プログラミングの本や記事を読んでいると、ときどき登場する「参照透過性」という言葉。
なんとなく難しそうに感じてスルーしてしまった経験はないでしょうか。
しかし、参照透過性は身近な例でイメージできる、とてもシンプルな考え方です。
本記事では、数学や関数型プログラミングの専門的な話に深入りしすぎず、「同じ入力なら同じ結果」という直感的な理解から、実際のコードや日常の例を通して参照透過性の本質をざっくりと押さえていきます。
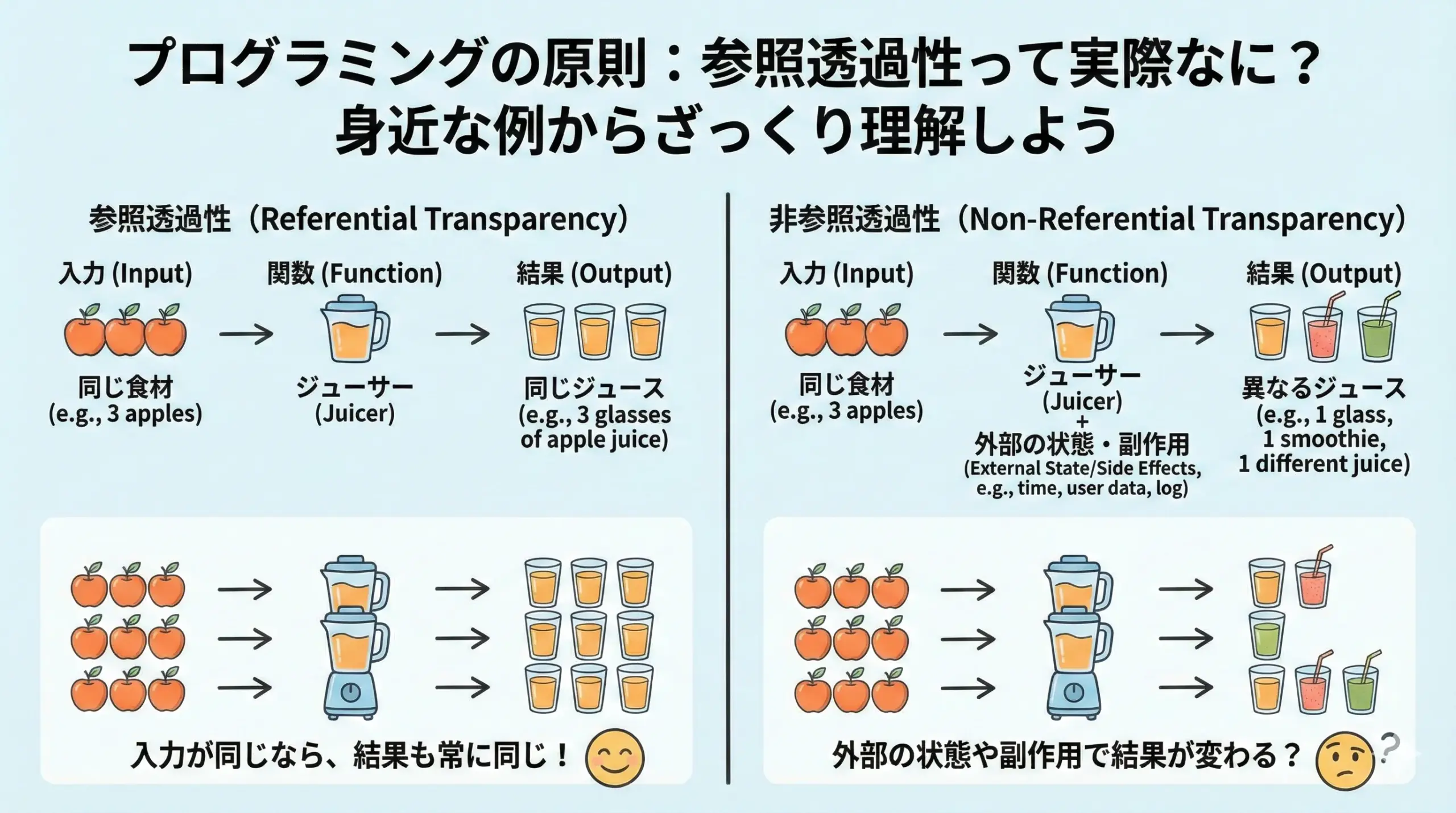
参照透過性とは何かをざっくり理解する
参照透過性のざっくりした意味
参照透過性とは、一言でいうと「その式(または関数呼び出し)を、その結果の値に置き換えても、プログラム全体の意味や結果が変わらない性質」のことです。
もう少しかみ砕くと、ある場所に出てくる式Aを、その評価結果である値Bに置き換えても、周りの挙動が一切変わらないような式や関数を「参照透過」と呼びます。
ここでいう「式」には、関数呼び出しも含まれます。
「式」と「結果の値」が、プログラムにとって完全に同じものとして扱えるとき、その式は参照透過である、というイメージです。
「同じ入力なら同じ結果」がキーワード
参照透過性を直感的に理解するためのキーワードが、「同じ入力なら、常に同じ結果が返ってくる」という性質です。
例えば、次のような関数を考えます。
- 引数に整数xを受け取り、xに2を足した値を返す関数
- 引数に文字列nameを受け取り、
"Hello, name"という挨拶文を返す関数
これらは、同じ引数を与えれば、いつ呼び出しても必ず同じ値を返します。
裏で隠れた状態を読み書きしたり、ランダムな値を使ったりしていないので、結果がぶれることがありません。
このような関数は参照透過と考えられます。
逆に次のようなものはどうでしょうか。
- 現在時刻を返す関数
- 毎回乱数を返す関数
- グローバル変数の値を更新しながら計算する関数
これらは、同じ引数(または引数なし)で呼んでも、呼ぶタイミングや回数によって結果が変わりえます。
つまり、「同じ入力なら同じ結果」というルールが守られていないので、参照透過とは言えません。
参照透過性 = 「同じ入力なら同じ結果」かつ「式を結果に置き換えても何も変わらない」と、2つセットで覚えておくと理解しやすくなります。
参照透過性がプログラミングで重要な理由
参照透過性は、数学的な性質として紹介されることが多いですが、実は「現場のプログラマの作業を楽にする」ための武器でもあります。
参照透過な関数や式が多いコードには、次のようなメリットがあります。
- 理解しやすい
同じ入力に対して結果が変わらないため、「この関数は何をするのか」がシンプルに説明できます。 - デバッグしやすい
入力と出力の対応だけ追えばよいので、バグの原因を絞り込みやすくなります。 - テストしやすい
副作用(ファイル書き込み、ネットワーク、グローバル状態の更新など)がないか少ないため、単体テストが簡単になります。 - 並列処理しやすい
状態を共有して書き換える処理が少ないため、複数スレッド・複数プロセスから同時に呼んでも安全になりやすいです。
参照透過性は「きれいな理論」というより、実務での保守性やバグ削減に直結する実践的な考え方として押さえておくと便利です。
身近な例でイメージする参照透過性
足し算の式で考える参照透過性の例
まずはプログラムから少し離れて、算数の足し算で考えてみます。
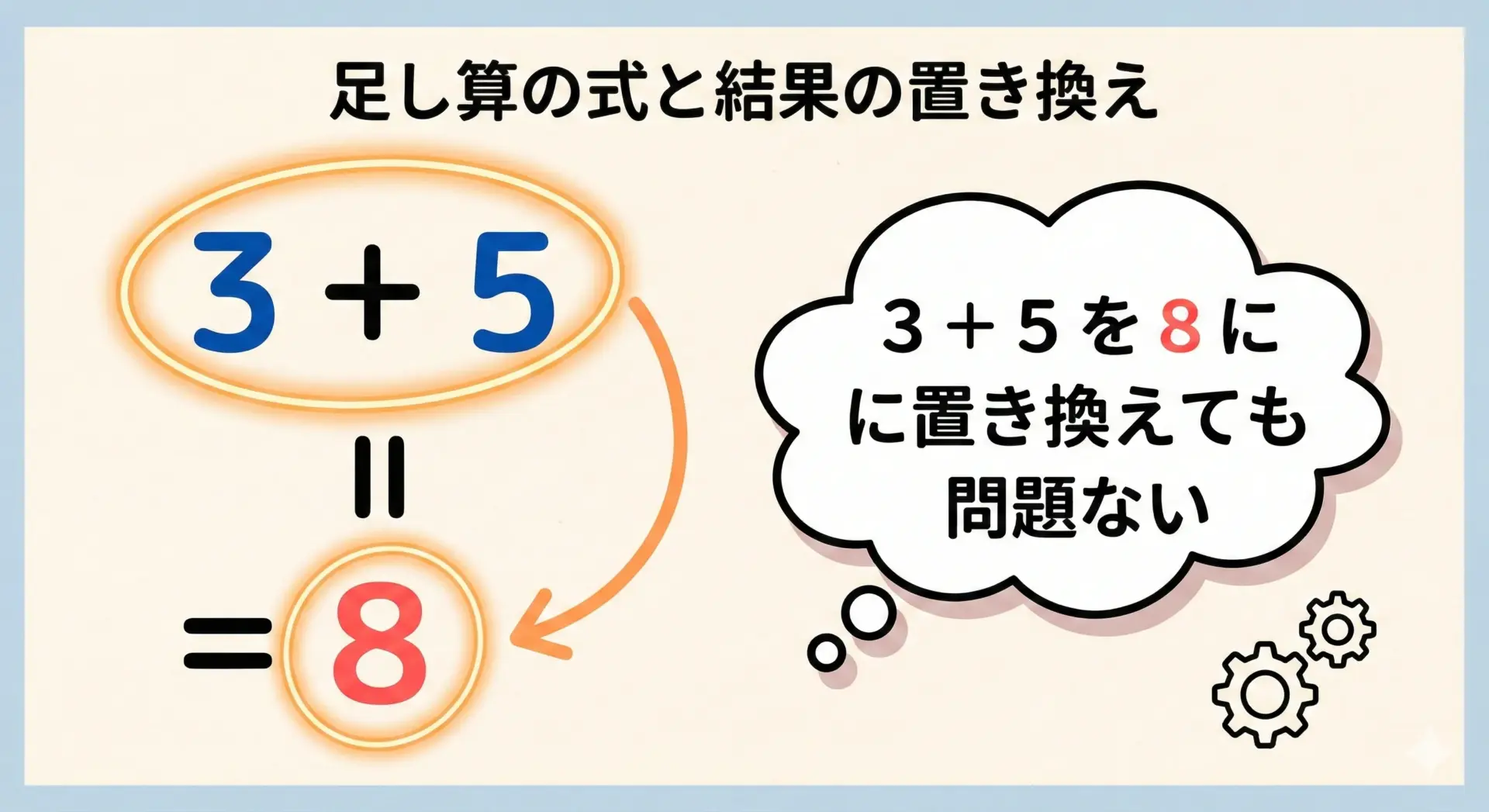
足し算の式3 + 5を考えると、この式の結果は常に8です。
何回計算しても8になり、時刻や環境によって変わることはありません。
したがって、次の2つは「意味が同じ」とみなせます。
3 + 58
どんな文脈であっても、式3 + 5を、その結果である8に置き換えても、全体の意味は変わりません。
これはまさに参照透過性の典型的なイメージです。
例えば、次のような計算があったとします。
(3 + 5) * 2
ここで3 + 5を8に置き換えた8 * 2も、同じく結果は16です。
途中の「3 + 5」を「8」にしてしまっても計算全体に悪影響がない、つまり参照透過だといえます。
電卓と自動販売機を比べて考える
参照透過性を、日常生活の2つの機械「電卓」と「自動販売機」で比べてみましょう。

電卓で10 + 20と入力すると、いつ何度計算しても30が表示されます。
電卓の内部状態がどうであれ、「同じ入力なら同じ結果」がほぼ保証されているため、参照透過性のイメージにかなり近い存在です。
一方、自動販売機はどうでしょうか。
例えば「150円を入れて、オレンジジュースのボタンを押す」という「入力」を考えます。
- 在庫があれば → オレンジジュースが出てくる
- 在庫がなければ → 売り切れランプが点灯し、別の動きになる
- 故障していれば → そもそも動かないかもしれない
同じ「150円 + オレンジジュースのボタン」という操作でも、自販機の内部状態(在庫や故障の状態)によって結果が変わるため、参照透過的ではありません。
電卓は「中身の状態にあまり依存せず、同じ計算式ならいつも同じ結果」、 自販機は「内部状態によって結果が変わる」、 という違いが、参照透過性の有無に対応しています。
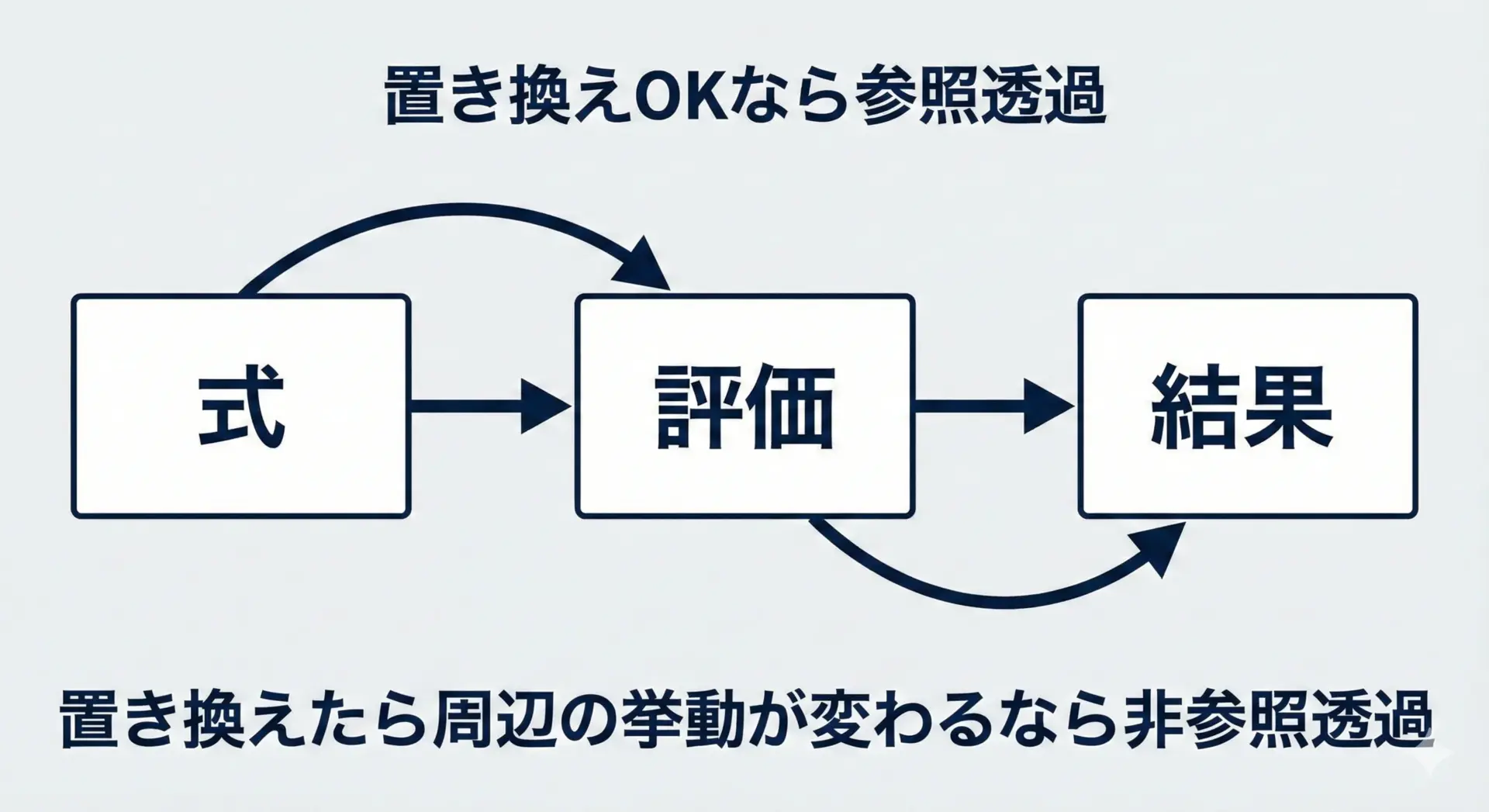
「結果が変わらない置き換え」ができるかどうか
参照透過性の本質は、「その式を、その結果の値に置き換えても大丈夫かどうか」という一点にあります。
例えば、次のような2つの式を考えます。
3 + 5- 現在時刻を返す関数
now()
1の場合、3 + 5を8に置き換えても、周囲の計算結果は変わりません。
どこまで行っても「3 + 5」と「8」は同じものとして扱えます。
2の場合、「いまこの瞬間にnow()を評価した結果」が、仮に2025-11-24 10:00:00だとして、その値に置き換えてしまうとどうでしょうか。
数秒後にもう一度now()を呼んだ場合、本来は別の時刻が返ってきますが、最初の値に固定してしまうと、本来の挙動とは違う振る舞いになってしまいます。
このように、「評価前の式」と「1回評価して得た値」を、全く同じものとして扱えない場合は、非参照透過と考えられます。
コードで見る参照透過性の具体例
ここからは、実際のコード例で参照透過性を確認していきます。
ここでは例として、JavaScript風の疑似コードを使いますが、多くの言語で同じ発想が当てはまります。
参照透過な関数のコード例
まずは、参照透過な関数の例です。
function add(a, b) {
return a + b;
}
const x = add(3, 5); // 常に 8このadd関数には、次の特徴があります。
- 入力は
aとbだけ - 戻り値は
a + bだけ - 関数の外側の状態を読んだり書き換えたりしていない
- 実行するたびに結果が変わらない
したがって、同じ引数(3, 5)に対して、常に8が返ってきます。
このとき、次の置き換えが常に安全です。
add(3, 5)→8に置き換えてもOK
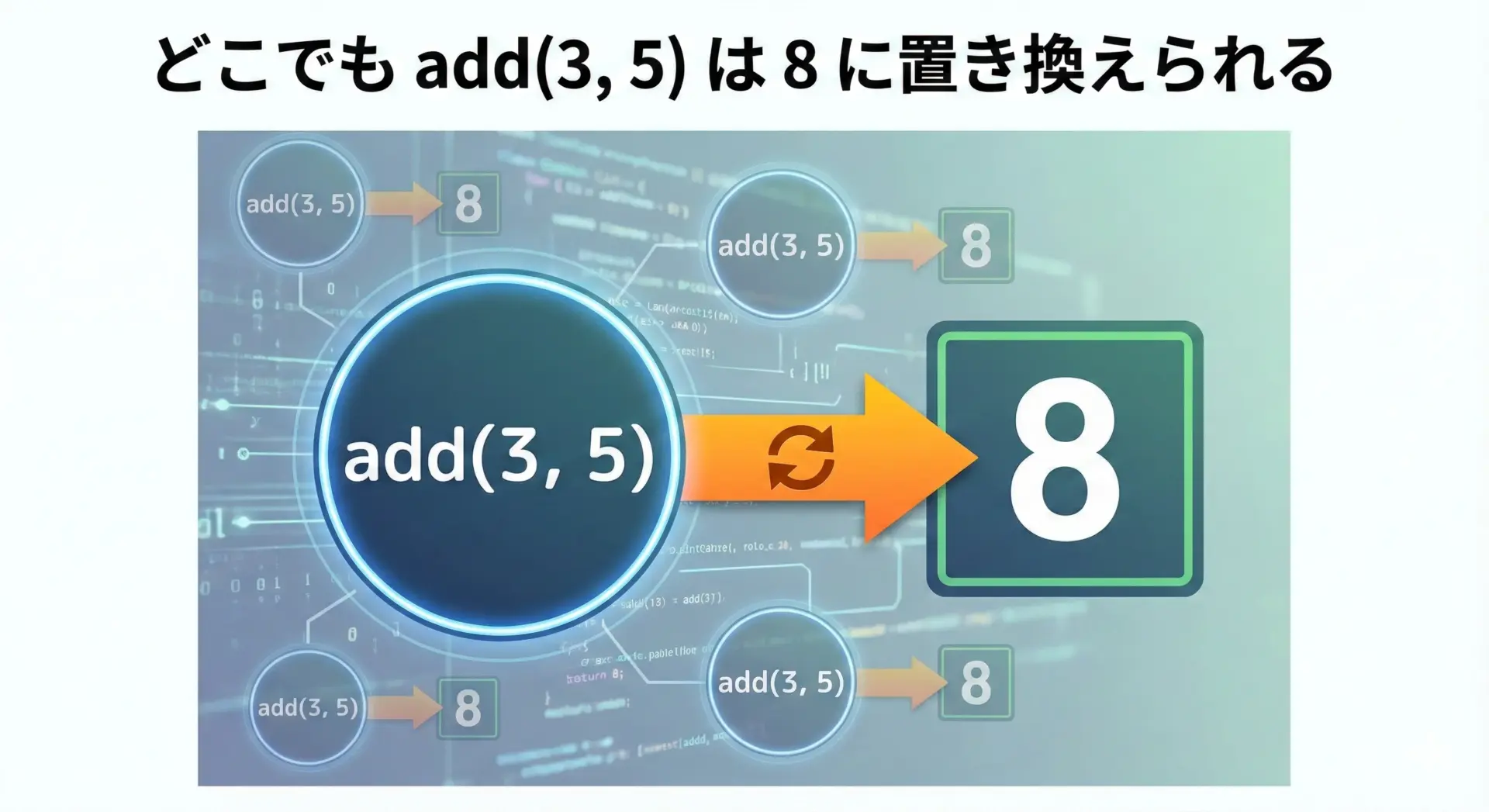
このような関数は、参照透過な関数(純粋関数とも呼ばれます)の代表例です。
参照透過ではない関数のコード例
次に、参照透過ではない関数の例を見てみます。
例1: グローバルカウンタを増やす関数
let counter = 0;
function increment() {
counter = counter + 1;
return counter;
}
const a = increment(); // 1
const b = increment(); // 2increment()は、呼び出すたびにcounterを1ずつ増やし、その結果を返します。
この関数は次の点で参照透過ではありません。
- 同じ呼び出し
increment()でも、呼ぶ順番によって結果(1,2,3…)が変わる - グローバル変数
counterの状態に依存・変更している
そのため、increment()を一度評価して1が返ってきたからといって、プログラム中のincrement()をすべて1に置き換えると、本来得られるべき結果が失われてしまいます。
例2: 現在時刻を返す関数
function now() {
return new Date(); // 現在時刻
}
const t1 = now();
const t2 = now(); // t1 と t2 は通常異なるnow()も、同様に参照透過ではありません。
- 呼び出すタイミングによって結果(時刻)が変わる
now()を固定の値に置き換えたら、本来の「時間が進む」という挙動が表現できない
結果が変わること自体が悪いのではなく、「同じ入力で結果が変わる」うえに「式を結果の値で置き換えると意味が変わる」ことが、非参照透過であると理解できます。
変数代入と参照透過性の関係
参照透過性とよく絡めて語られるのが、変数代入です。
とくに「同じ変数名を別の値で上書きする代入」が増えると、参照透過性は壊れやすくなります。
let x = 3;
let y = x + 5; // y = 8
x = 10;
let z = x + 5; // z = 15このコードでは、式x + 5の結果は、xの値によって変わります。
1回目はx = 3なのでx + 5 = 8ですが、xを書き換えたあとは15になります。
ここで、「このx + 5を、最初の計算結果である8に置き換えてもよいか?」を考えます。
- 1行目の
x + 5→8に置き換えるのは安全 - 3行目の
x + 5→8に置き換えると、本来の結果15とは変わってしまう
つまり、「x + 5」という式は、そのときどきの環境(変数xの値)に依存しており、常に同じものとして扱えません。
これが、参照透過性と変数代入の関係がしばしば問題になる理由です。
もちろん、「代入がすべて悪」というわけではありません。
ただし、代入によって同じ式の結果が変わる回数が増えると、「この式は本当に置き換えても安全なのか?」を常に頭の中で追跡しなければならなくなり、コードの理解が難しくなる、という点が重要です。
グローバル変数と状態変更の注意点
参照透過性を意識するうえで、グローバル変数と状態変更には特に注意が必要です。
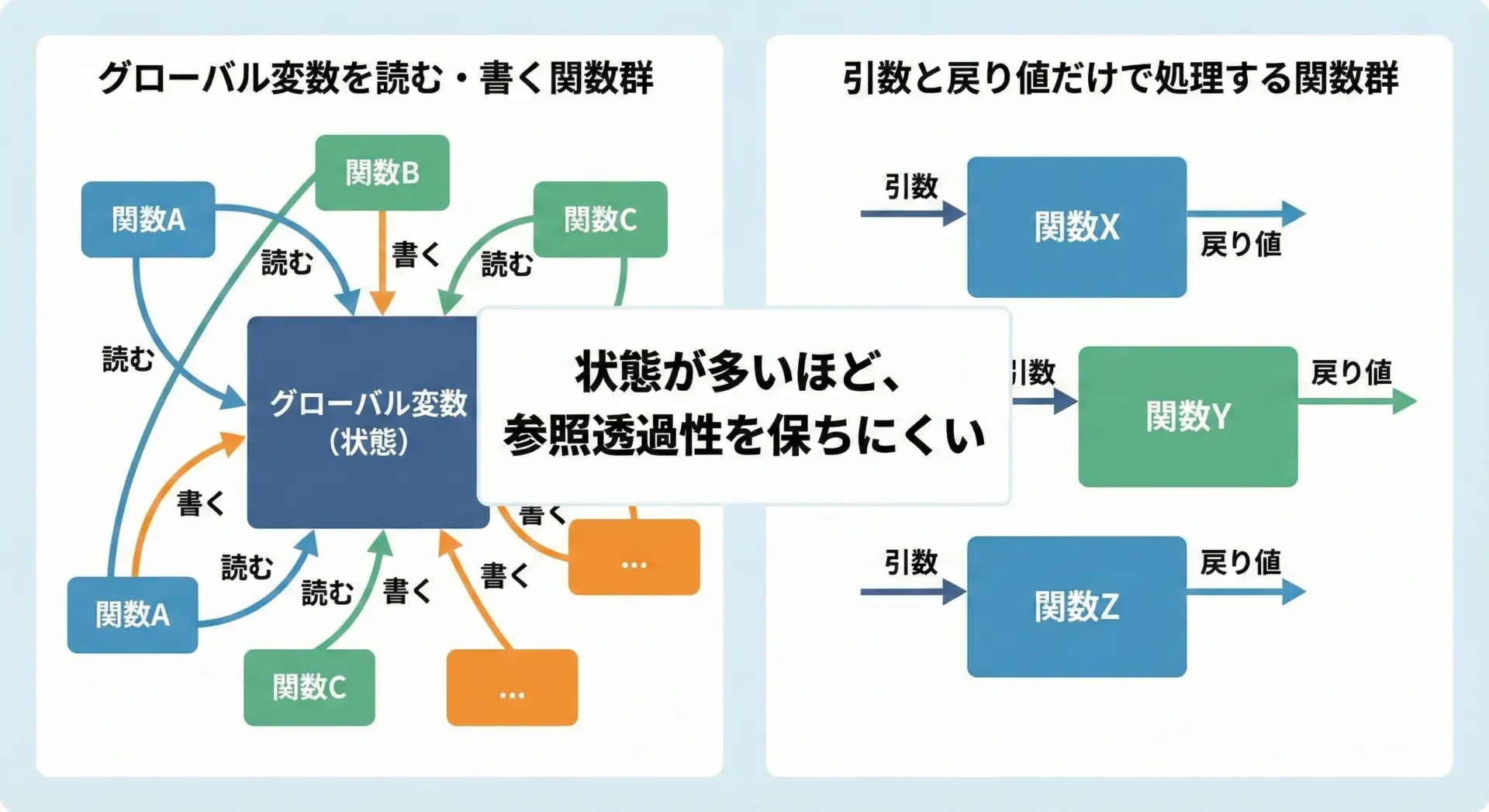
グローバル変数を読む関数
let rate = 1.1;
function calcPrice(price) {
return price * rate;
}このcalcPriceは、一見すると参照透過に見えますが、rateがグローバル変数で、途中で書き換えられる場合は話が変わります。
let rate = 1.1;
const a = calcPrice(100); // 110
rate = 1.2;
const b = calcPrice(100); // 120同じcalcPrice(100)でも、rateの値が変わると結果が変わってしまいます。
このように、外部の状態に依存する関数は、表面的な引数だけでは挙動が決まらないため、参照透過性が弱くなります。
グローバル変数を書き換える関数
let logCount = 0;
function log(message) {
console.log(message);
logCount = logCount + 1;
}このlog関数は、外部に副作用(標準出力への書き込みと、logCountの更新)を持っています。
呼び出すたびにlogCountの値は変化するため、「log() を logCount の最終値に置き換える」といったことは意味をなさなくなります。
グローバル変数や共有状態を参照・更新するコードは、参照透過性を壊しやすく、その分だけ推論やテストが難しくなりがちだと覚えておくとよいでしょう。
参照透過性が役立つ場面と注意点
デバッグしやすくなる理由
参照透過な関数が多いコードは、デバッグが圧倒的に楽になります。
理由は単純で、「この関数は、与えられた引数だけを見れば何を返すか決まる」からです。
外部の状態や呼び出し順序に左右されないため、バグ調査の際には次のようなシンプルな手順で済みます。
- 問題のある出力を見つける
- その出力を返している関数を特定する
- その関数に渡された引数の値を確認する
- 入力と出力の対応だけをチェックする
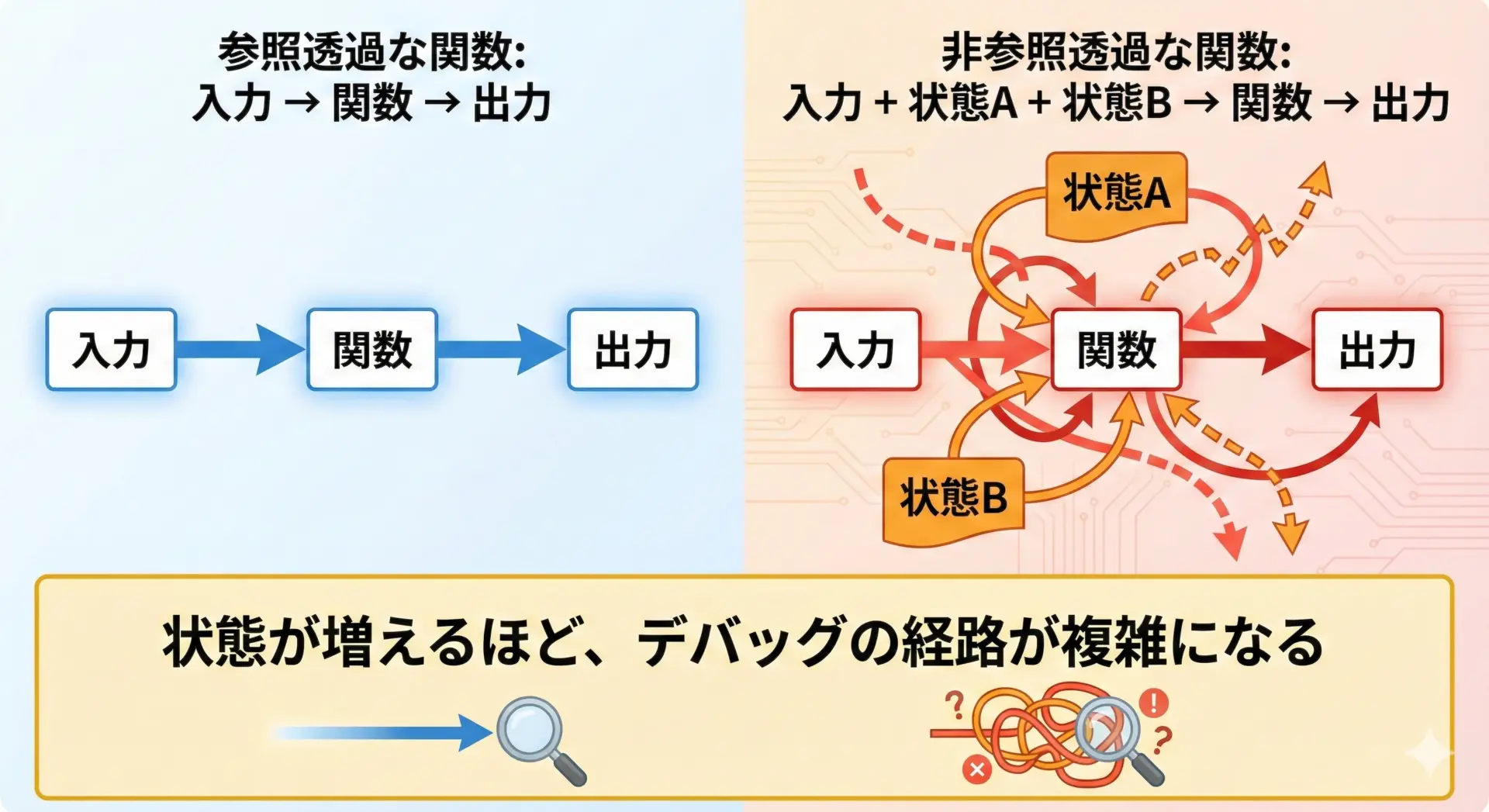
一方で、非参照透過な関数が多いコードでは、「この時点でグローバル変数は何だったか」「前にどんな関数が呼ばれていたか」など、周辺の状況まで遡って追いかける必要があります。
これが、複雑なバグの温床になりがちです。
テストしやすくなる理由
参照透過な関数は、単体テストがとても書きやすいという特徴もあります。
例えば、次のような関数をテストする場合を考えます。
function double(x) {
return x * 2;
}この関数は参照透過なので、テストは「入力と期待される出力のペア」を並べるだけで済みます。
// 疑似テストコード
assert(double(1) === 2);
assert(double(5) === 10);
assert(double(-3) === -6);- 外部リソース(ファイル、DB、ネットワーク)のセットアップは不要
- 実行順序によってテスト結果が変わる心配もない
- テストを並列に走らせても安全
1つの関数を「箱」とみなし、箱に入力を入れて、出てくる出力だけを検証すればよいという単純さが、テストのコストを大きく下げてくれます。
一方で、外部の状態を読み書きする非参照透過な関数では、次のような準備が必要になることが多いです。
- 事前にデータベースへテスト用データを投入する
- テスト後にファイルやDBの内容を元に戻す
- テストの実行順序を制御する
このようなテストは壊れやすく、実行時間も長くなりがちです。
並列処理や関数型プログラミングとの関係
参照透過性は、並列処理や関数型プログラミングとも深く関係しています。
並列処理との関係
複数のスレッドやプロセスから同時にコードを実行する場合、共有しているデータを書き換える処理があると、一気に難易度が上がります。
- あるスレッドが変数を書き換えた直後に、別のスレッドが読むと結果が変わる
- タイミングによって、バグが出たり出なかったりする(レースコンディション)
参照透過な関数は、外部の状態に依存せず、状態を書き換えないため、どれだけ並列に実行しても互いに干渉しません。
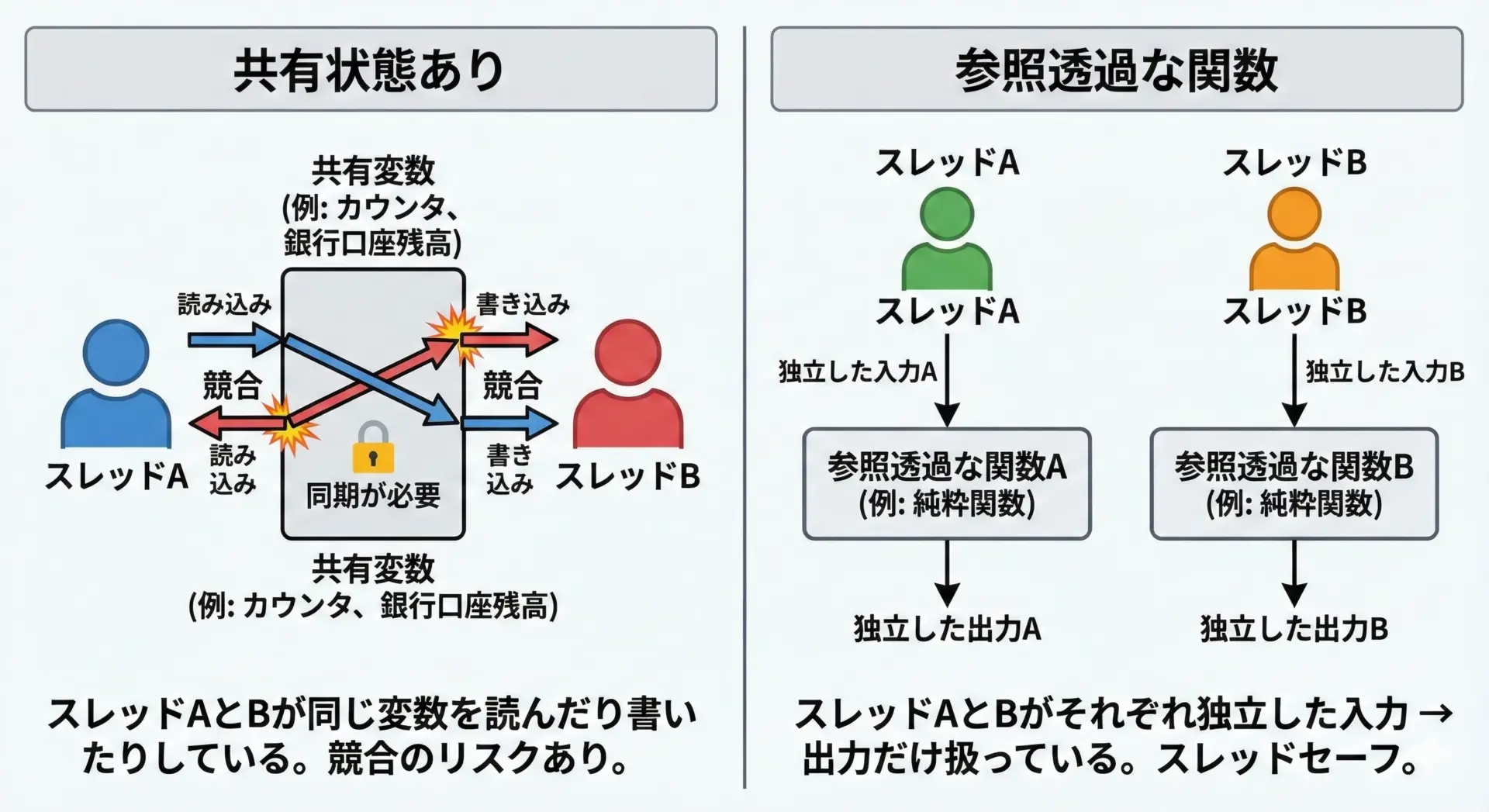
このため、関数型言語や関数型スタイルのプログラミングでは、参照透過な関数を増やし、副作用を持つコードを最小限に閉じ込めることが、並列処理の安全性を高める戦略としてよく用いられます。
関数型プログラミングとの関係
関数型プログラミングは、ざっくり言うと「関数を第一級の値として扱い、参照透過な関数を中心にプログラムを組み立てるスタイル」です。
- 関数を他の関数の引数や戻り値として扱う
- できるだけ副作用を持たない関数でロジックを記述する
- 副作用が必要な箇所(入出力など)を、境界部分に閉じ込める
このとき、関数が参照透過であるほど、組み合わせたり差し替えたりしやすくなります。
まさに、「式をその結果に置き換えてもよい」「関数呼び出しを結果の値に置き換えてもよい」という性質が、再利用性と安全性を高めてくれます。
参照透過性だけでは書けない処理との付き合い方
ここまで読むと、「じゃあ、すべての関数を参照透過にすればよいのでは?」と思うかもしれません。
しかし、現実のアプリケーションでは、参照透過では書けない処理もたくさんあります。
- ファイルやデータベースへの読み書き
- ネットワーク通信
- 画面への表示やユーザーからの入力
- 現在時刻の取得、乱数の生成 など
これらは本質的に副作用を伴うため、完全に参照透過にすることはできません。
重要なのは、それでも「参照透過な部分」と「そうでない部分」をうまく分離することです。
例: 「ロジック」と「入出力」を分ける
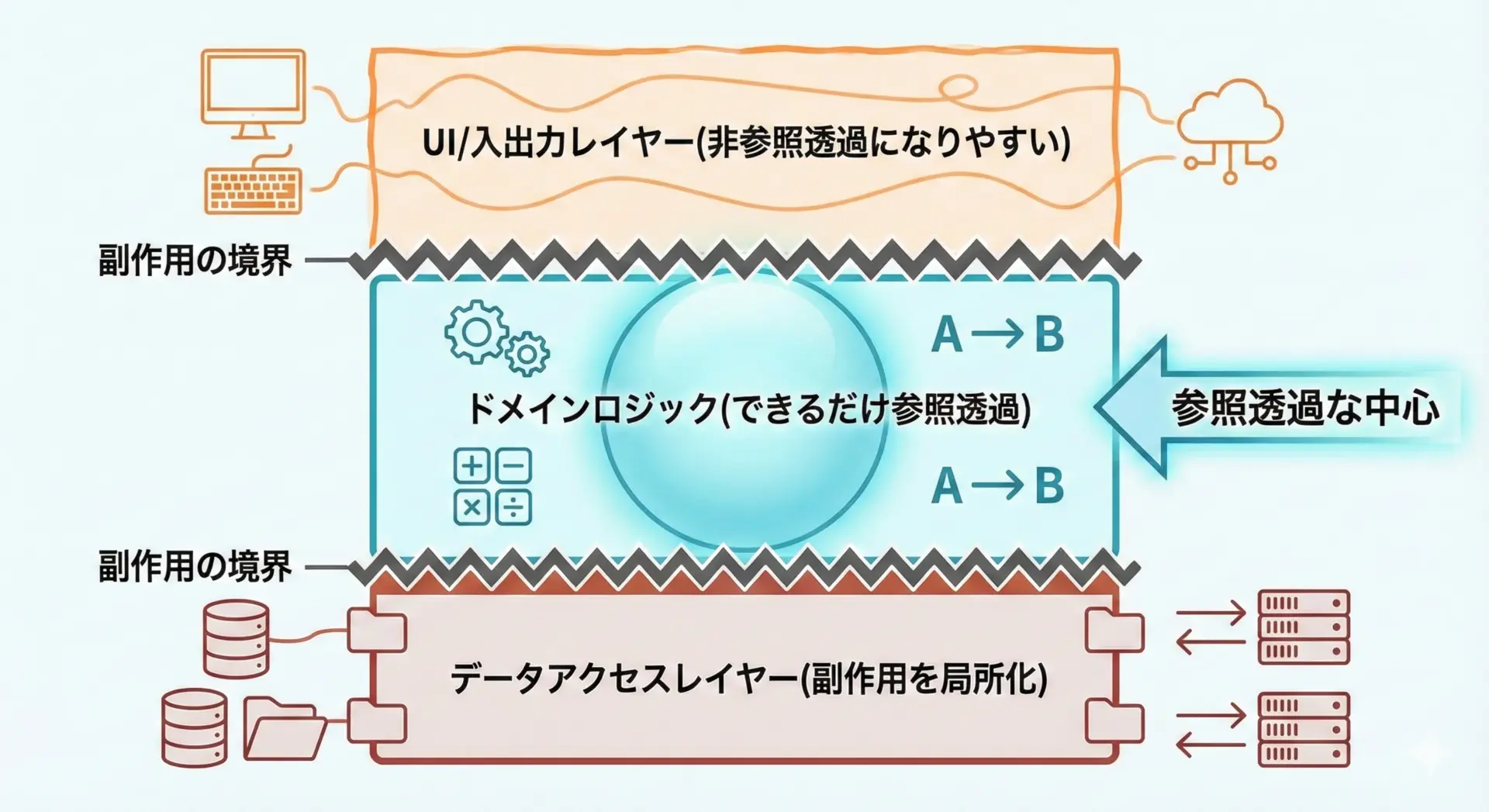
例えば、「ユーザーから数値を入力してもらい、それを2倍にして表示する」という処理を考えてみます。
// 参照透過なロジック
function double(x) {
return x * 2;
}
// 入出力を担当する部分 (非参照透過になりがち)
function run() {
const input = readLine(); // ユーザー入力 (副作用)
const num = parseInt(input);
const result = double(num); // ここは参照透過
console.log(result); // 出力 (副作用)
}このように、「本質的な計算ロジック」は参照透過な関数に閉じ込め、「入出力」などの副作用は周辺に追いやると、次のような利点があります。
- ロジック部分だけを簡単にテストできる
- 入出力の方法(コンソール、Web UI、APIなど)を差し替えやすい
- 並列化や再利用の対象にしやすい
参照透過性は「全部そうしなければならない」という厳格なルールではなく、「できるところから増やしていくことで、コードの扱いやすさを上げるための指針」と捉えるとよいでしょう。
まとめ
参照透過性は、専門用語だけを見ると難しそうに感じますが、その本質はとてもシンプルです。
- 同じ入力なら、いつも同じ結果が返ってくる関数や式であり
- その式を、その結果の値に置き換えても、プログラム全体の意味が変わらないという性質を持ちます。
足し算や電卓のような身近な例から、自動販売機やグローバル変数のような「状態に依存するもの」を対比させると、参照透過性のイメージがつかみやすくなります。
実際のプログラミングでは、参照透過な関数を増やすことで、
- デバッグしやすくなる
- テストしやすくなる
- 並列処理が安全になりやすくなる
- 関数の再利用性が高まる
といった具体的なメリットが得られます。
一方で、入出力や時刻取得など、参照透過では書けない処理も現実には存在します。
そのため、ロジック部分はできるだけ参照透過にし、副作用を持つコードを周辺に局所化するという設計が重要です。
今後、コードを書くときに「この関数は同じ入力に対して常に同じ結果を返すか?」「この式は結果に置き換えても問題ないか?」と、ほんの少し意識してみてください。
参照透過性という考え方が、コードの読みやすさや保守のしやすさを高める、強力な道具になっていくはずです。
