列を delete[] します
Person デストラクタ
Person デストラクタ
Person デストラクタこのように、クラス型では特に、new[]とdelete[]の組み合わせを間違えるとデストラクタが正しく呼ばれず、リソースリークを招くため注意が必要です。
よくある間違いと危険なパターン
delete[]の書き忘れによるメモリリーク
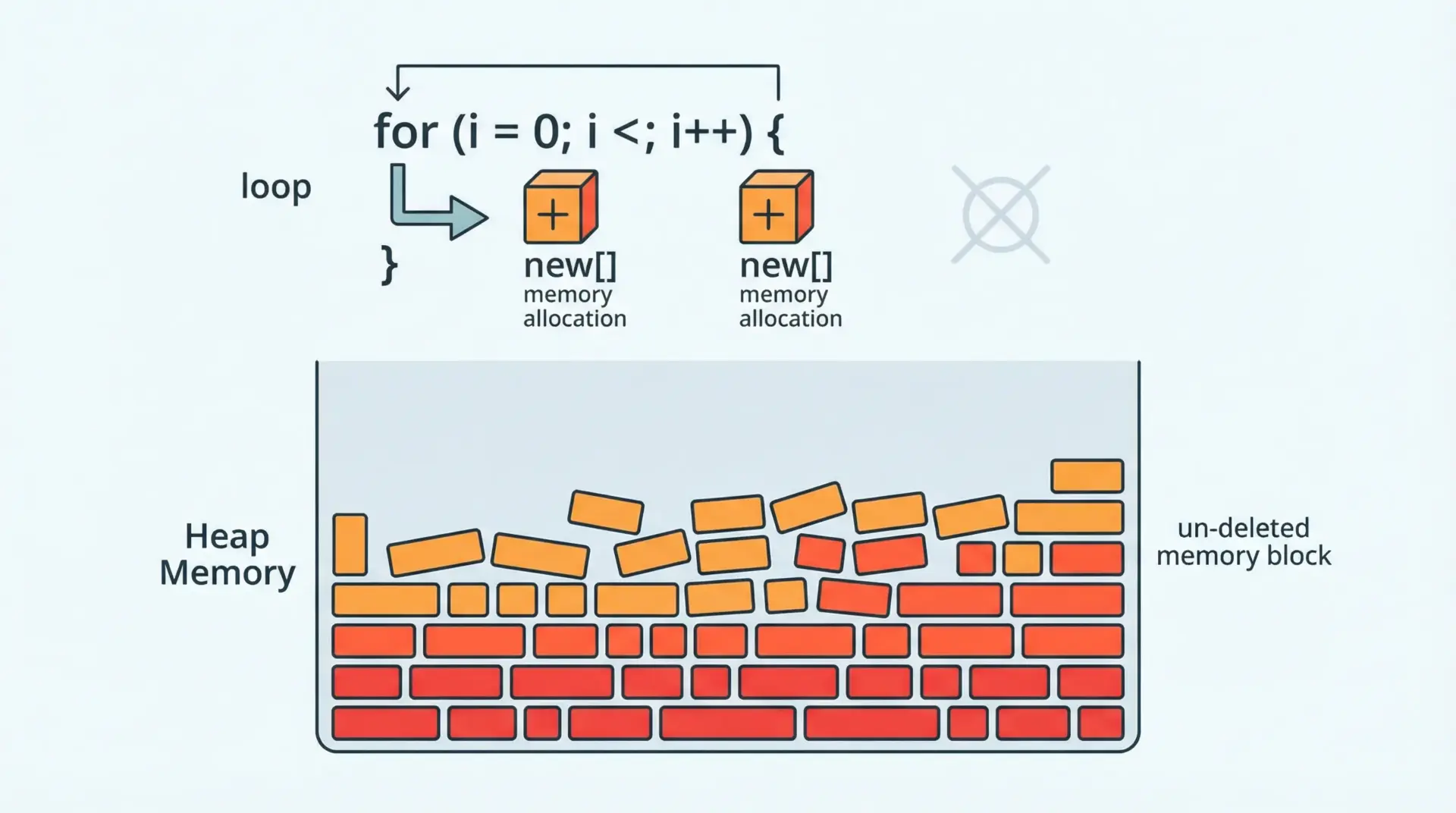
最も典型的なミスはdelete[]を書き忘れることです。
void func() {
int n = 1000;
int* arr = new int[n];
// 何かの処理
// delete[] arr; // ← これを忘れるとメモリリーク
}この関数が何度も呼ばれると、そのたびにヒープにメモリが確保され、解放されないまま溜まっていきます。
長時間動くプログラムでは、最終的にメモリ不足で異常終了する原因になります。
ポインタを上書きしてしまうバグ
int* arr = new int[10];
// うっかり別の場所を代入してしまう
arr = nullptr; // ここで元の配列へのポインタを失う
// delete[] arr; を呼ぶ術がなくなり、リークするこのようにポインタ変数を上書きしてしまうと、元のメモリアドレスを失い、もう解放できなくなります。
これもメモリリークの原因です。
現代C++でのより安全な選択肢(std::vectorとの比較)
なぜ生のnew[]を避けるべきと言われるのか
C++11以降では、原則として生のnew[]/delete[]は使わず、std::vectorやstd::unique_ptrを使うことが推奨されます。
その理由は、人間が手動でメモリ管理するとミスが入りやすいからです。
std::vectorを使うと、サイズ可変の配列を安全に扱うことができます。
#include <iostream>
#include <vector>
int main() {
int n = 0;
std::cout << "要素数を入力してください: ";
std::cin >> n;
// std::vector を使えば new[]/delete[] は不要
std::vector<int> data(n, 0); // n 要素、すべて0で初期化
for (int i = 0; i < n; ++i) {
data[i] = i * 2;
}
for (int i = 0; i < n; ++i) {
std::cout << "data[" << i << "] = " << data[i] << '\n';
}
// スコープを抜けると自動的にメモリが解放される
return 0;
}このようにstd::vectorを使えば、delete[]を書き忘れる心配がなくなるため、実用的なコードではvectorを第一候補にするのが安全です。
まとめ
new[]とdelete[]は、C++で配列を動的に確保・解放するための基本的な仕組みです。
new[]で確保したメモリは、必ずdelete[]で対応させて解放するというルールを守らないと、メモリリークや未定義動作の原因になります。
クラス型配列ではコンストラクタ・デストラクタの呼び出しも関わるため、組み合わせミスは特に危険です。
一方、現代C++ではstd::vectorなどのライブラリコンテナで動的配列を扱うのが標準的になっており、new[]/delete[]の直接利用は必要最小限にとどめるのが安全です。
用途に応じて適切な方法を選び、堅牢なメモリ管理を心がけてください。
