C++で文字列を扱うときに避けて通れないのがstd::stringです。
C言語の文字配列と違い、メモリ管理を意識せずに文字列を扱えるため、初心者から上級者まで幅広く使われています。
本記事では、基本的な使い方から便利な文字列操作、よくある落とし穴までを、サンプルコードとともに丁寧に解説します。
C++における文字列の基本
C文字列とstd::stringの違い
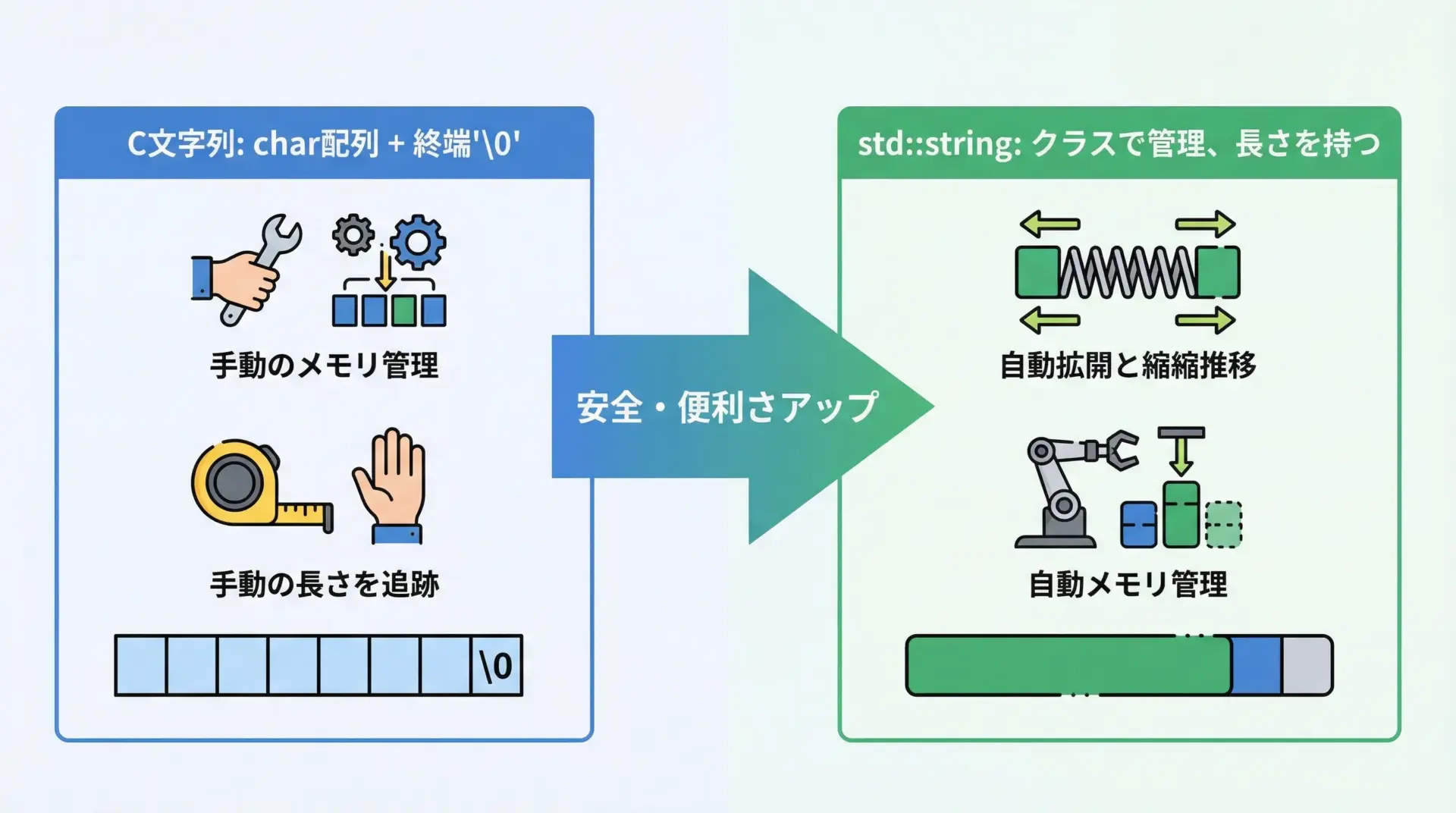
C++では、文字列を表現する方法として大きく2種類があります。
ひとつはC言語から受け継いだヌル終端文字列(C文字列)、もうひとつがC++標準ライブラリで提供されるstd::stringです。
C文字列はchar配列で表現され、末尾に'\0'(ヌル文字)を付けて終端を表します。
一方、std::stringはクラスであり、自身で長さ情報とメモリを管理します。
代表的な違いを表にまとめます。
| 項目 | C文字列(char配列) | std::string |
|---|---|---|
| メモリ管理 | 自分で配列サイズを決める | 自動で拡張・縮小 |
| 長さの取得 | strlenで毎回計算 | size()で即取得 |
| 代入・連結 | strcpy, strcatなど | 代入演算子=, +, += |
| 安全性 | バッファあふれを起こしやすい | より安全で直感的 |
| 標準ライブラリ連携 | 一部で必要 | C++の多くの機能と連携しやすい |
通常のC++プログラムでは、まずstd::stringを使うことを基本にするとよいです。
Cスタイル文字列は、レガシーAPIとの連携時など必要なときだけ使う、というスタンスが安全です。
std::stringを使うための準備
C++でstd::stringを使うには、#includeと名前空間に注意する必要があります。
#include <iostream> // 入出力に必要
#include <string> // std::stringを使うのに必要
int main() {
std::string s = "Hello, world!";
std::cout << s << std::endl;
return 0;
}Hello, world!ヘッダ<string>のインクルードを忘れるとコンパイルエラーになります。
using namespace std;は便利ですが、大規模開発では名前衝突の原因にもなるため、std::stringのようにstd::を付けて使う書き方に慣れておくと安心です。
std::stringの基本操作
文字列の宣言と初期化

std::stringには複数の宣言・初期化方法があります。
代表的な例を見てみます。
#include <iostream>
#include <string>
int main() {
// 空の文字列
std::string s1; // 中身は空
// 文字列リテラルから初期化
std::string s2 = "Hello";
std::string s3("World"); // コンストラクタ形式
// コピー初期化
std::string s4 = s2; // s4は"Hello"
// 同じ文字の繰り返しで初期化
std::string s5(5, 'A'); // "AAAAA"
std::cout << "s2: " << s2 << std::endl;
std::cout << "s3: " << s3 << std::endl;
std::cout << "s5: " << s5 << std::endl;
return 0;
}s2: Hello
s3: World
s5: AAAAAどの書き方でも最終的に生成されるのはstd::stringオブジェクトであり、用途や好みに合わせて選べます。
文字列の代入と連結
文字列の代入や連結は、整数などと同じ感覚で扱えます。
#include <iostream>
#include <string>
int main() {
std::string a = "Hello";
std::string b = "World";
// 代入
a = "Hi"; // aは"Hi"に変わる
// 連結(+)演算子
std::string c = a + " " + b; // "Hi World"
// 追記(+=)演算子
c += "!"; // "Hi World!"
std::cout << c << std::endl;
return 0;
}Hi World!std::stringは長さを自動で調整してくれるため、代入や連結をしても自分でメモリを確保し直す必要はありません。
文字列の長さと空判定
文字列の長さはsize()またはlength()で取得できます。
意味は同じです。
#include <iostream>
#include <string>
int main() {
std::string s = "Hello";
std::cout << "size(): " << s.size() << std::endl;
std::cout << "length(): " << s.length() << std::endl;
if (s.empty()) { // 空ならtrue
std::cout << "Empty" << std::endl;
} else {
std::cout << "Not empty" << std::endl;
}
return 0;
}size(): 5
length(): 5
Not empty空文字かどうかはempty()で判定するのが分かりやすく、安全です。
文字単位のアクセスと変更
インデックス演算子とat関数
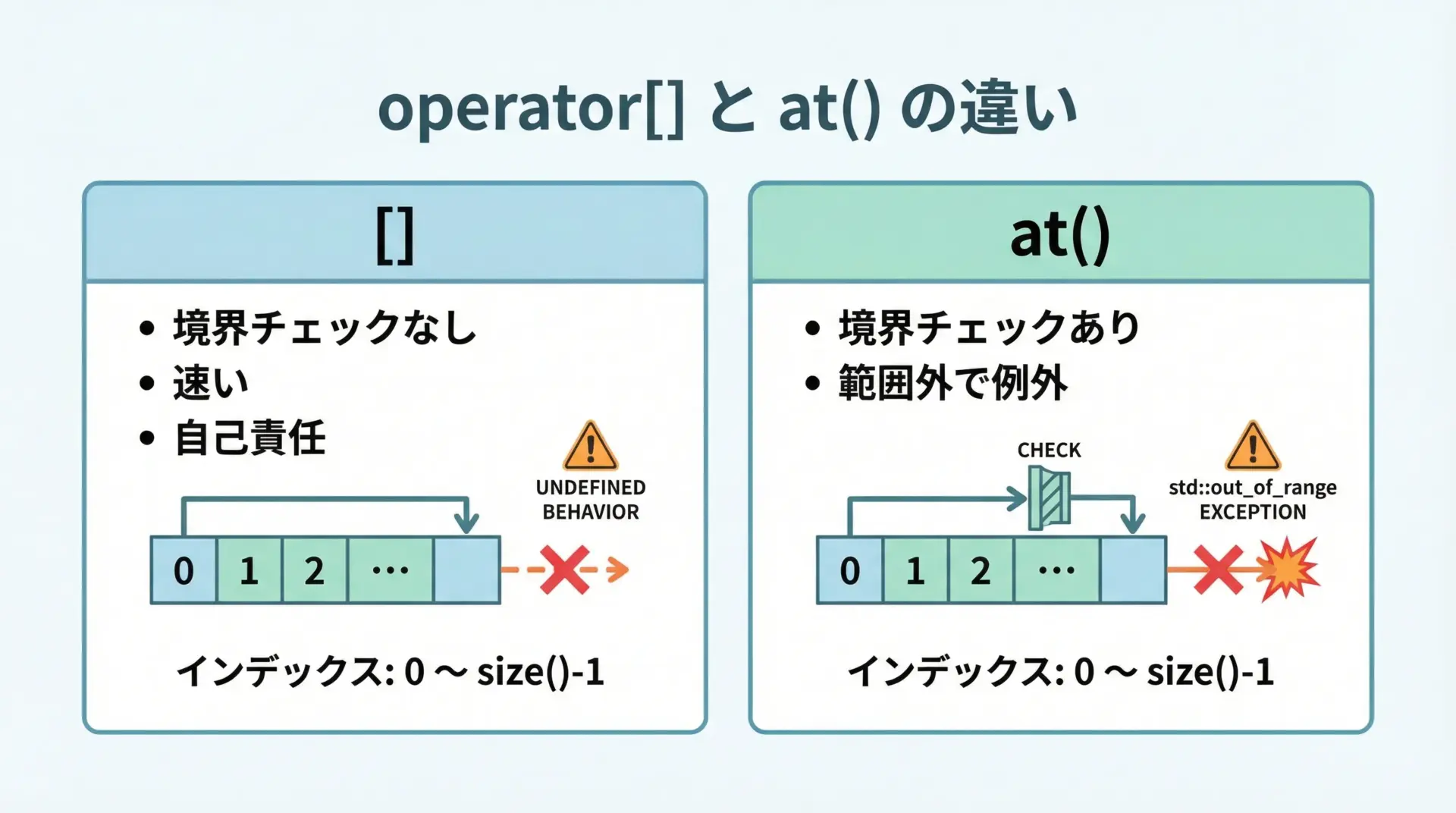
std::stringは配列のように[]で個々の文字にアクセスできます。
#include <iostream>
#include <string>
int main() {
std::string s = "ABC";
// 読み取り
char c0 = s[0]; // 'A'
char c1 = s.at(1); // 'B'
// 書き換え
s[2] = 'Z'; // "ABZ"
s.at(0) = 'X'; // "XBZ"
std::cout << s << std::endl;
return 0;
}XBZ[]とatの違いは境界チェックの有無です。
atは範囲外アクセス時にstd::out_of_range例外を投げるため、デバッグ時や安全性重視のコードではatの使用が推奨されることもあります。
ループで1文字ずつ処理する
文字列の各文字を順番に処理するには、インデックスループか範囲for文を使います。
#include <iostream>
#include <string>
int main() {
std::string s = "Hello";
// インデックスを使ったループ
for (std::size_t i = 0; i < s.size(); ++i) {
std::cout << s[i] << " ";
}
std::cout << std::endl;
// 範囲for文(C++11以降)
for (char ch : s) {
std::cout << "[" << ch << "]";
}
std::cout << std::endl;
return 0;
}H e l l o
[H][e][l][l][o]範囲for文は簡潔で読みやすく、バグも入りにくいため、C++11以降では積極的に利用するとよいです。
よく使う文字列操作メソッド
部分文字列の取得 substr

substrは、元の文字列から一部を切り出して新しい文字列を作成します。
#include <iostream>
#include <string>
int main() {
std::string s = "Hello World";
// 位置0から5文字
std::string a = s.substr(0, 5); // "Hello"
// 位置6から末尾まで
std::string b = s.substr(6); // "World"
std::cout << "a: " << a << std::endl;
std::cout << "b: " << b << std::endl;
return 0;
}a: Hello
b: Worldsubstrの第1引数は開始位置、第2引数は長さです。
第2引数を省略すると末尾までが対象になります。
検索 find / rfind
文字列内から特定の文字や文字列を探すにはfindやrfindを使います。
#include <iostream>
#include <string>
int main() {
std::string s = "abcdeabc";
// 先頭から検索
std::size_t pos1 = s.find("abc"); // 0
// 指定位置から検索
std::size_t pos2 = s.find("abc", 1); // 5
// 後ろから検索
std::size_t pos3 = s.rfind("abc"); // 5
if (pos1 != std::string::npos) { // 見つかったか確認
std::cout << "pos1: " << pos1 << std::endl;
}
std::cout << "pos2: " << pos2 << std::endl;
std::cout << "pos3: " << pos3 << std::endl;
return 0;
}pos1: 0
pos2: 5
pos3: 5見つからなかった場合はstd::string::nposが返るため、必ずこの値との比較で判定します。
挿入 insert・削除 erase・置換 replace
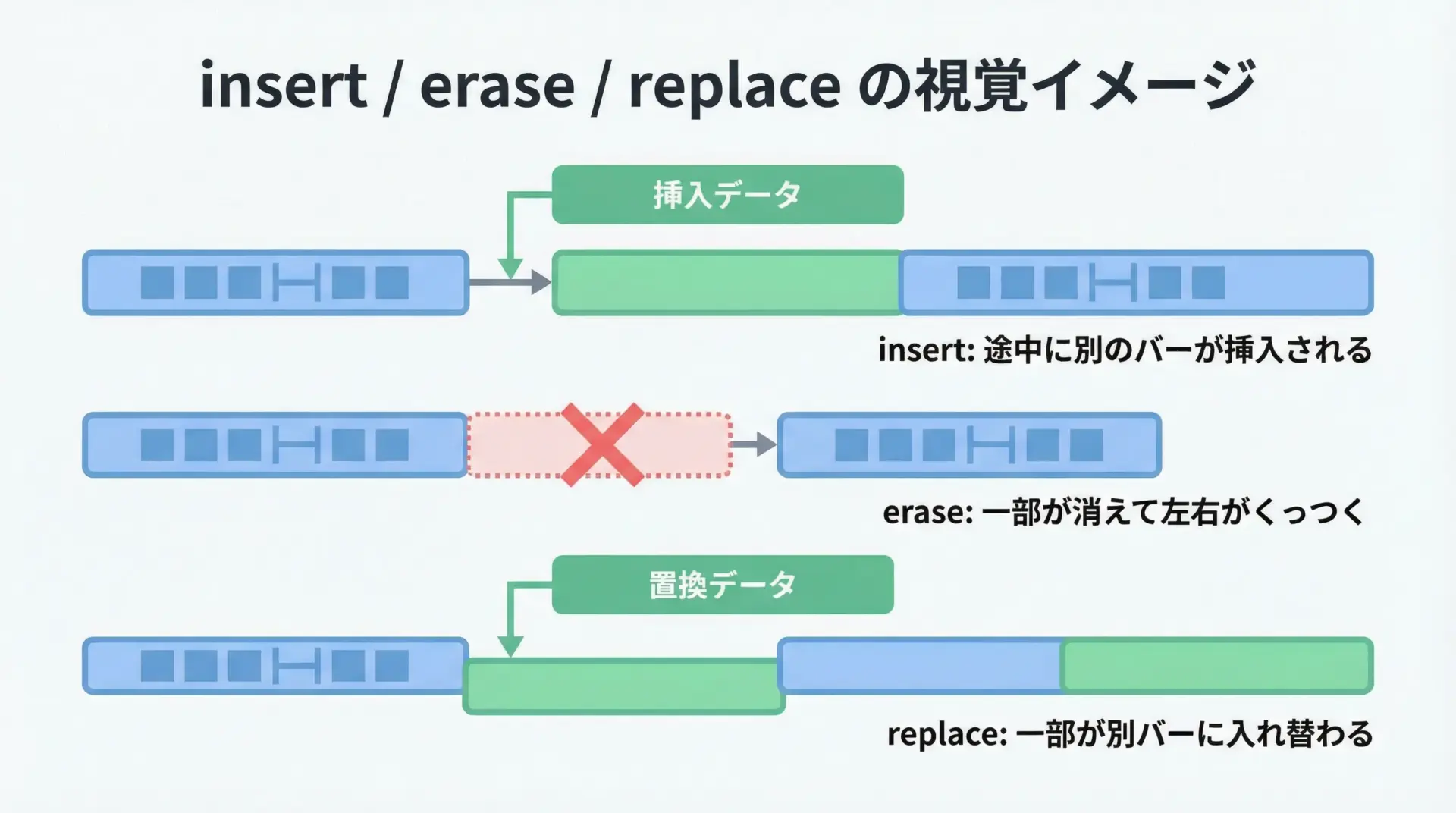
文字列の一部に対して挿入、削除、置換を行うメソッドもよく使われます。
#include <iostream>
#include <string>
int main() {
std::string s = "Hello World";
// 挿入: 位置5に","を挿入
s.insert(5, "," ); // "Hello, World"
// 削除: 位置5から1文字削除
s.erase(5, 1); // "Hello World"
// 置換: 位置6から5文字を"CPP"に置き換え
s.replace(6, 5, "CPP"); // "Hello CPP"
std::cout << s << std::endl;
return 0;
}Hello CPPinsert・erase・replaceはいずれも「位置と長さ」を指定するインターフェースで、配列操作のような感覚で扱えます。
入出力と数値変換
標準入力・出力との連携
std::stringはstd::cinやstd::coutと直接やり取りできます。
#include <iostream>
#include <string>
int main() {
std::string name;
std::cout << "名前を入力してください: ";
std::cin >> name; // 空白で区切られる
std::cout << "こんにちは、" << name << " さん" << std::endl;
return 0;
}名前を入力してください: Taro
こんにちは、Taro さん空白を含む行全体を読みたい場合はstd::getlineを使う必要があります。
#include <iostream>
#include <string>
int main() {
std::string line;
std::cout << "1行入力してください: ";
std::getline(std::cin, line); // 改行までをすべて読み込む
std::cout << "入力した行: " << line << std::endl;
return 0;
}1行入力してください: Hello C++ string
入力した行: Hello C++ string数値との相互変換

C++11以降では、文字列と数値の変換が非常に簡単になりました。
#include <iostream>
#include <string>
int main() {
std::string s1 = "123";
std::string s2 = "3.14";
// 文字列 → 数値
int n = std::stoi(s1); // "123" → 123
double d = std::stod(s2); // "3.14" → 3.14
// 数値 → 文字列
std::string s3 = std::to_string(n); // 123 → "123"
std::string s4 = std::to_string(d); // 3.14 → "3.140000" など
std::cout << "n: " << n << ", d: " << d << std::endl;
std::cout << "s3: " << s3 << ", s4: " << s4 << std::endl;
return 0;
}n: 123, d: 3.14
s3: 123, s4: 3.140000入力文字列が数値として解釈できない場合はstd::invalid_argument例外が投げられるため、実用コードでは例外処理も検討してください。
C文字列との相互運用
c_strでconst char*を取得
古いC言語の関数や一部のライブラリは、const char*形式の文字列(C文字列)しか受け取れません。
そのような場合、std::stringのc_str()メソッドでC文字列へのポインタを取得します。
#include <iostream>
#include <string>
#include <cstdio> // printfなどのC標準入出力
int main() {
std::string s = "Hello C API";
// Cのprintfに渡す
std::printf("message: %s\n", s.c_str());
return 0;
}message: Hello C APIc_str()はstd::string内部バッファへのポインタを返すだけで、コピーは行いません。
そのため、文字列オブジェクトが破棄された後にこのポインタを使うと未定義動作になります。
C文字列からstd::stringを作る
逆方向、つまりC文字列からstd::stringを作るのは簡単です。
コンストラクタや代入でそのまま渡せます。
#include <iostream>
#include <string>
int main() {
const char* cstr = "Hello from C string";
// C文字列からstd::stringを生成
std::string s1 = cstr;
std::string s2(cstr);
std::cout << s1 << std::endl;
std::cout << s2 << std::endl;
return 0;
}Hello from C string
Hello from C string可能な限り早い段階でC文字列をstd::stringに変換してしまうことで、その後の処理を安全かつ簡潔にできます。
よくある注意点とベストプラクティス
文字コードとマルチバイト文字
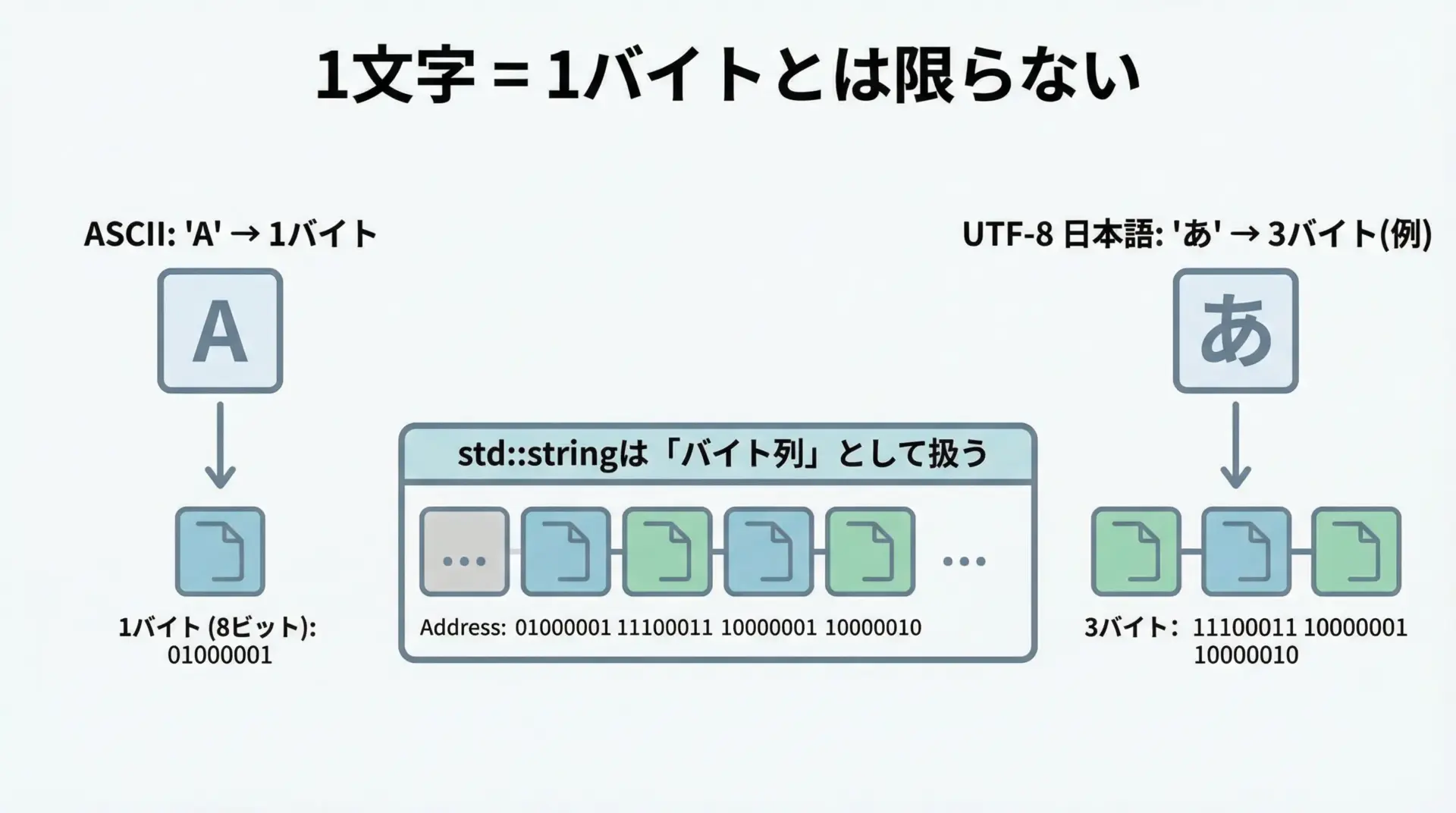
std::stringは「文字の並び」ではなく「バイト列の並び」として実装されていることが多く、特にUTF-8環境では日本語1文字が複数バイトになることに注意が必要です。
そのため、size()で取得できるのは「文字数」ではなく「バイト数」である場合があります。
日本語を1文字単位で正しく扱いたい場合はstd::u32stringなどや、外部ライブラリ(ICUなど)の利用も検討すべきです。
パフォーマンスを意識した使い方の一例
大量の連結を行う場合、安易に+を繰り返すと一時オブジェクトが増えて非効率になることがあります。
そのような場合は+=やreserve()での事前確保を検討します。
#include <iostream>
#include <string>
int main() {
std::string s;
s.reserve(1000); // 事前に1000バイト分を確保(目安)
for (int i = 0; i < 10; ++i) {
s += "abc"; // 連結を繰り返す
}
std::cout << s << std::endl;
return 0;
}abcabcabcabcabcabcabcabcabcabc小規模なコードではあまり気にしなくても構いませんが、大量の文字列処理を行う場合にはこのような工夫が効いてきます。
まとめ
std::stringは、C++での文字列処理を安全かつ直感的に行うための中核的なクラスです。
本記事では、宣言と初期化、代入・連結、長さや空判定、文字単位アクセス、substr・find・insert・erase・replaceといった基本操作、標準入出力との連携や数値変換、c_strによるC文字列との橋渡しなどを一通り紹介しました。
まずは日常的な文字列処理をすべてstd::stringで書いてみることで、その便利さと表現力を実感できるはずです。
