
Pythonでファイルの圧縮や解凍を扱えるようになると、ログの保管、バックアップ、ファイル転送の効率化など、実務の幅が大きく広がります。
本記事では標準ライブラリだけで使えるzipfileモジュールとgzipモジュールに焦点を当て、ZIP形式とgz形式の特徴から、実践的なコードパターンまでを丁寧に解説します。
ZIP/gz圧縮解凍を始める前に
zipfile・gzipモジュールとは
Pythonには、追加の外部ライブラリをインストールしなくても使える標準ライブラリが数多く用意されています。
その中でもzipfileモジュールとgzipモジュールは、ファイル圧縮・解凍を行ううえで中核となる存在です。
zipfileモジュールは、拡張子.zipのZIPファイルを読み書きするためのモジュールです。
複数ファイルやフォルダを1つのアーカイブにまとめ、圧縮する用途に向いています。
一方、gzipモジュールは、主に.gz拡張子の単一ファイル圧縮を扱うモジュールで、ログファイルやテキストファイルを1つずつ圧縮する場面でよく使われます。
どちらも標準ライブラリの一部であり、importするだけですぐに使える点が大きなメリットです。
実務では、用途に応じてこれら2つを使い分けることになります。
ZIPとgz形式の違い
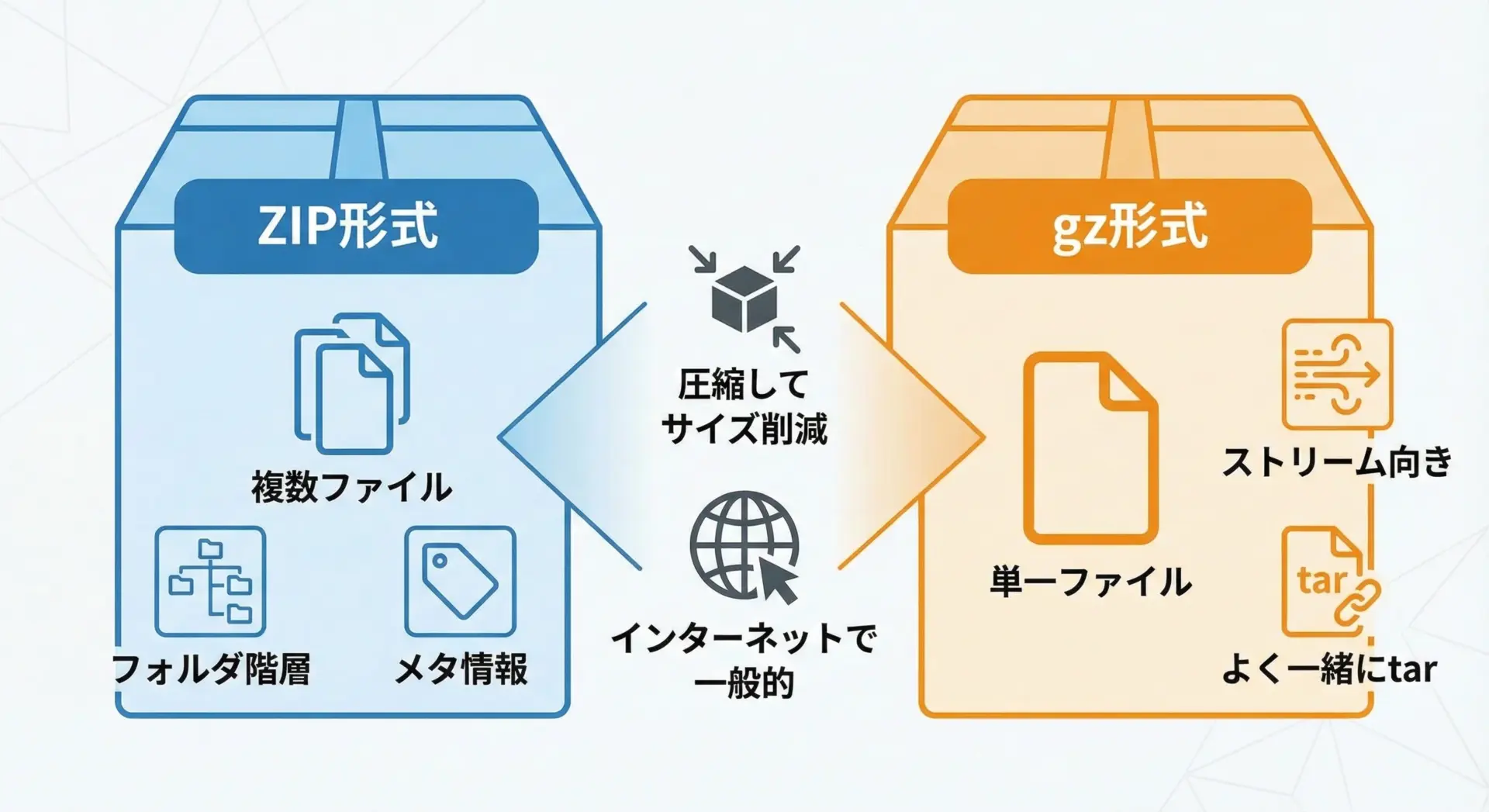
ZIP形式とgz形式は、どちらもファイルサイズを小さくするための圧縮形式ですが、設計思想や用途に明確な違いがあります。
ZIP形式はアーカイブと圧縮を1つにまとめた形式です。
複数のファイルやフォルダ構造を1つのファイルにまとめ、その中の各ファイルを個別に圧縮し、さらにファイル名や更新日時といったメタデータも持ちます。
そのため、WindowsやmacOSでも標準的にサポートされており、汎用性が非常に高い形式です。
一方、gz形式は単一のデータストリームを圧縮することに特化した形式です。
1つのファイル(あるいはバイト列)のみを扱い、フォルダ階層や複数ファイルを1つにまとめる機能は持ちません。
そのため、Unix系環境では、まずtarコマンドで複数ファイルを1つのアーカイブにまとめ(.tar)、それをさらにgzipで圧縮して.tar.gzとするのが一般的です。
この違いを理解しておくと、「複数ファイルを1つにまとめたいならZIP」「ストリームや単一ファイルを効率的に圧縮したいならgz」という大まかな指針が見えてきます。
圧縮方式別のメリット・デメリット
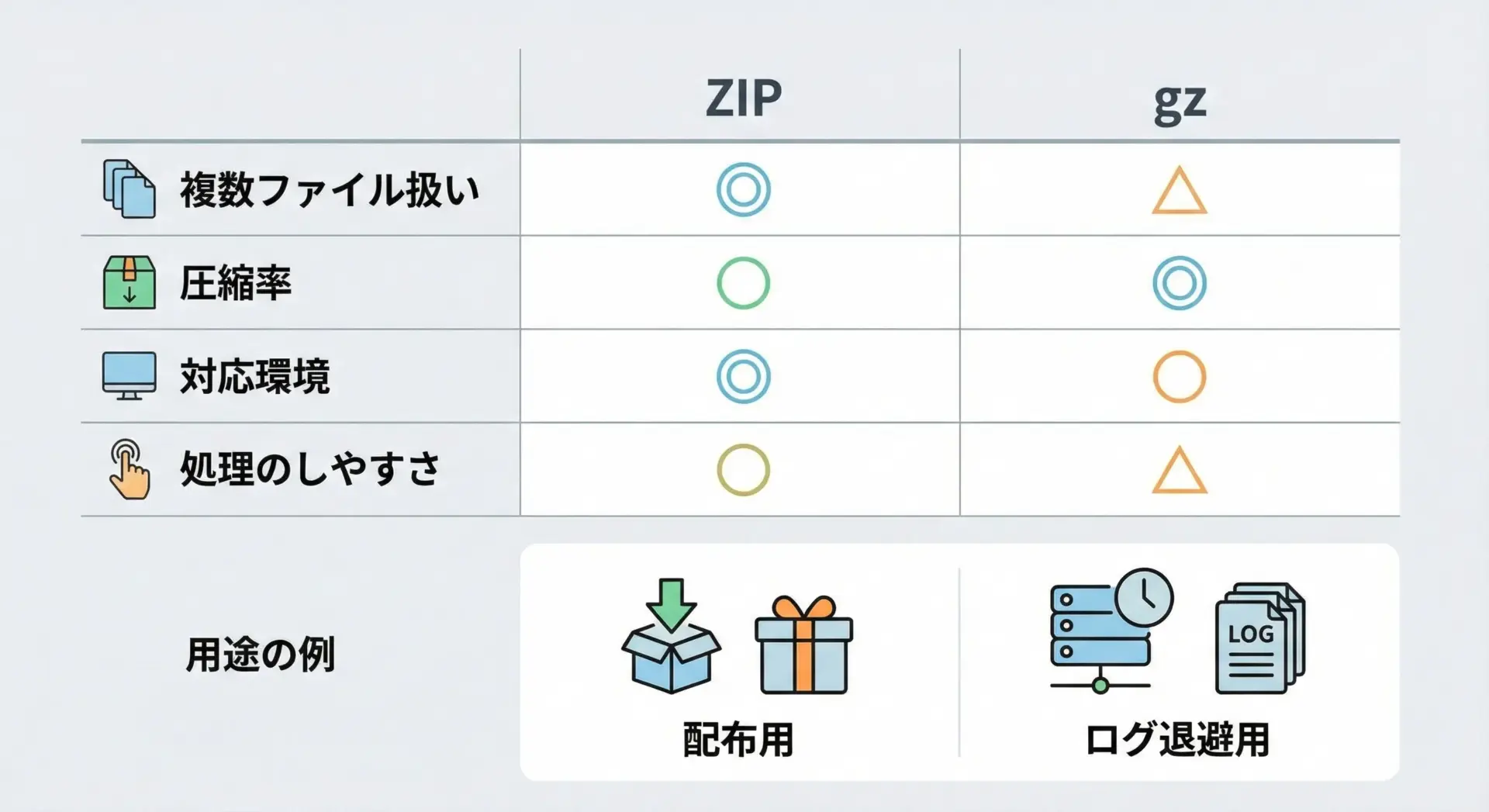
圧縮形式の選択では、単に「圧縮できるかどうか」だけでなく、運用のしやすさやツールの対応状況も重要です。
ここではZIPとgzを比較しながら、メリット・デメリットを整理します。
まずZIP形式のメリットとしては、複数ファイルやフォルダを1つのアーカイブにまとめられることが挙げられます。
ユーザーに配布する資料一式や、バックアップ対象のフォルダを丸ごと保存したい場合など、1つのファイルにまとめて扱いたいケースに非常に向いています。
またWindows環境での対応が良く、エクスプローラーからクリック操作だけで解凍できる点も大きな利点です。
一方で、gzと比べると実装が複雑であり、ストリーム処理や巨大ファイル処理ではやや扱いづらい側面があります。
gz形式のメリットは、ストリームとしての処理と単一ファイル圧縮に強いことです。
ログを順次書き出しながらその場で圧縮したり、ネットワーク越しに圧縮転送したりといった用途で、シンプルかつ高速に動作します。
また、tarと組み合わせることでフォルダ単位の圧縮も可能ですが、その場合はtarコマンドやtarfileモジュールなどとの併用が必要になります。
以下のように整理できます。
| 形式 | 特徴 | 向いている用途 |
|---|---|---|
| ZIP | 複数ファイル・フォルダを1つにまとめられる。Windows標準サポート。 | 資料一式の配布、バックアップ、フォルダ丸ごとアーカイブ |
| gz | 単一ファイル圧縮、ストリーム処理に強い。tarとの併用が前提になりやすい。 | ログファイルの圧縮保管、HTTPレスポンス圧縮、巨大ファイルのストリーム圧縮 |
日常的なファイル配布やバックアップにはZIP、サーバサイドのログ圧縮やストリーム処理にはgzと覚えておくと実務で迷いにくくなります。
zipfileでZIPファイルを操作する
ZIPファイルを新規作成する

ZIPファイルの基本操作は、まず新規にZIPファイルを作成してファイルを格納するところから始まります。
zipfileモジュールでは、zipfile.ZipFileクラスを使ってZIPファイルを開き、writeメソッドでファイルを追加します。
最もシンプルな例を見てみましょう。
import zipfile
from pathlib import Path
# 圧縮したいファイルを準備
files_to_zip = [
Path("docs/readme.txt"),
Path("images/logo.png"),
Path("data/sample.csv"),
]
# 新規にZIPファイルを作成する例
zip_path = Path("archive/example.zip")
# mode='w' は新規作成(既存があれば上書き)を意味します
with zipfile.ZipFile(zip_path, mode="w", compression=zipfile.ZIP_DEFLATED) as zf:
for file_path in files_to_zip:
# ZIP内での名前(アーカイブ名)を指定
# ここでは元のパスのファイル名だけを使います
arcname = file_path.name
# ファイルをZIPに追加
zf.write(file_path, arcname=arcname)
print(f"Added {file_path} as {arcname}")
print(f"Created ZIP: {zip_path}")上記コードではmode="w"を指定することで、ZIPファイルを新規作成しています。
すでに同名のZIPファイルが存在する場合、中身は全て上書きされるので注意が必要です。
またcompression=zipfile.ZIP_DEFLATEDを指定することで、一般的なDeflate圧縮を有効にしています。
アーカイブ内のディレクトリ構造を保つ
実際の運用では、元のディレクトリ構造をZIP内に保持したい場合も多くあります。
その場合は、元の相対パスをそのままarcnameに使うだけで実現できます。
import zipfile
from pathlib import Path
base_dir = Path("project") # 圧縮したいフォルダ
zip_path = Path("archive/project_backup.zip")
with zipfile.ZipFile(zip_path, mode="w", compression=zipfile.ZIP_DEFLATED) as zf:
for file_path in base_dir.rglob("*"):
if file_path.is_file():
# base_dir からの相対パスをZIP内のパスとして使う
arcname = file_path.relative_to(base_dir)
zf.write(file_path, arcname=arcname)
print(f"Added {file_path} as {arcname}")このようにrelative_toを活用することで、きれいな階層構造を保ったバックアップZIPを簡単に作成できます。
既存ファイルをZIPに追加する
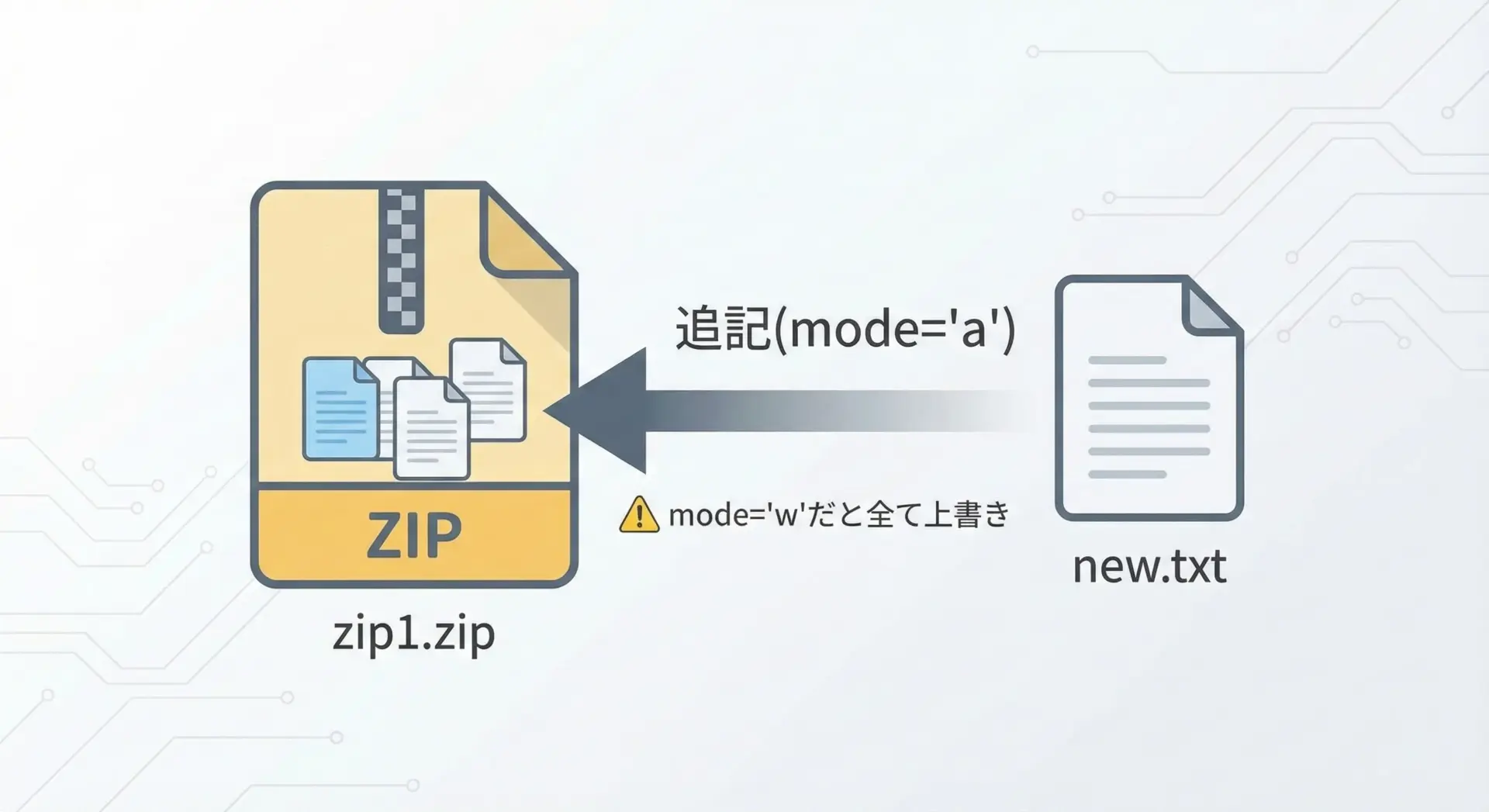
既存のZIPファイルにファイルを追加したい場合は、mode="a"(append)を使います。
「追記モード」では既存の中身を保持したまま、新たなファイルを付け足せる点がポイントです。
import zipfile
from pathlib import Path
zip_path = Path("archive/example.zip")
new_files = [
Path("extra/info.txt"),
Path("extra/config.json"),
]
# mode='a' で既存のZIPに追記します
with zipfile.ZipFile(zip_path, mode="a", compression=zipfile.ZIP_DEFLATED) as zf:
for file_path in new_files:
arcname = f"extra/{file_path.name}"
zf.write(file_path, arcname=arcname)
print(f"Appended {file_path} as {arcname}")
print(f"Updated ZIP: {zip_path}")Appended extra/info.txt as extra/info.txt
Appended extra/config.json as extra/config.json
Updated ZIP: archive/example.zipなお、ZIP内に同名ファイルがすでに存在する場合、新しいエントリが後ろに追加されるだけで、古いエントリはそのまま残るという仕様があります。
多くの解凍ツールは最後に書かれたエントリを採用しますが、「完全に上書きしたい」という場合には、再作成(wモード)を検討した方が安全です。
ZIPファイルを解凍する

ZIPファイルの中身を取り出すには、extractallやextractメソッドを使用します。
フォルダごと一括で解凍するパターンが最も一般的です。
import zipfile
from pathlib import Path
zip_path = Path("archive/example.zip")
extract_dir = Path("extracted")
# ZIPファイルを読み込みモードで開く
with zipfile.ZipFile(zip_path, mode="r") as zf:
# 全ファイルをextract_dir配下に展開
zf.extractall(path=extract_dir)
print(f"Extracted all files to: {extract_dir}")特定のファイルだけを取り出したい場合はextractを使います。
import zipfile
from pathlib import Path
zip_path = Path("archive/example.zip")
extract_dir = Path("extracted_single")
with zipfile.ZipFile(zip_path, mode="r") as zf:
# ZIP内の特定ファイル名を指定して抽出
member_name = "docs/readme.txt"
zf.extract(member_name, path=extract_dir)
print(f"Extracted {member_name} to {extract_dir}")ファイルパスの扱いに注意しつつ、必要に応じてPathでパス操作を行うと、OSを問わず安定したスクリプトになります。
パスワード付きZIPの扱いと制限

パスワード付きZIPについては、Pythonの標準zipfileモジュールには大きな制限があります。
zipfileで扱える暗号化は古いZipCrypto方式のみであり、それも基本的には読み取り専用と考えた方がよいです。
パスワード付きZIPの解凍(ZipCrypto)
zipfileではsetpassword、もしくはextractのpwd引数でパスワードを指定できます。
import zipfile
from pathlib import Path
zip_path = Path("protected.zip")
extract_dir = Path("protected_extracted")
password = "secret123" # 実際には環境変数などから安全に取得する
with zipfile.ZipFile(zip_path, "r") as zf:
# パスワードはbytesで渡す必要があります
zf.setpassword(password.encode("utf-8"))
zf.extractall(path=extract_dir)
print(f"Extracted encrypted ZIP to: {extract_dir}")パスワード付きZIPの作成に関する注意
標準のzipfileでは、安全性の高いAES暗号でのパスワード付きZIPを作成することはできません。
またZipCryptoでの書き込みも事実上サポート外です。
そのため、安全なパスワード付きZIPを作成したい場合は標準ライブラリだけでは不十分です。
AES対応のパスワード付きZIPを作成したい場合は、以下のような代替策を検討する必要があります。
- 外部コマンド(7-zip、zipコマンドなど)を
subprocessで呼び出す pyminizipなどのサードパーティライブラリを利用する- そもそもZIPのパスワードに頼らず、GPGなど別の暗号化手段を使う
セキュリティ要件が厳しいシステムでは、「zipfileは暗号化目的には使わない」と割り切る方が安全です。
圧縮レベルと圧縮方式を指定する
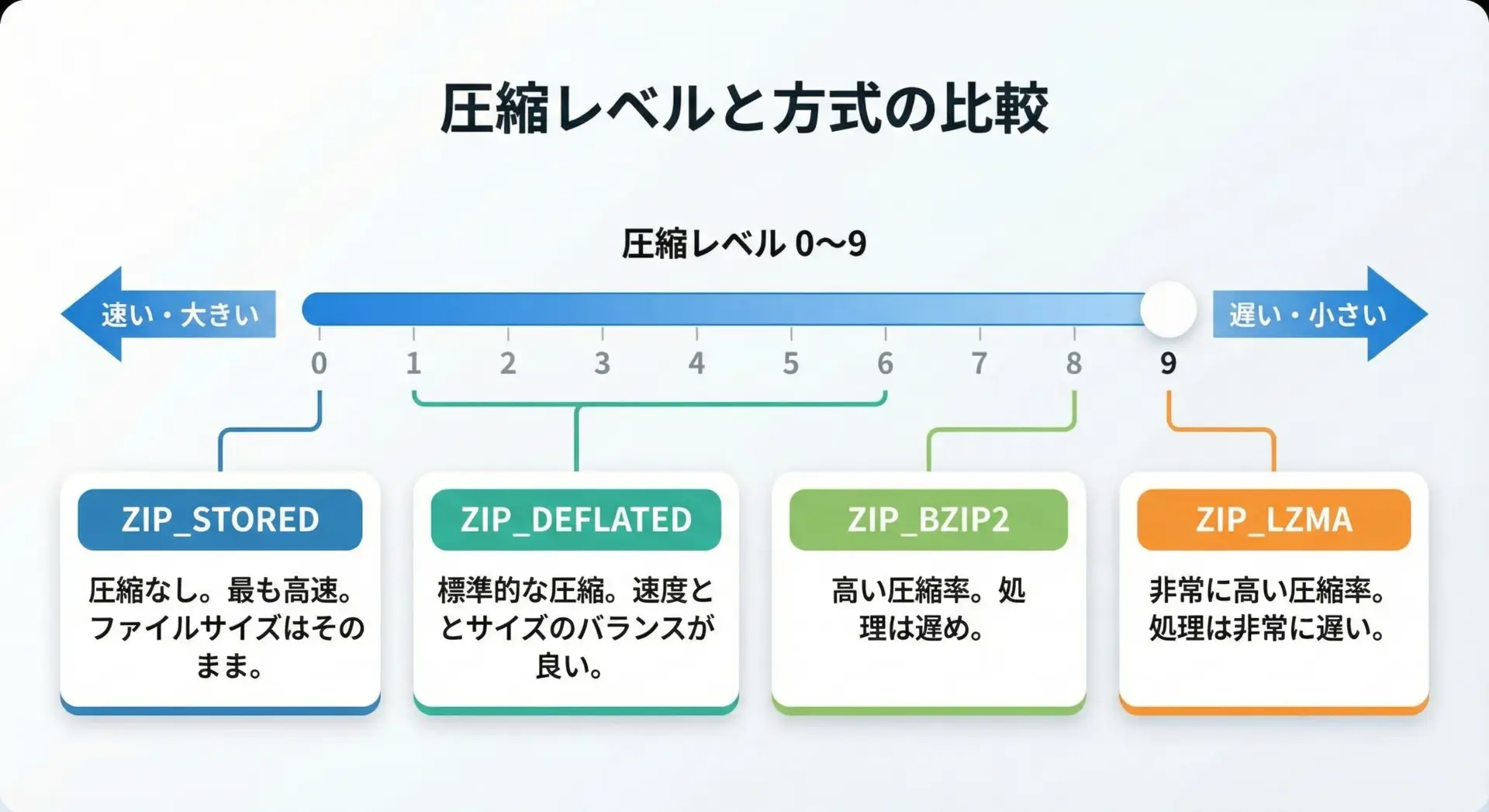
zipfileでは、圧縮方式(compression)と圧縮レベル(compresslevel)をある程度コントロールできます。
用途によっては「少しでも小さくしたい」「処理速度を優先したい」といった要望がありますので、基本的なパラメータを押さえておきましょう。
代表的な圧縮方式は次の通りです。
| 定数 | 内容 |
|---|---|
ZIP_STORED | 無圧縮(格納のみ) |
ZIP_DEFLATED | Deflate圧縮(最も一般的) |
ZIP_BZIP2 | bzip2圧縮(高圧縮だが遅め) |
ZIP_LZMA | LZMA圧縮(非常に高圧縮だがさらに遅い) |
圧縮レベルは、Deflateなど一部の方式でcompresslevel引数に0〜9の整数を指定できます。
値が大きいほど圧縮率は上がりますが、そのぶんCPU時間を消費します。
import zipfile
from pathlib import Path
files_to_zip = [Path("large_data.bin")]
# 高圧縮(時間はかかるがサイズを優先)
with zipfile.ZipFile(
"high_compress.zip",
mode="w",
compression=zipfile.ZIP_DEFLATED,
compresslevel=9, # 最大圧縮
) as zf:
for path in files_to_zip:
zf.write(path, arcname=path.name)
# 低圧縮(処理速度を優先)
with zipfile.ZipFile(
"fast_compress.zip",
mode="w",
compression=zipfile.ZIP_DEFLATED,
compresslevel=1, # 最小圧縮
) as zf:
for path in files_to_zip:
zf.write(path, arcname=path.name)Created high_compress.zip (smaller but slower)
Created fast_compress.zip (bigger but faster)ログやテキストファイルなどは圧縮効果が高いので圧縮レベルを上げる価値がありますが、すでに圧縮されている画像や動画ファイルでは効果が薄く、処理時間だけが増えてしまうこともあります。
対象ファイルの特性を踏まえ、適切な圧縮レベルを選択することが重要です。
ファイル一覧を取得する

ZIPファイルの中身を確認したい場合には、namelistやinfolistが役に立ちます。
namelistは単純にファイル名のリストを返し、infolistはZipInfoオブジェクトのリストを返すため、サイズや更新日時なども参照できます。
import zipfile
from datetime import datetime
zip_path = "archive/example.zip"
with zipfile.ZipFile(zip_path, "r") as zf:
print("=== namelist() ===")
for name in zf.namelist():
print(name)
print("\n=== infolist() ===")
for info in zf.infolist():
# info.filename, info.file_size, info.compress_size などが使えます
dt = datetime(*info.date_time)
ratio = (
100 * (1 - info.compress_size / info.file_size)
if info.file_size
else 0
)
print(
f"{info.filename:30} "
f"size={info.file_size:8} "
f"compressed={info.compress_size:8} "
f"saved={ratio:5.1f}% "
f"modified={dt}"
)出力例(イメージ):
=== namelist() ===
docs/readme.txt
data/sample.csv
images/logo.png
=== infolist() ===
docs/readme.txt size= 1234 compressed= 456 saved= 63.1% modified=2025-01-01 10:23:45
data/sample.csv size= 9876 compressed= 1234 saved= 87.5% modified=2025-01-01 10:23:46
images/logo.png size= 34567 compressed= 34500 saved= 0.2% modified=2025-01-01 10:23:47このように圧縮前後のサイズ差や更新日時を簡単に確認できるため、バックアップ状況のチェックやログとしての出力に便利です。
with文を使った安全なzipfileの書き方

zipfileに限った話ではありませんが、ファイルやネットワークリソースを扱うときはwith文を使うのがPythonの定石です。
with文を使うことで、処理中に例外が発生した場合でも確実にclose()が呼ばれ、ファイルハンドルが開きっぱなしになる問題を防げます。
悪い例と良い例を比較してみます。
# 悪い例: with文を使わずに明示的にcloseしている
import zipfile
zf = zipfile.ZipFile("example.zip", "w", compression=zipfile.ZIP_DEFLATED)
try:
zf.write("file1.txt")
# ここでエラーが起きると、zf.close() が呼ばれない可能性がある
zf.write("file2.txt")
finally:
zf.close()# 良い例: with文を使うことで自動的にcloseされる
import zipfile
with zipfile.ZipFile("example.zip", "w", compression=zipfile.ZIP_DEFLATED) as zf:
zf.write("file1.txt")
# ここでエラーが起きても、ブロック終了時に必ずcloseされる
zf.write("file2.txt")with文は可読性と安全性の両面でメリットが大きいため、本記事のサンプルでも一貫してwith文を使っています。
自分のコードでも、基本的にはzipfileをwith文のコンテキストマネージャとして利用するスタイルを徹底すると良いでしょう。
gzipでgzファイルを操作する
gzipファイルを作成する
gzipモジュールは、単一ファイルをgzip形式(.gz)で圧縮・解凍するためのモジュールです。
基本的な使い方は、gzip.openでファイルを開き、通常のファイルオブジェクトのように読み書きするだけです。
テキストファイルを圧縮する場合、以下のように書けます。
import gzip
text = "これはgzipで圧縮されたテキストのサンプルです。\n" * 10
# テキストモード('wt')で書き込み
with gzip.open("sample.txt.gz", mode="wt", encoding="utf-8") as f:
f.write(text)
print("Created sample.txt.gz")バイナリデータ(例えば画像やバイナリログ)を圧縮する場合は、バイナリモードを使います。
import gzip
from pathlib import Path
src_path = Path("image.png")
dst_path = Path("image.png.gz")
with src_path.open("rb") as src, gzip.open(dst_path, mode="wb") as dst:
# そのままバイナリコピーすればOK
dst.write(src.read())
print(f"Compressed to: {dst_path}")modeの末尾がtならテキスト、bならバイナリと覚えておくと混乱しにくくなります。
テキストデータをgzに圧縮・解凍する
テキストファイルをgzip圧縮して保存し、後から中身をテキストとして読み出すパターンは非常によく使われます。
特にログローテーションやアプリケーションのログ退避などで頻出です。
import gzip
text_path = "message.txt.gz"
# 書き込み(圧縮)
with gzip.open(text_path, mode="wt", encoding="utf-8") as f:
f.write("1行目のテキストです。\n")
f.write("2行目のテキストです。\n")
# 読み込み(解凍)
with gzip.open(text_path, mode="rt", encoding="utf-8") as f:
content = f.read()
print("=== content ===")
print(content)=== content ===
1行目のテキストです。
2行目のテキストです。encodingを明示的に指定することで、文字化けを防ぎ、他言語環境との互換性も高まります。
特にUTF-8を標準とするプロジェクトではencoding="utf-8"を常に指定する習慣を付けると良いでしょう。
バイナリデータをgzに圧縮・解凍する
バイナリデータの場合も基本は同じですが、モードはwbとrbを使い、encodingは指定しません。
import gzip
from pathlib import Path
src_path = Path("backup.bin")
gz_path = Path("backup.bin.gz")
restored_path = Path("backup_restored.bin")
# 圧縮
with src_path.open("rb") as src, gzip.open(gz_path, mode="wb") as dst:
# 大きなファイルにも対応できるよう、チャンク単位でコピー
while True:
chunk = src.read(1024 * 1024) # 1MBずつ読む
if not chunk:
break
dst.write(chunk)
# 解凍
with gzip.open(gz_path, mode="rb") as src, restored_path.open("wb") as dst:
while True:
chunk = src.read(1024 * 1024)
if not chunk:
break
dst.write(chunk)
print("Compressed and restored backup.bin")チャンク単位で読み書きすることで、巨大ファイルでもメモリを圧迫せずに処理できます。
このパターンは後述する大容量ファイルやストリーム処理でも再利用できます。
ストリームとしてgzip圧縮する
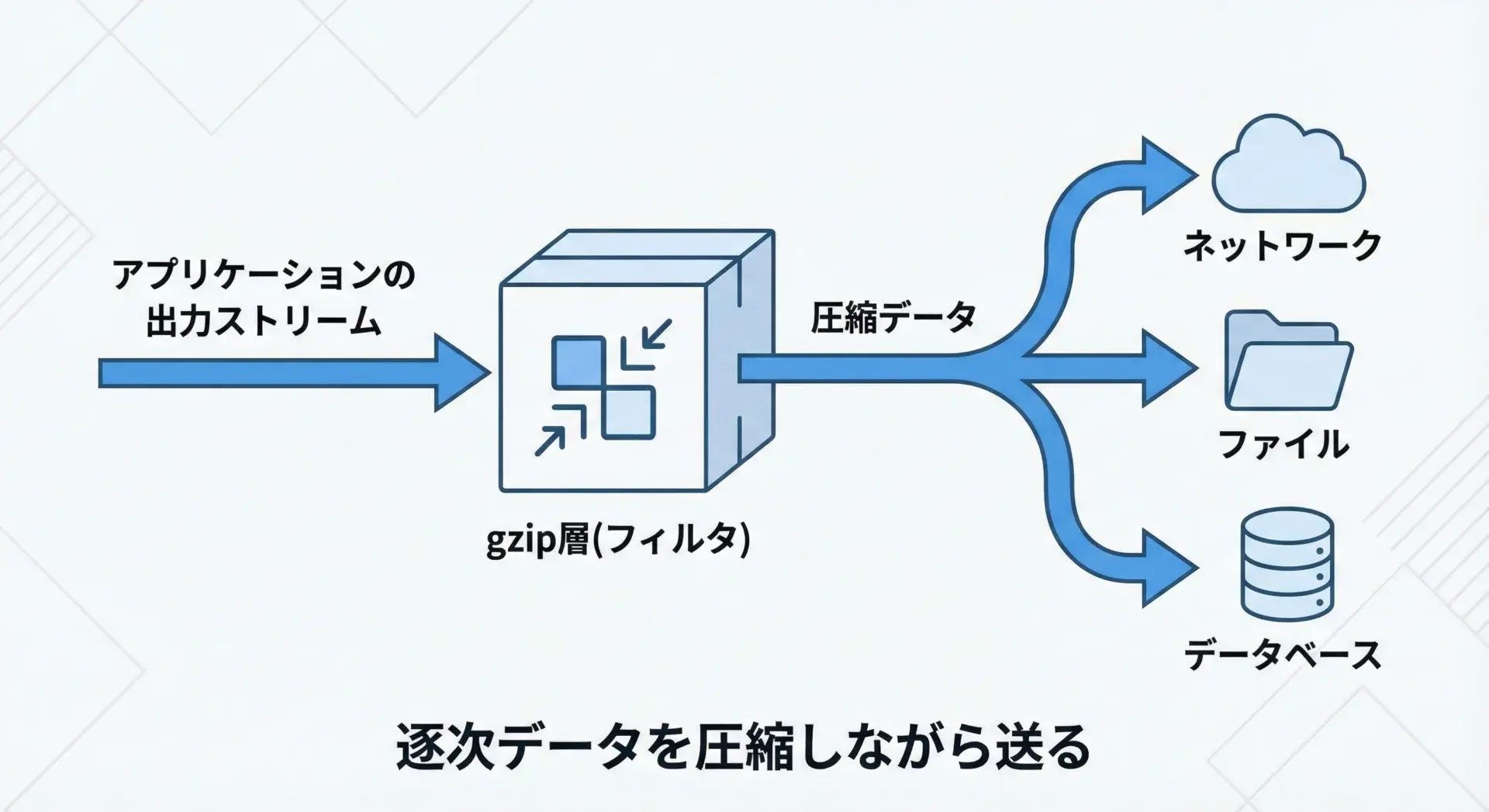
gzipはストリーム圧縮に向いているため、データを逐次生成しながら、その場で圧縮して書き出すという使い方ができます。
全データを一度メモリに載せる必要がないため、ログや大容量レスポンスに適しています。
import gzip
def generate_lines():
# 逐次データを生成するジェネレータの例
for i in range(1, 6):
yield f"{i}行目のログです。\n"
gz_path = "stream.log.gz"
with gzip.open(gz_path, mode="wt", encoding="utf-8") as f:
for line in generate_lines():
f.write(line)
print(f"Wrote streaming log to {gz_path}")このようにジェネレータと組み合わせることで、メモリ効率の良いgzip圧縮が簡単に実現できます。
Webフレームワークなどでは、このストリーム圧縮をHTTPレスポンスに適用していることが多いです。
gzipとtarの違い
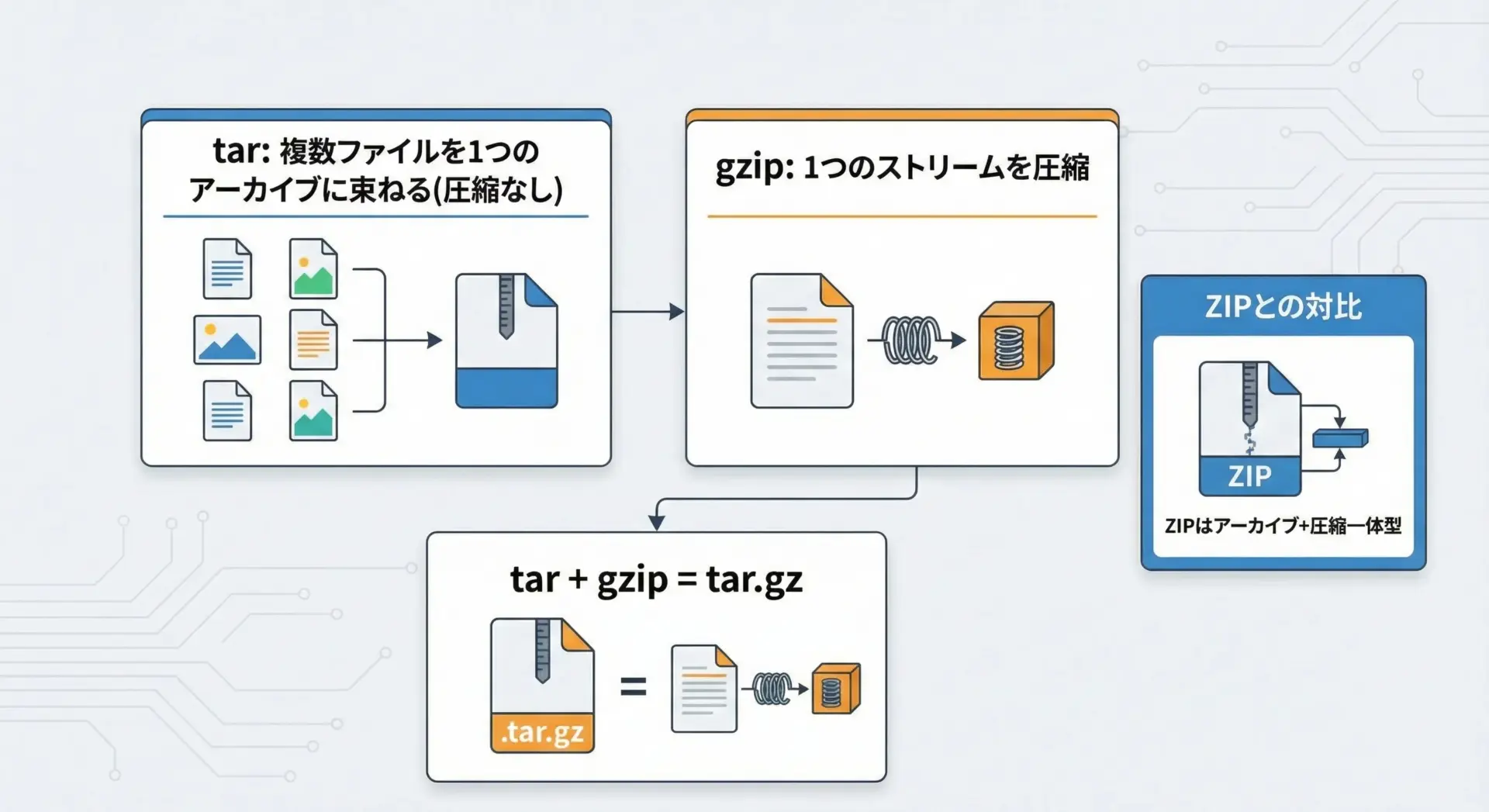
Unix系環境では.tar.gzという拡張子をよく目にします。
これはtarアーカイブをgzipで圧縮したもので、仕組み上はZIPとは異なります。
tar
複数ファイルやディレクトリを1つのアーカイブ(束)にまとめるだけで、圧縮自体は行いません。拡張子は通常.tarです。gzip
単一ストリームの圧縮を行うツールです。.tarで作ったアーカイブをgzipで圧縮すると.tar.gzや.tgzになります。
Pythonでは、tarfileモジュールとgzipモジュールを組み合わせて、.tar.gzの作成や解凍を行うことができます。
しかし、本記事の主眼はzipfileとgzipにあるため、詳しいtar操作については別の機会に譲ります。
ここでは「gzは単独では複数ファイルを束ねない。複数ファイルを扱いたいならtarやzipfileが必要」という点だけ押さえておいてください。
ZIP/gz圧縮解凍の実践パターン
フォルダ丸ごとをZIP圧縮する
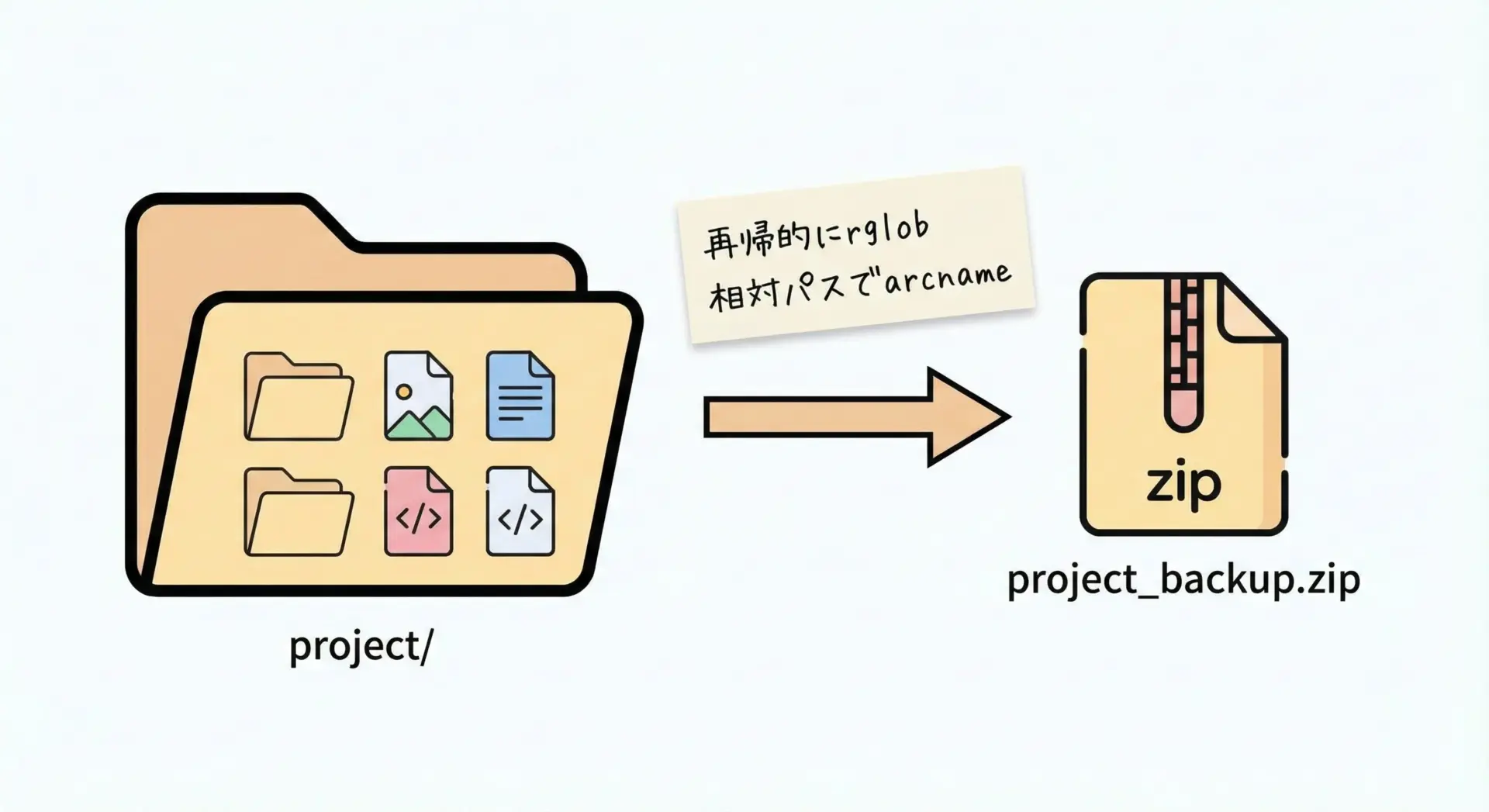
実務で最もよくあるパターンの1つがフォルダを丸ごとZIPバックアップする処理です。
すでに紹介したサンプルを発展させ、より実用的な関数にまとめてみます。
import zipfile
from pathlib import Path
def zip_directory(src_dir: Path, zip_path: Path, compresslevel: int = 6) -> None:
"""ディレクトリを再帰的に走査してZIPにまとめるユーティリティ関数"""
with zipfile.ZipFile(
zip_path,
mode="w",
compression=zipfile.ZIP_DEFLATED,
compresslevel=compresslevel,
) as zf:
for path in src_dir.rglob("*"):
if path.is_file():
# src_dirからの相対パスをそのままZIP内パスにする
arcname = path.relative_to(src_dir)
zf.write(path, arcname=arcname)
if __name__ == "__main__":
src = Path("project")
dst = Path("backup/project_backup.zip")
dst.parent.mkdir(parents=True, exist_ok=True)
zip_directory(src, dst, compresslevel=6)
print(f"Backed up {src} to {dst}")Backed up project to backup/project_backup.zipこのように関数化しておくと、定期バックアップやデプロイスクリプトに簡単に組み込めるため便利です。
ログファイルを自動でgz圧縮するスクリプト
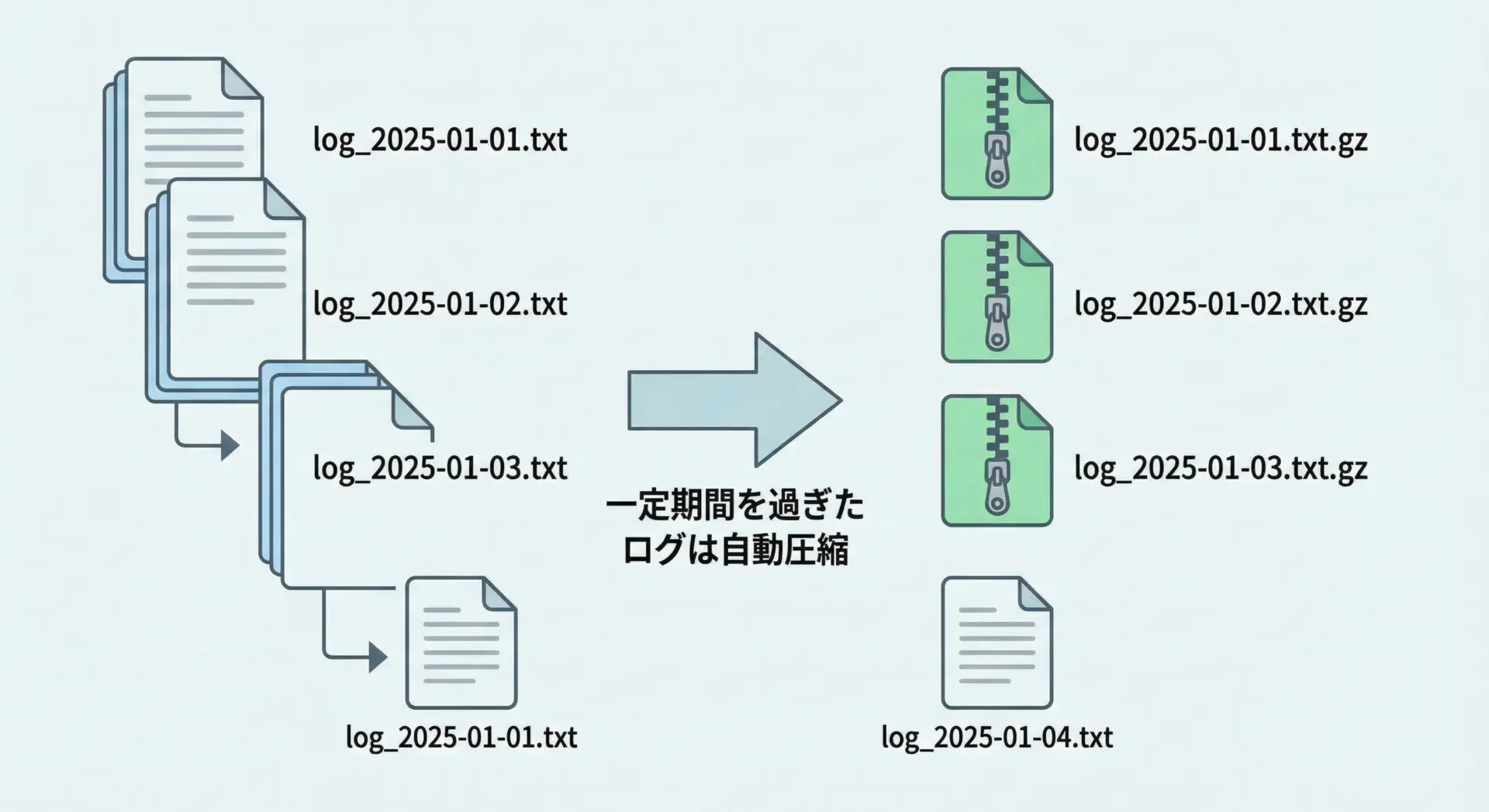
サーバ運用では、一定期間経過したログファイルを自動的にgz圧縮してディスク容量を節約するという運用がよく行われます。
ここでは「7日以上前のログを.gzに変換する」という簡単なスクリプト例を示します。
import gzip
from pathlib import Path
from datetime import datetime, timedelta
LOG_DIR = Path("logs")
DAYS_TO_KEEP_PLAIN = 7 # この日数より古いログを圧縮する
def compress_old_logs():
cutoff = datetime.now() - timedelta(days=DAYS_TO_KEEP_PLAIN)
for log_file in LOG_DIR.glob("*.log"):
# すでにgz済みのファイルは対象外
gz_file = log_file.with_suffix(log_file.suffix + ".gz")
if gz_file.exists():
continue
# 更新日時が古いものだけ圧縮
mtime = datetime.fromtimestamp(log_file.stat().st_mtime)
if mtime > cutoff:
continue
print(f"Compressing {log_file} to {gz_file}")
# 圧縮
with log_file.open("rb") as src, gzip.open(gz_file, "wb") as dst:
while True:
chunk = src.read(1024 * 1024)
if not chunk:
break
dst.write(chunk)
# 元のログファイルを削除
log_file.unlink()
if __name__ == "__main__":
LOG_DIR.mkdir(exist_ok=True)
compress_old_logs()このスクリプトをcronやWindowsタスクスケジューラで毎日実行すれば、ログディレクトリの容量を自動的に管理できます。
大容量ファイルを分割して圧縮・解凍する
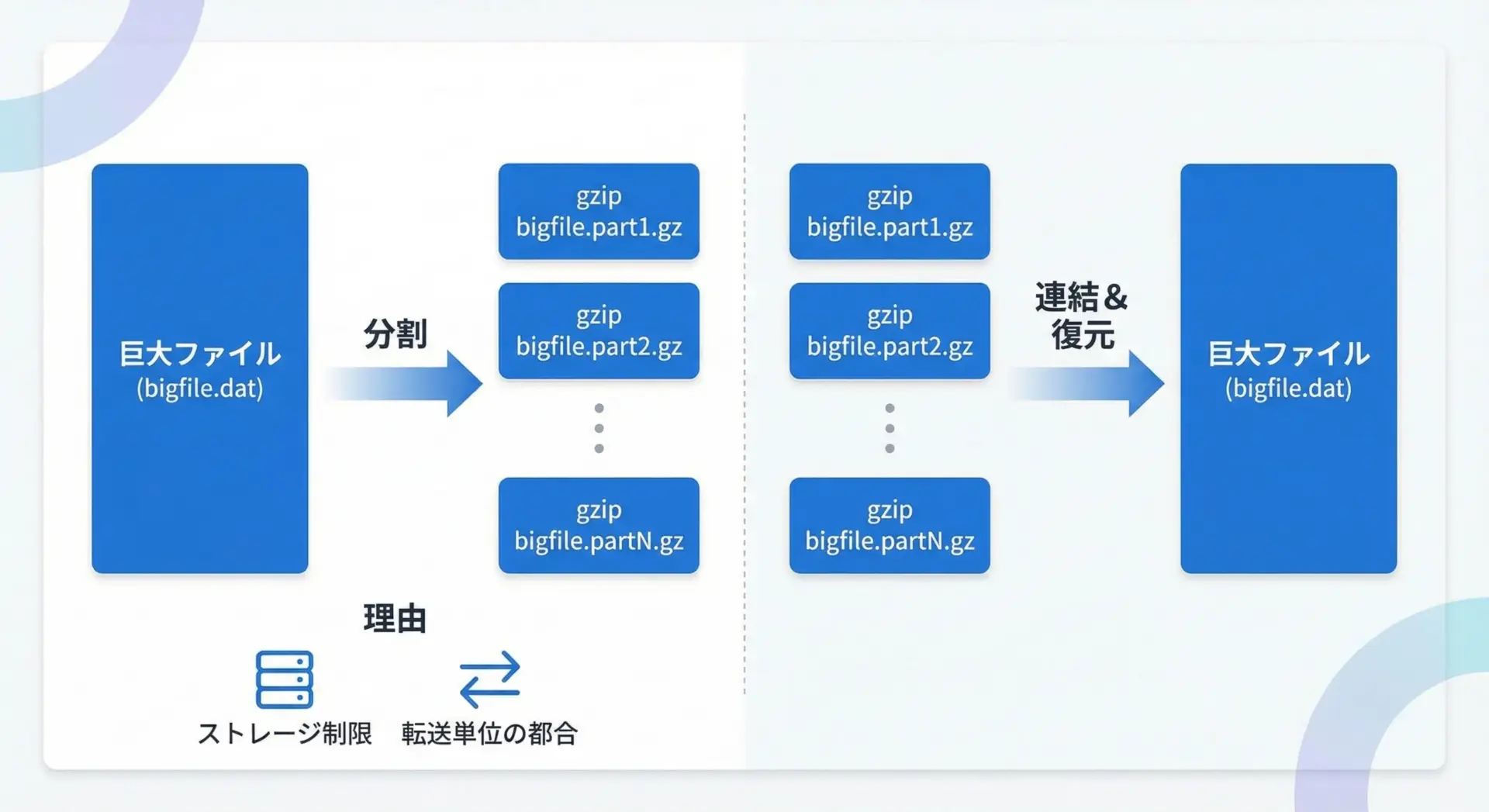
標準ライブラリだけで「マルチパートZIP」のような高度な機能を実装するのは容易ではありませんが、単純にファイルをチャンクに分割し、それぞれをgzip圧縮して保存することは可能です。
以下は、大きなファイルを一定サイズごとに分割圧縮するシンプルな例です。
import gzip
from pathlib import Path
CHUNK_SIZE = 50 * 1024 * 1024 # 50MBごとに分割
def split_and_compress(src_path: Path, out_dir: Path):
out_dir.mkdir(parents=True, exist_ok=True)
part_index = 1
with src_path.open("rb") as src:
while True:
chunk = src.read(CHUNK_SIZE)
if not chunk:
break
part_path = out_dir / f"{src_path.name}.part{part_index:03d}.gz"
with gzip.open(part_path, "wb") as dst:
dst.write(chunk)
print(f"Wrote {part_path} ({len(chunk)} bytes before compress)")
part_index += 1
def restore_from_parts(out_dir: Path, base_name: str, dst_path: Path):
with dst_path.open("wb") as dst:
part_index = 1
while True:
part_path = out_dir / f"{base_name}.part{part_index:03d}.gz"
if not part_path.exists():
break
with gzip.open(part_path, "rb") as src:
while True:
chunk = src.read(1024 * 1024)
if not chunk:
break
dst.write(chunk)
print(f"Restored from {part_path}")
part_index += 1
if __name__ == "__main__":
source = Path("bigfile.dat")
parts_dir = Path("parts")
restored = Path("bigfile_restored.dat")
split_and_compress(source, parts_dir)
restore_from_parts(parts_dir, source.name, restored)クラウドストレージのアップロード制限や、メール添付の容量制限など、ファイルを分割したい事情はいろいろあります。
上記のようなスクリプトをベースに、自分の環境に合わせた分割ロジックを組み込むことができます。
メモリ上のデータをZIP/gz圧縮する
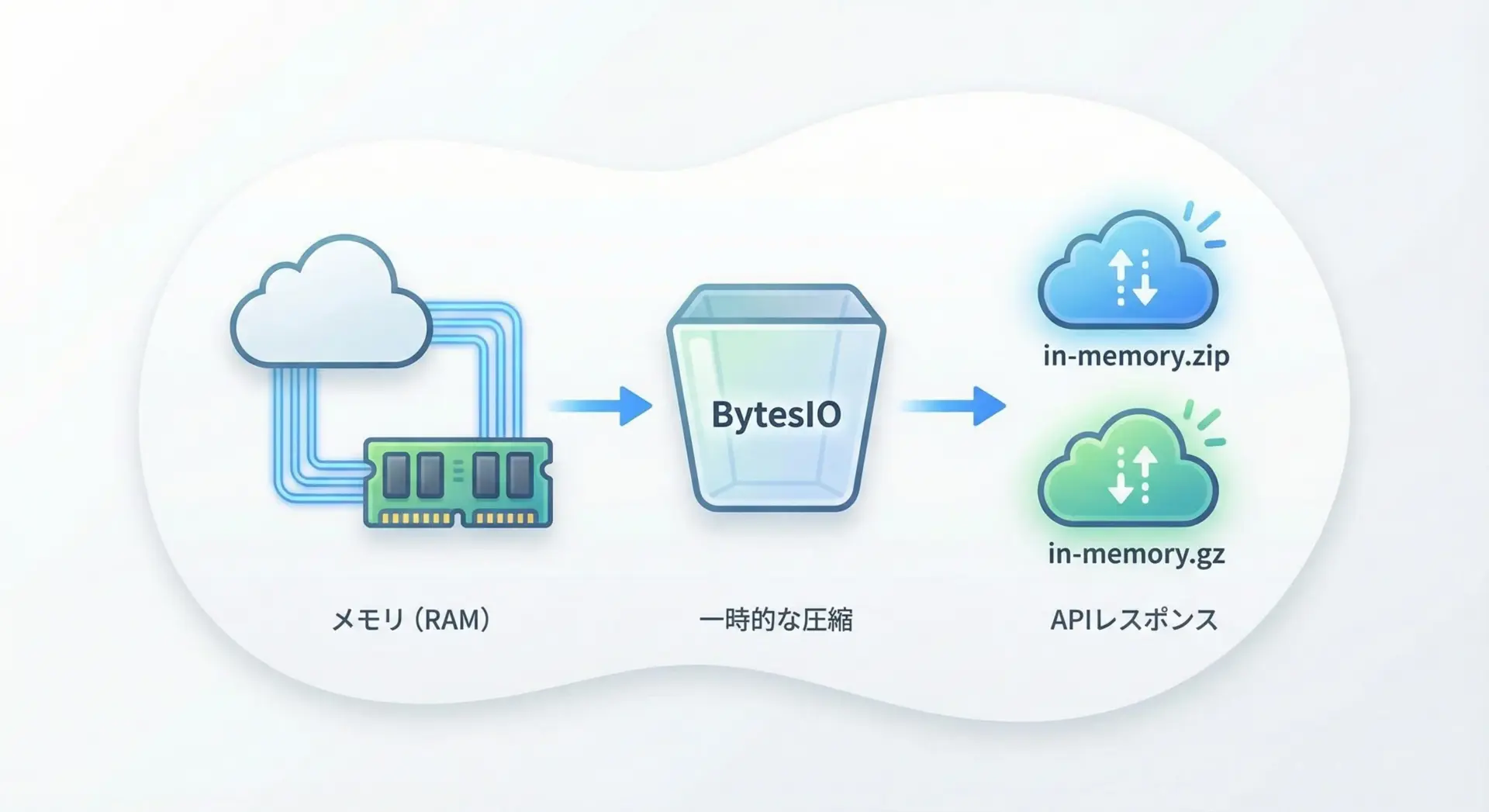
場合によっては、ディスクに一時ファイルを作らず、メモリ上で圧縮を完結させたいことがあります。
例えば、Web APIで動的に生成したデータを圧縮して返す場合などです。
そのようなときはio.BytesIOを使うと便利です。
メモリ上にZIPを作成する
import io
import zipfile
def create_in_memory_zip(files: dict[str, bytes]) -> bytes:
"""メモリ上にZIPファイルを生成し、そのバイト列を返す"""
buf = io.BytesIO()
with zipfile.ZipFile(buf, "w", compression=zipfile.ZIP_DEFLATED) as zf:
for name, data in files.items():
# writestrでメモリ上のバイト列を直接ZIPに書き込む
zf.writestr(name, data)
# バッファの内容をbytesとして取り出す
return buf.getvalue()
if __name__ == "__main__":
files = {
"hello.txt": "こんにちはZIP\n".encode("utf-8"),
"data.json": b'{"value": 123}',
}
zip_bytes = create_in_memory_zip(files)
print(f"ZIP size in memory: {len(zip_bytes)} bytes")ZIP size in memory: 262 bytesメモリ上にgzipを作成する
import io
import gzip
def compress_to_gzip_bytes(data: bytes, compresslevel: int = 6) -> bytes:
buf = io.BytesIO()
with gzip.GzipFile(fileobj=buf, mode="wb", compresslevel=compresslevel) as gz:
gz.write(data)
return buf.getvalue()
if __name__ == "__main__":
original = b"A" * 1000
gz_bytes = compress_to_gzip_bytes(original)
print(f"Original: {len(original)} bytes, Gzipped: {len(gz_bytes)} bytes")クラウド環境やFaaS(Lambdaなど)では、ディスクアクセスが遅かったり一時領域に制限があったりするため、このようなメモリベースの圧縮テクニックが有効です。
複数ファイルを一括圧縮・一括解凍するバッチ処理
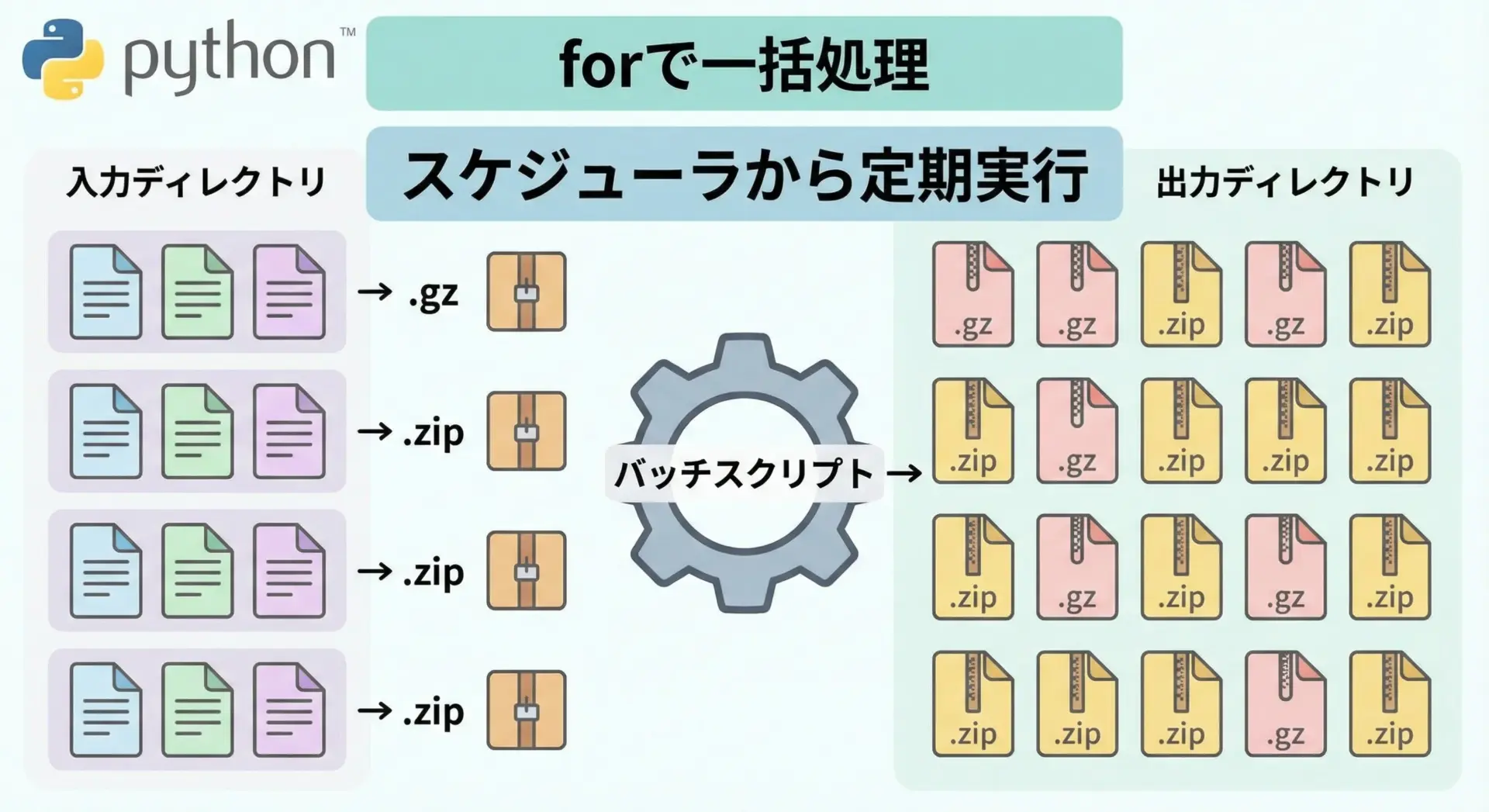
最後に、複数ファイルを一括圧縮・一括解凍するための簡易バッチスクリプトを紹介します。
環境に応じてディレクトリ名や拡張子を変更するだけで、さまざまな用途に応用できます。
ディレクトリ内の全テキストファイルをZIPにまとめる
import zipfile
from pathlib import Path
SRC_DIR = Path("texts")
ZIP_PATH = Path("texts_bundle.zip")
def batch_zip_texts():
with zipfile.ZipFile(ZIP_PATH, "w", compression=zipfile.ZIP_DEFLATED) as zf:
for path in SRC_DIR.glob("*.txt"):
zf.write(path, arcname=path.name)
print(f"Added {path}")
if __name__ == "__main__":
SRC_DIR.mkdir(exist_ok=True)
batch_zip_texts()
print(f"Created {ZIP_PATH}")ディレクトリ内の全gzファイルを解凍する
import gzip
from pathlib import Path
SRC_DIR = Path("gz_logs")
DST_DIR = Path("logs_unzipped")
def batch_gunzip():
DST_DIR.mkdir(parents=True, exist_ok=True)
for gz_path in SRC_DIR.glob("*.gz"):
dst_path = DST_DIR / gz_path.with_suffix("").name # .gzを取り除いた名前
print(f"Decompressing {gz_path} -> {dst_path}")
with gzip.open(gz_path, "rb") as src, dst_path.open("wb") as dst:
while True:
chunk = src.read(1024 * 1024)
if not chunk:
break
dst.write(chunk)
if __name__ == "__main__":
SRC_DIR.mkdir(exist_ok=True)
batch_gunzip()このようにフォルダをまたいだ一括処理スクリプトを用意しておくと、運用作業や定期バッチの効率が大きく向上します。
まとめ
本記事では、Python標準ライブラリであるzipfileモジュールとgzipモジュールを用い、ZIP形式とgz形式の違いから、基本操作、応用的な実践パターンまでを一通り解説しました。
フォルダ丸ごとのZIPバックアップ、ログの自動gz圧縮、メモリ上での圧縮処理など、ここで紹介したコードをベースにすれば、多くの現場ニーズに対応できます。
まずは小さなファイルで試しつつ、自分のプロジェクトに合わせてスクリプトを拡張し、「圧縮・解凍を自在に扱えるPythonスクリプト」を手に入れてください。
