
Pythonでのデータ分析では、グラフによる可視化が理解と意思決定の鍵になります。
本記事では、matplotlibとseabornを使って、基本グラフから実務レベルの可視化まで一気に身につけられるよう、図解とサンプルコードを交えながら丁寧に解説します。
初めての方でも手を動かしながら進められるよう構成しています。
Python×matplotlib×seabornの概要
Pythonでデータ可視化を行うメリット
Pythonで可視化を行う最大のメリットは、分析からレポート作成までをコードだけで一貫して行えることです。
ExcelやBIツールでもグラフは作成できますが、細かなカスタマイズや大量データの自動処理には限界があります。
Pythonでは、データの前処理、統計分析、機械学習、可視化を1つのノートブックやスクリプトにまとめられるため、再現性と生産性が高まります。
また、matplotlibやseabornはオープンソースであり、豊富なサンプルやドキュメントがあるため、困ったときの情報も得やすいです。
作成したグラフは、レポート用の画像として保存することはもちろん、Webアプリやダッシュボードに組み込むこともできます。
matplotlibとseabornの違いと役割
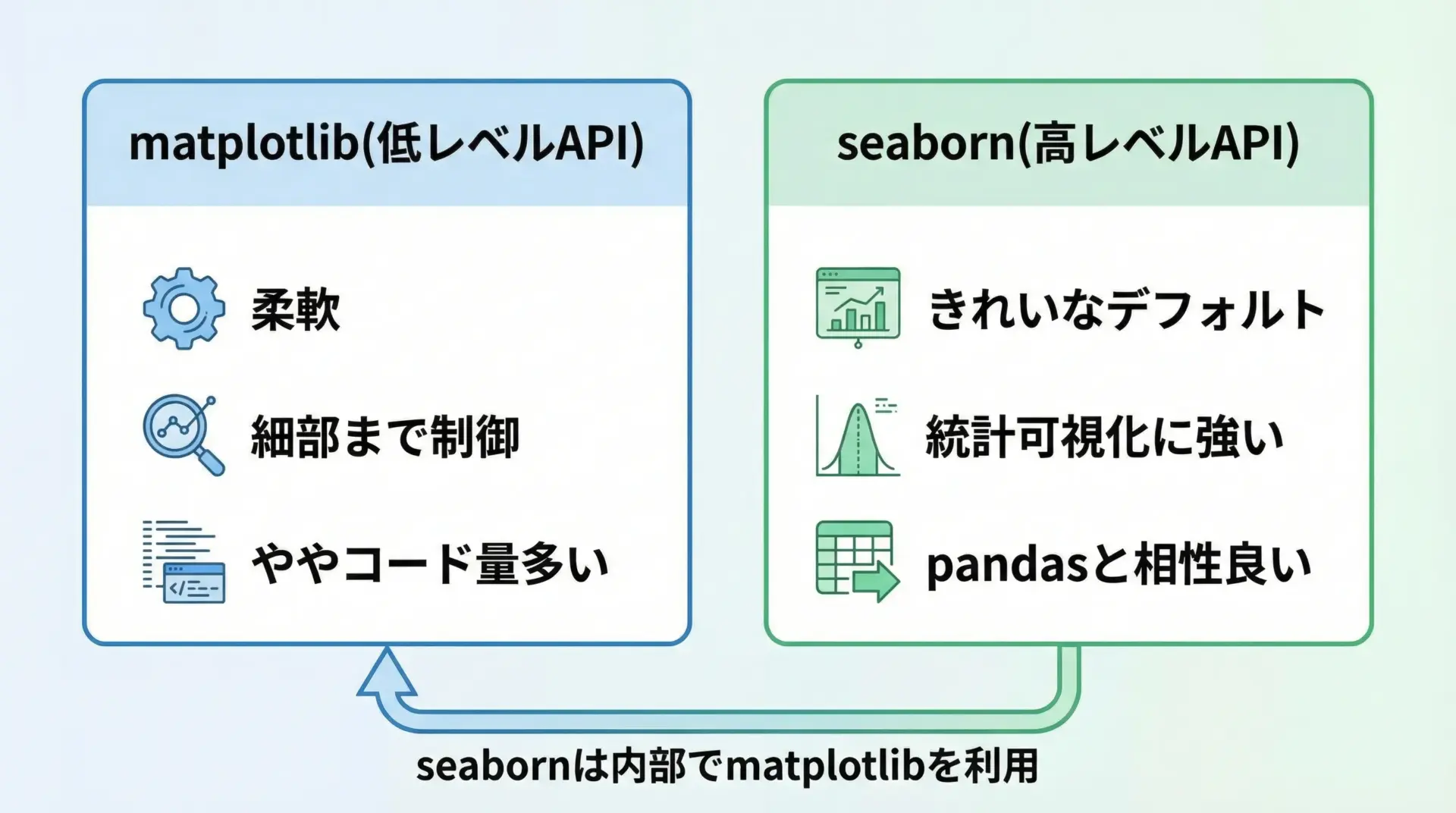
matplotlibは、Pythonにおける代表的なグラフ描画ライブラリで、「何でも描けるが、その分設定も自分で細かく行う」低レベルなAPIです。
軸や凡例、色、線種、レイアウトなどを1つ1つ指定できるため、学術論文レベルのきめ細かい図表も作成できます。
一方、seabornはmatplotlibをベースにした高レベルなラッパーライブラリで、少ないコードで「それなりにきれいで実用的なグラフ」を描くことに特化しています。
特に箱ひげ図やヒートマップ、カテゴリカルプロットなど、統計可視化に向いたグラフが充実しており、pandasのDataFrameと非常に相性が良いです。
実務では、まずseabornで素早く全体像を掴み、最終的な仕上げや細かな調整をmatplotlibで行うという使い分けがよく行われます。
環境構築とインストール方法
Pythonの可視化環境は、Anacondaを使う方法と、pipで個別にインストールする方法があります。
Anacondaでのセットアップ
Anacondaをインストールすると、Python本体に加え、pandas、numpy、matplotlib、seabornなど主要ライブラリが一括で導入されます。
データ分析をこれから本格的に始める場合はAnacondaがおすすめです。
インストール後は、Anaconda NavigatorからJupyterLabを起動し、ノートブック上で以下のように動作確認します。
import matplotlib
import seaborn as sns
print(matplotlib.__version__)
print(sns.__version__)pipでのインストール
既にPython環境がある場合は、pipでライブラリを追加できます。
pip install matplotlib seaborn pandas仮想環境(venvやpoetry、conda envなど)を使ってプロジェクトごとに環境を分けると、依存関係の衝突を避けられます。
matplotlib入門
matplotlibの基本構文とFigure・Axesの概念

matplotlibでグラフを描くときの基本構造は、Figure(図全体)とAxes(個々のグラフ領域)の2層構造で考えると理解しやすいです。
Figureはキャンバス全体、Axesはその中に配置される1枚のグラフだとイメージしてください。
最もよく使うパターンはplt.subplotsを使う書き方です。
import matplotlib.pyplot as plt
# FigureとAxesを1つずつ作成
fig, ax = plt.subplots(figsize=(6, 4)) # figsizeで図の大きさをインチ単位で指定
# Axesに対して描画命令を行う
ax.plot([1, 2, 3], [1, 4, 9]) # xとyの値を渡して折れ線グラフを描画
ax.set_title("Simple Line Plot") # タイトル設定
ax.set_xlabel("x") # x軸ラベル
ax.set_ylabel("y") # y軸ラベル
# 画面に表示
plt.show()このように、「Figureを作る → Axesを取り出す → Axesに対してplotなどのメソッドを呼ぶ」という流れが基本です。
慣れてきたら、複数のAxesを配置して、比較用のグラフを一度に表示することも簡単に行えます。
折れ線グラフ(line plot)の描き方とカスタマイズ
折れ線グラフは、時系列や連続的な変化を表現するのに最も基本的なグラフです。
まずは、シンプルな例と少しカスタマイズした例を見てみます。
import matplotlib.pyplot as plt
# サンプルデータ(月ごとの売上を想定)
months = [1, 2, 3, 4, 5, 6]
sales_a = [100, 120, 90, 150, 130, 160]
sales_b = [80, 110, 100, 120, 140, 150]
fig, ax = plt.subplots(figsize=(7, 4))
# 折れ線グラフの描画
ax.plot(
months,
sales_a,
label="Product A", # 凡例用ラベル
color="tab:blue", # 線の色
marker="o", # 点のマーカー
linestyle="-", # 実線
)
ax.plot(
months,
sales_b,
label="Product B",
color="tab:orange",
marker="s",
linestyle="--", # 破線
)
# 軸ラベルやタイトル
ax.set_title("Monthly Sales Trend")
ax.set_xlabel("Month")
ax.set_ylabel("Sales")
# グリッド線の表示
ax.grid(True, linestyle=":", alpha=0.6)
# 凡例の表示
ax.legend(loc="upper left")
plt.tight_layout()
plt.show()上記のように、折れ線グラフではcolor、marker、linestyle、labelを組み合わせることで、複数系列の比較が視覚的にわかりやすくなります。
「何を比較させたいのか」を意識したスタイル選びが重要です。
散布図(scatter plot)の描き方とスタイル設定
散布図は、2つの数値変数の関係性を調べるのに向いています。
matplotlibではax.scatterを使います。
import matplotlib.pyplot as plt
import numpy as np
# 再現性のため乱数シードを固定
np.random.seed(0)
# サンプルデータ(身長と体重を仮想的に生成)
height = np.random.normal(loc=170, scale=7, size=100)
weight = 0.6 * height + np.random.normal(loc=0, scale=5, size=100)
fig, ax = plt.subplots(figsize=(6, 4))
# 散布図を描画
scatter = ax.scatter(
height,
weight,
c=height, # カラーに身長を使ってみる
cmap="viridis", # カラーマップ
alpha=0.8, # 透明度
edgecolors="k", # 点のふちどり
)
ax.set_title("Height vs Weight")
ax.set_xlabel("Height(cm)")
ax.set_ylabel("Weight(kg)")
# カラーバーを追加して色の意味を示す
cbar = plt.colorbar(scatter, ax=ax)
cbar.set_label("Height(cm)")
plt.tight_layout()
plt.show()散布図では、色(c)、大きさ(s)、マーカー形状(marker)、透明度(alpha)を使い分けて、3〜4次元の情報を1枚の図に載せることができます。
情報を盛り込みすぎると読みづらくなるため、目的に沿って必要な要素だけを選ぶことが大切です。
棒グラフ(bar plot)・棒グラフ横向き(barh)の作成
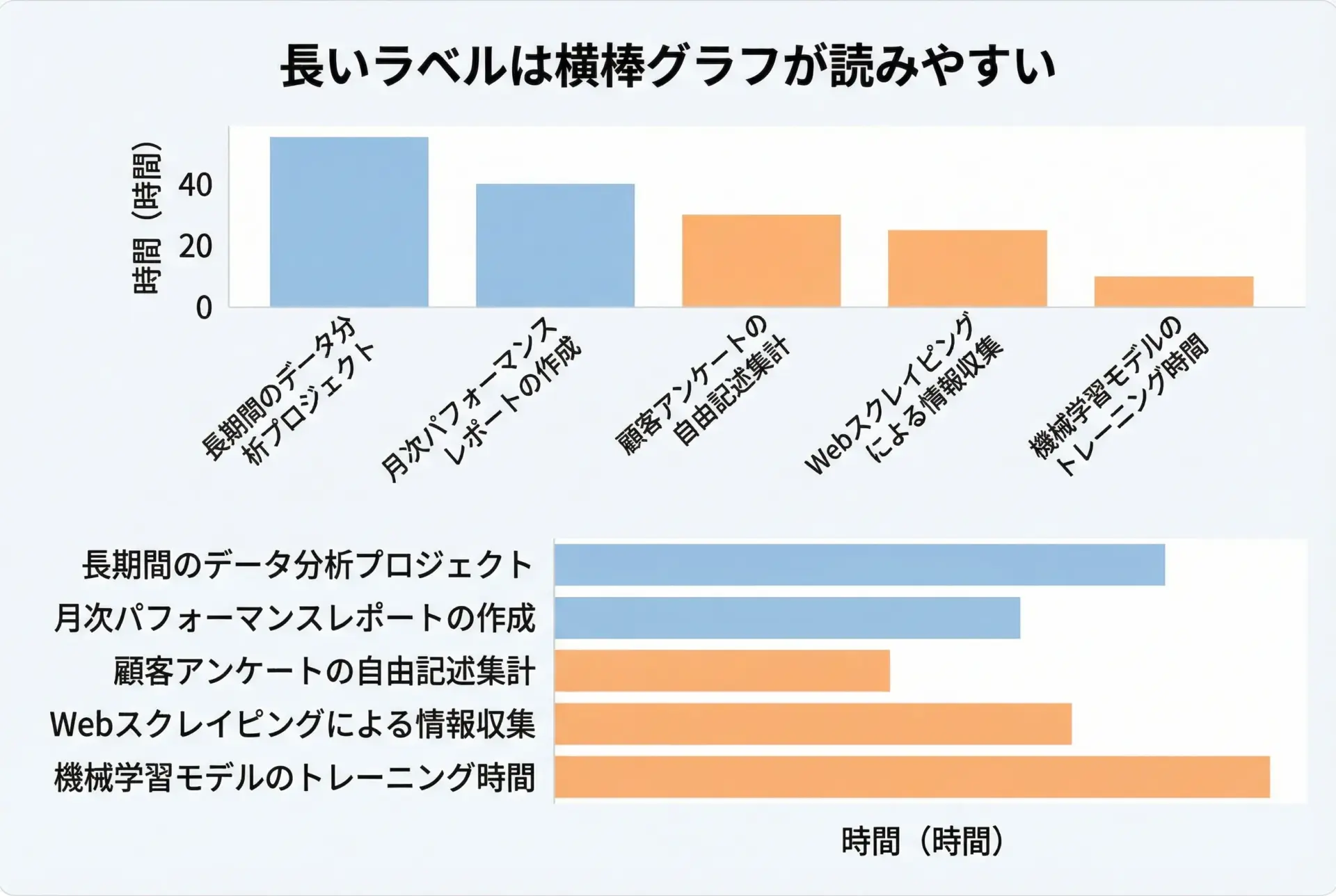
カテゴリごとの値を比較するには棒グラフが適しています。
matplotlibではbarとbarhで縦棒・横棒を描画します。
import matplotlib.pyplot as plt
# サンプルデータ(部門別売上)
departments = ["Sales", "Marketing", "Development", "HR"]
values = [350, 200, 420, 150]
fig, axes = plt.subplots(1, 2, figsize=(10, 4))
# 縦棒グラフ
axes[0].bar(departments, values, color="skyblue")
axes[0].set_title("Sales by Department (Vertical)")
axes[0].set_ylabel("Sales")
# 横棒グラフ
axes[1].barh(departments, values, color="salmon")
axes[1].set_title("Sales by Department (Horizontal)")
axes[1].set_xlabel("Sales")
plt.tight_layout()
plt.show()カテゴリ名が長くなる場合やランキングのように上下方向で比較したい場合は、横棒グラフ(barh)の方が視認性が高くなることが多いです。
棒の色や幅、境界線なども調整することで、より見やすいグラフを作れます。
ヒストグラム(histogram)・度数分布の可視化

ヒストグラムは、1つの数値変数の分布をざっくり把握するのに便利です。
matplotlibではax.histで作成します。
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(1)
data = np.random.normal(loc=0, scale=1, size=1000) # 標準正規分布のサンプル
fig, ax = plt.subplots(figsize=(6, 4))
ax.hist(
data,
bins=20, # ビンの数
color="steelblue",
edgecolor="black", # 枠線
alpha=0.8
)
ax.set_title("Histogram of Data")
ax.set_xlabel("Value")
ax.set_ylabel("Frequency")
plt.tight_layout()
plt.show()ヒストグラムではビン数(bins)の設定が見え方に大きく影響するため、いくつかの値を試してバランスを確認するのが良いです。
より滑らかな分布を見たい場合は、seabornのカーネル密度推定(KDE)を併用します(後述)。
グラフのタイトル・凡例・ラベル・フォント設定
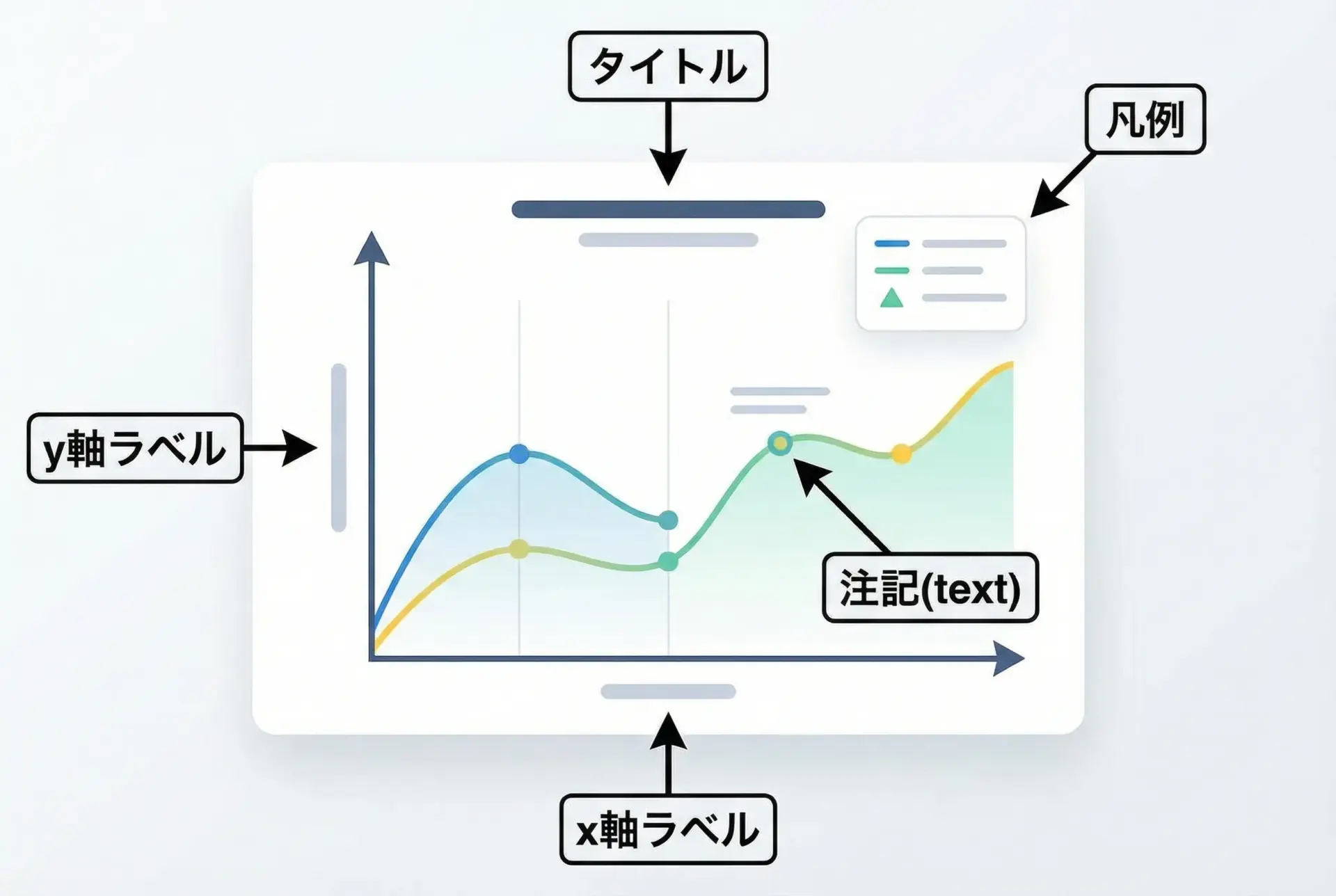
実務で共有するグラフでは、タイトルや軸ラベルなどのメタ情報が極めて重要です。
グラフ単体で見ても意味が分かるように整えましょう。
import matplotlib.pyplot as plt
x = [1, 2, 3, 4, 5]
y1 = [10, 15, 20, 25, 30]
y2 = [8, 16, 24, 32, 40]
fig, ax = plt.subplots(figsize=(6, 4))
ax.plot(x, y1, label="Plan", color="tab:blue")
ax.plot(x, y2, label="Actual", color="tab:orange")
# タイトルと軸ラベル
ax.set_title("Plan vs Actual", fontsize=14)
ax.set_xlabel("Month", fontsize=12)
ax.set_ylabel("Value", fontsize=12)
# 凡例の表示とフォントサイズ
ax.legend(loc="upper left", fontsize=10)
# メモ書き(注釈)の追加
ax.text(
1.0,
38,
"Actual exceeded Plan",
fontsize=9,
color="red"
)
plt.tight_layout()
plt.show()日本語を含むグラフを作りたい場合は、フォント設定が必要です。
これは後半の「日本語表示・フォント設定」で詳しく扱います。
seaborn入門
seabornの特徴とmatplotlibとの関係

seabornは、統計的なデータ可視化を手軽に行える高レベルライブラリです。
内部的にはmatplotlibを利用しており、描画後にmatplotlibの関数で細かい調整を行うこともできます。
特徴としては次のような点があります。
- pandasのDataFrameを前提としたAPIで、列名をそのまま指定してプロットできる
- デフォルトのテーマが整っており、コードを書かなくても見栄えの良いグラフが得られる
- 回帰直線やカテゴリ別の要約統計など、統計解析と相性の良いプロットが多数用意されている
統計可視化向きの基本API
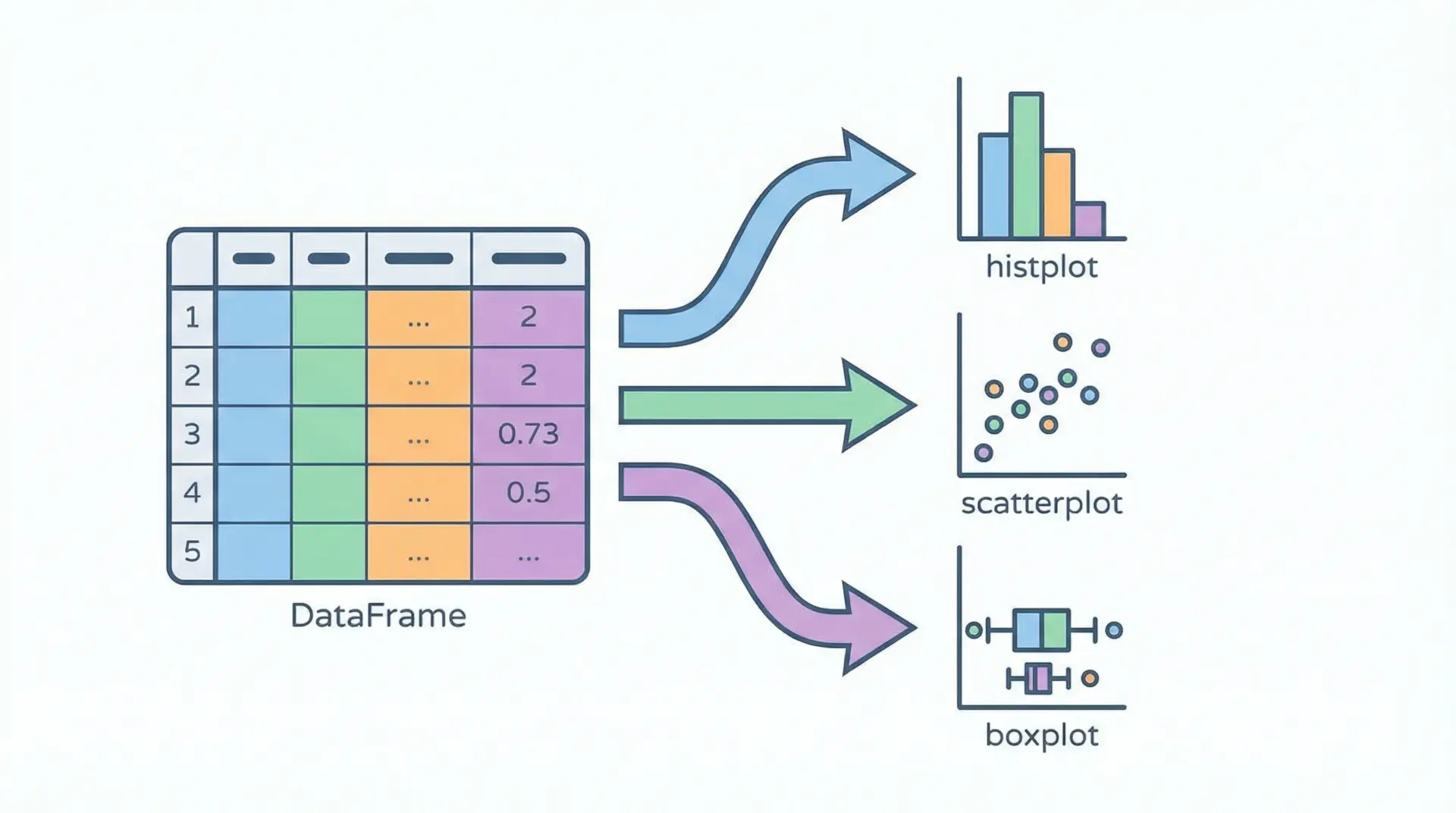
seabornには多くの関数がありますが、まずは基本的なものを把握しておくと便利です。
代表的なAPIを簡単に表にまとめます。
| 種類 | 関数名 | 概要 |
|---|---|---|
| 分布 | histplot | ヒストグラム、KDEの描画 |
| 分布 | kdeplot | カーネル密度推定の曲線 |
| 関係 | scatterplot | 散布図 |
| 関係 | lineplot | 折れ線グラフ(カテゴリ別などにも対応) |
| 関係 | regplot/lmplot | 散布図 + 回帰直線 |
| カテゴリ | boxplot | 箱ひげ図 |
| カテゴリ | violinplot | バイオリンプロット |
| カテゴリ | barplot | 平均値 + 信頼区間つき棒グラフ |
| 行列 | heatmap | ヒートマップ(相関行列など) |
| 複数 | pairplot | 変数ペアごとの散布図行列 |
これらはすべて、DataFrameと列名を渡すだけで動作するという共通点があります。
散布図と回帰直線(regplot・lmplot)の使い方
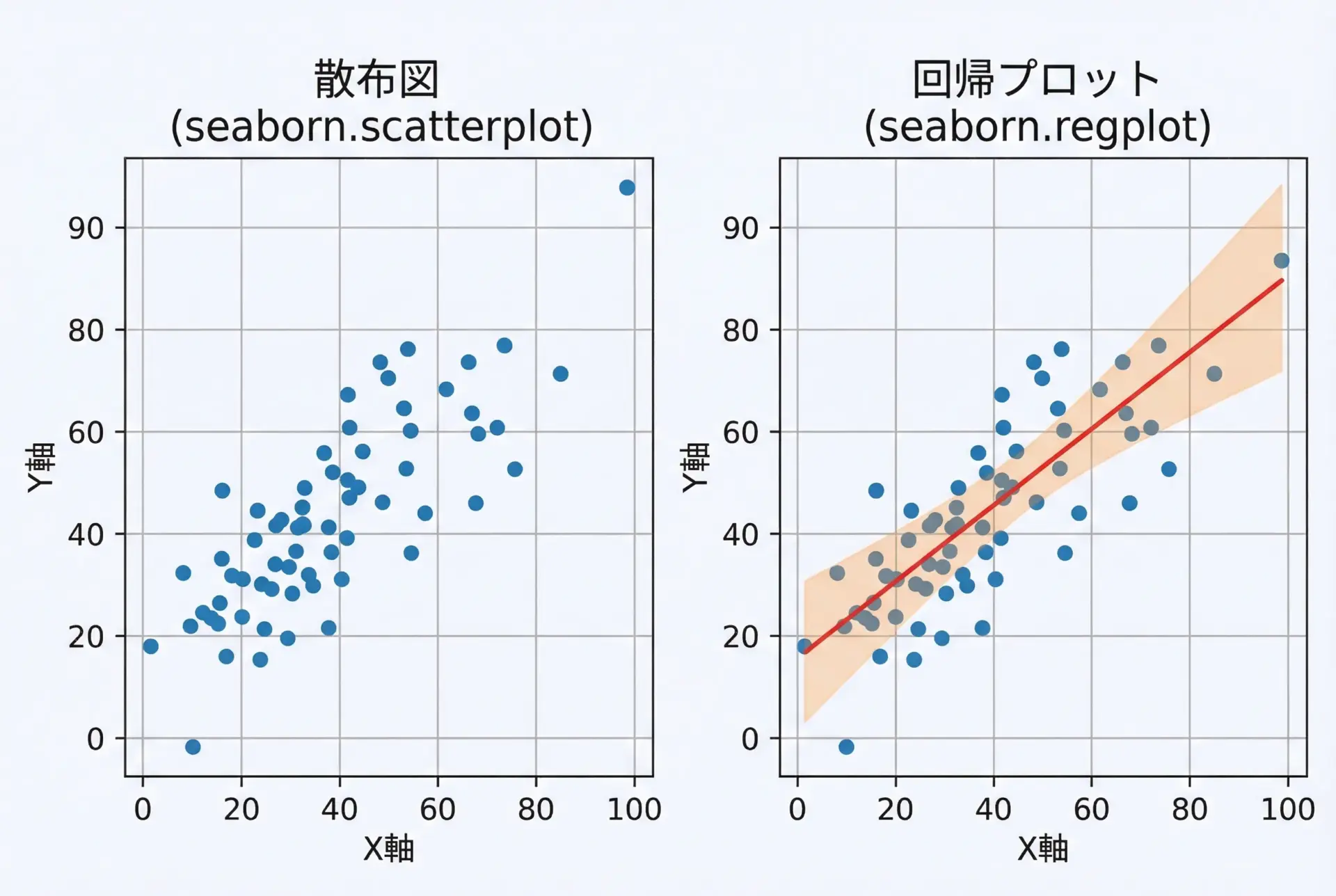
まずはサンプルデータとして、seaborn同梱のTitanicやtipsなどのデータセットを使うと便利です。
import seaborn as sns
import matplotlib.pyplot as plt
# 組み込みデータセット「tips」を読み込み
tips = sns.load_dataset("tips")
fig, axes = plt.subplots(1, 2, figsize=(10, 4))
# 単純な散布図
sns.scatterplot(
data=tips,
x="total_bill",
y="tip",
hue="time", # 昼食/夕食で色分け
style="sex", # 性別でマーカー形状を分ける
ax=axes[0]
)
axes[0].set_title("Scatterplot: total_bill vs tip")
# 回帰直線つき散布図
sns.regplot(
data=tips,
x="total_bill",
y="tip",
scatter_kws={"alpha": 0.6}, # 散布図のスタイル
line_kws={"color": "red"}, # 回帰直線のスタイル
ax=axes[1]
)
axes[1].set_title("Regplot with Regression Line")
plt.tight_layout()
plt.show()さらに、lmplotを使うと、カテゴリごとにサブプロットを分けた回帰図も簡単に描けます。
sns.lmplot(
data=tips,
x="total_bill",
y="tip",
hue="sex", # 性別ごとに回帰直線を色分け
col="time", # 昼食/夕食で列方向に分割
height=4,
aspect=1.1
)
plt.show()回帰直線を重ねることで、おおまかな傾向を直感的に把握できるようになりますが、外れ値に敏感な点にも注意が必要です。
箱ひげ図(boxplot)・バイオリンプロット

箱ひげ図は、中央値や四分位数、外れ値をコンパクトに表現できる代表的な統計グラフです。
バイオリンプロットは、箱ひげ図に分布形状の情報を追加したようなグラフです。
import seaborn as sns
import matplotlib.pyplot as plt
tips = sns.load_dataset("tips")
fig, axes = plt.subplots(1, 2, figsize=(10, 4))
# 箱ひげ図
sns.boxplot(
data=tips,
x="day",
y="total_bill",
ax=axes[0]
)
axes[0].set_title("Boxplot: total_bill by day")
# バイオリンプロット
sns.violinplot(
data=tips,
x="day",
y="total_bill",
inner="quartile", # 中央値や四分位数も描画
ax=axes[1]
)
axes[1].set_title("Violinplot: total_bill by day")
plt.tight_layout()
plt.show()データ量が多く、分布の形(歪み、裾の長さなど)も重視したい場合はバイオリンプロットが有効です。
観察数が少ない場合は、過度に滑らかな分布に見えてしまうことがあるため注意します。
カテゴリカルデータの可視化
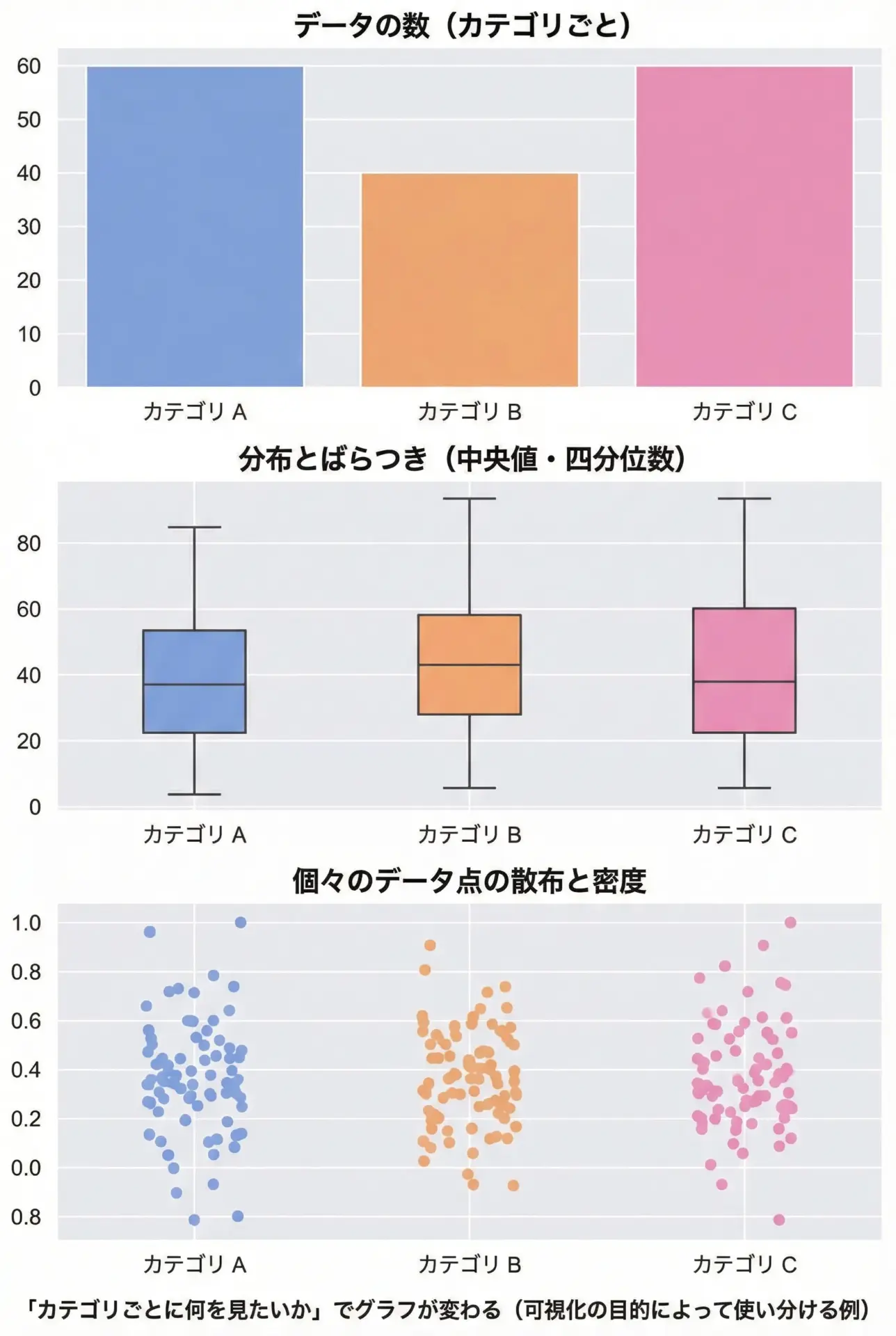
seabornはカテゴリカルデータの可視化が得意で、平均値や分布、件数などを簡潔に表現できます。
import seaborn as sns
import matplotlib.pyplot as plt
tips = sns.load_dataset("tips")
fig, axes = plt.subplots(3, 1, figsize=(7, 10))
# 件数を棒グラフで表示(countplot)
sns.countplot(
data=tips,
x="day",
ax=axes[0]
)
axes[0].set_title("Count of Records by Day")
# 箱ひげ図で分布を比較
sns.boxplot(
data=tips,
x="day",
y="total_bill",
ax=axes[1]
)
axes[1].set_title("Distribution of total_bill by Day")
# 個々のデータ点を散布図で重ねる(stripplot)
sns.stripplot(
data=tips,
x="day",
y="total_bill",
jitter=True, # 横方向に散らして重なりを減らす
alpha=0.6,
ax=axes[2]
)
axes[2].set_title("Individual total_bill by Day")
plt.tight_layout()
plt.show()「件数が知りたいのか」「分布が知りたいのか」「個々の値のばらつきが知りたいのか」によって、適切なグラフを選び分けることが大切です。
実務で使える可視化パターン
相関関係の可視化
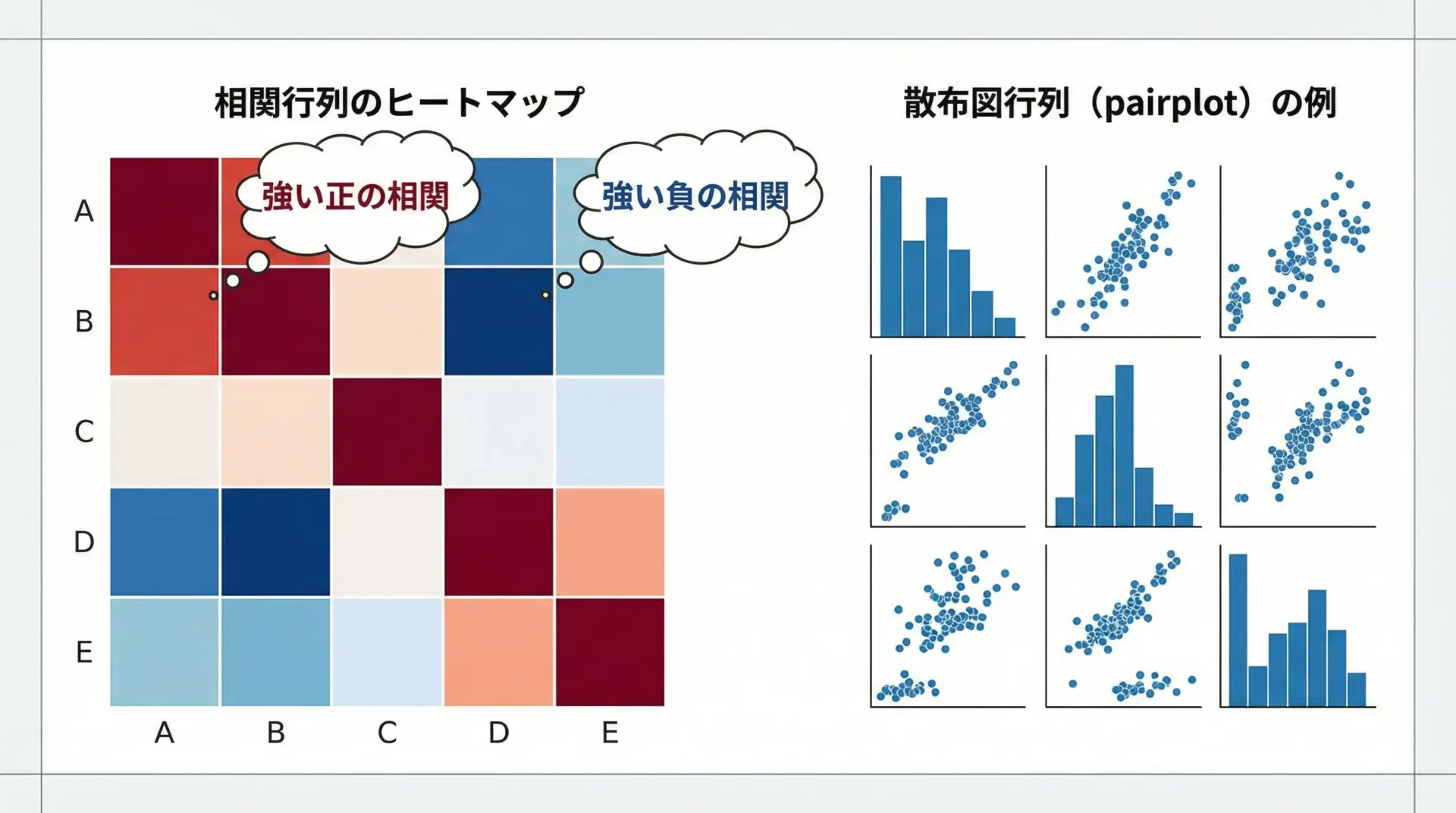
多変量データでは、どの変数同士が強く関係していそうかを素早く把握することが重要です。
相関行列のヒートマップと、散布図行列(pairplot)はその代表的な可視化です。
import seaborn as sns
import matplotlib.pyplot as plt
# 説明用に「iris」データセットを使用
iris = sns.load_dataset("iris")
# 相関行列を計算
corr = iris.drop(columns=["species"]).corr()
# ヒートマップで表示
plt.figure(figsize=(6, 5))
sns.heatmap(
corr,
annot=True, # 相関係数の値を表示
fmt=".2f",
cmap="coolwarm",
vmin=-1, vmax=1,
square=True
)
plt.title("Correlation Matrix (iris)")
plt.tight_layout()
plt.show()散布図行列は、全ての変数ペアについて散布図を並べたものです。
sns.pairplot(
iris,
hue="species", # 種類ごとに色分け
corner=True # 下三角部分だけ表示して冗長さを減らす
)
plt.show()これらの図から、強い相関のある変数ペアや、クラスごとに分離していそうな特徴量を直感的に把握できます。
時系列データの可視化
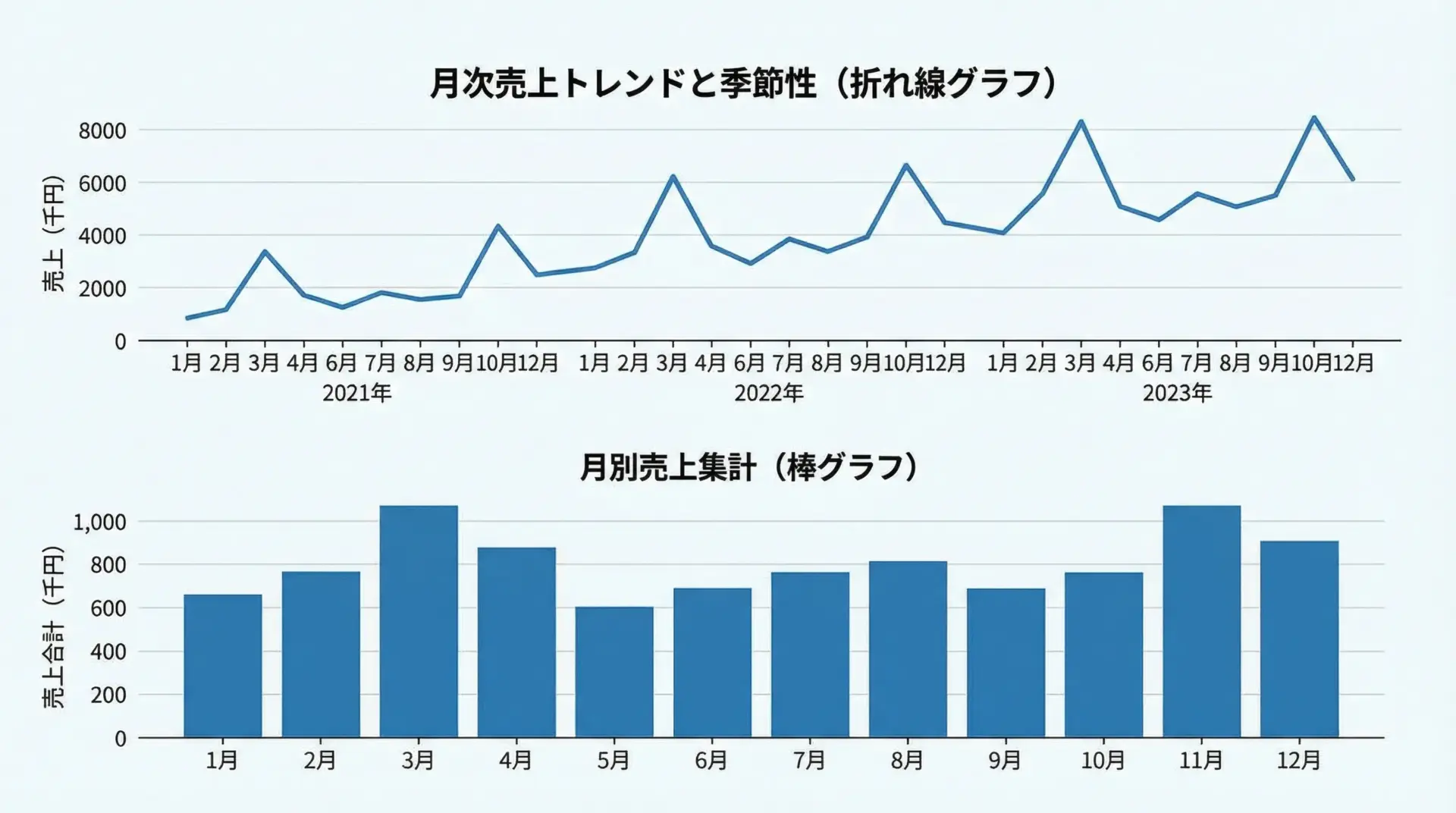
時系列データでは、トレンド(長期的な傾向)や季節性(周期的な変動)を把握するために折れ線グラフが基本となります。
ここでは簡単なサンプルを作り、pandasと組み合わせて可視化します。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 日次データを1年分作成(簡易なトレンド + ノイズ)
date_range = pd.date_range(start="2022-01-01", end="2022-12-31", freq="D")
np.random.seed(0)
values = np.linspace(100, 200, len(date_range)) + np.random.normal(scale=10, size=len(date_range))
ts = pd.DataFrame({"date": date_range, "value": values}).set_index("date")
fig, axes = plt.subplots(2, 1, figsize=(8, 6), sharex=False)
# 日次の折れ線グラフ
axes[0].plot(ts.index, ts["value"], color="tab:blue")
axes[0].set_title("Daily Value")
axes[0].set_ylabel("Value")
# 月ごとの平均値をバーに集計
monthly = ts["value"].resample("M").mean()
axes[1].bar(monthly.index.strftime("%Y-%m"), monthly.values, color="tab:orange")
axes[1].set_title("Monthly Average Value")
axes[1].set_ylabel("Avg Value")
axes[1].set_xticklabels(monthly.index.strftime("%Y-%m"), rotation=45, ha="right")
plt.tight_layout()
plt.show()日次の細かな変動を折れ線で、月次や週次の傾向を棒グラフや線でといった具合に、粒度を変えて眺めることで全体像と細部を両方確認できます。
分布比較の可視化
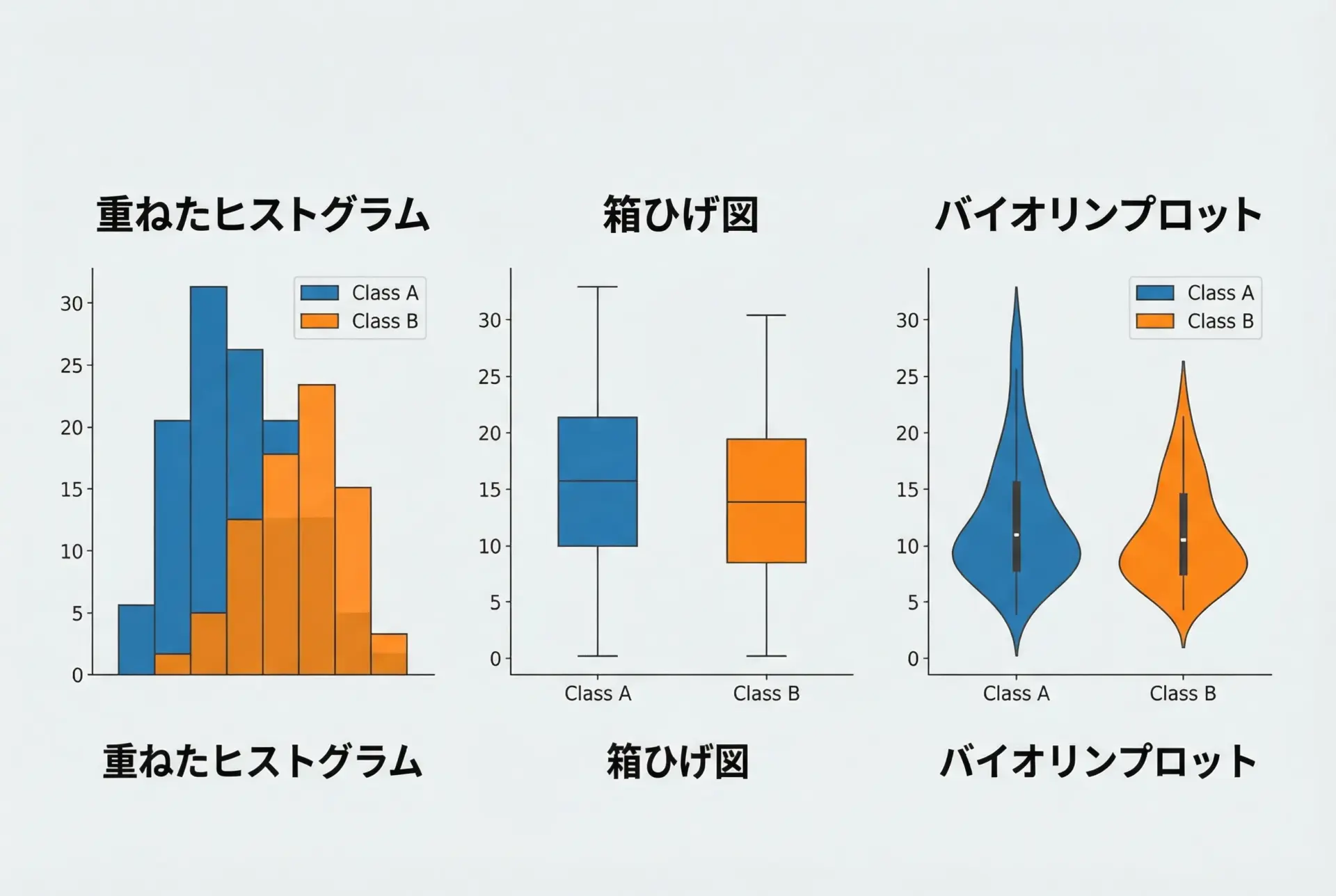
2つ以上のグループ間で分布を比較するには、ヒストグラム、箱ひげ図、バイオリンプロットなどを組み合わせて使うと理解しやすくなります。
import seaborn as sns
import matplotlib.pyplot as plt
tips = sns.load_dataset("tips")
fig, axes = plt.subplots(1, 3, figsize=(14, 4))
# ヒストグラム + KDE
sns.histplot(
data=tips,
x="total_bill",
hue="sex", # 性別で色分け
kde=True,
element="step",
stat="density",
common_norm=False,
ax=axes[0]
)
axes[0].set_title("Histogram & KDE by Sex")
# 箱ひげ図
sns.boxplot(
data=tips,
x="sex",
y="total_bill",
ax=axes[1]
)
axes[1].set_title("Boxplot by Sex")
# バイオリンプロット
sns.violinplot(
data=tips,
x="sex",
y="total_bill",
inner="quartile",
ax=axes[2]
)
axes[2].set_title("Violinplot by Sex")
plt.tight_layout()
plt.show()ヒストグラムは分布の全体像、箱ひげ図は代表値と外れ値、バイオリンプロットは形状の違いに着目すると、それぞれの強みを活かせます。
欠損値・外れ値の可視化と検知
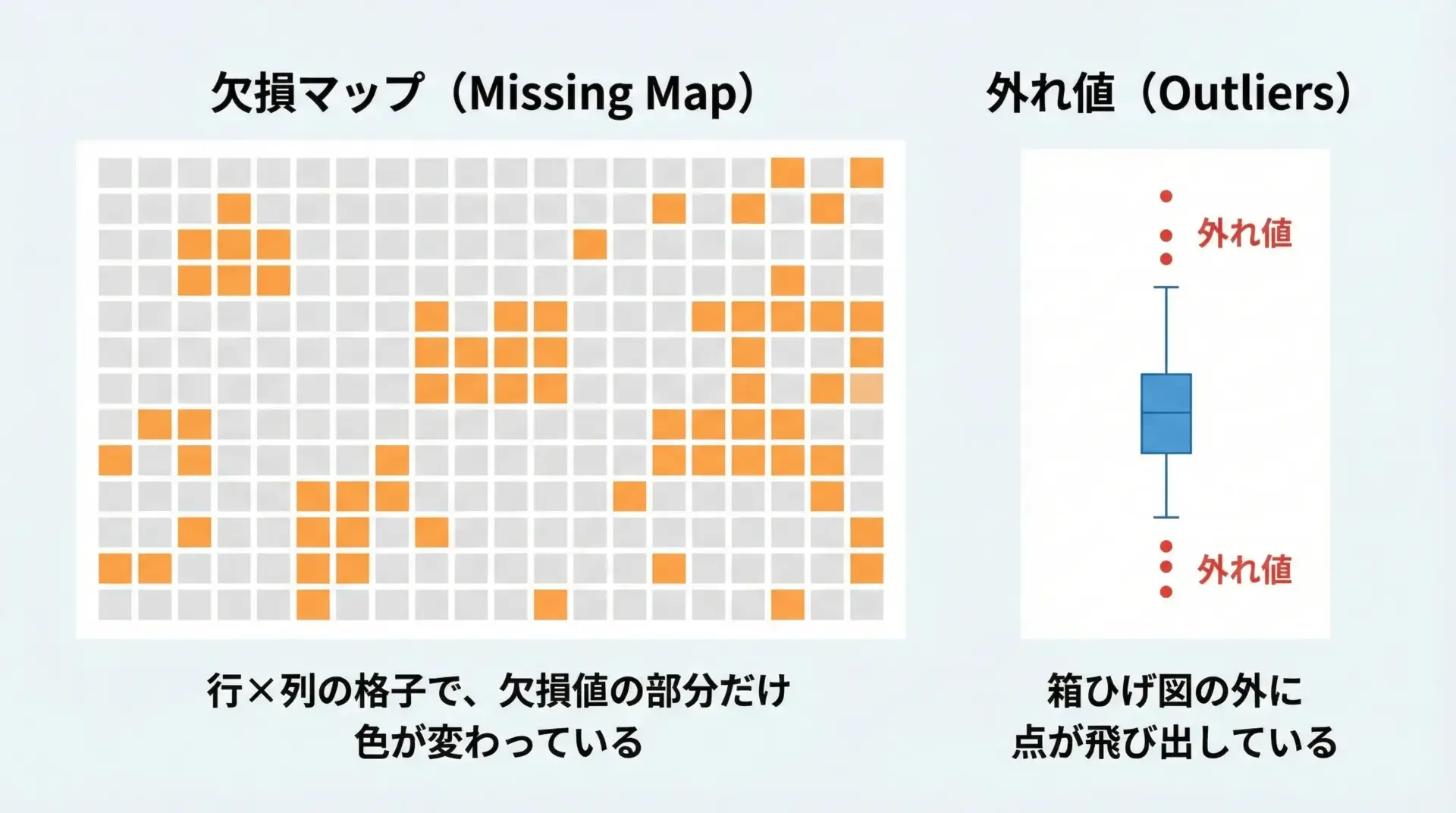
欠損値や外れ値は、モデルの性能や集計結果に大きな影響を与えるため、早い段階で可視化して把握しておくことが重要です。
シンプルな欠損可視化として、True/Falseのマスクをヒートマップで表示する方法があります。
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
# サンプルデータ(ランダムに欠損を入れる)
np.random.seed(0)
df = pd.DataFrame({
"A": np.random.randn(50),
"B": np.random.randn(50),
"C": np.random.randn(50),
})
df.loc[df.sample(frac=0.2).index, "A"] = np.nan
df.loc[df.sample(frac=0.1).index, "B"] = np.nan
plt.figure(figsize=(5, 4))
sns.heatmap(
df.isnull(),
cbar=False,
yticklabels=False
)
plt.title("Missing Value Map")
plt.xlabel("Columns")
plt.ylabel("Rows")
plt.tight_layout()
plt.show()外れ値は、箱ひげ図の「ひげ」から大きく外れた点として可視化されます。
先ほど紹介した箱ひげ図を活用すると、どのカテゴリ、どの変数に外れ値が多いかを直感的に把握できます。
カテゴリ別比較グラフ

カテゴリの組み合わせごとに平均値などを比較するには、seabornのbarplotやcatplotが便利です。
import seaborn as sns
import matplotlib.pyplot as plt
tips = sns.load_dataset("tips")
plt.figure(figsize=(7, 4))
sns.barplot(
data=tips,
x="day",
y="total_bill",
hue="sex", # 性別ごとに色分け
ci="sd" # 誤差バーとして標準偏差を表示(ci=Noneで非表示)
)
plt.title("Average total_bill by Day and Sex")
plt.tight_layout()
plt.show()さらにcatplotを使うと、複数のカテゴリでサブプロットを分割することもできます。
sns.catplot(
data=tips,
x="day",
y="total_bill",
hue="sex",
col="time", # 昼食/夕食で列方向に分割
kind="bar",
height=4,
aspect=1.0
)
plt.show()カテゴリ数が増えるほどグラフが複雑になるため、軸・色・サブプロットの3つをどう割り当てるかを意識することが大切です。
matplotlib×seabornのカスタマイズ技法
カラーマップと配色設計

配色は、グラフの読みやすさと印象を大きく左右する要素です。
連続値にはカラーマップ(cmap)、カテゴリにはカラーパレット(palette)を使い分けます。
matplotlibのカラーマップは、plt.colormaps()で一覧を確認できます。
seabornではcolor_paletteを使ってパレットを取得できます。
import seaborn as sns
import matplotlib.pyplot as plt
# seabornのカラーパレットを確認
palette = sns.color_palette("Set2", n_colors=6)
plt.figure(figsize=(6, 1))
sns.palplot(palette)
plt.title("Seaborn 'Set2' Palette")
plt.xticks([])
plt.yticks([])
plt.show()実務では、色覚多様性に配慮したパレット(例: “Set2”, “colorblind”)を選ぶことも重要です。
複数グラフのレイアウト
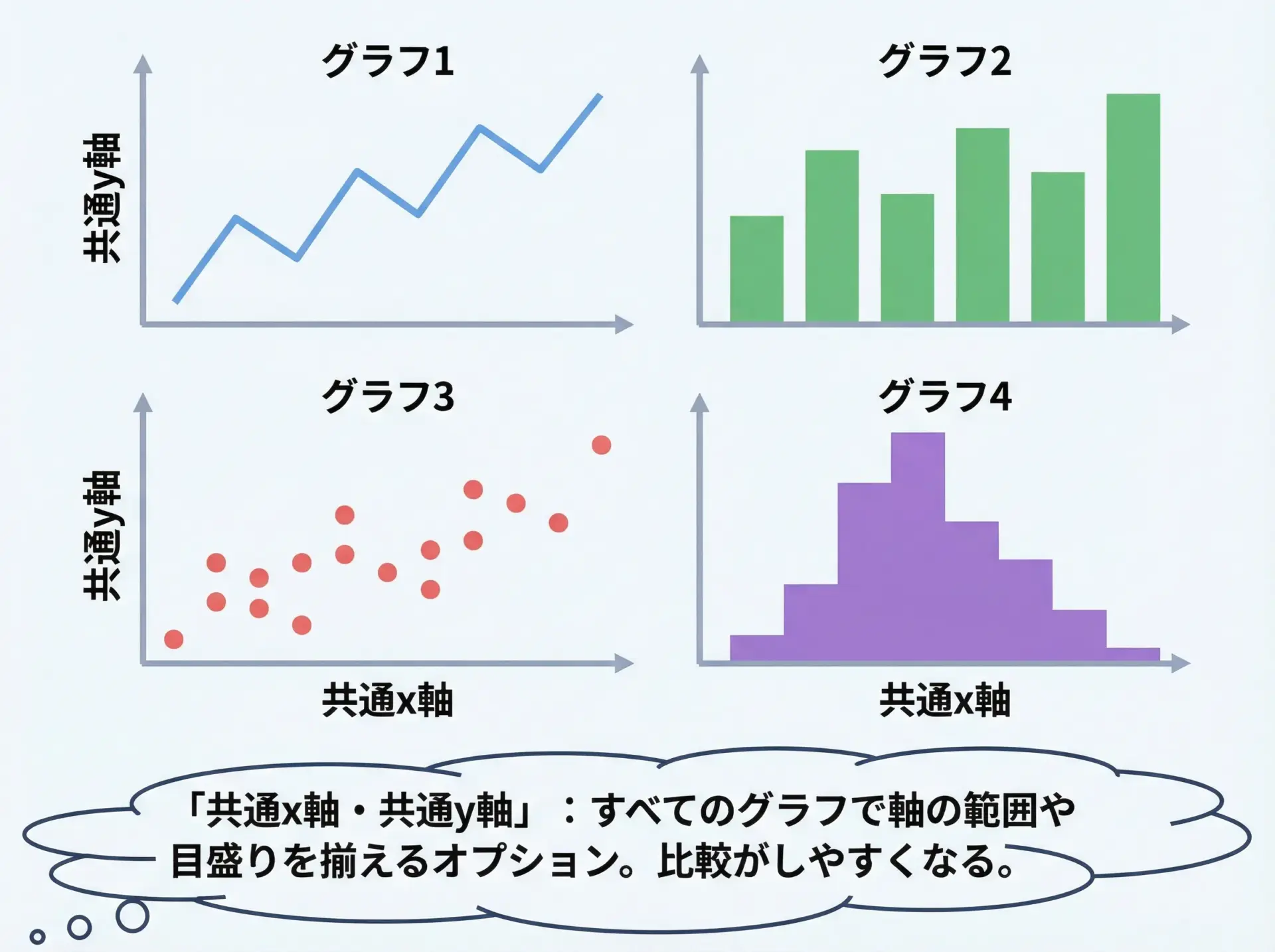
複数のグラフを並べて比較したいときは、plt.subplotsによるサブプロット配置が基本です。
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(0, 2 * np.pi, 100)
fig, axes = plt.subplots(2, 2, figsize=(8, 6), sharex=True)
axes[0, 0].plot(x, np.sin(x))
axes[0, 0].set_title("sin(x)")
axes[0, 1].plot(x, np.cos(x))
axes[0, 1].set_title("cos(x)")
axes[1, 0].plot(x, np.tan(x))
axes[1, 0].set_title("tan(x)")
axes[1, 0].set_ylim(-5, 5) # 極端な値をカット
axes[1, 1].plot(x, np.sin(x) + np.cos(x))
axes[1, 1].set_title("sin(x) + cos(x)")
plt.tight_layout()
plt.show()sharexやshareyを使うと、複数グラフで同じスケールを共有できるため、値の比較がしやすくなります。
軸スケール・対数スケール・二軸グラフの設定
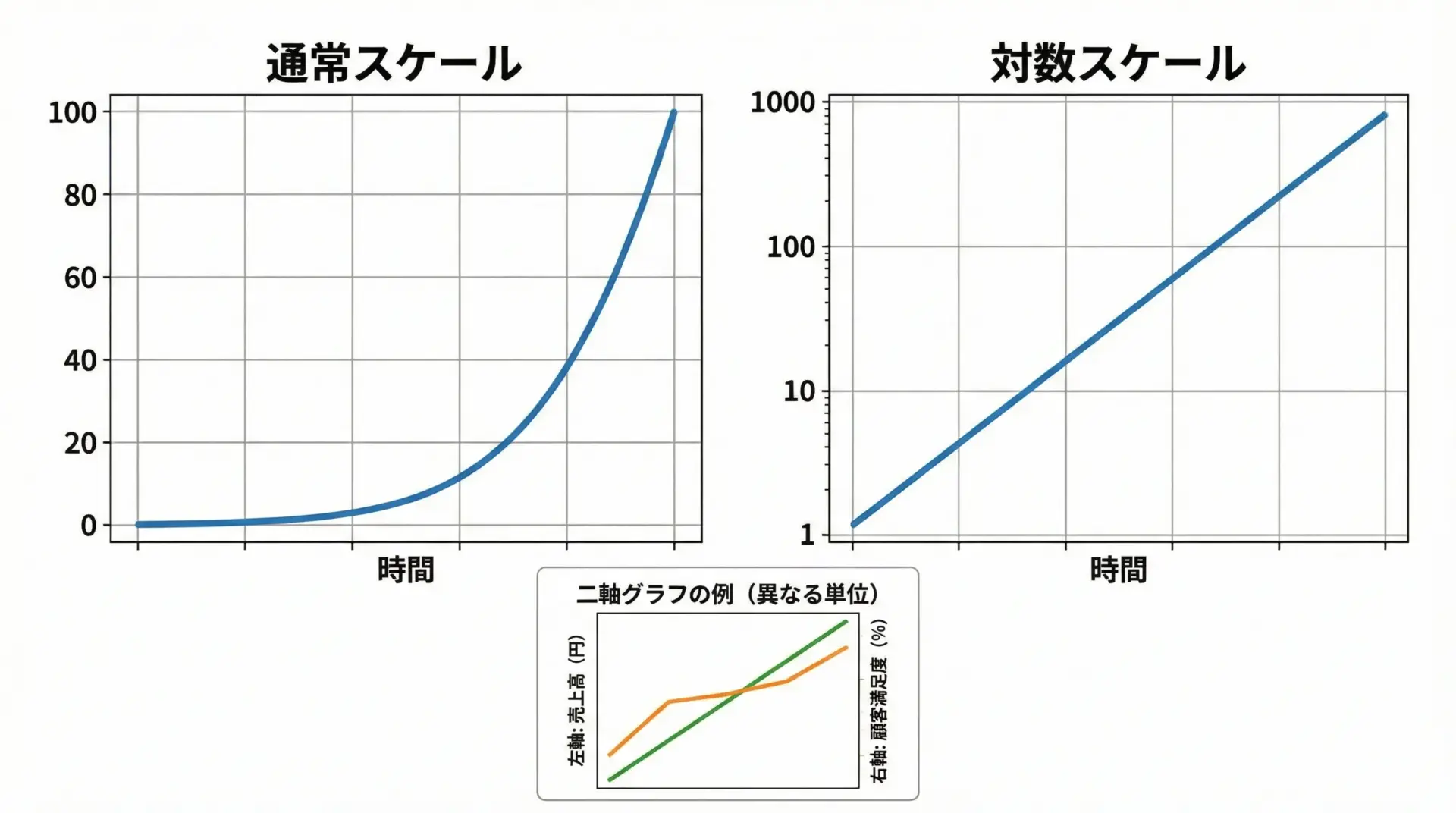
データの桁が大きく異なる場合や指数的な増加を捉えたい場合は、対数スケールが有効です。
import matplotlib.pyplot as plt
import numpy as np
x = np.arange(1, 100)
y = x ** 3 # 立方の関数
fig, axes = plt.subplots(1, 2, figsize=(10, 4))
axes[0].plot(x, y)
axes[0].set_title("Linear Scale")
axes[0].set_xlabel("x")
axes[0].set_ylabel("y = x^3")
axes[1].plot(x, y)
axes[1].set_yscale("log") # y軸を対数スケールに
axes[1].set_title("Log Scale (y)")
axes[1].set_xlabel("x")
axes[1].set_ylabel("log(y)")
plt.tight_layout()
plt.show()二軸グラフ(左右に別のy軸)はax.twinx()で作成できますが、乱用すると読みづらくなるため、本当に必要な場合に限定しましょう。
テーマ変更とスタイル設定
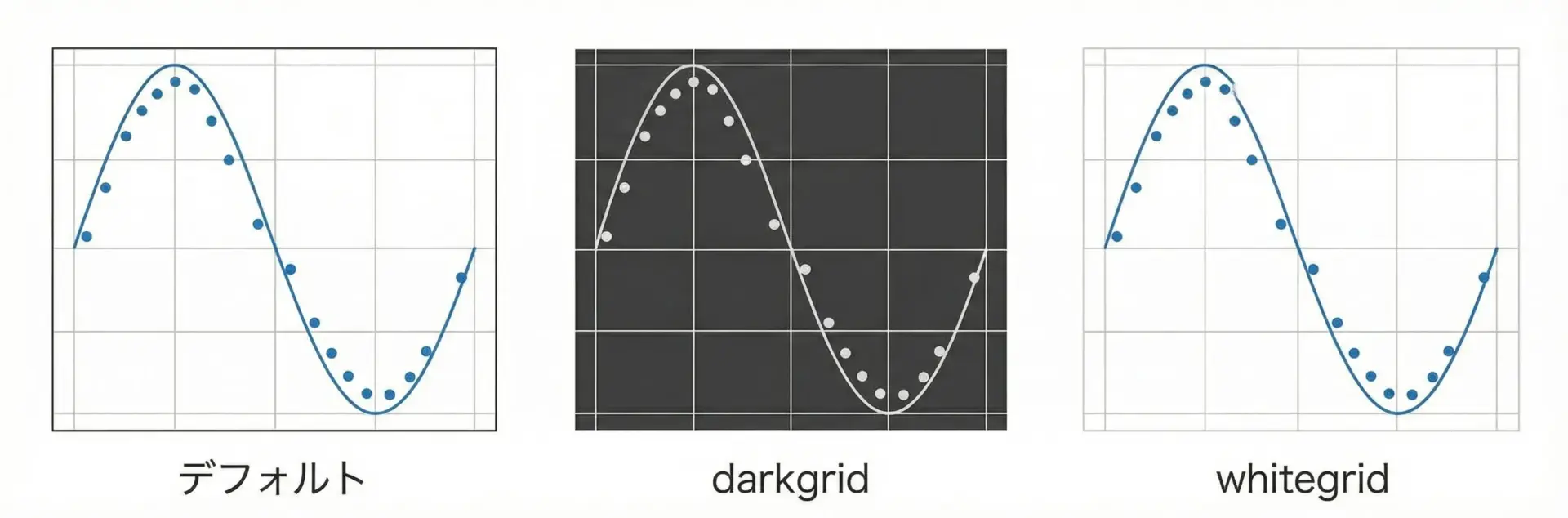
seabornではset_themeやset_styleで全体の見た目を一括変更できます。
import seaborn as sns
import matplotlib.pyplot as plt
tips = sns.load_dataset("tips")
# テーマを設定
sns.set_theme(style="whitegrid", context="talk", palette="Set2")
plt.figure(figsize=(6, 4))
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="sex")
plt.title("Scatterplot with Seaborn Theme")
plt.tight_layout()
plt.show()styleで背景やグリッドの有無、contextでフォントサイズ(用途に応じたスケール)、paletteで色をまとめて指定できるため、レポート用・プレゼン用など用途に応じて使い分けると便利です。
日本語表示・フォント設定とレイアウト調整
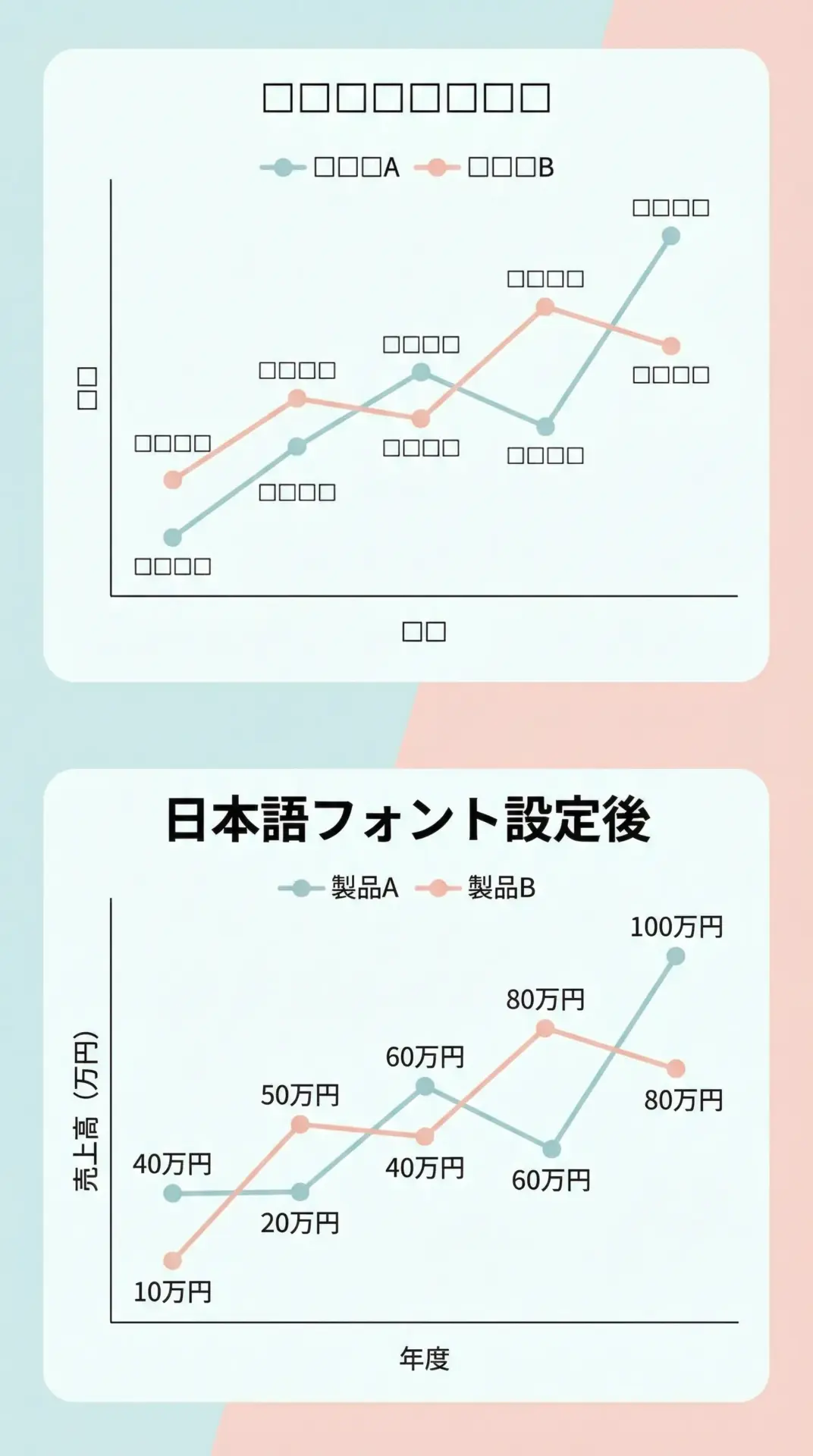
日本語を含むタイトルやラベルを表示する場合、デフォルト設定のままだと文字化けすることがあります。
その場合は、使用するフォントを明示的に指定します。
import matplotlib.pyplot as plt
from matplotlib import font_manager, rcParams
# 例: WindowsでMS Gothicを使う場合
rcParams["font.family"] = "MS Gothic"
# マイナス記号が文字化けする問題への対処
rcParams["axes.unicode_minus"] = False
fig, ax = plt.subplots(figsize=(6, 4))
ax.plot([1, 2, 3], [1, 4, 9])
ax.set_title("日本語タイトルのテスト")
ax.set_xlabel("横軸ラベル")
ax.set_ylabel("縦軸ラベル")
plt.tight_layout()
plt.show()フォント名は環境によって異なるため、font_manager.findSystemFonts()でインストールされているフォントを確認するとよいです。
レイアウトが要素同士で重なってしまう場合は、plt.tight_layout()やplt.subplots_adjust()で余白を調整します。
実務レベルの可視化ワークフロー
pandas×matplotlib×seaborn連携による可視化
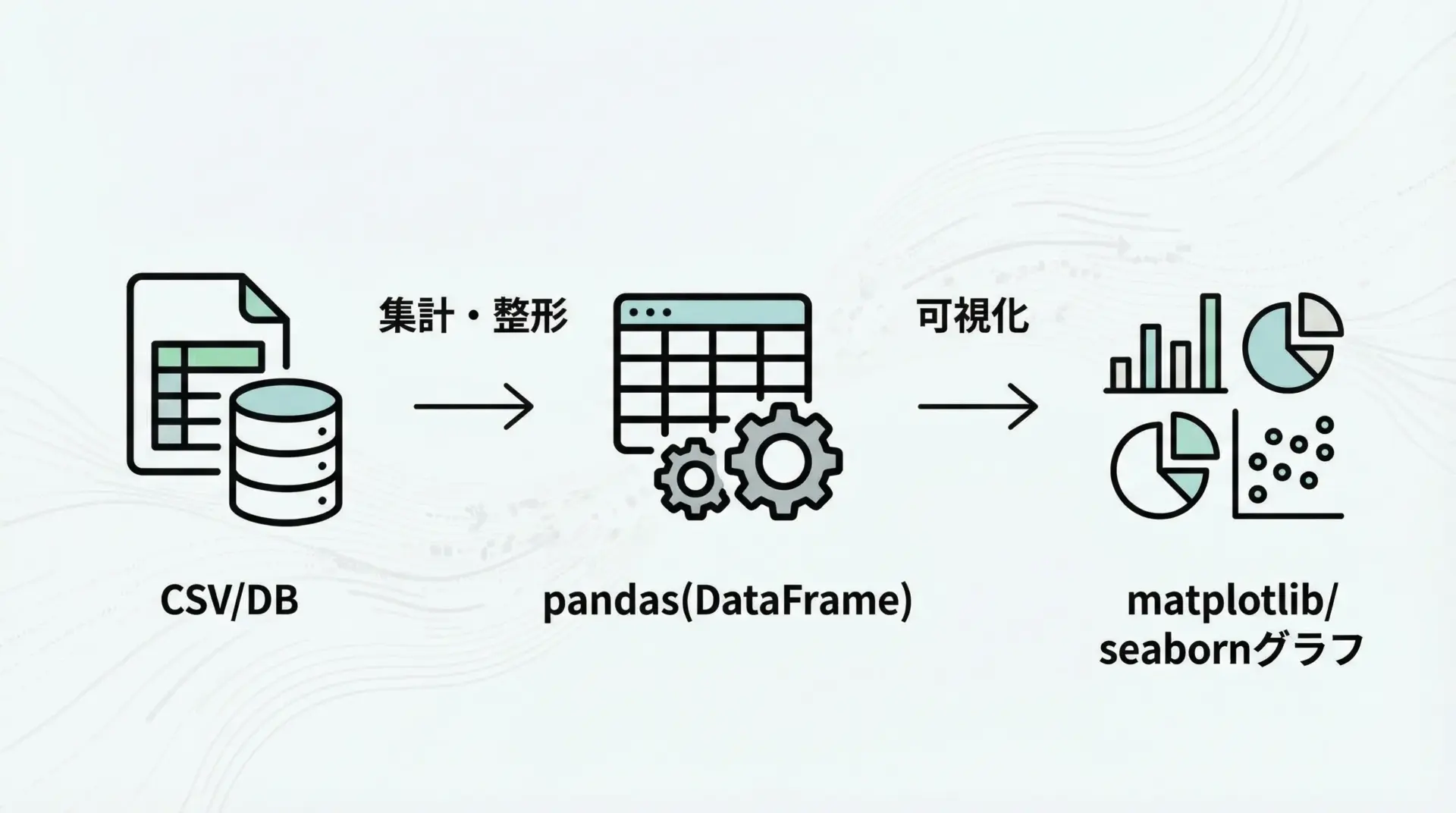
実務では、pandasでデータを読み込み・整形し、そのままseabornやmatplotlibで可視化する流れが最もよく使われます。
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# CSVから読み込み(例: 売上データ)
df = pd.read_csv("sales.csv", parse_dates=["date"])
# 月次売上を集計
monthly_sales = (
df
.groupby(pd.Grouper(key="date", freq="M"))["amount"]
.sum()
.reset_index()
)
# 折れ線グラフで可視化
plt.figure(figsize=(8, 4))
sns.lineplot(data=monthly_sales, x="date", y="amount", marker="o")
plt.title("Monthly Sales")
plt.xlabel("Month")
plt.ylabel("Sales Amount")
plt.tight_layout()
plt.show()pandasでの集計 → seabornでの可視化という分業を意識することで、コードが整理され、再利用しやすくなります。
EDA(探索的データ分析)でよく使うグラフ一覧

EDAでは、データの構造や問題点を把握するために、いくつかの定番グラフが繰り返し登場します。
| 目的 | よく使うグラフ | 具体例(関数) |
|---|---|---|
| 単変量の分布 | ヒストグラム、KDE | histplot, kdeplot |
| 欠損/外れ値 | 欠損マップ、箱ひげ図 | heatmap(df.isnull()), boxplot |
| 関係性 | 散布図、回帰直線、相関ヒートマップ | scatterplot, regplot, heatmap |
| 多変量 | ペアプロット、クラス別分布 | pairplot, catplot |
| カテゴリ比較 | 箱ひげ図、バイオリン、集計棒グラフ | boxplot, violinplot, barplot |
| 時系列 | 折れ線、季節性分解(※statsmodels併用) | lineplot, plot |
これらを一通り作成しておくと、データの全体像、特徴量の重要性、問題のありそうな箇所が見えやすくなります。
レポート・資料向けグラフの作成と保存設定

レポートやスライド用にグラフを使う場合は、サイズ・解像度・フォーマットを意識して保存する必要があります。
import matplotlib.pyplot as plt
import seaborn as sns
tips = sns.load_dataset("tips")
fig, ax = plt.subplots(figsize=(6, 4))
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="sex", ax=ax)
ax.set_title("total_bill vs tip")
plt.tight_layout()
# 画像として保存
fig.savefig(
"scatter_total_bill_tip.png",
dpi=300, # 解像度(印刷物には300以上推奨)
bbox_inches="tight" # 余白を自動調整
)
plt.show()フォーマットは、Web用途ならPNGやJPEG、印刷や拡大用途ならSVGやPDFを選ぶとよいです。
再利用しやすい可視化関数・テンプレート化のコツ
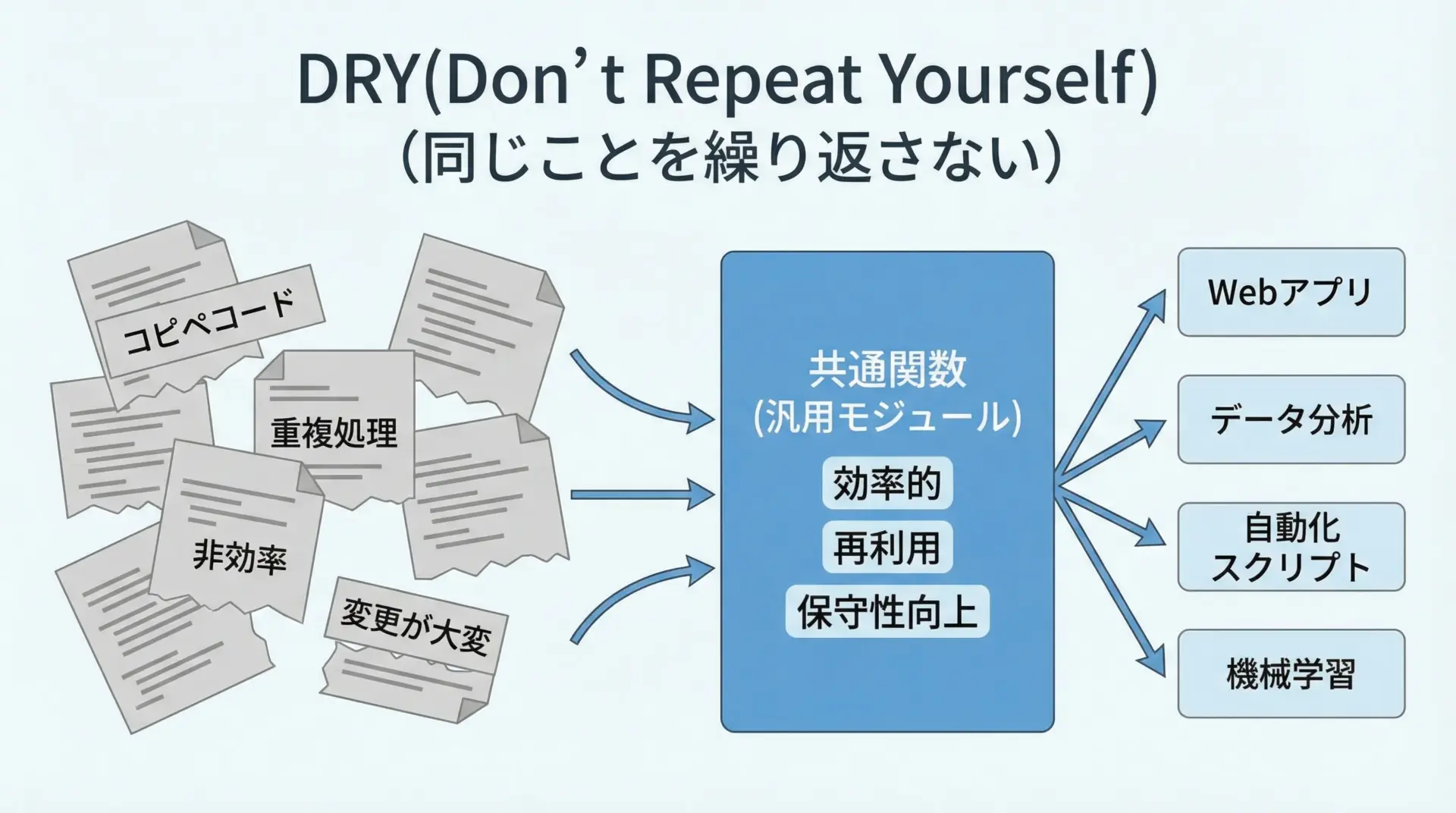
実務では、似たようなグラフを何度も作る場面が多いため、共通の可視化処理を関数化・テンプレート化しておくと効率が大きく向上します。
import matplotlib.pyplot as plt
import seaborn as sns
def plot_time_series(
df,
x_col,
y_col,
title=None,
xlabel=None,
ylabel=None,
save_path=None
):
"""時系列の折れ線グラフを標準スタイルで描画・保存する関数"""
plt.figure(figsize=(8, 4))
sns.lineplot(data=df, x=x_col, y=y_col, marker="o")
plt.title(title or f"{y_col} over time")
plt.xlabel(xlabel or x_col)
plt.ylabel(ylabel or y_col)
plt.tight_layout()
if save_path:
plt.savefig(save_path, dpi=300, bbox_inches="tight")
plt.show()
# 使用例:
# plot_time_series(monthly_sales, x_col="date", y_col="amount", title="Monthly Sales", save_path="monthly_sales.png")ポイントは、「よく使うオプションだけを引数にし、それ以外は関数内で標準設定にしておく」ことです。
これにより、プロジェクト全体で見た目を統一しつつ、必要な部分だけを簡単に変更できます。
まとめ
matplotlibとseabornを組み合わせることで、Python上で基本的なグラフから実務レベルの高度な可視化まで一貫して行える環境が整います。
matplotlibでFigure・Axesの概念と基礎的なグラフ描画を理解し、seabornで統計的な可視化やpandas連携を活用することで、EDAからレポート作成までのワークフローが大幅に効率化されます。
この記事のサンプルをベースに、まずは手元のデータで折れ線、散布図、箱ひげ図、ヒートマップあたりを一通り試し、自分なりのテンプレートや関数化に発展させていくと、日々の分析業務で強力な武器となります。
