
Pythonでできることは年々広がり続けており、それを支えているのが豊富なライブラリ群です。
本記事では、2026年時点で現場・学習の両方で「実際によく使われている」Pythonライブラリをジャンル別に整理し、人気ランキングTOP50として紹介します。
さらに、初心者から中級者へステップアップするために必ず押さえておきたい必修ライブラリ10選と、用途別の選び方・学び方まで詳しく解説します。
Pythonライブラリ人気ランキングTOP50とは
Pythonライブラリ人気ランキングの選定基準
まず、本記事で扱うランキングは、単なる「GitHubスター数の順番」や「一時的なバズ」のみで選んだものではありません。
2026年の現場での利用状況や学習ニーズを意識して、次のような複数の観点から総合的に選定しています。
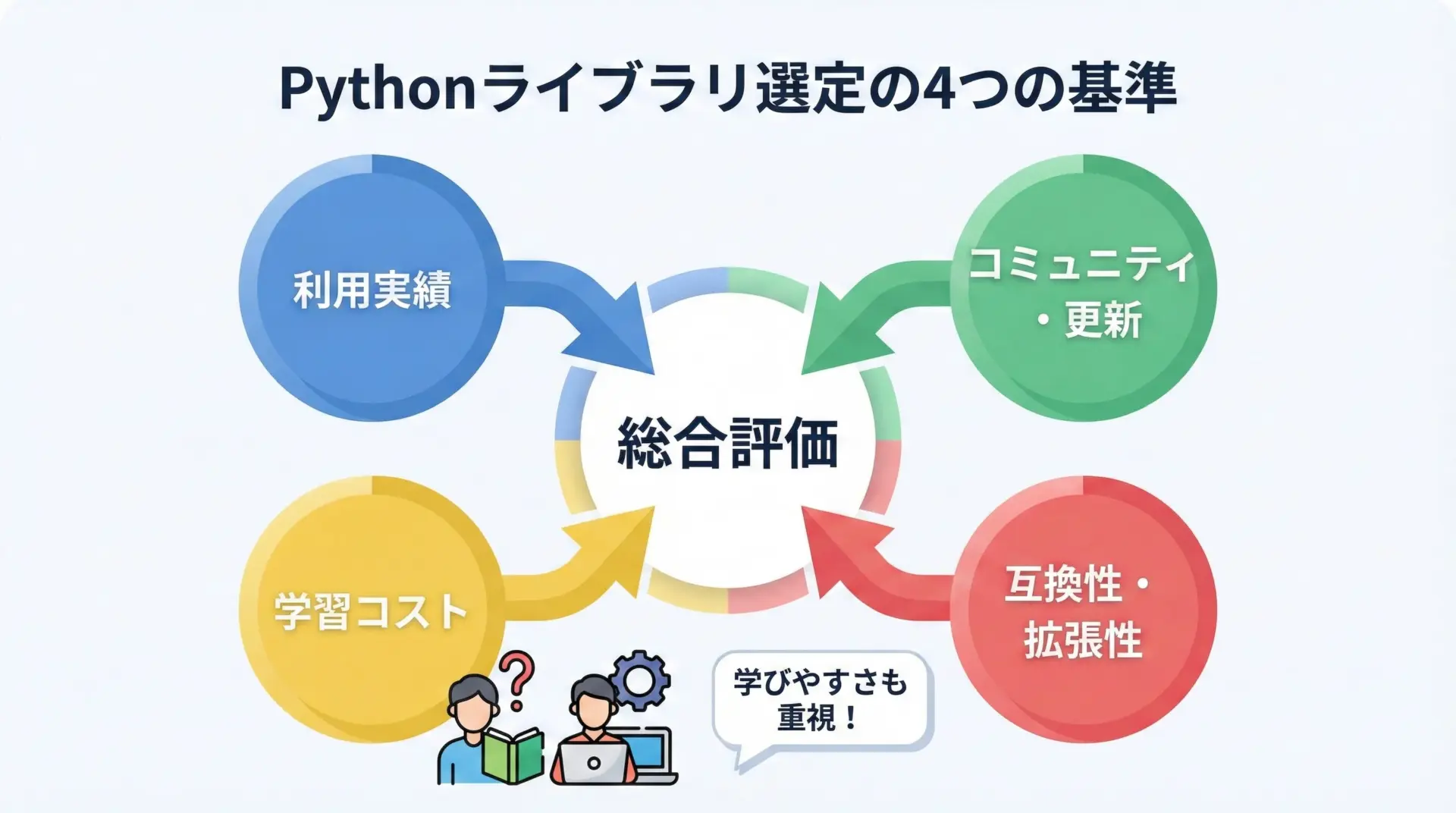
選定の主な基準は、以下の4点です。
1つ目は実務での利用実績です。
企業や研究機関などでの採用事例、求人票での記載頻度、技術ブログやカンファレンスでの登場回数などを参考に、単に理論的に優れているだけでなく、本当に使われているかどうかを重視しています。
2つ目はコミュニティの活発さと更新頻度です。
GitHubでのIssueやPull Requestの動き、最近のリリース状況、ドキュメントの整備度合いなどから、今後も継続的に使い続けられるかを評価しています。
3つ目は学習コストとドキュメントのわかりやすさです。
初心者や独学の方でもキャッチアップしやすいように、チュートリアルやサンプルコードが豊富なライブラリを優先しています。
同じ用途のライブラリが複数ある場合、より学びやすいものをランキングに含めています。
4つ目はエコシステムとの互換性・拡張性です。
NumPy・Pandas・scikit-learnなどの定番ライブラリと相性が良いか、他のツールと連携しやすいか、APIが標準的かどうかといった点も重要な判断材料としています。
このように、本ランキングは「2026年以降も安心して使い続けられそうか」という視点を強く意識している点が特徴です。
2026年版Pythonライブラリ動向の特徴
2026年時点でのPythonライブラリの動向には、いくつかはっきりしたトレンドが見られます。
1つ目はAI・機械学習ライブラリの統合と軽量化です。
従来はTensorFlowやPyTorchなどの巨大なフレームワークが中心でしたが、最近では軽量な推論向けライブラリや、高レベルAPIで簡潔に扱えるラッパー系ライブラリが増えています。
また、ONNXや専用ランタイムを使ったマルチプラットフォーム対応も進み、学習と推論を分けて考えることが一般的になってきました。
2つ目はデータ分析と可視化の一体化です。
Pandasを中心に、可視化やダッシュボード生成まで一気通貫で行えるツールが人気を集めています。
PlotlyやAltair、Streamlitなどのライブラリが、データ分析〜簡易Webアプリ化をスムーズにつなげてくれます。
3つ目は自動化・スクレイピング・RPA系ライブラリの利用増加です。
SaaS連携やNo-Code/Low-Codeと組み合わせた業務自動化のニーズが高まり、ブラウザ操作を自動化するPlaywright、API連携を簡素化するHTTPクライアント系ライブラリへの注目が強まっています。
4つ目はMLOps・インフラ系ライブラリの成長です。
DockerやKubernetesなどのコンテナ・オーケストレーション環境と連携するPythonツールや、MLflow・DVCなどの実験管理・データバージョン管理系ライブラリの利用が広がっています。
これは、機械学習がPoCにとどまらず、本番運用フェーズに移行していることの表れでもあります。
初心者と中級者で人気が分かれるポイント
Pythonライブラリの人気は、学習段階によっても大きく異なります。
特に初心者と中級者では「何を便利と感じるか」が変わってくる点を意識しておくと、自分に合ったライブラリ選びがしやすくなります。
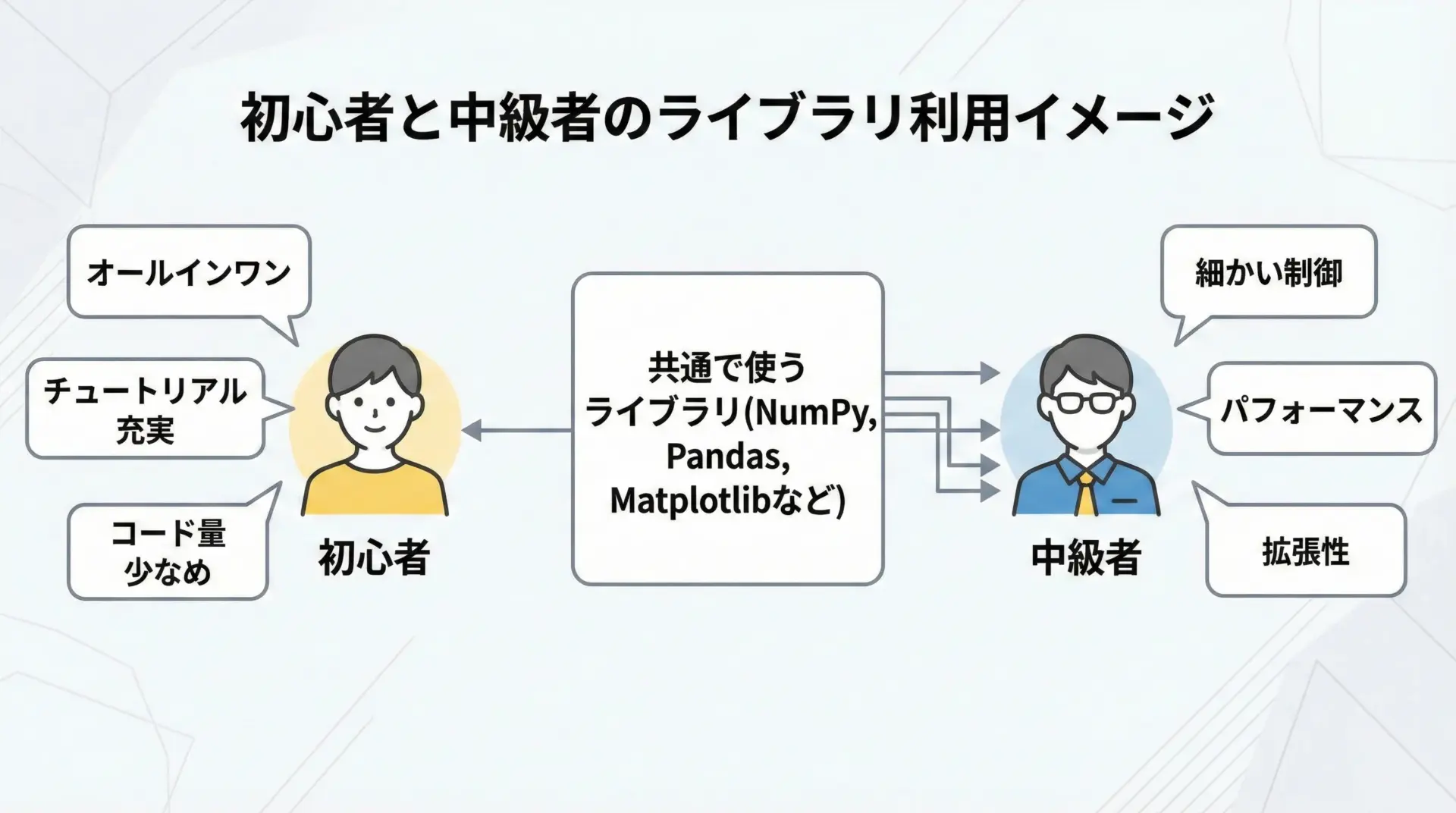
初心者の方は、1つ導入すると一通りのことができる高レベルなオールインワン系ライブラリや、公式ドキュメント・解説記事が豊富なものを好む傾向があります。
たとえば、機械学習ならscikit-learn、WebアプリならDjangoやStreamlitといった「考えることを減らしてくれる」ライブラリが人気です。
一方で中級者以上になると、処理の一部だけを差し替えたり、低レベルAPIも活用してカスタムしたりする場面が増えてきます。
そのため細かい制御が効くライブラリや、小粒ながらピンポイントで強いユーティリティ系ライブラリが好まれます。
たとえば、FastAPIで非同期処理を駆使したAPIサーバを構築したり、Pydanticで厳密なスキーマバリデーションを行ったりといった使い方です。
本記事では、この違いを踏まえながら、初心者にも中級者にも役立つバランスの良いライブラリを中心にラインナップしています。
2026年版Pythonライブラリ人気ランキングTOP50
ここからは、2026年時点で特に人気・利用頻度の高いPythonライブラリを、分野別に紹介していきます。
分野ごとにランキング形式で整理することで、自分の興味がある領域から効率よく学べるように構成しています。
データ分析系Pythonライブラリ人気ランキング
データ分析では、表形式データの処理から時系列解析、大規模データ対応まで幅広いニーズがあります。
ここでは、2026年時点でも定番として使われ続けているライブラリを中心に紹介します。

主なランキングは次の通りです。
- Pandas
- NumPy
- Polars
- Dask
- PySpark
- SQLAlchemy
- DuckDB (Pythonバインディング)
1位のPandasは、2026年においても事実上の標準データ分析ライブラリとして君臨しています。
表形式データの読み込み、加工、集計、結合など、多くの処理を一貫して提供し、学習教材やQiita・Zennなどの記事も豊富です。
NumPyはPandasの基盤となる数値計算ライブラリであり、多次元配列と高速なベクトル演算を提供します。
配列志向の処理や、機械学習モデルへのデータ投入時などにも頻繁に利用されます。
近年注目度が高いのがPolarsです。
これは列指向のデータフレームライブラリで、Rustで実装されており、高速なクエリ処理と低メモリ消費が特徴です。
「Pandasよりも高速な代替」として注目されていますが、API互換性の観点から、Pandasと併用されるケースも多くなっています。
さらに、大規模データを扱う場合にはDaskやPySparkが選択肢になります。
DaskはPandas互換のインターフェースで分散処理を提供するライブラリであり、ローカル環境からクラスタまでスケールさせやすい点が魅力です。
SQLAlchemyやDuckDBは、データベースやSQLとの連携を強力にするライブラリです。
SQLAlchemyはORMやクエリ構築を行うための標準的な選択肢であり、DuckDBは「組み込み向け分析用DB」として、Pandasとの親和性が高い点から人気を集めています。
機械学習系Pythonライブラリ人気ランキング
機械学習分野では、フレームワーク自体の成熟に加え、その周辺を支えるツールも含めてエコシステムとしての充実が進んでいます。

2026年時点での人気ランキングはおおよそ次のようになります。
- scikit-learn
- PyTorch
- TensorFlow / Keras
- XGBoost
- LightGBM
- CatBoost
- Optuna
- MLflow
scikit-learnは、教師あり・教師なし学習の基本アルゴリズムを幅広くカバーし、「機械学習を学ぶならまずこれ」と言える存在です。
シンプルなAPIで、学習・予測・評価まで一貫して行えることから、今も変わらず人気を維持しています。
深層学習フレームワークとしてはPyTorchが優勢で、研究コミュニティのみならず実務でも多く利用されています。
動的計算グラフやPythonらしい書き心地が支持されており、ライブラリ・モデルの公開もPyTorch前提が増えています。
TensorFlow / Kerasも依然として強力で、企業システムとの統合やモバイル・エッジ向けのエコシステムが充実している点が評価されています。
表形式データのコンペや実務では、XGBoost・LightGBM・CatBoostといったブースティング系ライブラリの人気が高い状態が続いています。
これらは少ない特徴量エンジニアリングでも高い精度を出しやすいことから、ビジネス用途でも多用されています。
OptunaやMLflowのように、ハイパーパラメータチューニングや実験管理を支援するライブラリも、機械学習の本番運用が一般的になるにつれて重要度を増しています。
Web開発系Pythonライブラリ人気ランキング
Web開発の分野では、フルスタックフレームワークから軽量APIフレームワーク、非同期対応ライブラリまで、用途に応じた選択肢が豊富に存在します。

主なランキングは次の通りです。
- Django
- FastAPI
- Flask
- Streamlit
- Starlette
- SQLAlchemy (Webアプリの永続化として)
Djangoは、フルスタックWebフレームワークの定番として、多くのWebサービスで採用されています。
認証機構や管理画面、ORMなど、多くの機能が同梱されており、設定さえ行えば素早く本格的なWebアプリケーションを構築できます。
FastAPIは、近年急速に人気を伸ばした高性能なAPIフレームワークです。
型ヒントを活用した自動ドキュメント生成、高速な非同期処理、シンプルな記法により、「機械学習モデルのAPI化」や「マイクロサービス用のバックエンド」として多く使われています。
Flaskはミニマルな設計の軽量フレームワークであり、1ファイルから始められる手軽さが魅力です。
拡張機能も豊富で、必要な機能だけを選んで組み合わせていくスタイルが好まれます。
StreamlitはWebフレームワークというより、データアプリ・ダッシュボード作成専用のフレームワークとして高い人気を誇ります。
Pythonコードを書く感覚でインタラクティブなWeb画面を構築できるため、データサイエンティストやアナリストにとって非常に使いやすい選択肢です。
自然言語処理系Pythonライブラリ人気ランキング
自然言語処理(NLP)分野は、トランスフォーマーモデルと大規模言語モデル(LLM)の登場により急激に様変わりしました。
2026年時点では、これらを簡便に扱うための高レベルなライブラリが人気です。
主なランキングは次のようになります。
- Hugging Face Transformers
- spaCy
- NLTK
- Sentence Transformers
- fugashi / MeCab-python3(日本語形態素解析)
- OpenAI・AnthropicなどLLM API用クライアントライブラリ
Transformersは、BERTやGPT系など、数多くの事前学習済みモデルを統一的なAPIで扱えるライブラリです。
「事前学習済みモデルをダウンロードして少し微調整するだけで高い性能が出せる」ことが、多くの開発者を引きつけています。
spaCyは、高性能な形態素解析・固有表現抽出などを提供する実務向けNLPライブラリです。
パイプラインの設計が洗練されており、大規模テキスト処理でも高速に動作します。
NLTKは教育・研究向けに歴史のあるライブラリで、コーパスや教材としての価値が今でも高いと言えます。
Sentence Transformersは、文ベクトル・埋め込み生成に特化したライブラリで、類似検索や意味検索といった用途にしばしば利用されます。
日本語処理ではfugashiやMeCab系のバインディングが、形態素解析基盤として広く使われています。
データ可視化系Pythonライブラリ人気ランキング
データ可視化では、シンプルな静的グラフからインタラクティブなWebベースの可視化まで、目的に応じて使い分けることが重要です。
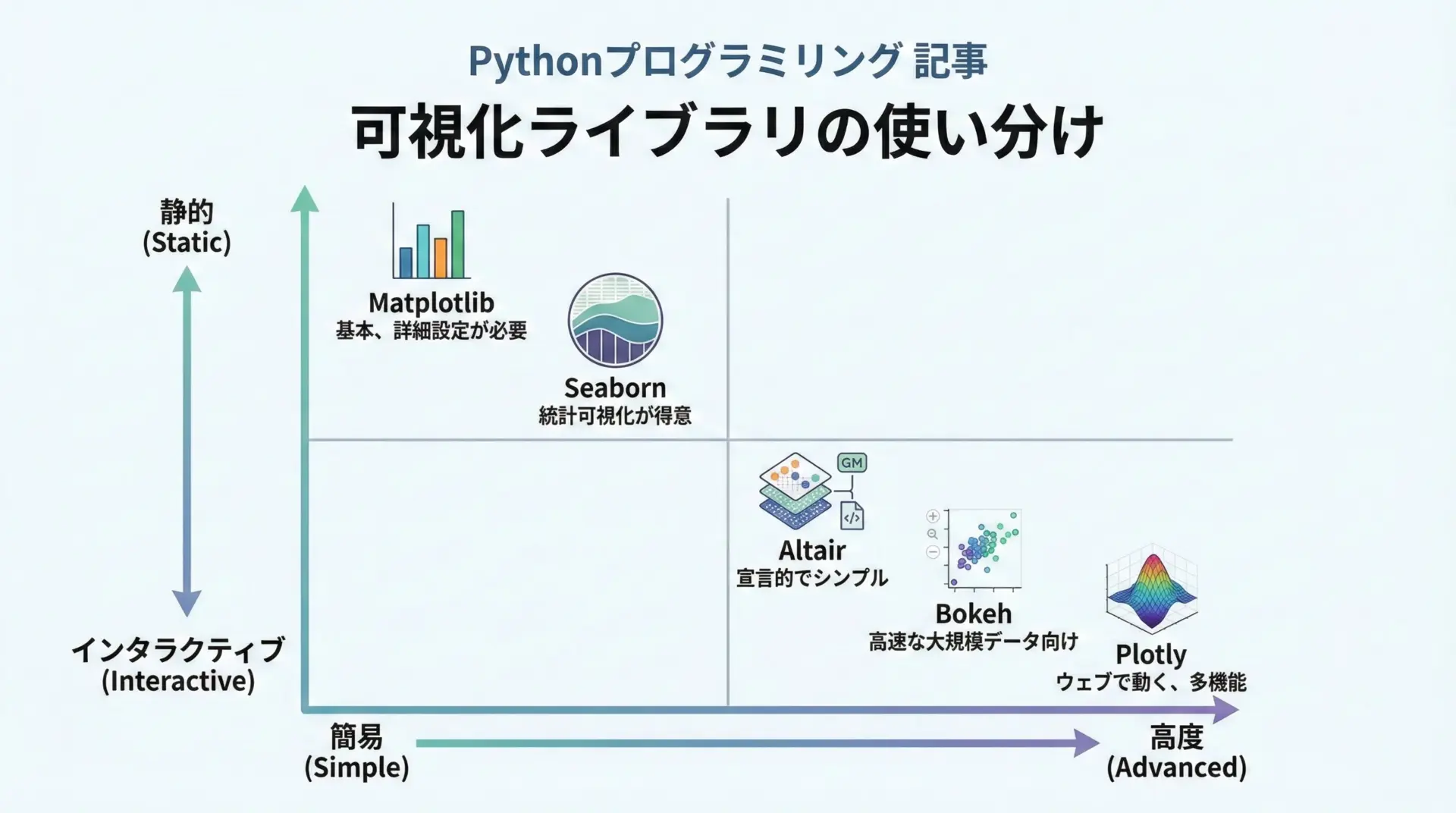
人気ランキングは次のようになります。
- Matplotlib
- Seaborn
- Plotly
- Altair
- Bokeh
Matplotlibは、Pythonの標準的な描画ライブラリとして、ほぼすべての可視化の土台となっています。
細かいカスタマイズが可能で、研究用途からレポート作成まで広く使われますが、その分コードがやや冗長になりがちです。
Seabornは、Matplotlibをベースにした高レベルな統計可視化ライブラリで、少ないコードで美しいグラフを描けることから、データ分析の初期段階で特に重宝されます。
PandasのDataFrameと相性が良い点も評価されています。
PlotlyやBokehは、インタラクティブなグラフ描画を得意とし、Webブラウザ上でズーム・ホバー・フィルタリングなどを行えます。
ダッシュボード用途ではPlotlyとDashの組み合わせが多く見られます。
Altairは宣言的なスタイルでグラフを定義するライブラリで、コードの見通しが良いことから学習用途にも適しています。
自動化・スクレイピング系Pythonライブラリ人気ランキング
自動化やスクレイピングの領域では、HTTPリクエストからHTML解析、ブラウザ操作、ファイル処理などを組み合わせることが多くなります。
ランキングの一例は次の通りです。
- requests
- httpx
- Beautiful Soup 4
- lxml
- Selenium
- Playwright
- PyAutoGUI
requestsは、PythonでHTTP通信を行う際の事実上の標準ライブラリとして長年使われています。
シンプルなAPIで、REST APIとの連携やWebページの取得などを簡単に行えます。
httpxは非同期対応やHTTP/2などに対応した新しめのHTTPクライアントで、FastAPIなどと相性が良く、人気が高まっています。
Beautiful Soup 4はHTMLやXMLをパースし、必要な要素を抽出するためのライブラリです。
requestsと組み合わせることで、基本的なWebスクレイピングを実現できます。
lxmlは高速・高機能なパーサとして、より大規模な解析やXPathを使った高度な抽出に利用されます。
ブラウザ自体を操作する場合には、SeleniumやPlaywrightが選択肢になります。
Seleniumは歴史が長く、多くの実績がある一方、Playwrightはより新しい設計でマルチブラウザサポートや高速な動作が特徴です。
デスクトップアプリの自動操作にはPyAutoGUIが利用されることもあります。
インフラ・MLOps系Pythonライブラリ人気ランキング
インフラ・MLOpsの文脈では、コンテナ・クラウド・CI/CD・実験管理・データバージョン管理など、多岐にわたるツールが存在します。
代表的なライブラリは次の通りです。
- MLflow
- DVC(Data Version Control)
- Docker SDK for Python
- prefect / Airflow(ワークフロー管理)
- kubernetes Python client
MLflowは、機械学習実験の記録・モデル管理・デプロイ支援を行うMLOpsプラットフォームで、Pythonクライアントを通じてログやパラメータの記録を簡単に行えます。
「どの実験でどんなパラメータを使い、どの結果が良かったのか」を可視化できるため、チーム開発にも欠かせません。
DVCはGitと連携してデータやモデルのバージョン管理を行うツールで、大容量ファイルを効果的に扱うことができます。
DockerやKubernetesのクライアントライブラリは、コンテナの制御やクラスタ上でのジョブ実行をPythonから自動化する際に利用されます。
Airflowやprefectはワークフローエンジンとして、ETLやバッチ処理のスケジューリング・監視を行うための重要な選択肢となっています。
科学技術・数値計算系Pythonライブラリ人気ランキング
科学技術計算の分野でもPythonは広く利用されており、シミュレーションや最適化、信号処理などに多くのライブラリが活用されています。
主なライブラリは以下の通りです。
- SciPy
- NumPy
- SymPy
- CuPy
- JAX
SciPyは、最適化・統計・信号処理・線形代数など、多くの数値計算アルゴリズムをまとめたライブラリであり、NumPyと組み合わせて使用することが一般的です。
「FortranやCで書かれた高速な数値計算ルーチンをPythonから利用できる」点が大きな魅力です。
SymPyは記号計算を扱うライブラリで、微積分・方程式の解法・式の簡約などを行えます。
数式をシンボルとして扱えるため、教育・研究分野で利用されます。
CuPyやJAXはGPUを利用した高速計算を可能にするライブラリであり、大規模数値計算や機械学習の研究用途で注目されています。
Python必修ライブラリ10選
ここからは、分野を超えて「Pythonを本気で使うなら必ず触れておきたい」ライブラリを10個に絞って紹介します。
学習順序や組み合わせの観点も踏まえて選定しています。
まず押さえるべきPython標準ライブラリと周辺ツール
Pythonには、追加インストール不要で使える標準ライブラリが多数含まれています。
これらを有効活用することで、外部ライブラリに頼らずとも多くの処理を実現できます。
特に押さえておきたい標準ライブラリ・周辺ツールとしては、次のようなものがあります。
- pathlib(ファイル・ディレクトリ操作)
- datetime(日付・時刻処理)
- json(JSONの読み書き)
- logging(ログ出力)
- argparse(コマンドライン引数処理)
- venv / pip(仮想環境・パッケージ管理)
これらを組み合わせるだけで、簡単な自動化スクリプトやユーティリティツールを作成できます。
サンプル: pathlibとdatetimeを組み合わせた簡単なログファイル作成
from pathlib import Path
from datetime import datetime
def write_log(message: str) -> None:
"""日付付きの簡単なログファイルを書き出す関数"""
# ログディレクトリを作成(存在しない場合のみ)
log_dir = Path("logs")
log_dir.mkdir(exist_ok=True)
# 今日の日付を使ってログファイル名を決める
today = datetime.now().strftime("%Y-%m-%d")
log_file = log_dir / f"{today}.log"
# 時刻付きでメッセージを追記する
timestamp = datetime.now().strftime("%H:%M:%S")
with log_file.open("a", encoding="utf-8") as f:
f.write(f"[{timestamp}] {message}\n")
if __name__ == "__main__":
write_log("Python標準ライブラリでログを書きました。")上記のようなコードは、小さな自動化スクリプトやバッチ処理でも頻繁に登場します。
まずは標準ライブラリだけで、どこまでできるかを意識してみると良いでしょう。
データ分析に必修のPythonライブラリ10選
データ分析を行うなら、次のライブラリは必修レベルと言えます。
- NumPy
- Pandas
- Matplotlib
- Seaborn
- Polars
- SQLAlchemy
- DuckDB
- scikit-learn(機械学習との橋渡しとして)
- Jupyter Notebook / JupyterLab(ツールですが実質必修)
- PyArrow(データフォーマットの橋渡しとして)
特にPandas・NumPy・Matplotlibの3つは、統計・機械学習・可視化など、どの分野に進んでも役に立ちます。
サンプル: PandasとSeabornを使ったシンプルなデータ分析
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# サンプルデータを作成(本来はCSV読み込みなど)
data = {
"age": [23, 31, 45, 52, 36, 40, 28],
"salary": [320, 450, 600, 720, 500, 580, 380],
"department": ["Sales", "HR", "Engineering", "Engineering", "Sales", "HR", "Sales"],
}
df = pd.DataFrame(data)
# 部署ごとの平均給与を集計
grouped = df.groupby("department")["salary"].mean().reset_index()
# 集計結果を表示
print(grouped)
# Seabornで棒グラフを描画
sns.barplot(data=grouped, x="department", y="salary")
plt.title("Average Salary by Department")
plt.ylabel("Salary (thousand)")
plt.show()上記のように、Pandasでデータを加工し、Seabornで可視化する流れは、あらゆる分析の基本パターンとなります。
機械学習を始めるなら必修のPythonライブラリ
機械学習を学ぶ場合、次のライブラリを中心に習得していくとスムーズです。
- scikit-learn
- NumPy / Pandas(前節と重複)
- Matplotlib / Seaborn(評価や可視化)
- XGBoostまたはLightGBM(ブースティング系)
- PyTorchまたはTensorFlow(深層学習)
特に最初の一歩としては、scikit-learnだけで完結する小さなプロジェクトに取り組むことをおすすめします。
サンプル: scikit-learnでのシンプルな分類タスク
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# Irisデータセットを読み込み
iris = load_iris()
X = iris.data
y = iris.target
# 学習用とテスト用に分割
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# ランダムフォレスト分類器を構築
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
# 予測と精度評価
y_pred = model.predict(X_test)
acc = accuracy_score(y_test, y_pred)
print(f"Accuracy: {acc:.3f}")Accuracy: 1.000このように、scikit-learnを使えば少ないコードで一通りの機械学習フローを体験できます。
Webアプリ開発に必修のPythonライブラリ
WebアプリをPythonで開発したい場合は、次のライブラリが必修となります。
- Django(フルスタックWebアプリ)
- FastAPI(APIサーバ)
- Flask(軽量Webフレームワーク)
- SQLAlchemy(データベース永続化)
- Jinja2(テンプレートエンジン)
まずはFlaskやFastAPIで小さなAPIサーバを立ち上げてみると、HTTPの仕組みやルーティングなどの基本が理解しやすくなります。
サンプル: FastAPIでのシンプルなAPIサーバ
from fastapi import FastAPI
# FastAPIアプリケーションのインスタンスを作成
app = FastAPI()
# ルートパス(/)へのGETリクエストを処理するエンドポイント
@app.get("/")
def read_root():
return {"message": "Hello, FastAPI!"}
# パラメータ付きのエンドポイント
@app.get("/items/{item_id}")
def read_item(item_id: int, q: str | None = None):
"""
- item_id: パスパラメータとして受け取る整数
- q: クエリパラメータ(任意)
"""
return {"item_id": item_id, "q": q}上のコードを実行し、ブラウザでhttp://127.0.0.1:8000/docsにアクセスすると、自動生成されたAPIドキュメントを確認できます。
これがFastAPIの大きな魅力の1つです。
自動化・業務効率化に必修のPythonライブラリ
業務効率化やRPA的な用途では、次のライブラリを押さえておくと幅広い自動化が可能になります。
- requests(API・Webアクセス)
- Beautiful Soup 4(HTML解析)
- Selenium / Playwright(ブラウザ操作)
- openpyxl / pandas(Excel操作)
- schedule / APScheduler(スケジューリング)
サンプル: requestsとBeautiful Soupを使った簡単スクレイピング
import requests
from bs4 import BeautifulSoup
def fetch_page_title(url: str) -> str | None:
"""指定URLのページタイトルを取得する簡単な関数"""
# Webページを取得
response = requests.get(url, timeout=10)
response.raise_for_status() # エラー時は例外を発生させる
# HTMLを解析
soup = BeautifulSoup(response.text, "html.parser")
# <title>タグのテキストを取得
title_tag = soup.find("title")
return title_tag.text.strip() if title_tag else None
if __name__ == "__main__":
url = "https://www.python.org/"
title = fetch_page_title(url)
print(f"Title: {title}")このようなコードをベースに、複数ページの巡回やExcel出力、メール通知などを組み合わせることで、実用的な業務自動化ツールを作ることができます。
Pythonライブラリの選び方と学び方
最後に、数多く存在するPythonライブラリの中から、どのように選び、どのような順番で学んでいけば良いかを整理します。
用途別にPythonライブラリを選ぶポイント
Pythonライブラリ選びでもっとも大切なのは、「自分が何をしたいのか」を先に明確にすることです。
目的がはっきりしていれば、選ぶべきライブラリも自然と絞り込まれていきます。
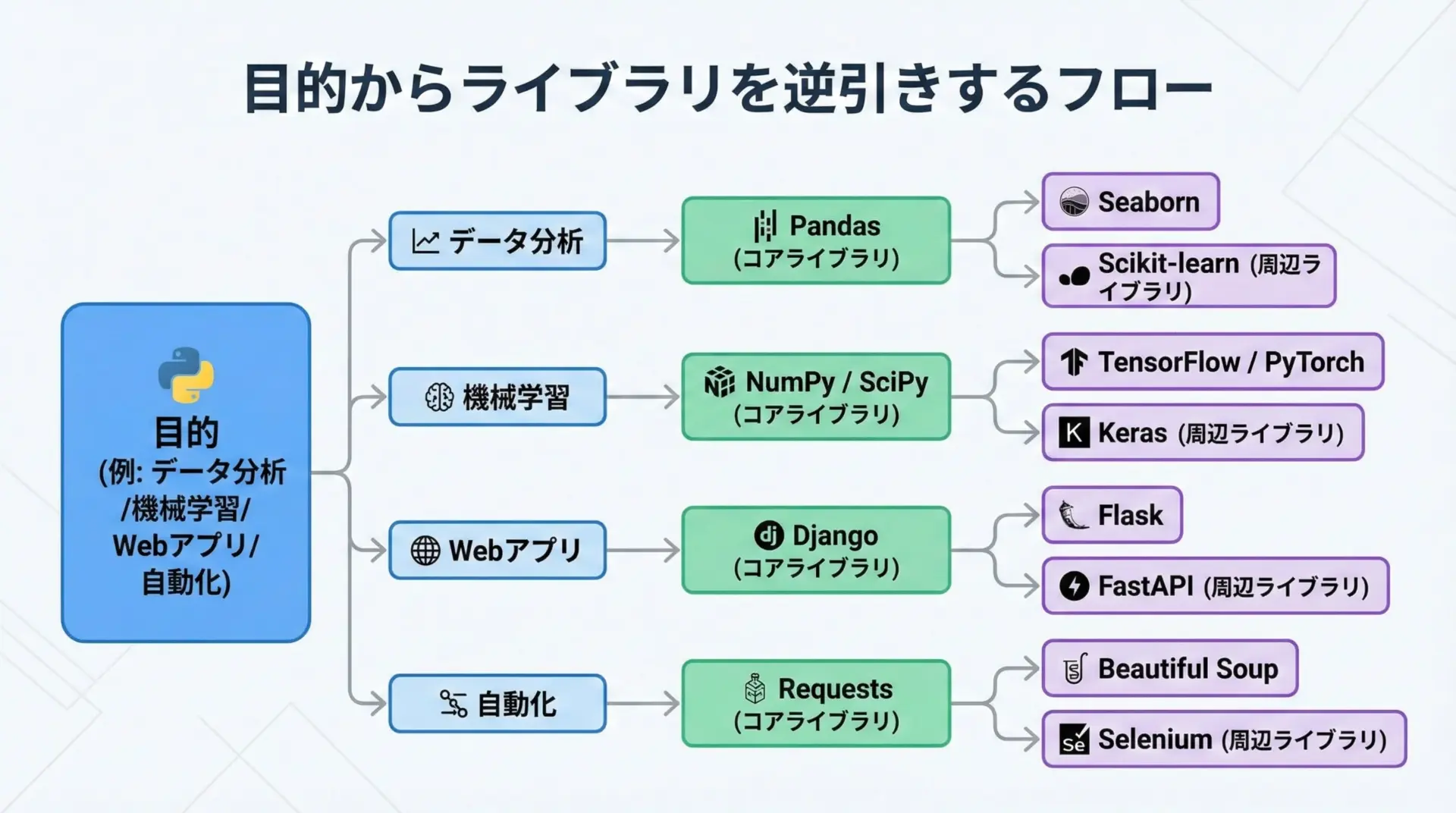
例えばデータ分析が目的であれば、まずPandasとNumPy、その次にSeabornやMatplotlibという順番で学んでいくのが自然です。
機械学習であれば、scikit-learnを起点に、必要に応じてXGBoostやPyTorchに広げていきます。
Webアプリ開発では、最初にFlaskやFastAPIで小さなサービスを作ってみて、より本格的なフレームワークが必要になったタイミングでDjangoに取り組むと、理解がスムーズになります。
2026年以降も使えるPythonライブラリの見極め方
ライブラリは日々生まれては消えていきます。
その中で「数年後も残っているであろうライブラリ」を選ぶことは、学習コストの観点から非常に重要です。
見極めのポイントとしては、次のような観点が挙げられます。
- GitHubリポジトリの更新頻度(直近1年でコミットがあるか)
- IssueとPull Requestのやり取りが活発かどうか
- ドキュメントや公式サイトが整備されているか
- 依存している他のライブラリが健全かどうか
- 企業や有名プロジェクトでの採用事例があるか
短期間で急激にスターが増えたライブラリは、一時的なブームの可能性もあるため、上記のポイントも併せて確認すると安心です。
また、NumPy・Pandas・scikit-learn・Djangoなど、長年使われ続けているライブラリは、今後も高い確率で生き残ると考えられます。
Pythonライブラリを効率よく学ぶステップ
効率的にライブラリを学ぶためには、「小さなプロジェクトベースで学ぶ」ことが効果的です。
学習ステップの一例として、次のような流れをおすすめします。
- 公式チュートリアルを一通りなぞり、基本的なAPIの使い方を把握する
- 自分で小さな目標を設定し(例: CSVを集計してグラフ化)、ライブラリを使って達成してみる
- エラーが出たら公式ドキュメントやStack Overflowを調べ、自力で解決する練習をする
- ある程度慣れてきたら、GitHub上のサンプルプロジェクトやチュートリアルノートブックを読む
ライブラリのドキュメントには、チュートリアル・クックブック・APIリファレンスなど、複数のレベルの情報が含まれています。
いきなりAPIリファレンスから読むのではなく、まずはチュートリアルや「Getting Started」から入ることを強くおすすめします。
人気Pythonライブラリを組み合わせた学習ロードマップ
最後に、本記事で紹介した人気ライブラリを組み合わせた学習ロードマップの一例を示します。
用途別に、自分に近いパターンを参考にしてみてください。
[図解作成の指示]
- タイトル: 「用途別Pythonライブラリ学習ロードマップ」
- 縦方向に「共通基礎」「データ分析」「機械学習」「Web開発」「自動化」の5レーン
- 横方向に時間軸(ステップ1〜4)を設定し、それぞれのレーンに「このタイミングで学ぶライブラリ名」の箱を配置
- 例: 共通基礎ステップ1に「標準ライブラリ・venv・pip」、データ分析ステップ2に「Pandas・Matplotlib」など
文章で整理すると、次のようなロードマップになります。
まずは全員共通で、Pythonの基本文法と標準ライブラリ(特にpathlib・datetime・json)を押さえ、仮想環境(venv)とpipの使い方を習得します。
その後、Jupyter Notebookを導入し、PandasとNumPyを使った簡単なデータ操作を練習します。
データ分析志向の方は、PandasとSeabornでのEDA(探索的データ分析)を繰り返し、必要に応じてSQLAlchemyやDuckDBを学びます。
機械学習志向の方は、scikit-learnで分類・回帰・クラスタリングを一通り経験した後、XGBoostやPyTorchに進むとスムーズです。
Web開発志向の方は、FlaskやFastAPIでJSON APIを作る練習を行い、その後Djangoでユーザー管理や管理画面を含む本格的なWebアプリケーションに挑戦します。
自動化志向の方は、requestsとBeautiful Soupでスクレイピングし、pandasやopenpyxlでExcelレポートを生成するといった小さなツールを量産していくと、実務に直結しやすくなります。
まとめ
2026年のPythonエコシステムは、データ分析・機械学習・Web開発・自動化・MLOpsなど、多様な分野で成熟したライブラリに支えられています。
本記事では、その中から人気ランキングTOP50を分野別に整理し、さらに必修ライブラリ10選と選び方・学び方の指針を解説しました。
重要なのは、すべてを一度に覚えようとするのではなく、目的に合った数個のライブラリから入り、小さなプロジェクトを通じて少しずつ範囲を広げていくことです。
ここで紹介したライブラリとロードマップを活用し、自分のやりたいことに最適なPython環境を育てていきましょう。
