C言語で配列に慣れてくると、必ず出てくるのが2次元配列です。
表データや画像、ゲームのマップなど、現実世界の多くの情報は2次元で表現できます。
本記事では、C言語の2次元配列について「宣言」「初期化」「アクセス」を順番に丁寧に解説し、イメージしやすい図解やサンプルコードも豊富に紹介します。
2次元配列とは
2次元配列の基本構造とイメージ
2次元配列は「配列の配列」です。
一次元配列が一直線の箱の並びだとすると、2次元配列は縦横に並んだ「表(マトリクス)」のような構造になります。

2次元配列int a[3][4];を宣言すると、「3行×4列」の整数の表が1つできた、というイメージで考えると理解しやすくなります。
行と列で考えるC言語の2次元配列
2次元配列では、先に行(index 0 から始まる)、次に列(index 0 から始まる)という順序で要素を指定します。
たとえばint a[3][4];という配列の場合、インデックスの意味は次のようになります。
- 最初の
[3]→ 行数(0〜2の3行) - 次の
[4]→ 列数(0〜3の4列)
要素a[i][j]は、「i行目・j列目の要素」を意味します。
| 宣言 | 行の範囲 | 列の範囲 | 全要素数 |
|---|---|---|---|
| int a[3][4]; | 0〜2 | 0〜3 | 3×4=12 |
| int b[2][5]; | 0〜1 | 0〜4 | 2×5=10 |
| int c[1][3]; | 0 | 0〜2 | 1×3=3 |
このように、行数と列数の組み合わせで全体のサイズが決まる点を意識しておくと、後のメモリサイズ計算にもスムーズにつながります。
2次元配列と一次元配列の違い
一次元配列と2次元配列の最大の違いは、「インデックスの数」と「論理的な見え方」にあります。
- 一次元配列
int x[5];
→ 要素はx[0]〜x[4]までの5個。一直線の並び。 - 二次元配列
int y[2][3];
→ 要素はy[0][0]〜y[1][2]までの6個。表(2行3列)として扱う。
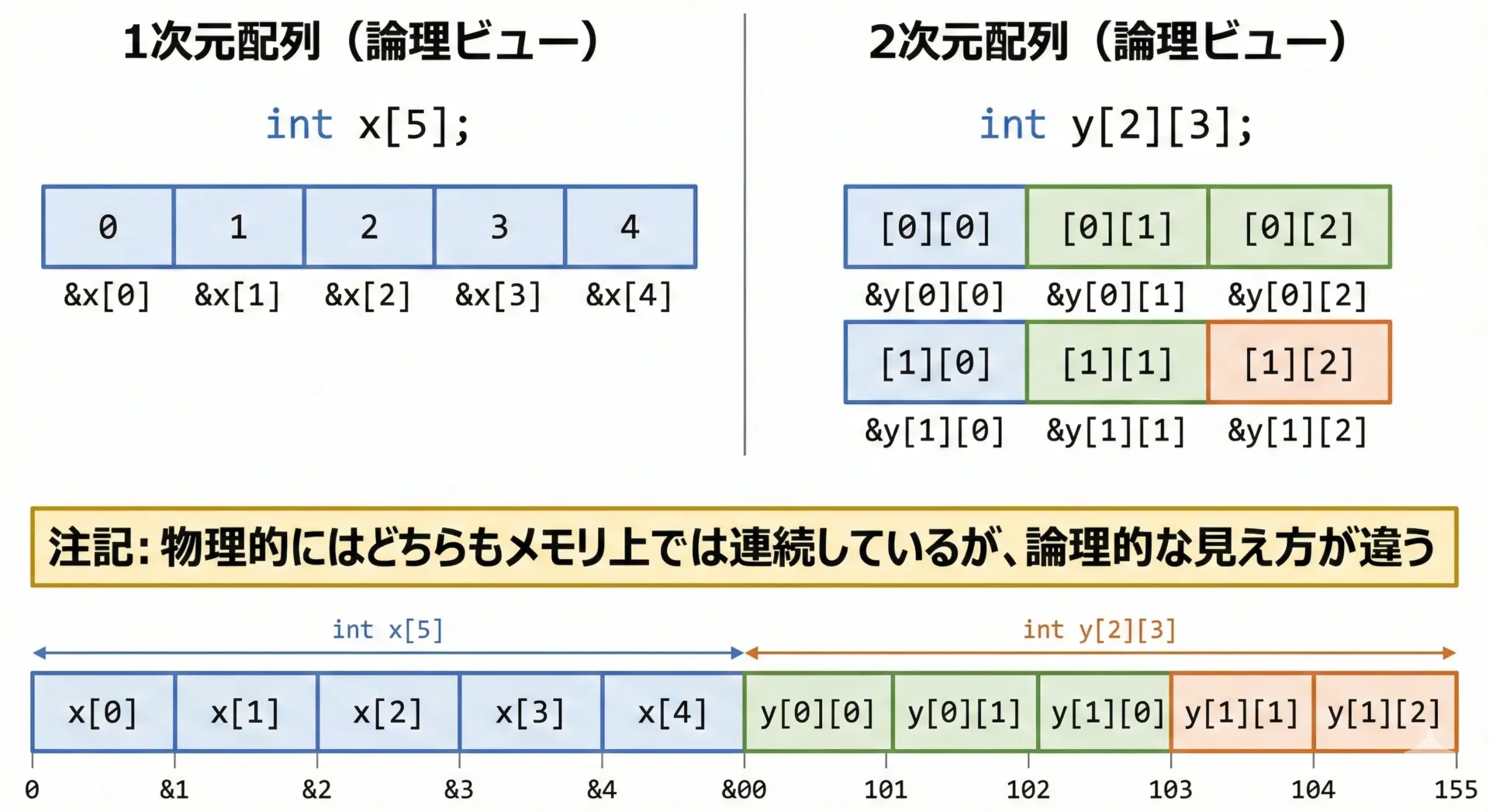
実際には、どちらもメモリ上には連続して並ぶのですが、2次元配列は「行と列」という2つの軸を持ったデータとして扱うことで、表計算や座標データなどが直感的に扱えるようになります。
2次元配列の宣言
2次元配列の基本的な宣言方法
C言語で2次元配列を宣言する基本形は次の通りです。
// 型 配列名[行数][列数];
int a[3][4]; // 3行4列のint型2次元配列
double m[2][5]; // 2行5列のdouble型2次元配列
char board[8][8]; // 8行8列のchar型(チェス盤などのイメージ)ポイントは「左から順に次元を増やしていく」ことです。
a[3][4]は、厳密には「要素数4の一次元配列が3つ並んでいる」という構造として解釈されます。
行数・列数とメモリサイズの関係
2次元配列のメモリサイズは、要素数の合計 × 型のサイズで求められます。
たとえばint a[3][4];の場合、
- 行数 = 3
- 列数 = 4
- 要素数 = 3×4 = 12
- int型のサイズ(多くの処理系で4バイト)とすると
→ 12×4 = 48バイト
この関係はsizeof演算子を使うとプログラムでも確認できます。
#include <stdio.h>
int main(void) {
int a[3][4];
// 配列全体のサイズ
printf("sizeof(a) = %zu bytes\n", sizeof(a));
// 1行分(a[0])のサイズ
printf("sizeof(a[0]) = %zu bytes\n", sizeof(a[0]));
// 要素1つ(a[0][0])のサイズ
printf("sizeof(a[0][0])= %zu bytes\n", sizeof(a[0][0]));
// 行数と列数を計算
size_t rows = sizeof(a) / sizeof(a[0]);
size_t cols = sizeof(a[0]) / sizeof(a[0][0]);
printf("rows = %zu, cols = %zu\n", rows, cols);
return 0;
}sizeof(a) = 48 bytes
sizeof(a[0]) = 16 bytes
sizeof(a[0][0])= 4 bytes
rows = 3, cols = 4このように配列全体・1行・1要素のサイズを比べることで、行数・列数を機械的に求めることもできます。
可読性を意識した2次元配列の宣言例
大きなプログラムになるほど、「何行×何列なのか」「何を表す配列なのか」が一目で分かる宣言が重要になります。
#include <stdio.h>
#define ROWS 3 // 行数(定数マクロ)
#define COLS 4 // 列数(定数マクロ)
int main(void) {
// 成績表(3人分×4科目)を表す配列
int scores[ROWS][COLS];
// 使う側からも、ROWSとCOLSで意味が分かりやすい
printf("行数 = %d, 列数 = %d\n", ROWS, COLS);
return 0;
}行数 = 3, 列数 = 4マクロや定数を使って「行数」「列数」に名前を付けることで、コードを読んだ人が配列の意図を理解しやすくなります。
2次元配列の初期化
波括弧を使った2次元配列の初期化
2次元配列も一次元配列と同様に、宣言と同時に初期値リストで初期化できます。
#include <stdio.h>
int main(void) {
// 3行4列の2次元配列を、全て明示的に初期化
int a[3][4] = {
{ 1, 2, 3, 4 }, // 0行目
{ 5, 6, 7, 8 }, // 1行目
{ 9, 10, 11, 12 } // 2行目
};
// 確認のために表示
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 4; j++) {
printf("%2d ", a[i][j]);
}
printf("\n");
}
return 0;
} 1 2 3 4
5 6 7 8
9 10 11 12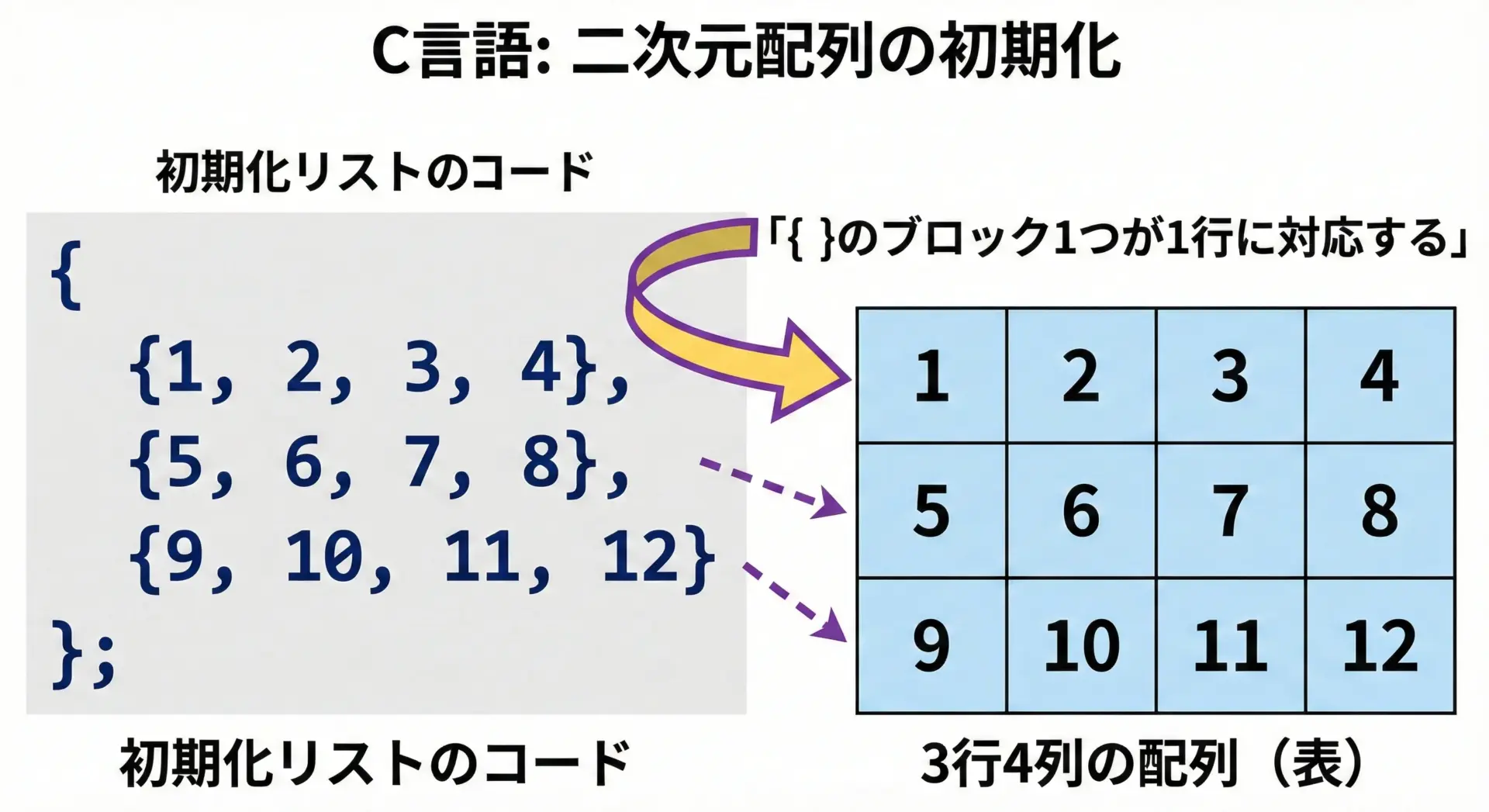
外側の波括弧全体が2次元配列全体を表し、内側の波括弧ごとに1行分の一次元配列が対応していると考えると分かりやすくなります。
行ごとにまとめて2次元配列を初期化する書き方
行ごとの初期値を、見た目も「表」のように整列させると、後から見たときに非常に読みやすくなります。
#include <stdio.h>
#define ROWS 3
#define COLS 3
int main(void) {
// 単位行列(対角成分だけ1、それ以外は0)
int identity[ROWS][COLS] = {
{ 1, 0, 0 }, // 1行目
{ 0, 1, 0 }, // 2行目
{ 0, 0, 1 } // 3行目
};
// 表示して確認
for (int i = 0; i < ROWS; i++) {
for (int j = 0; j < COLS; j++) {
printf("%d ", identity[i][j]);
}
printf("\n");
}
return 0;
}1 0 0
0 1 0
0 0 1このように行単位で揃えて記述することで、対角線に1が並んでいることが一目で分かるようになります。
省略形での2次元配列の初期化
行数や列数、あるいは一部の中括弧を省略してもよい場合があります。
具体的には、「行数を省略」「1次元として並べる」といった書き方が可能です。
行数の省略
外側の要素数(行数)は、省略すると初期値の個数から自動的に決定されます。
#include <stdio.h>
int main(void) {
// 行数を省略(コンパイラが初期値から行数を推定)
int a[][3] = {
{ 1, 2, 3 },
{ 4, 5, 6 }
};
// → 行数は2と推定される(int a[2][3]と同じ)
printf("行数 = %zu\n", sizeof(a) / sizeof(a[0]));
printf("列数 = %zu\n", sizeof(a[0]) / sizeof(a[0][0]));
return 0;
}行数 = 2
列数 = 3ここで列数は必ず明示する必要がある点に注意してください。
int a[][] = {…}; のように両方を省略することはできません。
1次元っぽく並べて初期化する
中括弧で行を分けずに、すべての要素を1次元配列のように並べて初期化することもできます。
#include <stdio.h>
int main(void) {
// 3行3列の配列を、1次元風に初期化
int a[3][3] = {
1, 2, 3, // 0行目
4, 5, 6, // 1行目
7, 8, 9 // 2行目
};
// 中身を表示して確認
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; j++) {
printf("%d ", a[i][j]);
}
printf("\n");
}
return 0;
}1 2 3
4 5 6
7 8 9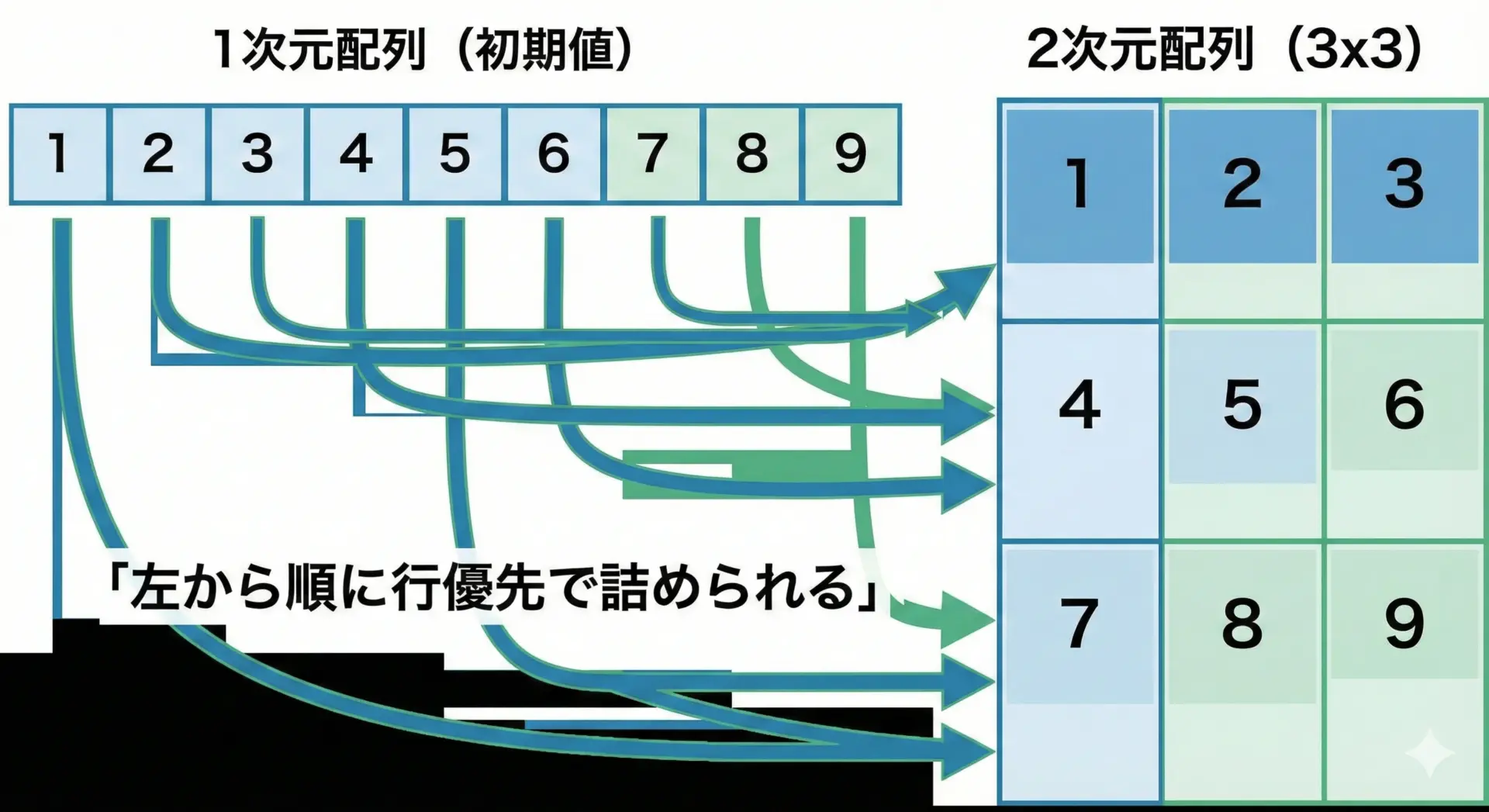
コンパイラは左から順番に要素を埋めていき、1行分が埋まったら次の行に移る、というルールで解釈します。
未初期化要素とゼロ初期化の挙動
2次元配列の初期化で、すべての要素を指定しなかった場合、指定しなかった部分はどうなるでしょうか。
C言語では、静的な初期化では「指定していない要素は0で埋められる」というルールがあります。
#include <stdio.h>
int main(void) {
// 一部だけ初期化(残りは0で埋められる)
int a[2][3] = {
{ 1 }, // → {1, 0, 0} とみなされる
{ 2, 3 } // → {2, 3, 0} とみなされる
};
// 値を確認
for (int i = 0; i < 2; i++) {
for (int j = 0; j < 3; j++) {
printf("%d ", a[i][j]);
}
printf("\n");
}
return 0;
}1 0 0
2 3 0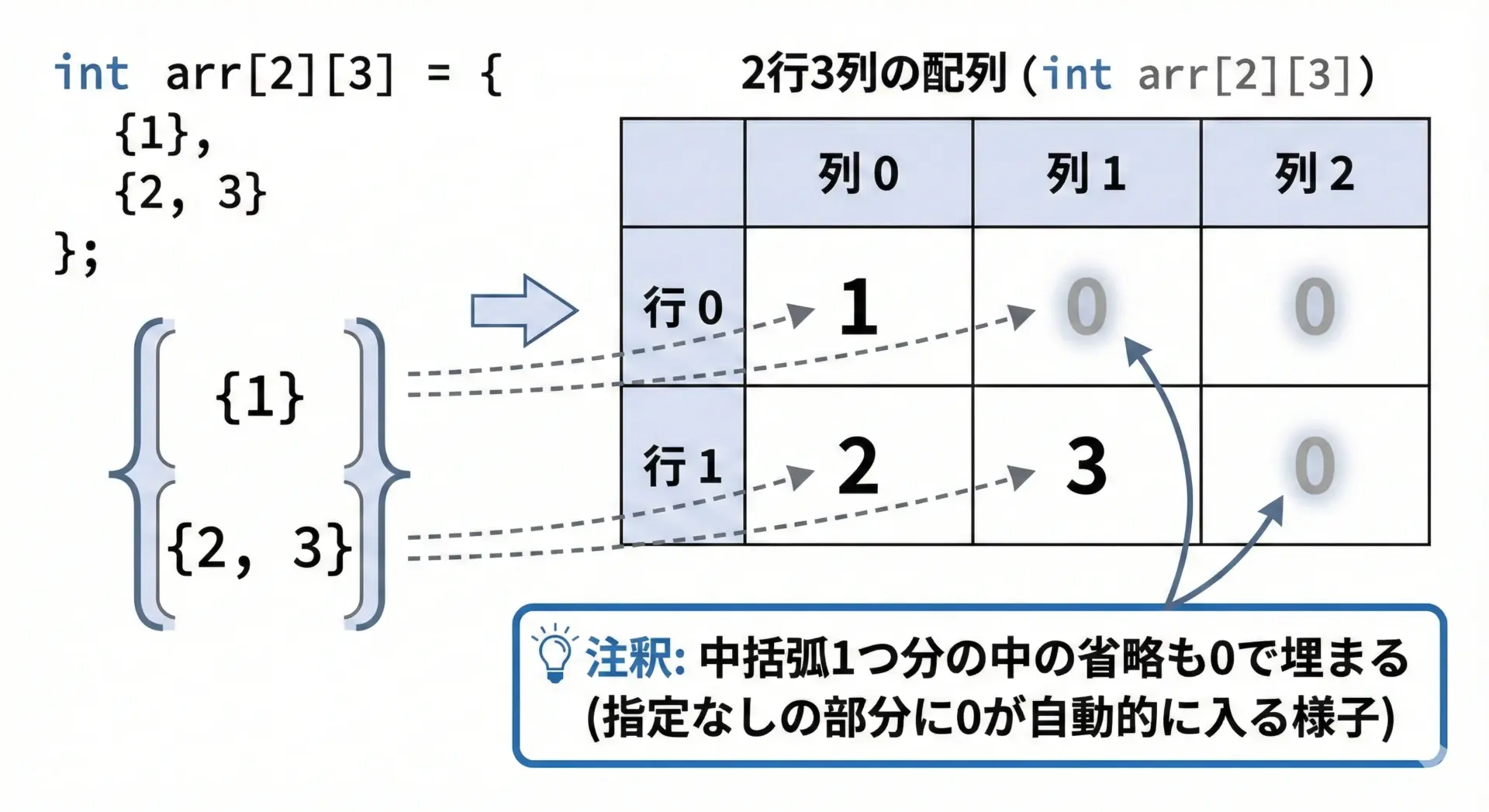
明示していない部分がゴミ値になるわけではなく、0で埋められるという挙動は、特定の部分だけ値を指定したい場合に非常に便利です。
2次元配列へのアクセス
インデックスを使った要素アクセスの基本
2次元配列の要素にアクセスするには、行インデックスと列インデックスの2つを指定します。
#include <stdio.h>
int main(void) {
int a[2][3] = {
{ 10, 20, 30 },
{ 40, 50, 60 }
};
// 個別要素へのアクセス
printf("a[0][0] = %d\n", a[0][0]); // 1行目1列目
printf("a[0][2] = %d\n", a[0][2]); // 1行目3列目
printf("a[1][1] = %d\n", a[1][1]); // 2行目2列目
// 値の書き換え
a[1][2] = 999; // 2行目3列目の値を変更
printf("a[1][2] = %d\n", a[1][2]); // 変更後の値を表示
return 0;
}a[0][0] = 10
a[0][2] = 30
a[1][1] = 50
a[1][2] = 999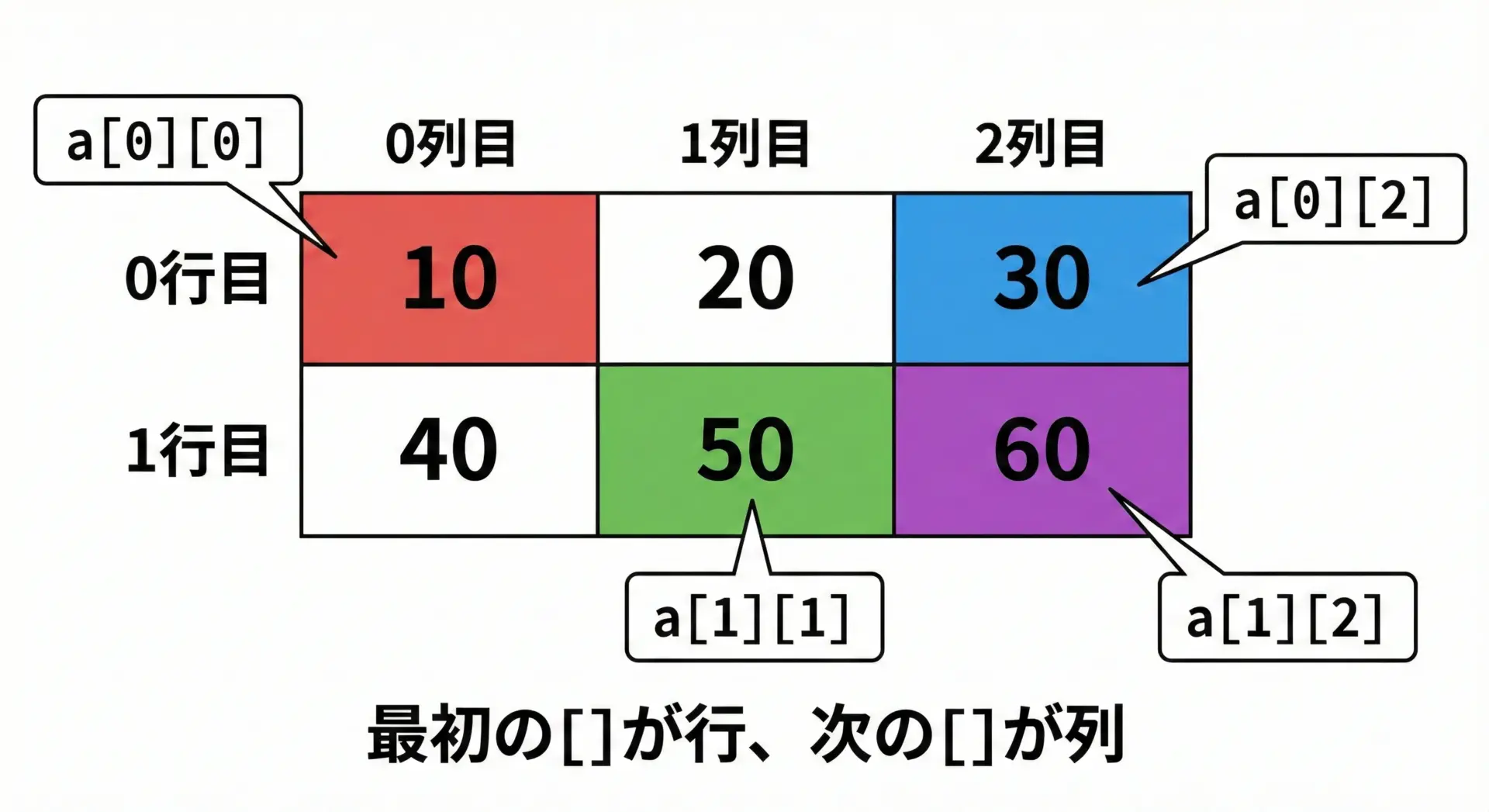
最初のインデックスが「行」、次のインデックスが「列」であることを混同しないように注意してください。
二重ループで2次元配列を走査する方法
2次元配列の全要素を使う場面では、二重ループ(ネストしたfor文)で走査するのが基本です。
#include <stdio.h>
#define ROWS 3
#define COLS 4
int main(void) {
int a[ROWS][COLS] = {
{ 1, 2, 3, 4 },
{ 5, 6, 7, 8 },
{ 9, 10, 11, 12 }
};
// 全要素を表示
for (int i = 0; i < ROWS; i++) { // 外側のループが行を担当
for (int j = 0; j < COLS; j++) { // 内側のループが列を担当
printf("%2d ", a[i][j]);
}
printf("\n");
}
return 0;
} 1 2 3 4
5 6 7 8
9 10 11 12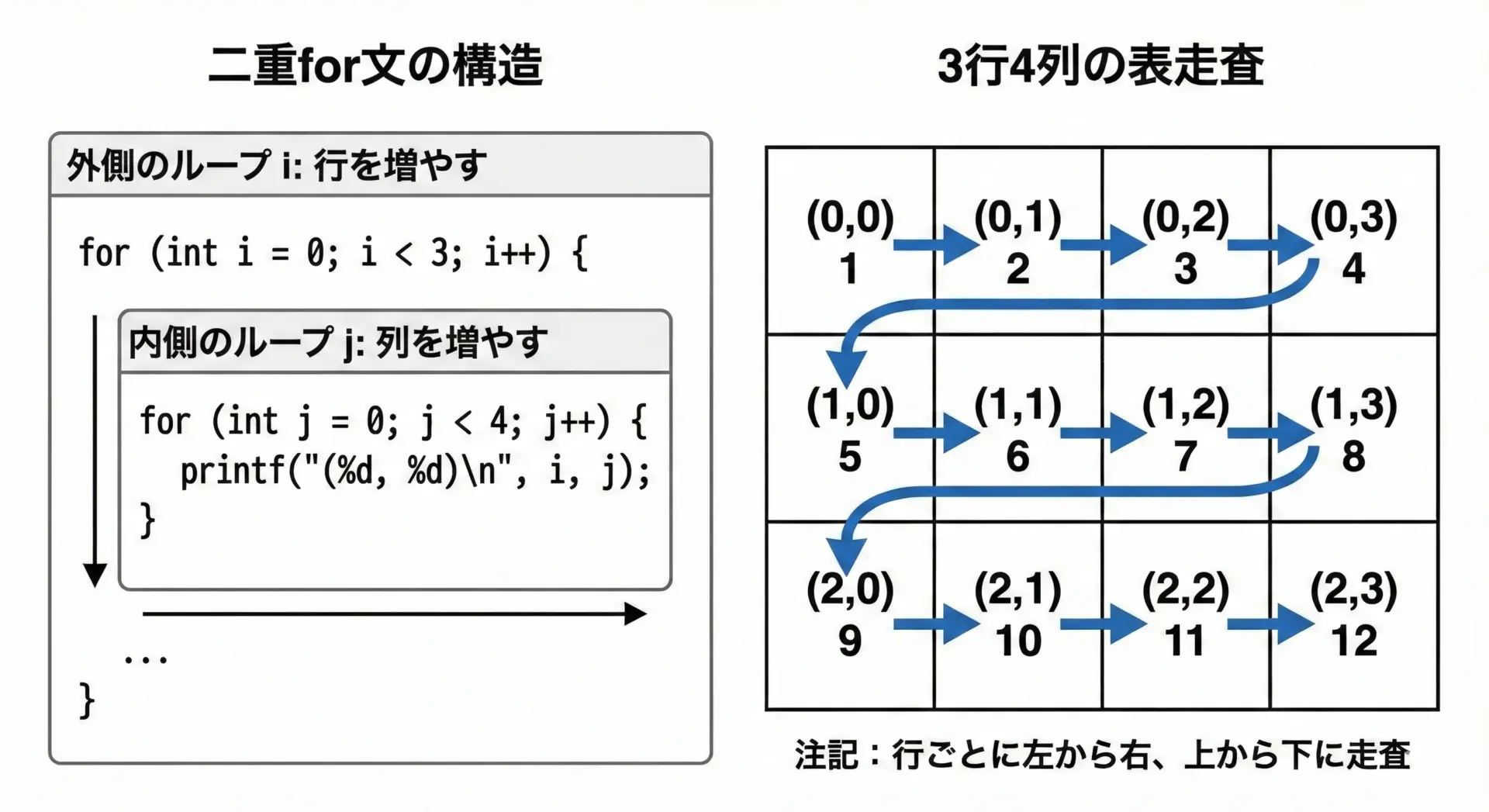
外側ループで行を、内側ループで列を回すのが最も一般的な書き方です。
行優先(行メジャー)とメモリアクセス効率
C言語では、2次元配列は行優先(行メジャー: row-major)でメモリに配置されます。
これは、「同じ行の要素がメモリ上で連続して格納される」という意味です。
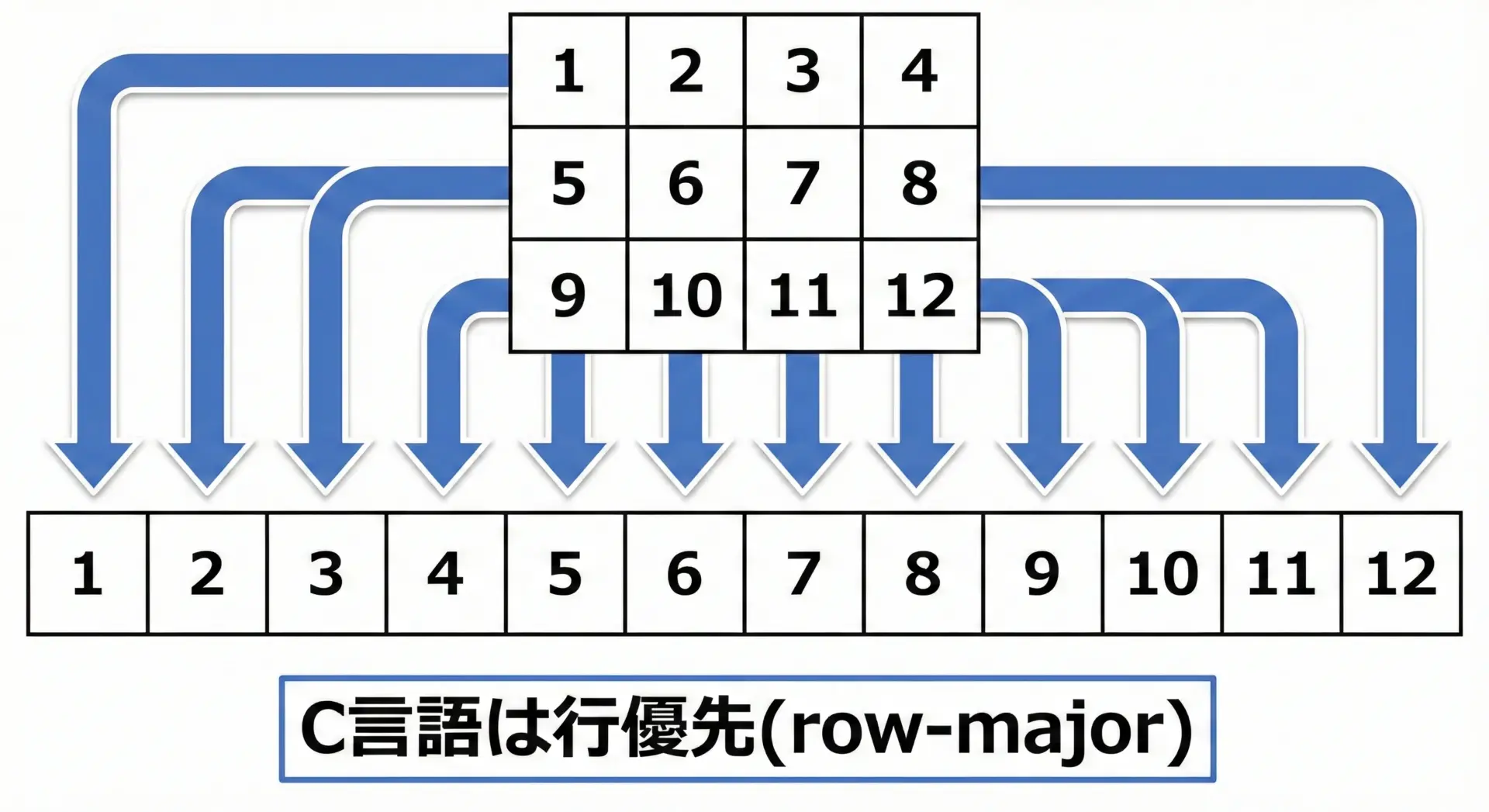
この性質を踏まえると、メモリアクセスの効率を良くするには、メモリ上で連続している順番にアクセスすることが重要になります。
行優先アクセスと列優先アクセスの違い
#include <stdio.h>
#define N 3
int main(void) {
int a[N][N] = {
{ 1, 2, 3 },
{ 4, 5, 6 },
{ 7, 8, 9 }
};
printf("行優先の走査順:\n");
// 行優先(通常の書き方): iが行、jが列
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
printf("%d ", a[i][j]);
}
}
printf("\n\n");
printf("列優先の走査順:\n");
// 列優先: jが行、iが列(あえて逆にしている)
for (int j = 0; j < N; j++) {
for (int i = 0; i < N; i++) {
printf("%d ", a[i][j]);
}
}
printf("\n");
return 0;
}行優先の走査順:
1 2 3 4 5 6 7 8 9
列優先の走査順:
1 4 7 2 5 8 3 6 9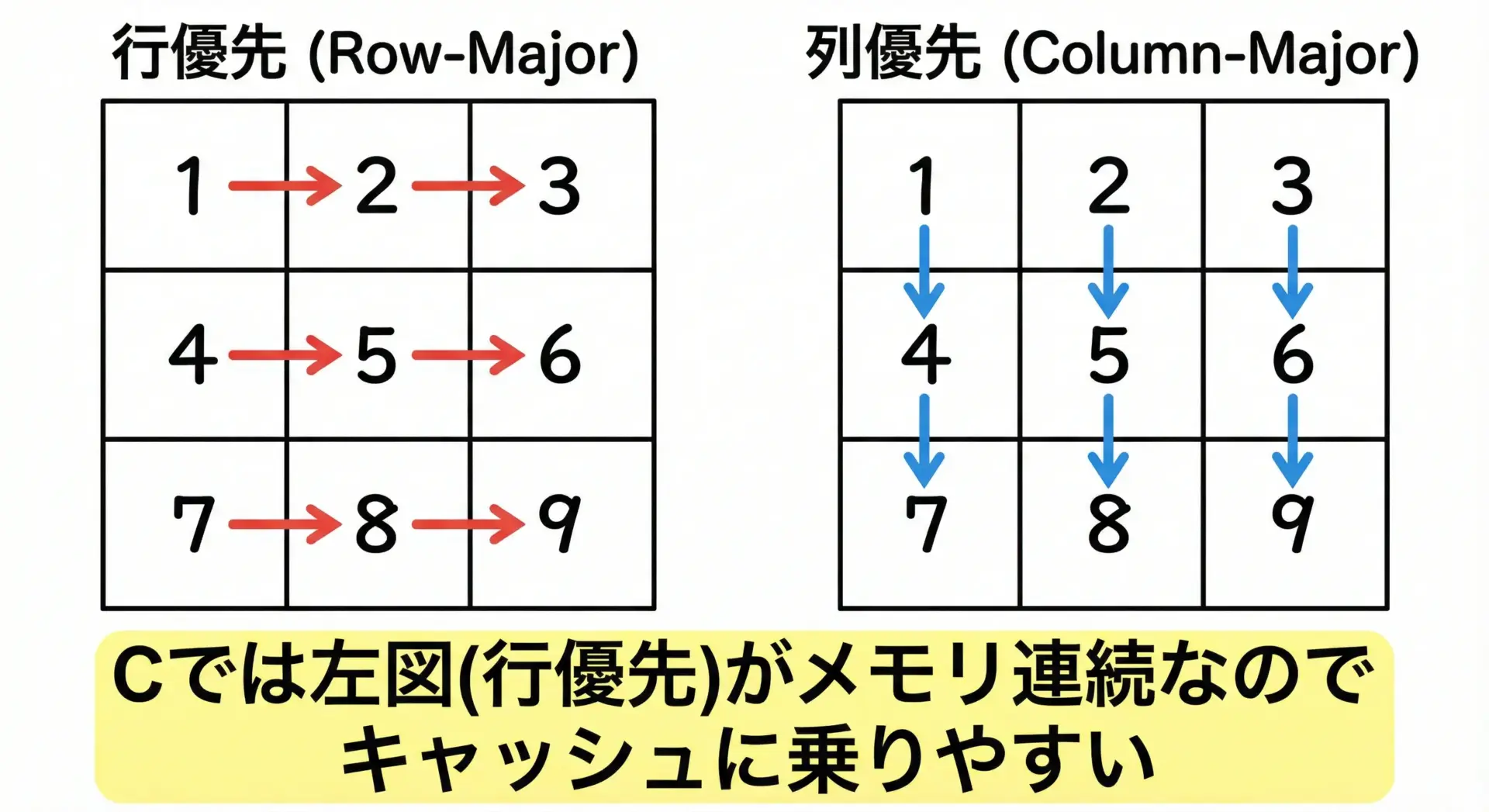
CPUやキャッシュの仕組み上、メモリ上で連続しているデータを順番に読む処理の方が速くなることが多いため、C言語では行優先の走査が基本と覚えておくとよいです。
2次元配列とポインタの関係と注意点
2次元配列は、ポインタと密接な関係があります。
ただし、「int** と int[ ][ ] は同じではない」という点がよく混乱を生むポイントです。
配列名と「行ポインタ」
2次元配列int a[3][4];の場合、aという配列名は「4個のintからなる配列へのポインタ(int (*)[4])」として振る舞います。
#include <stdio.h>
int main(void) {
int a[3][4] = {
{ 1, 2, 3, 4 },
{ 5, 6, 7, 8 },
{ 9,10,11,12 }
};
// a は「1行目(a[0])へのポインタ」として扱われる
printf("a = %p\n", (void*)a);
printf("&a[0][0] = %p\n", (void*)&a[0][0]);
// a + 1 は「次の行(a[1])」を指す
printf("a + 1 = %p\n", (void*)(a + 1));
printf("&a[1][0] = %p\n", (void*)&a[1][0]);
return 0;
}a = 0x7ffdxxxxxxxx
&a[0][0] = 0x7ffdxxxxxxxx
a + 1 = 0x7ffdxxxxxxxx+16 付近
&a[1][0] = 0x7ffdxxxxxxxx+16 付近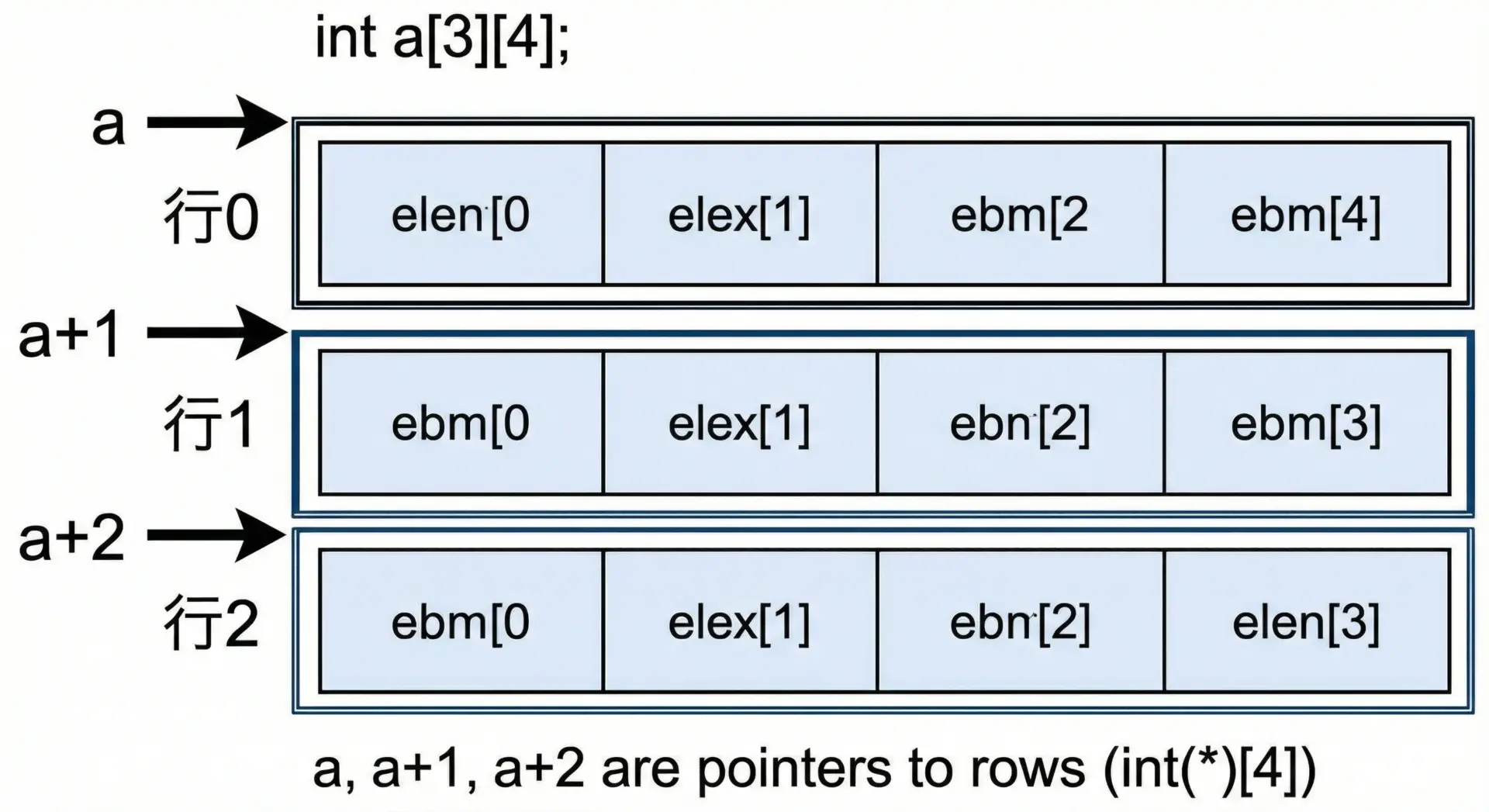
ここから分かるように、a は「先頭行の先頭アドレス」と等価ですが、その型はint (*)[4]、つまり「intを4つ持つ配列へのポインタ」です。
関数引数での宣言と列数の必須性
2次元配列を関数に渡したいとき、列数は必ず指定する必要があります。
#include <stdio.h>
#define ROWS 3
#define COLS 4
// 2次元配列を受け取る関数(列数は明示が必須)
void print_matrix(int m[][COLS], int rows) {
for (int i = 0; i < rows; i++) {
for (int j = 0; j < COLS; j++) {
printf("%2d ", m[i][j]);
}
printf("\n");
}
}
int main(void) {
int a[ROWS][COLS] = {
{ 1, 2, 3, 4 },
{ 5, 6, 7, 8 },
{ 9, 10, 11, 12 }
};
print_matrix(a, ROWS); // a は「行ポインタ」として渡される
return 0;
} 1 2 3 4
5 6 7 8
9 10 11 12int** や int* で代用しようとすると、想定と違うメモリレイアウトになるため危険です。
「int型の2次元配列」として扱うなら、必ず列数を含めた形で宣言するようにしてください。
なぜ int** ではダメなのか(概念的な説明)
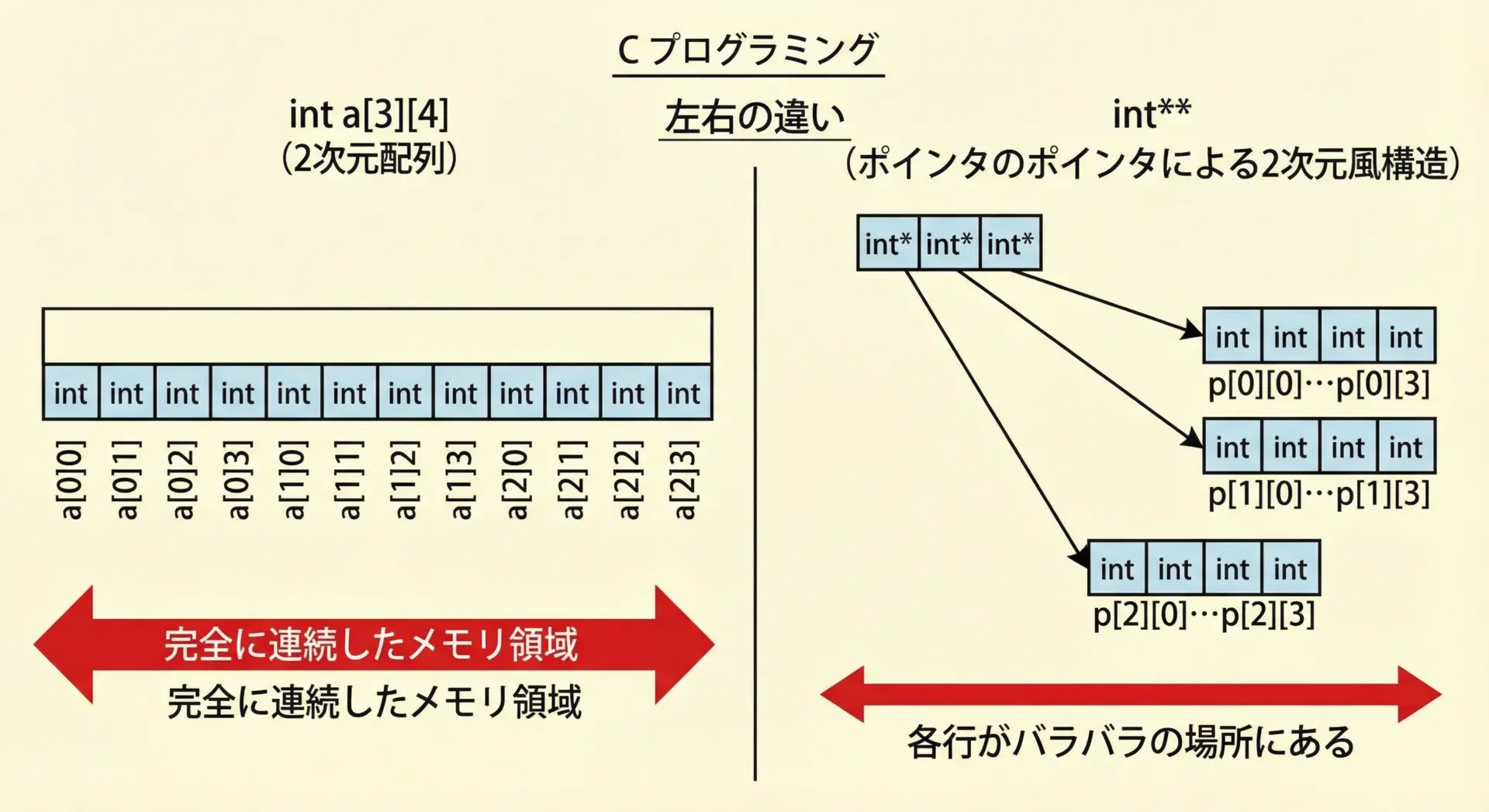
組み込みの2次元配列(int a[3][4])は「きっちり行列状に連続配置」されますが、int** を使った構造は、行ごとにバラバラの場所を指すことができる別物の構造です。
そのため、両者を混同してキャストしたり、引数の型を変えたりすると、重大なバグにつながります。
まとめ
C言語の2次元配列は、「配列の配列」として行×列の表を扱うための基本的な仕組みです。
宣言では行数と列数を明確にし、初期化では波括弧を用いて表の形を意識しながら値を並べることで、コードの可読性が大きく向上します。
アクセス時は行インデックス・列インデックスの順序を守り、二重ループで行優先に走査することでメモリアクセスも効率的になります。
また、関数引数などで扱う際には「2次元配列とポインタの型の違い」に注意し、列数を必ず指定することが安全なコードにつながります。
