Pythonでは、ユーザー入力やファイルから読み込んだ値が文字列になっていることが多く、そのままでは足し算や平均値の計算ができません。
本記事では、文字列を数値(int・float)に変換する基本から、エラーを防ぐテクニック、実務での活用方法までを、サンプルコードと図解を交えながら丁寧に解説していきます。
Pythonで文字列を数値に変換する基本
文字列をint型に変換する
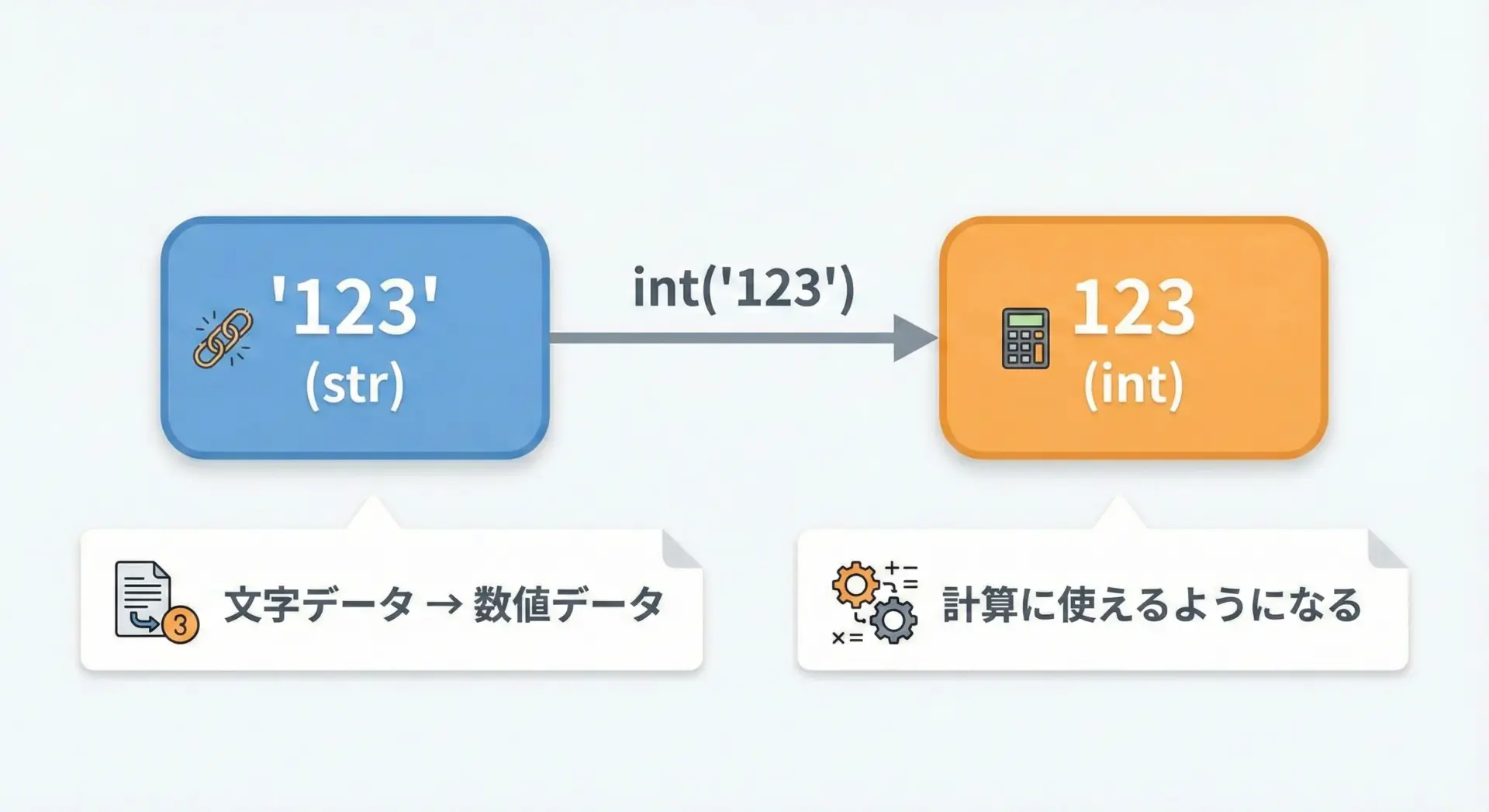
Pythonでは、文字列を整数に変換するにはint()関数を使います。
たとえば、文字列"123"を整数の123に変換したい場合は、次のように書きます。
# 文字列を整数(int)に変換する基本例
text = "123" # これは文字列
number = int(text) # int()で整数に変換
print(text, type(text)) # 変換前の型を確認
print(number, type(number)) # 変換後の型を確認123 <class 'str'>
123 <class 'int'>このように見た目は同じでも、型がstrからintへ変わることで、足し算や比較などの数値演算が可能になります。
よくあるパターンとして、ユーザー入力input()の結果は必ず文字列になるため、そのままでは計算できません。
後ほど詳しく扱いますが、基本形は次のようになります。
age_text = input("年齢を入力してください: ") # ここでは str 型
age = int(age_text) # int に変換してから使う
print(f"来年の年齢は {age + 1} 歳です。")文字列をfloat型に変換する

小数点を含む数値を扱いたい場合はfloat()関数を使います。
たとえば、身長や金額など、端数を含む値は整数では足りません。
# 文字列を浮動小数点数(float)に変換する基本例
text = "3.14" # 文字列としての「3.14」
value = float(text) # float()で小数として扱えるようにする
print(text, type(text)) # 変換前
print(value, type(value)) # 変換後
print(value * 2) # 小数の演算もできる3.14 <class 'str'>
3.14 <class 'float'>
6.28小数点を含む文字列をint()で変換しようとするとエラーになることに注意してください。
この場合はfloat()を使う必要があります。
intとfloatの違いと使い分けポイント

Pythonでは数値型として代表的なものにintとfloatがあります。
ざっくりまとめると、次のような違いがあります。
| 型名 | 例 | 小数点 | 主な用途 |
|---|---|---|---|
| int | 0, 10, -3 | なし | 個数、回数、年齢、IDなど |
| float | 0.0, 3.14, -2.5 | あり | 金額(税計算)、距離、割合、平均値など |
使い分けのイメージとしては、「必ず整数で表現されるものはint」「小数が出る可能性が少しでもあるならfloat」と考えると分かりやすいです。
また、型が違うと計算結果の型も変わります。
a = 2 # int
b = 3 # int
c = 2.0 # float
print(a + b, type(a + b)) # int + int → int
print(a + c, type(a + c)) # int + float → float5 <class 'int'>
4.0 <class 'float'>整数同士の計算はintですが、どちらか一方がfloatになると結果もfloatになる点も覚えておくと、型の混在時に迷いにくくなります。
数値変換でよく使う関数と書き方
intで10進数の文字列を整数に変換する方法

日常で扱う通常の数値(10進数)の文字列を整数に変換する場合、int()をそのまま使います。
# 10進数の文字列を int に変換する
print(int("10")) # 10
print(int("0")) # 0
print(int("-5")) # -5
# 先頭や末尾に空白がある場合も、int() は自動で無視してくれます
print(int(" 42")) # 42
print(int("7\n")) # 7 (改行付き文字列)10
0
-5
42
7空白や改行を含む場合でも、自動的に読み飛ばして変換してくれるため、基本的な入力処理ではあまり気にしなくても構いません。
ただし、余計な文字(カンマや単位など)が混ざるとエラーになるので、必要に応じて前処理を行います。
intで基数(2進数・16進数など)を指定して変換する方法
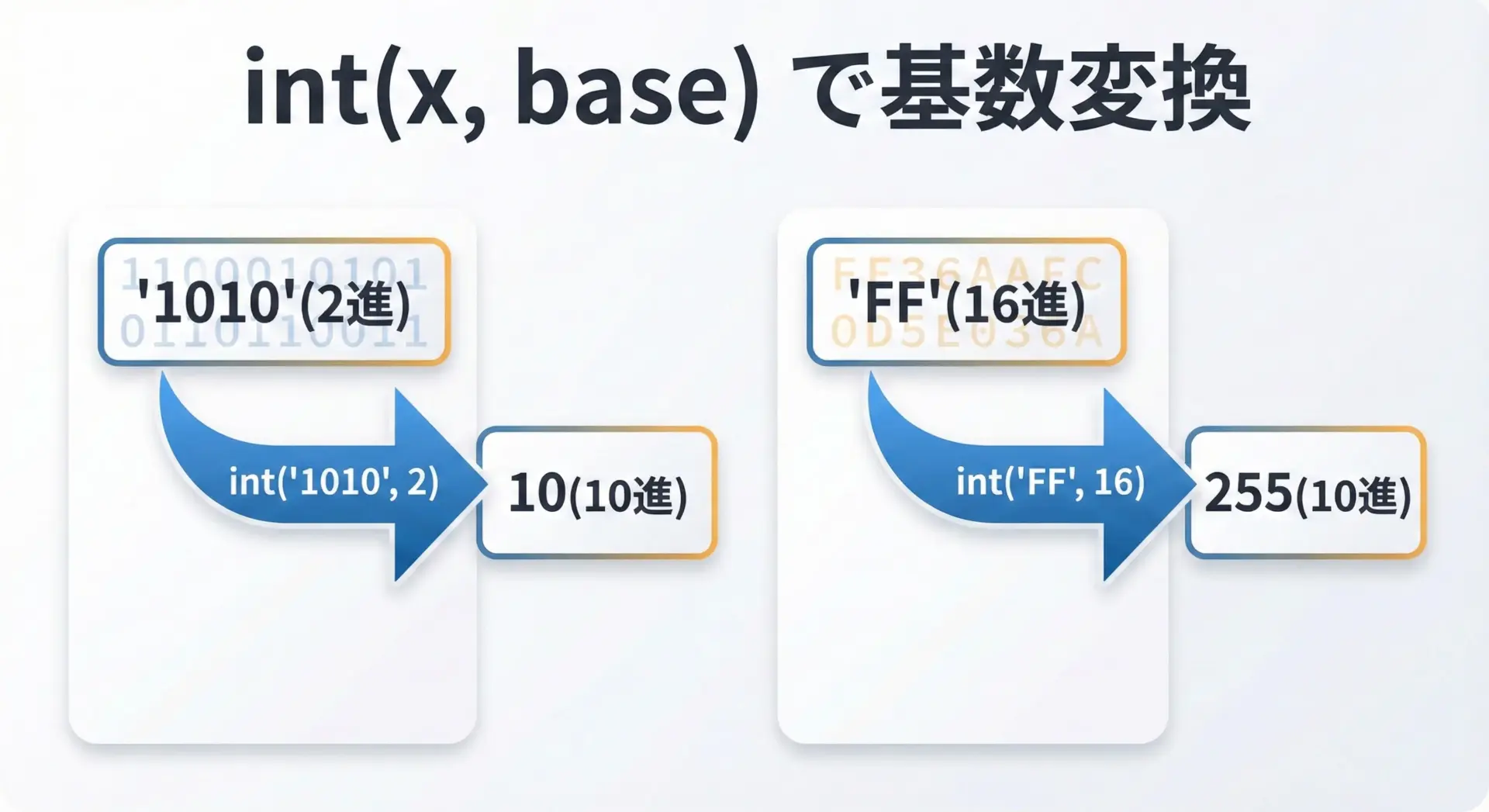
int()は第2引数に基数(base)を指定することで、2進数や16進数など、さまざまな表現から10進数の整数に変換できます。
# 2進数(基数2)の文字列を10進数の int に変換
print(int("1010", 2)) # 2進数の1010 → 10進数の10
# 8進数(基数8)
print(int("17", 8)) # 8進数の17 → 10進数の15
# 16進数(基数16)
print(int("FF", 16)) # 16進数のFF → 10進数の255
print(int("ff", 16)) # 大文字小文字どちらでもOK10
15
255
255第2引数を省略した場合の基数は10です。
そのため、通常の数値文字列を扱う限りは1引数のint("123")の形で問題ありません。
基数を使うのは、バイナリ表現やカラーコード(16進)などを処理する場面です。
floatで小数を含む文字列を数値に変換する方法

float()を使うと、小数点や指数表現を含んだ文字列も変換できます。
# 小数を含む文字列を float に変換
print(float("3.14")) # 3.14
print(float("-0.5")) # -0.5
# 指数表現(サイエンティフィック表記)も変換可能
print(float("1e3")) # 1 × 10^3 → 1000.0
print(float("2.5e-2")) # 2.5 × 10^-2 → 0.0253.14
-0.5
1000.0
0.025「1000」など小数点のない文字列でもfloat()で変換できますが、その場合の結果は1000.0になります。
整数として扱ってよい値はint()を、小数点以下が必要な値や、将来的に小数になる可能性がある値はfloat()を使うとよいです。
数値から文字列へ変換する方法
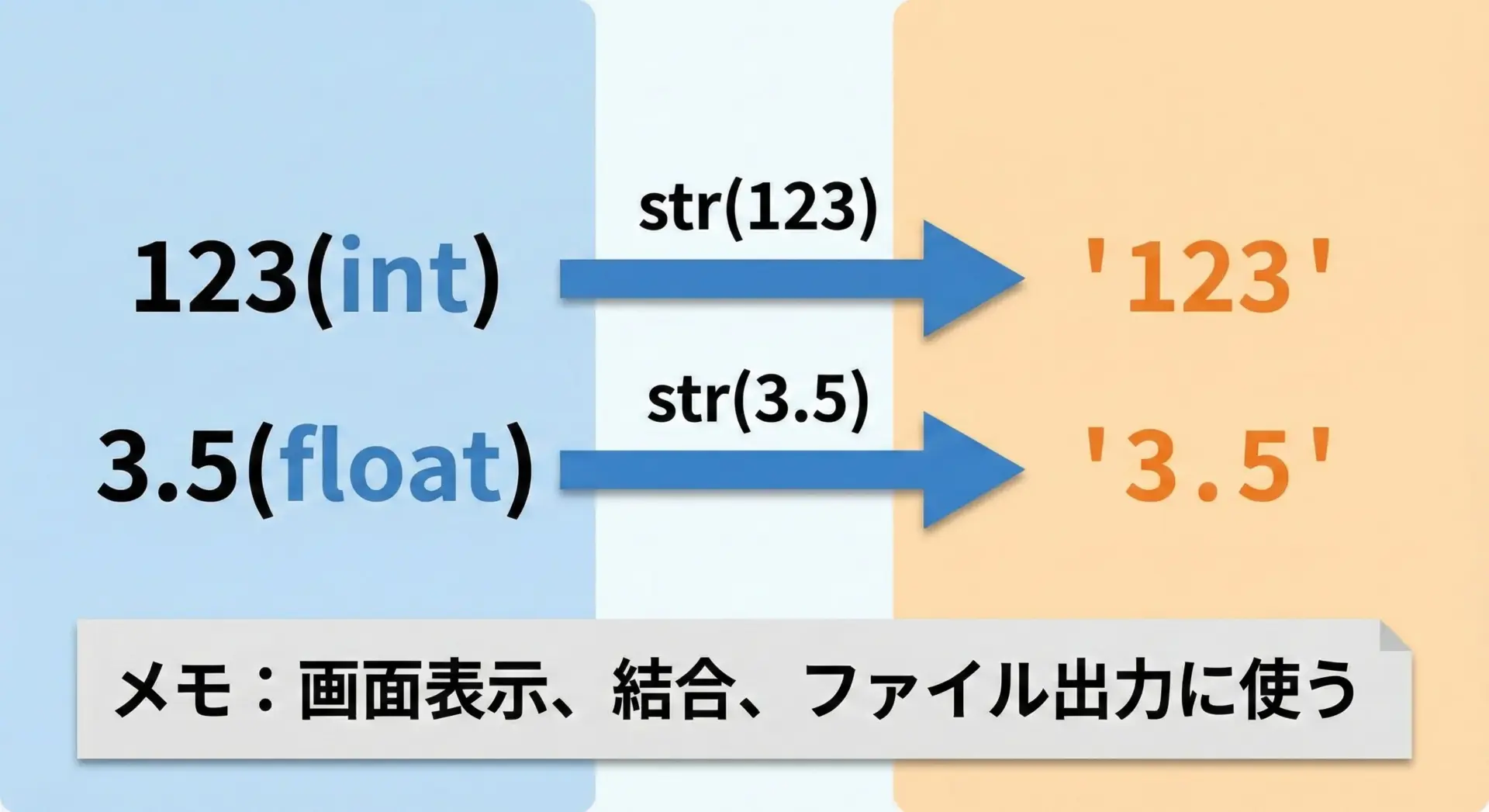
逆に、数値を文字列にしたい場面も非常に多くあります。
代表的な用途は文字列結合やメッセージ表示です。
この場合はstr()を使います。
# 数値から文字列へ変換する
num_int = 123
num_float = 3.5
text_int = str(num_int) # "123"
text_float = str(num_float) # "3.5"
print(text_int, type(text_int))
print(text_float, type(text_float))
# 文字列結合の例
message = "合計は " + str(1500) + " 円です。"
print(message)123 <class 'str'>
3.5 <class 'str'>
合計は 1500 円です。最近では、f"..."形式のフォーマット文字列を使うことも多く、f文字列は内部で自動的にstr()変換をしてくれます。
price = 1500
tax = 0.1
total = price * (1 + tax)
# f文字列を使うと str() を明示的に書かなくてよい
message = f"税込金額は {total} 円です。"
print(message)税込金額は 1650.0 円です。エラーを防ぐ文字列から数値への変換テクニック
int・float変換時のValueErrorと原因
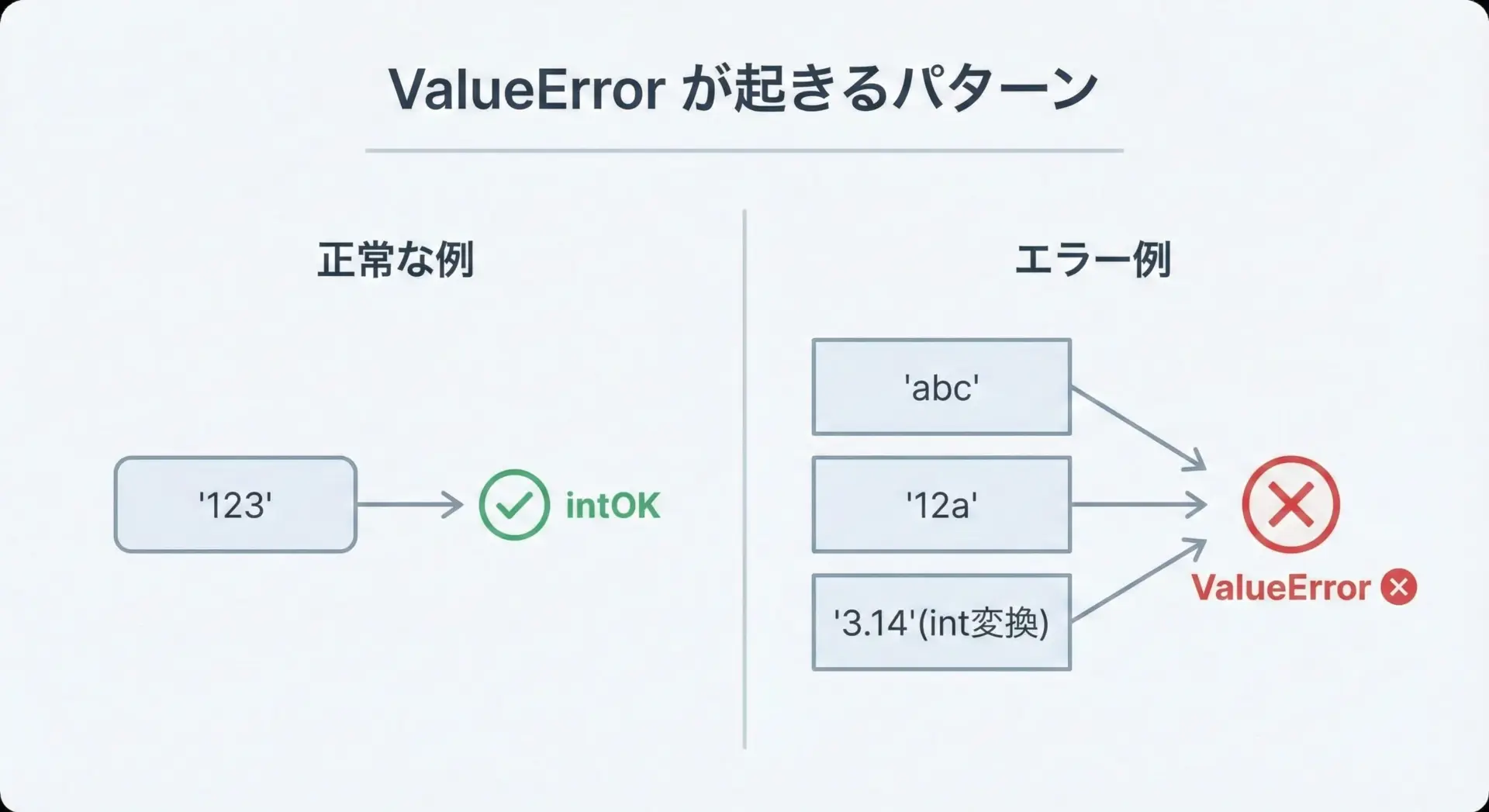
int()やfloat()で変換できない文字列を渡すと、ValueErrorという例外が発生します。
# ValueError が発生する例
print(int("abc")) # 数字ではない → エラー
print(int("12a")) # 一部に文字が混ざっている → エラー
print(int("3.14")) # int() は小数点付きには使えない → エラーTraceback (most recent call last):
...
ValueError: invalid literal for int() with base 10: 'abc'原因は「渡された文字列が、その型として有効な数値表現になっていない」ことです。
対策としては、次の2ステップを組み合わせます。
- 変換前に文字列が数値として妥当かをチェックする
- 万が一のエラーを
try-exceptで受け止める
それぞれ、次の見出しで詳しく解説します。
isdigitやisnumericで数値文字列かチェックする方法
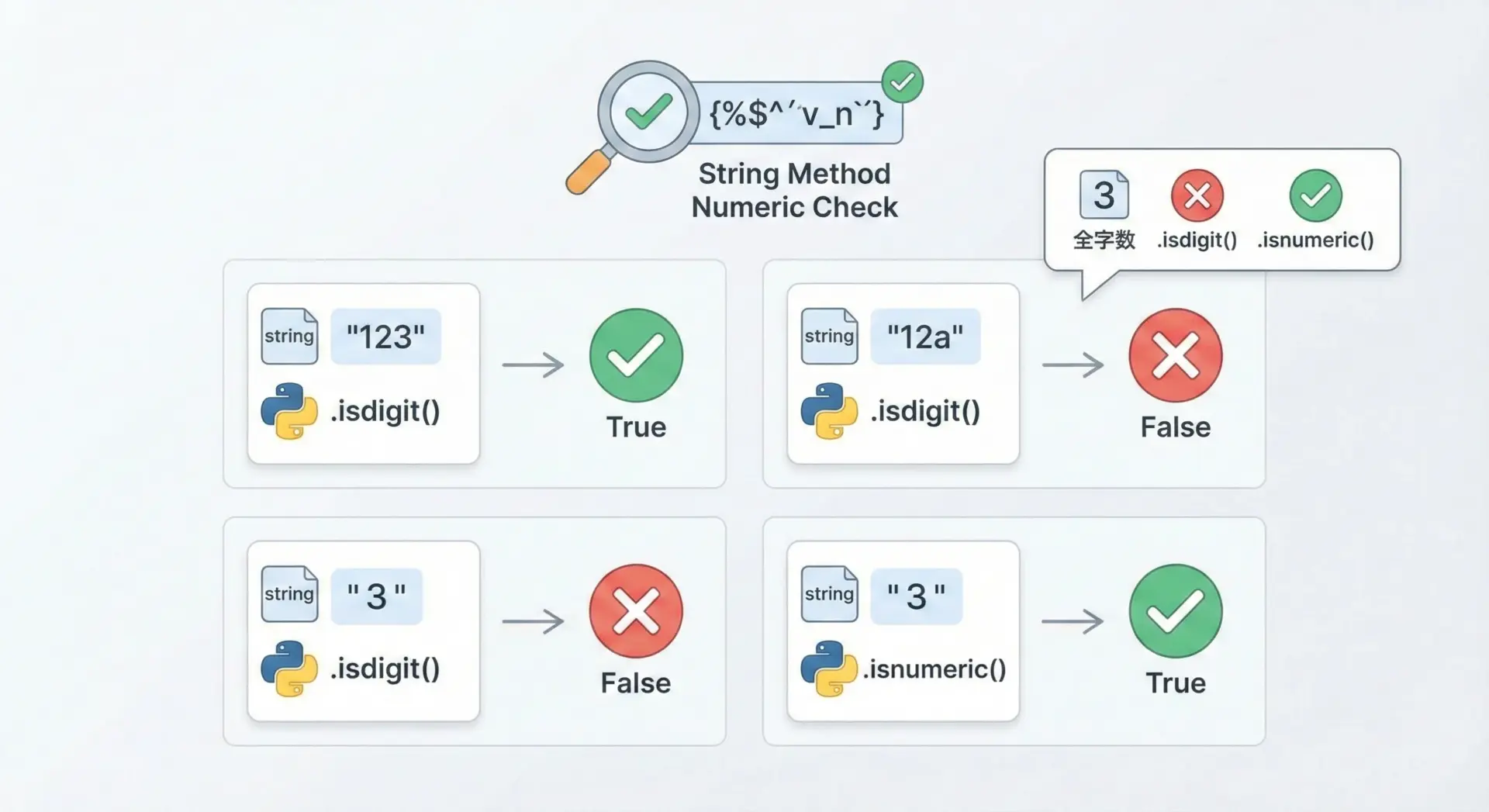
変換前に、その文字列が数字だけで構成されているかを確認するには、str.isdigit()やstr.isnumeric()といったメソッドが使えます。
# isdigit() と isnumeric() の基本例
print("123".isdigit()) # True
print("12a".isdigit()) # False
print("".isdigit()) # False (空文字は数字ではない)
# 全角数字
full_width = "3"
print(full_width.isdigit()) # False になることが多い
print(full_width.isnumeric()) # True になるケースがあるTrue
False
False
False
True一般的なASCII数字(0〜9)だけを許可したい場合はisdigit()で十分です。
一方で、全角数字やローマ数字など、広い意味での数値文字を扱う場合はisnumeric()を使うと安全です。
ただし、小数点やマイナス記号を含む文字列はisdigit()/isnumeric()では数値とみなされないため、次のようなケースでは自前でチェックするか、例外処理を使う必要があります。
print("-10".isdigit()) # False (マイナス記号が含まれる)
print("3.14".isdigit()) # False (小数点が含まれる)例外処理(try-except)で安全に数値変換する方法
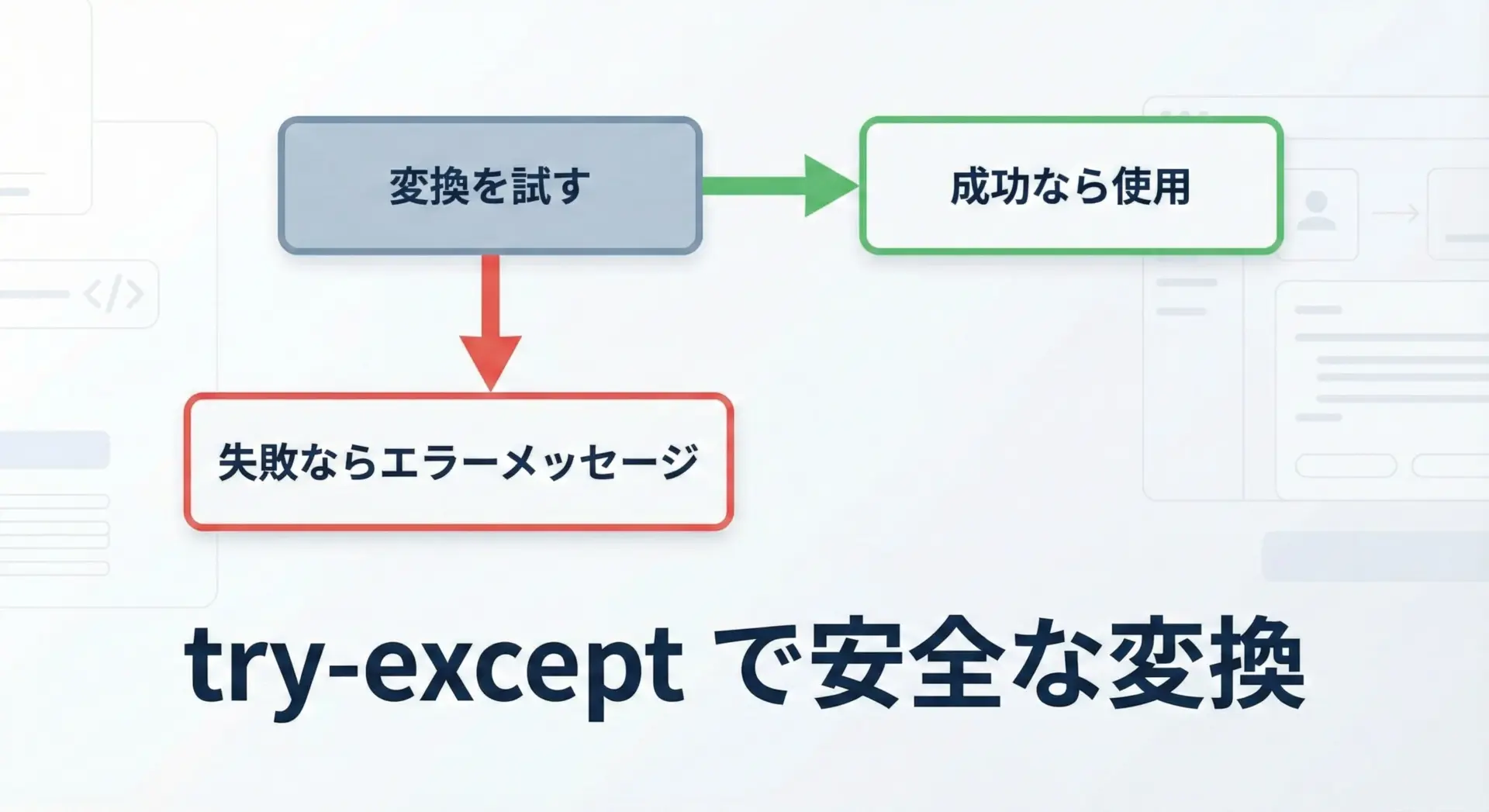
どんな文字列が来るか完全には予測できない場合は、try-exceptで変換処理を囲み、エラーが起きてもプログラムが止まらないようにします。
# 例外処理を使って安全に int 変換する関数の例
def to_int_safe(text):
try:
# まず変換を試す
return int(text)
except ValueError:
# 変換できなかった場合の処理
print(f"'{text}' は整数に変換できませんでした。")
return None # 変換に失敗したことを示す
values = ["10", "abc", "3.14", "-5"]
for v in values:
result = to_int_safe(v)
print(v, "→", result)10 → 10
'abc' は整数に変換できませんでした。
abc → None
'3.14' は整数に変換できませんでした。
3.14 → None
-5 → -5例外処理は「ダメ元でやってみて、ダメなら別の処理に切り替える」ための仕組みです。
ユーザー入力やファイルからの読み込みなど、外部要因でエラーが起こりやすい場所では必須のテクニックと言えます。
空文字・None・全角数字などのハマりどころ

文字列から数値への変換で、初心者が特につまずきやすいポイントを整理します。
1つ目は空文字""です。
見た目には「何も入力されていない」だけですが、そのままint("")やfloat("")するとエラーになります。
print(int("")) # ValueError空文字を許容する場合は、変換前にif text == "":のように条件分岐しておきましょう。
2つ目はNoneを数値に変換しようとするケースです。
これはValueErrorではなくTypeErrorになります。
value = None
print(int(value)) # TypeError: int() argument must be a string, a bytes-like object or a real number, not 'NoneType'3つ目は全角数字です。
ユーザーが日本語入力のまま数字を打つと、"3"のような全角になり、int("3")はエラーになります。
この場合はtranslate()や外部ライブラリで半角に変換するなどの前処理が必要です。
4つ目はカンマや単位付きの文字列です。
たとえば"1,000"や"100円"はそのままでは変換できませんが、置換で対処できます。
text = "1,000"
clean = text.replace(",", "") # カンマを除去
print(int(clean)) # 10001000このような「想定外の文字」が混ざるケースでは、前処理 + 例外処理を組み合わせて堅牢な実装にしていくことが重要です。
文字列の数値変換を演算・実務で活用する方法
入力値(input)を数値に変換して計算する方法
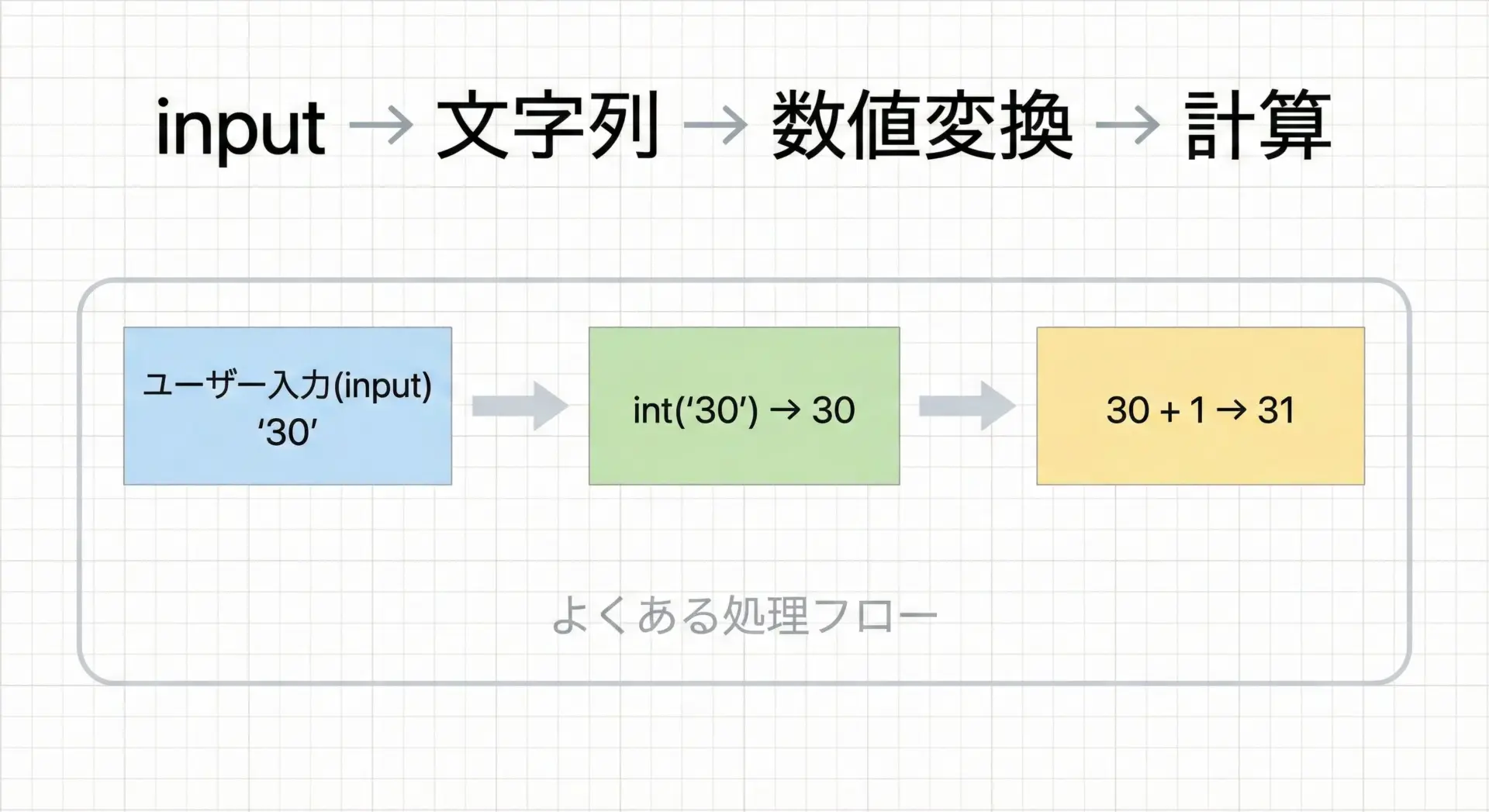
ユーザーから数値を入力してもらい、計算に利用する処理は非常によく登場します。
input()は必ず文字列を返すため、int()やfloat()での変換が必須です。
# ユーザー入力を数値に変換して使う例
age_text = input("年齢を入力してください: ")
try:
age = int(age_text) # 整数に変換
print(f"10年後は {age + 10} 歳です。")
except ValueError:
print("数値として解釈できる年齢を入力してください。")年齢を入力してください: 25
10年後は 35 歳です。このように、入力 → 文字列 → 数値変換 → 計算という流れが、インタラクティブなプログラムの基本パターンです。
リスト内包表記で複数の文字列を一括変換する方法

複数の文字列数値をまとめて整数や小数に変換したいときには、リスト内包表記が便利です。
# 文字列のリストを整数のリストに変換する
str_numbers = ["1", "2", "3", "4", "5"]
# 通常のループでの書き方
int_numbers_loop = []
for s in str_numbers:
int_numbers_loop.append(int(s))
# リスト内包表記を使った書き方
int_numbers_comp = [int(s) for s in str_numbers]
print("ループ:", int_numbers_loop)
print("内包表記:", int_numbers_comp)ループ: [1, 2, 3, 4, 5]
内包表記: [1, 2, 3, 4, 5]1行でスッキリ書けるため、データ変換処理では頻出のパターンです。
ただし、途中に変換できない文字列が混ざるとValueErrorになるため、必要に応じて条件付きで変換する、あるいは例外処理付きの関数を呼び出すなどの工夫をします。
CSVやファイルの数値データを文字列から変換する方法
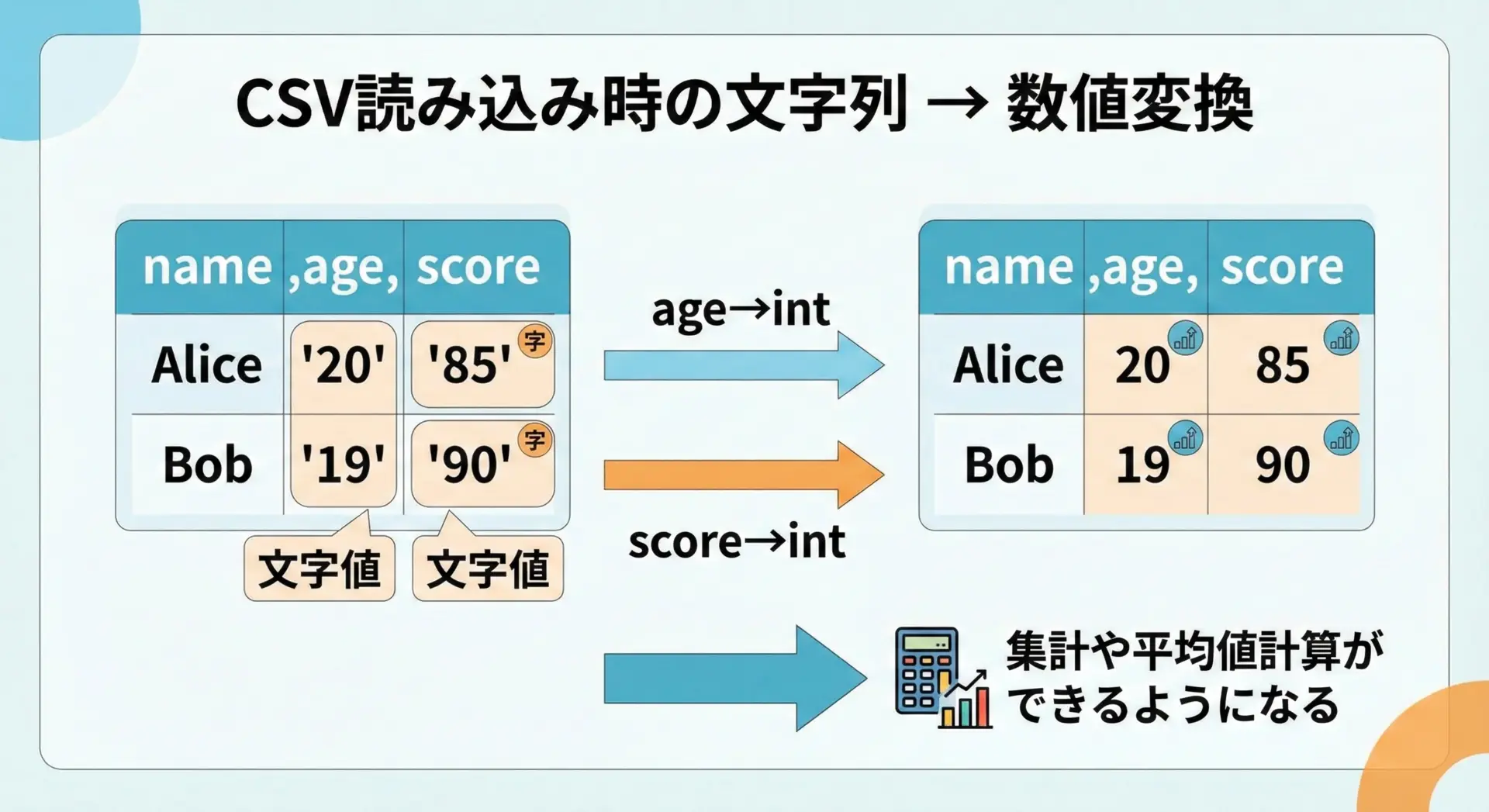
ファイル(CSVなど)から読み込んだデータは、基本的に全て文字列として扱われます。
集計や統計処理を行うには、必要な列を数値に変換する必要があります。
以下は、標準ライブラリcsvを使った簡単な例です。
import csv
# サンプル用にCSV文字列を用意(通常はファイルから読み込む)
from io import StringIO
csv_data = """name,age,score
Alice,20,85
Bob,19,90
Charlie,21,78
"""
file_like = StringIO(csv_data)
reader = csv.DictReader(file_like) # 1行ごとに dict で取得できる
total_score = 0
count = 0
for row in reader:
# row は {"name": "...", "age": "...", "score": "..."} という文字列辞書
age = int(row["age"]) # 年齢を整数に
score = int(row["score"]) # 点数を整数に
total_score += score
count += 1
average = total_score / count
print(f"平均点は {average} 点です。")平均点は 84.33333333333333 点です。このように、ファイル読み込み → 文字列として取得 → 必要な列だけ数値に変換 → 計算という流れが、データ処理の基本形になります。
実務では、ここにエラー処理や欠損値処理などが加わります。
文字列数値の変換・演算を組み合わせたサンプルコード
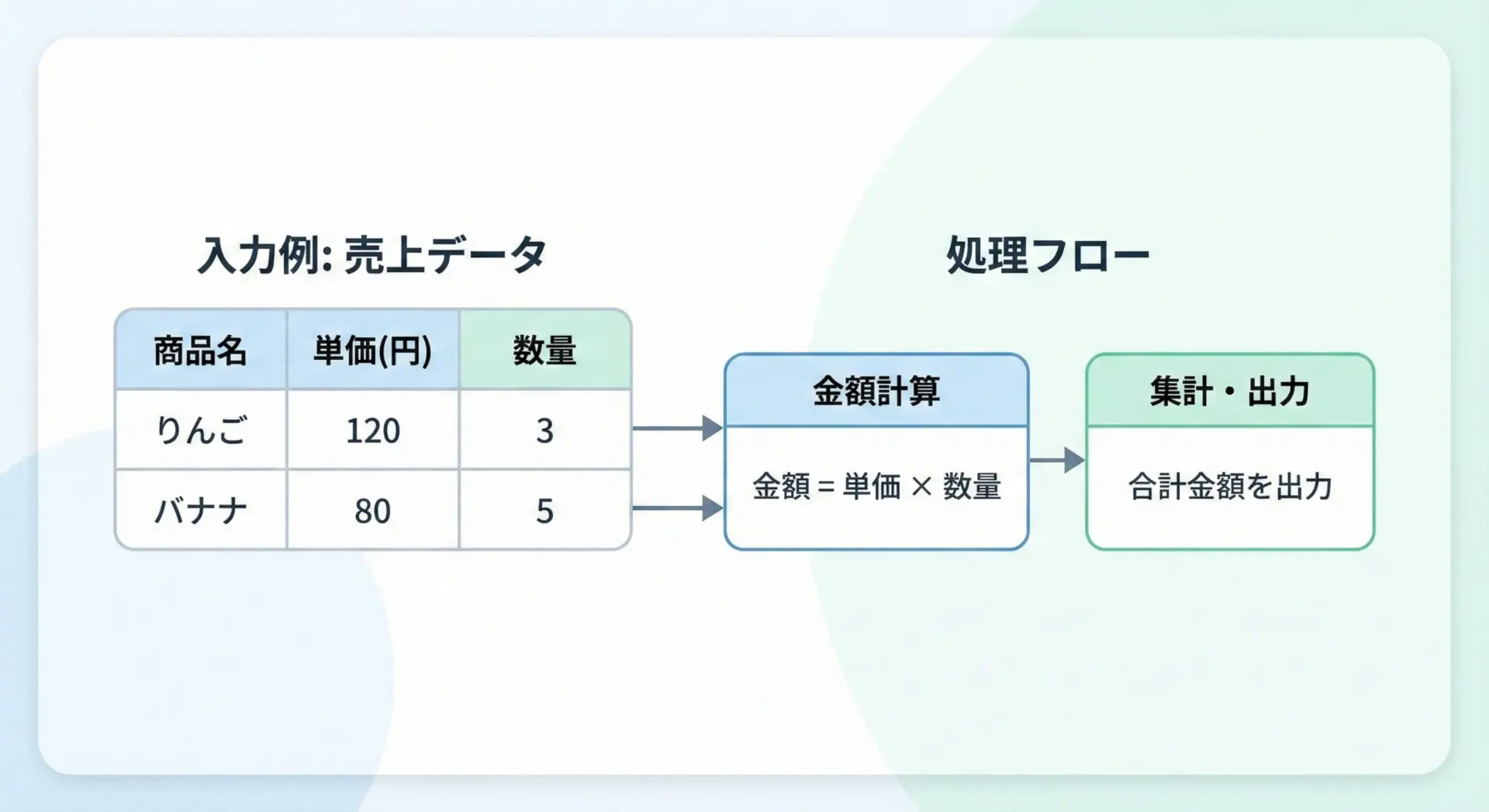
最後に、これまでの内容を組み合わせた少し実務寄りのサンプルを示します。
ここでは、文字列として与えられた単価と数量から、商品ごとの金額と合計金額を計算します。
# 売上データを文字列から数値に変換して集計する総合サンプル
items = [
{"name": "りんご", "price": "120", "quantity": "3"},
{"name": "バナナ", "price": "80", "quantity": "5"},
{"name": "オレンジ", "price": "150", "quantity": "2"},
{"name": "ぶどう", "price": "300", "quantity": "1"},
]
total_amount = 0
for item in items:
# 文字列の単価・数量を int に変換
try:
price = int(item["price"])
quantity = int(item["quantity"])
except ValueError:
# 変換できないデータがあればその行はスキップ
print(f"{item['name']} のデータに不正な値があります。スキップします。")
continue
amount = price * quantity # 金額を計算
total_amount += amount
print(f"{item['name']} の金額: {amount} 円")
print("-" * 20)
print(f"合計金額: {total_amount} 円")りんご の金額: 360 円
バナナ の金額: 400 円
オレンジ の金額: 300 円
ぶどう の金額: 300 円
--------------------
合計金額: 1360 円このサンプルでは、次のようなポイントを押さえています。
- データはすべて文字列として与えられる
- 単価と数量だけ
int()で変換し、計算に利用する - 変換時に
ValueErrorが起きた場合は、その商品だけスキップする
「入力やデータは文字列」「計算に使うときだけ数値に変換」という考え方は、実務のコードでも非常に重要です。
まとめ
Pythonでの文字列から数値への変換は、int()とfloat()を使い分けることが基本ですが、実際の開発ではValueError対策・事前チェック・例外処理が欠かせません。
ユーザー入力やCSVファイルなど、外部から入るデータはまず文字列として受け取り、isdigit()などで妥当性を確認しつつ、必要な部分だけを数値へ変換します。
入力→変換→演算という流れを押さえておけば、集計処理やWebアプリのフォーム処理など、さまざまな場面で安全かつ柔軟に数値を扱えるようになります。
