
Web APIへのアクセスやログインが必要なサイトのスクレイピングなどで、毎回ログイン処理を書くのはとても面倒です。
このような場面で活躍するのがrequests.Sessionです。
本記事では、Pythonの定番HTTPライブラリであるrequestsのSession機能を使って、Cookieや認証情報を自動で引き継ぎ、再ログイン不要な実装を行う方法を、具体的なコード例とともに詳しく解説します。
requests.Sessionとは何か
requestsとの違いとSessionの仕組み
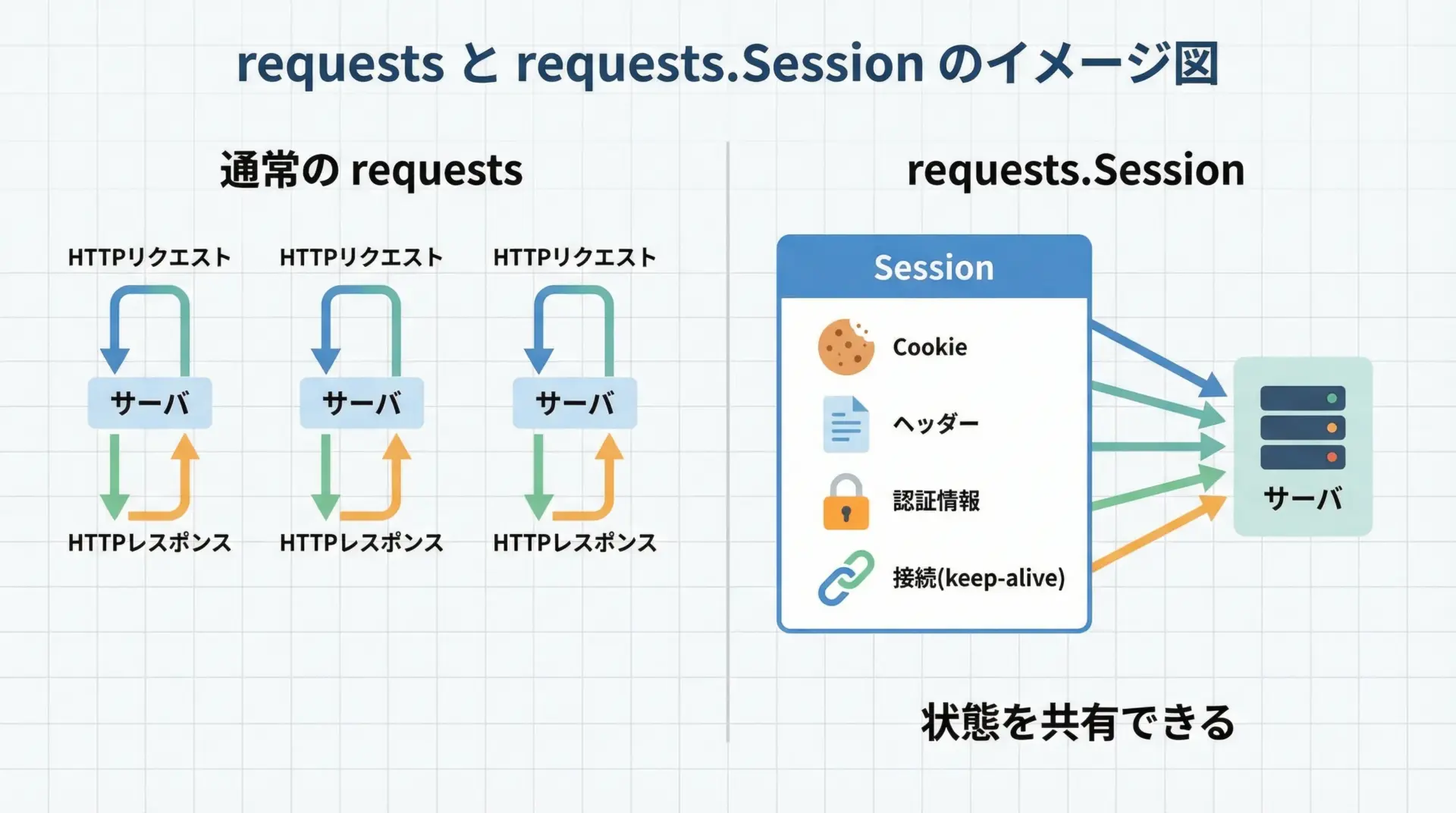
requests.Sessionは、Pythonのrequestsライブラリが提供するHTTPセッション(状態を持った通信のまとまり)を扱うためのクラスです。
通常のrequests.getやrequests.postは、1回のリクエストごとに完結しますが、Sessionオブジェクトを使うと、複数回のリクエストにまたがって以下の情報を自動的に共有します。
- Cookie
- デフォルトヘッダー
- 認証情報
- 一部の接続情報(keep-alive接続による性能向上)
つまり、「同じブラウザタブからの連続アクセス」のような状態を、Python側で再現できるのがrequests.Sessionです。
通常のrequestsでは、毎回ヘッダーやクッキーを自分で付け直さなければいけません。
しかしSessionを使えば、一度設定してしまえば、以降のリクエストに自動的に引き継がれます。
セッション管理でできること
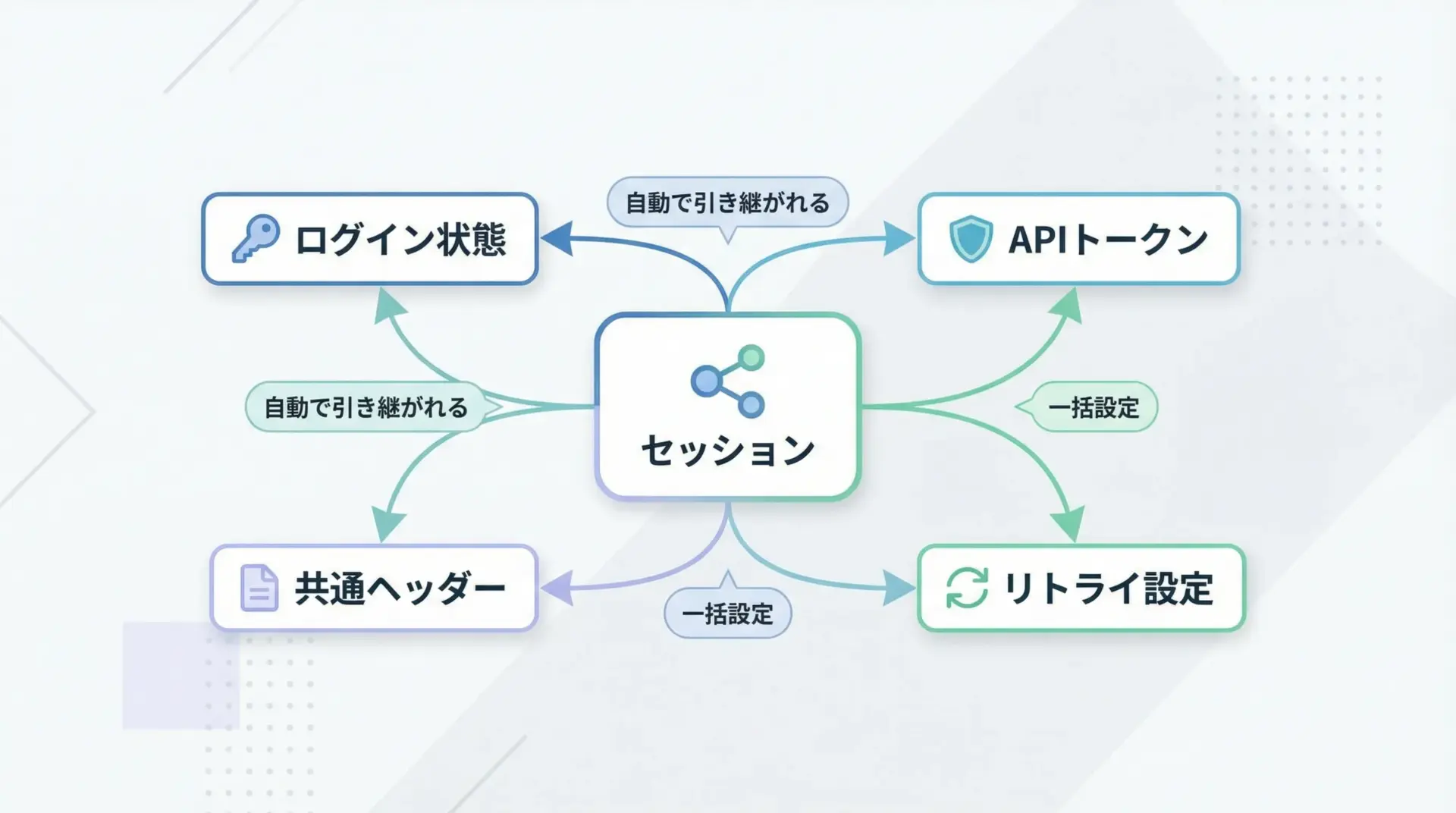
Sessionをうまく使うと、次のような便利なことが可能になります。
1つ目は、ログイン後のCookieを引き継いで、再ログインせずに連続アクセスできることです。
スクレイピングや社内システムの自動操作などで、毎回ログインフォームを叩かずに済みます。
2つ目は、ベーシック認証やトークン認証の設定を共通化できることです。
APIクライアントを作るときに、一度Sessionに認証情報を設定すれば、あとはURLとボディだけに集中できます。
3つ目は、タイムアウトやリトライ戦略などの通信設定を一括で管理できる点です。
これにより、全API呼び出しで安定した挙動を保ちやすくなります。
このようにrequests.Sessionは、「状態を持つHTTPクライアント」として扱うとイメージしやすいです。
Cookieを保持する基本的な使い方
SessionでのCookie自動送受信
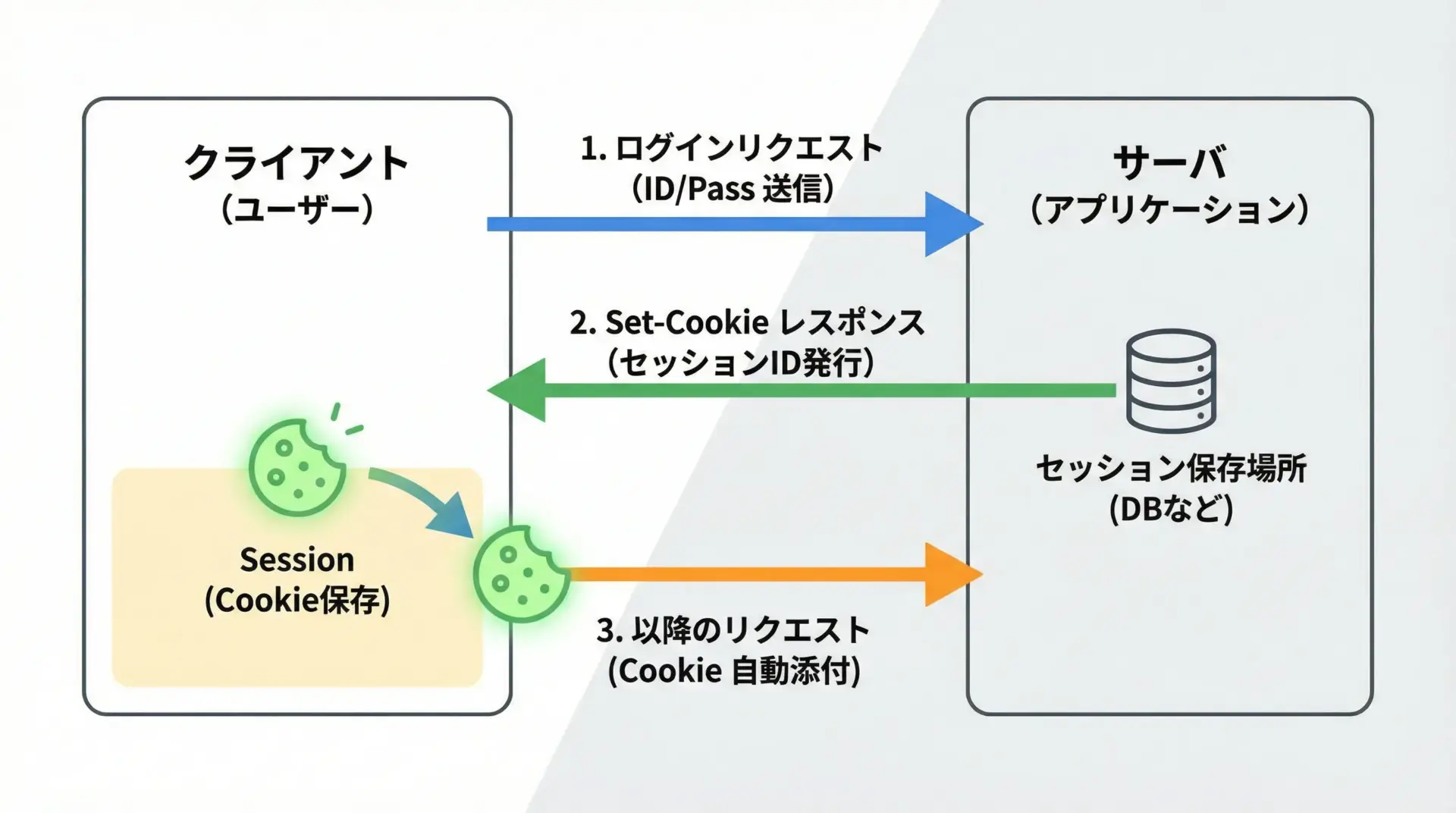
SessionはCookieを自動で受信・保持・送信してくれます。
ブラウザがCookieを扱うのと同じような動きを、Python側で実現できます。
まずは、Cookieが自動的に保持される簡単なサンプルコードを見てみます。
import requests
def simple_cookie_session():
# Sessionオブジェクトを生成
session = requests.Session()
# 1回目のアクセスでCookieを設定するエンドポイント(例)
login_url = "https://httpbin.org/cookies/set/sessionid/abc123"
# 1回目: Cookieを設定するためのアクセス
res1 = session.get(login_url)
print("1回目アクセス後のレスポンスURL:", res1.url)
# Sessionが保持しているCookieを確認
print("Sessionが保持しているCookie:")
for cookie in session.cookies:
print(f" {cookie.name} = {cookie.value}")
# 2回目: Cookieを送信して、サーバ側でどう見えるか確認
check_url = "https://httpbin.org/cookies"
res2 = session.get(check_url)
print("2回目アクセス時にサーバが受け取ったCookie情報:")
print(res2.text)
if __name__ == "__main__":
simple_cookie_session()上記コードでは、1回目のアクセスでsessionidというCookieを設定し、その後のアクセスで自動的に送信されていることを確認しています。
session.cookiesに対してループを回すことで、Sessionに保存されているCookieの一覧を確認できます。
ログイン後のCookieを使った継続アクセス

実際のWebサイトでは、ログインフォームにユーザ名とパスワードを送信し、成功するとセッションIDなどのCookieが発行されます。
このCookieをSessionが自動的に保持し、その後のページにも引き継いでくれるため、再ログインなしで保護されたページにアクセスできます。
以下は、ログイン後にマイページへアクセスする一般的なパターンのイメージコードです。
import requests
def login_and_access_mypage(username: str, password: str):
# Sessionを作成
session = requests.Session()
# ログインURLとマイページURL(ここでは例)
login_url = "https://example.com/login"
mypage_url = "https://example.com/mypage"
# ログインフォームに送信するデータ(サイトごとに名前は異なります)
payload = {
"username": username, # 実際のname属性に合わせて変更
"password": password,
}
# 1. ログインフォームにPOST
# Sessionを使うことで、レスポンスで設定されたCookieを自動保持します
login_res = session.post(login_url, data=payload)
# ログインが成功しているか簡易チェック
if login_res.status_code != 200:
raise RuntimeError("ログインリクエストが失敗しました")
# 2. ログイン後のみアクセスできるマイページへアクセス
mypage_res = session.get(mypage_url)
# マイページの一部を表示(実際にはHTMLパースなどを行う)
print("マイページのステータスコード:", mypage_res.status_code)
print("マイページHTML冒頭100文字:")
print(mypage_res.text[:100])
if __name__ == "__main__":
# ダミー呼び出し(実際のサイトでは正しいURLと項目名に変更してください)
login_and_access_mypage("your_username", "your_password")このように、一度だけログイン処理を行い、その後は同じSessionインスタンスを使っていけば、Cookieベースのログイン状態を維持し続けることができます。
認証付きアクセスをSessionで簡略化
ベーシック認証(Basic認証)をSessionで扱う方法
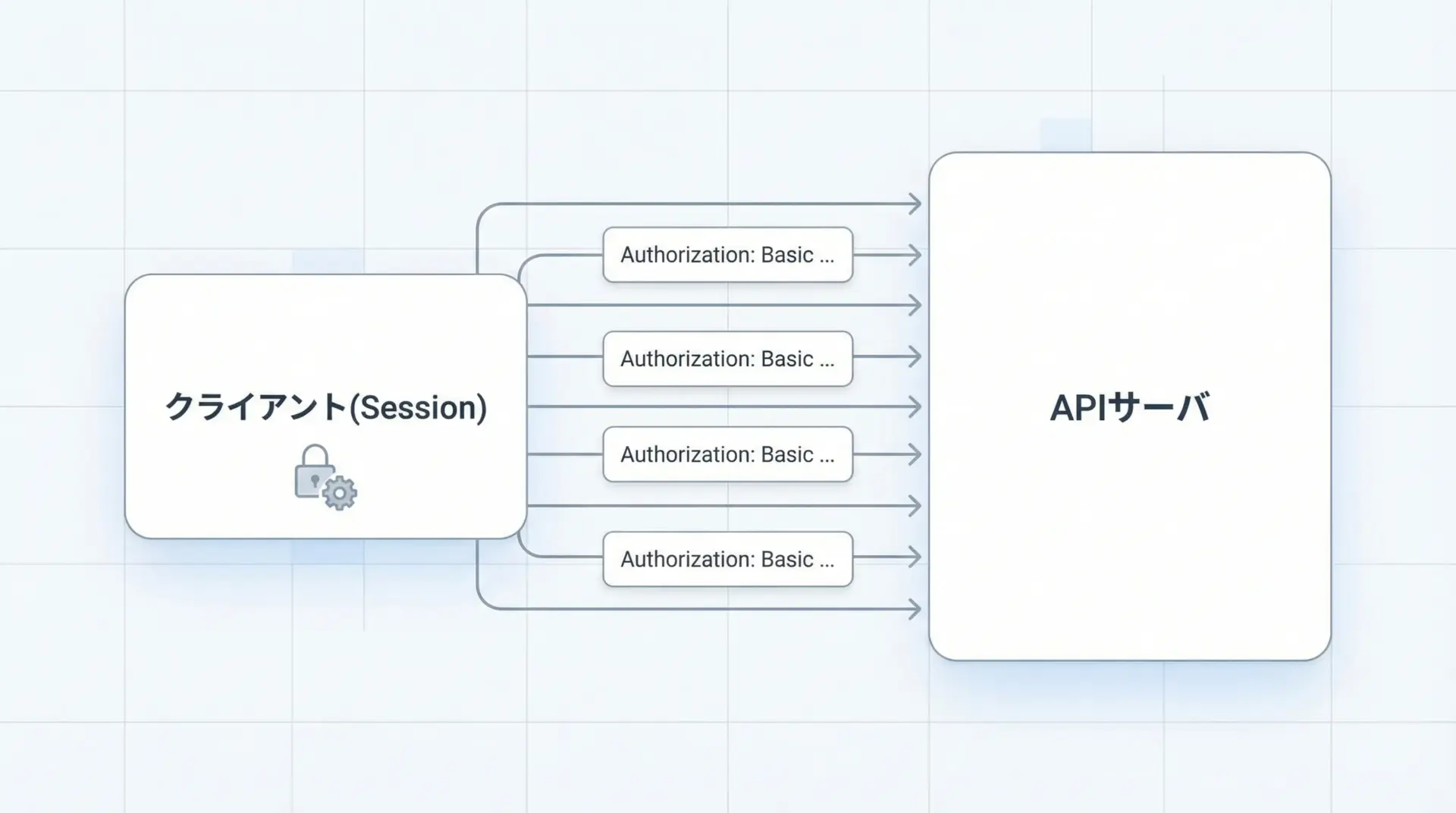
ベーシック認証は、HTTPヘッダーAuthorizationにユーザ名とパスワードをBase64エンコードした文字列を付与する方式です。
requestsでは、auth引数にタプルを渡す簡単な書き方が利用できます。
通常の1回限りのリクエストでは次のように書きます。
import requests
# 1回だけのBasic認証リクエスト
res = requests.get(
"https://httpbin.org/basic-auth/user/pass",
auth=("user", "pass"), # (ユーザ名, パスワード)
)
print(res.status_code)
print(res.json())Sessionを使えば、一度だけauthを設定して、すべてのリクエストで使い回すことができます。
import requests
def create_basic_auth_session(username: str, password: str) -> requests.Session:
# Sessionを生成
session = requests.Session()
# Session.authに設定すると、そのSessionで行う全リクエストにBasic認証ヘッダーが付与されます
session.auth = (username, password)
return session
if __name__ == "__main__":
session = create_basic_auth_session("user", "pass")
# 1回目のアクセス
res1 = session.get("https://httpbin.org/basic-auth/user/pass")
print("1回目:", res1.status_code, res1.json())
# 2回目のアクセス(毎回auth指定を書く必要がない)
res2 = session.get("https://httpbin.org/basic-auth/user/pass")
print("2回目:", res2.status_code, res2.json())このようにsession.authを設定しておくことで、APIラッパ関数側では認証情報を意識せずに実装できるようになります。
トークン認証(Bearerトークンなど)とヘッダー共通化
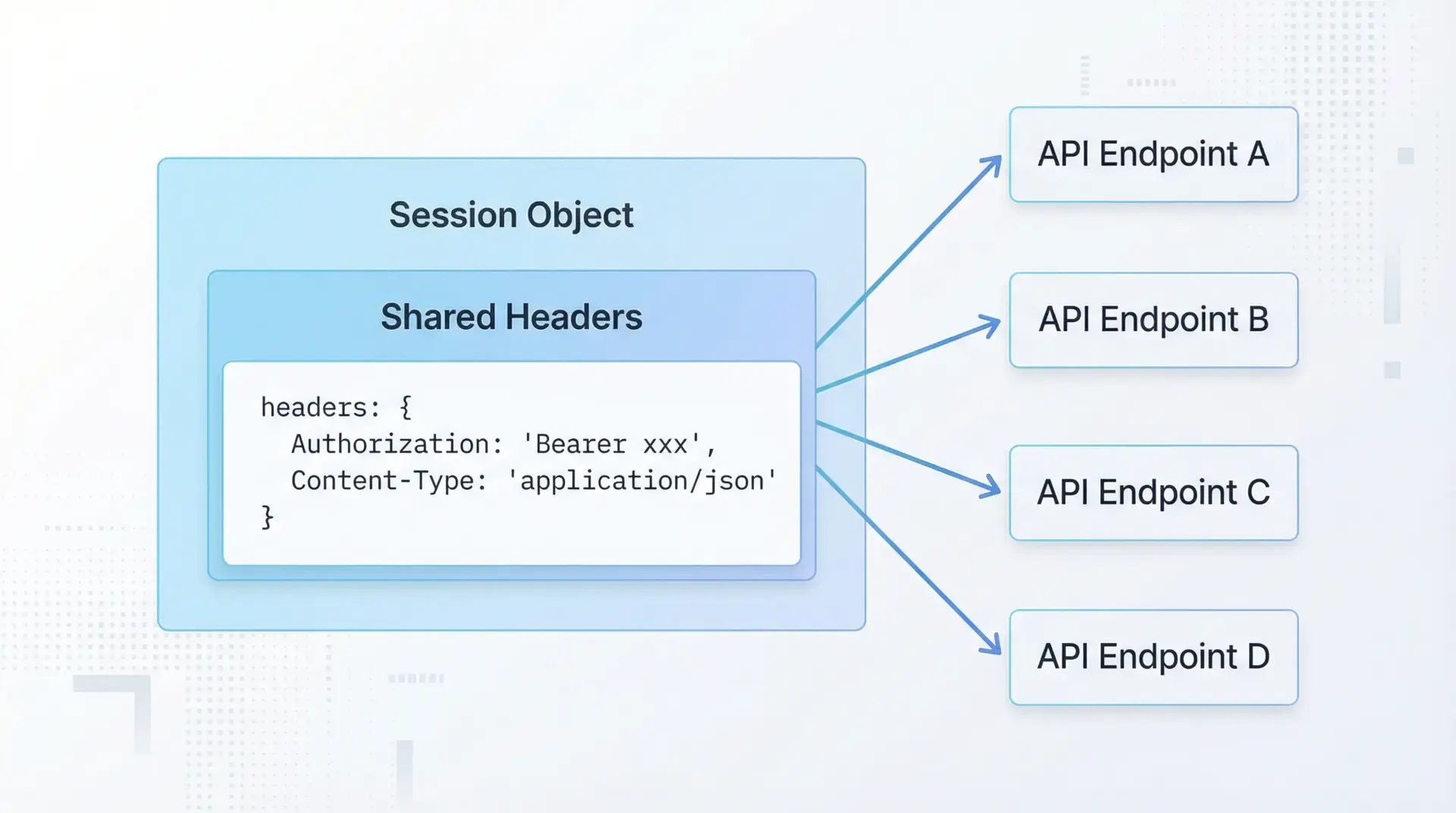
最近のAPIでは、Bearerトークンや各種トークンベースの認証が主流です。
多くの場合、Authorization: Bearer <token>のようなヘッダーを付与します。
Sessionではsession.headersに共通ヘッダーを設定することで、全てのリクエストに自動付与させることができます。
import requests
def create_token_session(token: str) -> requests.Session:
session = requests.Session()
# 共通ヘッダーを設定
session.headers.update({
"Authorization": f"Bearer {token}",
"Accept": "application/json",
# 必要に応じて他の共通ヘッダーも
})
return session
if __name__ == "__main__":
# 実際には事前に取得したアクセストークンを使います
dummy_token = "YOUR_ACCESS_TOKEN"
session = create_token_session(dummy_token)
# 以降のリクエストではAuthorizationヘッダーを明示的に書かなくてよい
res = session.get("https://httpbin.org/bearer")
print("ステータスコード:", res.status_code)
print("レスポンス:", res.text)このようにヘッダーを共通化することで、APIクライアントのコードから認証まわりの重複を取り除き、保守性を高めることができます。
再ログイン不要にするセッション管理
ログイン処理を1回だけ行う実装パターン
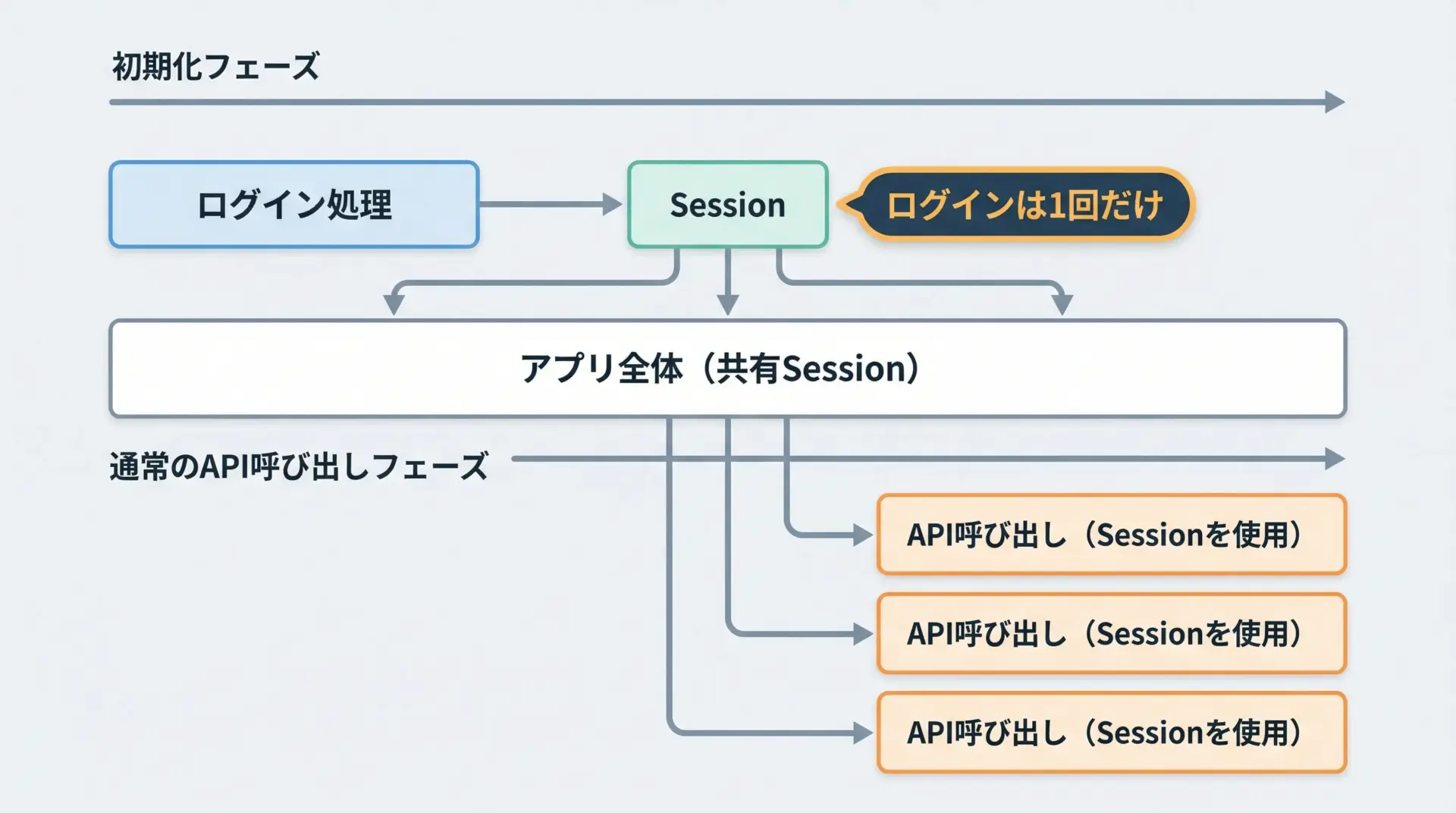
毎回ログイン処理をしてしまうと、以下の問題が発生しやすくなります。
- サーバ側の負荷やログイン試行回数制限にひっかかる
- 処理時間が無駄に長くなる
- 不要なセッションが大量に作られる
そのため、アプリケーション起動時などに1回だけログインしてSessionを作り、そのSessionを使い回すパターンがよく採用されます。
import requests
class MyServiceClient:
"""特定サービス向けのAPIクライアント"""
def __init__(self, username: str, password: str, base_url: str):
self.base_url = base_url.rstrip("/")
self.session = requests.Session()
self._login(username, password)
def _login(self, username: str, password: str) -> None:
"""コンストラクタから呼ばれる内部用ログイン処理"""
login_url = f"{self.base_url}/login"
payload = {"username": username, "password": password}
res = self.session.post(login_url, data=payload)
if res.status_code != 200:
raise RuntimeError("ログインに失敗しました")
# この時点でSessionにはログインCookieが入っている想定です
def get_profile(self):
"""ログイン後しか取得できないプロフィール情報を取得"""
url = f"{self.base_url}/api/profile"
res = self.session.get(url)
res.raise_for_status()
return res.json()
def list_items(self):
"""一覧API"""
url = f"{self.base_url}/api/items"
res = self.session.get(url)
res.raise_for_status()
return res.json()
if __name__ == "__main__":
client = MyServiceClient(
username="your_user",
password="your_pass",
base_url="https://example.com",
)
# 以降は、ログイン済みSessionを通じてAPIを呼び出せる
profile = client.get_profile()
print("プロフィール:", profile)
items = client.list_items()
print("アイテム一覧:", items)このようにクラス内でSessionを保持すると、「ログイン処理はコンストラクタ内の1回だけ」「以降のメソッドはログイン済みを前提として書ける」というシンプルな構造にできます。
セッションタイムアウト時の自動再ログイン設計
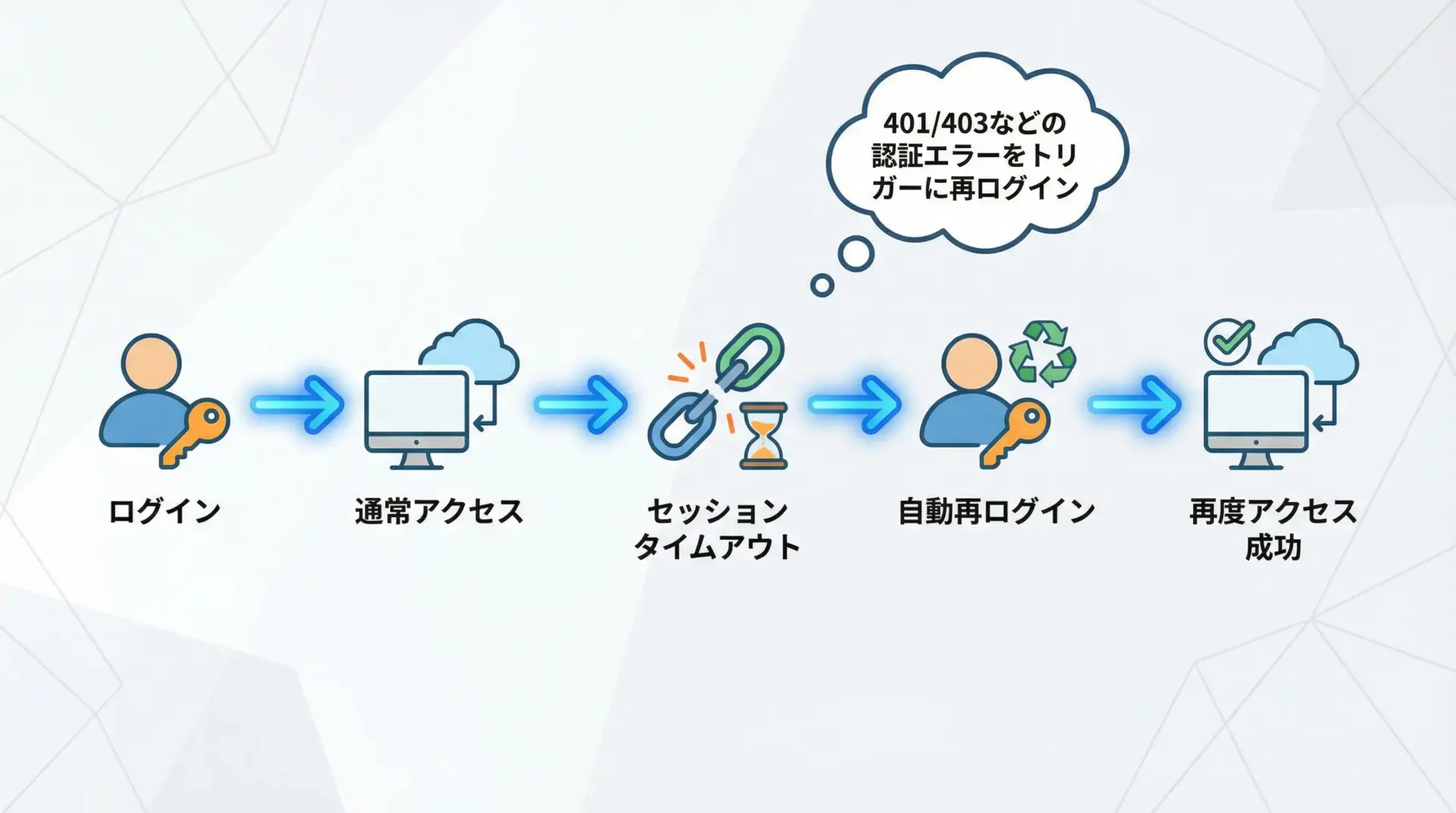
多くのサービスでは、一定時間でセッションがタイムアウトし、ログイン状態が失効します。
その場合、ログイン後APIにアクセスしようとしても、HTTPステータス401 Unauthorizedや403 Forbiddenが返ってきます。
このようなケースに対処するためには、エラーを検知したときだけ自動的に再ログインする仕組みを入れておくと便利です。
import requests
from typing import Any, Dict
class AutoReloginClient:
def __init__(self, username: str, password: str, base_url: str):
self.base_url = base_url.rstrip("/")
self.username = username
self.password = password
self.session = requests.Session()
self._login()
def _login(self) -> None:
login_url = f"{self.base_url}/login"
payload = {"username": self.username, "password": self.password}
res = self.session.post(login_url, data=payload)
if res.status_code != 200:
raise RuntimeError("ログインに失敗しました")
def _request_with_relogin(self, method: str, path: str, **kwargs) -> requests.Response:
"""
1. 通常リクエストを送る
2. 認証エラー(例: 401/403)なら再ログインして1回だけリトライ
"""
url = f"{self.base_url}/{path.lstrip('/')}"
# 1回目リクエスト
res = self.session.request(method, url, **kwargs)
if res.status_code in (401, 403):
# 認証切れと判断し、再ログイン
print("認証エラー検出。再ログインを試みます。")
self._login()
# 古いレスポンスは破棄して再度リクエスト
res = self.session.request(method, url, **kwargs)
return res
def get_json(self, path: str, **params: Any) -> Dict[str, Any]:
res = self._request_with_relogin("GET", path, params=params)
res.raise_for_status()
return res.json()
if __name__ == "__main__":
client = AutoReloginClient("user", "pass", "https://example.com")
# セッションが切れていても、自動的に再ログインしてから再実行される
data = client.get_json("/api/some-resource")
print(data)このような仕組みを入れておくと、長時間動かし続けるバッチ処理や常駐プロセスでも、手動で再ログインを意識せずに済むようになります。
実装パターンとコード例
初期化関数でSessionを生成する設計
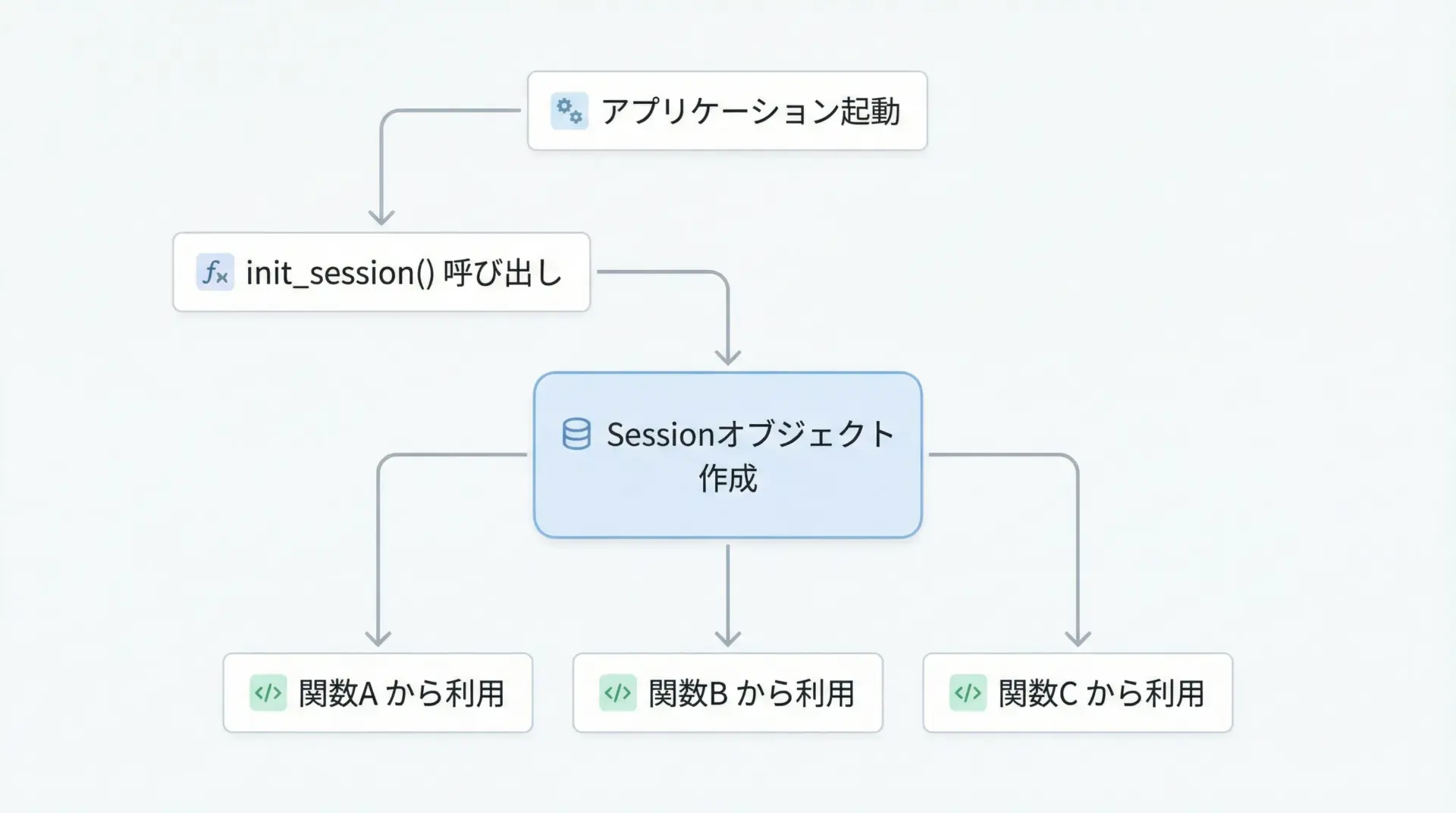
オブジェクト指向にせず、関数ベースでシンプルに書きたい場合は、初期化関数でSessionを生成し、それを他の関数に渡す形が扱いやすいです。
import requests
def init_session(base_url: str, token: str) -> requests.Session:
"""API用Sessionを初期化して返す関数"""
session = requests.Session()
session.base_url = base_url.rstrip("/") # 独自属性を持たせることも可能
# 認証ヘッダーなど共通設定
session.headers.update({
"Authorization": f"Bearer {token}",
"Accept": "application/json",
})
return session
def get_user_info(session: requests.Session, user_id: int):
"""ユーザー情報取得API"""
url = f"{session.base_url}/api/users/{user_id}"
res = session.get(url)
res.raise_for_status()
return res.json()
def get_projects(session: requests.Session):
"""プロジェクト一覧取得API"""
url = f"{session.base_url}/api/projects"
res = session.get(url)
res.raise_for_status()
return res.json()
if __name__ == "__main__":
session = init_session("https://api.example.com", token="YOUR_TOKEN")
user = get_user_info(session, user_id=123)
print("ユーザー情報:", user)
projects = get_projects(session)
print("プロジェクト一覧:", projects)このような設計にすると、Sessionの初期設定が一箇所にまとまり、設定変更や差し替えが容易になります。
コンテキストマネージャ(with文)でのSession管理
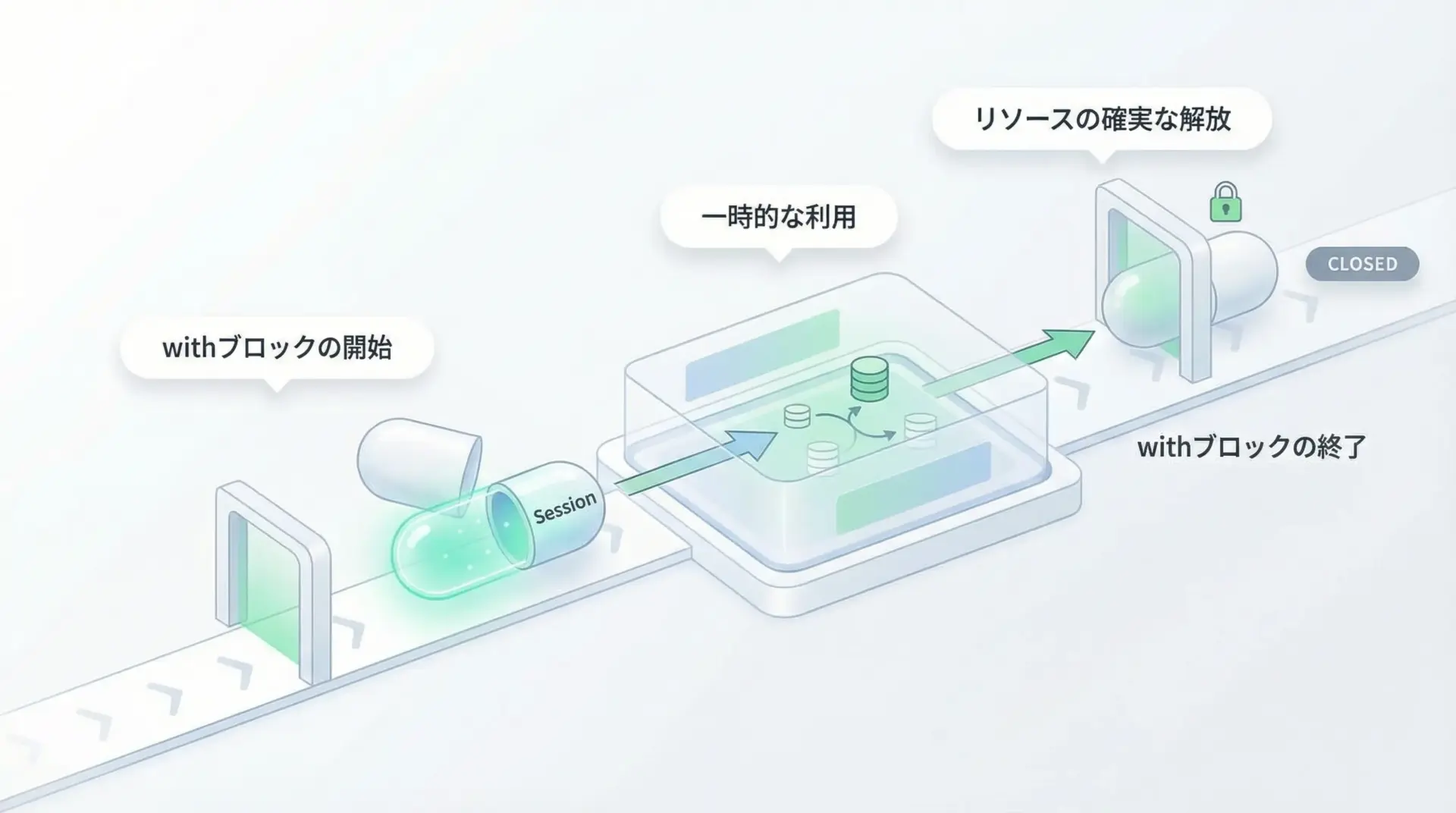
Sessionは内部でコネクションプールなどのリソースを持つため、使い終わったらclose()しておくのが望ましいです。
with文を使えば、自動的にクローズされるので安心です。
import requests
def fetch_multiple_urls(urls):
# with文の中でSessionを利用し、抜けると自動的にclose()されます
with requests.Session() as session:
results = {}
for url in urls:
res = session.get(url, timeout=5)
res.raise_for_status()
results[url] = res.text[:80] # 冒頭だけ格納
return results
if __name__ == "__main__":
urls = [
"https://httpbin.org/get",
"https://example.com",
]
contents = fetch_multiple_urls(urls)
for url, head in contents.items():
print(f"{url} の冒頭:")
print(head)
print("-" * 40)このパターンは、「ある処理ブロックの中だけでSessionを完結させたい」場合に特に有効です。
スクリプトの一部で一時的に大量のリクエストをまとめて投げるときなどに使うと、後処理漏れを防げます。
リトライ設定やタイムアウトを含めたSession活用
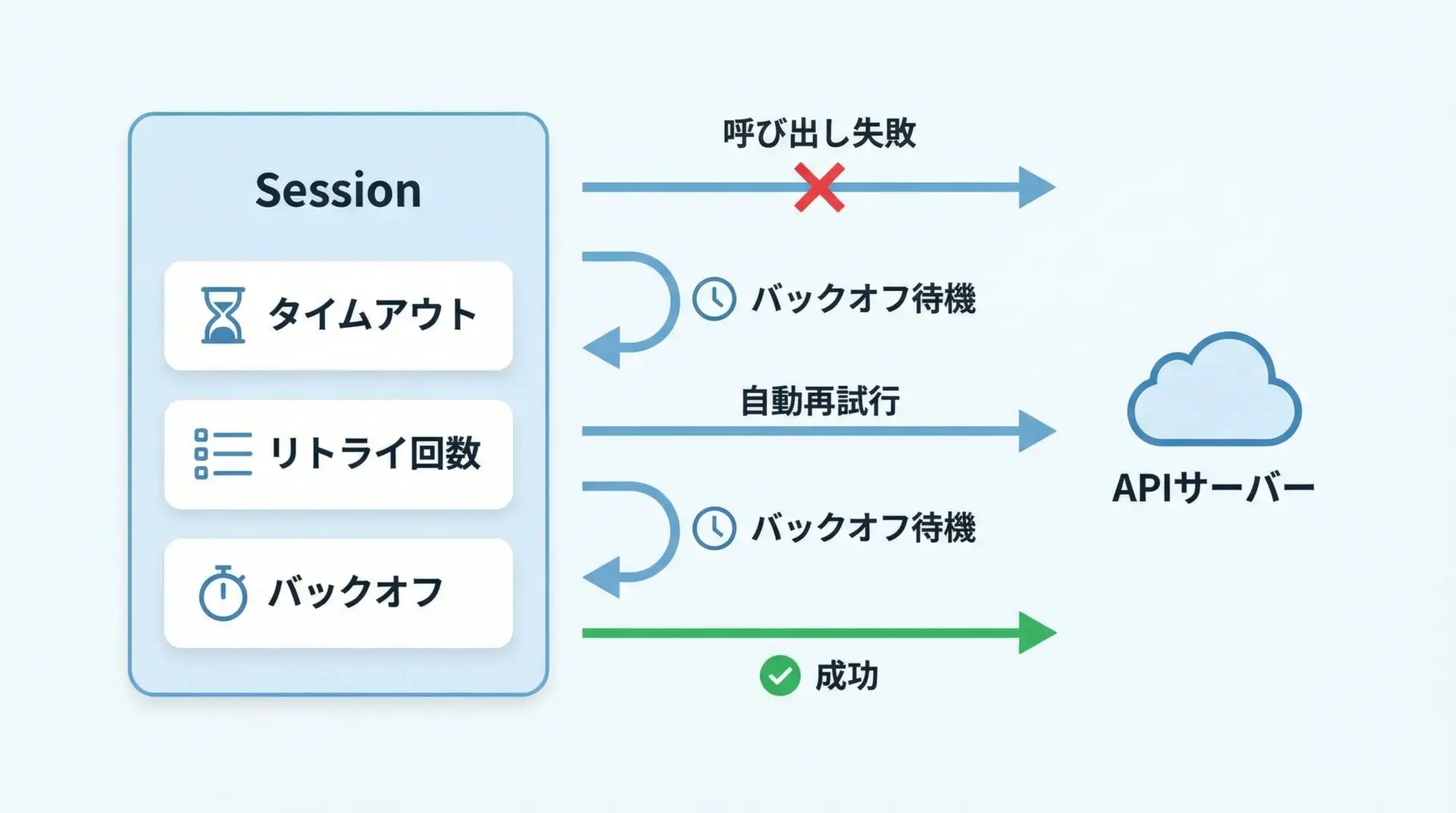
ネットワークやAPIサーバは一時的に不安定になることがあります。
そのため、タイムアウトやリトライ設定を組み込んだSessionを用意しておくと、実運用での安定性が大きく向上します。
requestsそのものには高レベルなリトライ機能はありませんが、urllib3.util.retry.Retryとrequests.adapters.HTTPAdapterを組み合わせることで、Session単位でリトライ戦略を適用できます。
import requests
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
def create_robust_session() -> requests.Session:
session = requests.Session()
# リトライ戦略を定義
retry_strategy = Retry(
total=3, # 最大リトライ回数
backoff_factor=1.0, # リトライ間隔(指数バックオフ: 1秒, 2秒, 4秒...)
status_forcelist=[502, 503, 504], # リトライ対象のステータスコード
allowed_methods=["GET", "POST"], # リトライ対象メソッド
)
# 上記戦略を持つHTTPAdapterを作成してSessionにマウント
adapter = HTTPAdapter(max_retries=retry_strategy)
session.mount("http://", adapter)
session.mount("https://", adapter)
return session
if __name__ == "__main__":
session = create_robust_session()
try:
# 各リクエストでタイムアウトも付けることで、ハングを防止
res = session.get("https://httpbin.org/status/503", timeout=5)
print("最終ステータスコード:", res.status_code)
except requests.exceptions.RequestException as e:
print("リクエストに失敗しました:", e)このように一度リトライ戦略を設定したSessionを使い回すことで、全てのAPI呼び出しに一貫した耐障害性を持たせることができます。
よくあるハマりどころと注意点
Cookieが引き継がれないときの確認ポイント
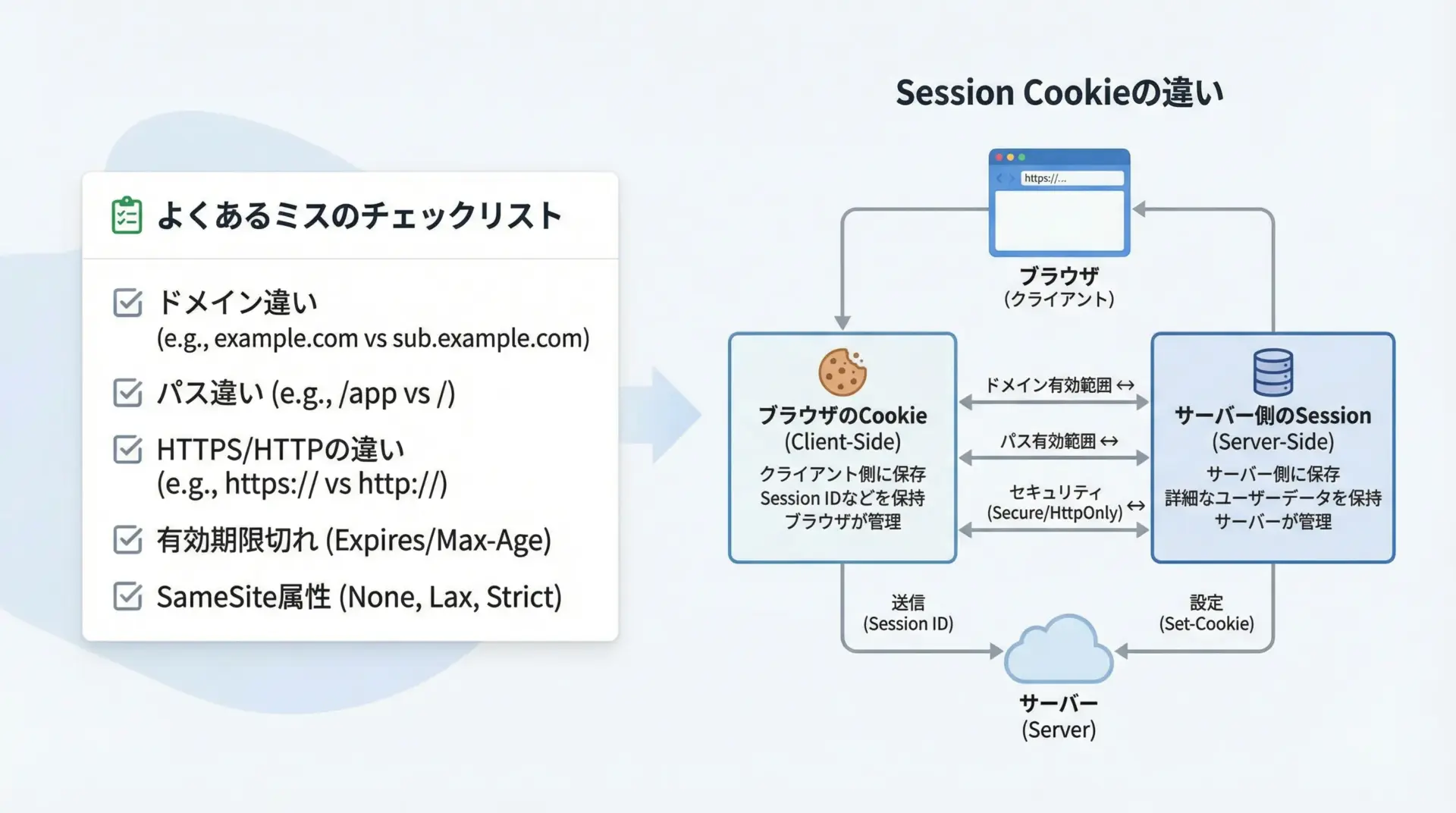
Sessionを使っているのにCookieが引き継がれていないように見える場合、次のようなポイントを確認すると原因を特定しやすくなります。
最初に確認すべきなのは、同じSessionインスタンスを使い回しているかです。
毎回requests.Session()を新しく生成していると、そのたびにCookieがリセットされてしまいます。
次に、URLのドメインやパスがCookieの有効範囲に収まっているかを確認します。
CookieにはDomainやPath属性があり、これに合致しないリクエストには自動送信されません。
例えばexample.comで発行されたCookieはsub.example.comには送信されない場合があります。
また、HTTPとHTTPSが混在している場合も注意が必要です。
Secure属性付きのCookieはHTTPS接続でしか送信されません。
そのため、HTTPでアクセスしているとCookieが見えないように感じます。
最後に、JavaScriptで設定されるCookieにも注意が必要です。
ブラウザではJavaScript経由でCookieが設定されますが、requestsはJavaScriptを実行しないため、サーバ側からのSet-CookieヘッダーでしかCookieを取得できない点を理解しておくとトラブルを避けやすくなります。
Cookieの内容はsession.cookiesをprintするだけでも確認できますが、より詳しく見たい場合は次のようにして一覧表示するとよいです。
def debug_cookies(session: requests.Session):
print("=== Cookie一覧 ===")
for cookie in session.cookies:
print(
f"name={cookie.name}, value={cookie.value}, "
f"domain={cookie.domain}, path={cookie.path}, secure={cookie.secure}"
)セッション使い回しによるバグとスレッドセーフティ

Sessionはとても便利ですが、むやみに使い回すと逆にバグの温床になることもあります。
代表的な問題として、複数のユーザーを扱う処理でSessionを共有してしまうケースがあります。
例えば、ユーザーAでログインしたSessionを、誤ってユーザーB用の処理でも使ってしまうと、認可されていないデータにアクセスしてしまうなどの重大なバグにつながる可能性があります。
もう1つ重要なのが、マルチスレッド環境でのSession共有です。
requestsのSessionはスレッドセーフと明言されておらず、同じSessionインスタンスに対して並列にリクエストを投げると、内部状態(Cookieやコネクションプールなど)の一貫性が崩れるリスクがあります。
そのため、以下のような方針を守ると安全です。
1つ目は、ユーザーやコンテキストごとにSessionを分けることです。
ユーザー認証を伴う場合、ユーザーA用SessionとユーザーB用Sessionを別々に持ち、絶対に混在させないようにします。
2つ目は、スレッドごとにSessionを作るか、もしくはスレッドローカルな変数にSessionを持たせることです。
これにより、各スレッドが自身のSessionのみを扱うようにできます。
3つ目は、長期間生き続けるグローバルSessionを慎重に扱うことです。
アプリ全体で1つのグローバルSessionを使い回す設計は、一見効率的ですが、バグの影響範囲が非常に広くなりがちです。
用途が限定されている場合にのみ、慎重に採用するようにします。
まとめ
requests.Sessionは、Cookieや認証情報を自動的に引き継ぐことで、「ログイン状態を維持した連続アクセス」や「共通設定を持つAPIクライアント」を簡潔に実装できる強力な仕組みです。
ログイン後のCookie保持、Basic認証やBearerトークンの共通化、リトライやタイムアウト戦略を含んだ堅牢なSession設計まで、用途に応じて柔軟に活用できます。
一方で、Cookieが引き継がれない原因や、セッション共有によるバグ、スレッドセーフティなどの注意点も理解しておくことが重要です。
これらのポイントを押さえたうえでSessionを使いこなせば、PythonでのHTTP通信が格段に扱いやすくなります。
