C言語の文字列は、単に文字が並んでいるだけではなく、配列・ポインタ・終端文字など複数の要素が密接に関わっています。
本記事ではC言語の文字列をメモリレベルから図解で丁寧に解説し、配列とポインタの違い、終端文字の重要性、安全な文字列操作のコツまで、実践で困らない知識を体系的に身につけられるよう解説します。
C言語の文字列とは
C言語における文字列の基本定義
C言語において文字列(string)とは、単に「文字がいくつか並んだもの」ではなく、最後に必ず終端文字'\0'(ヌル文字)が付いているchar型の並びを指します。
C標準では、文字列は概ね次のように定義できます。
「メモリ上に連続して格納されたcharの列で、末尾に'\0'があるもの」
ここで重要なのは、「長さ」と「領域サイズ」が違うという点です。
文字列の「長さ」は'\0'までの文字数であり、実際に用意した配列サイズやメモリ領域の大きさとは別物です。
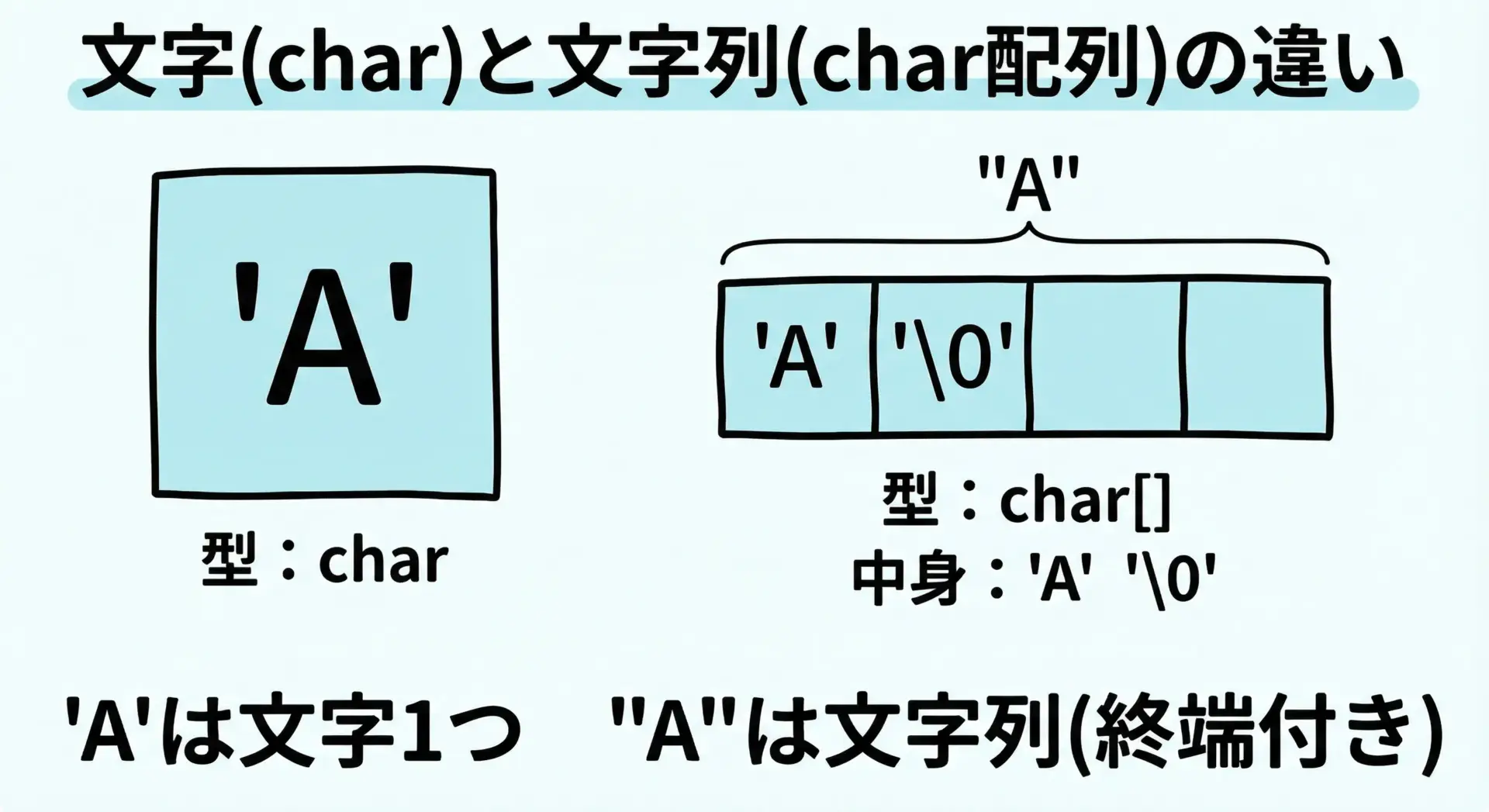
文字と文字列の違い
C言語では「1文字」と「文字列」は型レベルで異なります。
代表的な違いを説明します。
たとえば次のように書いた場合を比較します。
#include <stdio.h>
int main(void) {
char ch = 'A'; // 1文字。char型
char str[] = "A"; // 文字列。"A"と'\0'の2文字分
printf("ch = %c\n", ch);
printf("str = %s\n", str);
return 0;
}ch = A
str = A見た目はどちらも「A」と出力されますが、型もメモリ上の構造もまったく別物です。
- 文字(char)
1バイト(多くの環境)の整数型で、'A'など' 'で囲む表記を使います。 - 文字列(char配列 / 文字列リテラル)
複数のcharが並び、最後に'\0'が自動的に付きます。"A"など" "で囲む表記を使います。
ここで「文字は1つの値」「文字列は配列(実体)か、その先頭を指すポインタ(アドレス)」というイメージを持っておくと、この後の配列・ポインタの理解がとてもスムーズになります。
C言語文字列のメモリ上のイメージ
C言語の文字列を理解するうえで欠かせないのがメモリ上でどのように格納されているかという視点です。
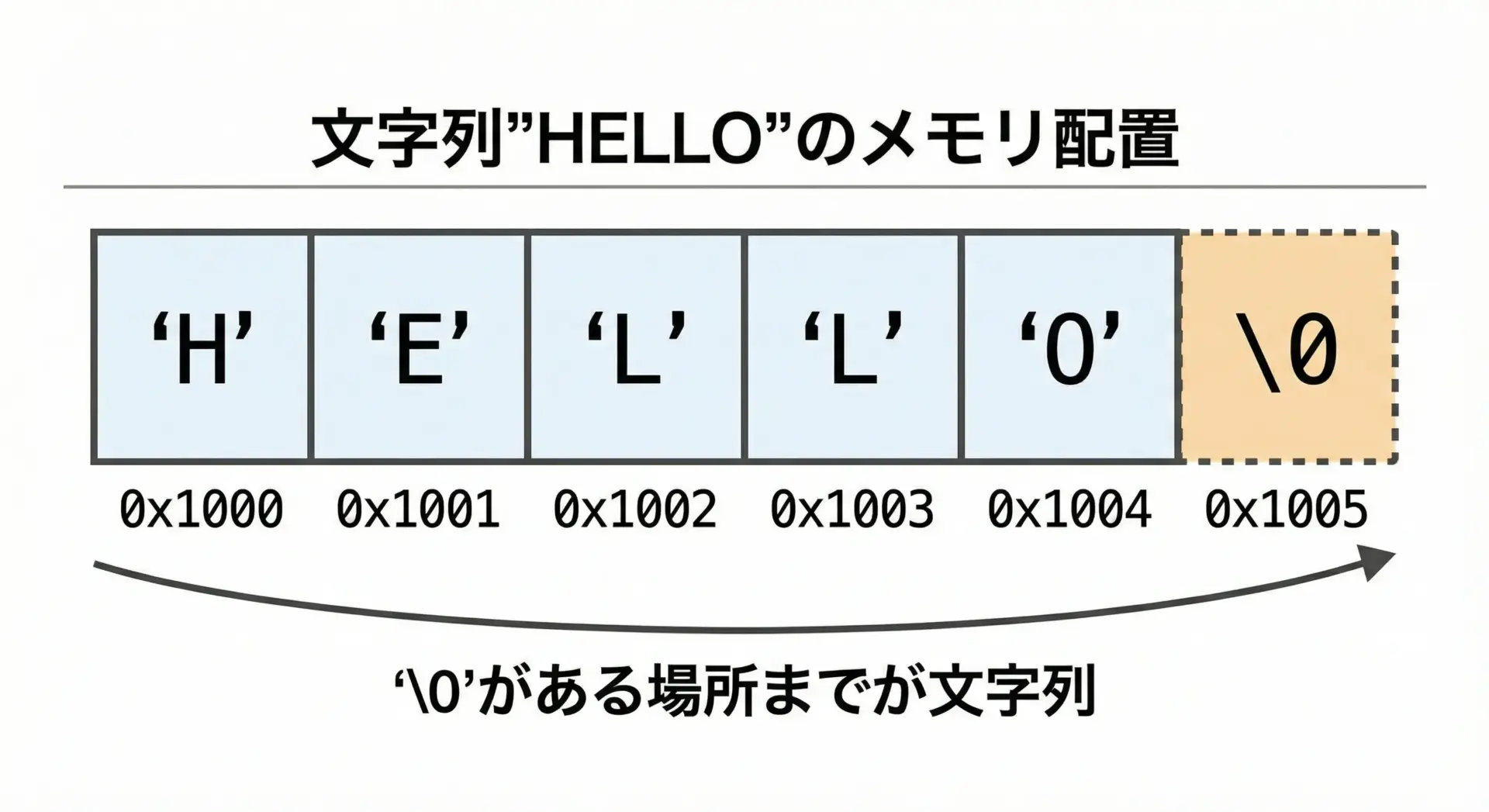
たとえば次のように宣言したとします。
char str[] = "HELLO";これはメモリ上では次のようになります。
'H''E''L''L''O''\0'← 終端文字
終端文字'\0'がある場所までが、その文字列の有効範囲です。
関数printfの%sやstrlenなどは、この'\0'を見つけるまでメモリを順に読み進めます。
文字列と配列の基礎
char配列での文字列の宣言と初期化
文字列を扱う最も基本的な方法はchar配列です。
代表的な宣言方法を比較してみます。
#include <stdio.h>
int main(void) {
// 1. 文字列リテラルで初期化
char str1[] = "Hello"; // 自動でサイズ6(5文字 + '\0')
// 2. 明示的に要素を並べる
char str2[] = { 'H', 'e', 'l', 'l', 'o', '\0' };
// 3. サイズを指定して初期化
char str3[10] = "Hello"; // 残りは0で初期化される
// 4. 1文字ずつ代入(あまり推奨はされない)
char str4[6];
str4[0] = 'H';
str4[1] = 'e';
str4[2] = 'l';
str4[3] = 'l';
str4[4] = 'o';
str4[5] = '\0'; // 終端を忘れるとバグの元
printf("str1 = %s\n", str1);
printf("str2 = %s\n", str2);
printf("str3 = %s\n", str3);
printf("str4 = %s\n", str4);
return 0;
}str1 = Hello
str2 = Hello
str3 = Hello
str4 = Helloここで必ず意識すべきポイントは次の2点です。
- 文字列のためには文字数 + 1個分の配列サイズが必要
- その「+1」が終端文字
'\0'のための領域
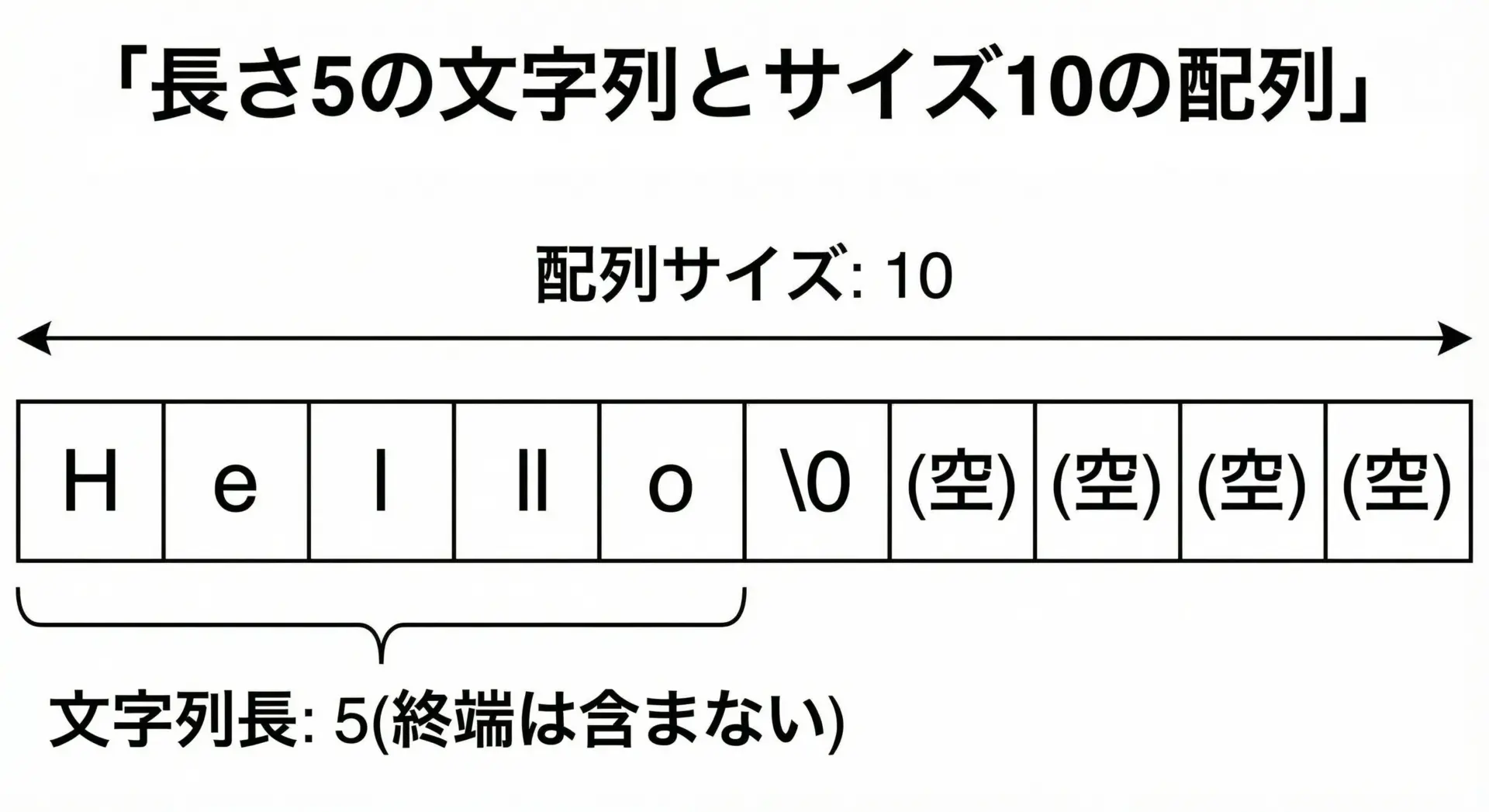
配列による文字列の長さと領域サイズ
文字列をchar配列で扱うとき、「配列のサイズ」と「文字列の長さ」は別物です。
この区別はバッファオーバーフローの防止にも直結します。
例として、次のコードで確認してみます。
#include <stdio.h>
#include <string.h> // strlenを使うため
int main(void) {
char str[10] = "Hello";
// sizeofは配列全体のバイト数
printf("配列のバイト数(sizeof): %zu\n", sizeof(str));
// strlenは'\0'までの文字数
printf("文字列の長さ(strlen): %zu\n", strlen(str));
return 0;
}配列のバイト数(sizeof): 10
文字列の長さ(strlen): 5sizeofは配列全体のバイト数、strlenは終端'\0'までの文字数であることをしっかり区別しておくことが重要です。
文字配列と終端文字(null文字)の関係
文字列をchar配列で保持するとき、終端文字'\0'が存在しなければそれは「文字列」ではありません。
単なるcharの並びです。
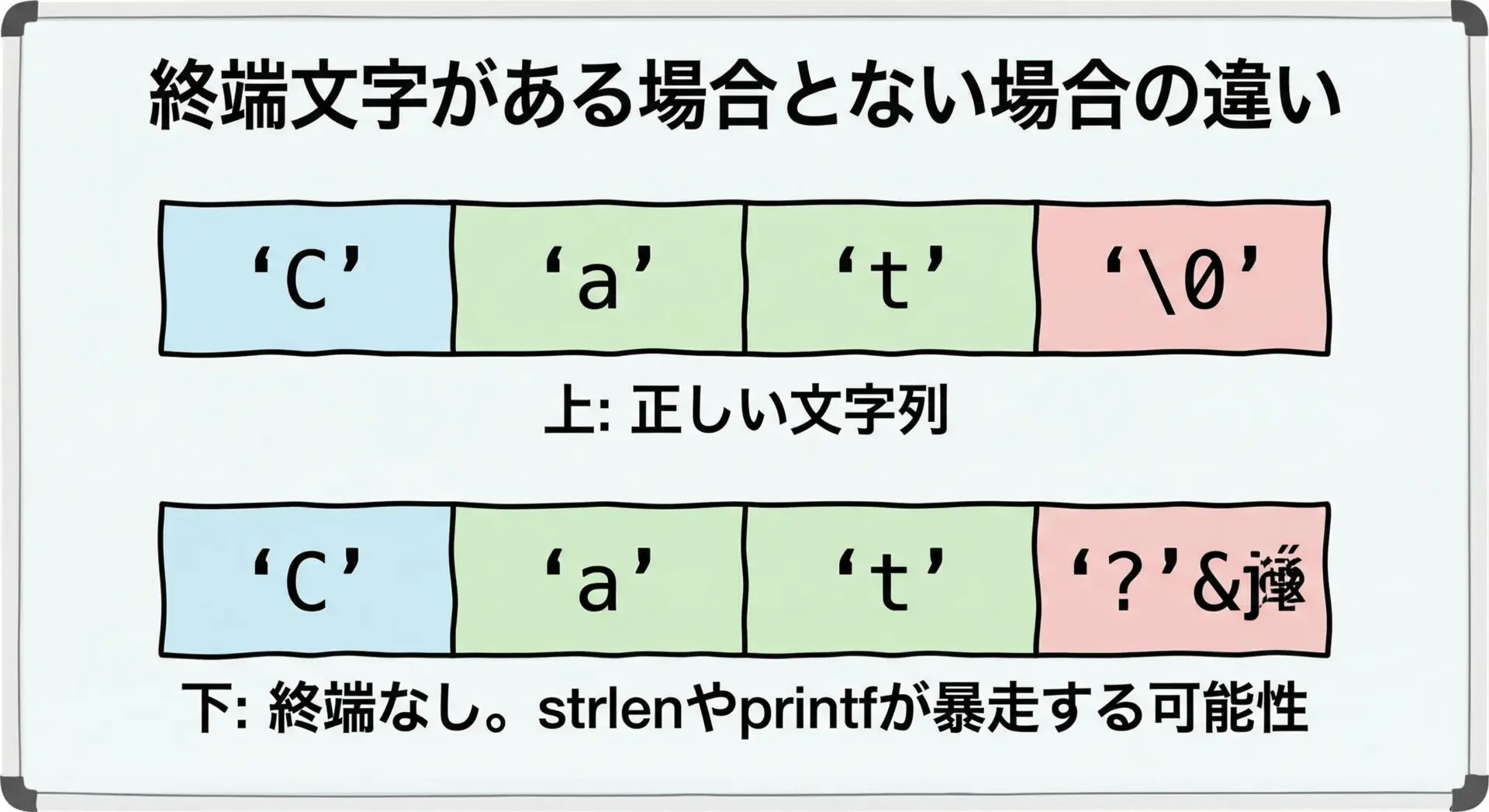
次の例で違いを確認してみます。
#include <stdio.h>
int main(void) {
char ok[4] = { 'C', 'a', 't', '\0' }; // 正しい文字列
char ng[3] = { 'D', 'o', 'g' }; // 終端なし。文字列ではない
printf("ok = %s\n", ok);
// ngを文字列として扱うのは未定義動作(危険)
printf("ng = %s\n", ng); // たまたま動く場合もあるが、安全ではない
return 0;
}ok = Cat
ng = Dog▒▒▒▒...実際の出力は環境によって変わりますが、ngの方はゴミが続いたりクラッシュしたりする可能性があります。
これは、終端文字がないためにprintfがどこまで読めばよいか分からないからです。
図解で理解する配列ベースの文字列格納
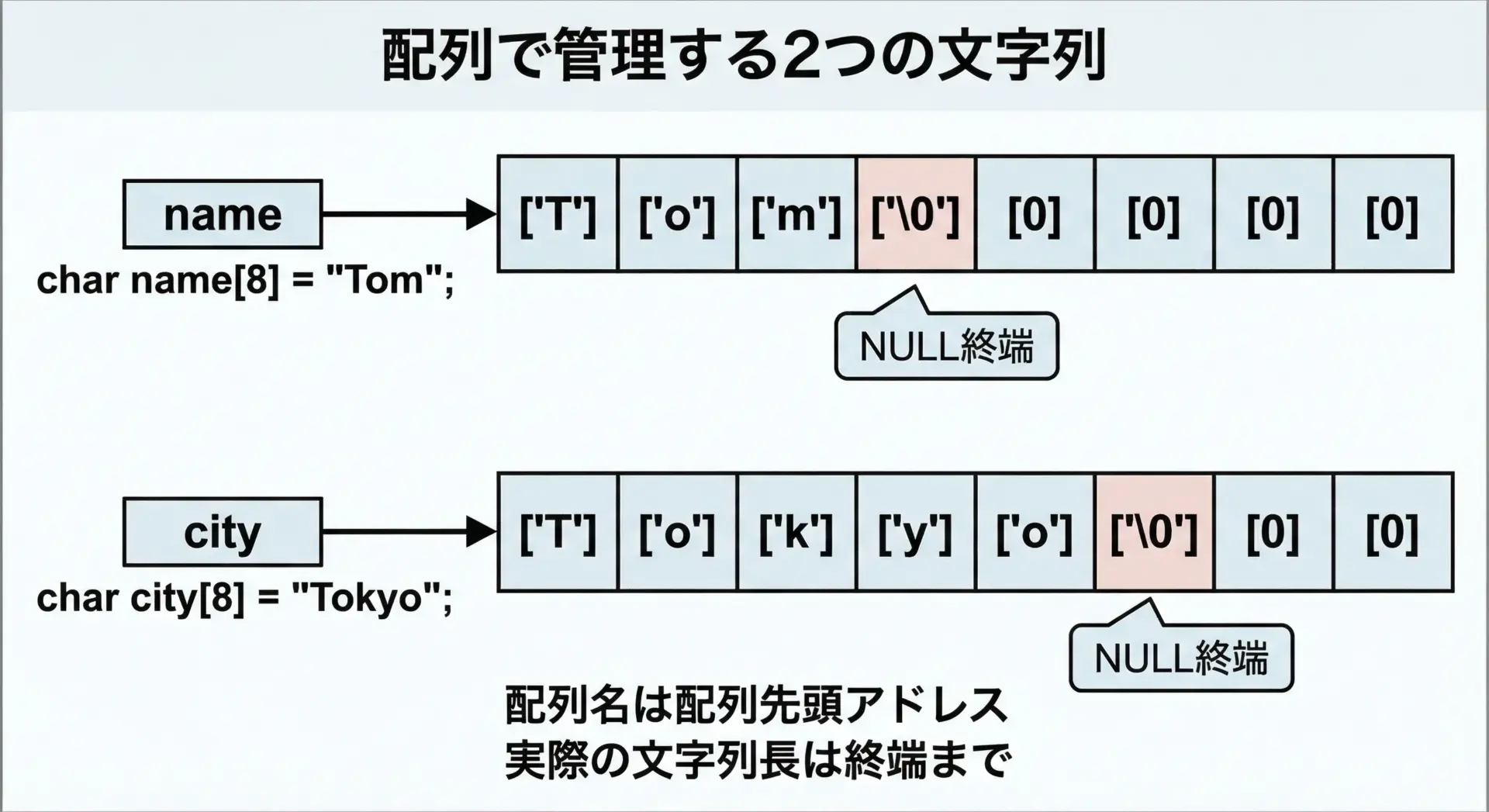
このように、char配列で文字列を扱う場合は、次のように意識すると分かりやすくなります。
- 配列は「入れ物」
用意したサイズ分だけ文字を入れられます。 - 文字列の長さは「実際に入っている文字の数」
終端'\0'の手前までの要素数です。 - 終端
'\0'を境に、前が「文字列」、後ろは「空き」
後ろは次の文字列や追加データのための予約領域になります。
文字列とポインタの使い方
文字列リテラルとポインタ(charポインタ)の違い
配列だけでなく、ポインタを使って文字列を扱うことも非常に多いです。
その代表例が文字列リテラルです。
#include <stdio.h>
int main(void) {
char *p = "Hello"; // 文字列リテラルへのポインタ
printf("%s\n", p); // "Hello"が表示される
return 0;
}ここでの"Hello"は実行ファイル内に格納された読み取り専用の領域(多くの処理系)に置かれ、その先頭アドレスがpに代入されます。
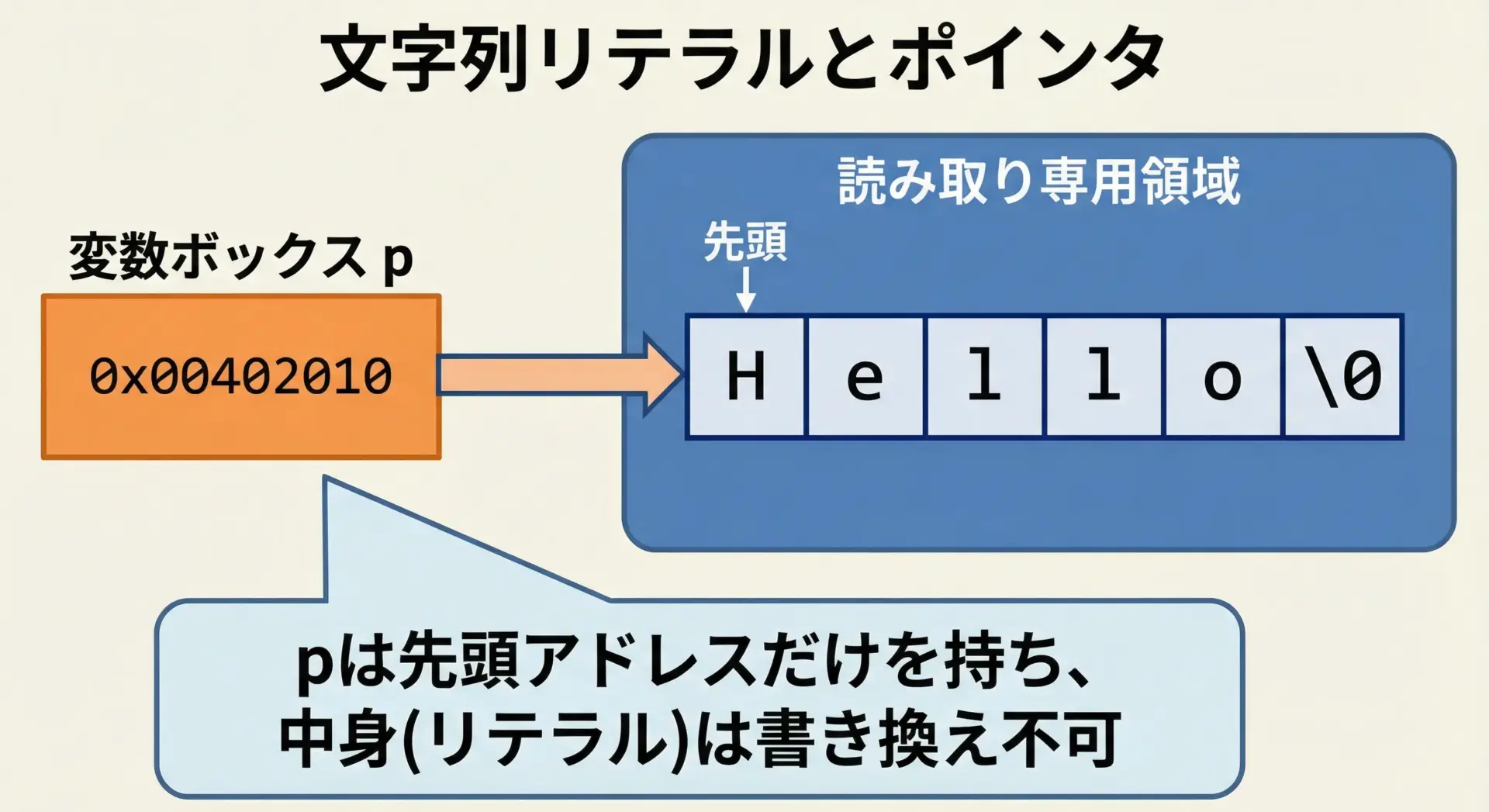
一方、配列で宣言した場合は次のようになります。
char a[] = "Hello"; // 書き換え可能な配列
char *p = "Hello"; // 読み取り専用リテラルへのポインタ- a
ローカル変数としてスタック上などに配列領域が確保され、その中身は書き換え可能です。 - p
実行時に用意された文字列リテラル領域の先頭アドレスを保持し、その領域は書き換えてはいけません。
配列とポインタの使い分けと注意点
配列とポインタは似ているようで、意味も寿命も違うため、使い分けが重要です。
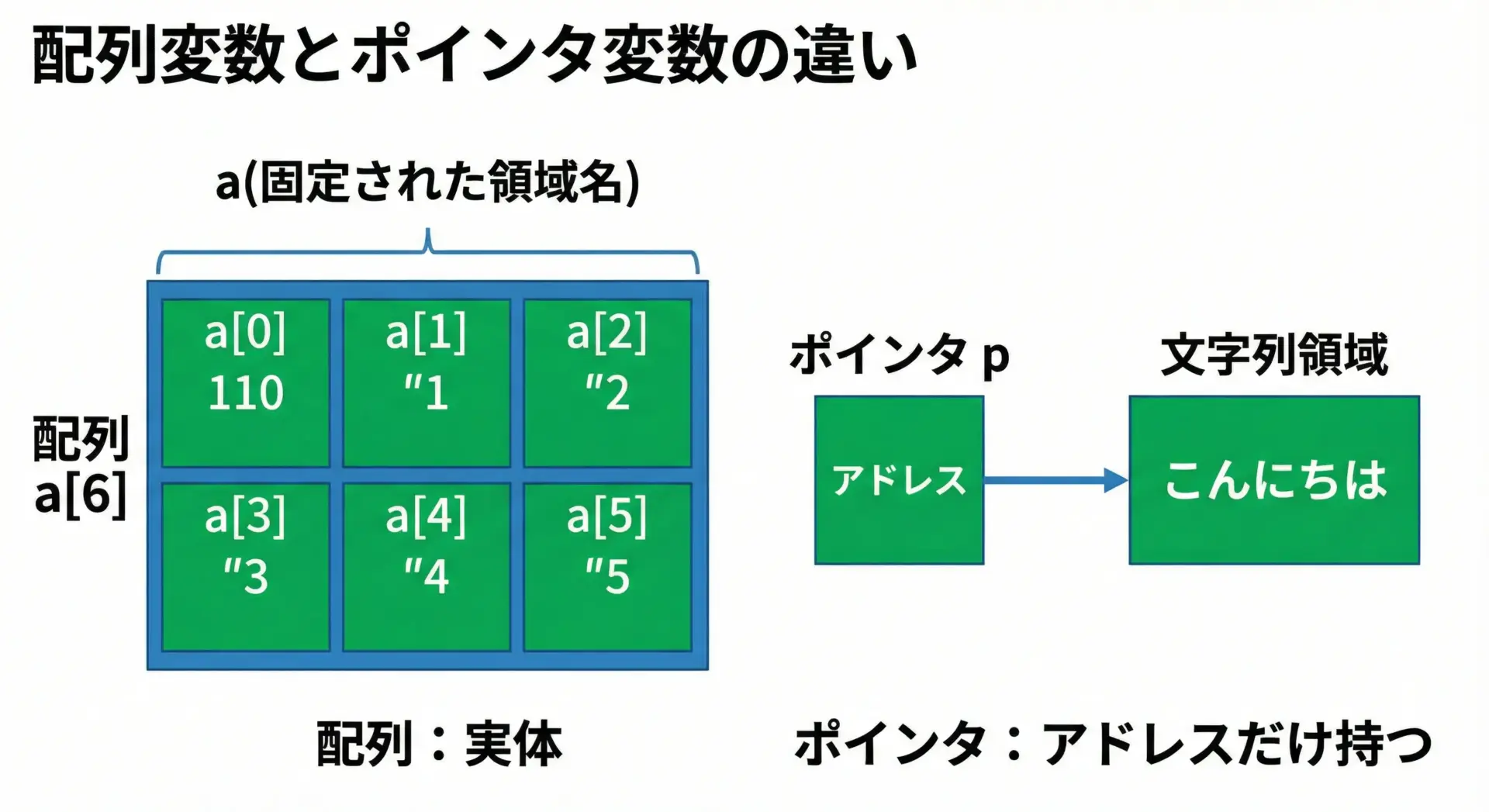
典型的な違いと注意点をコードで確認します。
#include <stdio.h>
int main(void) {
char a[] = "Hello"; // 配列: 実体を持つ
char *p = "World"; // ポインタ: リテラルの先頭アドレス
// 1. sizeofの違い
printf("sizeof(a) = %zu\n", sizeof(a)); // 配列全体のサイズ
printf("sizeof(p) = %zu\n", sizeof(p)); // ポインタのサイズ(アドレスの大きさ)
// 2. 書き換えの可否
a[0] = 'h'; // OK: 配列の中身は書き換え可能
printf("a = %s\n", a);
// p[0] = 'w'; // 危険: 多くの処理系で未定義動作(書き換え禁止領域)
return 0;
}sizeof(a) = 6
sizeof(p) = 8 ← 64bit環境の例
a = helloここから分かる重要ポイントは次の2つです。
- 配列名
aは「その配列領域そのもの」であり、sizeof(a)は中身のサイズになります。 - ポインタ
pは「アドレスを入れる変数」であり、sizeof(p)はアドレスのサイズになります。
ポインタ演算でたどる文字列
文字列をポインタで扱うと、ポインタ演算を使って1文字ずつたどることができます。
#include <stdio.h>
int main(void) {
char str[] = "ABC";
char *p = str; // 配列strの先頭アドレス
// インデックスでアクセス
printf("str[0] = %c\n", str[0]);
printf("str[1] = %c\n", str[1]);
printf("str[2] = %c\n", str[2]);
// ポインタ演算でアクセス
printf("*(p) = %c\n", *p);
printf("*(p + 1) = %c\n", *(p + 1));
printf("*(p + 2) = %c\n", *(p + 2));
// ループで1文字ずつたどる
for (char *q = str; *q != '\0'; q++) {
// qが指す文字が'\0'になるまで1文字ずつ進める
printf("%c ", *q);
}
printf("\n");
return 0;
}str[0] = A
str[1] = B
str[2] = C
*(p) = A
*(p + 1) = B
*(p + 2) = C
A B C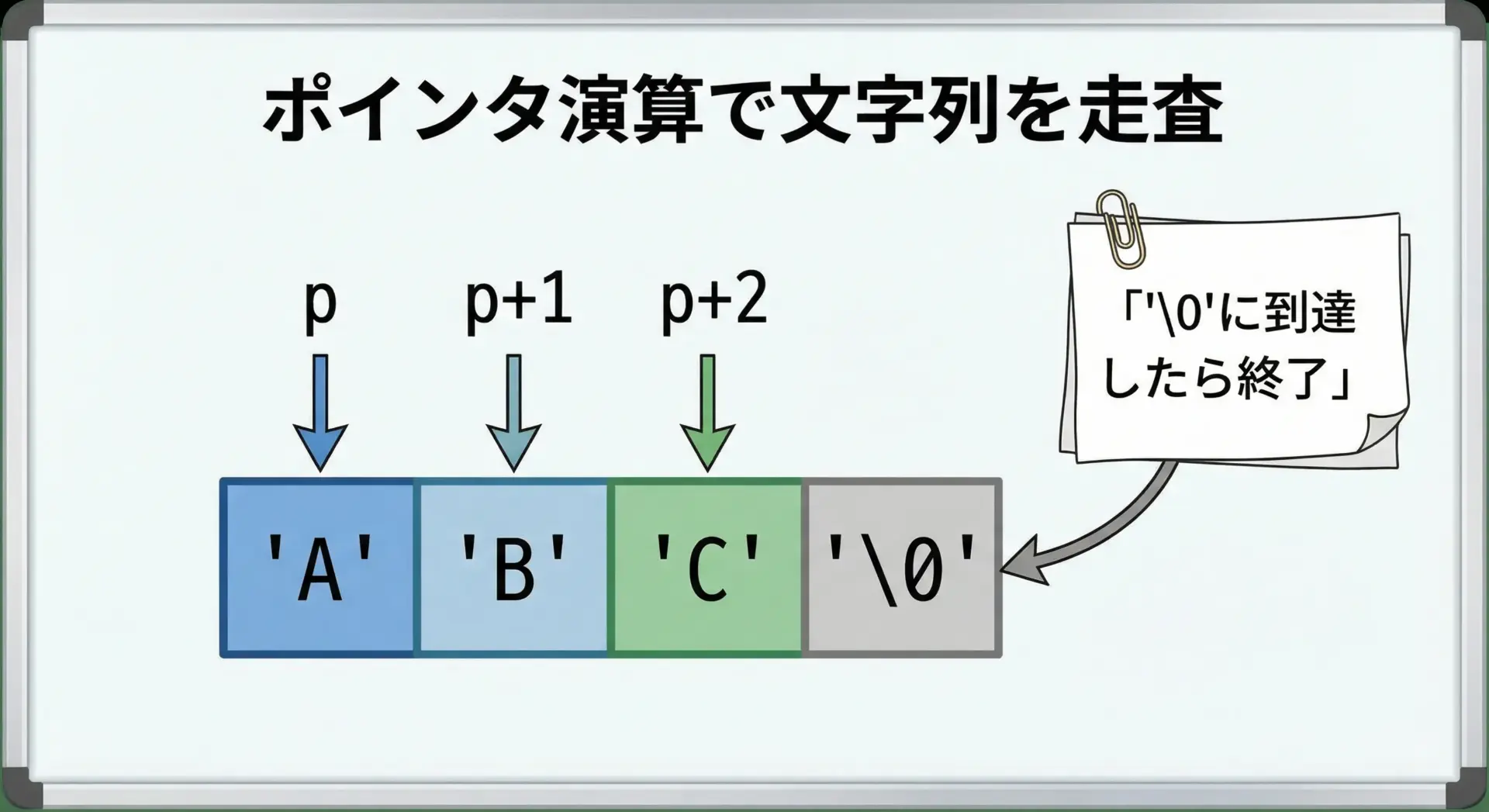
このように、配列インデックスstr[i]と、ポインタ演算*(p + i)は本質的に同じです。
どちらを使うかは好みや可読性、APIとの整合性で選ばれます。
const修飾子と文字列リテラルの安全な扱い方
文字列リテラルは多くの処理系で読み取り専用領域に置かれます。
そのため書き換えようとすると未定義動作になります。
安全に扱うためにはconst修飾子を付けるのがよい習慣です。
#include <stdio.h>
int main(void) {
// constを付けて「書き換えない」意図を明示
const char *msg = "Hello";
printf("%s\n", msg);
// msg[0] = 'h'; // コンパイルエラーになるべき: 書き換え禁止
return 0;
}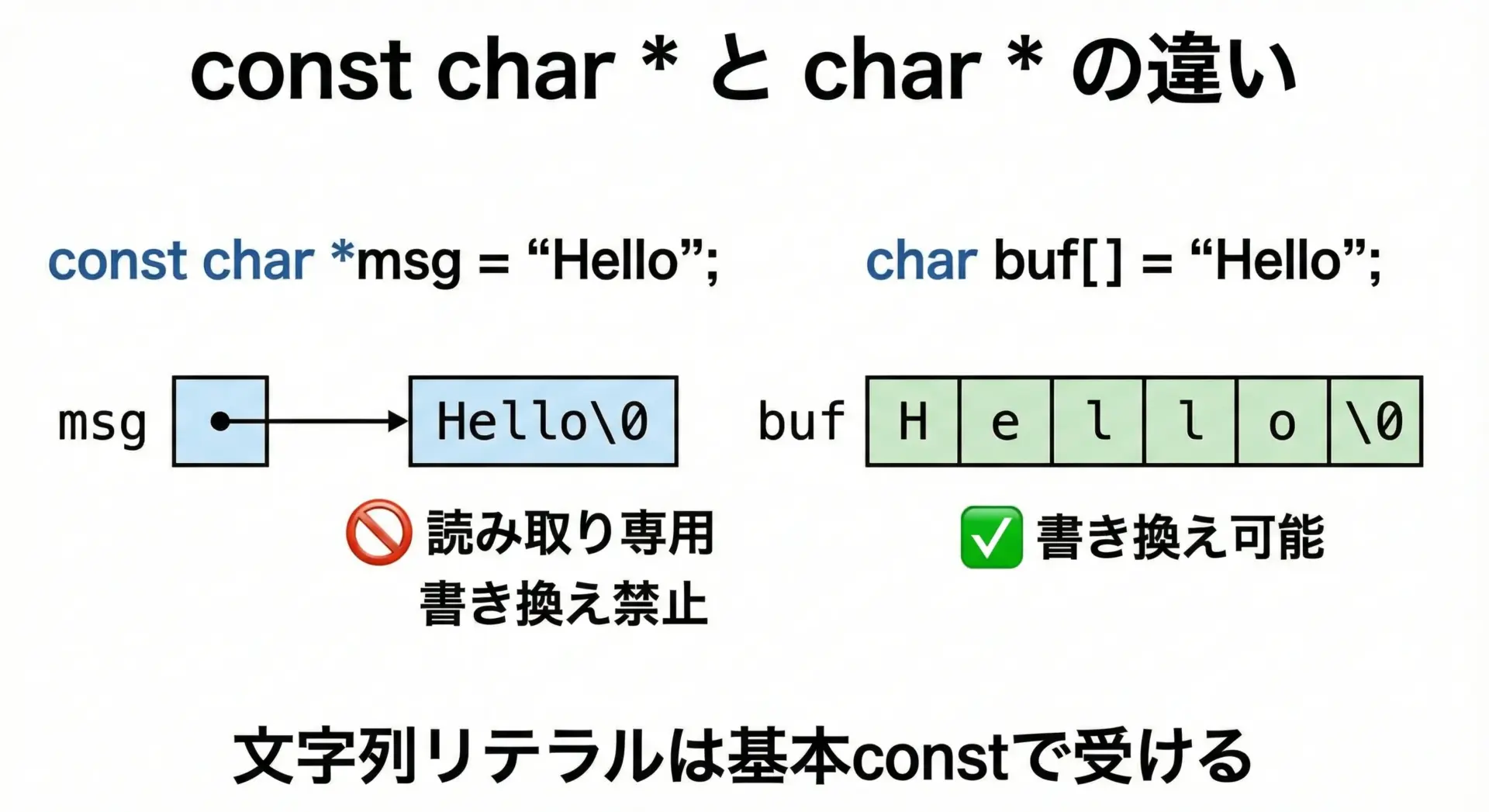
ルールとして、文字列リテラルを指すポインタにはconst char *を使うようにしておくと、誤って書き換えようとしてもコンパイラが警告・エラーを出してくれるため、安全性が高まります。
終端文字と文字列操作の落とし穴
終端文字(‘\0’)の役割と仕組み
C言語の文字列では、終端文字'\0'が文字列の終わりを示す唯一の手がかりです。
文字列を扱う標準関数はすべて、この'\0'を探しながら処理を行います。
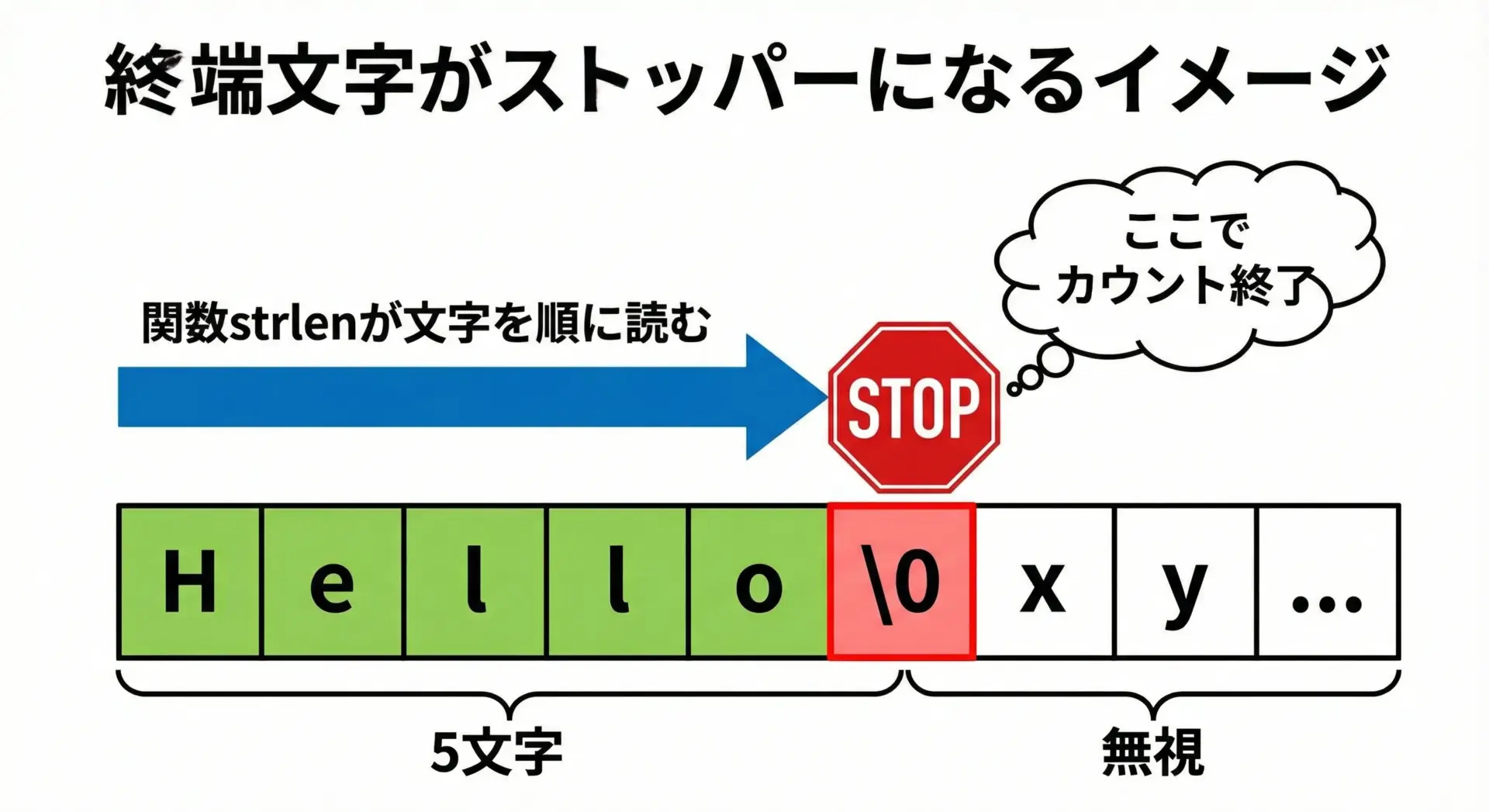
たとえばstrlenの動作は、ざっくりと次のような疑似コードで表せます。
size_t my_strlen(const char *s) {
size_t len = 0;
// '\0'に出会うまで1文字ずつ進める
while (*s != '\0') {
len++;
s++; // ポインタを次の文字へ
}
return len;
}このように、終端文字がないと関数はどこまでもメモリを読み続けてしまい、未定義動作を引き起こします。
終端忘れで起こるバグと典型的な危険パターン
終端文字を忘れる・壊してしまう典型パターンを見てみます。
1文字足りない配列サイズ
#include <stdio.h>
#include <string.h>
int main(void) {
char str[5] = "Hello"; // バグ: "Hello"は6文字必要("Hello" + '\0')
printf("str = %s\n", str); // 未定義動作
printf("strlen(str) = %zu\n", strlen(str)); // これも未定義動作
return 0;
}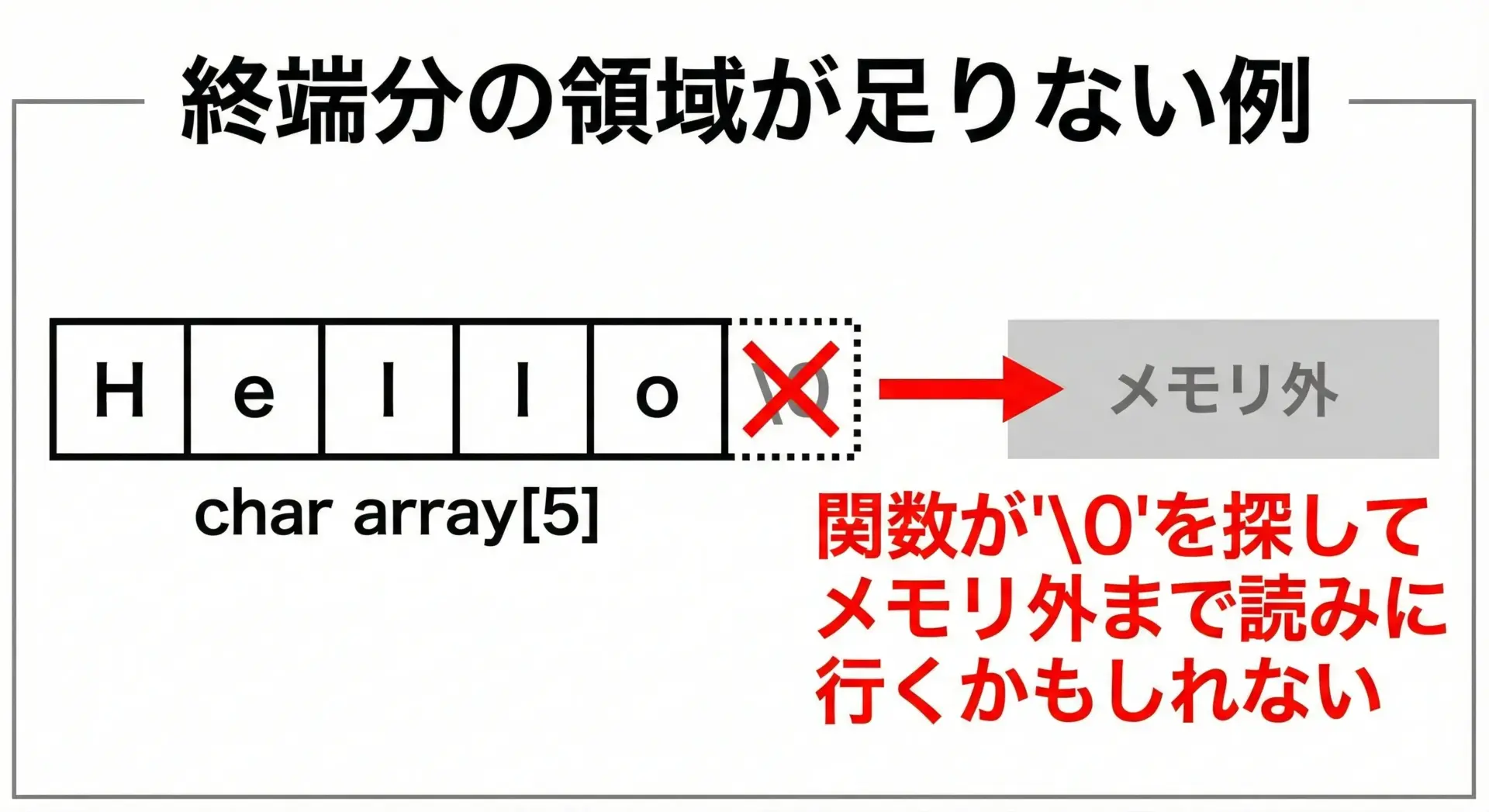
このようなミスはコンパイラが警告してくれることもありますが、必ず「文字数 + 1」を意識して配列サイズを決める必要があります。
終端を上書きしてしまう
#include <stdio.h>
int main(void) {
char str[6] = "Hello"; // 'H','e','l','l','o','\0'
// 終端の位置に別の文字を書いてしまう
str[5] = '!'; // ここに本来は'\0'があった
printf("%s\n", str); // 未定義動作(たまたま動くか、ゴミが出る)
return 0;
}Hello!▒▒▒▒...この場合、終端が消えてしまうため、以降のメモリにたまたまある'\0'が見つかるまで読み続けてしまいます。
strcpyなど標準関数とバッファサイズの関係
文字列を扱う標準関数は便利ですが、バッファサイズを自分で守らなければならないという大きな落とし穴があります。
代表的な関数strcpyの危険パターンを見てみます。
#include <stdio.h>
#include <string.h>
int main(void) {
char src[] = "1234567890"; // 長さ10
char dest[5]; // 小さいバッファ
// 危険: destのサイズより大きい文字列をコピー
strcpy(dest, src); // バッファオーバーフロー(未定義動作)
printf("dest = %s\n", dest); // 何が起こるか分からない
return 0;
}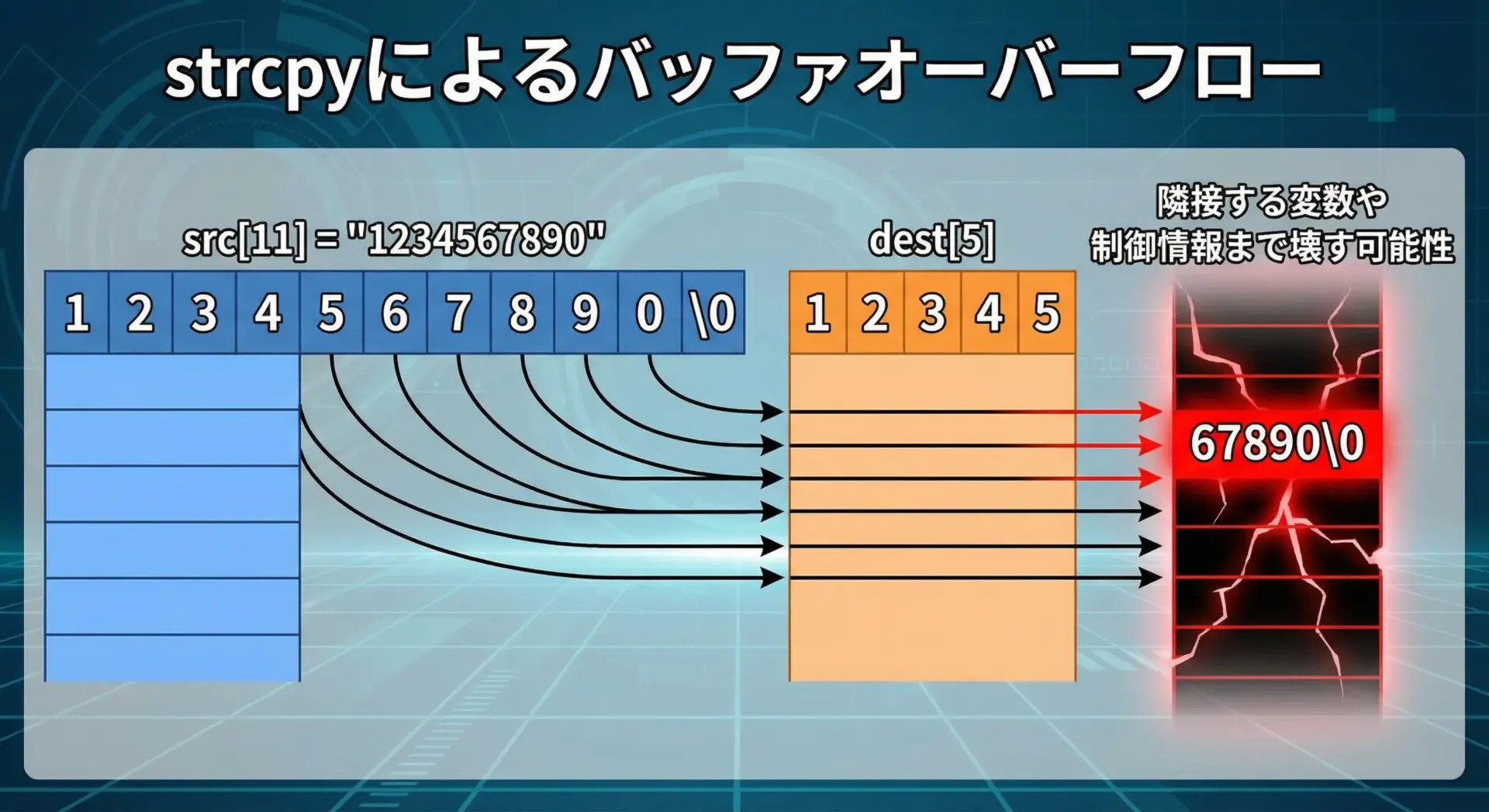
strcpyは「相手のバッファサイズ」を一切知らないため、自分で「相手のサイズ-1」までに収まるように管理しなければなりません。
安全な文字列操作関数の選び方と実践ルール
C標準ライブラリや処理系拡張には、より安全に文字列を扱うための関数がいくつか用意されています。
ここでは代表的なパターンと、実務でも使いやすいルールを紹介します。
サイズ指定付きのコピー関数を使う
strncpyや処理系拡張のstrlcpyなど、先のバッファサイズを指定できる関数を利用すると安全性が高まります。
#include <stdio.h>
#include <string.h>
int main(void) {
char src[] = "1234567890";
char dest[5];
// strncpyを使う場合
// destのサイズ-1までコピーし、最後に自前で'\0'を入れるのが定石
strncpy(dest, src, sizeof(dest) - 1);
dest[sizeof(dest) - 1] = '\0'; // 念のため終端を保証
printf("dest = %s\n", dest); // "1234" と表示される
return 0;
}dest = 1234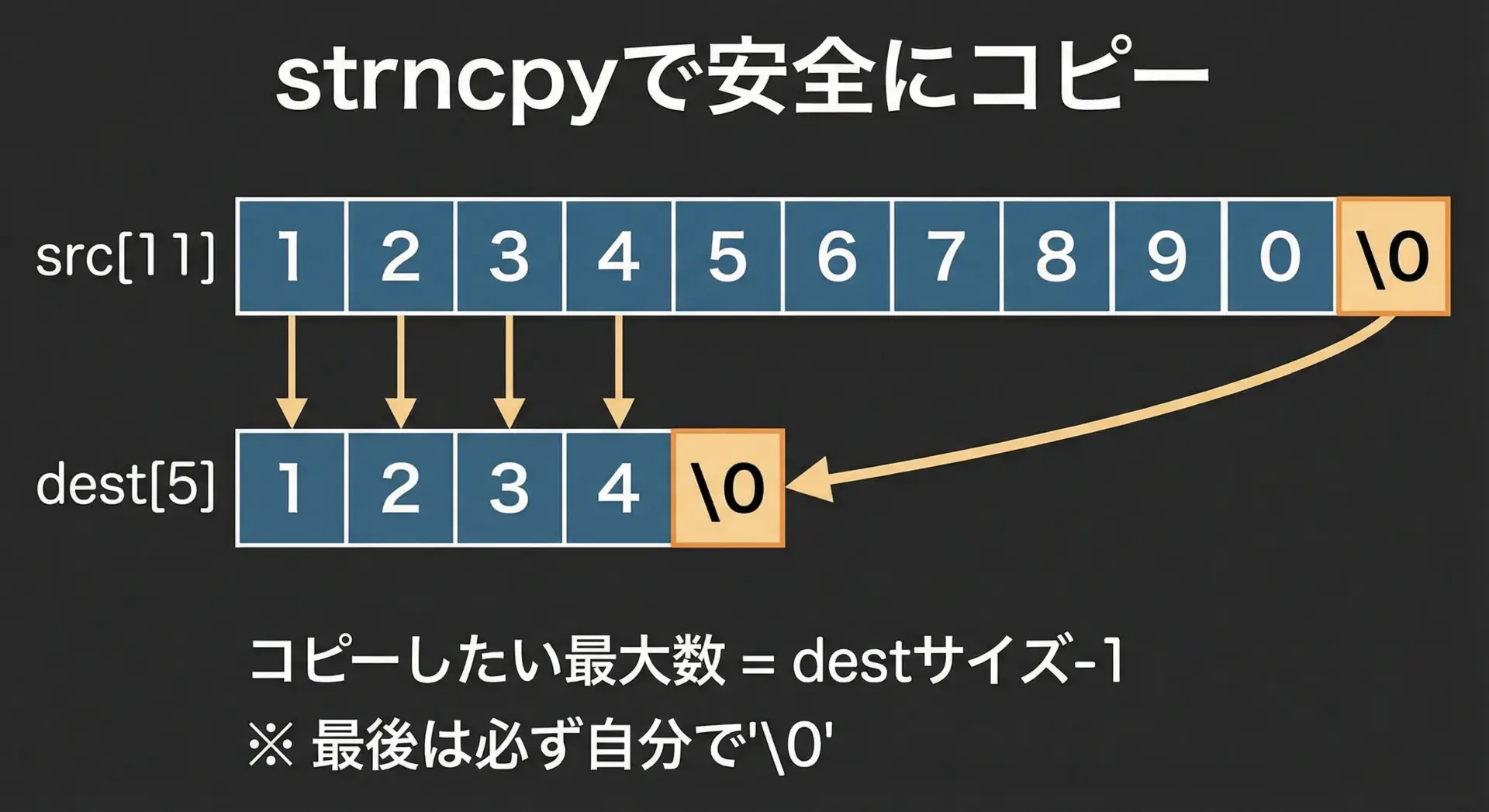
「コピー先のサイズ – 1」を上限にしてコピーし、最後に自分で'\0'を入れるというパターンを習慣化すると、多くのバグを未然に防げます。
実務での安全な文字列操作ルール
文字列バグを防ぐための実践的なルールを、文章で整理します。
まず、「常にバッファサイズを意識する」ことが最重要です。
配列を宣言するときは「入りうる最大文字数 + 1」を必ず考え、sizeofで配列全体のサイズを取得しながらコピー上限を決めます。
次に、「終端文字'\0'を自分で保証する」という意識が必要です。
strncpyのように、自動で終端を付けてくれない関数もあるため、コピー後にdest[サイズ-1] = '\0';と書く癖を付けると安全です。
さらに、文字列リテラルは常にconst char *で受けるように統一しておくと、書き換え禁止であることが型から分かるため、誤って壊してしまうリスクを減らせます。
最後に、可能であれば安全性を重視したラッパ関数やユーティリティ関数を自作し、プロジェクト全体で共有して使うと、毎回のコピーミスを防ぎやすくなります。
以下は、その一例として安全コピーのヘルパー関数を自作したコードです。
#include <stdio.h>
#include <string.h>
// 安全な文字列コピー関数の例
// dest: コピー先バッファ
// dest_size: コピー先バッファのサイズ(sizeof(dest)など)
// src: コピー元文字列
// 戻り値: 実際にコピーした文字数(終端'\0'は含まない)
size_t safe_str_copy(char *dest, size_t dest_size, const char *src) {
if (dest_size == 0) {
return 0; // コピー先が0バイトなら何もしない
}
// 最大でdest_size - 1文字までコピー
size_t i = 0;
for (; i < dest_size - 1 && src[i] != '\0'; i++) {
dest[i] = src[i];
}
// 必ず終端を付ける
dest[i] = '\0';
return i; // コピーした長さを返す
}
int main(void) {
char buf[8];
size_t copied = safe_str_copy(buf, sizeof(buf), "Hello, world!");
printf("buf = %s\n", buf); // "Hello, " など途中まで
printf("copied = %zu\n", copied); // 実際にコピーした文字数
printf("buf size = %zu\n", sizeof(buf));
return 0;
}buf = Hello,
copied = 7
buf size = 8このような関数を用意しておくと、常に「サイズを意識してコピーする」スタイルを強制できるため、プロジェクト全体の安全性が格段に高まります。
まとめ
C言語の文字列は、「char配列」「ポインタ」「終端文字'\0'」の3つが組み合わさった仕組みです。
配列ではサイズと実際の文字列長を区別し、ポインタではどの領域を指しているか(配列かリテラルか)と寿命を意識する必要があります。
また、終端文字を忘れたり壊したりすると未定義動作に直結するため、コピー時にはsizeofでバッファサイズを確認し、必要に応じて自前で'\0'を保証することが重要です。
この記事の図解とサンプルコードを参考に、配列・ポインタ・終端文字をセットで理解することで、C言語の文字列を安全かつ自在に扱えるようになっていただければ幸いです。
