
コンパイルを変えていないのに、少し書き方を変えただけでプログラムが驚くほど速くなった経験はないでしょうか。
その裏側には、CPUだけでなくキャッシュメモリという仕組みが大きく関わっています。
本記事では、ハードウェアの専門知識がなくても理解できるように、キャッシュメモリの役割を日常的なイメージとプログラミングの視点から、直感重視で解説していきます。
キャッシュメモリとは何か
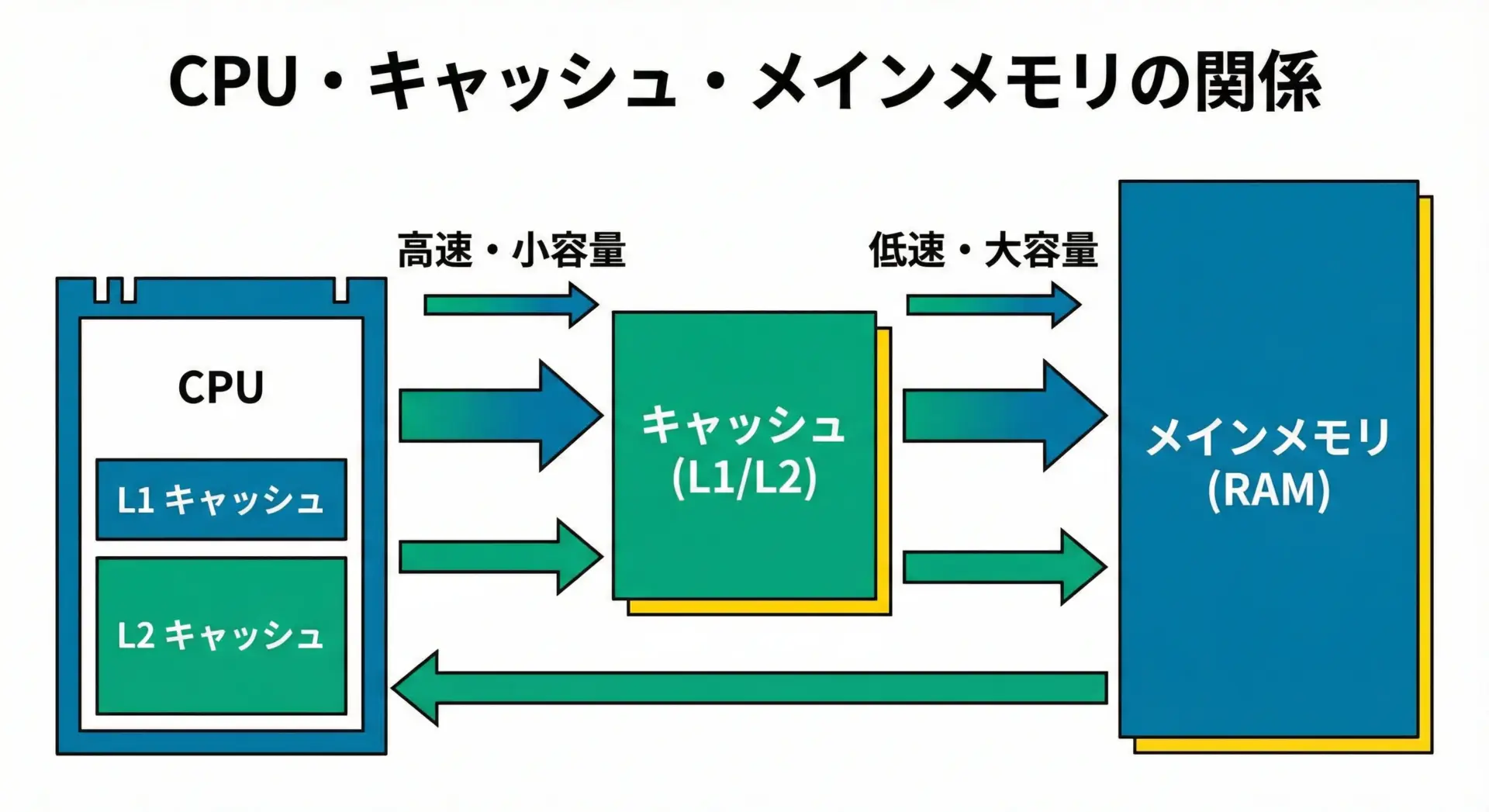
キャッシュメモリは、CPUのすぐ近くにある、小さくて高速な記憶装置です。
プログラムの命令やデータは通常メインメモリ(RAM)に置かれますが、CPUは毎回そこから直接アクセスしているわけではありません。
頻繁に使うデータをキャッシュメモリに「一時的にコピー」しておき、そこから読み書きすることで、全体の処理速度を引き上げています。
キャッシュメモリの基本的な役割
キャッシュメモリの役割を一言で表すと、「よく使うデータを、CPUから一番近い場所に置いておくこと」です。
CPUは非常に高速に動作しますが、メインメモリはそれほど速くありません。
この速度差をそのままにしておくと、CPUはメモリ待ちでほとんどの時間を浪費してしまいます。
そこで、CPUは次のような動きをします。
- 必要なデータをキャッシュメモリにコピーしておく
- 以降は、まずキャッシュメモリを覗きに行く
- あれば高速に処理し、なければメインメモリから読み込む
このように、メインメモリへのアクセスをできるだけ減らすためのバッファとして働くのがキャッシュメモリです。
CPUとメインメモリの速度差とは
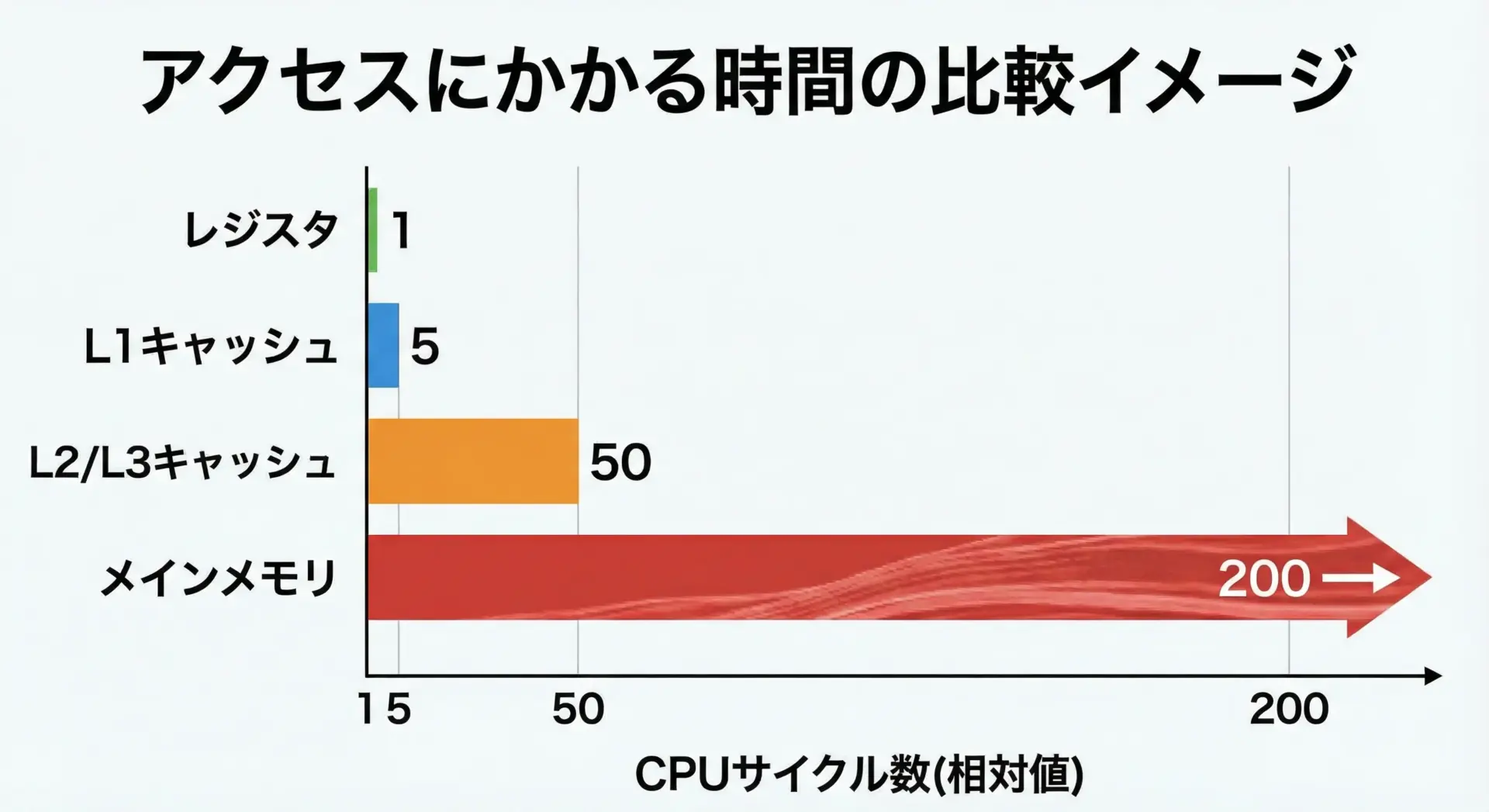
キャッシュメモリの重要性を実感するには、CPUとメインメモリの速度差をイメージすることが大切です。
具体的な数値は環境によって異なりますが、感覚的には次のような違いがあります。
- CPUレジスタやL1キャッシュへのアクセス: 数サイクル程度
- L2 / L3キャッシュへのアクセス: 数十サイクル程度
- メインメモリ(RAM)へのアクセス: 数百サイクル程度
CPUが1サイクルで1つの命令を実行できるとすると、メインメモリへの1回のアクセスで、数百命令分の時間が失われるイメージです。
なぜキャッシュメモリが必要になるのか
CPUが年々高速になる一方で、メインメモリの速度向上はそれほど急ではありません。
このギャップが広がるほど、「CPUが待たされる時間」が増えてしまいます。
その結果、本来のCPU性能を活かしきれなくなります。
キャッシュメモリは、このギャップを埋めるための仕組みです。
CPUから見れば「ほとんどのメモリアクセスは高速なキャッシュで済む」ようにしつつ、「どうしても必要なときだけ遅いメインメモリに行く」という構造にすることで、体感の処理速度を大幅に引き上げています。
キャッシュメモリでプログラムが速くなる理由
キャッシュメモリの存在自体はハードウェアの話ですが、その効果は直接プログラムの実行速度に現れます。
同じアルゴリズムでも、キャッシュを意識した書き方とそうでない書き方で何倍も速度が変わることは珍しくありません。
キャッシュヒットとキャッシュミスのイメージ
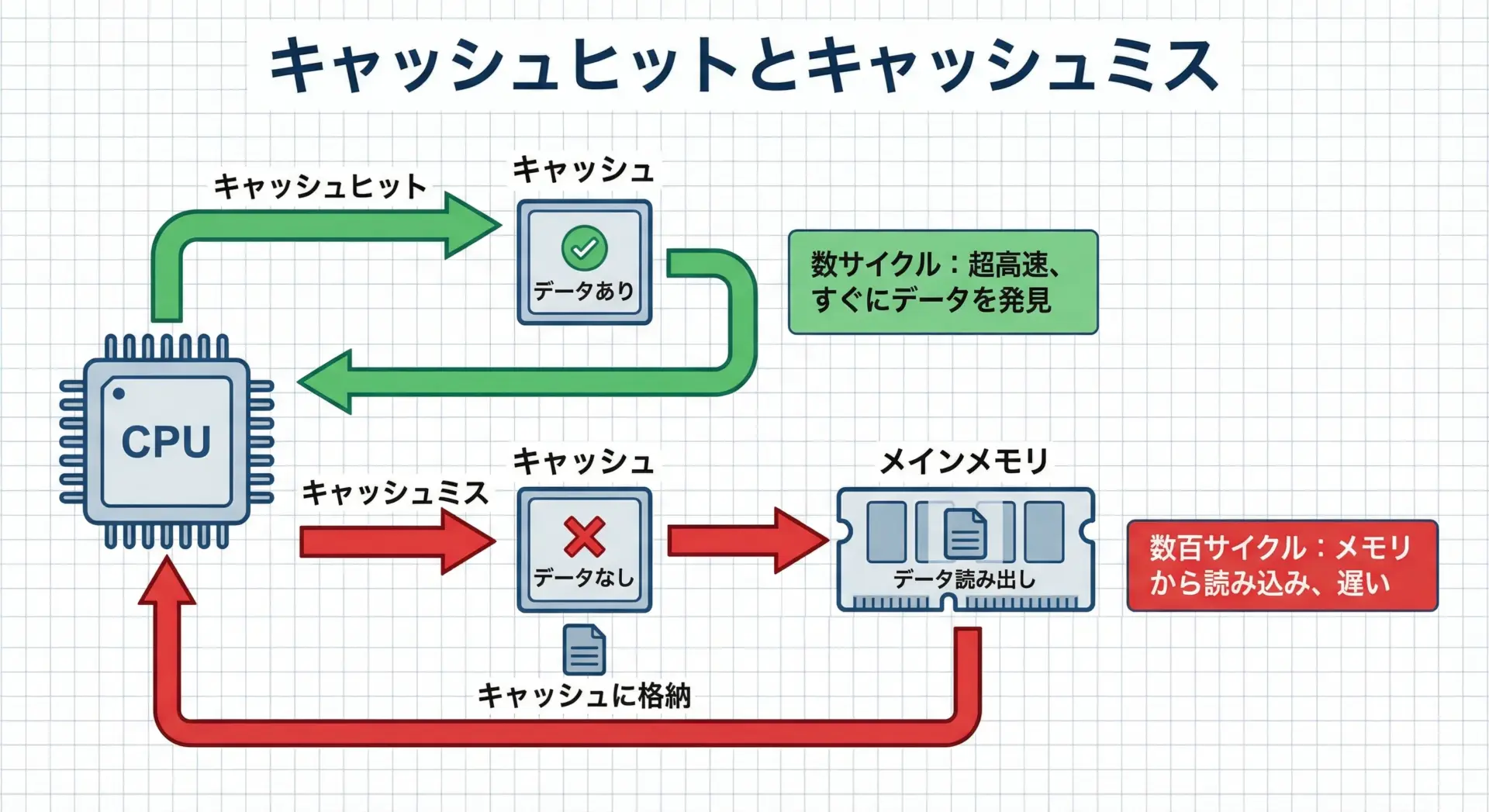
キャッシュメモリには、キャッシュヒットとキャッシュミスという重要な概念があります。
- キャッシュヒット: CPUが必要としたデータがキャッシュメモリ内に存在する状態
- キャッシュミス: 必要なデータがキャッシュに存在せず、メインメモリから読みに行く必要がある状態
キャッシュヒットのとき、CPUはほとんど待たずに処理を続けられます。
一方、キャッシュミスが発生すると、数十〜数百サイクル単位でCPUが待たされることになります。
メモリアクセス時間が処理速度に与える影響
CPUは「計算」と「メモリアクセス」を組み合わせて動作します。
もしプログラムが高頻度でキャッシュミスを起こすと、CPUは次の命令やデータを待つために、処理の大部分を「待ち時間」として過ごすことになります。
例えば、次のような単純化したモデルを考えてみます。
- 計算: 1命令あたり1サイクル
- キャッシュヒット: メモリアクセス1回あたり4サイクル
- キャッシュミス: メモリアクセス1回あたり200サイクル
もし100回のメモリアクセスのうち、
- 95回がヒット、5回がミスなら
- 合計時間はおおよそ
95×4 + 5×200 = 380 + 1000 = 1380サイクル
- 合計時間はおおよそ
- 50回がヒット、50回がミスなら
50×4 + 50×200 = 200 + 10000 = 10200サイクル
ヒット率が半分になるだけで、トータル時間は約7倍以上に膨らみます。
このように、キャッシュミスをどれだけ減らせるかが、プログラムの高速化に直結します。
プログラムが遅く感じる典型的な原因
プログラムが「計算が重いから遅い」と思われがちですが、実際にはメモリアクセスがボトルネックになっていることも多くあります。
典型的なケースとしては、次のようなものが挙げられます。
- 巨大な配列やリストを、ランダムな順番で参照している
- ポインタの飛び先がバラバラで、メモリ上に連続していないデータ構造を大量にたどる
- キャッシュに入りきらないほど大きなデータを、一度に何度もなめ回す処理
このようなパターンでは、アルゴリズムの計算量がそこまで大きくなくても、キャッシュミスの多発により実行時間が極端に伸びることがあります。
キャッシュメモリのしくみを直感的に理解する
ここからは、キャッシュメモリをより直感的に捉えるためのイメージや、プログラムとの具体的な関係について掘り下げていきます。
「よく使うデータを手元に置く」という考え方
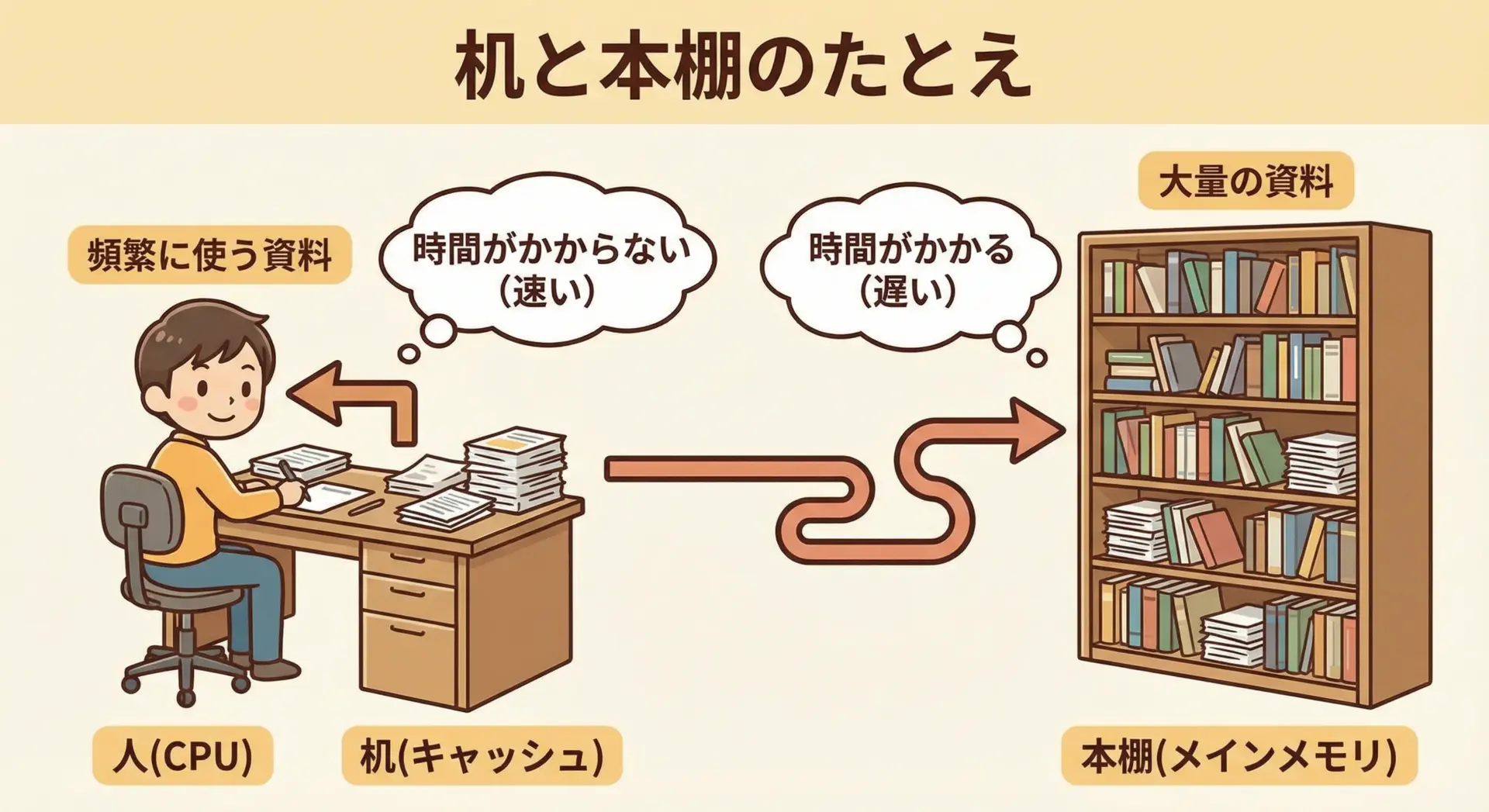
キャッシュメモリは、「よく使うものは机の上に、たまにしか使わないものは本棚に」という整理術に近い考え方で動いています。
- CPU: 仕事をする人
- キャッシュ: 机の上(手を伸ばせばすぐ届く)
- メインメモリ: 部屋の本棚(取りに行くと少し時間がかかる)
よく使う資料を本棚に置きっぱなしにしていると、取りに行く時間ばかりかかって仕事が進みません。
そこで、最近よく参照した資料や、近いうちに使いそうな資料を、あらかじめ机の上に置いておきます。
これがまさに、CPUがよく使うデータをキャッシュに置くという動きに相当します。
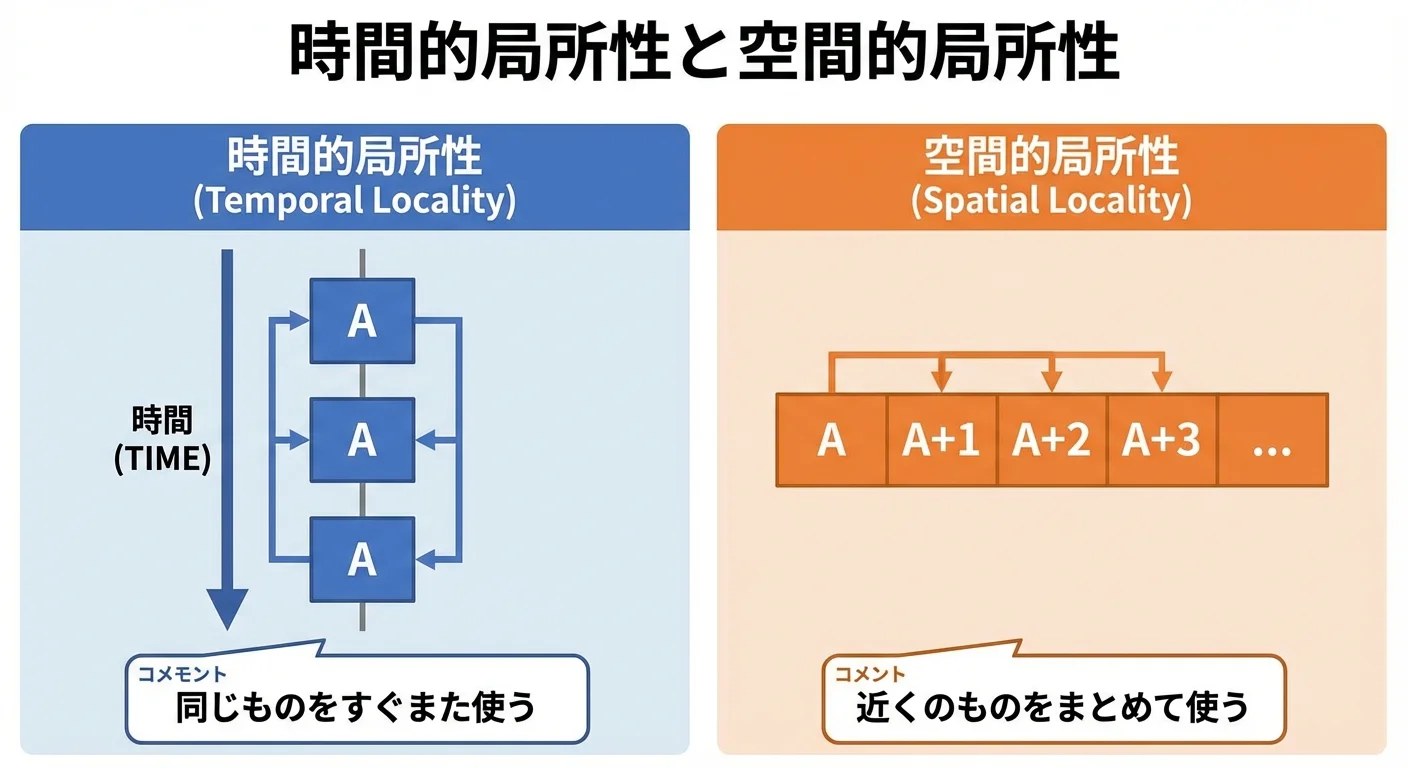
局所性(時間的局所性・空間的局所性)とは
キャッシュが効果的に働くための前提として、プログラムには局所性(locality)という性質があります。
局所性には主に2種類あります。
- 時間的局所性(temporal locality)
- 「一度使われたデータは、近い将来もう一度使われやすい」という性質
- 例: ループ内で同じ変数を何度も参照する、最近アクセスした配列要素を再度参照する
- 空間的局所性(spatial locality)
- 「あるデータの近くにあるデータも一緒に使われやすい」という性質
- 例: 配列を先頭から順番に走査する、構造体のフィールドをまとめて読む
キャッシュは、「過去にアクセスされたデータ」や「その近くのデータ」を優先的に保持することで、この局所性を活かしています。
配列アクセスとキャッシュメモリの関係
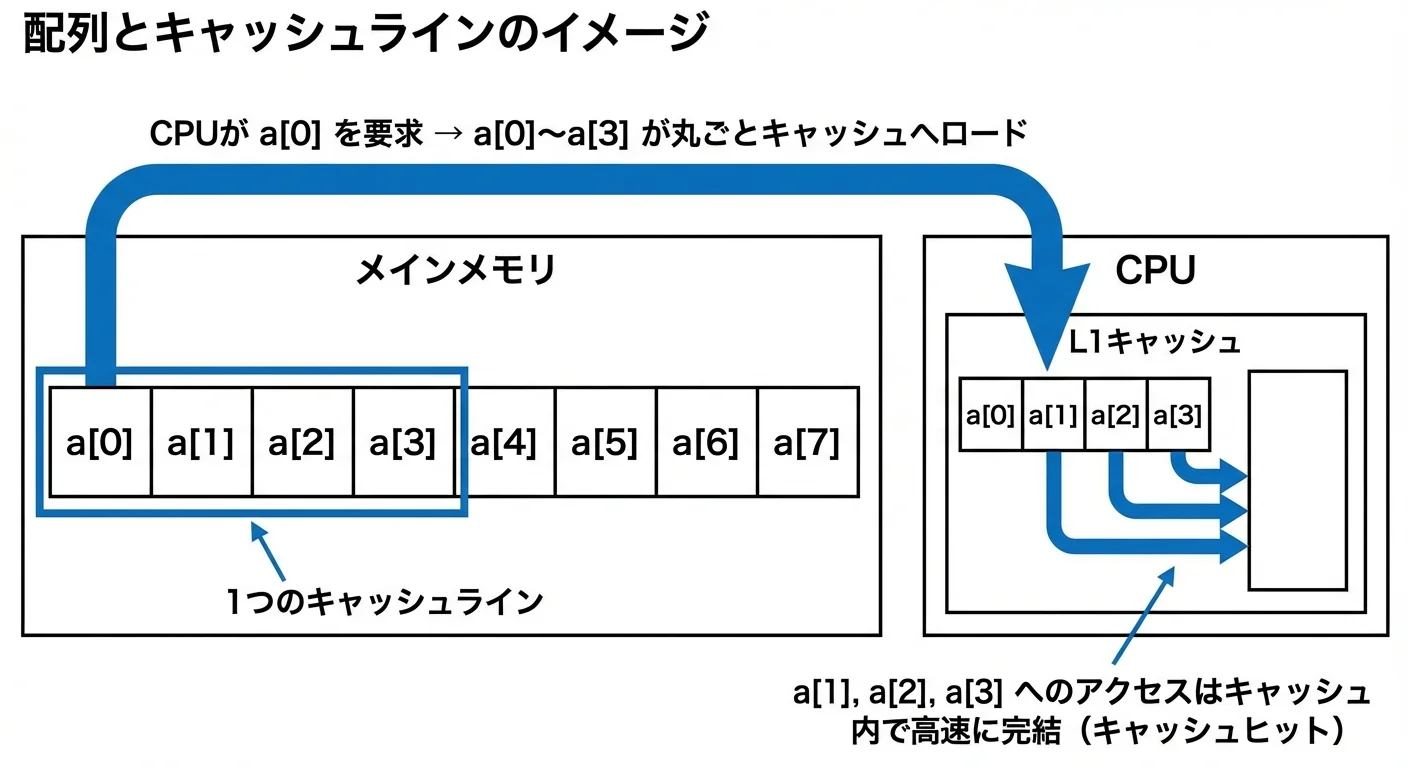
配列は、局所性を理解するうえで非常に良い例です。
配列の要素はメモリ上に連続して並びます。
つまり、a[0] のすぐ隣に a[1] があり、その隣に a[2] があるという並び方になっています。
このとき、CPUが a[0] を読み込むと、キャッシュは「どうせ近くのデータもすぐ使うだろう」と判断して、a[0] だけでなく、その周辺の要素もまとめてキャッシュに読み込みます。
たとえば、次のようなループを考えます。
for (int i = 0; i < N; i++) {
sum += a[i];
}この場合、アクセス順が 0, 1, 2, 3, … と連続しているため、空間的局所性が非常に高いといえます。
キャッシュに読み込まれたブロックの中に、これから使う要素が次々と含まれているため、キャッシュヒットが起こりやすくなります。
ランダムアクセスが遅くなる理由
一方で、配列を次のようにランダムな順番でアクセスするとどうなるでしょうか。
for (int k = 0; k < N; k++) {
int i = random_index[k]; // バラバラなインデックス
sum += a[i];
}この場合、アクセス順が 10, 1000, 3, 50000, … のようにバラバラであれば、「近くのデータも一緒に使われる」という前提が崩れます。
キャッシュは周辺のデータをまとめて持ってきても、それらが使われる前に別の遠い場所に飛ばされてしまうため、キャッシュミスが連発しやすくなります。
つまり、同じ配列でも、アクセスパターン次第で高速にも低速にもなりうるのです。
これは、単に「配列だから速い」「リストだから遅い」といった単純な話ではなく、メモリ上でどのように並んでいるか、そしてどの順番でアクセスするかが重要であることを示しています。
プログラミングで意識したいキャッシュメモリ活用のコツ
ここからは、実際にプログラムを書くときにキャッシュメモリを意識して書くための具体的なポイントを紹介します。
すべてを完璧に理解する必要はありませんが、意識するだけでもパフォーマンス改善につながる場面は多くあります。
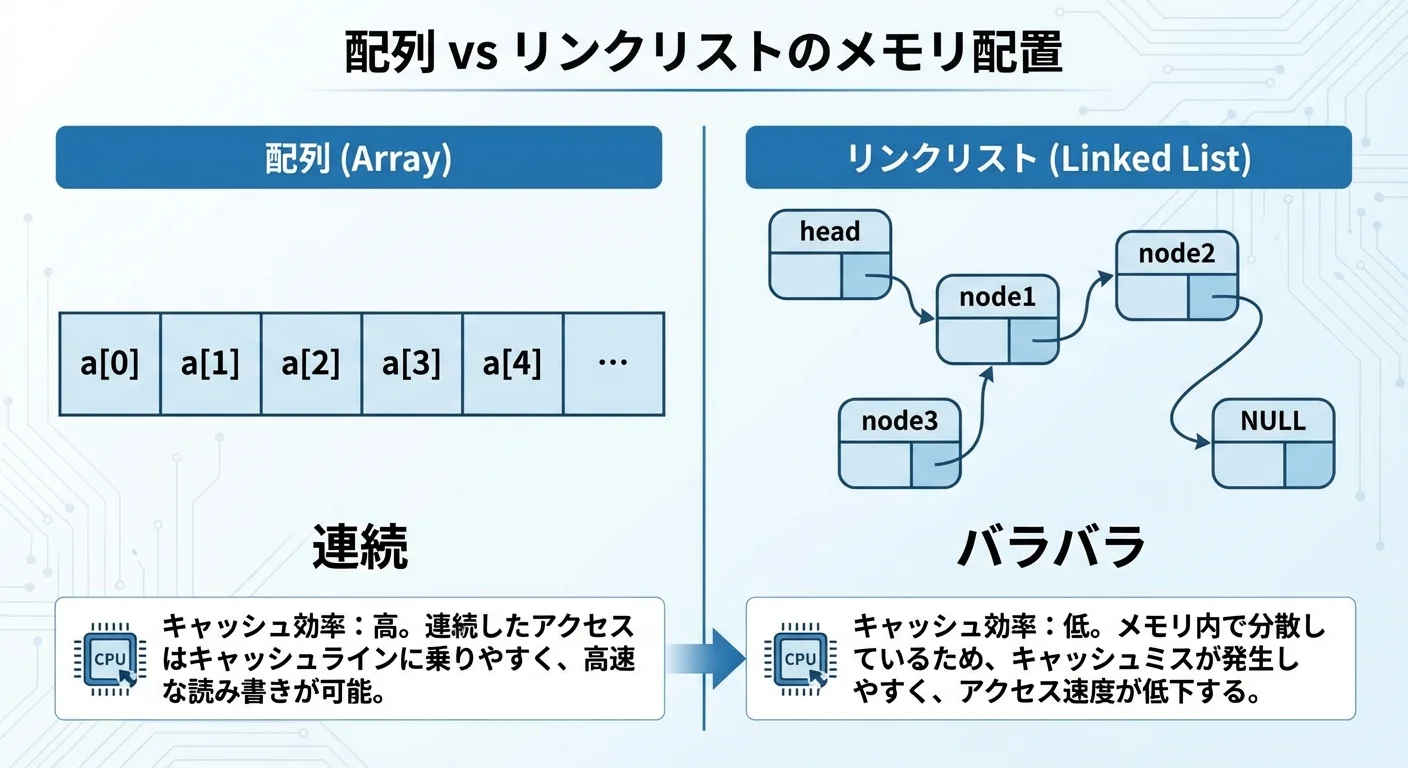
データ構造とメモリ配置を意識する
まず重要なのは、データがメモリ上でどのように配置されるかを意識することです。
配列は要素が連続して並ぶため、空間的局所性が高くなりやすい構造です。
一方、リンクリストのようにポインタで次の要素を指す構造は、各要素がメモリ上のどこにあるかがバラバラになりがちで、キャッシュ効率が悪くなりやすいという特徴があります。
例えば、次のようなケースを比べてみます。
- 配列ベースのデータ構造
- 要素が連続して格納される
- ループで順に走査するだけで高いキャッシュ効率を得やすい
- ポインタベースのデータ構造(リンクリストやツリーなど)
- 要素の配置がバラバラになりやすい
- たどるたびにキャッシュミスが起こる可能性が高い
もちろん、リンクリストやツリーにも利点がありますが、キャッシュ効率という観点では配列のほうが有利な場面が多いことを頭の片隅に置いておくと設計の判断材料になります。
ループの書き方とキャッシュ効率
ループの書き方も、キャッシュ効率に大きな影響を与えます。
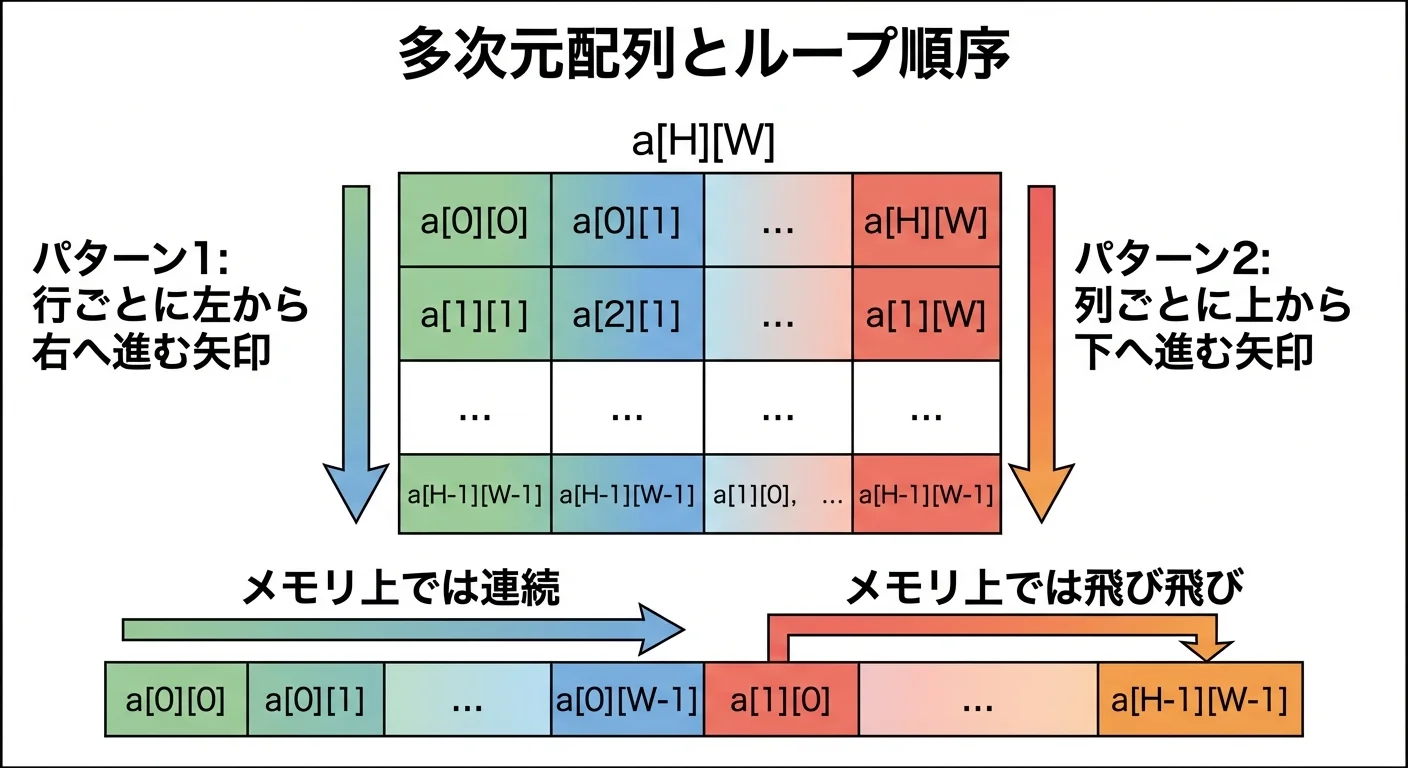
特に多次元配列を扱うときは注意が必要です。
C言語やC++では、多次元配列は行優先(row-major)で格納されます。
つまり、a[i][0], a[i][1], a[i][2], … がメモリ上で連続して配置されます。
このとき、次の2つのループを比べてみます。
// パターン1: i が外側, j が内側
for (int i = 0; i < H; i++) {
for (int j = 0; j < W; j++) {
sum += a[i][j];
}
}
// パターン2: j が外側, i が内側
for (int j = 0; j < W; j++) {
for (int i = 0; i < H; i++) {
sum += a[i][j];
}
}行優先のメモリ配置では、パターン1のほうがメモリ上の連続した領域を順番にアクセスすることになります。
そのため、空間的局所性が高く、キャッシュヒット率も高くなりやすいです。
一方、パターン2では、メモリ上を飛び飛びにアクセスすることになり、キャッシュミスが増えやすくなります。
このように、「どのインデックスを内側のループに置くか」だけでも、実行速度が大きく変わることがあります。
キャッシュフレンドリーなコードの具体例
最後に、キャッシュを意識した「キャッシュフレンドリー」なコードのパターンを簡単に紹介します。
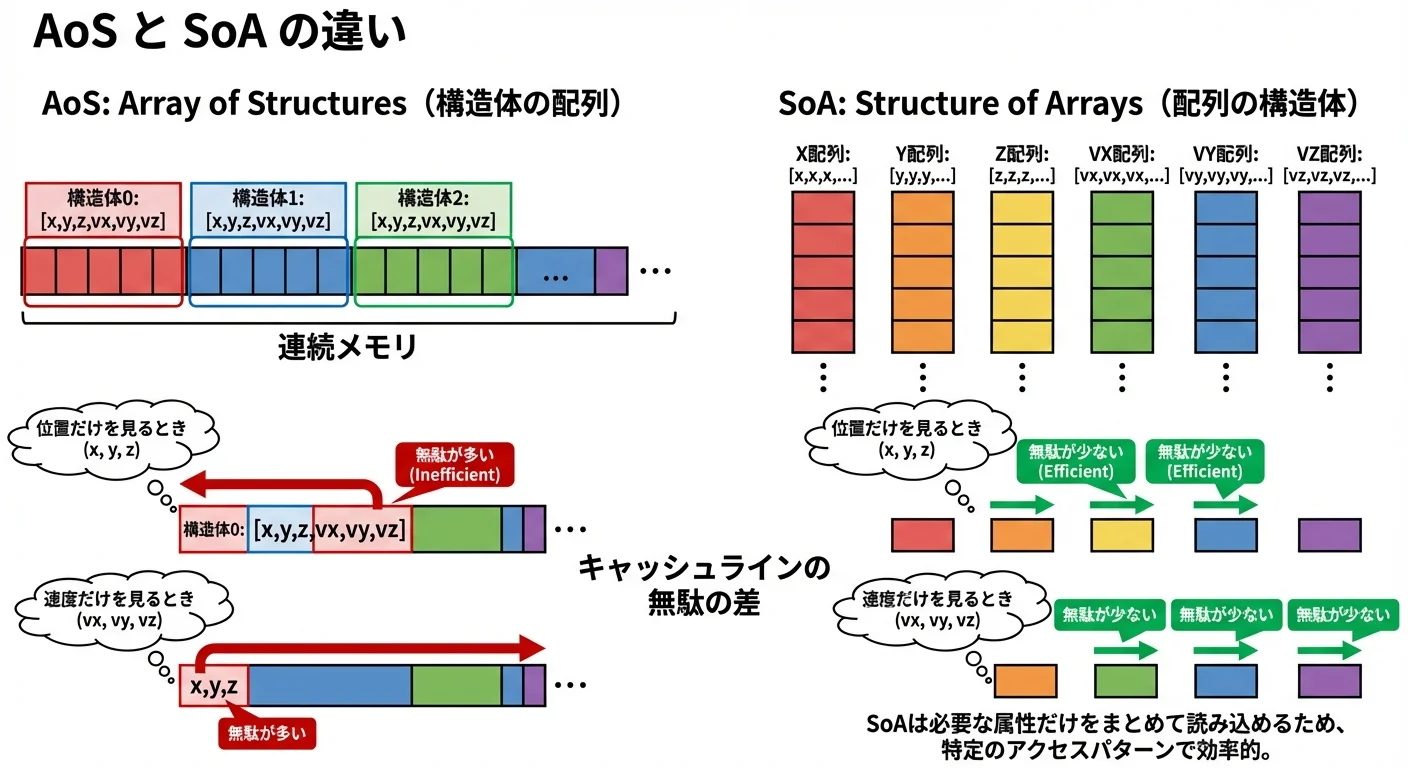
例1: 構造体配列の分割(SoA vs AoS)
ゲームやシミュレーションなどで、多数のオブジェクトを扱う場合を考えます。
// AoS (Array of Structures): 構造体の配列
typedef struct {
float x, y, z;
float vx, vy, vz;
} Particle;
Particle particles[N];
void update_positions(float dt) {
for (int i = 0; i < N; i++) {
particles[i].x += particles[i].vx * dt;
particles[i].y += particles[i].vy * dt;
particles[i].z += particles[i].vz * dt;
}
}このコードでもそこそこ効率的ですが、もし「位置だけ」「速度だけ」を大量に処理する場面があるなら、構造体を分割して別々の配列にすることでキャッシュ効率をさらに上げられます。
// SoA (Structure of Arrays): 配列の構造
float pos_x[N], pos_y[N], pos_z[N];
float vel_x[N], vel_y[N], vel_z[N];
void update_positions(float dt) {
for (int i = 0; i < N; i++) {
pos_x[i] += vel_x[i] * dt;
pos_y[i] += vel_y[i] * dt;
pos_z[i] += vel_z[i] * dt;
}
}このようにすると、必要なデータだけを連続した配列として扱えるため、キャッシュラインに無駄なデータが混ざりにくくなります。
例2: ブロッキング(タイル化)による行列計算の高速化
行列の掛け算など、大きな2次元データを扱う処理では、ブロッキング(タイル化)と呼ばれるテクニックがよく使われます。
大きな行列全体を一気に処理するのではなく、キャッシュに乗るサイズの小さなブロックに分割して処理することで、キャッシュヒット率を高める方法です。
擬似コードレベルでは、次のようなイメージです。
for (int ii = 0; ii < N; ii += B) {
for (int jj = 0; jj < N; jj += B) {
for (int kk = 0; kk < N; kk += B) {
// 小さいブロック (ii..ii+B, jj..jj+B, kk..kk+B) を計算
}
}
}ここでは詳細には踏み込みませんが、「一度キャッシュに乗ったデータを、できるだけ何度も再利用する」という発想がキャッシュフレンドリーなコードの基本にあります。
まとめ
キャッシュメモリは、CPUとメインメモリの速度差を埋めるための、小さくて高速な中間メモリです。
プログラムの実行時には、頻繁に使うデータがキャッシュに載ることで高速に処理でき、逆にキャッシュミスが多いとCPUはメモリ待ちで足を引っ張られてしまいます。
本記事で扱ったポイントを振り返ると、次のように整理できます。
- キャッシュメモリは「よく使うデータを手元に置く」ことでメモリアクセスを高速化する
- キャッシュヒットとキャッシュミスの差は、数十〜数百サイクルにもなり、全体の性能を大きく左右する
- プログラムには、同じデータを繰り返し使う時間的局所性と、近くのデータをまとめて使う空間的局所性があり、キャッシュはこれを前提として設計されている
- 配列を連続的にアクセスするコードはキャッシュに乗りやすく、ランダムアクセスやポインタで飛び回る構造はキャッシュミスを招きやすい
- データ構造の選び方やループのインデックスの順序など、ちょっとした書き方の違いがキャッシュ効率と性能に大きく影響する
アルゴリズムの計算量解析と同じくらい、「メモリにどうアクセスするか」を意識することは、現代のプログラミングでは重要になっています。
キャッシュメモリの存在を頭に入れてコードを書くことで、なぜプログラムが速くなったのか、あるいは遅くなってしまったのかを、より深く説明できるようになるはずです。
