
Pythonで開発していると、TypeErrorに悩まされる場面は少なくありません。
とくに「list is not callable」や「’int’ object is not callable」などのエラーは、初心者だけでなく中級者でもうっかり遭遇する代表例です。
本記事では、PythonのTypeErrorの基本から、頻出パターン15例、そして「list is not callable」を中心に、原因の読み解き方と防ぎ方を丁寧に解説していきます。
- PythonのTypeErrorとは
- TypeError頻出パターン15例
- 1.list is not callableの原因と対処法
- 2.'int' object is not callableが出る典型ケース
- 3.'str' object is not callableで関数呼び出しに失敗する理由
- 4.'NoneType' object is not callableになるパターン
- 5.'list' object is not subscriptableとcallableの取り違え
- 6.can only concatenate str(not "int") to strの意味
- 7.unsupported operand type(s) for +の原因
- 8.unsupported operand type(s) for /や*など演算子関連TypeError
- 9.cannot unpack non-iterable XXX objectのパターン
- 10.'XXX' object is not iterableでループできない理由
- 11.TypeError: 'module' object is not callableの落とし穴
- 12.TypeError: 'type' object is not subscriptable
- 13.TypeError: object of type 'XXX' has no len
- 14.TypeError: slice indices must be integers or None or have an __index__ method
- 15.TypeError: missing 1 required positional argumentなど引数関連エラー
- list is not callableエラーを徹底解説
- TypeErrorの防ぎ方とデバッグのコツ
- まとめ
PythonのTypeErrorとは
TypeErrorの意味と発生するタイミング
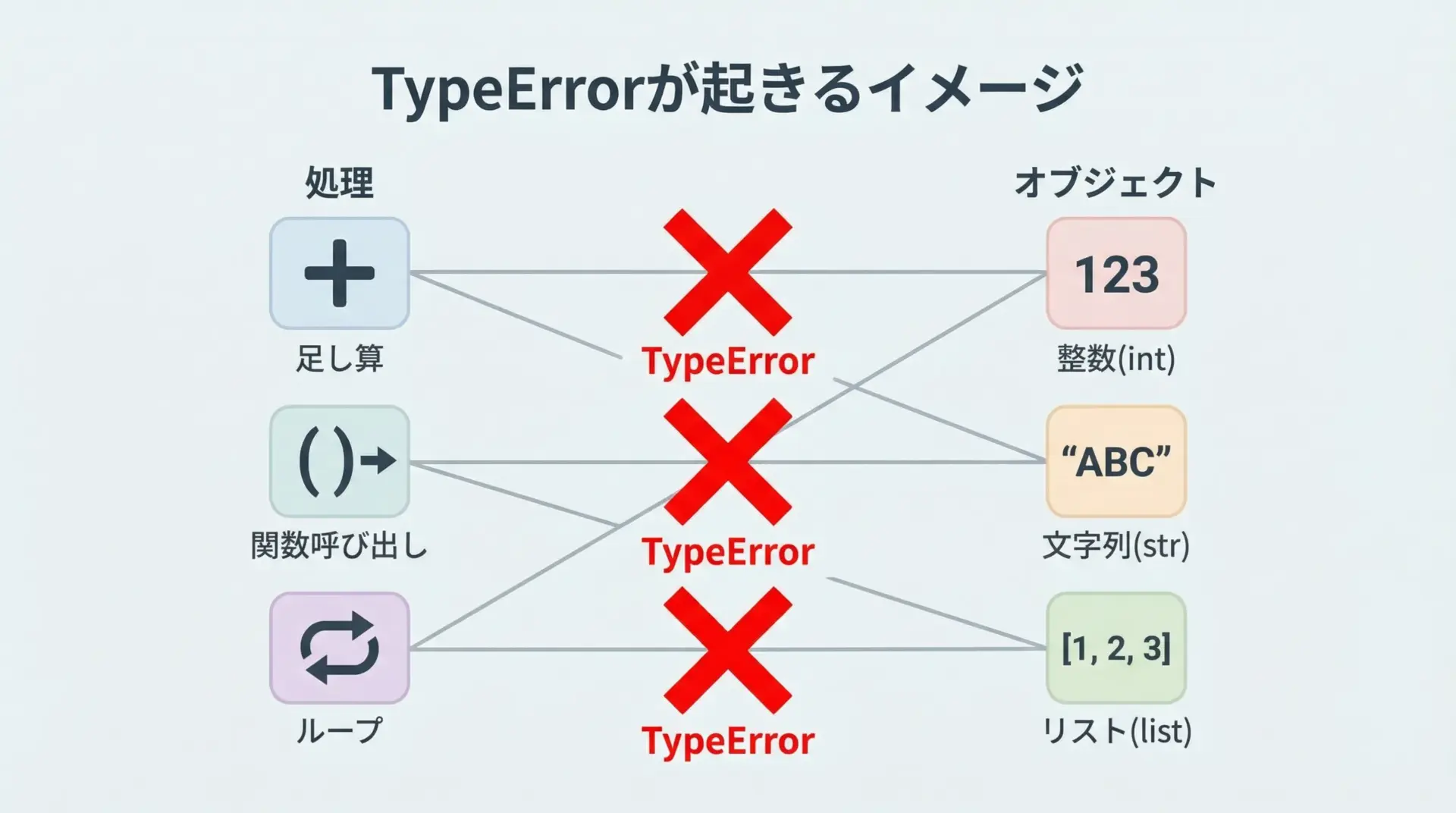
PythonのTypeErrorは、「その型(タイプ)のオブジェクトに対して、その操作はできません」という意味のエラーです。
もう少し具体的に言うと、次のような場面で発生します。
たとえば、整数と文字列をそのまま+で足そうとしたり、リストを関数のように()で呼び出そうとしたり、イテレートできないオブジェクトをfor文で回そうとしたときなどです。
Pythonは「この型に対して、この操作は定義されていません」と判断し、TypeErrorを投げます。
このようにTypeErrorは、「演算子・関数・文法上の操作」と「オブジェクトの型」の組み合わせミスによって起きると考えると理解しやすくなります。
「型」と「オブジェクト」の基本をおさらい
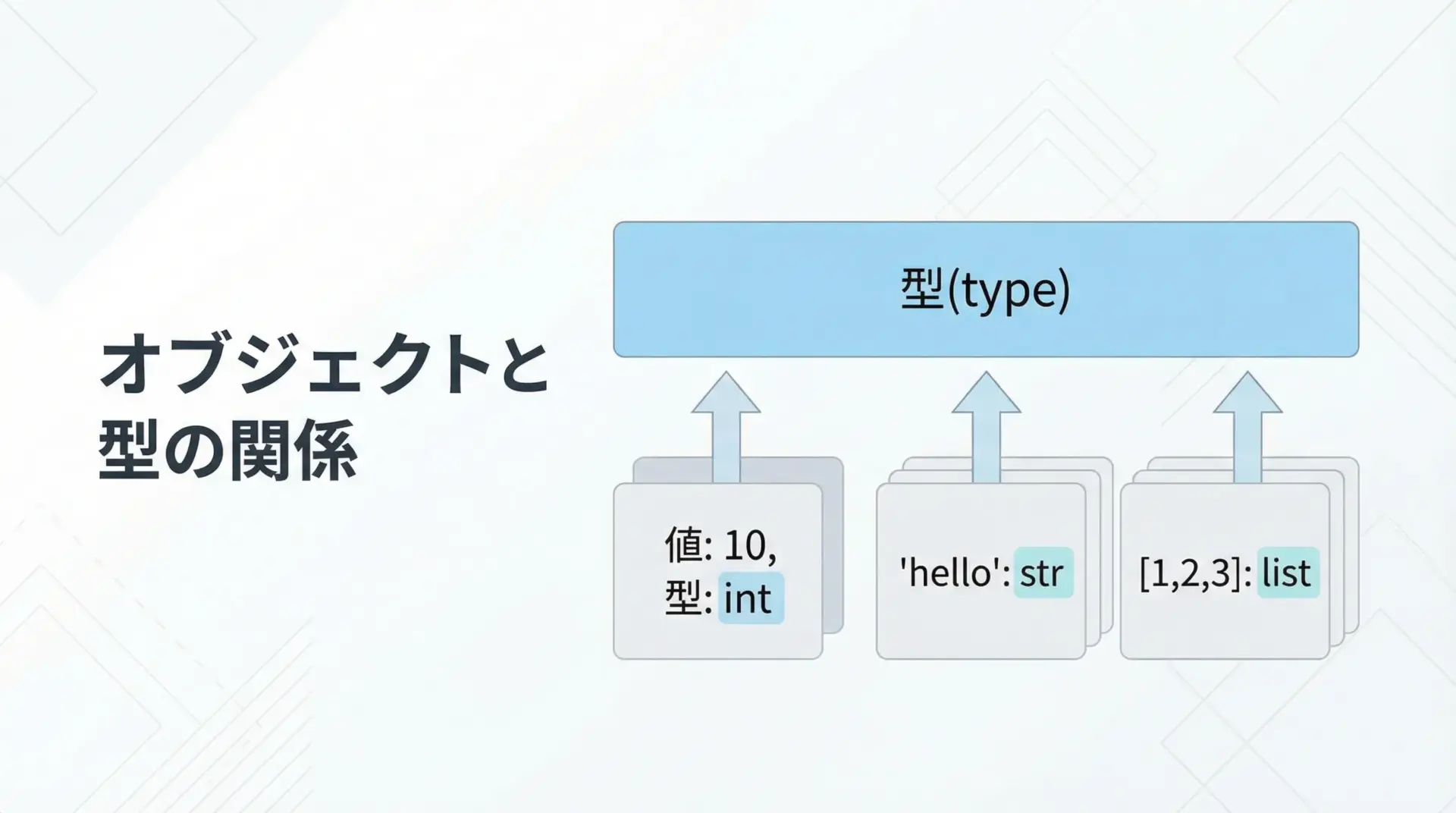
Pythonでは、すべてがオブジェクトです。
整数も文字列もリストも関数も、すべてオブジェクトとして扱われます。
そして、各オブジェクトは必ず「型(type)」を持っています。
代表的な型には次のようなものがあります。
- int型: 整数
- float型: 小数
- str型: 文字列
- list型: リスト
- dict型: 辞書
- function型: 関数オブジェクト
Pythonでは、オブジェクトがどの型なのかによって使える演算子やメソッド、振る舞いが変わります。
たとえば+演算子は、int同士なら数値としての加算、str同士なら文字列の結合として働きます。
しかしintとstrを混ぜて+しようとすると、後述するTypeErrorになります。
TypeErrorを読むコツとエラーメッセージの構造
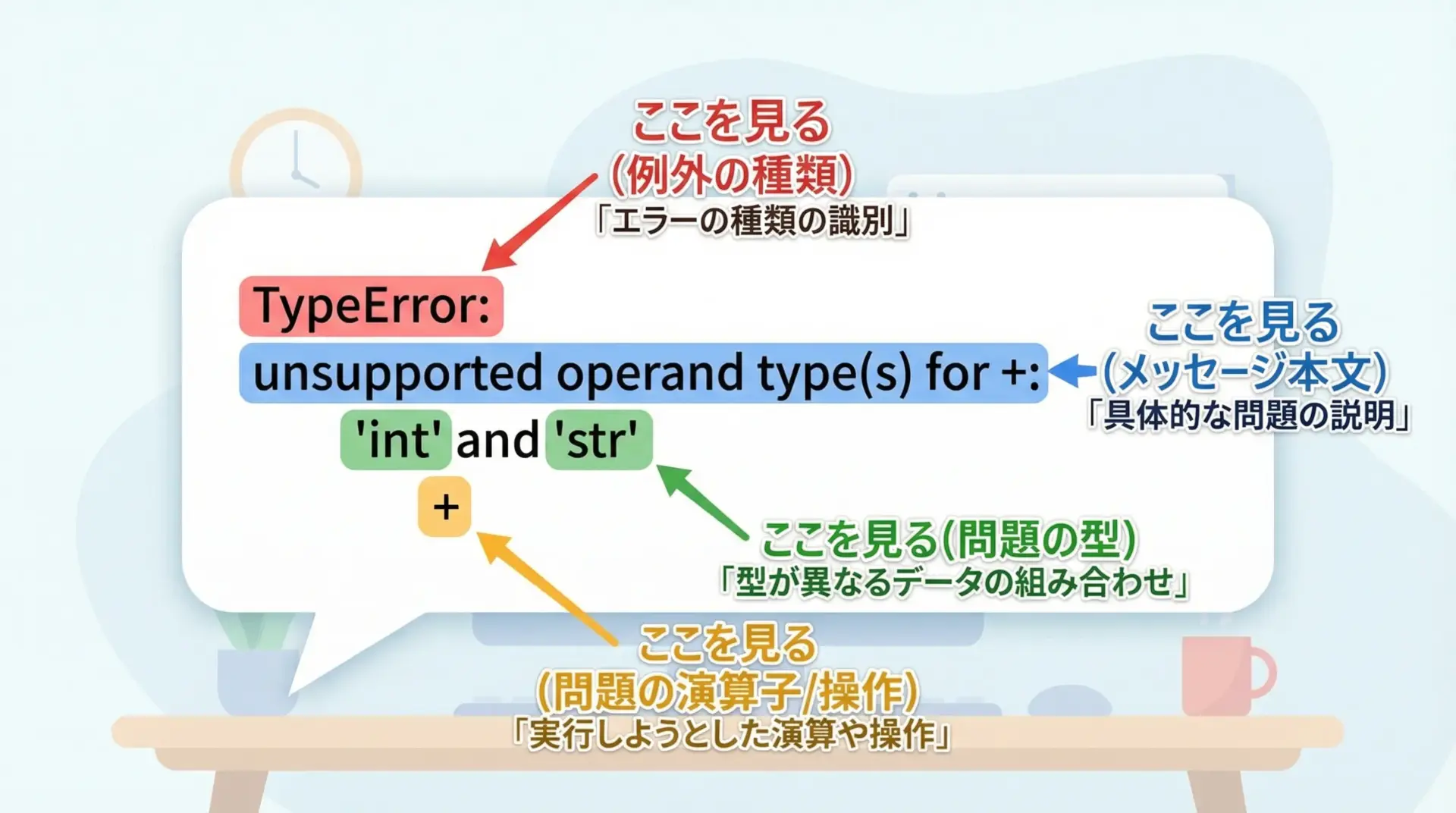
Pythonのエラーメッセージにはパターンがあります。
TypeErrorの場合、「TypeError: メッセージ本文」という形式で表示され、そのメッセージ本文を読み解くのが重要です。
例えば、次のようなエラーを見てみます。
x = 10
print(x())このコードを実行すると、次のようなエラーメッセージになります。
TypeError: 'int' object is not callableこのメッセージを分解すると次のようになります。
- ‘int’ object: 問題を起こしたオブジェクトの型
- is not callable: 「関数として呼び出せない」という意味
つまり「int型のオブジェクトを関数のように呼び出そうとしましたが、それはできません」という意味になります。
このように、エラーメッセージの中に「どの型」で「どんな操作」が問題になっているかがほぼ必ず書かれているので、そこを手がかりに原因を特定していきます。
同じように、unsupported operand type(s) for +なら「この+で足そうとした型の組み合わせはサポートされていません」、object is not iterableなら「ループ可能(iterable)な型ではありません」と読むことができます。
TypeError頻出パターン15例
ここからは、Pythonで特によく遭遇するTypeErrorパターン15例を、原因と対処法を交えながら解説します。
コード例にはコメントを多く付けて、どこで何が起きているのかが分かるようにしています。
1.list is not callableの原因と対処法

もっとも有名なエラーの1つがTypeError: ‘list’ object is not callableです。
代表的な原因は、変数名としてlistを使ってしまい、組み込み関数list()を上書きしてしまうことです。
# 組み込み関数 list を上書きしてしまう例
list = [1, 2, 3] # ここで変数名 list を使っている
# 本当は list() で型変換をしたい
numbers = list("123") # ここで TypeError が発生TypeError: 'list' object is not callableこの場合、2行目でlistにリストオブジェクトを代入したため、名前listはもはや「関数」ではなく「リスト」を指してしまっています。
その状態でlist("123")と書くと、リストを関数のように呼び出そうとしてしまい、「リストは呼び出せません」と怒られるわけです。
対処法としては、組み込み関数名(list, str, intなど)を変数名に使わないことが最善です。
どうしても既に上書きしてしまっている場合は、変数名を変更し、Pythonインタプリタを再起動することで元に戻せます。
2.’int’ object is not callableが出る典型ケース

TypeError: ‘int’ object is not callableは、整数型のオブジェクトを関数のように()で呼び出そうとしたときに発生します。
代表的には次のようなケースがあります。
x = 10
# 本当は関数 x を呼び出したかったのに、
# どこかで x に数値を代入してしまっているパターン
result = x() # ここで 'int' object is not callableあるいは、次のような「関数名と変数名の衝突」も典型的です。
def calc():
return 10
calc = calc() # 関数を実行して、結果(10)を calc に代入
# 以降、calc はもう関数ではなく「10」という整数になる
calc() # ここで 'int' object is not callableこのように、関数を結果で上書きしてしまうと、以降その名前は関数ではなくなるため注意が必要です。
関数実行結果を保持したい場合は、別の変数名を用意するのが安全です。
3.’str’ object is not callableで関数呼び出しに失敗する理由

TypeError: ‘str’ object is not callableは、文字列を関数として呼び出そうとしたときのエラーです。
典型例を見てみます。
text = "hello"
# () を付けると関数呼び出しになる
text() # 'str' object is not callableもう少し現実的な例として、printを上書きしてしまい、文字列になっているケースもあります。
print = "出力" # 組み込みの print 関数を上書き
print("hello") # ここで 'str' object is not callableこのエラーも本質的には、「関数名として使うつもりの名前に、別の型のオブジェクトを代入してしまっている」ことが原因です。
組み込み関数名を変数名として利用しないこと、関数と同じ名前の変数を無意識に作らないことが重要になります。
4.’NoneType’ object is not callableになるパターン
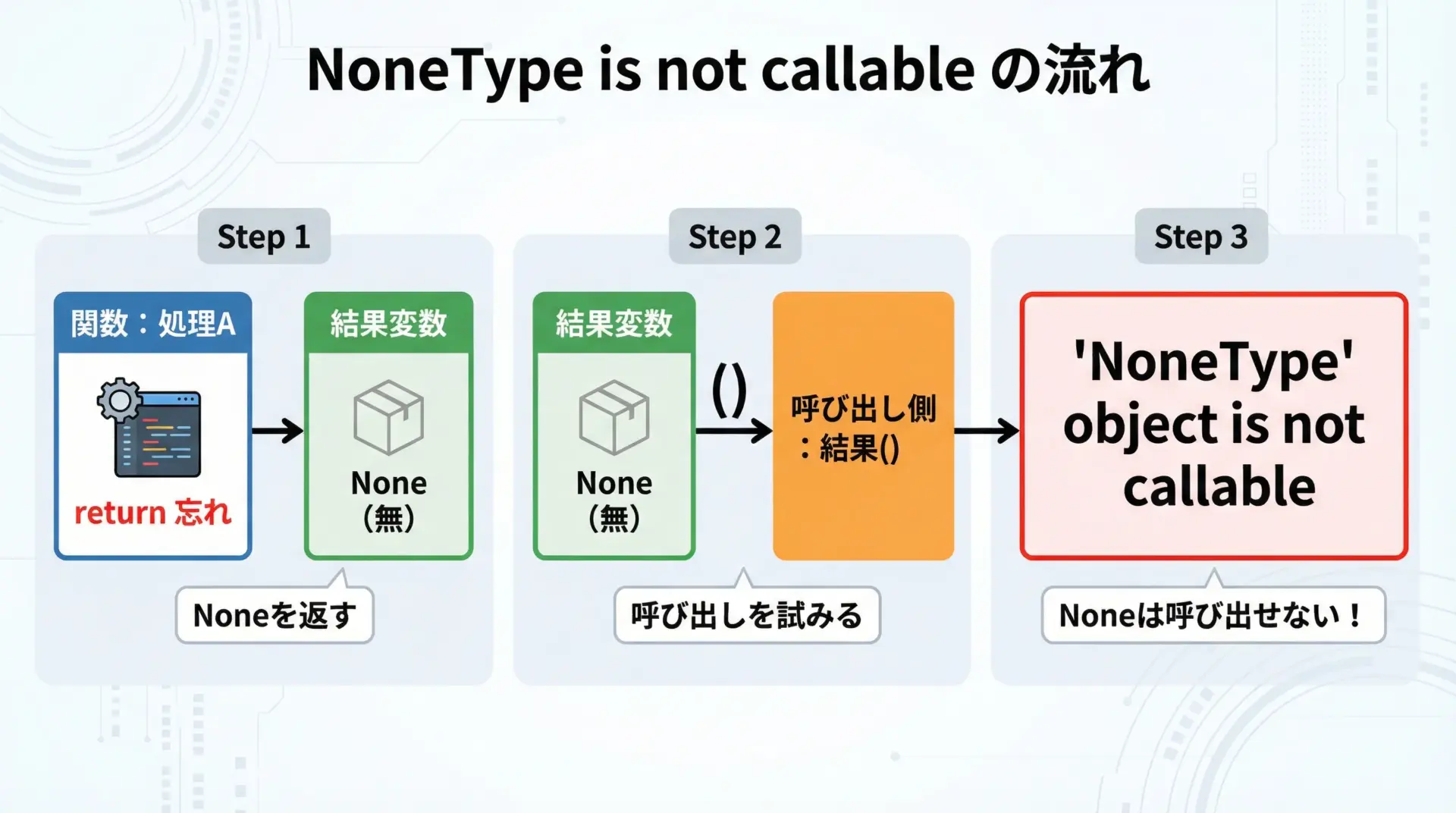
TypeError: ‘NoneType’ object is not callableは、None(何もないことを表す特別な値)を関数として呼び出してしまったときに発生します。
次のようなケースが典型的です。
def func():
print("処理だけして、値は返さない関数です") # return がないので None を返す
result = func() # result は None になる
result() # ここで 'NoneType' object is not callable処理だけして、値は返さない関数です
TypeError: 'NoneType' object is not callable原因は、「関数の返り値が関数そのものだと思い込んで、もう一度()を付けて呼び出している」ことです。
関数を呼び出した結果が何なのかを意識し、必要であればprint(result)などで確認しながらデバッグすると原因が見えやすくなります。
5.’list’ object is not subscriptableとcallableの取り違え

TypeError: ‘list’ object is not subscriptableという似たエラーもあり、callable(呼び出せる)とsubscriptable(添字アクセス可能)を混同しやすいので注意が必要です。
「subscriptable」は[]で要素を取り出せるオブジェクトかどうかを表します。
例えば次のようなケースで起きます。
x = 10
# 数値は [] で要素アクセスできない
value = x[0] # 'int' object is not subscriptable一方で'list' object is not callableは()に関するエラーです。
エラー文言がよく似ているため、どちらの記号で間違えたのかをメッセージから読み取る意識を持つと、原因の切り分けが早くなります。
6.can only concatenate str(not “int”) to strの意味
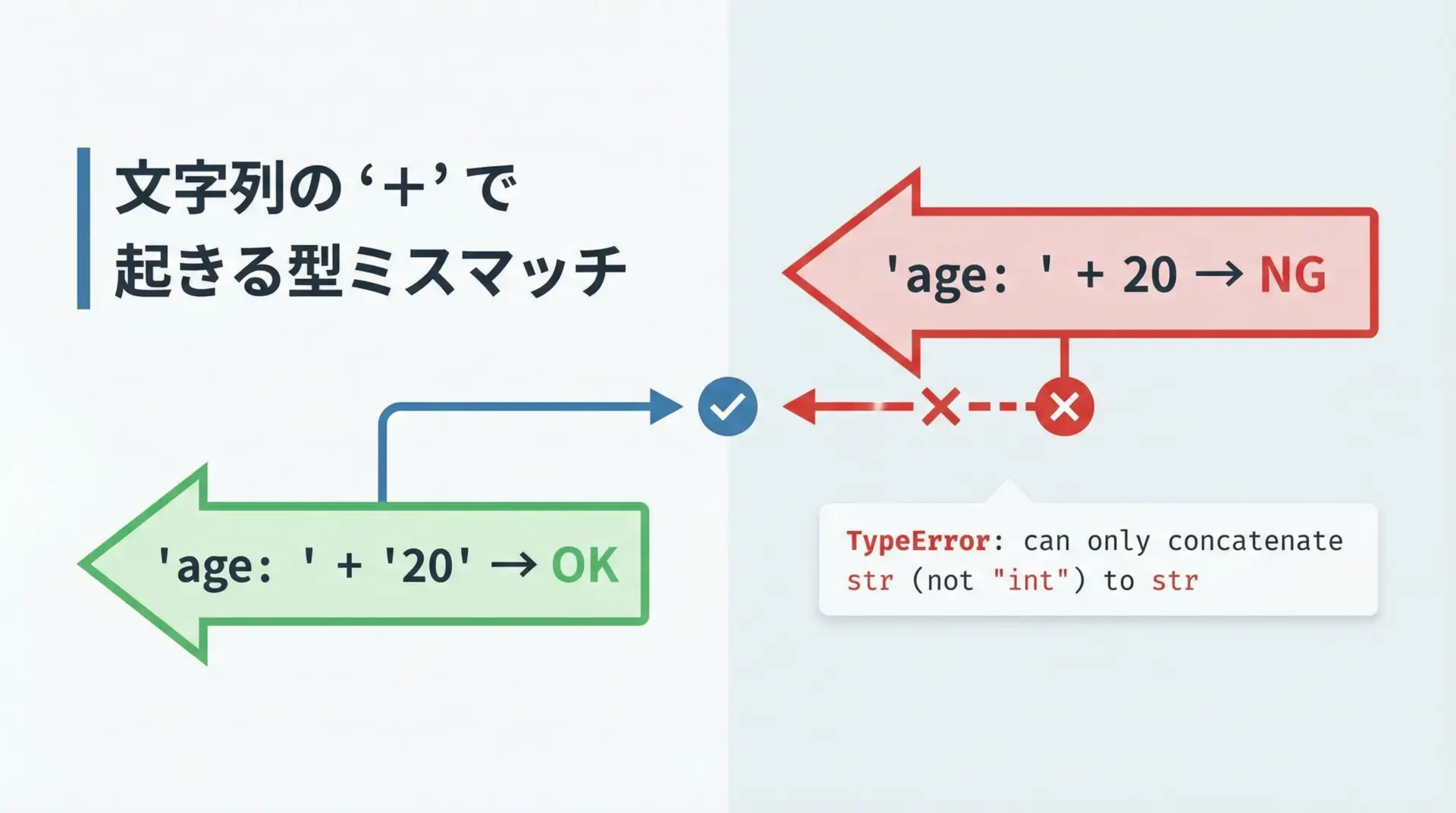
TypeError: can only concatenate str (not “int”) to strは、文字列同士しか+で連結できないのに、文字列と整数をそのまま足そうとしたときに起きるエラーです。
age = 20
# 文字列と整数をそのまま + している
msg = "年齢は " + age + " 歳です" # ここで TypeErrorTypeError: can only concatenate str (not "int") to strメッセージを直訳すると「strにはstrだけを連結できます(intはダメです)」という意味です。
対処法は、整数をstr()で文字列に変換するか、f文字列やformatを使うことです。
age = 20
# 対処法1: str()で文字列に変換
msg = "年齢は " + str(age) + " 歳です"
# 対処法2: f文字列を使う
msg2 = f"年齢は {age} 歳です"
print(msg)
print(msg2)年齢は 20 歳です
年齢は 20 歳です7.unsupported operand type(s) for +の原因
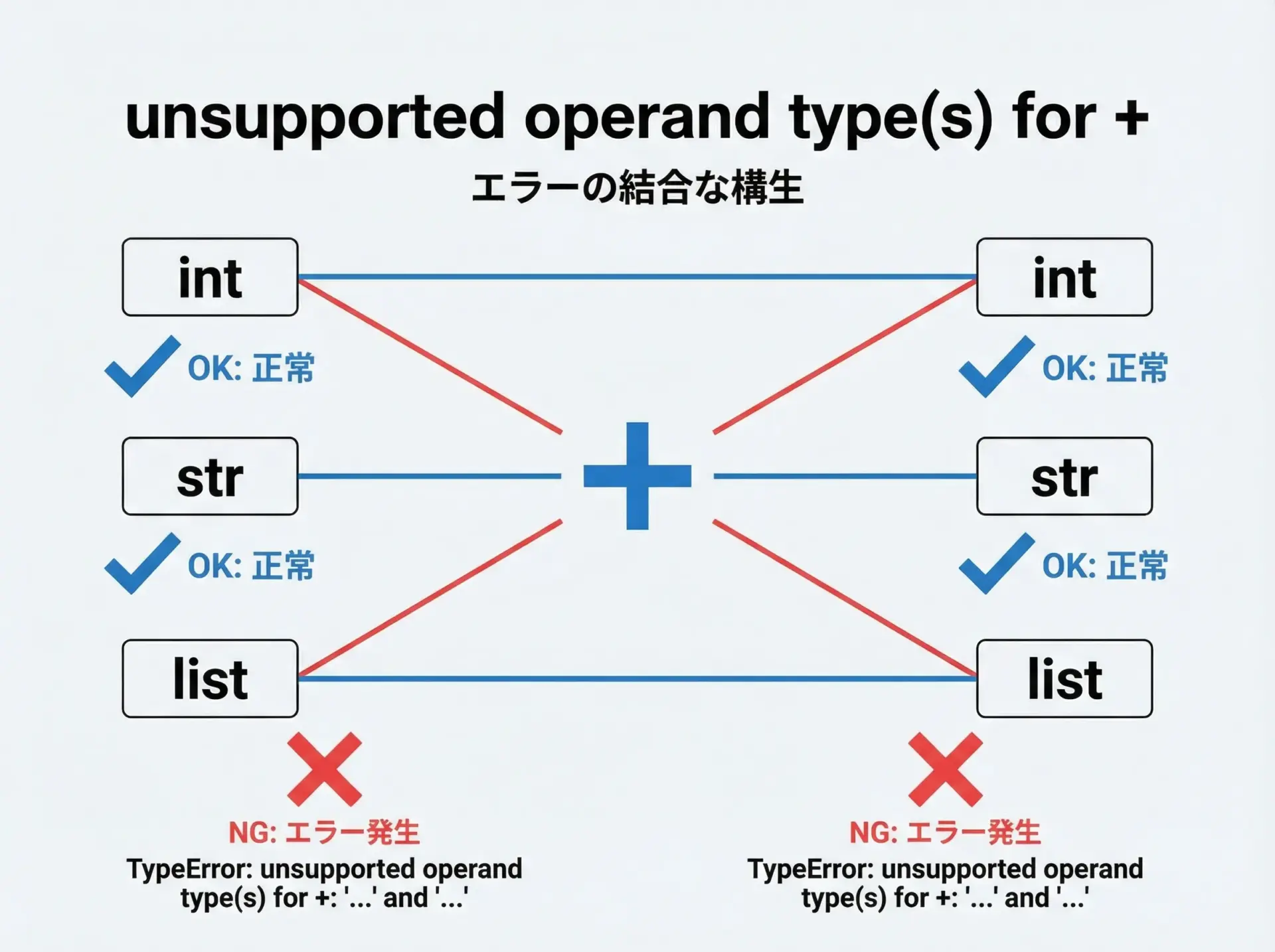
TypeError: unsupported operand type(s) for +: ‘XXX’ and ‘YYY’は、その2つの型の組み合わせに対して+演算子が定義されていないことを示します。
例えば次のようなコードです。
a = 10 # int
b = [1, 2] # list
c = a + b # int と list を足そうとしているTypeError: unsupported operand type(s) for +: 'int' and 'list'このメッセージから、「intとlistの組み合わせでは+は使えません」と読み取れます。
どちらか一方を変換するのか、そもそも+ではなく別の処理(h関数やappendなど)を使うべきなのかを検討して修正します。
8.unsupported operand type(s) for /や*など演算子関連TypeError

unsupported operand type(s)は+以外の演算子でも頻出します。
たとえば/や*で次のようなコードを書いた場合です。
a = "10"
b = 2
result = a / b # 文字列と数値で割り算TypeError: unsupported operand type(s) for /: 'str' and 'int'割り算に限らず、演算子は「どの型とどの型の組み合わせに対応しているか」が決まっているため、それを外れるとTypeErrorになります。
とくに入力値を外部から受け取る場面では、数値に変換できているか、文字列のままではないかを確認することが重要です。
9.cannot unpack non-iterable XXX objectのパターン
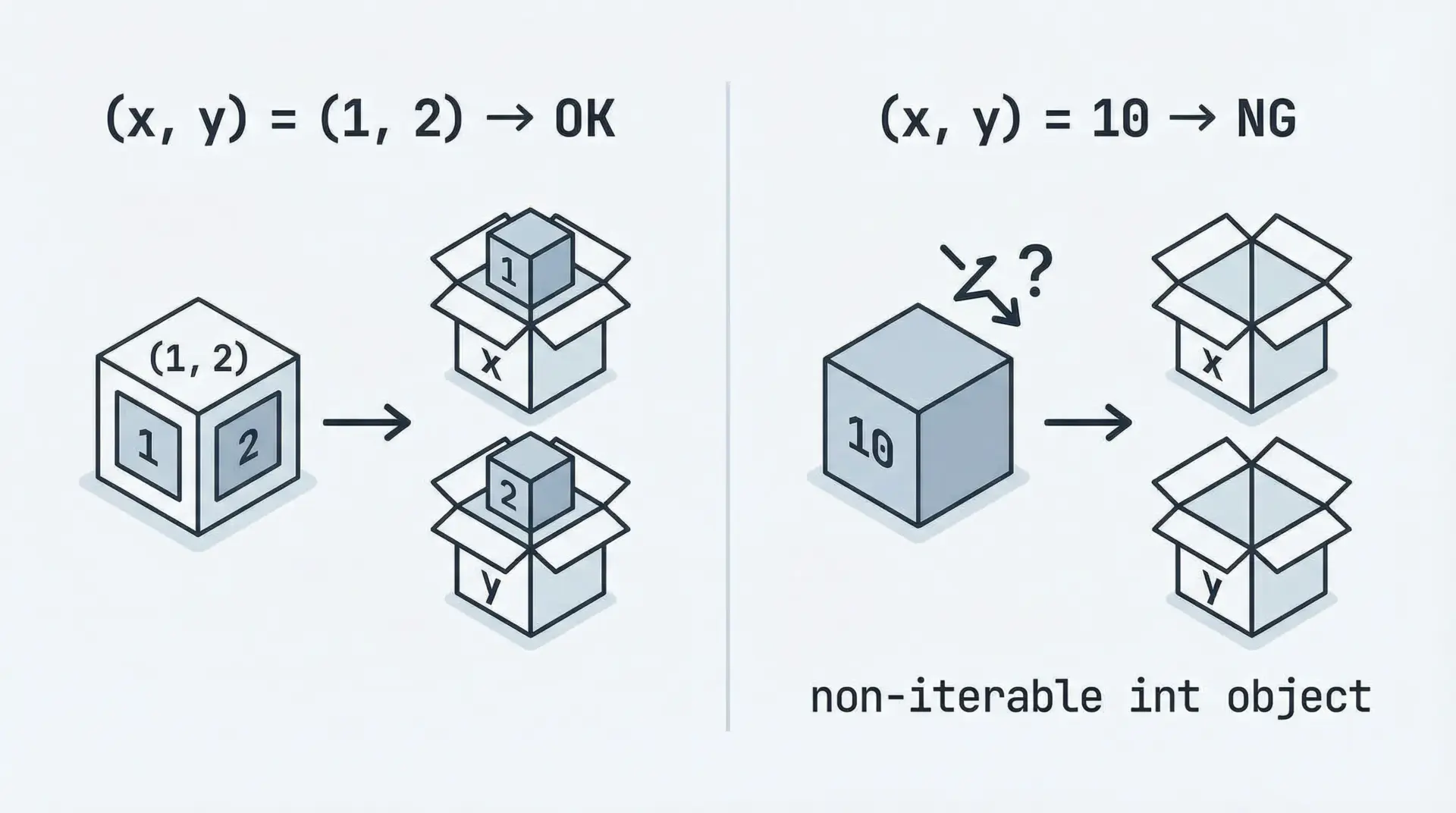
TypeError: cannot unpack non-iterable XXX objectは、反復不可能(non-iterable)なオブジェクトを複数の変数にアンパックしようとしたときのエラーです。
value = 10 # int は iterable ではない
# 左辺に2つの変数があるので、右辺から2つの値を取り出そうとする
a, b = value # ここで TypeErrorTypeError: cannot unpack non-iterable int object一方で、タプルやリストなどのイテラブルであればアンパックできます。
pair = (1, 2)
a, b = pair # OK
print(a, b)1 2エラーメッセージのXXXの部分に注目すると、どの型をアンパックしようとしていたかが分かるので、意図した型になっているかを確認するのがデバッグの第一歩になります。
10.’XXX’ object is not iterableでループできない理由
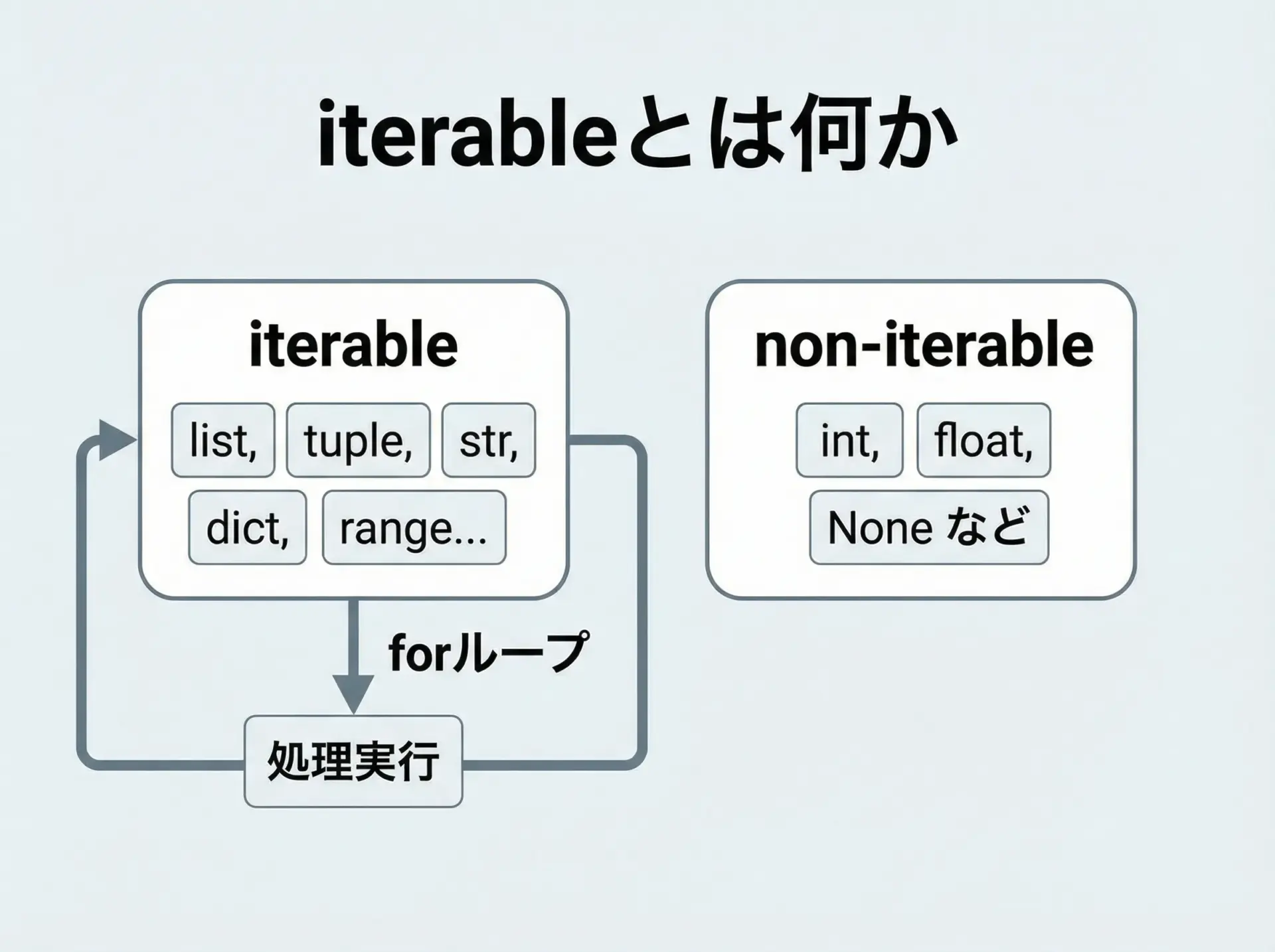
TypeError: ‘XXX’ object is not iterableは、forループやアンパックなどで「繰り返し可能(iterable)」なオブジェクトでないものを使ったときに発生します。
n = 10
for x in n: # int は iterable ではない
print(x)TypeError: 'int' object is not iterableiterableとは「順番に要素を取り出せるオブジェクト」のことです。
list, tuple, str, dict, rangeなどはiterableですが、intやfloat、Noneはiterableではありません。
このエラーが出たときは、「forの右側に置いているものは、本当にリストやタプルなどか?」と確認してみてください。
タプルを返すはずが、1つの値しか返していない関数などでもよく出るエラーです。
11.TypeError: ‘module’ object is not callableの落とし穴
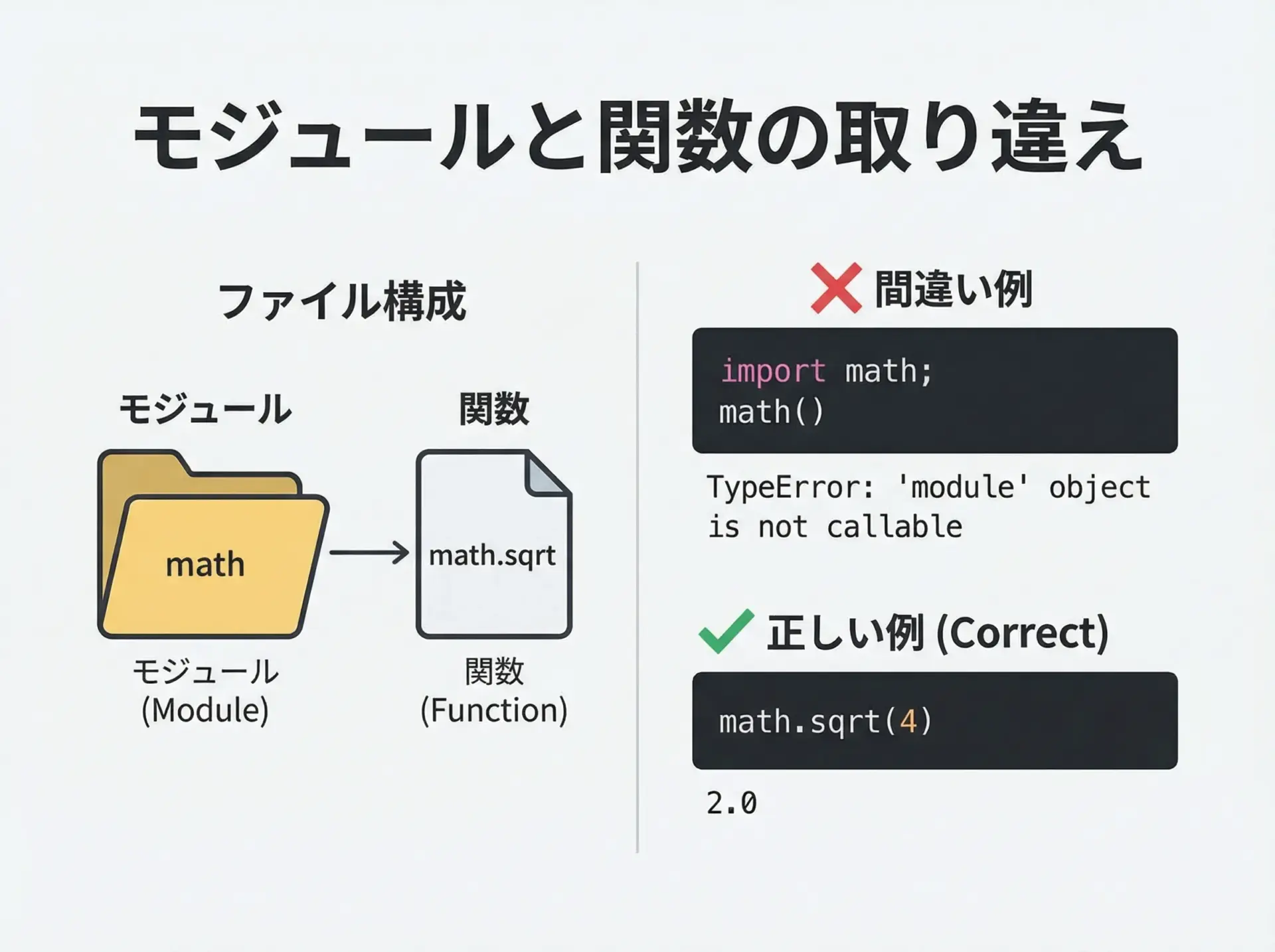
TypeError: ‘module’ object is not callableは、モジュールそのものを関数のように呼び出してしまったときに起きます。
import math
# math はモジュール(ファイルの集合)なので、関数ではない
result = math() # ここで TypeErrorTypeError: 'module' object is not callable同様に、次のようなパターンも落とし穴になりがちです。
import mymodule # mymodule.py というファイルをインポートしたとする
# mymodule の中に main() という関数があるのに、
# ファイル名そのものを呼び出そうとしている
mymodule() # 'module' object is not callable対処法は、モジュール内の関数やクラスを指定して呼び出すことです。
例えばmath.sqrt(4)のようにモジュール名.関数名という形でアクセスします。
12.TypeError: ‘type’ object is not subscriptable
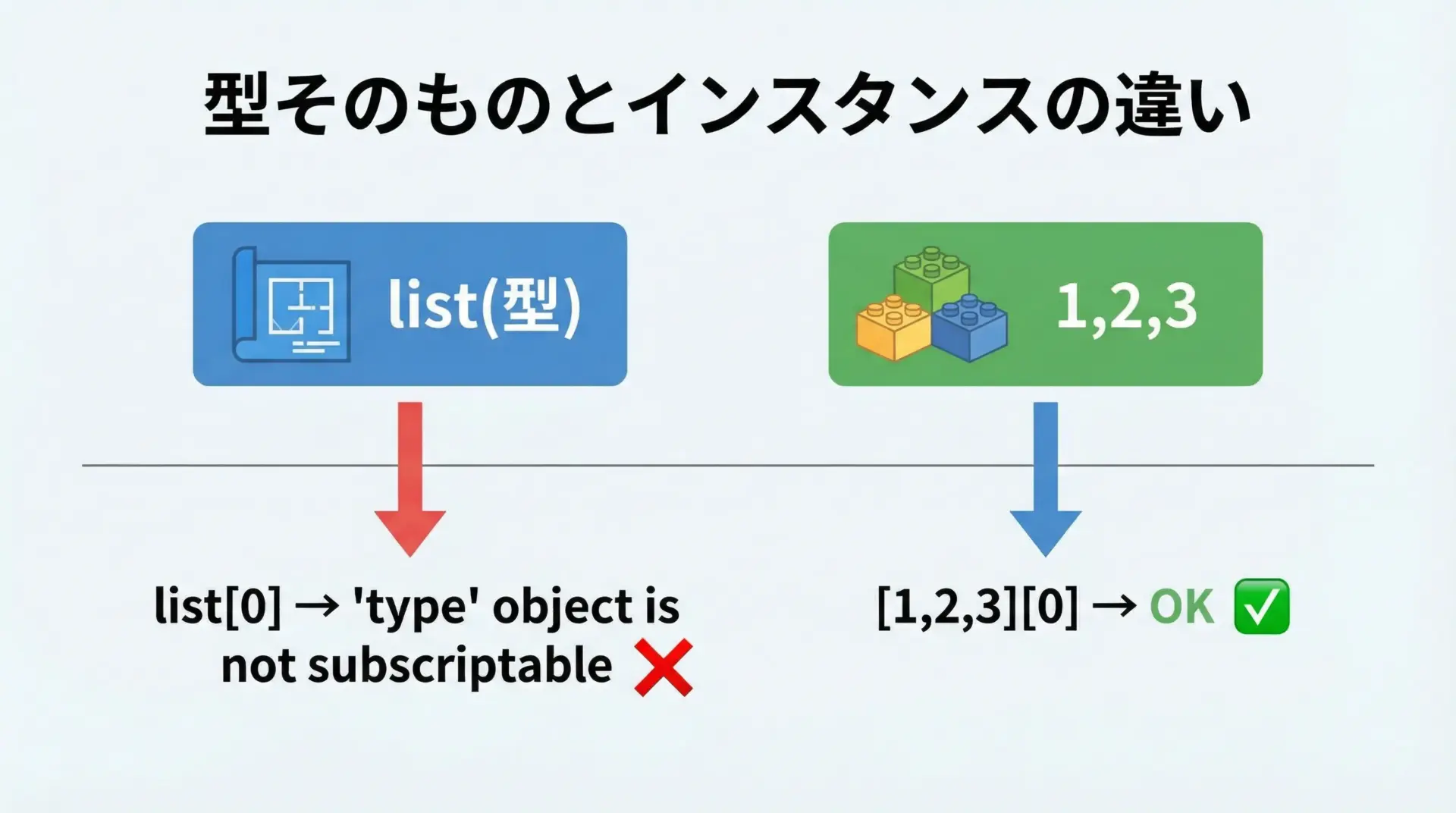
TypeError: ‘type’ object is not subscriptableは、型そのもの(クラス)に対して[]で添字アクセスしようとしたときに発生します。
# list は「型」そのもの
value = list[0] # ここで TypeErrorTypeError: 'type' object is not subscriptable添字アクセスできるのは、その型のインスタンス(具体的なオブジェクト)です。
data = [1, 2, 3] # list 型のインスタンス(オブジェクト)
value = data[0] # OK
print(value)1型とインスタンスを混同しているときに起きることが多いので、変数が「型」なのか「インスタンス」なのかを意識して名前を付けると、この種のミスを減らせます。
13.TypeError: object of type ‘XXX’ has no len
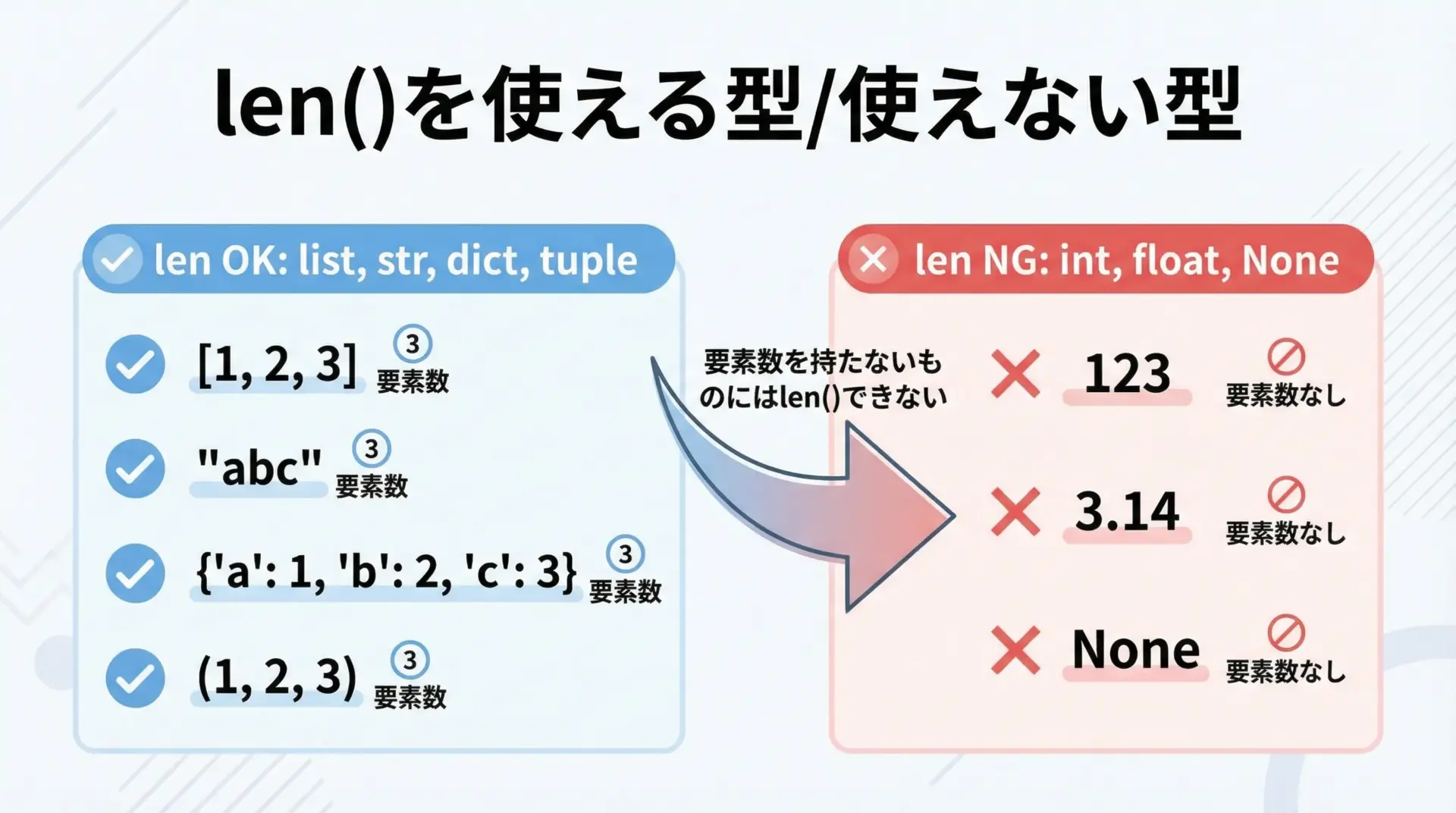
TypeError: object of type ‘XXX’ has no len()は、len()関数を、その型に対しては定義されていないのに使おうとしたときのエラーです。
n = 10
length = len(n) # int に対して len() を呼び出しているTypeError: object of type 'int' has no len()len()は「要素の個数」を返す関数なので、要素の概念がある型(リスト、タプル、文字列、辞書など)に対して意味を持ちます。
一方でintやfloatのようなスカラ値には、要素数という概念がありません。
このエラーが出た場合は、本当にlen()を呼びたい相手がどの変数なのかを再確認すると良いです。
リストを想定していたのに、1つの値だけを渡しているといったミスが多く見られます。
14.TypeError: slice indices must be integers or None or have an __index__ method

このエラーメッセージは少し長いですが、意味は「スライスのインデックスには整数かNone、あるいは__index__メソッドを持つオブジェクトしか使えません」というものです。
text = "hello"
# インデックスに文字列を使ってしまっている
part = text["1":"3"] # ここで TypeErrorTypeError: slice indices must be integers or None or have an __index__ method通常の利用では、スライスのインデックスに「文字列」や「浮動小数点」などを使ってしまっているケースがほとんどです。
インデックスが整数になっているかどうかを確認し、必要であればint()で変換します。
text = "hello"
start = "1"
end = "3"
# 文字列を整数に変換してから使う
part = text[int(start):int(end)]
print(part)el15.TypeError: missing 1 required positional argumentなど引数関連エラー
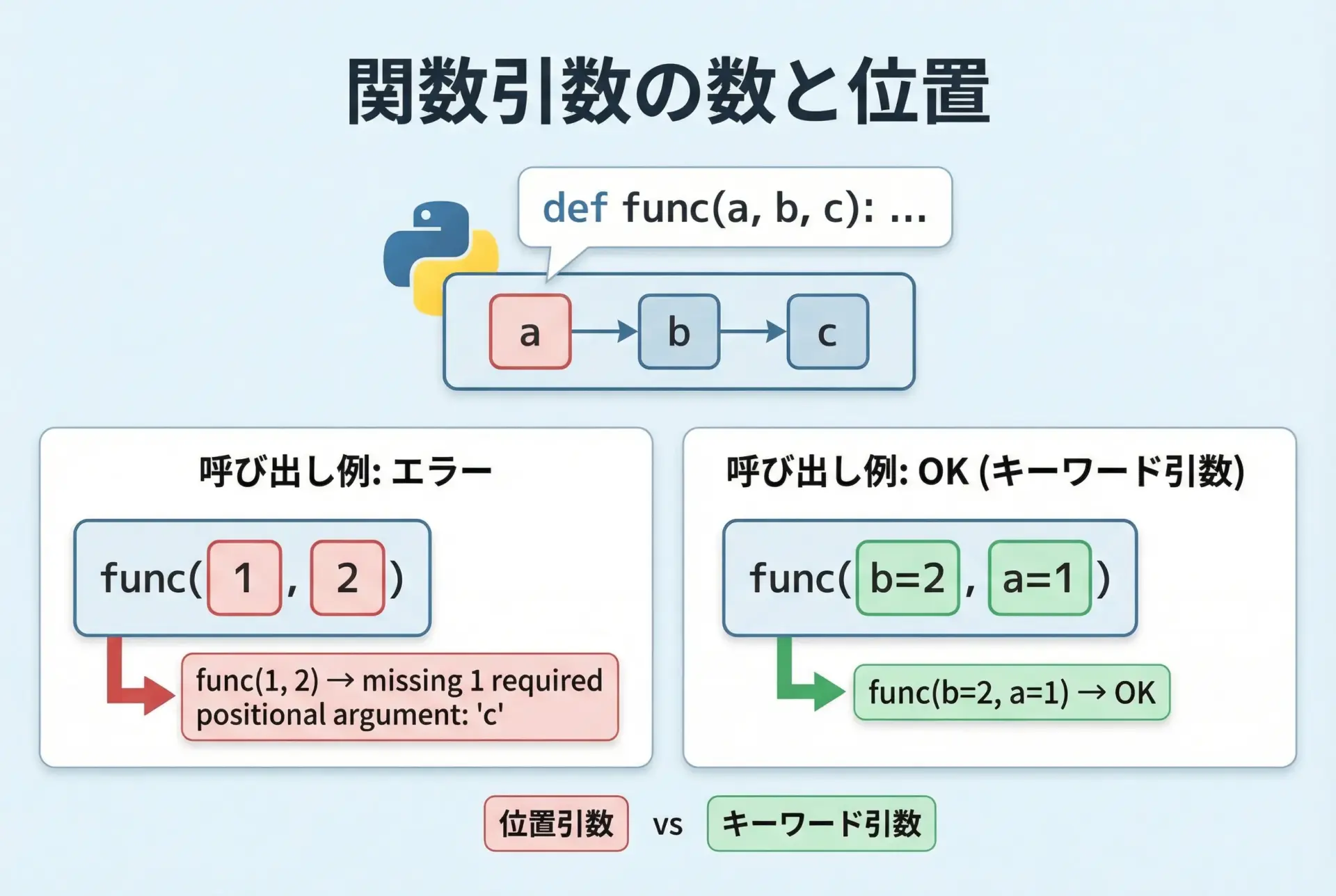
最後に、TypeError: missing 1 required positional argument: ‘xxx’のような、関数の引数の数や渡し方に関するTypeErrorです。
def add(a, b):
return a + b
# 引数が1つ足りない
result = add(10) # ここで TypeErrorTypeError: add() missing 1 required positional argument: 'b'メッセージの中の'b'は、足りない引数の名前を示しています。
逆に、takes 2 positional arguments but 3 were givenのように、「渡しすぎ」の場合もあります。
この種のエラーが出たときは、関数の定義と呼び出し側の引数の個数・名前を見比べることがもっとも確実な確認方法です。
list is not callableエラーを徹底解説
ここからは、本記事のタイトルにも含まれている「list is not callable」に絞って、もう少し深く掘り下げて解説します。
list is not callableが起きる典型コード例

典型的なパターンはすでに軽く触れましたが、もう少し具体例を見てみます。
# ユーザーから入力された数値を1文字ずつのリストにしたい
numbers_str = input("数字を入力してください: ")
list = [] # 良くない例: 変数名に list を使用
# 本当は list() を使って文字列を1文字ずつリストにしたい
digits = list(numbers_str) # ここで 'list' object is not callable
print(digits)数字を入力してください: 123
TypeError: 'list' object is not callableこのコードの問題は、「自分で定義した変数listが、Python組み込みのlist()関数を上書きしてしまっている」ことです。
そのためlist(numbers_str)は「空リスト[]を関数として呼び出そうとしている」ことになり、TypeErrorになります。
変数名と組み込み関数名の衝突(上書き)パターン
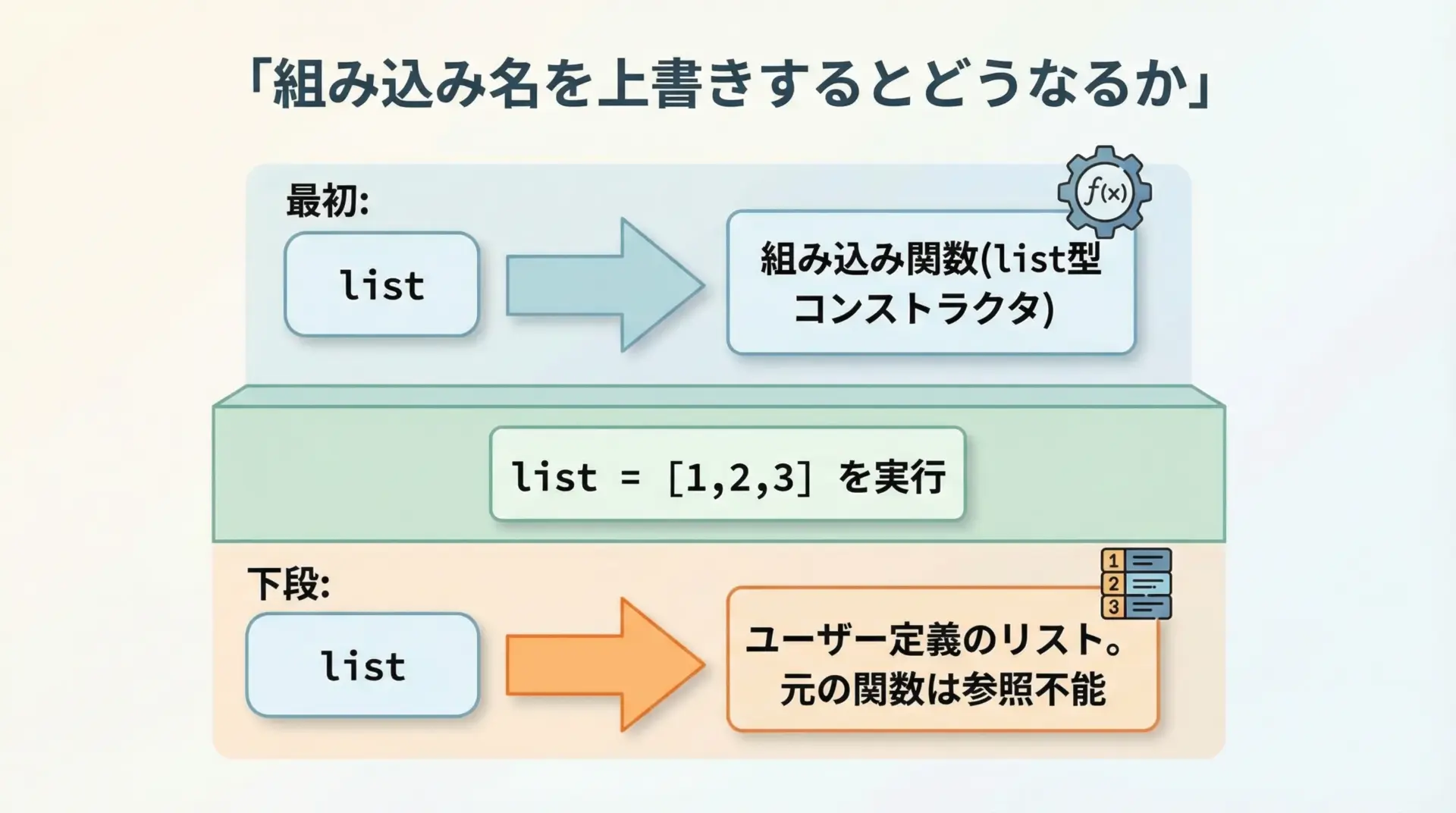
Pythonでは、同じ名前を後から再代入すると、もともとの意味は上書きされます。
これは組み込み関数名であっても同じです。
print(list) # <class 'list'> が表示される(組み込みの list 型)
list = [1, 2, 3] # ここで上書き
print(list) # [1, 2, 3] が表示される(ただのリスト)<class 'list'>
[1, 2, 3]この状態でlist("123")とすると、すでにlistは「関数」ではなく「リスト」を指しているため、「リストオブジェクトは呼び出せません」という意味で'list' object is not callableが出るというわけです。
このパターンはlist以外にも、str, int, dict, set, printなど、さまざまな組み込み名前で起こりえます。
list()と[]の使い分けとベストプラクティス

list()と[]はどちらもリストに関係しますが、役割が少し違います。
次の表で違いを整理します。
| 用途 | list() | [] |
|---|---|---|
| 空リストを作る | list() | [] |
| 既存イテラブルをリスト化 | list("abc") → ['a','b','c'] | 対応なし(構文では不可) |
| リテラルで要素を直接指定 | 冗長(list([1,2])など) | [1, 2]が標準 |
空リストを作るときは[]を使うのが一般的で、他のイテラブルからリストを作りたいときにlist()を使うと覚えておくとよいです。
# 空リストを作る一般的な書き方
result = []
# rangeオブジェクトからリストを作るときは list()
numbers = list(range(5)) # [0, 1, 2, 3, 4]list is not callableを防ぐ変数命名のコツ

「list is not callable」を根本的に防ぐには、変数名の付け方を少し工夫するのが効果的です。
おすすめのコツは次の通りです。
1つ目に、組み込み名と同じ名前を付けないことです。
代表的な組み込み名にはlist, str, int, dict, set, input, printなどがあるので、これらは変数名にしないようにします。
2つ目に、「中身」を表す意味のある名前を付けることです。
たとえばリストならitems, numbers, user_listなど、「何のリストか」が分かる名前にすると、組み込み名との衝突も避けやすくなります。
3つ目に、エディタやLinterの警告を活用することです。
多くのIDEやLinterは、組み込み名を上書きしようとすると警告を出してくれます。
VS CodeやPyCharmなどを利用している場合は、これらの警告を有効にしておくと安心です。
TypeErrorの防ぎ方とデバッグのコツ
最後に、TypeError全般を減らし、発生したときに素早く原因を特定するためのテクニックを紹介します。
Pythonの型チェックでTypeErrorを事前に防ぐ方法

Pythonは動的型付け言語ですが、型ヒントや補助的なチェックによってTypeErrorを事前に防ぐことができます。
代表的な方法としては、次のようなものがあります。
- 関数に型ヒントを付ける
- 静的型チェッカー(mypyなど)を使う
- テストコードを書き、さまざまな入力パターンで実行してみる
型ヒントを付けるだけでも、エディタが「ここにはintが入るべき」「ここにはstrが入るべき」と推論しやすくなり、明らかな型ミスを早期に発見しやすくなります。
isinstanceとtypeで型を確認する手順

デバッグのときに非常に役立つのがtype()やisinstance()です。
これらを使って、「今この変数は本当にどの型なのか?」を確認できます。
def debug_type(value):
print("値:", value, "型:", type(value))
x = [1, 2, 3]
debug_type(x)
y = "hello"
debug_type(y)値: [1, 2, 3] 型: <class 'list'>
値: hello 型: <class 'str'>isinstance()を使うと、ある型かどうかを判定できます。
value = [1, 2, 3]
if isinstance(value, list):
print("value はリストです")
else:
print("value はリストではありません")value はリストですTypeErrorが発生している箇所の直前にprint(type(x))などを入れて実際の型を確認すると、「リストのはずがNoneになっている」といった問題にすぐ気づけるようになります。
mypyなど型ヒント(typing)を使った静的チェック

型ヒント(typing)と静的型チェッカーを併用することで、実行前にTypeErrorの予備軍を検出できます。
簡単な例を見てみます。
# sample.py
def add(a: int, b: int) -> int:
return a + b
result = add(10, "20") # 本当は str を渡してしまっている
print(result)このコードはPythonとしては実行できますが、実行時にunsupported operand type(s) for +のTypeErrorが出ます。
ここでmypyを使うと、実行前に問題を指摘してくれます。
mypy sample.pysample.py:5: error: Argument 2 to "add" has incompatible type "str"; expected "int"
Found 1 error in 1 file (checked 1 source file)このように、型ヒントと静的チェックを導入しておくと、「本来はintを期待している関数にstrを渡している」といったミスを早い段階で見つけることができます。
トレースバック(traceback)から原因を特定する読み方

最後に、TypeErrorに限らずPythonのエラー全般で重要なのが、トレースバック(traceback)の読み方です。
トレースバックは「どのファイルの何行目で、どの関数経由でエラーに至ったか」の履歴です。
簡単な例を示します。
def inner():
x = 10
print(x())
def outer():
inner()
outer()これを実行すると次のようなトレースバックが出ます。
Traceback (most recent call last):
File "example.py", line 8, in <module>
outer()
File "example.py", line 6, in outer
inner()
File "example.py", line 3, in inner
print(x())
TypeError: 'int' object is not callable読み方のポイントは次の通りです。
- 一番下の行に「例外の種類(TypeError)」と「メッセージ本文」が書かれている
- その直前の行が実際にエラーが起きた場所(ファイル・行番号・コード行)を示す
- さらにその上に、「どの関数から呼ばれてここに至ったか」の履歴がスタック状に並んでいる
TypeErrorが出たときは、一番下のメッセージで「どの型」で「どんな操作」が問題なのかを把握し、その直前のコード行を注意深く確認することが、原因特定の近道になります。
まとめ
PythonのTypeErrorは、「型」と「操作」の組み合わせミスを教えてくれる重要なサインです。
「list is not callable」や「’int’ object is not callable」など、頻出する15のパターンを理解しておくと、エラーメッセージを見ただけで原因の見当がつくようになります。
とくに組み込み名と変数名の衝突、演算子と型の対応、iterableやcallableといった性質を意識すると、TypeErrorはぐっと減らせます。
型ヒントやmypy、isinstance()による確認、そしてトレースバックの読み方を身につけ、TypeErrorを「怖いもの」ではなく「バグ発見のガイド」として活用していきましょう。
