
Pythonのrequestsは便利ですが、timeoutを正しく設計しないと、本番環境で「ハングして見える」致命的なトラブルを引き起こします。
本記事では、timeoutの基本概念から、具体的な設定レシピ、エラー処理やチューニングの実践テクニックまでを体系立てて解説します。
サンプルコードはすべてコピペで試せる形で掲載しています。
requestsのtimeout基礎
timeoutとは何かと必要性

HTTP通信では、ネットワークの遅延や外部サービスの障害などにより、応答が返ってこない状況が起こり得ます。
timeoutとは「この時間を過ぎても応答がなければ通信を中断する」という上限時間のことです。
Pythonのrequestsは、timeoutを指定しない場合、OS側のソケットの設定に依存し、実質「かなり長い」時間待ち続けることがあります。
これは次のような問題を引き起こします。
- バッチ処理が終わらず、後続ジョブが詰まる
- Webアプリのワーカーが塞がり、サービス全体が重くなる
- 外部API障害時に、アプリ全体が巻き込まれてダウンする
そのため、外部サービスにアクセスするコードには、基本的に必ずtimeoutを指定することが重要です。
接続timeoutと読み取りtimeoutの違い
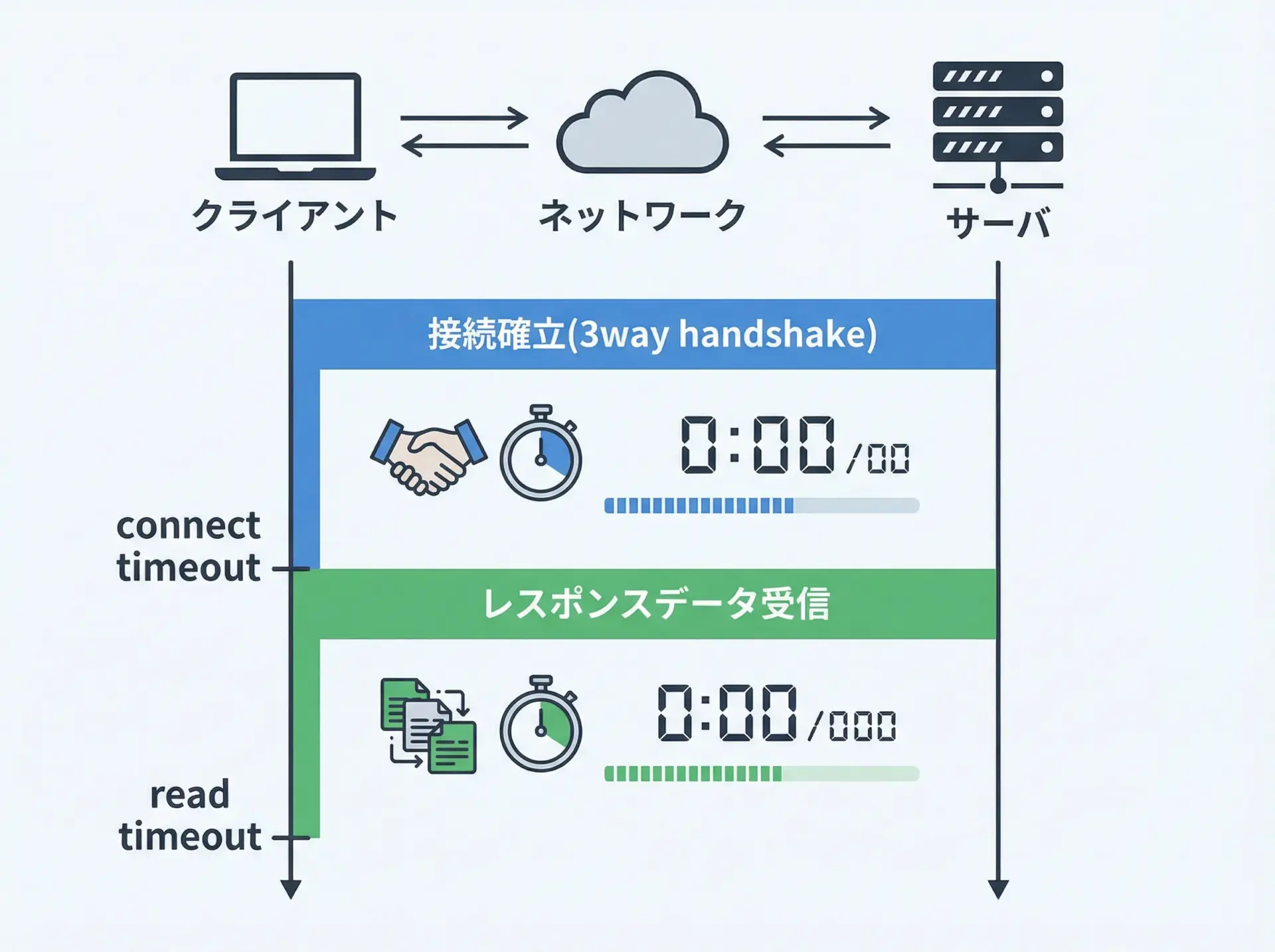
timeoutには大きく2種類あります。
1つ目は接続timeout(connect timeout)です。
これは、クライアントからサーバへのTCP接続を確立するまでに待つ最大時間です。
サーバがダウンしていたり、DNS解決ができないような場合は、接続timeoutが発生します。
2つ目は読み取りtimeout(read timeout)です。
これは、接続はできたものの、サーバからレスポンスデータが返ってくるまでに待つ最大時間です。
サーバ内部の処理が遅い場合や、高負荷で応答が返せない場合には、読み取りtimeoutの問題になります。
connect timeoutは短め(数秒)、read timeoutはある程度長め(要求に応じて数秒〜数十秒)にするのが典型的な設計です。
理由として、接続できない状況は待っても改善が少ない一方で、正常な重い処理(レポート生成など)では、レスポンス時間自体が長くなることがあるためです。
デフォルト動作と注意点
Pythonのrequestsでは、timeoutを指定しないと、「無制限」ではありませんが、実務上ほぼ無制限に近い長さで待ち続ける挙動となります。
公式ドキュメントでも、timeoutの指定を推奨しています。
以下のようなコードは、実運用では避けた方が安全です。
import requests
# timeoutを指定していないNG例
resp = requests.get("https://api.example.com/data")
print(resp.status_code)環境によっては、外部APIが一時的にハングしただけで、この行で数分〜十数分止まり続ける可能性があります。
本番コードでは、原則としてすべてのHTTP通信にtimeoutを明示指定すると考えておくと安全です。
timeoutの指定パターンと書き方
単一値で指定するtimeoutの基本
もっともシンプルな指定方法は、timeout引数に単一の数値(秒)を渡す方法です。
この場合、connectとreadの両方に同じ値が適用されます。
import requests
# 両方に5秒のtimeoutを設定する例
response = requests.get(
"https://httpbin.org/delay/3", # 3秒後に応答を返すテストAPI
timeout=5 # connect + read に5秒を設定
)
print(response.status_code, response.elapsed.total_seconds())200 3.0このとき、接続確立とレスポンス読み取りのいずれかが、合計で5秒を超えてしまうとrequests.exceptions.Timeoutが送出されます。
簡易的なスクリプトや検証コードでは、timeout=5のような指定でも問題ありません。
ただし、本番システムや長期運用を前提としたアプリでは、connectとreadを分けて設計する方が望ましいです。
タプル(connect, read)で指定するtimeout
requestsでは、timeout=(connect, read)という形でタプルを渡すと、接続timeoutと読み取りtimeoutを個別に指定できます。
import requests
# (connect_timeout, read_timeout) のタプルで指定
url = "https://httpbin.org/delay/3" # 3秒遅延
response = requests.get(
url,
timeout=(2.0, 5.0) # 接続は2秒まで、レスポンス読み取りは5秒まで
)
print("status:", response.status_code)
print("elapsed:", response.elapsed.total_seconds())status: 200
elapsed: 3.0この例では、接続確立が2秒以内に終わり、その後レスポンスの読み取りに最大5秒まで待つ設計になっています。
典型的な組み合わせとしては、次のようなパターンがよく使われます。
- 外部APIコール:
timeout=(3.0, 5.0) - やや重めの処理(レポート生成など):
timeout=(3.0, 20.0) - バッチ処理の長時間待ち:
timeout=(5.0, 60.0)
このように、接続timeoutは短く、read timeoutはユースケースに応じて調整するのが定石です。
セッション(Session)とtimeoutの組み合わせ
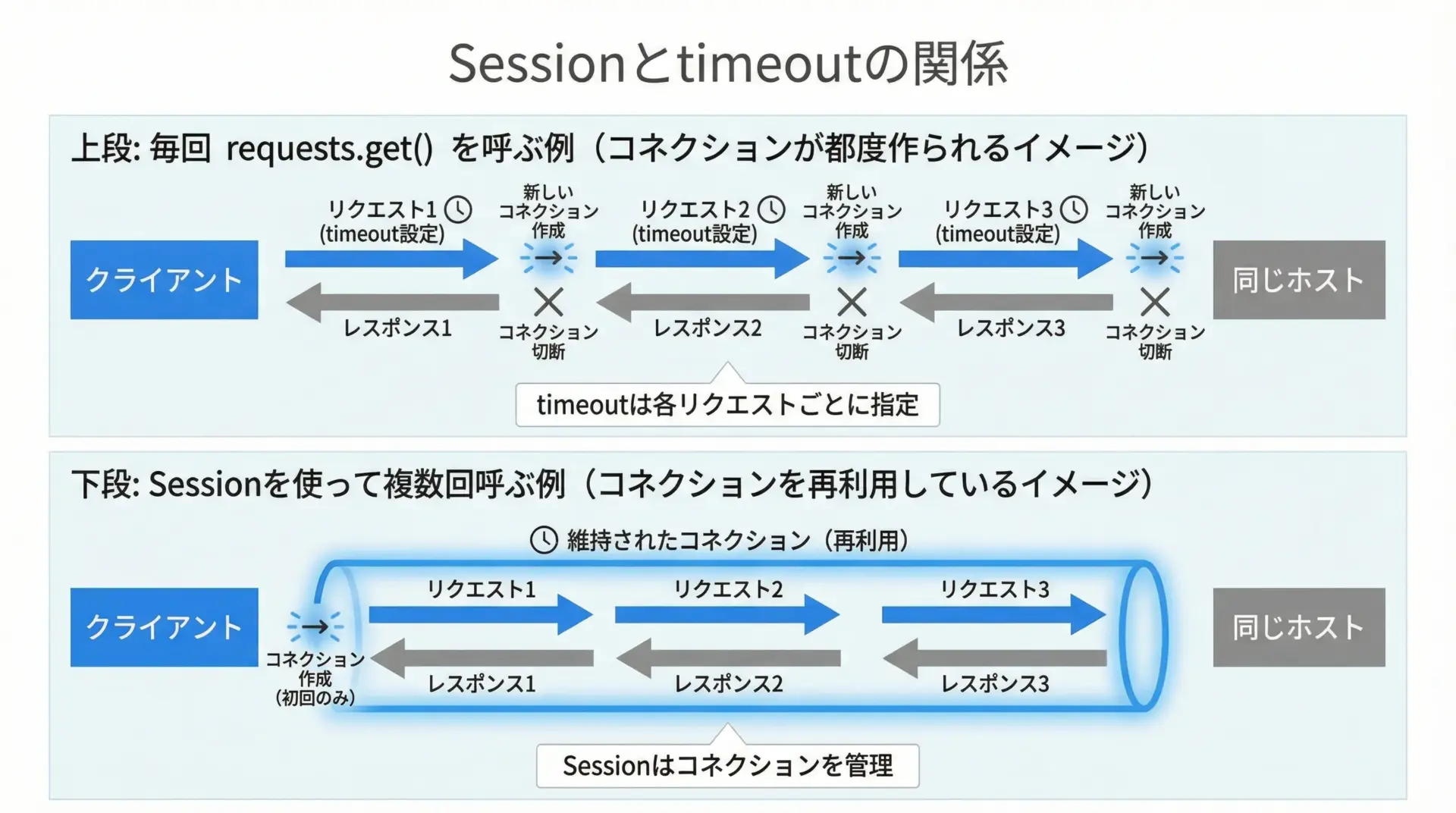
requests.Sessionを使うと、コネクションの再利用や共通ヘッダの設定ができ、パフォーマンスや可読性が向上します。
timeout自体はSessionオブジェクトに「デフォルト値」として直接保持されないため、各リクエストごとにtimeout引数を指定する必要があります。
import requests
session = requests.Session()
session.headers.update({"User-Agent": "my-app/1.0"})
def fetch_with_default_timeout(url, timeout=(3.0, 5.0)):
# 共通のtimeoutを関数でラップして使いやすくする
return session.get(url, timeout=timeout)
resp = fetch_with_default_timeout("https://httpbin.org/get")
print(resp.status_code)200このように、Sessionと小さなヘルパー関数を組み合わせて「共通のtimeoutポリシー」を適用するのが実務でよく使われるパターンです。
代表的なtimeout設定レシピ
外部API向けの安全なtimeout設定例
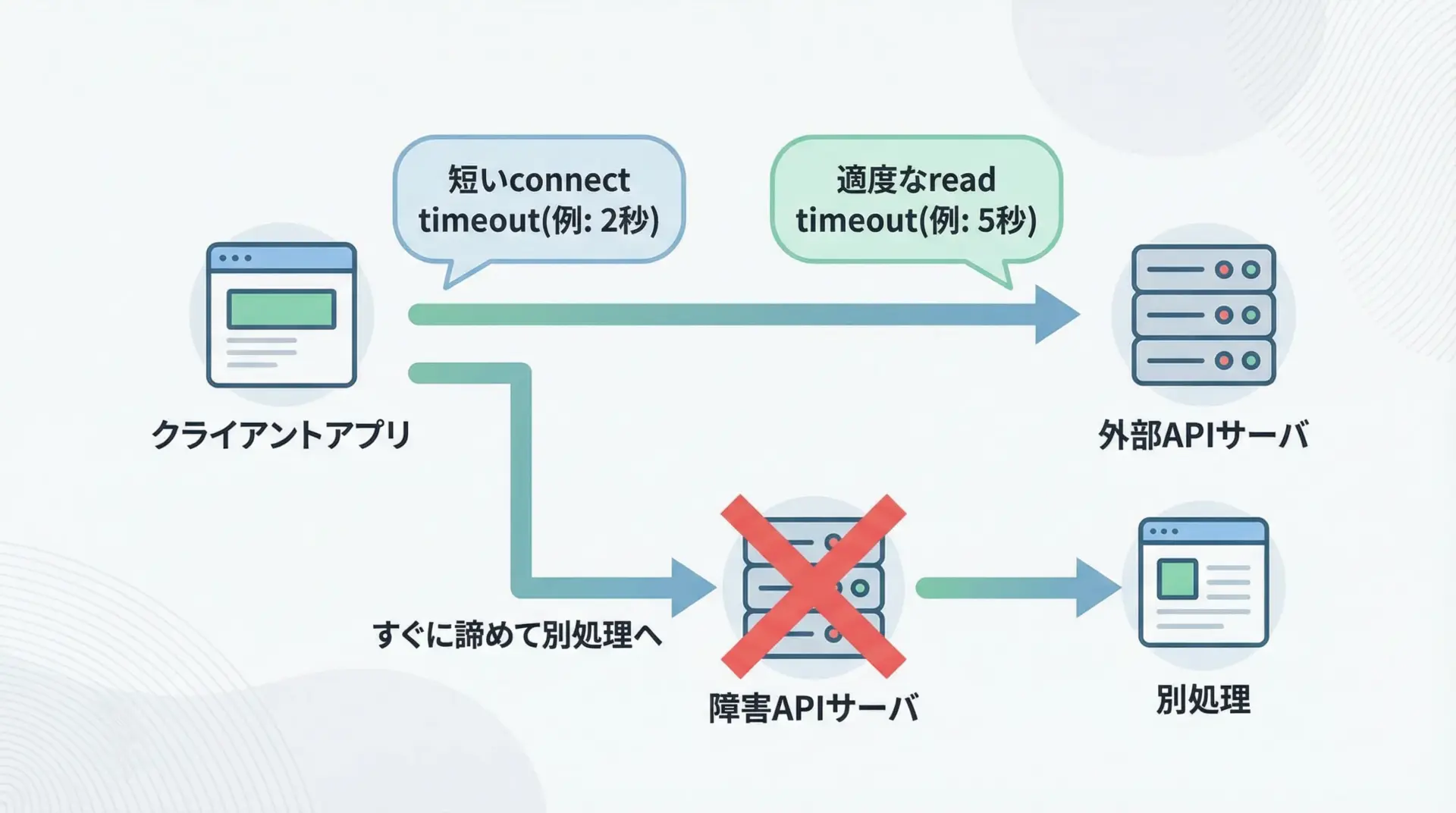
外部APIは、自社システムからは制御できないため、「落ちる」「遅い」ことを前提に防御的に設計する必要があります。
代表的な例として、次のようなtimeoutポリシーがあります。
- 接続timeout: 1〜3秒
- 読み取りtimeout: 3〜10秒程度(サービスのSLOや要件に応じて)
実装例を示します。
import requests
from requests.exceptions import Timeout, RequestException
API_TIMEOUT = (2.0, 6.0) # (connect, read)
def call_external_api():
url = "https://api.example.com/v1/resource"
try:
resp = requests.get(url, timeout=API_TIMEOUT)
resp.raise_for_status()
return resp.json()
except Timeout:
# 外部APIの遅延・障害
# ログ出力やフォールバック処理などを行う
return {"status": "timeout", "data": None}
except RequestException as e:
# その他の通信エラー
return {"status": "error", "detail": str(e)}
result = call_external_api()
print(result){'status': 'timeout', 'data': None}(※実際の結果は接続先や環境に依存します)
このように、外部APIには明示的なtimeoutと、タイムアウト時のフォールバック戦略をセットで設計することが重要です。
バッチ処理での長めtimeout設定パターン
夜間バッチなど、一括処理で時間に多少の余裕がある場面では、通常のオンライン処理より長めのtimeoutを設定することがあります。
ただし、無制限に伸ばすのではなく、「上限は必ず決める」ことがポイントです。
import requests
from requests.exceptions import Timeout
BATCH_TIMEOUT = (5.0, 60.0) # バッチ専用の長めtimeout
def download_large_report(job_id: str):
url = f"https://report.example.com/jobs/{job_id}/result"
try:
resp = requests.get(url, timeout=BATCH_TIMEOUT)
resp.raise_for_status()
return resp.content # バイナリ(例: PDF)
except Timeout:
# バッチジョブなら、リトライやステータス更新などを行う
raise RuntimeError(f"Job {job_id} timed out while downloading report")
content = download_large_report("job-123")
print(len(content))102400(サイズは仮の例です)
このように、バッチ処理用・オンライン処理用でtimeoutを分けて設計すると、ユーザー体験と処理の安定性のバランスを取りやすくなります。
Webアプリ(Django/Flask)でのtimeout設計
Webアプリケーションでは、1リクエストあたりの処理時間が長くなると、ワーカー数が枯渇してサービス全体がダウンしやすくなります。
そのため、外部API呼び出しに対するtimeoutは特に重要です。
典型的な目安としては、次のようなガイドラインが考えられます。
- ユーザー操作に対するレスポンス目標: 0.5〜2秒
- 外部APIを複数呼ぶ場合、その合計をこの中に収める
- 1つのAPI呼び出しに許せるtimeoutは、数百ミリ秒〜1秒台が望ましい
Flaskを例にして、requestsのtimeoutとユーザーへの応答をセットで設計する例を示します。
from flask import Flask, jsonify
import requests
from requests.exceptions import Timeout
app = Flask(__name__)
API_TIMEOUT = (1.0, 2.0) # Webアプリ用に短めのtimeout
@app.route("/profile/<user_id>")
def profile(user_id):
url = f"https://api.example.com/users/{user_id}"
try:
resp = requests.get(url, timeout=API_TIMEOUT)
resp.raise_for_status()
data = resp.json()
return jsonify({"ok": True, "profile": data})
except Timeout:
# 一定時間待っても応答がない場合は、簡易情報のみ返すなどのフォールバックも検討
return jsonify({
"ok": False,
"error": "timeout",
"message": "現在プロフィール情報を取得できません。しばらくしてから再度お試しください。"
}), 504
if __name__ == "__main__":
app.run(debug=True) * Running on http://127.0.0.1:5000ここでのポイントは、timeout発生時に「ユーザー向けのエラー応答」を明確に設計している点です。
詳細は後述のエラー処理の章で解説します。
再試行(retry)とtimeoutを組み合わせる
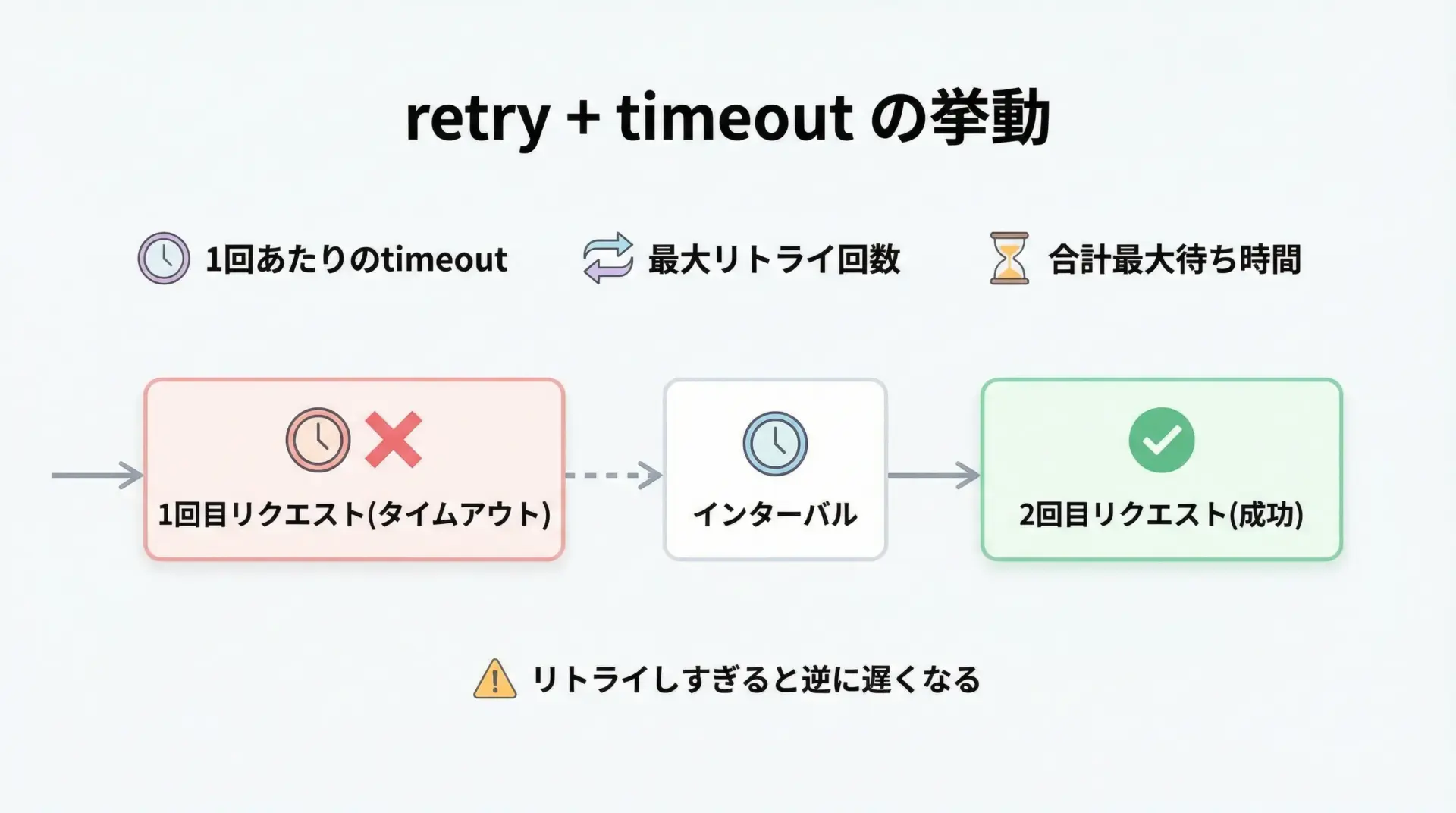
一時的なネットワーク障害であれば、短いtimeoutと複数回のretryを組み合わせることで成功率を高められます。
ただし、retry回数を増やしすぎると全体の待ち時間が伸びるため、「1回あたりのtimeout × リトライ回数」が許容範囲内に収まるよう設計します。
requests単体には高機能なretry機能はありませんが、urllib3.util.retry.RetryとHTTPAdapterを組み合わせて実現できます。
import requests
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
def create_session_with_retry(
total_retries=3,
backoff_factor=0.5,
status_forcelist=(500, 502, 503, 504),
timeout=(1.0, 2.0),
):
session = requests.Session()
retry = Retry(
total=total_retries,
read=total_retries,
connect=total_retries,
backoff_factor=backoff_factor, # 再試行間隔(指数的に増加)
status_forcelist=status_forcelist,
allowed_methods=["GET", "POST"],
raise_on_status=False,
)
adapter = HTTPAdapter(max_retries=retry)
session.mount("http://", adapter)
session.mount("https://", adapter)
# timeoutはアダプタには設定できないので、呼び出し側で指定する
session.request_timeout = timeout # 自前プロパティとして保持しておく
return session
session = create_session_with_retry()
try:
resp = session.get(
"https://httpbin.org/status/500",
timeout=session.request_timeout
)
print(resp.status_code)
except requests.exceptions.RequestException as e:
print("error:", e)500この例では、サーバが一時的に500を返した場合に自動的に再試行します。
timeoutとretryの掛け合わせにより、最悪ケースでの待ち時間(タイムライン)を事前に計算しておくことが重要です。
エラー処理と例外ハンドリング
timeout例外(RequestException, Timeout)の扱い方
requestsのtimeoutに関連する代表的な例外は、次の2つです。
requests.exceptions.Timeoutrequests.exceptions.RequestException(通信全般の基底クラス)
TimeoutはRequestExceptionのサブクラスなので、優先的にTimeoutを捕捉し、それ以外の通信エラーはRequestExceptionでまとめて扱うパターンが多いです。
import requests
from requests.exceptions import Timeout, RequestException
def fetch(url, timeout=(2.0, 5.0)):
try:
resp = requests.get(url, timeout=timeout)
resp.raise_for_status()
except Timeout as e:
# timeoutは明確に区別して扱う
raise RuntimeError(f"Request to {url} timed out") from e
except RequestException as e:
# DNSエラー、接続拒否、HTTPエラーなど
raise RuntimeError(f"Request to {url} failed: {e}") from e
else:
return resp.text
print(fetch("https://httpbin.org/get")[:80]){
"args": {},
"headers": {
"Accept": "*/*",このように、timeoutを特別扱いすることで、障害時の挙動(リトライやフォールバック)を細かく制御できます。
ログ設計とリトライ戦略の考え方
timeoutや通信エラーが発生した場合、適切なログを残して原因分析や監視に活用することが重要です。
最低限、次の情報をログに含めると役に立ちます。
- 呼び出したURL
- timeout設定値(connect, read)
- リトライ回数と経過時間
- ステータスコード(応答があった場合)
- エラー種別(Timeout、ConnectionErrorなど)
簡易的なログ実装例を示します。
import logging
import time
import requests
from requests.exceptions import Timeout, RequestException
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def fetch_with_retry(url, timeout=(1.0, 2.0), retries=2):
for attempt in range(1, retries + 2): # 初回 + リトライ回数
start = time.time()
try:
resp = requests.get(url, timeout=timeout)
resp.raise_for_status()
elapsed = time.time() - start
logger.info(
"success url=%s status=%s elapsed=%.2f attempt=%s",
url, resp.status_code, elapsed, attempt
)
return resp
except Timeout as e:
elapsed = time.time() - start
logger.warning(
"timeout url=%s timeout=%s elapsed=%.2f attempt=%s error=%s",
url, timeout, elapsed, attempt, e
)
except RequestException as e:
elapsed = time.time() - start
logger.error(
"request_error url=%s elapsed=%.2f attempt=%s error=%s",
url, elapsed, attempt, e
)
break # リトライしても無駄そうな場合は中断
raise RuntimeError(f"Failed to fetch {url} after {retries + 1} attempts")
fetch_with_retry("https://httpbin.org/delay/3", timeout=(1.0, 1.0), retries=1)WARNING:__main__:timeout url=https://httpbin.org/delay/3 timeout=(1.0, 1.0) elapsed=1.00 attempt=1 error=...
ERROR:__main__:request_error url=https://httpbin.org/delay/3 elapsed=1.00 attempt=2 error=...
Traceback (most recent call last):
...
RuntimeError: Failed to fetch https://httpbin.org/delay/3 after 2 attemptsこのように、ログの粒度とリトライ戦略をセットで設計しておくと、障害解析や監視設定が行いやすくなります。
ユーザー向けエラーメッセージ設計

timeoutエラーが発生したとき、ユーザーにスタックトレースや内部URLをそのまま見せるのは望ましくありません。
内部ログとユーザー向けメッセージを分離して設計します。
例えばWebアプリなら、次のような方針が考えられます。
- ログには詳細なエラー内容(URL、timeout値、スタックトレース)を出力
- ユーザーには「現在サービスが混み合っています」「しばらくしてから再度お試しください」のように、簡潔で安心感のあるメッセージを表示
- APIの場合は、「504 Gateway Timeout」「一時的なエラーコード」など、クライアントがリトライ可能か判断できるステータスとエラーコードを返す
擬似コード的な例を示します。
from flask import Flask, jsonify
import logging
import requests
from requests.exceptions import Timeout
app = Flask(__name__)
logger = logging.getLogger(__name__)
@app.route("/search")
def search():
query = "example"
url = f"https://api.example.com/search?q={query}"
timeout = (1.0, 2.0)
try:
resp = requests.get(url, timeout=timeout)
resp.raise_for_status()
return jsonify(resp.json())
except Timeout as e:
# 内部ログ(詳細)
logger.warning("search timeout url=%s timeout=%s error=%s", url, timeout, e)
# ユーザー向けレスポンス(簡潔)
return jsonify({
"ok": False,
"error": "timeout",
"message": "検索結果の取得に時間がかかっています。時間をおいて、もう一度お試しください。"
}), 504
if __name__ == "__main__":
app.run() * Running on http://127.0.0.1:5000このように、内部では詳細に、外部には簡潔にという住み分けを意識することが大切です。
実践テクニックとベストプラクティス
グローバル設定と共通関数でtimeoutを一元管理
プロジェクトが大きくなると、あちこちのコードでバラバラにtimeoutを指定してしまい、全体のポリシーが見えなくなることがあります。
これを防ぐために、共通モジュールでtimeoutを一元管理するのがおすすめです。
# http_client.py
import requests
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
DEFAULT_TIMEOUT = (2.0, 5.0)
class TimeoutHTTPAdapter(HTTPAdapter):
"""デフォルトtimeoutを持つHTTPAdapter"""
def __init__(self, *args, timeout=DEFAULT_TIMEOUT, **kwargs):
self.timeout = timeout
super().__init__(*args, **kwargs)
def send(self, request, **kwargs):
timeout = kwargs.get("timeout")
if timeout is None:
kwargs["timeout"] = self.timeout
return super().send(request, **kwargs)
def create_http_session(timeout=DEFAULT_TIMEOUT, retries=2):
session = requests.Session()
retry = Retry(
total=retries,
backoff_factor=0.3,
status_forcelist=[500, 502, 503, 504],
allowed_methods=["GET", "POST"],
)
adapter = TimeoutHTTPAdapter(max_retries=retry, timeout=timeout)
session.mount("http://", adapter)
session.mount("https://", adapter)
return session# 使用側のコード
from http_client import create_http_session
session = create_http_session()
# timeoutを明示しなくてもDEFAULT_TIMEOUTが適用される
resp = session.get("https://httpbin.org/get")
print(resp.status_code)200このように、デフォルトtimeoutを持つHTTPクライアント層を用意しておけば、アプリケーションコード側ではtimeoutを意識する場面を減らしつつ、必要な箇所だけ上書きできます。
requests.adaptersで接続プールとtimeoutを最適化
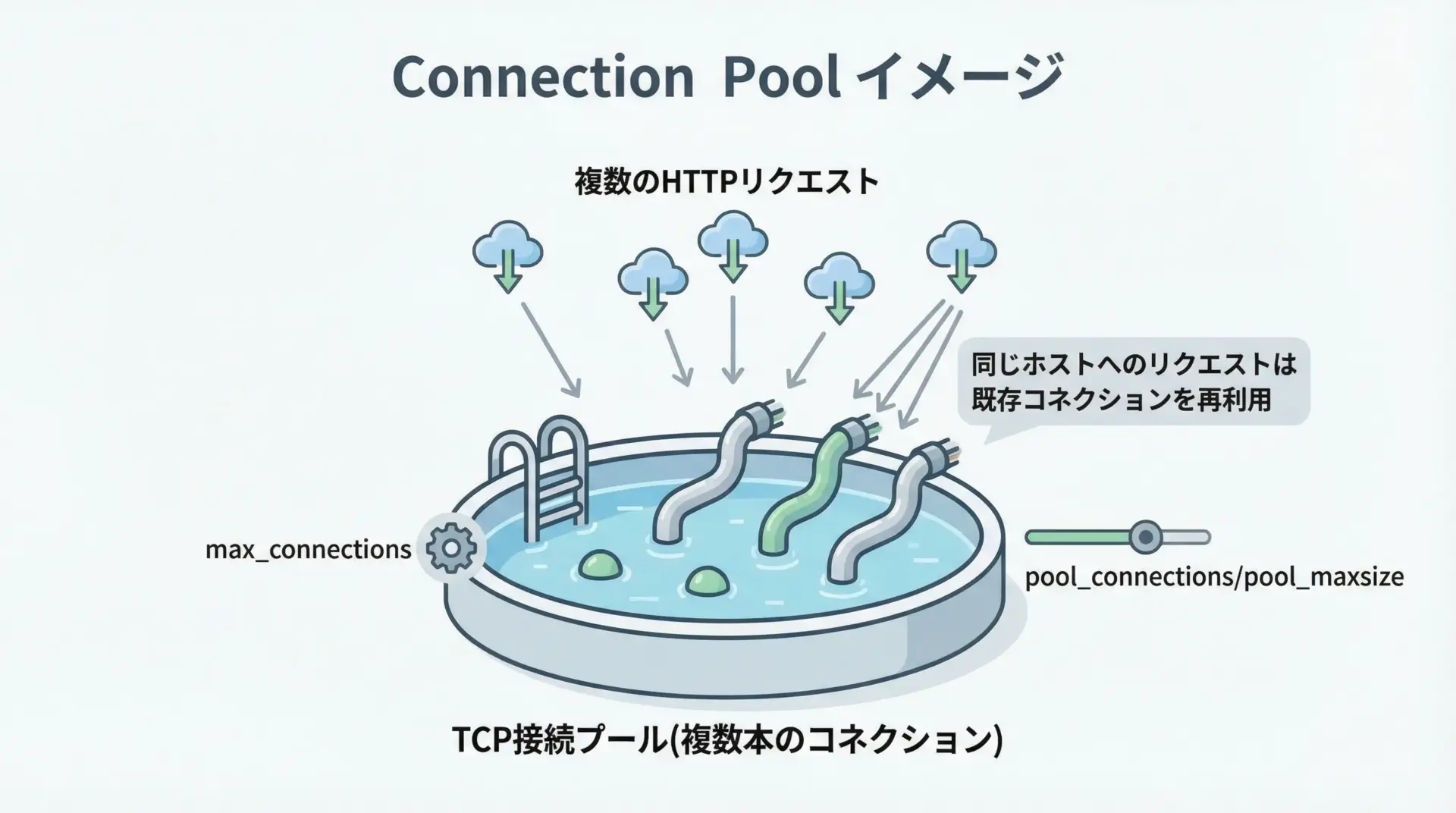
requests.adapters.HTTPAdapterを使うと、接続プールのサイズや再試行戦略を細かく制御できます。
大量のリクエストを送るサービスでは、この調整が性能と安定性に直結します。
代表的なパラメータは次の通りです。
pool_connections: ホストごとのコネクションプール数pool_maxsize: 各プールの最大接続数max_retries: 再試行戦略(Retryオブジェクト)
サンプルコードを示します。
import requests
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
def create_optimized_session():
session = requests.Session()
retry = Retry(
total=3,
connect=3,
read=3,
backoff_factor=0.2,
status_forcelist=[500, 502, 503, 504],
allowed_methods=["GET", "POST"],
)
adapter = HTTPAdapter(
max_retries=retry,
pool_connections=20, # 接続プール数
pool_maxsize=50, # 各プールの最大接続数
)
session.mount("http://", adapter)
session.mount("https://", adapter)
return session
session = create_optimized_session()
response = session.get("https://httpbin.org/get", timeout=(2.0, 5.0))
print(response.status_code)200このように、timeoutの設計だけでなく、接続プールの設定も合わせてチューニングすることで、より高トラフィックな環境でも安定した動作が期待できます。
timeout設定のチューニング手順とチェックポイント
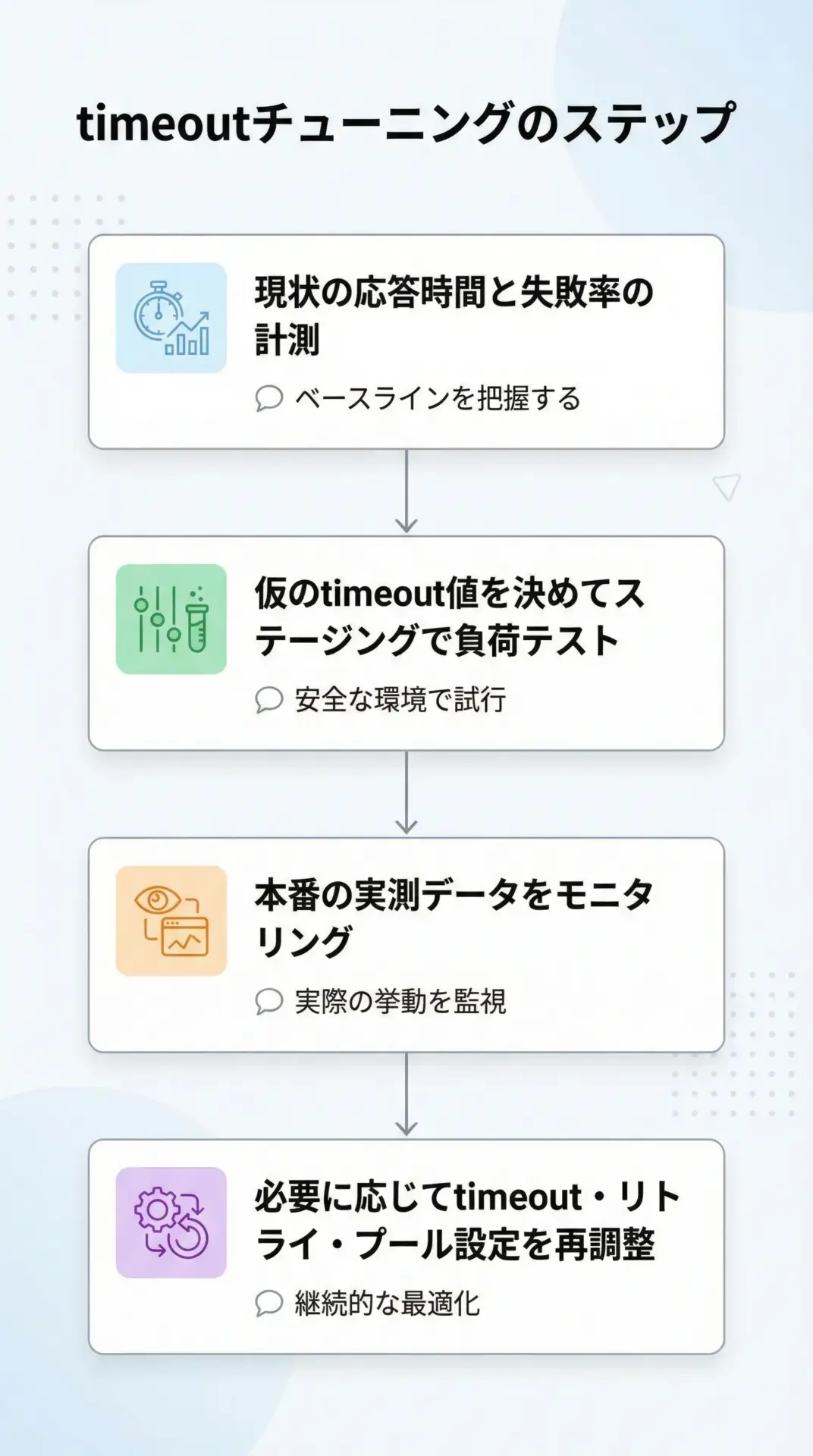
timeoutは勘に頼って決めるのではなく、実測データに基づいてチューニングするのが理想です。
典型的な手順は次のようになります。
- まず、外部APIや自社サービスの現状のレスポンス時間分布(p50/p90/p95/p99など)を計測する
- 許容できるユーザー待ち時間やバッチ処理時間から、理想的なtimeoutの上限を逆算する
- ステージング環境で、決めたtimeout値で負荷テストを行い、タイムアウト頻度や再試行の影響を確認する
- 本番導入後も、timeoutエラー率や全体の遅延をモニタリングし、必要に応じて調整する
チェックすべきポイントとしては、次のような観点があります。
- timeoutが短すぎて、正常なリクエストまで頻繁に切っていないか
- timeoutが長すぎて、ワーカーが占有されリクエスト待ちが増えていないか
- retry回数とtimeoutの掛け合わせで、「最悪ケースの処理時間」がどれくらいになるかを把握しているか
- 外部API側のレートリミットやSLAに対して、こちらのretry戦略が過度な負荷になっていないか
このように、timeoutは一度決めたら終わりではなく、運用しながら継続的に見直すべきパラメータと言えます。
まとめ
本記事では、Pythonのrequestsにおけるtimeout設定の基礎から実戦的なレシピまでを解説しました。
connectとreadの違いを理解し、単一値とタプルを使い分け、SessionやHTTPAdapterで共通ポリシーを実装することで、外部API障害時にも安定して動作する堅牢なクライアントを構築できます。
さらに、timeoutとretry、接続プール、ログ設計を総合的に設計し、実測値に基づいてチューニングしていくことで、パフォーマンスと信頼性の両立が可能になります。
運用中のサービスでまだtimeoutを明示していない箇所があれば、まずはそこから着手してみてください。
