
Webサイトのログインやフォーム送信を毎回手で操作するのは面倒ですし、ミスも起きやすくなります。
PythonとSeleniumを使えば、ブラウザ操作を自動化して、このような繰り返し作業をプログラムに任せることができます。
本記事では、「とにかく最短でSeleniumを動かす」ことをゴールに、環境構築からログイン自動化までを丁寧に解説します。
Seleniumとは
Seleniumで自動化できるブラウザ操作
- 左に「通常モード」として実際の画面が描かれているイメージ
- 右に「ヘッドレスモード」として画面がない状態のイメージ
- 真ん中に「挙動差が出やすいポイント」として「画面サイズ」「フォント・レンダリング」「ポップアップ挙動」などを箇条書き風に並べる
Seleniumは、Webブラウザ(ChromeやEdgeなど)をプログラムから操作するためのツールです。
人間がブラウザで行う操作の多くを、Seleniumは自動で実行できます。
たとえば、次のような操作を自動化できます。
- URLを開く、リンクをクリックしてページ遷移する
- テキストボックスに文字を入力する
- ボタンをクリックしてフォームを送信する
- 画面をスクロールして、画面外の要素を表示する
- 表やリストから情報を取得して保存する
「人間がブラウザでできるほとんどのことは、Seleniumでも同じように実行できる」と考えていただいて問題ありません。
Python+Seleniumを使うメリット
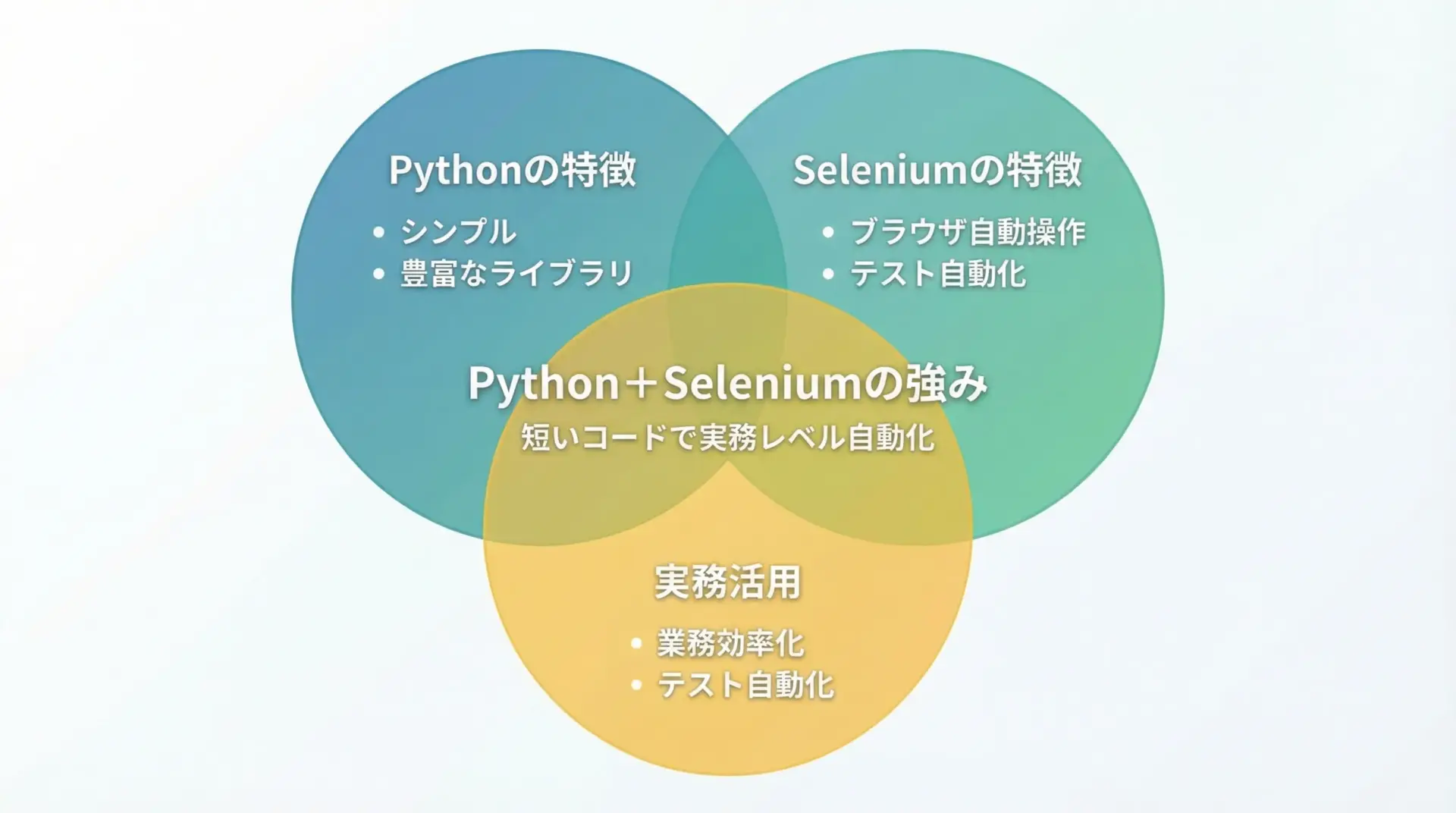
ブラウザ自動化といえばSelenium以外にもツールはありますが、Pythonと組み合わせることで次のようなメリットがあります。
まずPythonは文法がシンプルで読みやすく、初心者でも学びやすい言語です。
短いコードで多くの処理を書けるため、「とりあえず動く自動化スクリプト」を素早く作りやすいという利点があります。
また、PythonにはSelenium以外にも、Excel操作、ファイル操作、メール送信、APIとの連携など、多くのライブラリがそろっています。
SeleniumでWebから情報を取得し、その結果をすぐに他の処理と組み合わせられるので、ブラウザ操作だけで完結しない実務レベルの自動化がしやすいのが大きな強みです。
PythonでSeleniumを最短セットアップ
必要な環境
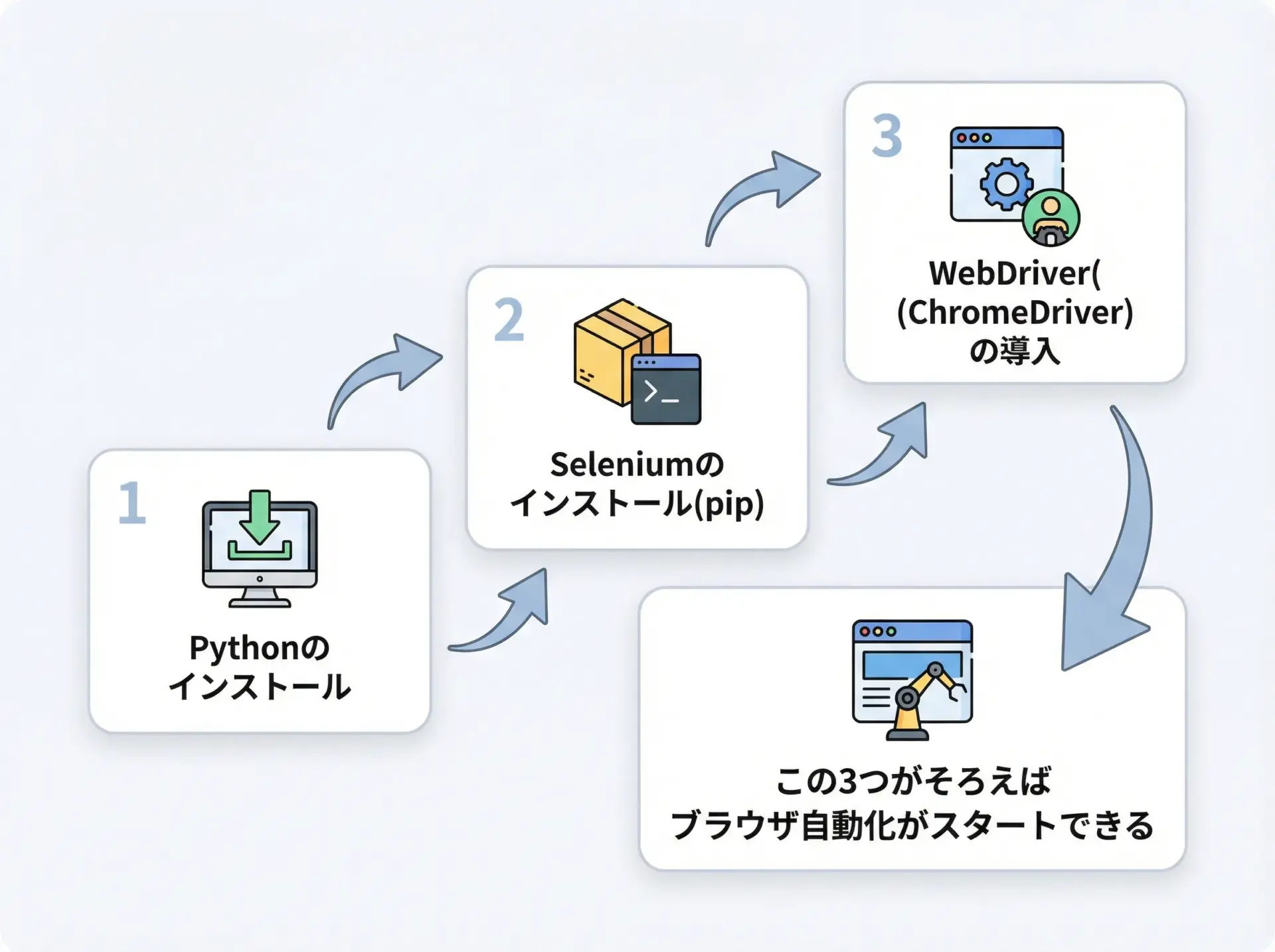
PythonでSeleniumを動かすには、最低限次の3つの環境が必要です。
- Python本体
- Seleniumライブラリ
- WebDriver(ChromeならChromeDriver)
Pythonは3系(3.9〜3.12あたり)であれば基本的に問題ありません。
公式サイトからインストーラをダウンロードしてインストールしてください。
Windowsの場合、インストール時にAdd python.exe to PATHにチェックを入れておくと後の作業がスムーズになります。
pipでSeleniumをインストールする手順
Pythonがインストールできたら、次にパッケージ管理ツールのpipでSeleniumを追加します。
ターミナル(コマンドプロンプト)で次のコマンドを実行します。
# Windows / macOS / Linux 共通
pip install selenium環境によってはpip3コマンドを使う必要があります。
# Python3向けに明示する場合
pip3 install seleniumインストール後、次のコマンドでバージョンが表示されれば導入成功です。
python -c "import selenium; print(selenium.__version__)"WebDriver(ChromeDriver)の導入とパス設定
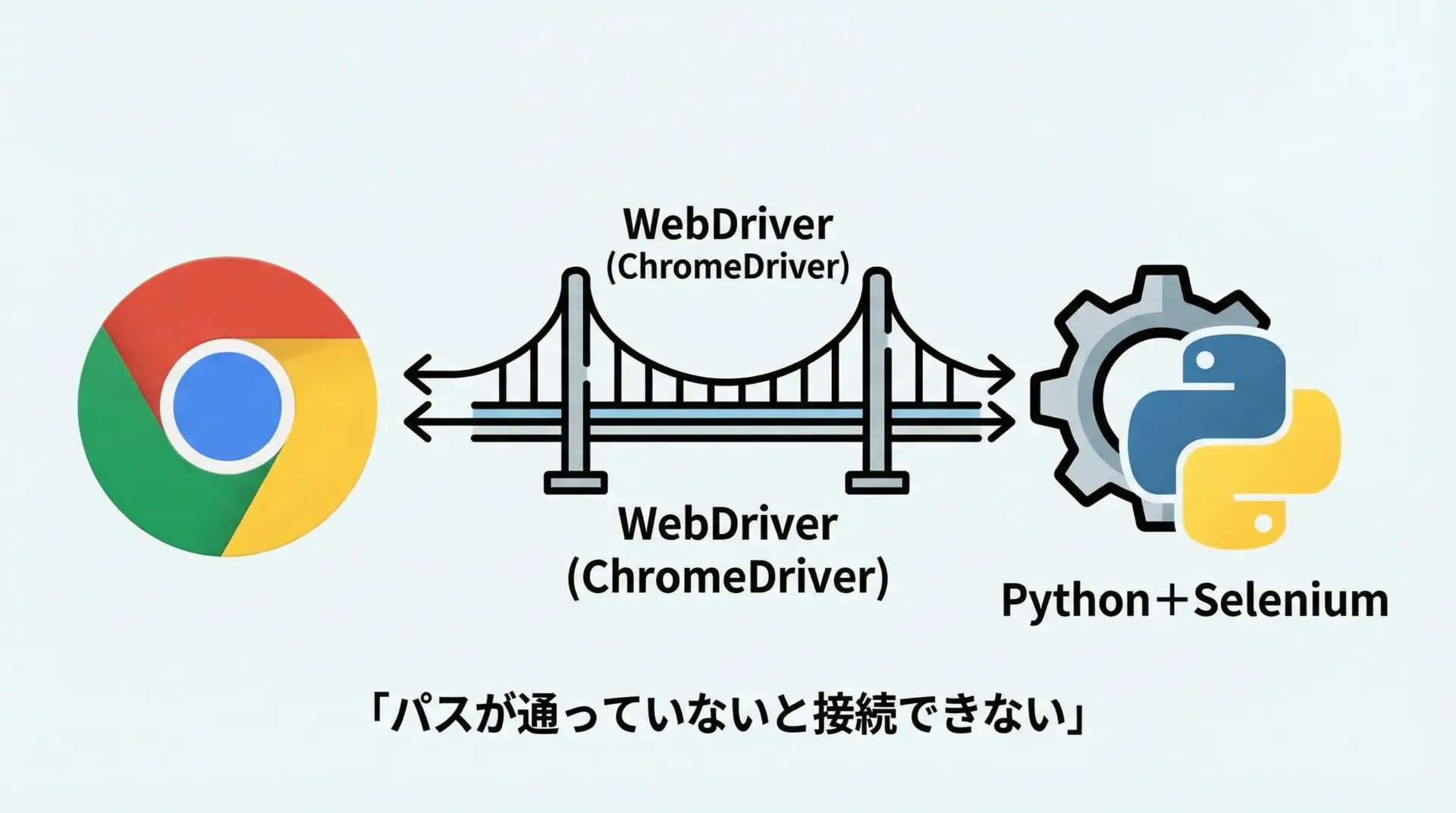
Seleniumはブラウザ本体と直接話すことはできず、その仲介役となるのがWebDriverです。
Chromeを操作したければChromeDriver、Edgeならmsedgedriverと、ブラウザごとに専用のドライバが必要です。
ここでは例としてChromeDriverを使います。
ChromeDriverの導入手順(概要)
- 今使っているChromeのバージョンを確認
Chrome右上のメニュー → 設定 → Chromeについて からバージョンを確認します。 - 対応するChromeDriverをダウンロード
ChromeDriverの公式サイトから、インストール済みChromeのバージョンに対応したものをダウンロードします。 - 解凍して任意のフォルダに配置
たとえばC:\tools\chromedriver\や/usr/local/binなど、分かりやすい場所に置きます。 - PATHを通す、またはフルパスで指定
OSの環境変数PATHにChromeDriverを置いたフォルダを追加するか、Pythonコード側でフルパスを渡します。
最新のSelenium(4.6以降)では、webdriver-manager的な自動ダウンロード機能が備わっているため、簡易的な利用であれば明示的にドライバをダウンロードしなくても動かせるケースがあります。
本記事のサンプルでは、この自動取得機能を活用したコードも紹介します。
Seleniumでブラウザを動かす最小コード
Pythonでブラウザを起動するサンプルコード

まずは「ブラウザを起動してすぐ閉じるだけ」の最小コードから確認します。
ここではChromeを例にします。
# sample_open_browser.py
# SeleniumでChromeブラウザを起動する最小サンプル
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
def main():
# Chromeのオプションを作成
options = Options()
# ここでは特別なオプションは付けない(後でヘッドレスなど追加可能)
# Chromeブラウザを起動
# Selenium 4.6以降では、driverの自動取得機能が動く環境があります
driver = webdriver.Chrome(options=options)
# ブラウザが起動したことを確認するために、しばらく待つ
input("ブラウザが起動しました。Enterキーを押すと終了します...")
# ブラウザを閉じる
driver.quit()
if __name__ == "__main__":
main()このスクリプトを実行すると、Chromeが起動して何も表示されていないウィンドウが立ち上がります。
Enterキーを押すとブラウザが閉じます。
python sample_open_browser.pyページを開く・待機する基本操作
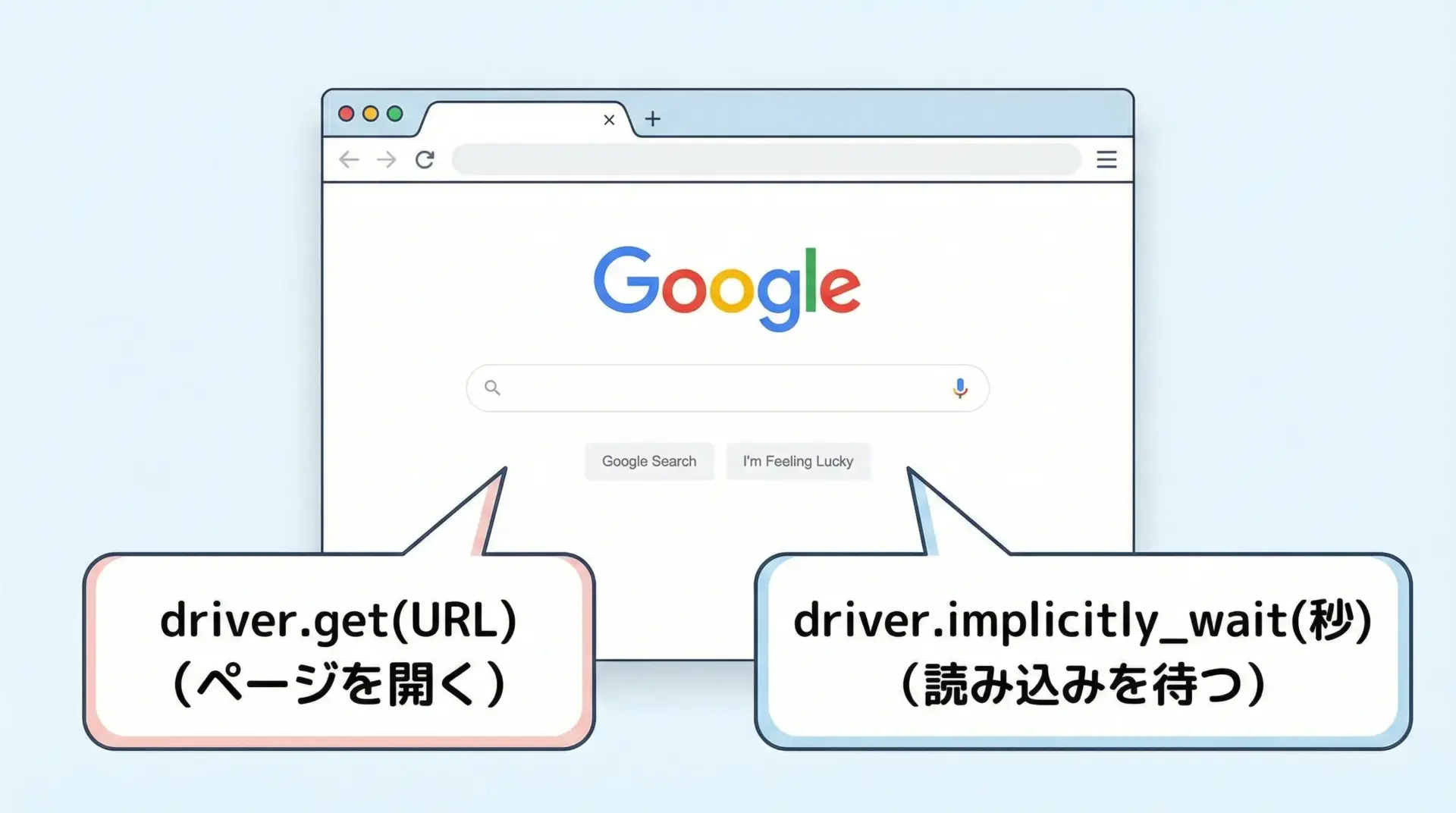
次に、特定のURLを開いて、ページ読み込みをある程度待つ処理を追加します。
# sample_open_page.py
# 特定のURLを開き、数秒待機するサンプル
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
def main():
options = Options()
driver = webdriver.Chrome(options=options)
# Googleのトップページを開く
driver.get("https://www.google.com")
# ページが目視できるように数秒待機
time.sleep(5)
driver.quit()
if __name__ == "__main__":
main()このコードではdriver.get()でURLを開き、time.sleep(5)で単純に5秒間停止しています。
後ほど、より賢い待機方法(WebDriverWait)も紹介しますが、「まずは動かす」という観点ではこのシンプルな方法が分かりやすいです。
ブラウザを閉じる処理を追加する
ブラウザを閉じる処理はdriver.quit()です。
これを忘れると、バックグラウンドにブラウザプロセスが残り続けることがあります。
より安全に終了させるには、try/finallyで囲んでおくと、エラーが起きても最後に必ずブラウザを閉じられます。
# sample_safe_quit.py
# エラーがあってもブラウザを閉じる安全な書き方
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
def main():
options = Options()
driver = webdriver.Chrome(options=options)
try:
driver.get("https://www.google.com")
time.sleep(3)
# ここで何かエラーが起きても
# finally節でdriver.quit()が呼ばれます
# raise Exception("テスト用のエラー")
finally:
# 最後に必ずブラウザを閉じる
driver.quit()
if __name__ == "__main__":
main()要素を探してクリック・入力する基本操作
find_elementでHTML要素を取得する方法
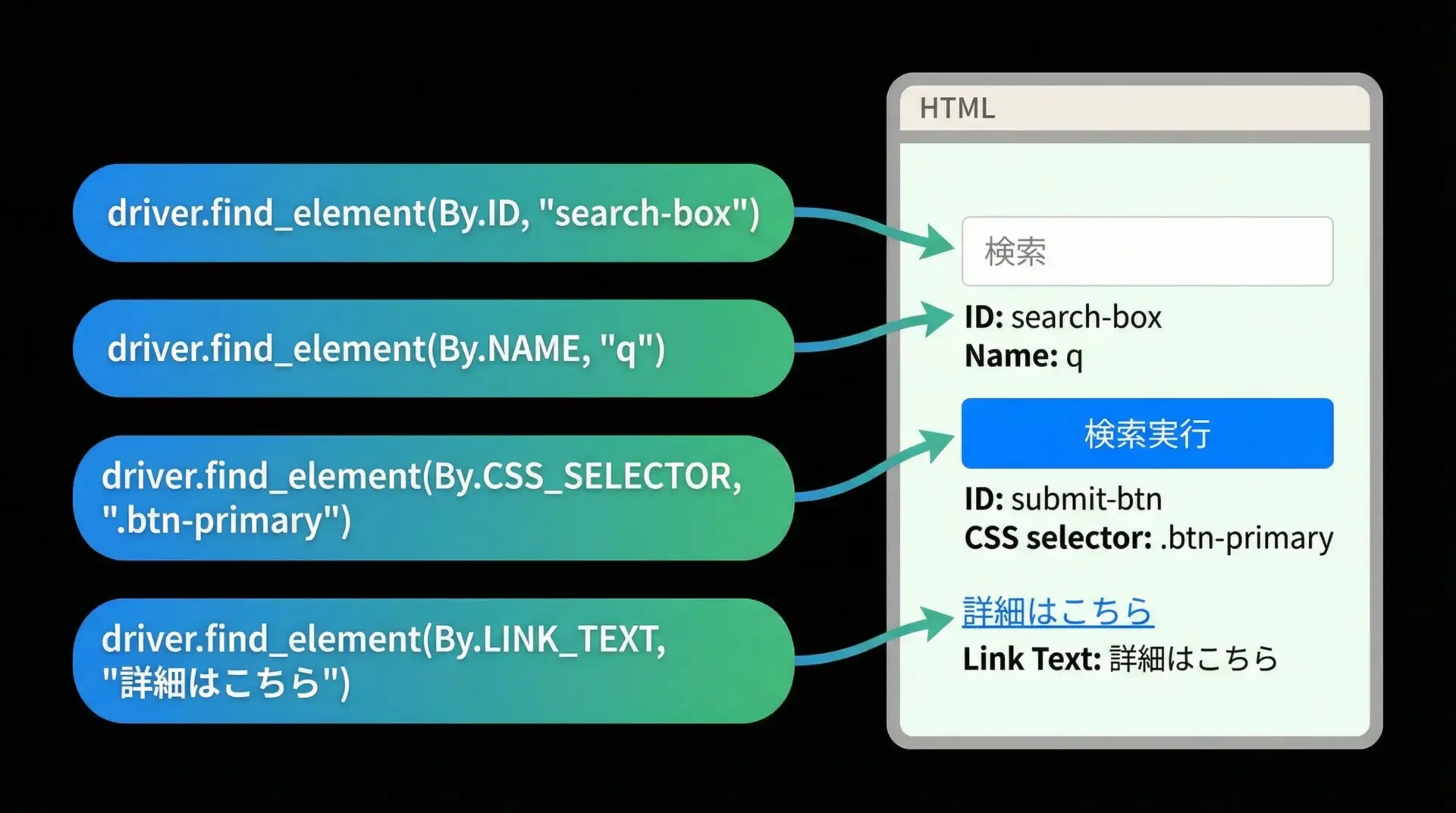
Seleniumで何か操作をするには、まず「どの要素に対して操作するか」を特定する必要があります。
これを行うのがfind_elementです。
代表的な指定方法は次の通りです。
- IDで指定:
find_element(By.ID, "element_id") - name属性で指定:
find_element(By.NAME, "username") - CSSセレクタで指定:
find_element(By.CSS_SELECTOR, "input[type='text']") - XPathで指定:
find_element(By.XPATH, "//input[@type='text']")
実際のコード例を見てみます。
# sample_find_element.py
# Googleの検索ボックスをfind_elementで取得する例
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import time
def main():
options = Options()
driver = webdriver.Chrome(options=options)
try:
driver.get("https://www.google.com")
time.sleep(2)
# name属性が "q" の検索ボックスを取得
search_box = driver.find_element(By.NAME, "q")
# 要素が取得できたか簡易的に確認(タグ名を表示)
print("取得した要素のタグ名:", search_box.tag_name)
time.sleep(2)
finally:
driver.quit()
if __name__ == "__main__":
main()実行すると、コンソールにタグ名(多くの場合input)が表示されます。
取得した要素のタグ名: inputclickでボタンを押す操作
ボタンのクリックも同様で、まず要素をfind_elementで取得し、その上でclick()メソッドを呼び出します。
# sample_click_button.py
# Googleの「検索」ボタンをクリックするシンプルな例
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import time
def main():
options = Options()
driver = webdriver.Chrome(options=options)
try:
driver.get("https://www.google.com")
time.sleep(2)
# 検索ボックスに適当なキーワードを入れてみる
search_box = driver.find_element(By.NAME, "q")
search_box.send_keys("Selenium Python")
time.sleep(1)
# 「Google 検索」ボタンをCSSセレクタで取得してクリック
search_button = driver.find_element(By.CSS_SELECTOR, "input[name='btnK']")
search_button.click()
# 検索結果が表示されるのを待つ
time.sleep(3)
finally:
driver.quit()
if __name__ == "__main__":
main()ここでは後述するsend_keys()も同時に使っています。
send_keysでフォームに文字入力する方法

テキストボックスなどのフォームに文字を入力するには、send_keys()メソッドを使います。
人間がキーボードで入力する代わりに、文字列をそのまま渡すイメージです。
# sample_send_keys.py
# 入力フォームに文字を入力する基本例
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import time
def main():
options = Options()
driver = webdriver.Chrome(options=options)
try:
driver.get("https://www.google.com")
time.sleep(2)
# 検索ボックスを取得
search_box = driver.find_element(By.NAME, "q")
# 文字列を入力
search_box.send_keys("自動化テスト 入門")
# しばらく入力状態を確認
time.sleep(3)
finally:
driver.quit()
if __name__ == "__main__":
main()「要素を探す → send_keysで入力 → clickで送信」の3ステップが、フォーム送信の基本パターンです。
ログイン自動化を最短で実装
ログイン画面の要素を特定する手順

ログイン自動化の第一歩は、「ユーザー名欄」「パスワード欄」「ログインボタン」を特定することです。
実際にはブラウザの開発者ツールを使って、該当するHTML要素の属性(IDやnameなど)を確認します。
流れとしては次のようになります。
- 対象サイトのログインページを人間の手で開く
- ユーザー名入力欄を右クリック → 検証(Inspect)
- HTMLの構造から、IDやname属性を確認
- 同様にパスワード欄とログインボタンも調べる
たとえば次のようなHTMLが見つかったとします。
<input id="login_id" name="username" type="text">
<input id="login_pass" name="password" type="password">
<button id="login_button">ログイン</button>この場合、SeleniumではBy.IDまたはBy.NAMEを使って簡単に要素を取得できます。
Pythonコードでログイン処理を自動化
要素が特定できれば、実際のログイン処理はこれまで学んだsend_keysとclickの組み合わせで実現できます。
ここでは説明用に、サンプル用のURL/ID/パスワードを仮に記述します。
# sample_login.py
# ログインフォームにID/パスワードを入力してログインボタンを押す例
# ※実際のサイトのHTML構造と属性名に合わせて書き換えてください
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import time
LOGIN_URL = "https://example.com/login" # ログインページのURL(例)
# 実際には環境変数や設定ファイルから読み込むことを推奨
USERNAME = "your_username"
PASSWORD = "your_password"
def main():
options = Options()
driver = webdriver.Chrome(options=options)
try:
# ログインページを開く
driver.get(LOGIN_URL)
time.sleep(2)
# ユーザー名欄をIDで取得して入力
username_input = driver.find_element(By.ID, "login_id")
username_input.send_keys(USERNAME)
# パスワード欄をIDで取得して入力
password_input = driver.find_element(By.ID, "login_pass")
password_input.send_keys(PASSWORD)
# ログインボタンをIDで取得してクリック
login_button = driver.find_element(By.ID, "login_button")
login_button.click()
# ログイン後の画面が表示されるのを数秒待つ
time.sleep(5)
finally:
driver.quit()
if __name__ == "__main__":
main()実運用では、ユーザー名やパスワードをソースコードに直接ベタ書きするのは避け、環境変数や設定ファイル、秘密情報管理ツールを使うことをおすすめします。
ログイン後の画面遷移を待つ方法
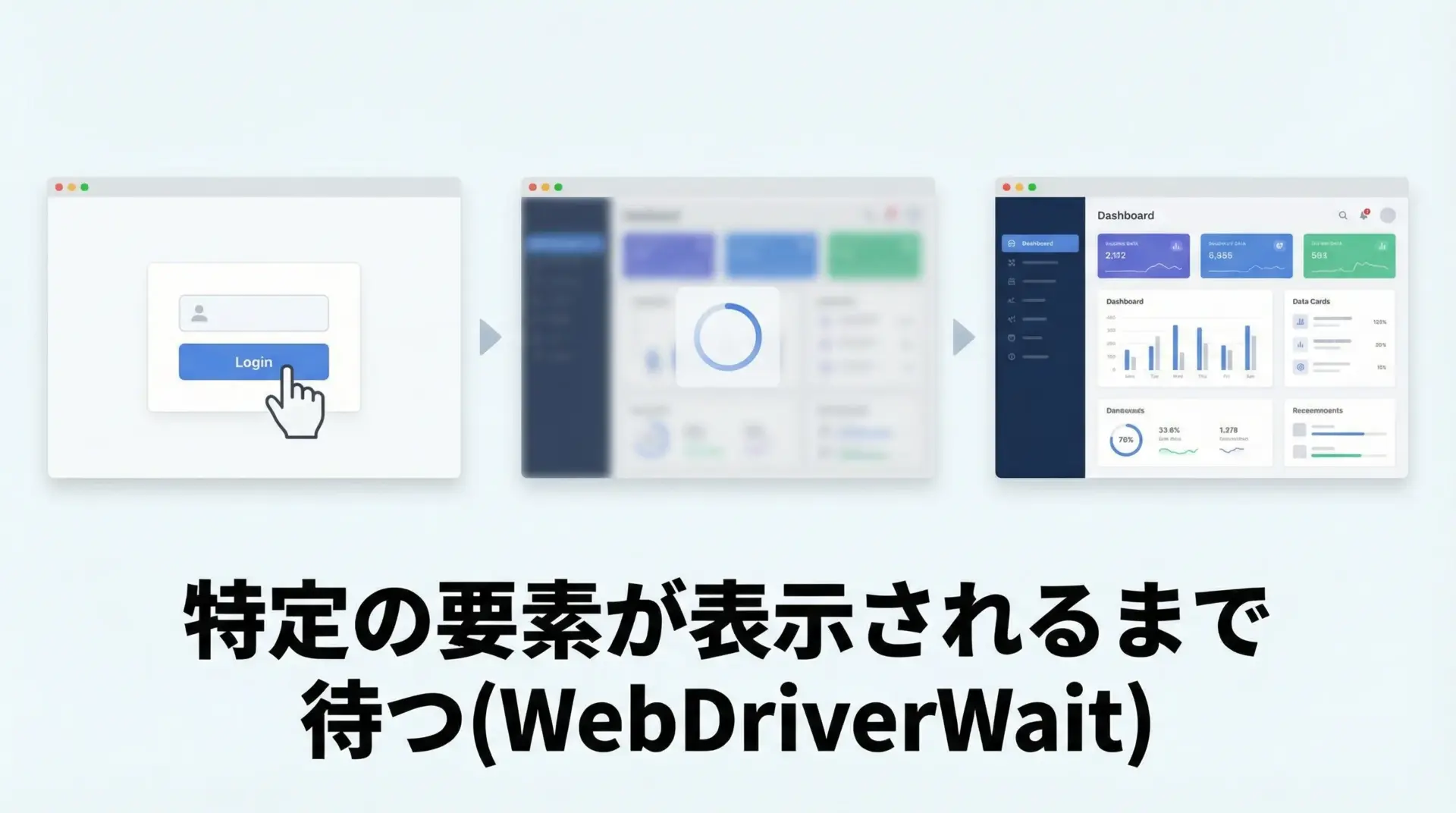
ログインボタンを押した直後は、画面が切り替わっている途中で、まだ要素が表示されていないことがよくあります。
この状態で次の操作をしようとすると「要素が見つかりません」などのエラーが出やすくなります。
そこで、「特定の要素が表示されるまで待つ」処理としてWebDriverWaitを使います。
# sample_login_wait.py
# ログイン後、特定の要素が現れるまで待機する例
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
LOGIN_URL = "https://example.com/login"
USERNAME = "your_username"
PASSWORD = "your_password"
def main():
options = Options()
driver = webdriver.Chrome(options=options)
try:
driver.get(LOGIN_URL)
# ログイン情報を入力
driver.find_element(By.ID, "login_id").send_keys(USERNAME)
driver.find_element(By.ID, "login_pass").send_keys(PASSWORD)
driver.find_element(By.ID, "login_button").click()
# ここからWebDriverWaitを使って、
# ログイン後画面にしか存在しない要素が表示されるまで待つ
# 例: IDが "dashboard" の要素が出るまで最大10秒待機
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "dashboard"))
)
print("ログイン後の画面が表示されました")
finally:
driver.quit()
if __name__ == "__main__":
main()WebDriverWait(driver, 10)は「最大10秒まで待つ」という意味で、指定した条件(ここではpresence_of_element_located)が満たされたら、10秒を待たずに即座に処理が進みます。
待機処理とエラー対策の基本
time.sleepとWebDriverWaitの違い
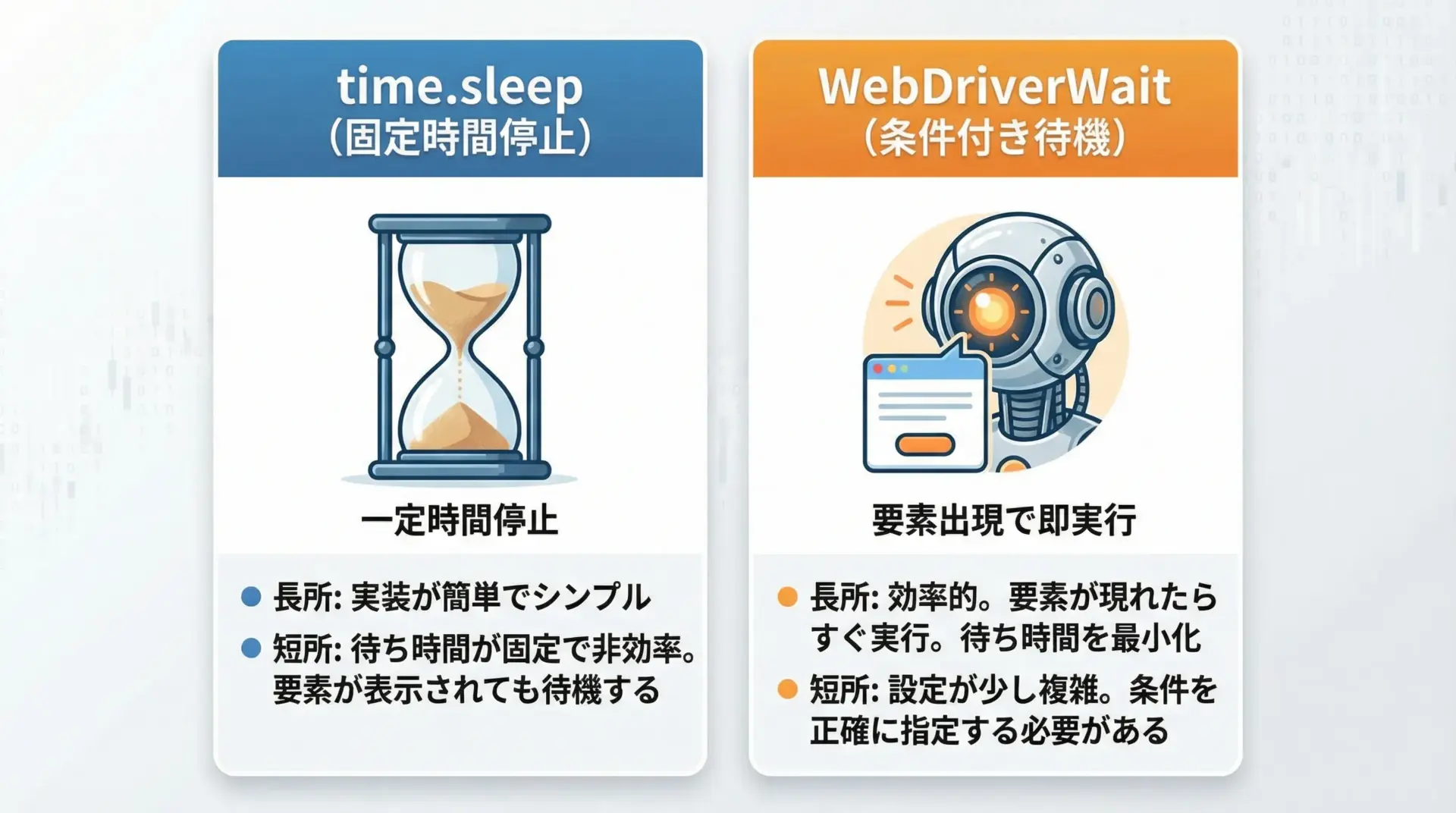
待機処理には大きく分けて2種類あります。
1つはtime.sleep(秒数)による固定時間の待機です。
とてもシンプルで分かりやすく、最初に試すには適している方法です。
ただし、ページが早く読み込まれても、指定した秒数は必ず待ってしまうため、無駄に時間がかかることがあります。
もう1つがWebDriverWaitです。
こちらは「ある条件が満たされるまで待機する」という仕組みで、要素が表示された瞬間に次の処理に進めるため、柔軟かつ効率的です。
用途としては、開発中や検証時にはtime.sleepでざっくり動きを確認し、本格的な運用ではWebDriverWaitに置き換えていく流れが実務では多いです。
要素が見つからない時の原因と対処
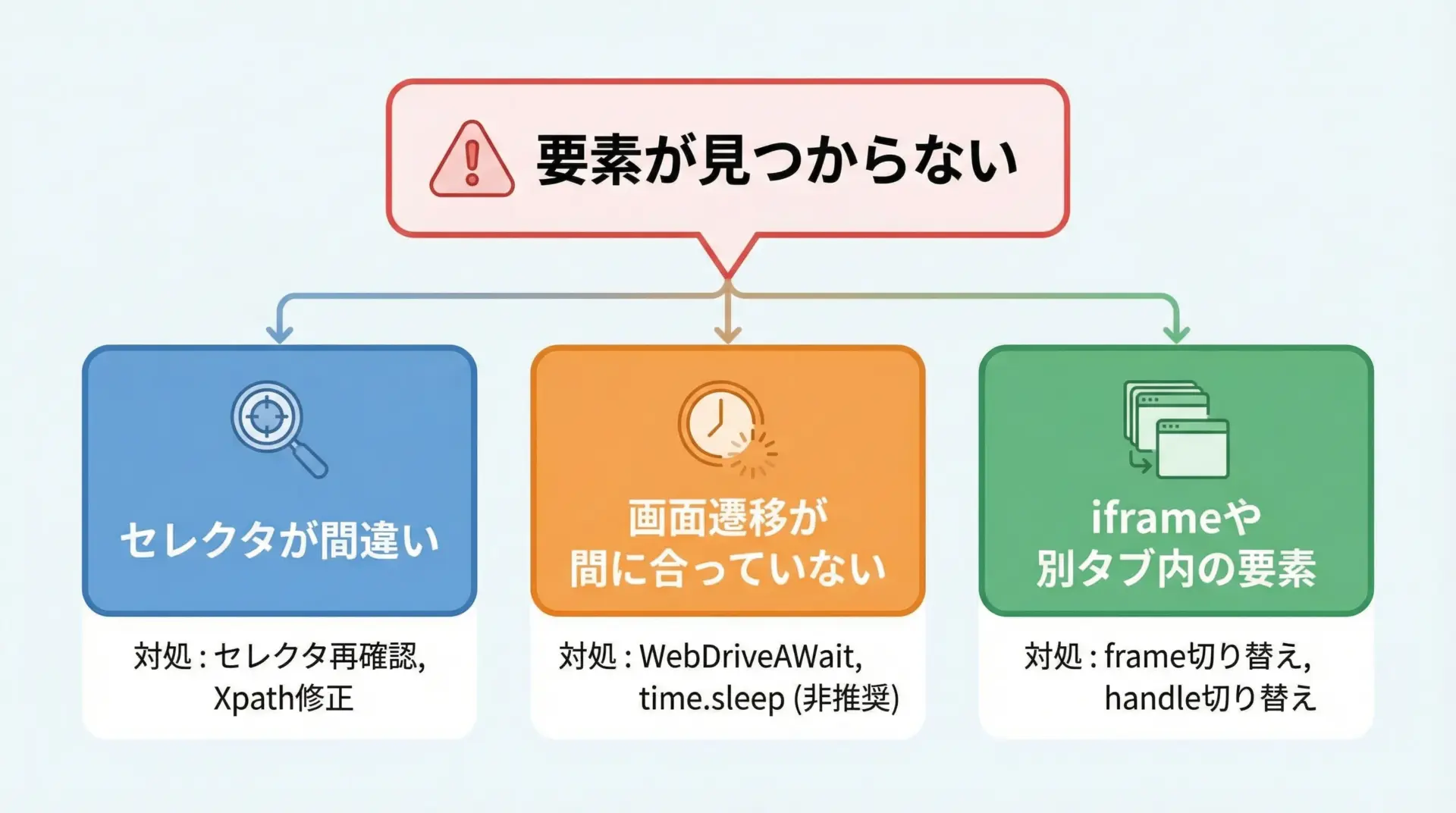
Seleniumでよく遭遇するエラーの1つがNoSuchElementException(要素が見つからない)です。
主な原因と対処は次のようなものがあります。
- セレクタ(指定方法)が間違っている
開発者ツールでIDやname、CSSセレクタを再確認し、実際のHTMLと一致しているか確認します。 - ページの読み込みが終わっていない
クリック直後やページ遷移直後に要素を取りに行くと、まだDOMに存在していないことがあります。この場合はWebDriverWaitを使って、要素が現れるまで待つようにします。 - iframeやポップアップ内の要素を探している
要素がiframeの中にある場合、driver.switch_to.frame()でフレームを切り替えてから要素を探す必要があります。タブやウィンドウが切り替わるケースではdriver.switch_to.window()を使います。
単純にtime.sleepを増やして対応しようとすると、処理時間が無駄に長くなりがちなので、まずはセレクタと画面構造を疑うことをおすすめします。
例外処理でSeleniumエラーを防ぐ
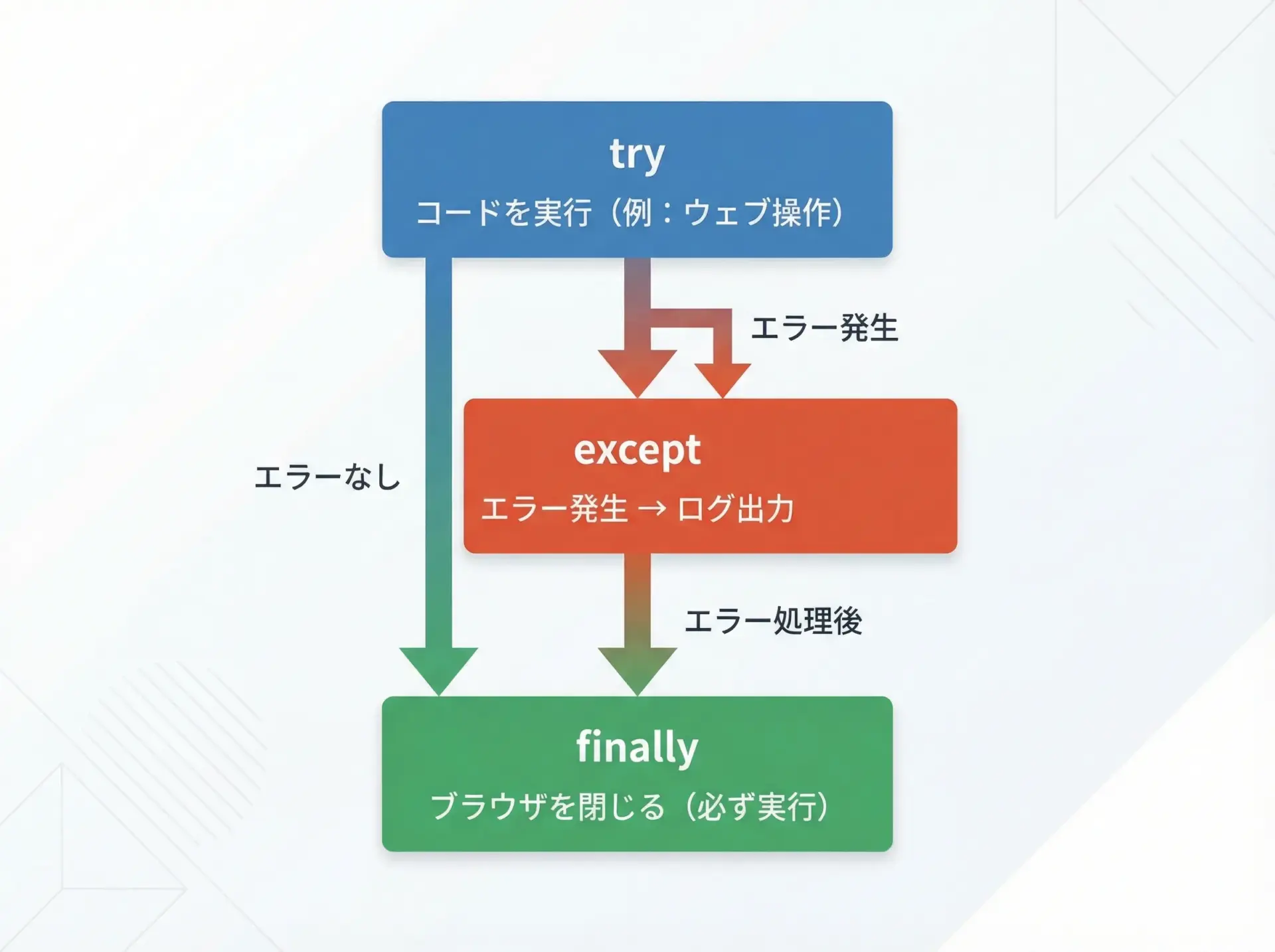
本番運用を意識するなら、エラーが起きたときにブラウザを閉じずに放置してしまうのは避けたいところです。
try/except/finallyを使って例外を捕捉し、必要な後処理を確実に行うようにしましょう。
# sample_exception_handling.py
# Selenium実行時のエラーを捕捉して安全に終了する例
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.common.by import By
def main():
options = Options()
driver = webdriver.Chrome(options=options)
try:
driver.get("https://www.google.com")
# わざと存在しない要素を探す
try:
driver.find_element(By.ID, "this_id_does_not_exist")
except NoSuchElementException as e:
print("要素が見つかりませんでした")
print("詳細:", e)
except Exception as e:
# 想定外の例外もここでログに残せる
print("予期せぬエラーが発生しました:", e)
finally:
# 最後に必ずブラウザを閉じる
driver.quit()
if __name__ == "__main__":
main()このようにしておけば、たとえ予期しないエラーが起きてもブラウザプロセスをきちんと終了させることができます。
ヘッドレスブラウザでバックグラウンド実行
ヘッドレスモードの設定方法
ヘッドレスモードとは、ブラウザの画面を表示せずに裏側だけ動かすモードです。
サーバー上で定期実行したい場合や、画面を表示する必要がない大量の自動処理を行う場合に便利です。
Chromeの場合、Optionsにヘッドレス用のフラグを追加するだけで有効化できます。
# sample_headless.py
# ヘッドレスモードでブラウザを起動する例
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
def main():
options = Options()
# ヘッドレスモードを有効化
options.add_argument("--headless=new") # 新しいヘッドレスモード推奨
options.add_argument("--window-size=1280,720") # 画面サイズを指定することも多い
driver = webdriver.Chrome(options=options)
try:
driver.get("https://www.google.com")
# ページタイトルを取得して標準出力に表示
print("ページタイトル:", driver.title)
finally:
driver.quit()
if __name__ == "__main__":
main()実行するとブラウザウィンドウは表示されませんが、ページタイトルはコンソールに出力されます。
ページタイトル: Googleヘッドレスで注意すべきポイント
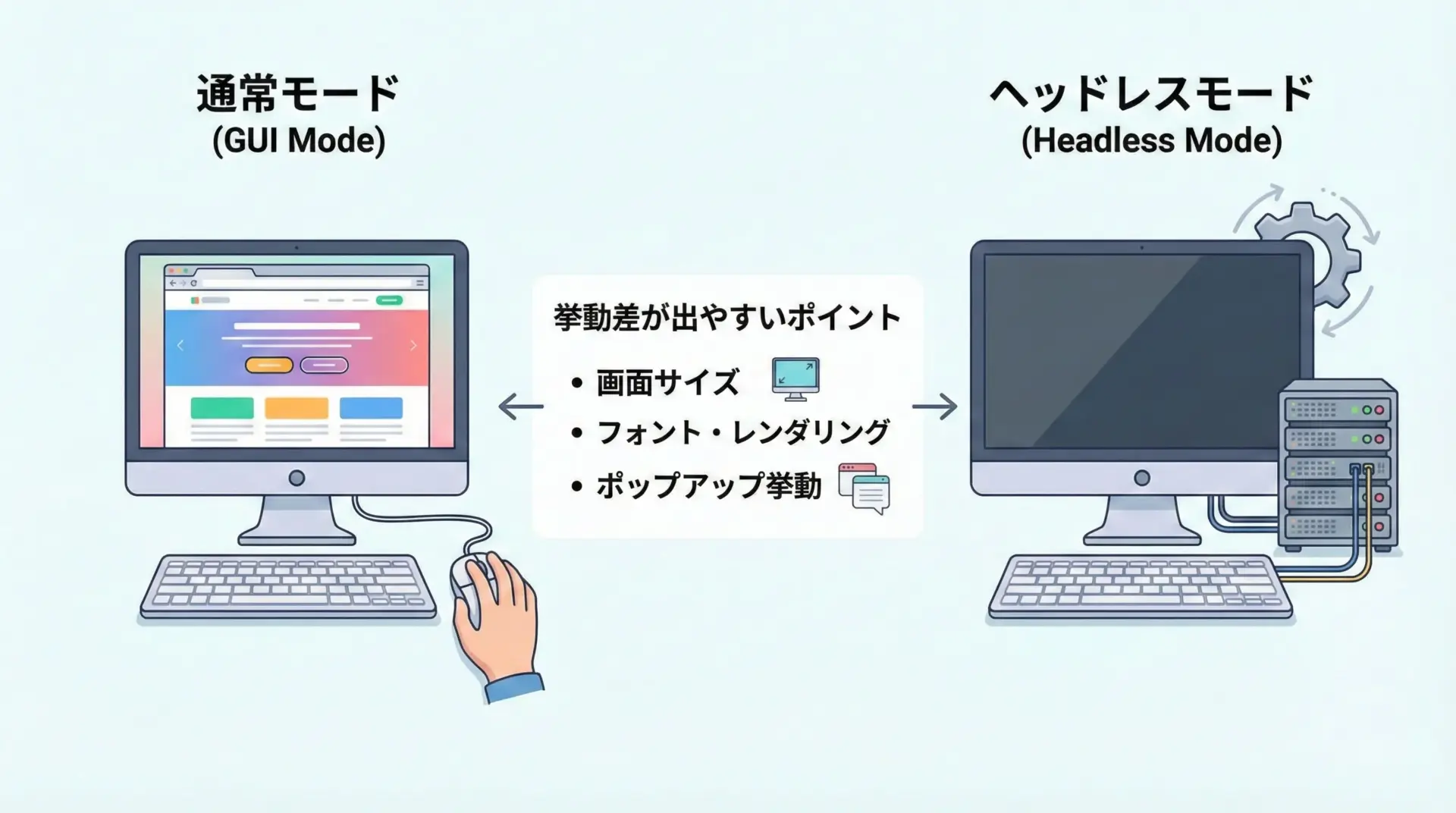
ヘッドレスモードは便利ですが、通常表示モードと微妙に動作が異なることがあります。
特に注意したいのは次の点です。
- 画面サイズが小さくなり、レスポンシブデザインが変わる
ヘッドレスではデフォルトのウィンドウサイズが小さく、スマホ表示に切り替わるサイトもあります。必要に応じて--window-sizeオプションで幅と高さを指定することが重要です。 - 一部のJavaScript挙動が異なる場合がある
極端に古いサイトや特殊な検出ロジックを持つサイトでは、「ヘッドレス環境」を検知して挙動を変えるケースがあります。その場合はヘッドレスをオフにする、またはUser-Agentを調整するなどの工夫が必要です。 - デバッグしにくい
画面が見えないため、「どこまで処理が進んだのか」「画面上でどんな状態になっているのか」が分かりにくくなります。実装時やトラブル発生時は通常モードで動作確認し、その後ヘッドレスに切り替える運用が現実的です。
「開発時は通常モード、運用時はヘッドレス」という切り替え方を意識しておくと、トラブルに対応しやすくなります。
Selenium自動化でよくあるつまずき
パスが通らない・ドライバが動かない時
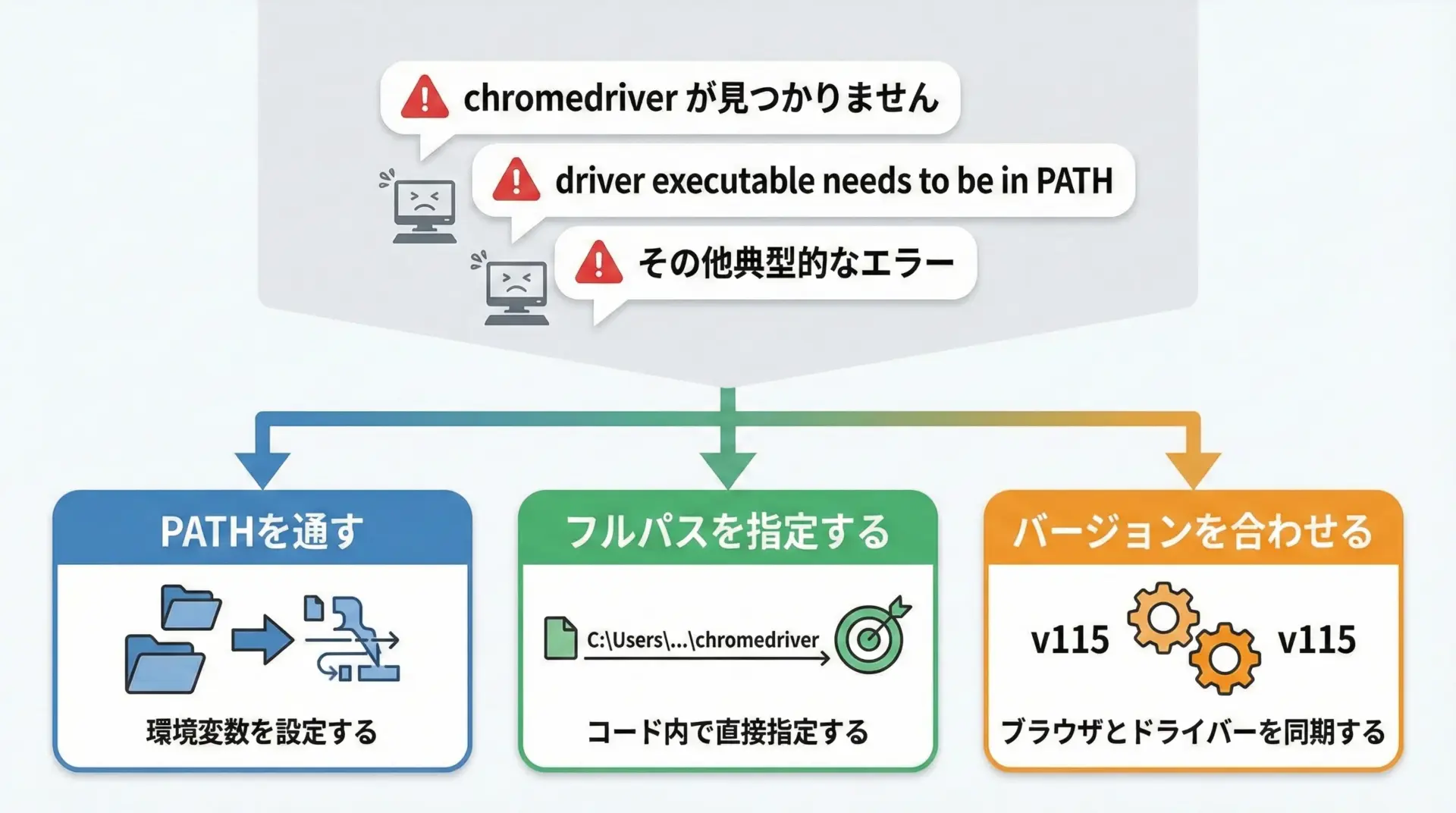
Seleniumを初めて触るときによく遭遇するのが、WebDriver周りのエラーです。
例えば次のようなメッセージが出ることがあります。
Message: 'chromedriver' executable needs to be in PATH.selenium.common.exceptions.WebDriverException: unknown error: cannot find Chrome binary
原因として多いのは次の3つです。
- ChromeDriverの場所がPATHに通っていない
→ OSの環境変数PATHにChromeDriverを置いたフォルダを追加するか、webdriver.Chrome(executable_path="...")のようにフルパスを指定します。 - Chrome本体がインストールされていない、または場所が特殊
→ Chromeを通常の手順でインストールしたか確認し、ポータブル版など特殊な配置をしている場合はbinary_locationオプションでパスを指定します。 - ChromeとChromeDriverのバージョンが噛み合っていない
→ Chromeのバージョンに対応したDriverをダウンロードし直すか、Seleniumの自動取得機能が使えるバージョンであればそちらを活用します。
最近のSeleniumでは、自動で適切なDriverをダウンロード・管理してくれる機能が搭載されており、従来よりもこの問題には遭遇しにくくなっています。
それでもエラーが出る場合は、エラーメッセージ全文をよく読み、どのパスが見つかっていないのかを確認すると解決の糸口になります。
要素のセレクタ変更に対応するコツ
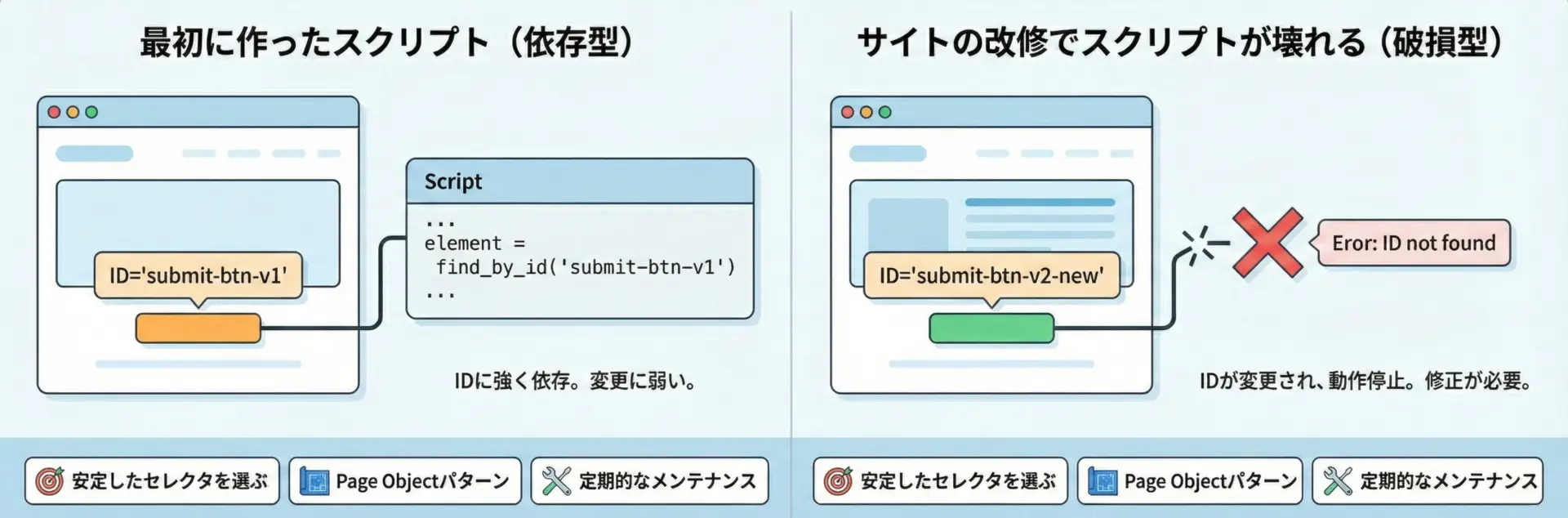
Webサイトは日々更新されるため、セレクタ(要素の指定方法)が変更されてスクリプトが動かなくなることは避けられません。
これを完全に防ぐことは難しいですが、影響を小さくする工夫はできます。
次のポイントを意識すると、変更に強い自動化コードを書きやすくなります。
- IDが安定しているならIDを優先して使う
IDは基本的にページ内で一意で、意味のある名前が付けられていることが多く、改修でも変えられにくい傾向があります。 - CSSセレクタやXPathは「構造に強く依存しすぎない」
親子関係や階層に強く依存したXPath(//div[2]/div[3]/span[1]のようなもの)は、少しのレイアウト変更ですぐ壊れます。できるだけクラス名や属性値に基づいた指定にしましょう。 - セレクタを1か所にまとめて管理する
コードのあちこちにfind_element(By.ID, "xxx")を書き散らさず、「セレクタ定数をまとめたモジュール」や「Page Objectパターン」を採用しておくと、変更への対応コストが大きく下がります。 - 開発者とコミュニケーションできる環境なら、テスト用IDを付けてもらう
フロントエンド側と調整できるなら、自動テスト用の安定したIDや属性(data-testidなど)を付けてもらうのが理想です。
「サイトは変わる前提で、自動化コードもメンテナンスするもの」と捉え、セレクタ設計を工夫しておくことが長期運用の鍵になります。
まとめ
PythonとSeleniumを組み合わせることで、日常的なブラウザ操作をプログラムに任せられるようになります。
本記事では、環境構築から最小コード、要素の取得・クリック・入力、ログイン自動化、待機処理、エラー対策、ヘッドレス実行、そして運用時につまずきやすいポイントまでを一通り解説しました。
まずは「自分が毎回手でやっている定型作業」を1つ選び、本記事のサンプルをベースに自動化してみてください。
小さな成功体験を積み重ねることで、より高度な自動化やテスト自動化への応用も自然と見えてきます。
