
C言語では文字を扱う場面が多く、入力チェックやパース処理では「その文字が数字なのか、英字なのか、記号なのか」を正しく判定することが重要です。
本記事では、ASCIIコードを直接使う方法と標準ライブラリ(ctype.h)の関数を使う方法の両方を解説し、最後に実用的なサンプルまで丁寧に紹介します。
C言語で文字判定の基本
文字の種類(数字・英字・記号)をどう分類するか
文字判定を行う前に、まず何をどのように分類するかを明確にしておく必要があります。
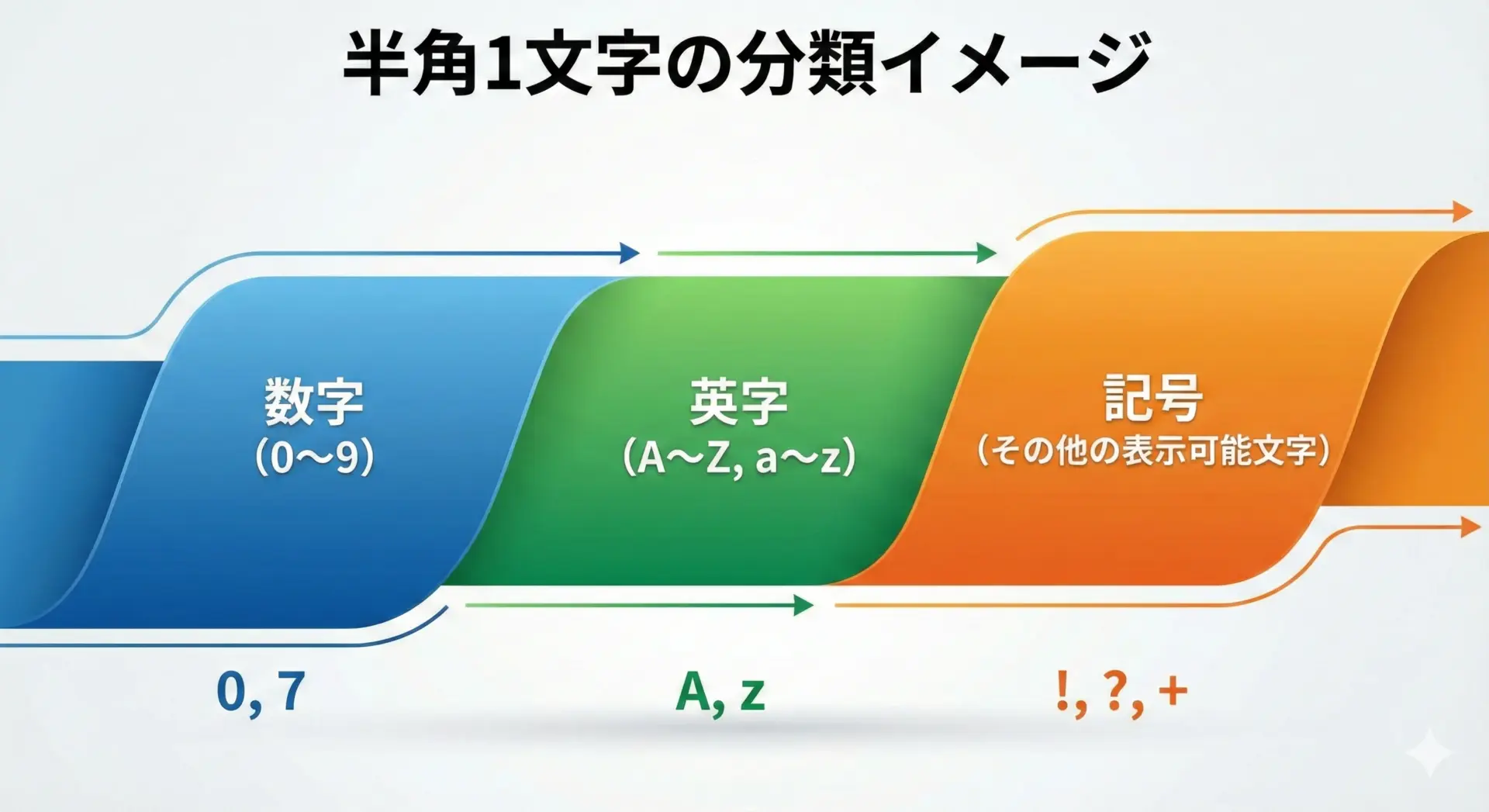
ここでは、典型的な「半角1文字」を次の3種類に分けて考えます。
- 数字(0〜9)
- 英字(A〜Z, a〜z)
- 記号(上記以外の表示可能な半角文字)
ここでいう「記号」には、例えば次のような文字が含まれます。
- 句読点や記号:
!、?、.、,、:、;など - 演算子:
+、-、*、/、%など - かっこ類:
(、)、[、]、{、}など
空白文字(スペースやタブ、改行など)は、通常これらとは別カテゴリとして扱います。
本記事では主に「数字・英字・記号」の3分類にフォーカスし、必要に応じて空白なども補足的に触れます。
プログラムで扱うときの前提
C言語ではchar型やunsigned char型で文字を保存します。
これは内部的には「文字コードという数値」として扱われます。
そのため、文字を比較したり分類したりするときは、最終的には数値の大小比較になっていると理解しておくと整理しやすくなります。
文字コード(ASCII)を使った判定の考え方
C言語の基本的な文字判定では、ASCIIコードを前提として考えることが多いです。
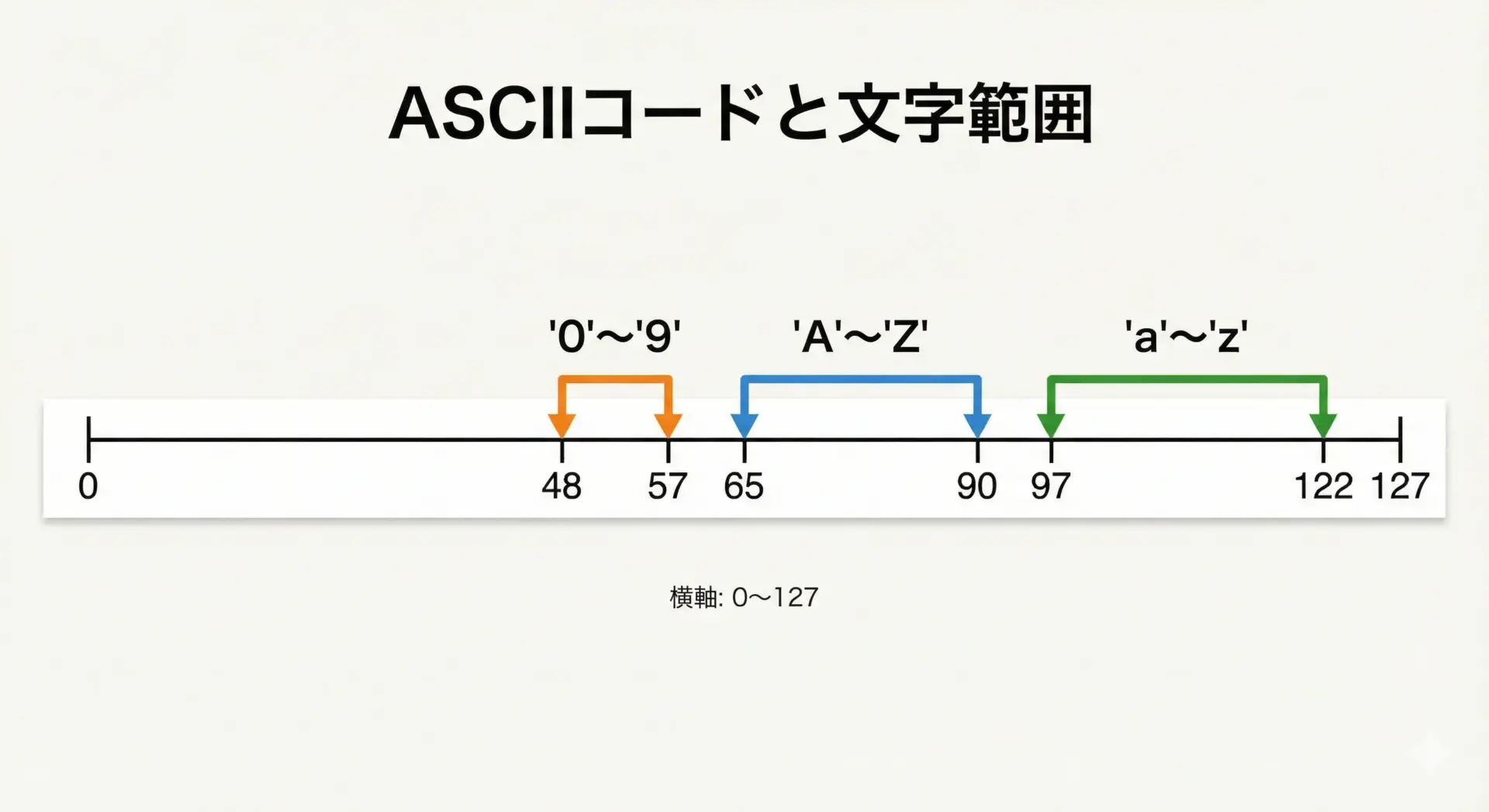
ASCIIは0〜127までの整数値で、英数字や基本的な記号に固定の番号を割り当てています。
代表的な範囲は次のようになっています。
- 数字
'0'〜'9': コード値 48〜57 - 大文字
'A'〜'Z': コード値 65〜90 - 小文字
'a'〜'z': コード値 97〜122
この範囲をそのまま利用することで、次のような判定が可能です。
cが数字か? →'0' <= c && c <= '9'cが英字か? →('A' <= c && c <= 'Z') || ('a' <= c && c <= 'z')
文字リテラルを使う理由
実際に比較するときには、数値そのもの(48など)ではなく'0'のような文字リテラルを使うことが推奨されます。
これは次のようなメリットがあるためです。
- コードの可読性が高くなる
- 環境によってASCIIと完全互換でない場合でも柔軟に対応できる
- 記号のコード値を覚える必要がない
たとえば、c >= '0'と書けば、「0という文字以上」という意味がすぐに理解できます。
標準ライブラリ(ctype.h)を使うメリット
ASCIIコードを直接比較する方法に対して、C言語には標準ライブラリctype.hが用意されています。
このヘッダには、文字の種類を判定するための関数が多数含まれています。
代表的なものとして、次のような関数があります。
isdigit: 数字かどうかisalpha: 英字かどうかisalnum: 英数字(アルファベットまたは数字)かどうかispunct: 記号かどうかisspace: 空白文字かどうかisupper/islower: 大文字か小文字か
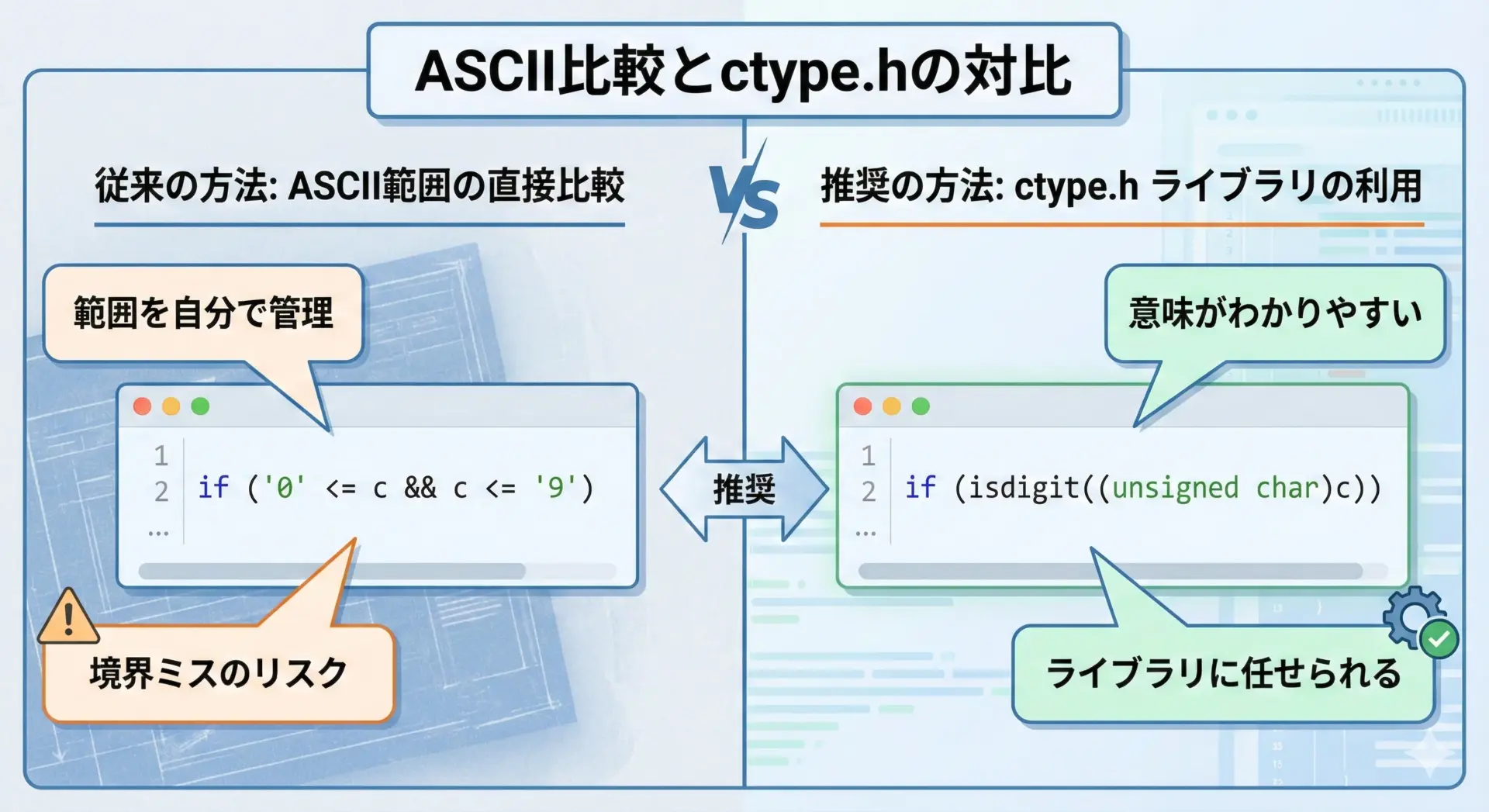
ASCIIコードを自前で比較するよりも、ctype.hの関数を使うことには次の大きな利点があります。
- コードが短く、読みやすくなる
- ロケール(言語設定)に応じた判定が可能になる場合がある
- 細かい境界条件(例えば制御文字など)を意識しなくてよい
ASCIIコードを使った文字判定
ここからは、まずASCIIコードを直接利用して文字を判定する方法を、具体的なコード例とともに説明します。
これは文字コードの理解を深めるうえでとても良い練習になります。
数字かどうかを判定する
数字の文字(0〜9)は、ASCIIコードで48〜57の連続した範囲に割り当てられています。
C言語では、通常は次のように'0'と'9'を使って判定します。
#include <stdio.h>
int main(void) {
char c;
printf("1文字入力してください: ");
scanf("%c", &c);
// '0'〜'9'の範囲かどうかを判定
if ('0' <= c && c <= '9') {
printf("入力された文字 '%c' は数字です。\n", c);
} else {
printf("入力された文字 '%c' は数字ではありません。\n", c);
}
return 0;
}上記のif文では「2つの条件をANDでつなぐ」ことで、cが範囲の中にあるかどうかを確認しています。
'0' <= cで「0以上」c <= '9'で「9以下」- 両方満たせば「0〜9」なので数字とみなす
英字(大文字・小文字)かどうかを判定する
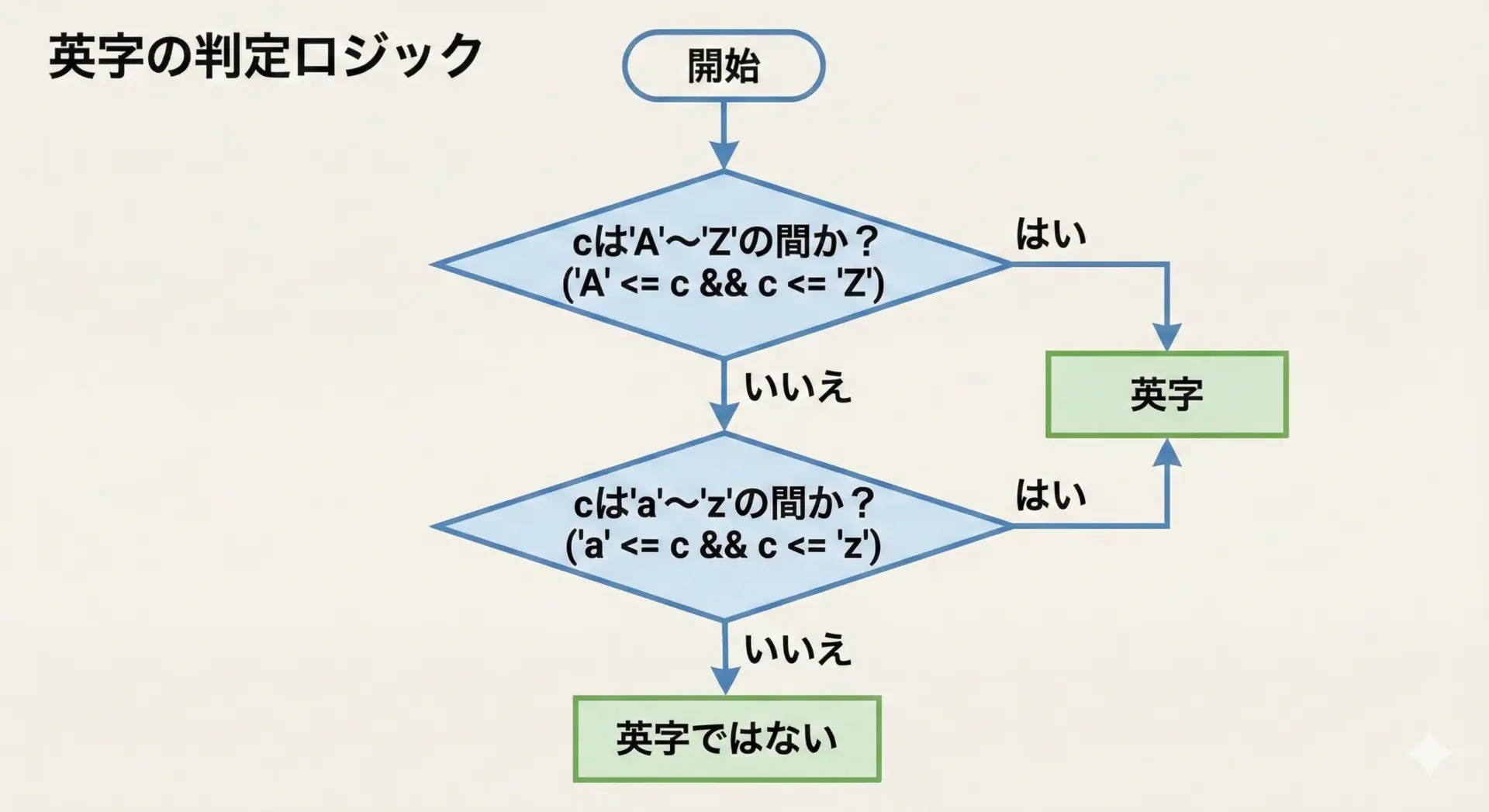
英字は大文字と小文字でコード範囲が分かれています。
そのため、どちらかの範囲に入っていれば英字と判定することができます。
#include <stdio.h>
int main(void) {
char c;
printf("1文字入力してください: ");
scanf("%c", &c);
if (('A' <= c && c <= 'Z') || ('a' <= c && c <= 'z')) {
printf("入力された文字 '%c' は英字です。\n", c);
} else {
printf("入力された文字 '%c' は英字ではありません。\n", c);
}
return 0;
}ここでは、||(論理OR)を使うことで大文字か小文字のどちらか一方でも条件を満たせば英字と見なすようにしています。
記号かどうかを判定する
ASCIIにおける「記号」はやや幅広く、厳密にどこからどこまでと決めるのは難しい部分がありますが、「英数字以外で、かつ、表示可能な文字」を記号とみなす方法がよく使われます。
ASCIIのうち、0x20(スペース)から0x7E(チルダ'~')までが表示可能な文字です。
その中から数字と英字を除いたものを記号と定義すると、次のように書けます。
#include <stdio.h>
int main(void) {
char c;
printf("1文字入力してください: ");
scanf("%c", &c);
// 表示可能文字かどうか
int is_printable = (0x20 <= (unsigned char)c && (unsigned char)c <= 0x7E);
// 数字かどうか
int is_digit = ('0' <= c && c <= '9');
// 英字かどうか
int is_alpha = (('A' <= c && c <= 'Z') || ('a' <= c && c <= 'z'));
if (is_printable && !is_digit && !is_alpha) {
printf("入力された文字 '%c' は記号です。\n", c);
} else {
printf("入力された文字 '%c' は記号ではありません。\n", c);
}
return 0;
}ここでは簡単のため、スペース(半角空白)も記号として扱われることになります。
用途によっては、スペースを別扱いにするなど、条件を調整してください。
if文と条件演算子で一括判定するサンプルコード
次に、1文字を入力して、数字・英字・記号のどれに分類されるかを一括で判定するサンプルを示します。
ここでは、if文と条件演算子?:の両方を使って、分類ラベルを決めてみます。
#include <stdio.h>
int main(void) {
char c;
const char *type; // 文字種を示す文字列へのポインタ
printf("1文字入力してください: ");
scanf("%c", &c);
// まずは数字かどうか
if ('0' <= c && c <= '9') {
type = "数字";
}
// 次に英字(大文字・小文字)かどうか
else if (('A' <= c && c <= 'Z') || ('a' <= c && c <= 'z')) {
type = "英字";
}
// 上記以外で、表示可能文字なら記号とみなす
else if (0x20 <= (unsigned char)c && (unsigned char)c <= 0x7E) {
type = "記号";
}
// それ以外は制御文字などとみなす
else {
type = "その他(制御文字など)";
}
printf("入力された文字 '%c' は「%s」です。\n", c, type);
// 条件演算子を使って、数字かどうかをメッセージにする例
const char *digit_or_not =
('0' <= c && c <= '9') ? "数字です" : "数字ではありません";
printf("また、'%c' は %s。\n", c, digit_or_not);
return 0;
}上記では、「優先度の高いものから順にifで判定していく」形にすることで、コードの見通しをよくしています。
また、条件演算子?:は、単純な2択をメッセージに変換する用途に向いています。
ctype.h関数で数字・英字・記号を一括判定
続いて、標準ライブラリctype.hの関数を使って、より読みやすく、保守しやすいコードにする方法を紹介します。
isdigitで数字を判定する使い方
isdigit関数は、引数に渡した文字が「10進数の数字(0〜9)かどうか」を判定します。
関数の宣言は次のとおりです。
int isdigit(int c);戻り値は「0以外なら真」「0なら偽」と解釈します。
#include <stdio.h>
#include <ctype.h> // isdigitを使うために必要
int main(void) {
int ch; // 注意: int型で受けるのが正式な形
printf("1文字入力してください: ");
ch = getchar(); // 文字を1つ読み込む
// isdigitの戻り値は「0以外なら真」
if (isdigit(ch)) {
printf("入力された文字 '%c' は数字です。\n", ch);
} else {
printf("入力された文字 '%c' は数字ではありません。\n", ch);
}
return 0;
}重要なポイントとして、isdigitに渡すのはint型ですが、その値はunsigned charとして解釈できる範囲か、もしくはEOFでなければなりません。
この点は後半の「signed charと文字コードの落とし穴」で詳しく述べます。
isalphaで英字を判定する使い方
isalpha関数は、引数が英字(アルファベット)かどうかを判定します。
#include <stdio.h>
#include <ctype.h>
int main(void) {
int ch;
printf("1文字入力してください: ");
ch = getchar();
if (isalpha(ch)) {
printf("入力された文字 '%c' は英字です。\n", ch);
} else {
printf("入力された文字 '%c' は英字ではありません。\n", ch);
}
// 大文字か小文字かをさらに判定する例
if (isalpha(ch)) {
if (isupper(ch)) {
printf("しかも大文字です。\n");
} else if (islower(ch)) {
printf("しかも小文字です。\n");
}
}
return 0;
}isupperとislowerを組み合わせると、大文字・小文字の区別も簡単に行えます。
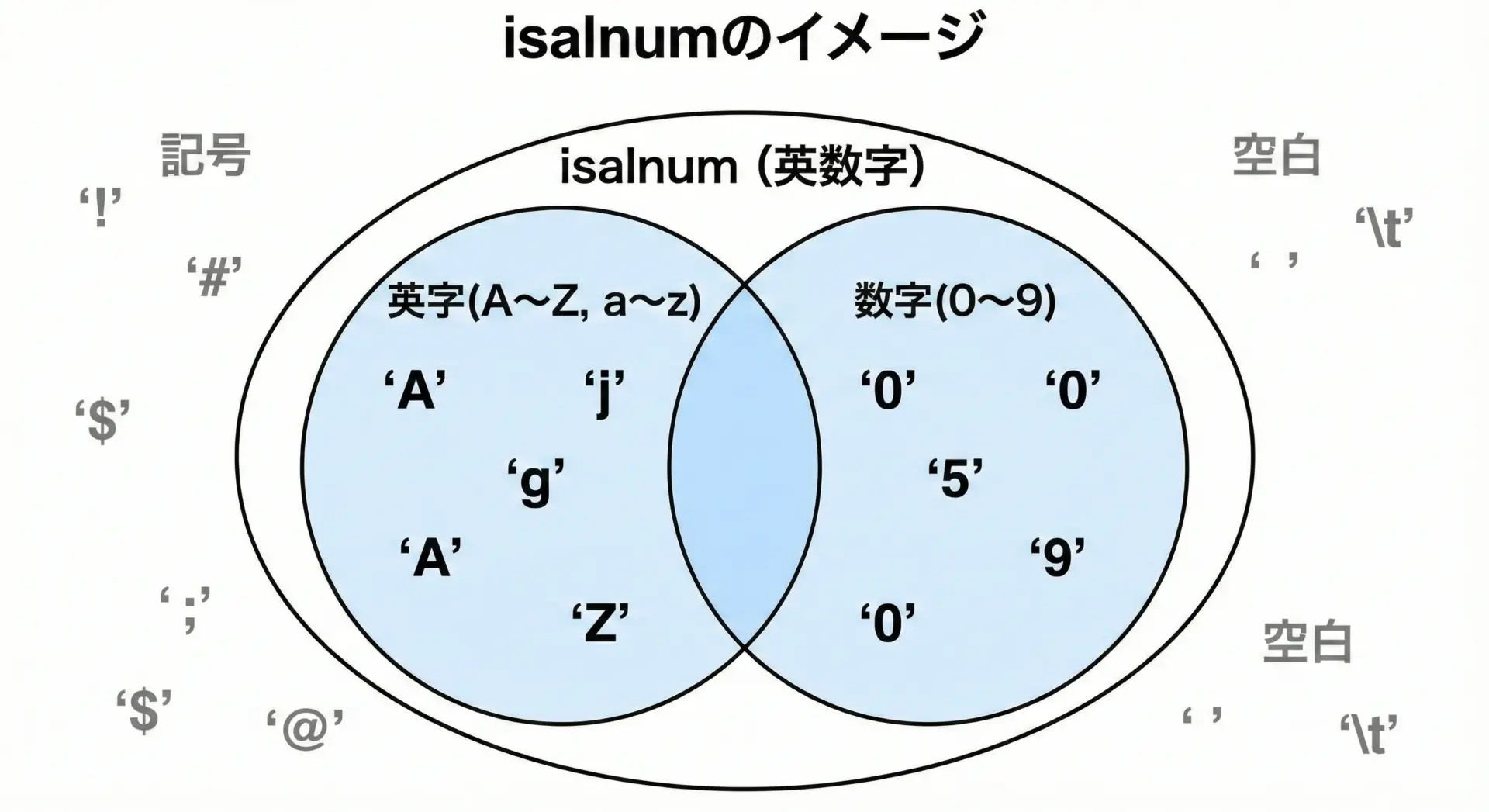
isalnumで英数字をまとめて判定する
isalnum関数は、「英字または数字かどうか」を一度に判定できます。
実質的には、isalpha(c) || isdigit(c)と同じ意味です。
#include <stdio.h>
#include <ctype.h>
int main(void) {
int ch;
printf("1文字入力してください: ");
ch = getchar();
if (isalnum(ch)) {
printf("入力された文字 '%c' は英数字です。\n", ch);
} else {
printf("入力された文字 '%c' は英数字ではありません。\n", ch);
}
return 0;
}
ispunctで記号を判定する方法
ispunct関数は、「英数字、空白以外の表示可能文字」かどうかを判定します。
つまり、多くの場合には「記号」とみなして問題ありません。
#include <stdio.h>
#include <ctype.h>
int main(void) {
int ch;
printf("1文字入力してください: ");
ch = getchar();
if (ispunct(ch)) {
printf("入力された文字 '%c' は記号(句読点・演算子など)です。\n", ch);
} else {
printf("入力された文字 '%c' は記号ではありません。\n", ch);
}
return 0;
}どの文字がispunctの対象になるかは、実装やロケールによって多少異なる可能性がありますが、少なくとも典型的なASCII範囲内の記号(例: !、?、+、- など)は含まれます。
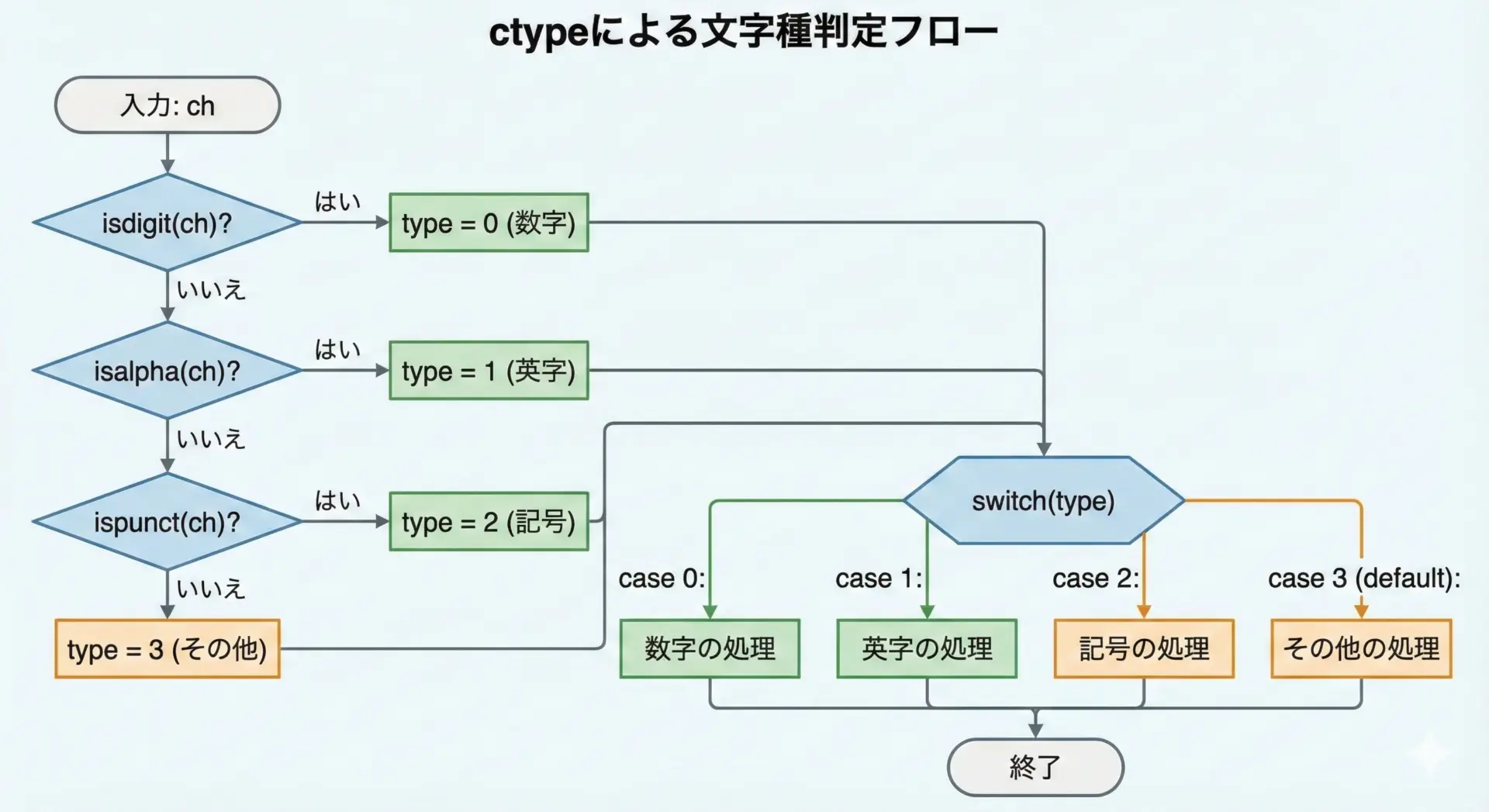
switch文で数字・英字・記号を振り分ける例
ctype.hの関数を使って、1文字を数字・英字・記号・その他に振り分ける例を、switch文を利用して書いてみます。
#include <stdio.h>
#include <ctype.h>
int main(void) {
int ch;
int type; // 0:数字, 1:英字, 2:記号, 3:その他
printf("1文字入力してください: ");
ch = getchar();
if (isdigit(ch)) {
type = 0;
} else if (isalpha(ch)) {
type = 1;
} else if (ispunct(ch)) {
type = 2;
} else {
type = 3;
}
// 判定結果をswitchで分類して表示
switch (type) {
case 0:
printf("入力された文字 '%c' は数字です。\n", ch);
break;
case 1:
printf("入力された文字 '%c' は英字です。\n", ch);
break;
case 2:
printf("入力された文字 '%c' は記号です。\n", ch);
break;
default:
printf("入力された文字 '%c' は空白や制御文字などのその他の文字です。\n", ch);
break;
}
return 0;
}
このようにctype.hの関数を使うと、個々のコード値を知らなくても意図を明確にした分類が行えます。
文字判定の注意点と拡張
ここまでで一通りの文字判定方法を学びましたが、実務レベルで運用するにはいくつか注意すべき落とし穴があります。
この章では、特に重要なポイントと拡張的な活用例を説明します。
signed charと文字コードの落とし穴
C言語のchar型は、実装によって符号付き(signed)か符号なし(unsigned)かが異なります。
これがctype.hの関数と組み合わせたときに問題を起こすことがあります。
ctype.hの関数(例: isdigit、isalphaなど)は、引数としてunsigned charに変換可能な値、またはEOFだけを受け付けると規定されています。
もしcharが符号付きであり、その値が128以上の文字コードを扱っている場合、charからintに昇格したときに負の値になってしまうことがあります。
この負の値をそのままisdigitなどに渡すと、未定義動作となり、正しく動かなかったりクラッシュしたりする危険があります。
この問題を避けるには、常にunsigned charにキャストしてからctype関数に渡すことが推奨されます。
#include <stdio.h>
#include <ctype.h>
int main(void) {
char c = 'A'; // ここではASCII範囲だが、慣習としてキャストを徹底すると安全
// 安全な呼び出し方
if (isalpha((unsigned char)c)) {
printf("'%c' は英字です。\n", c);
}
return 0;
}ポイントとして、シンプルそうに見えてもctype.hを使うときは(unsigned char)キャストを心がけると、後々のバグを防ぎやすくなります。
全角文字やマルチバイト文字の場合の注意点
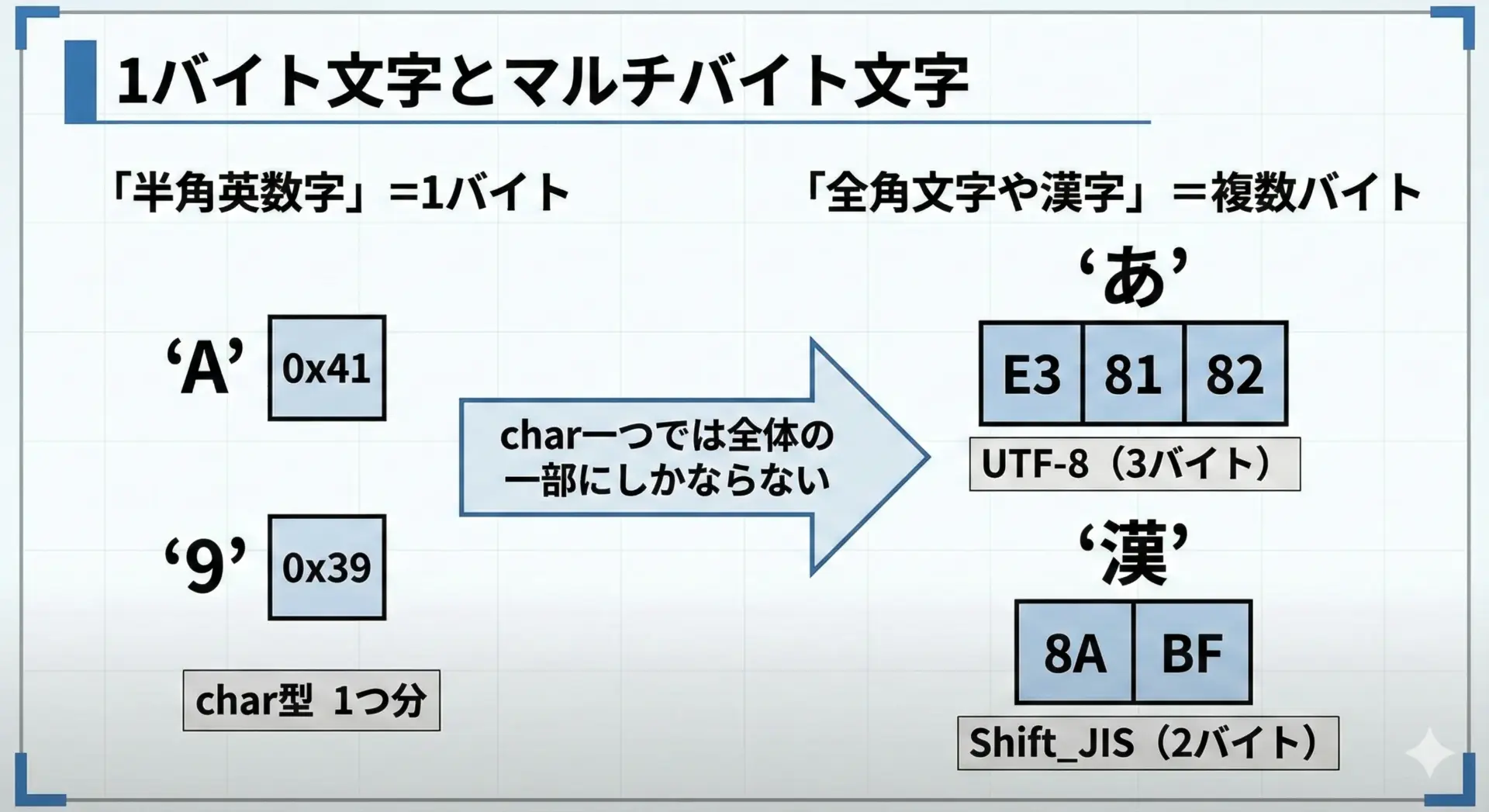
ここまで説明してきた内容は、基本的に「1バイトで表現される半角文字」を前提としています。
しかし、日本語環境では次のような文字も頻繁に扱います。
- 全角数字(例:
Q、10) - 全角英字(例:
A、z) - ひらがな・カタカナ・漢字
- 絵文字などのマルチバイト文字
これらは多くの場合、UTF-8やShift_JISといったマルチバイト文字コードで表現されており、1文字が1バイトとは限りません。
そのため、char1つを見て数字かどうか、英字かどうかと判定することはできません。
重要な注意点として、isdigitやisalphaは、ロケール設定により一部の拡張文字を扱える場合もありますが、一般にマルチバイト文字全体を認識して「全角数字かどうか」などと判定するものではありません。
マルチバイト文字列を対象に「数字だけかどうか」などを判定したい場合は、次のような対策が必要になります。
- マルチバイト対応のライブラリ(例:
wchar_tとwctype.h、あるいは外部ライブラリ)を使う - 文字コードごとに「全角数字の領域」を自前で扱う
- UTF-8ならユニコードコードポイントを解析する
本記事では詳細には踏み込みませんが、ASCIIベースの半角文字に限定した判定であることを意識しておくことが大切です。
文字列中の数字・英字・記号を数える実用サンプル
最後に、ここまでの知識を使って「文字列の中に含まれる数字・英字・記号の個数を数える」実用的なサンプルプログラムを作ってみます。
ここではctype.hを使うバージョンを示します。
#include <stdio.h>
#include <ctype.h>
#include <string.h>
int main(void) {
char buf[256];
printf("文字列を入力してください(最大255文字): ");
// 空白も含めて1行取得するためにfgetsを使用
if (fgets(buf, sizeof(buf), stdin) == NULL) {
printf("入力エラーです。\n");
return 1;
}
int digits = 0; // 数字の個数
int alphas = 0; // 英字の個数
int puncts = 0; // 記号の個数
int spaces = 0; // 空白文字の個数
int others = 0; // 上記以外の文字の個数
// 末尾の改行文字('\n')があれば取り除く
size_t len = strlen(buf);
if (len > 0 && buf[len - 1] == '\n') {
buf[len - 1] = '\0';
}
// 1文字ずつ走査
for (size_t i = 0; buf[i] != '\0'; i++) {
unsigned char ch = (unsigned char)buf[i]; // 安全のためunsigned charに変換
if (isdigit(ch)) {
digits++;
} else if (isalpha(ch)) {
alphas++;
} else if (ispunct(ch)) {
puncts++;
} else if (isspace(ch)) {
spaces++;
} else {
others++;
}
}
printf("解析結果:\n");
printf(" 数字 : %d 文字\n", digits);
printf(" 英字 : %d 文字\n", alphas);
printf(" 記号 : %d 文字\n", puncts);
printf(" 空白文字 : %d 文字\n", spaces);
printf(" その他 : %d 文字\n", others);
return 0;
}想定される実行例は次のようになります。
文字列を入力してください(最大255文字): Hello, C lang 2025!!
解析結果:
数字 : 4 文字
英字 : 9 文字
記号 : 3 文字
空白文字 : 2 文字
その他 : 0 文字このようなプログラムは、ログ解析や入力チェック、パスワード強度チェックなど、多くの場面でそのまま応用できます。
まとめ
本記事では、C言語で文字が数字・英字・記号のどれに当たるかを判定する方法を、ASCIIコードを直接比較する方法とctype.hの関数を使う方法の両面から解説しました。
前者は文字コードの理解を深めるのに役立ち、後者は読みやすく安全な実用コードを書くのに向いています。
また、signed charの扱いやマルチバイト文字での制限といった落とし穴にも触れ、最後に文字列中の各文字種を数えるサンプルで全体をつなげました。
日常的な入力チェックから本格的なテキスト処理まで、ここで紹介した考え方とテクニックを組み合わせて活用してみてください。
