
C言語で文字列を比較するとき、最もよく使われる標準関数がstrcmpです。
数値の比較は==などの演算子で行えますが、文字列は少し勝手が違います。
本記事では、strcmpの基本的な役割から戻り値の意味、実践的な使い方、そしてよくある間違いと注意点まで、サンプルコードと図解を交えながら丁寧に解説します。
strcmpとは
strcmpの役割
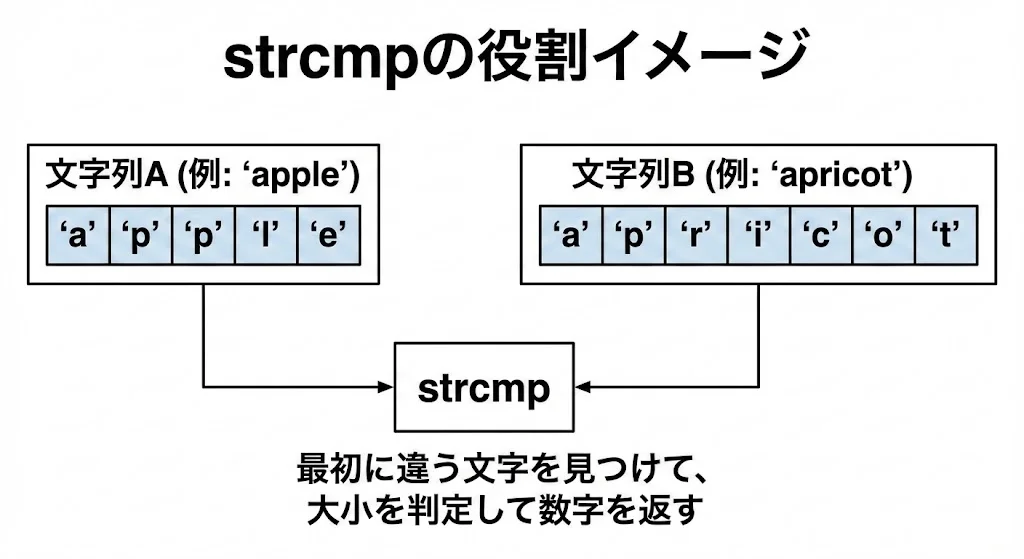
strcmpは、2つの文字列を「辞書順(レキシカル順)」で比較する関数です。
具体的には、次のような処理を行います。
1つ目の文字列と2つ目の文字列を、先頭から1文字ずつ比較していき、最初に異なる文字が見つかった位置で、その文字同士の大小関係から正負の値を返す、という仕組みになっています。
すべての文字が同じで、かつ両方が同じ位置で終端文字'\0'に到達した場合のみ、戻り値は0となります。
ここでいう「大小」は、文字コード(ASCIIなど)の値を基準に判断されます。
そのため「アルファベット順・数値文字の順番・大文字小文字の順番」なども、文字コードの並びに従うことになります。
strcmpの関数プロトタイプとヘッダファイル
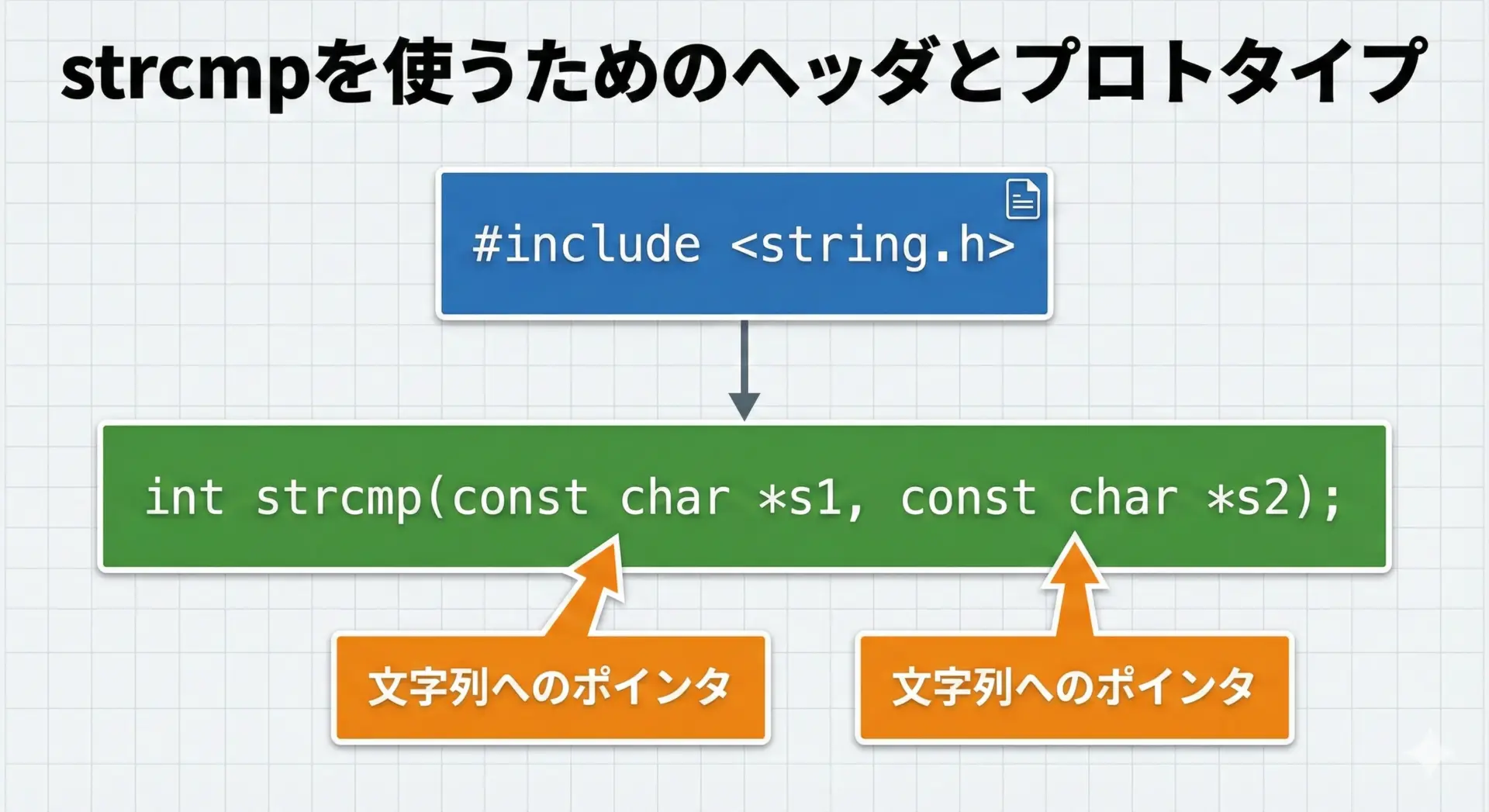
strcmpは標準ライブラリstring.hに定義されている関数です。
使用するには、ソースファイルの先頭付近でヘッダファイルをインクルードする必要があります。
#include <string.h> // strcmpなどの文字列関数の宣言が含まれる
int strcmp(const char *s1, const char *s2);プロトタイプの意味は次の通りです。
- 戻り値:
int(比較結果を表す整数) - 第1引数:
const char *s1(比較対象の1つ目の文字列) - 第2引数:
const char *s2(比較対象の2つ目の文字列)
どちらの引数もconst char *になっているため、strcmpは渡された文字列を変更しません。
ただし、NULLポインタを渡してはいけない点には注意が必要です(後述します)。
strcmpが比較する範囲と終端文字
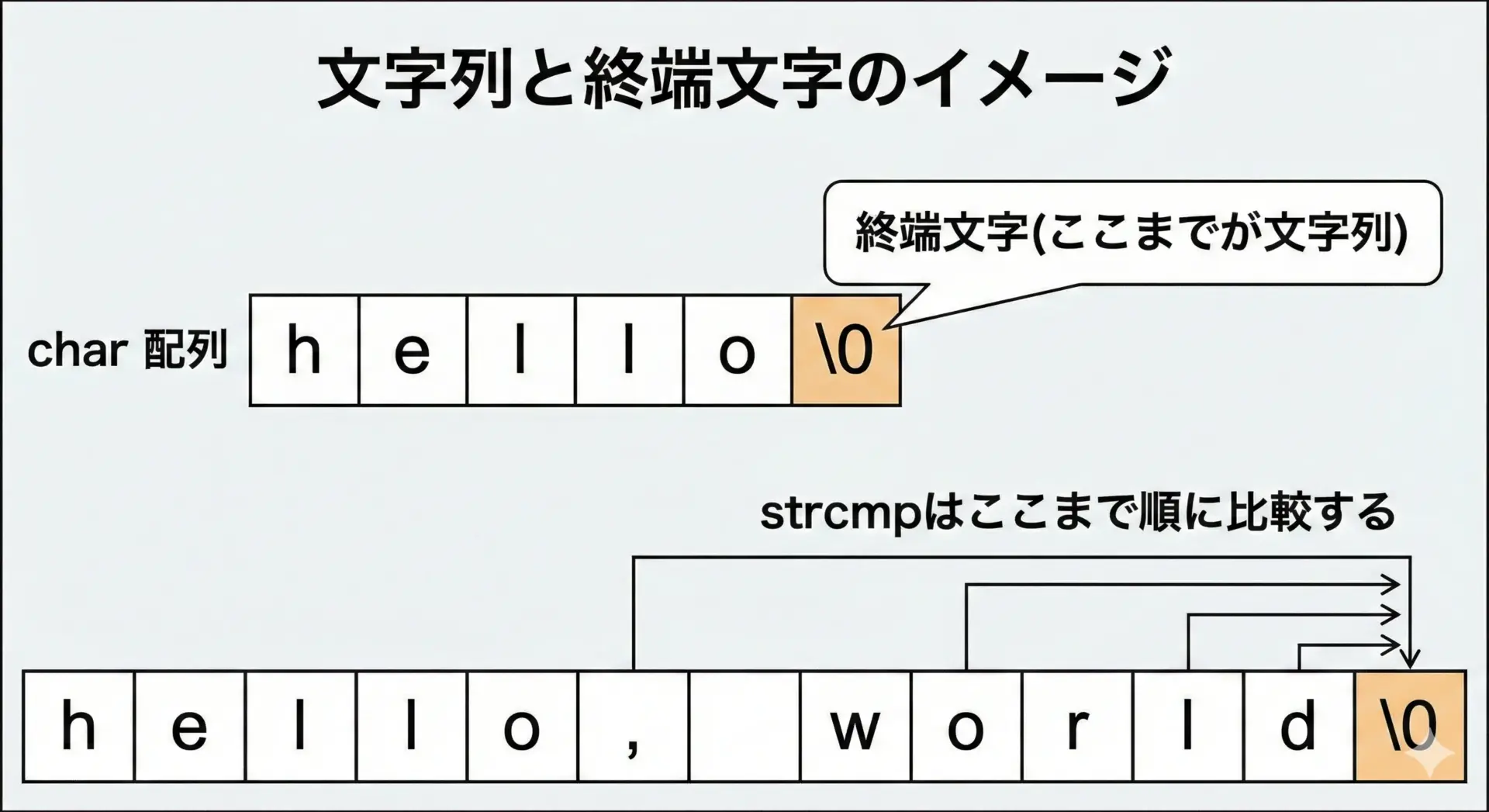
C言語の文字列は、最後に必ず'\0'(ヌル文字)が付いた文字列として表現されます。
strcmpは、この終端文字に到達するまで1文字ずつ比較し、次のいずれかのタイミングで処理を終了します。
- 途中で異なる文字を見つけたとき
- どちらかの文字列が
'\0'に達したとき(文字列の長さが違う場合を含む)
たとえば"abc"と"abcd"を比較する場合、先頭3文字'a''b''c'までは同じですが、4文字目で"abc"側は'\0'、"abcd"側は'd'となるため、ここで比較が行われます。
この結果、'\0'と'd'の比較になります。
strcmpは配列のサイズではなく、終端文字'\0'までを「有効な文字列」として扱うことを理解しておくことが重要です。
strcmpの戻り値と意味
戻り値が0のとき
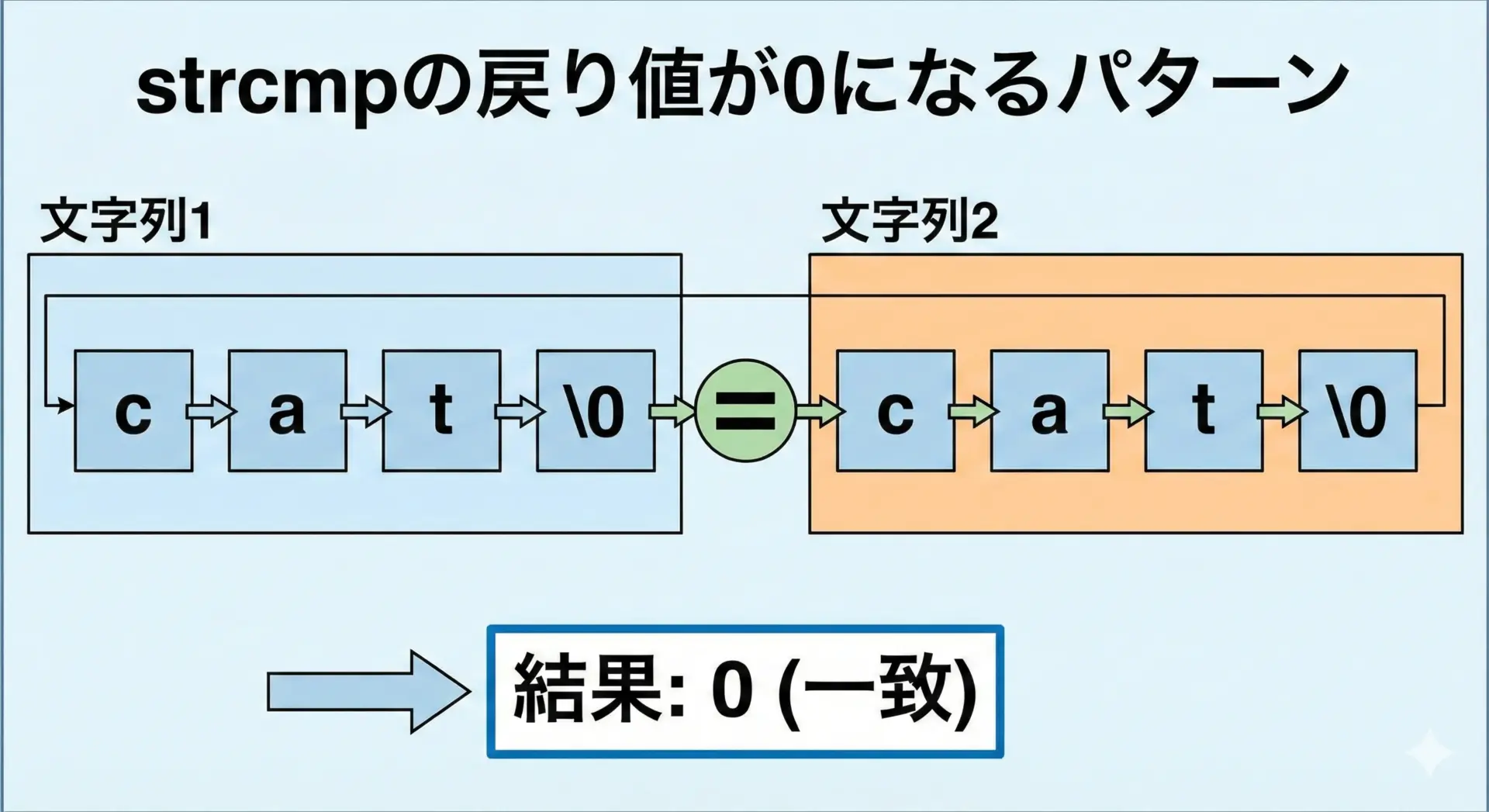
strcmpの戻り値が0のとき、2つの文字列はまったく同じ内容であることを意味します。
ここでいう「同じ」とは、次の条件を満たすことです。
- 各位置の文字がすべて一致している
- かつ、両方の文字列が同じ文字数で、同じ位置で
'\0'を迎えている
例えば"hello"と"hello"は0を返しますが、"hello"と"hello "(末尾にスペースがある)は異なる文字列とみなされ、0以外が返ってきます。
戻り値が正のとき
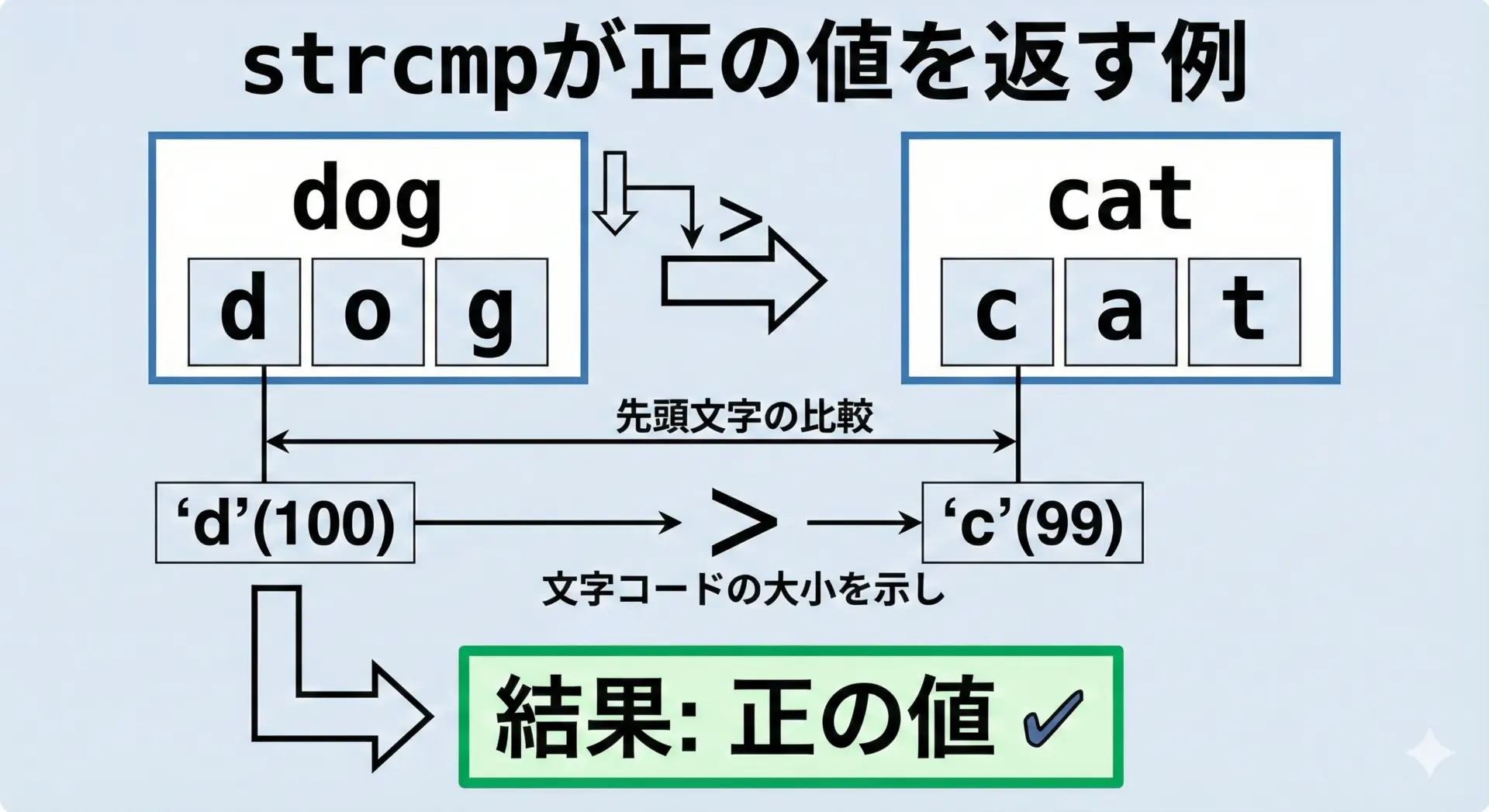
strcmpが正の値を返すときは、「第1引数の文字列のほうが、第2引数の文字列よりも大きい(辞書順で後ろ)」という意味になります。
例えば以下のような場合です。
strcmp("dog", "cat")→ 正の値strcmp("hello", "he")→ 正の値(3文字目までは同じだが、短い方が'\0'となるため、'l'>'\0')
ここで「どのくらい大きいか」という数値自体には重要な意味はありません。
0より大きいかどうかだけを判定に使うのが正しい使い方です。
戻り値が負のとき
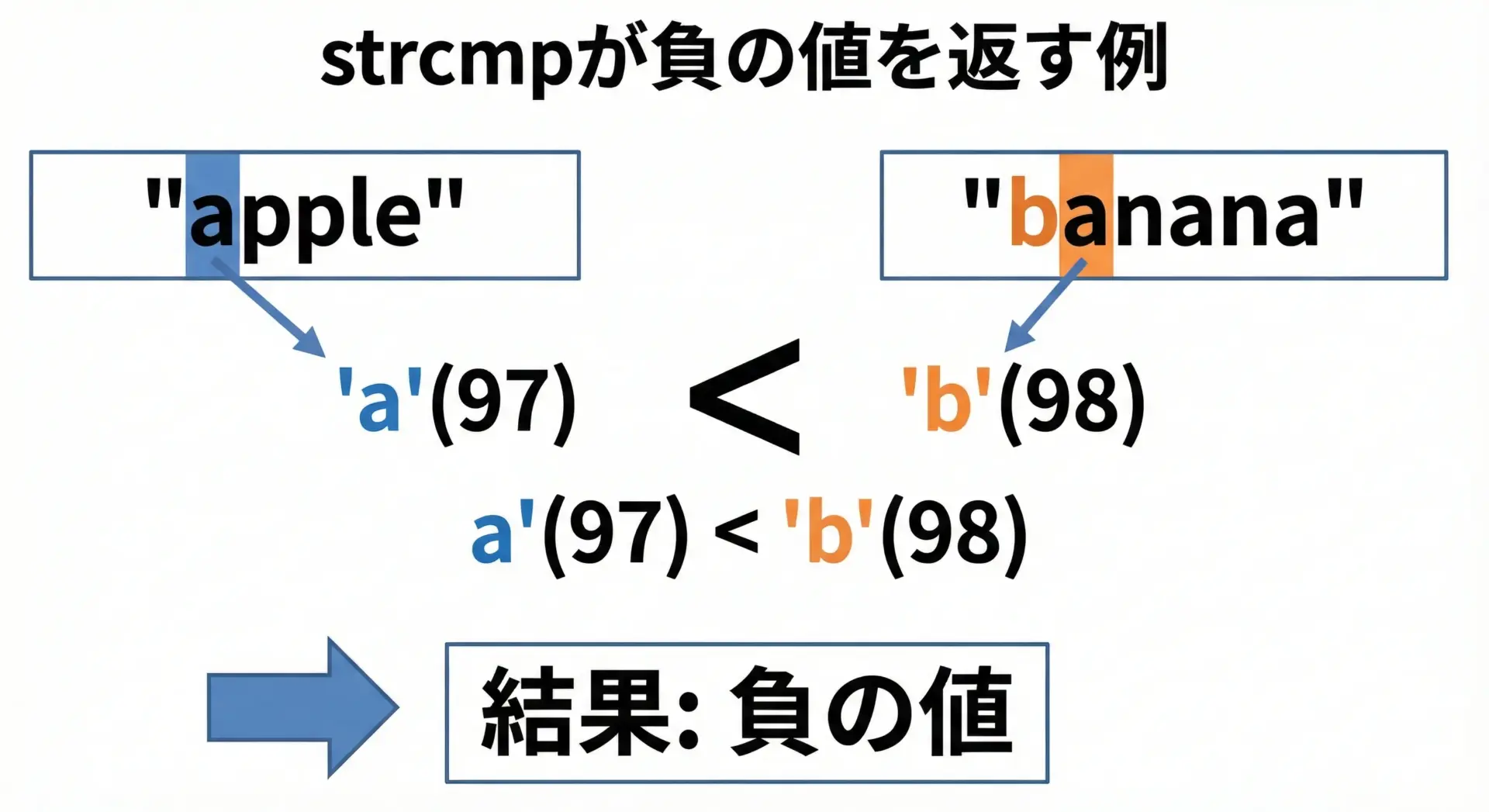
strcmpが負の値を返す場合は、「第1引数の文字列のほうが、第2引数の文字列よりも小さい(辞書順で前)」ことを意味します。
例えば次のようなケースがあります。
strcmp("apple", "banana")→ 負の値strcmp("abc", "abcd")→ 負の値(3文字目までは同じだが、"abc"側が'\0'となり、'\0'<'d')
こちらも、どれくらい小さいか(具体的な数値)は基本的に使いません。
戻り値の値そのものに意味はない理由
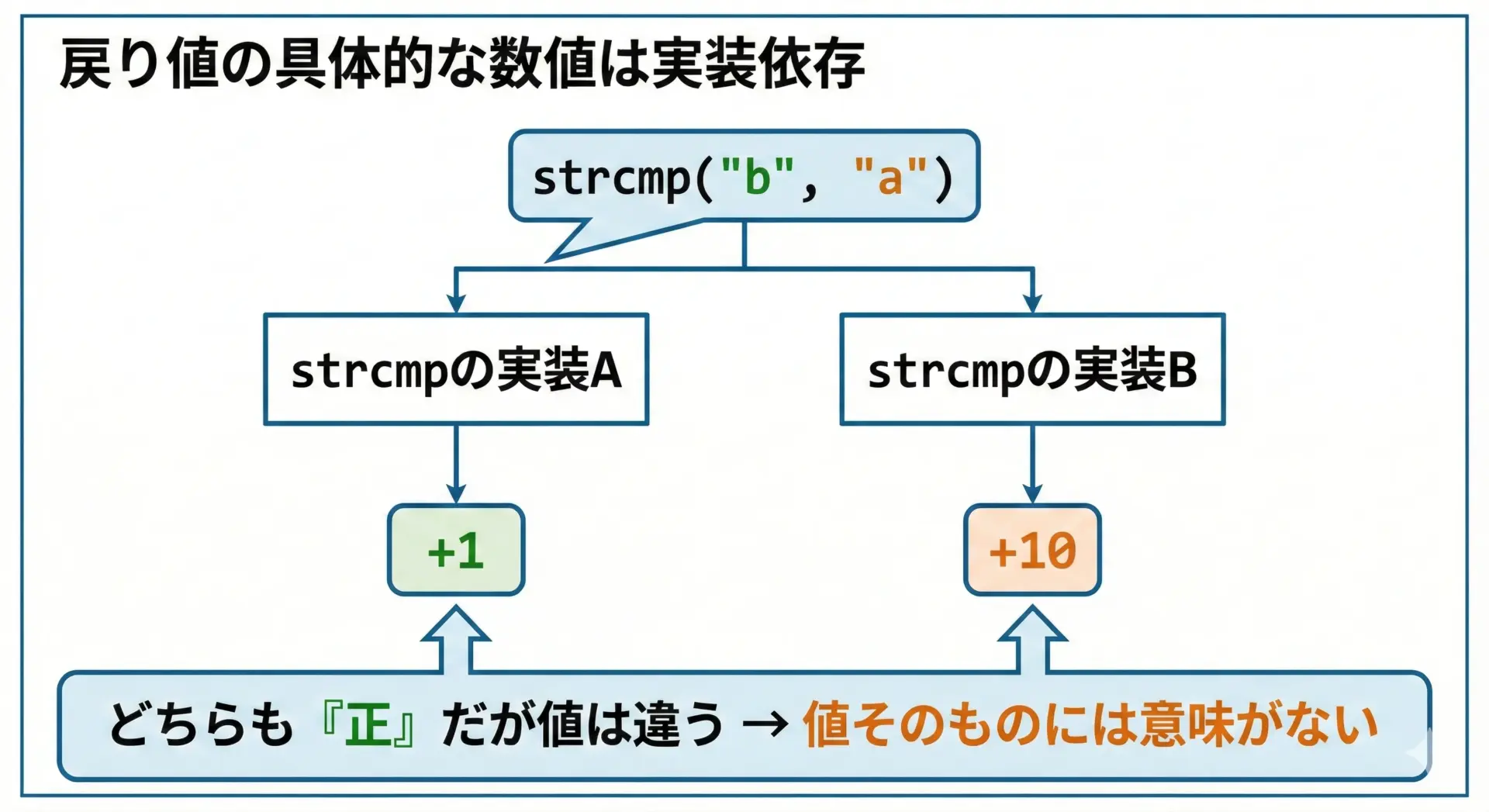
strcmpの戻り値には「負」「0」「正」の3パターンがありますが、負のときに必ず-1、正のときに必ず+1が返るわけではありません。
多くの実装では、次のように計算されます。
- 最初に異なった位置の文字コード同士の差(cst-code>s1[i] – s2[i])を、そのまま
intとして返す
しかしこれは標準仕様として「そう決まっている」わけではなく、あくまで代表的な実装に過ぎません。
そのため、プログラムでは「0かどうか」「0より小さいか」「0より大きいか」だけを見るように書く必要があります。
例えば、次のようなコードは誤った使い方になります。
// NG例: 戻り値が「-1」であることを期待してしまっている
if (strcmp(s1, s2) == -1) {
// ここに来るとは限らない
}このような書き方をすると、環境やコンパイラの実装によっては意図した動作にならない可能性があります。
必ず次のように、0との大小比較で判定してください。
// OK例: 0との大小で判定する
int r = strcmp(s1, s2);
if (r < 0) {
// s1 が s2 より小さい
} else if (r > 0) {
// s1 が s2 より大きい
} else {
// s1 と s2 は等しい
}strcmpの使い方とコード例
strcmpの基本的な使い方
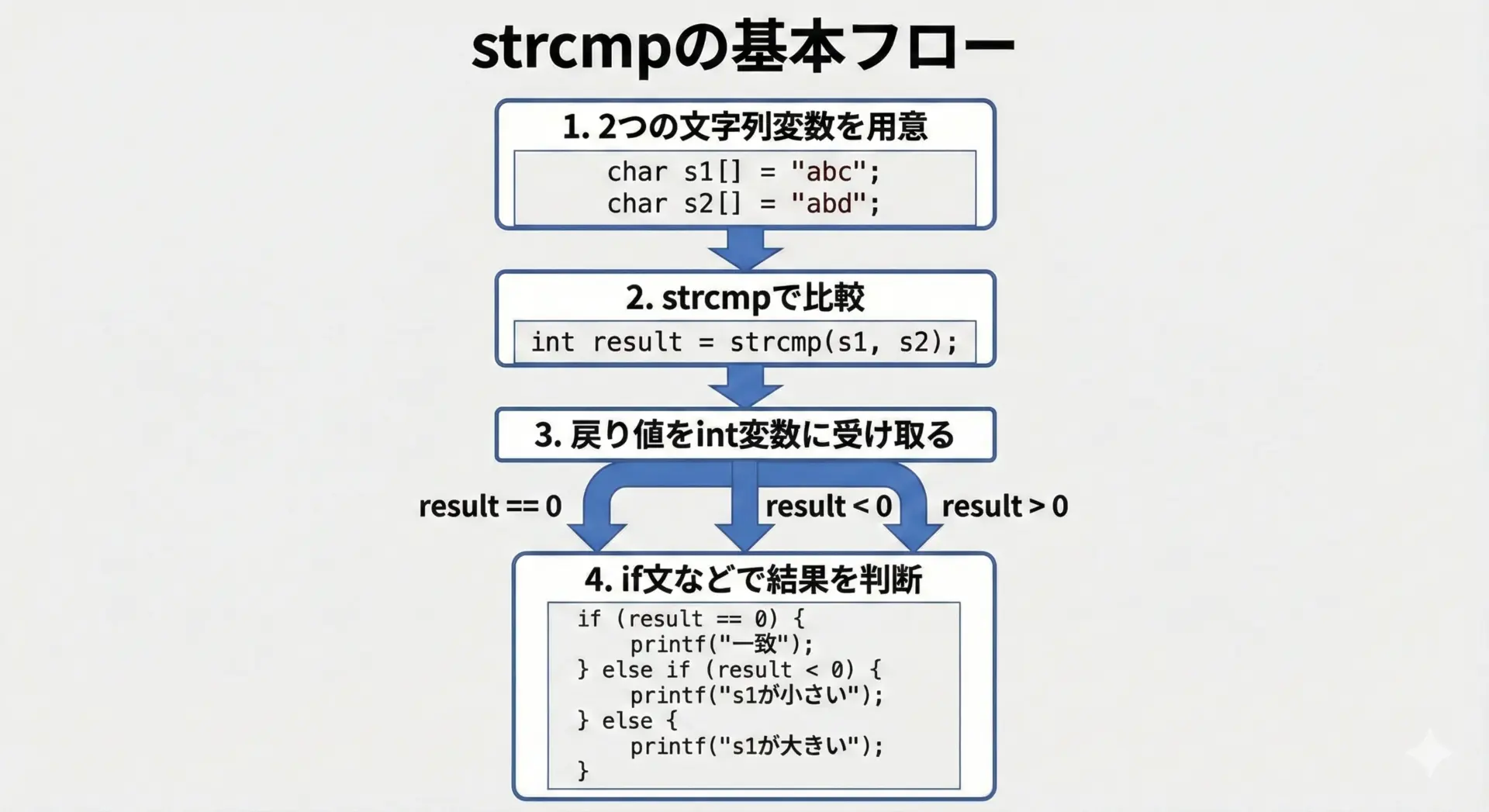
ここでは、最も基本的なstrcmpの使い方を、サンプルコードと出力結果で確認します。
#include <stdio.h>
#include <string.h>
int main(void) {
// 比較する文字列を用意
const char *s1 = "apple";
const char *s2 = "banana";
// strcmpの結果を受け取る
int result = strcmp(s1, s2);
// 結果を表示してみる
printf("s1 = %s\n", s1);
printf("s2 = %s\n", s2);
printf("strcmp(s1, s2) の結果 = %d\n", result);
// 0との比較で関係を判定
if (result == 0) {
printf("s1 と s2 は等しい文字列です。\n");
} else if (result < 0) {
printf("s1 は s2 より小さい(辞書順で前)文字列です。\n");
} else { // result > 0
printf("s1 は s2 より大きい(辞書順で後ろ)文字列です。\n");
}
return 0;
}s1 = apple
s2 = banana
strcmp(s1, s2) の結果 = -1 ← 例: 実装によって値は変わる可能性あり
s1 は s2 より小さい(辞書順で前)文字列です。ポイントは「戻り値をいったん変数に受け取り、0との比較で判断する」ことです。
直接strcmp(s1, s2) < 0としても構いませんが、値を表示して確認したいときなどには変数に保存するほうが便利です。
if文とstrcmpで文字列を比較する方法
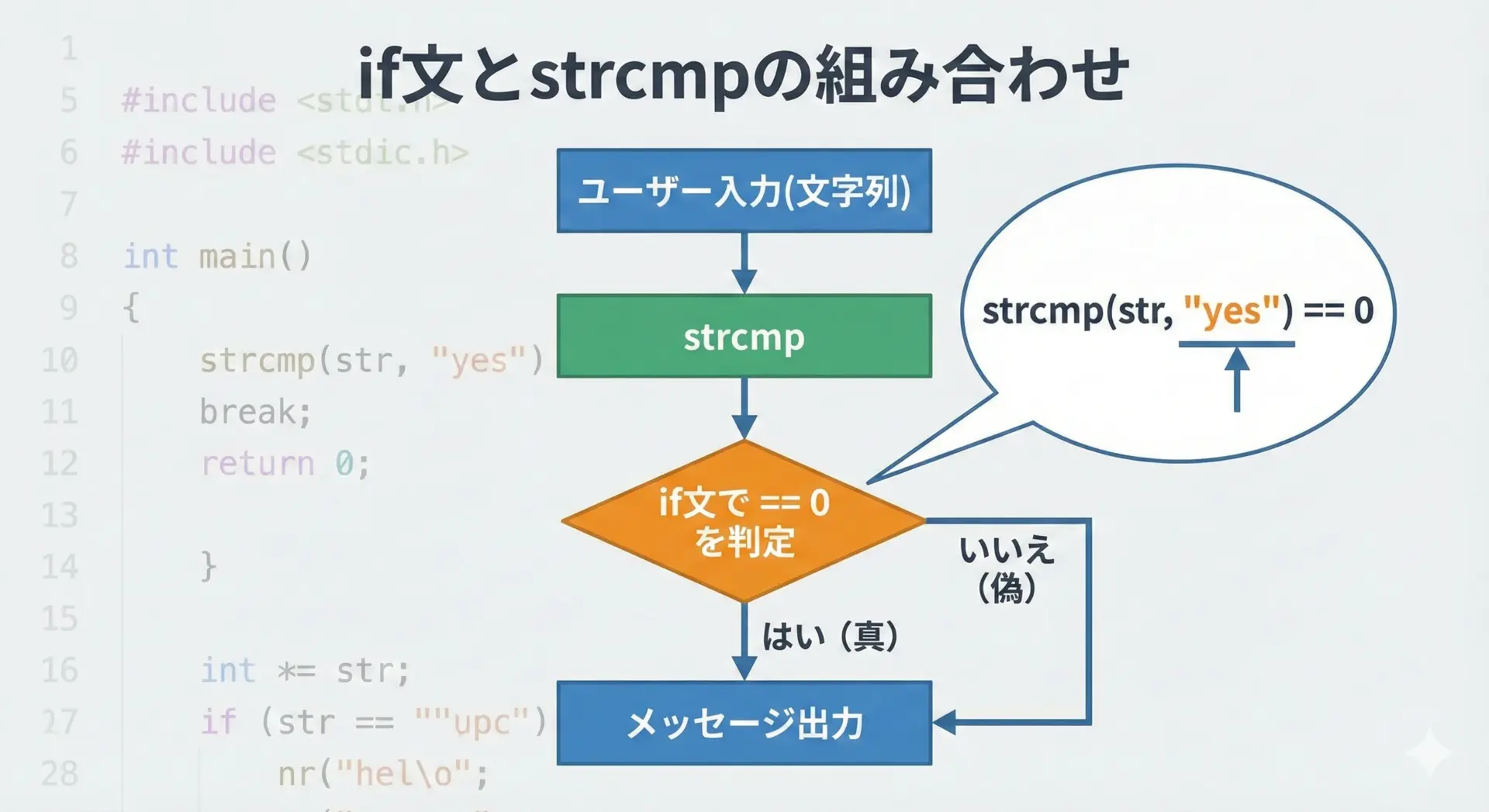
文字列を比較するとき、if文の条件式でstrcmpを使うのが、ごく一般的な書き方です。
数値比較の==とは異なり、strcmp()を用いて== 0で等しさを判定します。
#include <stdio.h>
#include <string.h>
int main(void) {
const char *correct = "yes";
// ユーザーの入力を模した文字列
const char *input1 = "yes";
const char *input2 = "no";
// input1 を比較
if (strcmp(input1, correct) == 0) {
printf("input1 は正解の文字列です。\n");
} else {
printf("input1 は正解ではありません。\n");
}
// input2 を比較
if (strcmp(input2, correct) == 0) {
printf("input2 は正解の文字列です。\n");
} else {
printf("input2 は正解ではありません。\n");
}
return 0;
}input1 は正解の文字列です。
input2 は正解ではありません。「文字列が等しいかどうか」を調べたいだけなら、戻り値が0かどうかだけを見れば十分です。
辞書順の大小関係まで必要ない場合は、この書き方だけ覚えておけば実務でもほぼ困りません。
ユーザー入力とstrcmpでコマンド判定する例
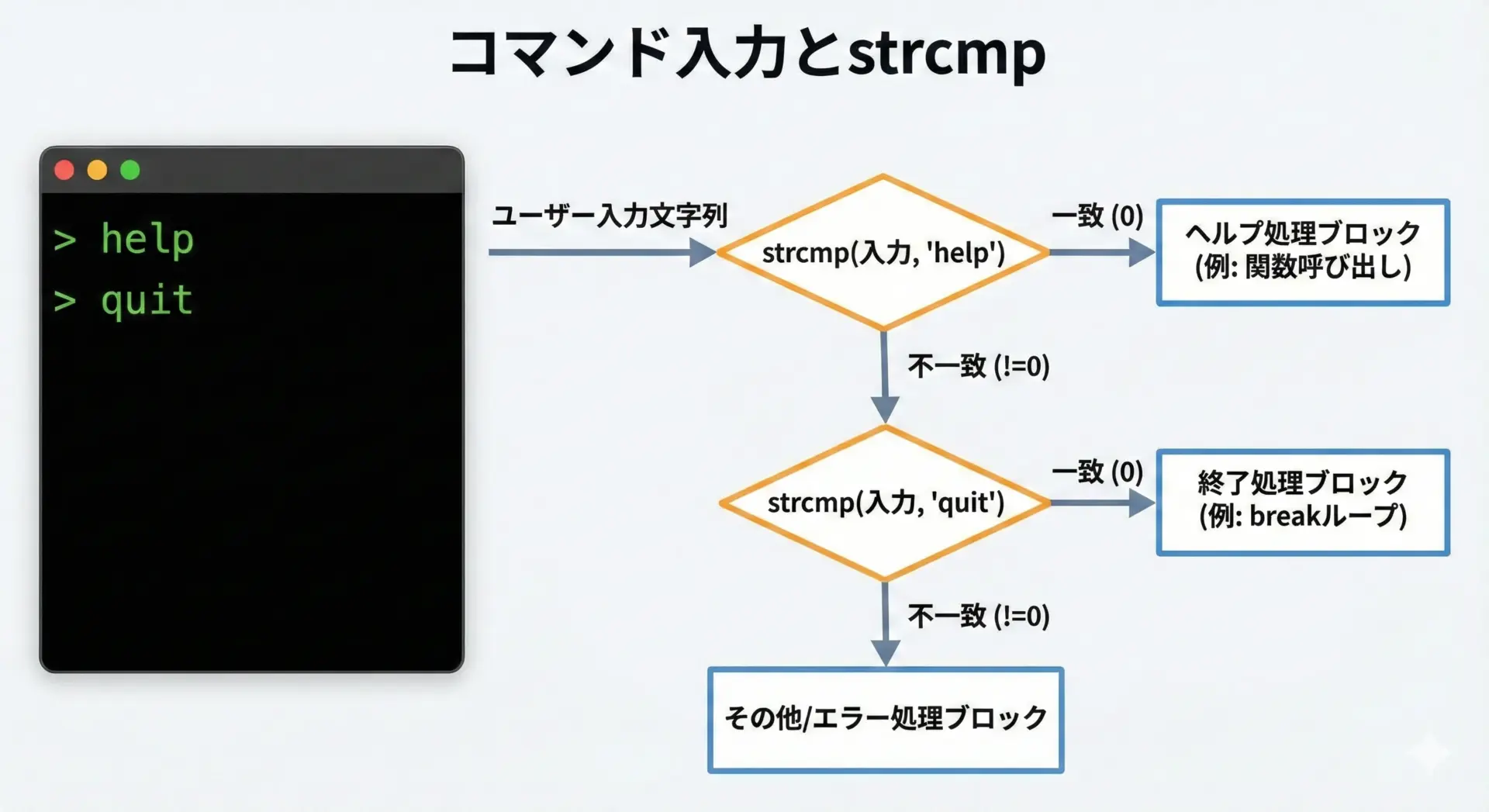
次に、標準入力から受け取った文字列を簡易コマンドとして判定する実用的な例を示します。
ここではfgetsを使って1行分の入力を受け取り、"help"や"quit"と比較します。
#include <stdio.h>
#include <string.h>
#define BUF_SIZE 100
// 改行文字を取り除くヘルパー関数
void chomp(char *s) {
// 文字列を先頭から走査して '\n' を見つけたら '\0' に置き換える
for (int i = 0; s[i] != '\0'; i++) {
if (s[i] == '\n') {
s[i] = '\0';
break;
}
}
}
int main(void) {
char command[BUF_SIZE];
printf("簡易コマンド( help / quit )を入力してください。\n");
while (1) {
printf("> ");
if (fgets(command, sizeof(command), stdin) == NULL) {
// 入力エラーまたはEOF
printf("入力を終了します。\n");
break;
}
// fgetsで読み込んだ文字列には末尾に改行が含まれることがあるので削除
chomp(command);
// "help" コマンドの判定
if (strcmp(command, "help") == 0) {
printf("利用できるコマンド:\n");
printf(" help - このヘルプを表示\n");
printf(" quit - 終了\n");
}
// "quit" コマンドの判定
else if (strcmp(command, "quit") == 0) {
printf("終了コマンドが入力されました。プログラムを終了します。\n");
break;
}
// どのコマンドにも一致しない場合
else {
printf("不明なコマンドです: %s\n", command);
}
}
return 0;
}簡易コマンド( help / quit )を入力してください。
> help
利用できるコマンド:
help - このヘルプを表示
quit - 終了
> foo
不明なコマンドです: foo
> quit
終了コマンドが入力されました。プログラムを終了します。ここではfgetsで読み込んだ文字列の末尾に付く改行文字'\n'を、比較前に取り除いている点が重要です。
改行が残ったままだと、"help\n"と"help"は別の文字列として扱われてしまうため、strcmpは0を返しません。
この点は後ほど「改行コード付き文字列の落とし穴」で詳しく説明します。
日本語文字列とstrcmpを使う際の注意点
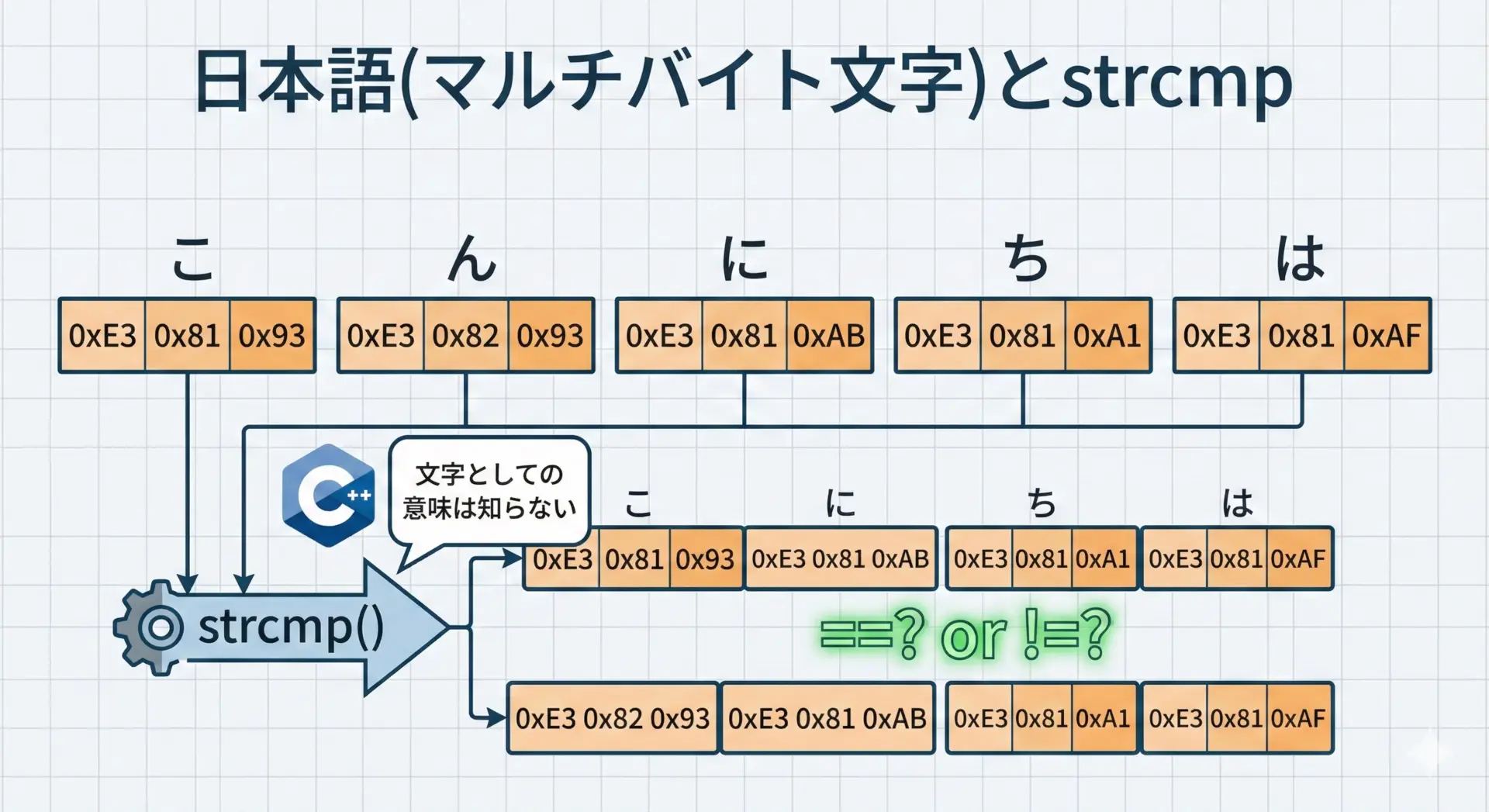
strcmpは「文字列」を比較するといっても、その実体は「バイト列の比較」です。
ASCII文字(英数字や記号)だけを使う場合はほとんど意識する必要はありませんが、日本語のようなマルチバイト文字を扱うときには注意が必要になります。
代表的な注意点を挙げます。
- 文字コードやエンコーディングによって結果が変わる
UTF-8やShift_JISなど、どの文字コードで文字列が表現されているかによって、バイト列の内容は変化します。strcmpは文字コードの意味を理解せず、生のバイト列をそのまま比較するだけなので、「辞書順」が人間の感覚と一致しないこともあります。 - 「五十音順」のような日本語特有の並び順は考慮されない
たとえば「あ」「い」「う」の順に並べたい場合でも、strcmpはUnicodeやShift_JISなどの文字コード表に基づく順序でしか比較しません。「濁点・半濁点・長音」「全角・半角」なども、そのコード値の並びで扱われます。 - マルチバイトの途中で不正なバイト列があると結果が不定になる
途中で文字化けしたり、文字列の途中で'\0'が入ってしまうと、そこまでのバイト列しか比較されません。特にバイナリデータや外部からの入力を扱うときには注意が必要です。
そのため、日本語の文字列を「五十音順」でソートしたい、辞書的な順序で比較したい、といった高度な要件がある場合には、ロケール対応の比較関数(例: strcoll)や外部ライブラリを検討することが多いです。
strcmpはあくまで「バイト列としての文字列比較である」と理解しておくとよいです。
strcmp使用時の注意点とよくある間違い
==とstrcmpの違い
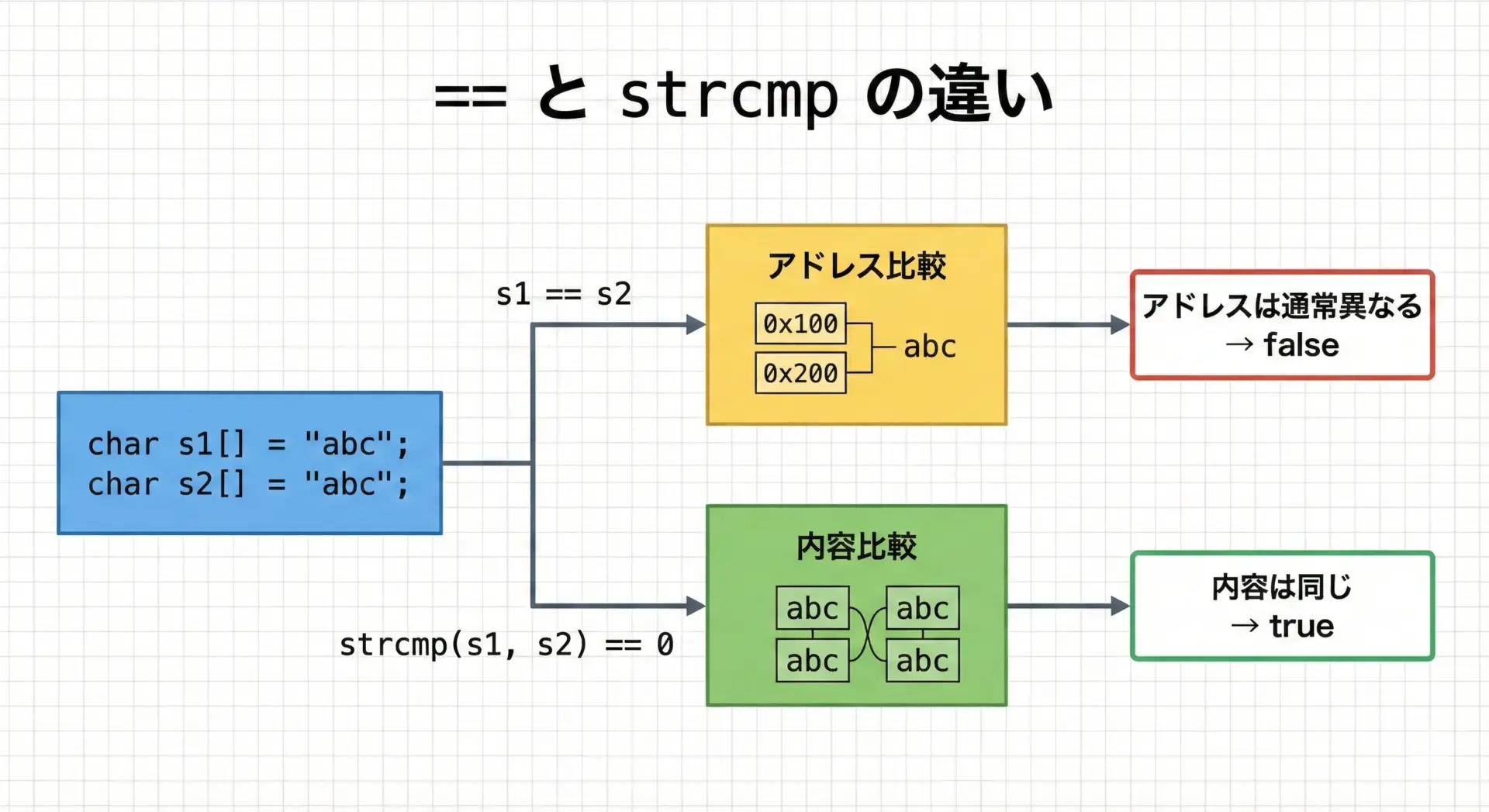
文字列の等価比較に==演算子を使ってしまうのは、C言語で最もよくある間違いの1つです。
char s1[] = "hello";
char s2[] = "hello";
if (s1 == s2) {
// これは「文字列が同じ」ことを意味しない
}このコードでs1 == s2が比較しているのは、「文字列の内容」ではなく配列(ポインタ)のアドレスです。
配列として宣言すると、通常は別々のメモリ領域に配置されるため、s1 == s2はfalseになります。
文字列の内容を比較したいときには、必ずstrcmpを使用し、strcmp(s1, s2) == 0と書く必要があります。
#include <stdio.h>
#include <string.h>
int main(void) {
char s1[] = "hello";
char s2[] = "hello";
// アドレスの比較
if (s1 == s2) {
printf("s1 == s2 は同じアドレスです。\n");
} else {
printf("s1 == s2 は異なるアドレスです。\n");
}
// 文字列の内容の比較
if (strcmp(s1, s2) == 0) {
printf("strcmp(s1, s2) == 0 なので、文字列の内容は等しいです。\n");
} else {
printf("文字列の内容は異なります。\n");
}
return 0;
}s1 == s2 は異なるアドレスです。
strcmp(s1, s2) == 0 なので、文字列の内容は等しいです。「アドレスを比較したいのか」「文字列の内容を比較したいのか」を常に意識することが大切です。
NULLポインタとstrcmpの危険性
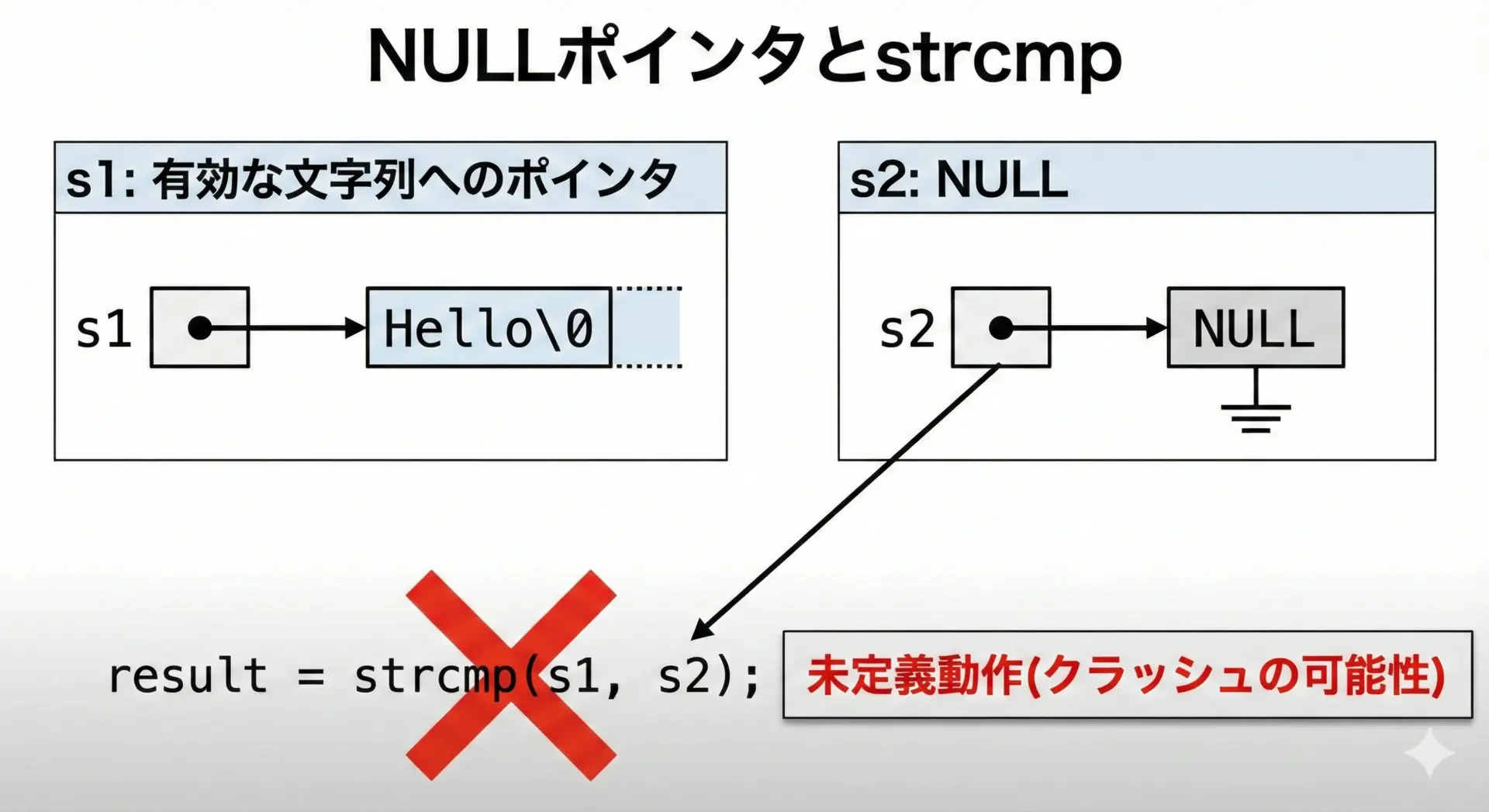
strcmpは、有効な文字列(終端'\0'を含む)へのポインタを引数として受け取ることが前提です。
もしNULLポインタを渡してしまうと、その動作は「未定義」であり、プログラムがクラッシュしたり、予期せぬ挙動を引き起こす恐れがあります。
#include <stdio.h>
#include <string.h>
int main(void) {
const char *s1 = "hello";
const char *s2 = NULL; // 何も指していない
// この呼び出しは未定義動作です。絶対にやってはいけません。
int r = strcmp(s1, s2);
printf("結果: %d\n", r);
return 0;
}このコードは、一見コンパイルできてしまうかもしれませんが、実行時にNULLポインタを経由してメモリにアクセスしてしまうため、大抵はセグメンテーションフォルトなどで異常終了します。
そのため、strcmpを呼ぶ前に、ポインタがNULLかどうかを必ずチェックする習慣をつけると安全です。
if (s1 == NULL || s2 == NULL) {
// エラー処理: どちらかがNULLなので比較できない
} else {
int r = strcmp(s1, s2);
// 以降でrを使う
}「NULLを渡したときにどう振る舞うか」は標準仕様では一切保証されていないため、避けなければならないということを覚えておきましょう。
改行コード付き文字列とstrcmpの落とし穴
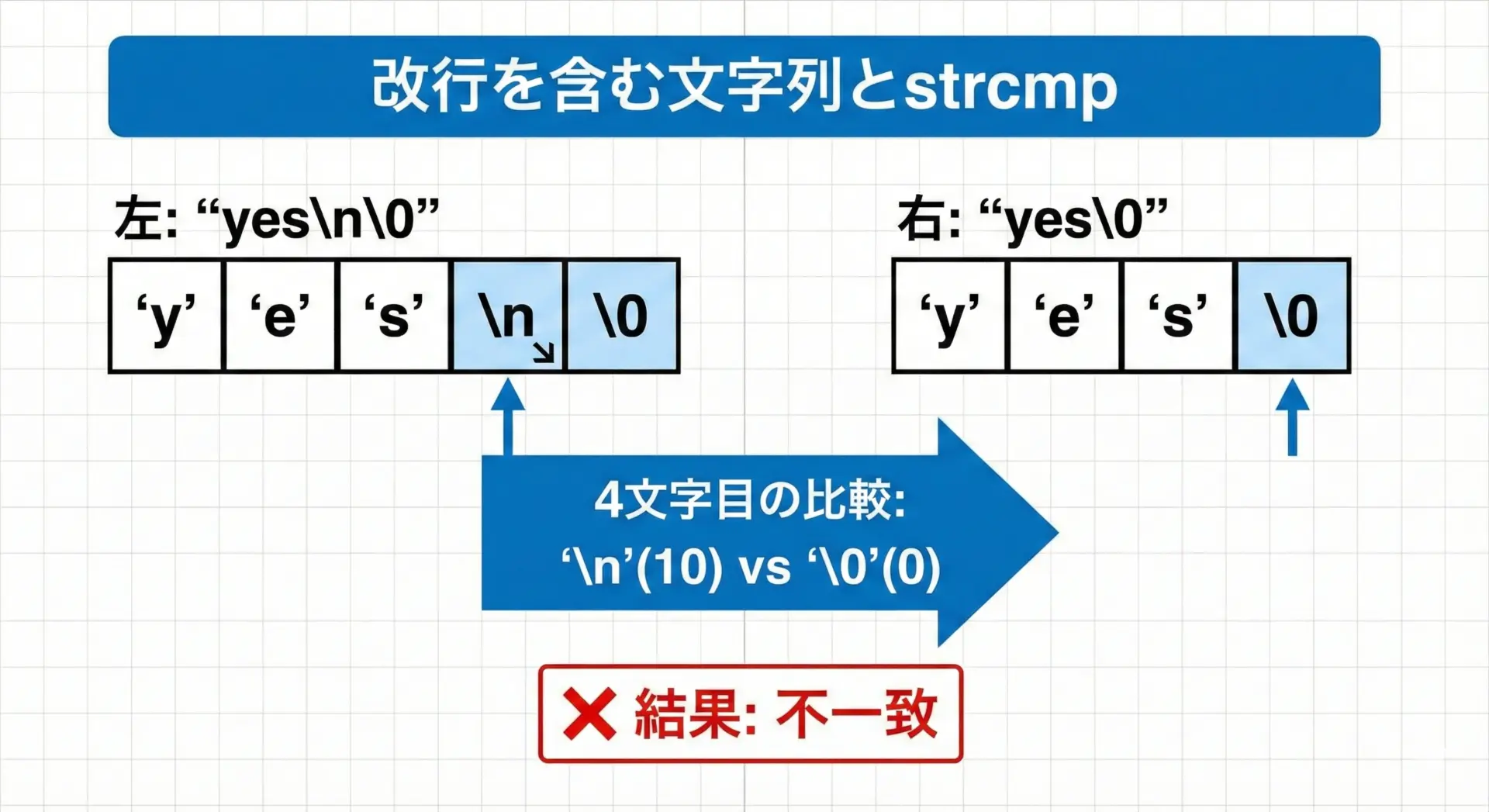
標準入力から文字列を取得するfgetsは、末尾に改行文字'\n'を含めて読み込むという特徴があります。
そのため、"yes"と入力したつもりでも、実際の文字列は"yes\n"になっていることが多いです。
この状態で、リテラル"yes"とstrcmpで比較すると、次のようになります。
- 1文字目:
'y'と'y'→ 一致 - 2文字目:
'e'と'e'→ 一致 - 3文字目:
's'と's'→ 一致 - 4文字目:
'\n'と'\0'→ 不一致(比較がここで終わる)
結果として、strcmpは0以外を返し、「等しくない」と判定されてしまいます。
この落とし穴を避けるためには、比較する前に末尾の改行を削除する処理を行う必要があります。
先ほどのコマンド判定の例で使ったchomp関数のようなものを用意しておくと便利です。
#include <stdio.h>
#include <string.h>
#define BUF_SIZE 100
void chomp(char *s) {
for (int i = 0; s[i] != '\0'; i++) {
if (s[i] == '\n') {
s[i] = '\0';
break;
}
}
}
int main(void) {
char buf[BUF_SIZE];
printf("文字列を入力してください: ");
if (fgets(buf, sizeof(buf), stdin) == NULL) {
return 1;
}
printf("chomp前: \"%s\"\n", buf);
chomp(buf);
printf("chomp後: \"%s\"\n", buf);
if (strcmp(buf, "yes") == 0) {
printf("yes と一致しました。\n");
} else {
printf("yes とは一致しませんでした。\n");
}
return 0;
}文字列を入力してください: yes⏎
chomp前: "yes
"
chomp後: "yes"
yes と一致しました。入力とstrcmpを組み合わせるときには、「改行が残っていないか」を必ず意識するようにしましょう。
大文字・小文字を区別しない比較との違い
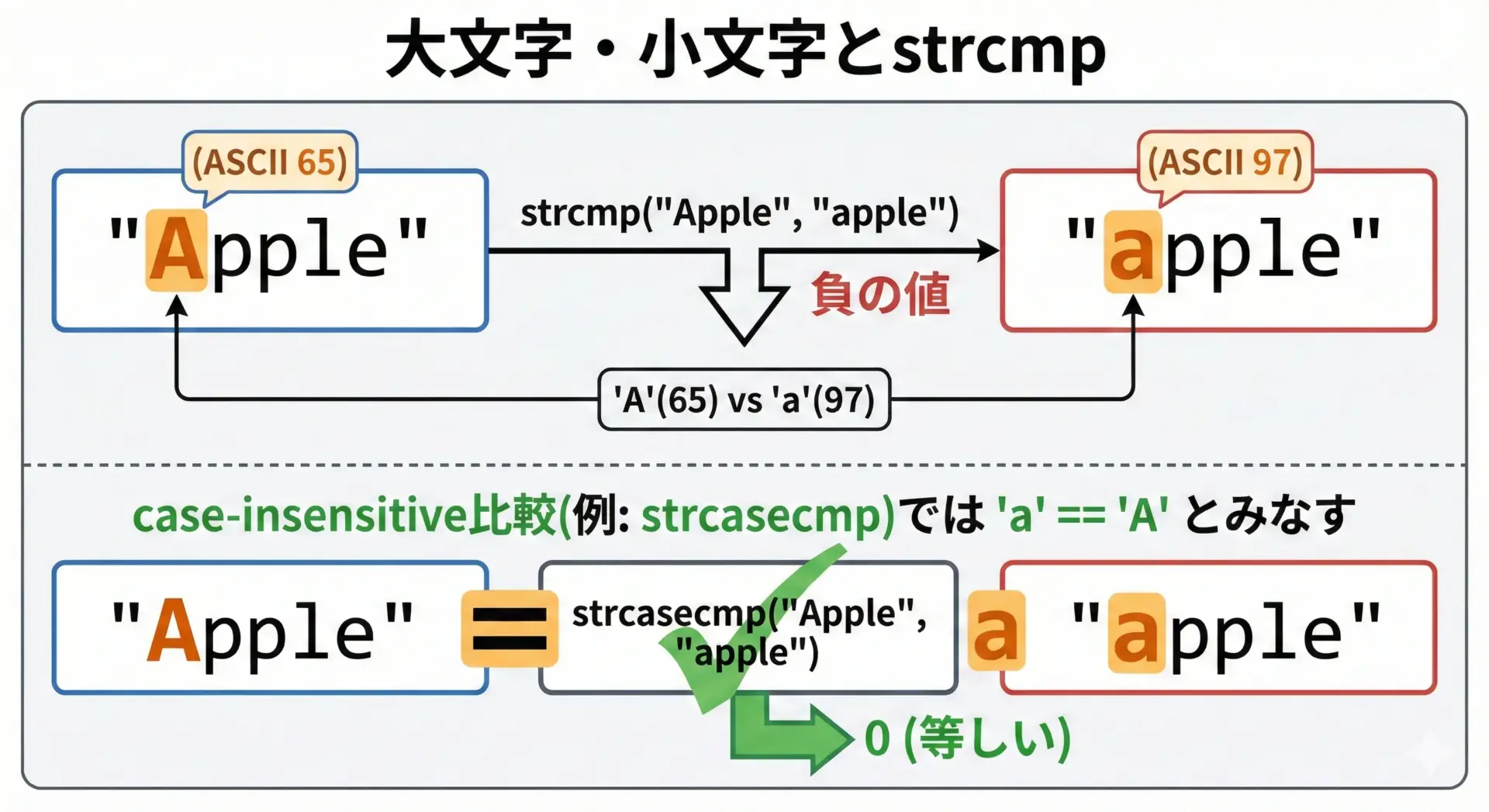
strcmpは、大文字と小文字を区別して比較します。
つまり"Apple"と"apple"は、異なる文字列として扱われます。
#include <stdio.h>
#include <string.h>
int main(void) {
const char *s1 = "Apple";
const char *s2 = "apple";
int r = strcmp(s1, s2);
printf("strcmp(\"%s\", \"%s\") = %d\n", s1, s2, r);
if (r == 0) {
printf("2つの文字列は等しいと判定されました。\n");
} else {
printf("2つの文字列は異なると判定されました。\n");
}
return 0;
}strcmp("Apple", "apple") = -32 ← 例: 'A'(65) - 'a'(97) の差
2つの文字列は異なると判定されました。ユーザー入力で「YES」「Yes」「yes」などを同じ意味として扱いたい場合には、strcmpだけでは不十分です。
次のようなアプローチが考えられます。
- 入力文字列をすべて小文字(または大文字)に変換してからstrcmpで比較する
- 環境に
strcasecmp(または_stricmpなど)があれば、それを利用する - 自前で大文字・小文字を無視する比較関数を実装する
例として、すべて小文字に変換してから比較する方法を示します。
#include <stdio.h>
#include <string.h>
#include <ctype.h>
#define BUF_SIZE 100
// 文字列をすべて小文字に変換する関数
void to_lower_str(char *s) {
for (int i = 0; s[i] != '\0'; i++) {
// toupper/tolower を使うときは、引数を必ずunsigned charにキャストするのが安全
s[i] = (char)tolower((unsigned char)s[i]);
}
}
int main(void) {
char buf[BUF_SIZE];
printf("yes/YES/Yes などを入力してください: ");
if (fgets(buf, sizeof(buf), stdin) == NULL) {
return 1;
}
// 改行を削除
for (int i = 0; buf[i] != '\0'; i++) {
if (buf[i] == '\n') {
buf[i] = '\0';
break;
}
}
// 入力を小文字に変換
to_lower_str(buf);
if (strcmp(buf, "yes") == 0) {
printf("大文字・小文字を無視して yes と判断されました。\n");
} else {
printf("yes とは判断されませんでした。\n");
}
return 0;
}yes/YES/Yes などを入力してください: YES⏎
大文字・小文字を無視して yes と判断されました。このように、strcmpはあくまで「厳密なバイト列比較」であり、大文字・小文字の違いを吸収するような機能は持っていないことを理解しておく必要があります。
まとめ
strcmpは、C言語で文字列の内容を比較するための基本関数です。
==がアドレスを比較するのに対し、strcmpは終端文字'\0'まで1文字ずつ比較し、「負・0・正」の戻り値で辞書順を示します。
戻り値の具体的な値には意味がなく、0との大小で判断すること、NULLポインタや改行付き文字列を渡さないこと、大文字小文字や日本語の扱いなどの特性を理解していれば、誤りを避けながら安全に利用できます。
実務でも頻出する関数なので、挙動と注意点をしっかり押さえておくと安心です。
