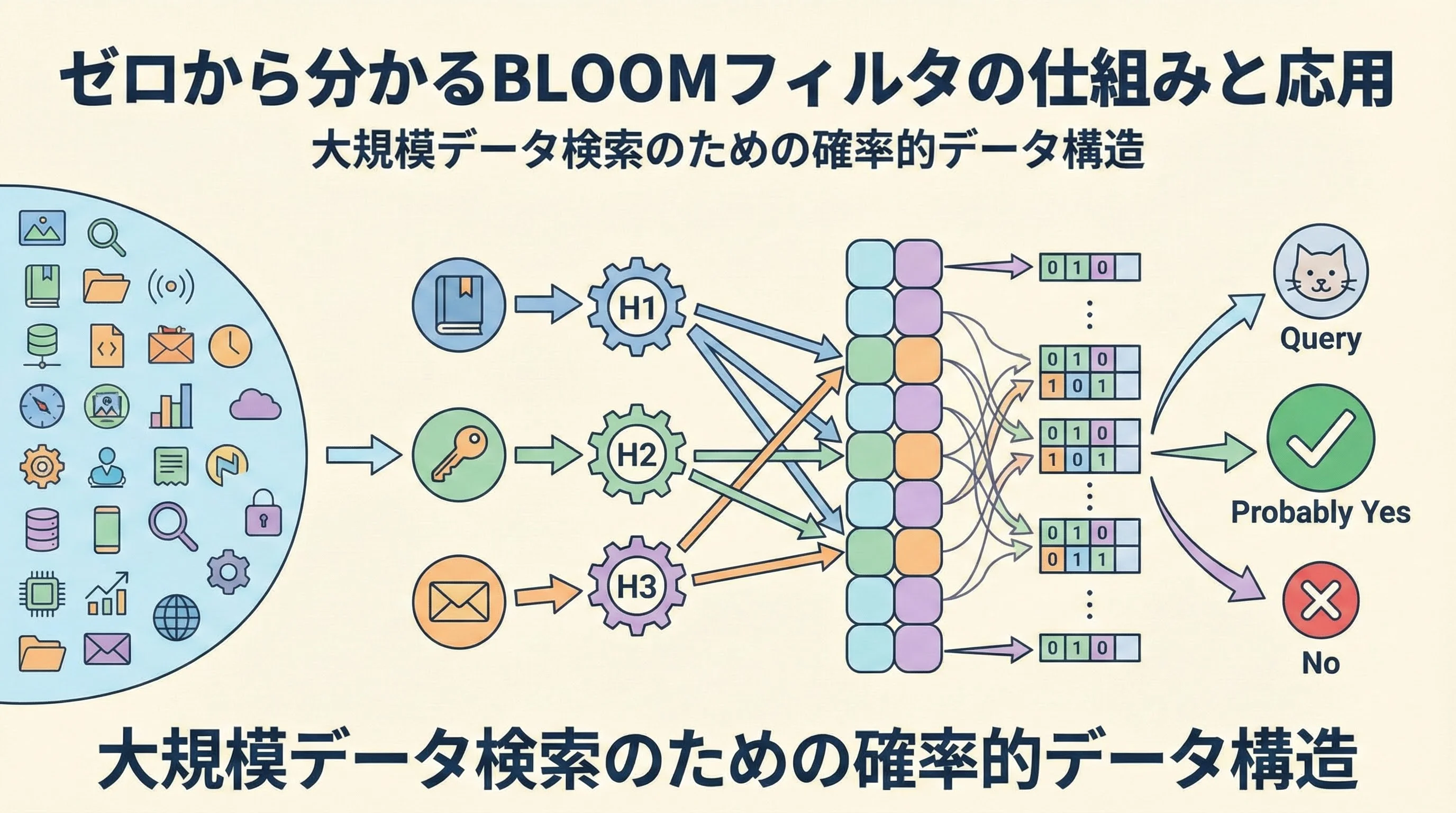
大量のデータの中から「あるか・ないか」を高速に判定したいとき、全件検索やデータベース問合せではどうしても遅くなってしまいます。
そこで登場するのがBLOOMフィルタです。
本記事では、数学やアルゴリズムに詳しくない方でも理解できるように、BLOOMフィルタの基本原理から、実際の応用例、使うときの注意点までを丁寧に解説します。
BLOOMフィルタとは何か
BLOOMフィルタ(Bloom filter)は、1970年にBurton Howard Bloomによって提案された確率的データ構造です。
主な目的は、ある要素が集合に「含まれる可能性があるか」「確実に含まれないか」を、とても少ないメモリで高速に判定することです。
ここで重要なのは、BLOOMフィルタは「たぶん含まれる」「絶対に含まれない」という2種類の答えしか返さない点です。
つまり、誤って「含まれる」と判断してしまう可能性(擬陽性)はありますが、「含まれないものを含まれるとは決して言わない」ように設計されています。
BLOOMフィルタで分かること・分からないこと
BLOOMフィルタが返す答えと、その信頼性を整理すると次のようになります。
| 判定結果 | 実際の状態 | 特徴 |
|---|---|---|
| 含まれない | 本当に含まれない | 常に正しい |
| 含まれる可能性がある | 含まれる / 含まれない | 間違うことがある(擬陽性) |
「ない」ことを高速かつ確実に言い切れる、というのが最大の特徴です。
BLOOMフィルタの基本構造
BLOOMフィルタは、主に次の2つの要素から構成されます。
- 固定長のビット配列(bit array)
- 複数のハッシュ関数(hash function)
直感的には、「0と1しか入らない細長い箱(ビット配列)に、複数のスタンプ(ハッシュ関数)で印を押していく」イメージです。
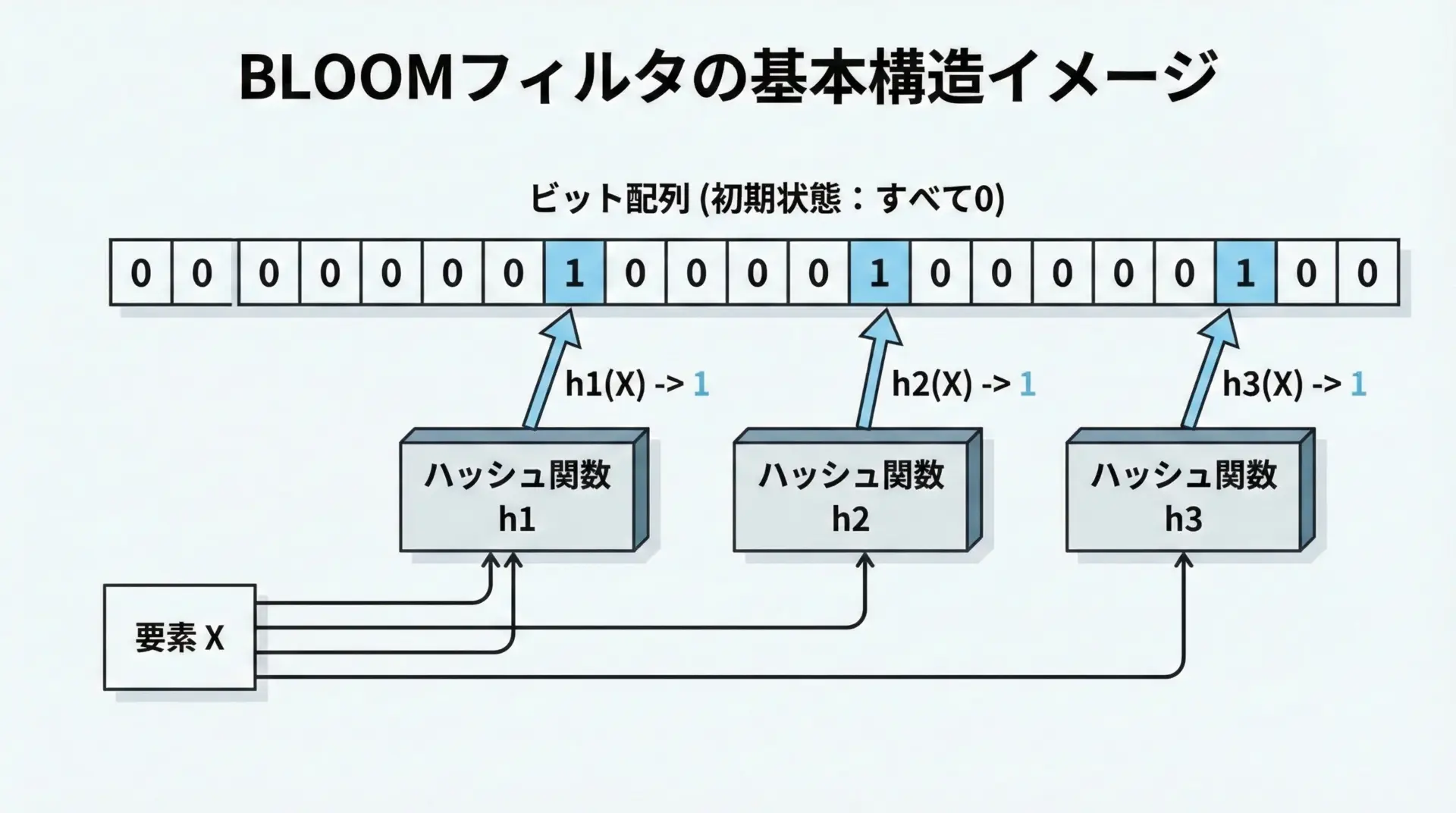
ビット配列とは
ビット配列は、例えばm個の要素を持つ0/1フラグの並びです。
初期状態では、すべて0に設定されます。
- 0 … その位置にはまだ「印」が押されていない
- 1 … その位置には何らかの要素によって「印」が押された
という意味になります。
ハッシュ関数とは
ハッシュ関数は、入力(文字列や数値)をほぼランダムな位置に写像する関数です。
BLOOMフィルタでは、次の条件を満たすようなハッシュ関数を複数個使います。
- 同じ入力に対しては必ず同じ出力を返す
- 出力はビット配列のインデックス(0 ~ m-1)になるようにする
- 異なるハッシュ関数同士は、できるだけ偏りなくバラけていることが望ましい
要素の追加と検索の仕組み
ここでは、BLOOMフィルタがどのように要素を登録し、どのように存在判定を行うのかを、ステップを追って説明します。
要素を追加する(Add)
要素xを追加するときの流れは次の通りです。
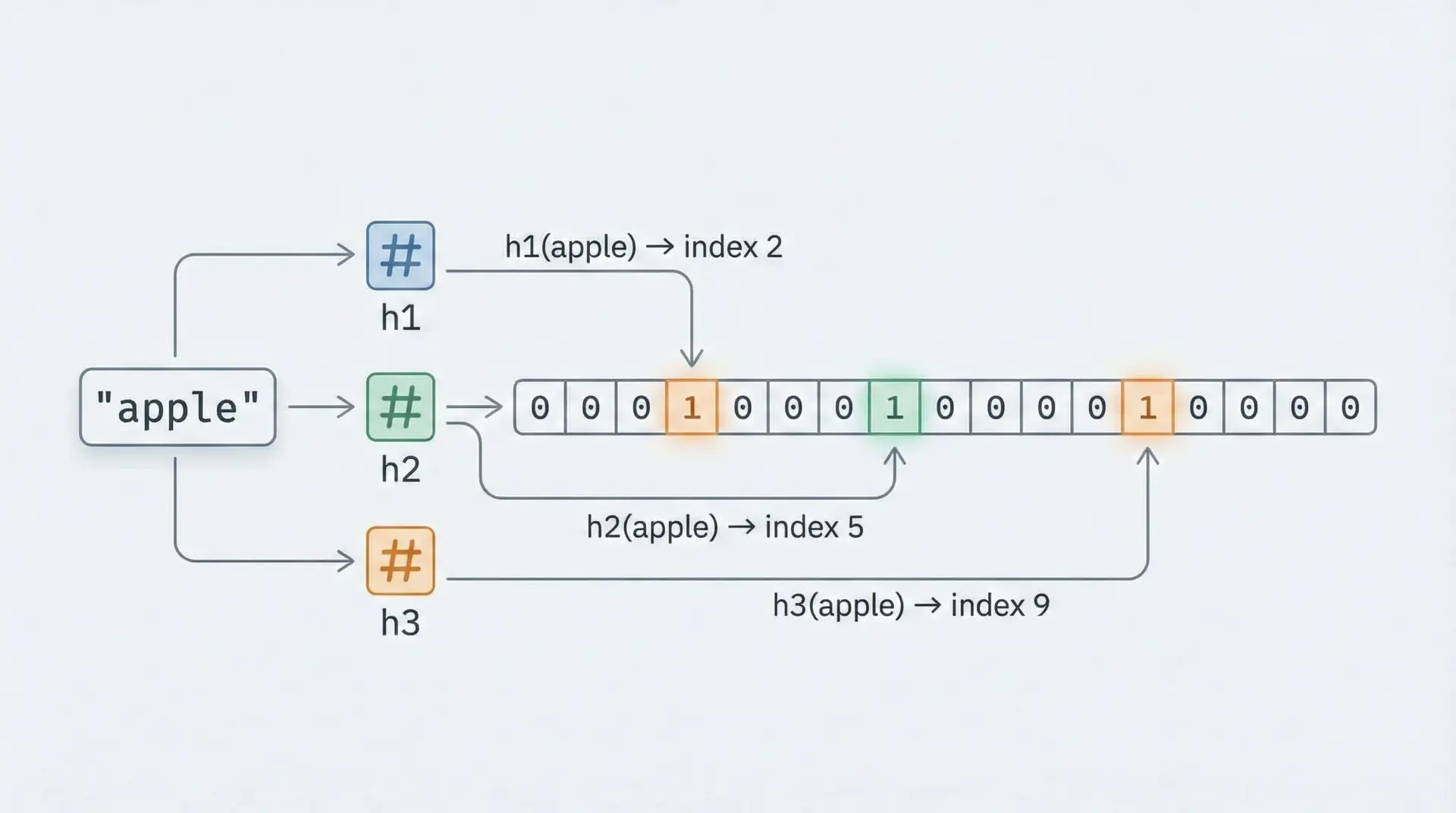
- 要素
xを、準備してあるk個のハッシュ関数にそれぞれ入力します。 - 各ハッシュ関数は、ビット配列のインデックスを1つずつ返します。
- 返されたインデックスの位置のビットを、すべて
1に設定します。
このとき注意したいのは、すでに1になっているビットも、上書きで1のままになるだけで重複カウントはしないという点です。
そのため、BLOOMフィルタは「同じ要素が何回追加されたか」は分かりません。
要素を検索する(Query)
次に、要素yがすでに追加されているかを確認する手順です。
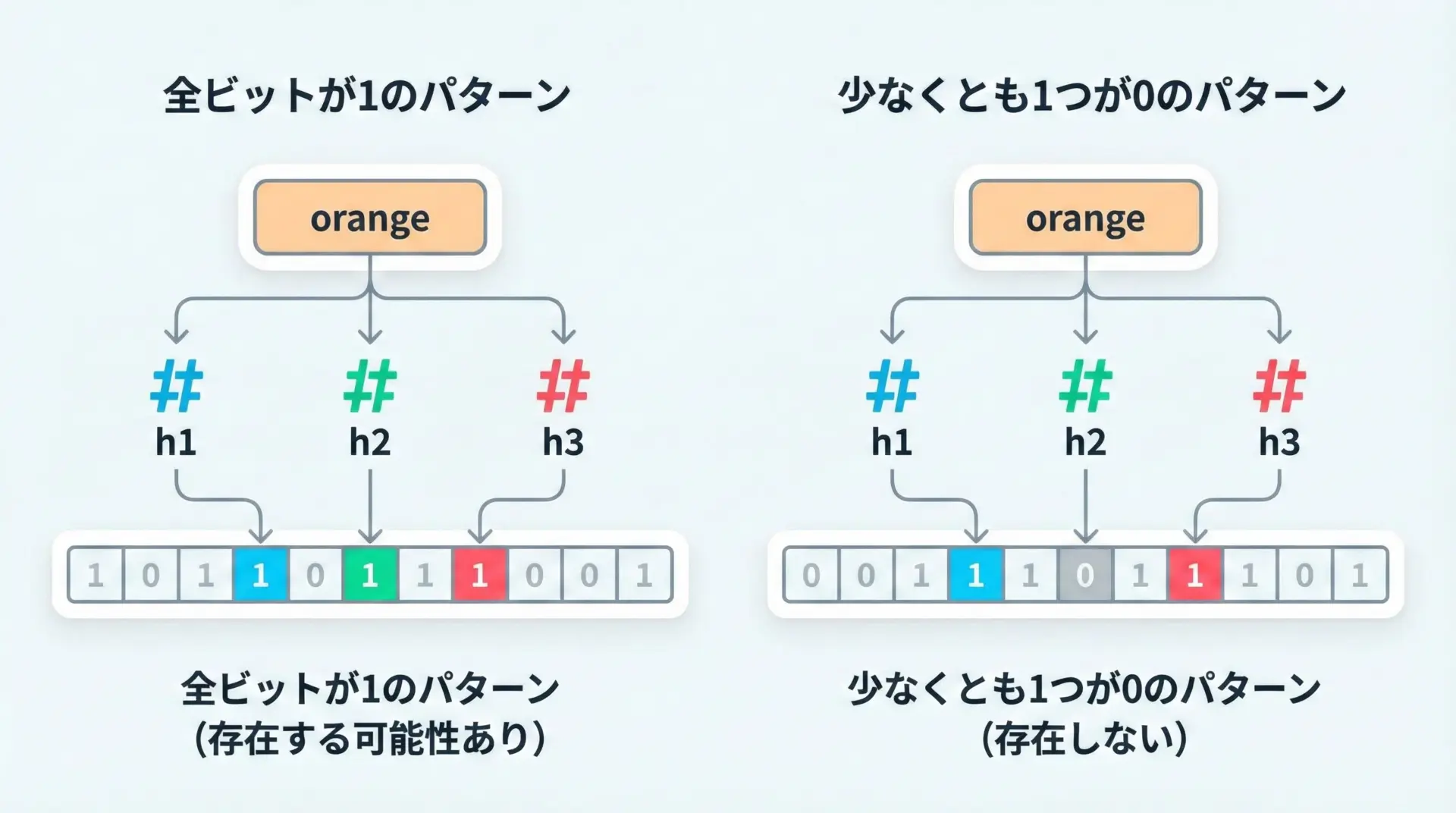
- 要素
yを、同じくk個のハッシュ関数に入力します。 - 各ハッシュ関数が返すインデックスのビットを順にチェックします。
- もし1つでも0のビットが見つかれば、その要素は「集合に含まれていないことが確実」と言えます。
- 逆に、すべてのビットが1であれば、「集合に含まれている可能性が高い」と判断します。
ここで重要なのが、ビットが全部1でも、それが本当にその要素だけによるものとは限らないという点です。
他の要素の追加によって、たまたま同じ位置が1になっていた可能性があります。
これが、BLOOMフィルタ特有の擬陽性(false positive)です。
擬陽性とメモリ・精度のトレードオフ
BLOOMフィルタでは、メモリ使用量と擬陽性率の間に明確なトレードオフがあります。
より少ないメモリで多くの要素を扱おうとすると、ビット配列中の1の割合が増え、擬陽性も増えてしまいます。
擬陽性が起こる理由
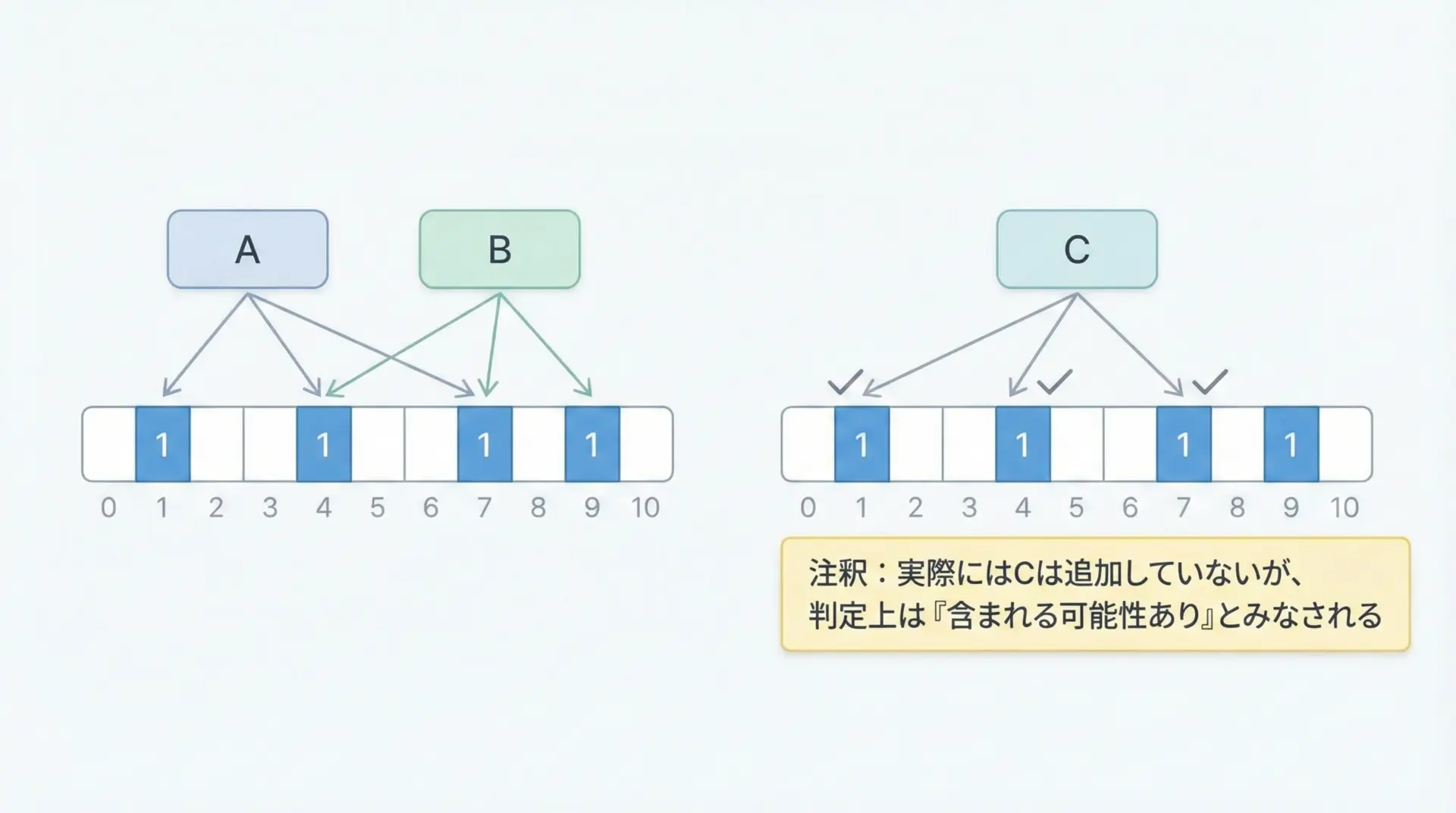
複数の異なる要素を追加していくと、ビット配列のあちこちが1に変わっていきます。
ある程度ビットが埋まってくると、本来その要素のために立てたフラグではない1の組み合わせが、偶然そろってしまうことがあります。
このとき、実際には追加していない要素にもかかわらず、「含まれる可能性がある」と判定されてしまいます。
パラメータ設計の考え方
BLOOMフィルタを設計する際に重要となるパラメータは主に3つです。
- ビット配列の長さ:
m - 追加する予定の要素数:
n - ハッシュ関数の個数:
k
これらには最適な関係が知られており、理論的には
- 最適なハッシュ関数の個数:
k ≒ (m / n) * ln 2
といった式で近似されます。
要素数nに対してビット配列が短すぎると、すぐにビットが1で埋め尽くされ、擬陽性率が急激に上昇します。
実務では、次のような観点でパラメータを決めることが多いです。
- 許容できる擬陽性率(例: 1%、0.1% など)
- 想定される最大要素数
- 利用可能なメモリ量(例: 数MB以内など)
BLOOMフィルタの代表的な応用例
ここからは、BLOOMフィルタが実際にどのような場面で使われているのかを、具体例とともに紹介します。
データベース・キャッシュの問い合わせ削減
もっとも典型的な応用はデータベースやキャッシュへの不要な問い合わせを減らす用途です。
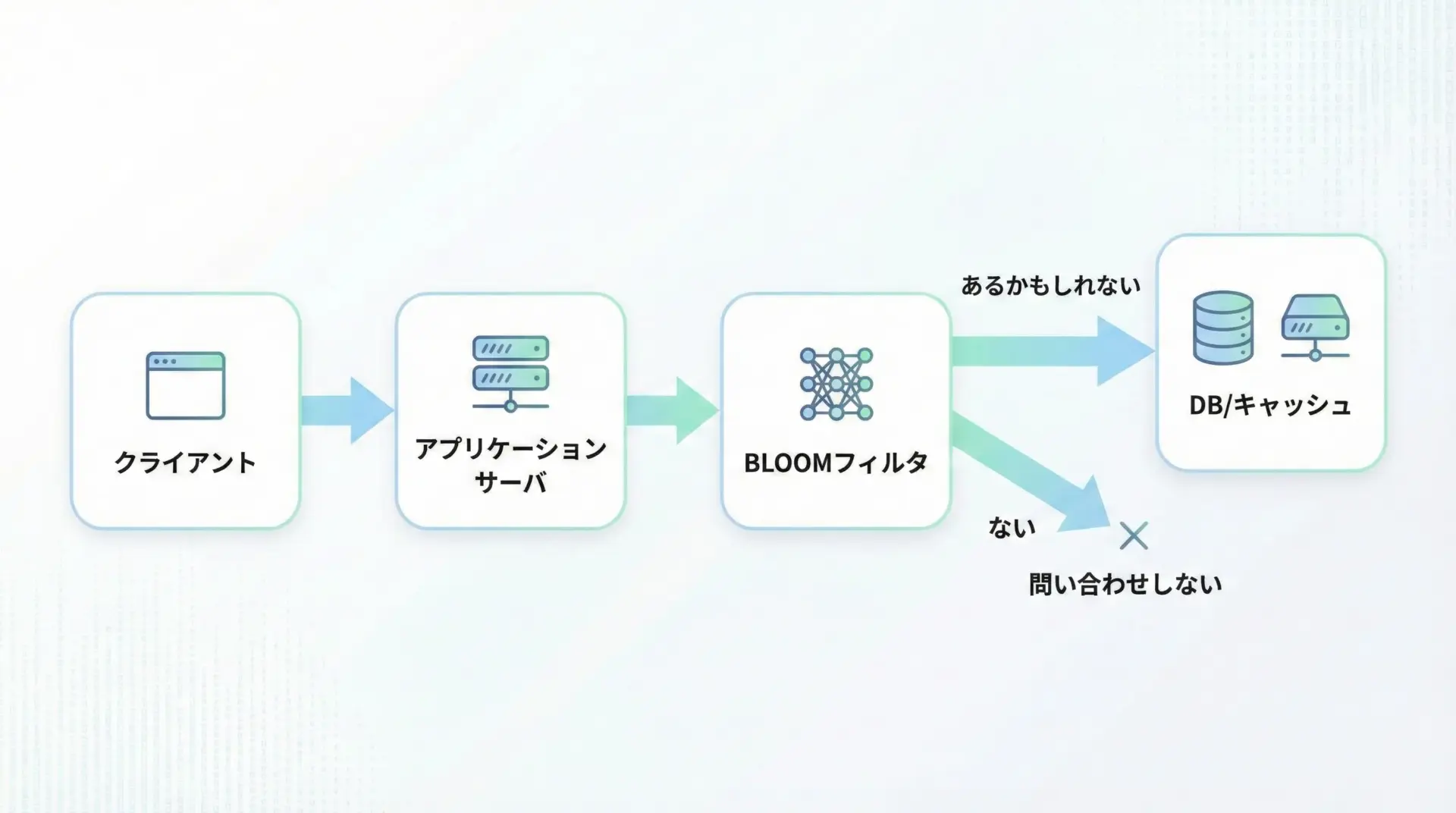
例えば、キーに対応するデータがキャッシュにあるかどうかを毎回DBに問い合わせていては、遅延が大きくなります。
そこで、キャッシュに存在するキーをあらかじめBLOOMフィルタに登録しておき、次のように動作させます。
- まずBLOOMフィルタを参照し、「そのキーが存在する可能性があるか」を確認する。
- 「絶対に存在しない」と分かった場合は、DBやキャッシュに問い合わせることなく即座に「なし」と判断する。
- 「存在する可能性がある」と判定された場合だけ、実際にDBやキャッシュに問い合わせる。
この仕組みにより、存在しないキーに対する無駄な問い合わせを大幅に減らすことができます。
Webサービスの重複チェック・スパム検知
BLOOMフィルタは、大量のIDやURL、メールアドレスなどを扱うWebサービスでも活躍します。
URLのクロール重複チェック クローラーがWebページを巡回する際、「すでに訪れたURLかどうか」を毎回データベースで確認していると、膨大な負荷がかかります。
そこで、訪問済みURLをBLOOMフィルタに登録しておき、再訪問の可能性が高いURLを事前に弾くことができます。
メールスパム送信元アドレスのブラックリスト 大量のスパム送信元IPアドレスやメールアドレスを記録する場合、すべてを完全な形で保存するとメモリやストレージを圧迫します。
ここでも、ブラックリストの「存在しない」ことを高速に言い切る用途でBLOOMフィルタを活用できます。
分散システム・ビッグデータ基盤での活用
分散KVSやHadoop系のストレージなど、ビッグデータ基盤でもBLOOMフィルタは広く利用されています。
SSTable や LSM-tree 系ストア RocksDB、LevelDB、HBase などのストレージエンジンは、ディスク上のテーブル(SSTable)の前にBLOOMフィルタを置き、そのテーブルに目的のキーが含まれないことを事前に判定しています。
これにより、無駄なディスク読み込みを抑え、ランダムアクセスを削減できるため、性能が大きく向上します。
セキュリティ・ネットワーク分野での利用
ネットワーク機器やセキュリティ製品でも、BLOOMフィルタは活用されています。
- パケットフィルタリングや侵入検知における既知の攻撃パターンIDの事前フィルタリング
- CDN(コンテンツ配信ネットワーク)でのキャッシュ対象オブジェクトの存在確認
など、「膨大な候補の中から、ないものを素早く捨てたい」場面にフィットします。
BLOOMフィルタの弱点と注意点
便利なBLOOMフィルタにも、いくつか重要な制約があります。
設計段階でこれらを理解しておかないと、大きなトラブルの原因になります。
要素の削除が基本的にできない
標準的なBLOOMフィルタでは、一度追加した要素を正確に削除することができません。
理由は、あるビットが1になっているとき、それが「どの要素によって1にされたのか」が分からないためです。
この欠点を補うために、ビットの代わりにカウンタを持たせるCounting Bloom Filterという拡張もありますが、その分メモリ使用量は増加します。
一定以上の要素数を超えると精度が急落
BLOOMフィルタは、想定している要素数nを大きく超えて要素を追加すると、ビット配列中の1の割合が増えすぎて、ほとんどの要素が「含まれる可能性あり」と判定される状態に陥ります。
この状態では、もはやフィルタとしての役割を果たせません。
そのため、実装時には
- 最大要素数の見積もり
- 上限を超えた場合のローテーションや再構築
といった運用設計が重要になります。
「必ず正確」と誤解しないこと
BLOOMフィルタは確率的なデータ構造であり、「存在する可能性がある」と判定された場合は、必ず裏側で本物のデータ構造(データベースなど)と照合して最終判断する必要があります。
BLOOMフィルタ単体を、真偽を断定する唯一の情報源として扱うのは危険です。
実装のイメージと活用のポイント
最後に、BLOOMフィルタを実際に使ってみる際の、おおまかな実装イメージとポイントを整理します。
実装のイメージ
多くのプログラミング言語には、BLOOMフィルタのライブラリが用意されていますが、自前で実装する場合も構造はシンプルです。
擬似コードのイメージは次のようになります。
# 初期化
m = 1000000 # ビット配列の長さ
k = 7 # ハッシュ関数の個数
bit_array = [0] * m
function add(x):
for i in 1..k:
index = hash_i(x) mod m
bit_array[index] = 1
function contains(x):
for i in 1..k:
index = hash_i(x) mod m
if bit_array[index] == 0:
return "definitely not in set"
return "possibly in set"実際には、hash_iを完全に別々の関数として用意するのではなく、1つのハッシュ値から複数の値を生成するテクニックがよく使われます。
これにより、計算コストを抑えつつランダム性を確保できます。
活用のポイント
BLOOMフィルタを有効に活用するためには、次のようなポイントを押さえるとよいでしょう。
- 本当に必要なのは「ない」と言い切る機能かどうかを確認する
- 許容できる擬陽性率を事前に決める
- 想定要素数とメモリ制約から、ビット配列の長さとハッシュ関数の数を設計する
- 削除が必要な場合は Counting Bloom Filter などの拡張も検討する
- 判定結果を最終確定させるバックエンド(データベースやKVS)との組み合わせを前提にする
まとめ
BLOOMフィルタは、「あるかもしれない」「絶対にない」を超高速かつ低メモリで判定できる確率的データ構造です。
ビット配列と複数のハッシュ関数という非常にシンプルな構成でありながら、データベース、キャッシュ、分散ストレージ、Webクローラ、セキュリティ分野など、幅広い実システムで実戦投入されています。
一方で、擬陽性が存在すること、要素の削除が基本的にできないこと、想定要素数を超えると精度が急落することといった制約も明確です。
これらを理解したうえで、BLOOMフィルタをあくまで「前段のフィルタリング」役として活用すれば、大規模データ処理における性能向上に大きく貢献してくれます。
今後、データ量の増加とともに、完全性よりも効率性を優先するデータ構造の重要性はますます高まっていきます。
その代表例として、BLOOMフィルタの考え方と仕組みを理解しておくことは、システム設計やサービス開発において大きな武器になるはずです。
