
C言語で整数型を安全に扱うには、型ごとの最大値・最小値を把握しておくことがとても重要です。
特にオーバーフローはバグの原因になりやすく、実装環境に依存する部分でもあります。
この記事では、標準ヘッダであるlimits.hを使って、整数型の最大値・最小値を正しく取得し、実践的に活用する方法を丁寧に解説します。
C言語における整数型の基本
整数型とは何か
C言語では、整数を扱うために複数の型が用意されています。
代表的なものとしてchar、short、int、long、long longがあります。
これらは次の観点で異なります。
- 何ビットで表現されるか(ビット幅)
- 符号付きか符号なしか(負の値を表せるか)
- 取りうる値の範囲(最小値・最大値)
C言語の仕様では、これらのビット幅や具体的な範囲を厳密には固定していません。
その代わりに「最低限これだけの範囲は保証する」という形で規定されており、それを具体的な数値として与えてくれるのがlimits.hです。
整数型の分類と符号の有無
整数型は、大きく次の2種類に分類できます。
- 符号付き整数型(負の値〜正の値)
- 符号なし整数型(0以上の値のみ)
符号付きと符号なしの違いによって最大値・最小値は大きく変わります。
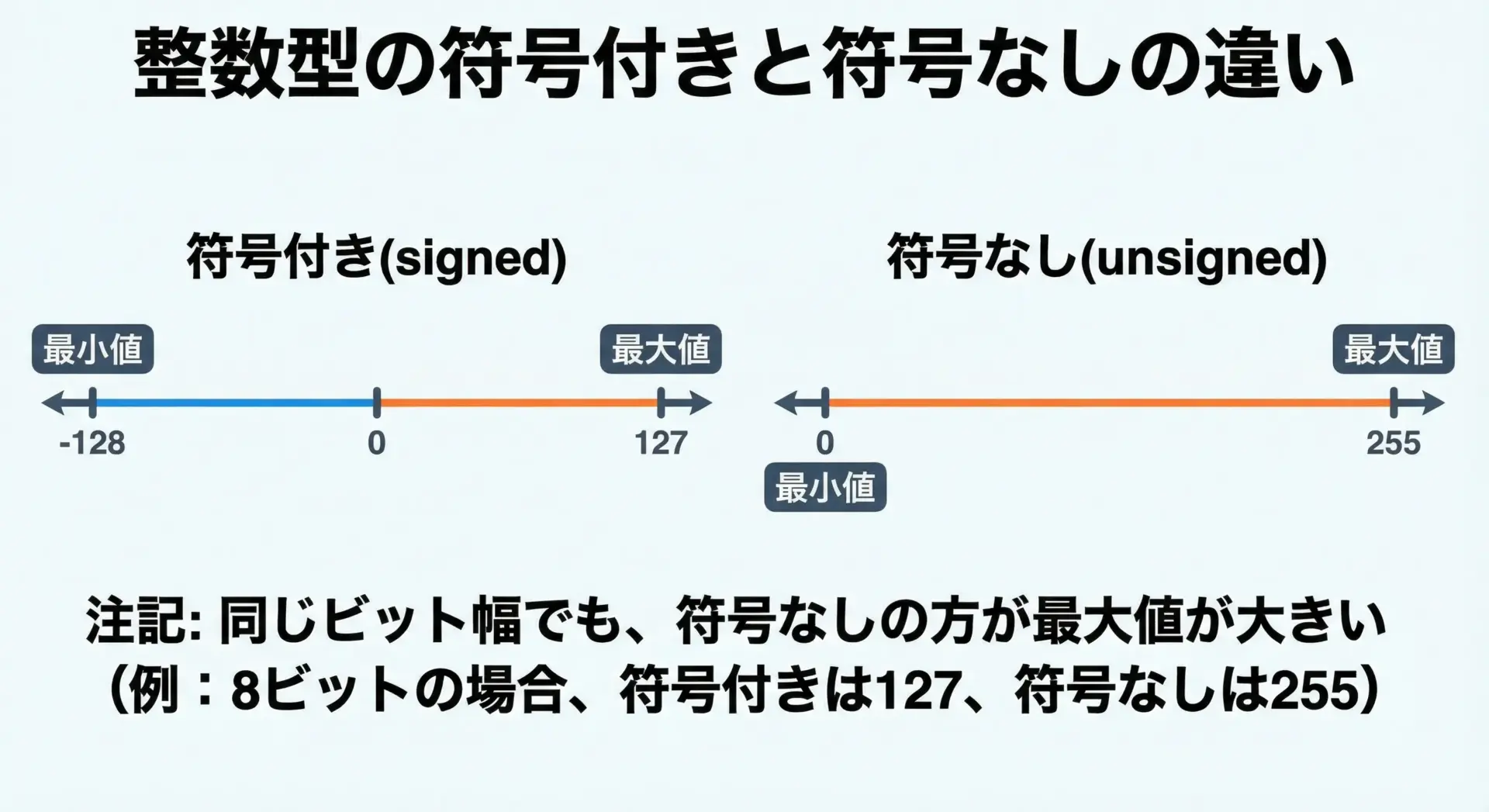
符号付き整数型では、ビットの一部が符号(プラスかマイナスか)を表すため、同じビット幅でも最大値は符号なしより小さくなります。
逆に符号なし整数型では、すべてのビットを値として使えるため、0から大きな正の数までを表現できます。
limits.hとは何か
limits.hの役割
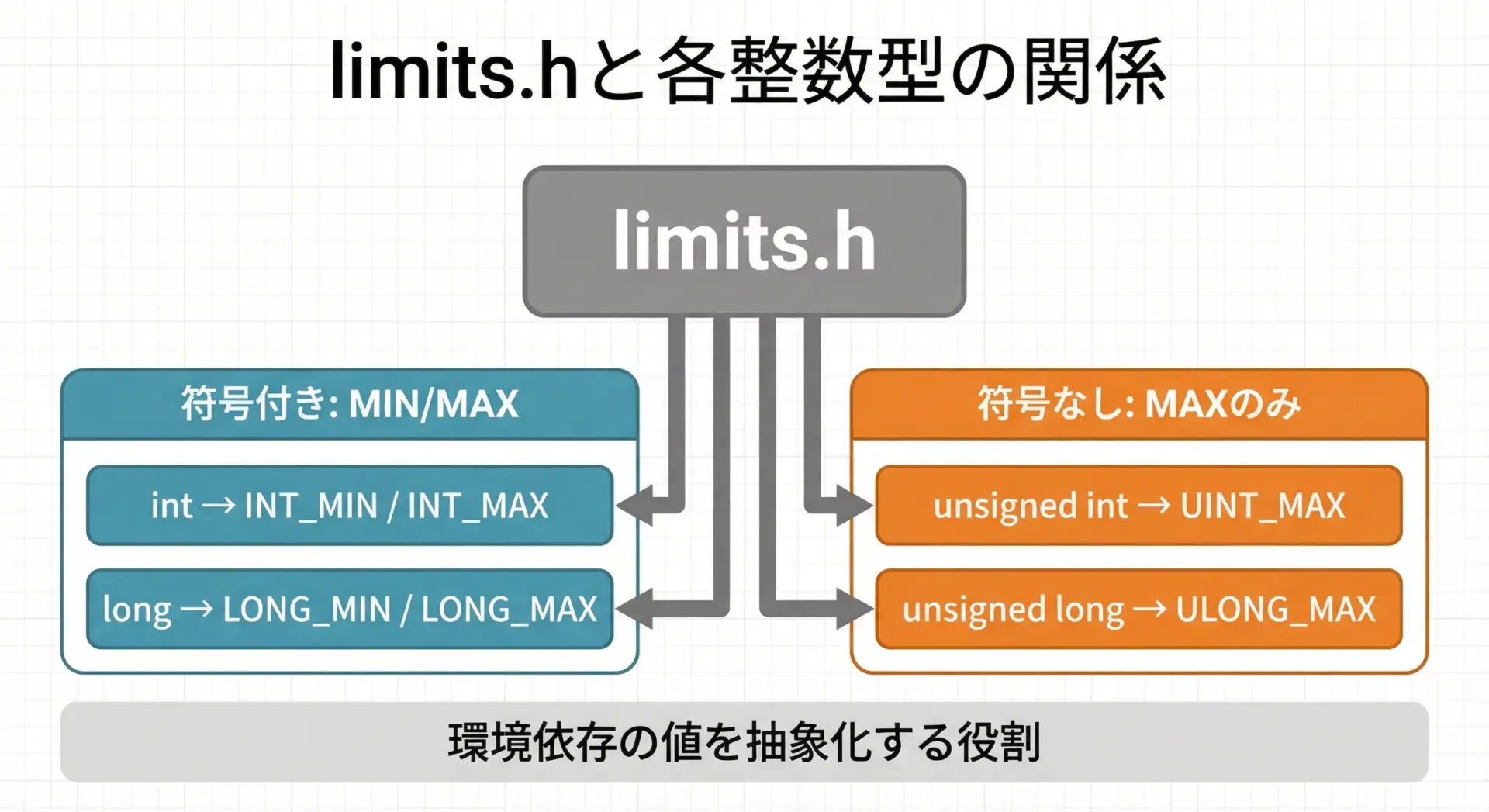
limits.hは、C言語標準ライブラリのヘッダファイルの1つで、コンパイル環境に依存する「各整数型の特性」をマクロとして提供します。
代表的な情報は次の通りです。
- 各整数型の最小値と最大値
char型が符号付きかどうかcharが表現できる最小値・最大値MB_LEN_MAXなど、マルチバイト文字に関する制約
環境によってintが32ビットであったり16ビットであったりするような違いを吸収し、ソースコード側はマクロを使って安全に境界値チェックができるようにするのが目的です。
limits.hを使うメリット
limits.hを利用することで、次のようなメリットがあります。
- 「intは2,147,483,647まで」といった環境依存の思い込みに頼らない
- コンパイラやプラットフォームが変わっても、コードがそのまま動作しやすい
- オーバーフローやアンダーフローを事前に検出しやすくなる
- テスト時に境界値テスト(最大値・最小値付近の値)を容易に行える
limits.hで定義される主なマクロ一覧
主な整数型と対応するマクロ
limits.hでよく使うマクロを、代表的な整数型ごとに整理します。
| 型名 | 最小値マクロ | 最大値マクロ |
|---|---|---|
| signed char | SCHAR_MIN | SCHAR_MAX |
| unsigned char | 0 | UCHAR_MAX |
| char(符号付き/なしは環境依存) | CHAR_MIN | CHAR_MAX |
| short | SHRT_MIN | SHRT_MAX |
| unsigned short | 0 | USHRT_MAX |
| int | INT_MIN | INT_MAX |
| unsigned int | 0 | UINT_MAX |
| long | LONG_MIN | LONG_MAX |
| unsigned long | 0 | ULONG_MAX |
| long long | LLONG_MIN | LLONG_MAX |
| unsigned long long | 0 | ULLONG_MAX |
符号なし型は最小値が必ず0なので、最小値用のマクロは存在せず、最大値のみが定義されている点がポイントです。
その他の関連マクロ
整数範囲そのものではありませんが、limits.hには次のような関連マクロもあります。
CHAR_BIT: 1バイトに含まれるビット数(通常は8)MB_LEN_MAX: マルチバイト文字列における最大バイト数CHAR_MIN/CHAR_MAX:char型の範囲(符号付きかどうかは実装依存)
CHAR_BITと最小限保証されるビット数
CHAR_BITとは
CHAR_BITは、1バイトに含まれるビット数を表します。
ほとんどのモダン環境では8ビット(1バイト = 8ビット)ですが、C言語の仕様上は「少なくとも8ビットである」ことしか決まっておらず、必ずしも8であるとは限りません。
#include <stdio.h>
#include <limits.h>
int main(void) {
// 1バイトあたりのビット数を表示
printf("CHAR_BIT = %d\n", CHAR_BIT);
return 0;
}CHAR_BIT = 8このように、環境ごとにCHAR_BITを参照することで、文字型や整数型のビット幅を推定することができます。
各整数型の最小限保証ビット幅
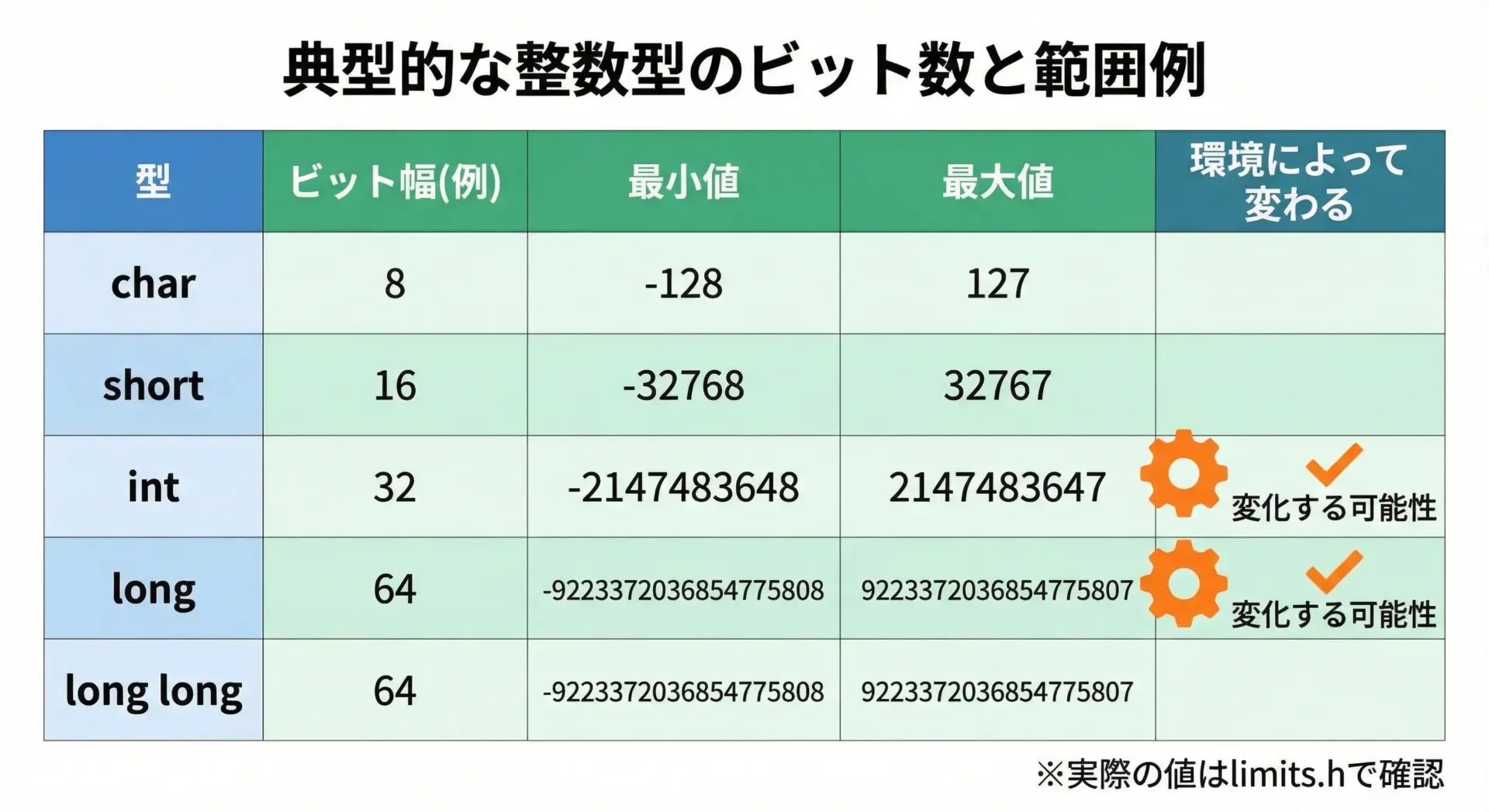
C言語規格では、各整数型について「少なくとも何ビット以上でなければならないか」が定められています。
代表的なものを整理すると、次のようになります。
| 型名 | 最小限保証されるビット数(概念) |
|---|---|
| signed char | 8ビット以上 |
| short | signed charと同じかそれ以上 |
| int | shortと同じかそれ以上 |
| long | intと同じかそれ以上 |
| long long | longと同じかそれ以上 |
実際には、典型的な32ビット/64ビット環境では次のようになることが多いです。
| 型名 | 典型的なビット数(例) |
|---|---|
| char | 8ビット |
| short | 16ビット |
| int | 32ビット |
| long | 32ビットまたは64ビット |
| long long | 64ビット |
「intは必ず32ビット」とは限らないところが重要で、これを吸収するためにlimits.hのマクロが存在しています。
整数型ごとの最大値・最小値を確認するサンプル
代表的な整数型の範囲を表示するプログラム
ここでは、主要な整数型の最大値・最小値をまとめて表示するサンプルコードを示します。
自分の環境で実際に実行して、どの型が何ビット相当かを確認してみると理解が深まります。
#include <stdio.h>
#include <limits.h>
int main(void) {
// 1バイトあたりのビット数
printf("=== 基本情報 ===\n");
printf("CHAR_BIT = %d\n\n", CHAR_BIT);
// char関連
printf("=== char 系 ===\n");
printf("signed char : SCHAR_MIN = %d, SCHAR_MAX = %d\n", SCHAR_MIN, SCHAR_MAX);
printf("unsigned char : UCHAR_MAX = %u\n", UCHAR_MAX);
printf("char : CHAR_MIN = %d, CHAR_MAX = %d\n\n", CHAR_MIN, CHAR_MAX);
// short関連
printf("=== short 系 ===\n");
printf("short : SHRT_MIN = %d, SHRT_MAX = %d\n", SHRT_MIN, SHRT_MAX);
printf("unsigned short : USHRT_MAX = %u\n\n", USHRT_MAX);
// int関連
printf("=== int 系 ===\n");
printf("int : INT_MIN = %d, INT_MAX = %d\n", INT_MIN, INT_MAX);
printf("unsigned int : UINT_MAX = %u\n\n", UINT_MAX);
// long関連
printf("=== long 系 ===\n");
printf("long : LONG_MIN = %ld, LONG_MAX = %ld\n", LONG_MIN, LONG_MAX);
printf("unsigned long : ULONG_MAX = %lu\n\n", ULONG_MAX);
// long long関連
printf("=== long long 系 ===\n");
printf("long long : LLONG_MIN = %lld, LLONG_MAX = %lld\n", LLONG_MIN, LLONG_MAX);
printf("unsigned long long : ULLONG_MAX = %llu\n", ULLONG_MAX);
return 0;
}=== 基本情報 ===
CHAR_BIT = 8
=== char 系 ===
signed char : SCHAR_MIN = -128, SCHAR_MAX = 127
unsigned char : UCHAR_MAX = 255
char : CHAR_MIN = -128, CHAR_MAX = 127
=== short 系 ===
short : SHRT_MIN = -32768, SHRT_MAX = 32767
unsigned short : USHRT_MAX = 65535
=== int 系 ===
int : INT_MIN = -2147483648, INT_MAX = 2147483647
unsigned int : UINT_MAX = 4294967295
=== long 系 ===
long : LONG_MIN = -9223372036854775808, LONG_MAX = 9223372036854775807
unsigned long : ULONG_MAX = 18446744073709551615
=== long long 系 ===
long long : LLONG_MIN = -9223372036854775808, LLONG_MAX = 9223372036854775807
unsigned long long : ULLONG_MAX = 18446744073709551615※上記の結果は64ビット環境(LP64モデル)の一例です。
32ビット環境などではlongの値が異なる場合があります。
オーバーフローとlimits.hの関係
オーバーフローとは
オーバーフローとは、ある整数型で表現できる範囲を超える演算を行ったときに、値が正しく表現できなくなる現象です。
例えば、32ビットのint型でINT_MAX + 1を計算しようとすると、正しい数学的結果(2147483648)をintでは表現できません。
符号付き整数のオーバーフローは未定義動作であり、コンパイラや環境によって結果が変わったり、最悪の場合はプログラムの動作が予測できなくなったりします。
一方、符号なし整数型では、オーバーフロー時にモジュロ演算(剰余)のように値が折り返す挙動が規定されています。
ただし、こちらも意図しない値になってバグになることが多いため、注意が必要です。
limits.hでオーバーフローを事前に防ぐ
オーバーフローを防ぐには、演算前に結果が範囲内に収まることをチェックするのが基本です。
このとき、チェックに利用するのがINT_MAXやLLONG_MAXなどのマクロです。

実践例1: 加算時のオーバーフロー防止
INT_MAXを使った加算チェック
2つのint値aとbを足し算するとき、結果がintの範囲を超えないかどうかを確認する例を示します。
#include <stdio.h>
#include <limits.h>
#include <stdbool.h>
// a + b が int の範囲に収まるかチェックする関数
bool safe_add_int(int a, int b, int *result) {
// b が正の場合: a <= INT_MAX - b なら安全
if (b > 0 && a > INT_MAX - b) {
return false; // オーバーフローの可能性
}
// b が負の場合: a >= INT_MIN - b なら安全
if (b < 0 && a < INT_MIN - b) {
return false; // アンダーフローの可能性
}
// ここまで来れば安全に加算できる
*result = a + b;
return true;
}
int main(void) {
int a = INT_MAX;
int b = 1;
int sum;
if (safe_add_int(a, b, &sum)) {
printf("安全に計算できました: %d + %d = %d\n", a, b, sum);
} else {
printf("オーバーフローの可能性があるため、計算を中止しました。\n");
}
return 0;
}オーバーフローの可能性があるため、計算を中止しました。このように、演算前にINT_MAXとINT_MINを使って境界をチェックすることで、安全に加算を行うことができます。
実践例2: 型変換(キャスト)時の範囲チェック
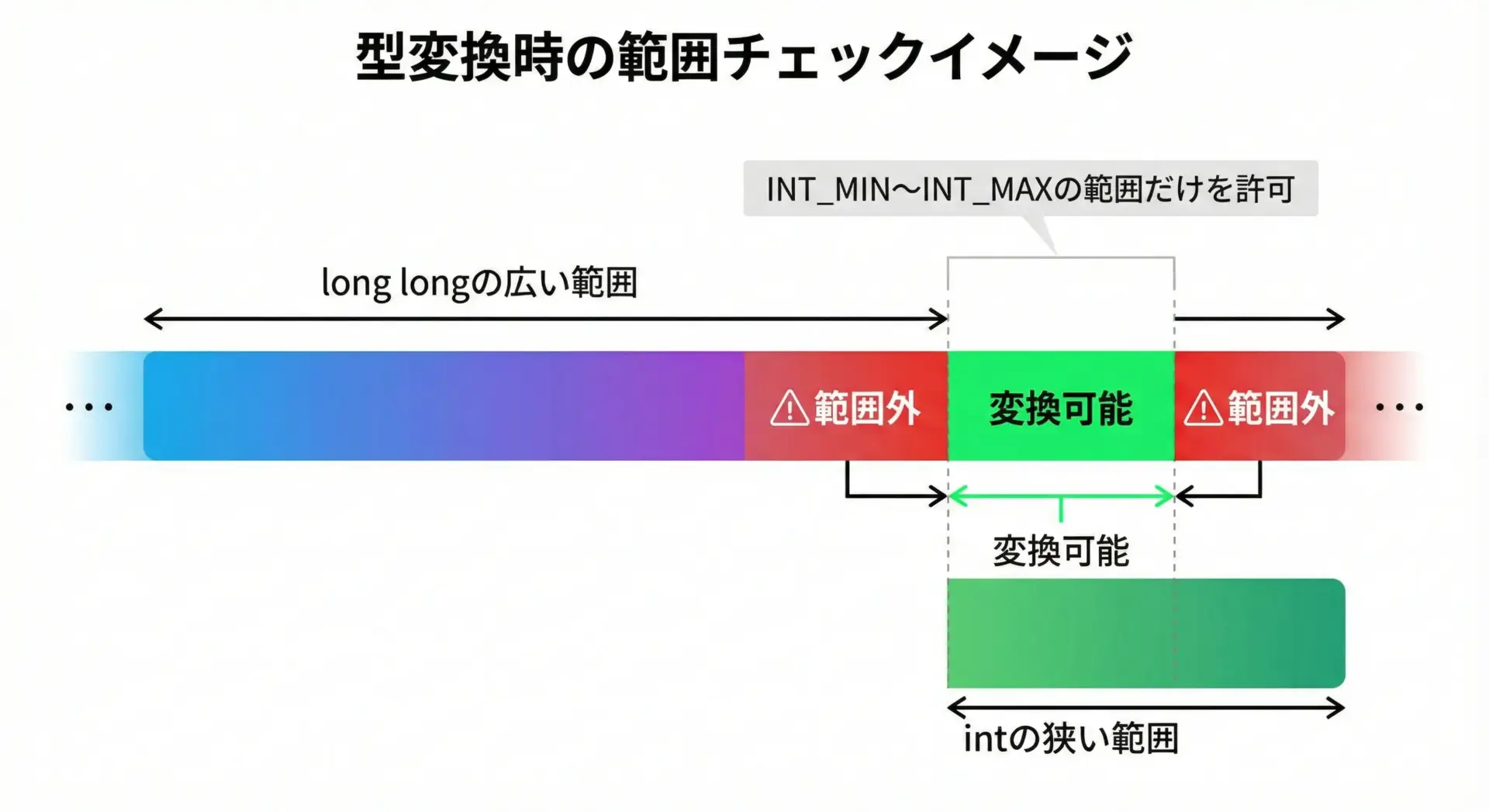
long longからintへの変換を安全に行う
より大きな範囲を持つlong longからintへキャストするとき、値がintの範囲を超えていないか確認するサンプルです。
#include <stdio.h>
#include <limits.h>
#include <stdbool.h>
// long long の値を int に安全に変換する関数
bool safe_ll_to_int(long long src, int *dst) {
// int の範囲に収まっているかをチェック
if (src < INT_MIN || src > INT_MAX) {
return false; // 変換すると値が壊れる可能性
}
// 範囲内なので安全にキャストできる
*dst = (int)src;
return true;
}
int main(void) {
long long values[] = {
123, // 安全な値
(long long)INT_MAX + 1, // INT_MAX より大きい値
(long long)INT_MIN - 1 // INT_MIN より小さい値
};
for (int i = 0; i < 3; i++) {
int converted;
if (safe_ll_to_int(values[i], &converted)) {
printf("values[%d] = %lld は int に変換可能: %d\n",
i, values[i], converted);
} else {
printf("values[%d] = %lld は int の範囲外です\n",
i, values[i]);
}
}
return 0;
}values[0] = 123 は int に変換可能: 123
values[1] = 2147483648 は int の範囲外です
values[2] = -2147483649 は int の範囲外ですキャストの前にINT_MIN / INT_MAXで挟み込むようにチェックすることで、不正な型変換を防ぐことができます。
実践例3: 入力値の妥当性チェック
ユーザーからの入力を安全にintへ格納する
標準入力から数値を読み取るとき、ユーザーが想定以上に大きな値を入力するかもしれません。
そのため、文字列として受け取り、strtollなどでlong longに変換した上で、intの範囲に収まっているかをチェックする方法がよく使われます。
以下は、その簡略版の例です。
#include <stdio.h>
#include <stdlib.h>
#include <limits.h>
#include <errno.h>
#include <stdbool.h>
// 文字列を int に安全に変換する関数
bool parse_int(const char *str, int *out) {
char *endptr = NULL;
errno = 0;
// まず long long として変換
long long val = strtoll(str, &endptr, 10);
// 変換できなかった(数字がなかった)場合
if (endptr == str) {
return false;
}
// オーバーフロー/アンダーフローを検知
if (errno == ERANGE) {
return false;
}
// int の範囲に収まっているか
if (val < INT_MIN || val > INT_MAX) {
return false;
}
// ここまで来れば安全に int にキャスト可能
*out = (int)val;
return true;
}
int main(void) {
const char *tests[] = {
"123",
"2147483647", // INT_MAX
"2147483648", // INT_MAX + 1
"-2147483649", // INT_MIN - 1
"abc"
};
for (int i = 0; i < 5; i++) {
int value;
if (parse_int(tests[i], &value)) {
printf("入力 \"%s\" は有効な int 値です: %d\n", tests[i], value);
} else {
printf("入力 \"%s\" は有効な int 値ではありません\n", tests[i]);
}
}
return 0;
}入力 "123" は有効な int 値です: 123
入力 "2147483647" は有効な int 値です: 2147483647
入力 "2147483648" は有効な int 値ではありません
入力 "-2147483649" は有効な int 値ではありません
入力 "abc" は有効な int 値ではありませんこの例では、文字列 → long long → intという段階的な変換と、INT_MIN / INT_MAXによる範囲チェックを組み合わせています。
charの符号有無とCHAR_MIN/CHAR_MAX
charがsignedかunsignedかは実装依存
C言語では、char型がsigned charとして扱われるかunsigned charとして扱われるかは実装依存です。
そのため、次のような違いが発生します。
- signed charの場合:
CHAR_MINは負の値(例:-128)、CHAR_MAXは正の値(例:127) - unsigned charの場合:
CHAR_MINは0、CHAR_MAXは正の値(例:255)
自分の環境でどちらになっているかを知りたい場合、CHAR_MINとCHAR_MAXを表示してみると分かります。
#include <stdio.h>
#include <limits.h>
int main(void) {
printf("CHAR_MIN = %d\n", CHAR_MIN);
printf("CHAR_MAX = %d\n", CHAR_MAX);
if (CHAR_MIN < 0) {
printf("この環境では char は signed です。\n");
} else {
printf("この環境では char は unsigned です。\n");
}
return 0;
}CHAR_MIN = -128
CHAR_MAX = 127
この環境では char は signed です。
limits.hを使うときの注意点
コンパイラと環境による違い
limits.hのマクロは、コンパイル時に使用しているコンパイラとターゲット環境に依存して定義されます。
そのため、次のような点に注意が必要です。
- 32ビット環境か64ビット環境かで
longの範囲が異なる - WindowsとLinuxで
longのビット幅が異なる(Linux 64bitでは64ビット、Windowsでは32ビットが一般的) - コンパイラにより、
charの符号有無などの初期設定が異なることがある
ただし、limits.hのマクロを使っていれば、この違いを意識する場面は大幅に減るため、環境依存の不具合を抑えることができます。
フォーマット指定子との組み合わせ
printfなどで表示する際には、INT_MAXやLONG_MAXなどのマクロに対して、適切なフォーマット指定子を使う必要があります。
int:%d/%ulong:%ld/%lulong long:%lld/%llu
型とフォーマット指定子が合っていないと、未定義動作になり、不正な値が表示されたりクラッシュしたりする可能性があります。
まとめ
C言語で整数型を安全に扱うためには、limits.hが提供する各型の最大値・最小値マクロを正しく理解し、活用することが欠かせません。
環境ごとに異なりうるビット幅や範囲を意識せずに、INT_MAXやLONG_MINといったマクロを使えば、オーバーフロー防止や型変換の妥当性チェックを汎用的に実装できます。
自分の開発環境で実際にマクロの値を出力し、その範囲を確認しながら、境界値チェックや入力検証を組み込んでいくことで、より堅牢で移植性の高いCプログラムを構築できるようになります。
