
PythonでWebサイトから情報を自動取得するスクレイピングは、うまく使えばデータ収集や調査の強力な味方になります。
本記事では、特に扱いやすいrequestsライブラリを使って、環境構築から最速で動くコード例、実践で使えるテクニック、さらにはマナーや法律面の注意点までを、初心者の方にも分かりやすく解説します。
Pythonのrequestsスクレイピングとは
requestsスクレイピングの基本概要
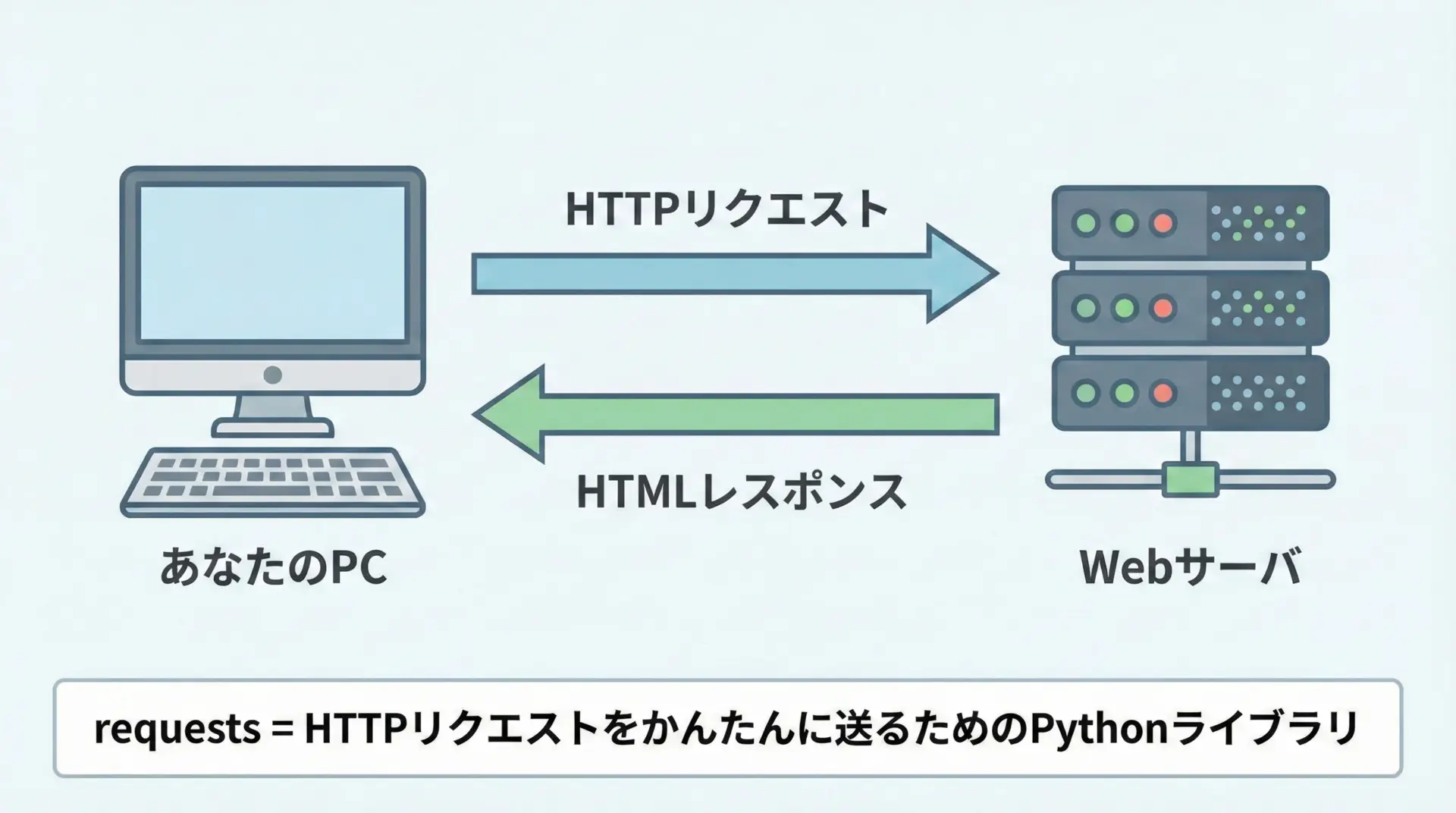
スクレイピングとは、Webページに人間がブラウザでアクセスする代わりに、プログラムからアクセスして情報を自動的に取得することを指します。
Pythonのrequestsライブラリは、WebサーバにHTTPリクエストを送り、レスポンスとしてHTMLやJSONなどのデータを受け取るためのライブラリです。
通常、ブラウザでページを開くと、内部的にはHTTPリクエストとレスポンスのやり取りが行われています。
requestsスクレイピングとは、ブラウザの代わりにPythonとrequestsを使って、そのやり取りを直接行い、必要な情報を取得する技術だと考えると理解しやすいです。
WebスクレイピングにPythonが向いている理由

Pythonがスクレイピングに向いている理由はいくつかあります。
まず、コードが比較的短く、直感的に書けることが挙げられます。
初心者でも数行のコードでWebページの内容を取得できるのは大きな強みです。
さらに、スクレイピングと相性の良いライブラリが非常に充実しています。
例えば、HTTP通信のrequests、HTML解析のためのBeautifulSoupやlxml、動的なページ操作に使えるSeleniumなどです。
Pythonを選べば、データの取得から解析、保存や可視化までを1つの言語で完結できるため、学習効率が高くなります。
Python環境構築とrequestsのインストール
Pythonとpipの準備
Pythonでrequestsスクレイピングを行うためには、まずPython本体とパッケージ管理ツールであるpipが必要です。
多くの環境では、公式サイトからPythonをインストールすれば、pipも一緒に導入されます。

Pythonのインストールが完了したら、ターミナル(またはコマンドプロンプト)で次のように入力して、正しくインストールされているか確認します。
python --version
pip --versionこれらのコマンドでバージョン情報が表示されれば、準備は整っています。
もしコマンドが見つからないといったエラーが出る場合は、PATH設定に問題がある可能性が高いので、インストール手順を再確認してください。
requestsライブラリのインストール手順
requestsは標準ライブラリではないため、pipを使って別途インストールする必要があります。
インストールは非常に簡単で、次の1行を実行するだけです。
pip install requests環境によってはpip3コマンドを使う必要がある場合があります。
その場合は次のように入力します。
pip3 install requestsインストール後、Pythonインタプリタを起動して次のように打ち込み、エラーなく終了すれば準備完了です。
import requests
print(requests.__version__)上記でバージョン番号が表示されれば、requestsを使ったスクレイピングを始めるための環境が整ったことになります。
最速で動くrequestsスクレイピングの基本コード
最小コード例
まずは、最速で動く最小限のサンプルから見てみます。
これが理解できれば、以降の応用もスムーズになります。
import requests # requestsライブラリを読み込む
# 取得したいURLを指定
url = "https://example.com"
# GETリクエストを送信してレスポンスを受け取る
response = requests.get(url)
# レスポンスの本文(HTML)を文字列として表示
print(response.text)このコードを実行すると、指定したURLのHTMLソースがそのまま表示されます。
実際のスクレイピングでは、このHTMLからさらに必要な情報を抽出していきますが、まずは「ページの中身を取得できる」という感覚をつかむことが重要です。
URLにGETリクエストを送る基本パターン

requestsで最もよく使うのがGETリクエストです。
これはブラウザでURLを入力してページを開くのと同じ動作に相当します。
基本的な書き方は次の通りです。
import requests
url = "https://www.python.org"
# GETメソッドでリクエストを送る
response = requests.get(url)
# ステータスコード(成功かどうか)を確認
print("ステータスコード:", response.status_code)
# 最終的にアクセスしたURL(リダイレクト後のURLなど)を確認
print("アクセス先URL:", response.url)ステータスコード: 200
アクセス先URL: https://www.python.org/ここで表示されるstatus_codeは、リクエストが成功したかどうかを示す重要な情報です。
200番台であれば概ね成功、それ以外は何らかの問題があると判断できます。
レスポンスからHTMLを取得する方法
レスポンスから取得できる情報にはさまざまなものがありますが、特にスクレイピングでよく使うのは次の3つです。
- HTML本文そのもの
- エンコーディング
- ヘッダー情報
これらを確認するサンプルコードを示します。
import requests
url = "https://example.com"
response = requests.get(url)
# 1. HTML本文を取得(text属性)
html = response.text
print("HTMLの先頭100文字:")
print(html[:100]) # 長すぎるので先頭だけ表示
# 2. レスポンスのエンコーディングを確認
print("エンコーディング:", response.encoding)
# 3. レスポンスヘッダーを確認
print("レスポンスヘッダー:")
for key, value in response.headers.items():
print(f"{key}: {value}")HTMLの先頭100文字:
<!doctype html>
<html>
<head>
<title>Example Domain</title>
...
エンコーディング: UTF-8
レスポンスヘッダー:
Content-Encoding: gzip
Accept-Ranges: bytes
...このように、HTML本文はresponse.textで取得でき、文字コードもresponse.encodingから確認できます。
スクレイピング時に文字化けが起こる場合は、このエンコーディング設定を適切に変更する必要があります。
HTML要素の取得とテキスト抽出
requestsだけではHTMLを取得するところまでです。
実際に欲しいタイトルや見出しのテキストを取り出すには、HTMLパーサと組み合わせるのが一般的です。
ここでは代表的なBeautifulSoupを併用した例を示します。
タイトルや見出しを取得するサンプルコード
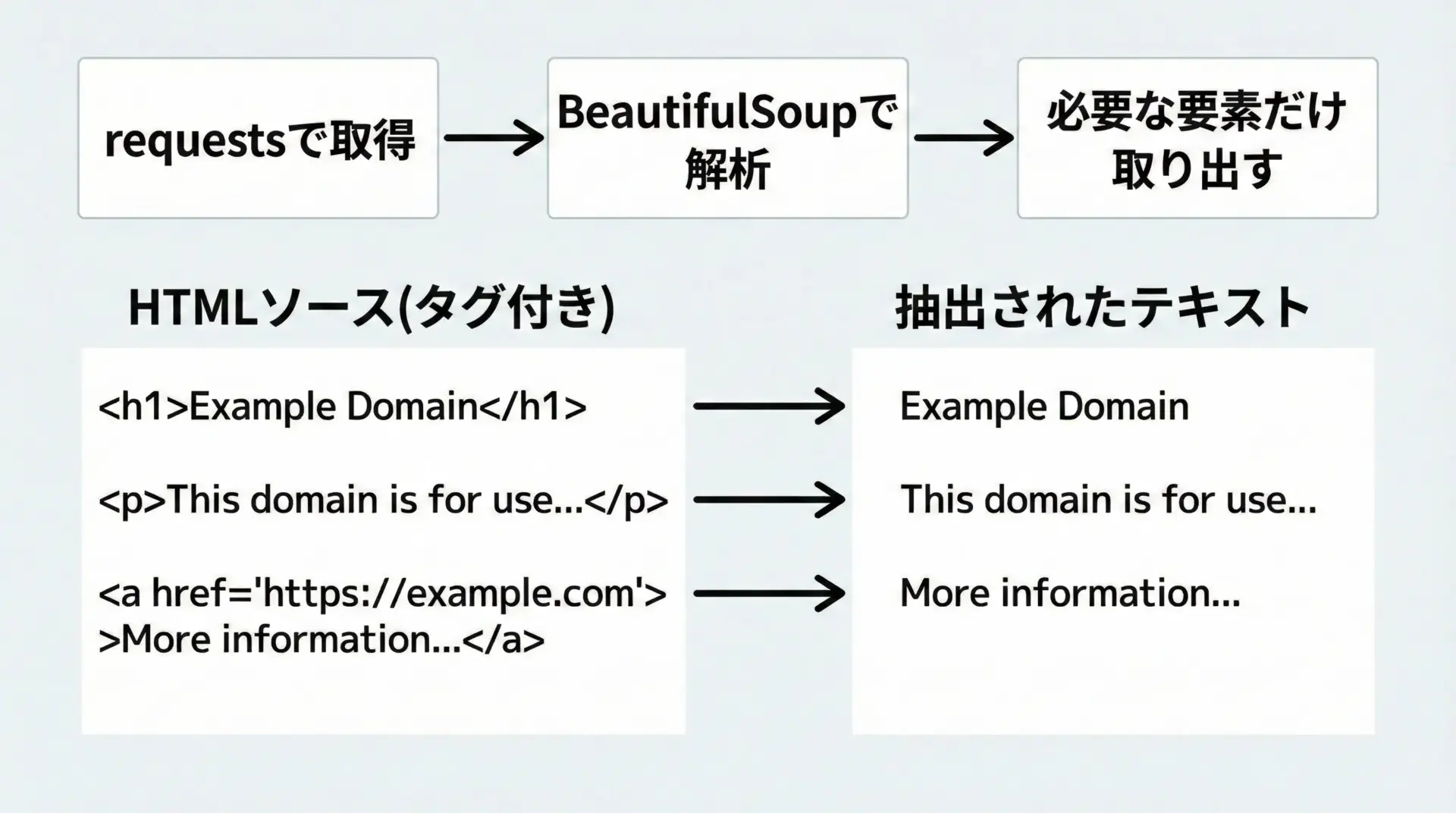
まずはBeautifulSoupをインストールします。
pip install beautifulsoup4次に、タイトルや見出しを抜き出すサンプルコードです。
import requests
from bs4 import BeautifulSoup # HTML解析用ライブラリをインポート
url = "https://example.com"
response = requests.get(url)
# レスポンスのHTMLをBeautifulSoupで解析
soup = BeautifulSoup(response.text, "html.parser")
# ページタイトル(<title>タグ)を取得
title_tag = soup.title
print("titleタグそのもの:", title_tag)
print("titleのテキスト:", title_tag.get_text())
# ページ内の見出し(<h1>タグ)を取得
h1_tag = soup.find("h1") # 最初のh1要素を取得
print("h1タグ:", h1_tag)
print("h1のテキスト:", h1_tag.get_text())titleタグそのもの: <title>Example Domain</title>
titleのテキスト: Example Domain
h1タグ: <h1>Example Domain</h1>
h1のテキスト: Example Domainこのサンプルではsoup.titleやsoup.find("h1")を使って、特定のタグを簡単に取得しています。
HTMLの構造を意識しながら、欲しい情報がどのタグに含まれているかを調べることが、スクレイピング設計の第一歩です。
クラス名やidを指定して要素を取得する方法
実際のWebサイトでは、単にタグ名だけではなく、クラス名やidを使って要素を指定する場面が多くなります。
BeautifulSoupでは、クラスやidを次のように指定できます。
import requests
from bs4 import BeautifulSoup
url = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
# idで指定して要素を取得する例
element_by_id = soup.find(id="main") # id="main"の要素を取得
print("id='main'の要素:")
print(element_by_id)
# classで指定して複数要素を取得する例
# class引数はPythonの予約語と重なるため、class_という名前で指定
elements_by_class = soup.find_all("p", class_="description") # <p class="description">をすべて取得
print("class='description'の<p>要素一覧:")
for p in elements_by_class:
print("-", p.get_text().strip())上記のように、idはid="..."で一意の要素、classはclass="..."で複数の要素を識別するのが一般的です。
スクレイピング対象のページのHTMLをブラウザの開発者ツールなどで確認し、適切なセレクタを選ぶことで、狙った情報だけを効率よく抜き出すことができます。
requestsスクレイピングの実践テクニック
実際に運用レベルでスクレイピングを行う際には、ヘッダー設定やタイムアウト、例外処理、クエリパラメータなどを適切に扱うことが重要です。
ここでは、すぐに役立つ基本テクニックを紹介します。
ヘッダー(User-Agent)の設定方法
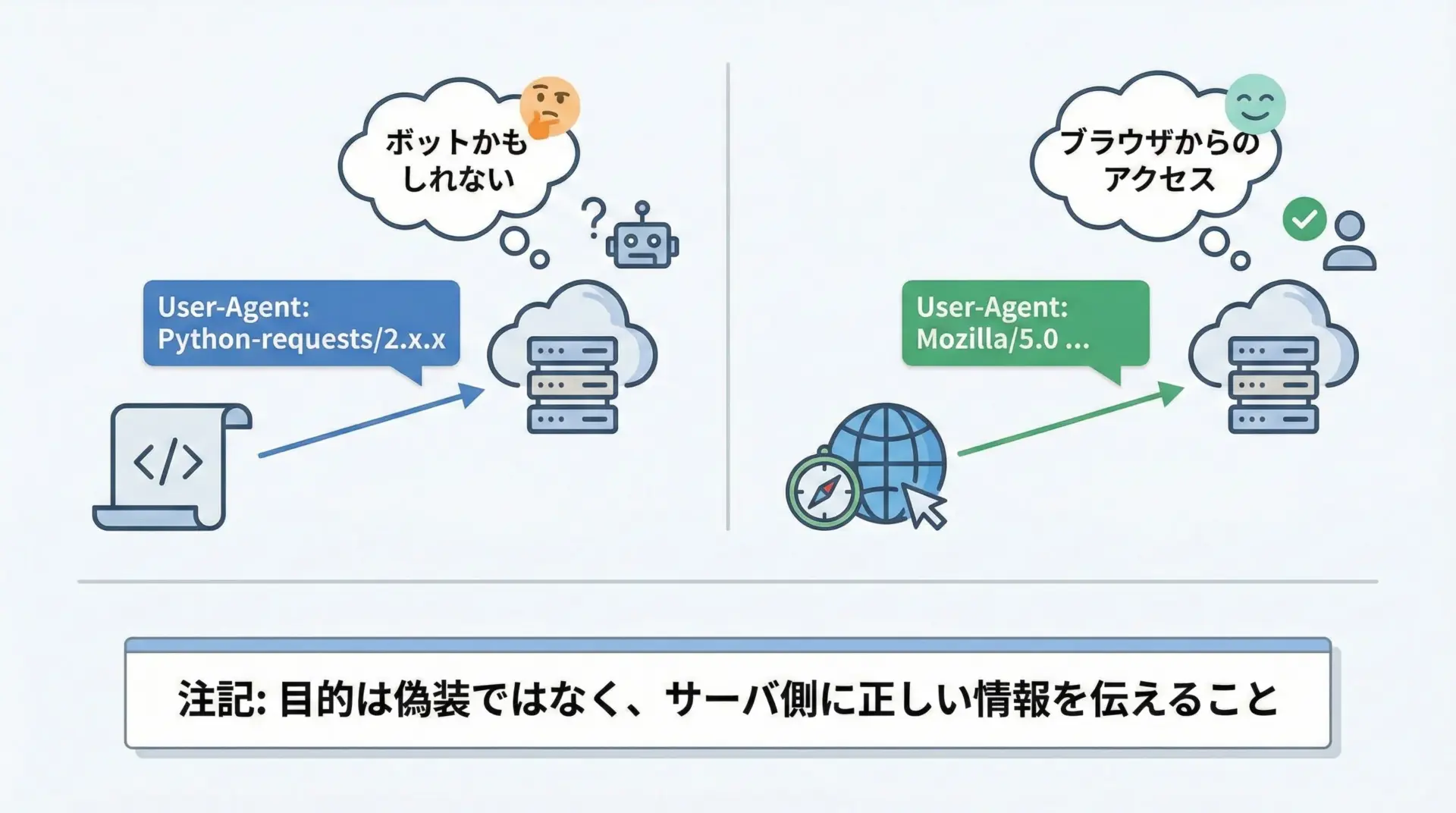
多くのWebサーバでは、リクエストヘッダーのUser-Agentを見て、アクセス元がブラウザかプログラムかを判断しています。
デフォルトのままでも動く場合は多いですが、正しく振る舞うためには適切なUser-Agentを明示的に設定した方がよい場合もあります。
import requests
url = "https://example.com"
# ブラウザに近いUser-Agentを設定(例として一般的なChromeの例)
headers = {
"User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/120.0.0.0 Safari/537.36"
)
}
response = requests.get(url, headers=headers)
print("ステータスコード:", response.status_code)
print("User-Agentを設定したアクセス先:", response.url)User-Agentの設定は、サイト側のポリシーに従って正しく設定することが重要です。
アクセス元を偽るためではなく、プログラムからのアクセスであることを明示するポリシーを採用するケースもありますので、利用規約を確認しつつ運用してください。
タイムアウトと例外処理の書き方
ネットワーク通信では、いつまでも応答が返ってこないなどの問題が起きることがあります。
そのような場合に備え、タイムアウトと例外処理を必ず入れておくべきです。
import requests
url = "https://example.com"
try:
# timeoutは「何秒待つか」を指定(接続と応答の合計の目安)
response = requests.get(url, timeout=5)
response.raise_for_status() # ステータスコードが4xx/5xxなら例外を投げる
except requests.exceptions.Timeout:
print("タイムアウトしました。このURLへの接続に時間がかかりすぎています。")
except requests.exceptions.HTTPError as e:
print("HTTPエラーが発生しました:", e)
except requests.exceptions.RequestException as e:
# 上記以外のrequests関連の例外をまとめて捕捉
print("通信中にエラーが発生しました:", e)
else:
print("正常に取得できました。ステータスコード:", response.status_code)このようにtry〜except構文を用いることで、実行中の想定外の停止を防ぎつつ、問題の内容を把握しやすくなります。
クエリパラメータの指定
検索機能や絞り込みを行うページでは、URLの末尾に?q=python&page=2のようなクエリパラメータが付いていることがよくあります。
requestsでは、クエリパラメータを辞書で指定するのが安全で読みやすい方法です。
import requests
url = "https://httpbin.org/get"
# クエリパラメータを辞書で指定
params = {
"q": "python requests",
"page": 2
}
response = requests.get(url, params=params)
print("最終的なリクエストURL:", response.url)
print("レスポンスのJSON:")
print(response.json()) # httpbin.org/getは送られたパラメータをJSONで返すテスト用サイト最終的なリクエストURL: https://httpbin.org/get?q=python+requests&page=2
レスポンスのJSON:
{'args': {'page': '2', 'q': 'python requests'}, ...}このようにparams引数を使うと、URLエンコードなどの細かい処理をrequestsが自動で行ってくれるため、文字列連結でURLを組み立てるより安全で確実です。
動的ページへの対処と限界
requestsでできること・できないこと
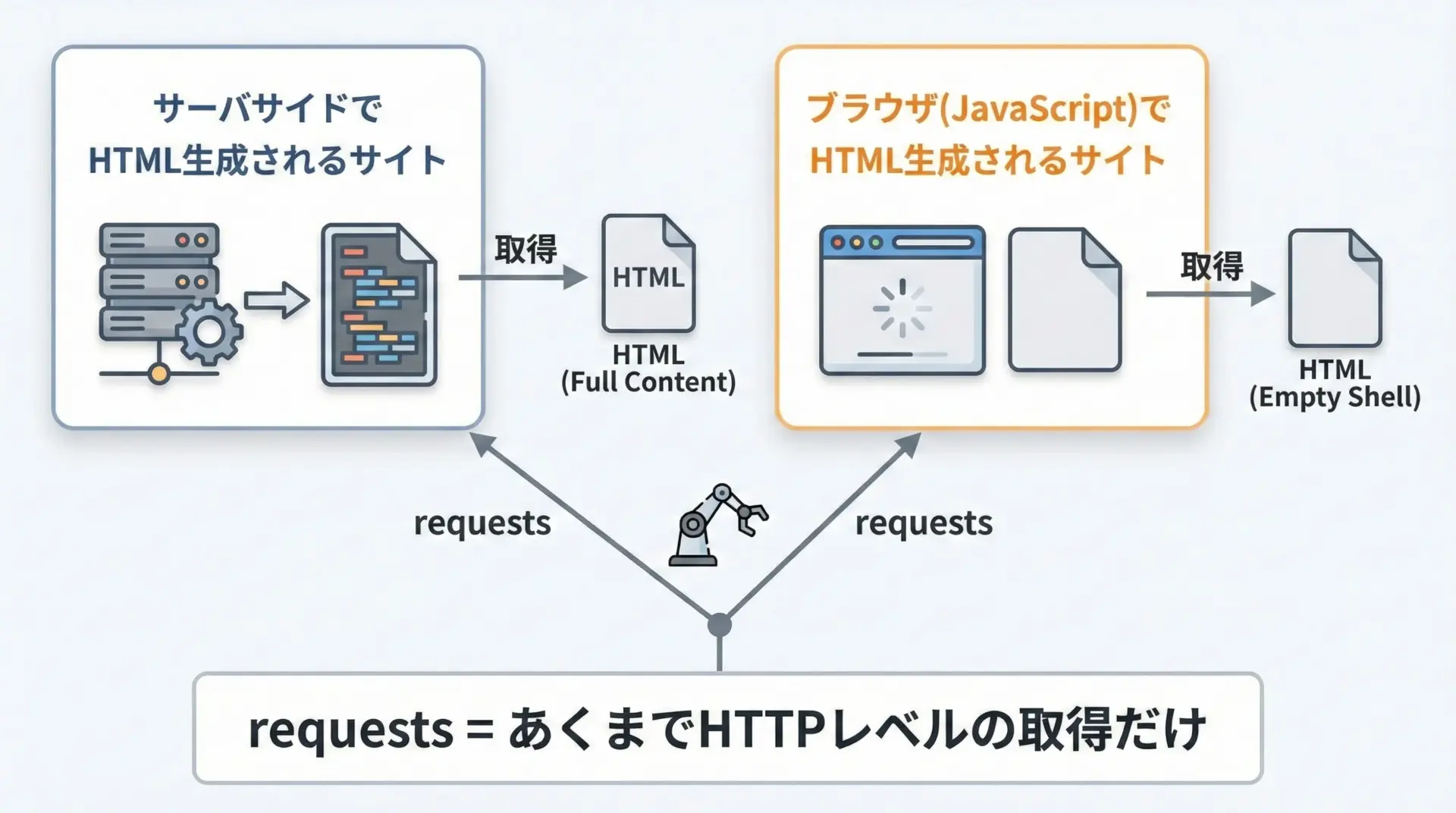
requestsは非常に便利ですが、「HTTPで取得できる生のレスポンス」までが守備範囲です。
つまり、サーバ側で完成したHTMLが返ってくるページであれば、requestsだけで十分にスクレイピングできます。
一方で、次のようなケースではrequestsだけでは不十分になることがあります。
- HTMLは最小限で、実際の内容はJavaScriptで後から読み込まれる
- ページ表示後にAjaxで別のAPIからデータを取得している
- ボタンクリックやスクロールなど、ユーザー操作に応じて内容が変化する
このような場合、requestsで取得したHTMLには欲しい内容が含まれていないため、Seleniumなど、ブラウザを自動操作できるツールが必要になることもあります。
JavaScriptレンダリングが必要なサイトの見分け方

JavaScriptでレンダリングされるサイトかどうかは、次のような手順で見分けることができます。
まずブラウザでページを開き、見た目上のテキストがHTMLソースにあるかを確認します。
右クリックからページのソースを表示を選び、検索機能で表示されている文字列を探してみてください。
見た目には表示されているのに、ソース内にテキストが見つからない場合は、JavaScriptで後から挿入されている可能性が高いです。
次に、ブラウザの開発者ツールを開き、NetworkタブでXHRやFetchなどの通信を確認すると、ページ表示時に裏側でどのようなAPIが叩かれているかが分かります。
場合によっては、そのAPIに対してrequestsで直接アクセスできるため、ブラウザ自動操作よりも効率的にデータを取得できることがあります。
ただし、そのようなAPIへのアクセスが利用規約で許可されているかどうかは必ず確認し、ルールに従って利用する必要があります。
スクレイピングのマナーと法律面の注意
スクレイピングは技術的には容易ですが、無制限に何でもしてよいわけではありません。
ここでは、最低限押さえておくべきマナーと法律面の注意点を説明します。
robots.txtの確認とアクセス頻度の配慮
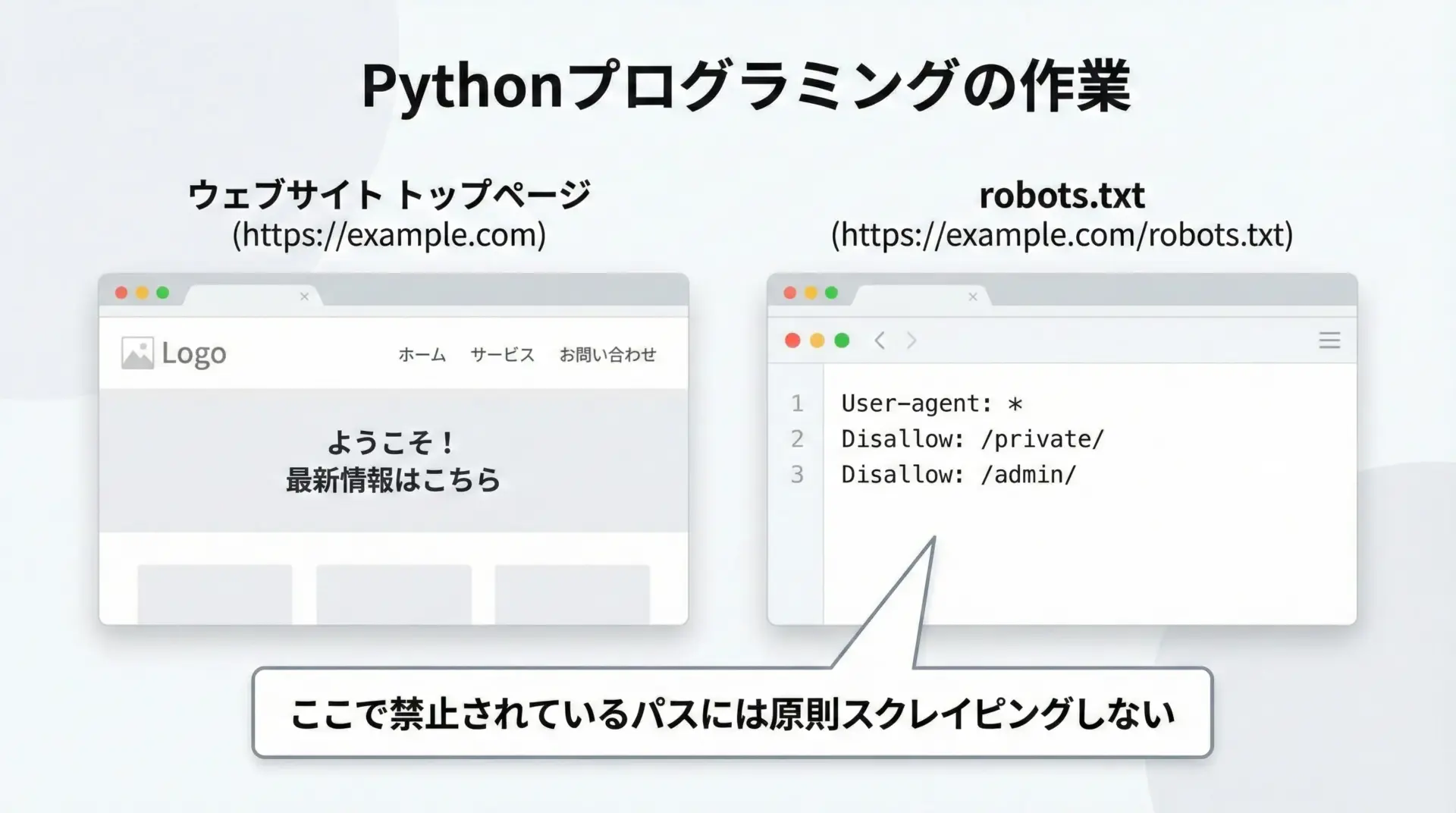
Webサイトにはrobots.txtというファイルが置かれていることがあり、クローラーやボットに対して「どのパスにアクセスしてよいか」を示しています。
たとえば、次のようなURLで確認できます。
https://example.com/robots.txtこのファイルにDisallowとして明示的に禁止されているパスについては、スクレイピングを行わないのが基本的なマナーです。
robots.txtは法的拘束力があるとは限りませんが、サイト運営者の意向を示す重要な手がかりなので、必ず確認するようにしましょう。
また、アクセス頻度についても配慮が必要です。
短時間に大量のリクエストを送ると、相手サーバに負荷をかけ、サービスに支障をきたす恐れがあります。
requestsでスクレイピングする際は、time.sleep()などを使って、リクエスト間隔を十分に空けることが望ましいです。
import time
import requests
urls = [
"https://example.com/page1",
"https://example.com/page2",
# ...
]
for url in urls:
response = requests.get(url)
print(url, "ステータスコード:", response.status_code)
# サーバ負荷軽減のため、1〜3秒程度のスリープを挟む
time.sleep(2)このように適度な間隔をあけながらリクエストを送ることで、相手側にも自分にもやさしいスクレイピングになります。
利用規約と著作権への注意ポイント
スクレイピングにおいて最も重要なのは、Webサイトの利用規約と著作権の扱いです。
多くのサイトでは、利用規約の中で自動取得や再配布に関するルールが定められています。
例えば次のような事項に注意が必要です。
- 自動取得やクローリングを禁止していないか
- 商用利用が許可されているか
- 二次利用や再配布が許可されているか
- APIが提供されており、その利用が推奨されていないか
利用規約に反するスクレイピングは、最悪の場合、法的なトラブルに発展する可能性もあります。
特に、取得したデータを第三者に提供したり、商用サービスで利用したりする場合は、専門家への相談も含め、慎重な判断が求められます。
また、Webページのテキストや画像は著作物であることが多く、その利用には著作権法上の制約があります。
個人的な学習目的での利用と、公開や再配布を伴う利用では扱いが大きく異なるため、自身の利用ケースがどこに該当するかをよく整理しておくことが大切です。
まとめ
本記事では、Pythonのrequestsを使ったスクレイピングの基本から、HTML解析の流れ、ヘッダー設定やタイムアウトなどの実践的なテクニック、さらに動的ページへの対応やマナー・法律面の注意点までを解説しました。
最小コードでまず動かし、その後にBeautifulSoupでの解析やエラーハンドリングを少しずつ足していくことで、無理なくステップアップできます。
実際の運用では、必ず利用規約とrobots.txtを確認し、アクセス頻度も抑えながら、健全で安全なスクレイピングを心がけてください。
