
C言語では、データ型を正しく理解することが、バグの少ないプログラムを書くための大きな鍵になります。
本記事ではC言語で扱えるデータ型を一覧し、サイズ(バイト数)・値の範囲・使い分け方を、サンプルコードと図解イメージを交えながら丁寧に解説します。
32bit環境と64bit環境の違いにも触れつつ、実務で迷いやすいポイントも整理します。
C言語のデータ型とは
C言語の基本データ型一覧
C言語の基本データ型は、大きく次の4つに分類できます。
- 整数型(int, char, short, long など)
- 浮動小数点型(float, double など)
- 論理型(_Bool)
- その他の型(ポインタ、配列、構造体、共用体、列挙型など)
ここでは、まず「基本データ型」がどのように分類されるかを一覧表で整理します。
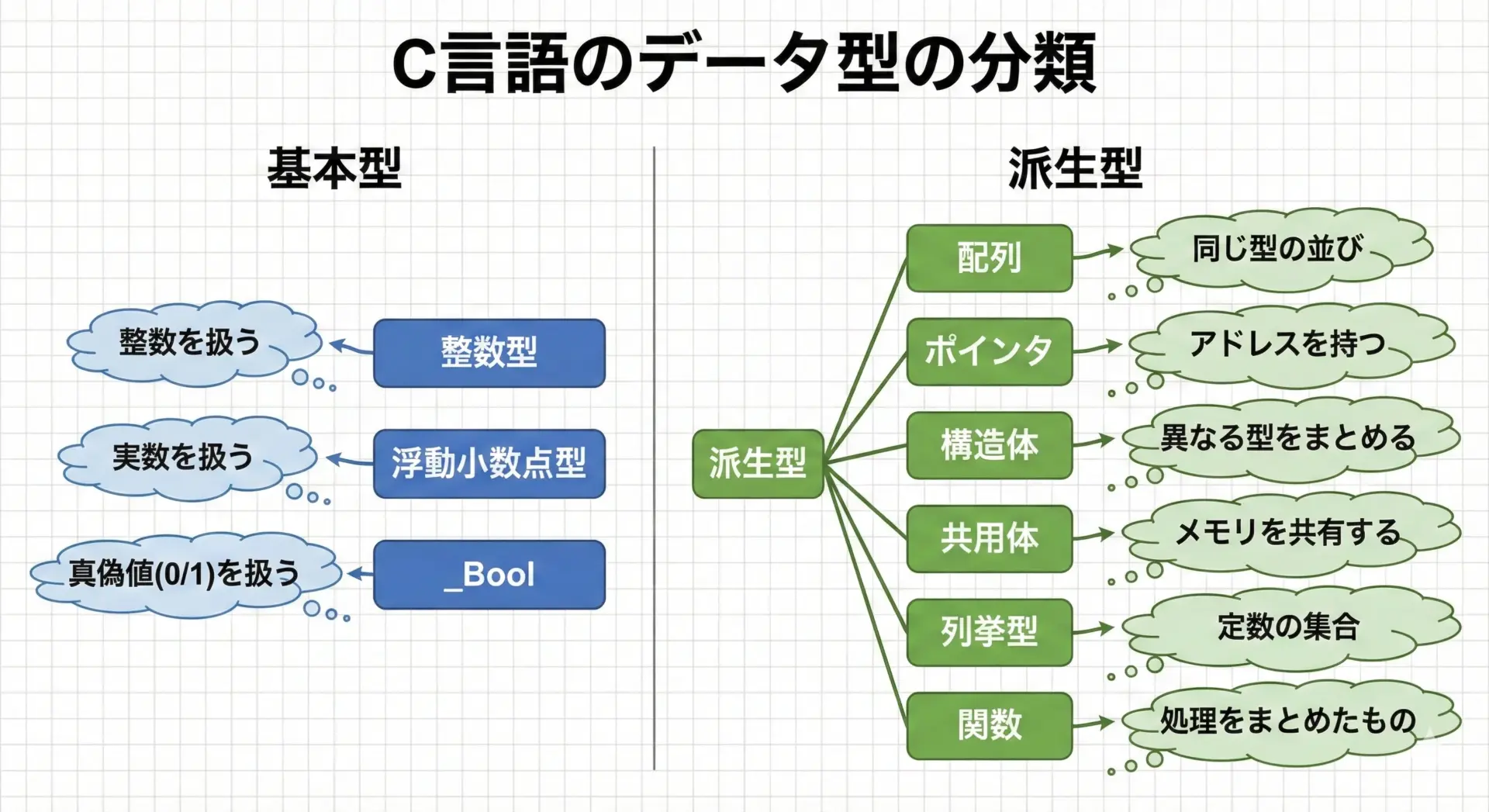
C言語の型は次のように整理できます。
| 分類 | 代表的な型 | 概要 |
|---|---|---|
| 整数型 | char, short, int, long, long long | 整数(小数なし)を表す型です。符号付きと符号なし(unsigned)があります。 |
| 浮動小数点型 | float, double, long double | 実数(小数を含む)を表す型です。精度と範囲が異なります。 |
| 論理型 | _Bool | 真偽値を表すための型です。C99で追加されました。 |
| 派生型 | int*, int[10], struct, union, enum など | 基本型を組み合わせることで作られる型です。 |
C言語は「型安全性」が高くない言語なので、異なるデータ型同士の変換が比較的容易に行えますが、そのぶんサイズや範囲を理解しておかないとオーバーフローや意図しない型変換が起こりやすくなります。
データ型ごとのサイズと値の範囲の考え方
C言語において「型のサイズ」は、一般にsizeof演算子で調べることができます。
サイズは「バイト数」で表現され、その型がどれだけ大きな値を表現できるかに直結します。
整数型の範囲の基本的な考え方は次の通りです。
- 符号付き整数型(signed)
- ビット数を
Nとすると、範囲は- 最小値:
-2^(N-1) - 最大値:
2^(N-1) - 1
- 最小値:
- ビット数を
- 符号なし整数型(unsigned)
- ビット数を
Nとすると、範囲は- 最小値:
0 - 最大値:
2^N - 1
- 最小値:
- ビット数を
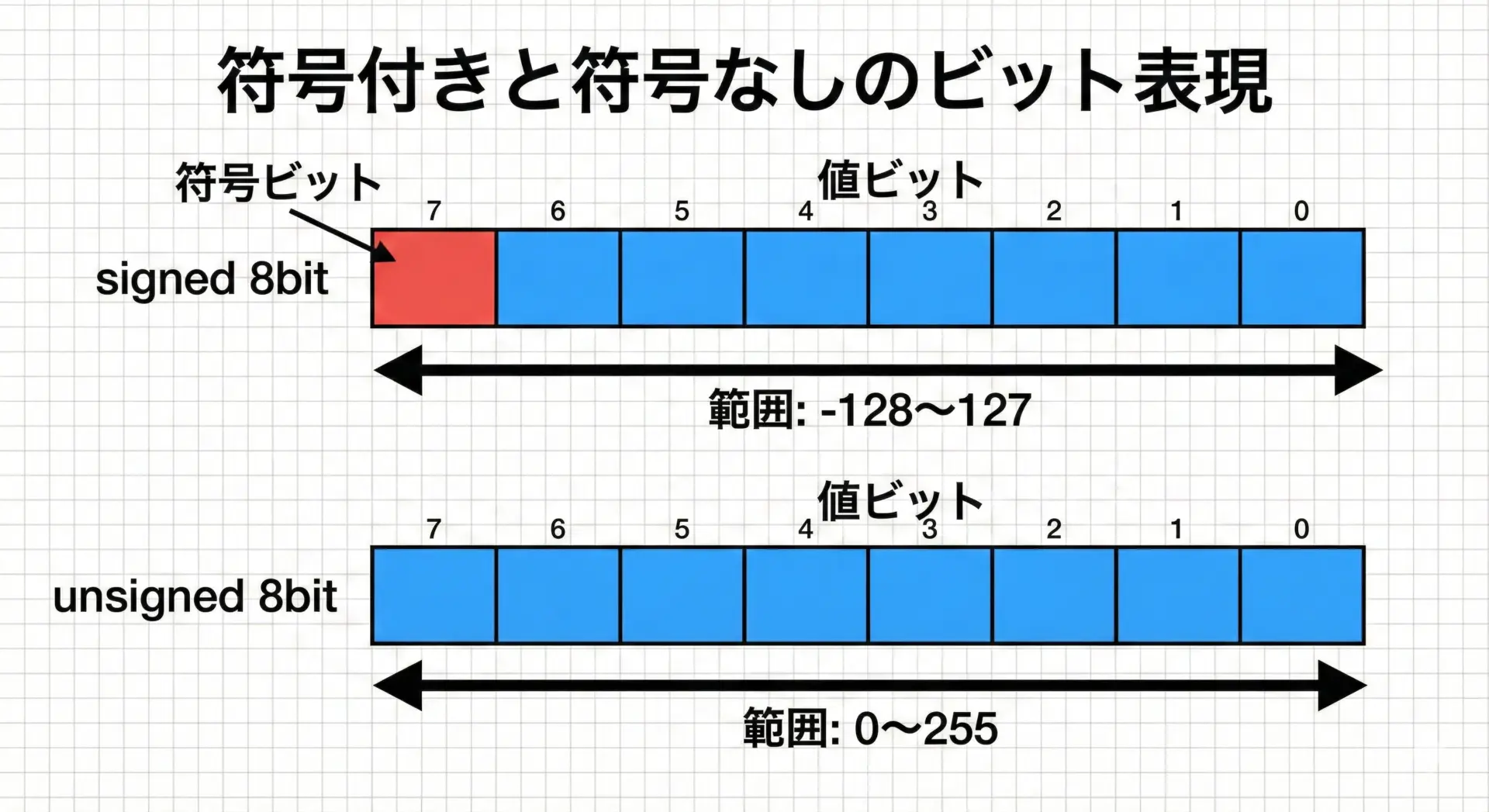
実際のビット数は型により異なりますが、考え方はこの図と同じです。
32bit環境と64bit環境での違い
C言語では環境(コンパイラ・OS・CPUアーキテクチャ)によって型のサイズが異なる可能性があります。
特に32bit環境と64bit環境では、ポインタサイズやlongのサイズなどが変わることが多いです。
代表的な環境でのサイズの違いを、ざっくりと表にまとめます。
| 型 | 32bit環境(例: Windows 32bit) | 64bit LP64系(例: Linux 64bit, macOS) |
|---|---|---|
char | 1バイト | 1バイト |
short | 2バイト | 2バイト |
int | 4バイト | 4バイト |
long | 4バイト | 8バイト |
long long | 8バイト | 8バイト |
void* | 4バイト | 8バイト |
size_t | 4バイト | 8バイト |
ポイントは、64bit環境でもintは4バイトのままであることが多く、代わりにlongやポインタ、size_tが8バイトになっていることです。
実際に、自分の環境で型のサイズを確認するプログラムを示します。
#include <stdio.h>
int main(void) {
// 各種整数型とポインタ型のサイズを表示するサンプルプログラムです。
printf("sizeof(char) = %zu\n", sizeof(char));
printf("sizeof(short) = %zu\n", sizeof(short));
printf("sizeof(int) = %zu\n", sizeof(int));
printf("sizeof(long) = %zu\n", sizeof(long));
printf("sizeof(long long) = %zu\n", sizeof(long long));
printf("sizeof(float) = %zu\n", sizeof(float));
printf("sizeof(double) = %zu\n", sizeof(double));
printf("sizeof(long double) = %zu\n", sizeof(long double));
printf("sizeof(void*) = %zu\n", sizeof(void*));
printf("sizeof(int*) = %zu\n", sizeof(int*));
printf("sizeof(char*) = %zu\n", sizeof(char*));
return 0;
}例: Linux 64bit (gcc) での実行結果の一例
sizeof(char) = 1
sizeof(short) = 2
sizeof(int) = 4
sizeof(long) = 8
sizeof(long long) = 8
sizeof(float) = 4
sizeof(double) = 8
sizeof(long double) = 16
sizeof(void*) = 8
sizeof(int*) = 8
sizeof(char*) = 8このように環境ごとの差はsizeofで必ず確認し、ハードコードされた「4バイト固定」などの思い込みに頼らないことが重要です。
C言語の整数型一覧
charとsigned char・unsigned charの違い
charは、文字を扱うための型として有名ですが、実際には「最小の整数型」でもあります。
そのため、次の3つの使い分けが重要です。
charsigned charunsigned char
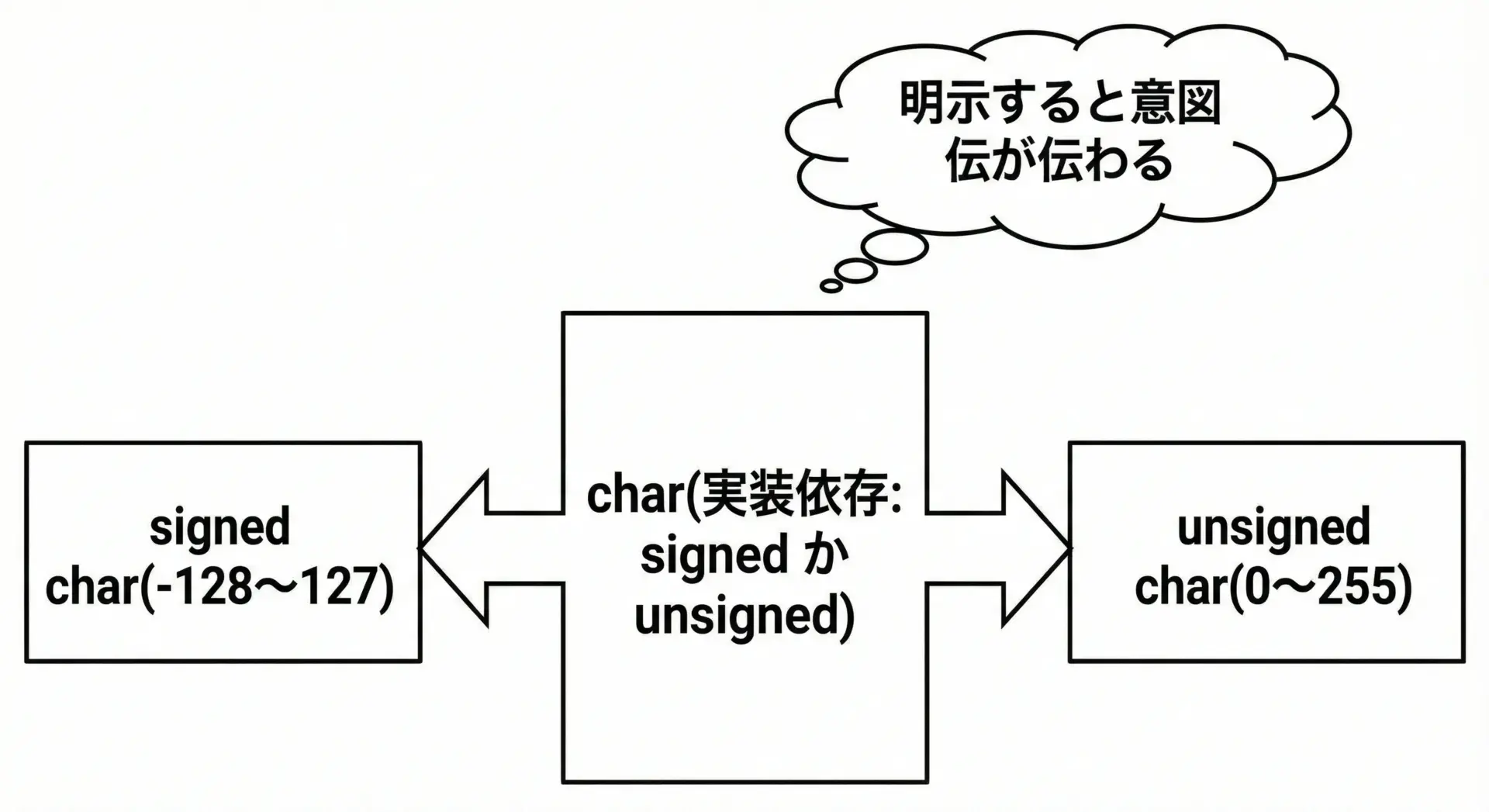
重要な点は、char単体では符号付きか符号なしかは処理系依存ということです。
コンパイラや環境によって、charがsigned charとして扱われる場合もあれば、unsigned charとして扱われる場合もあります。
したがって、整数としての用途でcharを使う場合は、意図に応じて
- 負の値も扱いたい →
signed char - バイトデータとして0〜255を扱いたい →
unsigned char
と明示的に型を指定することが推奨されます。
#include <stdio.h>
int main(void) {
char c = 200; // char が signed の処理系では負の値になる可能性あり
signed char sc = 200; // signed char は -128〜127 の範囲
unsigned char uc = 200; // unsigned char は 0〜255 の範囲
printf("c = %d\n", c); // char は %d で表示するとき int に拡張される
printf("sc = %d\n", sc);
printf("uc = %u\n", uc); // unsigned char は %u で表示
return 0;
}例: char が signed の処理系での実行結果例
c = -56
sc = -56
uc = 200この例のように、charがsignedの場合、200という値を入れるとマイナスの値に丸められることがあります。
バイナリデータや画像データを扱う場合にはunsigned charを使うのが一般的です。
short int・int・long int・long longのサイズと範囲
C言語の整数型の階層構造は、次のようになっています。
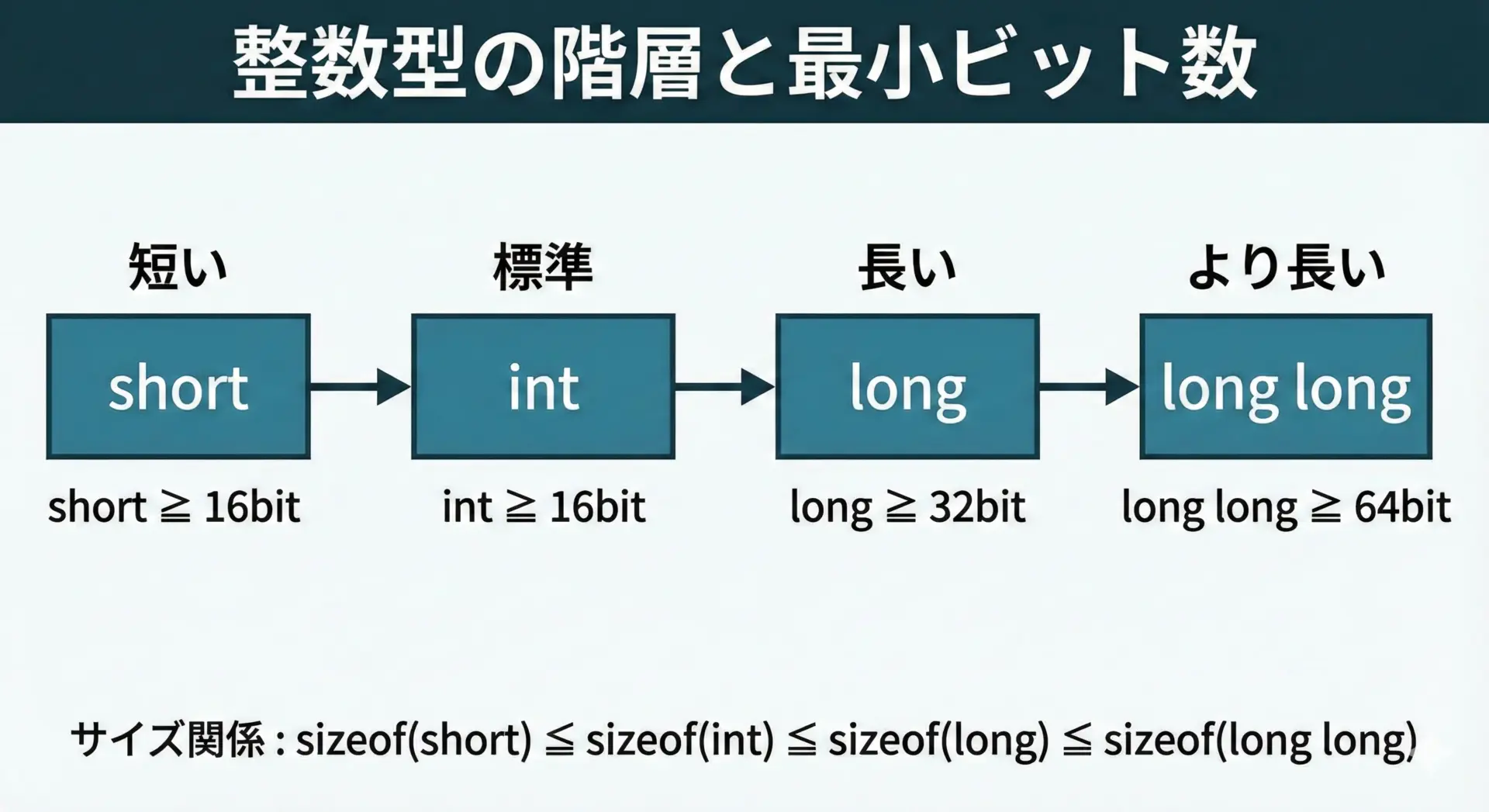
標準規格では「正確なサイズ」は決まっていませんが、次の関係だけは保証されています。
| 型 | 最低ビット数 | サイズ関係(保証) |
|---|---|---|
short | 16ビット以上 | sizeof(short) <= sizeof(int) |
int | 16ビット以上 | sizeof(int) <= sizeof(long) |
long | 32ビット以上 | sizeof(long) <= sizeof(long long) |
long long | 64ビット以上 |
一般的な環境(LP64 など)では次のようになることが多いです。
| 型 | 典型的なサイズ | 典型的な範囲(signed) |
|---|---|---|
short | 2バイト(16bit) | -32768〜32767 |
int | 4バイト(32bit) | 約 -2.1×10^9 〜 +2.1×10^9 |
long | 4または8バイト | 32bitならintと同等、64bitなら約 -9.2×10^18 〜 +9.2×10^18 |
long long | 8バイト(64bit) | 約 -9.2×10^18 〜 +9.2×10^18 |
#include <stdio.h>
#include <limits.h>
int main(void) {
// limits.h に定義されている各整数型の最小値・最大値を表示します。
printf("short: %d 〜 %d\n", SHRT_MIN, SHRT_MAX);
printf("int: %d 〜 %d\n", INT_MIN, INT_MAX);
printf("long: %ld 〜 %ld\n", LONG_MIN, LONG_MAX);
printf("long long: %lld 〜 %lld\n", LLONG_MIN, LLONG_MAX);
return 0;
}例: Linux 64bit (gcc) の一例
short: -32768 〜 32767
int: -2147483648 〜 2147483647
long: -9223372036854775808 〜 9223372036854775807
long long: -9223372036854775808 〜 9223372036854775807実際の範囲はlimits.hのマクロで確認するのが安全です。
signedとunsignedの使い分け
整数型には符号付き(signed)と符号なし(unsigned)があり、用途に応じて使い分けます。
- signed整数型:
- 正の値・0・負の値を扱う一般的な計算に使用します。
intと書けばsigned intと同義です。
- unsigned整数型:
- マイナスを扱わず、0以上の値だけを扱います。
- 同じビット数ならsignedよりも大きな最大値を表現できます。
- ビット演算やビットフラグ、サイズやインデックス(
size_t)などに使用されることが多いです。
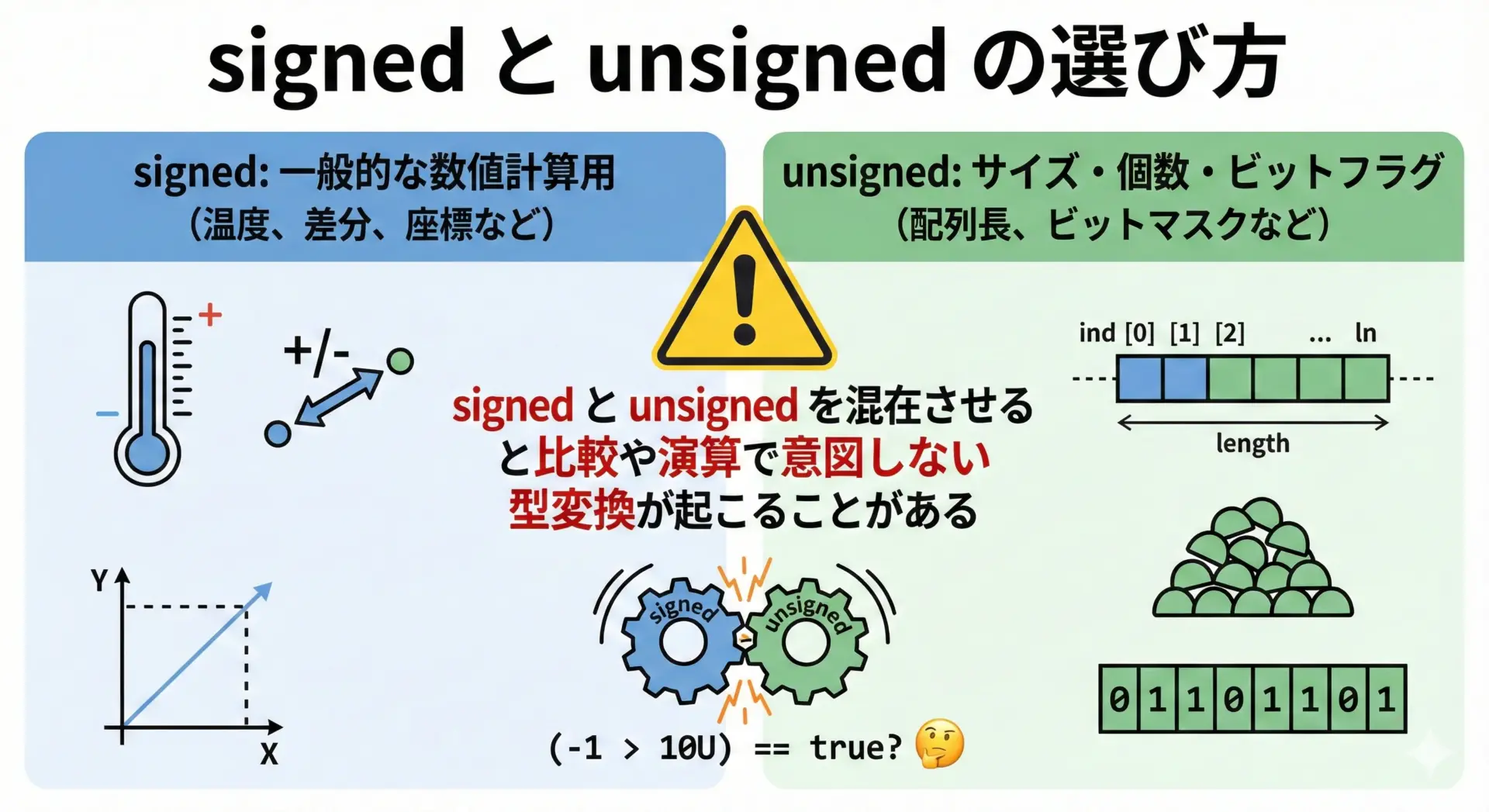
特にsigned と unsigned を同じ式で混ぜると、型変換によって予期しない結果になることがあります。
#include <stdio.h>
int main(void) {
int a = -1;
unsigned int b = 1;
// a < b を期待しそうですが、実は違う結果になることがあります。
if (a < b) {
printf("a < b\n");
} else {
printf("a >= b\n");
}
printf("a = %d, b = %u\n", a, b);
return 0;
}例: 多くの処理系での実行結果
a >= b
a = -1, b = 1このような結果になる理由は、aがunsigned intに変換されて非常に大きな値として扱われるためです。
signedとunsignedを安易に混在させないことが重要です。
整数リテラルの型とサフィックス一覧
C言語では、整数リテラル(数値そのもの)にも型があります。
何もサフィックスを付けない場合は、値の大きさと基数に応じて次の順に型が決まります。
- 10進整数リテラルの場合:
int→long→long longの順で収まる型 - 8進(先頭0)・16進(先頭0x)の場合:
int→unsigned int→long→unsigned long→long long→unsigned long long
リテラルにサフィックスを付けることで、型を明示的に指定できます。
| サフィックス | 型(10進) | 型(8進・16進) |
|---|---|---|
| なし | int / long / long long | int / unsigned int / long / unsigned long / long long / unsigned long long |
u または U | unsigned int / unsigned long / unsigned long long | 同左 |
l または L | long / long long | long / unsigned long / long long / unsigned long long |
ul, lu, UL など | unsigned long / unsigned long long | 同左 |
ll または LL | long long | long long / unsigned long long |
ull, LLU など | unsigned long long | 同左 |
#include <stdio.h>
int main(void) {
// 代表的な整数リテラルとその型の例です。
// 実際の型は処理系依存な部分もありますが、意図を伝えるためにサフィックスを活用します。
int a = 100; // int
long b = 100L; // long
long long c = 100LL; // long long
unsigned int ua = 100U; // unsigned int
unsigned long ub = 100UL; // unsigned long
unsigned long long uc = 100ULL; // unsigned long long
printf("a=%d, b=%ld, c=%lld\n", a, b, c);
printf("ua=%u, ub=%lu, uc=%llu\n", ua, ub, uc);
return 0;
}a=100, b=100, c=100
ua=100, ub=100, uc=100大きな定数やビットマスクにはUやULを付けることで、意図した型で扱えるようにするのが実務では一般的です。
C言語の浮動小数点型一覧
float・double・long doubleの精度と範囲
C言語の浮動小数点型は、通常IEEE 754規格に準拠した形式で実装されます(必須ではありませんが、ほとんどの環境が準拠しています)。
代表的な環境でのサイズ・有効桁数・おおよその範囲は次の通りです。
| 型 | 典型的なサイズ | 有効桁数(10進) | おおよその範囲 |
|---|---|---|---|
float | 4バイト | 約 6〜7桁 | 約 ±1.17×10^-38 〜 ±3.40×10^38 |
double | 8バイト | 約 15〜16桁 | 約 ±2.22×10^-308 〜 ±1.79×10^308 |
long double | 8〜16バイト(処理系依存) | 15〜(拡張精度) | 範囲も処理系による |

一般的なルールとしては、通常の実数計算にはdoubleを使うのが推奨されます。
floatはメモリ・帯域が厳しい場面(大量データ、組み込み)で選択されることが多く、long doubleは金融計算などごく一部の場面で使われます。
#include <stdio.h>
#include <float.h>
int main(void) {
// 各浮動小数点型の最小値・最大値・有効桁数を表示します。
printf("float: min=%e, max=%e, digits=%d\n", FLT_MIN, FLT_MAX, FLT_DIG);
printf("double: min=%e, max=%e, digits=%d\n", DBL_MIN, DBL_MAX, DBL_DIG);
printf("long double: min=%Le, max=%Le, digits=%d\n",
LDBL_MIN, LDBL_MAX, LDBL_DIG);
return 0;
}例: Linux 64bit (gcc) の一例
float: min=1.175494e-38, max=3.402823e+38, digits=6
double: min=2.225074e-308, max=1.797693e+308, digits=15
long double: min=3.362103e-4932, max=1.189731e+4932, digits=18浮動小数点の丸め誤差と注意点
浮動小数点数は2進数で小数を表現しているため、10進数で表したときに「ぴったり表現できない数」が大量に存在します。
その結果、丸め誤差が発生します。
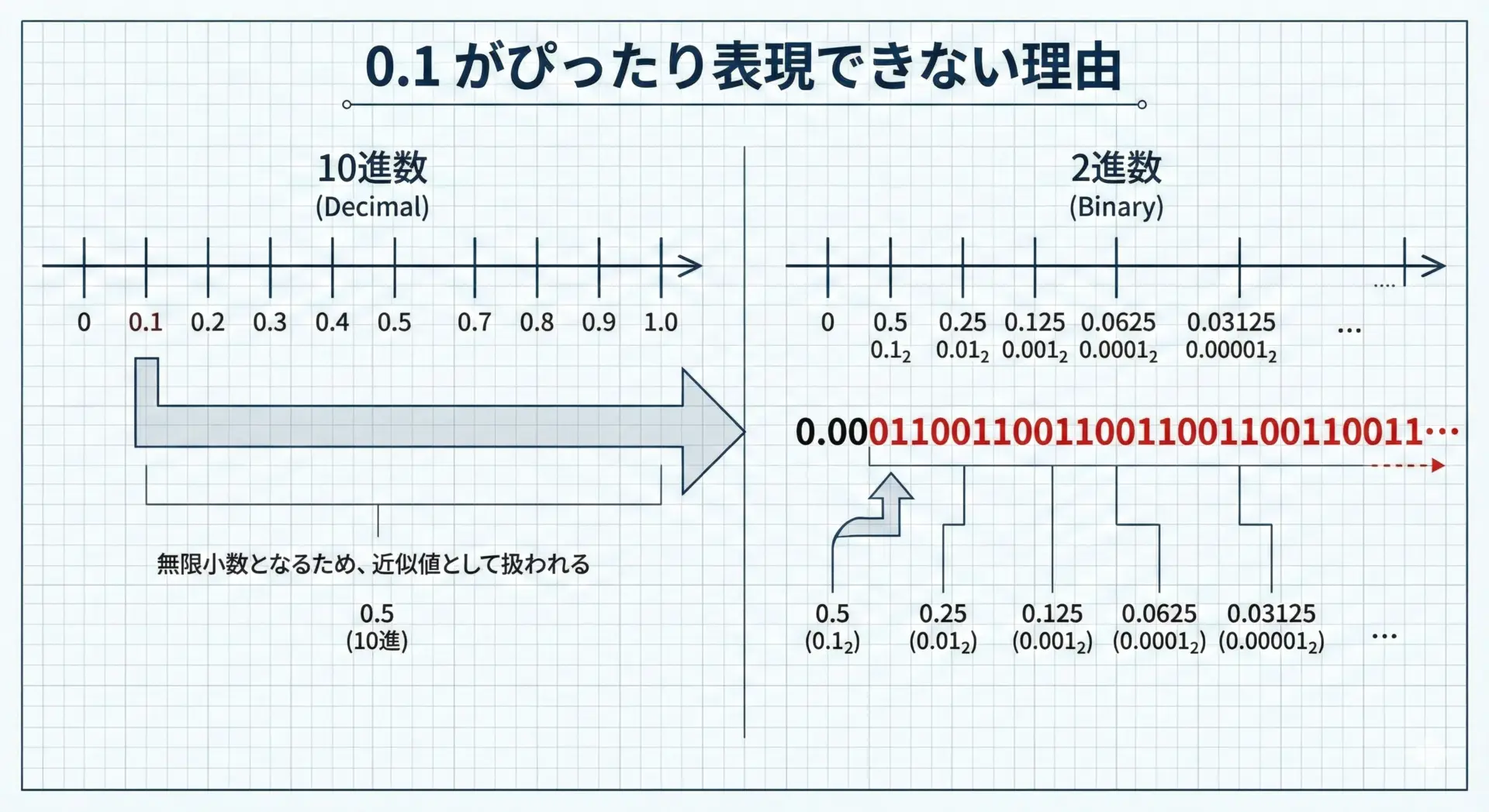
典型的な例を示します。
#include <stdio.h>
int main(void) {
double x = 0.1;
double y = 0.2;
double z = 0.3;
printf("x + y = %.17f\n", x + y);
printf("z = %.17f\n", z);
if (x + y == z) {
printf("x + y と z は等しい\n");
} else {
printf("x + y と z は等しくない\n");
}
return 0;
}x + y = 0.30000000000000004
z = 0.29999999999999999
x + y と z は等しくないこのように浮動小数点数を「==」で直接比較するのは危険です。
一般には許容誤差(イプシロン)を設けた比較を行います。
#include <stdio.h>
#include <math.h>
int main(void) {
double x = 0.1;
double y = 0.2;
double z = 0.3;
double eps = 1e-12; // 許容誤差
if (fabs((x + y) - z) < eps) {
printf("x + y は z とほぼ等しいとみなす\n");
} else {
printf("x + y は z と異なるとみなす\n");
}
return 0;
}x + y は z とほぼ等しいとみなす浮動小数点リテラルと指数表記
浮動小数点リテラルには、少なくとも1つの.または指数表記(e、E)が含まれます。
代表的な書き方は次の通りです。
- 10進表記:
3.140.5.25(先頭の0は省略可能)
- 指数表記:
1.0e3(1.0 × 10^3 = 1000)2.5E-4(2.5 × 10^-4 = 0.00025)
また、サフィックスを付けることで型を明示できます。
| サフィックス | 型 |
|---|---|
| なし | double |
f または F | float |
l または L | long double |
#include <stdio.h>
int main(void) {
float f1 = 3.14f; // float リテラル
double d1 = 3.14; // double リテラル(デフォルト)
double d2 = 1e3; // 1.0 × 10^3
double d3 = 2.5e-4; // 2.5 × 10^-4
long double ld1 = 3.14L; // long double リテラル
printf("f1 = %.7f\n", f1);
printf("d1 = %.15f\n", d1);
printf("d2 = %.1f\n", d2);
printf("d3 = %.10f\n", d3);
printf("ld1 = %.15Lf\n", ld1);
return 0;
}f1 = 3.1400001
d1 = 3.140000000000000
d2 = 1000.0
d3 = 0.0002500000
ld1 = 3.140000000000000「3.14」はdoubleである点に注意が必要です。
float変数に格納する場合は3.14fのようにサフィックスfを付けるのが望ましいです。
C言語のその他のデータ型一覧
_Boolと論理型の扱い
C99から_Boolという論理値を表す型が追加されました。
_Bool型の値は
- 0 なら偽(false)
- 0以外なら真(true)として扱われます。
stdbool.hヘッダをインクルードすると、bool、true、falseというマクロが利用でき、より直感的な記述ができます。
#include <stdio.h>
#include <stdbool.h> // bool, true, false を使うためのヘッダ
int main(void) {
bool flag1 = true; // 実際には _Bool 型
bool flag2 = false;
printf("flag1 = %d\n", flag1); // true は 1 として表示されることが多い
printf("flag2 = %d\n", flag2); // false は 0
if (flag1) {
printf("flag1 は真です\n");
}
if (!flag2) {
printf("flag2 は偽です\n");
}
return 0;
}flag1 = 1
flag2 = 0
flag1 は真です
flag2 は偽です従来のCでは「0以外は真」というルールでintを用いて表現されていましたが、C99以降は_Boolとstdbool.hを積極的に使うと、意図が明確になります。
ポインタ型(void*・int*など)のサイズ
ポインタ型は「アドレス」を格納するための型です。
int、char、void*など、多数のポインタ型がありますが、同じ環境では「ポインタのサイズ」はすべて同じであることが多いです。
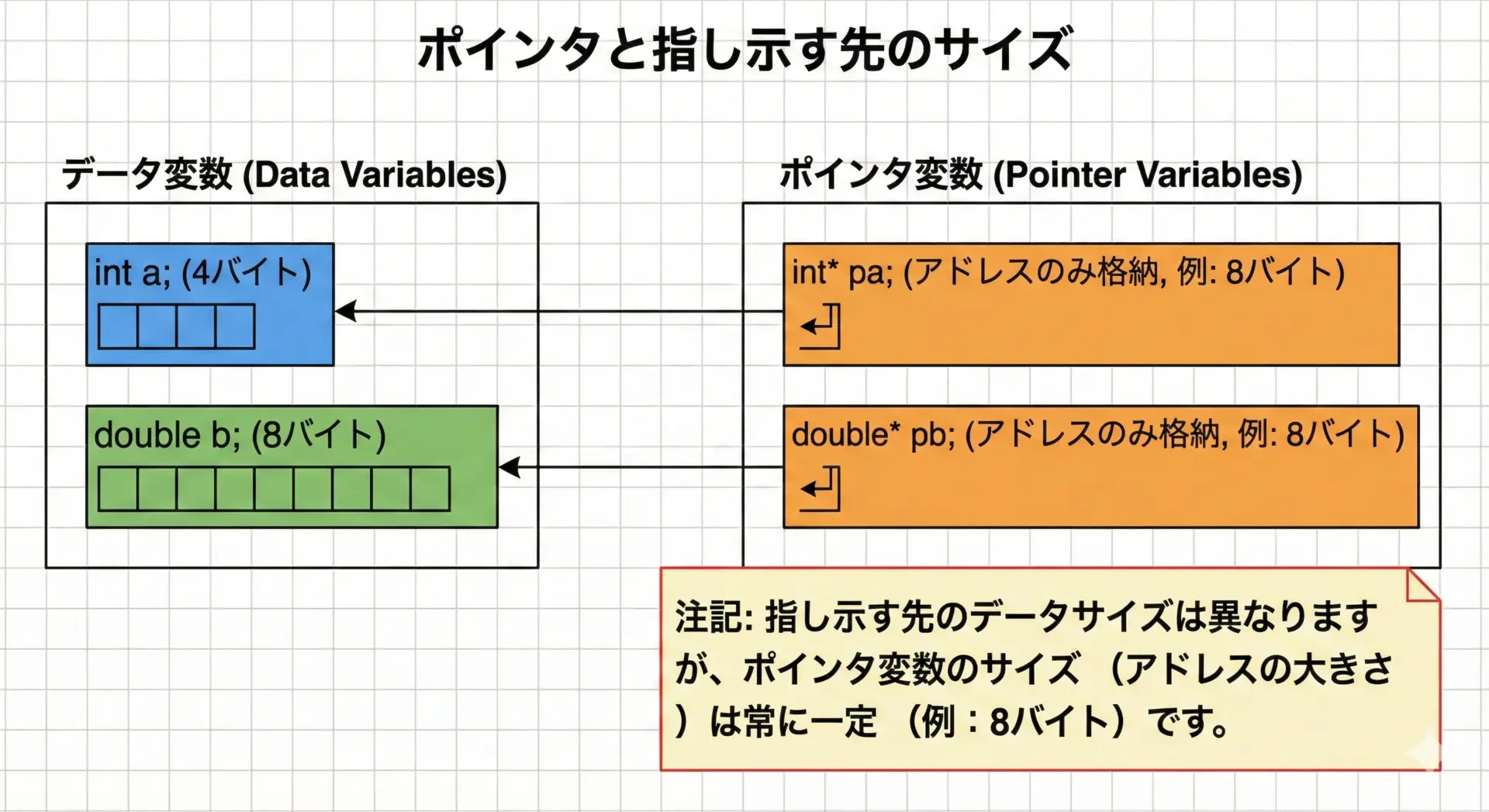
#include <stdio.h>
int main(void) {
printf("sizeof(void*) = %zu\n", sizeof(void*));
printf("sizeof(int*) = %zu\n", sizeof(int*));
printf("sizeof(char*) = %zu\n", sizeof(char*));
printf("sizeof(double*) = %zu\n", sizeof(double*));
return 0;
}例: 64bit 環境の一例
sizeof(void*) = 8
sizeof(int*) = 8
sizeof(char*) = 8
sizeof(double*) = 8voidは「どんな型のポインタでも代入できる汎用ポインタ型」であり、mallocなどのメモリ確保関数はvoid型を返します。
ただしvoid* をそのまま参照(間接アクセス)することはできないため、適切な型にキャストしてから使います。
size_t・ptrdiff_tなど標準型の一覧
Cの標準ライブラリでは、環境に依存しがちな「サイズ」や「ポインタ差分」などを安全に扱うために、いくつかの標準型が定義されています。
代表的なものをまとめます。
| 型 | 定義ヘッダ | 主な用途 | 典型的な実体 |
|---|---|---|---|
size_t | stddef.h, stdio.h など | オブジェクトのサイズ、配列長、sizeofの結果 | unsigned の整数型 |
ptrdiff_t | stddef.h | ポインタの差分(p2 – p1) | signed の整数型 |
intptr_t | stdint.h | ポインタを整数に安全に格納できる型 | ポインタと同じビット幅の signed 整数 |
uintptr_t | stdint.h | ポインタを符号なし整数に格納できる型 | ポインタと同じビット幅の unsigned 整数 |
time_t | time.h | 時刻を表す型(time関数の戻り値など) | 実装依存(int, long など) |
#include <stdio.h>
#include <stddef.h>
#include <stdint.h>
int main(void) {
printf("sizeof(size_t) = %zu\n", sizeof(size_t));
printf("sizeof(ptrdiff_t) = %zu\n", sizeof(ptrdiff_t));
printf("sizeof(intptr_t) = %zu\n", sizeof(intptr_t));
printf("sizeof(uintptr_t) = %zu\n", sizeof(uintptr_t));
int arr[10];
size_t len = sizeof(arr) / sizeof(arr[0]); // 配列長の計算に size_t を使用
printf("arr length = %zu\n", len);
return 0;
}例: 64bit 環境の一例
sizeof(size_t) = 8
sizeof(ptrdiff_t) = 8
sizeof(intptr_t) = 8
sizeof(uintptr_t) = 8
arr length = 10サイズやインデックスにはsize_tを使うのが、標準ライブラリとの整合性の面でも推奨されます。
列挙型(enum)・構造体(struct)・共用体(union)の概要
整数型・浮動小数点型のほかに、C言語には複合データを表現するための型が用意されています。
その代表例がenum、struct、unionです。
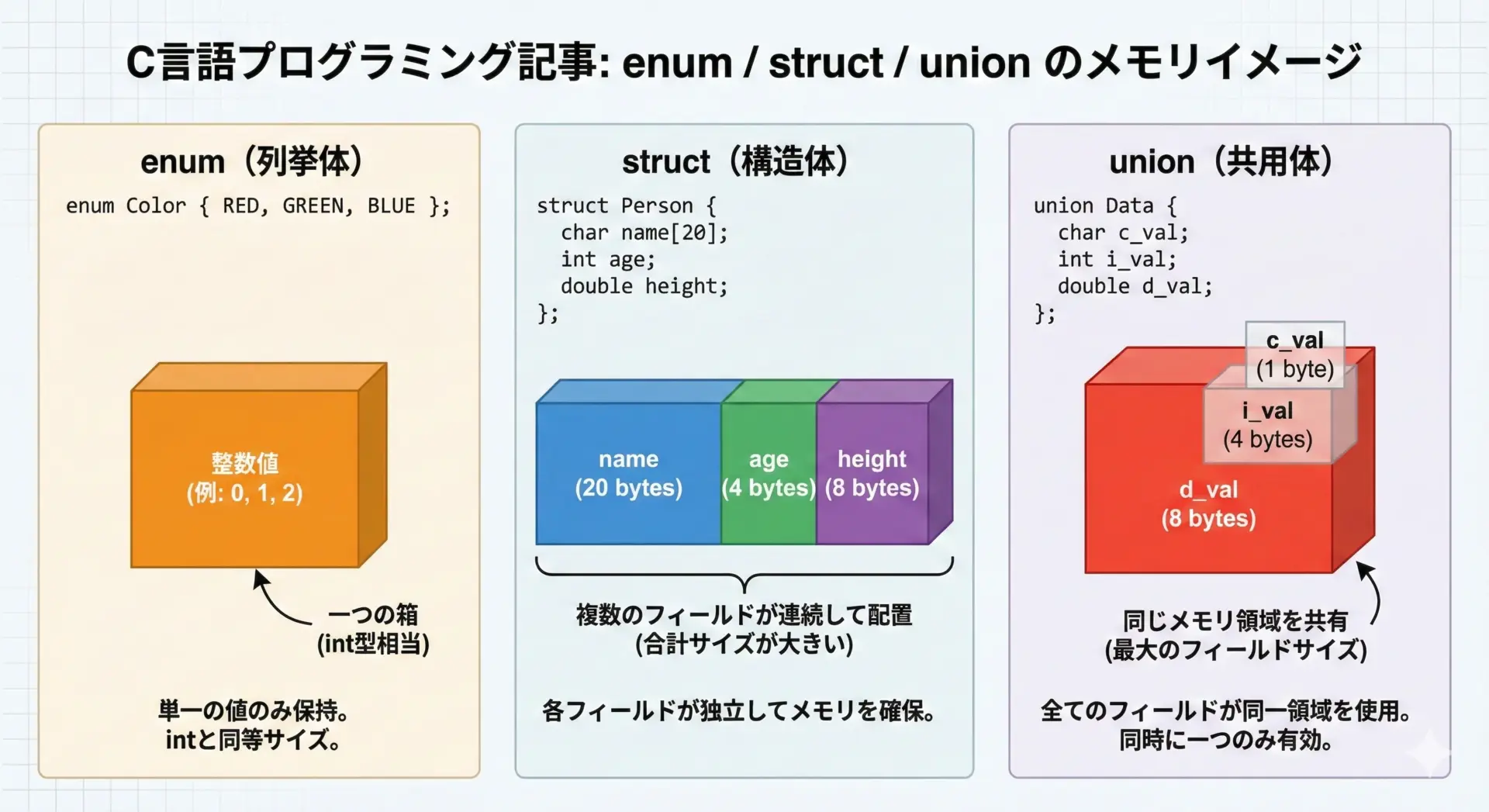
列挙型(enum)
enumは関連する整数定数に名前を付けてグループ化する型です。
#include <stdio.h>
enum Color {
COLOR_RED, // 0
COLOR_GREEN, // 1
COLOR_BLUE // 2
};
int main(void) {
enum Color c = COLOR_GREEN;
printf("c = %d\n", c); // 実体は整数値
return 0;
}c = 1デフォルトでは0から順に整数値が割り当てられますが、明示的に値を指定することもできます。
構造体(struct)
structは異なる型のメンバをまとめて1つの「レコード」として扱う型です。
#include <stdio.h>
struct Person {
char name[32];
int age;
float height;
};
int main(void) {
struct Person p = { "Taro", 20, 170.5f };
printf("name = %s, age = %d, height = %.1f\n",
p.name, p.age, p.height);
return 0;
}name = Taro, age = 20, height = 170.5構造体は現代Cプログラミングで頻繁に利用される重要な機能です。
共用体(union)
unionは複数のメンバが同じメモリ領域を共有する型です。
「同じ領域を、用途に応じて別の型として解釈する」用途で使われます。
#include <stdio.h>
union Data {
int i;
float f;
};
int main(void) {
union Data d;
d.i = 0x3f800000; // IEEE754 で 1.0f に相当するビットパターン
printf("as int : 0x%x\n", d.i);
printf("as float: %f\n", d.f); // 同じメモリを float として解釈
return 0;
}as int : 0x3f800000
as float: 1.000000共用体はビットレベルのトリックが絡むため取り扱いに注意が必要ですが、組み込み系や低レベルプログラミングで使われます。
typedefによる独自型定義と型エイリアスの使い方
typedefを使うと、既存の型に対して別名(エイリアス)を定義できます。
長い型名を短くしたり、抽象化のために用いたりします。
#include <stdio.h>
// int に MyInt という別名を付ける
typedef int MyInt;
// 構造体に別名を付ける
typedef struct Person {
char name[32];
int age;
float height;
} Person; // ここで struct Person に Person という別名を与える
int main(void) {
MyInt x = 10; // 実体は int
Person p = { "Hanako", 25, 160.0f };
printf("x = %d\n", x);
printf("name = %s, age = %d, height = %.1f\n",
p.name, p.age, p.height);
return 0;
}x = 10
name = Hanako, age = 25, height = 160.0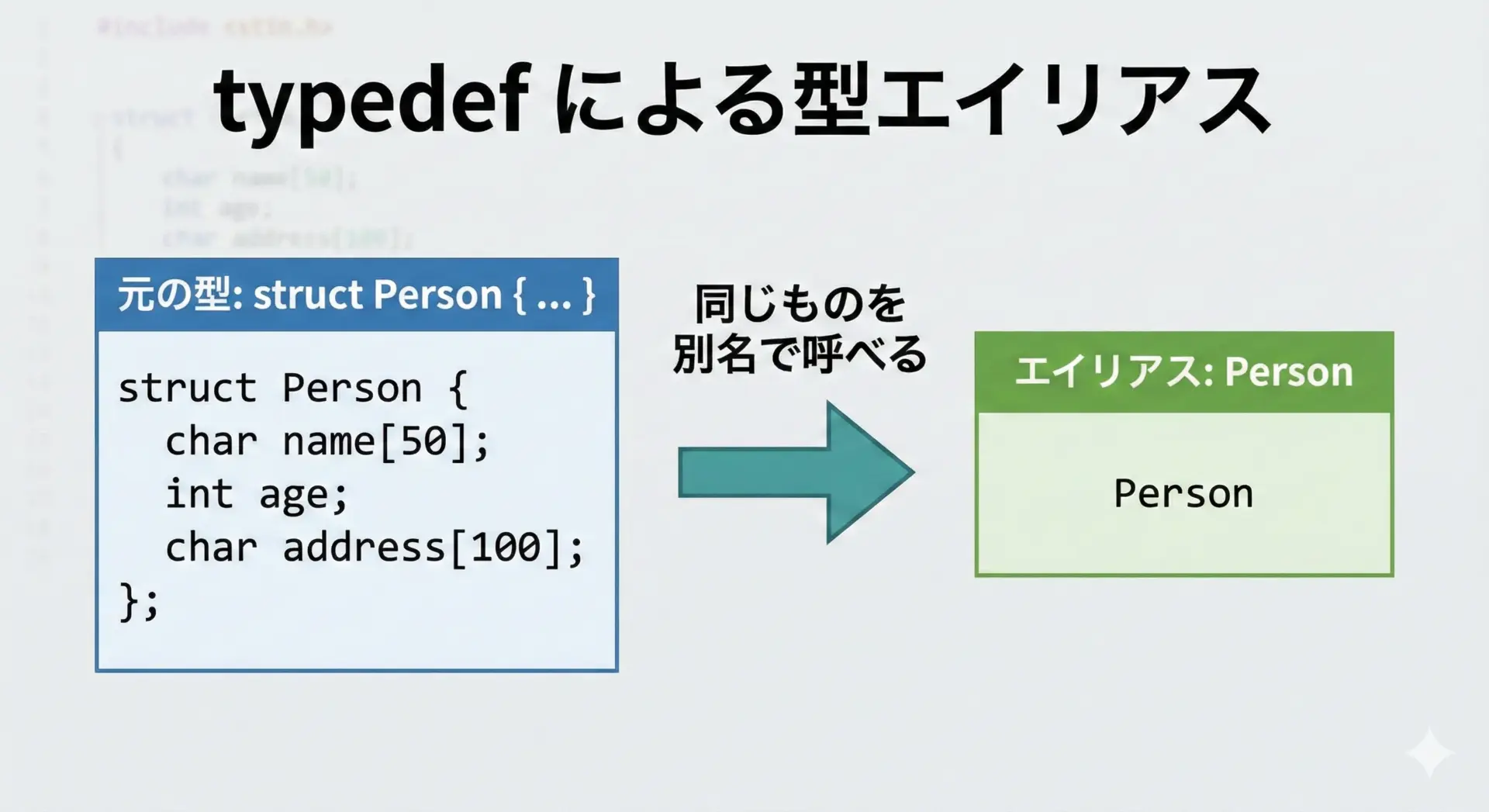
また、ポインタ型のエイリアスを定義する場合には宣言の位置に注意が必要です。
#include <stdio.h>
typedef int* IntPtr; // 「int*」全体に IntPtr という別名
int main(void) {
int value = 42;
IntPtr p1 = &value; // p1 は int* 型
IntPtr p2 = NULL; // p2 も int* 型
printf("*p1 = %d\n", *p1);
return 0;
}*p1 = 42typedefは「新しい型を作る」のではなく「既存の型に別名を付けるだけ」という点を意識すると、混乱が少なくなります。
まとめ
C言語のデータ型は、一見すると種類が多く複雑に見えますが、「整数型」「浮動小数点型」「論理型」「複合型・ポインタ型」という大きな枠で整理すると理解しやすくなります。
特に、サイズや範囲、32bit/64bit環境での違いはsizeofやlimits.h・float.hで必ず確認し、思い込みに頼らないことが重要です。
本記事を参考に、自分のコードで使っている型の意味や選び方を見直し、より安全で分かりやすいCプログラムを書けるようになってください。
