
C++で少し大きめのプログラムを書くようになると、関数名や変数名が他とぶつかってしまう問題に必ず直面します。
そこで登場するのが名前空間(namespace)です。
この記事では、C++のnamespaceの基礎から、実務でよく使う書き方や注意点までを、サンプルコードを交えながら丁寧に解説します。
これからC++のコードを整理していきたい方の指針として、ぜひ役立ててください。
C++の名前空間(namespace)とは
名前空間の役割とねらい
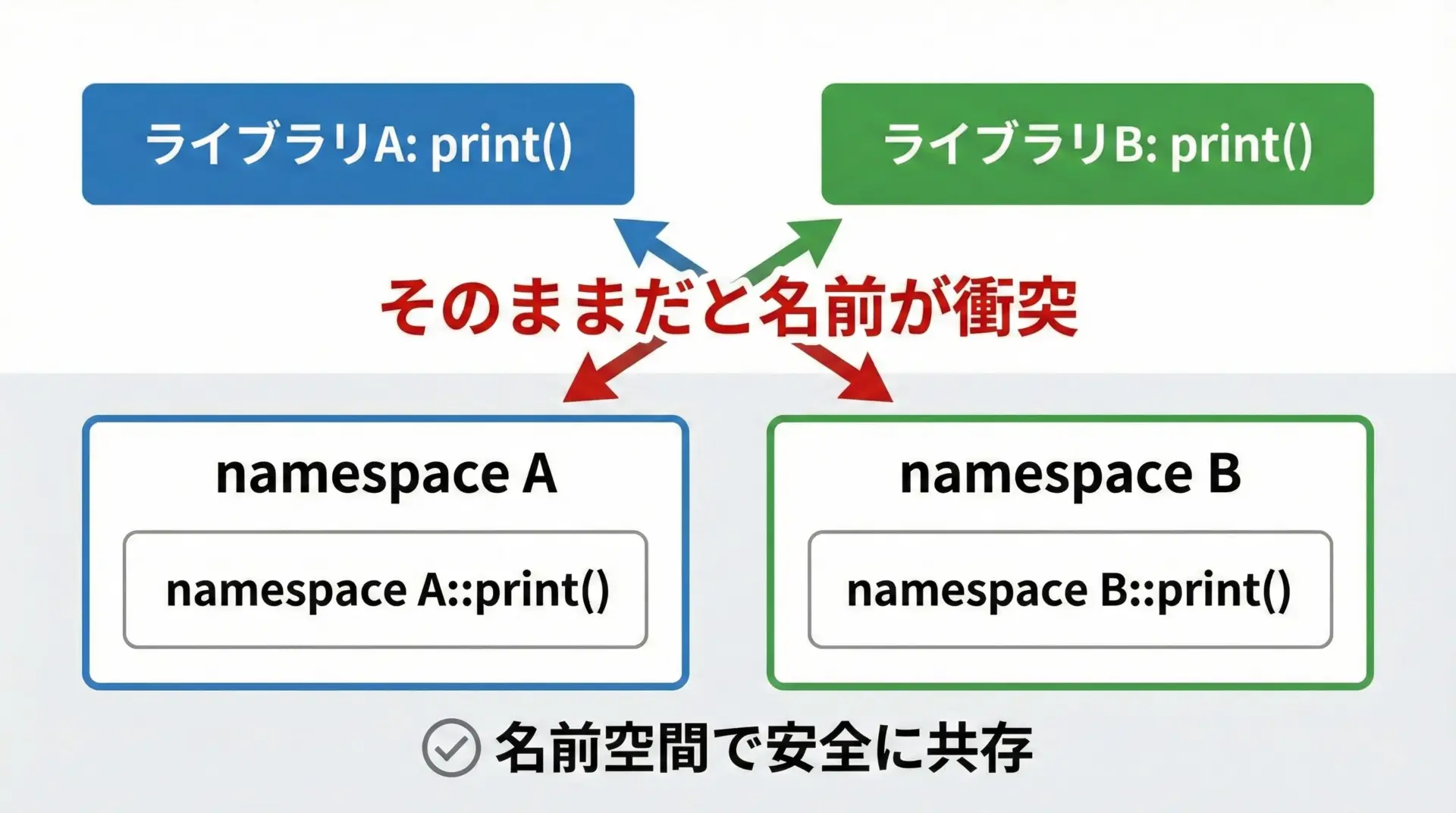
名前空間(namespace)とは、識別子(関数名・変数名・クラス名など)をグループ分けする仕組みです。
より実務寄りに言うと、次のような目的で使われます。
- ライブラリ同士で同じ名前の関数やクラスがあっても、衝突させないようにする
- プロジェクトごと、モジュールごとにコードを整理し、どこに何があるか分かりやすくする
- 大きなシステムで「名前がかぶる事故」を未然に防ぐ
C++標準ライブラリのstd::coutやstd::stringなども、実はstdという名前空間の中に定義されています。
基本構文と最小サンプル
名前空間は、次のような構文で定義します。
namespace 名前空間名 {
// ここに関数や変数、クラスなどを定義
}簡単なサンプルで動作を確認してみます。
#include <iostream>
// 名前空間Aの定義
namespace A {
// A::print という関数になります
void print() {
std::cout << "This is A::print()" << std::endl;
}
}
// 名前空間Bの定義
namespace B {
// B::print という関数になります
void print() {
std::cout << "This is B::print()" << std::endl;
}
}
int main() {
// 名前空間を指定して呼び出す
A::print(); // Aのprint
B::print(); // Bのprint
return 0;
}This is A::print()
This is B::print()このように同じprintという関数名でも、名前空間が違えば問題なく共存できます。
なぜnamespaceが必要なのか
名前衝突(シンボルの衝突)の問題

C言語風にグローバル関数を増やしていくと、次のような問題が発生します。
#include <iostream>
// ライブラリ1の関数
void print() {
std::cout << "Lib1 print" << std::endl;
}
// ライブラリ2の関数(同じ名前)
void print() {
std::cout << "Lib2 print" << std::endl;
}
int main() {
print();
}このようなコードはコンパイルエラーになります。
同じスコープ(ここではグローバル)にprintが2回定義されているからです。
名前空間を使うと、これを安全に分離できます。
namespace Lib1 {
void print();
}
namespace Lib2 {
void print();
}というように、「どのグループのprintなのか」を明示できるようになります。
グローバル名前空間とは
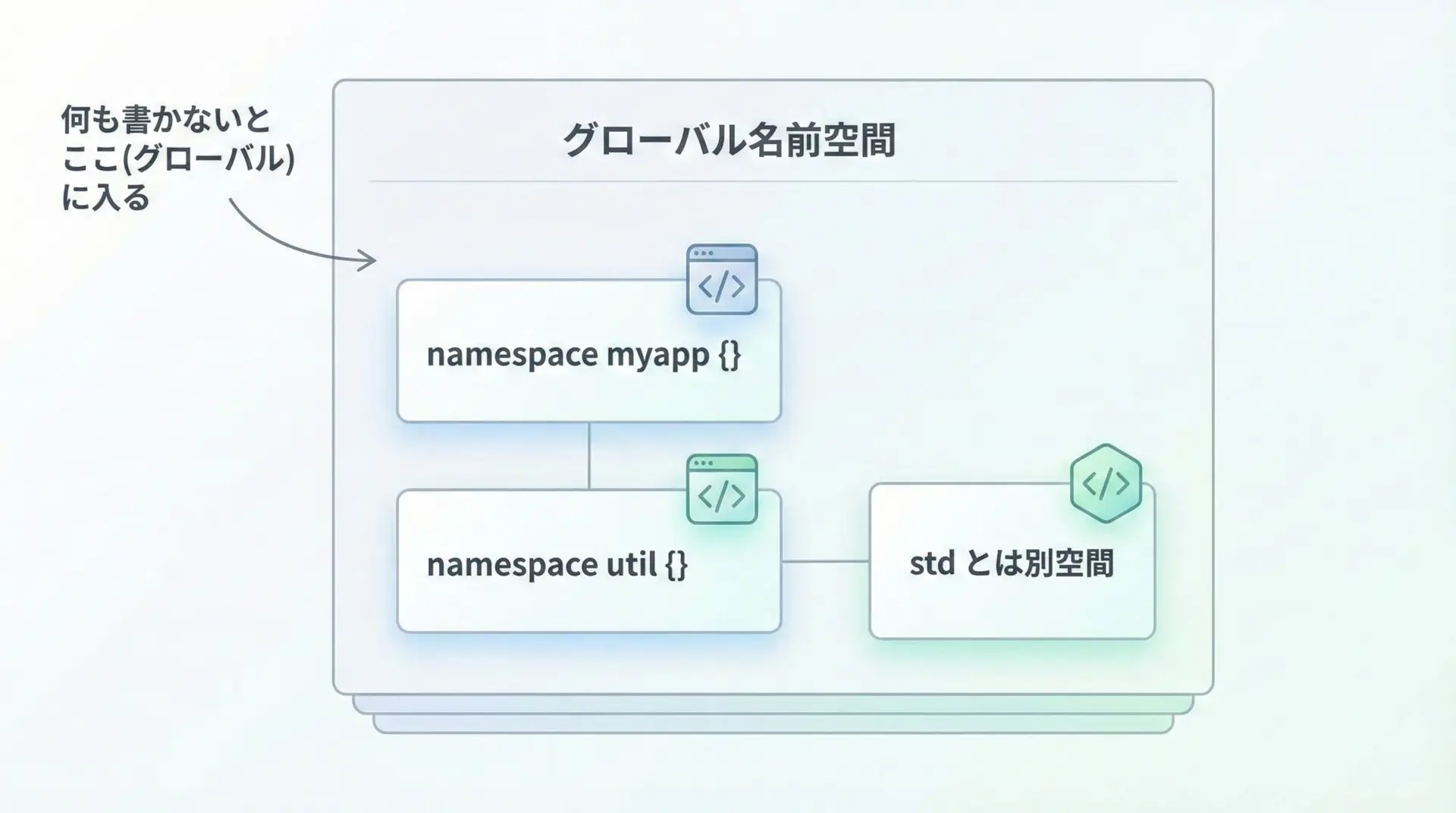
C++には暗黙の「グローバル名前空間」があります。
ファイルの先頭に、何の名前空間にも入れずに定義した関数や変数は、すべてこのグローバル名前空間に属します。
int value = 42; // グローバル名前空間のvalue
void func() {} // グローバル名前空間のfuncグローバル空間は便利ですが、何でも置いてしまうとすぐに名前が混雑して衝突しやすくなるため、ライブラリや大きなプロジェクトでは独自のnamespaceを定義するのが一般的です。
namespaceの基本的な使い方
名前空間の定義とネスト
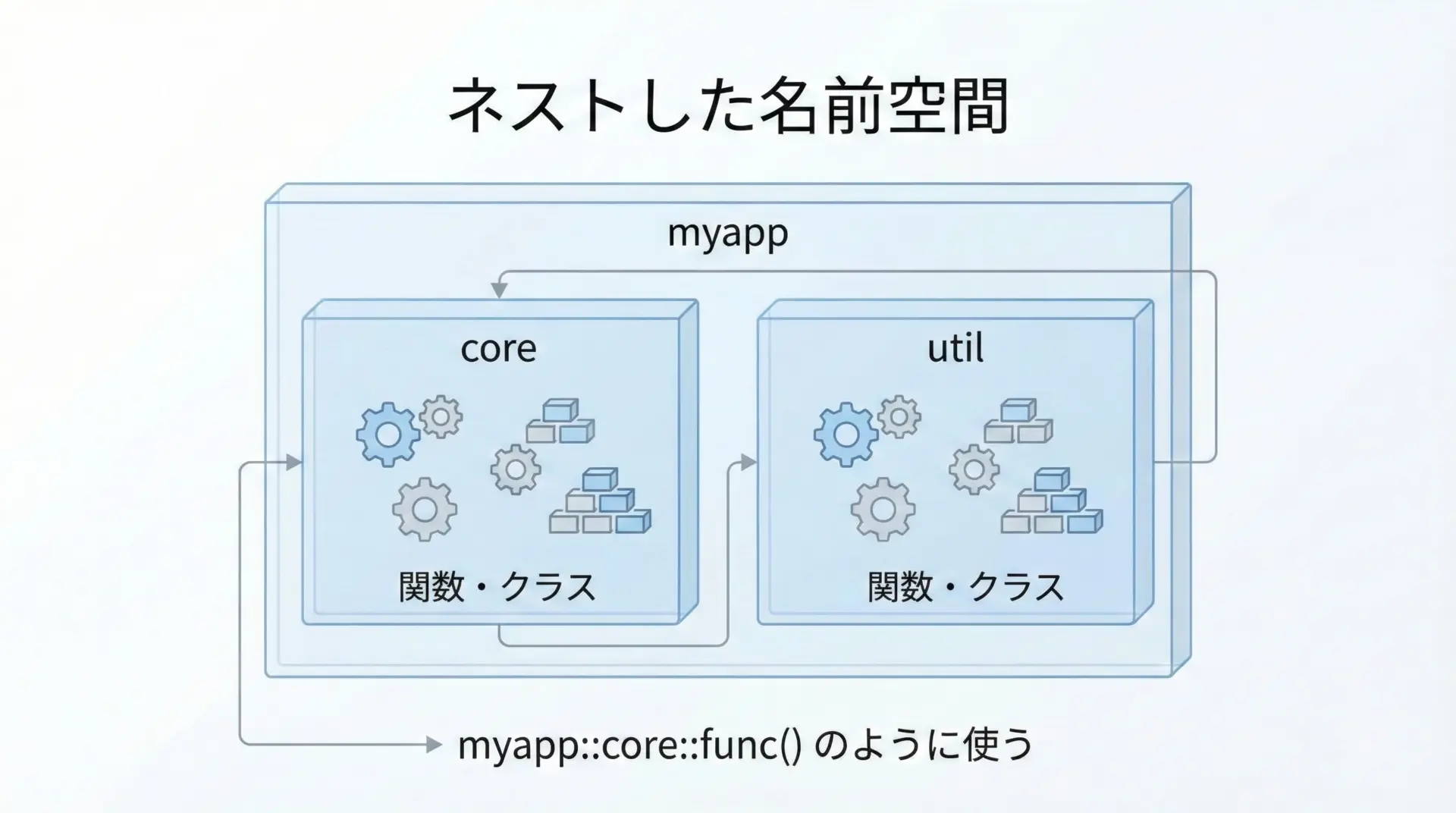
名前空間は入れ子(ネスト)にして定義することができます。
#include <iostream>
namespace myapp {
int version = 1;
namespace core {
void run() {
std::cout << "myapp::core::run(), version = "
<< version << std::endl; // 外側namespaceの変数にアクセス
}
}
namespace util {
void helper() {
std::cout << "myapp::util::helper()" << std::endl;
}
}
}
int main() {
// 完全修飾名で呼び出し
myapp::core::run();
myapp::util::helper();
}myapp::core::run(), version = 1
myapp::util::helper()ネストを使うことで、機能ごとに名前空間を分け、さらにプロジェクト単位のルートnamespaceでまとめると、構造がはっきりして読みやすくなります。
C++17のネスト名前空間省略記法
C++17以降では、ネストした名前空間を次のように簡潔に書けます。
// 従来(C++11など)
namespace myapp {
namespace core {
void run();
}
}
// C++17以降の省略記法
namespace myapp::core {
void run();
}見た目がすっきりするだけでなく、「このブロックはmyapp::coreに属している」ことが一目で分かるため、大きなプロジェクトでは特に読みやすくなります。
using宣言・usingディレクティブ
using宣言で特定の名前だけ取り込む

using宣言は、特定の名前だけを現在のスコープに持ち込むものです。
#include <iostream>
namespace mylib {
void print() {
std::cout << "mylib::print()" << std::endl;
}
}
int main() {
using mylib::print; // mylib::print を現在のスコープでそのまま使えるようにする
print(); // mylib::print() が呼ばれる
// mylib::print(); // もちろんこれでもOK
return 0;
}mylib::print()このように「よく使うが、名前空間名まで書くと長くて読みにくい」という場合に、特定の関数やクラスだけを取り込むのがusing宣言です。
衝突のリスクを抑えつつ、記述量も減らせるため、推奨される使い方です。
usingディレクティブで名前空間全体を取り込む
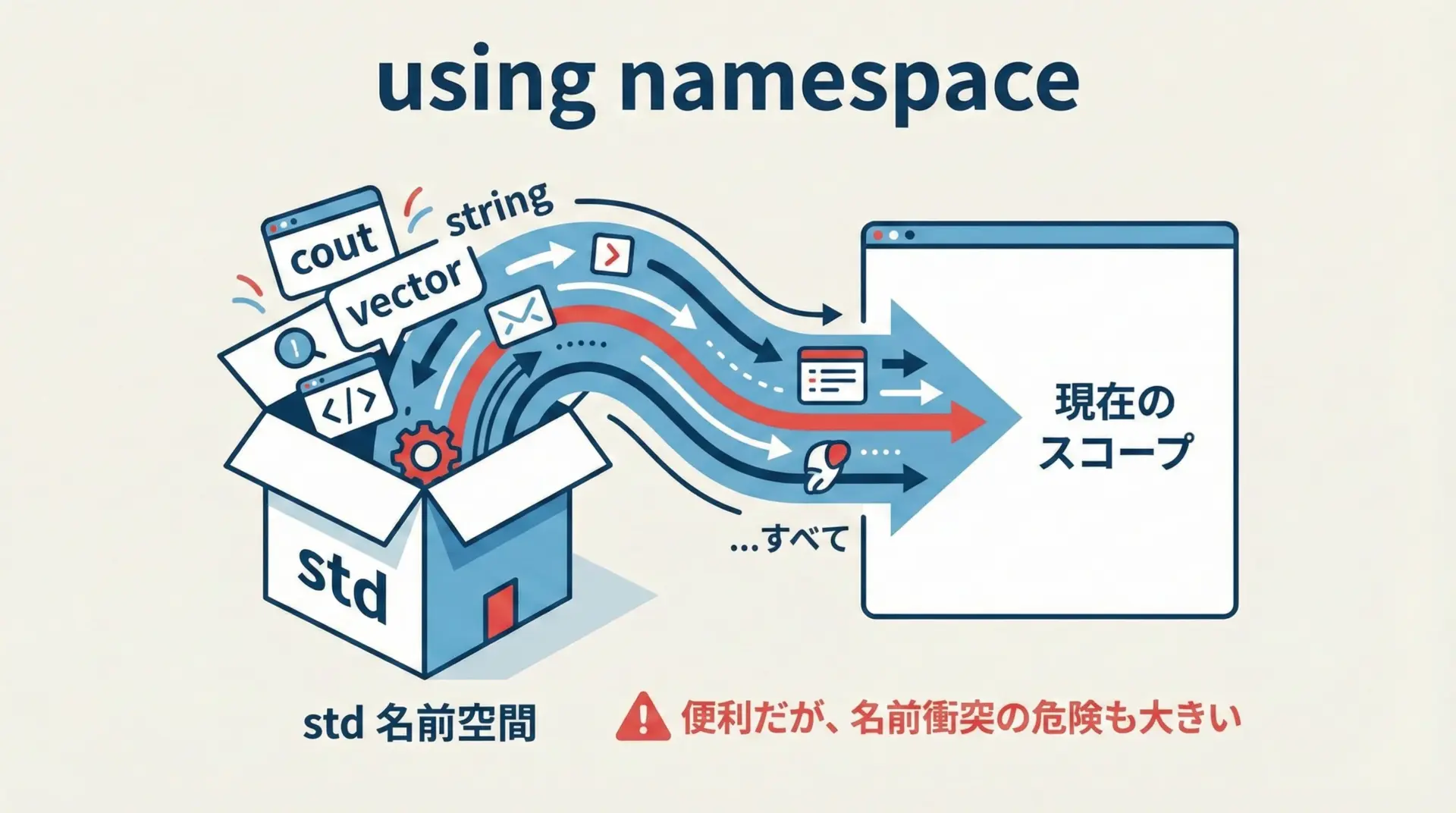
usingディレクティブは、名前空間内のすべての名前を現在のスコープに持ち込みます。
#include <iostream>
using namespace std; // std:: を省略できる
int main() {
cout << "Hello, world!" << endl; // std::cout, std::endl と書かなくてよい
return 0;
}Hello, world!とても便利ですが、名前の衝突を起こしやすいため、実務では次のような方針がよく取られます。
- ヘッダファイルでは
using namespaceを書かない - 実装ファイル(cpp)でも、できるだけ
std::を明示するか、using std::string;のように限定的なusing宣言を使う
小さなサンプルコードや学習用コード以外では、using namespace std;は控えると覚えておくのが安全です。
無名名前空間(anonymous namespace)
無名名前空間とは何か
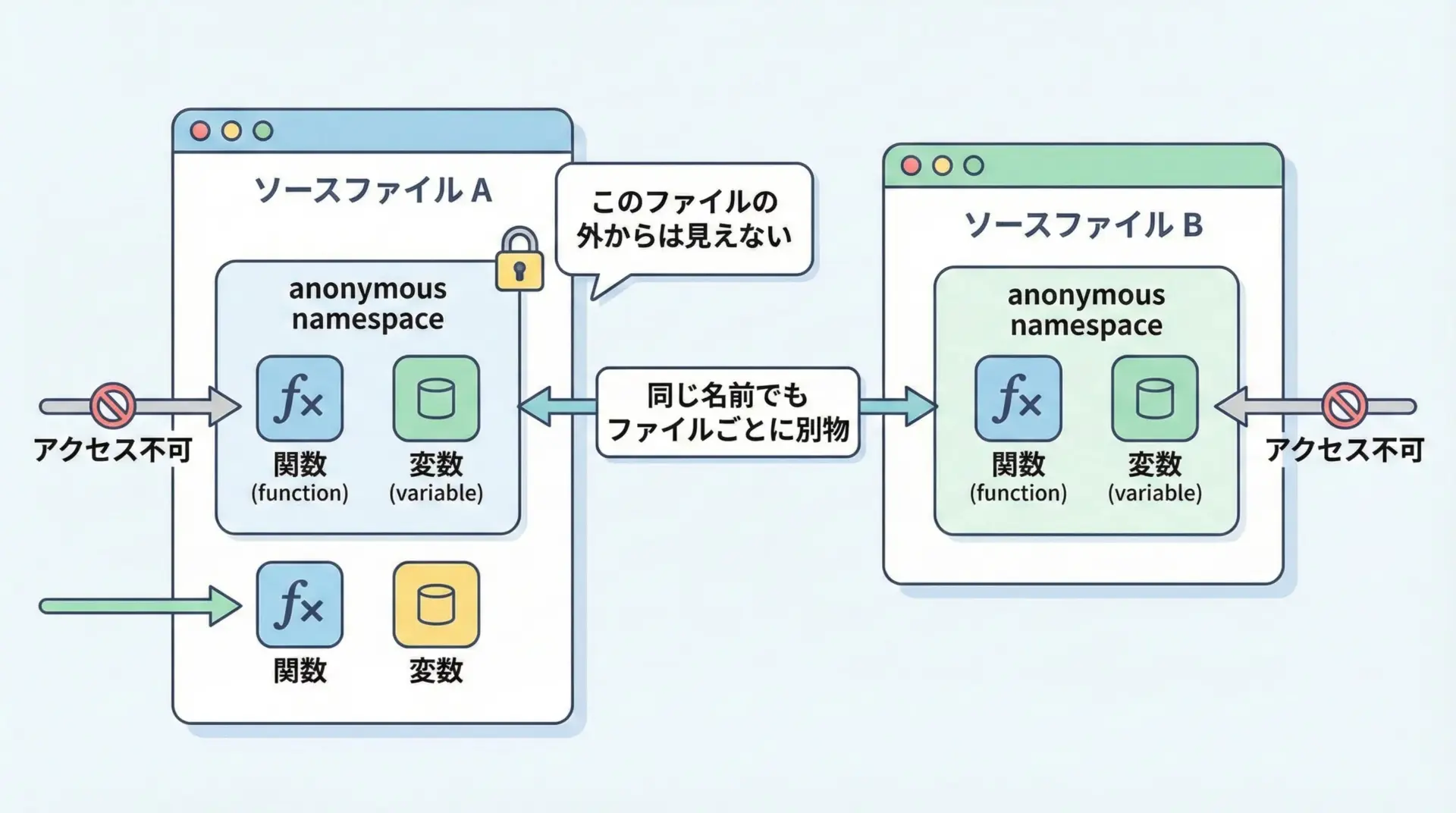
無名名前空間(anonymous namespace)とは、名前を付けないnamespaceのことです。
namespace {
int internal_value = 0;
void internal_func() {
// 何か処理
}
}無名名前空間に定義したものは、そのソースファイル内からしか見えません。
C言語でいうstaticなグローバル変数・関数と似た役割で、ファイル内限定の「内部リンク」を持つ識別子を作る目的で使われます。
簡単なサンプル
#include <iostream>
// 無名名前空間によるファイル内限定の変数・関数
namespace {
int counter = 0;
void increment() {
++counter;
}
}
int main() {
increment();
increment();
std::cout << "counter = " << counter << std::endl;
return 0;
}counter = 2このcounterやincrementは、同じプロジェクト内の他のソースファイルからは参照できません。
「このファイルの中だけで完結させたい実装」を隠すために便利です。
namespaceの実務的な設計例
プロジェクト用のトップレベルnamespaceを持つ
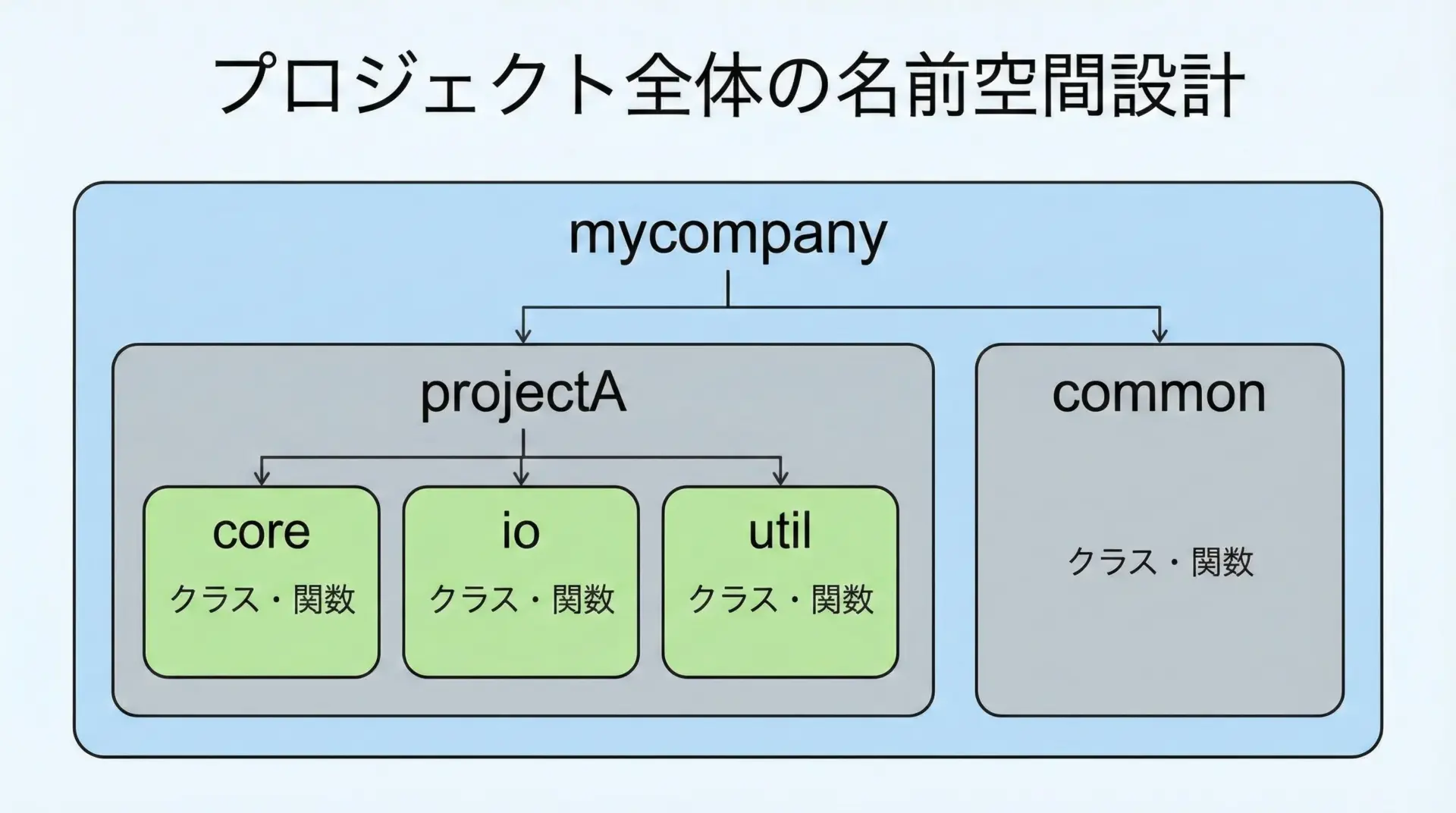
中規模以上のプロジェクトでは、次のような構造がよく採用されます。
- 会社や組織名をトップレベルnamespaceにする(cst-code>mycompany)
- プロジェクト名を第2階層にする(cst-code>mycompany::projectA)
- 機能別にさらに分ける(cst-code>core,
io,utilなど)
コード例は次のようになります。
// mycompany_projectA_core.h
#pragma once
#include <string>
namespace mycompany::projectA::core {
class Engine {
public:
void run();
};
std::string version();
} // namespace mycompany::projectA::core// mycompany_projectA_core.cpp
#include "mycompany_projectA_core.h"
#include <iostream>
namespace mycompany::projectA::core {
void Engine::run() {
std::cout << "Engine running, version = " << version() << std::endl;
}
std::string version() {
return "1.0.0";
}
} // namespace mycompany::projectA::core// main.cpp
#include "mycompany_projectA_core.h"
int main() {
mycompany::projectA::core::Engine engine;
engine.run();
return 0;
}Engine running, version = 1.0.0このように自分たちだけの「空間」を持っておくことで、他のライブラリと名前がぶつかりにくくなり、長期的に安全です。
namespaceエイリアスで長い名前を短くする
名前空間の階層が深くなると、毎回フルネームを書くのが大変になります。
その場合はnamespaceエイリアスが便利です。
#include "mycompany_projectA_core.h"
// 長い名前空間に短い別名をつける
namespace core = mycompany::projectA::core;
int main() {
core::Engine engine; // 短いエイリアスを通じて利用
engine.run();
return 0;
}Engine running, version = 1.0.0エイリアスは読みやすさと入力のしやすさを両方向上させるので、深い名前空間を扱うときには積極的に検討すると良いです。
namespaceを使うときの注意点
ヘッダファイルでのusing namespace禁止
ヘッダファイルでusing namespaceを書くと、そのヘッダをインクルードしたすべてのファイルに影響が及びます。
// bad_header.h
#pragma once
#include <iostream>
using namespace std; // これは避けるべき
void func();このヘッダをインクルードしたファイルは、意図せずstdのすべての名前が現在のスコープに流れ込んでしまいます。
別のライブラリのシンボルと衝突したり、名前解決が分かりづらくなったりするため、ヘッダではusing namespaceを書かないのが定石です。
同じnamespaceの再オープン
同じ名前空間を複数の場所で「開き直す」ことができますが、分割しすぎるとどこに何があるか分かりにくくなります。
// file1.cpp
namespace mylib {
void func1();
}
// file2.cpp
namespace mylib {
void func2();
}このように分けること自体は禁止されていませんが、論理的なまとまりごとにファイルやnamespaceを整理することを意識しないと、保守性が下がります。
まとめ
名前空間(namespace)は、C++で名前の衝突を防ぎ、コードを論理的なグループに整理するための重要な仕組みです。
stdに代表されるように、プロジェクト固有のトップレベルnamespaceを設け、その下をネストしていくことで、規模が大きくなっても見通しのよい構成にできます。
さらに、using宣言やnamespaceエイリアス、無名名前空間などを組み合わせることで、記述量を抑えつつ安全にスコープを管理できます。
サンプルコードを参考にしながら、自分のプロジェクトでもnamespaceの設計を意識してみてください。
