C言語で構造体を使いこなすには、メンバへのアクセス方法をしっかり理解しておくことが重要です。
本記事では、.演算子と->演算子に焦点を当てて、構造体とポインタの基本から、typedefや関数との組み合わせまで、丁寧に解説します。
これから構造体を学ぶ方でも、自信を持ってコードを書けるようになることを目標にします。
C言語の構造体とメンバアクセスの基本
構造体(struct)とは何かをシンプルに理解する
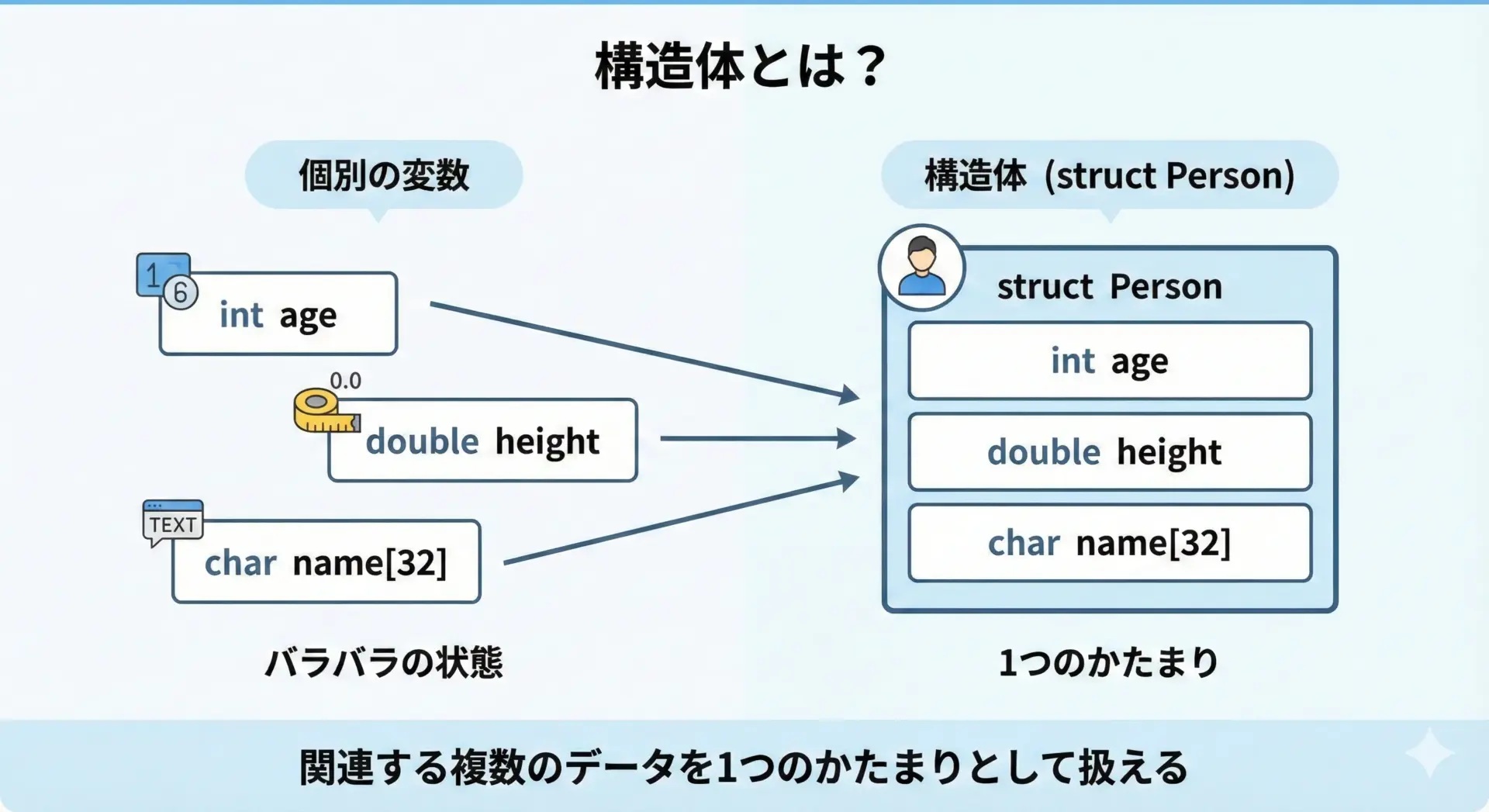
構造体(struct)とは、関連する複数のデータを1つのかたまりとして扱うための仕組みです。
C言語では、intやdoubleのような単純な型だけでなく、これらを組み合わせた独自の型を作成できます。
その代表が構造体です。
例えば、人の情報を扱いたい場合、年齢(age)や身長(height)、名前(name)をそれぞれ別々の変数で持つこともできますが、管理が煩雑になります。
そこで、これらを1つの「人型」としてまとめるのが構造体です。
構造体を使うことで、データのグループ化が明確になり、コードの可読性が上がります。
また、関数への受け渡しや配列での管理もしやすくなります。
構造体メンバとは何か

構造体の中に含まれる個々の変数をメンバ(member)と呼びます。
構造体は「型の名前」と「その中に定義されるメンバの集合」で構成されます。
例えば、次のような定義を考えます。
struct Person {
int age; // 年齢というメンバ
double height; // 身長というメンバ
char name[32]; // 名前というメンバ
};この場合、age、height、nameが構造体Personのメンバです。
メンバはそれぞれ異なる型をとることができ、構造体全体として複合的なデータ型を表現できます。
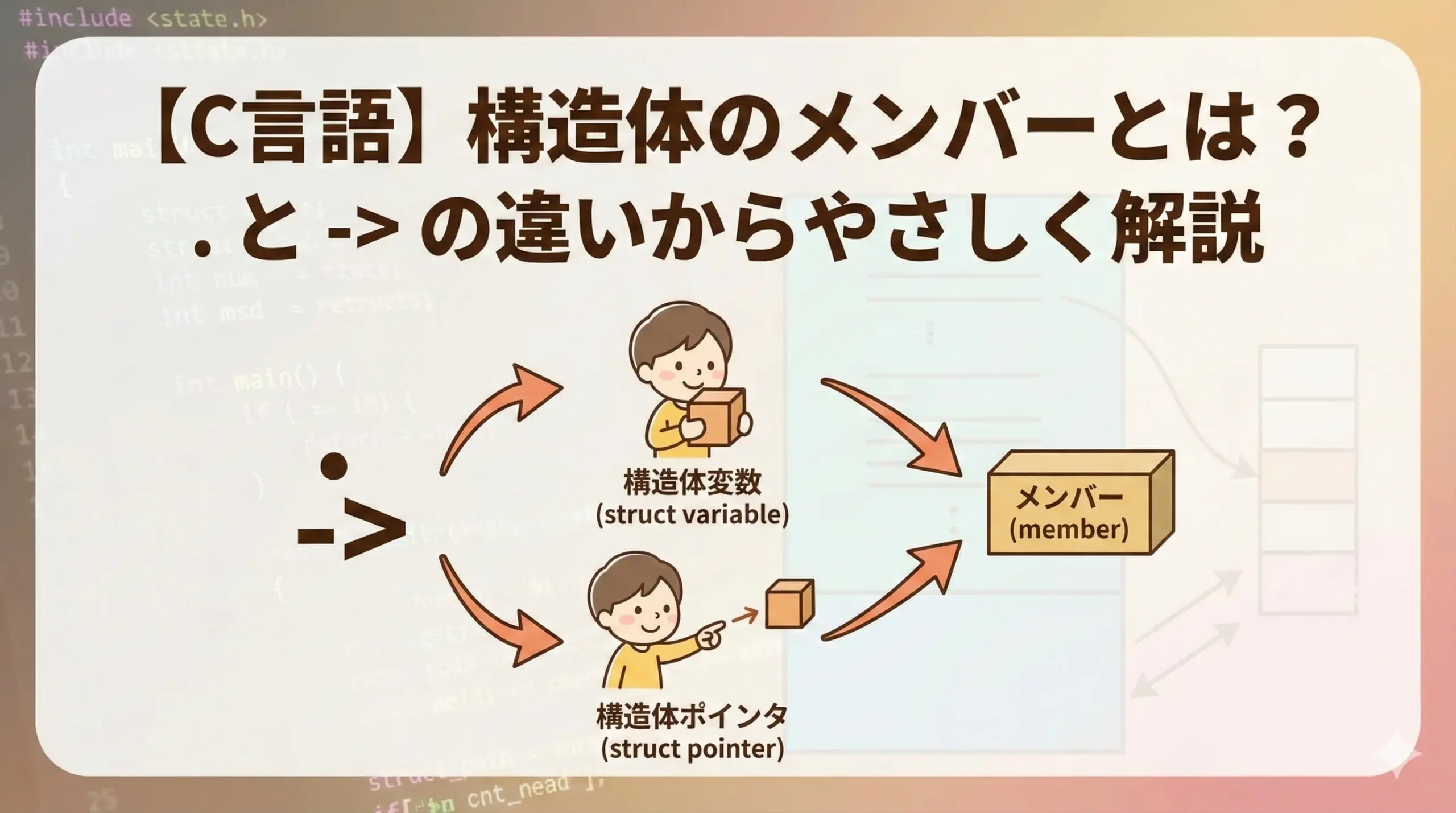
メンバアクセス演算子(. と ->)の概要と違い
構造体のメンバにアクセスするには、.演算子(ドット)と->演算子(アロー)の2種類のメンバアクセス演算子を使います。
基本的な違いは次のとおりです。
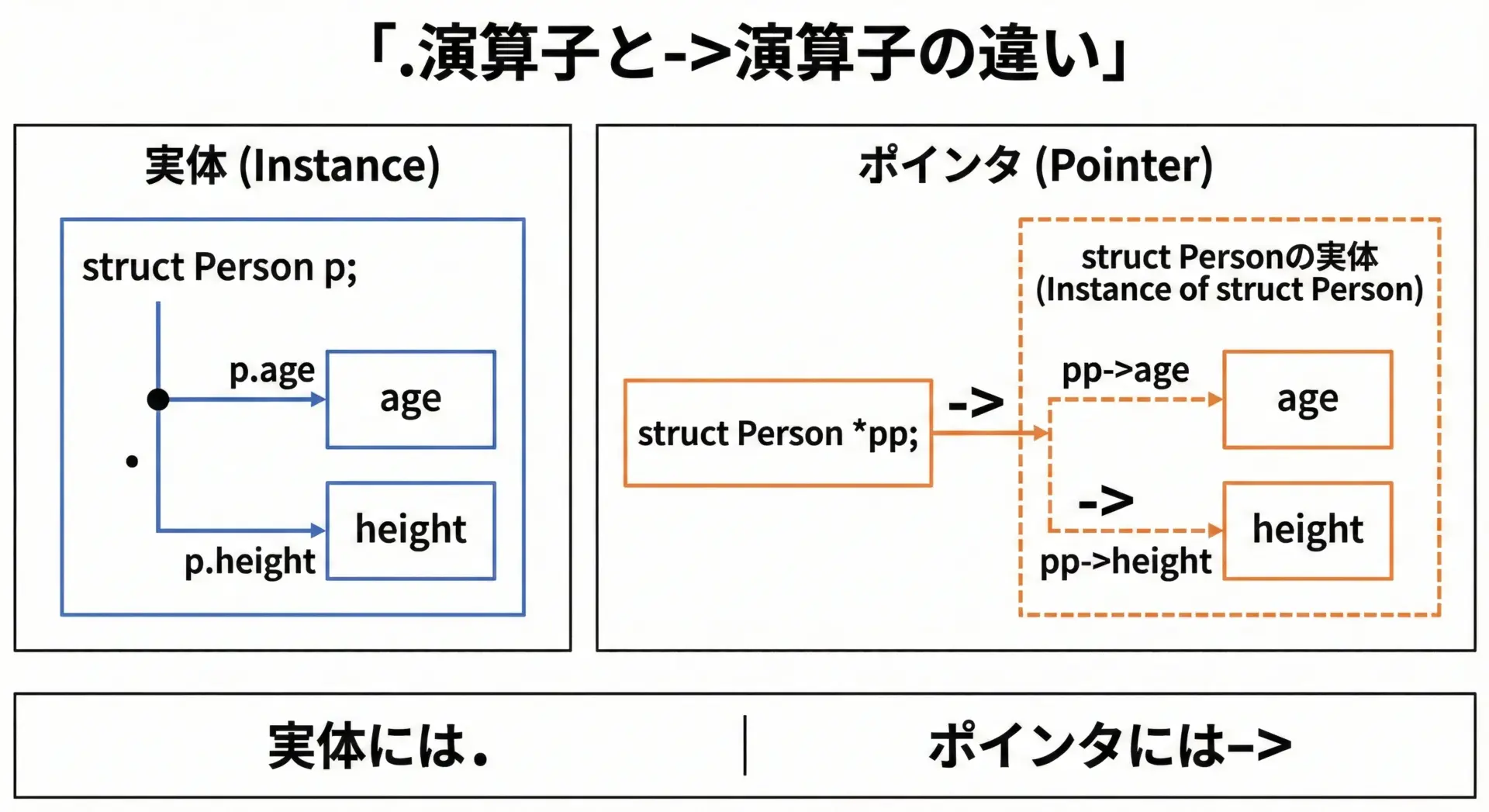
- .演算子: 構造体そのもの(実体)からメンバにアクセスするときに使います
例:p.age - ->演算子: 構造体へのポインタからメンバにアクセスするときに使います
例:pp->age
これが. と -> の最も重要な違いです。
どちらも「構造体の中のメンバに到達する」という意味では同じですが、手元にあるのが「構造体の実体」か「ポインタ」かで使う演算子が変わります。
構造体メンバへのアクセス
構造体の宣言とメンバ定義の書き方
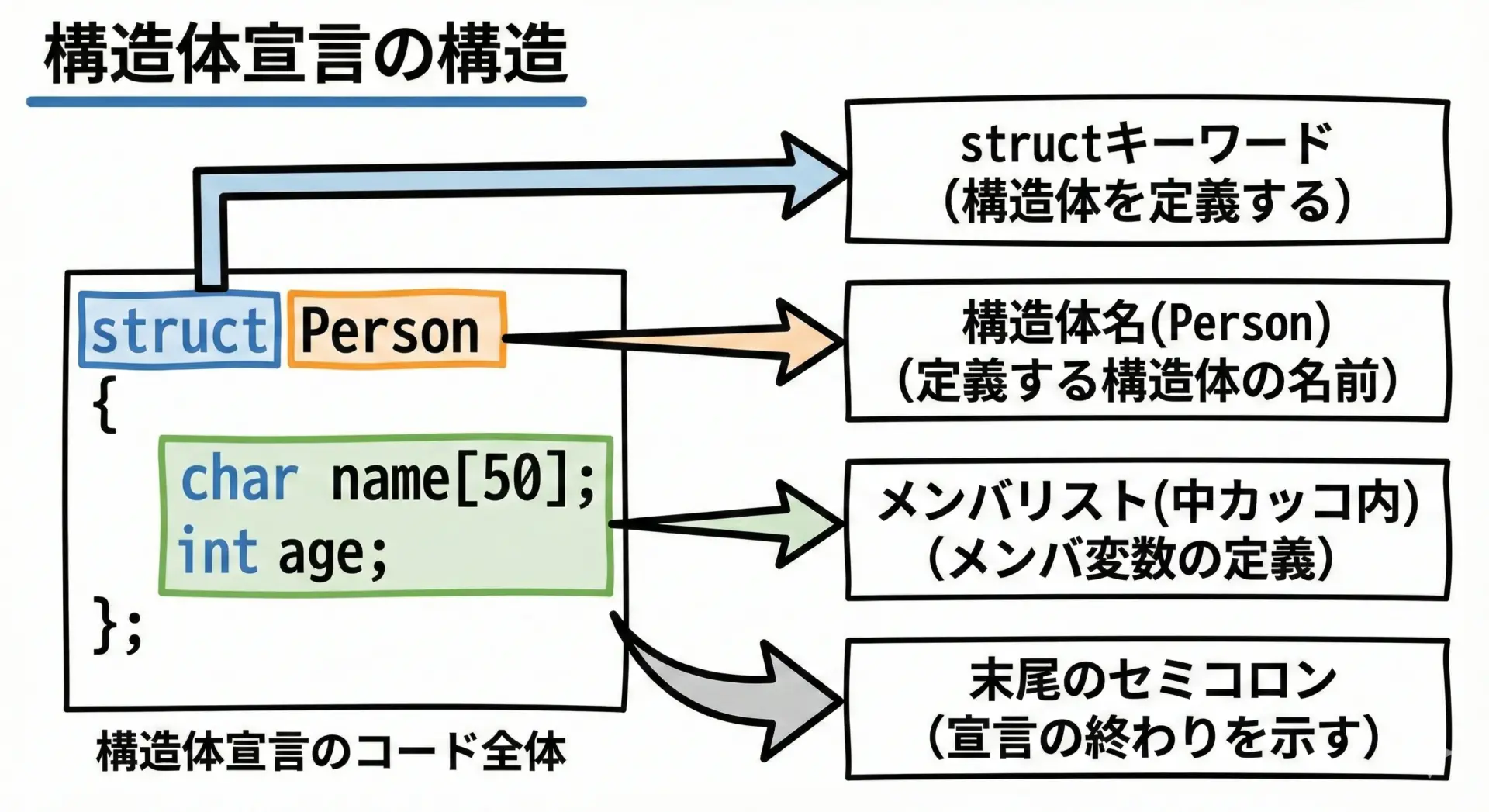
構造体を使うには、まず構造体型の宣言を行います。
基本形は次のようになります。
#include <stdio.h>
// 構造体の宣言(定義)
struct Person {
int age; // 年齢
double height; // 身長
char name[32]; // 名前(最大31文字 + 終端文字)
}; // セミコロンを忘れないようにするポイントを整理すると次のようになります。
struct: 構造体を宣言するキーワードです。Person: 構造体のタグ(名前)です。構造体の型名のように扱われます。{ ... }の中: メンバ変数を列挙します。各メンバは通常の変数宣言と同じ書き方です。- 最後の
;: 構造体宣言の終わりを示す必須のセミコロンです。
この宣言によって、struct Personという新しい「型」がプログラム中で使用可能になります。
構造体変数の定義と初期化方法
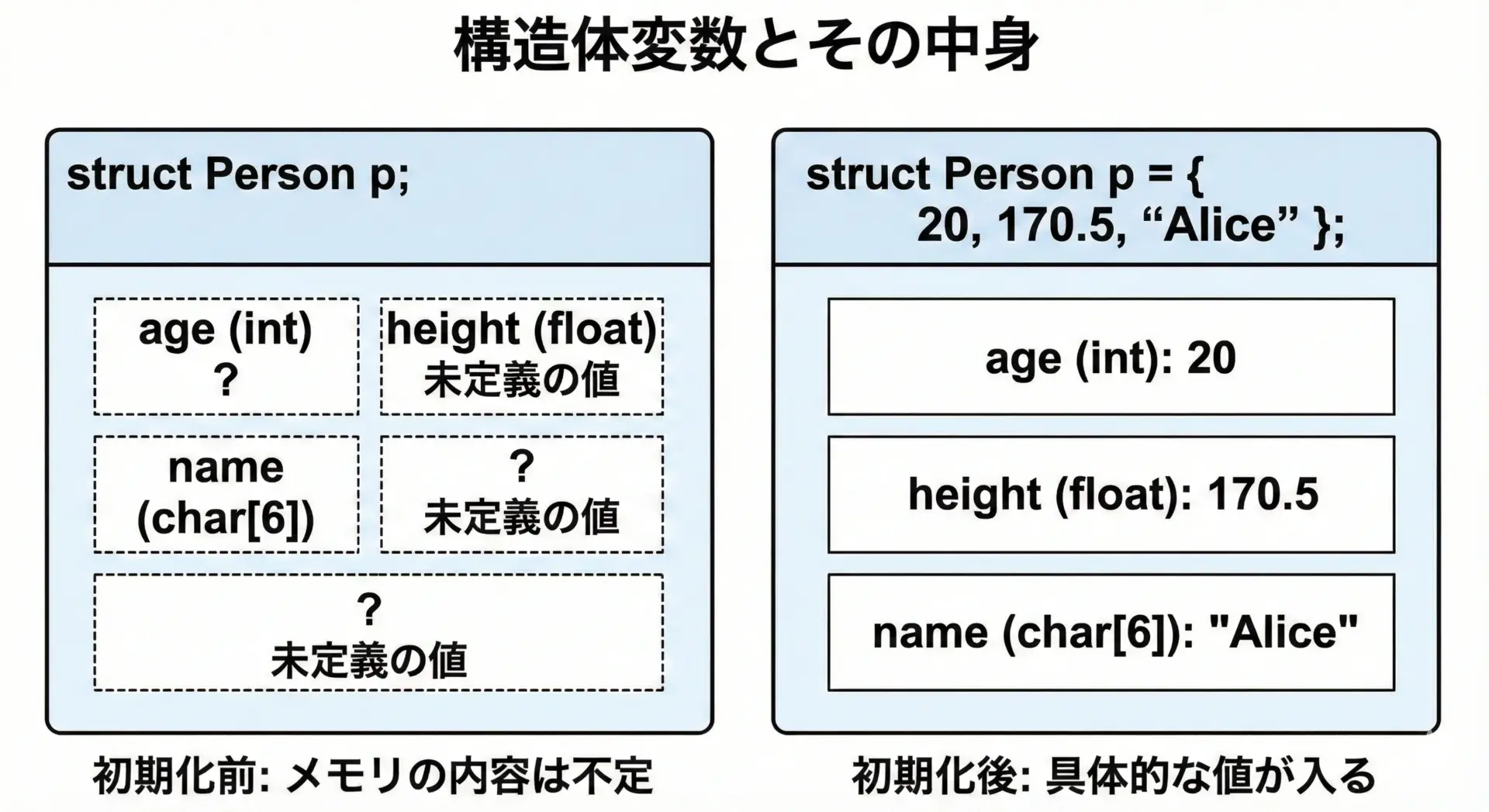
構造体を宣言しただけでは、まだ実際のデータはありません。
構造体型の変数を定義して初めて、データを格納する領域が確保されます。
構造体変数の定義
#include <stdio.h>
struct Person {
int age;
double height;
char name[32];
};
int main(void) {
struct Person p1; // 構造体変数の定義(中身は未初期化)
return 0;
}構造体変数の初期化(配列風の書き方)
構造体は配列に似た初期化記法でまとめて初期化できます。
#include <stdio.h>
struct Person {
int age;
double height;
char name[32];
};
int main(void) {
// 宣言と同時に初期化
struct Person p1 = { 20, 170.5, "Alice" };
// メンバ名を指定した初期化(C99以降)
struct Person p2 = {
.age = 25,
.height = 180.2,
.name = "Bob"
};
printf("p1: %d, %.1f, %s\n", p1.age, p1.height, p1.name);
printf("p2: %d, %.1f, %s\n", p2.age, p2.height, p2.name);
return 0;
}p1: 20, 170.5, Alice
p2: 25, 180.2, Bobメンバ名を指定した初期化は、順序を入れ替えられるので、可読性が高く、メンバが多い構造体で特に便利です。
構造体変数からのメンバアクセス
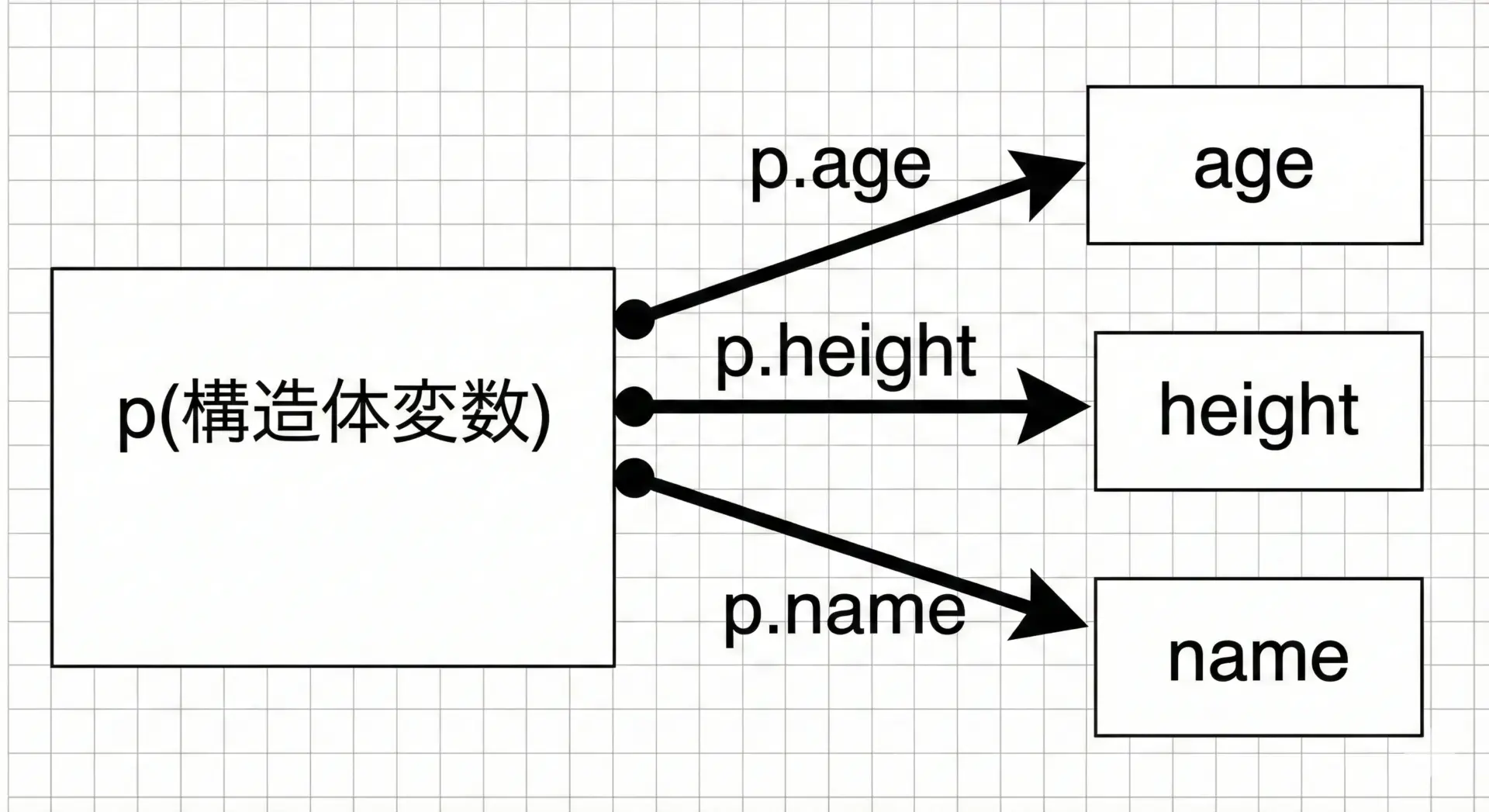
構造体の実体(変数)からメンバにアクセスする場合は.演算子を使います。
#include <stdio.h>
struct Person {
int age;
double height;
char name[32];
};
int main(void) {
struct Person p = { 30, 165.0, "Charlie" };
// 読み取り
printf("名前: %s\n", p.name); // pのnameメンバを参照
printf("年齢: %d\n", p.age); // pのageメンバを参照
printf("身長: %.1f\n", p.height); // pのheightメンバを参照
// 書き込み(更新)
p.age = 31; // ageメンバに代入
p.height = 166.5; // heightメンバに代入
printf("更新後の年齢: %d\n", p.age);
printf("更新後の身長: %.1f\n", p.height);
return 0;
}名前: Charlie
年齢: 30
身長: 165.0
更新後の年齢: 31
更新後の身長: 166.5このように、変数名.メンバ名という形で、メンバを単なる変数のように扱うことができます。
const構造体とメンバアクセスの注意点
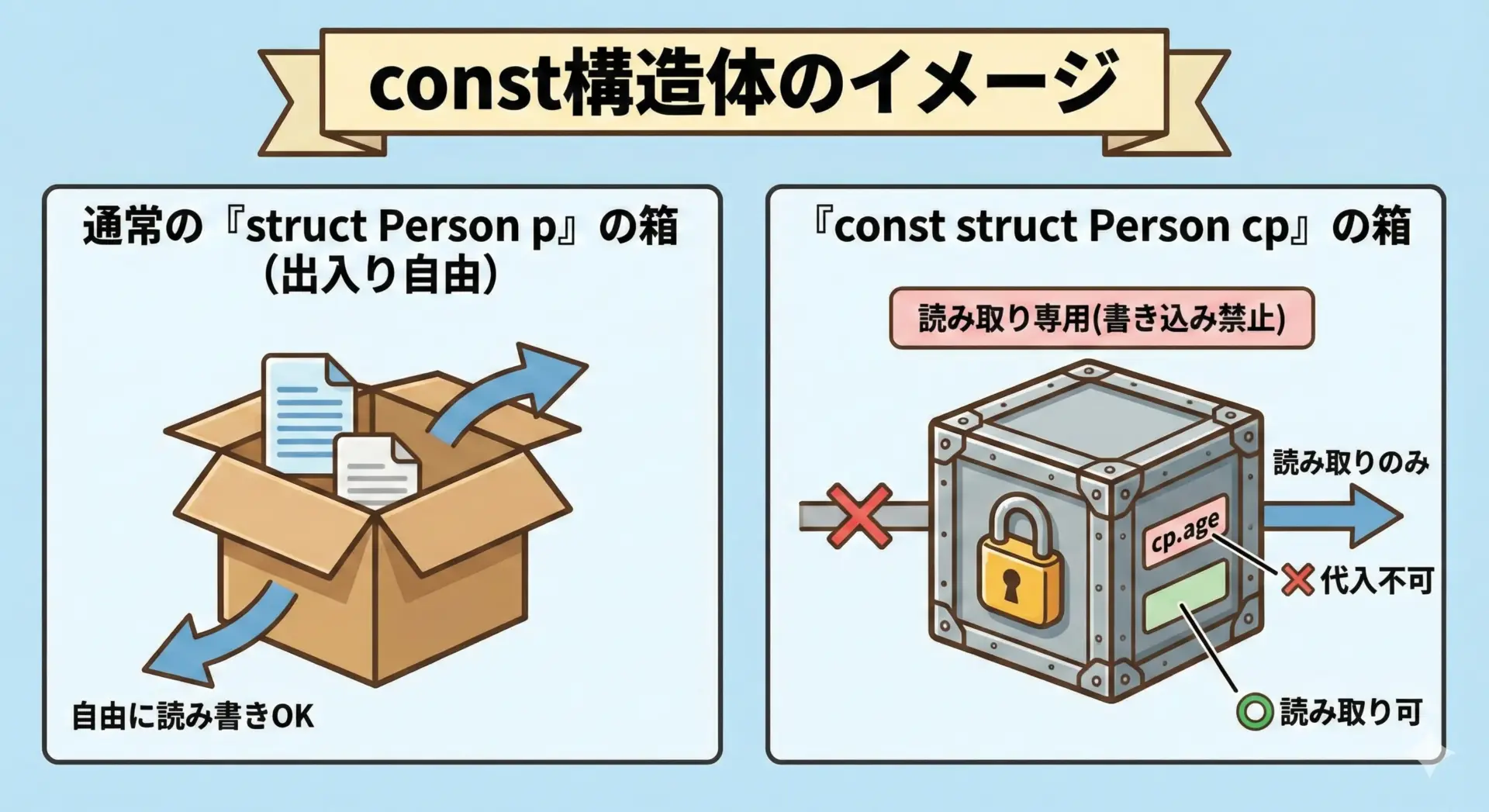
構造体変数をconst修飾すると、そのメンバを変更できなくなります。
これは構造体全体を読み取り専用にするイメージです。
#include <stdio.h>
struct Person {
int age;
double height;
char name[32];
};
int main(void) {
const struct Person cp = { 40, 172.3, "Dave" };
// 読み取りは可能
printf("名前: %s\n", cp.name);
printf("年齢: %d\n", cp.age);
// 書き込みはコンパイルエラーになる
// cp.age = 41; // エラー
// cp.height = 173.0; // エラー
return 0;
}このように、const struct Person cpと宣言すると、cp.ageやcp.heightなど全てのメンバへの代入が禁止されます。
関数に引数として構造体を渡すときに、関数内で中身を書き換えてほしくない場合は、const struct Person pやconst struct Person *pのようにconstを付けると安全です。
構造体ポインタと->演算子
構造体へのポインタとは
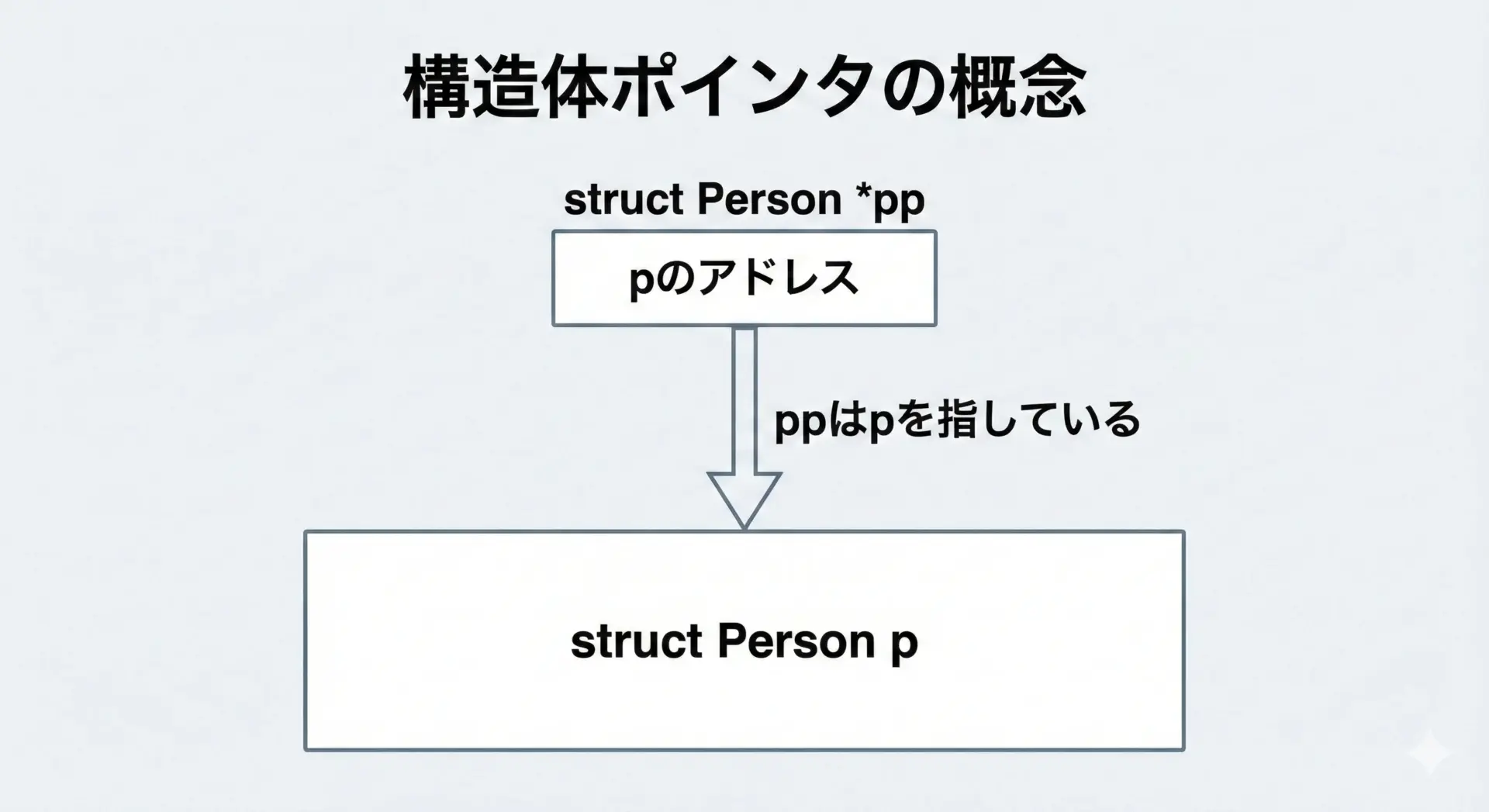
ポインタは「アドレス(場所)を保持する変数」でした。
構造体に対しても、その構造体を指すポインタを扱うことができます。
これが構造体ポインタです。
struct Person *pp;のように宣言すると、ppには「どこかにあるstruct Person型の実体のアドレス」を入れることができます。
構造体ポインタを使う主な目的は次のようなものです。
- 大きな構造体を効率よく関数に渡す(コピーを避ける)
- 動的メモリ確保(
mallocなど)で構造体を扱う - 配列やリストなど、複雑なデータ構造を表現する
構造体ポインタの宣言とアドレスの取得
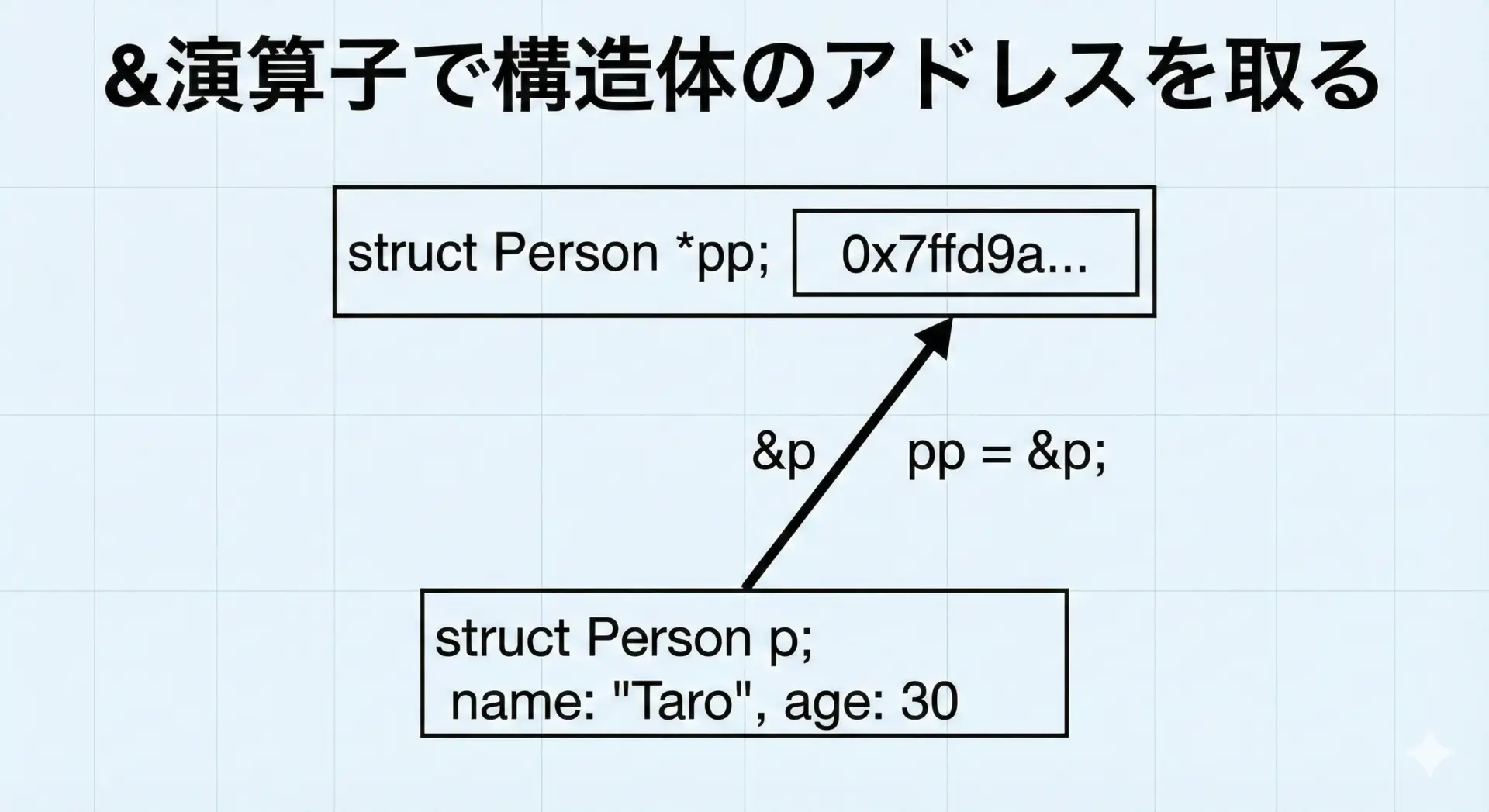
構造体ポインタの宣言と、アドレスの代入例を見てみます。
#include <stdio.h>
struct Person {
int age;
double height;
char name[32];
};
int main(void) {
struct Person p = { 22, 160.0, "Emma" };
// 構造体へのポインタ
struct Person *pp;
// 構造体変数pのアドレスを取得して代入
pp = &p;
printf("pのアドレス: %p\n", (void *)&p);
printf("ppの値(指しているアドレス): %p\n", (void *)pp);
return 0;
}pのアドレス: 0x7ff... (実行環境によって異なる)
ppの値(指しているアドレス): 0x7ff... (pのアドレスと同じ)&pによって、構造体変数pのアドレスが取得でき、それをstruct Person *型のポインタppに代入しています。
アロー演算子(->)によるメンバアクセス
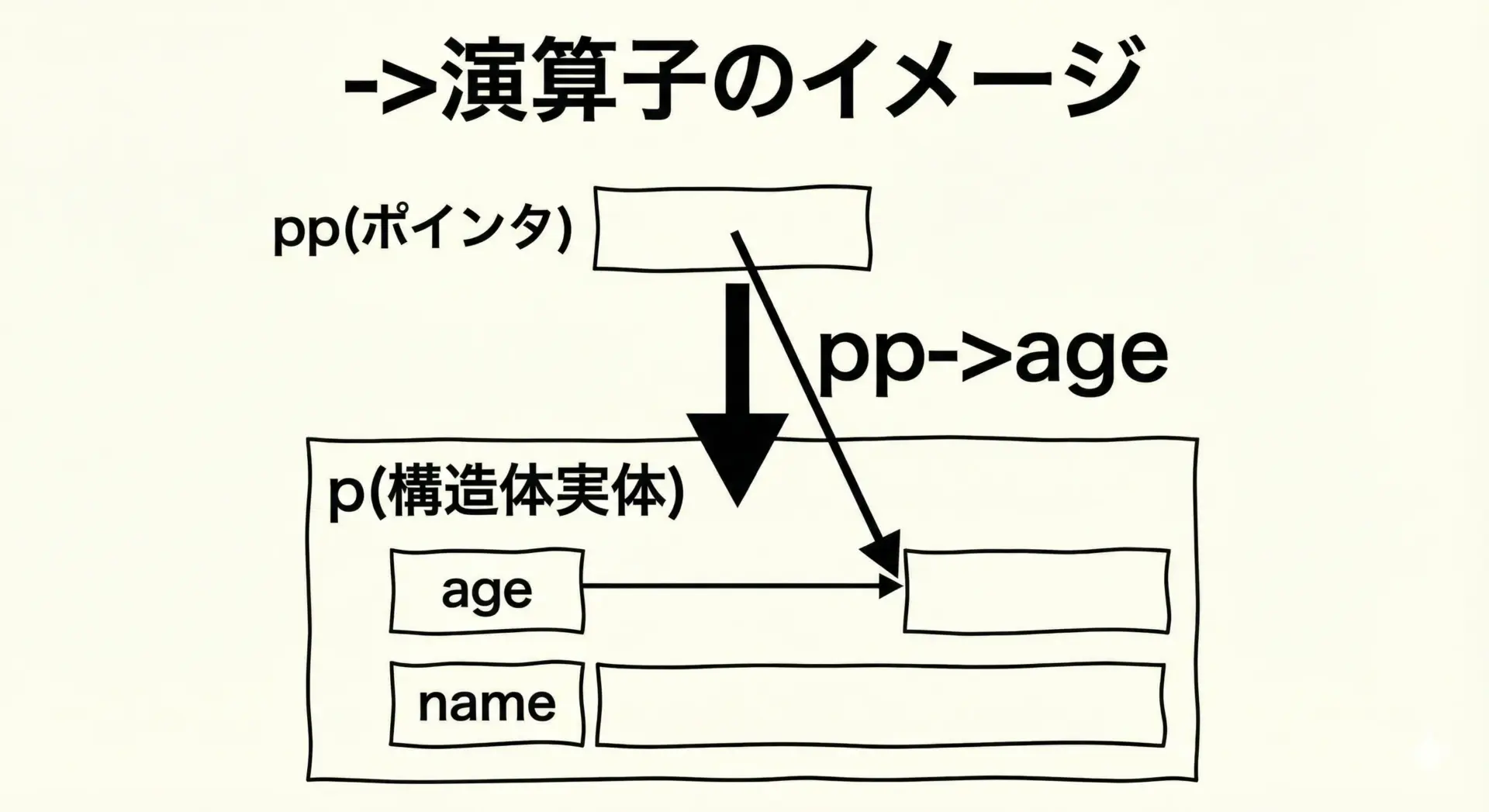
構造体ポインタppを通じてメンバにアクセスする場合、アロー演算子(->)を使います。
#include <stdio.h>
struct Person {
int age;
double height;
char name[32];
};
int main(void) {
struct Person p = { 28, 175.5, "Frank" };
struct Person *pp = &p; // pを指すポインタ
// ポインタを使ったメンバアクセス(読み取り)
printf("名前: %s\n", pp->name); // (*pp).name と同じ
printf("年齢: %d\n", pp->age); // (*pp).age と同じ
printf("身長: %.1f\n", pp->height); // (*pp).height と同じ
// ポインタを使ったメンバの更新
pp->age = 29;
pp->height = 176.0;
printf("更新後の年齢: %d\n", p.age); // p自体も更新されている
printf("更新後の身長: %.1f\n", p.height);
return 0;
}名前: Frank
年齢: 28
身長: 175.5
更新後の年齢: 29
更新後の身長: 176.0->演算子は「ポインタが指す構造体の、そのメンバ」にアクセスするための記法です。
ポインタから直接.は使えないため、pp.ageのような書き方はコンパイルエラーになります。
(*p).member と p->member の違いと等価性
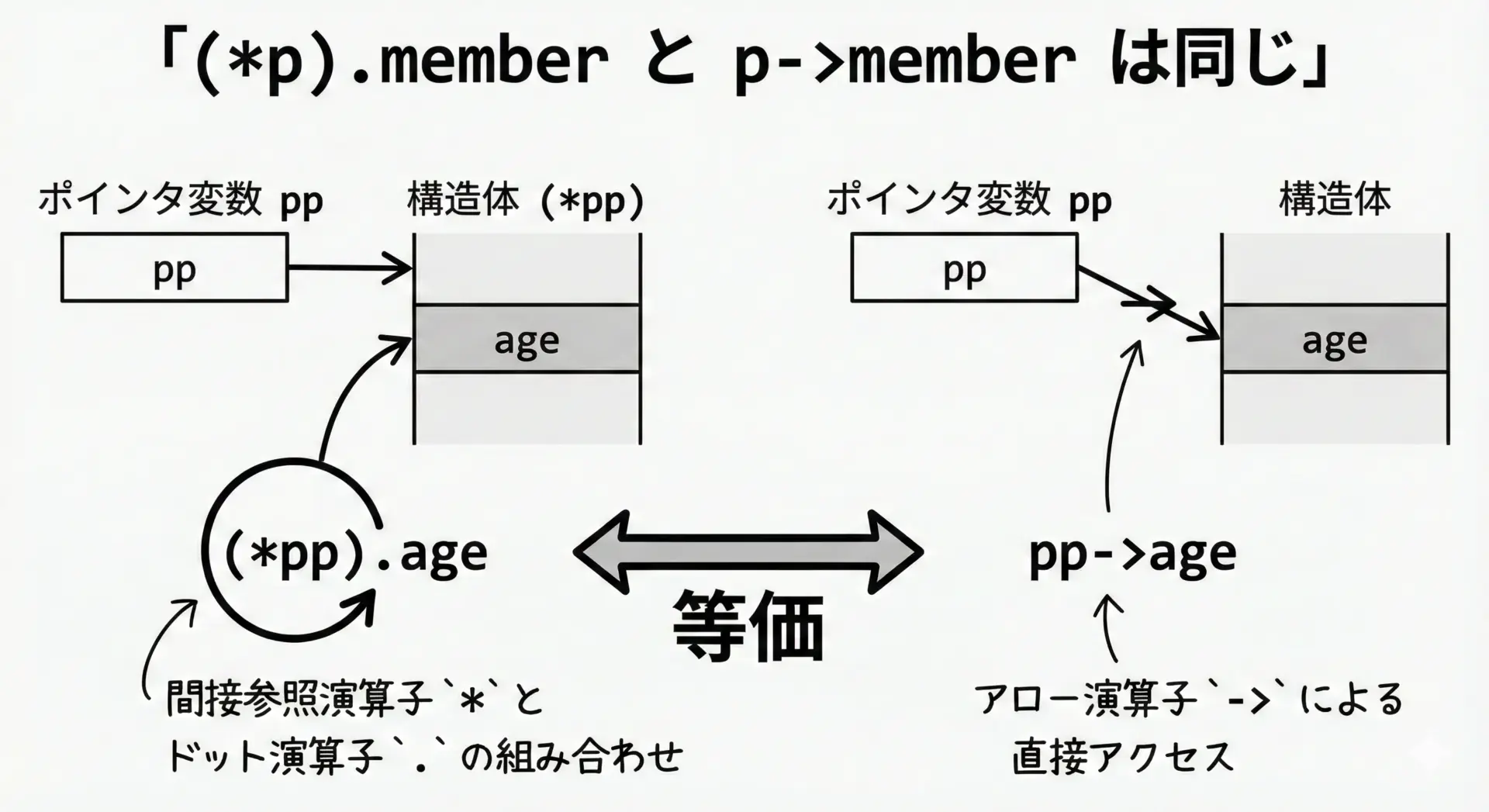
->演算子は実は「糖衣構文(シンタックスシュガー)」です。
次の2つの書き方は完全に同じ意味になります。
(*pp).agepp->age
仕組みを分解すると次のようになります。
*ppで、「ppが指す構造体そのもの」にアクセスします。- その結果(構造体実体)に対して
.ageでメンバを指定します。
#include <stdio.h>
struct Person {
int age;
double height;
};
int main(void) {
struct Person p = { 35, 180.0 };
struct Person *pp = &p;
// 2通りの書き方
printf("pp->age : %d\n", pp->age);
printf("(*pp).age : %d\n", (*pp).age);
// 書き換えも同じ結果
pp->age = 36;
printf("更新後 age(->): %d\n", pp->age);
(*pp).age = 37;
printf("更新後 age(*.): %d\n", (*pp).age);
return 0;
}pp->age : 35
(*pp).age : 35
更新後 age(->): 36
更新後 age(*.): 37実務では圧倒的にpp->ageが使われますが、仕組みを理解するためには(*pp).ageの形も知っておくと役に立ちます。
ポインタ経由の構造体メンバ更新と読み取り
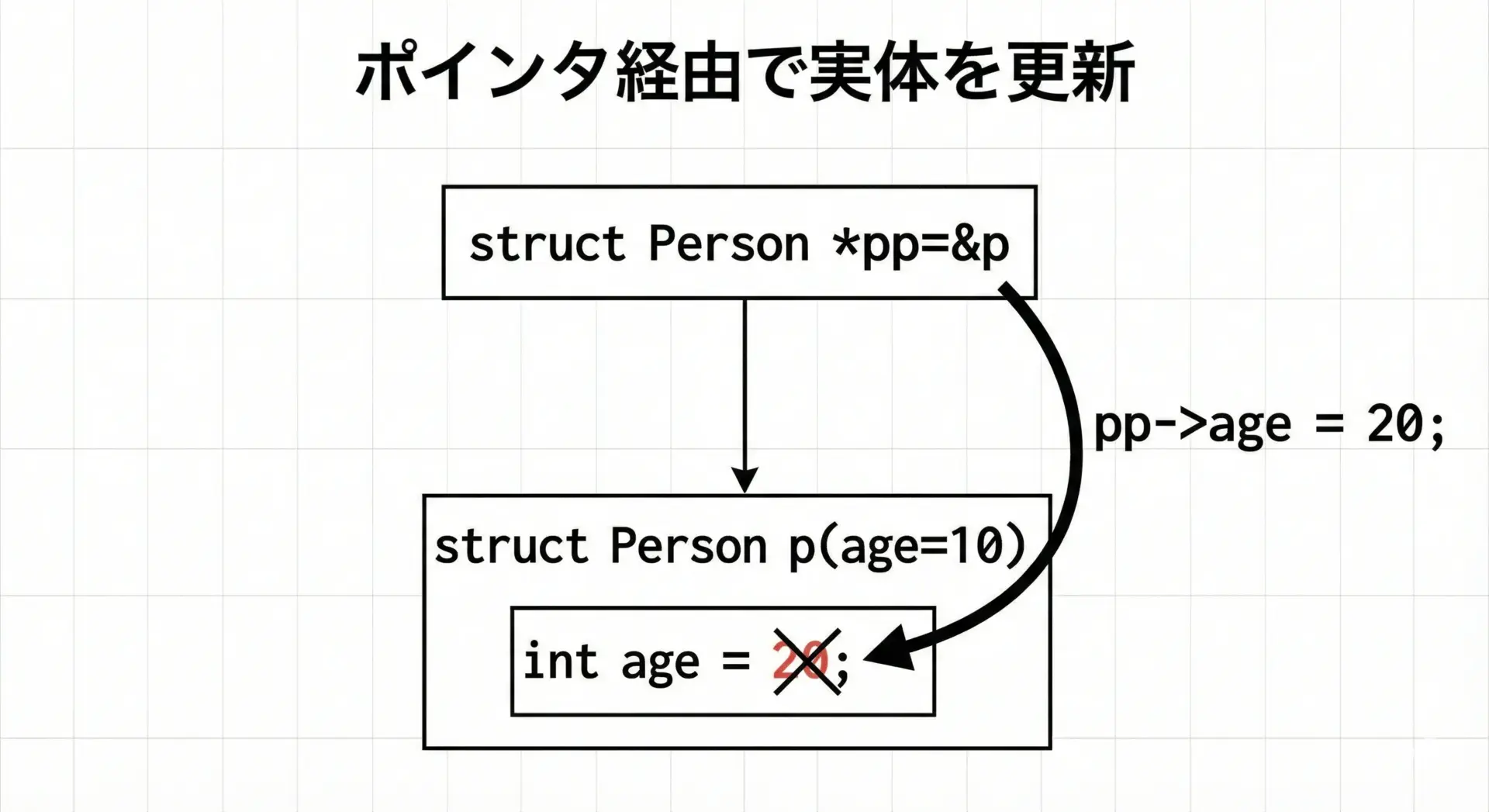
構造体ポインタを通じてメンバを書き換えると、そのポインタが指している元の構造体変数そのものが更新されます。
#include <stdio.h>
struct Counter {
int value;
};
void increment(struct Counter *cp) {
// ポインタ経由でメンバを更新
cp->value = cp->value + 1;
}
int main(void) {
struct Counter c = { 0 };
struct Counter *pc = &c;
printf("初期値: %d\n", c.value);
increment(pc); // ポインタ経由で更新
printf("1回目: %d\n", c.value);
increment(&c); // &cを直接渡しても同じ
printf("2回目: %d\n", c.value);
return 0;
}初期値: 0
1回目: 1
2回目: 2このように、関数に構造体ポインタを渡してメンバを更新させるのは、C言語でよく使われるパターンです。
NULLポインタと->演算子使用時の注意点
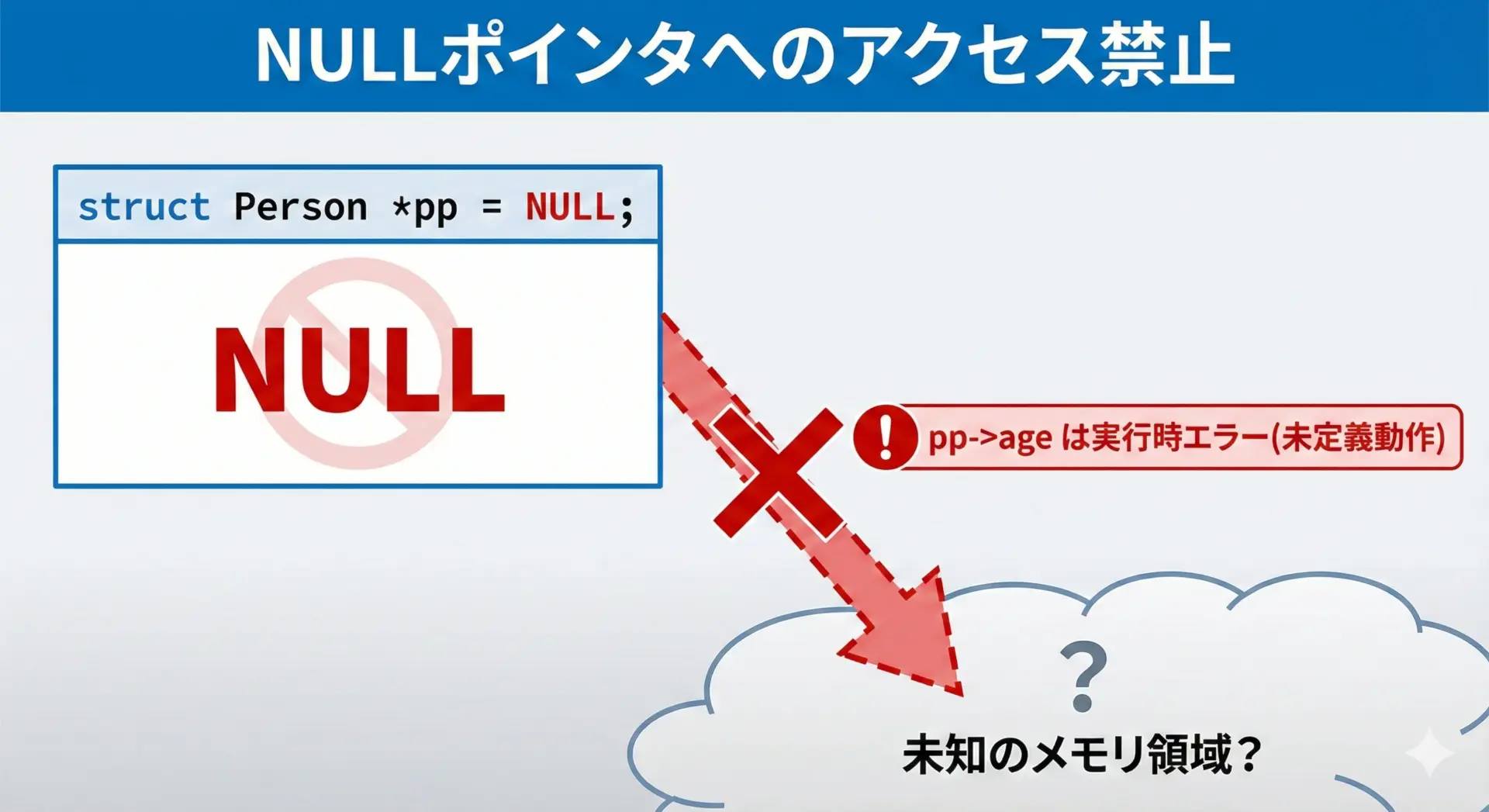
NULLポインタに対して->演算子を使うのは非常に危険で、未定義動作になります。
多くの場合、プログラムがクラッシュします。
#include <stdio.h>
struct Person {
int age;
};
int main(void) {
struct Person *pp = NULL;
// 非常に危険: 実行してはいけない例
// pp->age = 10; // 未定義動作(クラッシュの可能性大)
return 0;
}このため、ポインタを使うときにはNULLチェックを行うことが重要です。
#include <stdio.h>
struct Person {
int age;
};
void set_age(struct Person *p, int age) {
if (p == NULL) {
// 防御的プログラミング
printf("エラー: NULLポインタです\n");
return;
}
p->age = age;
}
int main(void) {
struct Person person = { 0 };
struct Person *pp = &person;
struct Person *np = NULL;
set_age(pp, 20); // 正常
printf("person.age = %d\n", person.age);
set_age(np, 30); // NULLポインタ。エラー処理が働く
return 0;
}person.age = 20
エラー: NULLポインタです「->を使う前にNULLチェック」は、構造体ポインタを扱う上での重要な習慣です。
構造体とtypedef・応用的な使い方
typedefによる構造体型エイリアスとメンバアクセス
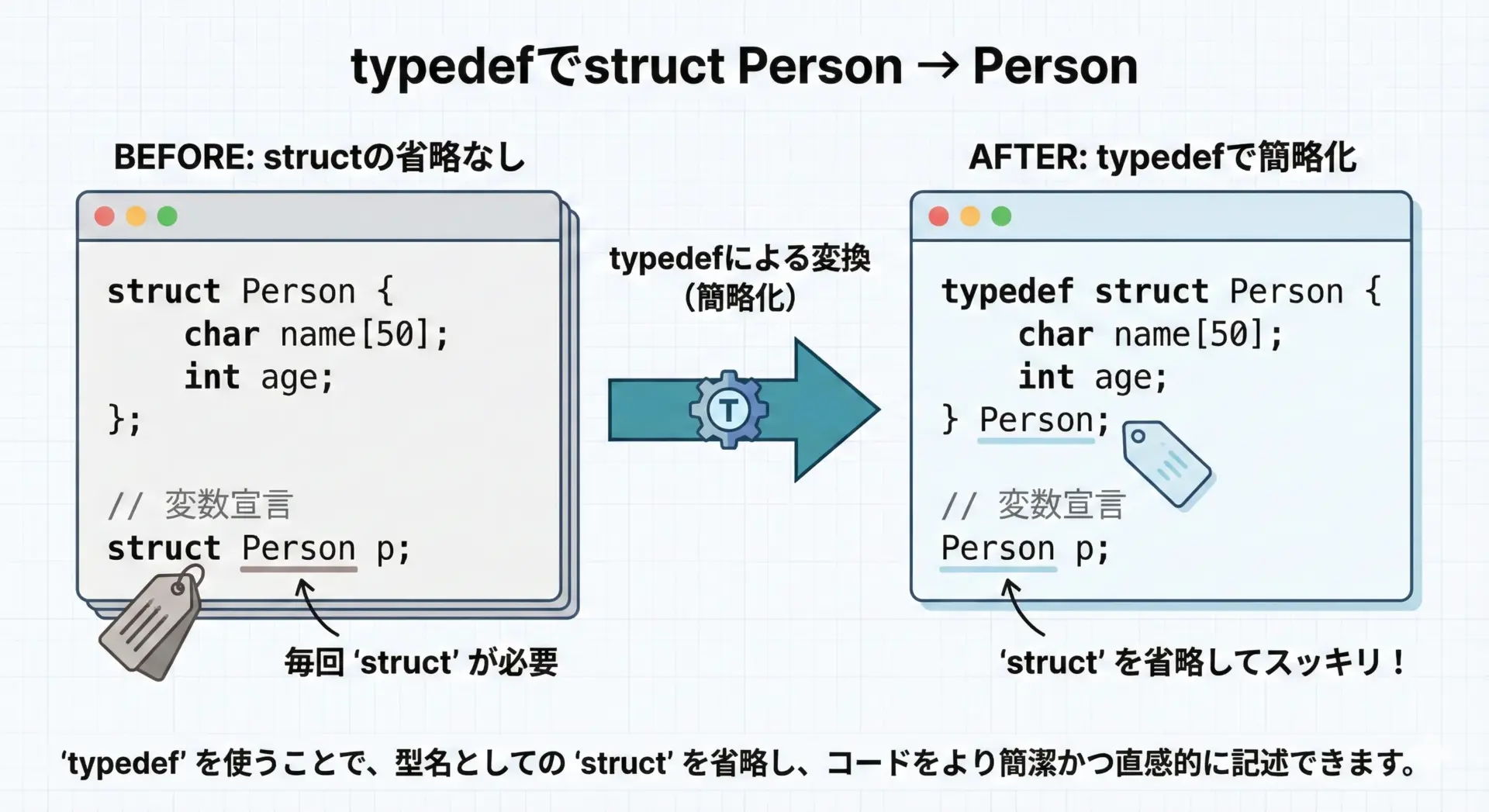
C言語では、typedefを使って構造体の型名に別名(エイリアス)を付けることができます。
これにより、毎回structと書かなくても構造体変数を宣言できるようになります。
#include <stdio.h>
// struct Person に Person という別名を付ける
typedef struct Person {
int age;
double height;
char name[32];
} Person;
int main(void) {
// typedefを使ったので、structを省略できる
Person p = { 18, 155.2, "Grace" };
printf("名前: %s\n", p.name);
printf("年齢: %d\n", p.age);
return 0;
}名前: Grace
年齢: 18メンバアクセス自体は. や -> の使い方が全く同じで、単に型名がPersonになっただけです。
さらに、よくある別の書き方として、タグ名を省略する方法もあります。
typedef struct {
int x;
int y;
} Point; // structのタグ名なしでPointだけを使うこの場合、struct付きの名前(例えばstruct Point)は存在せず、Pointだけが型名として使われます。
構造体配列とポインタによるメンバアクセス
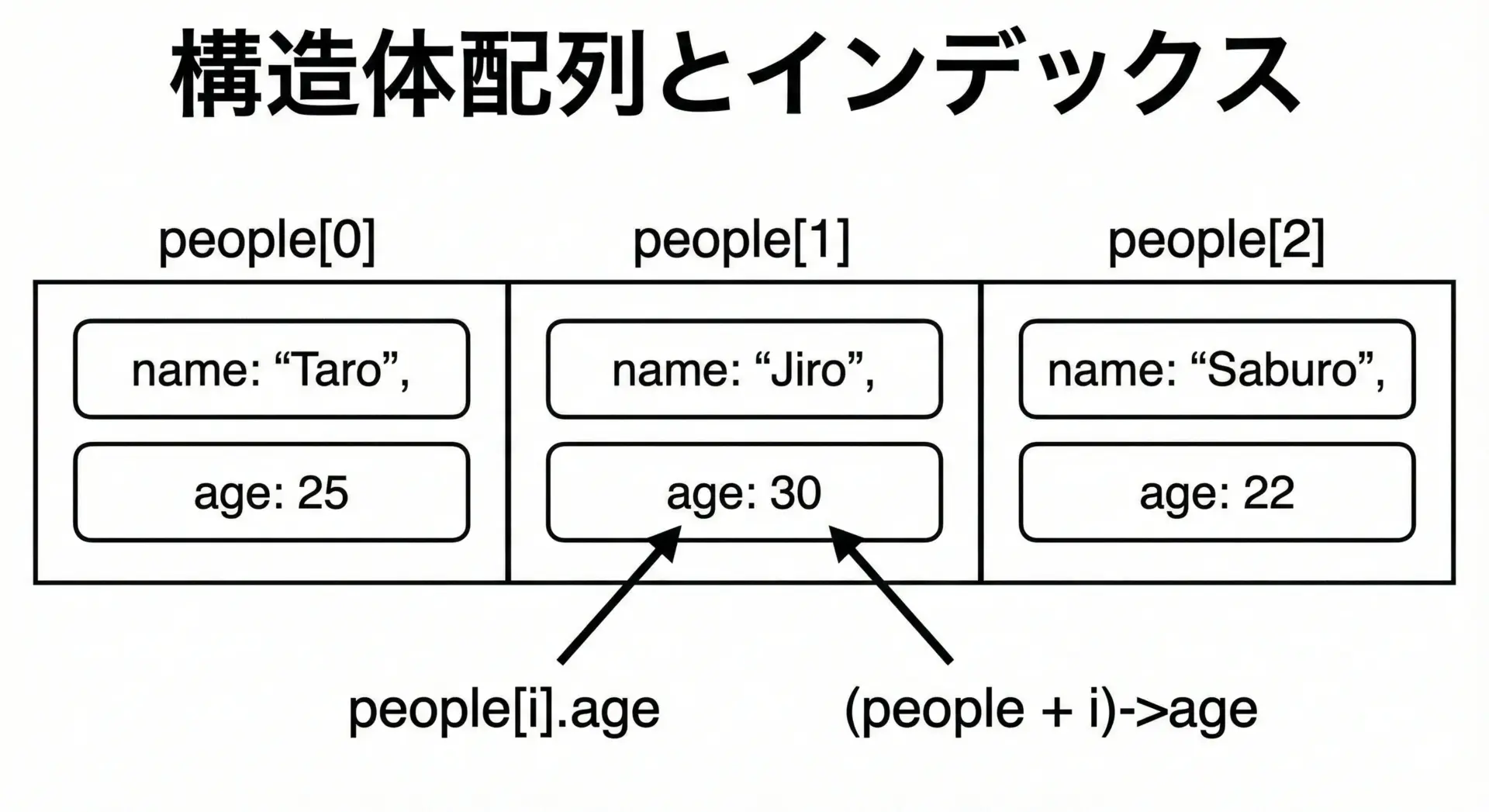
構造体を配列にすると、同じ種類のデータを一覧で扱えるようになります。
#include <stdio.h>
typedef struct {
int id;
char name[32];
} User;
int main(void) {
// 構造体の配列
User users[3] = {
{ 1, "Alice" },
{ 2, "Bob" },
{ 3, "Carol" }
};
// 配列インデックスと.演算子
for (int i = 0; i < 3; i++) {
printf("users[%d]: id=%d, name=%s\n",
i, users[i].id, users[i].name);
}
return 0;
}users[0]: id=1, name=Alice
users[1]: id=2, name=Bob
users[2]: id=3, name=Carol構造体配列の先頭アドレスは、構造体ポインタとしても扱えます。
#include <stdio.h>
typedef struct {
int id;
char name[32];
} User;
int main(void) {
User users[2] = {
{ 10, "Foo" },
{ 20, "Bar" }
};
// 配列先頭を指すポインタ
User *p = users; // = &users[0] と同じ
// p[0] と p[1] も使える
printf("p[0].id = %d, p[0].name = %s\n", p[0].id, p[0].name);
printf("p[1].id = %d, p[1].name = %s\n", p[1].id, p[1].name);
// ポインタ演算 + -> でもアクセス可能
printf("(p+1)->id = %d\n", (p + 1)->id);
printf("(p+1)->name = %s\n", (p + 1)->name);
return 0;
}p[0].id = 10, p[0].name = Foo
p[1].id = 20, p[1].name = Bar
(p+1)->id = 20
(p+1)->name = Bar配列 × 構造体 × ポインタは実務で頻出の組み合わせです。
users[i].memberと(users + i)->memberは等価であることも覚えておくと、ポインタ計算を理解しやすくなります。
構造体を関数に渡す
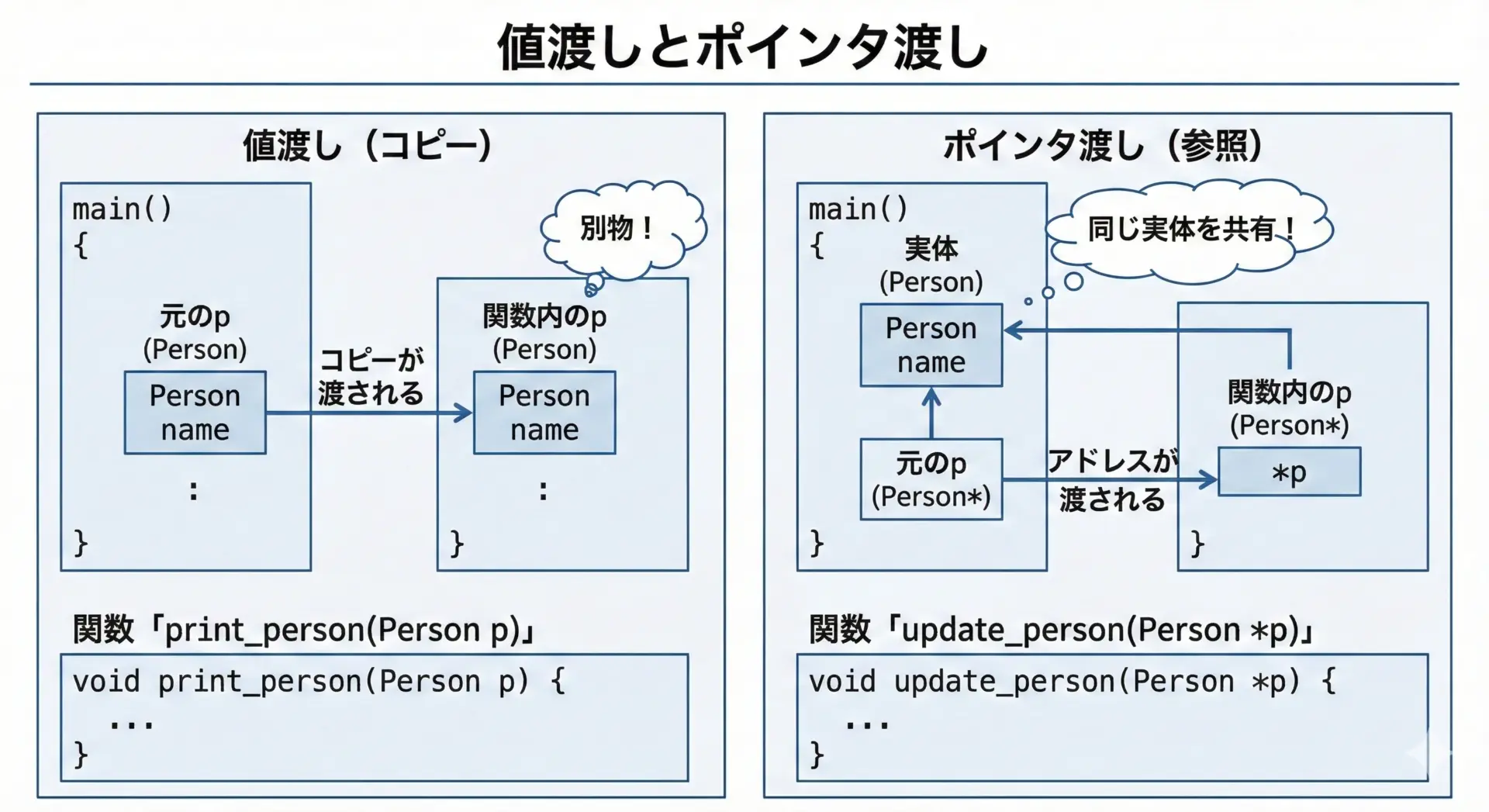
構造体はそのまま関数の引数に渡すことができます。
この場合、値渡しになるので、関数側ではコピーが扱われます。
#include <stdio.h>
typedef struct {
int age;
double height;
} Person;
// 構造体を値渡し
void show_person(Person p) {
printf("show_person: age=%d, height=%.1f\n", p.age, p.height);
p.age = 999; // 呼び出し元には影響しない
}
int main(void) {
Person p = { 25, 170.0 };
show_person(p);
printf("main: age=%d, height=%.1f\n", p.age, p.height);
return 0;
}show_person: age=25, height=170.0
main: age=25, height=170.0関数内で構造体の中身を変更したい場合は、ポインタを渡す必要があります。
#include <stdio.h>
typedef struct {
int age;
double height;
} Person;
// 構造体ポインタを渡す(元の値を変更できる)
void grow(Person *p) {
if (p == NULL) {
return;
}
p->age += 1;
p->height += 0.5;
}
int main(void) {
Person p = { 25, 170.0 };
grow(&p); // &p を渡す
printf("after grow: age=%d, height=%.1f\n", p.age, p.height);
return 0;
}after grow: age=26, height=170.5このように、構造体そのものを引数にするか、構造体へのポインタを引数にするかで、関数内から元のデータを書き換えられるかどうかが変わります。
構造体を返す関数とポインタでの扱い方
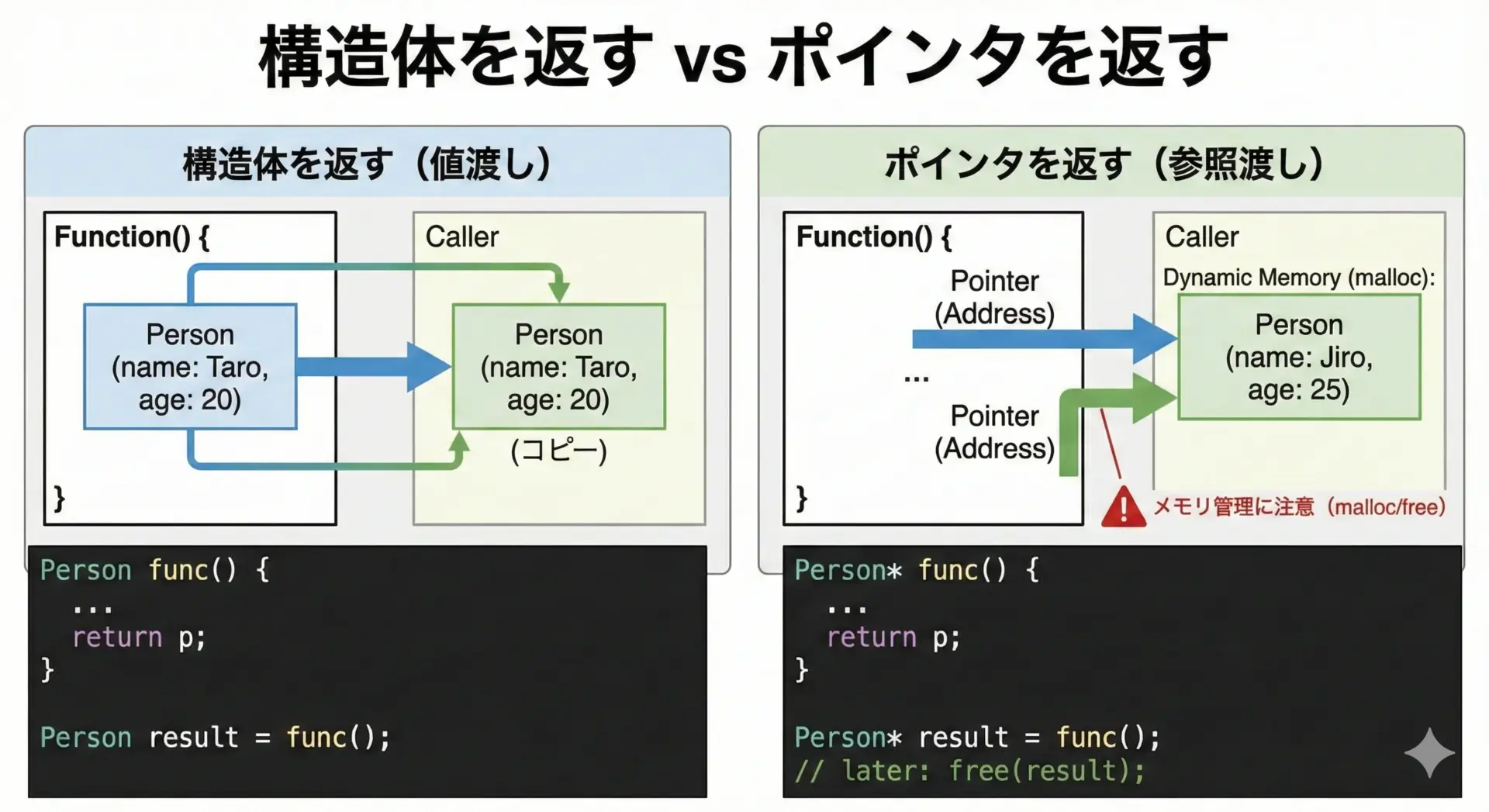
関数は構造体を戻り値として返すこともできます。
#include <stdio.h>
typedef struct {
int x;
int y;
} Point;
// 構造体を値として返す
Point make_point(int x, int y) {
Point p;
p.x = x;
p.y = y;
return p; // コピーされて呼び出し元に返る
}
int main(void) {
Point p1 = make_point(10, 20);
printf("p1 = (%d, %d)\n", p1.x, p1.y);
return 0;
}p1 = (10, 20)構造体のサイズが大きくなるとコピーコストが気になる場合は、ポインタで返すパターンもありますが、その場合は寿命(どこで確保し、どこで解放するか)に注意が必要です。
#include <stdio.h>
#include <stdlib.h>
typedef struct {
int x;
int y;
} Point;
// 動的に確保してポインタを返す例
Point *create_point(int x, int y) {
Point *p = malloc(sizeof(Point)); // ヒープに確保
if (p == NULL) {
return NULL;
}
p->x = x;
p->y = y;
return p;
}
int main(void) {
Point *p = create_point(5, 7);
if (p == NULL) {
printf("メモリ確保に失敗しました\n");
return 1;
}
printf("p = (%d, %d)\n", p->x, p->y);
// 使い終わったら解放
free(p);
return 0;
}p = (5, 7)関数のローカル変数(自動変数)のアドレスを返すことは絶対に避けてください。
関数終了とともに破棄される領域を指すことになり、未定義動作になります。
構造体メンバアクセスの書き方パターン整理
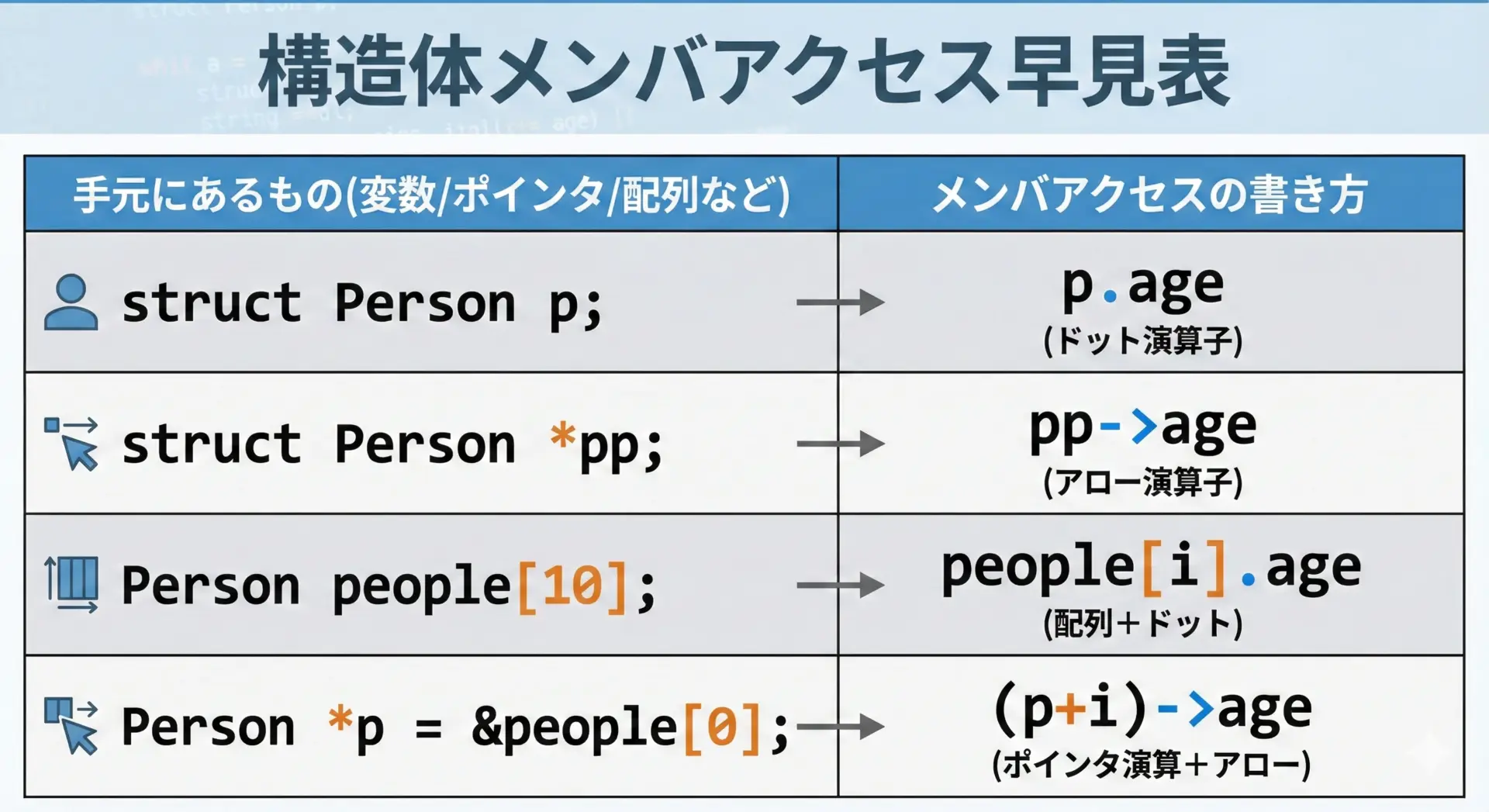
最後に、ここまでのメンバアクセスパターンを表形式で整理します。
| 手元にあるものの型/状況 | メンバアクセスの例 | 説明 |
|---|---|---|
struct Person p; | p.age | 構造体実体。.でアクセス |
Person p;(typedef済み) | p.age | typedefしても書き方は同じ |
struct Person *pp; | pp->age | ポインタ。->でアクセス |
(*pp).age | pp->ageと等価 | |
Person people[10]; | people[i].age | 構造体配列 + . |
(people + i)->age | ポインタ演算 + -> | |
Person *p = people; | p[i].age | 配列先頭へのポインタを配列風に |
(p + i)->age | 明示的なポインタ演算 |
「実体には.」「ポインタには->」という基本ルールを軸に、インデックスやポインタ演算を組み合わせて考えると混乱しにくくなります。
まとめ
構造体は、関連するデータを1つにまとめて扱えるC言語の重要な機能です。
構造体の実体からは.演算子で、構造体ポインタからは->演算子でメンバにアクセスするというルールを押さえることで、多くのコードが理解しやすくなります。
また、typedefで型名を簡潔にしたり、配列や関数・ポインタと組み合わせることで、実践的なプログラムを効率よく書けるようになります。
まずは本記事のサンプルを手で書いて動かしながら、.と->の使い分けを体に馴染ませていきましょう。
