C言語でファイルから値を読み取るとき、最初に候補に上がる関数がfscanfです。
しかし、改行やスペース、数値や文字列の扱いを正しく理解していないと、思わぬバグや無限ループを引き起こしてしまいます。
本記事では、fscanfの基本から改行・空白の挙動、数値・文字列読み取りのコツ、エラー処理や日本語(マルチバイト文字)の注意点までを、図解とサンプルコードを交えながら詳しく解説します。
fscanfの基本的な使い方
fscanfとは?基本仕様とprintfとの違い
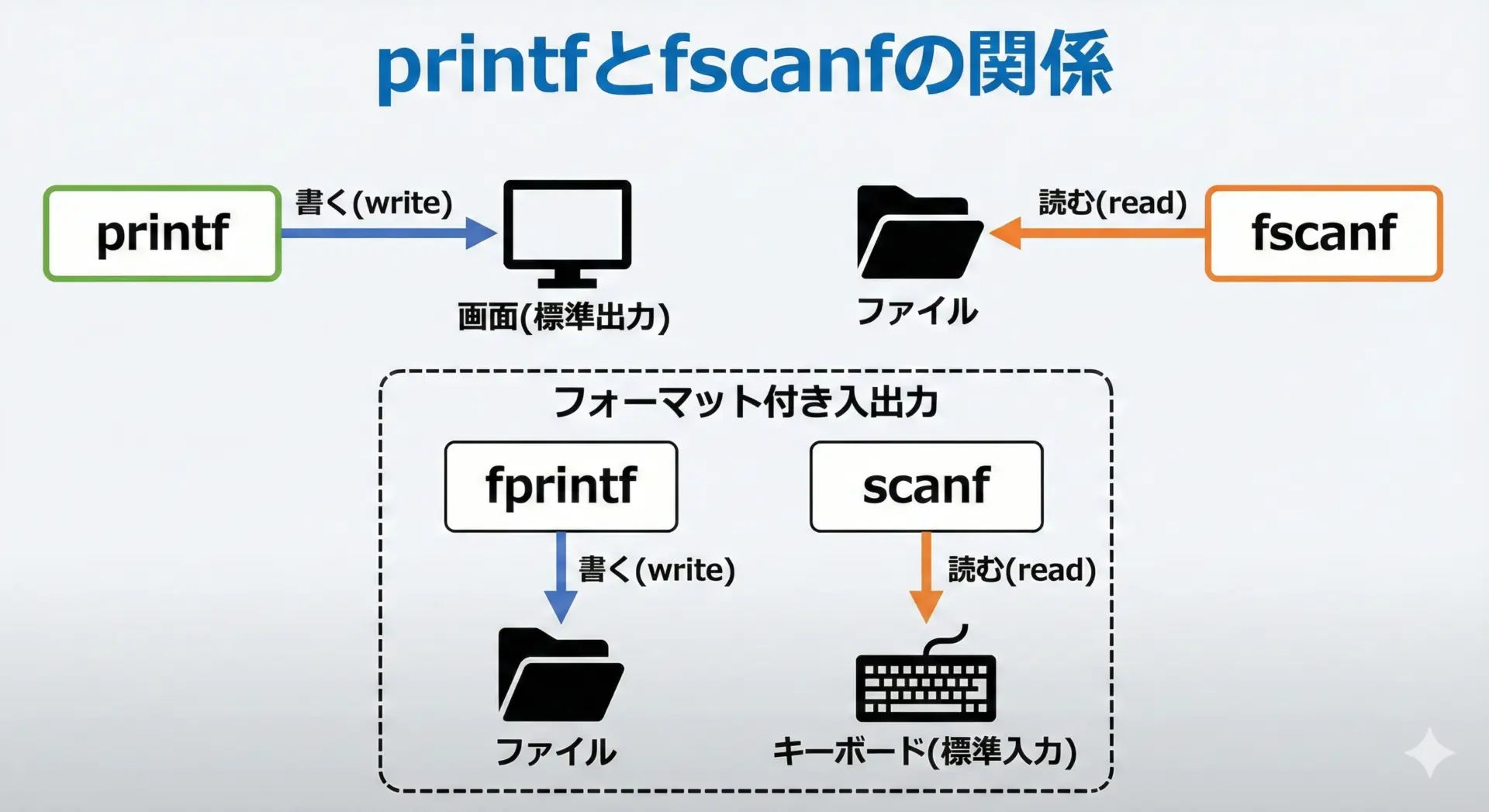
fscanfは、ファイルから書式付きでデータを読み取る関数です。
似た名前のscanfは標準入力から、fprintfやprintfは書き込み用という位置付けです。
大まかな役割は次のように整理できます。
printf… 画面(標準出力)に「書式付きで」出力fprintf… ファイルに「書式付きで」出力scanf… 標準入力から「書式付きで」入力fscanf… ファイルから「書式付きで」入力
つまりfscanfは、printfの“読み取り版”とも言えます。
ただし、出力と違って入力では、
- ファイルの終端(EOF)
- 入力フォーマットの不一致
- 改行やスペースの解釈
など、細かいルールを理解していないと簡単にバグに繋がる点が大きな違いです。
fscanfの基本構文と書式指定子
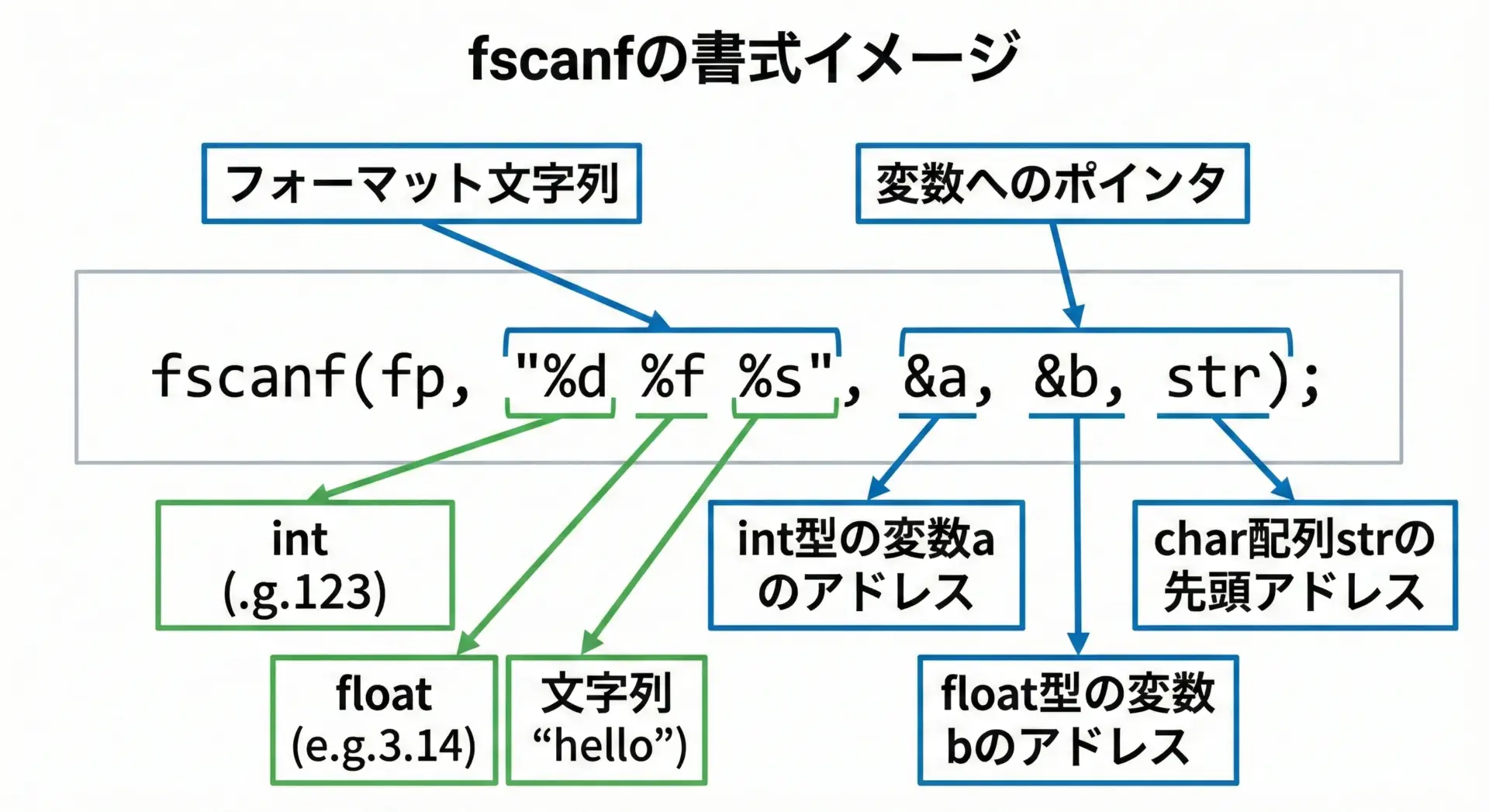
fscanfの最も基本的な構文は次の形です。
int fscanf(FILE *stream, const char *format, ...);通常の使い方は、次のようになります。
#include <stdio.h>
int main(void) {
FILE *fp;
int id;
double score;
char name[32];
// ファイルを読み取りモード("r")で開く
fp = fopen("data.txt", "r");
if (fp == NULL) {
// エラー処理
perror("fopen");
return 1;
}
// data.txt から "番号 名前 点数" 形式で読み取る例
// 例: 1 Taro 82.5
if (fscanf(fp, "%d %31s %lf", &id, name, &score) == 3) {
printf("id=%d, name=%s, score=%f\n", id, name, score);
} else {
printf("入力形式が正しくありません。\n");
}
fclose(fp);
return 0;
}この例では、"%d %31s %lf"というフォーマット文字列により、
%d…int型%31s… 最大31文字の文字列(char name[32]用)%lf…double型
を指定し、それぞれに対応するアドレス(ポインタ)を渡しています。
変数そのものではなく&変数を渡す必要がある点が、初心者の方がつまずきやすいポイントです。
代表的な書式指定子を表にまとめます。
| 書式指定子 | 意味(入力先の型) | 例 |
|---|---|---|
%d | 10進整数(int) | int x; fscanf(fp, "%d", &x); |
%u | 符号なし10進整数(unsigned int) | unsigned int u; |
%f | float(ただし引数はdouble) | float f; fscanf(fp, "%f", &f); |
%lf | double | double d; fscanf(fp, "%lf", &d); |
%s | 空白で区切られた文字列(char配列) | char s[100]; fscanf(fp, "%99s", s); |
%c | 1文字(char) | char c; fscanf(fp, "%c", &c); |
%[…]s | 指定集合の文字列 | "%[^\n]"など |
入力されるデータの形式と、フォーマット文字列が合っていることが非常に重要です。
これがずれると、以降すべての読み取りがおかしくなることがあります。
標準入力(stdin)とファイルポインタ(FILE *)の違い
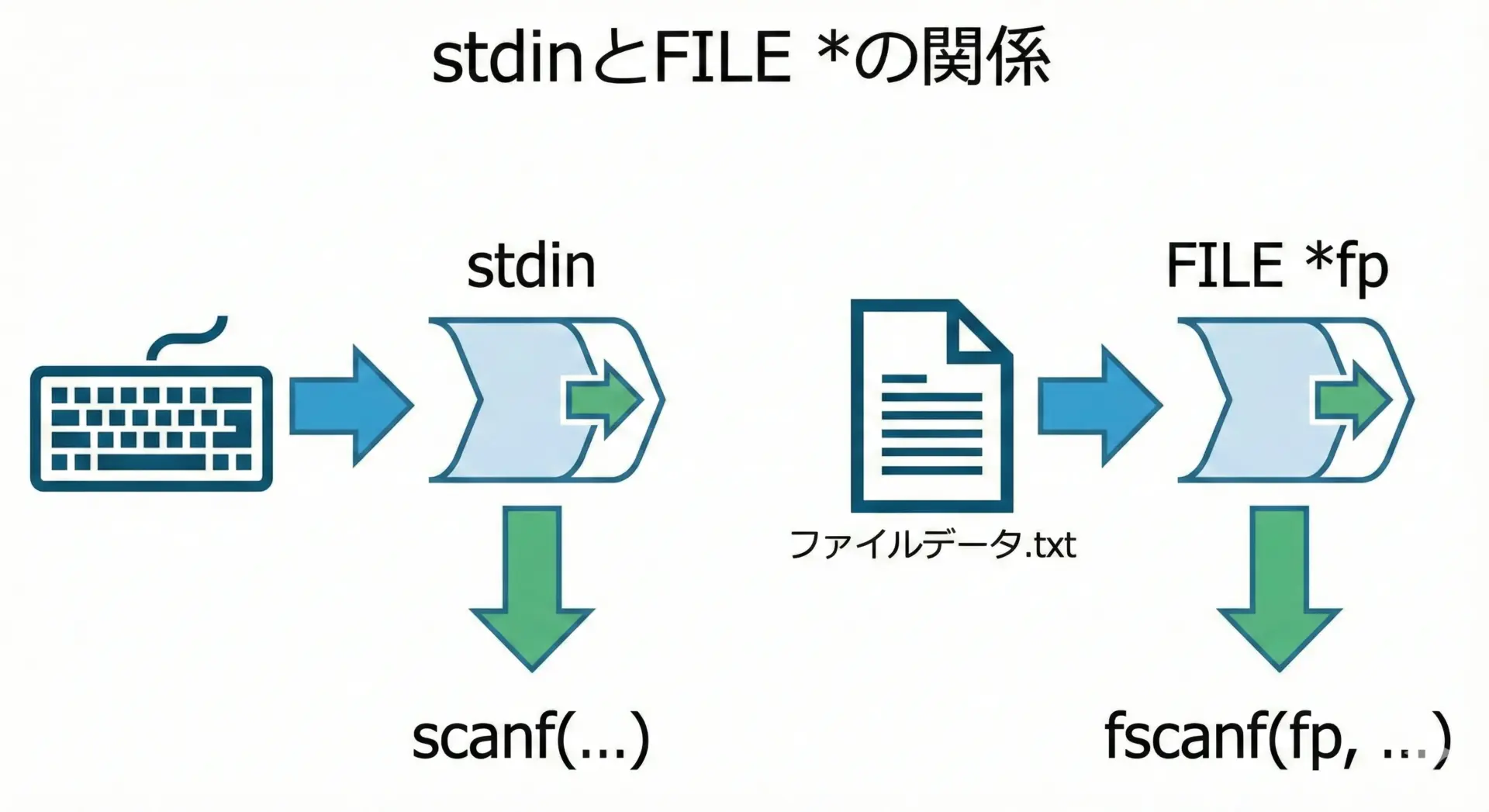
scanfとfscanfは、よく似た関数です。
実はscanfは「標準入力(stdin)に固定されたfscanf」と捉えると分かりやすくなります。
標準入力から読む場合は次のように書きます。
int x;
scanf("%d", &x); // 標準入力(stdin)から整数を読み取るこれとほぼ同じ意味のfscanfを書こうとすると、次のようになります。
int x;
fscanf(stdin, "%d", &x); // stream に stdin を渡しただけ違いは先頭の引数にFILE *を渡すかどうかだけです。
ファイルの場合は、fopenで開いたポインタを使います。
FILE *fp = fopen("input.txt", "r");
if (fp == NULL) {
perror("fopen");
return 1;
}
int x;
fscanf(fp, "%d", &x);stdin… プログラム開始時から自動的に開かれている「標準入力」FILE *fp…fopenで開いた任意のファイル
という違いがあるだけで、動作のルール(書式指定子や空白の扱いなど)は基本的に同じです。
fscanfによる改行・スペースの扱い
空白文字(スペース・タブ・改行)の読み取りルール

fscanfでは、「空白を無視する書式指定子」と「空白も含めてそのまま読む書式指定子」があります。
まず、この違いを理解することが重要です。
おおまかに次のように分かれます。
- 空白をスキップする代表
%d、%u、%f、%lf、%sなど
これらは直前の空白(スペース・タブ・改行など)をすべて読み飛ばしてから有効な文字の読み取りを開始します。 - 空白も含めてそのまま読む代表
%c、%[…](条件付き文字列、一部例外あり) など
こちらは1文字(またはパターンに合う文字)をそのまま読み取るので、改行やスペースでも構わず読みます。
例えば、ファイルに次のようなデータがあるとします。
123 456
789これを次のように読むと、
int a, b;
fscanf(fp, "%d%d", &a, &b);aには123bには456
が入り、改行は自動的に読み飛ばされてしまいます。
一方で、%cの場合は次のようになります。
char c1, c2, c3;
fscanf(fp, "%c%c%c", &c1, &c2, &c3);ファイル先頭が'1''2''3'であれば、
c1= ‘1’c2= ‘2’c3= ‘3’
というように空白を特別扱いせずに1文字ずつ読み取ります。
改行を無視したい場合の書式指定と注意点
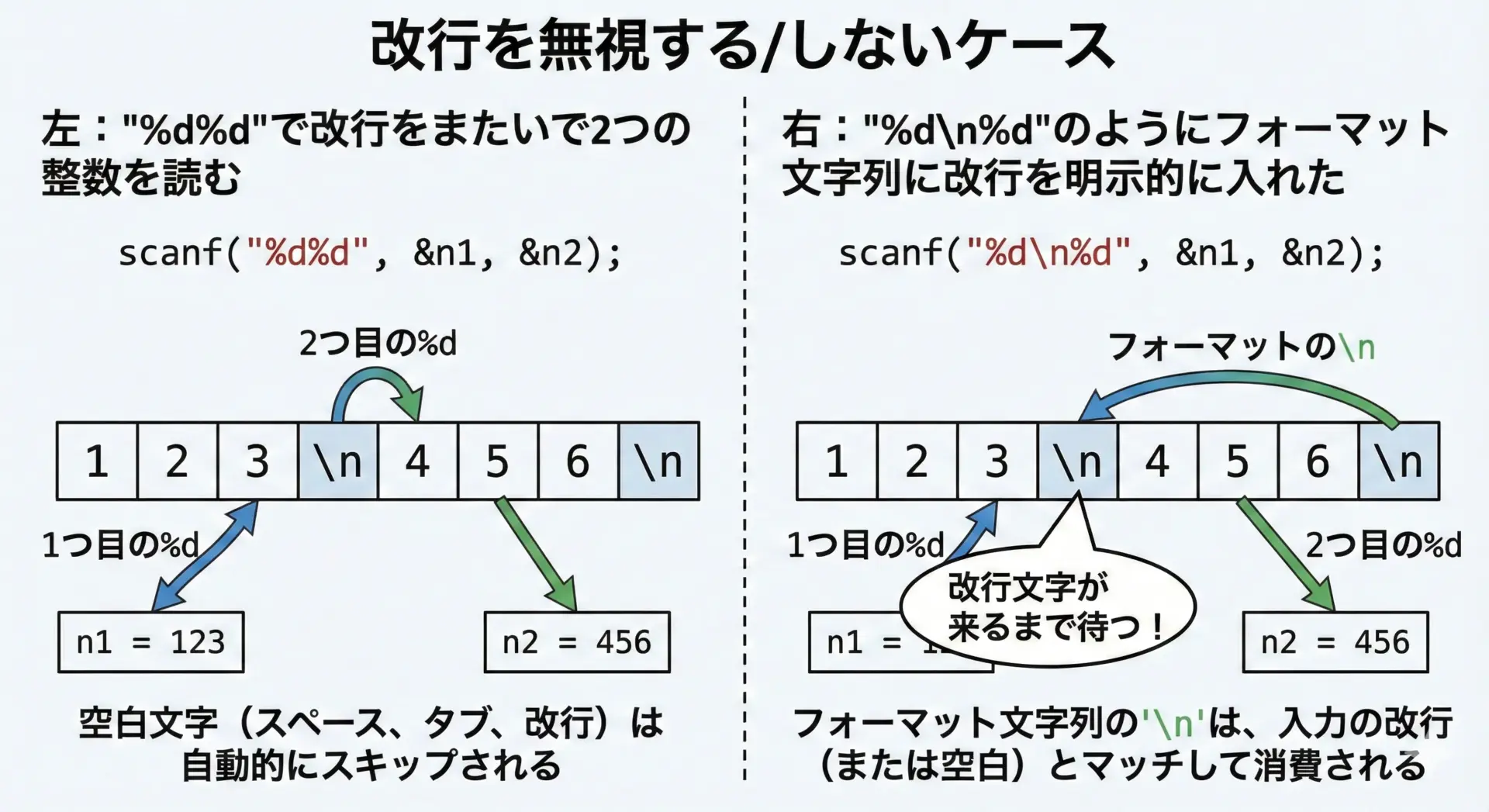
多くの場合、「改行は無視して数値や単語を順番に読みたい」というニーズがあると思います。
このときは、フォーマット文字列中に余計な空白(特に改行)を入れないようにします。
たとえば、次の2つは動作が異なります。
// 改行を特別扱いしない(空白は自動スキップ)
fscanf(fp, "%d %d", &a, &b);
// 改行を1つ要求してから次の整数を読むイメージ
fscanf(fp, "%d\n%d", &a, &b);2行目のように"\n"を入れると、フォーマット内の空白は「0個以上の空白文字」を消費するという仕様のため、最終的な挙動は近いものになりますが、実装や入力状況によっては、
- 想定外に読み取りがブロックされる
- 余分な空白を読み飛ばさずに残ってしまう
などの微妙な差が出てしまうことがあります。
基本的には、フォーマット文字列の中では、意味のある空白だけを書くと覚えると安全です。
特に“%d\n%d”のような書き方は、意図せず読み取りが止まる原因になるため、あまりおすすめできません。
改行やスペースを含む文字列の読み取り方法
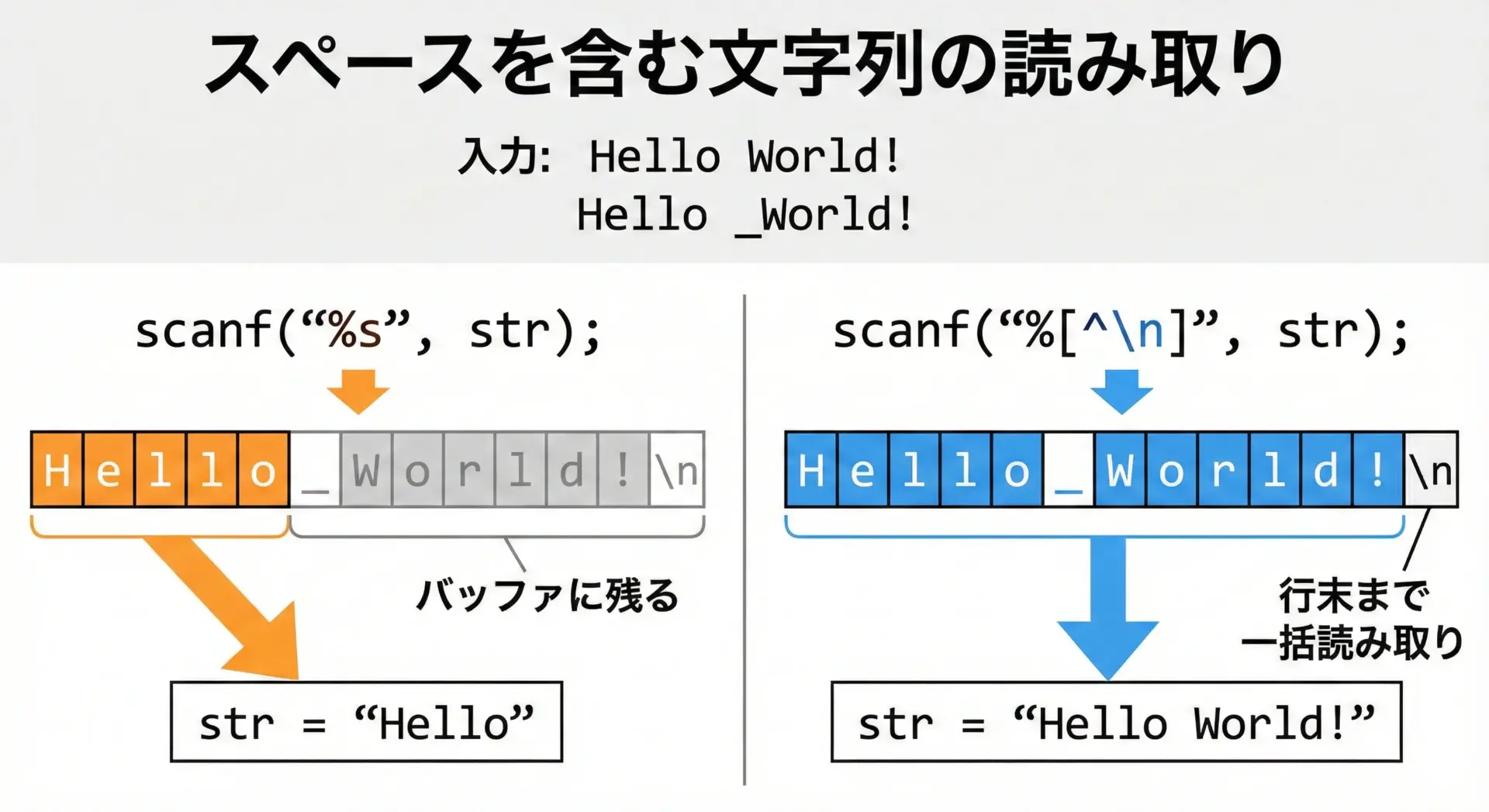
%sは空白文字(スペース・タブ・改行など)で区切られた1単語しか読み取りません。
そのため、
Hello World!という行を"%s"で読むと、"Hello"だけが読み取られ、後ろの"World!"は次の読み取りに残ってしまいます。
改行までを丸ごと1つの文字列として読みたい場合には、フォーマット指定"%[^\n]"を使います。
#include <stdio.h>
int main(void) {
FILE *fp;
char line[256];
fp = fopen("message.txt", "r");
if (fp == NULL) {
perror("fopen");
return 1;
}
// 改行文字('\n')が出てくるまでを読み取る
// [^\n] は「改行以外の任意の文字」の意味
if (fscanf(fp, "%255[^\n]", line) == 1) {
printf("line = %s\n", line);
} else {
printf("行の読み取りに失敗しました。\n");
}
fclose(fp);
return 0;
}たとえばmessage.txtが次の内容であれば、
Hello World!
This is a pen.最初のfscanfで"Hello World!"がlineに読み取られ、次の呼び出しでは次の行を読み取ることができます。
この%[^\n]という書き方は「スキャンセット」と呼ばれる機能で、[]の内側に許可する文字集合を指定することができます。
^が先頭にあると「それ以外の文字」という意味になります。
ただし、この方法でも改行文字そのもの('\n')はファイル中に残ったままになるため、次に%cなどで読むと、改行を拾ってしまうことがあります。
その場合は、後で説明するfgetsのほうが扱いやすいです。
1行単位で読みたい場合のfgetsとの使い分け
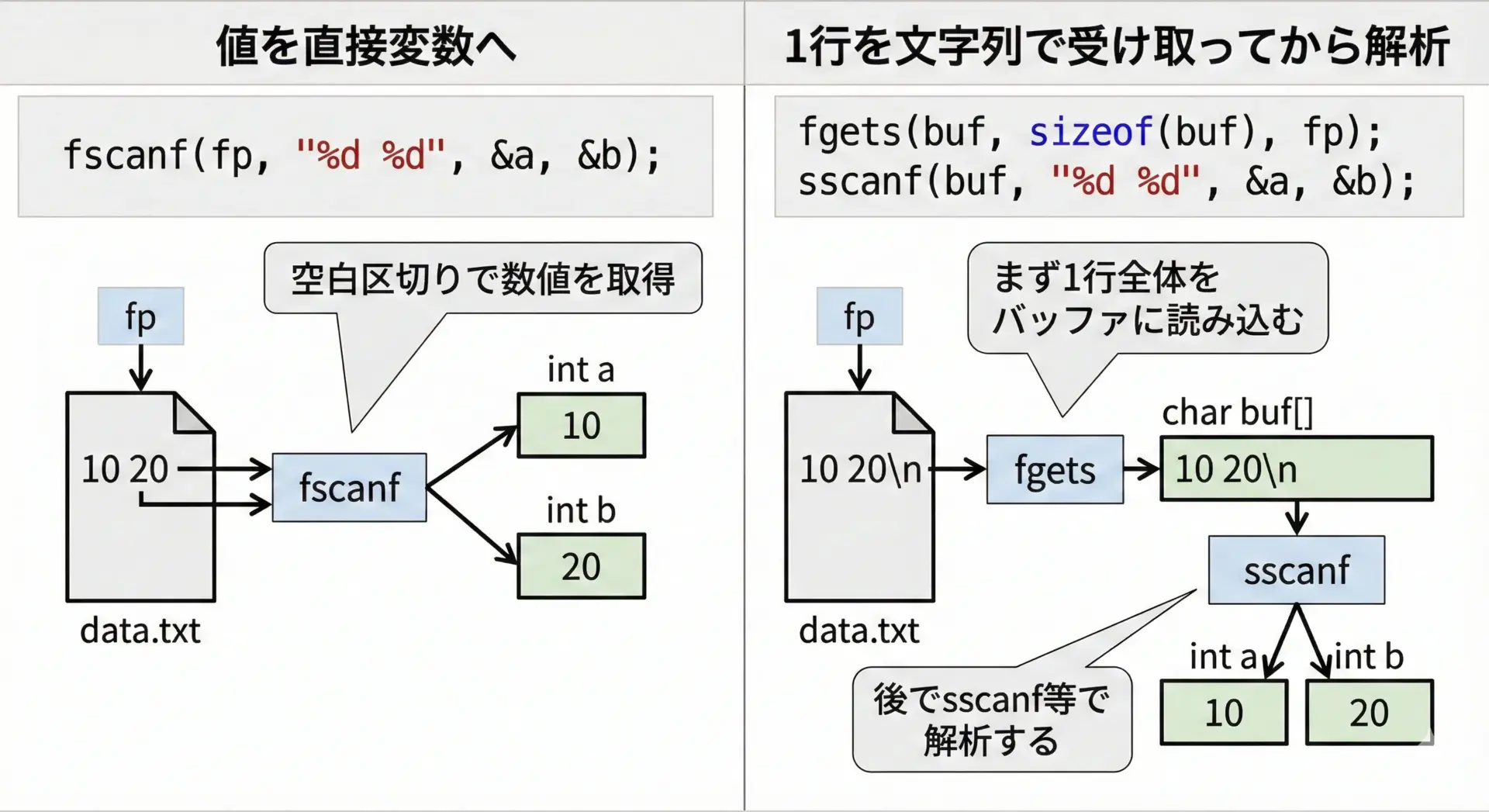
1行まるごとを扱いたい場合には、実務ではfscanfよりfgetsを使うことが多いです。
fgetsは、指定したサイズまで、あるいは改行が来るまでを文字列として読み取ります。
char buf[256];
// 1行分を文字列として読む(改行も含まれる)
if (fgets(buf, sizeof(buf), fp) != NULL) {
// ここで buf を解析する
}- fscanf … 「数値や単語など、すでに形式が決まったデータ」を直接変数に読み込むのに便利
- fgets + sscanf/strtok など … 「1行の中身を自分で柔軟に解析したい」ときに便利
という使い分けが一般的です。
たとえば、1行に"id,name,score"のようなCSV風のデータがある場合、
fgetsで1行読み込む- 文字列として
strtokやsscanfで分解する
という流れのほうが、エラー処理や異常行のスキップがやりやすくなります。
fscanfでの数値・文字列読み取り
intやdoubleなど数値型をfscanfで読み取る方法
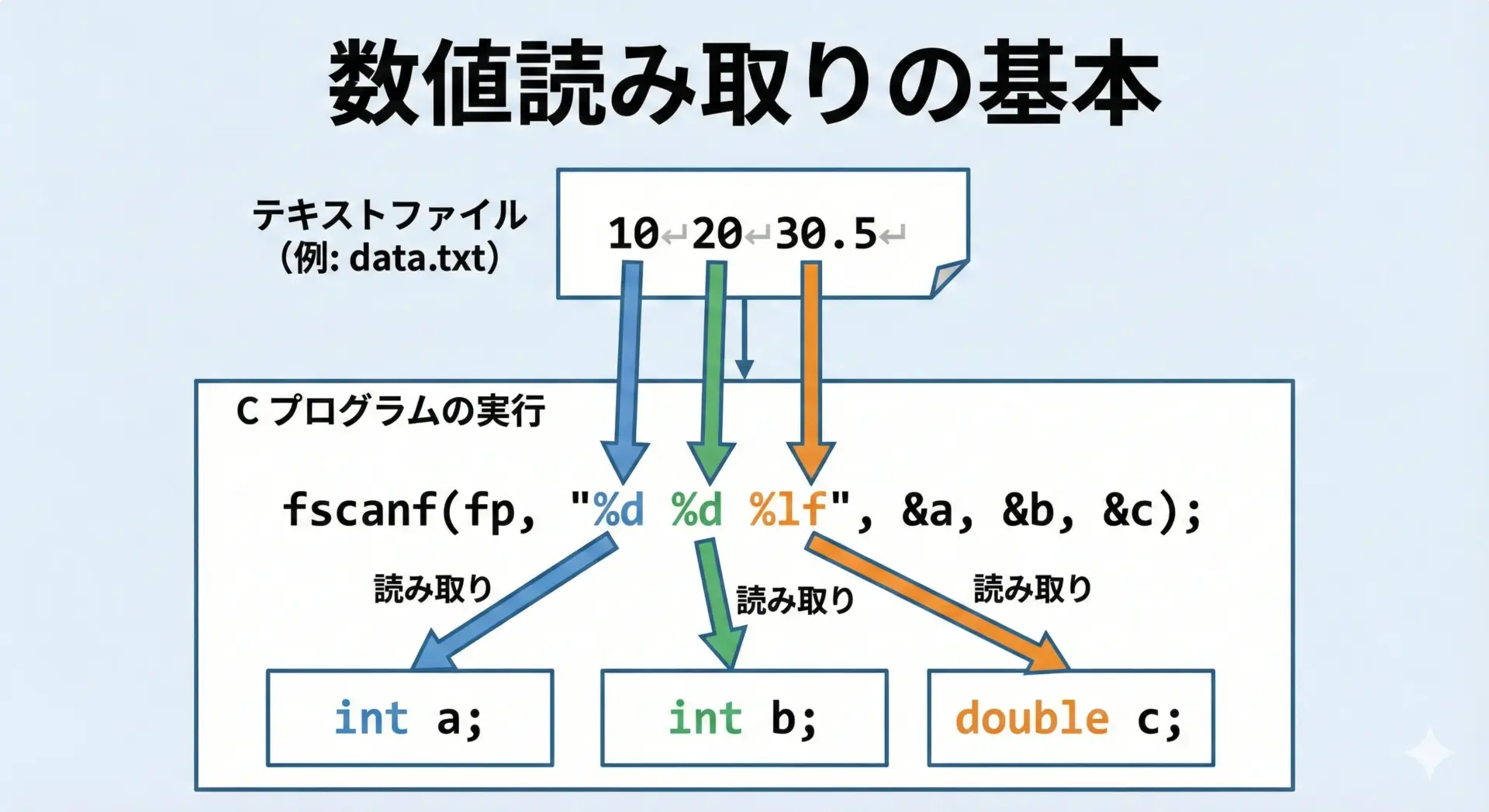
数値を読み取る基本的な例を示します。
#include <stdio.h>
int main(void) {
FILE *fp;
int a, b;
double c;
fp = fopen("numbers.txt", "r");
if (fp == NULL) {
perror("fopen");
return 1;
}
// numbers.txt の内容が「10 20 30.5」のような場合
if (fscanf(fp, "%d %d %lf", &a, &b, &c) == 3) {
printf("a = %d, b = %d, c = %.2f\n", a, b, c);
} else {
printf("数値の読み取りに失敗しました。\n");
}
fclose(fp);
return 0;
}想定されるnumbers.txt:
10 20 30.5a = 10, b = 20, c = 30.50このように、空白(スペースや改行)で区切られた整数や小数は、対応する書式指定子を並べて読み取るのが基本です。
%d・%f・%lfなど数値フォーマットの注意点

数値フォーマットで特に注意が必要なのが%fと%lfです。
printfとscanf系で意味が違うため、混乱しやすくなっています。
| フォーマット | printf側の意味 | scanf/fscanf側の意味 |
|---|---|---|
%f | double を出力 | float を読み取る(ただし引数型はdouble扱い) |
%lf | double を出力(※C99以降は%fと同じ) | double を読み取る |
実際の使い方の例です。
#include <stdio.h>
int main(void) {
FILE *fp;
float f;
double d;
fp = fopen("data.txt", "r");
if (fp == NULL) {
perror("fopen");
return 1;
}
// data.txt: "1.23 4.56"
// 先に float, 次に double として読む例
if (fscanf(fp, "%f %lf", &f, &d) == 2) {
printf("f = %f, d = %f\n", f, d);
} else {
printf("読み取りに失敗しました。\n");
}
fclose(fp);
return 0;
}実際には、Cの「引数の型の自動昇格」により、floatもdoubleとして関数に渡されます。
そのため、%fと%lfはどちらも「doubleを書き込む」という意味で動作しますが、読み取り先の変数の型に合わせて正しい書式を使うのが推奨です。
間違った例として、次のようなものは未定義動作になります。
double d;
fscanf(fp, "%f", &d); // 誤りの例: %f に double* を渡しているコンパイラが警告を出してくれることも多いので、警告は必ずチェックして修正するようにしてください。
文字列(%s)読み取り時のバッファサイズ指定と危険性
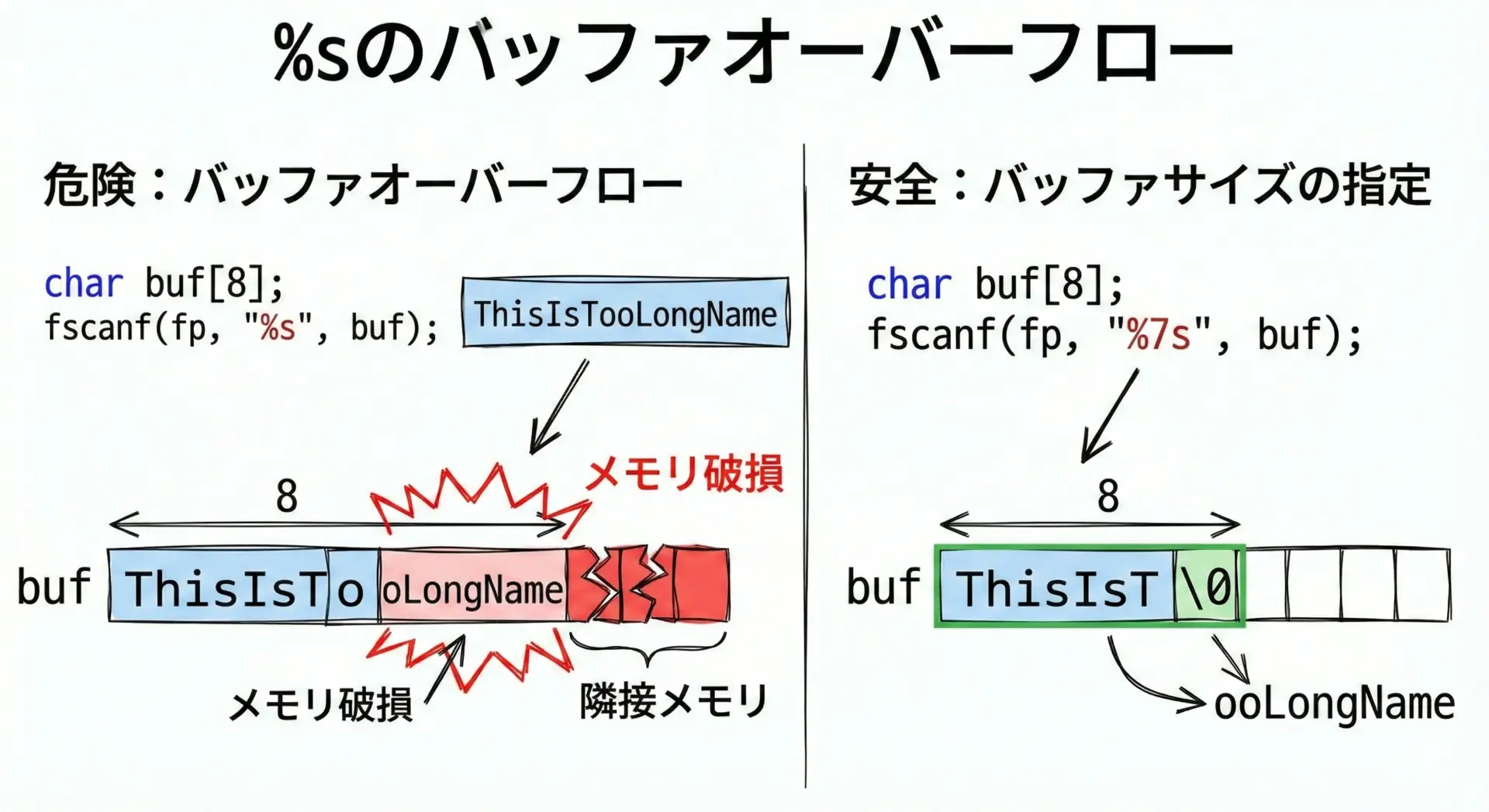
%sで文字列を読み取るときに最も重要なポイントは、必ず読み取り可能な最大文字数を指定することです。
そうしないと、入力が長すぎたときにバッファオーバーフローを起こし、クラッシュやセキュリティホールにつながります。
危険な例:
char name[16];
// 危険: %s だけだと、いくらでも読み込もうとする
fscanf(fp, "%s", name);安全な書き方:
char name[16];
// 最大 15 文字 + 終端'\0' のため "%15s"
if (fscanf(fp, "%15s", name) == 1) {
printf("name = %s\n", name);
}配列サイズ N のときは、%Nsではなく%(N-1)sと指定するのが基本です。
最後の1文字は文字列終端の'\0'用に必ず残す必要があります。
また、%sは先ほど説明したように空白で区切られた1単語しか読まないため、スペースを含む文章を扱う場合には向きません。
その場合はfgetsや%[^\n]のような方法を検討します。
1文字読み取り(%c)で改行を誤読しないためのコツ
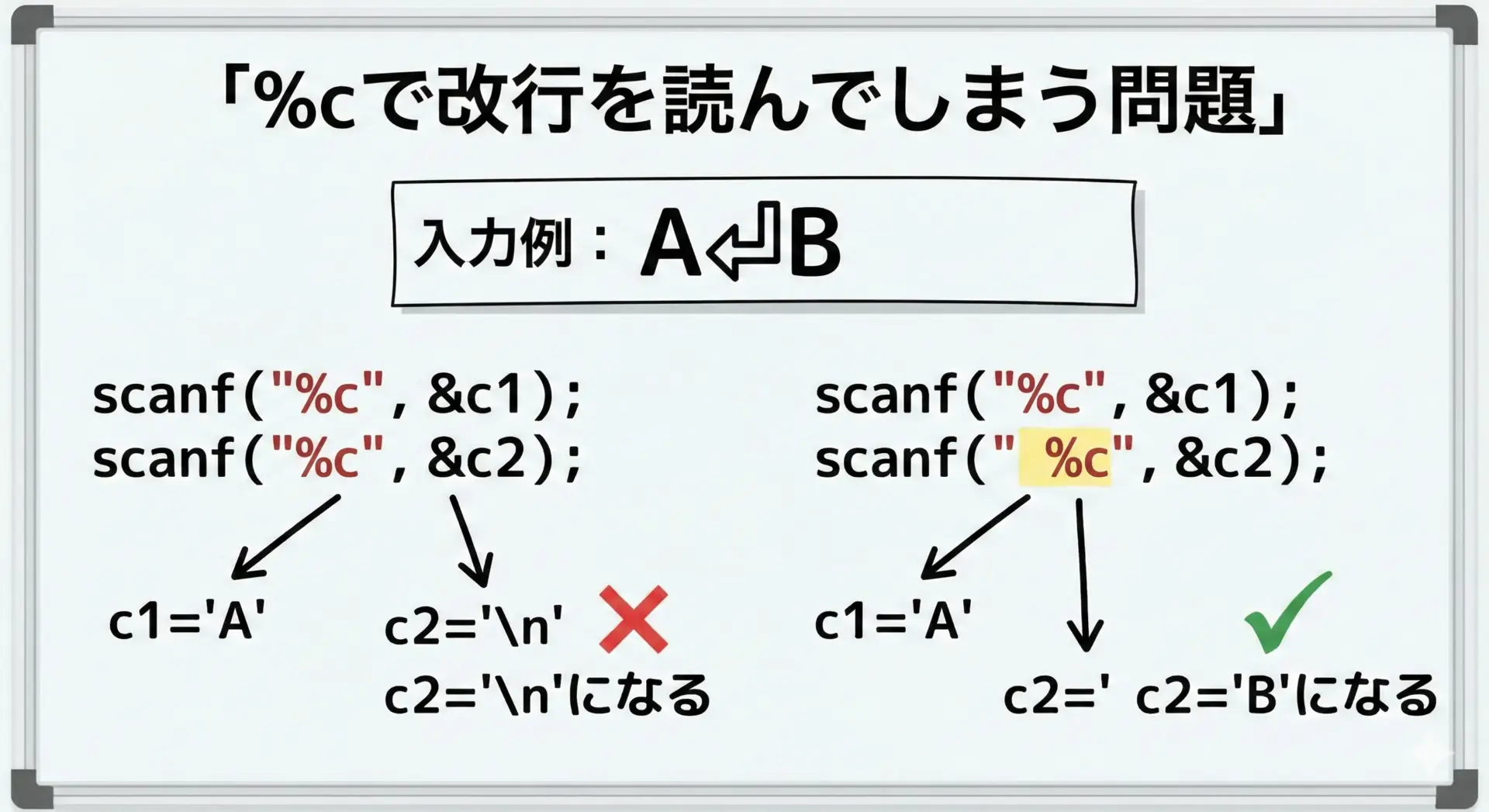
%cは空白文字も含めて1文字をそのまま読むと説明しました。
そのため、直前に%dや%sで行末まで読んだつもりでも、実際には'\n'が残っており、次の%cでその改行を拾ってしまうことがよくあります。
典型的なパターン:
int x;
char c;
fscanf(fp, "%d", &x); // 数値を読む
fscanf(fp, "%c", &c); // ここで改行を読んでしまう可能性が高いこの問題を避ける1つのコツは、フォーマット文字列の%cの前に空白を入れることです。
int x;
char c;
fscanf(fp, "%d", &x);
// " %c" の先頭の空白が、改行やスペースを読み飛ばす役割をする
if (fscanf(fp, " %c", &c) == 1) {
printf("c = %c\n", c);
}フォーマット文字列中の「空白」は、入力側の「0個以上の空白文字」にマッチして読み飛ばすというルールがあるため、残っている改行やスペースを先に処理してから、実際にほしい文字を読み取ることができます。
fscanfの注意点とエラー処理
戻り値(返り値)によるエラー判定とEOF処理
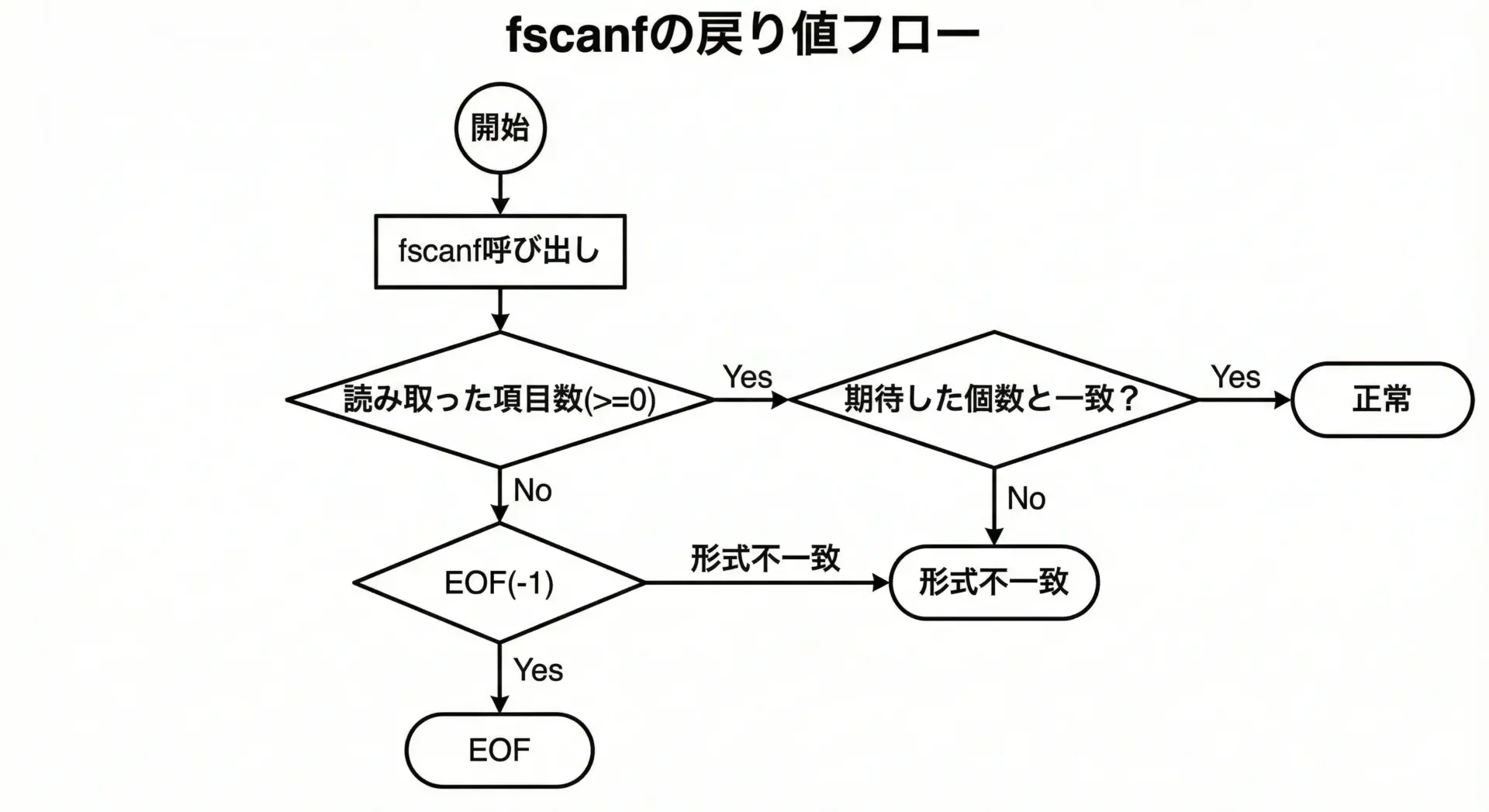
fscanfの戻り値は、エラー処理で最も重要な情報です。
戻り値の意味は次の通りです。
- 0以上 … 実際に成功した入力項目数
EOF(通常は -1) … 入出力エラーか、ファイル終端に到達
期待している入力項目数と一致するかどうかを必ずチェックするのが基本です。
典型的な読み取りループの例:
#include <stdio.h>
int main(void) {
FILE *fp;
int x, y;
fp = fopen("pairs.txt", "r");
if (fp == NULL) {
perror("fopen");
return 1;
}
// 例: pairs.txt に「10 20」「30 40」… のような2整数ペアが並んでいるとする
while (1) {
int ret = fscanf(fp, "%d %d", &x, &y);
if (ret == EOF) {
// EOF (またはエラー) に到達したのでループ終了
break;
} else if (ret != 2) {
// フォーマット不一致などで2つ読めなかったケース
fprintf(stderr, "形式不正な行があります。\n");
// 必要に応じて不正行をスキップしたり終了したりする
break;
}
printf("x=%d, y=%d\n", x, y);
}
fclose(fp);
return 0;
}実行例(入力が以下のとき)
10 20
30 40x=10, y=20
x=30, y=40戻り値を無視すると、EOFやエラーに気づけずに無限ループに陥ることがよくあります。
必ずret == 期待項目数かどうかをチェックする習慣をつけましょう。
読み取りフォーマットと入力形式の不一致によるバグ
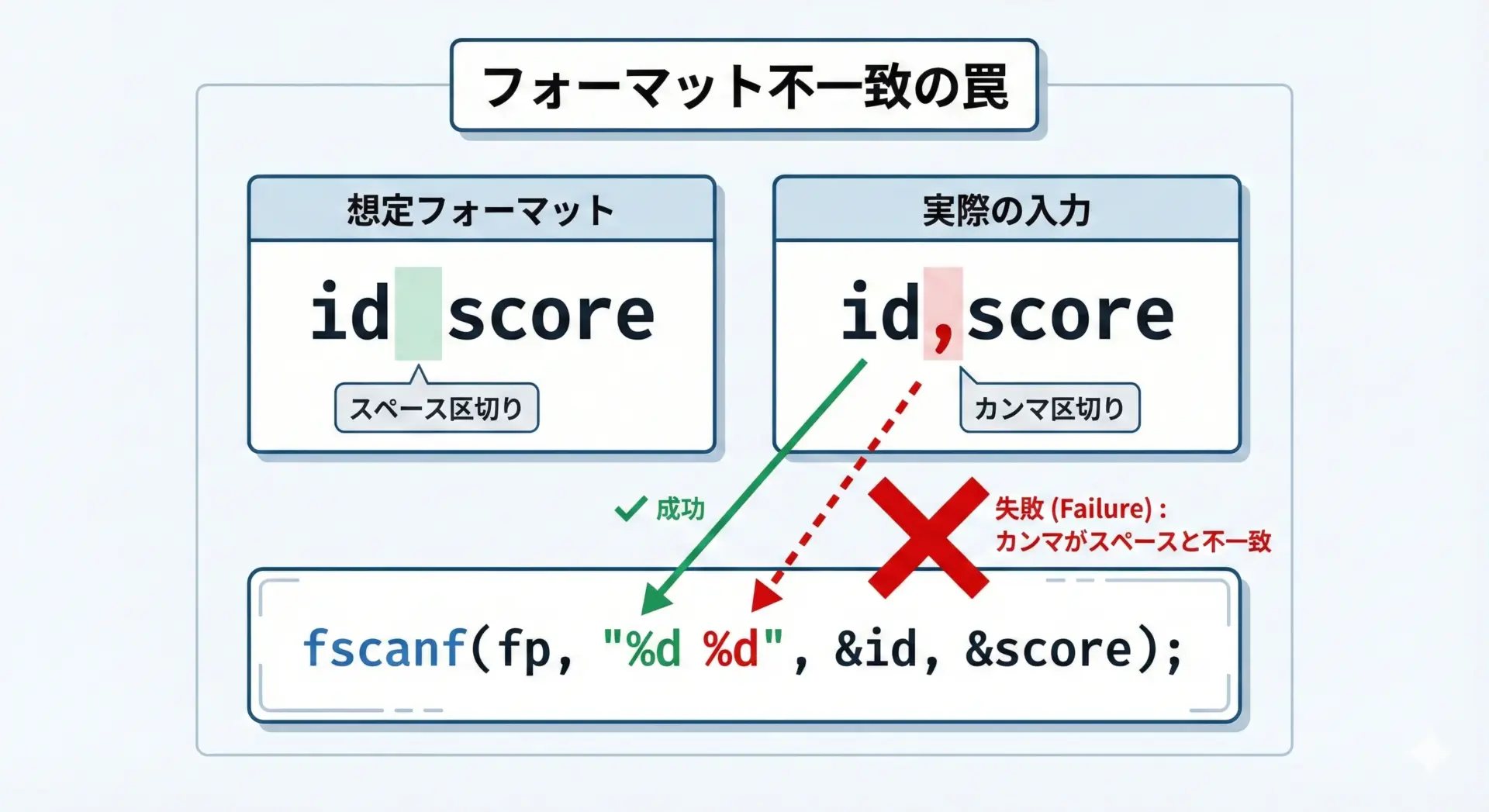
フォーマットと実際の入力が少しでもずれると、以降の読み取りがすべて崩れることがあります。
たとえば、次のようなファイルを想定して、
1 100
2 200次のように読み取っていたとします。
int id, score;
if (fscanf(fp, "%d %d", &id, &score) != 2) {
// エラー
}ところが、実際のファイルが誰かの変更で次のように変わっていたとします。
1,100
2,200このとき、"%d %d"というフォーマットは、1,100を正しく読み取ることができません。
最初の%dで1は読めても、次の%dは','のところで止まってしまい、戻り値は1になります。
フォーマットを変更する際は、入力データの仕様と常にセットで管理し、テストデータで検証することが大切です。
また、%dで整数を読むつもりが、誤って"%f"と書いてしまうなど、コード側のフォーマット指定ミスもよくあるバグの原因です。
コンパイラの警告(特に-Wall -Wextraなど)を有効にしておくと、かなりのケースを検出してくれます。
無限ループを防ぐfscanfとwhileループの書き方
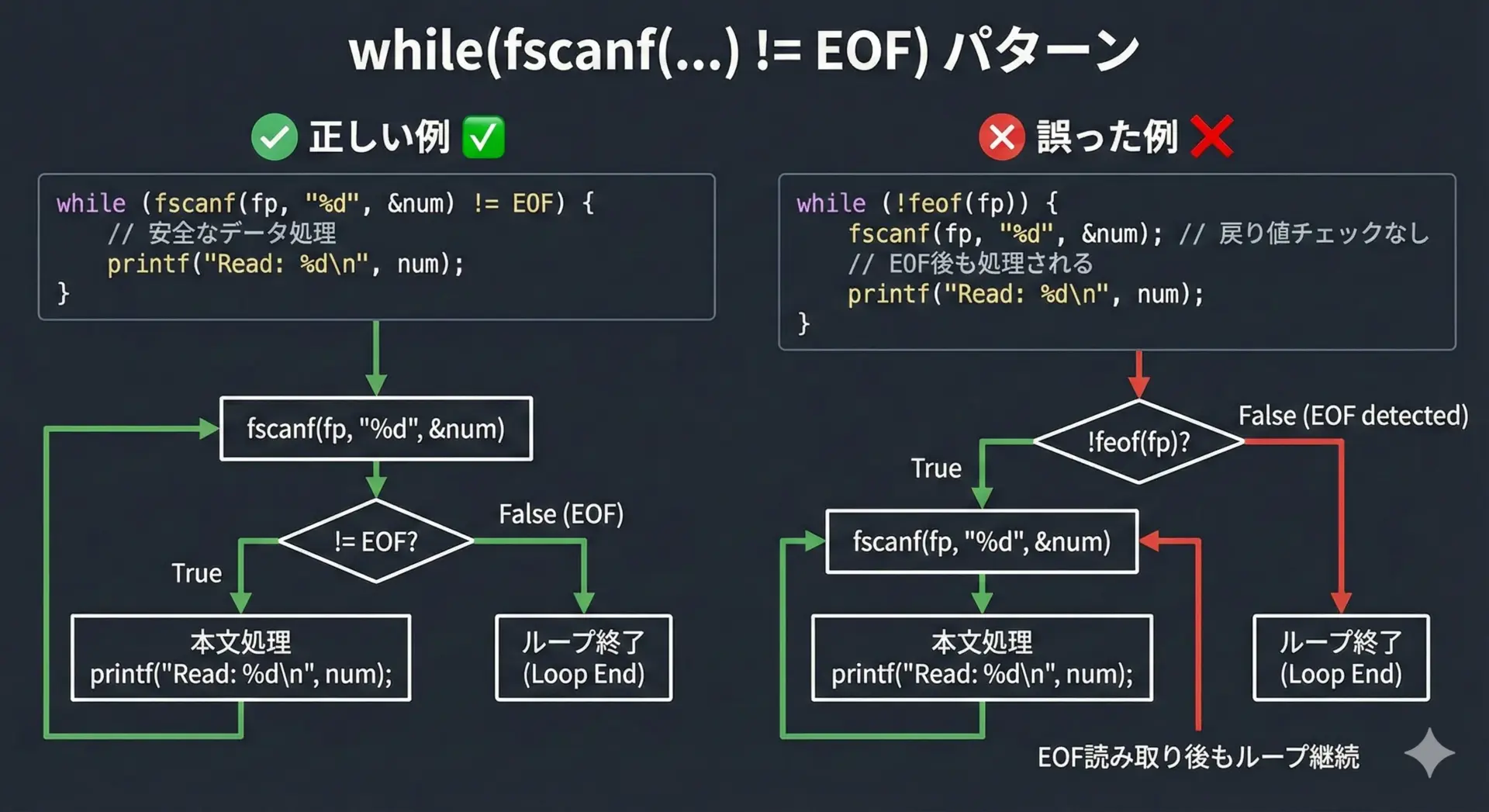
fscanfを使ったループでよくあるバグが、EOF検出を誤って無限ループになるパターンです。
安全な書き方の典型例は次のようになります。
#include <stdio.h>
int main(void) {
FILE *fp;
int value;
fp = fopen("values.txt", "r");
if (fp == NULL) {
perror("fopen");
return 1;
}
// 正しいパターン: while の条件部で読み取りと EOF 判定を同時に行う
while (fscanf(fp, "%d", &value) == 1) {
printf("value = %d\n", value);
}
// ここに来た時点で、EOF かエラー
if (feof(fp)) {
printf("ファイル終端に到達しました。\n");
} else if (ferror(fp)) {
printf("入出力エラーが発生しました。\n");
}
fclose(fp);
return 0;
}入力例values.txt:
10 20 30value = 10
value = 20
value = 30
ファイル終端に到達しました。一方で、ありがちな誤った例は次のようなものです。
// 誤った例
while (!feof(fp)) {
fscanf(fp, "%d", &value);
printf("value = %d\n", value);
}この書き方では、
feof(fp)は「直前の読み取りでEOFを検出した後」にしか真にならない- EOFを超えて読み取りを試みてからでないとループが止まらない
- エラーや形式不一致を考慮していない
といった問題があります。
そのため、EOF判定は必ずfscanfの戻り値か、またはfeof/ferrorと組み合わせて慎重に行う必要があります。
日本語・マルチバイト文字を扱うときの注意点
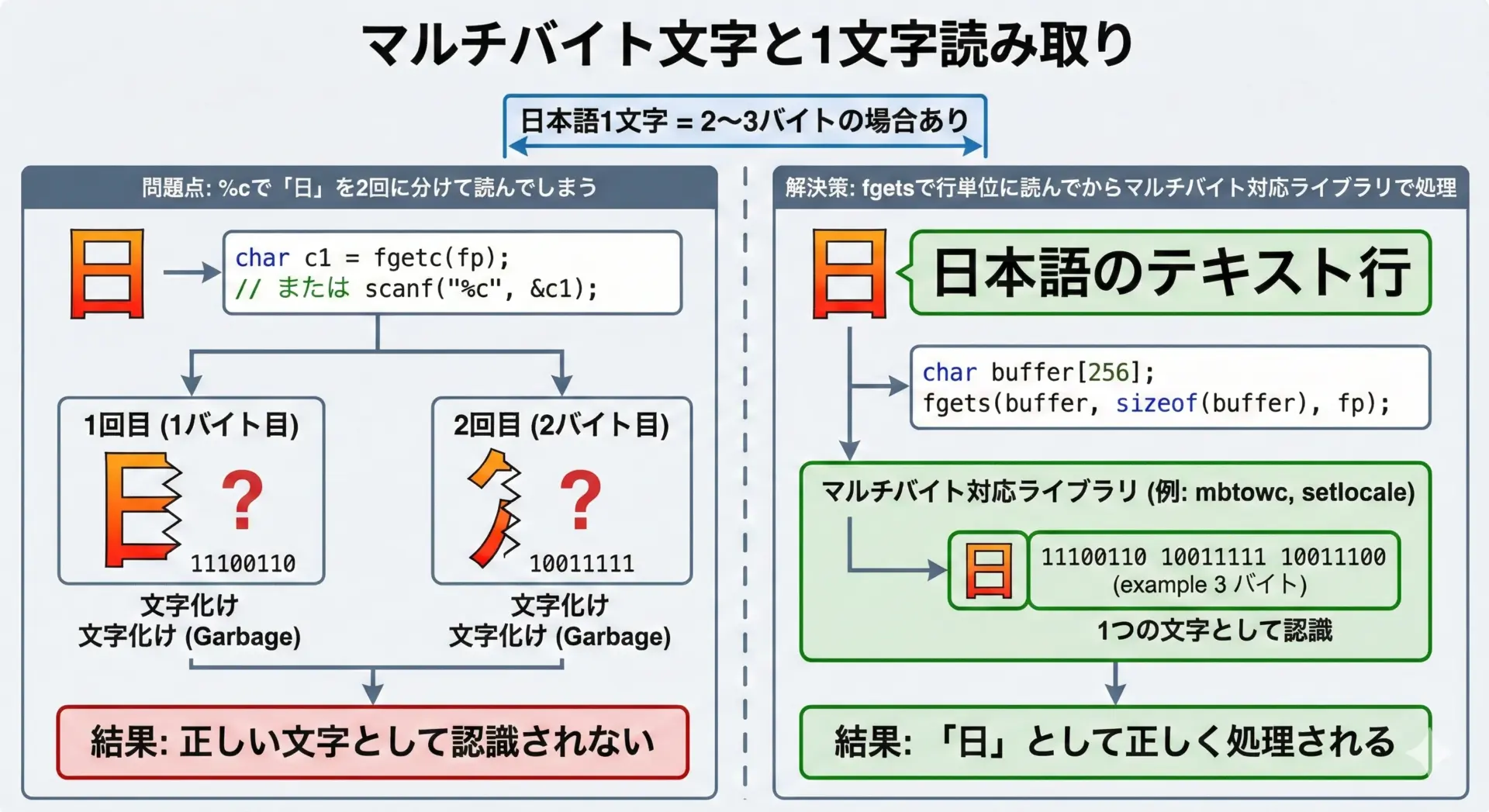
日本語(UTF-8やShift_JISなど)を扱う場合、1文字が1バイトとは限らないことに注意が必要です。
多くの文字コードでは、日本語1文字は2バイト以上の「マルチバイト文字」として表現されます。
%cやfgetcなど、バイト単位の関数は1バイトだけを読み取ります。
そのため、日本語1文字を構成する途中のバイトを切り取ってしまい、文字化けや不正なバイト列になることがあります。
たとえば、UTF-8の"日"は3バイトで表現されますが、fscanf(fp, "%c", &c);を3回実行すると、それぞれ別々のバイトとしてcに入り、正しい文字としては扱えません。
日本語を扱うときは、次のような方針がおすすめです。
- 行単位で
fgetsなどを使って文字列として読み込む - その後、ロケール設定(
setlocale)やマルチバイト文字用関数(mbstowcs、mbrtowcなど)で処理する - 文字数ではなくバイト数ベースで扱っても支障がない用途(ログのそのまま表示など)に限定して扱う
Windows環境では、_wfopenやワイド文字版関数(fwscanfなど)を使う選択肢もありますが、環境依存が強くなるため、まずは「マルチバイト=1バイトではない」と理解することが何より重要です。
まとめ
この記事では、C言語のfscanfの使い方と注意点について、基本構文から空白文字の扱い、数値・文字列読み取り、エラー処理、日本語を含むマルチバイト文字の注意点まで解説しました。
特に「空白をスキップする書式としない書式の違い」「%s使用時のサイズ指定」「戻り値チェックとEOF判定」は、バグやクラッシュを防ぐうえで重要です。
実務ではfscanfとfgetsを状況に応じて使い分けながら、安全で読みやすい入出力コードを書くよう心がけてください。
