
Pythonでバグを見つけるたびにprint地獄に陥っていませんか。
そんなときこそ、標準で付属している対話型デバッガpdbの出番です。
本記事では、インストール不要のpdbを使って、コードを1行ずつ追いかけながら原因を特定する方法を、初心者の方でも迷わないように図解とサンプルコードたっぷりで解説していきます。
pdbデバッガとは何か
Python標準のpdbとは
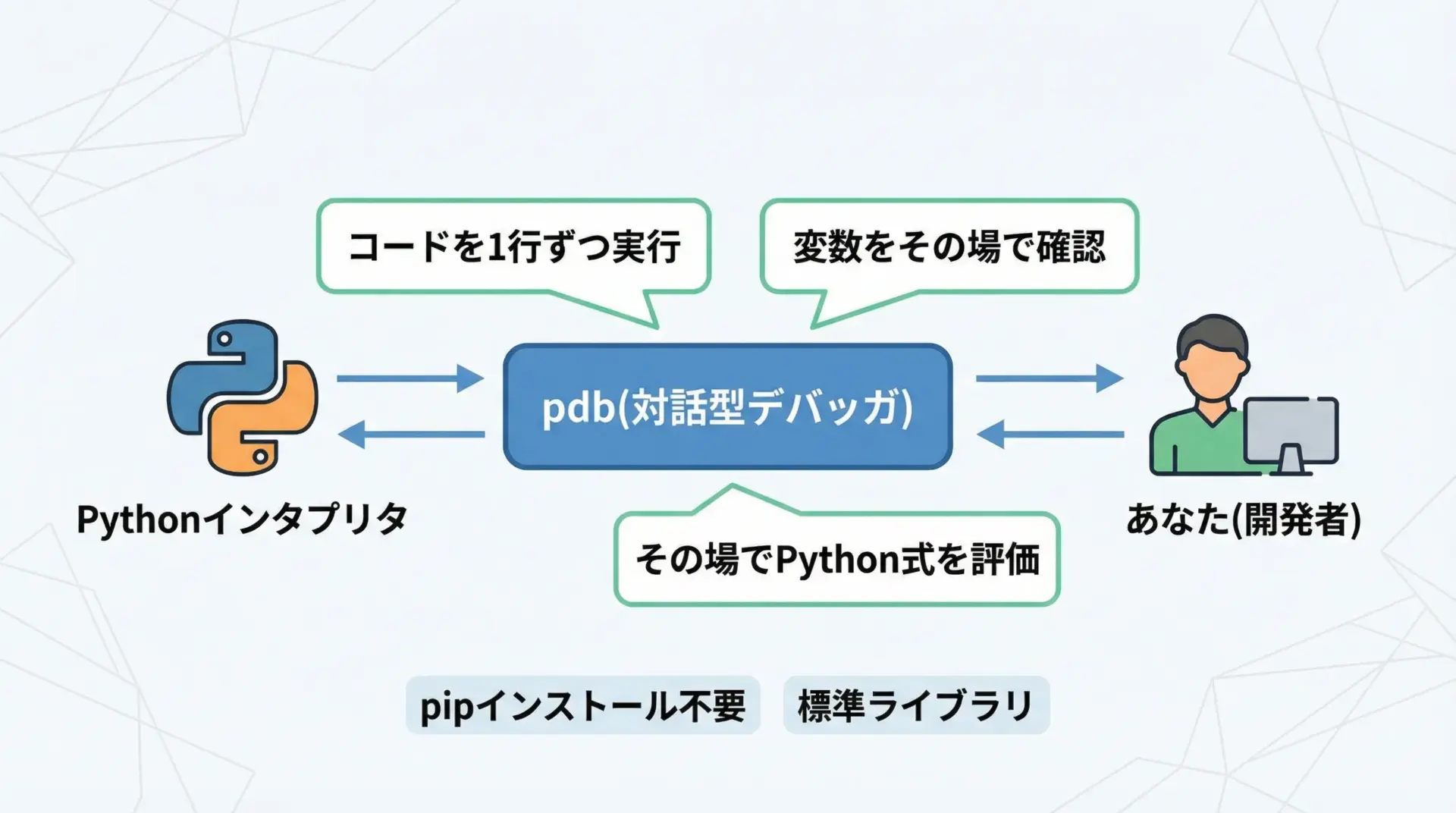
Pythonには、標準ライブラリとしてpdb(Python Debugger)というデバッガが用意されています。
追加インストールは不要で、Pythonをインストールした時点で必ず使える状態になっています。
pdbは、プログラムの実行を一時停止し、次のような操作を対話的に行えるツールです。
- 実行を1行ずつ進める
- 任意の行や関数の手前で一時停止する
- 変数の中身を確認する
- その場で簡単なPythonコードを実行して挙動を確かめる
対話型の「プログラム実行のリモコン」のようなものだとイメージすると分かりやすいです。
printデバッグとの違い
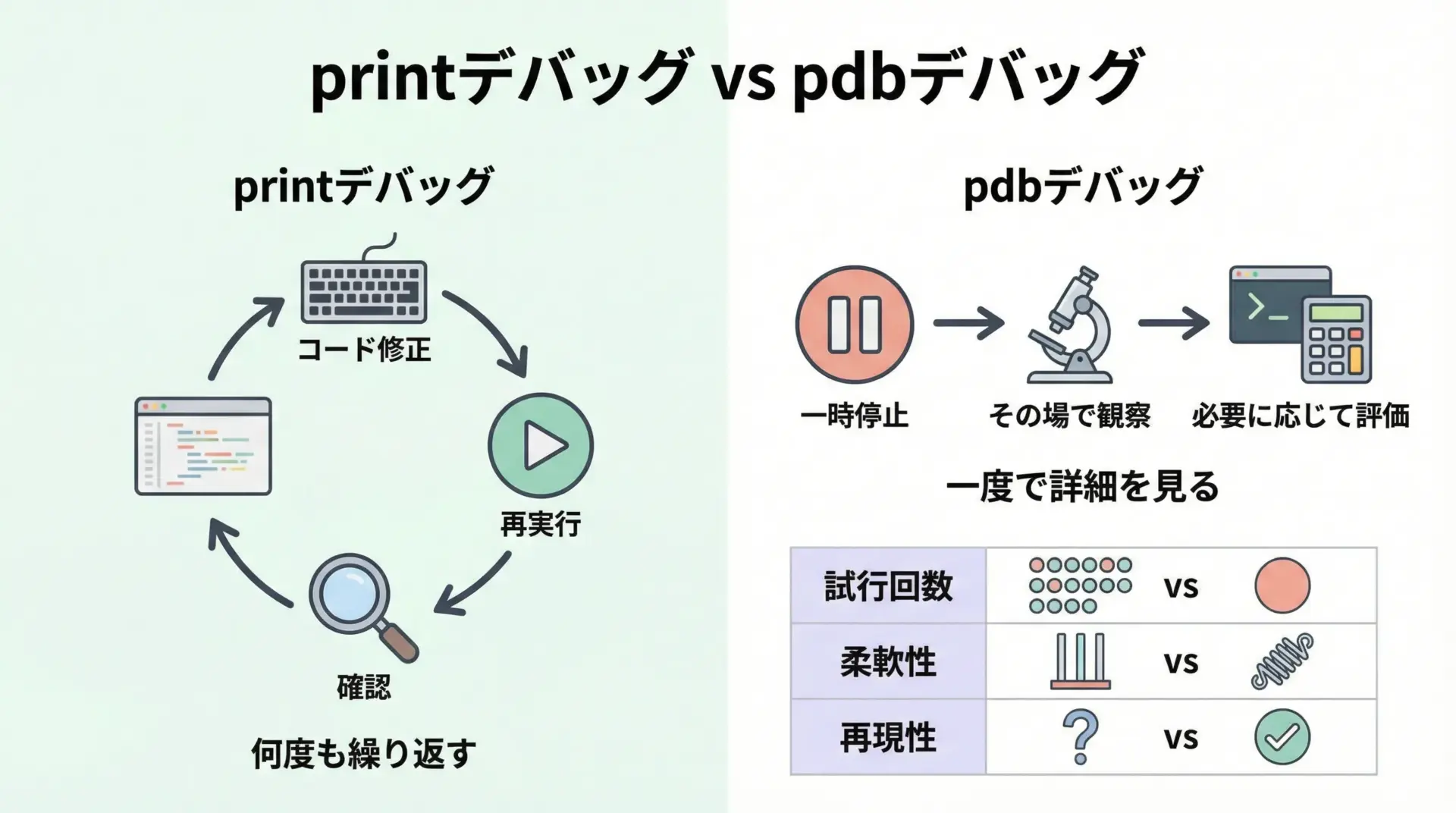
Python初心者の多くは、まずprint関数を使ったデバッグから始めます。
もちろん、printデバッグも有効ですが、次のような違いがあります。
printデバッグは、あらかじめprintを埋め込んでおき、プログラムを最後まで実行してログを眺めるスタイルです。
そのため、確認したい情報が足りなければコードを修正して再実行する必要があります。
一方、pdbデバッグでは、一時停止したその場で必要な情報を次々に引き出せるという大きな違いがあります。
例えば、ある行で止めてから
- 変数AとBを比べる
- 試しに関数を別の引数で呼び出してみる
- 条件式がTrueになるかどうかを手動で確かめる
といった操作を、プログラムを止めたまま何度でも行えます。
pdbを使うメリット・デメリット
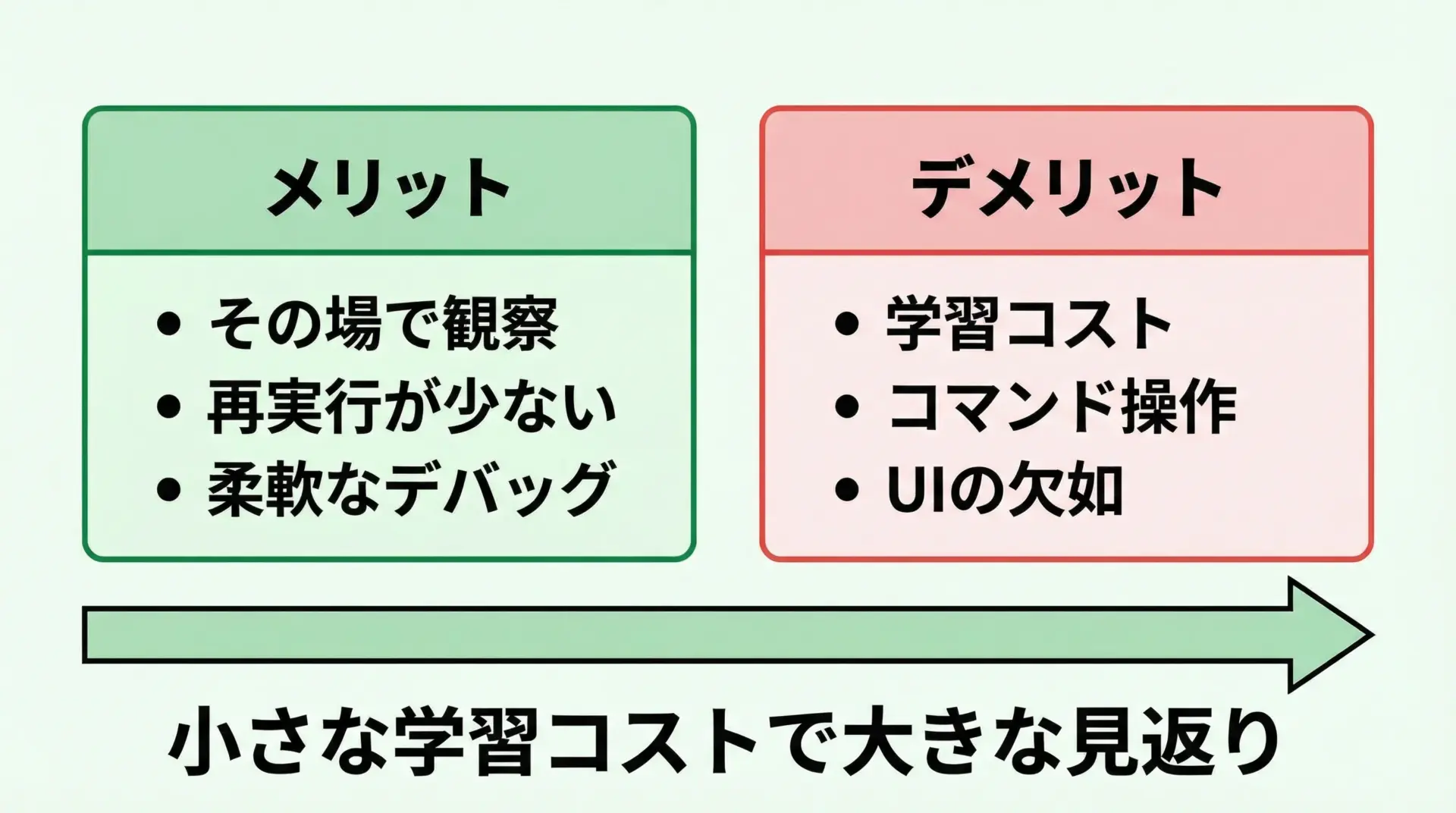
pdbには多くのメリットがありますが、もちろんデメリットも存在します。
メリットとしては、まずバグの原因にたどり着くまでの試行回数を大きく減らせることが挙げられます。
また、ループの中の特定の条件でだけ再現するバグなど、printだけでは追い付きにくいケースでも、pdbなら効率的に追跡できます。
一方で、デメリットとして最初にコマンドを覚える学習コストが必要です。
とはいえ、日常的によく使うのは一握りのコマンドなので、最初に10個程度だけ覚えてしまえば一気に世界が変わるツールだと考えてよいでしょう。
pdbデバッグの基本的な使い方
pdbを起動する(run)方法3パターン

pdbには、状況に応じていくつかの起動方法があります。
ここでは基本となる3パターンを整理しておきます。
1つ目は、スクリプト自体をpdb付きで実行する方法です。
これはpython -m pdb スクリプト名.pyの形式で呼び出します。
2つ目は、後述するset_traceを使って、コードの中で任意の位置からpdbを立ち上げる方法です。
3つ目は、例外が発生したときに自動的にpdbを起動する方法で、モジュールpdbのpmやpost_mortemを利用します。
この方法は、再現が難しい例外の原因をその場で確認したいときに役立ちます。
コード内にブレークポイント(set_trace)を仕込む
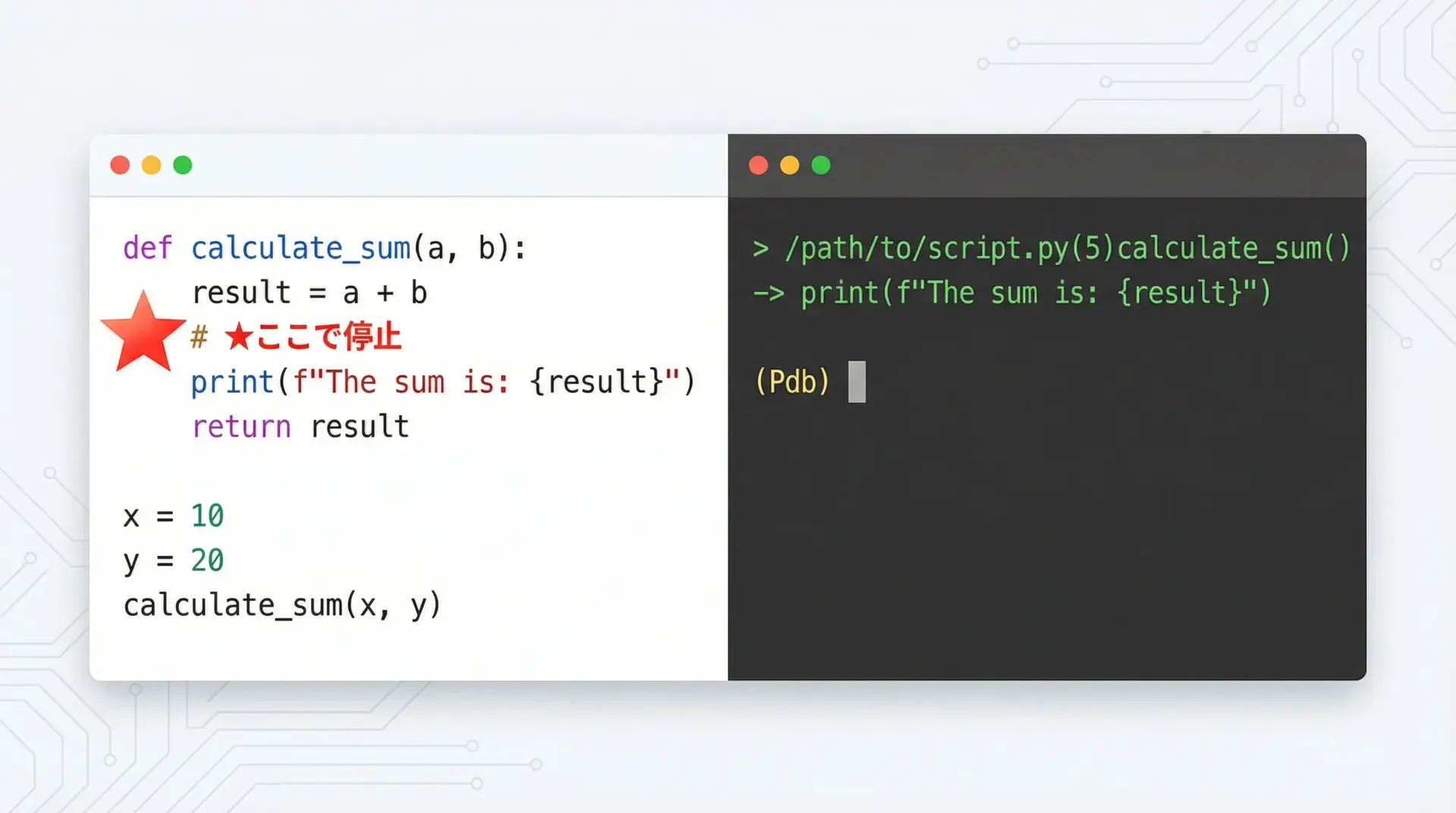
ブレークポイントとは、「ここで一度止まってほしい」という位置を指定するものです。
pdbではset_traceを呼び出すことで、任意の場所にブレークポイントを仕込めます。
以下のシンプルな例で仕組みを確認してみます。
# debug_sample.py
import pdb # pdbモジュールをインポート
def add(a, b):
result = a + b
return result
def main():
x = 10
y = 20
# ここで一時停止したい
pdb.set_trace() # ブレークポイントを設定
z = add(x, y)
print("結果:", z)
if __name__ == "__main__":
main()このスクリプトを通常どおりpython debug_sample.pyで実行すると、pdb.set_trace()の行で実行が停止し、ターミナルにpdbのプロンプト(Pdb)が表示されます。
> /path/to/debug_sample.py(16)main()
-> z = add(x, y)
(Pdb)ここから、pdbコマンドを入力してステップ実行や変数確認を行うことができます。
コマンドラインからpdbでスクリプトを実行する
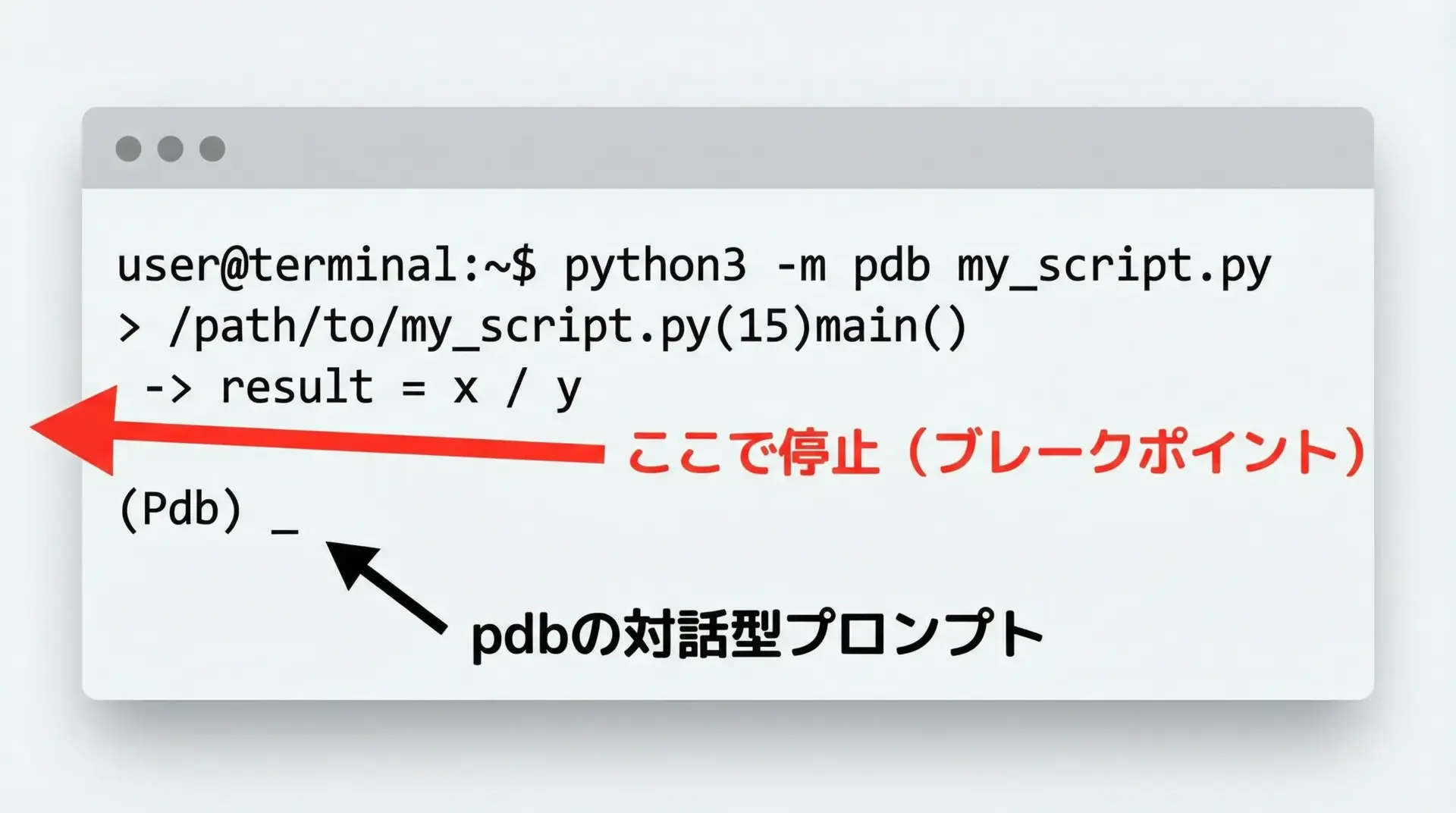
もう1つの基本的な起動方法が、python -m pdbでスクリプトを丸ごとpdb管理下で実行する方法です。
この場合、スクリプトの先頭行から実行が始まり、pdbのプロンプトで操作しながら進めていきます。
python -m pdb debug_sample.py起動直後には、最初の行で停止した状態になります。
ここでl(list)やn(next)などのコマンドを使って、気になる箇所まで進めていきます。
この方法の特徴は、コードに一切手を入れずにデバッグを開始できる点です。
変更を加えたくない外部スクリプトや、すでに運用中のコードを一時的に調査したい場合に向いています。
VSCodeなどIDEからpdbを使う方法の概要
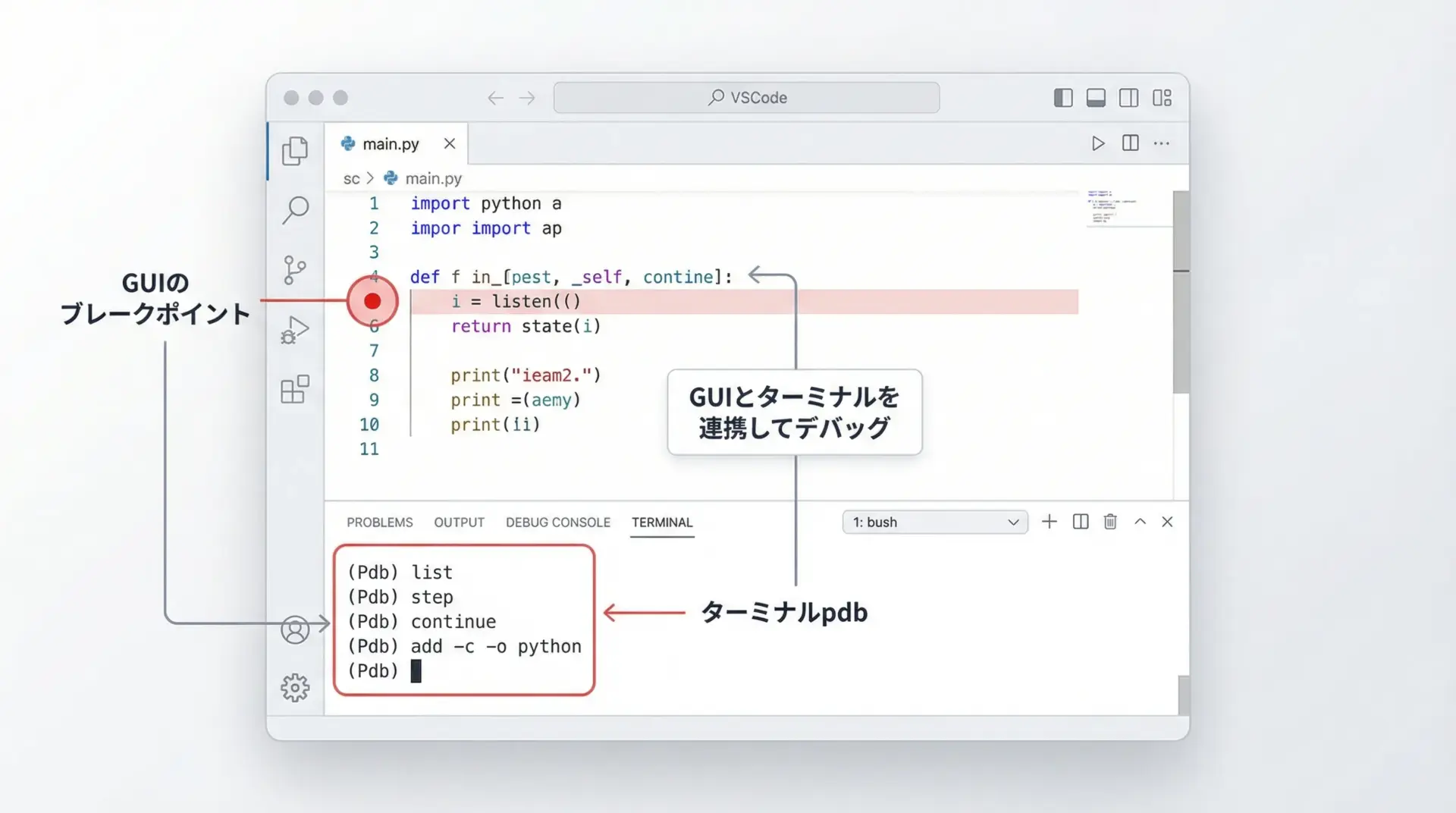
多くのIDEやエディタ(VSCode、PyCharmなど)には独自のデバッガ機能がありますが、その内部でpdbを利用している場合もあります。
ここでは詳細な設定方法には踏み込みませんが、pdbの概念に慣れておくとIDEのデバッガも理解しやすくなることを押さえておくとよいです。
VSCodeのPython拡張機能では、エディタ左側の行番号付近をクリックして赤い点(ブレークポイント)を置き、デバッグ実行を開始するだけで、GUIでのステップ実行や変数ウォッチが可能になります。
内部ではpdbと同じ概念、つまり「特定の行で一時停止し、そこから1行ずつ進めていく」という動きをしていると考えれば理解しやすくなります。
まず覚えたいpdbの基本コマンド
ステップ実行(step s n)の使い方
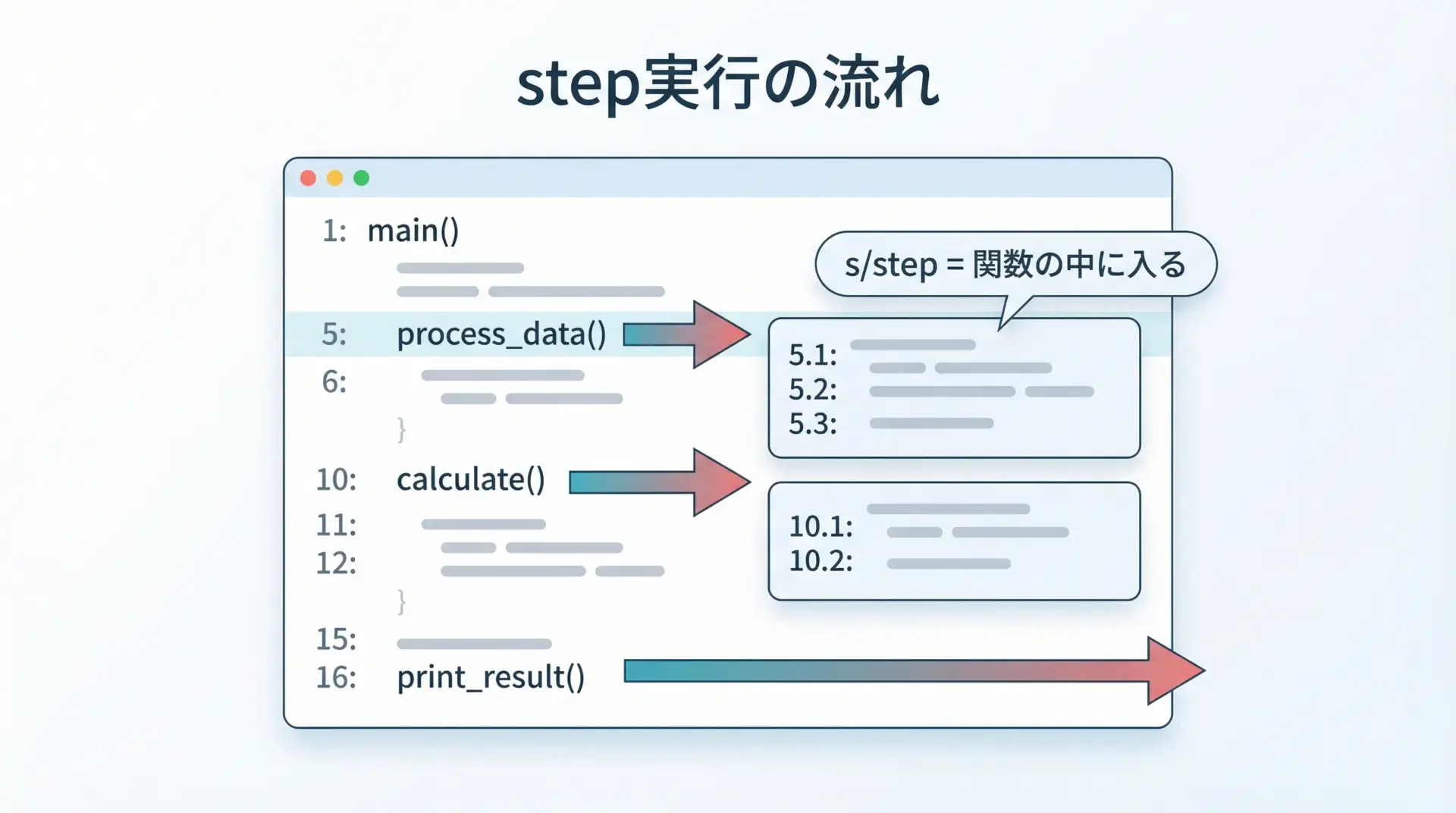
pdbで最もよく使うのが、stepコマンドです。
短縮形はsで、関数呼び出しの中に入っていきながら1行ずつ実行する動きをします。
次のようなコードを例に、実行の流れを見てみます。
# step_example.py
def double(x):
# 2倍して返すだけの単純な関数
return x * 2
def main():
a = 5
b = double(a) # ここから double 関数の中に入りたい
print("結果:", b)
if __name__ == "__main__":
import pdb
pdb.set_trace()
main()このスクリプトを実行し、(Pdb)プロンプトでnなどを使ってb = double(a)の行まで進んだとします。
その状態でsと入力すると、double関数の1行目に実行位置が移動します。
(Pdb) s
> /path/to/step_example.py(4)double()
-> return x * 2
(Pdb)このように、stepは関数の内部処理まで細かく追いかけたいときに使用します。
次の行まで進む(next n)の使い方
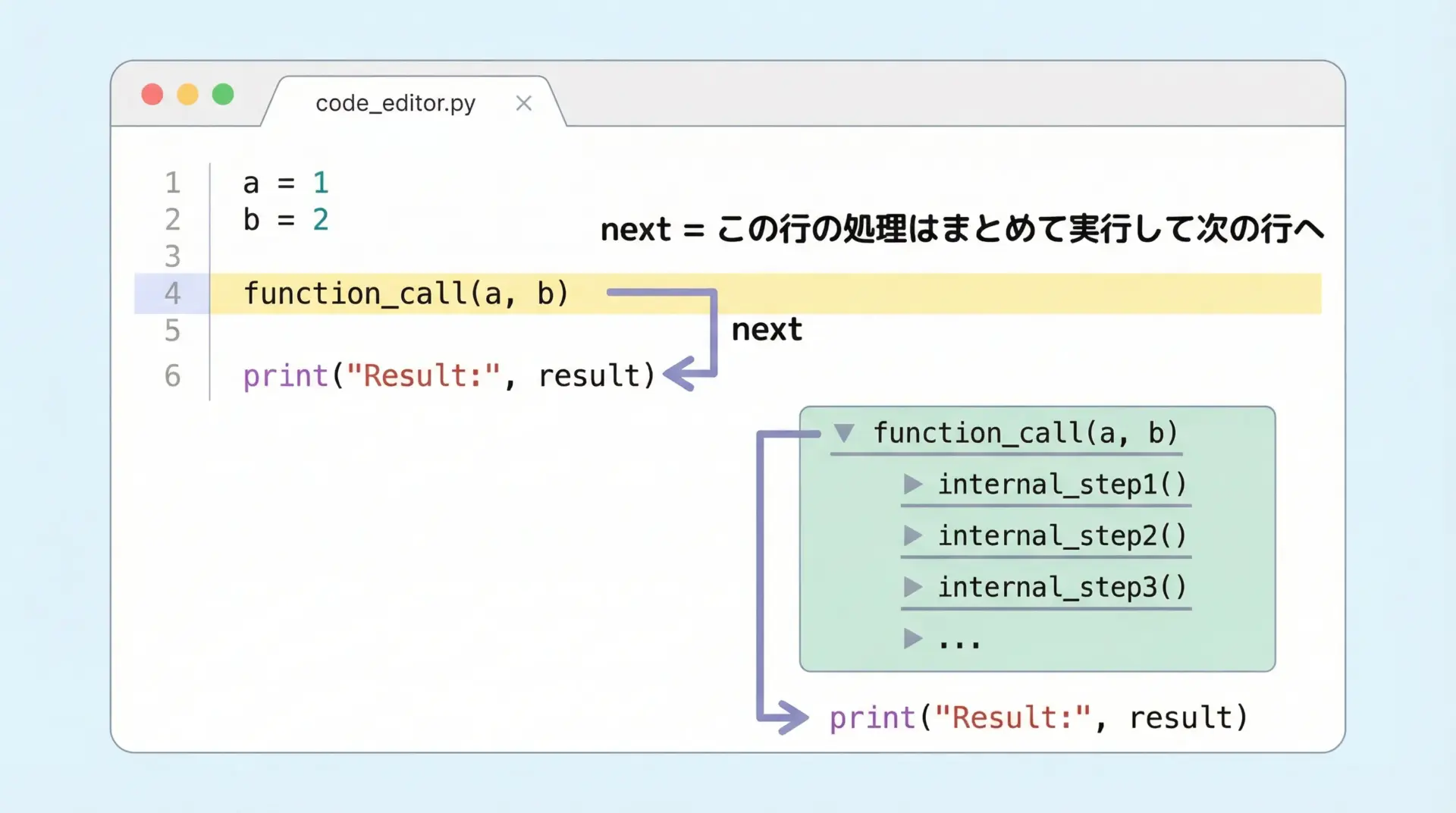
next(短縮形n)は、現在の関数の中だけで次の行まで実行を進めるコマンドです。
関数呼び出しがあっても、その内部には入らず「まとめて」実行します。
先ほどと同じコードで、再びb = double(a)の行にいるときにnを入力すると、double関数は内部まで追わずに実行され、次のprintの行まで一気に進みます。
(Pdb) n
> /path/to/step_example.py(9)main()
-> print("結果:", b)
(Pdb)このように、内部の動きには興味がなく、結果だけ確認できればよい場面ではnextを使うと効率的です。
stepとnextを使い分けることで、欲しい粒度で処理を追いかけられます。
関数から抜ける(return r)の使い方

関数の内部に入りすぎてしまったとき、最後まで一行ずつ進めるのは面倒です。
そんなときに便利なのがreturn(短縮形r)です。
現在の関数のreturn(もしくは終了位置)まで一気に進めることができます。
例えば、次のような多段階の計算を行う関数があるとします。
# return_example.py
def complex_calc(x):
step1 = x + 10
step2 = step1 * 3
step3 = step2 - 5
return step3
def main():
import pdb
pdb.set_trace()
result = complex_calc(7)
print("結果:", result)
if __name__ == "__main__":
main()pdbでstepを使ってcomplex_calcの中まで入った後、やはり内部の詳細は今は不要と判断したとします。
その時点でrと入力すると、complex_calcの終了位置まで進み、呼び出し元に戻ることができます。
(Pdb) r
--Return--
> /path/to/return_example.py(6)complex_calc()->26
-> return step3
(Pdb)これにより、途中経過に興味がない場面でのステップ数を大幅に削減できます。
変数を確認する
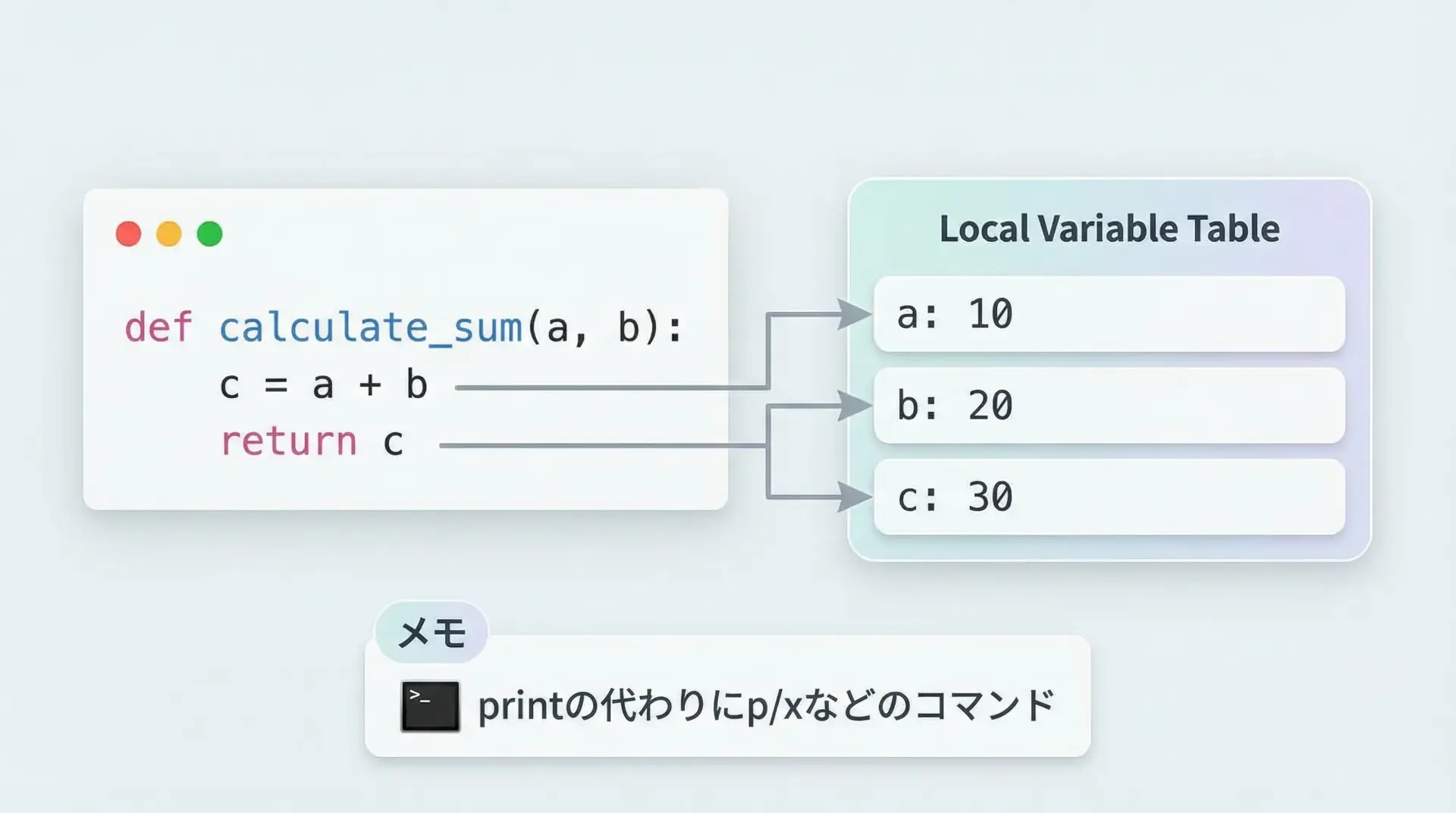
pdbでは、変数の中身を確認する方法がいくつか用意されています。
最もシンプルなのは、変数名をそのまま入力する方法です。
(Pdb) x
10
(Pdb) y
20ただし、変数名の評価結果を明示的に表示したい場合にはp(print)コマンドを使うと分かりやすくなります。
(Pdb) p x
10
(Pdb) p x + y
30pコマンドは「Python式の評価結果を表示する」ためのもので、単なる変数だけでなく、len(list_data)やobj.attributeといった式も確認できます。
また、ローカル変数の一覧が欲しい場合にはlocals()を評価するのも1つの手です。
(Pdb) p locals()
{'x': 10, 'y': 20, 'z': 30}実行位置を確認する

現在どの行で止まっているのか分からなくなったときは、list(短縮形l)コマンドが役に立ちます。
現在行を中心に前後数行のソースコードを表示してくれます。
(Pdb) l
10 x = 10
11 y = 20
12 pdb.set_trace()
13 -> z = x + y
14 print("結果:", z)
15
(Pdb)矢印->が付いている行が、現在の実行位置です。
必要に応じて、l 1,30のように行番号を指定して広い範囲を表示することもできます。
実行を続行する
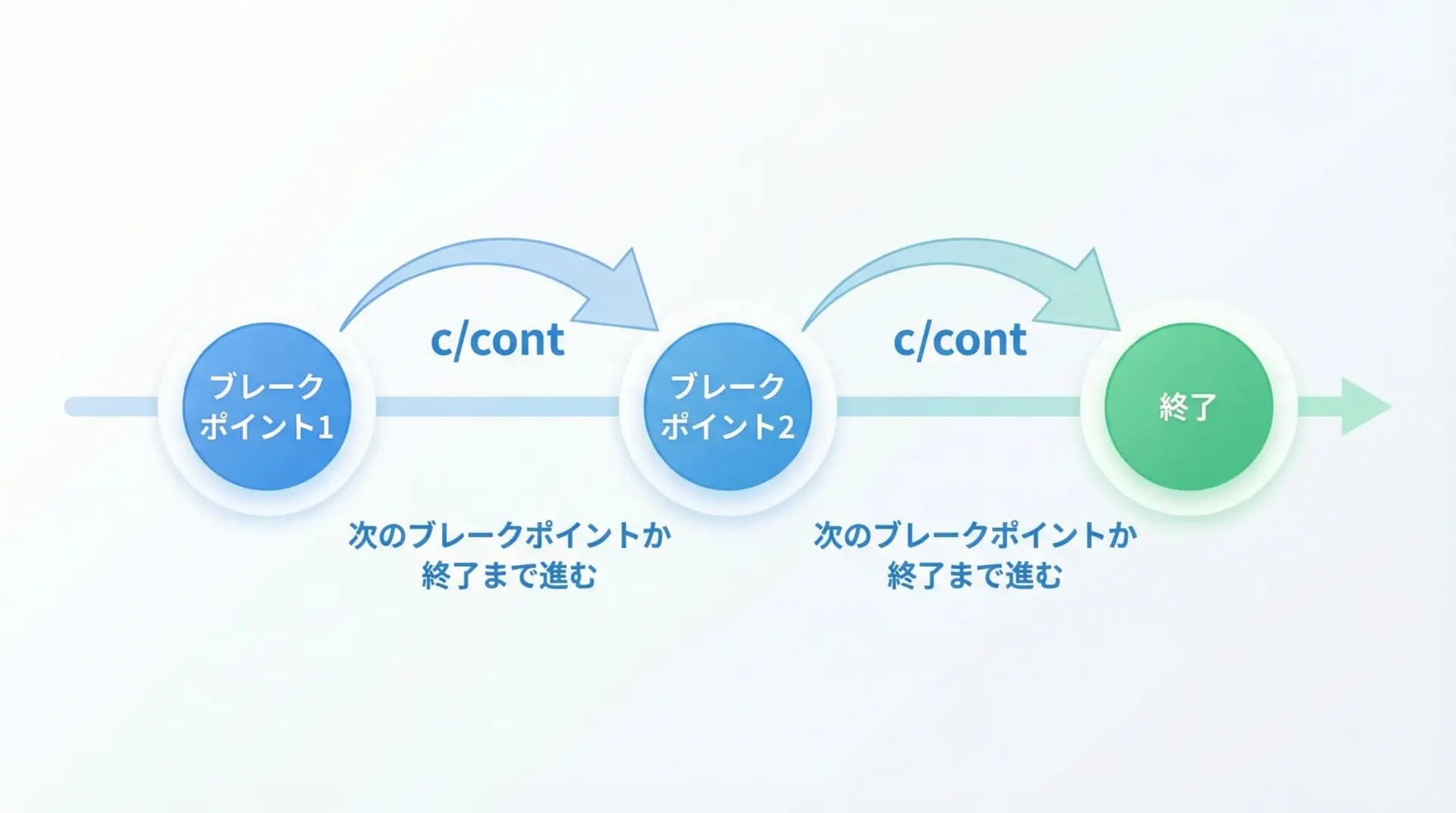
特定の行での調査が終わったら、プログラムを続きから実行したくなります。
そのときに使うのがcontinue(短縮形c)です。
continueは「次のブレークポイント、もしくはプログラム終了まで」一気に実行します。
途中にpdb.set_trace()などのブレークポイントがあればそこでもう一度停止し、なければそのまま完了します。
(Pdb) c
結果: 30
--Return--
> /path/to/debug_sample.py(19)main()->None
-> if __name__ == "__main__":
(Pdb)このように、必要なポイントだけで止まりたいときにcontinueを使うと、余計なステップ実行を避けられます。
一時停止を終了して終了する
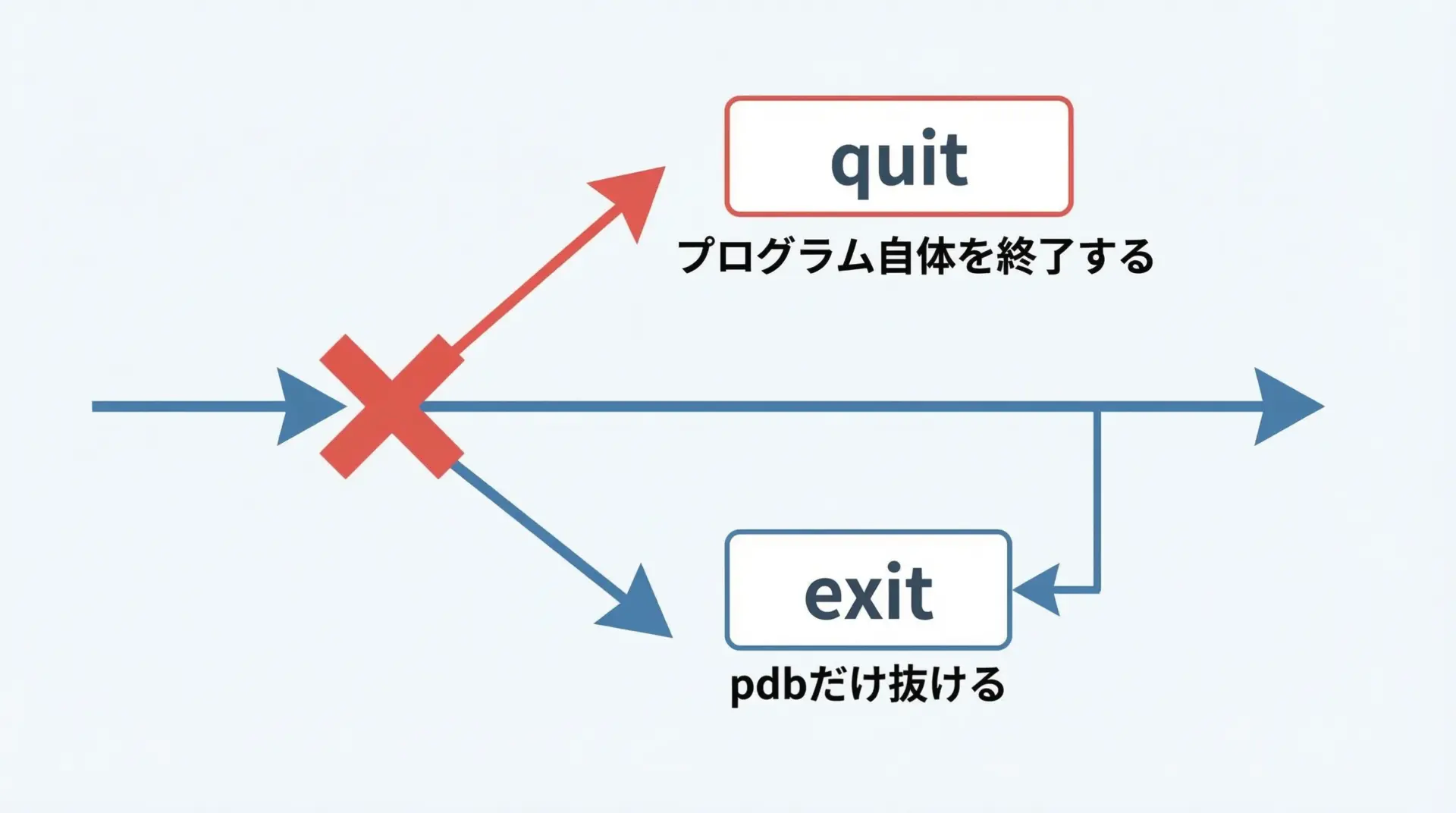
デバッグ中に「もうこの実行は中止してよい」と判断したときは、quit(短縮形q)でpdbを終了し、プログラム自体も打ち切ります。
(Pdb) qこれにより、現在のプロセスはそこで即座に終了します。
再度デバッグしたい場合は、あらためてスクリプトを実行し直します。
pdbセッションだけを終了して通常実行に戻したい、という要求は基本的には想定されていないため、「デバッグをやめる = 今回の実行を終了する」と覚えておくとよいです。
実践的なpdbデバッグテクニック
条件付きブレークポイントの設定

ループの中で特定の条件が成り立ったときだけ停止したい、という場面は頻繁にあります。
pdbでは条件付きブレークポイントを設定することで、不要な停止を避けながら効率的にデバッグできます。
簡単な例として、次のようなループを考えます。
# cond_break.py
import pdb
def process_numbers():
for i in range(100):
# 条件付きでブレークしたいポイント
pdb.set_trace()
print("処理中:", i)
if __name__ == "__main__":
process_numbers()このままだと、全てのループでpdbが起動してしまいます。
そこで、pdbの中でブレークポイントに条件を設定します。
> /path/to/cond_break.py(8)process_numbers()
-> print("処理中:", i)
(Pdb) condition 1 i == 50
(Pdb) cここでcondition 1 i == 50というコマンドは、「ブレークポイント番号1番に、i == 50という条件を設定する」という意味です。
以降は、iが50になったときにだけ停止するようになります。
なお、ブレークポイント番号はbコマンドを使うと一覧表示できます。
(Pdb) b
Num Type Disp Enb Where
1 breakpoint keep yes at cond_break.py:7
stop only if i == 50ループ処理を効率よくデバッグするコツ
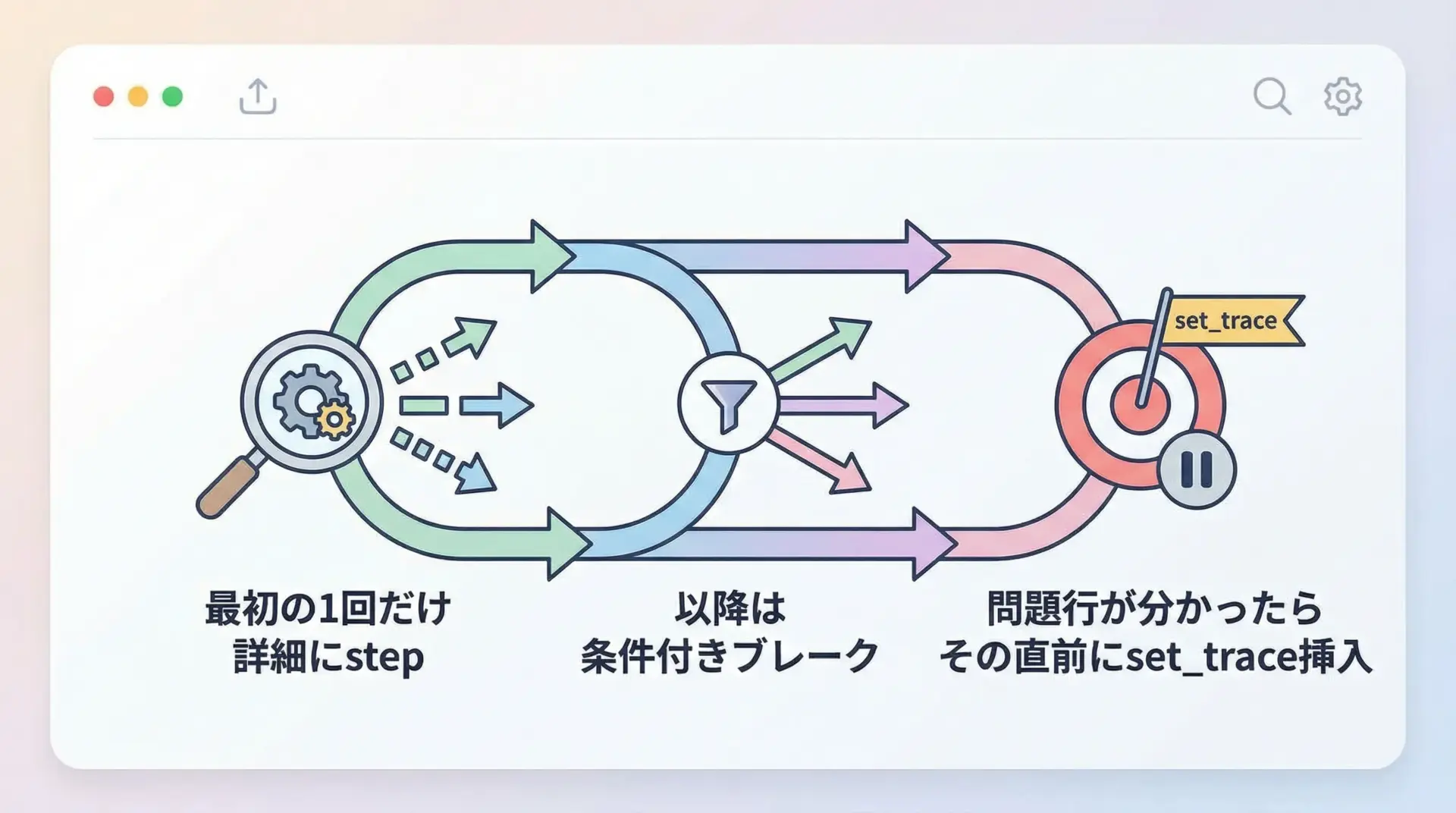
ループ処理をデバッグするときに、全ての反復で停止していては時間がいくらあっても足りません。
そこで、pdbならではのコツを押さえておくと効率が上がります。
まず、1回目のループだけstepやnextで詳しく追いかけ、処理の流れを把握します。
その上で、「この条件でだけおかしくなる」という仮説が立てられたら、先ほど紹介した条件付きブレークポイントに切り替えます。
さらに、問題になっている行が特定できた場合は、その直前にpdb.set_trace()を一時的に埋め込み、その行の前後だけを重点的に観察する方法も有効です。
この段階では、ループを前から順に追う必要はなく、「問題の瞬間」だけを切り取る意識でデバッグすると効率的です。
例外発生時に自動でpdbを起動する
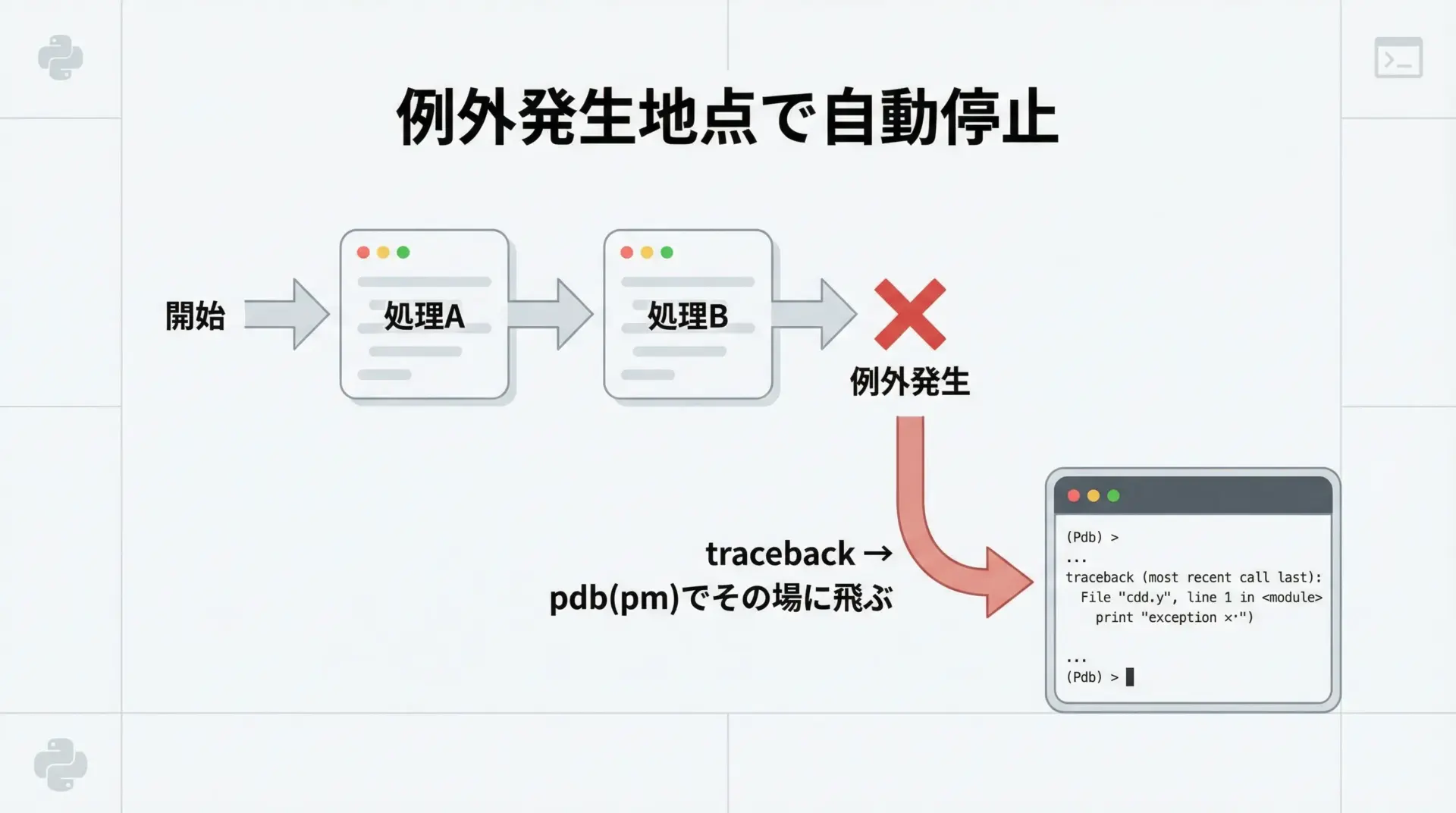
再現しにくいバグや、本番環境に近いデータでだけ起きる問題では、例外が発生した瞬間の状態を直接調べたいことがあります。
その際に便利なのがpost-mortemデバッグです。
基本的な使い方は、例外が発生したあとにpdb.pm()を呼び出す方法です。
例えば、対話型シェルで次のように操作します。
import pdb
def buggy():
x = 10
y = 0
return x / y # ここで ZeroDivisionError が発生
try:
buggy()
except Exception:
# 例外発生時のスタックトレースに飛んでpdbを起動
pdb.pm()実行すると、例外が発生した行に対応する場所でpdbが立ち上がり、その時点の変数などを確認できます。
> /path/to/example.py(6)buggy()
-> return x / y
(Pdb)また、コマンドラインからpython -m pdb -c continue script.pyのように実行しておけば、例外発生時に自動でpdbに入ることも可能です。
外部ライブラリの中身をpdbで追いかける

自分で書いたコードだけでなく、外部ライブラリやフレームワークの内部挙動を確認したくなることもあります。
pdbはPythonで書かれたライブラリであればそのまま内部に入って追跡できます。
例えば、標準ライブラリのjsonモジュールを使っている場面で、どのように文字列がパースされているか調べたいとします。
その場合、自分のコード側にpdb.set_trace()を仕込み、json.loads()を呼び出している行でstepを使えば、jsonモジュールのソースコードに入り込むことができます。
ただし、ライブラリ内部は行数も多く複雑なので、深追いしすぎると迷子になりがちです。
ライブラリ内でどこまで追うか、どこからはnextやreturnで抜けるかを、目的に応じてあらかじめ決めておくとよいです。
pdbとloggingを併用するデバッグ手法
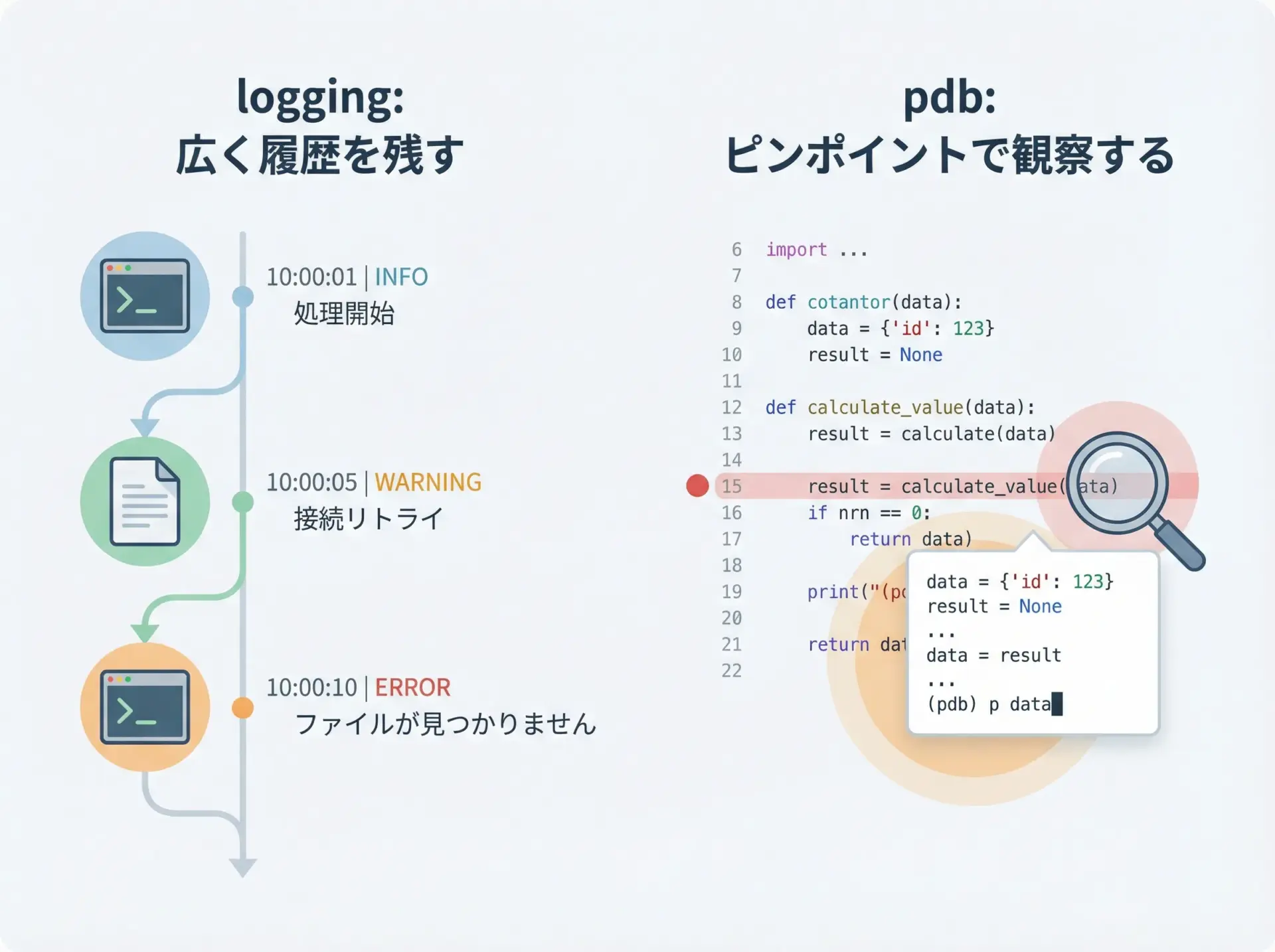
大規模なプロジェクトや長時間動くバッチ処理では、pdbだけで全ての挙動を追いかけるのは現実的ではありません。
そこで有効なのがloggingとpdbの併用です。
loggingは、長時間の実行履歴をファイルなどに記録し、後から振り返るのに向いています。
一方でpdbは、「今この瞬間」の状態を徹底的に観察するのに適しています。
例えば、次のような使い方が考えられます。
# logging_pdb_example.py
import logging
import pdb
logging.basicConfig(level=logging.INFO)
def process_item(i):
logging.info("処理開始 i=%s", i)
if i == 5:
# 特定条件のときだけ詳細に調査したい
pdb.set_trace()
# ここに実際の処理が続く
logging.info("処理終了 i=%s", i)
def main():
for i in range(10):
process_item(i)
if __name__ == "__main__":
main()実行ログによって「どのタイミングで何が起きていたか」の全体像を把握し、その中で怪しい箇所にだけpdbを仕込む、という戦略を取ると、広く浅い観察(logging)と、狭く深い観察(pdb)を両立できます。
まとめ
pdbは、Pythonに標準で備わっている強力な対話型デバッガです。
set_traceで任意の位置にブレークポイントを置き、stepとnextで処理の流れを追い、pコマンドで変数を確認するという基本さえ押さえれば、printデバッグよりも少ない試行回数で原因にたどり着けるようになります。
さらに、条件付きブレークポイントや例外発生時の自動起動、loggingとの併用などを取り入れることで、実践的なデバッグ力が大きく向上します。
まずは小さなスクリプトでpdbの操作感に慣れ、日々の開発に少しずつ取り入れてみてください。
