
Pythonは、AI開発やデータ分析の現場で最もよく使われるプログラミング言語の1つです。
文法がシンプルで、初心者でも学びやすい一方、巨大なライブラリ群と豊富な実績に支えられ、現場レベルの開発にもそのまま使える力を持っています。
本記事では、PythonがなぜAI・データ分析に強いのか、そしてどのように学び始めればよいのかを、初心者向けに段階を踏んで解説していきます。
Pythonとは?初心者でもわかる基礎知識
Pythonとは何か
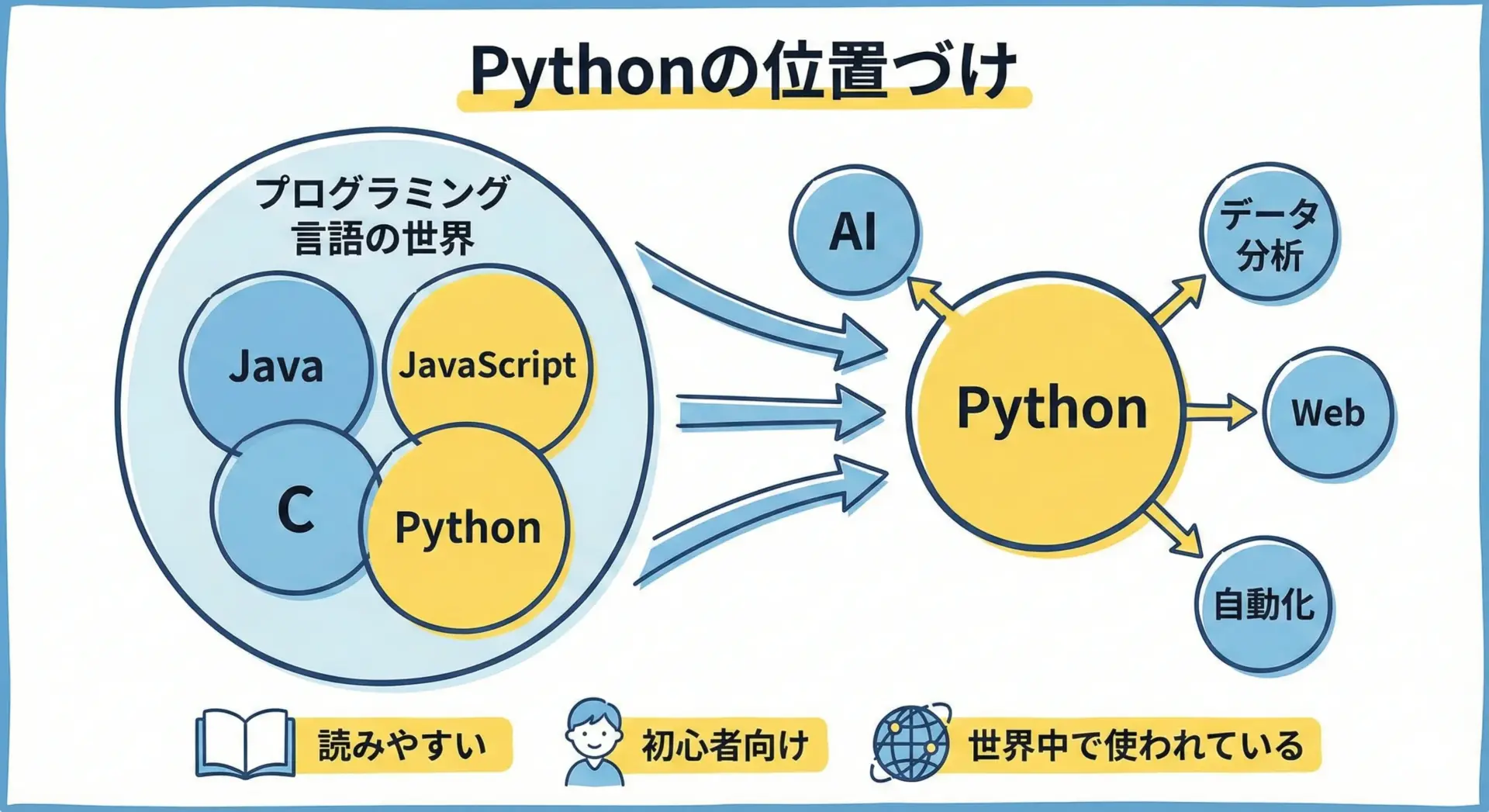
Python(パイソン)とは、オランダ出身のプログラマGuido van Rossum氏が開発した汎用プログラミング言語です。
汎用という言葉の通り、Webアプリ開発からデータ分析、AI(機械学習・深層学習)、業務自動化、スクレイピング、ゲーム制作まで、幅広い開発に使われています。
Pythonの最大の特徴は、コードの見た目がシンプルで読みやすいことです。
プログラミング初心者がつまずきやすい「複雑な記号」や「難しい構文」が比較的少なく、英語の文章を読んでいるような感覚でコードを理解できます。
加えて、Pythonはオープンソースであり、誰でも無料で利用できます。
世界中の開発者コミュニティがライブラリやツールを日々アップデートしており、その結果として、AIやデータ分析に適した環境が自然と整ってきました。
Pythonが人気の理由

Pythonが人気を集めている背景には、複数の要素が重なっています。
1つだけの理由ではなく、エコシステム全体として使いやすい状態が作られていることが重要です。
まず、文法が簡潔であるため、初めてプログラミングを学ぶ人が「最初の1言語」として選びやすいことが挙げられます。
実際、多くの入門書やプログラミングスクールが、最初の学習言語としてPythonを採用しています。
次に、AIやデータ分析の分野で事実上の標準言語になっている点です。
NumPyやPandas、TensorFlow、PyTorchなどの強力なライブラリがPythonベースで提供されており、これらを使えば、数学的な知識や低レベルな最適化を自分で実装しなくても、高度な分析や学習モデルを扱えます。
また、世界中にユーザーが多いため、インターネット上の日本語・英語の情報量が非常に豊富で、困ったときに検索すれば、同じ問題に直面した人の質問や解決策を見つけやすいことも大きなメリットです。
Pythonと他の言語(Java・JavaScript・C言語)の違い
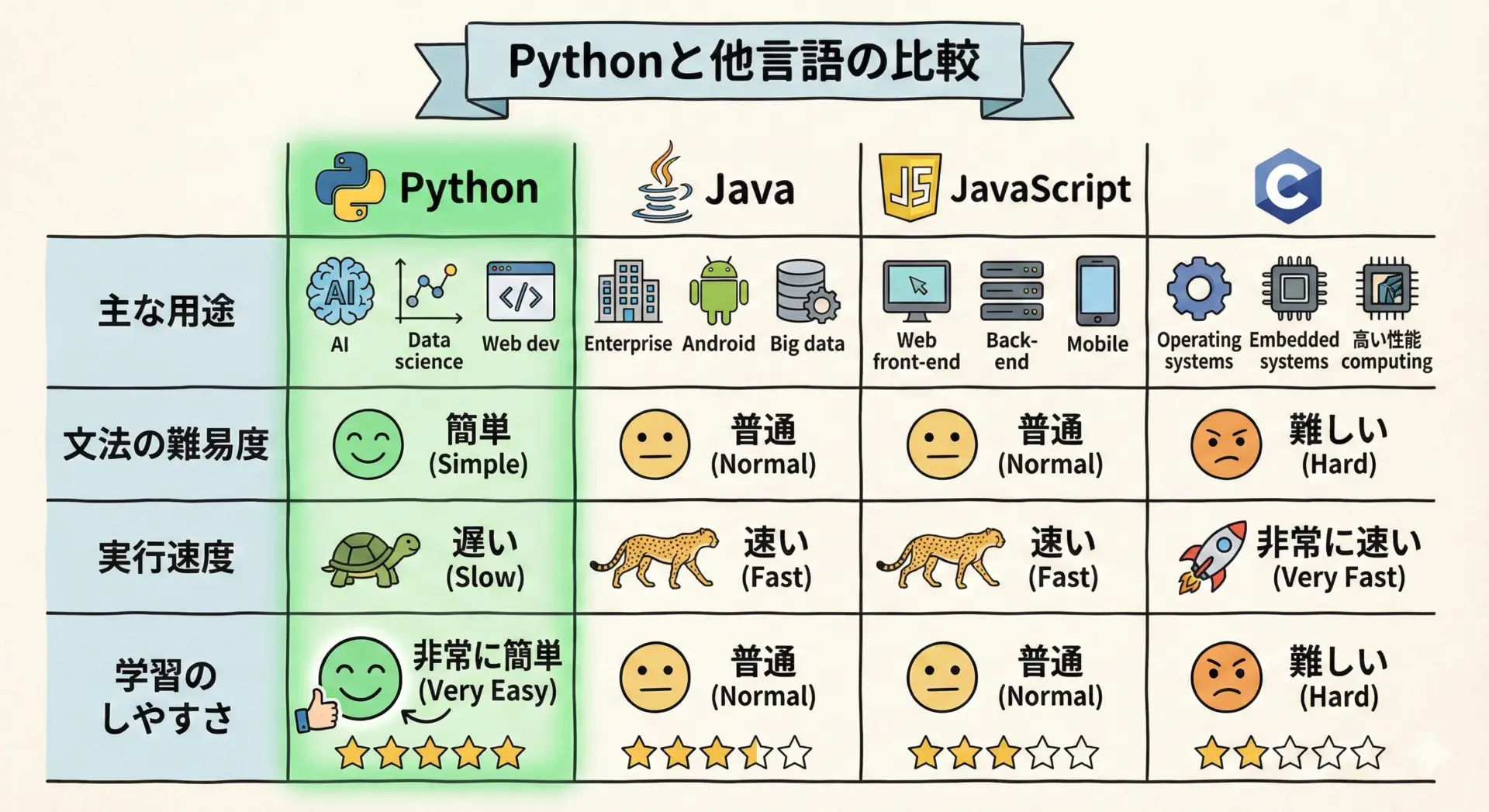
ここでは、よく比較される3つの言語(Java、JavaScript、C言語)とPythonの違いを、初心者目線で整理します。
まず、全体像を表形式で見てみます。
| 言語 | 主な用途 | 文法の難易度(初心者視点) | 実行速度のイメージ | 特徴的なポイント |
|---|---|---|---|---|
| Python | AI、データ分析、Web、スクリプト | 比較的やさしい | やや遅い〜普通 | 読みやすさ重視、ライブラリが非常に豊富 |
| Java | 大規模Webシステム、業務システム | やや難しい | 速い | 厳密な型、安全性が高く大規模開発に強い |
| JavaScript | Webフロント、Webアプリ | 普通 | 普通 | ブラウザで動作、動的なWebページに必須 |
| C言語 | 組み込み、OS、低レベル制御 | 難しい | 非常に速い | ハードウェアに近い、高い自由度と責任 |
Pythonはインタプリタ言語で、対話的にコードを入力しながらすぐに実行結果を確かめられます。
これに対して、JavaやC言語はコンパイルが必要で、初心者には少し準備や構造が複雑に感じられることが多いです。
実行速度の観点では、C言語やJavaの方が一般的には高速です。
しかしAIやデータ分析の現場では、重い計算処理の部分はCやC++で書かれたライブラリに任せ、Pythonは「指揮官」としてライブラリを呼び出す役割を担います。
この構成により、Pythonの書きやすさと低レベル言語の速さの両立が可能になっています。
また、JavaScriptはWebブラウザ上で動作することが前提の言語ですが、Pythonは基本的にブラウザでは動かず、サーバ側やローカル環境での処理に使われます。
この違いから、Webの見た目を制御したい場合はJavaScript、AI・分析・自動化を行いたい場合はPython、といった使い分けが一般的です。
Pythonでできること一覧
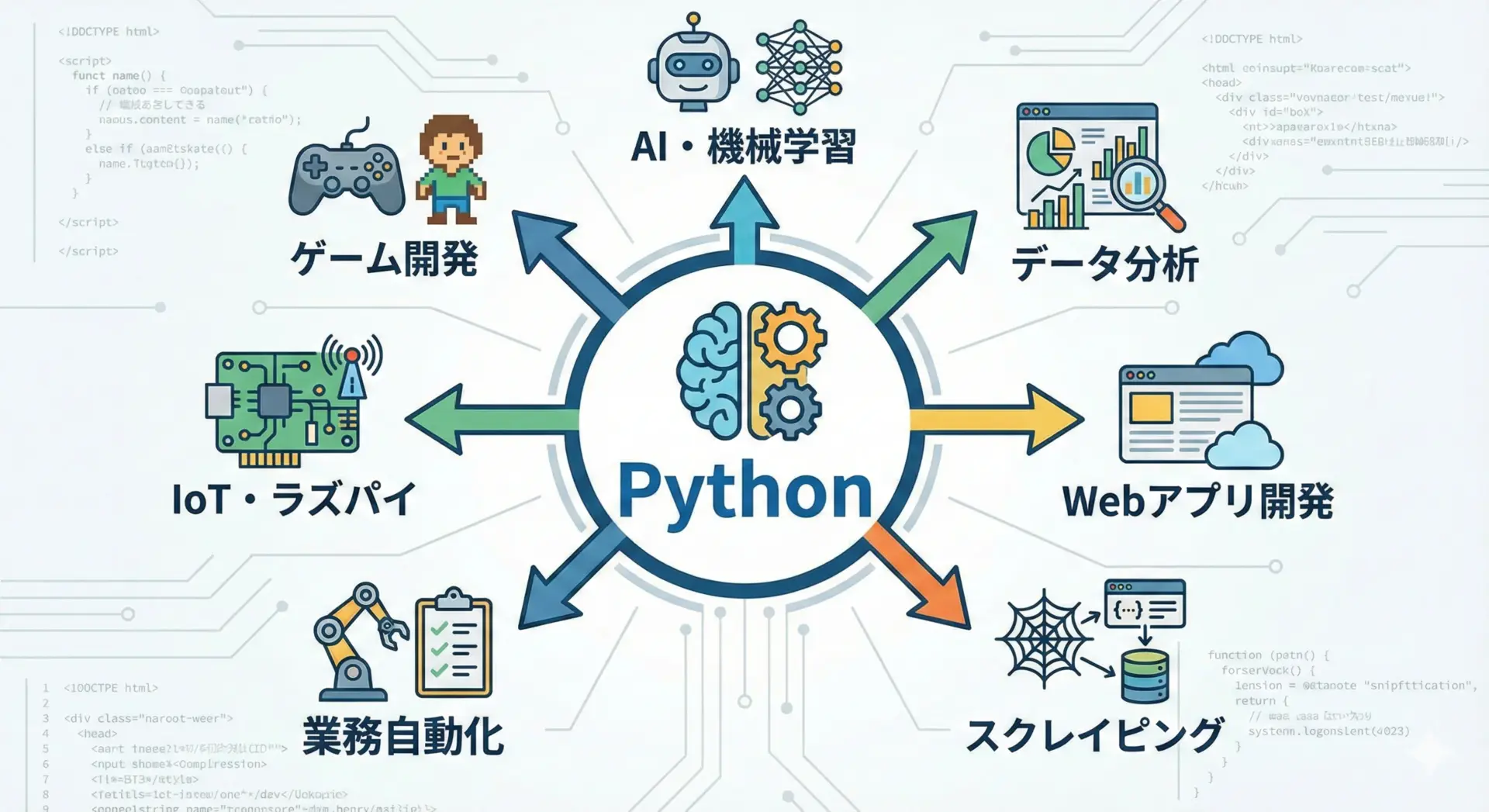
Pythonでできることは非常に多岐にわたります。
主な分野だけでも、以下のような活用が可能です。
文章で整理すると、PythonはまずAI・機械学習の分野で広く利用されています。
画像認識や自然言語処理、音声認識など、多くの研究や実サービスがPythonをベースに開発されています。
次に、データ分析と可視化にも強く、企業の売上データ分析や、Webサービスのログ解析、マーケティングデータの分析など、いわゆる「データサイエンス」領域で重宝されています。
さらに、DjangoやFastAPIなどのフレームワークを使えば、Webアプリケーションの開発も可能です。
会員制サイトやAPIサーバ、社内業務システムなどをPythonで構築できます。
その他にも、Webサイトから情報を自動で取得するスクレイピング、Excelやメール操作などの業務自動化、Raspberry Piを用いたIoT開発、シンプルなゲーム開発など、アイデア次第でさまざまな用途に使えます。
PythonがAIに強い理由
AI開発とPythonの関係

AI開発は、大きく分けてデータの準備、モデルの構築と学習、評価と改善、そして実際のサービスへの組み込みという流れで進みます。
Pythonは、このAI開発のほぼすべての工程を1つの言語でカバーできる点が大きな強みです。
たとえば、データの収集にはAPIやWebスクレイピングのスクリプトを書く必要がありますが、これもPythonで記述できます。
データの前処理やクリーニングにはPandasなどの分析ライブラリを使い、モデルの学習にはTensorFlowやPyTorchといった機械学習ライブラリを利用します。
さらに、学習したモデルをWebサービスとして公開する段階でも、FastAPIやFlaskなどのWebフレームワークをPythonで使うことができます。
このように、最初から最後まで同じ言語で完結できることが、現場でPythonが重宝される理由の1つです。
AIに必須のPythonライブラリ

AI分野でPythonが強い最大の理由は、強力で実績のあるライブラリが揃っていることです。
ここでは代表的なものを役割ごとに整理します。
まず土台となるのがNumPyです。
NumPyは多次元配列(ベクトル・行列)を効率的に扱うためのライブラリで、ほとんどのAIライブラリが内部でNumPyを利用しています。
その上に、表形式データを扱うPandasや、グラフ描画ライブラリのMatplotlib、Seabornが乗る構造です。
機械学習のアルゴリズムを幅広く提供するライブラリとしてはscikit-learnがあります。
回帰、分類、クラスタリングなど、多くの手法が簡単なコードで試せるため、AI入門に最適です。
深層学習(ディープラーニング)の分野では、TensorFlowとPyTorchが2大ライブラリとして有名です。
どちらもGPUを活用した高速な学習が可能で、大規模なニューラルネットワークや最新の研究で使われています。
これらのライブラリの多くは、内部の重い計算をC/C++で高速実装し、その上にPython向けの使いやすいインターフェースを用意しているという構造をとっています。
そのため「Pythonは書きやすいのに、処理は速い」という状態を実現できるのです。
簡単なAIライブラリ利用のサンプルコード
ここでは、scikit-learnを使って「手書き数字」を分類する非常にシンプルな例を紹介します。
コードの雰囲気をつかむことが目的なので、細かい理論は理解できなくても問題ありません。
# 必要なライブラリのインポート
from sklearn.datasets import load_digits # 手書き数字データセット
from sklearn.model_selection import train_test_split # 学習用とテスト用に分割
from sklearn.linear_model import LogisticRegression # ロジスティック回帰モデル
from sklearn.metrics import accuracy_score # 精度を評価する関数
# 1. データを読み込む
digits = load_digits() # 手書き数字(0〜9)の画像データ
X = digits.data # 画像を数値ベクトルにしたデータ(特徴量)
y = digits.target # 正解ラベル(0〜9の数字)
# 2. 学習用とテスト用に分割する
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 3. モデルを作成し、学習させる
model = LogisticRegression(max_iter=1000) # 繰り返し回数を増やして学習
model.fit(X_train, y_train) # 学習(フィッティング)
# 4. テストデータで予測する
y_pred = model.predict(X_test)
# 5. 精度(正解率)を計算する
accuracy = accuracy_score(y_test, y_pred)
print("正解率:", accuracy)正解率: 0.95前後(実行環境により多少変動)このように、数行〜数十行のコードで、本格的な機械学習の処理を試せることが、Pythonとそのライブラリの大きな魅力です。
PythonがAIエンジニアに選ばれる理由

AIエンジニアがPythonを選ぶ理由は、単に「ライブラリが豊富だから」だけではありません。
現場視点で見ると、次の点が特に大きいです。
まず、コードが短く書けて可読性が高いため、研究者やエンジニア同士でコードを共有・レビューしやすいことです。
AI開発では、論文などの研究成果をコードで再現し、改良を加えていく作業が多くなりますが、その際に読みやすいPythonは非常に相性が良いと言えます。
また、AIの研究コミュニティでPythonが事実上の標準となっているため、新しいライブラリやモデルがPython対応で提供されることがほとんどです。
最新の技術をいち早く試しやすいという点も、AIエンジニアに選ばれる理由です。
さらに、学習用の教材やオンラインコース、サンプルコードがPython前提で用意されているケースが多く、学びやすさと現場での活用が直結しやすいというメリットもあります。
AIプロジェクトにおけるPythonの役割
[図解作成の指示]
- プロジェクトの登場人物(データサイエンティスト、MLエンジニア、バックエンドエンジニア)のイラスト
- それぞれの足元に「Python + ライブラリ名」が書かれたラベル
- 真ん中に「共通言語としてのPython」というタイトル
AIプロジェクトでは、1人のエンジニアがすべてを行うのではなく、役割ごとに複数の専門家が協力することが一般的です。
その際に、Pythonが「共通言語」として機能することが多くの現場で見られます。
たとえば、データサイエンティストはPandasやscikit-learnを使ってデータ分析とモデルの検証を行います。
機械学習エンジニア(MLエンジニア)は、PyTorchやTensorFlowを使ってモデルを高度化・高速化し、学習パイプラインを構築します。
バックエンドエンジニアは、FastAPIなどを用いて学習済みモデルをWebAPIとして提供します。
このように、各ロールが扱うライブラリやフレームワークは異なりますが、すべてPythonをベースとして連携できるため、プロジェクト全体の開発効率や保守性が高まります。
コードの一部を他のメンバーが引き継いだり、分析用ノートブック(Jupyter Notebook)から本番コードへの移行もしやすくなるのです。
Pythonがデータ分析に強い理由
Pythonによるデータ分析の流れ

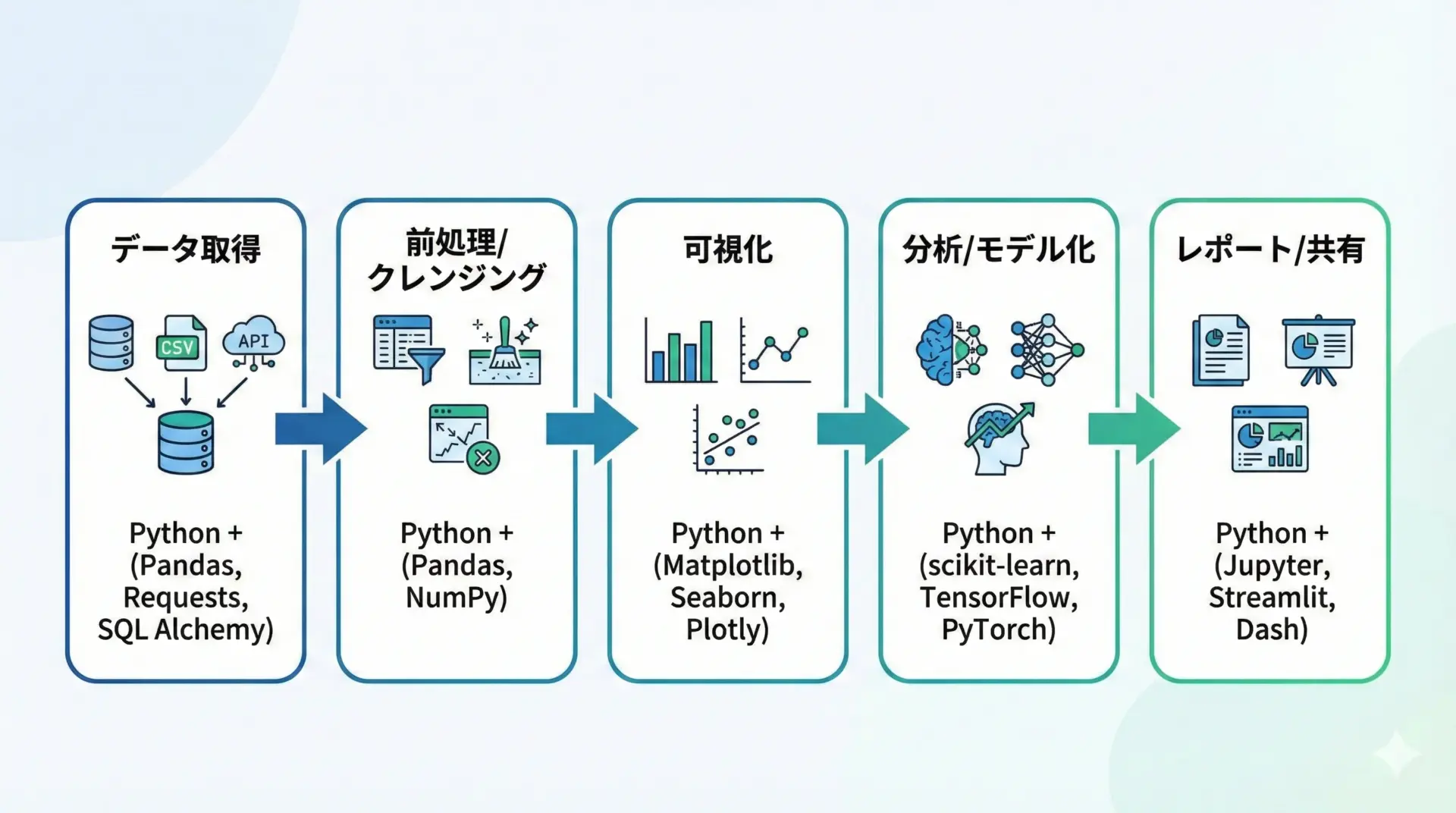
Pythonによるデータ分析は、ある程度決まった流れに沿って進みます。
典型的な手順は次のようになります。
まず、CSVやExcel、データベース、APIなどからデータを取得します。
Pythonでは、Pandasや標準ライブラリを使って様々な形式のデータを読み込めます。
次に、欠損値の処理や異常値チェック、型変換などの前処理やクレンジングを行います。
このステップでデータの質を高めておかないと、後の分析結果が信用できなくなってしまうため、非常に重要です。
前処理が済んだら、グラフや表を使って可視化します。
分布や傾向、相関などを目で見て把握することで、次に行うべき詳細分析の方針を立てられます。
その後、統計的な分析や機械学習を用いたモデル化を実施します。
売上予測や離反予測、顧客セグメント化など、目的に応じて手法を選びます。
最後に、結果をレポートやダッシュボードの形で共有します。
Jupyter Notebookをそのまま共有したり、グラフを画像として資料に埋め込んだり、Webアプリとして公開したりと、さまざまな形が選べます。
Pythonは、これらすべてのステップを1つの言語で一貫して行えるため、ツール間のデータ受け渡しが少なく、分析の再現性も高めやすいのが強みです。
データ分析の代表的ライブラリ
データ分析の現場で頻繁に使われるPythonライブラリを、役割とともに整理します。
Pandasは、表形式(行と列)のデータを扱うためのライブラリです。
ExcelのようなテーブルをPython上で操作できるイメージで、列の抽出や行のフィルタリング、集計、結合などを簡潔なコードで行えます。
NumPyはすでにAIの項目でも触れましたが、データ分析の基盤としても重要です。
大量の数値データを高速に処理できるため、Pandasも内部的にNumPyを利用しています。
Matplotlibは、折れ線グラフや棒グラフ、散布図などを作成するための標準的な可視化ライブラリです。
細かいカスタマイズが可能で、出版品質の図表を作ることもできます。
Seabornは、Matplotlibをベースに、より少ないコードで美しい統計グラフを描画できるライブラリです。
相関関係を示すペアプロットやヒートマップなど、データ分析でよく使うグラフを簡単に作れます。
PandasとMatplotlibによる簡単な分析例
以下は、仮の売上データを使って月ごとの売上合計を集計し、グラフにする簡単なサンプルです。
import pandas as pd # 表データ操作ライブラリ
import matplotlib.pyplot as plt # グラフ描画ライブラリ
import japanize_matplotlib # 日本語対応ライブラリ
# 1. サンプルデータを作成する
data = {
"date": ["2024-01-10", "2024-01-15", "2024-02-01", "2024-02-20", "2024-03-05"],
"amount": [10000, 15000, 20000, 18000, 22000]
}
df = pd.DataFrame(data) # 辞書からDataFrame(表形式データ)を作成
# 2. 日付を日付型に変換し、月情報を取り出す
df["date"] = pd.to_datetime(df["date"]) # 文字列→日付型に変換
df["month"] = df["date"].dt.to_period("M") # 年-月単位に変換
# 3. 月ごとの売上合計を集計する
monthly_sum = df.groupby("month")["amount"].sum()
# 4. 集計結果をグラフに描画する
monthly_sum.plot(kind="bar", title="月別売上合計")
plt.xlabel("月")
plt.ylabel("売上金額")
plt.tight_layout()
plt.show()(棒グラフが表示され、2024-01〜2024-03までの売上合計が棒として描画される)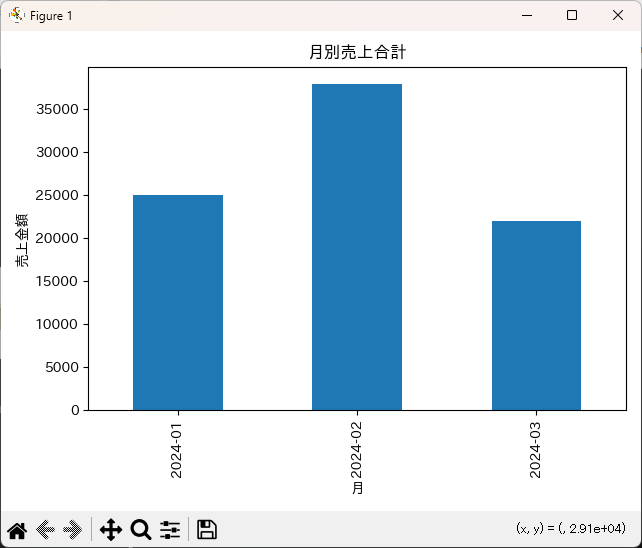
このような処理は、Excelでも可能ではありますが、Pythonを使えばコードとして何度でも同じ処理を再現でき、自動化や応用もしやすくなります。
PythonとExcelの違い
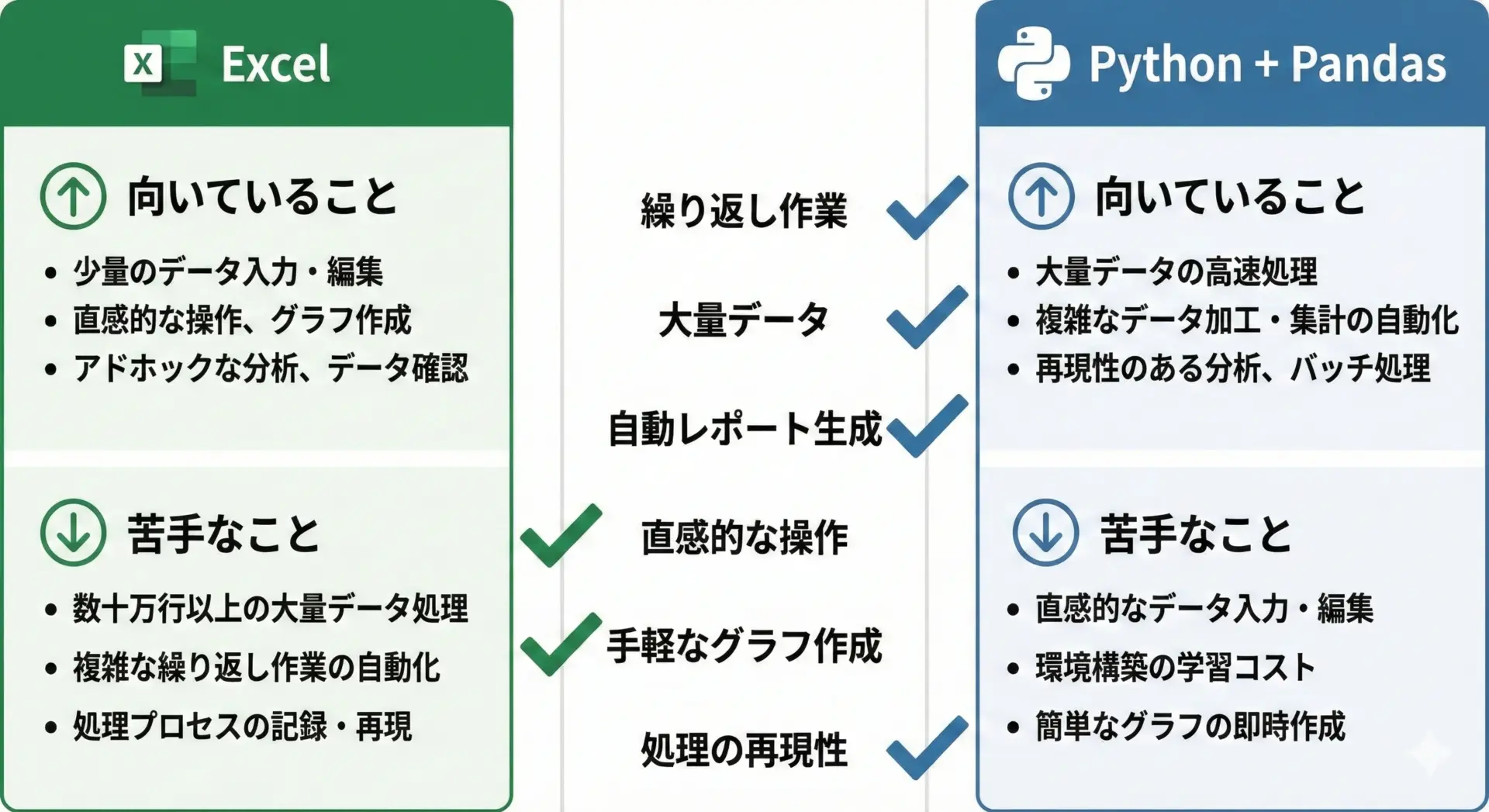
データ分析と言えば、まずExcelを思い浮かべる方も多いと思います。
PythonとExcelはどちらが優れているというものではなく、向き・不向きが異なると考えるのが良いです。
Excelは、少量〜中規模のデータを手で確認しながら分析するのに適しており、グラフ作成や簡単な集計もGUI操作で直感的に行えます。
一方で、数十万行を超えるデータや、複雑な前処理、定期的に同じ処理を繰り返すタスクには限界が出てきます。
Pythonは、最初の習得こそ必要ですが、1度コードを書いてしまえば同じ処理を自動で何度でも再現できます。
また、条件分岐やループを使った柔軟な処理、大量データの高速処理にも対応しやすいです。
ExcelとPythonの違いを、観点ごとに整理すると次のようになります。
| 観点 | Excel | Python(Pandasなど) |
|---|---|---|
| 操作方法 | マウス中心、GUI操作 | コード(cst-code)で操作 |
| 向いているデータ量 | 数万行程度まで | 数十万行〜数百万行以上も扱いやすい |
| 同じ処理の繰り返し | マクロや手作業が必要 | コードを再実行するだけで自動処理 |
| バージョン管理・再現性 | 手作業だと記録が難しい | コードが「手順書」としてそのまま残る |
| 高度な分析・機械学習 | 限定的(アドインなどが必要) | ライブラリを使えば多種多様な手法が利用可能 |
「最初の探索やざっくり確認はExcel」「本格的な分析や自動化はPython」というように、役割分担を意識すると理解しやすいです。
データサイエンティストがPythonを使う理由
データサイエンティストは、ビジネス課題をデータから解決する役割を担う職種です。
彼らがPythonを主に使う理由は、単に計算ができるからではなく、仕事の流れ全体をスムーズに回せるからです。
データサイエンティストは、SQLやPythonを使ってデータベースからデータを取得し、Pandasで前処理を行い、統計的な分析や機械学習で仮説検証を進めます。
その過程をJupyter Notebookに記録しておけば、コード・グラフ・テキストを1つにまとめた「分析レポート」としてチームメンバーと共有できます。
また、検証段階で使ったPythonコードを、実際のシステムに組み込む段階でも再利用しやすいため、「PoC(お試し)から本番までの距離」が短いことも大きな利点です。
さらに、Pythonは他のツールとの連携も得意で、Excelへの書き出し、BIツール用データの生成、ダッシュボードアプリの作成など、一連のタスクを1つの言語で実装できます。
この柔軟性が、データサイエンティストから支持される理由となっています。
Pythonの具体的な活用シーンと始め方
Pythonの活用シーン
Pythonは、個人の小さな作業効率化から、企業レベルの大規模システムまで、幅広い場面で活用できます。
たとえば、日々の業務で発生する「毎朝CSVファイルを開いて加工し、メールで送信する」といったルーティン作業を、Pythonスクリプトで自動化すれば、大幅な時間短縮が可能です。
このレベルであれば、AIや難しい理論を知らなくても、基本的なPython文法とPandasの使い方を覚えるだけで実現できます。
一方で、WebサービスのバックエンドとしてPythonを採用し、ユーザー認証や決済処理、API連携などを実装することもできます。
さらに、AIを組み込んだレコメンド機能やチャットボットなど、高度なサービス機能も同じPythonの上に追加できます。
このように、小さな自動化から本格的なAIプロジェクトまで、成長に合わせて一貫して使い続けられる点が、Pythonを学ぶ価値の大きな部分です。
AI分野での活用シーン

AI分野でのPythonの活用シーンは、非常にバリエーション豊かです。
代表的なものを挙げると、まず画像認識があります。
工場での不良品検出や、医療画像の診断支援、顔認証システムなど、画像からパターンを読み取るタスクは、ほぼPythonと深層学習ライブラリで実装されています。
自然言語処理の分野では、チャットボット、感情分析、自動要約、機械翻訳など、多くのサービスがPythonによって支えられています。
最近の大規模言語モデル(LLM)を扱うライブラリ(例: Transformers)もPythonが中心です。
レコメンドシステムも、Pythonと機械学習の組み合わせで実装されることが多く、ECサイトの商品推薦や、動画サービスのコンテンツ推薦などに使われています。
さらに、需要予測や異常検知といったビジネスの裏側を支えるAIも、Pythonによって構築されているケースが多数あります。
これらの活用シーンは、いずれもデータ分析とAIの知識を組み合わせつつ、Pythonで実装されているのが共通点です。
データ分析の活用シーン
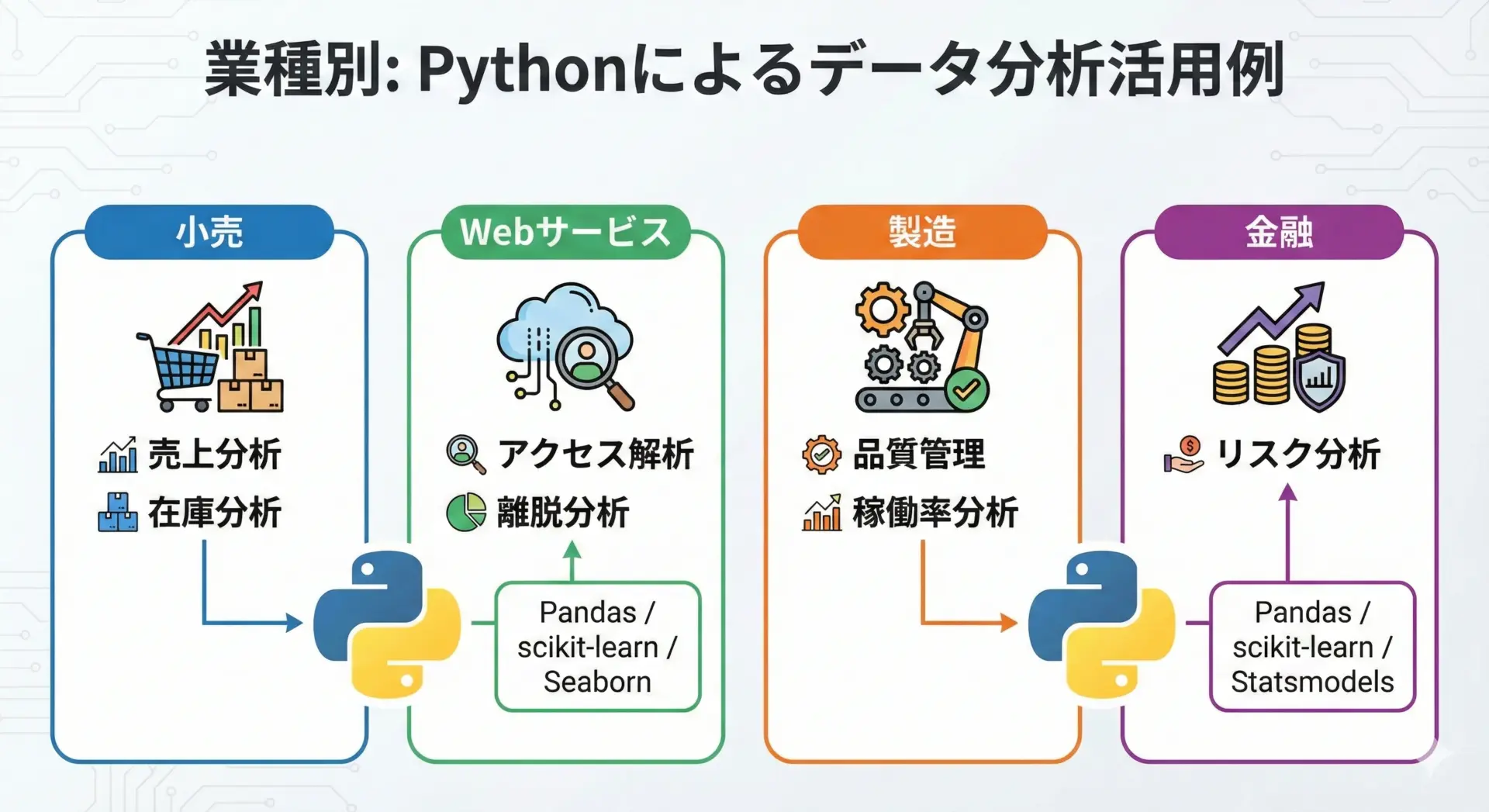
Pythonによるデータ分析は、ほぼすべての業種で活用できます。
たとえば小売業では、売上データや在庫データを分析して需要予測や発注量の最適化に役立てています。
Pythonを使えば、店舗ごとの売上推移や商品カテゴリ別の構成比などを簡単に集計し、可視化できます。
Webサービスの分野では、アクセスログやユーザー行動データをPythonで処理し、どのページで離脱が多いか、どの施策がコンバージョン向上に効いているかといった分析を行います。
A/Bテストの結果評価なども、Pythonと統計手法の組み合わせで行われています。
製造業では、センサーから取得した稼働データをPythonで分析し、設備の故障予兆検知や生産ラインのボトルネック可視化に利用するケースが増えています。
金融業界では、取引データや市場データの分析にPythonが使われており、リスク管理や不正検知、投資戦略の検証など、ミッションクリティカルな領域でもPythonが活躍しています。
Python学習の始め方
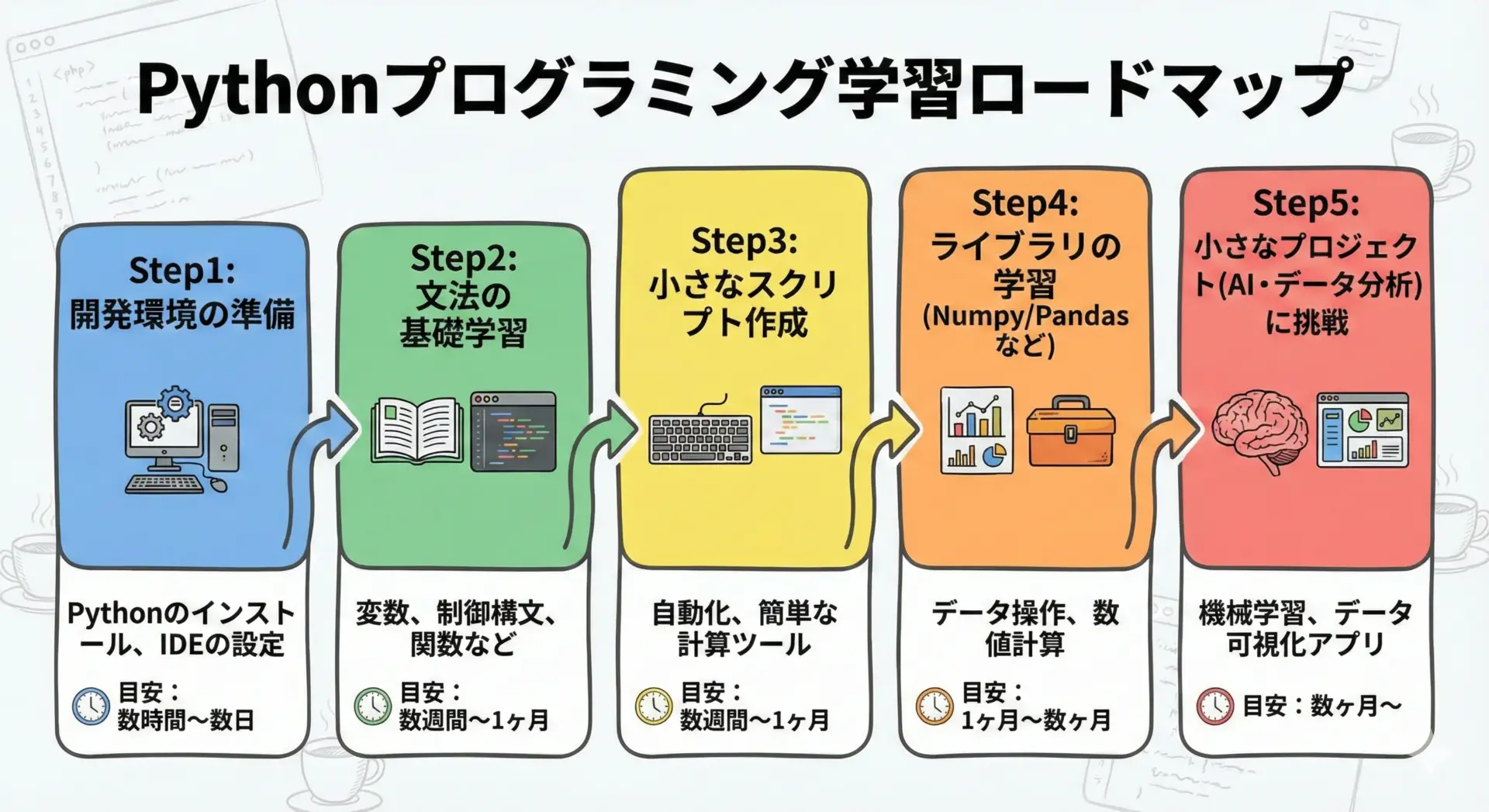
Pythonをこれから学びたい初心者向けに、具体的な始め方を段階的に説明します。
最初の一歩は、開発環境の準備です。
公式サイトからPythonをインストールする方法もありますが、AIやデータ分析が目的であれば、Anaconda(アナコンダ)というディストリビューションを入れるのがおすすめです。
Anacondaを使うと、Python本体に加えて、NumPyやPandas、Jupyter Notebookなど、必要なライブラリが一括でインストールされます。
環境が整ったら、Pythonの基本文法を学びます。
変数、データ型(数値・文字列・リスト・辞書など)、条件分岐(if)、繰り返し(for, while)、関数定義(def)といった要素を、サンプルコードを動かしながら理解していきます。
とても簡単なPythonコード例
以下のコードは、リストの中から偶数だけを取り出して表示するシンプルなプログラムです。
# numbersという名前のリストを用意
numbers = [1, 2, 3, 4, 5, 6]
# 偶数だけを集めるための空のリストを用意
even_numbers = []
# numbersの中身を1つずつ取り出してチェック
for n in numbers:
if n % 2 == 0: # 2で割って余りが0なら偶数
even_numbers.append(n) # 偶数ならリストに追加
# 結果を表示
print("偶数の一覧:", even_numbers)偶数の一覧: [2, 4, 6]このレベルのコードを難なく書けるようになれば、次のステップであるライブラリ学習(PandasやNumPyなど)に進んでも問題ありません。
初心者におすすめのPython学習ロードマップ
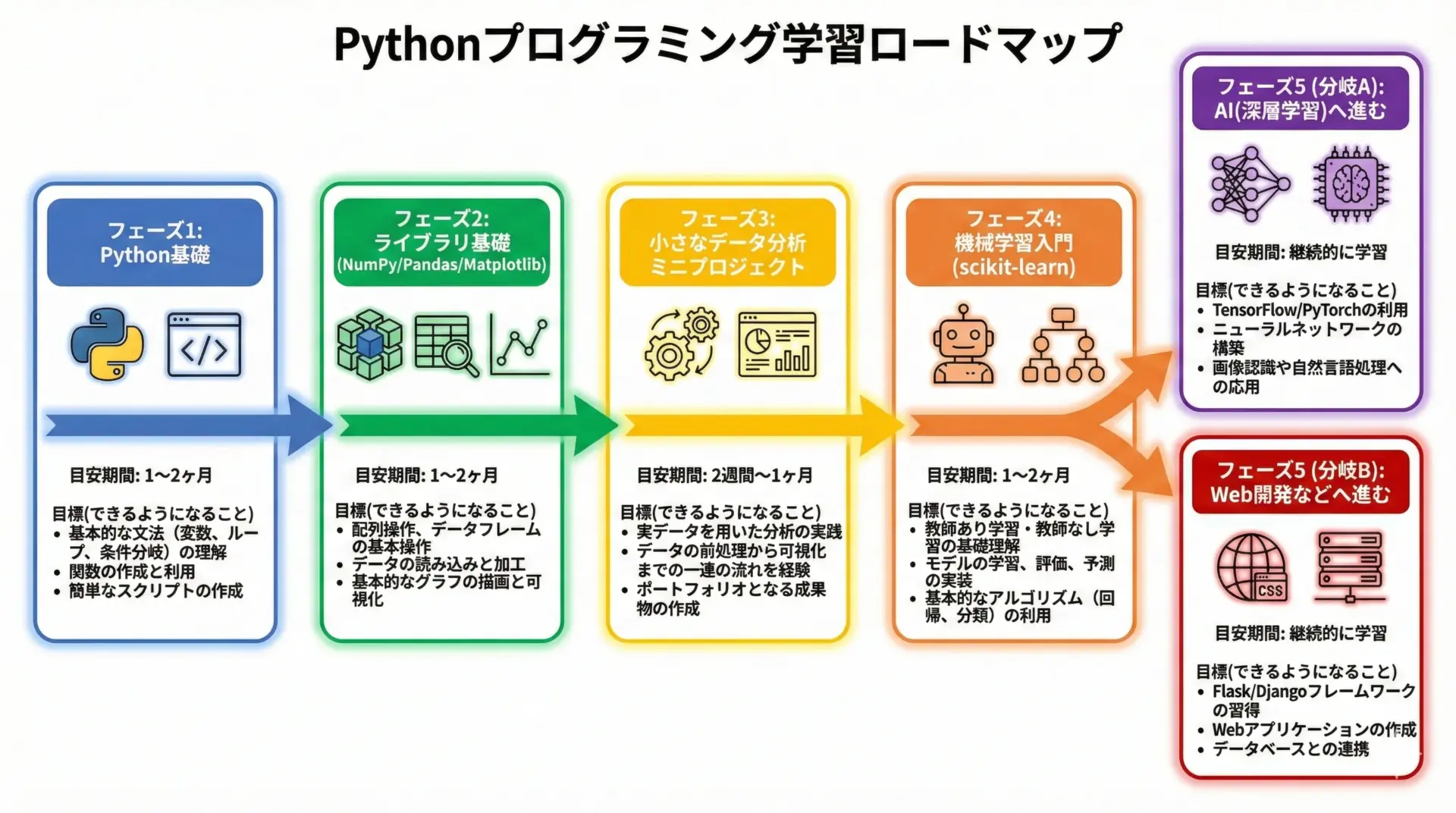
初心者が挫折しにくく、かつAIやデータ分析に活かせるPythonスキルを身につけるための学習ロードマップを提案します。
あくまで一例ですが、順番を意識すると理解がスムーズになります。
フェーズ1: Python基礎(2〜4週間)
まずはPythonの文法基礎を身につけます。
ゴールは、簡単な計算や文字列操作、リスト・辞書を使った処理、if文・for文での分岐や繰り返しが書けることです。
この段階では、AIのことは一旦忘れて、言語そのものに慣れることを優先します。
フェーズ2: ライブラリ基礎(2〜4週間)
次に、NumPy・Pandas・Matplotlibといった、データ分析の基本ライブラリを学びます。
小さなCSVファイルを読み込み、集計やグラフ作成を行いながら、「ExcelでやっていたことをPythonでやってみる」感覚で練習します。
フェーズ3: ミニデータ分析プロジェクト(2〜4週間)
ここでは、実際のデータセットを1つ選び、自分なりの問いを立てて分析する経験を積みます。
例えば「ある商品の売上推移とキャンペーンの関係」「天気データと事故件数の関係」など、身近なテーマを選ぶとモチベーションが続きやすいです。
フェーズ4: 機械学習入門(scikit-learn)(3〜6週間)
Pandasでの前処理に慣れてきたら、scikit-learnを使って機械学習に入門します。
まずは線形回帰(売上予測など)や、分類(スパムメール判定など)といった基本的な手法から試し、「データを学習させて、未知のデータを予測する」というAIの基本サイクルを体験します。
フェーズ5: 応用分野へ(継続)
最後に、興味や仕事で必要な分野に応じて、深層学習(TensorFlow/PyTorch)や自然言語処理、画像認識、あるいはWebアプリ開発(Django/FastAPI)へと進みます。
ここまで来ると、Pythonはすでに「言語」ではなく「道具」として使える状態になっており、新しいライブラリも自力でドキュメントを読みながら習得できるはずです。
まとめ
Pythonは、文法がシンプルで初心者にも学びやすく、それでいてAIやデータ分析といった高度な分野でも第一線で使われている言語です。
NumPyやPandas、scikit-learn、TensorFlowなどの豊富なライブラリが、難しい数理処理を裏側で支えてくれるため、学び始めて早い段階から「実用的なこと」に手を伸ばせます。
まずはPythonの基本とデータ分析ライブラリからスタートし、小さなプロジェクトを通して経験を積むことで、AIや本格的なデータサイエンスの世界へ自然と踏み出していくことができます。
