C言語で本格的にファイル処理を行う場合、テキストファイルだけでなくバイナリファイルの扱いが重要になります。
バイナリファイルは、構造体や数値データをそのまま保存できるため、高速かつ効率的な入出力が可能です。
本記事ではfreadとfwriteを中心に、バイナリファイルの読み書き方法と注意点を、図解とサンプルコードを交えながら丁寧に解説します。
C言語のバイナリファイル入門
テキストファイルとバイナリファイルの違い
テキストファイルとバイナリファイルは、どちらもファイルであることに変わりはありませんが、中身の表現方法が大きく異なります。
テキストファイルは人間が読むことを前提としており、文字コード(UTF-8やShift_JISなど)に従って文字としてデータを保存します。
一方でバイナリファイルは、人間が直接読むことはあまり想定せず、メモリ上のビット列をそのままファイルに書き出す形式です。
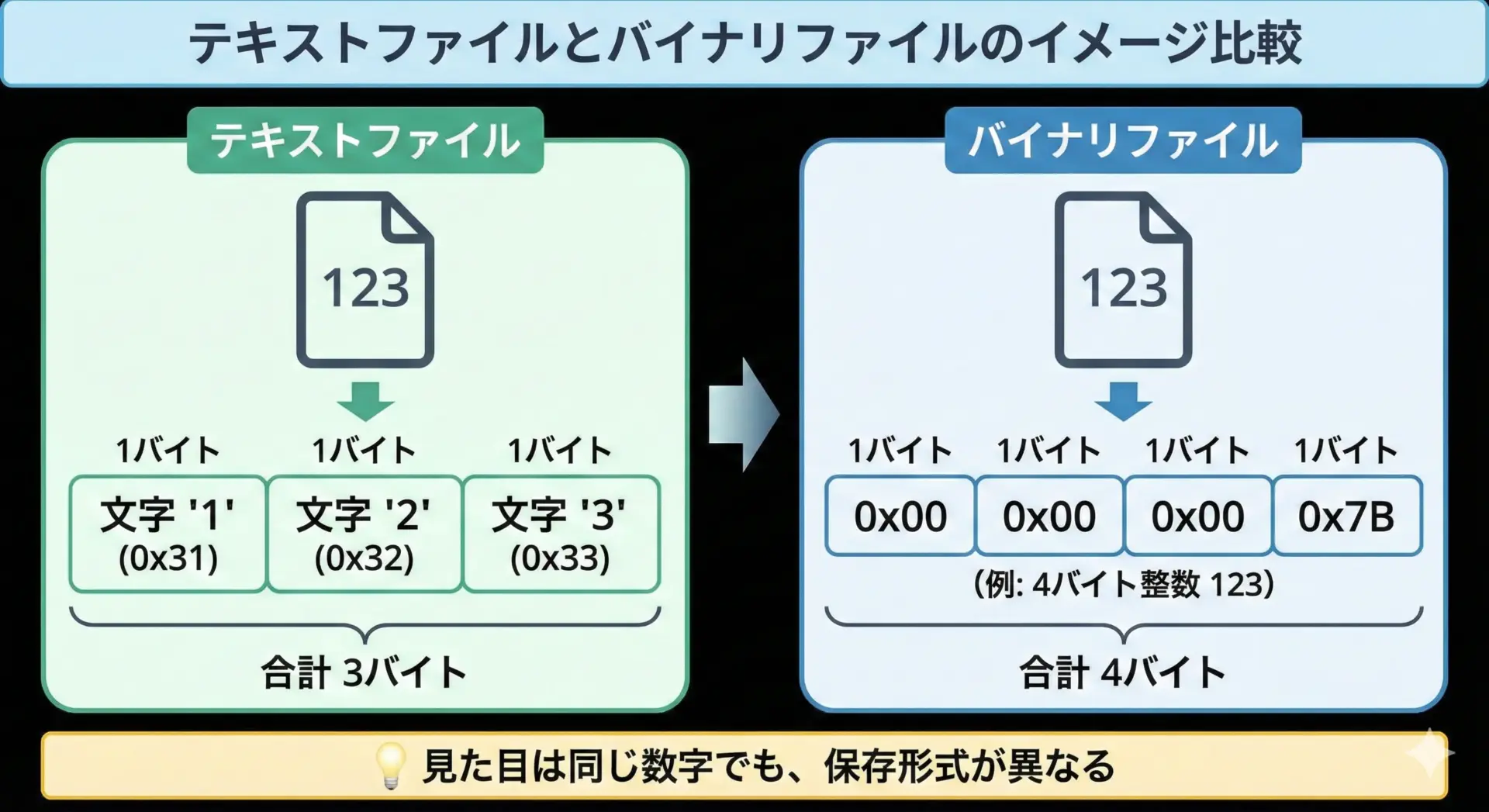
テキストファイルでは、たとえば整数の123を保存すると、'1'、'2'、'3'という3文字、つまり3バイト分のデータとして記録されます。
それに対してバイナリファイルにint型の値123を書き込むと、多くの環境では4バイト(32ビット)の整数として保存されます。
同じ「123」でも、ファイルの中身はまったく違うものになるわけです。
この違いは、改行コードや文字コードの変換にも影響します。
テキストファイルは、OSによって改行コードを自動変換する場合があり、WindowsとUnix系(Linux、macOSなど)で挙動が異なります。
対してバイナリファイルは一切変換せず、そのままのビット列を扱うため、構造体や数値を正確に保存するのに向いています。
バイナリファイル入出力でfreadとfwriteを使う理由
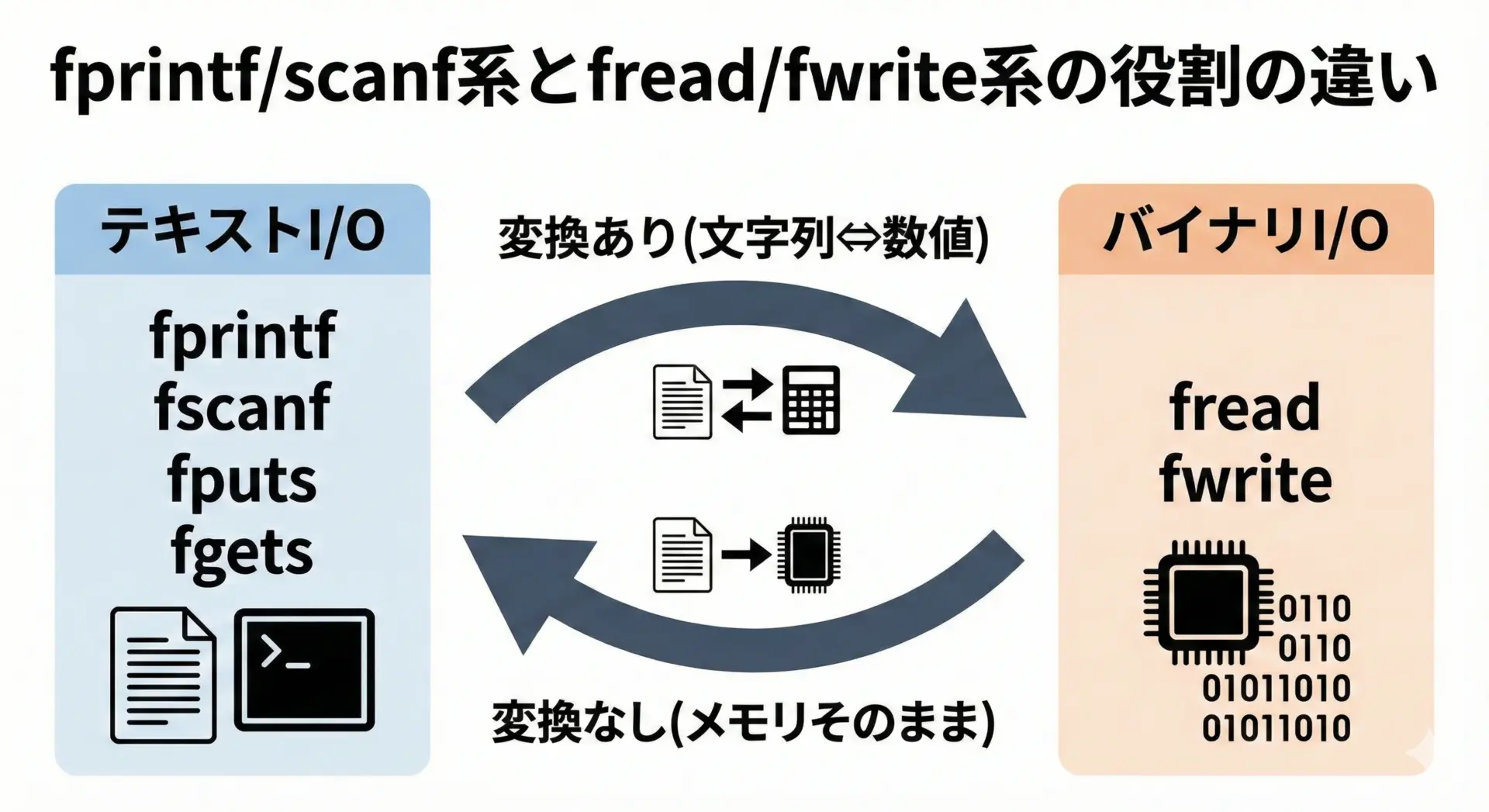
C言語でファイル入出力を行うとき、多くの方が最初に学ぶのはfprintfやfscanf、fgetsやfputsといったテキスト入出力関数です。
これらは「数値や構造体を文字列に変換してから書き込む」、あるいは「文字列として読み込んでから数値に変換する」という処理を行います。
それに対してfreadとfwriteは、メモリ上のデータを変換せず、そのままバイト列として読み書きする関数です。
このため、次のようなメリットがあります。
- 構造体や配列をそのまま一括で書き込める
- 数値を文字列に変換するオーバーヘッドがないため、高速
- データのサイズが予測しやすく、ファイル容量を抑えられる
一方で、バイト順序(エンディアン)や構造体のアライメント(パディング)の影響を受けるため、異なる環境間での互換性には注意が必要です。
この記事では、そうした注意点も含めて実務レベルで使えるバイナリ入出力の方法を解説していきます。
fwriteによるバイナリファイル出力
fwriteの基本的な使い方と書式
fwriteは、メモリ上のデータをバイナリ形式でファイルに書き込む標準関数です。
書式は次のようになります。
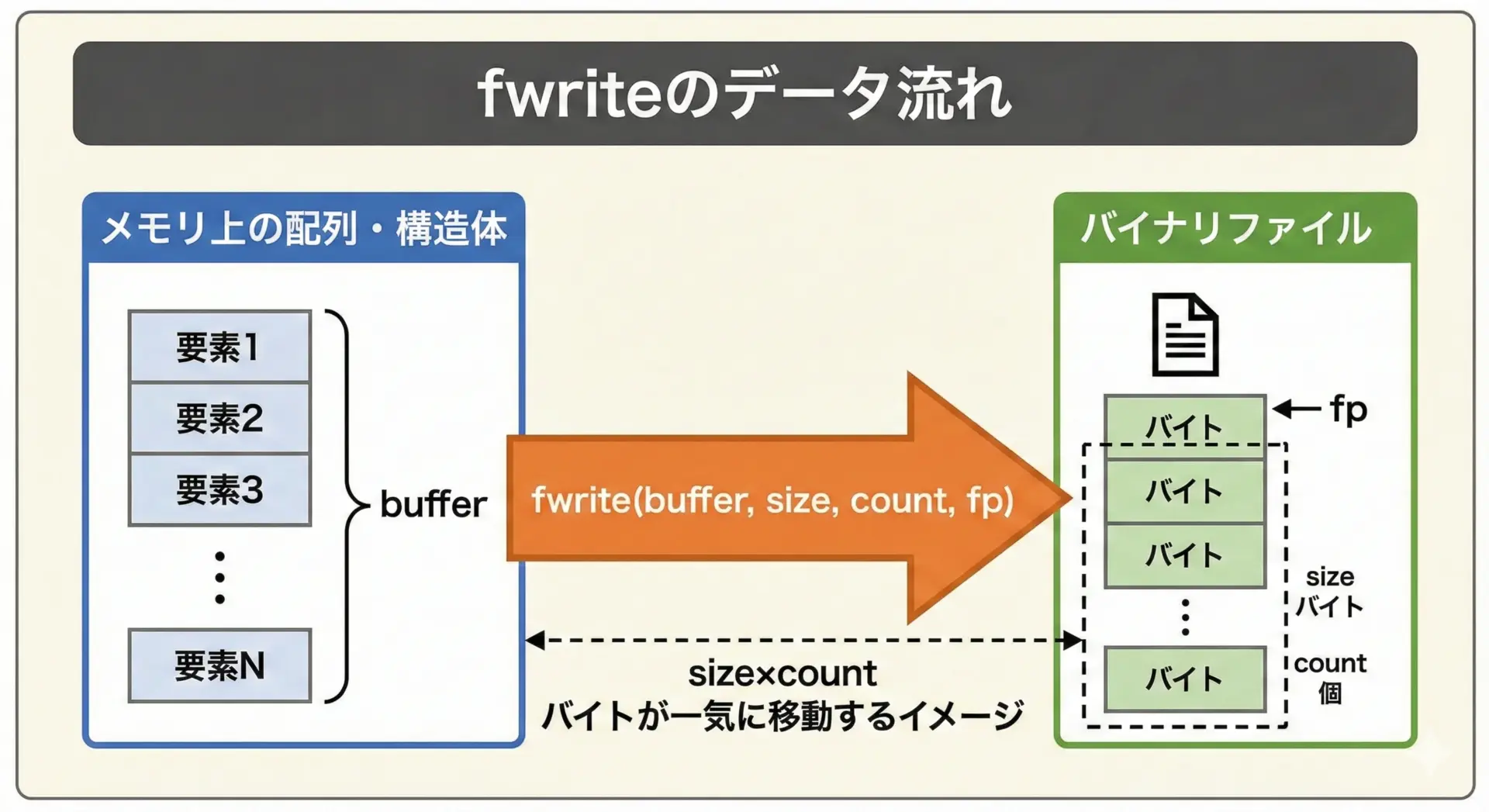
size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream);各引数の意味は次の通りです。
ptr
書き込み元データ(バッファ)の先頭アドレスです。配列や構造体など、どのような型のデータでも指定できます。size
1要素あたりのバイト数です。通常はsizeof(型)やsizeof *ptrといった書き方をします。nmemb
書き込む要素数です。配列全体を書き込む場合はその要素数を指定します。1つの構造体なら1を指定します。stream
書き込み対象のFILE *です。fopenで"wb"などのバイナリモードで開いたファイルポインタを指定します。
戻り値は、実際に書き込まれた要素数です。
期待したnmembと異なる場合は、エラーやディスク容量不足などが発生している可能性があります。
構造体(struct)をバイナリ書き込みするサンプルコード

構造体をバイナリファイルに保存すると、プログラム内のデータ構造をそのままの形に近い状態でファイルに退避できるため、設定ファイルや一時保存データなどに非常に便利です。
ここでは、学生情報を表す構造体をバイナリ書き込みするサンプルを示します。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define NAME_LEN 32
// 学生情報を表す構造体
typedef struct {
int id; // 学生ID
char name[NAME_LEN]; // 名前(固定長文字列)
double score; // 点数
} Student;
int main(void) {
// 書き込みたい学生データを準備
Student s1, s2;
s1.id = 1;
strncpy(s1.name, "Taro", NAME_LEN);
s1.name[NAME_LEN - 1] = '\0'; // 念のため終端
s1.score = 90.5;
s2.id = 2;
strncpy(s2.name, "Hanako", NAME_LEN);
s2.name[NAME_LEN - 1] = '\0';
s2.score = 82.0;
// バイナリモードで書き込み用にファイルを開く
FILE *fp = fopen("students.dat", "wb");
if (fp == NULL) {
perror("fopen");
return EXIT_FAILURE;
}
// 構造体を2件まとめて書き込む
// 第1引数: 書き込み元ポインタ
// 第2引数: 1要素あたりのバイト数
// 第3引数: 要素数(ここでは2件)
// 第4引数: ファイルポインタ
Student list[2] = { s1, s2 };
size_t written = fwrite(list, sizeof(Student), 2, fp);
if (written != 2) {
// 想定よりも少ない件数しか書き込めなかった場合のエラー処理
fprintf(stderr, "fwrite error: expected 2, wrote %zu\n", written);
fclose(fp);
return EXIT_FAILURE;
}
fclose(fp);
printf("Binary file 'students.dat' written successfully.\n");
return EXIT_SUCCESS;
}実行結果(コンソール出力)の例:
Binary file 'students.dat' written successfully.このプログラムは構造体配列をまとめて1回のfwriteで書き込んでいる点がポイントです。
要素ごとにループして書くこともできますが、配列として連続している場合はこのように一括書き込みしたほうがシンプルで高速です。
fwriteでよくあるミス

fwriteを使う際に特に多いミスとして、次のようなケースがあります。
1つ目はsizeとnmembの指定を取り違えるパターンです。
本来はsizeof(要素型)をsizeに、要素数をnmembに指定する必要がありますが、sizeof(配列全体)をsizeに入れてnmembを1にしてしまう例がよく見られます。
技術的には動作しますが、コードの意図が分かりづらくミスの温床になります。
2つ目はアドレスの渡し方を間違えるケースです。
配列int data[100]を渡すとき、本来はdataを指定すべきところを&dataとしてしまうと、配列全体へのポインタになり、意図と異なるサイズで書き込まれてしまうことがあります。
比較のために、よくない書き方と推奨される書き方を表にまとめます。
| ケース | よくない例 | 推奨される例 |
|---|---|---|
| 配列の書き込み | fwrite(buf, sizeof(buf), 1, fp) | fwrite(buf, sizeof *buf, N, fp) |
| 構造体1件の書き込み | fwrite(&st, sizeof(st), 1, fp) | fwrite(&st, sizeof st, 1, fp) |
| 構造体配列の書き込み | fwrite(&arr, sizeof(arr), 1, fp) | fwrite(arr, sizeof *arr, N, fp) |
「1要素の大きさ×要素数」で書き込む、という原則を意識すると、引数の指定ミスを防ぎやすくなります。
freadによるバイナリファイル入力
freadの基本的な使い方と書式
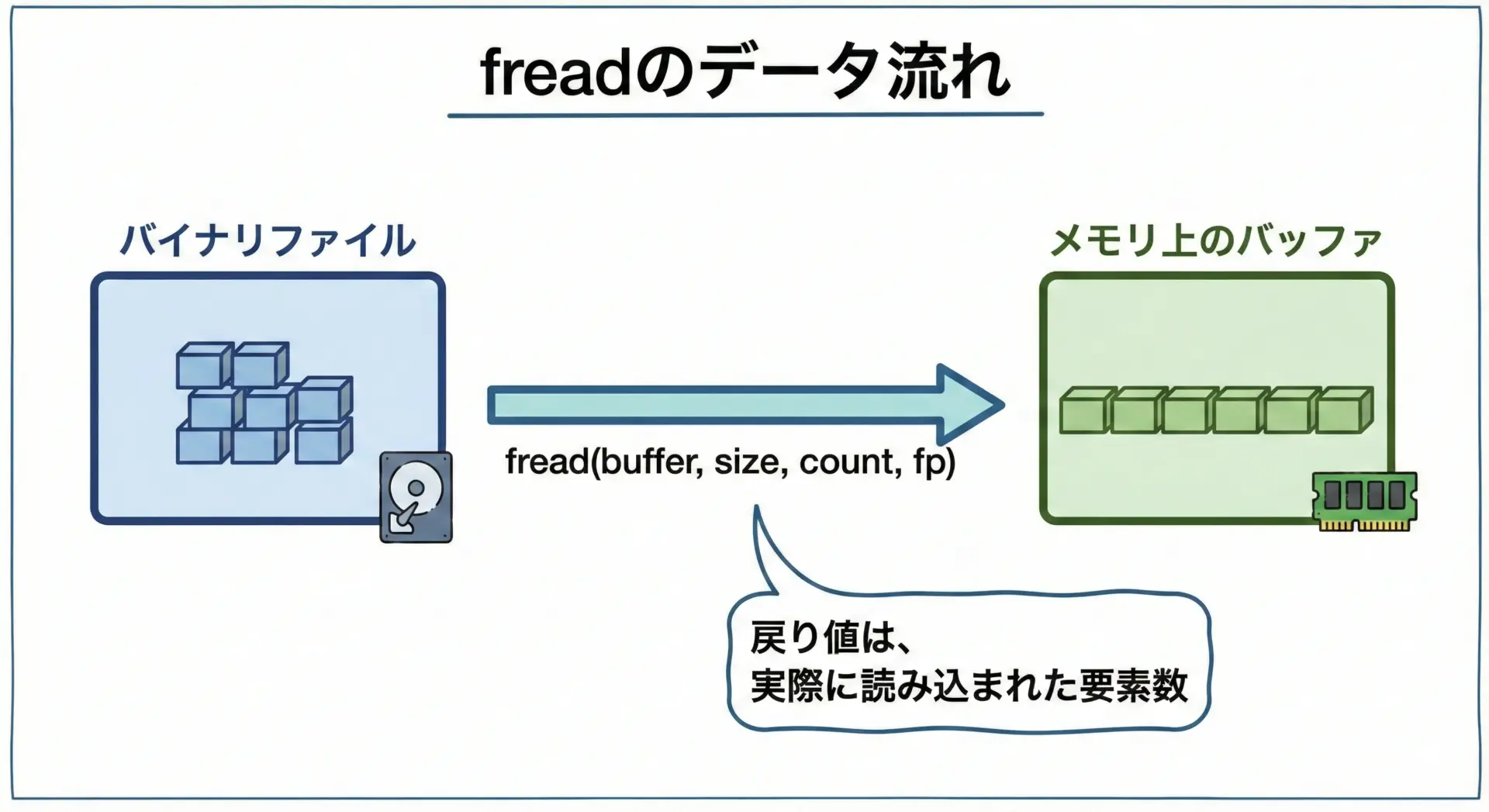
freadは、バイナリファイルからメモリ上のバッファにデータを読み込む関数です。
書式はfwriteと対称的で、次のようになっています。
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream);引数の意味はfwriteとほぼ同じです。
ptr
読み込み先のバッファの先頭アドレスです。配列や構造体変数のアドレスを指定します。size
1要素あたりのバイト数です。nmemb
読み込む要素数です。stream
読み込み対象のFILE *です。fopenで"rb"などのバイナリモードで開いたファイルポインタを指定します。
戻り値は、実際に読み込まれた要素数です。
ファイル終端に達した場合やエラーが発生した場合には、指定したnmembより小さい値が返ることがあります。
fwriteで書いたデータをfreadで読み込むサンプル

先ほどfwriteで書き込んだstudents.datを、今度はfreadで読み込んでみましょう。
構造体の定義が書き込み時と読み込み時で同一であることが重要です。
#include <stdio.h>
#include <stdlib.h>
#define NAME_LEN 32
typedef struct {
int id;
char name[NAME_LEN];
double score;
} Student;
int main(void) {
FILE *fp = fopen("students.dat", "rb");
if (fp == NULL) {
perror("fopen");
return EXIT_FAILURE;
}
Student list[2];
size_t read_count = fread(list, sizeof(Student), 2, fp);
if (read_count != 2) {
fprintf(stderr, "fread error: expected 2, read %zu\n", read_count);
fclose(fp);
return EXIT_FAILURE;
}
fclose(fp);
// 読み込んだ内容を表示
for (size_t i = 0; i < 2; i++) {
printf("ID: %d, Name: %s, Score: %.1f\n",
list[i].id, list[i].name, list[i].score);
}
return EXIT_SUCCESS;
}ID: 1, Name: Taro, Score: 90.5
ID: 2, Name: Hanako, Score: 82.0このように、書き込みと読み込みで同じ構造体定義とsizeofの指定を使うことで、データを往復させることができます。
逆に言えば、構造体定義を変更するとバイナリファイルの互換性が崩れるため、設計段階から意識しておく必要があります。
freadの戻り値とEOF(終端)の扱い方
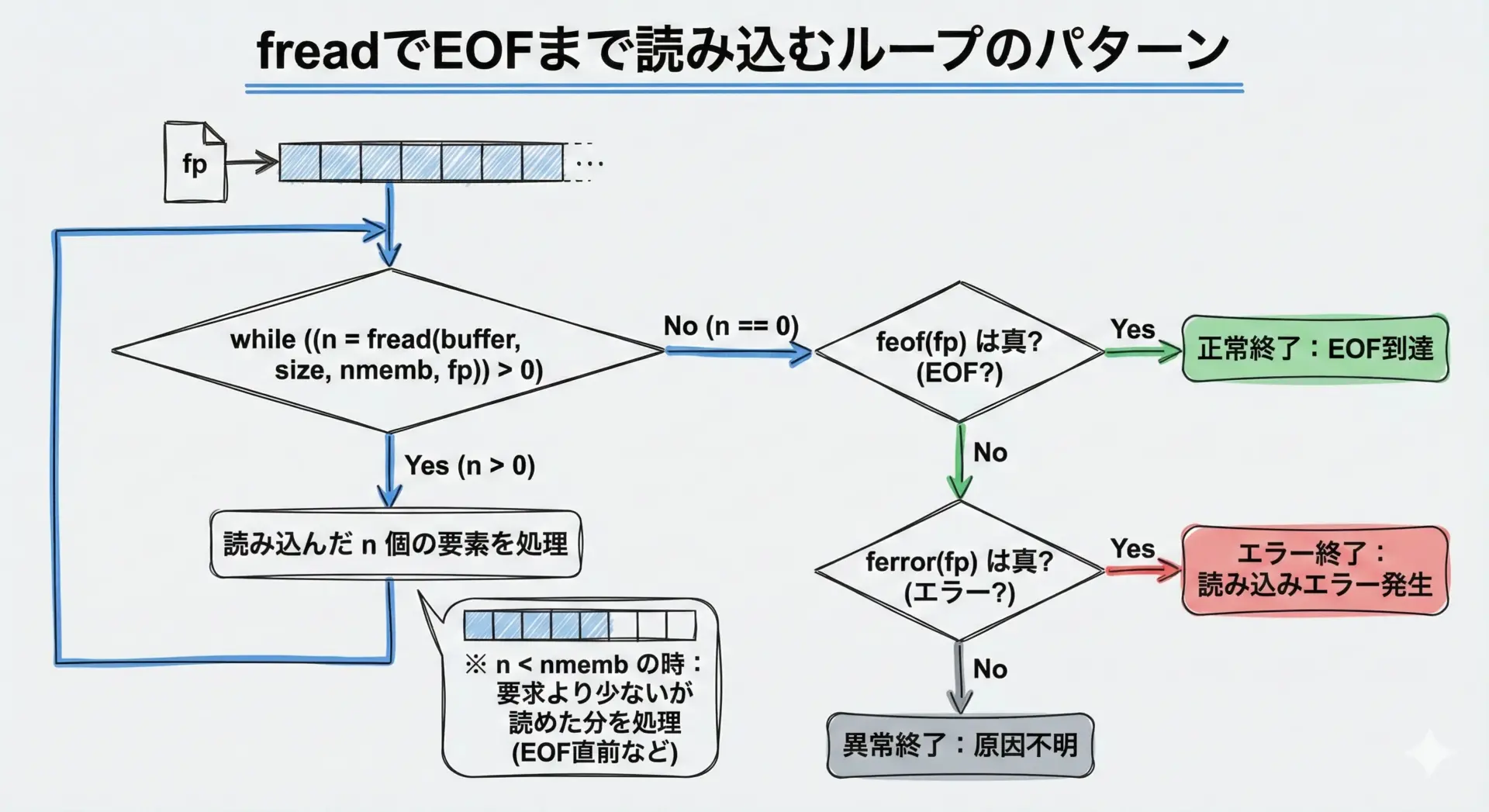
freadでは、戻り値を正しく扱うことが非常に重要です。
ファイル終端(EOF)やエラーを検出するために、次のようなパターンがよく使われます。
#include <stdio.h>
#include <stdlib.h>
int main(void) {
FILE *fp = fopen("data.bin", "rb");
if (fp == NULL) {
perror("fopen");
return EXIT_FAILURE;
}
int buf[16];
size_t n;
// EOFに達するまで繰り返し読む例
while ((n = fread(buf, sizeof(int), 16, fp)) > 0) {
// n 個の int が buf に読み込まれた
for (size_t i = 0; i < n; i++) {
printf("%d\n", buf[i]);
}
}
if (ferror(fp)) {
// 読み込み中にエラーが発生していないか確認
perror("fread");
fclose(fp);
return EXIT_FAILURE;
}
// feof(fp) が真であれば、EOF に達したことを意味する
if (feof(fp)) {
printf("End of file reached.\n");
}
fclose(fp);
return EXIT_SUCCESS;
}実行結果の例(ファイル内容に応じて変わります):
1
2
3
...
End of file reached.ポイントは、freadの戻り値が0になったからといって即座にエラーとは限らないことです。
EOFに達した場合にも0が返るため、ferrorやfeofを併用して、エラーと正常な終端を区別します。
バイナリファイル操作の実践テクニック
バイナリモードで開く(open)時の”rb””wb””ab”の使い分け
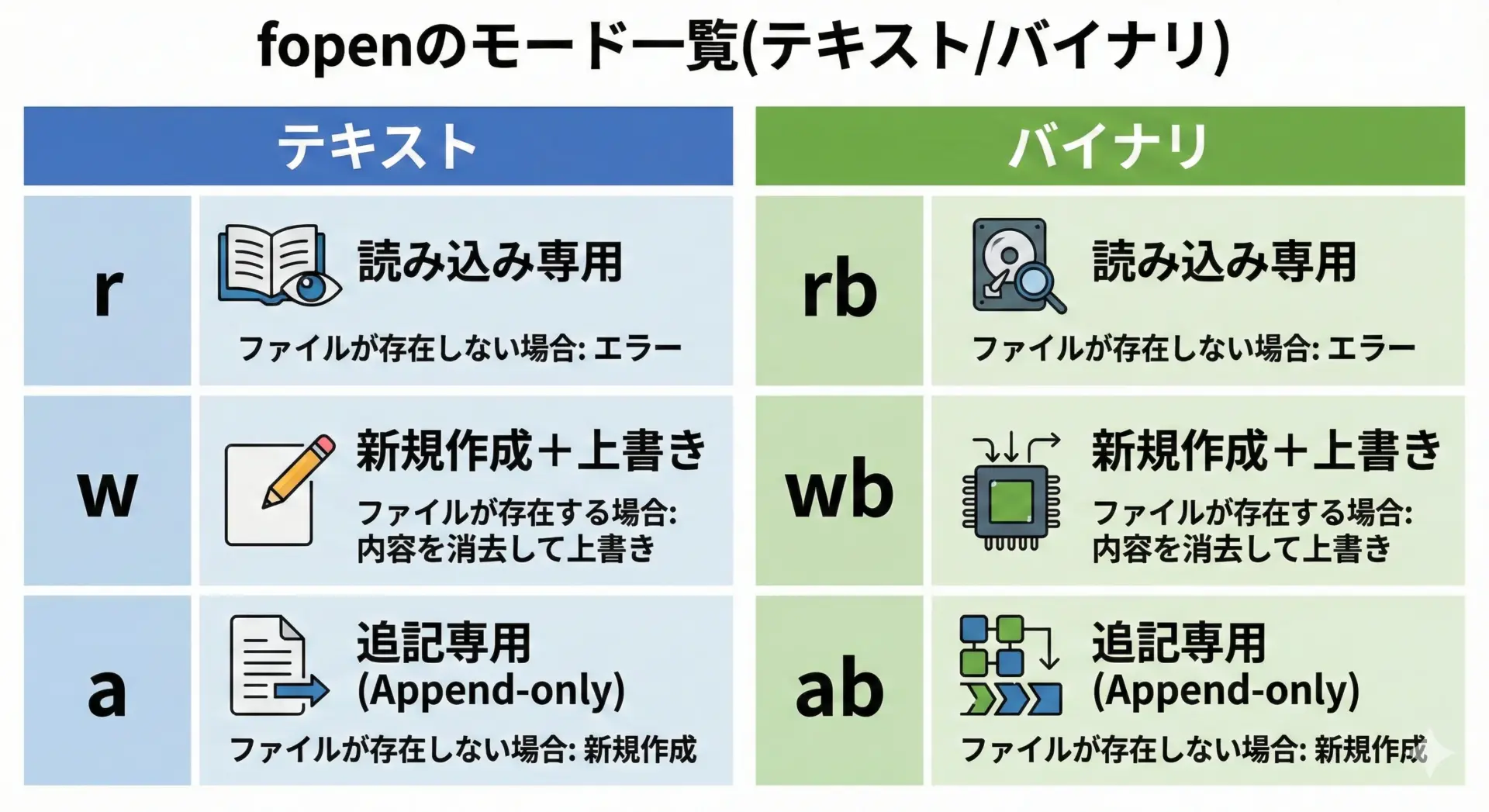
バイナリファイルを扱うときは、fopenでバイナリモードを指定する必要があります。
Windows環境では改行コードの自動変換を避けるためにも必須です。
代表的なモードを整理すると次のようになります。
| モード | 意味 | 備考 |
|---|---|---|
"rb" | 既存ファイルをバイナリ読み込み用に開く | 読み込み専用 |
"wb" | バイナリ書き込み用に新規作成(既存は全削除) | ファイルがなければ作成される |
"ab" | バイナリで追記用に開く | 常に末尾に書き足される |
"rb+" | 読み書き両用で開く(既存のみ) | ランダムアクセス時によく使用 |
"wb+" | 読み書き両用で新規作成(既存は全削除) | テスト用などで便利 |
UNIX系環境では"r"と"rb"の動作差はほぼありませんが、移植性を考えるとバイナリファイルには"rb"や"wb"を明示的に使うことをおすすめします。
ファイル位置の移動(fseek・ftell)とランダムアクセス

バイナリファイルの大きな利点の1つは、固定サイズのレコードをランダムにアクセスしやすいことです。
C言語ではfseekとftellを使って、ファイル内の任意位置へジャンプしたり、現在位置を取得したりできます。
代表的な使い方は次の通りです。
#include <stdio.h>
#include <stdlib.h>
typedef struct {
int id;
char name[32];
double score;
} Student;
int main(void) {
FILE *fp = fopen("students.dat", "rb");
if (fp == NULL) {
perror("fopen");
return EXIT_FAILURE;
}
// 4番目のレコード(インデックス3)に直接ジャンプ
long index = 3;
long offset = sizeof(Student) * index;
// ファイル先頭から offset バイト進める
if (fseek(fp, offset, SEEK_SET) != 0) {
perror("fseek");
fclose(fp);
return EXIT_FAILURE;
}
Student s;
size_t n = fread(&s, sizeof(Student), 1, fp);
if (n != 1) {
fprintf(stderr, "failed to read record %ld\n", index);
fclose(fp);
return EXIT_FAILURE;
}
printf("ID: %d, Name: %s, Score: %.1f\n", s.id, s.name, s.score);
// 現在位置をバイト単位で取得
long pos = ftell(fp);
if (pos != -1L) {
printf("Current file position: %ld bytes\n", pos);
}
fclose(fp);
return EXIT_SUCCESS;
}実行結果の例(データにより異なります):
ID: 4, Name: Jiro, Score: 75.0
Current file position: 128 bytesこのように1レコードのサイズが一定であれば、index × sizeof(レコード)で一発ジャンプできるため、テキストファイルよりも効率的な検索や更新が可能になります。
異なる環境間でのバイナリデータ互換性
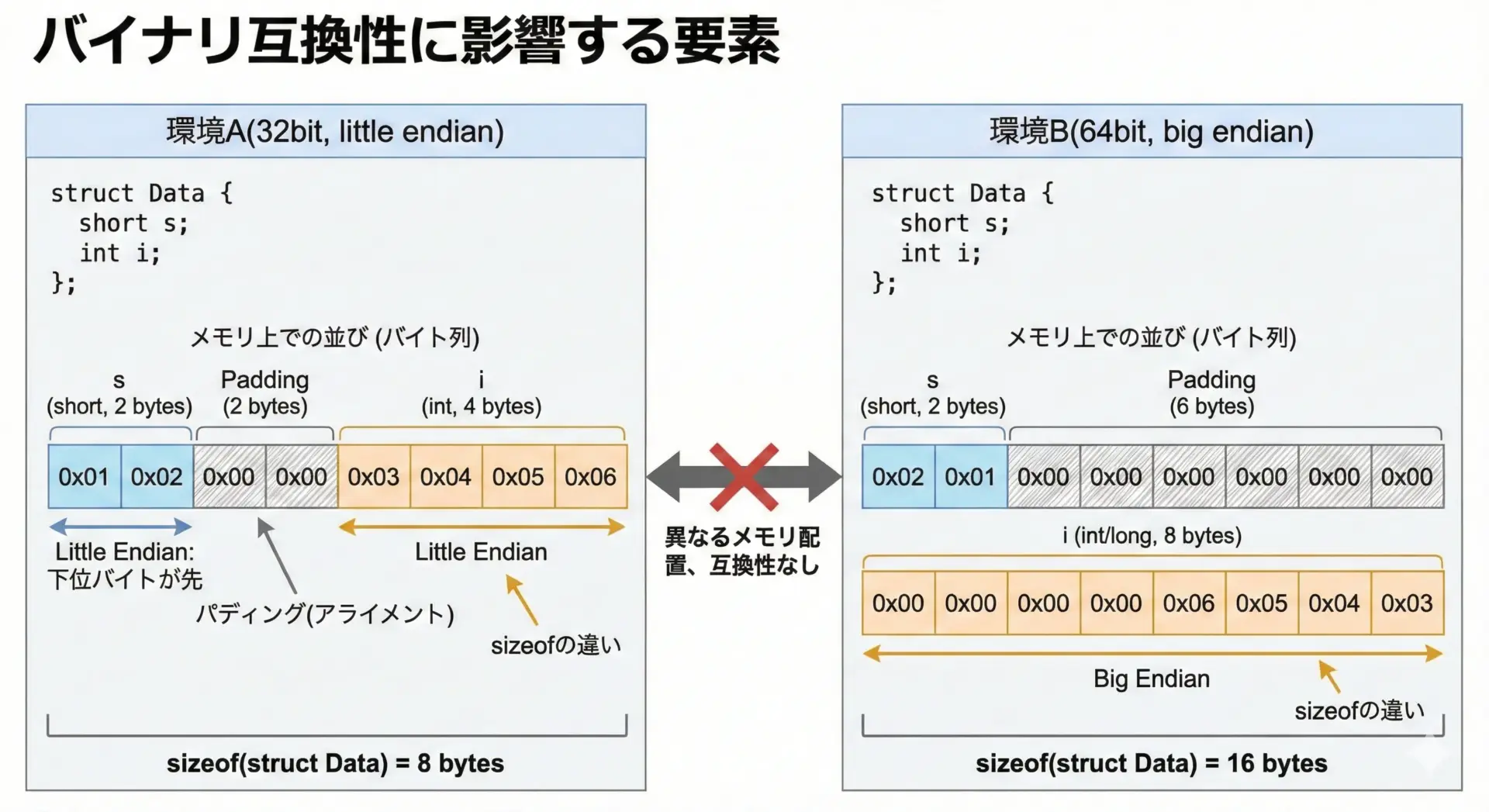
バイナリファイルはメモリのビット列をそのまま保存する性質上、異なる環境間での互換性に注意が必要です。
主に問題となるのは、次の3点です。
1つ目はエンディアン(バイト順序)です。
整数値を複数バイトで表現するとき、リトルエンディアン(下位バイトから格納)とビッグエンディアン(上位バイトから格納)という方式があります。
たとえば16進数0x12345678を保存する場合、リトルエンディアンでは78 56 34 12、ビッグエンディアンでは12 34 56 78となり、ファイル内容が一致しません。
2つ目はデータ型のサイズの違いです。
環境によってintが4バイトであったり2バイトであったり、longが4バイトか8バイトか、といった違いがあります。
sizeofの結果が変わると、同じソースコードでもバイナリファイルのレイアウトが変化してしまいます。
3つ目は構造体のパディング(アライメント)です。
コンパイラはアクセス効率を上げるために、構造体のメンバ間に隙間(パディング)を挿入することがあります。
この挙動はコンパイラやオプションによって変わるため、異なるコンパイラ間で同じ構造体でもバイト配列が一致しないという事態が起こりえます。
こうした問題を回避してポータブルなバイナリ形式を作るには、次のような工夫が有効です。
- ネットワークバイトオーダー(ビッグエンディアン)に統一して保存し、読み書き時に変換する
int32_tやuint16_tなど、固定幅整数型(<stdint.h>)を用いる- 構造体をそのまま書き出さず、各フィールドを個別にエンコードしてファイルに書き込む
- ファイル形式の仕様書を作り、バイト単位でのレイアウトを明示する
簡単な例として、32ビット整数をリトルエンディアンで保存・読み出しするヘルパー関数を示します。
#include <stdio.h>
#include <stdint.h>
// 32ビット符号なし整数をリトルエンディアンで書き込む
int write_uint32_le(FILE *fp, uint32_t value) {
unsigned char buf[4];
// 下位バイトから順に格納
buf[0] = (unsigned char)( value & 0xFF);
buf[1] = (unsigned char)((value >> 8 ) & 0xFF);
buf[2] = (unsigned char)((value >> 16) & 0xFF);
buf[3] = (unsigned char)((value >> 24) & 0xFF);
return (fwrite(buf, 1, 4, fp) == 4) ? 0 : -1;
}
// 32ビット符号なし整数をリトルエンディアンで読み込む
int read_uint32_le(FILE *fp, uint32_t *value) {
unsigned char buf[4];
if (fread(buf, 1, 4, fp) != 4) {
return -1;
}
*value = (uint32_t)buf[0]
| ((uint32_t)buf[1] << 8)
| ((uint32_t)buf[2] << 16)
| ((uint32_t)buf[3] << 24);
return 0;
}このように、自前でバイト列を定義して保存すれば、どの環境でも同じ意味で解釈できるバイナリフォーマットを構築できます。
実務的なアプリケーションやファイル形式を設計する際には、こうした手法を検討することが重要です。
まとめ
バイナリファイルはテキストファイルでは扱いにくい数値や構造体を効率的に保存・読み出しできる強力な手段です。
C言語ではfwriteとfreadを用いることで、メモリ上のデータをそのままファイルとやり取りできます。
ただし、開くモード(“rb””wb”)の指定や、戻り値によるエラー・EOF判定、fseek/ftellによるランダムアクセス、さらにはエンディアンや構造体のパディングによる互換性問題など、注意すべき点も少なくありません。
この記事で紹介したサンプルとポイントを押さえれば、実用的なバイナリファイル処理の基礎は十分に身につきますので、ぜひ実際にコードを書きながら理解を深めてみてください。
