
Pythonを始めたばかりの頃は、画面いっぱいに表示される英語のエラーメッセージに圧倒されてしまいがちです。
- 一番下の行でエラーの種類と理由を確認する
例:ZeroDivisionError: division by zero - そのすぐ上のブロックでエラーが実際に起きた行を確認する
例:File "error_example.py", line 3, in divide - さらにその上の行でどこからその関数が呼ばれたかをたどる
例:main()→divide(x, y)という呼び出し関係
しかし、エラーは決して敵ではなく、プログラムが「ここがおかしいよ」と教えてくれる大切なヒントです。
本記事では、Pythonのエラーメッセージの読み方の基本から、よくあるエラー原因ランキング、そしてエラーと上手に付き合うための習慣までを、図解や具体例を交えながら丁寧に解説します。
Pythonのエラーメッセージの基本の読み方
Pythonエラーの種類
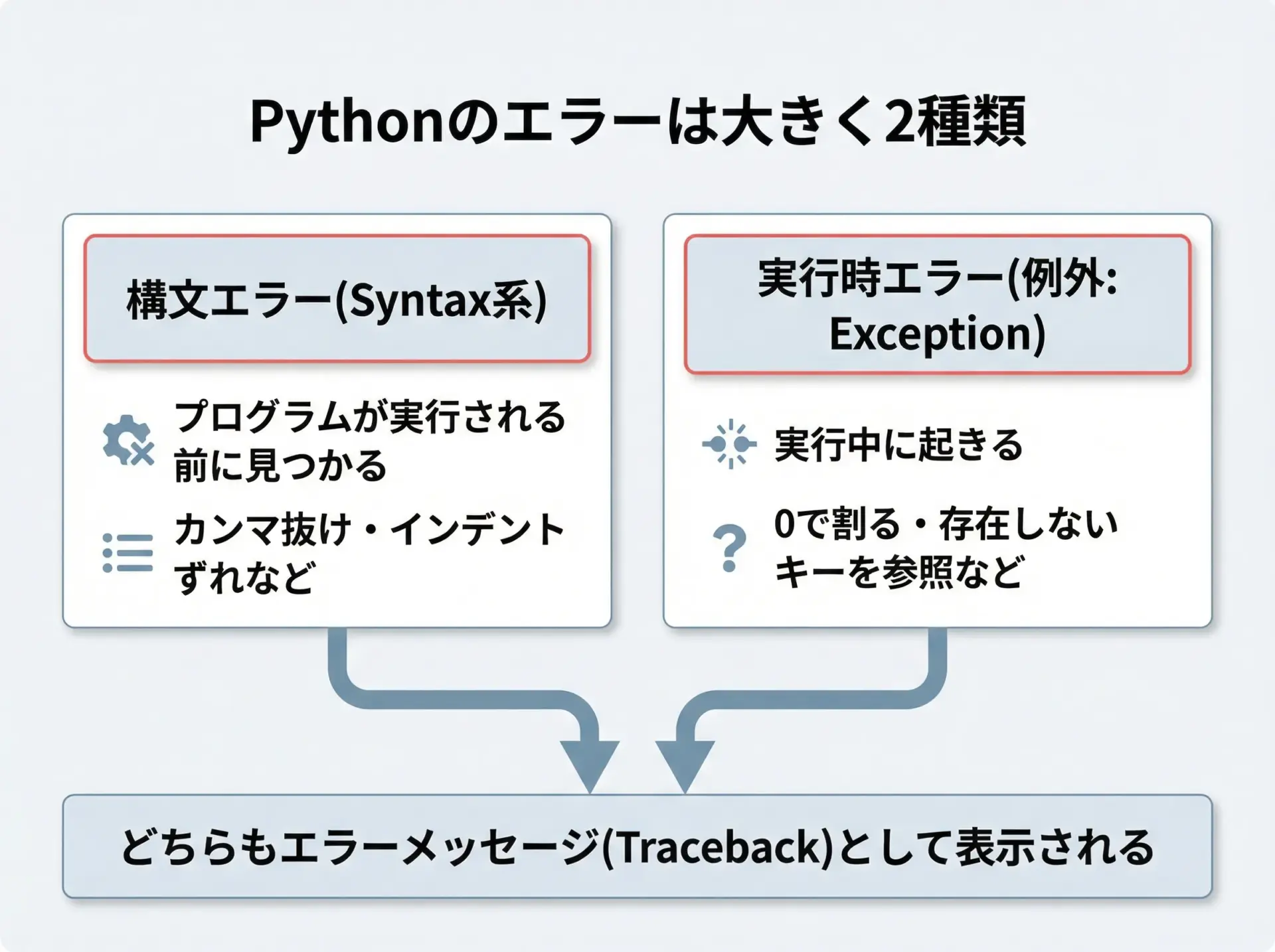
Pythonのエラーは、大きく分けると次の2種類があります。
1つ目は「構文エラー(SyntaxErrorなど)」で、コードの書き方そのものがPythonの文法ルールに反している場合に出るエラーです。
2つ目は「実行時エラー(例外: Exception)」で、文法は正しいけれど、実際に実行してみたときに値の状態や処理内容の問題によって発生するエラーです。
構文エラー(Syntax系)とは
構文エラーは、Pythonがコードを「翻訳」している段階で発見されます。
例えば、カンマの付け忘れや括弧の閉じ忘れ、インデントのずれなどです。
# 構文エラーの例(SyntaxError)
numbers = [1, 2, 3 # 右側の角かっこ ] が抜けている
print(numbers)このような場合、Pythonはプログラムを実行する前に「そもそも意味が解読できない」と判断し、SyntaxErrorとしてエラーを出します。
実行時エラー(例外: Exception)とは
一方、実行時エラーは、文法的には正しいコードでも、実際に動かしたときにだけ見つかる問題です。
例えば、0で割ろうとしたり、存在しないファイルを開こうとしたりしたときです。
# 実行時エラーの例(ZeroDivisionError)
x = 10
y = 0
result = x / y # 0で割っているので実行時にエラー
print(result)このようなエラーは、ZeroDivisionErrorやFileNotFoundErrorなど、原因に応じた例外名が付いて表示されます。
トレースバック(traceback)の見方と読む順番

Pythonでエラーが起きると、「Traceback (most recent call last):」から始まるメッセージが表示されます。
これをトレースバック(traceback)と呼びます。
トレースバックは、「どのファイルの」「どの行で」「どんな種類のエラーが」「どんな理由で」起きたかを教えてくれる履歴です。
読む順番にはコツがあり、基本的には一番下から上に向かって読んでいきます。
トレースバックの構造
次のような簡単な例を見てみます。
# error_example.py
def divide(a, b):
return a / b # ここで0除算の可能性
def main():
x = 10
y = 0
print(divide(x, y))
main()これを実行すると、次のようなトレースバックが表示されます。
Traceback (most recent call last):
File "error_example.py", line 9, in <module>
main()
File "error_example.py", line 6, in main
print(divide(x, y))
File "error_example.py", line 3, in divide
return a / b
ZeroDivisionError: division by zeroトレースバックは上から順に「呼び出しの歴史」が並んでいて、一番下にエラーの種類と理由が表示されています。
読む順番のポイント
トレースバックを読むときは、次の順番を意識します。
- 一番下の行でエラーの種類と理由を確認する
例:ZeroDivisionError: division by zero - そのすぐ上のブロックでエラーが実際に起きた行を確認する
例:File "error_example.py", line 3, in divide - さらにその上の行でどこからその関数が呼ばれたかをたどる
例:main()→divide(x, y)という呼び出し関係
最初から全部を細かく読む必要はなく、まず「一番下の2〜3行」をしっかり読むことが大切です。
エラーメッセージで確認すべき3つのポイント
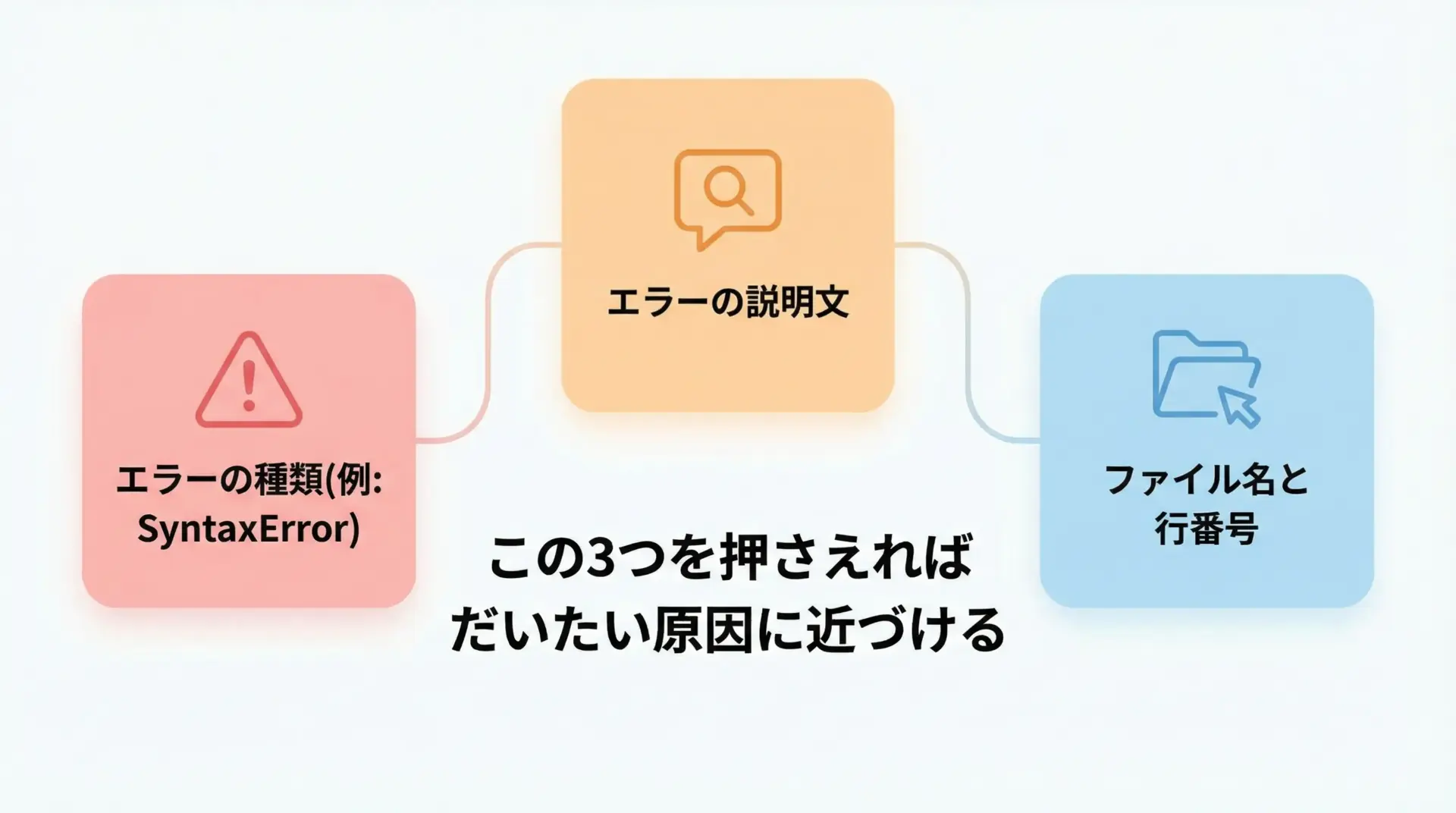
エラーメッセージを読むときに、最低限おさえておきたいのは次の3点です。
- エラーの種類(例外名)
- エラーの説明文
- ファイル名と行番号
この3つを組み合わせて読むことで、原因にかなり近づくことができます。
1. エラーの種類(例外名)
エラーの種類は、トレースバックの一番下にあるZeroDivisionErrorやSyntaxErrorなどの部分です。
これは「どんなタイプの問題か」を表しています。
例えば、
SyntaxErrorなら「文法が間違っている」NameErrorなら「その名前の変数や関数は知らない」TypeErrorなら「その型の値にその操作はできない」
といった大まかな傾向がわかります。
2. エラーの説明文
例外名の後ろに続く英語の文章は、「もう少し具体的な理由」を教えてくれます。
例えば、次のようなものです。
SyntaxError: invalid syntaxNameError: name 'x' is not definedTypeError: can only concatenate str (not "int") to str
ここにはトラブルシューティングに直結するヒントが書かれているので、可能な範囲で読解するようにします。
3. ファイル名と行番号
トレースバックの各ブロックの先頭には、次のような情報が並んでいます。
File "example.py", line 10, in <module>これは、どのファイルの何行目でエラーが起きたかを教えてくれます。
エディタでその行を開き、前後のコードも含めて確認することで、原因を特定しやすくなります。
英語のエラーメッセージを読むコツと最低限の単語

Pythonのエラーメッセージは基本的に英語ですが、全部を完璧に読めなくても大丈夫です。
まずはよく出る単語だけを拾うところから始めると、だんだん慣れてきます。
よく出てくる単語と意味を、表にまとめます。
| 英単語・表現 | 意味のイメージ |
|---|---|
| invalid | 無効な、おかしな |
| unexpected | 予期しない、想定外の |
| not defined | 定義されていない |
| not found / No such file | 見つからない、そのようなファイルはない |
| division by zero | 0で割ろうとした |
| out of range | 範囲外 |
| index | インデックス(位置、番号) |
| key | 辞書のキー |
| type | 型 |
| attribute | 属性(オブジェクトの持つ値やメソッド) |
例えば、NameError: name 'foo' is not defined であれば、name と not defined が読めれば、「fooという名前のものが定義されていないんだな」と推測できます。
すべての単語を辞書で調べる必要はなく、「エラーの種類」「not〜」「found」「invalid」などのキーワードだけを拾って原因を推測する姿勢が大切です。
Pythonでよくあるエラー原因ランキング
ここからは、Python初心者が特によく遭遇するエラーをランキング形式で解説します。
それぞれのエラーについて、発生しやすい典型パターンと、トレースバックの読み方をセットで理解すると、実務や学習でのつまずきが減っていきます。
第1位: SyntaxError
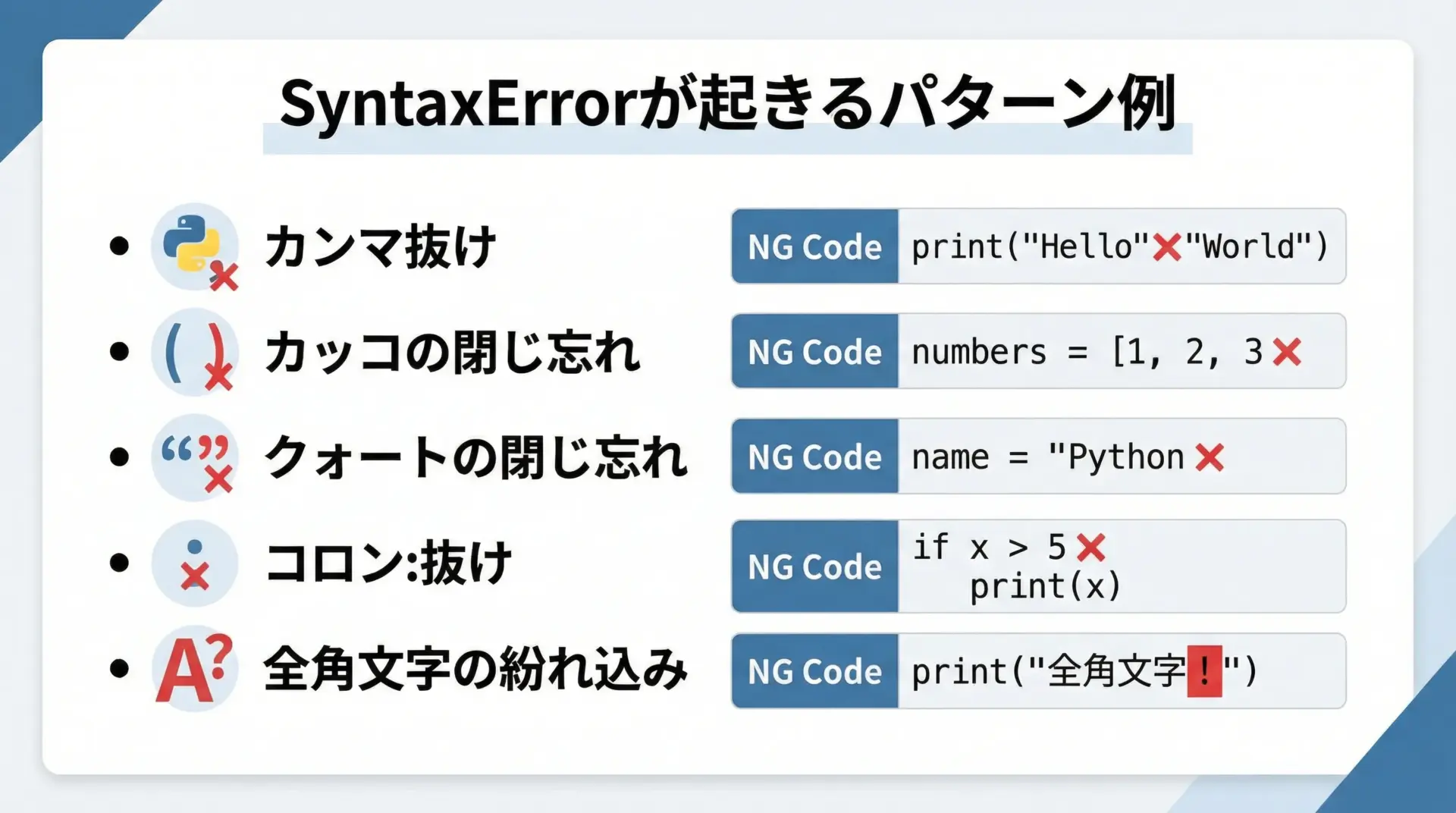
SyntaxErrorは、Python初心者が最も頻繁に遭遇するエラーです。
文法のどこかがPythonのルールに従っていないときに発生します。
代表的なSyntaxErrorの例
# 1. コロン: の付け忘れ
if x > 0 # ← 本来は末尾に : が必要
print("positive")
# 2. カッコの閉じ忘れ
print("Hello" # ← ) が抜けている
# 3. クォートの閉じ忘れ
message = "Hello # ← " が閉じられていないこれらを実行すると、次のようなメッセージになります。
File "example.py", line 2
if x > 0
^
SyntaxError: invalid syntax上の例では、^ の位置に注目します。
Pythonが「おかしい」と感じた位置を示してくれる記号です。
ただし、実際の原因は少し前にあることも多いので、その行の前後も確認するようにします。
SyntaxErrorの対処のコツ
SyntaxErrorが出たときは、次の順番で確認するとよいです。
- エラーメッセージの
line Xで該当行を開く - その行だけでなく、直前の行も確認する
- カンマ
,、コロン:、括弧()[]{}、クォート'"の対応関係をチェック
特に「前の行の末尾にカンマや括弧が足りない」のは、非常によくあるパターンです。
第2位: NameError
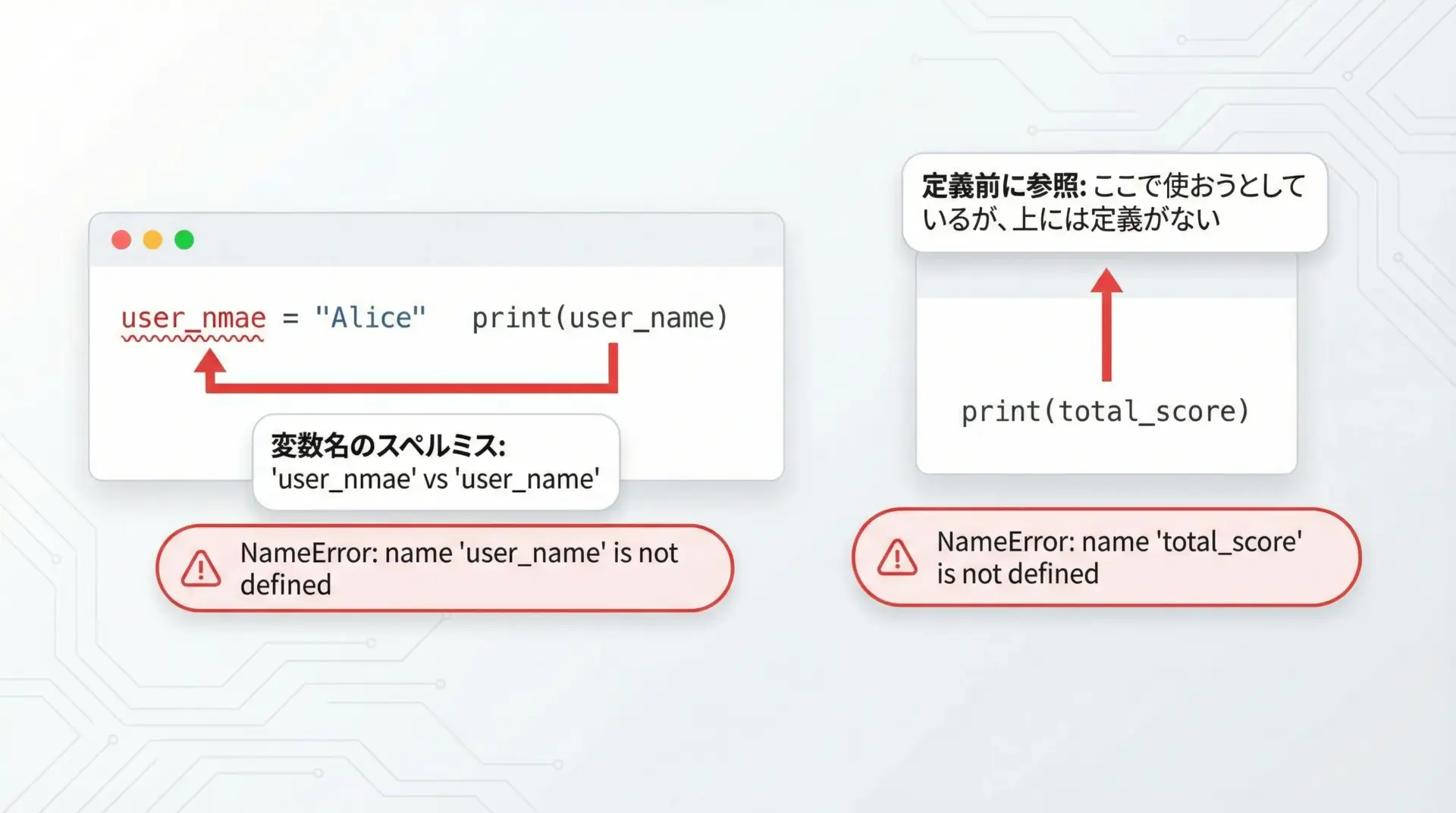
NameErrorは、「その名前の変数・関数・クラスなどは知らない」というエラーです。
NameErrorが起きる典型パターン
# 1. スペルミス
user_name = "Alice"
print(user_nmae) # ← スペルミス
# 2. 定義前に使ってしまう
print(count) # ここで使おうとしているが
count = 10 # 定義は後ろNameError: name 'user_nmae' is not definedこのエラーメッセージは、'user_nmae' という名前が定義されていないと教えてくれています。
NameErrorの対処のコツ
NameErrorが出たら、次の点を確認します。
- 変数名・関数名のスペルが完全に一致しているか
- 定義よりも前で参照していないか
- 関数やクラスのスコープ(有効範囲)の外から参照していないか
名前をコピーペーストして比較したり、エディタの「名前の一括置換」機能を使うと、スペルミスを防ぎやすくなります。
第3位: TypeError
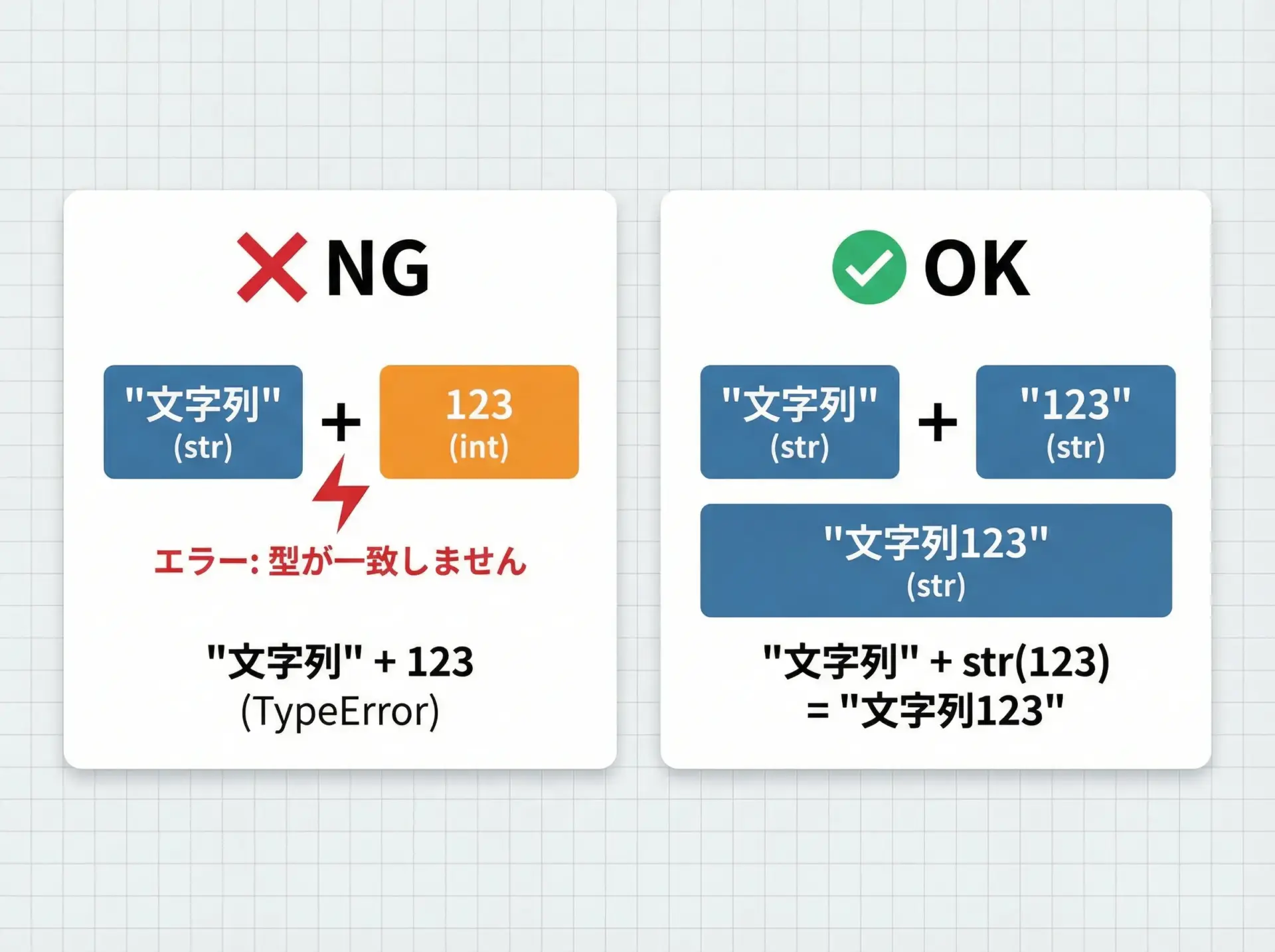
TypeErrorは、「その型の値に対して、その操作はできない」ときに発生します。
よくあるTypeErrorの例
# 文字列と整数の足し算
age = 20
message = "I am " + age + " years old" # ここでTypeError
print(message)実行すると、次のようなエラーになります。
TypeError: can only concatenate str (not "int") to strこれは直訳すると「文字列(str)だけを連結できます(整数intはダメ)」という意味です。
つまり、文字列と整数をそのまま+でつなぐことはできないということです。
対処方法の例
上記のコードは、整数を文字列に変換すれば解決します。
age = 20
# int を str に変換してから連結する
message = "I am " + str(age) + " years old"
print(message)I am 20 years oldTypeErrorが出たときは、「この演算子(+, -, *, / など)やこの関数は、どの型の値に対して使えるのか」を確認することが重要です。
第4位: AttributeError
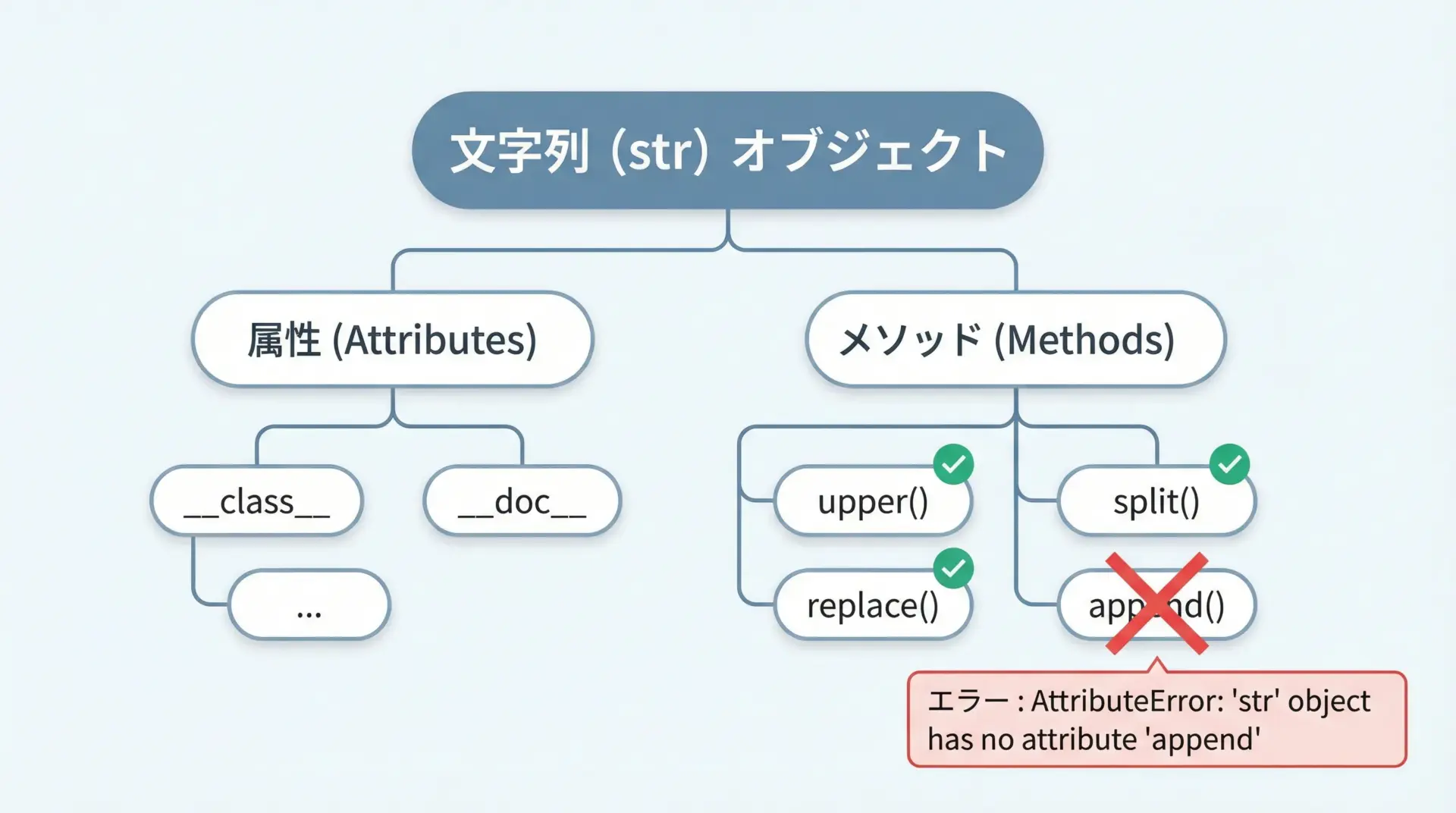
AttributeErrorは、「そのオブジェクトは、その名前の属性(メソッドや変数)を持っていない」というエラーです。
AttributeErrorの典型例
text = "hello"
text.append("!") # 文字列にappendメソッドはない実行すると、次のようなエラーが出ます。
AttributeError: 'str' object has no attribute 'append'メッセージを分解すると、「'str' object (文字列オブジェクト)には、'append' という属性はない」と言っています。
対処の考え方
AttributeErrorが出た場合は、次のどちらかの可能性を考えます。
- その型に存在しないメソッド・属性を呼び出している
例: 文字列にappendしようとしている - 本当は別の型を想定していたのに、別物が入っている
例: リストだと思っていた変数が、実はNoneだった
Pythonの公式ドキュメントやエディタの補完機能で、「その型にどんなメソッドがあるか」を確認する習慣をつけておくと、AttributeErrorは減っていきます。
第5位: IndexErrorとKeyError
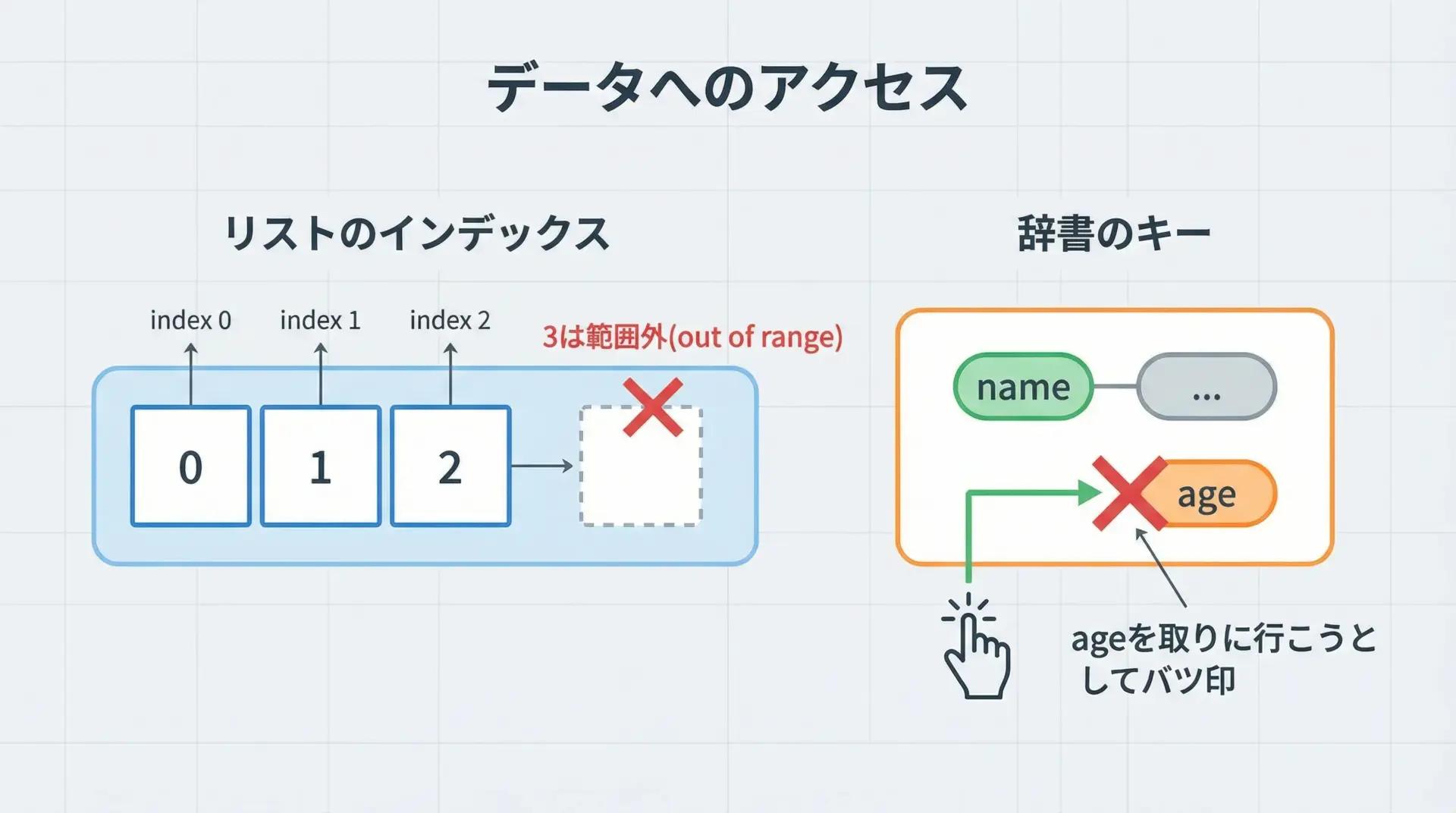
IndexErrorとKeyErrorは、どちらも「存在しない位置(または名前)を指定した」ときに発生するエラーです。
IndexErrorの例(リストなど)
numbers = [10, 20, 30]
print(numbers[3]) # インデックスは 0,1,2 までしかないIndexError: list index out of rangeout of rangeは「範囲外」という意味で、リストの長さに対して大きすぎるインデックスを指定したことを表しています。
KeyErrorの例(辞書)
user = {"name": "Alice"}
print(user["age"]) # "age" というキーは存在しないKeyError: 'age'KeyErrorでは、存在しないキーの名前がメッセージに表示されます。
対処のコツ
IndexErrorやKeyErrorが出た場合は、次の点を確認します。
- リストやタプルなどの長さ(len)を事前に確認しているか
- インデックスが0〜len()-1の範囲内に収まっているか
- 辞書のキーの一覧(user.keys())に、そのキーが含まれているか
必要に応じて、次のような安全なアクセス方法を使うこともあります。
# KeyErrorを避けるには get を使う
age = user.get("age", None) # なければ None を返す第6位: ImportErrorとModuleNotFoundError
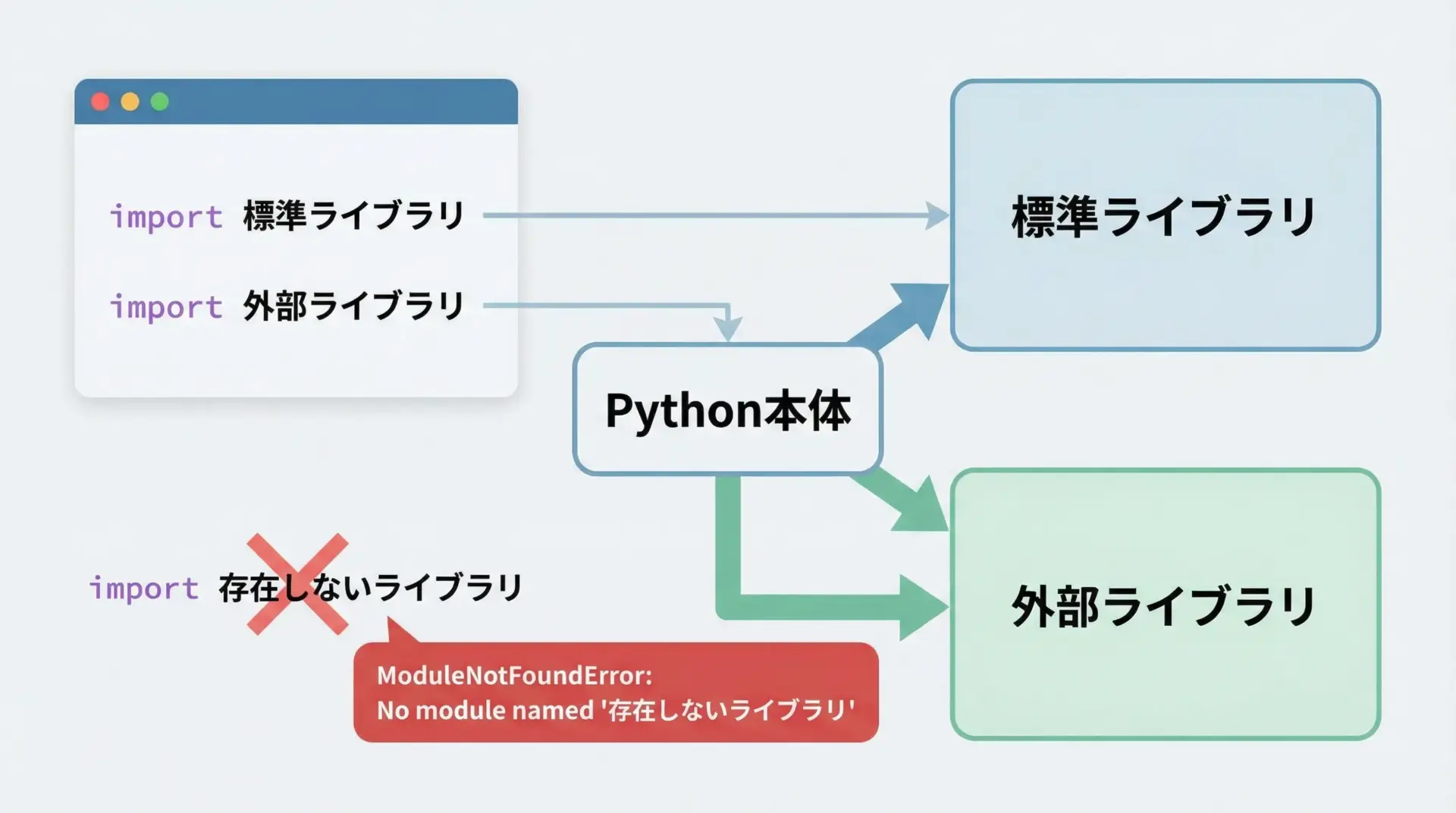
ImportErrorとModuleNotFoundErrorは、モジュールやパッケージの読み込みに失敗したときのエラーです。
ModuleNotFoundErrorの典型例
import numppy # numpy のスペルミスModuleNotFoundError: No module named 'numppy'No module named 'xxx' というメッセージは、「xxxという名前のモジュールは見つからない」と伝えています。
ImportErrorの例
from math import sqr # math モジュールに sqr という名前はないImportError: cannot import name 'sqr' from 'math'これは、「mathからsqrという名前はインポートできない」という意味です。
対処のポイント
ImportError/ModuleNotFoundErrorが出たときは、次を確認します。
- モジュール名のスペルが正しいか
- そのモジュールが本当にインストールされているか
(外部ライブラリの場合はpip install パッケージ名が必要) - 相対パスのパッケージ構成が正しいか
例えば、外部ライブラリrequestsをインポートしたい場合は、事前に次のようにインストールします。
pip install requests第7位: ValueError
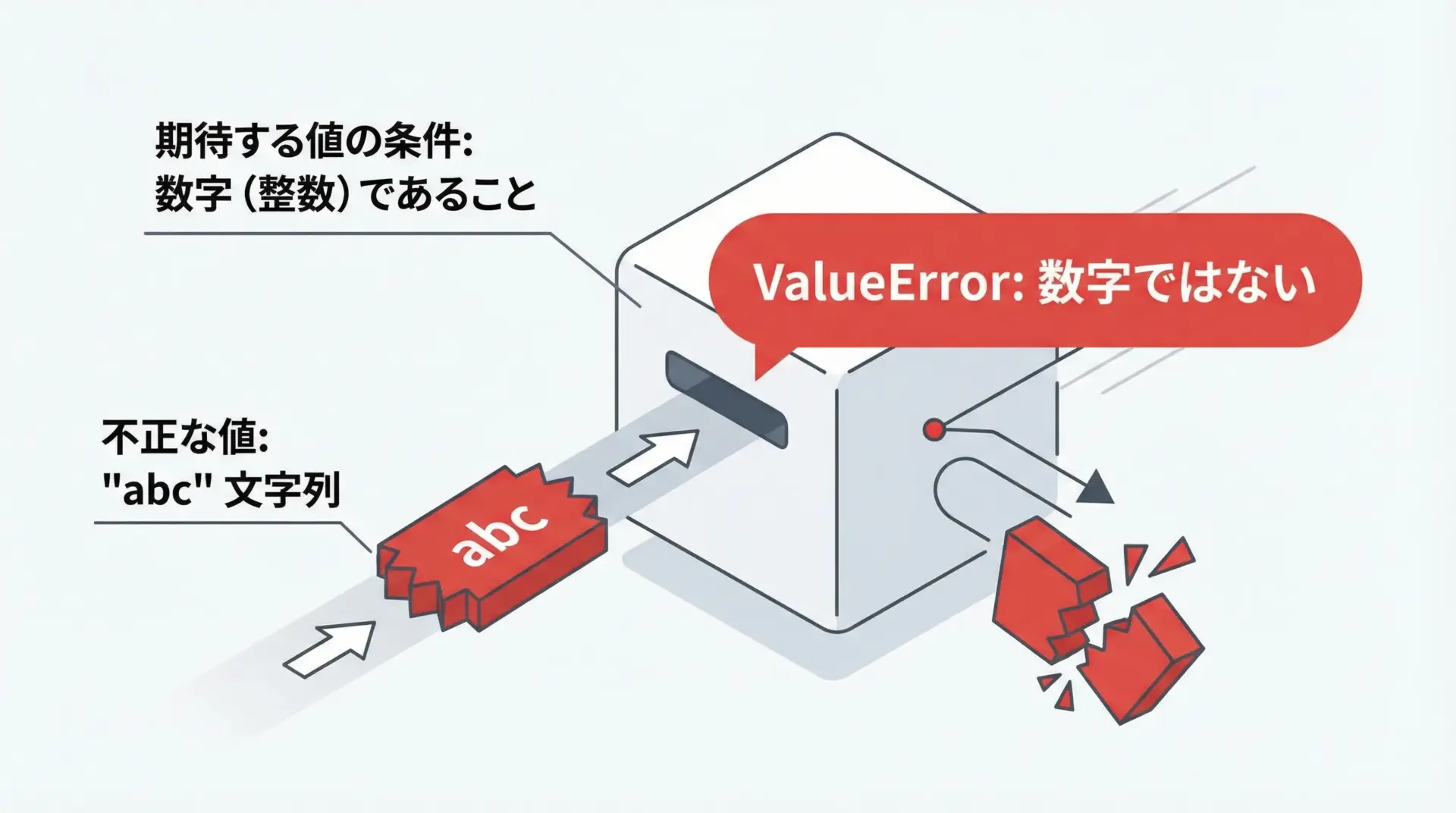
ValueErrorは、「型は合っているが、その中身(値)が不正」というエラーです。
よくあるValueErrorの例
# 文字列を整数に変換しようとしている
text = "abc"
number = int(text) # 文字列だが数字ではないのでエラーValueError: invalid literal for int() with base 10: 'abc'メッセージは「10進数としてint()に渡すには不正な文字列だ」と伝えています。
対処の考え方
ValueErrorが出たら、
- 関数やメソッドがどんな条件の値を期待しているかをドキュメントで確認する
- 処理前に値のチェックを挟む
といった対策が有効です。
第8位: IndentationError
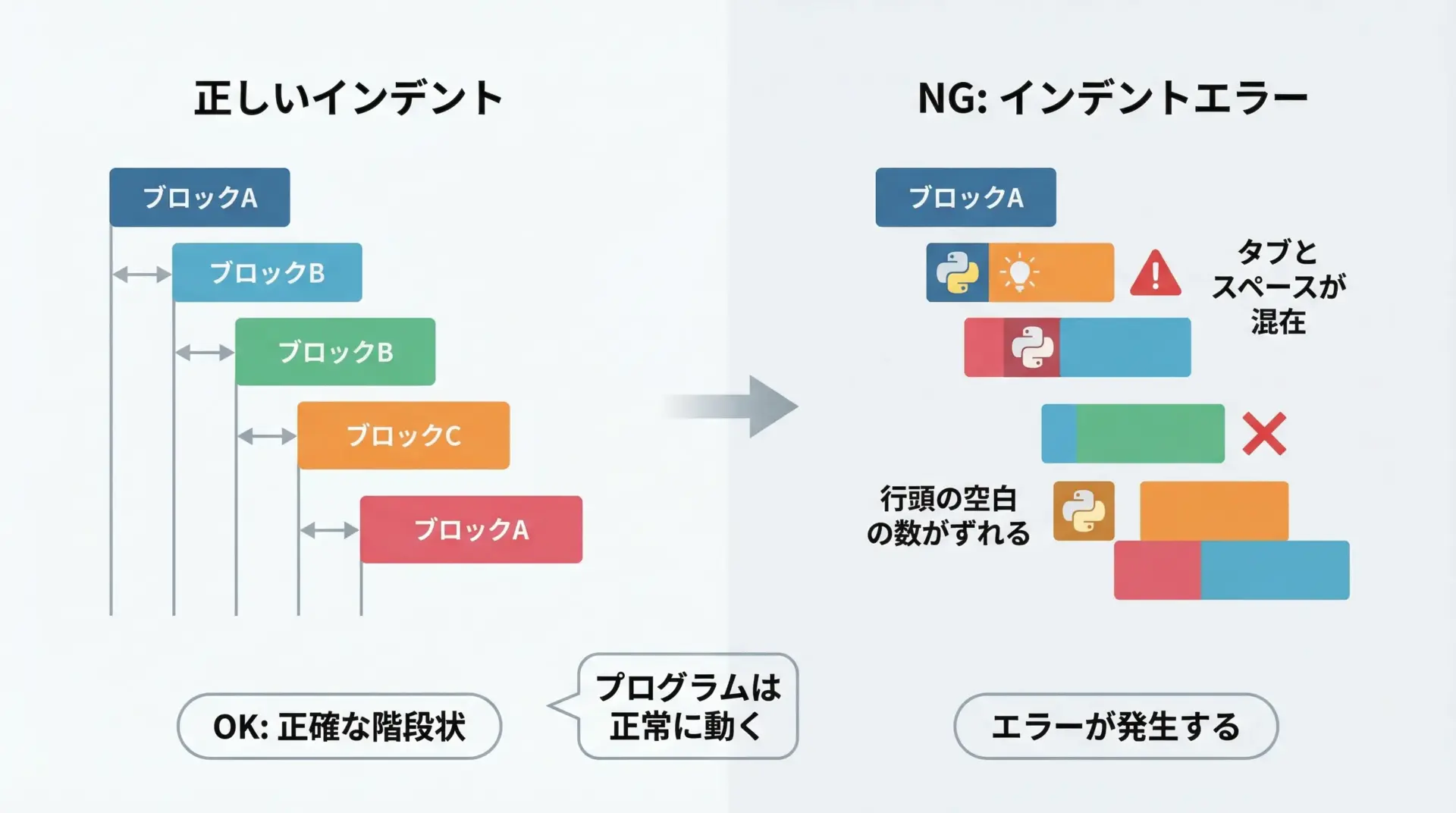
IndentationErrorは、インデント(行頭の空白)に問題がある場合に発生するエラーです。
def hello():
print("Hello") # インデントが必要だが無いIndentationError: expected an indented blockこのメッセージは「インデントされたブロックが必要だった」と伝えています。
対処のポイント
- 関数定義、if文、for文などの直後の行は必ずインデントする
- インデントはスペース4つに統一し、タブとスペースを混在させない
- エディタの設定で「タブをスペースに変換する」をオンにしておく
第9位: ZeroDivisionError
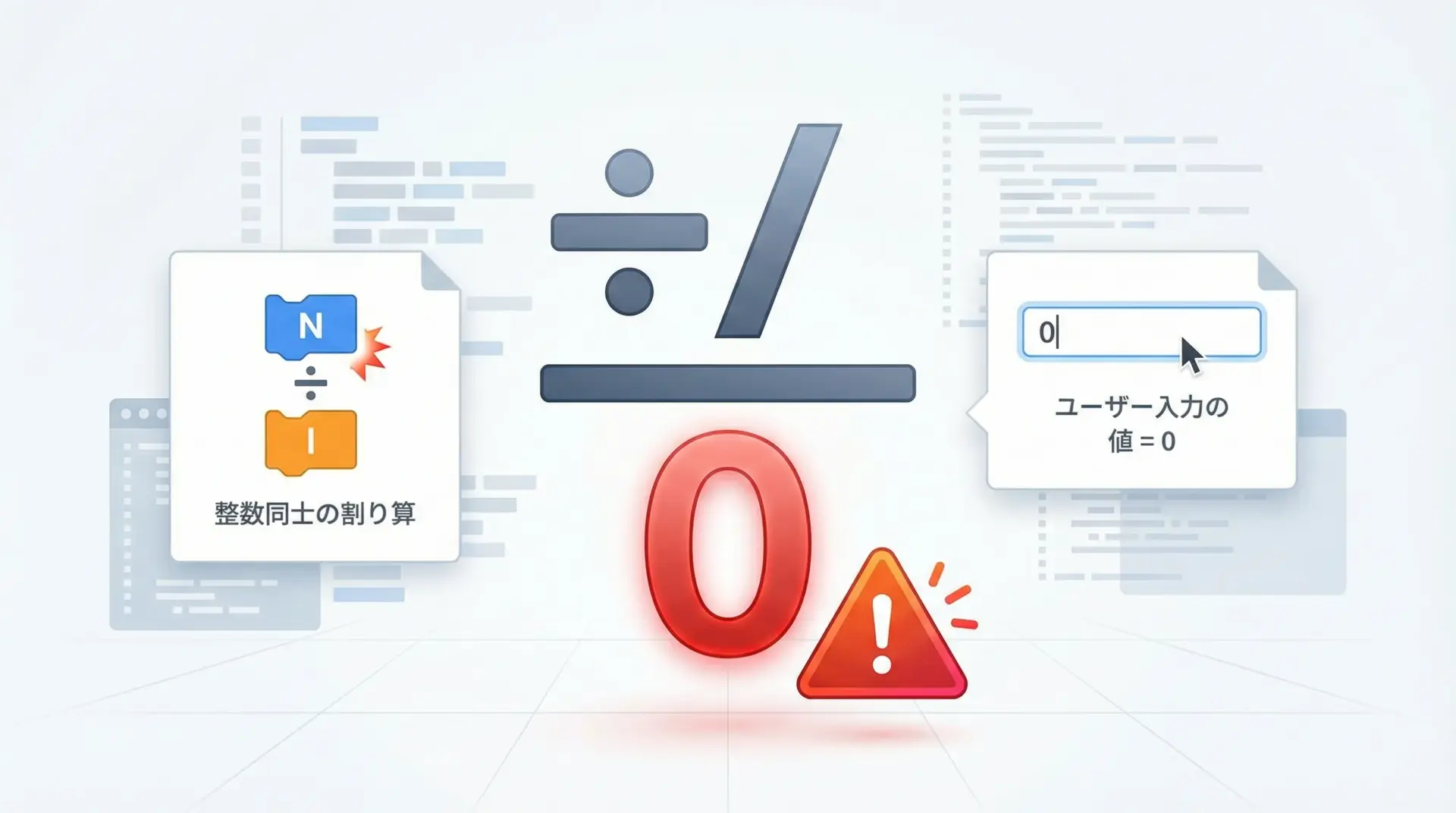
ZeroDivisionErrorは、その名の通り「0で割ろうとした」ときのエラーです。
x = 10
y = 0
print(x / y) # 0で割るZeroDivisionError: division by zero対策としては、割る前に0でないかをチェックすることが基本です。
if y == 0:
print("0では割れません")
else:
print(x / y)第10位: FileNotFoundErrorなどI/Oエラー
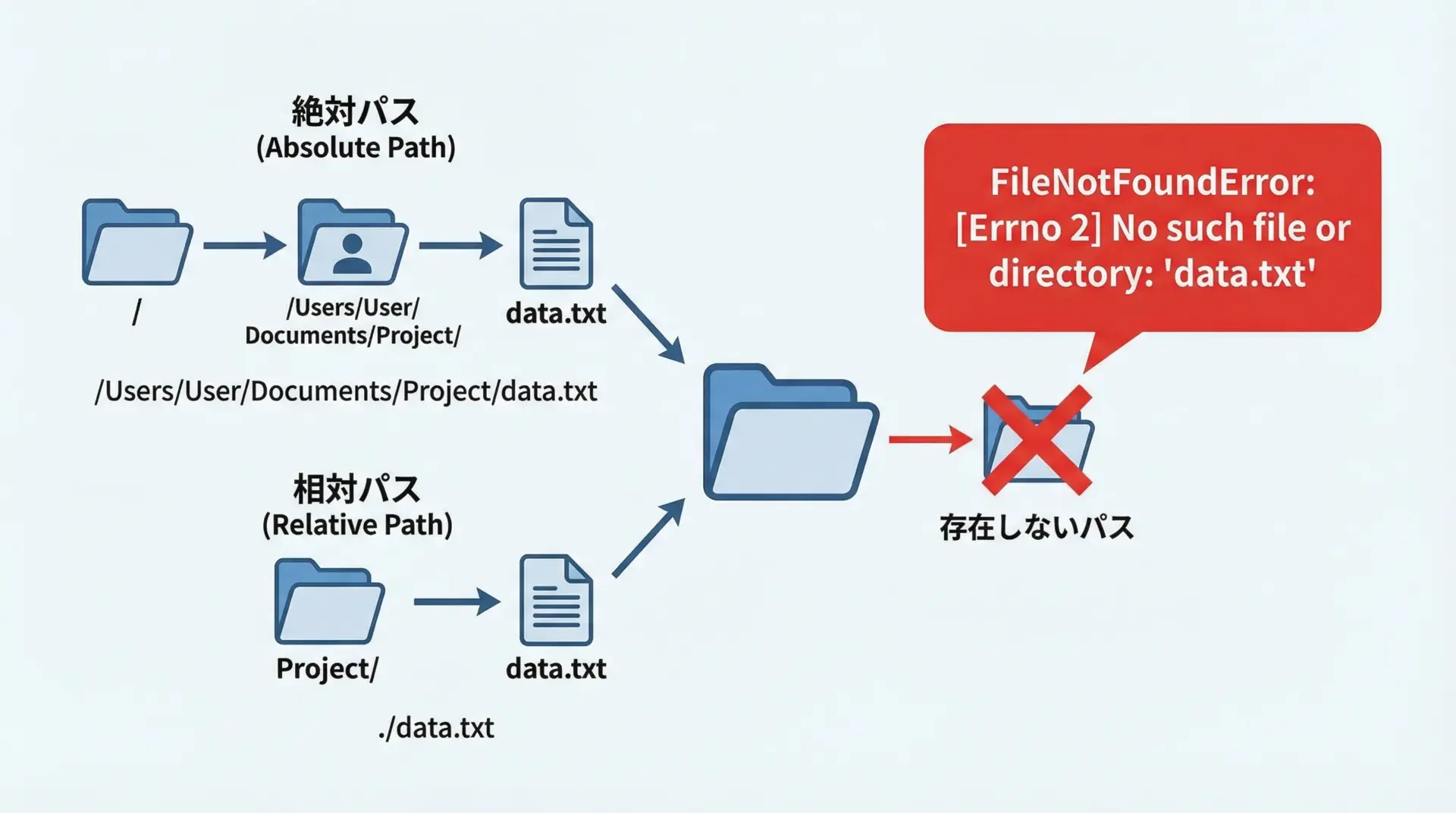
FileNotFoundErrorは、「指定したファイルやディレクトリが見つからない」ときに出るエラーです。
with open("data.txt") as f:
content = f.read()存在しないファイルを指定すると、次のようになります。
FileNotFoundError: [Errno 2] No such file or directory: 'data.txt'No such file or directory は「そのようなファイルやディレクトリはない」という意味です。
対処のコツ
- ファイルの場所(パス)が正しいかを確認する
- 実行しているカレントディレクトリを意識する
os.path.exists()やpathlib.Pathで存在確認を行う
エラー原因の見つけ方とデバッグの基本
エラー箇所を特定するためのtracebackのたどり方
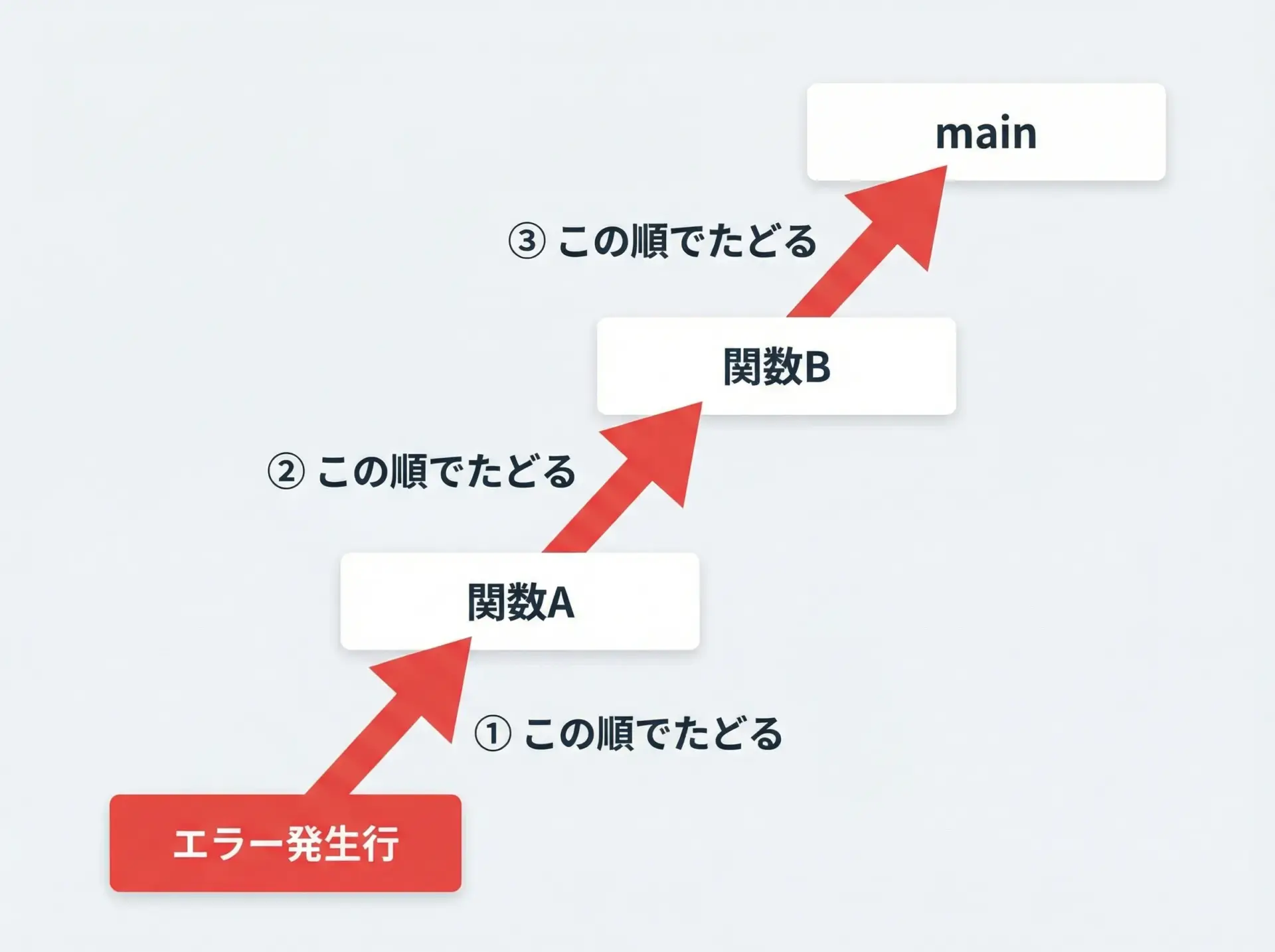
トレースバックを正しくたどることは、エラー原因の特定に直結する重要スキルです。
具体例でのたどり方
次のコードを見てみます。
def calc_discount(price, rate):
return price * rate / 100
def show_result():
price = "1000" # 本当は数値にしたかった
rate = 10
result = calc_discount(price, rate)
print(result)
show_result()実行すると、次のトレースバックが出ます。
Traceback (most recent call last):
File "example.py", line 10, in <module>
show_result()
File "example.py", line 7, in show_result
result = calc_discount(price, rate)
File "example.py", line 3, in calc_discount
return price * rate / 100
TypeError: can't multiply sequence by non-int of type 'str'たどり方は次の通りです。
- 一番下の
TypeErrorと説明文を読む - そのすぐ上の
line 3の行で、どの演算に問題があるかを見る - さらに上の
line 7で、どんな引数を渡しているかを確認する
この例では、文字列"1000"を数値のように扱おうとしたことが原因だとわかります。
エラー行だけでなく前後のコードも確認する理由

トレースバックには「line X」と行番号が出ますが、実際の原因はその1行だけとは限りません。
例えば、次のようなケースです。
total = 0
for i in range(10)
total += i # ← トレースバックでこの行が指摘されることがある本当の問題はfor行の:抜けなのに、エディタによっては次の行が強調されたりします。
そのため、エラー行だけでなく、その前後もセットで確認する習慣が重要です。
printデバッグとloggingの使い分け
エラーの原因がすぐには分からないとき、値の中身を確認するための手段として「printデバッグ」と「logging」があります。
printデバッグの例
def calc(a, b):
print("DEBUG: a =", a, "b =", b) # 途中経過を表示
return a / b
calc(10, 0)DEBUG: a = 10 b = 0
Traceback (most recent call last):
...
ZeroDivisionError: division by zeroprintは、素早く状況を確認するにはとても便利です。
ただし、コードが増えると「デバッグ用print」が散らばって管理しづらくなります。
loggingの利用
より本格的には、loggingモジュールを使います。
import logging
# ログの基本設定
logging.basicConfig(level=logging.DEBUG)
def calc(a, b):
logging.debug("a=%s, b=%s", a, b) # デバッグ情報をログとして出力
return a / b
calc(10, 0)DEBUG:root:a=10, b=0
Traceback (most recent call last):
...
ZeroDivisionError: division by zerologgingを使うと、表示のオンオフやログレベルの切り替えが簡単になるため、少し大きめのプログラムではこちらを使う方が適しています。
最小コードに切り出して再現させるテクニック
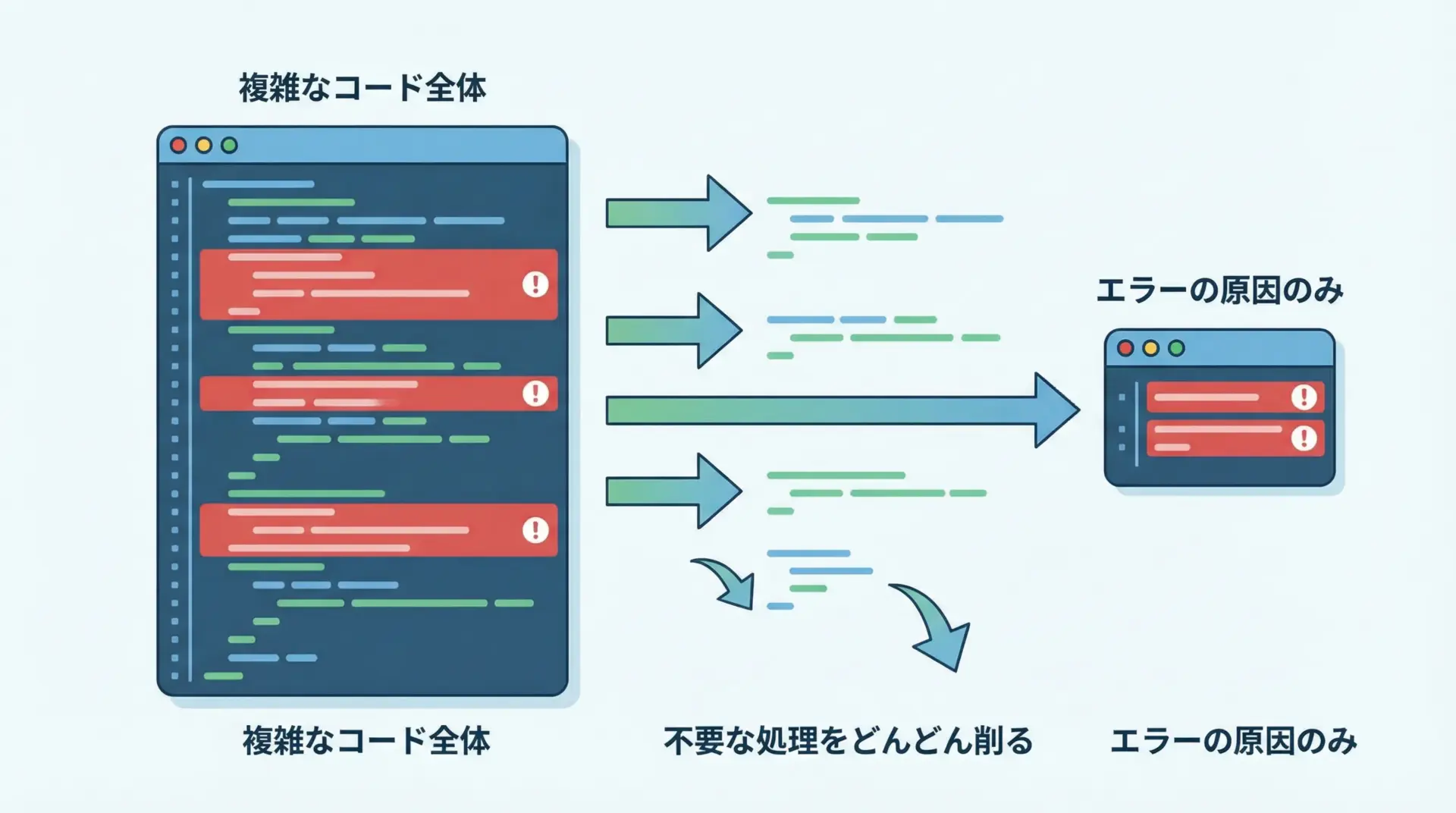
原因がなかなか特定できないときは、エラーを再現できる最小限のコード(最小再現コード)を作るのが有効です。
最小再現コードを作る手順
- エラーが出るスクリプトをコピーする
- 関係なさそうな処理や外部依存を一つずつ削ってみる
- それでもまだ同じエラーが出る部分だけを残す
これを繰り返すと、「何をしたときにエラーが出るのか」がクリアに見えてきます。
また、最小再現コードは質問サイトや他人に相談するときにも非常に役立ちます。
エラーを検索する時のキーワードの選び方

エラーで困ったとき、インターネット検索は強力な武器になります。
このときのキーワード選びとして、次を意識します。
- エラーの種類(例外名)を含める(
TypeErrorなど) - エラーの英文メッセージをできるだけそのままコピペする
- 追加で「python」「初心者」などを加える
例:
python TypeError can only concatenate str (not "int") to str
自分で意訳した日本語を検索するより、エラー文そのものを使う方が、ピンポイントな情報にたどり着きやすいです。
Python初心者がエラーで挫折しないための習慣
コードを書く前にエラーが出にくい書き方を意識する

エラーを減らすには、書き方の段階でミスを起こしにくいスタイルを意識することが有効です。
例えば、次の点を心がけます。
- 変数名や関数名を意味のある名前にする(後で読みやすくなる)
- 1行に詰め込みすぎず、ステップを分けて書く
- 条件分岐やループのブロックを空行やコメントで区切る
こうした工夫により、「どこがおかしいのか」を自分で目視しやすくなり、エラーの発見と修正がスムーズになります。
Linterや型チェックツールでエラーを事前に防ぐ

Pythonでは、Linter(静的解析ツール)や型チェックツールを使うことで、実行前にミスを検出できます。
代表的なツールには、次のようなものがあります。
| 種類 | ツール例 | 役割 |
|---|---|---|
| Linter | flake8, ruff | 文法ミスやスタイルの問題を指摘 |
| フォーマッタ | black | コードの書き方を自動で整形 |
| 型チェッカー | mypy, pyright | 型ヒントを使って型の不整合を検出 |
エディタ(VS Codeなど)と連携させると、コードを書いている最中から赤線・波線で問題箇所を警告してくれるので、SyntaxErrorやTypeErrorの多くを事前に防ぐことができます。
エラーメッセージを無視せず必ず読む習慣をつける

Pythonに限らず、プログラミングで大切なのは、エラーメッセージから逃げない習慣です。
最初は英語で難しく見えますが、ここまで見てきたように、
- エラーの種類(例外名)
- 英文の中のキーワード
- 行番号とファイル名
の3点を押さえるだけでも、かなりヒントを得られます。
「エラーが出たら、まずは一番下の2〜3行を声に出して読む」くらいのつもりで、少しずつ慣れていくとよいです。
エラーと向き合うための学習法とおすすめリファレンス
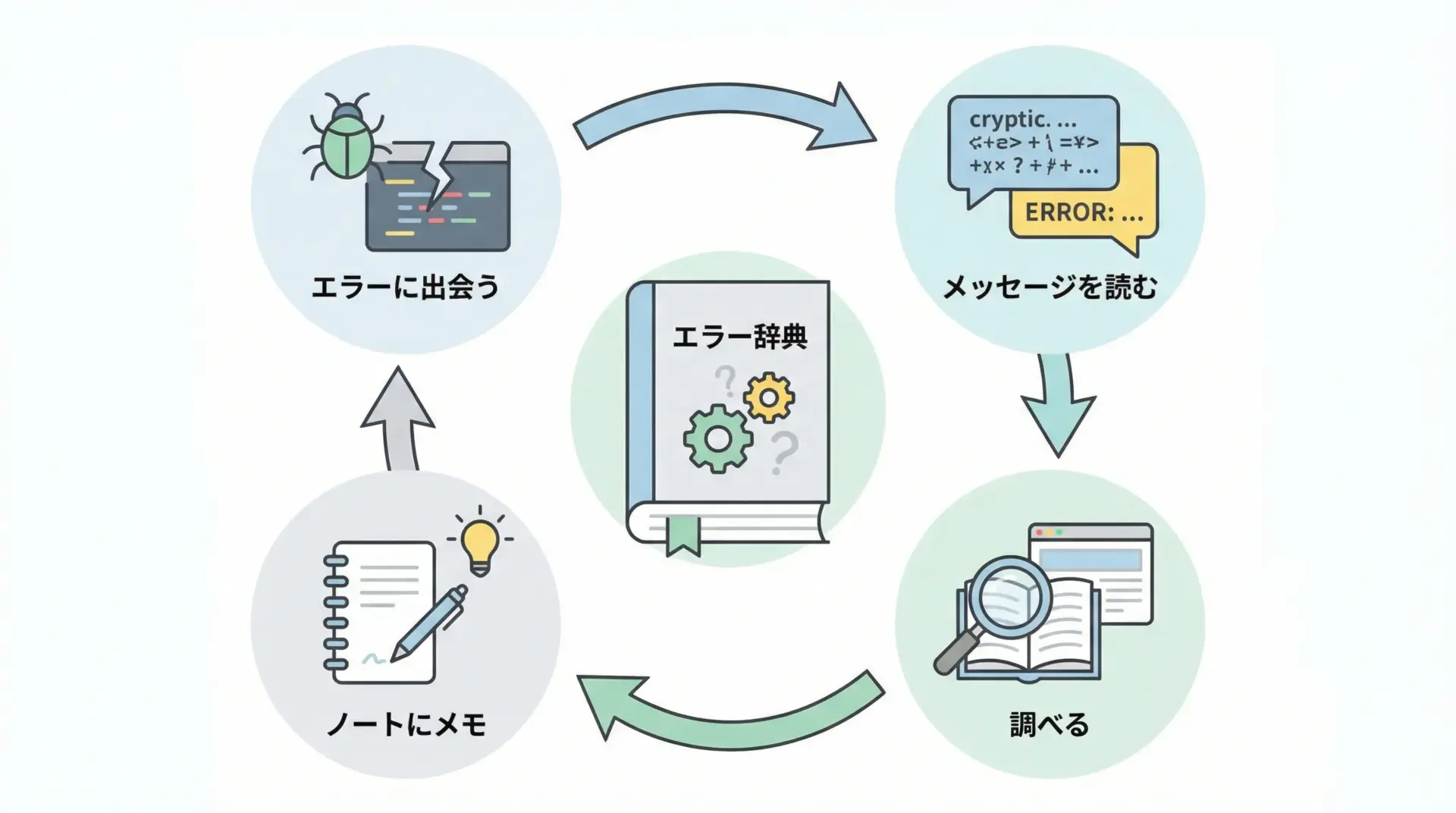
エラーは、自分の弱点や理解不足を教えてくれる「先生」のような存在です。
エラーと上手に付き合うために、次のような学習サイクルを意識するとよいです。
- エラーが出たら、まずメッセージを読む
- そのエラー名(例: SyntaxError, TypeErrorなど)をメモする
- インターネット検索や書籍で、そのエラーの意味と典型パターンを調べる
- 自分なりの「エラー辞典」ノートやメモアプリにまとめる
参考になる情報源としては、
- Python公式ドキュメント「Built-in Exceptions」
- 日本語のPython入門サイトや書籍の「エラー解説」章
- Q&Aサイト(Stack Overflow、teratailなど)
などがあります。
同じエラーに2回、3回と出会うたびに「前にも見たことがある」と感じられるようになれば、もう初心者卒業は目前です。
まとめ
Pythonのエラーメッセージは、最初こそ難しく感じられますが、「エラーの種類」「メッセージ」「行番号」の3点を押さえて、一番下から順に読むことを意識すれば、原因にたどり着きやすくなります。
本記事では、初心者が特につまずきやすいSyntaxErrorやNameErrorなどの代表的なエラーをランキング形式で紹介し、tracebackの読み方やprint/loggingによるデバッグ、最小再現コードの作り方など、実践的な対処法も解説しました。
エラーは失敗ではなく、プログラムからのフィードバックです。
エラーメッセージを味方につけ、少しずつ「読める」「直せる」経験を積み重ねていけば、Pythonでの開発はぐっと楽しく、頼もしいものになっていきます。
