
Pythonでスクレイピングを始めると、ついコードやライブラリに意識が向きがちですが、実務ではrobots.txtの確認と法的リスク・マナーの理解が不可欠です。
本記事では、Pythonエンジニア向けに、robots.txtの読み方から具体的な確認コード、さらに著作権法や利用規約との関係まで、実務でそのまま使えるレベルで整理して解説します。
スクレイピング前に知るべきrobots.txtと法律リスク
Pythonでスクレイピングする前に押さえるべきポイント
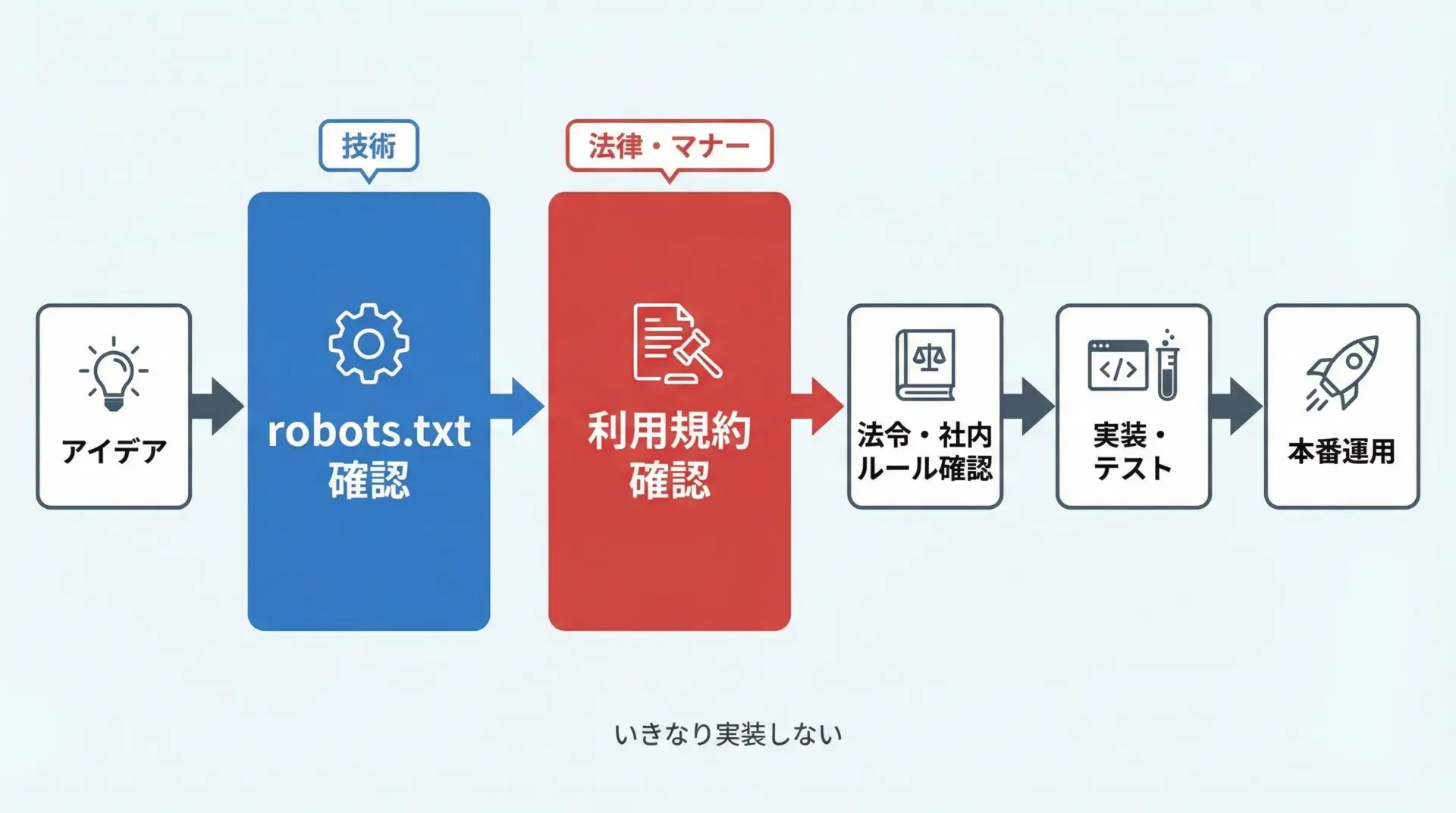
Pythonでスクレイピングを行う際には、ライブラリやHTML解析ロジックを組む前に、必ず対象サイトのルールと法的リスクを確認するステップを挟む必要があります。
具体的には、まずrobots.txtでクローラー向けの許可・禁止パスを確認し、その後利用規約(terms of service)で自動取得や商用利用の扱いをチェックします。
これに加えて、著作権法・不正アクセス禁止法・個人情報保護法など、一般的な法令の枠組みを理解しておくと、安全に設計判断ができるようになります。
robots.txt確認が重要な理由
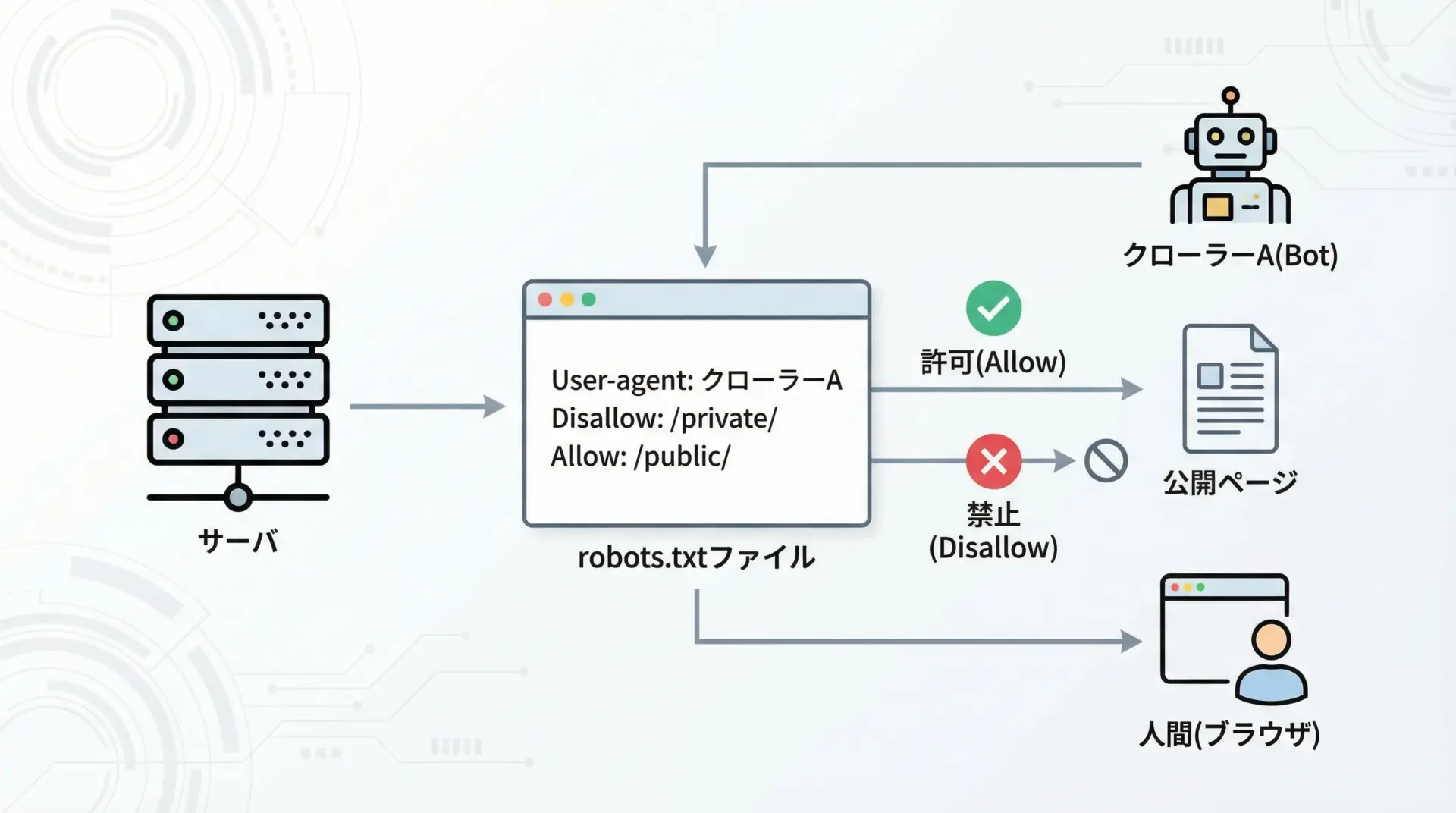
robots.txtは、サイト運営者がクローラーに対して「どのURLには来ないでほしいか」を示すファイルです。
法的拘束力は一般に限定的ですが、事実上の業界標準マナーとして扱われています。
Pythonでスクレイピングを行う場合、robots.txtを無視してしまうと、意図せず運営者がクローラーに来てほしくない領域を大量に取得してしまうことがあります。
その結果、サーバに過度な負荷をかけたり、テスト用・管理用ページなどをクロールしてトラブルの原因になることもあります。
特に企業サイトでは、robots.txtをクローラー制御の公式な窓口として運用しているケースが多く、事前確認は実務上ほぼ必須と考えるべきです。
法的リスクとマナーを理解するメリット
スクレイピングは、やろうと思えば技術的にはどこまでも実装できてしまいます。
その一方で、法的リスクとマナーの理解が不十分だと、本人が悪意を持っていなくても、結果として違法・迷惑行為につながる可能性があります。
逆に、robots.txtや利用規約を確認し、アクセス頻度や取得範囲に配慮した設計を行えば、以下のようなメリットがあります。
- 企業とのトラブルを避け、サービス停止や損害賠償リスクを減らせる
- 社内コンプライアンス審査をスムーズに通しやすくなる
- 長期運用可能なデータ取得基盤を構築できる
- エンジニアとしての信頼・評価が高まりやすい
このように、技術とマナー・法律知識をセットで身につけることが、スクレイピングを「仕事に耐える技術」にする鍵です。
robots.txtとは何かをPythonエンジニア向けに解説
robots.txtの役割と基本ルール
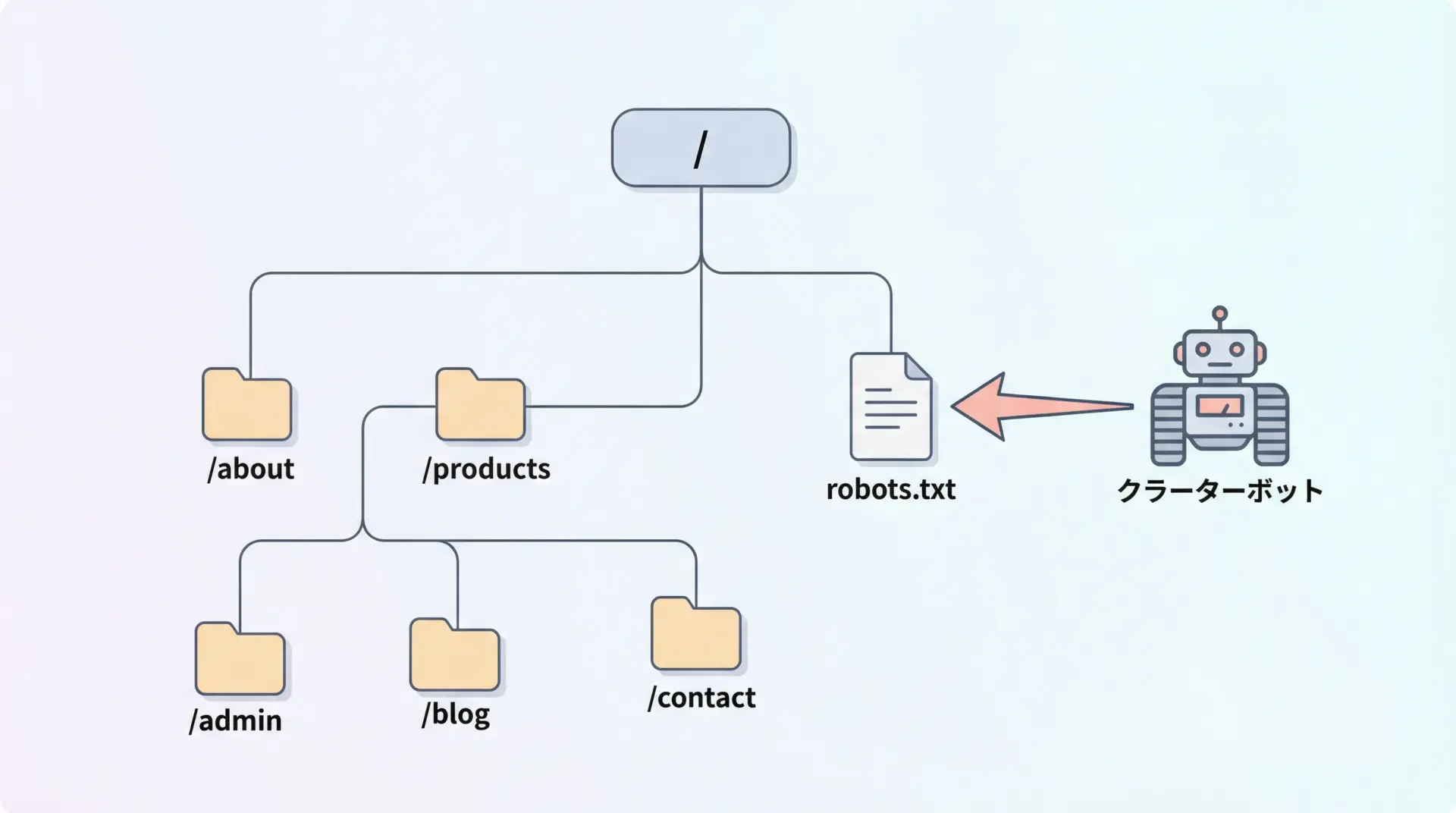
robots.txtは、Webサーバのドキュメントルート直下(例: https://example.com/robots.txt)に配置されるテキストファイルで、主に検索エンジンなどのクローラーに対して「どのURLにアクセスしてよいか・悪いか」を伝えるルールブックです。
代表的な特徴を整理すると次のようになります。
- テキスト形式で、人間もクローラーも簡単に読める
- ディレクティブ(命令)を行単位で記述するシンプルな書式
- クローラーを識別する
User-agentごとにルールを指定 - 主に
DisallowやAllowでアクセス可否を記述
例として、以下のようなrobots.txtを考えてみます。
User-agent: *
Disallow: /admin/
Disallow: /private/
User-agent: Googlebot
Allow: /admin/reports/このルールは、次のような意味になります。
- すべてのクローラー(
*)は/admin/と/private/以下に来ないでほしい - ただしGooglebotには
/admin/reports/だけは特別に許可する
Pythonエンジニアにとって重要なのは、自分が実装するクローラーが「どのUser-agentとして振る舞うか」と、そのUser-agentに対してrobots.txtが何を要求しているかを理解することです。
User-agentとDisallowなど主要ディレクティブ

robots.txtでよく登場する主要なディレクティブを整理します。
| ディレクティブ | 役割・意味 |
|---|---|
| User-agent | 対象となるクローラー名を指定します。*は全クローラーを意味します。 |
| Disallow | アクセスを禁止したいパス(またはパスのプレフィックス)を指定します。空の場合は全許可です。 |
| Allow | Disallowと組み合わせて、特定のパスだけ許可するときに使います。 |
| Crawl-delay | アクセス間隔(秒)を指定し、クローラーの頻度制御を依頼します。対応していないクローラーもあります。 |
| Sitemap | サイトマップ(XML)のURLを指定します。インデックス用クローラーに向けた情報です。 |
Python側でスクレイピングを行う際には、User-Agent文字列を自前で指定し、その文字列に対応するルールをrobots.txtから読み取ることが重要です。
また、Crawl-delayに関しては、すべてのクローラーが守るわけではありませんが、明示されている場合は、最低限のマナーとして自分のスクリプトでレートリミットを調整するのが望ましいです。
クローラー制御とスクレイピングの関係

robots.txtは、クローラー制御のための技術的・慣習的なルールであり、法令そのものではありません。
しかし、実務的には以下のような関係性があります。
- robots.txtは、クローラーがアクセスを控えるべき領域を明示する「意向表明」
- 利用規約は、サービス提供者と利用者との契約的なルール
- 法律は、それらを超えて全体を規律する枠組み
Pythonでスクレイピングを行うとき、robots.txtを守っていればすべて合法というわけではありません。
逆に、robots.txtに何も書かれていなくても、利用規約でクローリングを禁止していたり、技術的なアクセス制御を突破すると不正アクセス禁止法に抵触する可能性があります。
そのため、robots.txtは「最低ラインのマナー」として必ず確認しつつ、それとは別に利用規約や法令をチェックする二段構えを取ることが重要です。
Pythonでrobots.txtを確認する方法
Python標準ライブラリ(urllib.robotparser)による確認
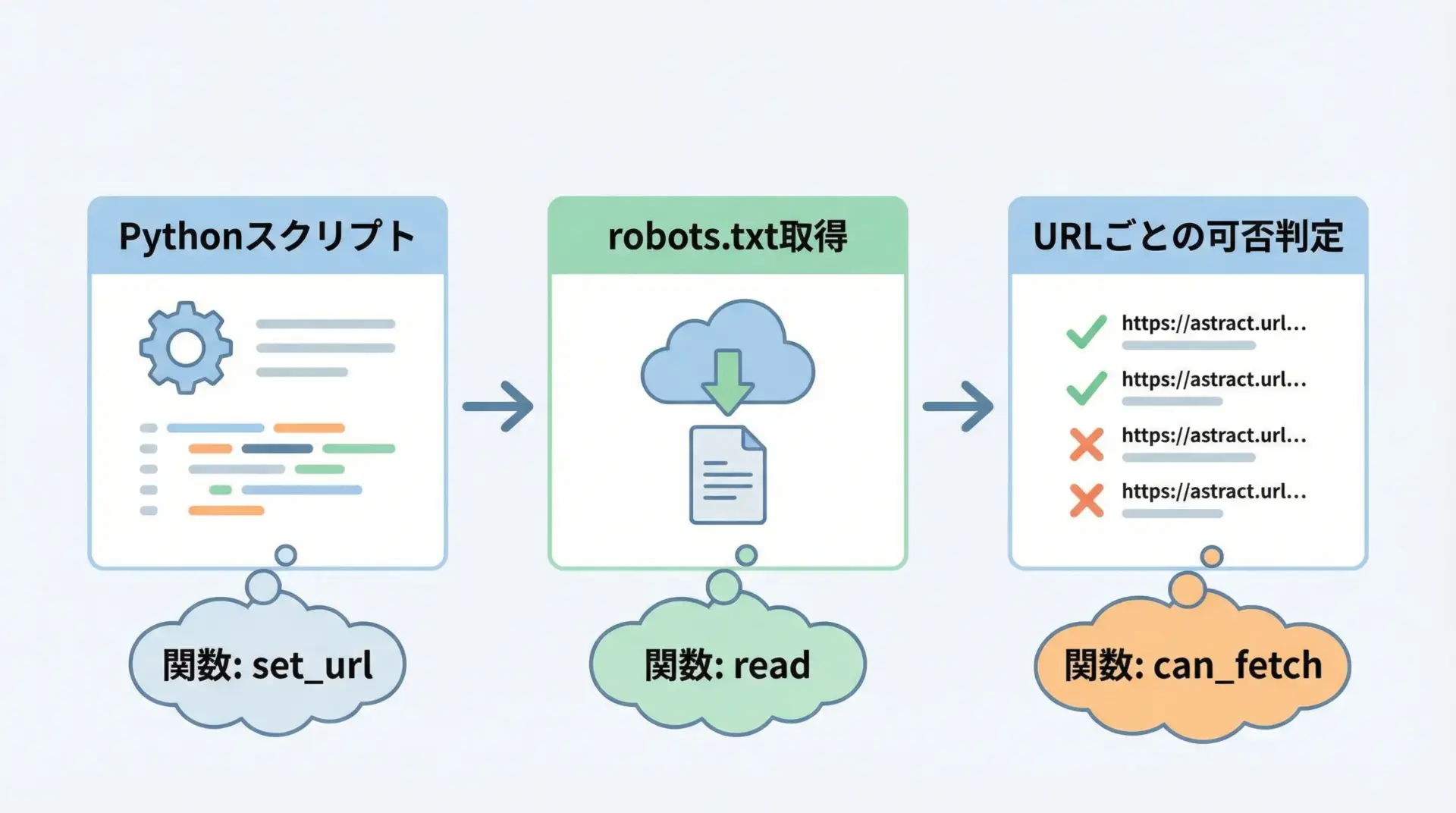
Pythonには、robots.txtを解析するための標準ライブラリurllib.robotparserが用意されています。
これを使うと、対象URLにアクセスしてよいかどうかを簡単に判定できます。
以下は、指定したURLに対して、任意のUser-Agentでアクセスしてよいかどうかを確認する基本的なサンプルです。
# robots_example_basic.py
# Python標準ライブラリのrobotparserを使ってrobots.txtを確認する例
from urllib.robotparser import RobotFileParser
from urllib.parse import urlparse
def can_fetch_url(target_url: str, user_agent: str = "MyPythonBot"):
"""
指定したURLに対して、robots.txtのルール上アクセス可能かを判定する関数です。
"""
parsed = urlparse(target_url)
# robots.txtのURLを組み立てる(例: https://example.com/robots.txt)
robots_url = f"{parsed.scheme}://{parsed.netloc}/robots.txt"
rp = RobotFileParser()
rp.set_url(robots_url) # どのrobots.txtを読むか指定
rp.read() # robots.txtを実際に取得して解析
# can_fetch(user_agent, path) でアクセス可否を判定
return rp.can_fetch(user_agent, target_url)
if __name__ == "__main__":
url = "https://www.python.org/dev/peps/"
ua = "MyPythonBot"
allowed = can_fetch_url(url, ua)
if allowed:
print(f"[OK] {ua} は {url} にアクセスしてよいと判定されました。")
else:
print(f"[NG] {ua} は {url} にアクセスすべきではないと判定されました。")想定される実行結果の一例は次のようになります(サイトの設定により変わる可能性があります)。
[OK] MyPythonBot は https://www.python.org/dev/peps/ にアクセスしてよいと判定されました。このように、実際にHTTPリクエストを送る前にcan_fetchでチェックするフローを組み込むことで、安全なスクレイピングの第一歩を踏み出せます。
requestsとrobotparserを組み合わせた実装例
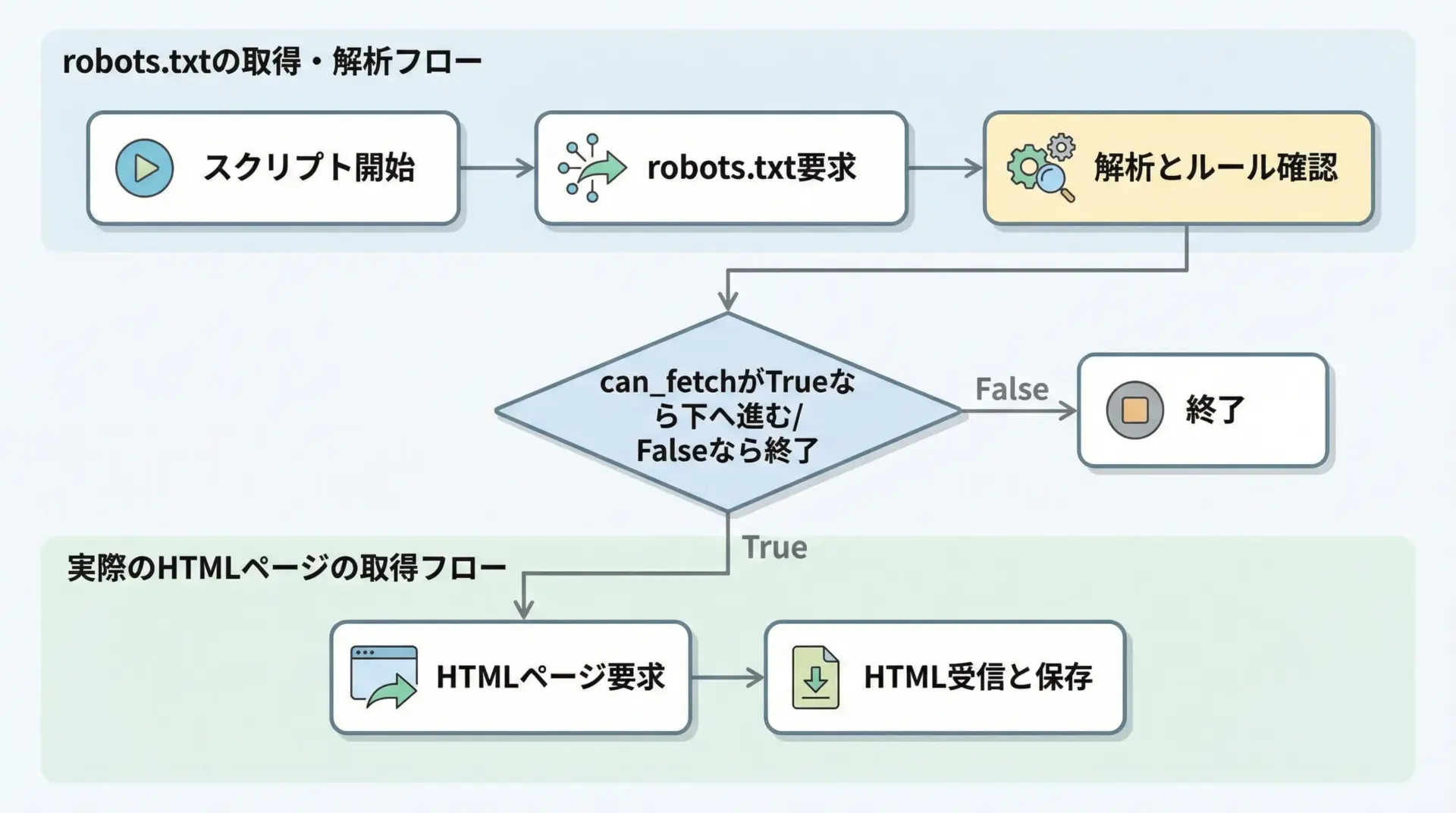
標準のRobotFileParserは内部でシンプルなHTTP取得を行いますが、タイムアウト制御やエラーハンドリングを自前で行いたい場合には、requestsと組み合わせる方法が有効です。
# robots_with_requests.py
# requestsでrobots.txtを取得し、RobotFileParserに手動で読み込ませる例
import requests
from urllib.robotparser import RobotFileParser
from urllib.parse import urlparse
def build_robot_parser(base_url: str, timeout: int = 5) -> RobotFileParser:
"""
指定したサイトのrobots.txtを取得してRobotFileParserに読み込ませるヘルパー関数です。
"""
parsed = urlparse(base_url)
robots_url = f"{parsed.scheme}://{parsed.netloc}/robots.txt"
resp = requests.get(robots_url, timeout=timeout)
rp = RobotFileParser()
if resp.status_code == 200:
# HTTPレスポンスのテキスト内容を直接パーサに渡す
rp.parse(resp.text.splitlines())
else:
# 404などでrobots.txtが存在しない場合の扱い
# 慣例的には「制限なし」と解釈されますが、
# サイトポリシーに応じて慎重に扱うべきです。
rp.disallow_all = False
return rp
def safe_get(url: str, user_agent: str = "MyPythonBot", timeout: int = 5):
"""
robots.txtを確認してから、GETリクエストを行う安全版の関数です。
"""
rp = build_robot_parser(url, timeout=timeout)
if not rp.can_fetch(user_agent, url):
raise PermissionError(f"robots.txt により {url} へのアクセスは許可されていません。")
headers = {
"User-Agent": user_agent,
}
resp = requests.get(url, headers=headers, timeout=timeout)
resp.raise_for_status()
return resp
if __name__ == "__main__":
target = "https://www.python.org/dev/peps/"
try:
response = safe_get(target, user_agent="MyPythonBot")
print("ページ取得に成功しました。HTMLの先頭200文字を表示します。")
print(response.text[:200])
except PermissionError as e:
print(f"[ACCESS DENIED] {e}")
except requests.RequestException as e:
print(f"[HTTP ERROR] {e}")ページ取得に成功しました。HTMLの先頭200文字を表示します。
<!doctype html>
<!--[if lt IE 7]> <html class="no-js lt-ie9 lt-ie8 lt-ie7"> <![endif]-->
<!--[if IE 7]> <html class="no-js lt-ie9 lt-ie8"> <![endif]-->
...このようにrobots.txtの判定と実際のHTTPアクセスを一体として扱うユーティリティを用意しておくと、プロジェクト全体でマナーを徹底しやすくなります。
Scrapyでrobots.txtを自動尊重する設定
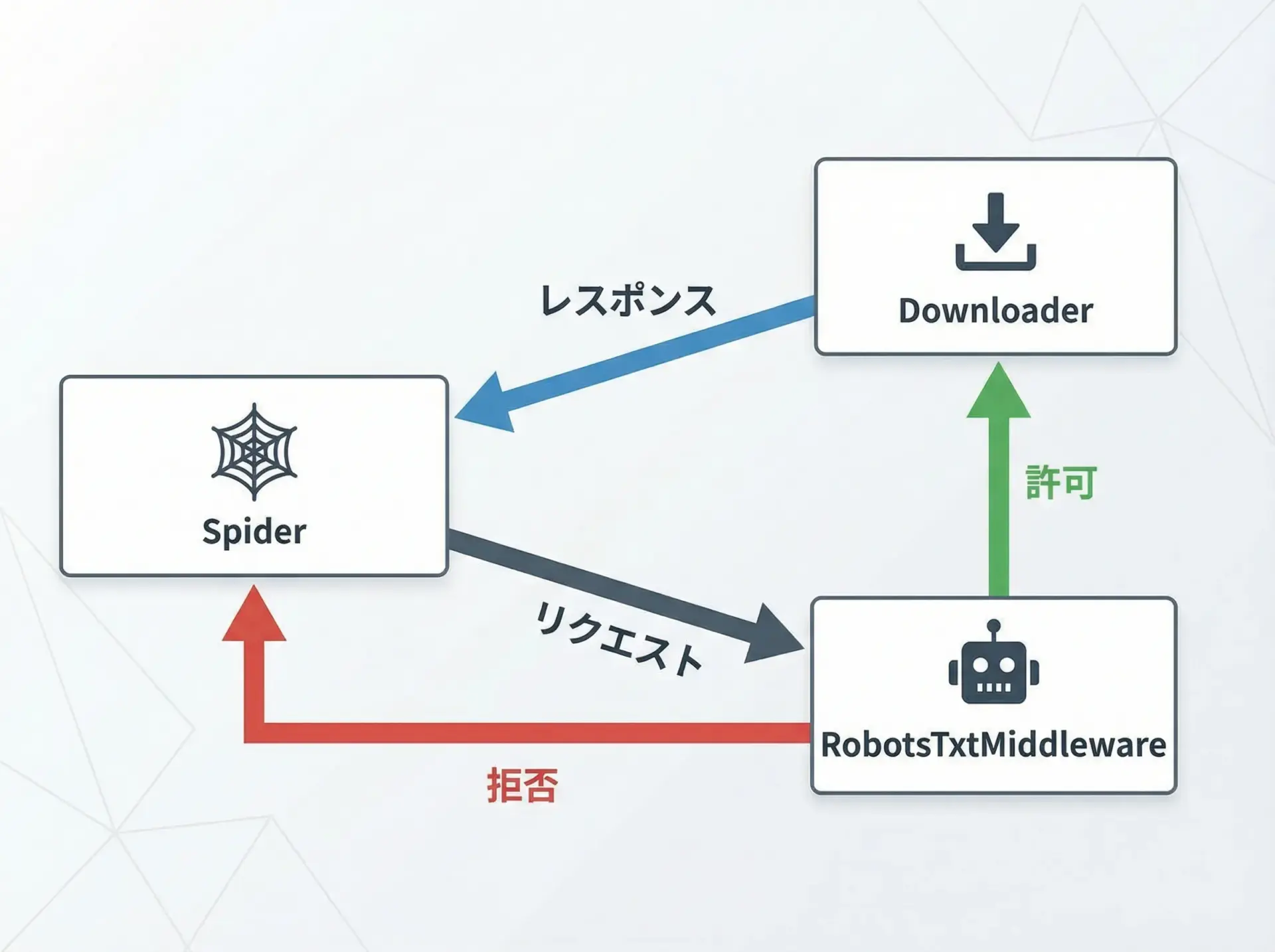
PythonのスクレイピングフレームワークであるScrapyには、robots.txtを自動的に尊重する機能が標準で組み込まれています。
Scrapyプロジェクトのsettings.pyでROBOTSTXT_OBEYをTrueに設定すると、robots.txtに反するリクエストは自動でブロックされます。
# settings.py (Scrapyプロジェクトの設定例)
# robots.txt を尊重するかどうかの設定
ROBOTSTXT_OBEY = True
# 自分のクローラーを識別するUser-Agentを設定
USER_AGENT = "MyScrapyBot/1.0 (+https://example.com/bot-info)"
# 過剰アクセスを避けるためのダウンロード間隔(秒)
DOWNLOAD_DELAY = 1.0ScrapyのSpider側は通常どおり実装して構いません。
# my_spider.py
import scrapy
class ExampleSpider(scrapy.Spider):
name = "example"
allowed_domains = ["example.com"]
start_urls = ["https://www.example.com/"]
def parse(self, response):
# ページタイトルをログ出力する簡単な例
title = response.css("title::text").get()
self.logger.info(f"取得したタイトル: {title!r}")Scrapyを実行すると、内部で自動的に/robots.txtが取得・解析され、許可されていないURLへのアクセスはSpiderに渡される前にフィルタされます。
特にチーム開発や大規模クロールでは、このようなフレームワークレベルの制御を活用することが、安全性向上につながります。
スクレイピングに関わる法的リスク
著作権法とスクレイピングの注意点
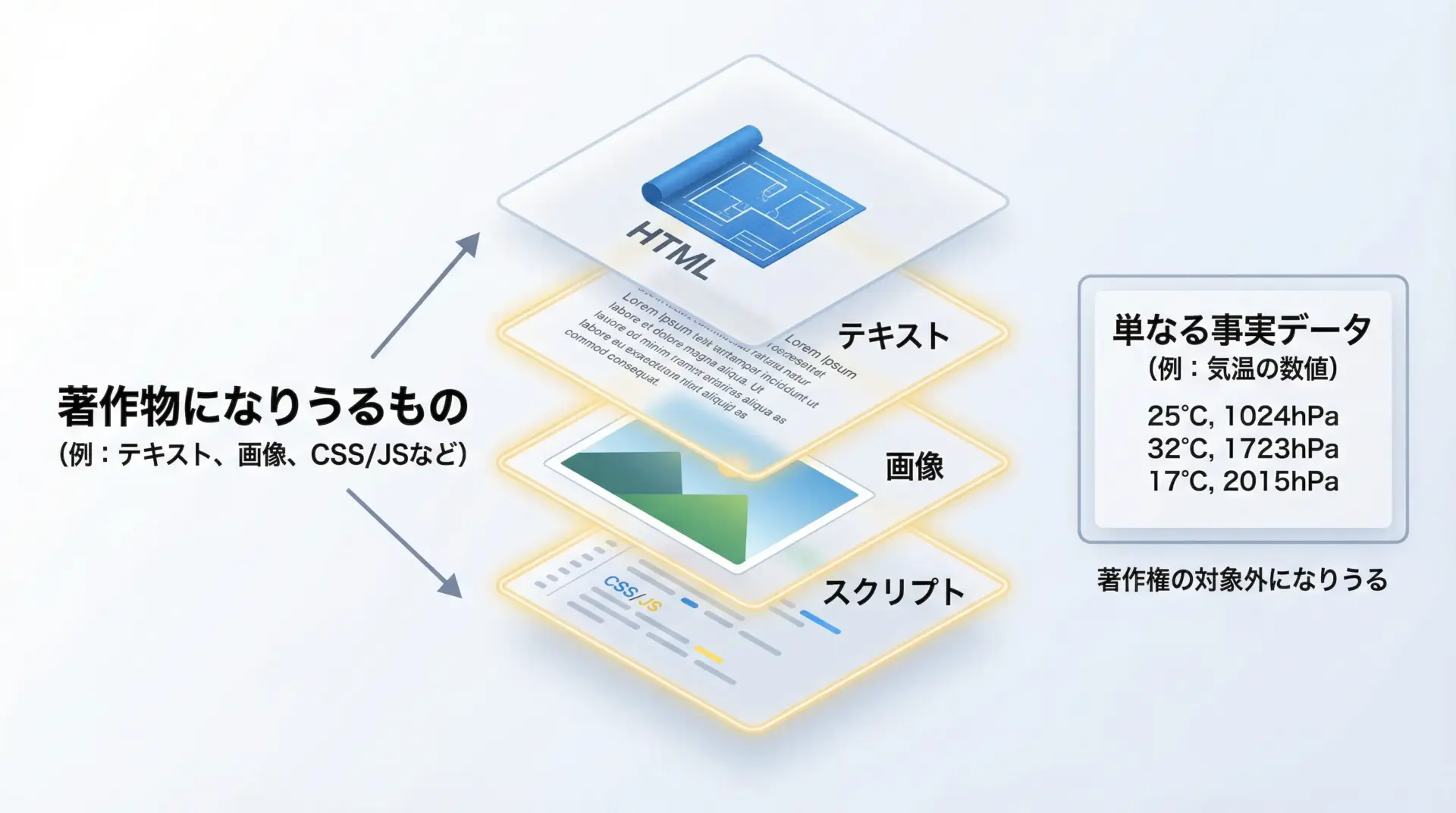
日本の著作権法では、創作的な表現は著作物として保護されます。
Webページに掲載されている文章・画像・レイアウトは、多くの場合この著作物に該当します。
そのため、スクレイピングによって取得したコンテンツを以下のように扱うと、著作権侵害のリスクが生じます。
- 記事本文をほぼそのまま別サイトに転載する
- 画像を無断で再配布する
- レイアウトやHTMLテンプレートをコピーして再利用する
一方で、気温・株価・統計数値などの「事実データ」自体は著作権の対象外とされる場合が多いとされています。
ただし、その収集・選択・構成に創作性があれば、データベースとして保護されることもあり、境界は必ずしも明確ではありません。
スクレイピングでは、「取得して解析する」こと自体よりも、「取得した内容をどのように利用するか」に著作権上の重要な論点があります。
社内での分析目的など、限定的な範囲であっても、利用規約や契約によって制限されている可能性もあるため、用途に応じた慎重な判断が必要です。
利用規約(terms of service)違反リスク

多くのWebサービスは、利用規約(terms of service)で、サービスの利用条件や禁止事項を定めています。
この中に、次のような条項が含まれていることがあります。
- 自動化された手段によるアクセス・データ取得の禁止
- 商用利用の禁止または事前許可の要否
- 競合サービスの構築を目的としたデータ利用の禁止
Pythonでスクレイピングを実施する際、利用規約を無視して自動取得を行うと、契約違反としてサービスからのアクセス遮断や法的措置を受けるリスクがあります。
特に商用サービスやクローズドな会員制サイトでは、利用規約違反のリスクが高くなりがちです。
そのため、robots.txtの確認とあわせて、対象サイトのフッター等から利用規約を開き、「自動取得」「Bot」「クローリング」「スクレイピング」などのキーワードを検索し、該当する条項がないかを確認することが重要です。
不正アクセス禁止法と技術的制限の回避

不正アクセス禁止法は、「アクセス制御されたコンピュータに対し、不正にアクセスすること」を禁じる法律です。
スクレイピングでは、次のような行為が問題となり得ます。
- ログインが必要な会員ページに対し、他人のID・パスワードを用いてアクセスする
- CAPTCHAやIP制限などの技術的なアクセス制御を回避するような自動化
- アカウントの作成・削除を大量に自動化して、サービス提供者の意図に反した利用をする
Pythonであれば技術的には実装可能なことでも、アクセス制御を突破してまでデータを取得する行為は、不正アクセス禁止法違反のリスクが非常に高いです。
実務では、次の方針を徹底することが重要です。
- ログインが必要なエリアのスクレイピングは、必ず運営者の明示的な許可を得る
- CAPTCHAなどによる制限がある場合は、それを尊重し、機械的な回避を試みない
- セキュリティ機構を検証・突破するような行為は、ペネトレーションテスト契約など、正式な枠組みの中でのみ行う
個人情報保護法と個人データの扱い
個人情報保護法は、「生存する個人に関する情報」で特定の個人を識別できるものを保護対象としています。
スクレイピングで以下のような情報を大量に収集すると、この法律の適用を受ける可能性があります。
- 本名・住所・電話番号
- メールアドレス・SNSアカウント
- 特定の個人と結び付いた行動履歴、購入履歴 など
企業や組織としてスクレイピングを行う場合、個人情報保護法上の「個人情報取扱事業者」としての義務が発生する可能性があり、収集目的の明確化や安全管理措置、第三者提供の制限など、多くの要件を満たす必要があります。
また、法令以前に、個人のプライバシーを侵害するようなデータ収集・再利用は、企業の信用を大きく損ないます。
Pythonで技術的に可能だからといって、公開プロフィールページを片っ端からクロールして名簿を構築するような行為は避けるべきです。
どうしても必要な場合は、対象サービス運営者への事前相談・契約や、法務部門との慎重な検討を行うようにしましょう。
robots.txtと法規制・利用規約の違い
robots.txtは法的拘束力がないが守るべき理由
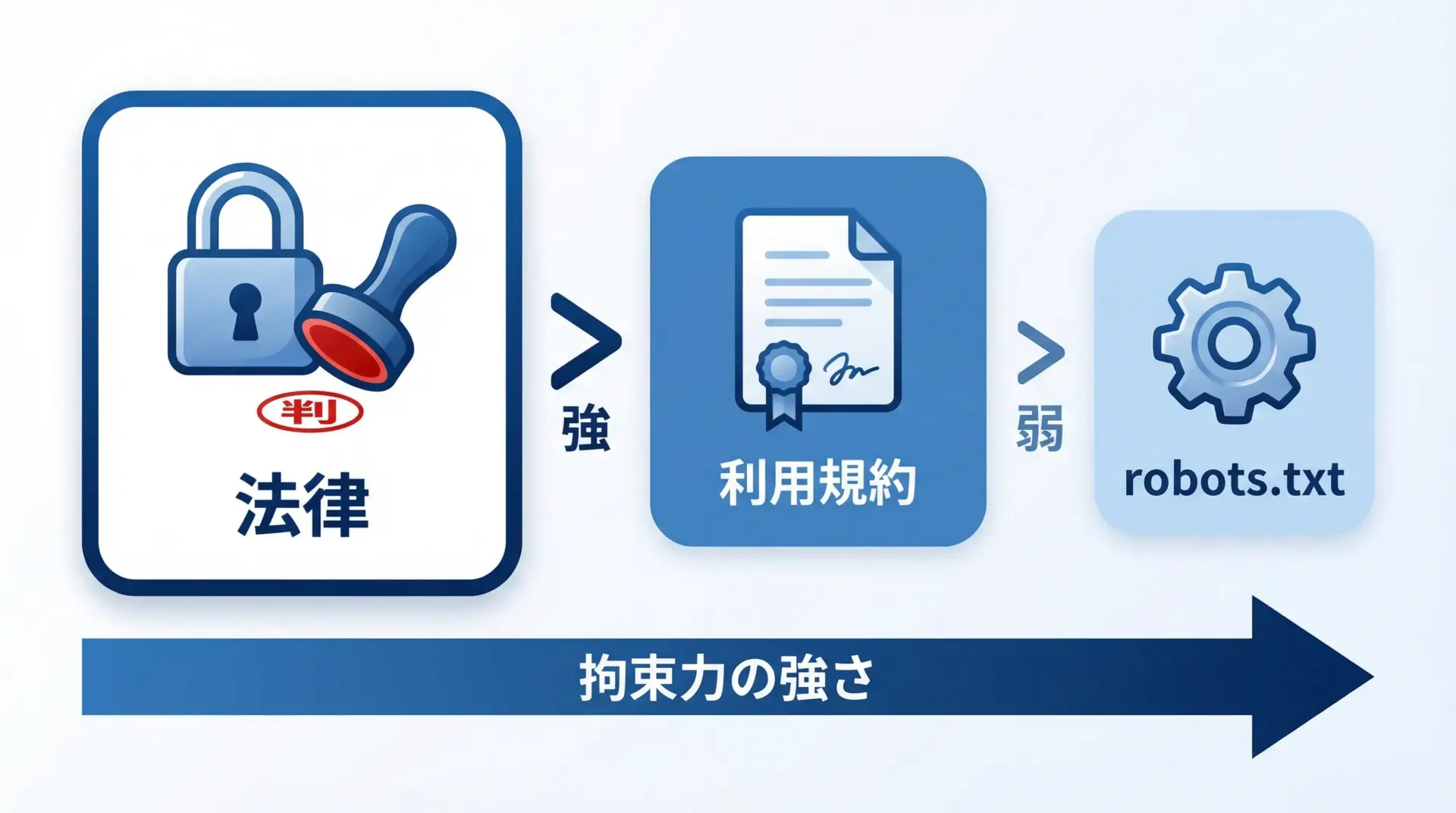
一般に、robots.txt自体には直接的な法的拘束力はないとされています。
つまり、robots.txtでDisallowされているパスにアクセスしたからといって、それだけで即座に違法になるわけではありません。
しかし、実務では次のような理由から、robots.txtを無視してスクレイピングすることは強く避けるべきです。
- 運営者の明確な「来ないでほしい」という意思表示を踏み躙る行為になる
- サーバ負荷の増大や障害の原因となりうる
- 後から問題になった際に、「業界の一般的なマナーにも反している」と評価される
- 利用規約や個別契約が存在する場合、robots.txt違反がその違反判断の一材料となり得る
そのため、法的リスクだけでなく、ビジネス上・倫理上のリスクを考え、robots.txtは原則として遵守するのが、現代的なエンジニアのスタンスと言えます。
利用規約とrobots.txtを両方確認すべきケース
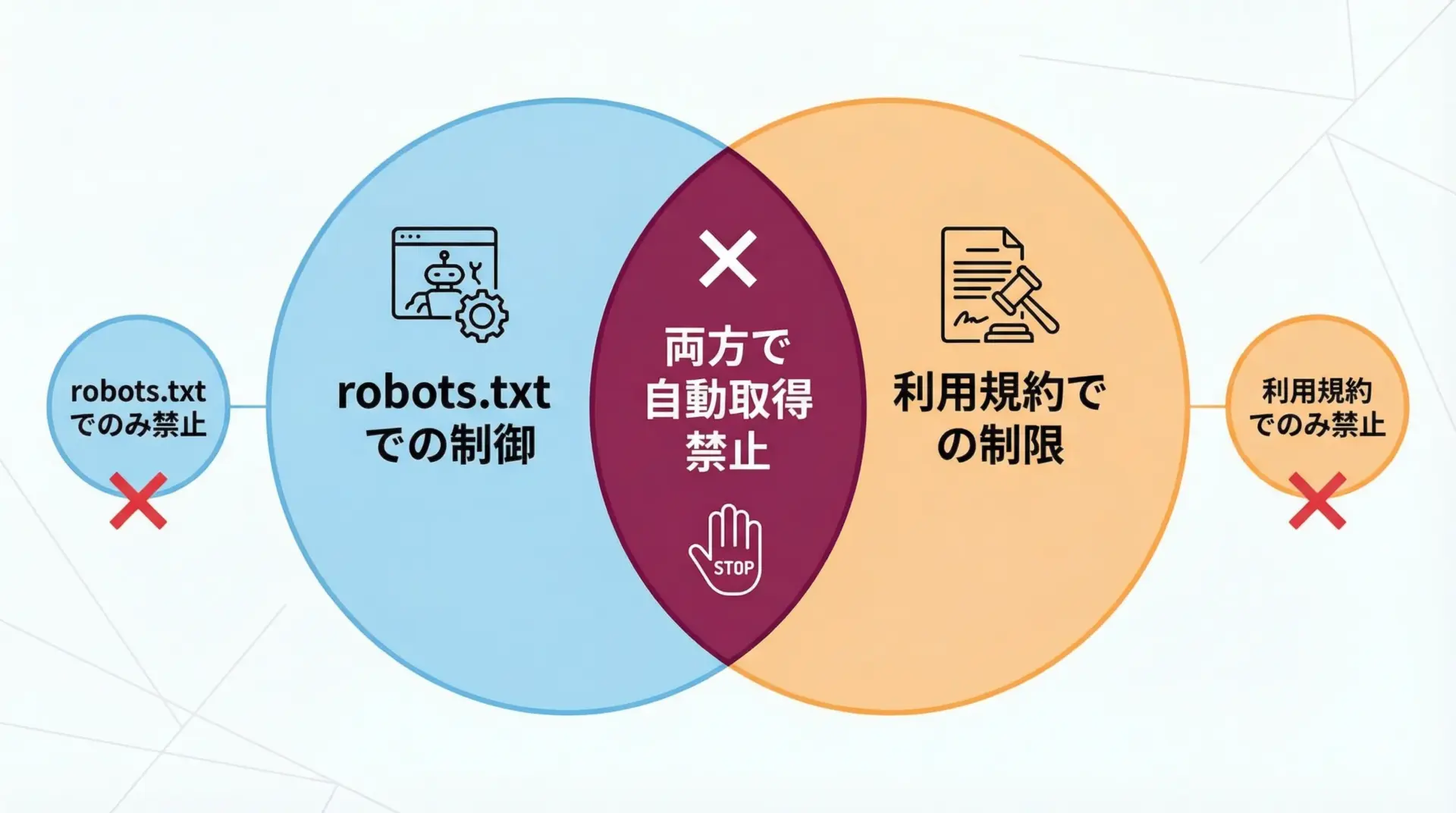
多くの実サービスでは、robots.txtと利用規約が補完関係にあります。
- robots.txt: 技術的にクロールしてよいパスとダメなパスをURI単位で指定
- 利用規約: 用途や手段、ボリュームなど、より包括的な条件を定める
たとえば、以下のようなパターンが考えられます。
- robots.txtでは全パスが許可されているが、利用規約では「自動取得は禁止」と明記されている
- robots.txtで一部のパスのみ禁止だが、利用規約で「商用利用は禁止」とされている
- robots.txtで一般クローラーは禁止だが、契約したパートナーにだけ特定のAPI利用を認めている
このように、robots.txtと利用規約は役割が異なるため、スクレイピング前に両方を確認することが重要です。
特にビジネス用途や長期運用を想定している場合は、法務部門と相談のうえで解釈を整理すると安心です。
探索エンジンとスクレイピングの扱いの違い
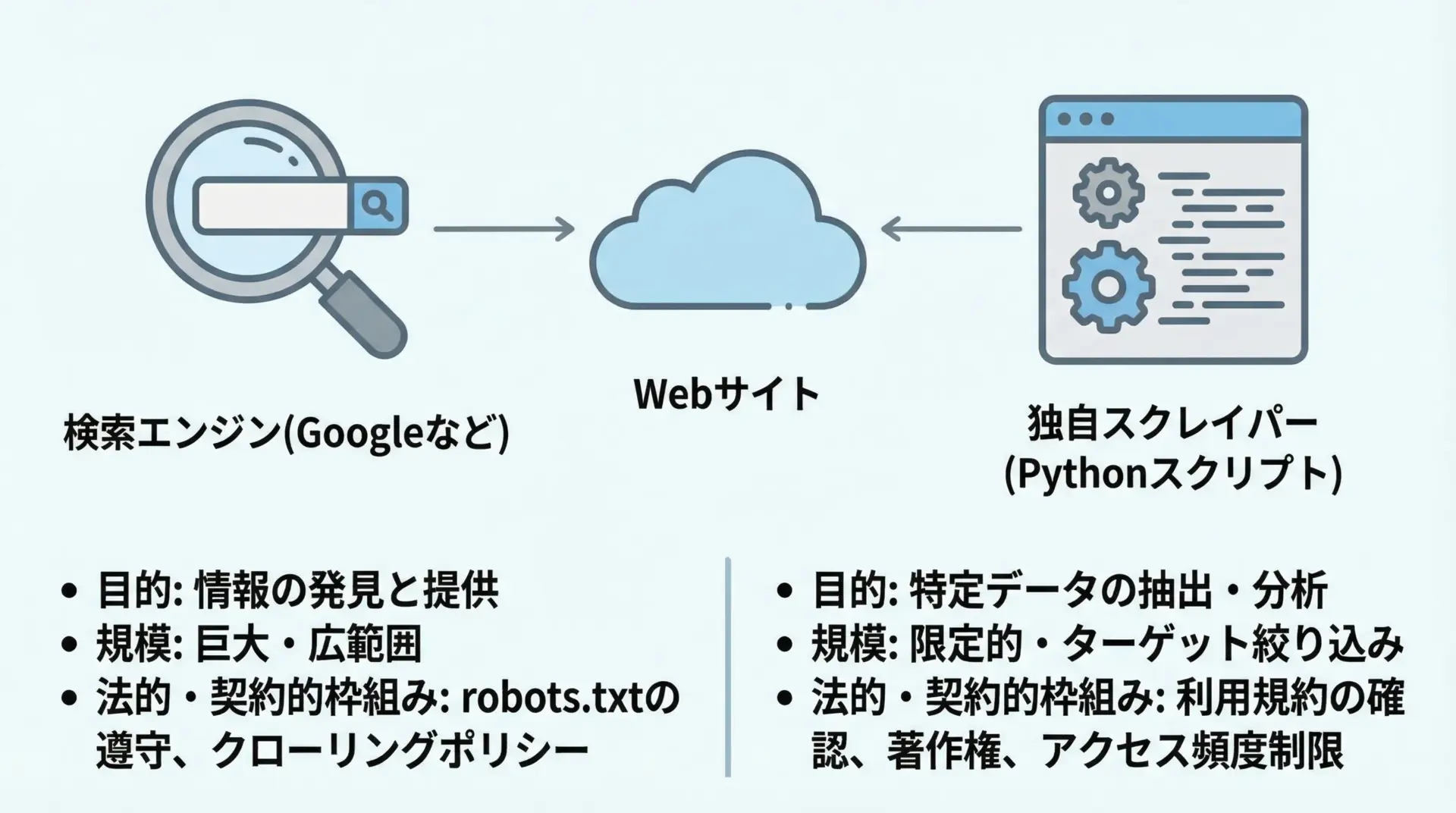
検索エンジンのクローラー(Googlebotなど)も、Pythonで書いたスクレイパーも、技術的には「HTTPでページを取得するプログラム」という点で似ています。
しかし、扱われ方・前提条件は大きく異なります。
- 検索エンジンのクローラーは、多くのサイト運営者にとって「トラフィックを増やすために歓迎される存在」であり、その振る舞いも公開されている
- 検索エンジン側は、各種の法令遵守や苦情対応の体制を整えている
- 多数のサイト運営者が、検索エンジン向けにrobots.txtやsitemapを整備している
一方で、個別企業・個人が運用するPythonスクレイパーは、運営者から見れば目的も責任体制も不明な「未知のBot」です。
同じアクセスであっても、検索エンジンだから許容される振る舞いが、自作スクレイパーでは許容されないことがあります。
そのため、「Googleがクロールしているから自分も同じようにやってよい」という発想は危険です。
自分のスクレイピングは、あくまで自分自身が法的・倫理的責任を負う行為であると認識し、慎重に設計しましょう。
Pythonで安全・マナー遵守のスクレイピング設計
アクセス頻度(レートリミット)の制御方法
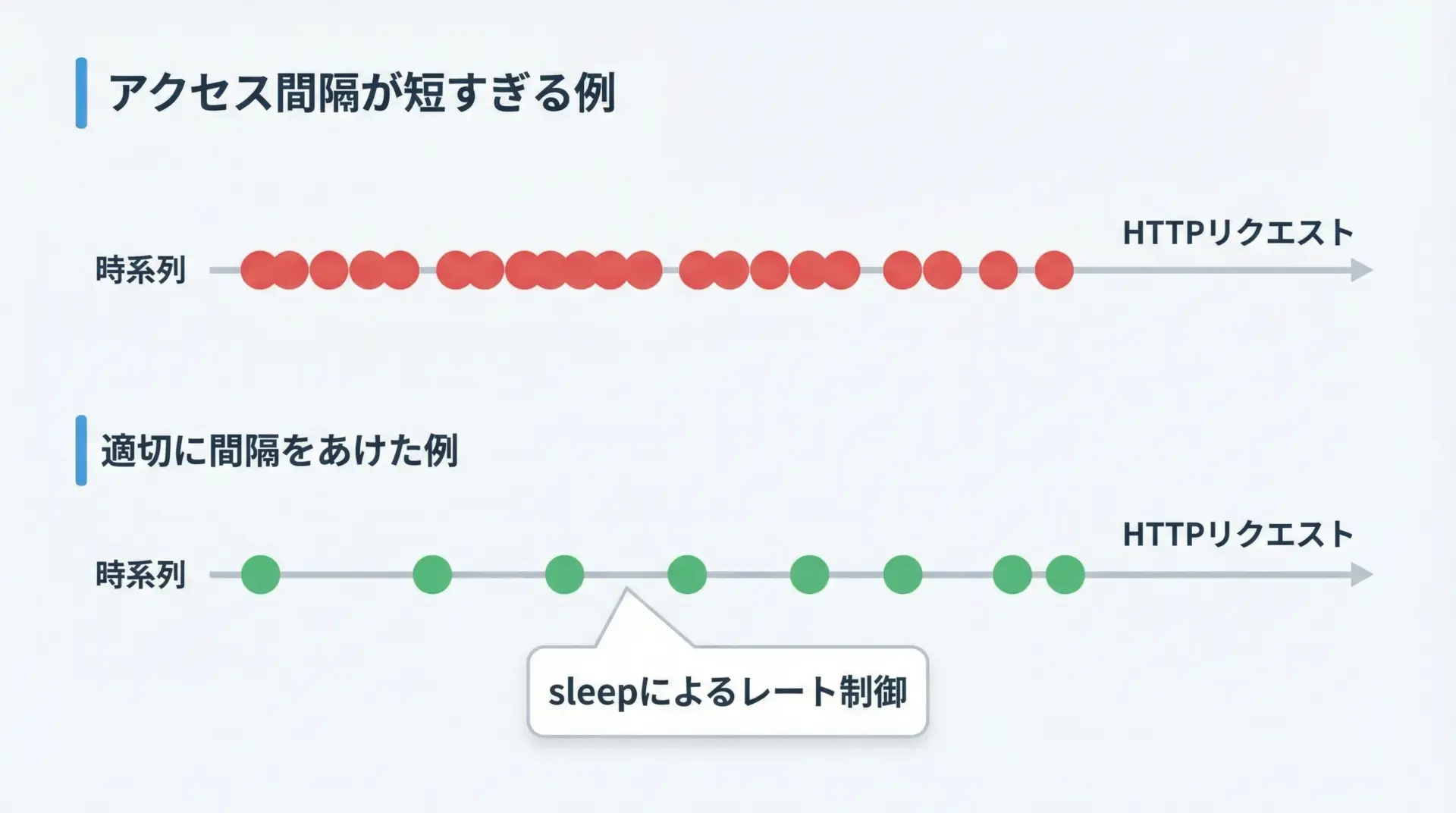
サーバに対するアクセス頻度が高すぎると、サイトのパフォーマンス低下や障害の原因になり、DoS攻撃に類似した迷惑行為と見なされるリスクがあります。
そのため、Pythonでスクレイピングを行う際には、意図的にアクセス間隔を空ける「レートリミット」を実装することが重要です。
シンプルな実装例を示します。
# rate_limit_example.py
# シンプルなレートリミット(sleep)を用いたスクレイピング例
import time
import requests
def crawl_urls(urls, user_agent="MyPythonBot", delay=1.0):
headers = {"User-Agent": user_agent}
for i, url in enumerate(urls, start=1):
print(f"{i}件目: {url} にアクセスします (delay={delay}秒)")
resp = requests.get(url, headers=headers, timeout=5)
print(f" -> ステータスコード: {resp.status_code}")
# サーバ負荷を考慮して、次のリクエストまで待機
time.sleep(delay)
if __name__ == "__main__":
target_urls = [
"https://www.python.org/",
"https://www.python.org/about/",
"https://www.python.org/downloads/",
]
crawl_urls(target_urls, delay=2.0)1件目: https://www.python.org/ にアクセスします (delay=2.0秒)
-> ステータスコード: 200
2件目: https://www.python.org/about/ にアクセスします (delay=2.0秒)
-> ステータスコード: 200
3件目: https://www.python.org/downloads/ にアクセスします (delay=2.0秒)
-> ステータスコード: 200実務では、サイトの規模・自分の用途・Crawl-delayの指定などを考慮し、1〜数秒以上の間隔を取ることが多いです。
より高度な制御が必要な場合は、トークンバケット方式などのレートリミットアルゴリズムを導入することも検討できます。
User-Agent設定とアクセス元の明示

User-Agentヘッダは、クライアント(ブラウザやBot)を識別するために利用されます。
Pythonのrequestsなどでは、デフォルトのUser-Agentがそのままだと「Python-requests/〜」といった文字列になります。
マナーと透明性の観点からは、自分のスクレイパー用に固有のUser-Agentを設定し、可能であれば問い合わせ先URLを含めるのが望ましいです。
# user_agent_example.py
import requests
HEADERS = {
# Bot名とバージョン、連絡・説明用のURLを含めるのが望ましい
"User-Agent": "MyCompanyCrawler/1.0 (+https://example.com/crawler-info)",
}
resp = requests.get("https://www.python.org/", headers=HEADERS, timeout=5)
print(resp.status_code)このようにしておけば、もし運営者がアクセスを問題視した場合でも、User-Agentから問い合わせ先をたどれるため、不要なブロックやトラブルを避けやすくなります。
逆に、一般的なブラウザ(Chromeなど)を偽装したUser-Agentを使うことは、誤解や不信感を招きやすく、避けるべきです。
時間帯・負荷を配慮したクロール設計
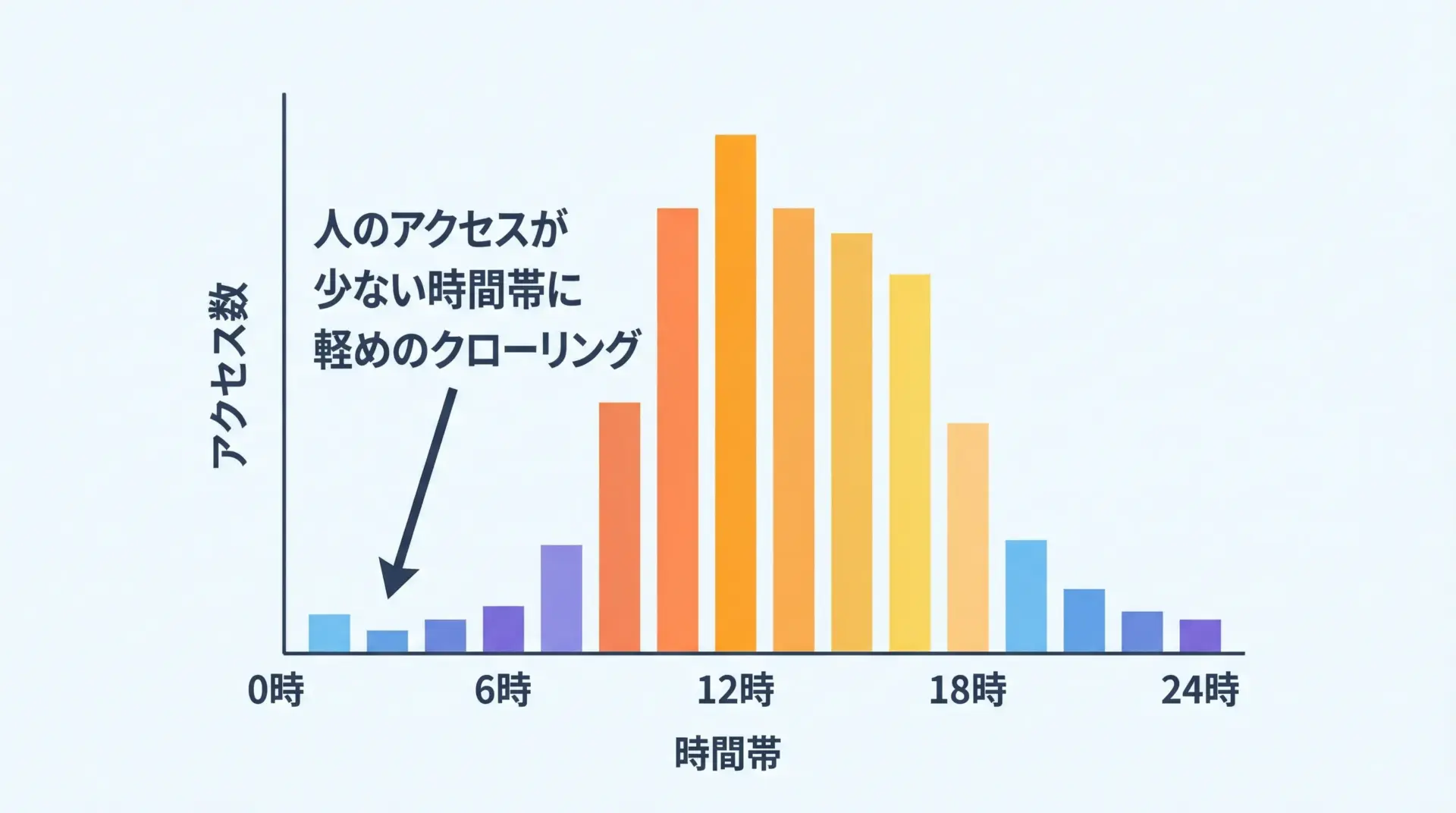
商用サイトやECサイトなどでは、昼間の混雑時間帯に負荷が集中します。
その時間帯に大量のスクレイピングを行うと、ユーザ体験の悪化や障害リスクが高まります。
そのため、以下のような配慮が有効です。
- 人間のアクセスが少ない深夜〜早朝にクロールを実行する
- サイトのピークタイムを避ける(日本向けサービスなら平日昼休み・夕方を避けるなど)
- スケジューラ(CronやAirflowなど)で実行時間を調整する
Python側からは、実行時間を変えるだけでなく、サイトごとに異なるレートリミットや時間帯制御を設定ファイルで持たせることで、後からの調整がしやすくなります。
取得データ量と保存期間の考え方
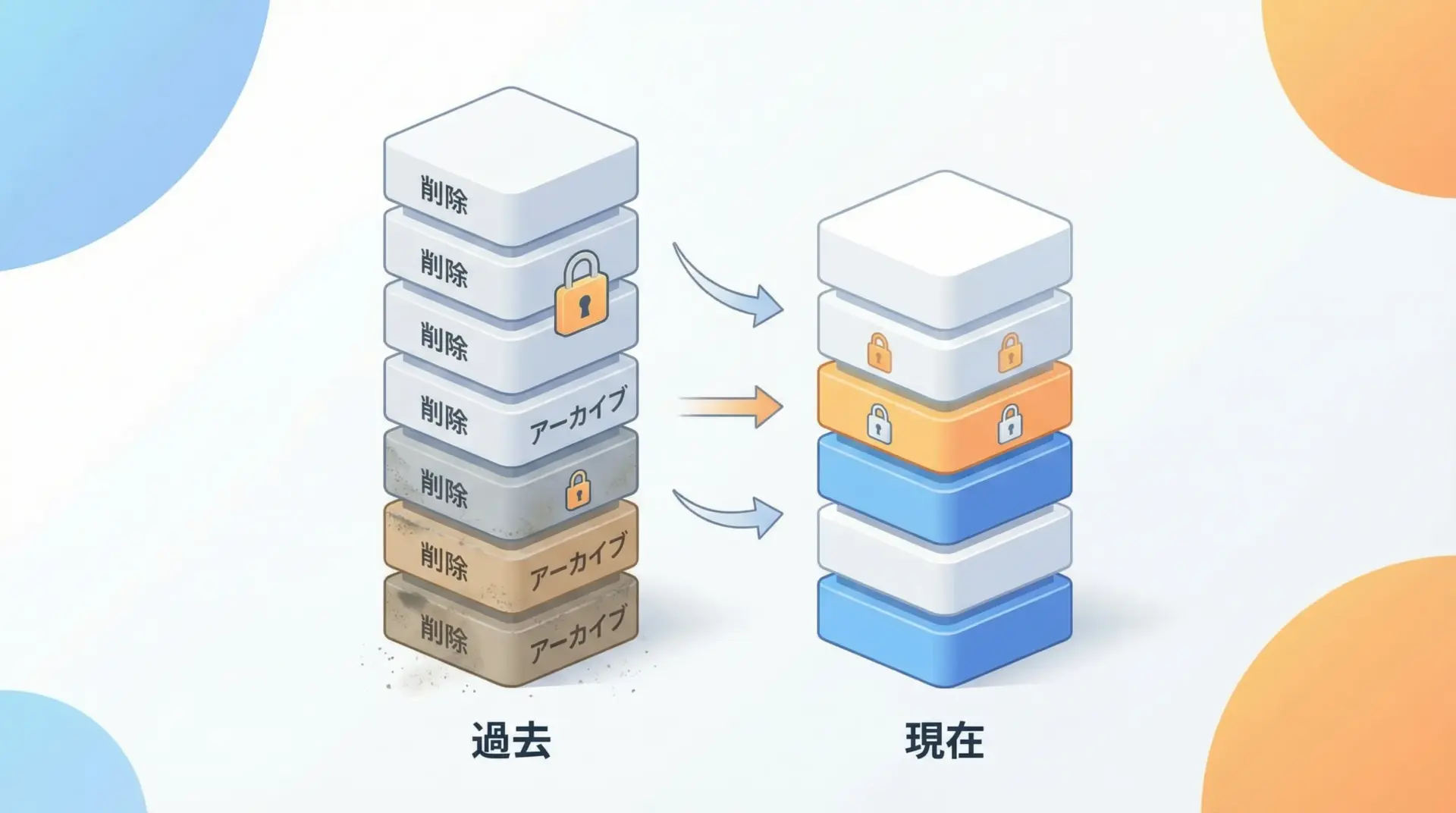
スクレイピングでは、「とりあえず全部取って全部保存しておこう」という発想になりがちですが、これは法的にも運用面でもリスクを高めます。
- 不要な個人データを長期間保持すると、漏えい時の影響が大きくなる
- 保存コストが増大し、バックアップ・管理が複雑になる
- 利用規約や契約で、保存期間や用途が制限されている場合がある
実務的には、「目的に必要な範囲だけを取得し、必要な期間だけ保存する」という考え方が重要です。
そのために、Python側の設計として次のような工夫が有効です。
- 取得対象のフィールドを明確に絞り込む(HTML全文ではなく必要な項目だけ)
- データベースに保存期限や削除フラグを持たせる
- 定期的に古いデータを削除・匿名化するバッチ処理を組む
企業サイト・APIをPythonで扱う際の注意点
公開APIがある場合はAPI利用を優先する
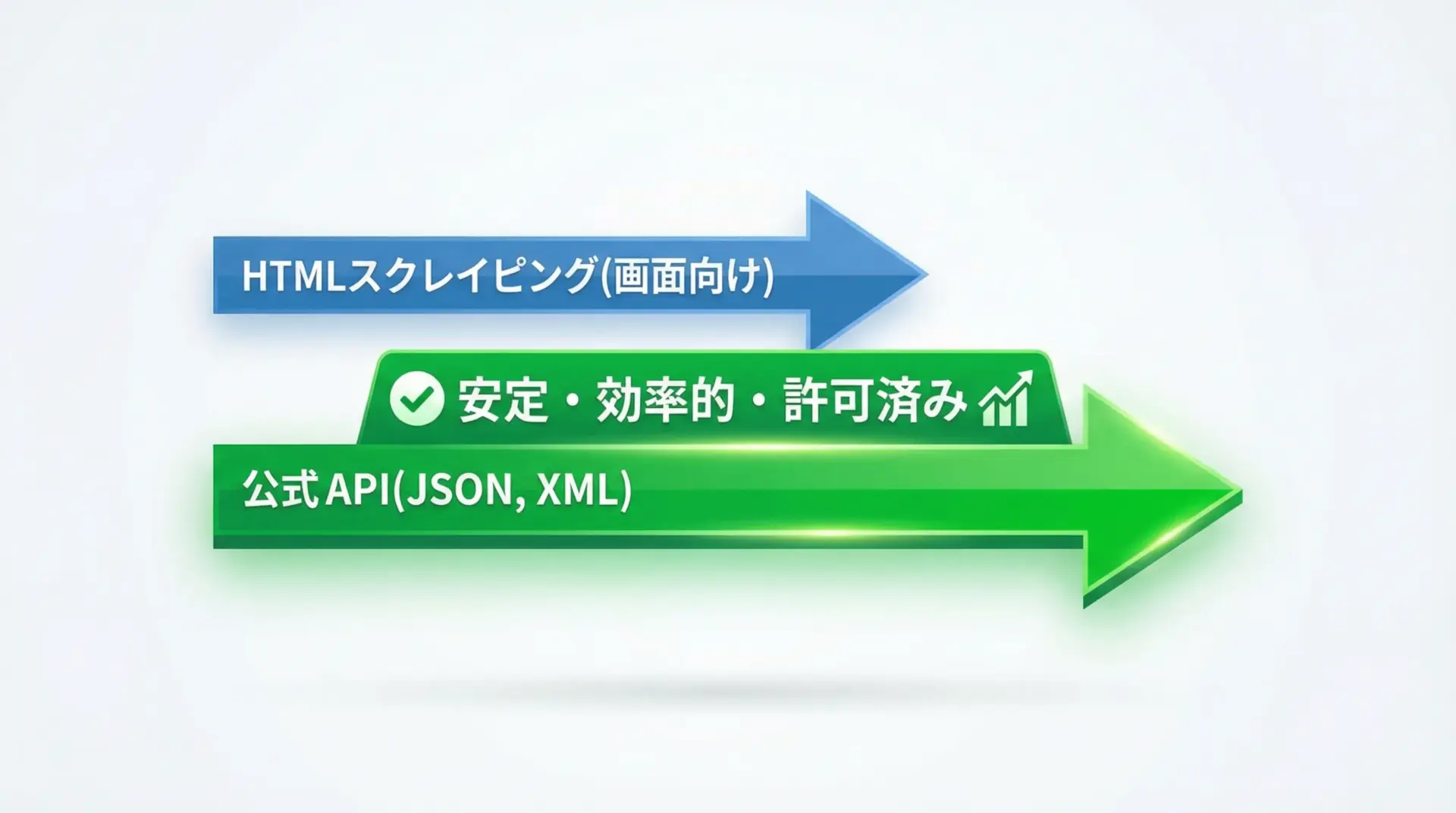
企業やサービス提供者が公式APIを提供している場合、HTMLスクレイピングよりもAPI利用を優先するのが原則です。
APIは、以下のような理由から好ましい選択肢です。
- 利用規約やドキュメントで、想定される利用方法が明示されている
- レスポンス形式(JSONなど)が機械処理に適しており、安定している
- レートリミットや認証機構が整備されており、サービス側も想定済みの負荷となる
Pythonではrequestsやhttpxなどを用いてAPIを利用できるため、HTMLパースに比べて実装もシンプルになります。
HTMLスクレイピングは、APIが存在しない・APIでは取得できない情報がどうしても必要といった場合の最終手段と考えるのが現実的です。
商用利用・機械学習用途でのスクレイピング注意点
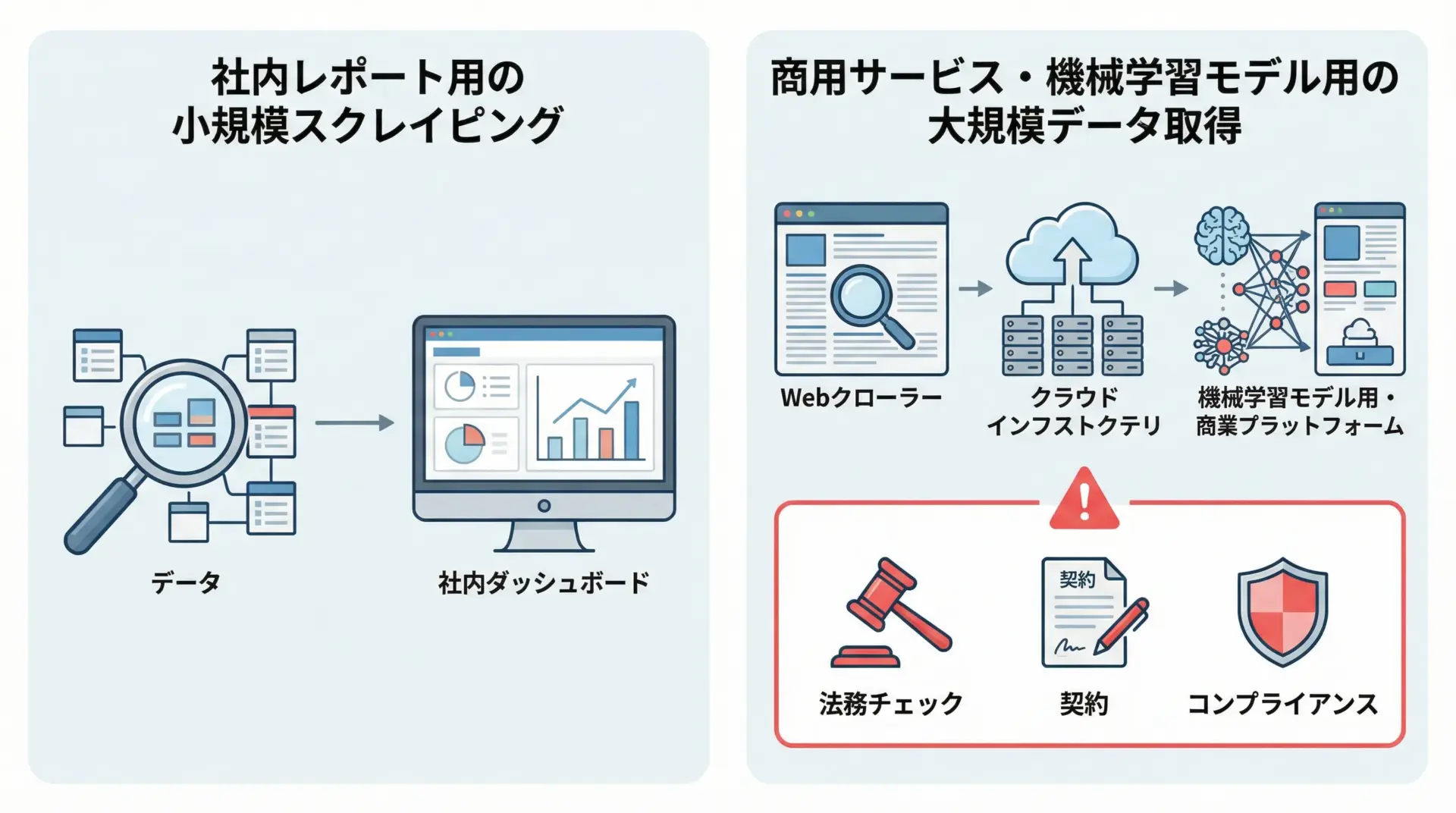
スクレイピングの用途が商用サービスや機械学習モデルの学習データなどに及ぶ場合、リスクは格段に高まります。
- 大量データの長期利用となるため、著作権・利用規約違反の影響が大きくなる
- 競合サービスの構築と見なされ、訴訟リスクが高まる場合がある
- 個人情報・センシティブ情報を含む可能性が高まる
そのため、このような用途ではエンジニア単独で判断せず、必ず法務部門・コンプライアンス部門と相談することが重要です。
必要に応じて、データ提供契約やAPI利用契約を結ぶ形で正規ルートを確保する方が、長期的には安全でコストも低くなります。
禁止事項が明記されているサイトの扱い
利用規約やサイトのヘルプページに、明確に次のような記載がある場合があります。
- 「スクレイピング・クローリング行為を禁止します」
- 「自動化されたアクセスは禁止です」
- 「事前許可なきBotのアクセスを禁じます」
このような明示的な禁止条項がある場合、原則としてスクレイピングは行わないと決めておくのが無難です。
どうしても必要な場合は、
- 正規のAPIやデータ提供サービスがないか再確認する
- 運営者に連絡し、目的や条件を説明して許可を得る
- 契約としてデータ提供を受けることを検討する
といった手順を踏むべきです。
「少しだけならバレないだろう」という発想は、ビジネスとしてはリスクが高すぎます。
Pythonスクレイピングを継続運用するためのチェックリスト
robots.txtと利用規約の定期確認
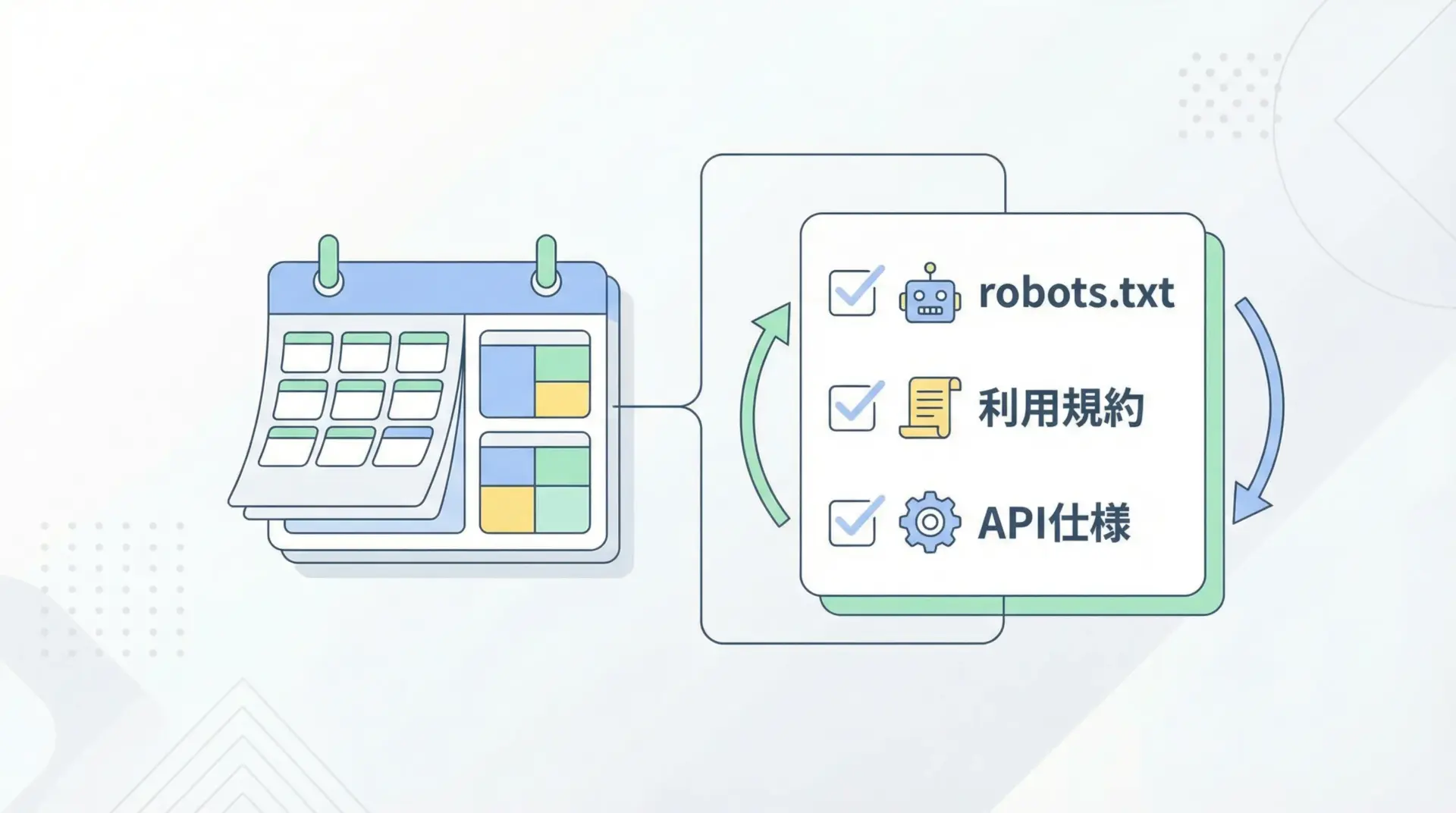
スクレイピングを一度実装して終わりではなく、継続運用する場合、対象サイト側のルール変更に追従することが重要です。
- robots.txtの内容が変更され、特定パスが新たにDisallowされる
- 利用規約が改訂され、自動取得に関する条項が追加される
- API仕様やレートリミットが変わる
このような変化に対応するため、次のような運用ルールを決めておくと安心です。
- 四半期ごとなど、定期的にrobots.txtと利用規約を確認する
- 大きな仕様変更やトラフィック急増があった際に、臨時レビューを行う
- 重要サイトについては、robots.txtの内容をログに保存し、変化を検知するスクリプトを用意する
コードレビューとログ監視のポイント
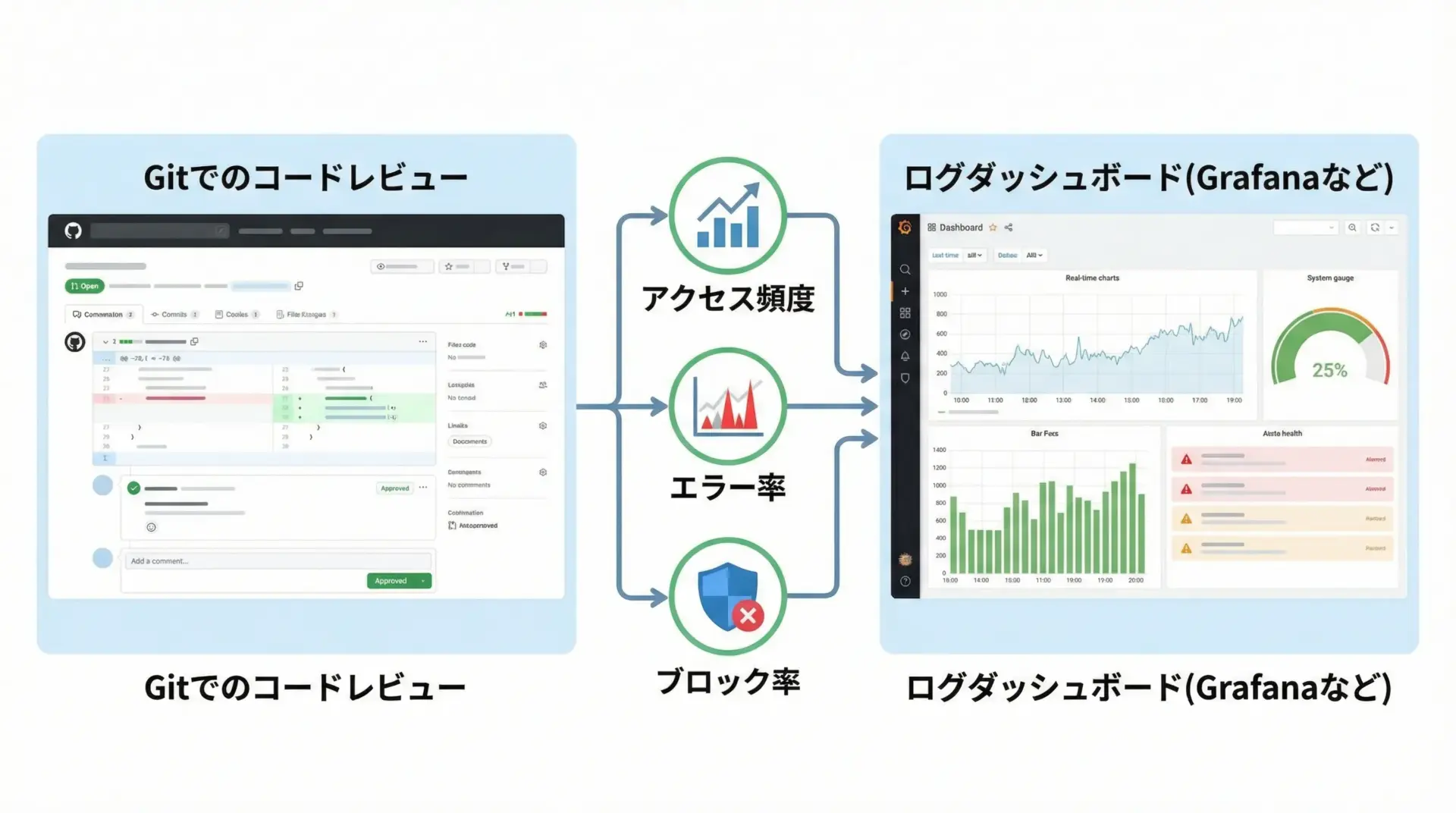
スクレイピングの安全性は、実装だけでなく運用プロセスにも依存します。
特にチーム開発では、次のようなポイントをコードレビュー・ログ監視でチェックすると効果的です。
コードレビューで見るべき点としては、
- robots.txtの確認ロジックが組み込まれているか
- レートリミットやリトライ戦略が適切か
- User-Agentや問い合わせ先の情報が適切か
- 利用規約や契約条件に反する挙動になっていないか
ログ監視では、
- サイトごとのリクエスト数・秒間リクエスト数
- HTTPステータスコードの分布(特に403, 429, 5xx)
- タイムアウトや接続エラーの増加傾向
- robots.txtの拒否判定数
などを把握し、異常な増加があれば早期に検知して一時停止や調整ができる体制を整えると安心です。
社内ルール・コンプライアンスとの整合性
企業や組織でスクレイピングを行う場合、社内の情報セキュリティポリシーやコンプライアンス規程と整合的であることが欠かせません。
- 外部サービスへの自動アクセスに関する社内ルール
- データの保存・持ち出し・再利用に関する規程
- 個人情報・機微情報の取り扱いに関するポリシー
これらと矛盾するスクレイピングを行うと、たとえ技術的・法的にグレーゾーンであっても、社内的には重大な規律違反となり得ます。
Pythonエンジニアとしては、
- プロジェクト開始前に関連する社内ルールを確認する
- 必要に応じて法務・情報セキュリティ部門に相談する
- プロジェクト完了後に、得られた知見を社内ガイドラインとして共有する
といった形で、「技術」と「組織のルール」を橋渡しできる役割を担うことが、長期的に評価される行動につながります。
まとめ
Pythonでスクレイピングを行う際には、ロジックやライブラリ選定だけでなく、robots.txt・利用規約・各種法令・マナーを踏まえた「安全設計」が欠かせません。
robots.txtは法的拘束力こそ限定的ですが、運営者の意向を示す重要なシグナルであり、標準ライブラリやScrapyの機能を使って事前に確認し、レートリミット・User-Agent・時間帯配慮などと組み合わせて守るべきものです。
特に商用利用や機械学習用途、大規模・長期運用のケースでは、著作権法・不正アクセス禁止法・個人情報保護法といった枠組みに加え、利用規約・社内コンプライアンスとの整合性を、法務や関係部門と連携しながら丁寧に検討してください。
技術的なスキルと法令順守・マナー意識を両立させることが、信頼されるPythonスクレイピングエンジニアへの近道です。
