
PythonでWebスクレイピングを始めると、最初にぶつかるのが「狙った要素だけを、正確に、壊れにくく取るにはどう書けば良いのか」という問題です。
本記事では、PythonのBeautifulSoupにおけるCSSセレクタにフォーカスし、初学者でも理解しやすい図解とサンプルコードを交えながら、スクレイピング精度を一気に高める実践的なテクニックを体系的に解説していきます。
BeautifulSoup入門とは
BeautifulSoupとスクレイピングの基本
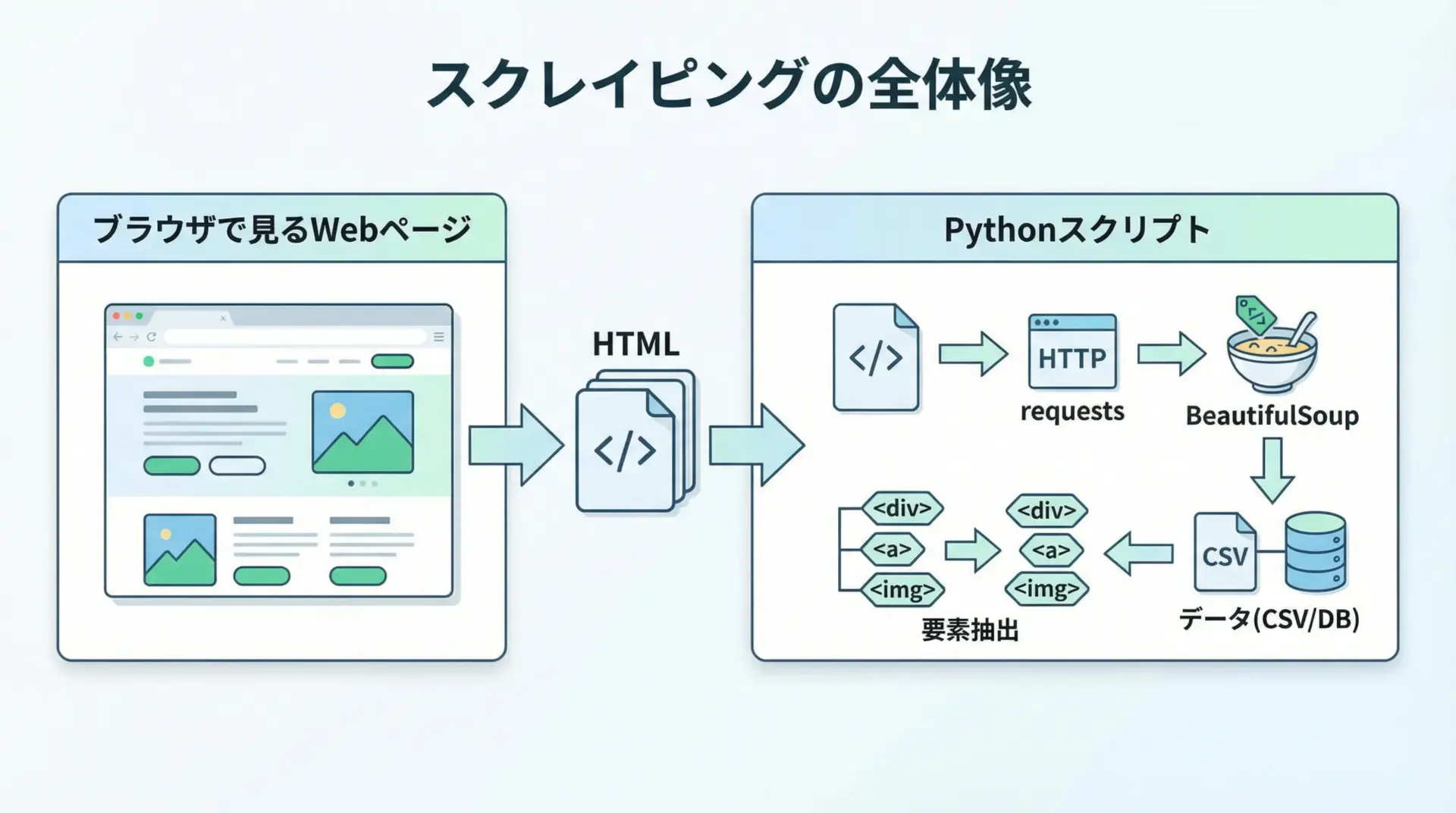
Webスクレイピングとは、WebページのHTMLを取得し、その中から必要な情報だけをプログラムで抜き出す技術のことです。
Pythonの代表的なスクレイピング用ライブラリがBeautifulSoupで、HTMLを扱いやすいオブジェクト構造に変換し、要素検索をシンプルな記述で行えるようにしてくれます。
通常は次のような流れでスクレイピングを行います。
まずrequestsなどを使ってWebページのHTMLを取得し、そのHTML文字列をBeautifulSoupに渡します。
その後、変換されたオブジェクトに対して.select()などのメソッドを使い、欲しいタグやテキストを抽出していきます。
最終的に、抽出したデータをCSVに書き出したり、データベースに保存したりすることで、再利用可能なデータとして活用できます。
BeautifulSoupとlxmlなど他ライブラリとの違い

PythonでHTMLやWebページを扱うライブラリはいくつかあります。
代表的なのはBeautifulSoupのほかにlxmlやSeleniumです。
これらは役割や得意分野が少しずつ異なります。
BeautifulSoupは使いやすさ重視のライブラリで、多少壊れたHTMLでも寛容にパースしてくれる点が大きな特徴です。
CSSセレクタやタグ名、属性条件など、直感的な書き方で要素を探せるため、学習コストが低く、入門用としても実務用としても広く利用されています。
一方lxmlは、C言語実装を含む高速なXML/HTML解析ライブラリで、XPathによる柔軟な要素指定が可能です。
処理速度が重要な大規模スクレイピングや、高度なXPathクエリを活用したい場合に向いています。
ただし、HTMLが壊れている場合には、BeautifulSoupほど寛容ではないケースもあります。
Seleniumはブラウザを自動操作して、実際にJavaScriptを実行した後の画面状態から情報を取得するためのツールです。
HTMLを直接パースするというよりは、動的に生成されるページに対応するための手段と考えると分かりやすいです。
動的サイトを対象としない限り、まずはrequests + BeautifulSoupで試し、必要に応じてSeleniumを使うという構成が現実的です。
CSSセレクタを押さえるメリット

BeautifulSoupでは、要素検索の方法としてfind()/find_all()や、CSSセレクタを指定するselect()/select_one()など、複数の手段が用意されています。
その中でもCSSセレクタを使いこなせるかどうかは、スクレイピングの精度や保守性に大きく関わります。
CSSセレクタを押さえるメリットは主に次のような点にあります。
まず、ブラウザの開発者ツールで確認したCSSパスを、そのままPython側のセレクタとして使いやすいため、実装がスムーズになります。
また、タグ名・class・id・属性などを組み合わせた柔軟な条件指定ができ、微妙に構造が違う要素の中から、目的の部分だけを抜き出すことが可能です。
さらに、構造が変更されても壊れにくい「安定したセレクタ」を設計しやすく、長期運用するスクレイピングスクリプトの保守性向上につながります。
BeautifulSoupの準備と基本構文
インストールと環境構築
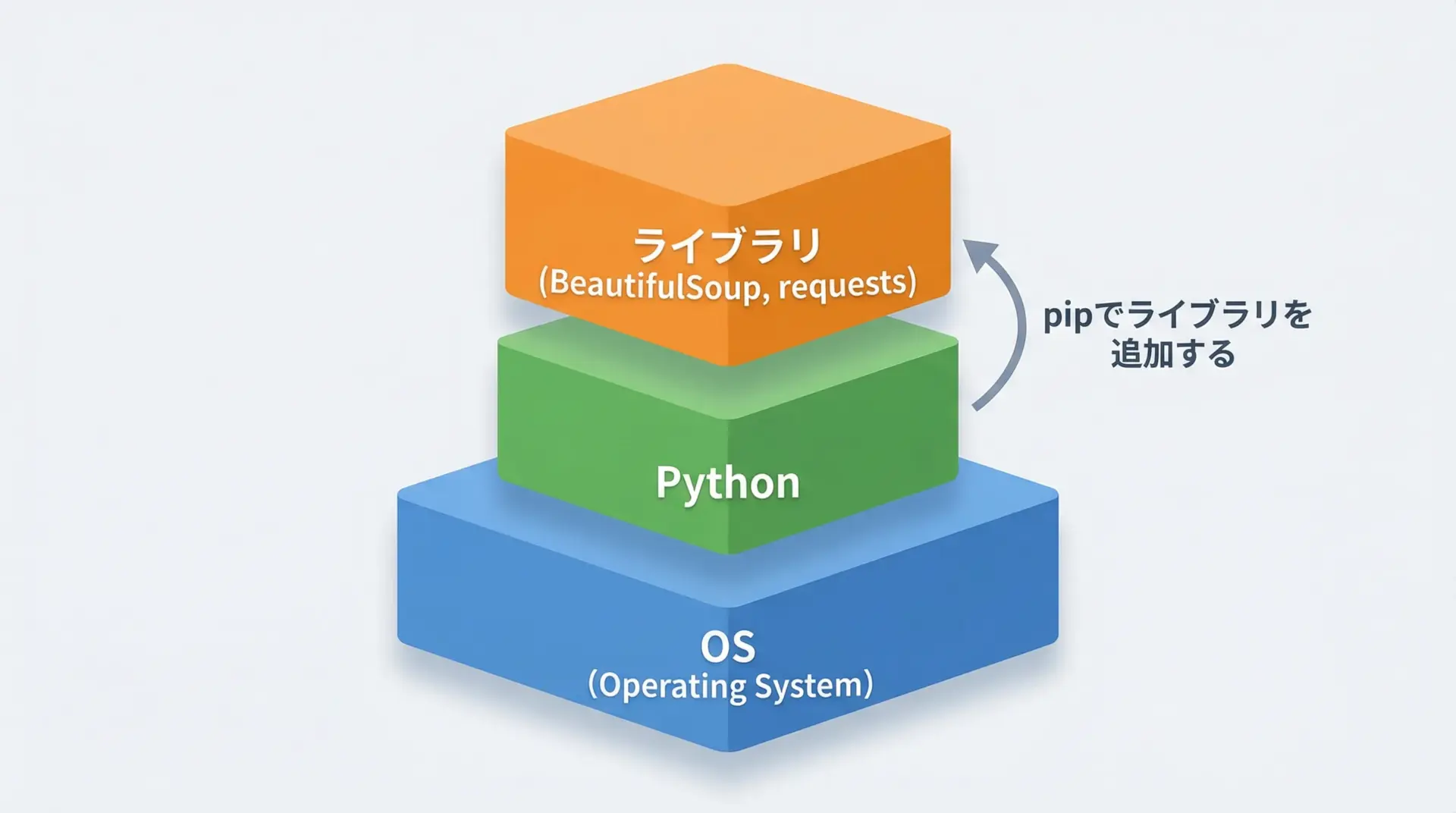
BeautifulSoupを使うには、まずPython本体のインストールが必要です。
Python公式サイトからインストーラをダウンロードし、インストール後にpython --versionやpython3 --versionでバージョンが表示されることを確認します。
その上で、pipを使って必要なライブラリを追加します。
スクレイピングの最小構成としては、beautifulsoup4とrequestsが入っていれば十分です。
# BeautifulSoup本体
pip install beautifulsoup4
# 高速なlxmlパーサを使いたい場合(任意)
pip install lxml
# HTMLを取得するためのHTTPクライアント
pip install requests仮想環境(venvやconda)を使う場合は、その環境をアクティブにしてからインストールすると、プロジェクトごとにライブラリを分離できて便利です。
HTMLを取得してBeautifulSoupで解析する手順
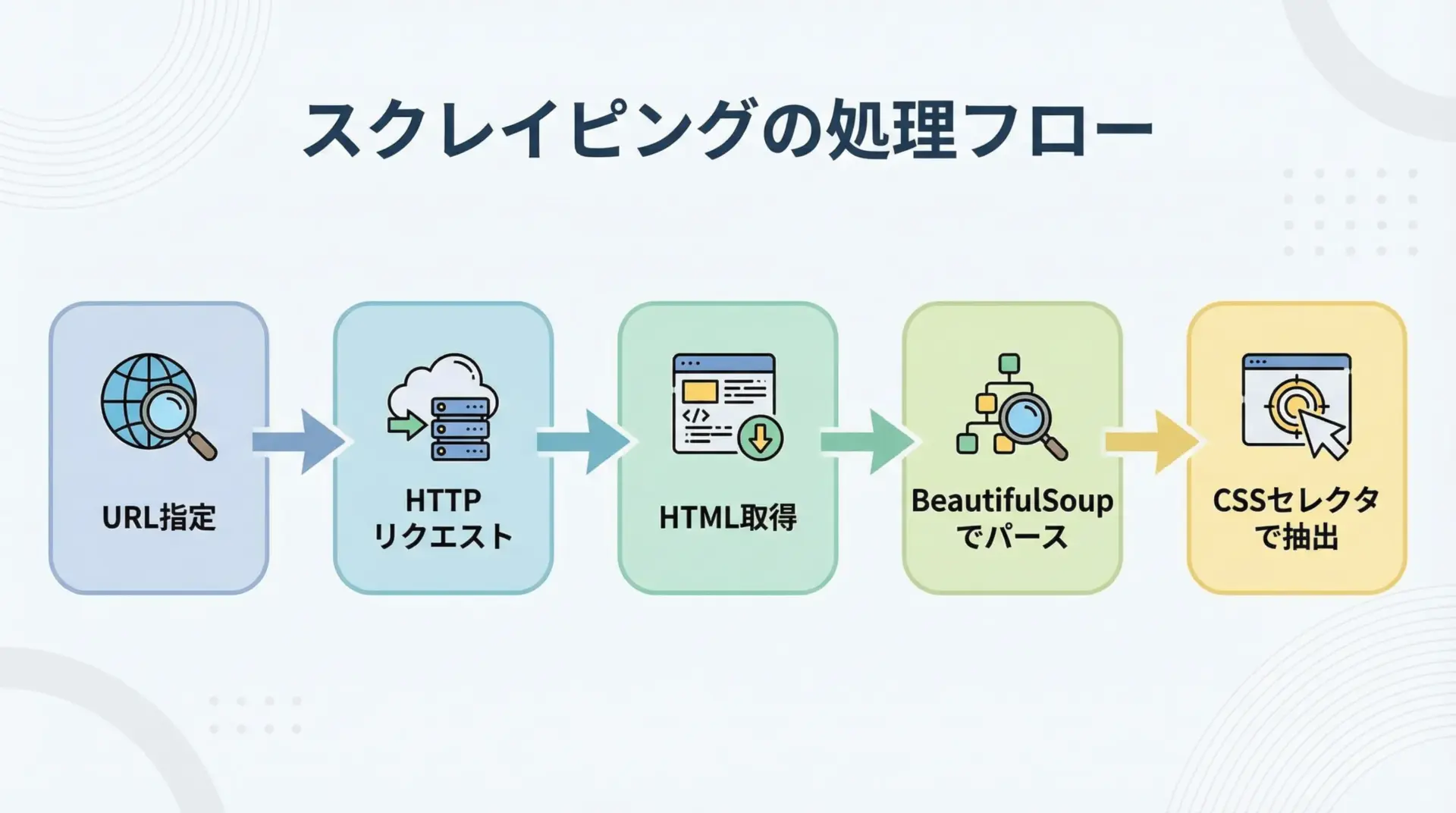
BeautifulSoupを実際に使う流れを、最もシンプルな例で確認してみます。
ここでは、架空のHTML文字列を使って基本的な処理を示します。
import requests
from bs4 import BeautifulSoup
# 1. スクレイピング対象のURLを指定
url = "https://example.com/"
# 2. HTTPリクエストでHTMLを取得
response = requests.get(url)
response.raise_for_status() # エラー時に例外を発生させる(デバッグしやすくするため)
# 3. レスポンスボディとしてHTMLテキストを取得
html = response.text
# 4. BeautifulSoupでHTMLを解析
# 第2引数に使用するパーサを指定する(html.parserやlxmlなど)
soup = BeautifulSoup(html, "html.parser")
# 5. CSSセレクタで要素を取得(例: ページ内のすべてのリンク)
links = soup.select("a")
for a in links:
# aタグのhref属性とテキストを表示
print(a.get("href"), a.get_text(strip=True))上記のコードでは、HTML取得から解析、要素抽出までのひととおりの流れを確認できます。
ここで重要なのは、BeautifulSoup自体は「すでに手元にあるHTML文字列」を解析するだけであり、HTMLを取得する部分はrequestsなど別のライブラリが担当しているという点です。
parserの種類(html.parser, lxml)の違い
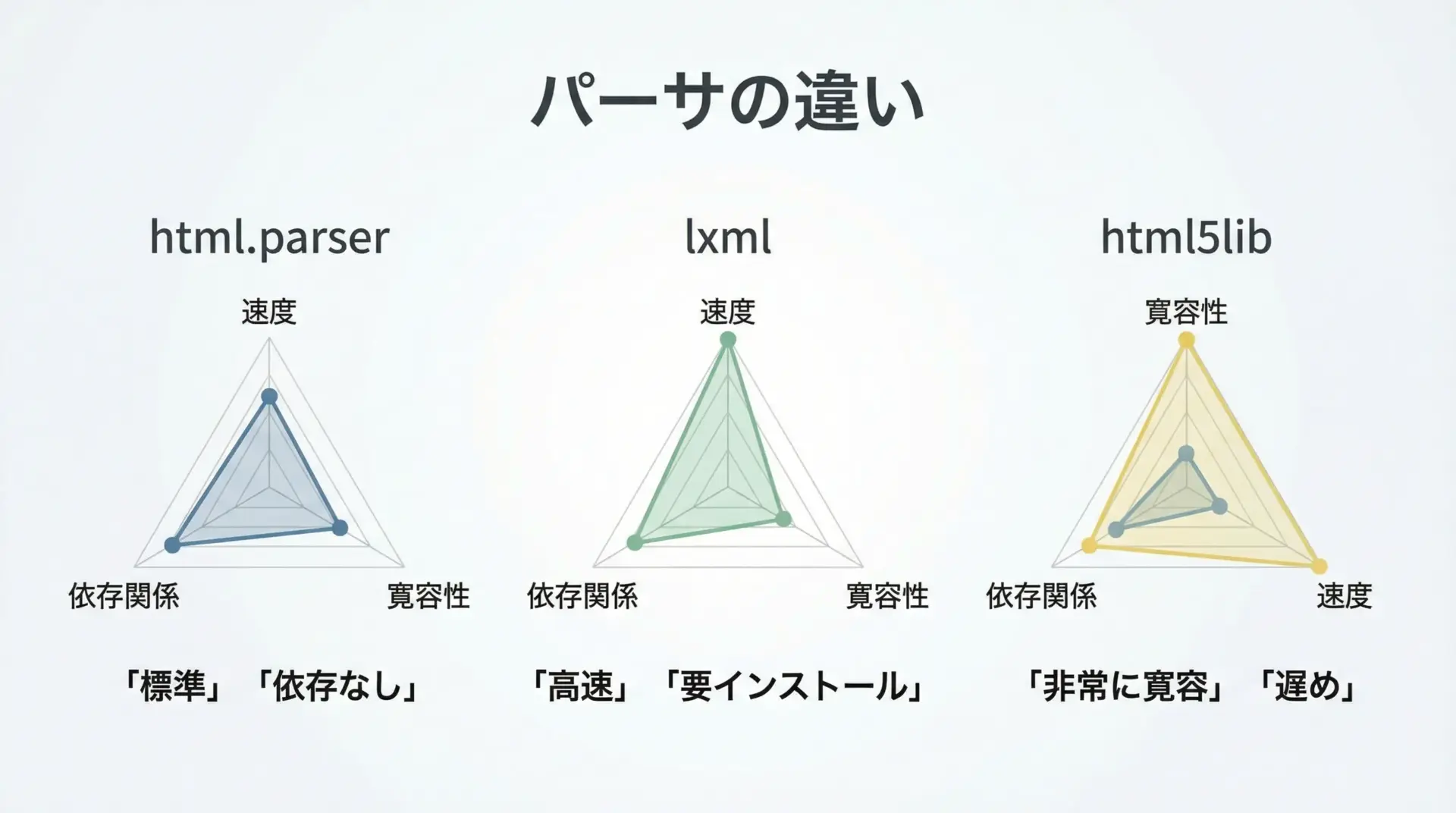
BeautifulSoupは、内部でHTMLを解析する「パーサ」に処理を委譲しています。
パーサにはいくつか種類があり、主なものとしてhtml.parserとlxml、html5libがあります。
代表的な特徴を簡単な表にまとめると次のようになります。
| パーサ名 | 特徴 | 速度感 | インストール |
|---|---|---|---|
| html.parser | Python標準。依存なしで使える | 中 | 不要 |
| lxml | 高速。XML/HTMLに強い | 速い | 必要 |
| html5lib | ブラウザ並みに寛容な解析 | 遅い | 必要 |
一般的なスクレイピングであれば、まずは"html.parser"で問題ありません。
速度を重視したい場合や、より厳密なパースを行いたい場合には"lxml"を検討すると良いでしょう。
使い分けの際には、下記のように第2引数だけを変えて試してみることができます。
from bs4 import BeautifulSoup
html = "<html><body><p>テスト</p></body></html>"
# 標準のhtml.parserを利用
soup1 = BeautifulSoup(html, "html.parser")
# lxmlパーサを利用
soup2 = BeautifulSoup(html, "lxml")
# html5libパーサを利用
soup3 = BeautifulSoup(html, "html5lib")
print(type(soup1), type(soup2), type(soup3))<class 'bs4.BeautifulSoup'> <class 'bs4.BeautifulSoup'> <class 'bs4.BeautifulSoup'>どのパーサを選んでも、最終的にはBeautifulSoupオブジェクトとして同様に扱える点がポイントです。
CSSセレクタの基礎
CSSセレクタとは何か
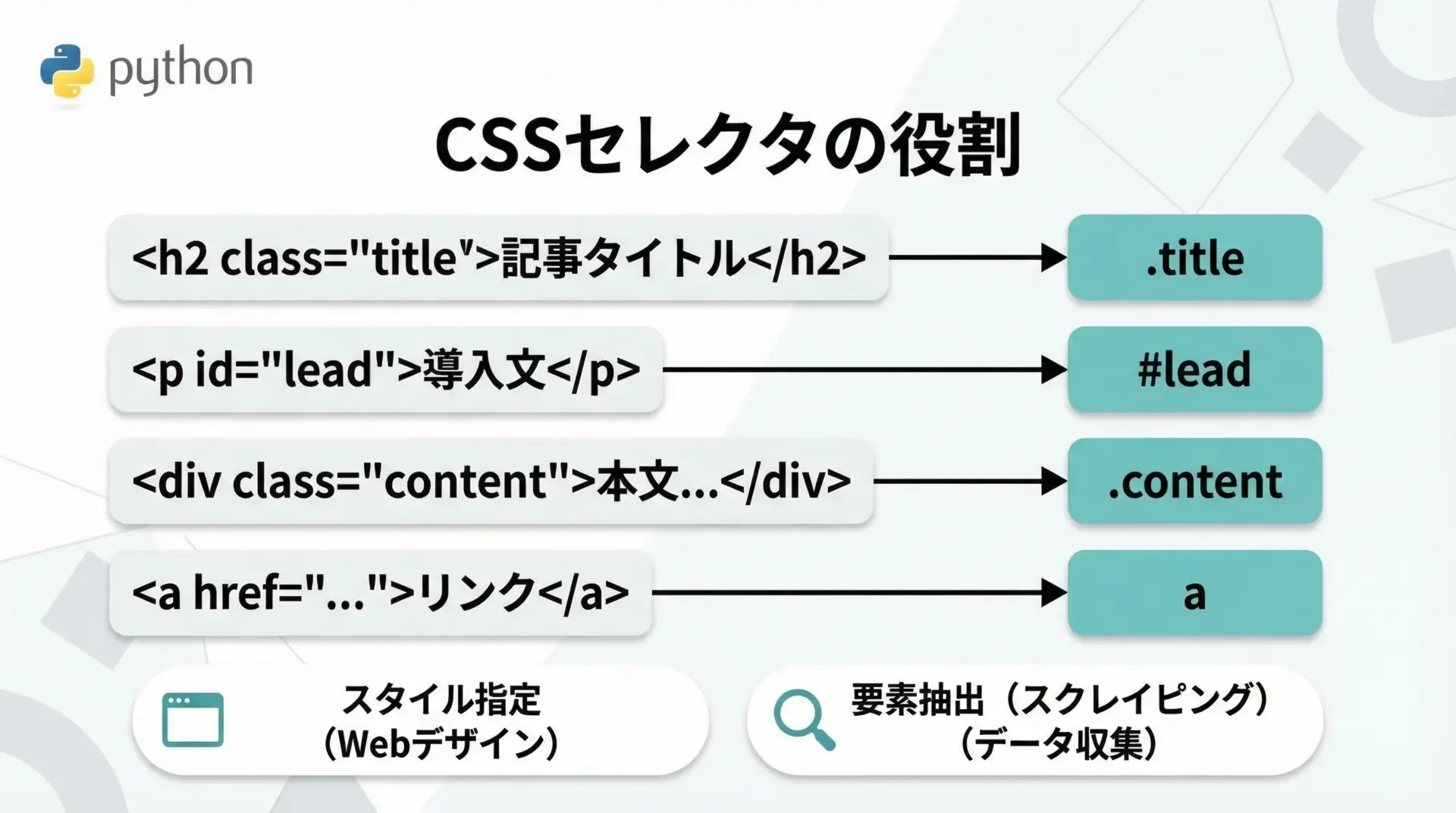
CSSセレクタとは、本来はWebページのスタイルシート(CSS)で「どの要素にどのスタイルを当てるか」を指定するための文法です。
たとえばpはすべての<p>タグ、.titleはclass属性が<title>の要素、#mainはid属性がmainの要素を表します。
スクレイピングにおいては、このCSSセレクタをスタイル指定ではなく、要素検索のためのクエリとして活用します。
つまり、「ブラウザがCSSでスタイルを当てるときに使うルール」を、そのまま「BeautifulSoupで要素を探し出すルール」として再利用するイメージです。
CSSセレクタは表現力が高く、タグ名・class・id・階層関係・属性条件などを柔軟に組み合わせられるため、スクレイピングに非常に相性の良い仕組みです。
id, class, タグ名セレクタの基本
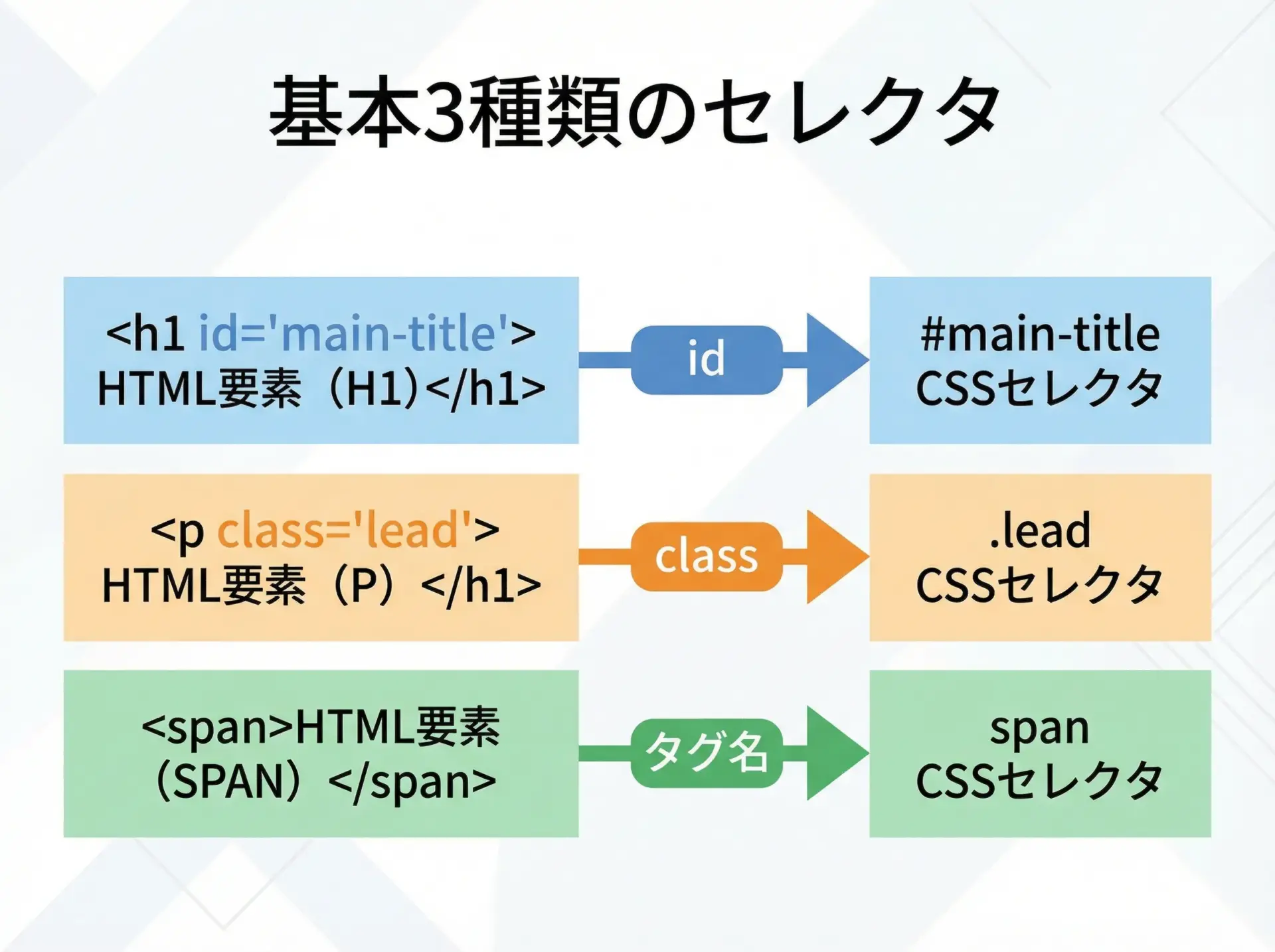
CSSセレクタの中でも、まず押さえておきたい基本は「タグ名」「id」「class」の3種類です。
日常的によく使うパターンは次の通りです。
| 対象 | HTML例 | セレクタ例 | 意味 |
|---|---|---|---|
| タグ名 | <p>テキスト</p> | p | すべてのpタグ |
| id属性 | <div id="main">...</div> | #main | idがmainの要素 |
| class属性 | <h2 class="title">見出し</h2> | .title | classがtitleの要素 |
| 複数クラス | <p class="lead highlight">...</p> | .lead.highlight | 両方のクラスを持つp要素 |
たとえば、BeautifulSoupでclassがtitleの要素を取得したい場合は、次のように書きます。
from bs4 import BeautifulSoup
html = """
<html>
<body>
<h2 class="title">記事タイトル1</h2>
<h2 class="title">記事タイトル2</h2>
<p class="lead">リード文</p>
</body>
</html>
"""
soup = BeautifulSoup(html, "html.parser")
# classが"title"の要素をすべて取得
titles = soup.select(".title")
for t in titles:
print(t.get_text())記事タイトル1
記事タイトル2このように、CSSセレクタはタグ名とclass/idを組み合わせて、目的の要素を簡潔に指定できます。
子孫セレクタと子セレクタの違い
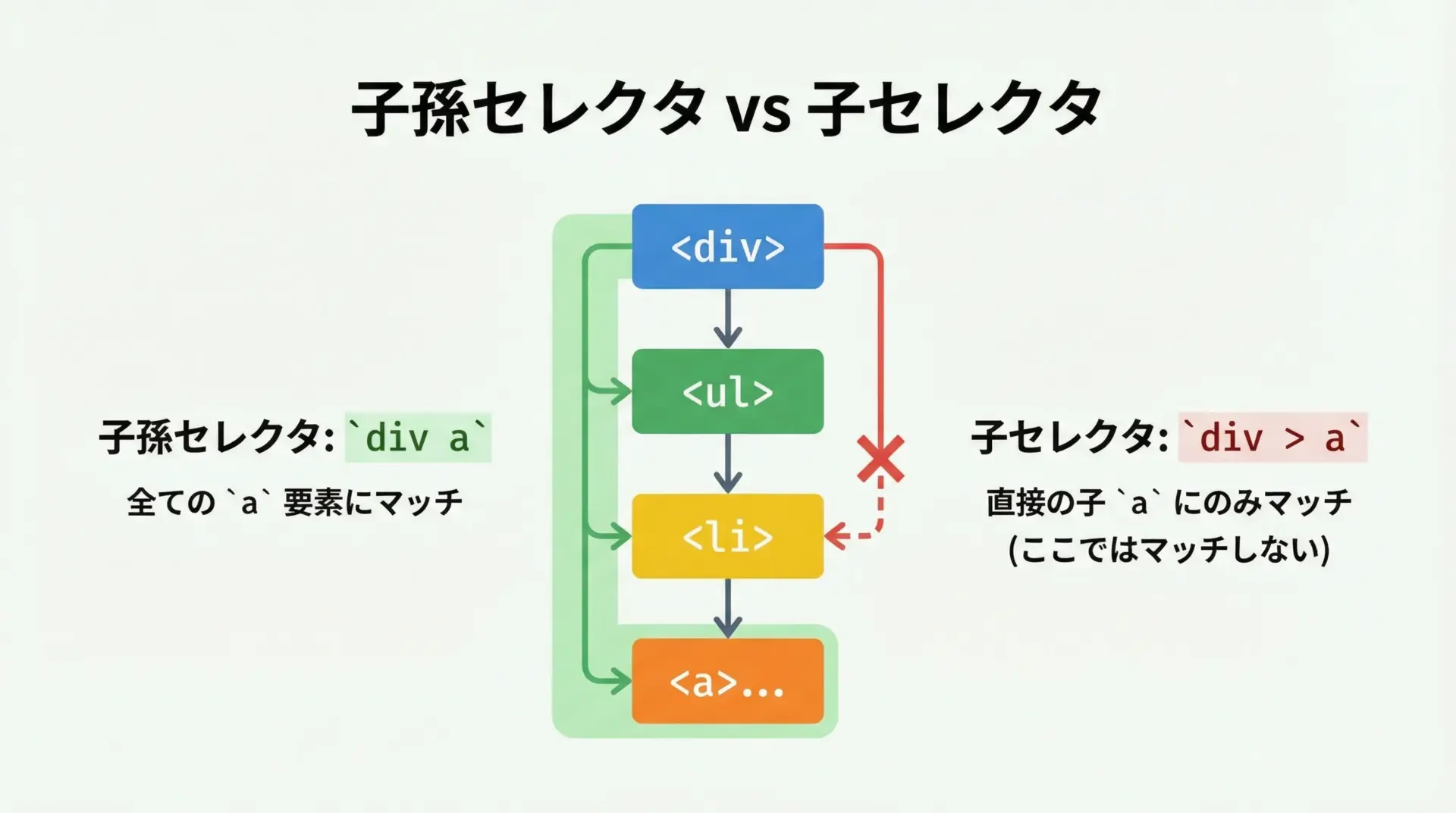
HTMLは入れ子構造になっているため、「どの要素の中にあるか」がとても重要です。
CSSセレクタでは、要素の階層関係を表すために、主に「子孫セレクタ」と「子セレクタ」を使います。
| 種類 | 記法 | 意味 |
|---|---|---|
| 子孫セレクタ | A B | Aの内側にあるすべてのB(何階層深くてもOK) |
| 子セレクタ | A > B | Aの直下の子要素であるB(1階層だけ) |
具体例で見てみます。
<div class="container">
<ul>
<li><a href="/a1">リンク1</a></li>
</ul>
<a href="/a2">リンク2</a>
</div>from bs4 import BeautifulSoup
html = """
<div class="container">
<ul>
<li><a href="/a1">リンク1</a></li>
</ul>
<a href="/a2">リンク2</a>
</div>
"""
soup = BeautifulSoup(html, "html.parser")
# 子孫セレクタ: .container の中にあるすべての a
descendant_links = soup.select(".container a")
# 子セレクタ: .container の直下にある a (1階層のみ)
child_links = soup.select(".container > a")
print("子孫セレクタ:", [a.get_text() for a in descendant_links])
print("子セレクタ:", [a.get_text() for a in child_links])子孫セレクタ: ['リンク1', 'リンク2']
子セレクタ: ['リンク2']スクレイピングでは、構造が少し変わっても動くようにしたい場合は子孫セレクタを、意図しない要素が混ざるのを避けたい場合は子セレクタを使うといった具合に、用途に応じて使い分けることが重要です。
属性セレクタと疑似クラスの概要
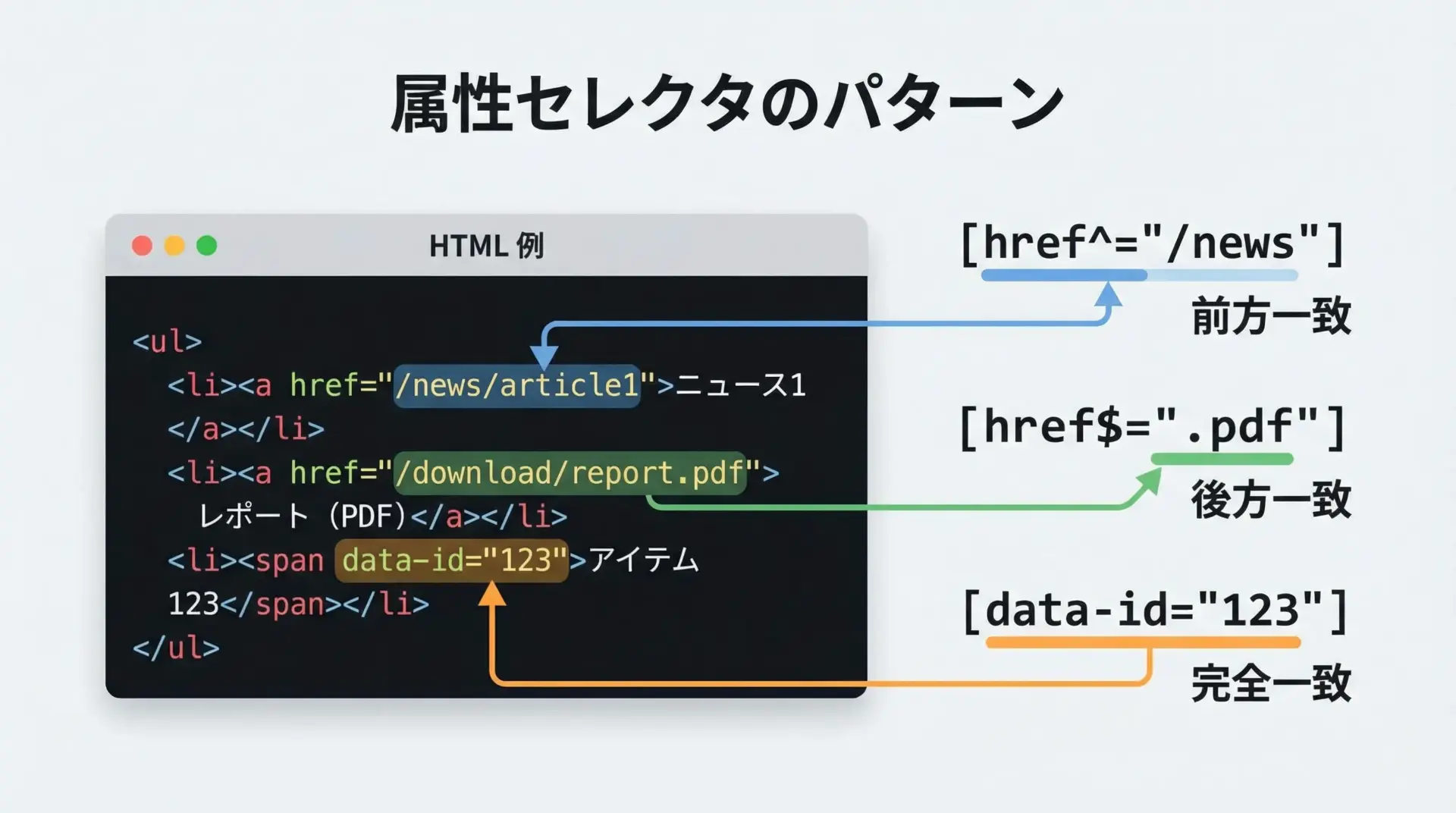
CSSセレクタでは、classやid以外にも、任意の属性を条件として指定する属性セレクタが使えます。
BeautifulSoupのCSSセレクタはCSSのサブセットですが、実務でよく使うパターンは一通り利用できます。
代表的な属性セレクタは次の通りです。
| 記法 | 意味 | 例 |
|---|---|---|
[attr="value"] | 属性attrがvalueと等しい | a[target="_blank"] |
[attr^="val"] | attrがvalで始まる(前方一致) | a[href^="https://"] |
[attr$="val"] | attrがvalで終わる(後方一致) | a[href$=".pdf"] |
[attr*="val"] | attrにvalが含まれる(部分一致) | a[href*="/news/"] |
疑似クラス(:hoverなど)は、基本的にBeautifulSoupのCSSセレクタでは使えませんが、スクレイピングではスタイル用途の疑似クラスよりも、属性セレクタで十分に柔軟な指定ができるため、大きな問題にはなりません。
BeautifulSoupでCSSセレクタを使う基本
selectとselect_oneの使い方
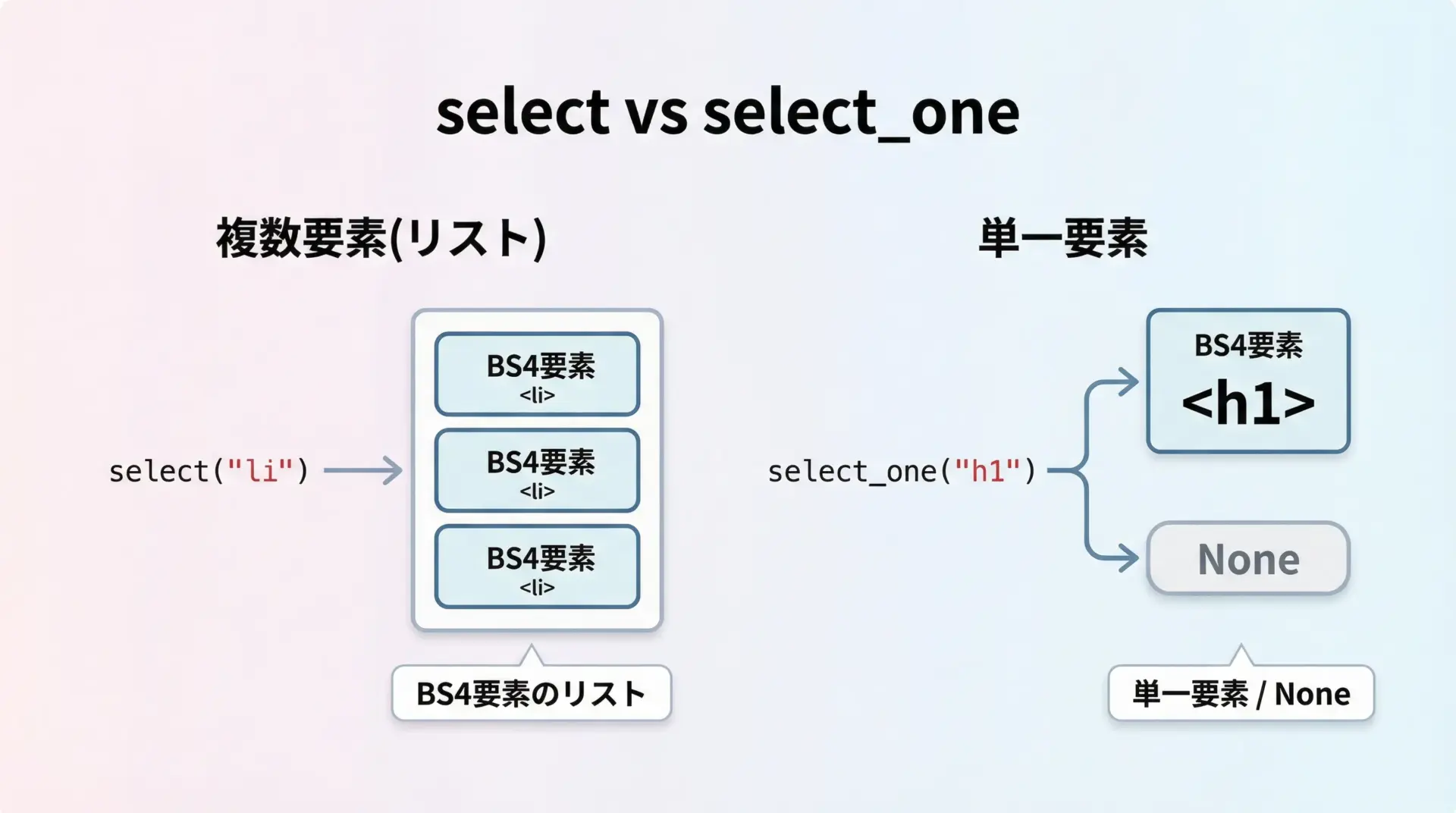
BeautifulSoupでCSSセレクタを使う際の中心となるメソッドがselect()とselect_one()です。
select(selector): セレクタにマッチするすべての要素をリストで返しますselect_one(selector): マッチした最初の1件だけを返し、見つからなければNoneになります
from bs4 import BeautifulSoup
html = """
<ul>
<li>りんご</li>
<li>バナナ</li>
<li>オレンジ</li>
</ul>
<h1>見出し</h1>
"""
soup = BeautifulSoup(html, "html.parser")
# すべてのli要素を取得
items = soup.select("li")
# 最初のh1要素を1件だけ取得
title = soup.select_one("h1")
print("liの数:", len(items))
print("h1のテキスト:", title.get_text())liの数: 3
h1のテキスト: 見出し基本的に「複数あり得る」要素にはselect、「1つだけのはず」の要素にはselect_oneを使うと、コードの意図が分かりやすくなります。
タグセレクタで要素を取得する
BeautifulSoupで最もシンプルなCSSセレクタは、タグ名そのものです。
ページ内のすべての<p>タグを取得したいときには"p"と書くだけで済みます。
from bs4 import BeautifulSoup
html = """
<article>
<h1>記事タイトル</h1>
<p>1段落目です。</p>
<p>2段落目です。</p>
<a href="/more">続きを読む</a>
</article>
"""
soup = BeautifulSoup(html, "html.parser")
# すべてのpタグを取得
paras = soup.select("p")
for i, p in enumerate(paras, start=1):
print(f"{i}段落目:", p.get_text())1段落目: 1段落目です。
2段落目: 2段落目です。タグ名だけのセレクタは対象が広いため、そのままだと余計な要素も含まれがちです。
実務では、次のように「親要素 + 子タグ」で範囲を狭めて使うことが多くなります。
# articleの中のpタグに限定して取得
paras = soup.select("article p")class, idセレクタで要素を絞り込む
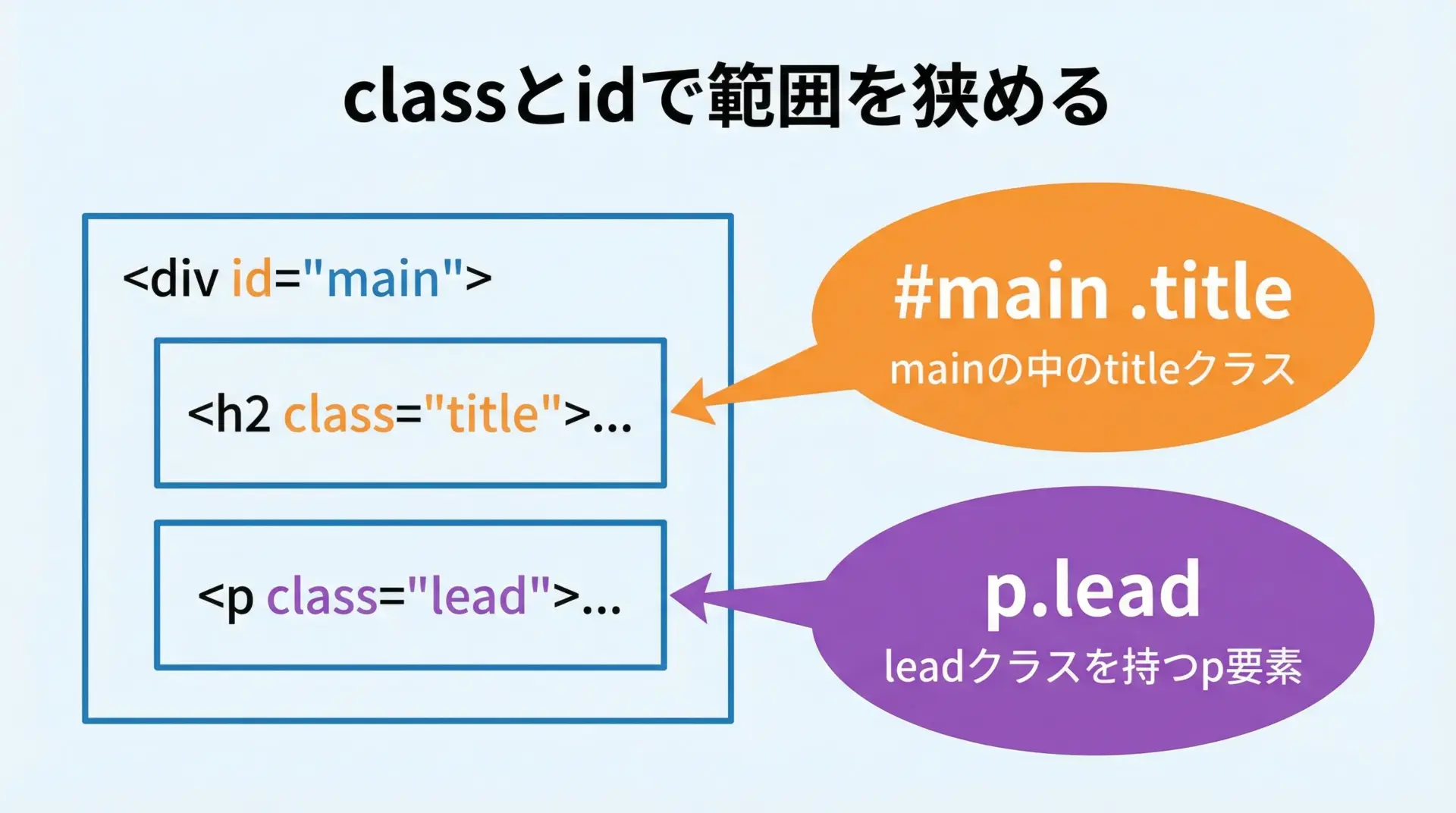
ページの中で特定のブロックやコンポーネントに対してclassやidが振られている場合、その情報を活用することで、セレクタの精度を一気に高めることができます。
from bs4 import BeautifulSoup
html = """
<div id="main">
<h2 class="title">メイン記事タイトル</h2>
<p class="lead">メインリード文。</p>
</div>
<div id="sidebar">
<h2 class="title">サイドバー見出し</h2>
<p>サイドバーの説明。</p>
</div>
"""
soup = BeautifulSoup(html, "html.parser")
# id=main の中にある class=title の要素だけ取得
main_title = soup.select_one("#main .title")
# classがleadのp要素を取得
lead = soup.select_one("p.lead")
print("メインタイトル:", main_title.get_text())
print("リード文:", lead.get_text())メインタイトル: メイン記事タイトル
リード文: メインリード文。このように、#id名と.class名を組み合わせることで、同じclass名を持つ要素が複数あっても、特定の領域内だけに絞り込むことができます。
複合セレクタで条件を組み合わせる
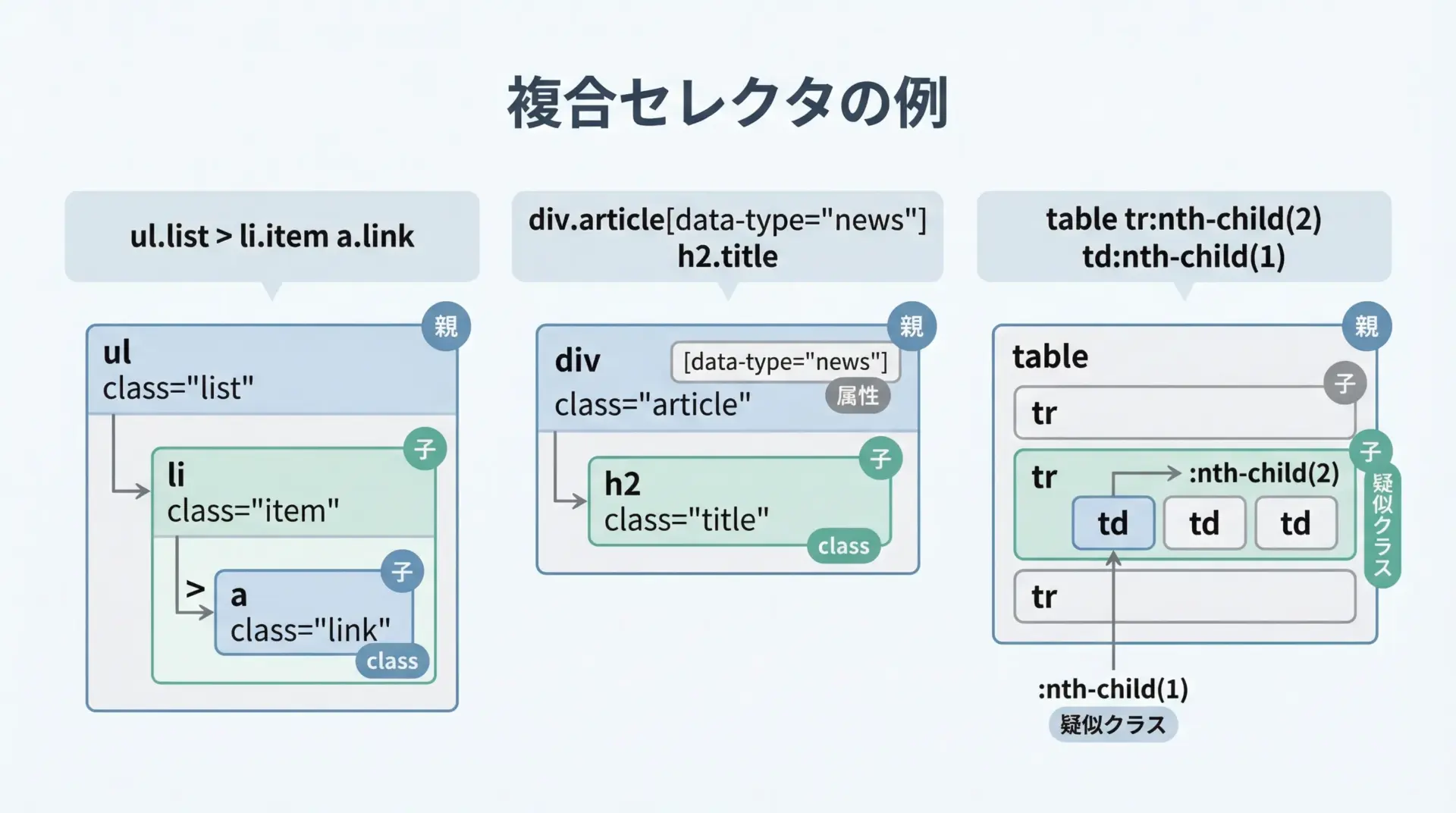
CSSセレクタの真価は、複数の条件を組み合わせて、「ここだけ取ってきてほしい」という要望をかなり細かく表現できる点にあります。
BeautifulSoupでは、次のような複合セレクタをそのまま使うことができます。
from bs4 import BeautifulSoup
html = """
<ul class="products">
<li class="item" data-id="p1">
<a class="link" href="/item/p1">商品1
</li>
<li class="item" data-id="p2">
<a class="link" href="/item/p2">商品2
</li>
</ul>
"""
soup = BeautifulSoup(html, "html.parser")
# productsクラスのulの直下にあるli.item内のa.link要素をすべて取得
links = soup.select("ul.products > li.item a.link")
for a in links:
print(a.get("href"), a.get_text())/item/p1 商品1
/item/p2 商品2この例では、タグ名<ul> + class + 子セレクタ + class + タグ名 + classという複数条件を組み合わせています。
構造とclass/id/属性を適切に組み合わせることで、「壊れにくく」「意図した要素だけ」を指定できるセレクタを設計できるようになります。
スクレイピング精度を上げるCSSセレクタ設計
安定したセレクタと壊れやすいセレクタの違い
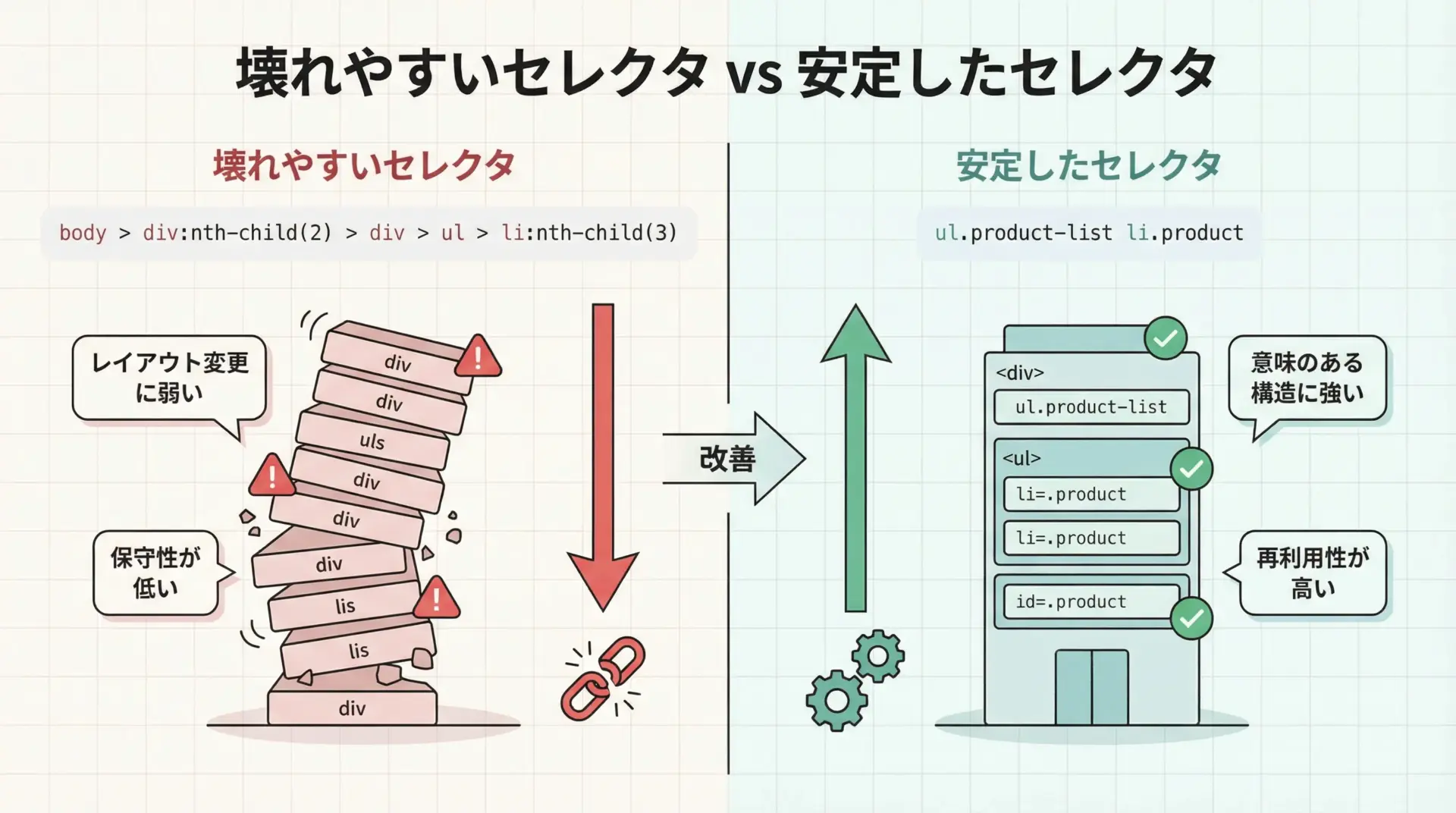
スクレイピングで問題になりやすいのが、「ある日突然、取得スクリプトが動かなくなる」現象です。
その多くは、セレクタの設計が脆いことが原因です。
壊れやすいセレクタの典型例として、nth-childを多用したフルパス指定があります。
/* 壊れやすい例 */
body > div:nth-child(2) > div > ul > li:nth-child(3)このような指定は、ページのレイアウトに少し変更が入るだけで、すぐにズレてしまいます。
一方で、次のような、意味のあるclassやid、属性を頼りにしたセレクタは構造変更に比較的強くなります。
/* 安定しやすい例 */
ul.product-list li.productBeautifulSoupでCSSセレクタを設計する際には、可能な限り次のような指針を意識すると良いです。
- レイアウト都合のwrap用divなどは極力頼らない
- 意味のあるclass/id(命名から役割が推測できるもの)を優先して使う
- 兄弟要素の順番に依存するnth-child系は最小限に抑える
- data属性など、データ寄りの情報を活用する
ネスト構造を踏まえたセレクタ設計
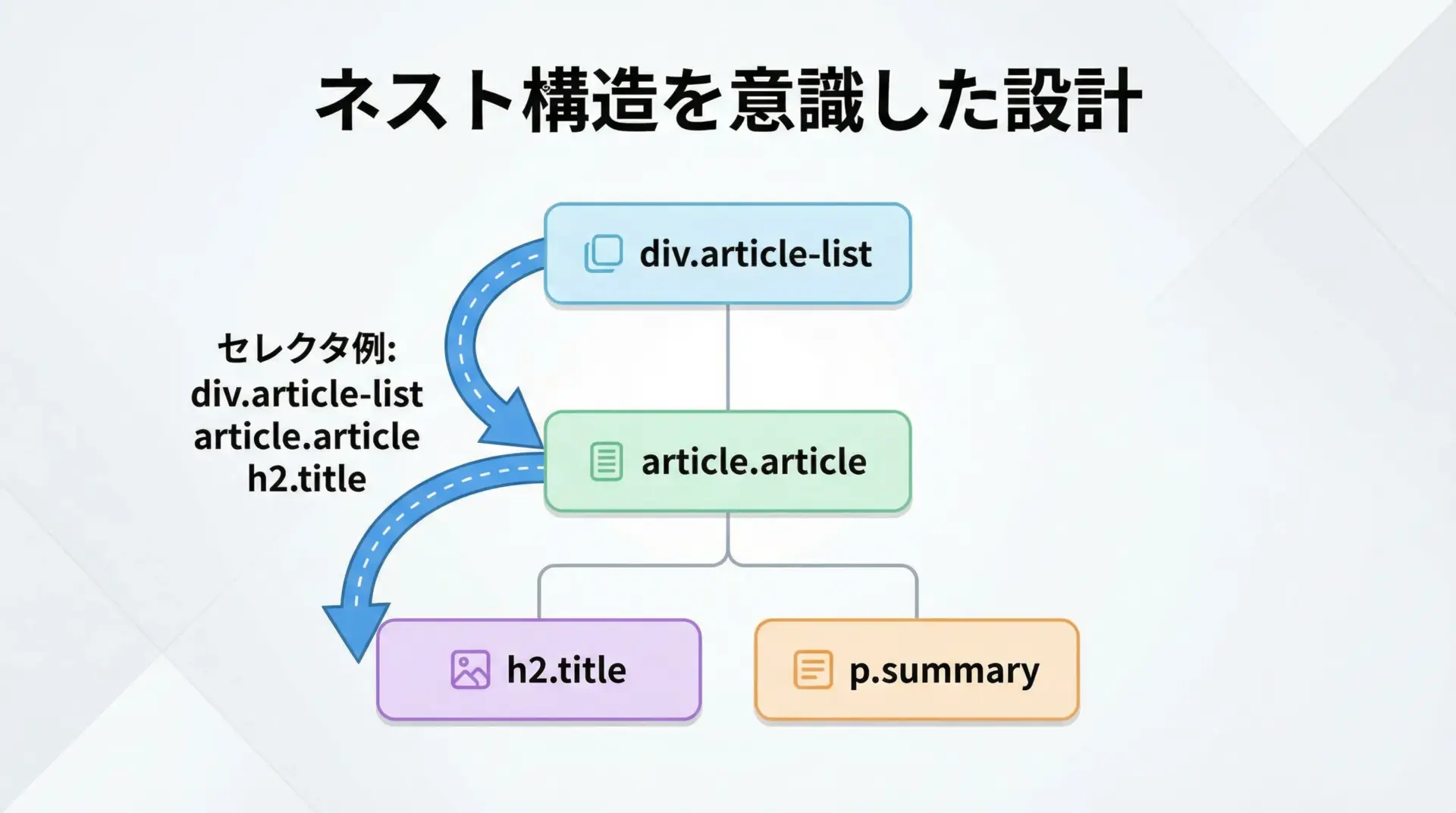
ページ構造をよく観察すると、対象の情報が<ul>や<article>、<section>などの入れ物要素にまとまっていることが多いです。
ネスト構造に沿って「入口」と「ゴール」を定めたセレクタは、読みやすく壊れにくい傾向があります。
from bs4 import BeautifulSoup
html = """
<div class="article-list">
<article class="article">
<h2 class="title">ニュース1</h2>
<p class="summary">要約1</p>
</article>
<article class="article">
<h2 class="title">ニュース2</h2>
<p class="summary">要約2</p>
</article>
</div>
"""
soup = BeautifulSoup(html, "html.parser")
# 記事リスト全体の「入口」セレクタ
articles = soup.select("div.article-list article.article")
for art in articles:
# 各article「内側」だけで相対的に検索
title = art.select_one("h2.title").get_text(strip=True)
summary = art.select_one("p.summary").get_text(strip=True)
print(title, "-", summary)ニュース1 - 要約1
ニュース2 - 要約2このように、まず「記事のまとまり」を表すarticleを入口として取得し、その中でタイトルや要約を探す形にすると、親子関係に従ったセレクタ設計ができ、変更にも強くなります。
属性値データ(data属性)を利用した抽出

近年のWebサイトでは、JavaScript向けのメタ情報としてdata属性(例: data-id, data-type)が多用されています。
これらはスタイルではなくデータの意味に関する情報であるため、構造変更の影響を受けにくい安定した手がかりになることがあります。
from bs4 import BeautifulSoup
html = """
<ul class="products">
<li class="product" data-sku="A001" data-stock="in">
<span class="name">商品A</span>
</li>
<li class="product" data-sku="B002" data-stock="out">
<span class="name">商品B</span>
</li>
</ul>
"""
soup = BeautifulSoup(html, "html.parser")
# 在庫あり(data-stock="in")の商品だけ取得
in_stock_products = soup.select('li.product[data-stock="in"]')
for p in in_stock_products:
name = p.select_one(".name").get_text(strip=True)
sku = p.get("data-sku")
print(sku, name)A001 商品Aこのように、[data-属性名="値"]の形式でセレクタを書くことで、画面に表示されていない内部的な状態(在庫有無や状態コードなど)を基準に、抽出対象をより厳密に絞り込めます。
テキストと構造を組み合わせた要素特定
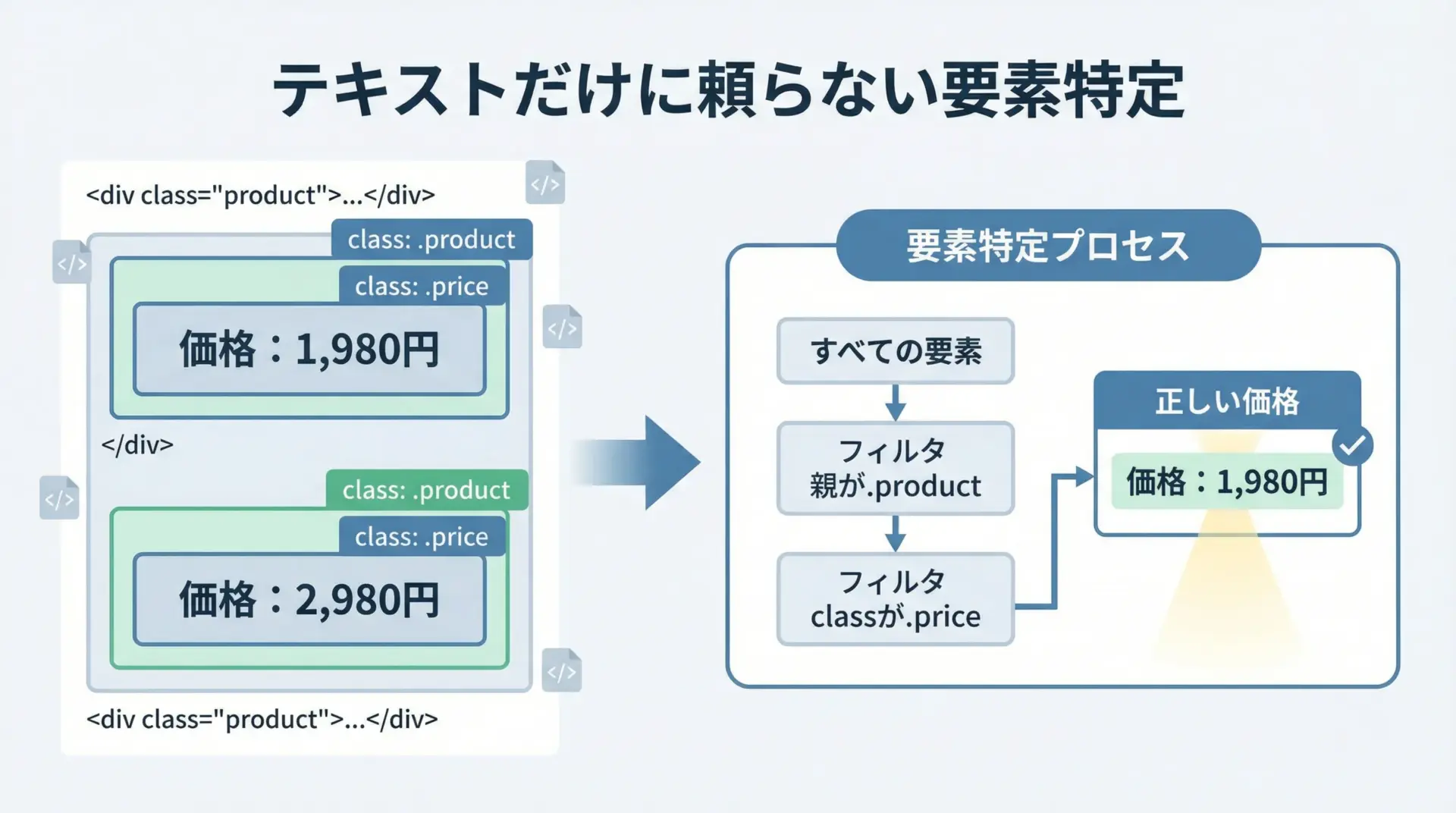
BeautifulSoupのCSSセレクタ自体は「テキスト内容」で条件を直接指定することはできませんが、CSSセレクタで構造を絞り込み、その後Pythonコードでテキストを判定するという組み合わせがよく使われます。
from bs4 import BeautifulSoup
html = """
<div class="product">
<span class="label">価格</span>
<span class="price">1,980円</span>
</div>
<div class="product">
<span class="label">セール価格</span>
<span class="price">1,500円</span>
</div>
"""
soup = BeautifulSoup(html, "html.parser")
# まずは構造ベースで候補を取得
price_spans = soup.select("div.product span.price")
for span in price_spans:
# 兄弟要素のラベルをチェック
label = span.find_previous_sibling("span")
price_text = span.get_text(strip=True)
if label and label.get_text(strip=True) == "価格":
print("通常価格:", price_text)通常価格: 1,980円この例では、CSSセレクタで「product内のprice」という要素だけに絞り込み、その上で隣接するラベルのテキストを確認することで、「通常価格」だけを抽出しています。
構造で8割絞り込み、テキストで残り2割を確定させるイメージで設計すると、精度の高い要素特定が可能になります。
実践例1 ニュースサイトをPythonでスクレイピング
※以下の例は、学習用の簡略化されたHTML構造を想定したものです。
実際のサイトに対して実行する場合は、必ず利用規約やrobots.txtを確認してください。
記事タイトル一覧をCSSセレクタで抽出
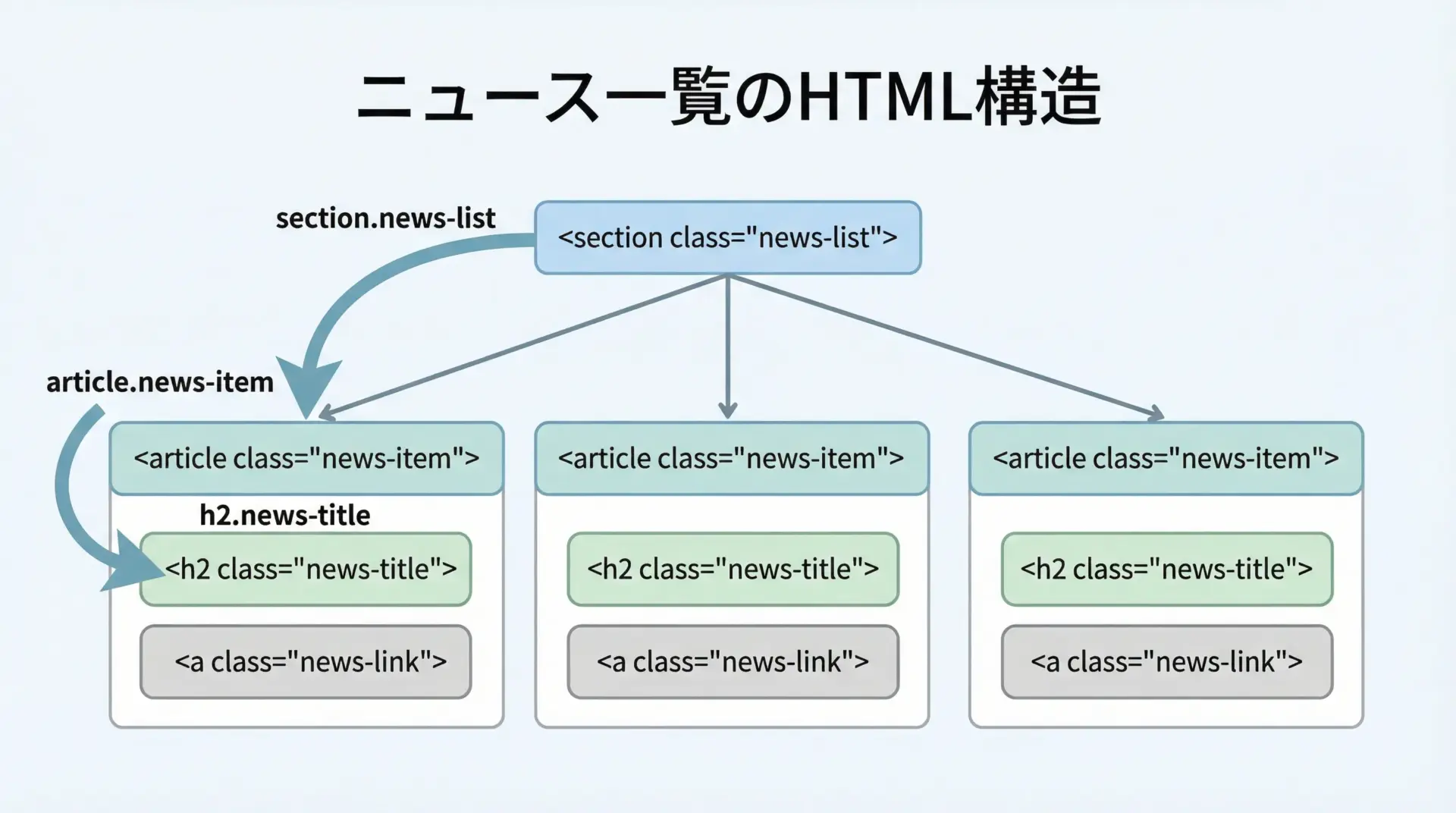
ニュースサイトのトップページには、記事一覧が並んでいることが多いです。
ここでは、次のようなHTMLを対象に、記事タイトルを抜き出す例を示します。
import requests
from bs4 import BeautifulSoup
url = "https://example.com/news" # 架空のURL
response = requests.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
# 記事タイトル(h2.news-title)をすべて取得
title_elems = soup.select("section.news-list article.news-item h2.news-title")
for t in title_elems:
print(t.get_text(strip=True))経済ニュース1
テクノロジー最新情報
スポーツ速報この例では、section.news-listというリスト全体の囲いからスタートし、その中のarticle.news-itemを経由して、最終的にh2.news-titleに到達する形でセレクタを構成しています。
日付やカテゴリを同時に取得する方法
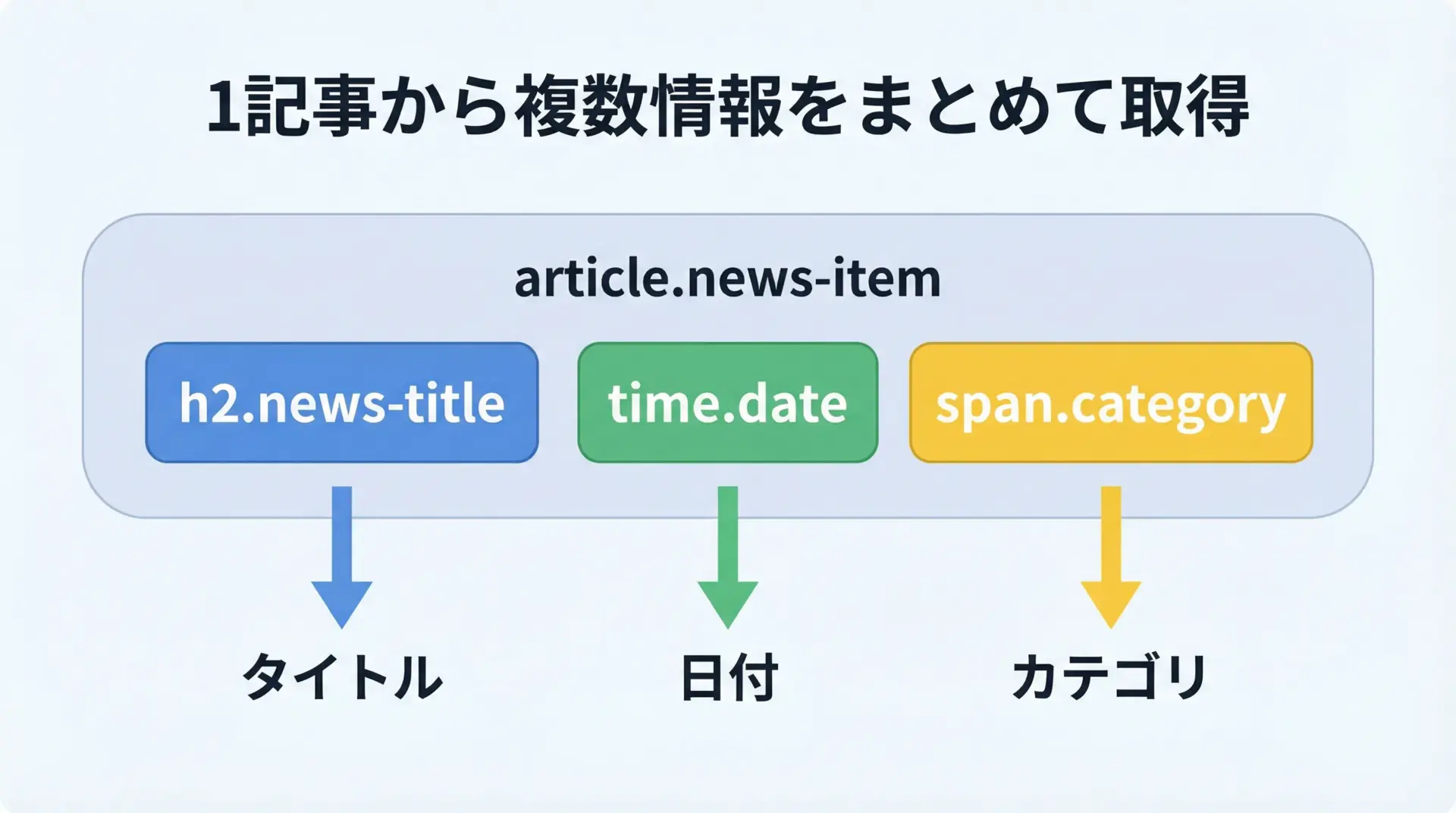
1件の記事につき、タイトルだけでなく日付やカテゴリも同時に取得したい場合は、まず記事ブロック(ここではarticle)を入口としてループし、その内側で相対的なCSSセレクタを使うのが基本パターンです。
import requests
from bs4 import BeautifulSoup
url = "https://example.com/news"
response = requests.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
# まずは記事ブロックをすべて取得
articles = soup.select("section.news-list article.news-item")
for art in articles:
title = art.select_one("h2.news-title").get_text(strip=True)
date = art.select_one("time.date").get_text(strip=True)
category = art.select_one("span.category").get_text(strip=True)
print(f"[{date}] ({category}) {title}")[2025-12-23] (経済) 経済ニュース1
[2025-12-23] (テクノロジー) テクノロジー最新情報
[2025-12-22] (スポーツ) スポーツ速報このように、「外側のまとまりをforで回し、内側のパーツに対してselect_oneする」というパターンは、ニュースサイトやブログなど、繰り返し構造のデータ取得で非常に有効です。
広告や不要な要素を除外するテクニック
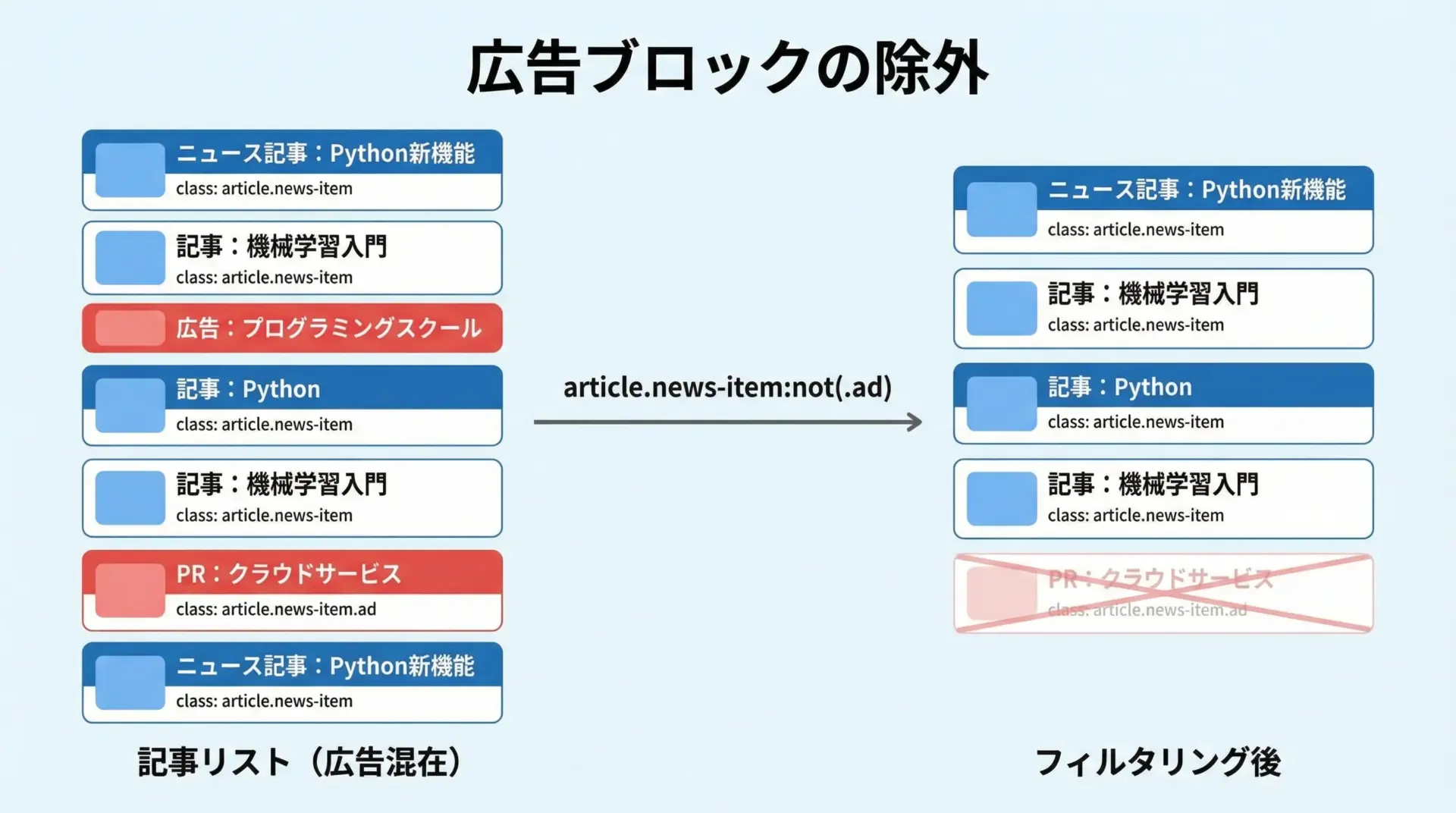
ニュースサイトには、記事一覧の中に広告が混ざっていることも多くあります。
こうしたノイズをセレクタの段階で除外しておくと、後続処理がシンプルになります。
BeautifulSoupのCSSセレクタは、完全なCSS4対応ではありませんが、:not()のような一部の疑似クラスを利用できます(バージョンによって挙動が異なることもあるため、実際にはテストが必要です)。
次のような書き方で、広告記事を除外できる場合があります。
import requests
from bs4 import BeautifulSoup
url = "https://example.com/news"
response = requests.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
# 広告(adクラス)が付いていない記事だけを取得
articles = soup.select("section.news-list article.news-item:not(.ad)")
for art in articles:
title = art.select_one("h2.news-title").get_text(strip=True)
print(title)経済ニュース1
テクノロジー最新情報
スポーツ速報もし:not()がうまく使えない場合には、先にすべてのarticleを取得し、Python側で"ad"クラスの有無をチェックして除外すると良いです。
実践例2 ECサイトの商品情報をスクレイピング
※実在のECサイトでスクレイピングを行う場合は、利用規約とrobots.txtを必ず確認し、禁止されている場合は行わないでください。
ここでは学習用の架空の構造を例示します。
商品名と価格をCSSセレクタで取得
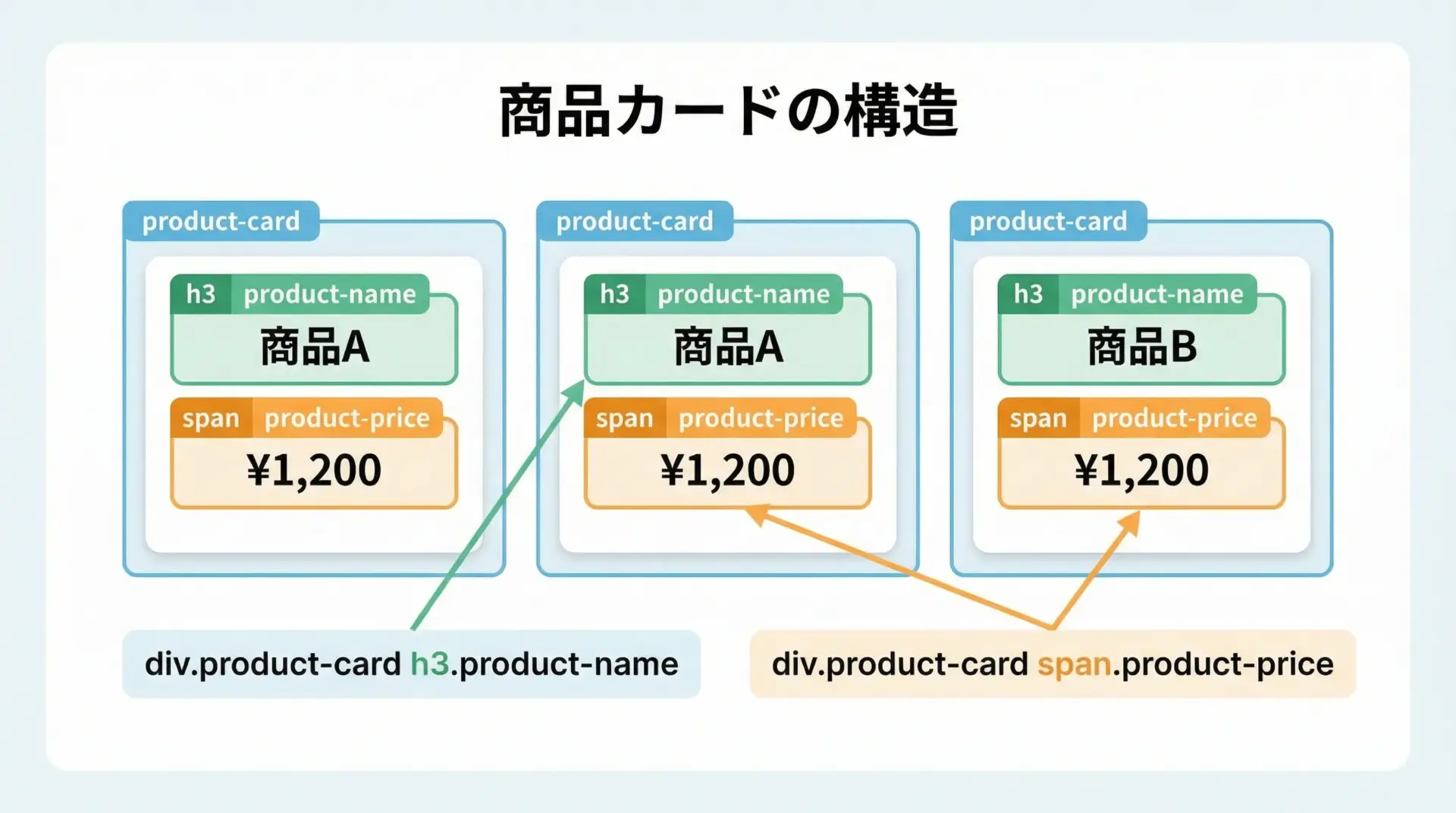
商品一覧ページでは、商品ごとにカード状のブロックが繰り返されることが多いです。
ここでもニュースサイトと同様、商品カードを入口として扱い、その中から必要要素を拾うパターンが有効です。
import requests
from bs4 import BeautifulSoup
url = "https://example.com/shop"
response = requests.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
# 商品カードをすべて取得
cards = soup.select("div.product-card")
for card in cards:
name = card.select_one("h3.product-name").get_text(strip=True)
price = card.select_one("span.product-price").get_text(strip=True)
print(name, "-", price)TシャツA - 1,980円
スニーカーB - 8,900円
バッグC - 5,500円この時点で、商品名と価格をまとめて取得できます。
ここから、さらにリンク先のURLや商品IDなどを同時に集めていくことも可能です。
ページネーションを辿る処理のパターン
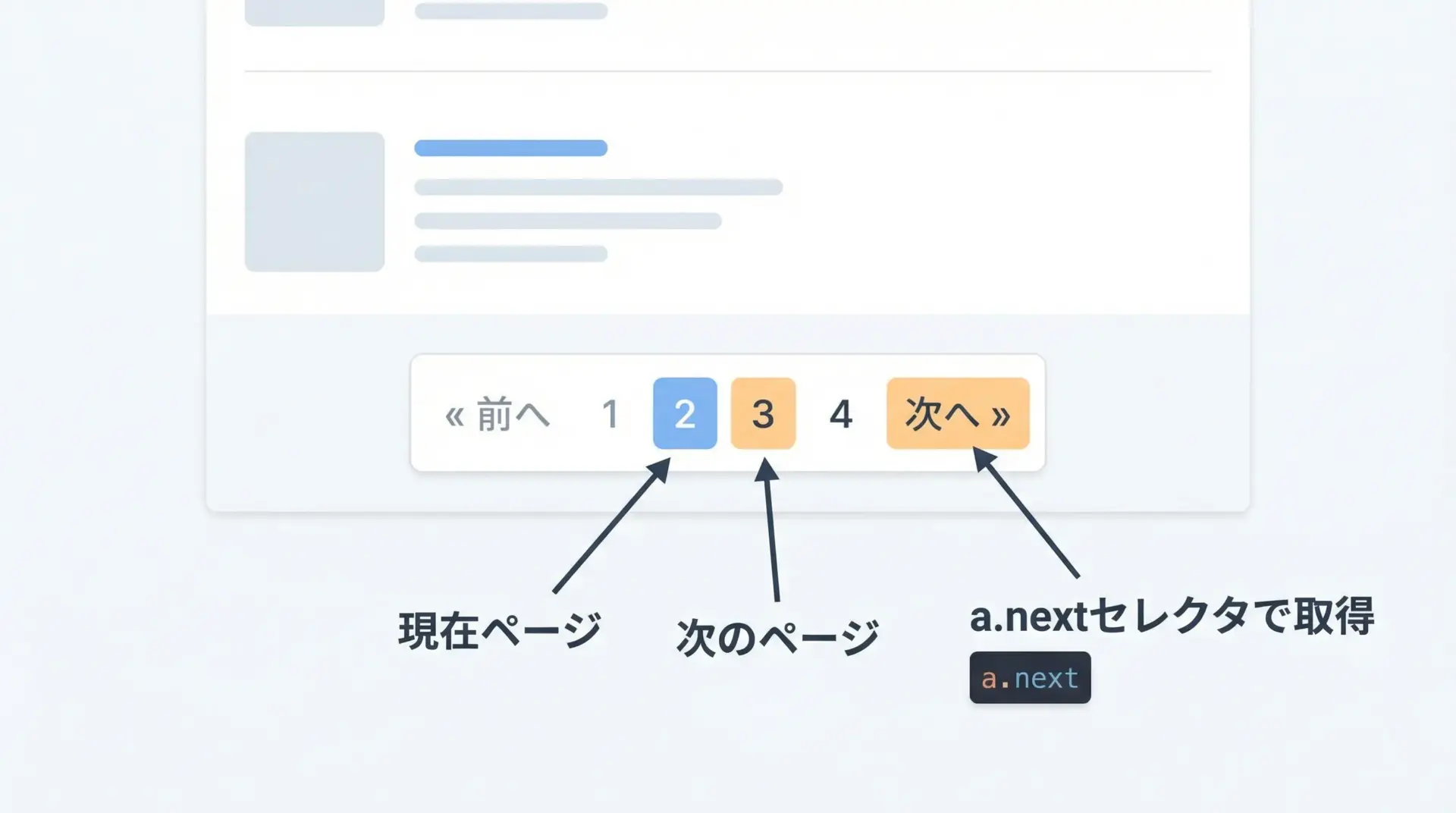
ECサイトや検索結果ページでは、商品が複数ページに分かれていることが一般的です。
ページネーションを辿るには、「次へ」リンクやページ番号リンクをCSSセレクタで取得し、ループ処理で追いかけていくパターンが使えます。
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
BASE_URL = "https://example.com/shop"
def fetch_page(url):
response = requests.get(url)
response.raise_for_status()
return BeautifulSoup(response.text, "html.parser")
url = BASE_URL
while url:
soup = fetch_page(url)
# 商品情報を取得(ここでは名前だけ)
for card in soup.select("div.product-card"):
name = card.select_one("h3.product-name").get_text(strip=True)
print(name)
# 「次へ」リンクを探す(例: a.next)
next_link = soup.select_one("a.next")
if next_link and next_link.get("href"):
# 相対URLの場合に備えてurljoinで絶対URLに変換
url = urljoin(url, next_link.get("href"))
else:
# 次のページがなければループ終了
url = Noneこのコードでは、a.nextというCSSセレクタで「次へ」ボタンを取得し、hrefを辿りながら全ページを回っています。
ページネーションのHTML構造が異なる場合でも、「現在ページを基準に、次のページだけを指すリンク」をどうCSSで表現できるかを考えれば、類似のパターンで対応できます。
在庫情報やレビュー要素の抽出
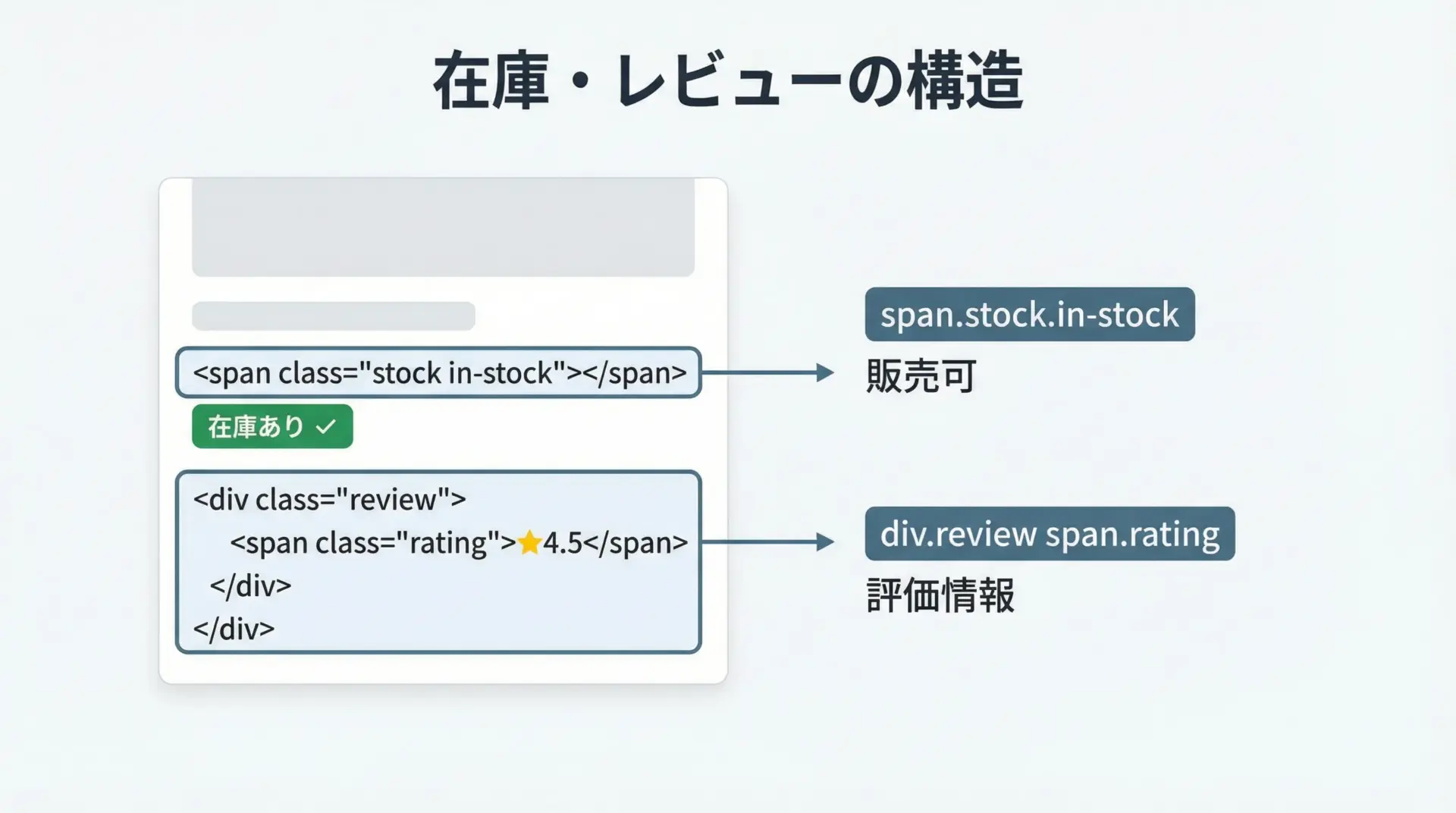
ECサイトでは、商品名と価格に加え、在庫情報やレビュー評価も重要なデータです。
これらはclassやdata属性で表現されていることが多く、CSSセレクタで簡潔に抽出できます。
import requests
from bs4 import BeautifulSoup
url = "https://example.com/shop"
response = requests.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
for card in soup.select("div.product-card"):
name = card.select_one("h3.product-name").get_text(strip=True)
price = card.select_one("span.product-price").get_text(strip=True)
# 在庫情報(例: span.stockに"in-stock"クラスがあるか)
stock_elem = card.select_one("span.stock")
in_stock = stock_elem and "in-stock" in stock_elem.get("class", [])
# レビュー評価(例: data-rating属性に数値が入っている)
rating_elem = card.select_one("div.review span.rating")
rating = rating_elem.get("data-rating") if rating_elem else None
print(name, price, "在庫あり" if in_stock else "在庫なし", "評価:", rating)TシャツA 1,980円 在庫あり 評価: 4.5
スニーカーB 8,900円 在庫なし 評価: 4.2
バッグC 5,500円 在庫あり 評価: 4.8このように、classの有無やdata属性をチェックすることで、見た目だけでは分からない商品状態も機械的に取得することができます。
よくあるエラーとCSSセレクタのデバッグ
要素が取得できない時のチェックポイント
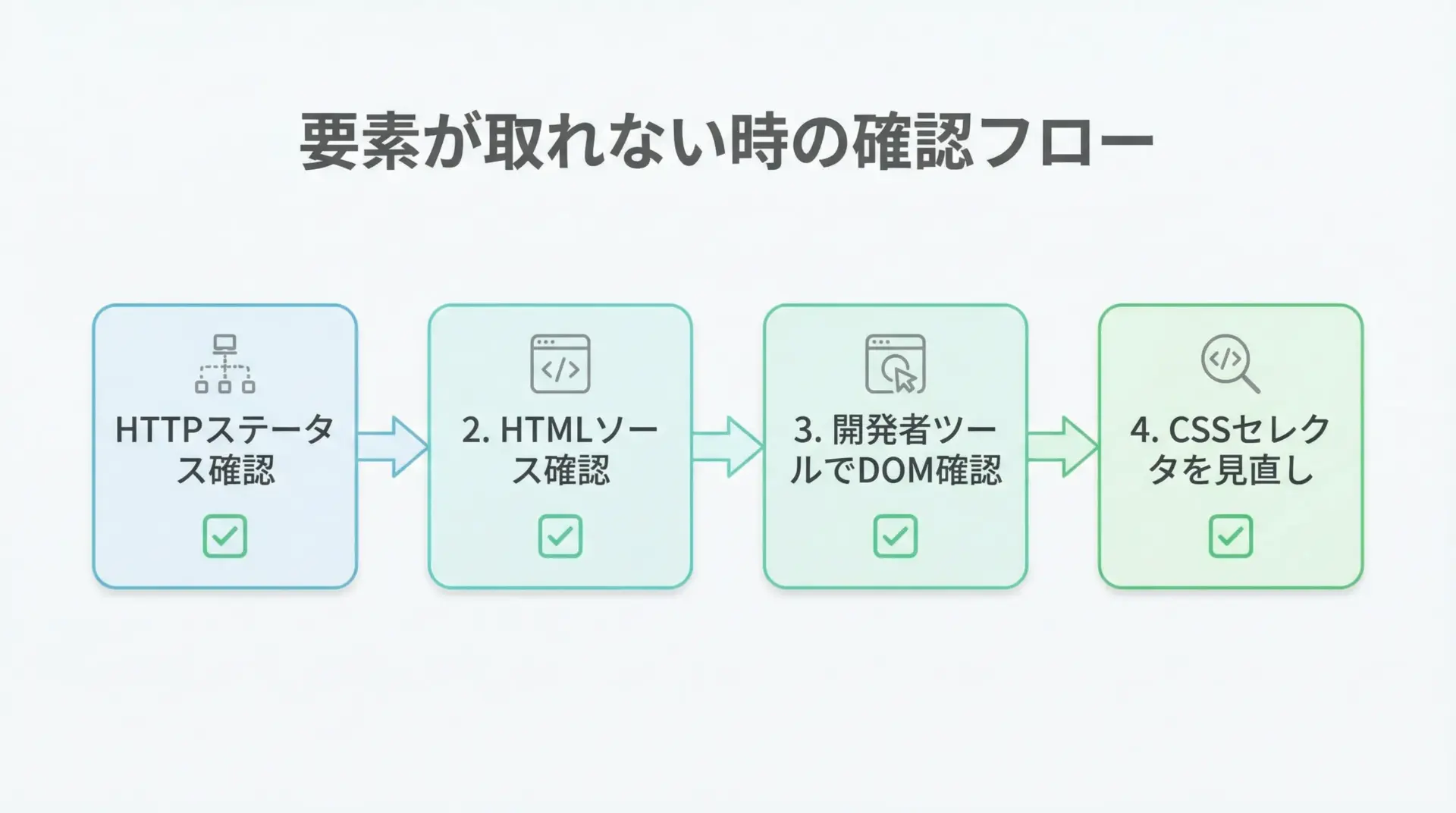
CSSセレクタを使っていて最もよく遭遇する問題が、「selectしても空リスト」「select_oneがNone」という状況です。
この場合、次のポイントを順に確認すると原因を特定しやすくなります。
1つ目は、本当にHTMLが取得できているかです。
ログにresponse.status_codeやresponse.text[:500]を出力して、予期せぬエラーページなどを拾っていないか確認します。
2つ目は、ブラウザで見ているDOM構造と、実際に取得しているHTMLが同じかです。
JavaScriptで後から書き換えられている場合、requestsで取得した段階ではまだ要素が存在しないことがあります。
3つ目が、CSSセレクタの記述ミスや余計な限定条件です。
例えば、実際のclass名が"news-item featured"であるのに、セレクタを".news_item"とタイプミスしている、などの事例は頻繁に起こります。
from bs4 import BeautifulSoup
html = """
<div class="news-item featured">
<h2 class="news-title">ニュース</h2>
</div>
"""
soup = BeautifulSoup(html, "html.parser")
# 誤ったセレクタ(クラス名をタイプミス)
wrong = soup.select(".news_item")
print("wrong:", wrong)
# 正しいセレクタ
correct = soup.select(".news-item")
print("correct:", correct)wrong: []
correct: [<div class="news-item featured">
<h2 class="news-title">ニュース</h2>
</div>]<select>結果が空のときは、まずはセレクタを極力シンプルにし(例: ".news-item"だけにする)、段階的に条件を追加していくと原因を絞りやすくなります。
ブラウザ開発者ツールでCSSパスを確認する
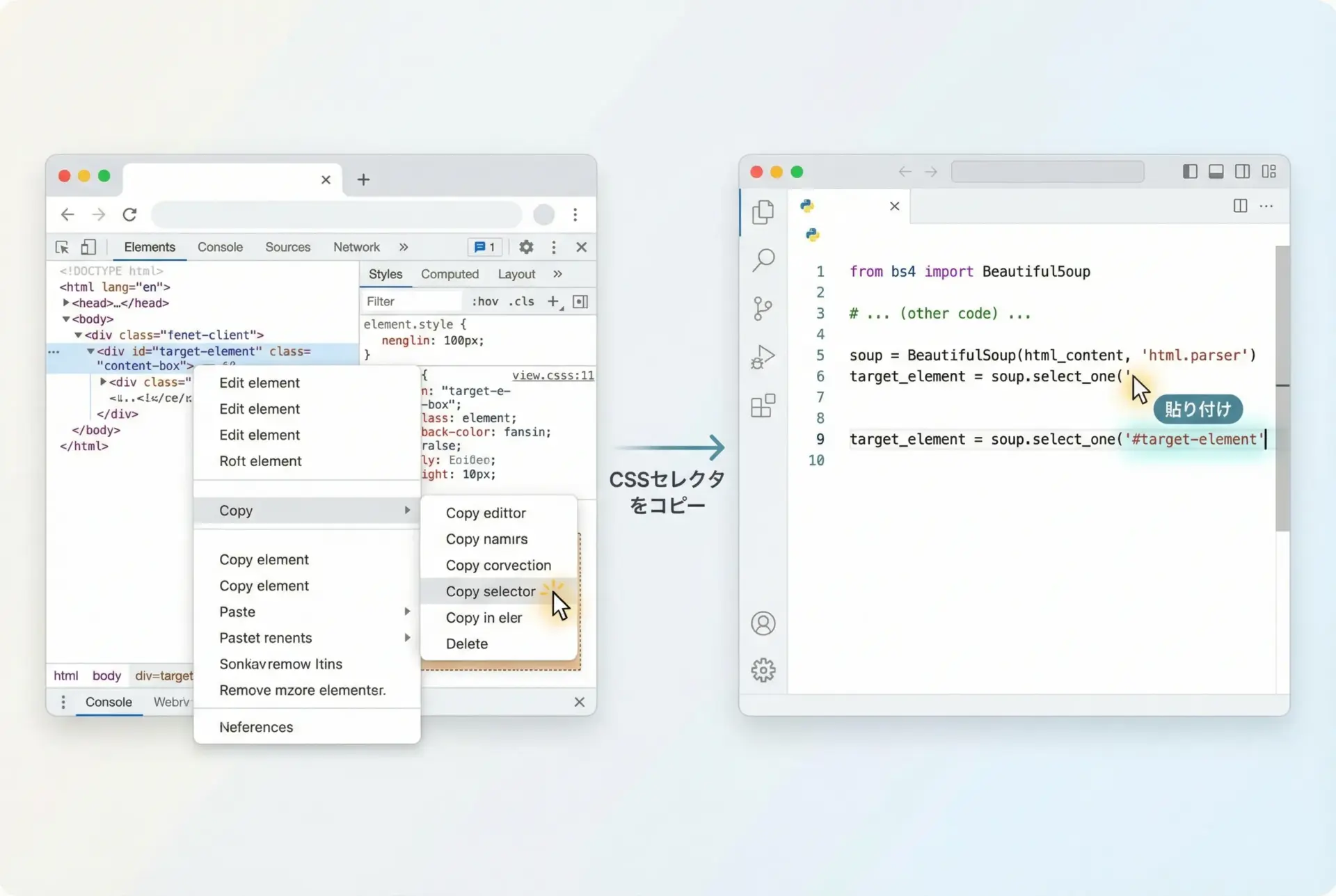
CSSセレクタの設計やデバッグで最も役立つのが、ブラウザの開発者ツールです。
ChromeやEdgeであれば、対象の要素を右クリックして「検証」を選ぶことで、Elementsタブに対応するDOMがハイライトされます。
そこから、さらに右クリックで「Copy」→「Copy selector」あるいは「Copy → Copy JS path」などを選ぶと、ブラウザが自動生成したCSSパスを取得できます。
このパスはしばしば冗長ですが、最低限必要な部分だけを残す参考情報として非常に有用です。
例として、ブラウザが生成したセレクタが次のような長いものだったとします。
body > div.container > section.news-list > article.news-item:nth-child(3) > h2.news-titleこれをそのまま使うと、構造変更に非常に弱いため、次のように意味のある部分だけに削るのが現実的です。
section.news-list article.news-item h2.news-title開発者ツールで実際にどの要素がマッチしているかを確認しながら、セレクタを試行錯誤することで、BeautifulSoup側でも同じセレクタを使って安定した抽出ができるようになります。
サイト構造変更への対応方法
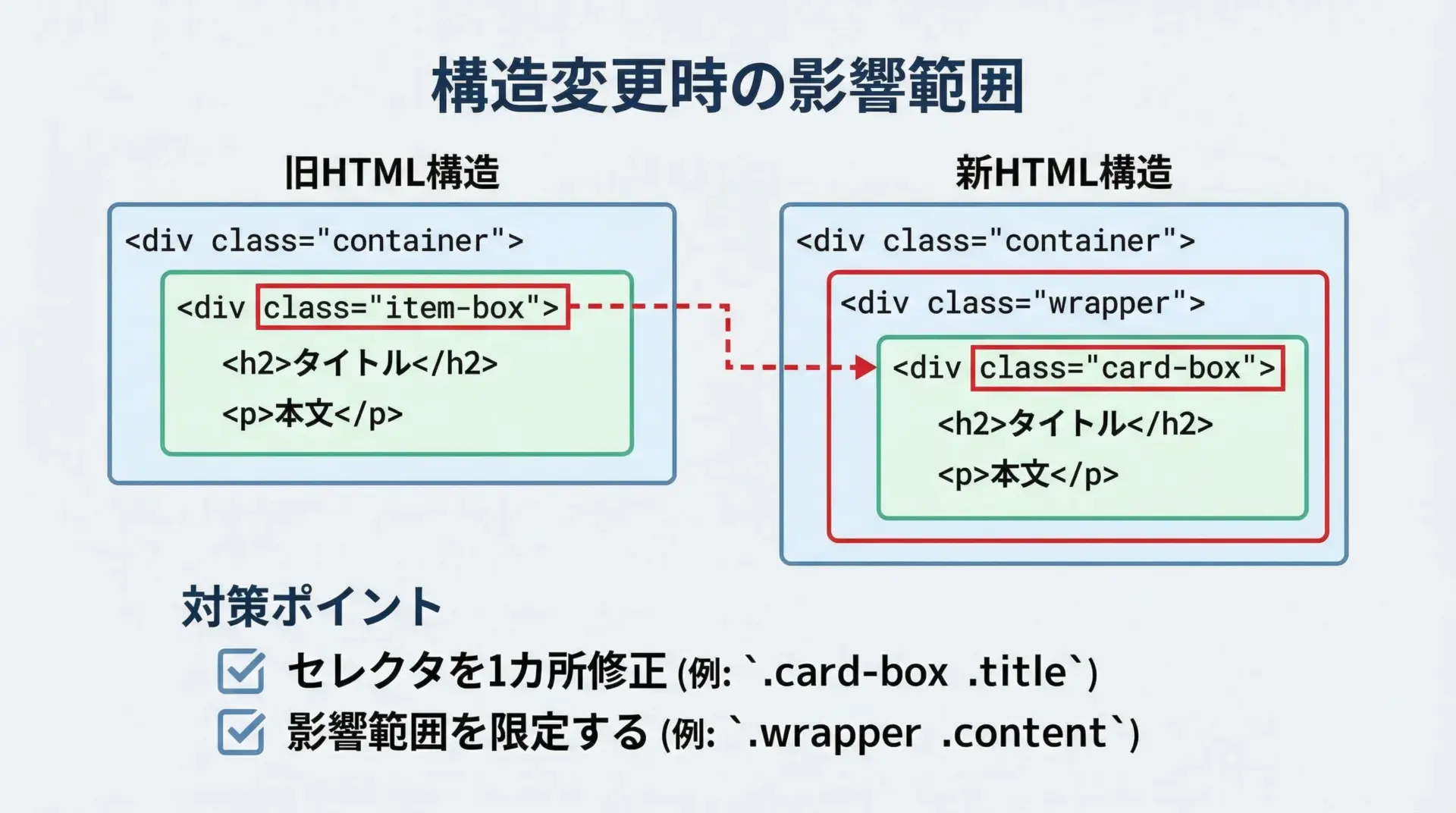
長期運用しているスクレイピングスクリプトでは、対象サイトのデザインリニューアルや小さな改修により、構造が変わって動かなくなることが避けられません。
完全に防ぐことは難しいですが、次のような工夫で影響範囲を最小限に抑えることができます。
まず、CSSセレクタの定義をコード中に散在させず、1カ所に集約して定数として管理する方法があります。
これにより、構造変更時に修正すべき箇所をすぐに特定できます。
# セレクタ定数をまとめる
NEWS_LIST_SELECTOR = "section.news-list article.news-item"
NEWS_TITLE_SELECTOR = "h2.news-title"
NEWS_DATE_SELECTOR = "time.date"
# 実際の利用箇所
articles = soup.select(NEWS_LIST_SELECTOR)
for art in articles:
title = art.select_one(NEWS_TITLE_SELECTOR).get_text(strip=True)
date = art.select_one(NEWS_DATE_SELECTOR).get_text(strip=True)また、最低限のサンプルHTMLをローカルに保存しておき、それに対するテストコードを書くことで、構造変更を早期に検知することもできます。
GitHub ActionsなどのCI環境で定期的にスクレイピングテストを実行し、異常を検知したらSlack等に通知する、といった運用も現実的です。
スクレイピング時の注意点とマナー
robots.txtと利用規約の確認
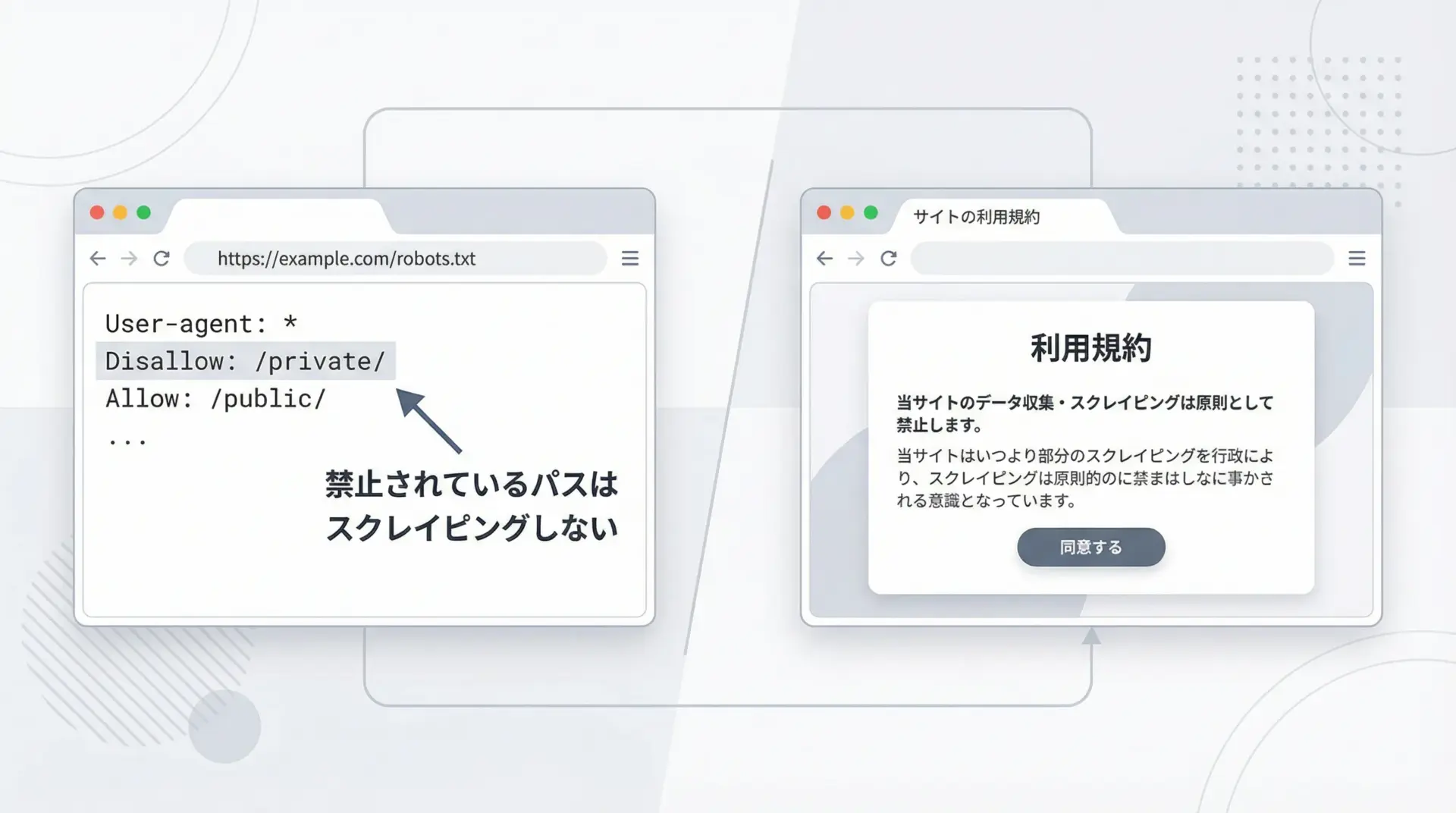
技術的にスクレイピングが可能だからといって、どんなサイトでも自由にデータを取得してよいわけではありません。
robots.txtと利用規約の確認は必須です。
robots.txtは、サイトの管理者がクローラーに対して「ここはクロールしてよい」「ここは禁止」といったルールを示すファイルです。
例えば、次のような内容が記載されている場合があります。
User-agent: *
Disallow: /private/この場合、/private/以下のパスはクローラーに対して拒否されています。
スクレイピングを行う前には、https://対象サイト/robots.txtにアクセスして内容を確認し、禁止されているパスにはアクセスしないようにします。
さらに、サイト固有の利用規約には、スクレイピング自体を明確に禁止しているケースもあります。
その場合は、robots.txtに明記されていなくても、規約に従ってスクレイピングを行わないのが原則です。
アクセス負荷を抑えるリクエスト設計
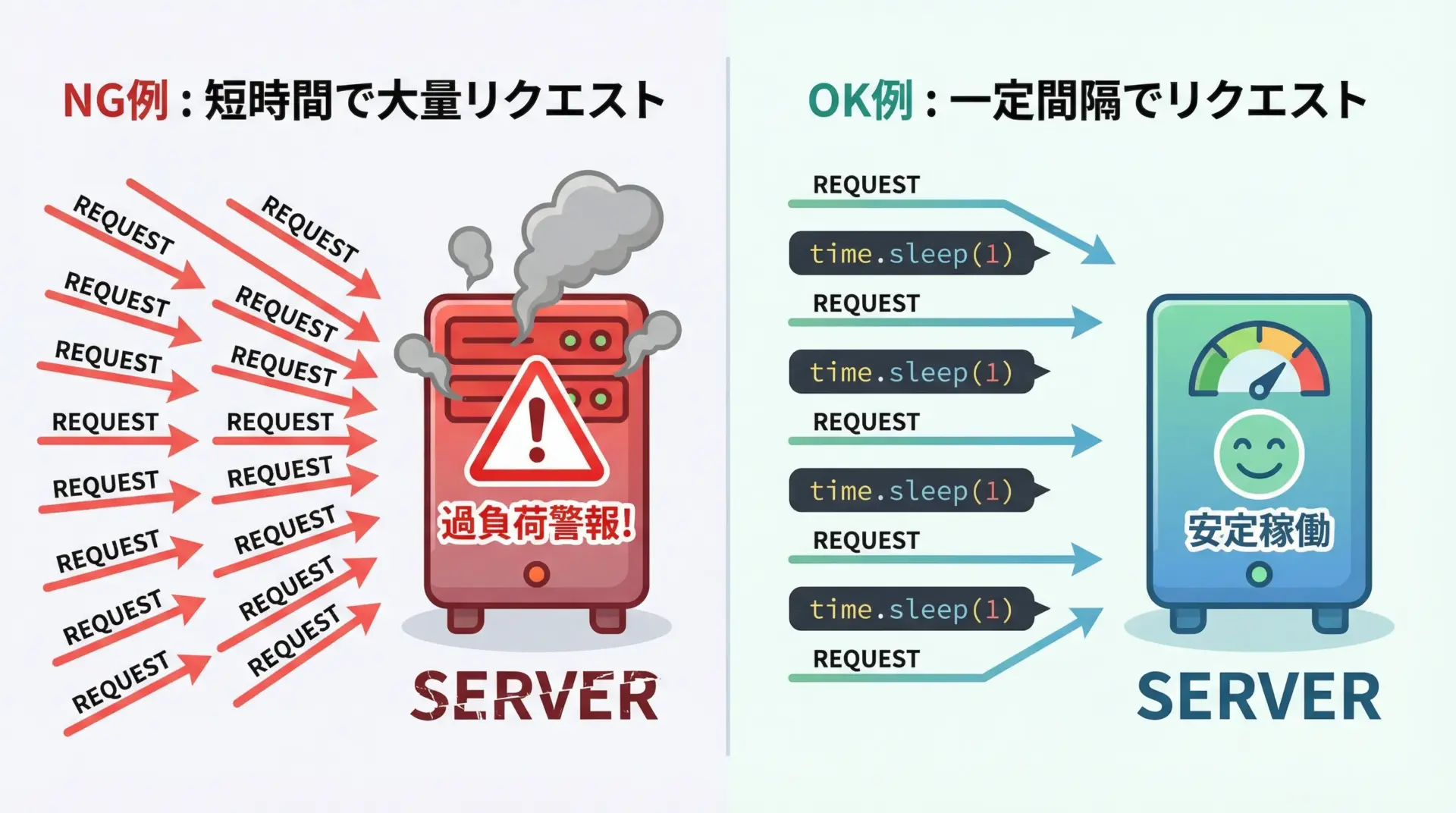
スクレイピングは対象サイトのサーバーに負荷をかける行為でもあります。
特に、短時間に大量のリクエストを送ると、サービス提供者に迷惑をかけるだけでなく、自分のIPアドレスがブロックされる可能性もあります。
負荷を抑えるためには、次のような配慮が重要です。
- 1秒以上の間隔をあけてアクセスする
time.sleep()を挟む - 不要なページにまでアクセスしないよう、URLの範囲を絞る
- 画像や動画など、大きなファイルを無駄に取得しない
- 適切なUser-Agentを設定する(クローラーであることを明示する場合もある)
import time
import requests
urls = ["https://example.com/page1", "https://example.com/page2"]
for url in urls:
response = requests.get(url)
# ここでHTML解析やデータ抽出を行う
print(url, response.status_code)
# 1秒待機してから次のリクエスト
time.sleep(1)このように、「人間が閲覧するのと同等か、それよりゆっくり」なペースでアクセスすることが、マナーとして重要です。
取得データの利用範囲と法的リスク
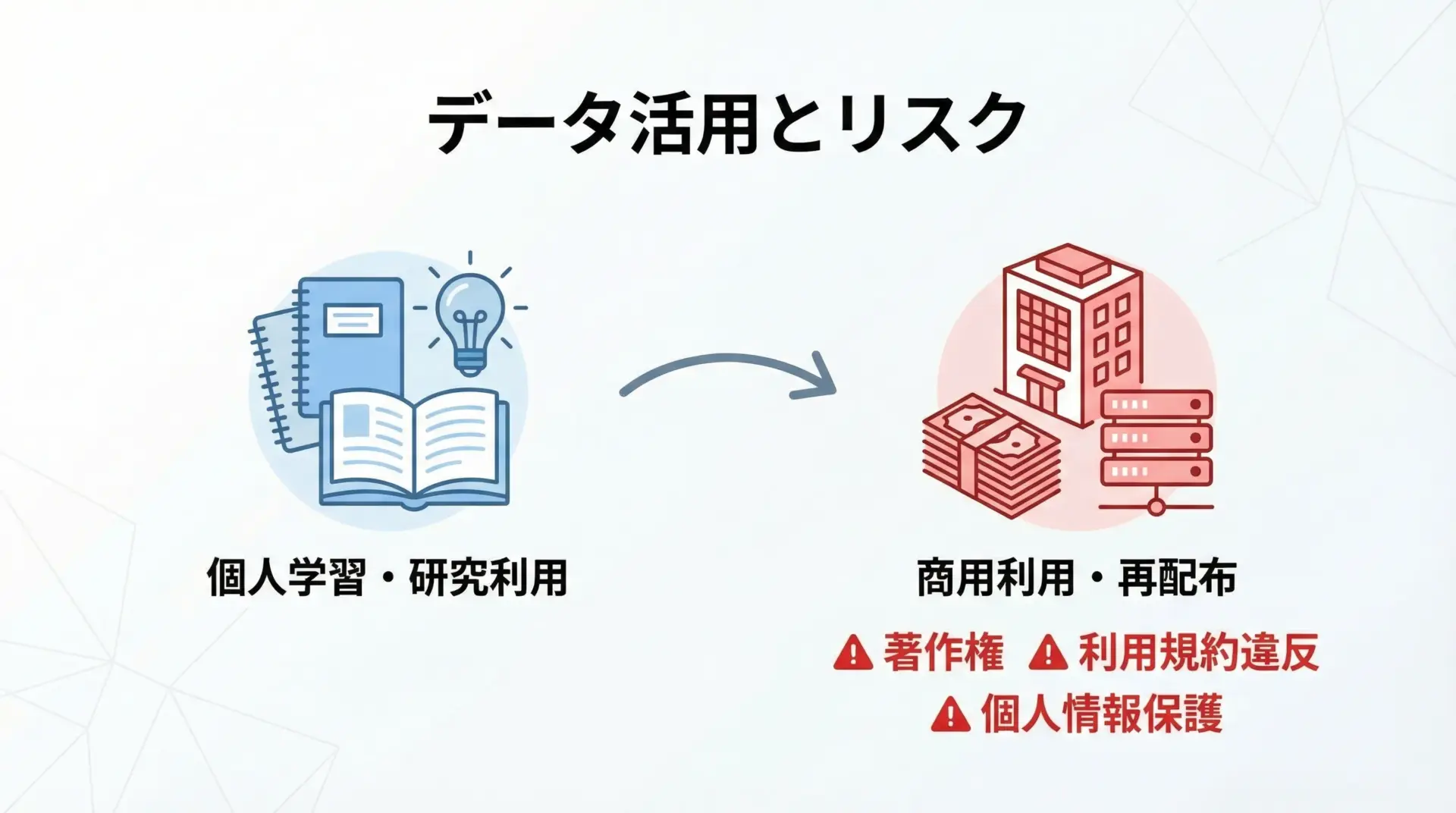
スクレイピングで取得したデータの利用方法によっては、著作権侵害や利用規約違反に当たる可能性があります。
特に、次のような利用には注意が必要です。
- 取得データをそのまま再配布する(別サイトで公開する、APIとして提供するなど)
- 取得データを商用サービスの主要なコンテンツとして利用する
- 個人情報を含むデータを収集・保存・共有する
一方で、自分のPC内での学習目的や研究目的での利用であれば、比較的リスクは低いと考えられます。
ただし、法的な判断は国や状況によって異なり、またサイトごとの利用規約によって明確に禁止されている場合もあるため、グレーなケースでは専門家(弁護士など)への相談も検討すべきです。
技術的にできることと、法的・倫理的に許されることは別であることを常に念頭に置き、スクレイピングを行う際には慎重な姿勢を保つことが大切です。
まとめ
本記事では、PythonのBeautifulSoupとCSSセレクタを組み合わせて、スクレイピング精度を高める方法を体系的に解説しました。
CSSセレクタの基本(タグ名、class、id、子孫・子セレクタ、属性セレクタ)から始め、ニュースサイトやECサイトを想定した実践例を通して、「構造を理解し、意味のあるclassやdata属性を手がかりに安定したセレクタを設計する」という考え方を紹介しました。
最後に触れたマナーや法的リスクにも注意しつつ、ブラウザ開発者ツールとBeautifulSoupのselect()/select_one()を駆使して、より精度の高い、安全なスクレイピングに挑戦してみてください。
